Digital Libraries
arXiv:cs.DL
Covers all aspects of the digital library design and document and text creation.
Covers all aspects of the digital library design and document and text creation.

We introduce LongDA, a data analysis benchmark for evaluating LLM-based agents under documentation-intensive analytical workflows. In contrast to existing benchmarks that assume well-specified schemas and inputs, LongDA targets real-world settings in which navigating long documentation and complex data is the primary bottleneck. To this end, we manually curate raw data files, long and heterogeneous documentation, and expert-written publications from 17 publicly available U.S. national surveys, from which we extract 505 analytical queries grounded in real analytical practice. Solving these queries requires agents to first retrieve and integrate key information from multiple unstructured documents, before performing multi-step computations and writing executable code, which remains challenging for existing data analysis agents. To support the systematic evaluation under this setting, we develop LongTA, a tool-augmented agent framework that enables document access, retrieval, and code execution, and evaluate a range of proprietary and open-source models. Our experiments reveal substantial performance gaps even among state-of-the-art models, highlighting the challenges researchers should consider before applying LLM agents for decision support in real-world, high-stakes analytical settings.

The adoption of artificial intelligence in dermatology promises democratized access to healthcare, but model reliability depends on the quality and comprehensiveness of the data fueling these models. Despite rapid growth in publicly available dermatology images, the field lacks quantitative key performance indicators to measure whether new datasets expand clinical coverage or merely replicate what is already known. Here we present SkinMap, a multi-modal framework for the first comprehensive audit of the field's entire data basis. We unify the publicly available dermatology datasets into a single, queryable semantic atlas comprising more than 1.1 million images of skin conditions and quantify (i) informational novelty over time, (ii) dataset redundancy, and (iii) representation gaps across demographics and diagnoses. Despite exponential growth in dataset sizes, informational novelty across time has somewhat plateaued: Some clusters, such as common neoplasms on fair skin, are densely populated, while underrepresented skin types and many rare diseases remain unaddressed. We further identify structural gaps in coverage: Darker skin tones (Fitzpatrick V-VI) constitute only 5.8% of images and pediatric patients only 3.0%, while many rare diseases and phenotype combinations remain sparsely represented. SkinMap provides infrastructure to measure blind spots and steer strategic data acquisition toward undercovered regions of clinical space.
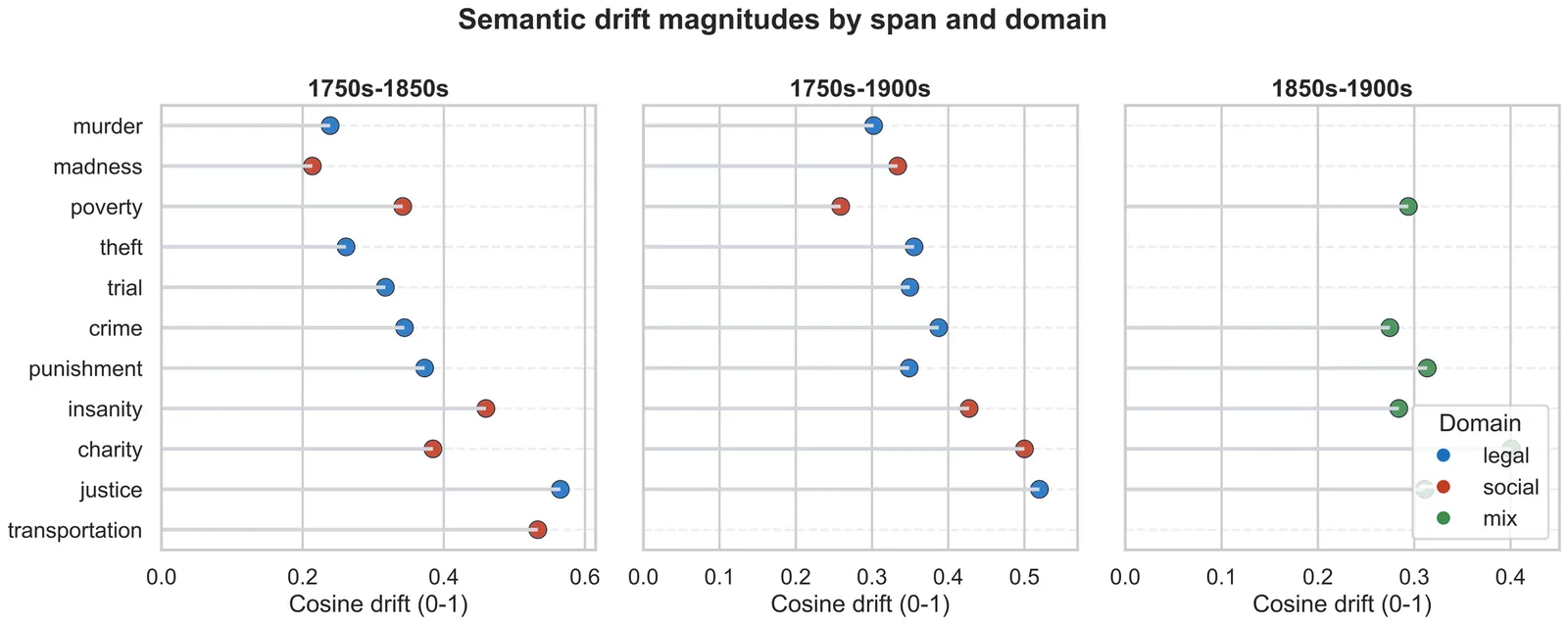
Digital-humanities work on semantic shift often alternates between handcrafted close readings and opaque embedding machinery. We present a reproducible expert-system style pipeline that quantifies and visualises lexical drift in the Old Bailey Corpus (1720--1913), coupling interpretable trajectories with legally meaningful axes. We bin proceedings by decade with dynamic merging for low-resource slices, train skip-gram embeddings, align spaces through orthogonal Procrustes, and measure both geometric displacement and neighborhood turnover. Three visual analytics outputs, which are drift magnitudes, semantic trajectories, and movement along a mercy-versus-retribution axis, expose how justice, crime, poverty, and insanity evolve with penal reforms, transportation debates, and Victorian moral politics. The pipeline is implemented as auditable scripts so results can be reproduced in other historical corpora.
