Trending in Computer Science
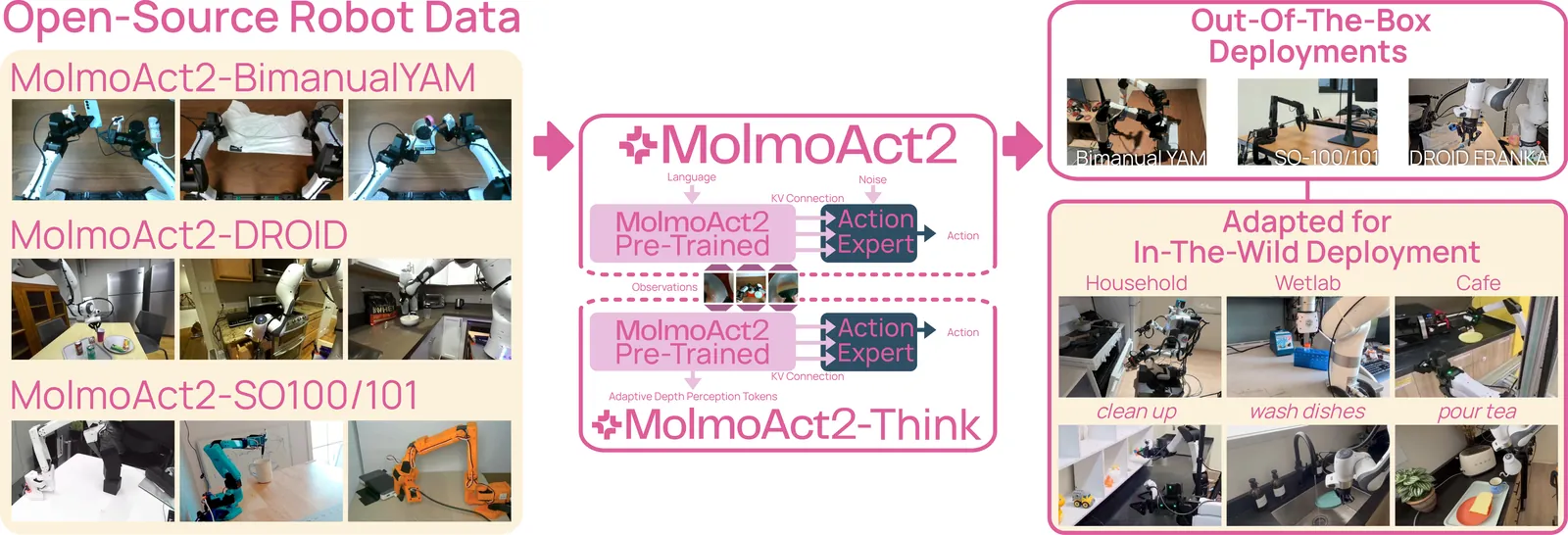
MolmoAct2: Action Reasoning Models for Real-world Deployment
Vision-Language-Action (VLA) models aim to provide a single generalist controller for robots, but today's systems fall short on the criteria that matter for real-world deployment. Frontier models are closed, open-weight alternatives are tied to expensive hardware, reasoning-augmented policies pay prohibitive latency for their grounding, and fine-tuned success rates remain below the threshold for dependable use. We present MolmoAct2, a fully open action reasoning model built for practical deployment, advancing its predecessor along five axes. We introduce MolmoER, a VLM backbone specialized for spatial and embodied reasoning, trained on a 3.3M-sample corpus with a specialize-then-rehearse recipe. We release three new datasets spanning low-to-medium cost platforms, including MolmoAct2-BimanualYAM, 720 hours of teleoperated bimanual trajectories that constitute the largest open bimanual dataset to date, together with quality-filtered Franka (DROID) and SO100/101 subsets. We provide OpenFAST, an open-weight, open-data action tokenizer trained on millions of trajectories across five embodiments. We redesign the architecture to graft a flow-matching continuous-action expert onto a discrete-token VLM via per-layer KV-cache conditioning. Finally, we propose MolmoThink, an adaptive-depth reasoning variant that re-predicts depth tokens only for scene regions that change between timesteps, retaining geometric grounding at a fraction of prior latency. In the most extensive empirical study of any open VLA to date, spanning 7 simulation and real-world benchmarks, MolmoAct2 outperforms strong baselines including Pi-05, while MolmoER surpasses GPT-5 and Gemini Robotics ER-1.5 across 13 embodied-reasoning benchmarks. We release model weights, training code, and complete training data. Project page: https://allenai.org/blog/molmoact2
2605.02881
May 2026Robotics
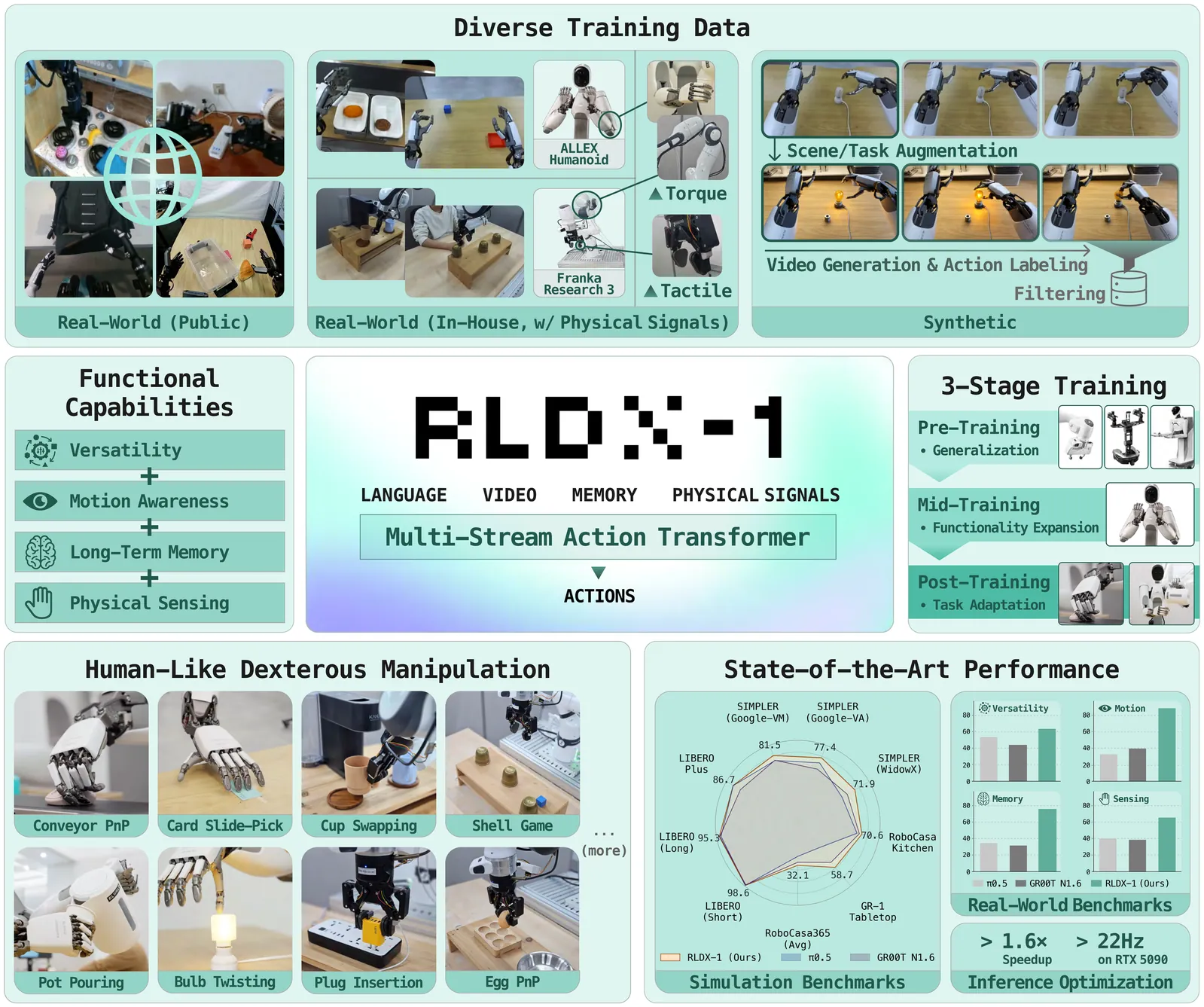
RLDX-1 Technical Report
While Vision-Language-Action models (VLAs) have shown remarkable progress toward human-like generalist robotic policies through the versatile intelligence (i.e. broad scene understanding and language-conditioned generalization) inherited from pre-trained Vision-Language Models, they still struggle with complex real-world tasks requiring broader functional capabilities (e.g. motion awareness, long-term memory, and physical sensing). To address this, we introduce RLDX-1, a general-purpose robotic policy for dexterous manipulation built on the Multi-Stream Action Transformer (MSAT), an architecture that unifies these capabilities by integrating heterogeneous modalities through modality-specific streams with cross-modal joint self-attention. RLDX-1 further combines this architecture with system-level design choices, including data synthesis for rare manipulation scenarios, learning procedures specialized for human-like manipulation, and inference optimizations for real-time deployment. Through empirical evaluation, we show that RLDX-1 consistently outperforms recent frontier VLAs (e.g. $π_{0.5}$ and GR00T N1.6) across both simulation benchmarks and real-world tasks that require broad functional capabilities beyond general versatility. In particular, RLDX-1 shows superiority in ALLEX humanoid tasks by achieving success rates of 86.8% while $π_{0.5}$ and GR00T N1.6 achieve around 40%, highlighting the ability of RLDX-1 to control a high-DoF humanoid robot under diverse functional demands. Together, these results position RLDX-1 as a promising step toward reliable VLAs for complex, contact-rich, and dynamic real-world dexterous manipulation.
2605.03269
May 2026Robotics
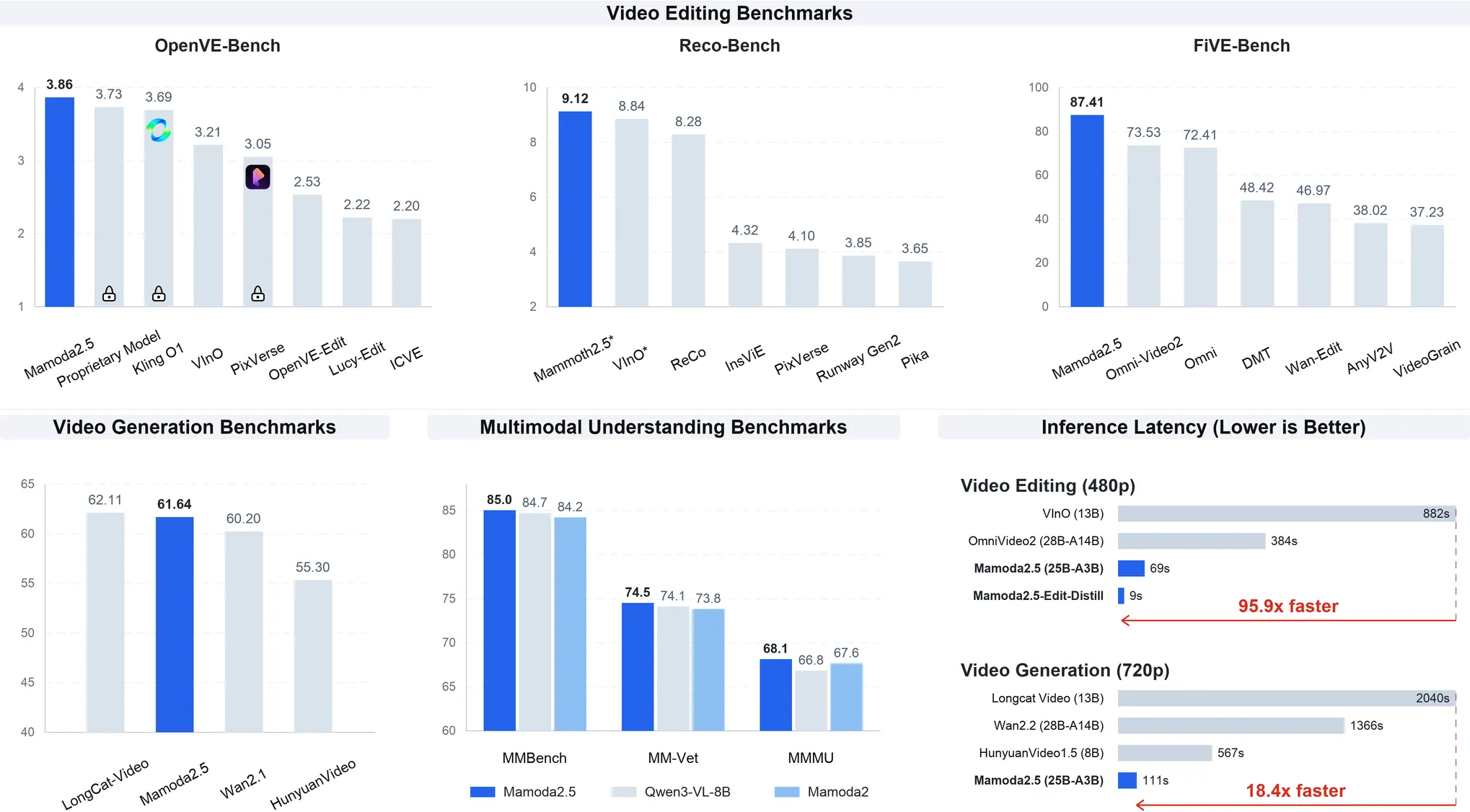
Mamoda2.5: Enhancing Unified Multimodal Model with DiT-MoE
We present Mamoda2.5, a unified AR-Diffusion framework that seamlessly integrates multimodal understanding and generation within a single architecture. To efficiently enhance the model's generation capability, we equip the Diffusion Transformer backbone with a fine-grained Mixture-of-Experts (MoE) design (128 experts, Top-8 routing), yielding a 25B-parameter model that activates only 3B parameters, significantly reducing training costs while scaling up the model capacity. Mamoda2.5 achieves top-tier generation performance on VBench 2.0 and sets a new record in video editing quality, surpassing evaluated open-source models and matching the performance of current top-tier proprietary models, including the Kling O1 on OpenVE-Bench. Furthermore, we introduce a joint few-step distillation and reinforcement learning framework that compresses the 30-step editing model into a 4-step model and greatly accelerates model inference. Compared to open-source baselines, Mamoda2.5 achieves up to $95.9\times$ faster video editing inference. In real-world applications, Mamoda2.5 has been successfully deployed for content moderation and creative restoration tasks in advertising scenarios, achieving a 98% success rate in internal advertising video editing scenario.
2605.02641
May 2026Computer Vision
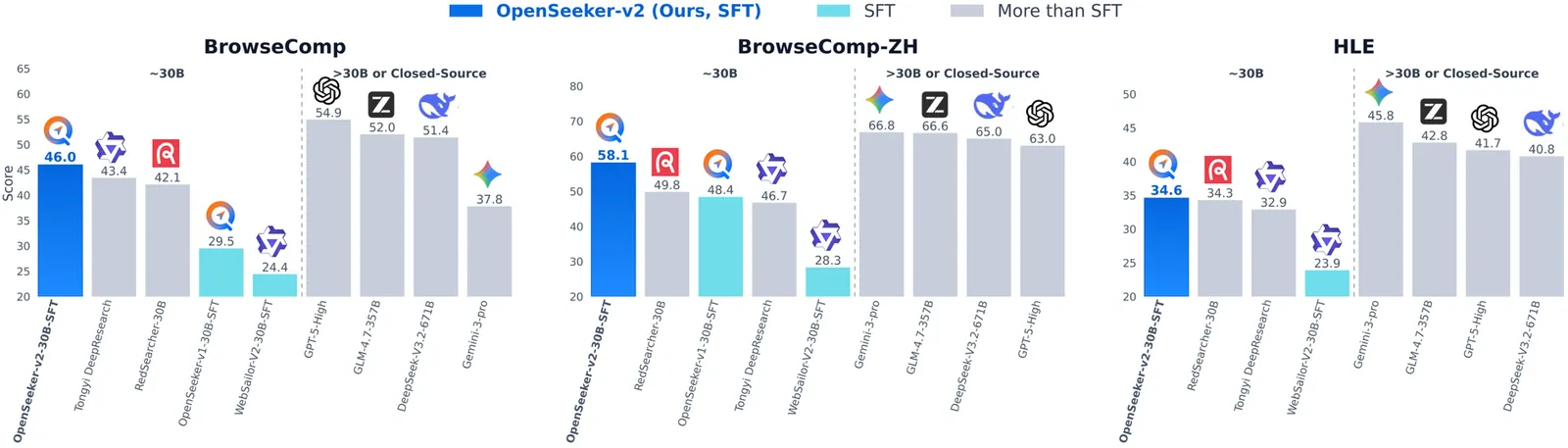
OpenSeeker-v2: Pushing the Limits of Search Agents with Informative and High-Difficulty Trajectories
Deep search capabilities have become an indispensable competency for frontier Large Language Model (LLM) agents, yet their development remains dominated by industrial giants. The typical industry recipe involves a highly resource-intensive pipeline spanning pre-training, continual pre-training (CPT), supervised fine-tuning (SFT), and reinforcement learning (RL). In this report, we show that when fueled with informative and high-difficulty trajectories, a simple SFT approach could be surprisingly powerful for training frontier search agents. By introducing three simple data synthesis modifications: scaling knowledge graph size for richer exploration, expanding the tool set size for broader functionality, and strict low-step filtering, we establish a stronger baseline. Trained on merely 10.6k data points, our OpenSeeker-v2 achieves state-of-the-art performance across 4 benchmarks (30B-sized agents with ReAct paradigm): 46.0% on BrowseComp, 58.1% on BrowseComp-ZH, 34.6% on Humanity's Last Exam, and 78.0% on xbench, surpassing even Tongyi DeepResearch trained with heavy CPT+SFT+RL pipeline, which achieves 43.4%, 46.7%, 32.9%, and 75.0%, respectively. Notably, OpenSeeker-v2 represents the first state-of-the-art search agent within its model scale and paradigm to be developed by a purely academic team using only SFT. We are excited to open-source the OpenSeeker-v2 model weights and share our simple yet effective findings to make frontier search agent research more accessible to the community.
2605.04036
May 2026Artificial Intelligence

HeavySkill: Heavy Thinking as the Inner Skill in Agentic Harness
Recent advances in agentic harness with orchestration frameworks that coordinate multiple agents with memory, skills, and tool use have achieved remarkable success in complex reasoning tasks. However, the underlying mechanism that truly drives performance remains obscured behind intricate system designs. In this paper, we propose HeavySkill, a perspective that views heavy thinking not only as a minimal execution unit in orchestration harness but also as an inner skill internalized within the model's parameters that drives the orchestrator to solve complex tasks. We identify this skill as a two-stage pipeline, i.e., parallel reasoning then summarization, which can operate beneath any agentic harness. We present a systematic empirical study of HeavySkill across diverse domains. Our results show that this inner skill consistently outperforms traditional Best-of-N (BoN) strategies; notably, stronger LLMs can even approach Pass@N performance. Crucially, we demonstrate that the depth and width of heavy thinking, as a learnable skill, can be further scaled via reinforcement learning, offering a promising path toward self-evolving LLMs that internalize complex reasoning without relying on brittle orchestration layers.
2605.02396
May 2026Artificial Intelligence
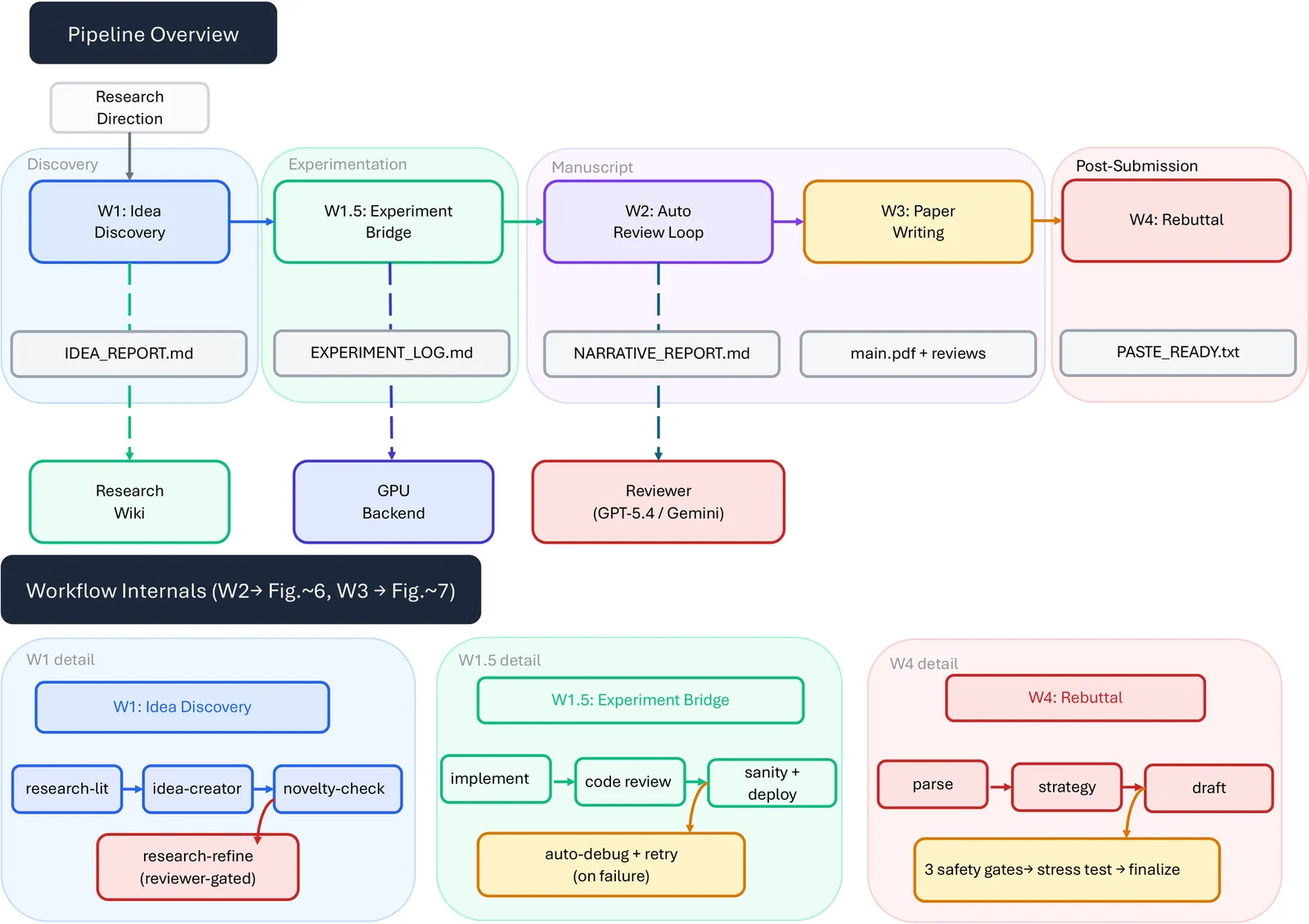
ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
This report describes ARIS (Auto-Research-in-sleep), an open-source research harness for autonomous research, including its architecture, assurance mechanisms, and early deployment experience. The performance of agent systems built on LLMs depends on both the model weights and the harness around them, which governs what information to store, retrieve, and present to the model. For long-horizon research workflows, the central failure mode is not a visible breakdown but a plausible unsupported success: a long-running agent can produce claims whose evidential support is incomplete, misreported, or silently inherited from the executor's framing. Therefore, we present ARIS as a research harness that coordinates machine-learning research workflows through cross-model adversarial collaboration as a default configuration: an executor model drives forward progress while a reviewer from a different model family is recommended to critique intermediate artifacts and request revisions. ARIS has three architectural layers. The execution layer provides more than 65 reusable Markdown-defined skills, model integrations via MCP, a persistent research wiki for iterative reuse of prior findings, and deterministic figure generation. The orchestration layer coordinates five end-to-end workflows with adjustable effort settings and configurable routing to reviewer models. The assurance layer includes a three-stage process for checking whether experimental claims are supported by evidence: integrity verification, result-to-claim mapping, and claim auditing that cross-checks manuscript statements against the claim ledger and raw evidence, as well as a five-pass scientific-editing pipeline, mathematical-proof checks, and visual inspection of the rendered PDF. A prototype self-improvement loop records research traces and proposes harness improvements that are adopted only after reviewer approval.
2605.03042
May 2026Software Engineering

T$^2$PO: Uncertainty-Guided Exploration Control for Stable Multi-Turn Agentic Reinforcement Learning
Recent progress in multi-turn reinforcement learning (RL) has significantly improved reasoning LLMs' performances on complex interactive tasks. Despite advances in stabilization techniques such as fine-grained credit assignment and trajectory filtering, instability remains pervasive and often leads to training collapse. We argue that this instability stems from inefficient exploration in multi-turn settings, where policies continue to generate low-information actions that neither reduce uncertainty nor advance task progress. To address this issue, we propose Token- and Turn-level Policy Optimization (T$^2$PO), an uncertainty-aware framework that explicitly controls exploration at fine-grained levels. At the token level, T$^2$PO monitors uncertainty dynamics and triggers a thinking intervention once the marginal uncertainty change falls below a threshold. At the turn level, T$^2$PO identifies interactions with negligible exploration progress and dynamically resamples such turns to avoid wasted rollouts. We evaluate T$^2$PO in diverse environments, including WebShop, ALFWorld, and Search QA, demonstrating substantial gains in training stability and performance improvements with better exploration efficiency. Code is available at: https://github.com/WillDreamer/T2PO.
2605.02178
May 2026Artificial Intelligence
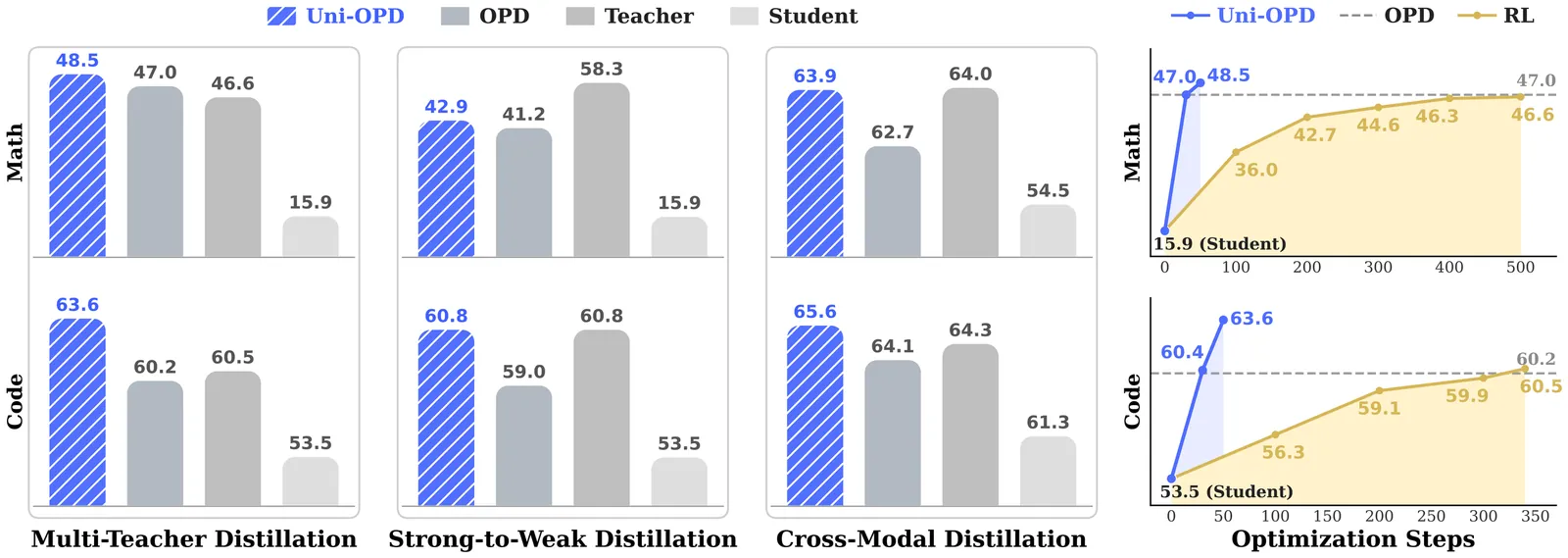
Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe
On-policy distillation (OPD) has recently emerged as an effective post-training paradigm for consolidating the capabilities of specialized expert models into a single student model. Despite its empirical success, the conditions under which OPD yields reliable improvement remain poorly understood. In this work, we identify two fundamental bottlenecks that limit effective OPD: insufficient exploration of informative states and unreliable teacher supervision for student rollouts. Building on this insight, we propose Uni-OPD, a unified OPD framework that generalizes across Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs), centered on a dual-perspective optimization strategy. Specifically, from the student's perspective, we adopt two data balancing strategies to promote exploration of informative student-generated states during training. From the teacher's perspective, we show that reliable supervision hinges on whether aggregated token-level guidance remains order-consistent with the outcome reward. To this end, we develop an outcome-guided margin calibration mechanism to restore order consistency between correct and incorrect trajectories. We conduct extensive experiments on 5 domains and 16 benchmarks covering diverse settings, including single-teacher and multi-teacher distillation across LLMs and MLLMs, strong-to-weak distillation, and cross-modal distillation. Our results verify the effectiveness and versatility of Uni-OPD and provide practical insights into reliable OPD.
2605.03677
May 2026Machine Learning
Audio-Visual Intelligence in Large Foundation Models
Audio-Visual Intelligence (AVI) has emerged as a central frontier in artificial intelligence, bridging auditory and visual modalities to enable machines that can perceive, generate, and interact in the multimodal real world. In the era of large foundation models, joint modeling of audio and vision has become increasingly crucial, i.e., not only for understanding but also for controllable generation and reasoning across dynamic, temporally grounded signals. Recent advances, such as Meta MovieGen and Google Veo-3, highlight the growing industrial and academic focus on unified audio-vision architectures that learn from massive multimodal data. However, despite rapid progress, the literature remains fragmented, spanning diverse tasks, inconsistent taxonomies, and heterogeneous evaluation practices that impede systematic comparison and knowledge integration. This survey provides the first comprehensive review of AVI through the lens of large foundation models. We establish a unified taxonomy covering the broad landscape of AVI tasks, ranging from understanding (e.g., speech recognition, sound localization) to generation (e.g., audio-driven video synthesis, video-to-audio) and interaction (e.g., dialogue, embodied, or agentic interfaces). We synthesize methodological foundations, including modality tokenization, cross-modal fusion, autoregressive and diffusion-based generation, large-scale pretraining, instruction alignment, and preference optimization. Furthermore, we curate representative datasets, benchmarks, and evaluation metrics, offering a structured comparison across task families and identifying open challenges in synchronization, spatial reasoning, controllability, and safety. By consolidating this rapidly expanding field into a coherent framework, this survey aims to serve as a foundational reference for future research on large-scale AVI.
2605.04045
May 2026Computer Vision
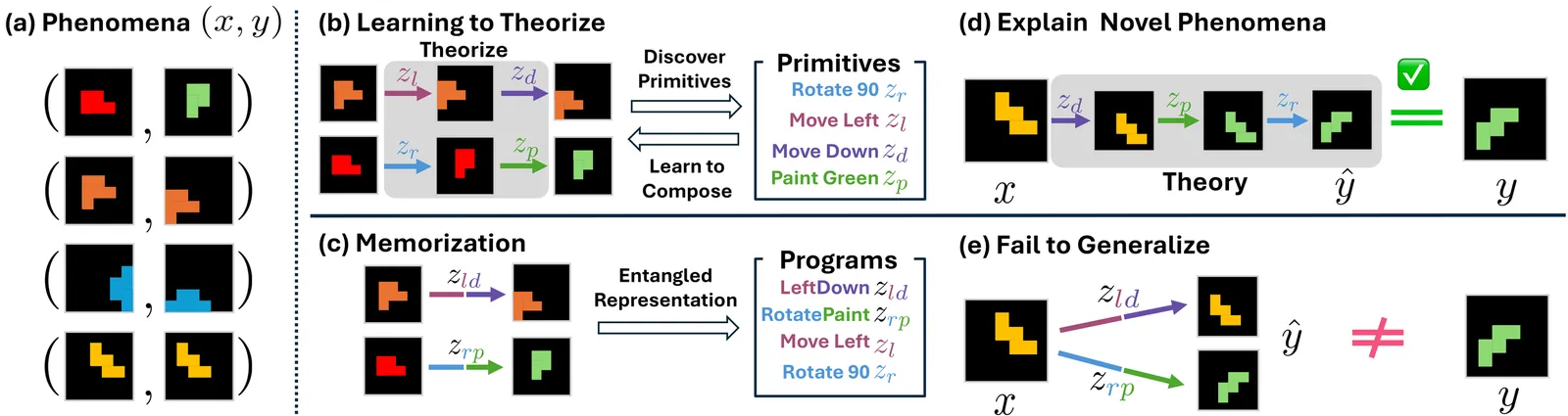
Learning to Theorize the World from Observation
What does it mean to understand the world? Contemporary world models often operationalize understanding as accurate future prediction in latent or observation space. Developmental cognitive science, however, suggests a different view: human understanding emerges through the construction of internal theories of how the world works, even before mature language is acquired. Inspired by this theory-building view of cognition, we introduce Learning-to-Theorize, a learning paradigm for inferring explicit explanatory theories of the world from raw, non-textual observations. We instantiate this paradigm with the Neural Theorizer (NEO), a probabilistic neural model that induces latent programs as a learned Language of Thought and executes them through a shared transition model. In NEO, a theory is represented as an executable, compositional program whose learned primitives can be systematically recombined to explain novel phenomena. Experiments show that this formulation enables explanation-driven generalization, allowing observations to be understood in terms of the programs that generate them.
2605.03413
May 2026Machine Learning
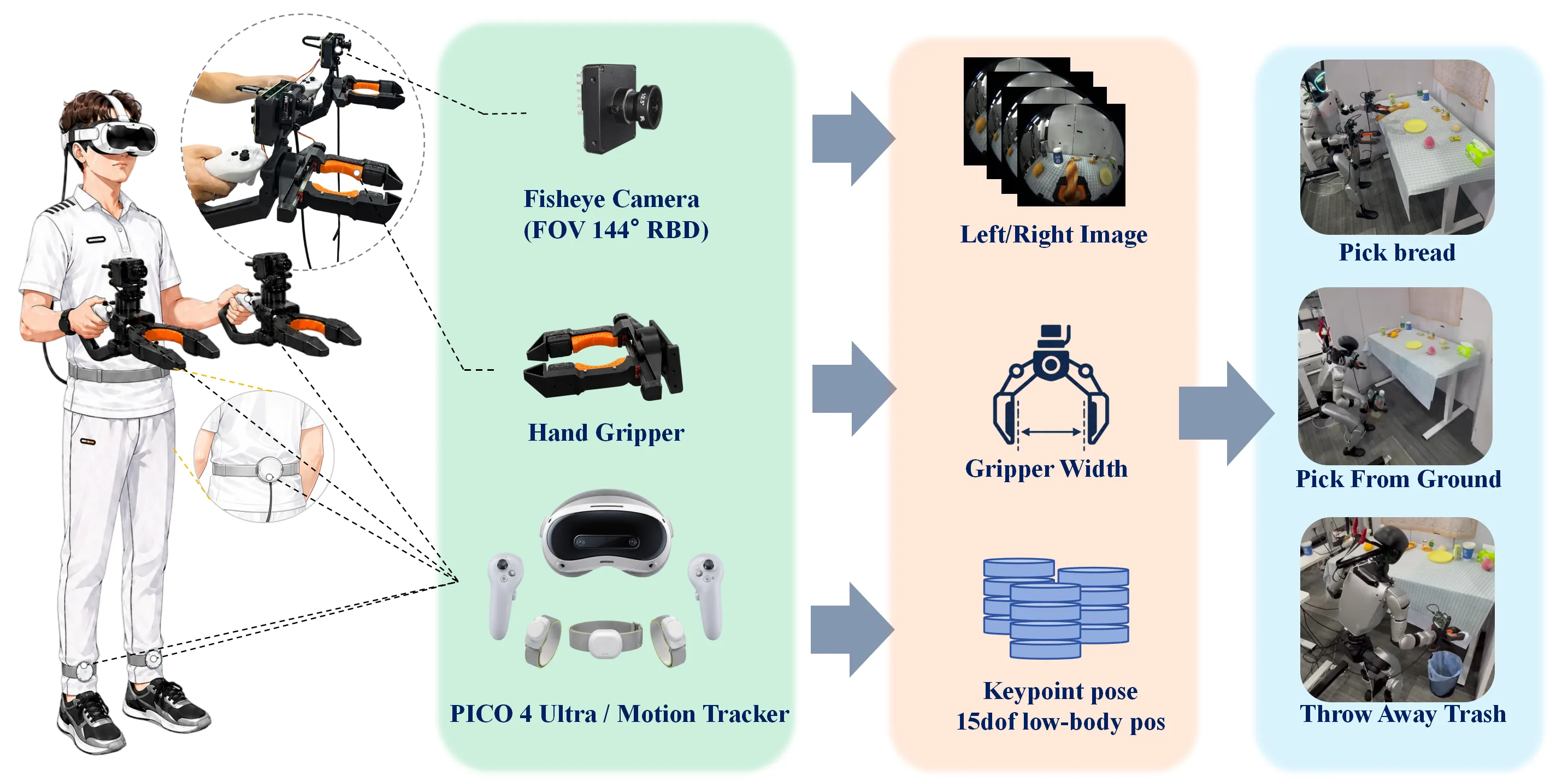
BifrostUMI: Bridging Robot-Free Demonstrations and Humanoid Whole-Body Manipulation
High-quality data collection is a fundamental cornerstone for training humanoid whole-body visuomotor policies. Current data acquisition paradigms predominantly rely on robot teleoperation, which is often hindered by limited hardware accessibility and low operational efficiency. Inspired by the Universal Manipulation Interface (UMI), we propose BifrostUMI, a portable, efficient, and robot-free data collection framework tailored for humanoid robots. BifrostUMI leverages lightweight VR devices to capture human demonstrations as sparse keypoint trajectories while simultaneously recording wrist-mounted visual data. These multimodal data are subsequently utilized to train a high-level policy network that predicts future keypoint trajectories conditioned on the captured visual features. Through a robust keypoint retargeting pipeline, keypoint trajectories are precisely mapped onto the robot's morphology and executed via a whole-body controller. This approach enables the seamless transfer of diverse and agile behaviors from natural human demonstrations to humanoid embodiments. We demonstrate the efficacy and versatility of the proposed framework across two distinct experimental scenarios.
2605.03452
May 2026Robotics
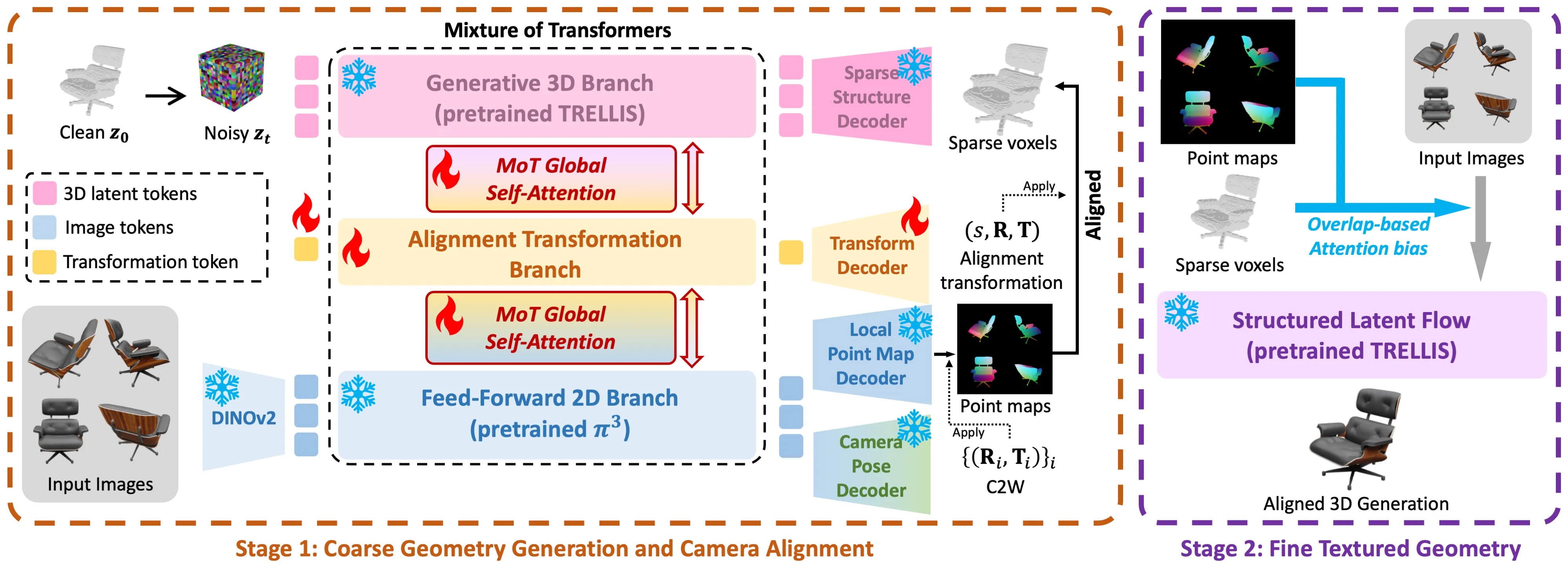
Mix3R: Mixing Feed-forward Reconstruction and Generative 3D Priors for Joint Multi-view Aligned 3D Reconstruction and Pose Estimation
Recent trends in sparse-view 3D reconstruction have taken two different paths: feed-forward reconstruction that predicts pixel-aligned point maps without a complete geometry, and generative 3D reconstruction that generates complete geometry but often with poor input-alignment. We present Mix3R, a novel generative 3D reconstruction method which mixes feed-forward reconstruction and 3D generation into a single framework in an aligned manner. Mix3R generates a 3D shape in two stages: a sparse voxel generation stage and a textured geometry generation stage. Unlike pure generative methods, our first-stage generation jointly produces a coarse 3D structure (sparse voxels), per-view point maps and camera parameters aligned to that 3D structure. This is made possible by introducing a Mixture-of-Transformers architecture that inserts global self-attentions to a feed-forward reconstruction model and a 3D generative model, both pretrained on large-scale data. This design effectively retains the pretrained priors but enables better 2D-3D alignment. Based on the initial aligned generations of sparse 3D voxels and point maps, we compute an overlap-based attention bias that is directly added to another pretrained textured geometry generation model, enabling it to correctly place input textures onto generated shapes in a training-free manner. Our design brings mutual benefits to both feed-forward reconstruction and 3D generation: The feed-forward branch learns to ground its predictions to a generative 3D prior, and conversely, the 3D generation branch is conditioned on geometrically informative features from the feed-forward branch. As a result, our method produces 3D shapes with better input alignment compared with pure 3D generative methods, together with camera pose estimations more accurate than previous feed-forward reconstruction methods. Our project page is at https://jsnln.github.io/mix3r/
2605.03359
May 2026Computer Vision

Perceptual Flow Network for Visually Grounded Reasoning
Despite the success of Large-Vision Language Models (LVLMs), general optimization objectives (e.g., standard MLE) fail to constrain visual trajectories, leading to language bias and hallucination. To mitigate this, current methods introduce geometric priors from visual experts as additional supervision. However, we observe that such supervision is typically suboptimal: it is biased toward geometric precision and offers limited reasoning utility. To bridge this gap, we propose Perceptual Flow Network (PFlowNet), which eschews rigid alignment with the expert priors and achieves interpretable yet more effective visual reasoning. Specifically, PFlowNet decouples perception from reasoning to establish a self-conditioned generation process. Based on this, it integrates multi-dimensional rewards with vicinal geometric shaping via variational reinforcement learning, thereby facilitating reasoning-oriented perceptual behaviors while preserving visual reliability. PFlowNet delivers a provable performance guarantee and competitive empirical results, particularly setting new SOTA records on V* Bench (90.6%) and MME-RealWorld-lite (67.0%).
2605.02730
May 2026Computer Vision
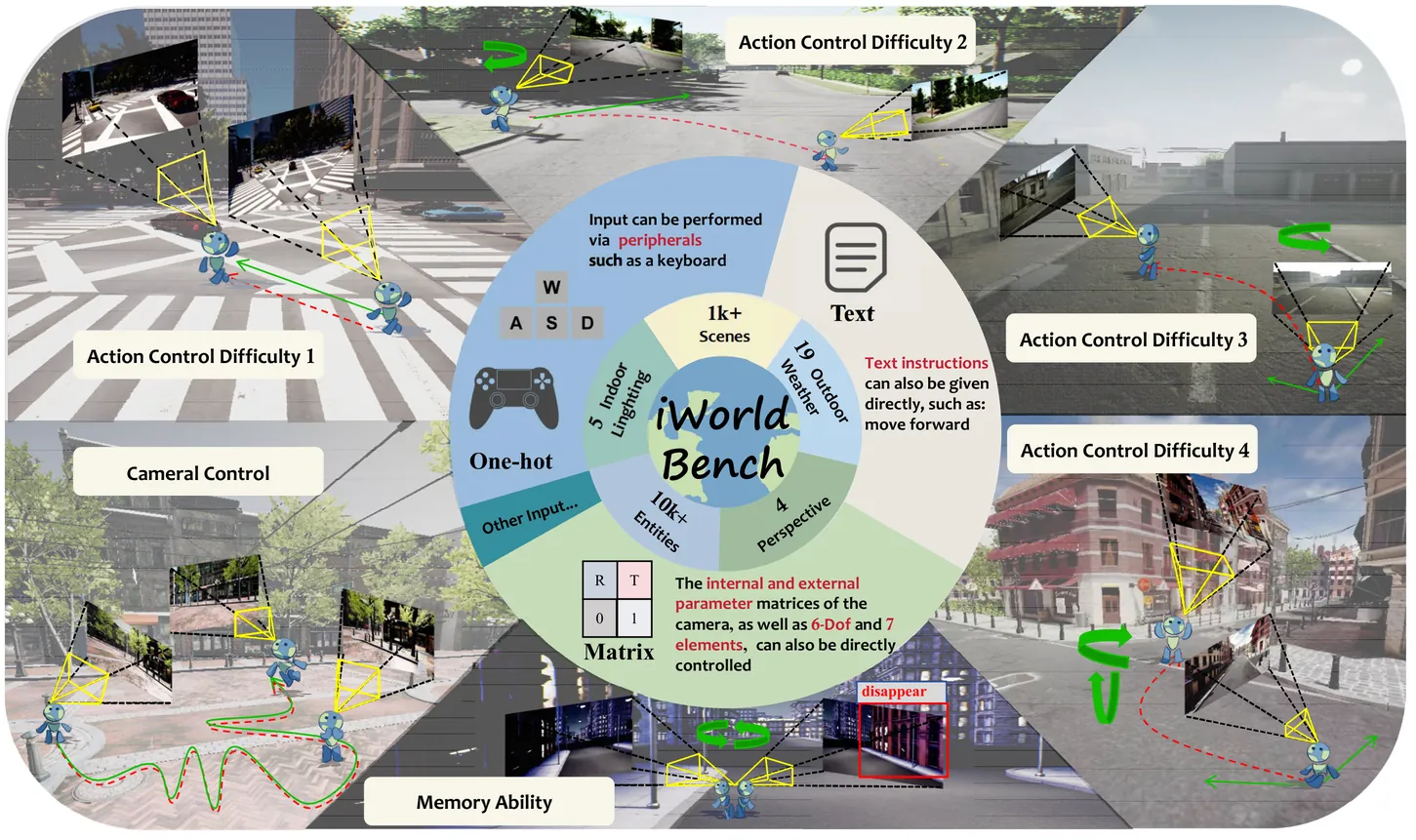
iWorld-Bench: A Benchmark for Interactive World Models with a Unified Action Generation Framework
Achieving Artificial General Intelligence (AGI) requires agents that learn and interact adaptively, with interactive world models providing scalable environments for perception, reasoning, and action. Yet current research still lacks large-scale datasets and unified benchmarks to evaluate their physical interaction capabilities. To address this, we propose iWorld-Bench, a comprehensive benchmark for training and testing world models on interaction-related abilities such as distance perception and memory. We construct a diverse dataset with 330k video clips and select 2.1k high-quality samples covering varied perspectives, weather, and scenes. As existing world models differ in interaction modalities, we introduce an Action Generation Framework to unify evaluation and design six task types, generating 4.9k test samples. These tasks jointly assess model performance across visual generation, trajectory following, and memory. Evaluating 14 representative world models, we identify key limitations and provide insights for future research. The iWorld-Bench model leaderboard is publicly available at iWorld-Bench.com.
2605.03941
May 2026Computer Vision
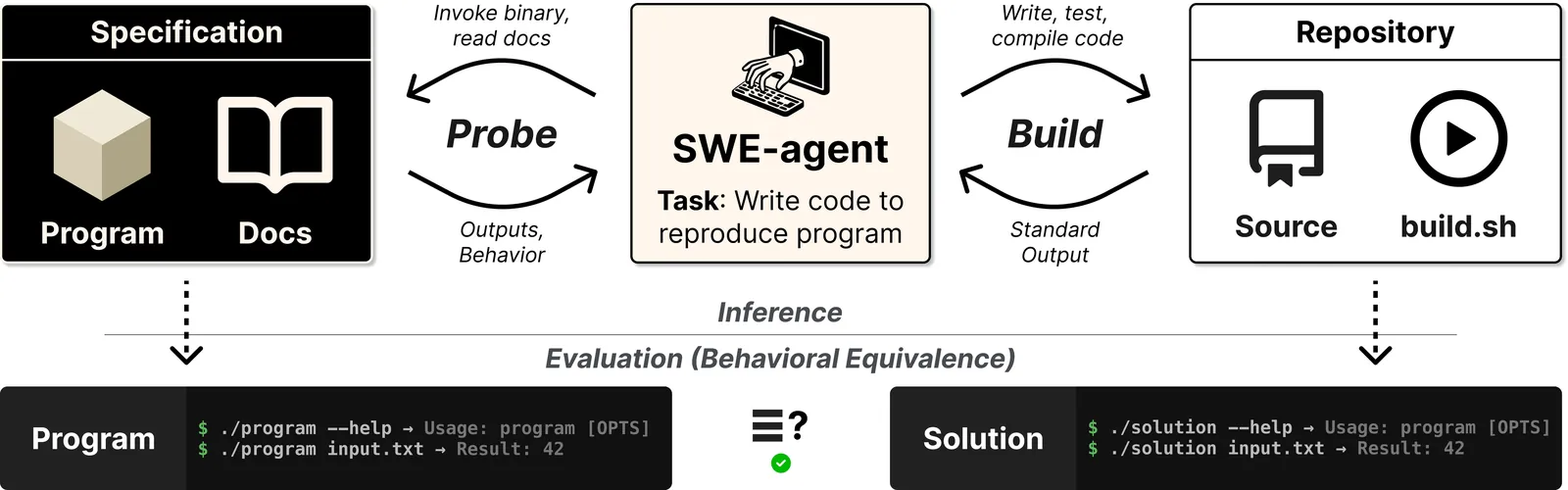
ProgramBench: Can Language Models Rebuild Programs From Scratch?
Turning ideas into full software projects from scratch has become a popular use case for language models. Agents are being deployed to seed, maintain, and grow codebases over extended periods with minimal human oversight. Such settings require models to make high-level software architecture decisions. However, existing benchmarks measure focused, limited tasks such as fixing a single bug or developing a single, specified feature. We therefore introduce ProgramBench to measure the ability of software engineering agents to develop software holisitically. In ProgramBench, given only a program and its documentation, agents must architect and implement a codebase that matches the reference executable's behavior. End-to-end behavioral tests are generated via agent-driven fuzzing, enabling evaluation without prescribing implementation structure. Our 200 tasks range from compact CLI tools to widely used software such as FFmpeg, SQLite, and the PHP interpreter. We evaluate 9 LMs and find that none fully resolve any task, with the best model passing 95\% of tests on only 3\% of tasks. Models favor monolithic, single-file implementations that diverge sharply from human-written code.
2605.03546
May 2026Software Engineering
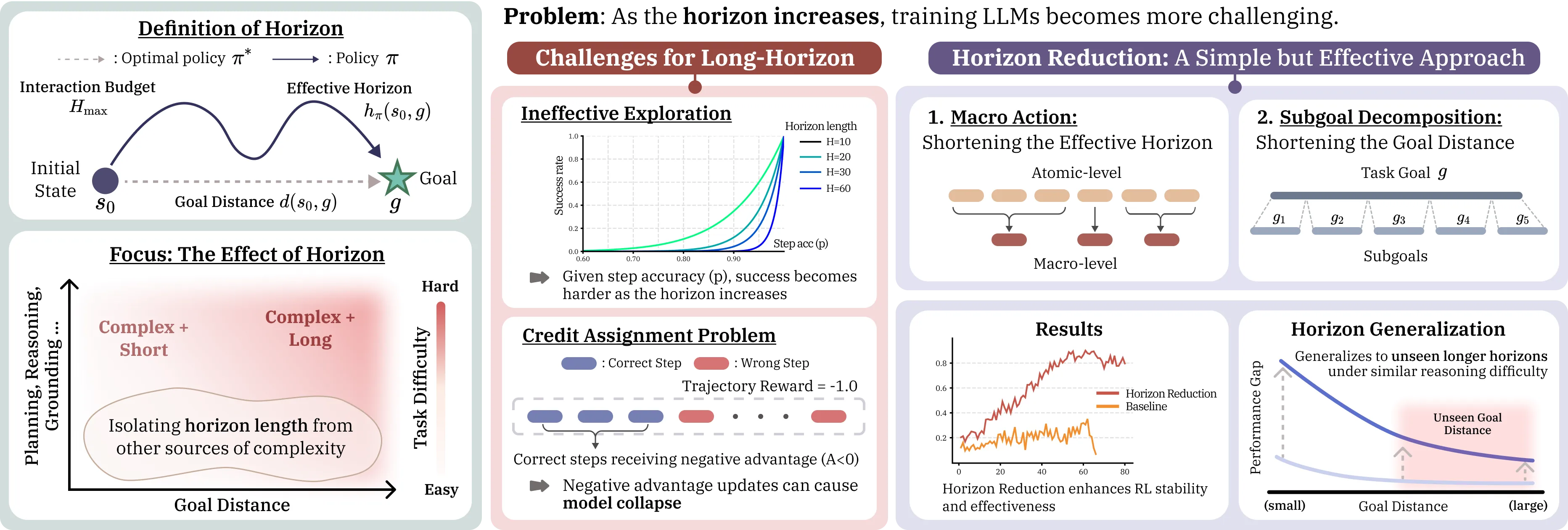
On Training Large Language Models for Long-Horizon Tasks: An Empirical Study of Horizon Length
Large language models (LLMs) have shown promise as interactive agents that solve tasks through extended sequences of environment interactions. While prior work has primarily focused on system-level optimizations or algorithmic improvements, the role of task horizon length in shaping training dynamics remains poorly understood. In this work, we present a systematic empirical study that examines horizon length through controlled task constructions. Specifically, we construct controlled tasks in which agents face identical decision rules and reasoning structures, but differ only in the length of action sequences required for successful completion. Our results reveal that increasing horizon length alone constitutes a training bottleneck, inducing severe training instability driven by exploration difficulties and credit assignment challenges. We demonstrate that horizon reduction is a key principle to address this limitation, stabilizing training and achieving better performance in long-horizon tasks. Moreover, we find that horizon reduction is related to stronger generalization across horizon lengths: models trained under reduced horizons generalize more effectively to longer-horizon variants at inference time, a phenomenon we refer to as horizon generalization.
2605.02572
May 2026Artificial Intelligence
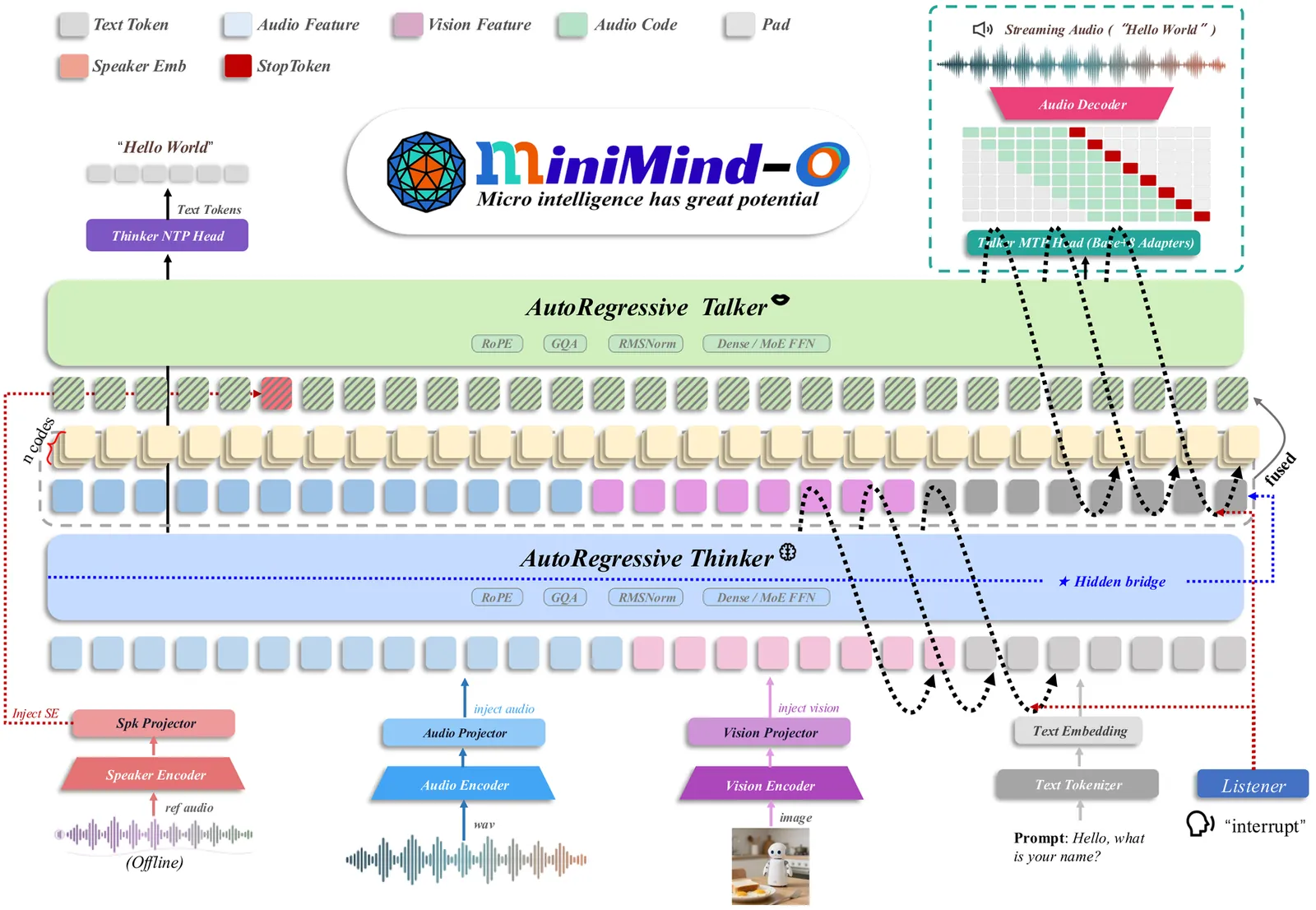
MiniMind-O Technical Report: An Open Small-Scale Speech-Native Omni Model
MiniMind-O is an open 0.1B-scale omni model built on the MiniMind language model. It accepts text, speech, and image inputs, and returns both text and streaming speech. The release includes model code, checkpoints, and the main Parquet training datasets for text-to-audio, image-to-text, and audio-to-audio training, making the complete interaction loop directly inspectable. The model uses a full MiniMind backbone as the Thinker and an independent four-layer Talker made from MiniMind blocks. Frozen SenseVoice-Small and SigLIP2 encoders provide speech and image features, which are mapped by lightweight MLP projectors and injected at modality-placeholder positions. The Talker reads a middle-layer Thinker state together with an autoregressive eight-layer Mimi-code buffer. Speaker control is handled by a dedicated speaker token, right-aligned reference codec prompts, and precomputed CAM++ speaker embeddings, so voice conditioning remains part of the audio-code context rather than a separate TTS module. With a 768-dimensional Talker, the dense and MoE variants reach average CERs of 0.0897 and 0.0900 in Thinker--Talker consistency evaluation, with overall voice-cloning similarities of 0.5995 and 0.5937. Beyond reporting a working system, the paper identifies three scale-critical design choices for small omni models: middle-layer semantic bridging, a released multimodal sequence format, and a parameter-efficient eight-codebook interface.
2605.03937
May 2026Sound
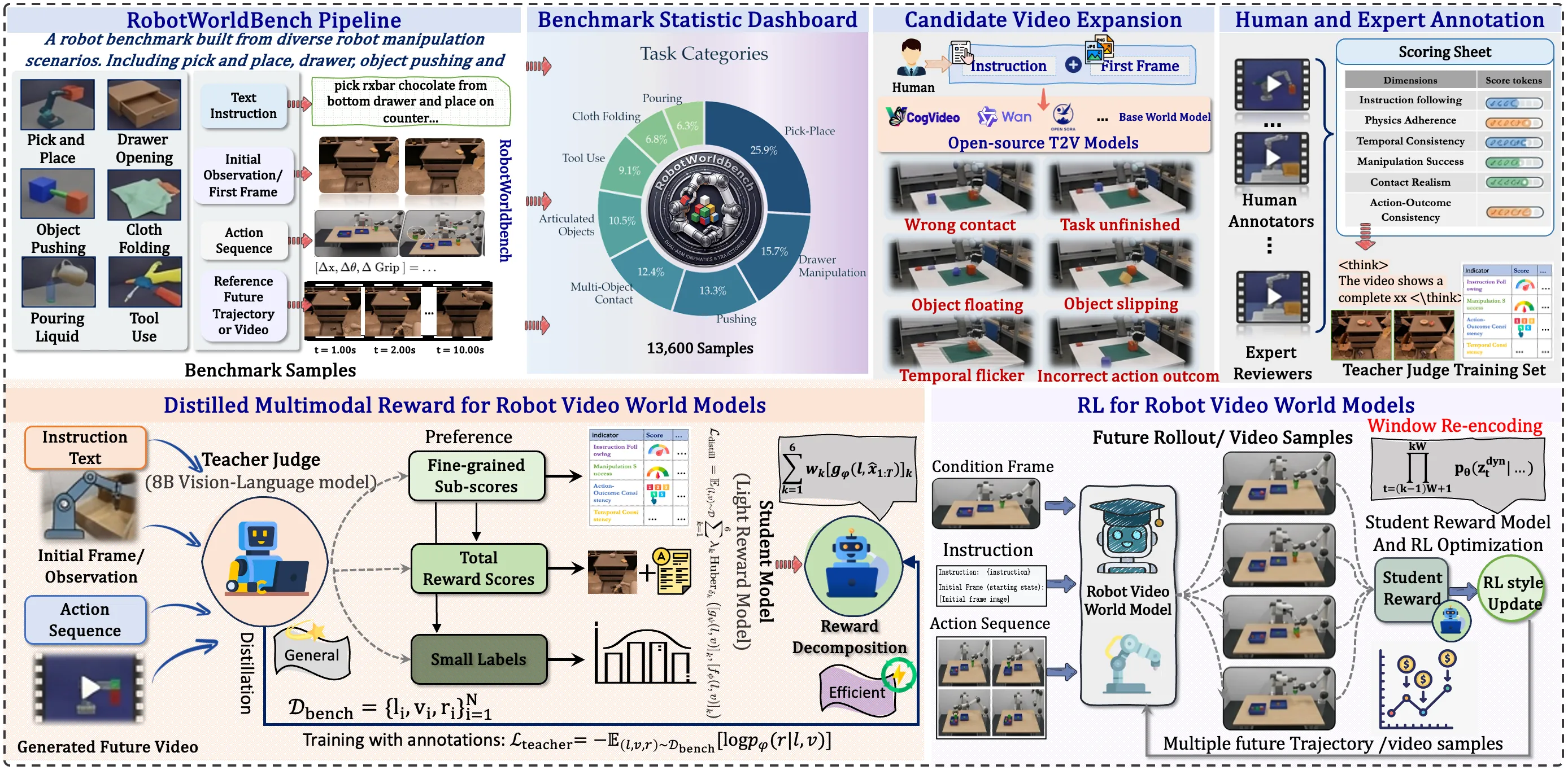
RoboAlign-R1: Distilled Multimodal Reward Alignment for Robot Video World Models
Existing robot video world models are typically trained with low-level objectives such as reconstruction and perceptual similarity, which are poorly aligned with the capabilities that matter most for robot decision making, including instruction following, manipulation success, and physical plausibility. They also suffer from error accumulation in long-horizon autoregressive prediction. We present RoboAlign-R1, a framework that combines reward-aligned post-training with stabilized long-horizon inference for robot video world models. We construct RobotWorldBench, a benchmark of 10,000 annotated video-instruction pairs collected from four robot data sources, and train a multimodal teacher judge, RoboAlign-Judge, to provide fine-grained six-dimensional evaluation of generated videos. We then distill the teacher into a lightweight student reward model for efficient reinforcement-learning-based post-training. To reduce long-horizon rollout drift, we further introduce Sliding Window Re-encoding (SWR), a training-free inference strategy that periodically refreshes the generation context. Under our in-domain evaluation protocol, RoboAlign-R1 improves the aggregate six-dimension score by 10.1% over the strongest baseline, including gains of 7.5% on Manipulation Accuracy and 4.6% on Instruction Following; these ranking improvements are further supported by an external VLM-based cross-check and a blinded human study. Meanwhile, SWR improves long-horizon prediction quality with only about 1% additional latency, yielding a 2.8% gain in SSIM and a 9.8% reduction in LPIPS. Together, these results show that reward-aligned post-training and stabilized long-horizon decoding improve task consistency, physical realism, and long-horizon prediction quality in robot video world models.
2605.03821
May 2026Robotics

Linearizing Vision Transformer with Test-Time Training
While linear-complexity attention mechanisms offer a promising alternative to Softmax attention for overcoming the quadratic bottleneck, training such models from scratch remains prohibitively expensive. Inheriting weights from pretrained Transformers provides an appealing shortcut, yet the fundamental representational gap between Softmax and linear attention prevents effective weight transfer. In this work, we address this conversion challenge from two perspectives: architectural alignment and representational alignment. We identify Test-Time Training (TTT) as a linear-complexity architecture whose two-layer dynamic formulation is structurally aligned with Softmax attention, enabling direct inheritance of pretrained attention weights. To further align representational properties, including key shift-invariance and locality, we introduce key instance normalization and a lightweight locality enhancement module. We validate our approach by linearizing Stable Diffusion 3.5 and introduce SD3.5-T$^5$ (Transformer To Test Time Training). With only 1 hour of fine-tuning on 4$\times$H20 GPUs, SD3.5-T$^5$ achieves comparable text-to-image quality to the fine-tuned Softmax model, while accelerating inference by 1.32$\times$ and 1.47$\times$ at 1K and 2K resolutions.
2605.02772
May 2026Computer Vision
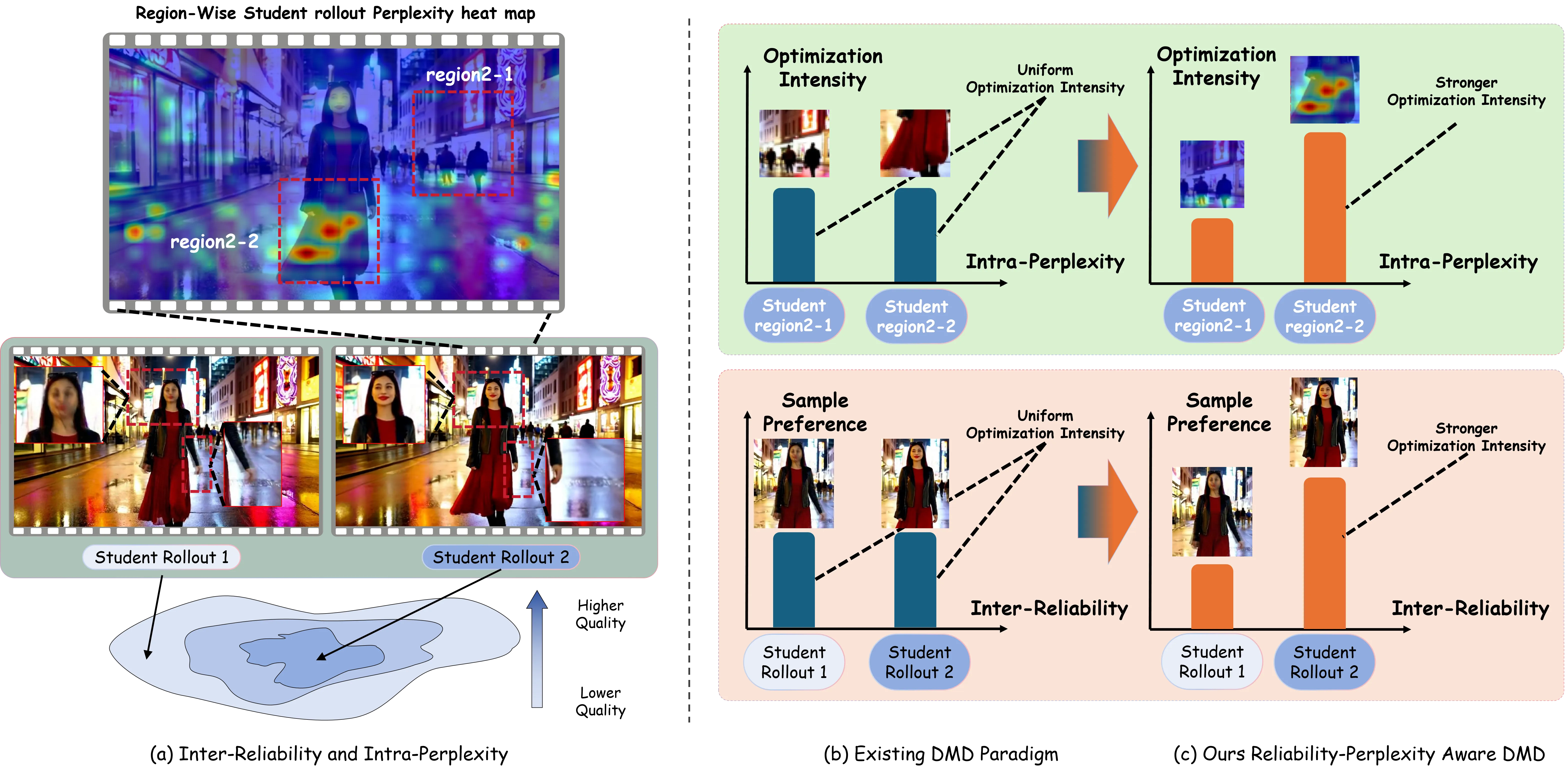
Stream-R1: Reliability-Perplexity Aware Reward Distillation for Streaming Video Generation
Distillation-based acceleration has become foundational for making autoregressive streaming video diffusion models practical, with distribution matching distillation (DMD) as the de facto choice. Existing methods, however, train the student to match the teacher's output indiscriminately, treating every rollout, frame, and pixel as equally reliable supervision. We argue that this caps distilled quality, since it overlooks two complementary axes of variance in DMD supervision: Inter-Reliability across student rollouts whose supervision varies in reliability, and Intra-Perplexity across spatial regions and temporal frames that contribute unequally to where quality can still be improved. The objective thus conflates two questions under a uniform weight: whether to learn from each rollout, and where to concentrate optimization within it. To address this, we propose Stream-R1, a Reliability-Perplexity Aware Reward Distillation framework that adaptively reweights the distillation objective at both rollout and spatiotemporal-element levels through a single shared reward-guided mechanism. At the Inter-Reliability level, Stream-R1 rescales each rollout's loss by an exponential of a pretrained video reward score, so that rollouts with reliable supervision dominate optimization. At the Intra-Perplexity level, it back-propagates the same reward model to extract per-pixel gradient saliency, which is factored into spatial and temporal weights that concentrate optimization pressure on regions and frames where refinement yields the largest expected gain. An adaptive balancing mechanism prevents any single quality axis from dominating across visual quality, motion quality, and text alignment. Stream-R1 attains consistent improvements on all three dimensions over distillation baselines on standard streaming video generation benchmarks, without architectural modification or additional inference cost.
2605.03849
May 2026Computer Vision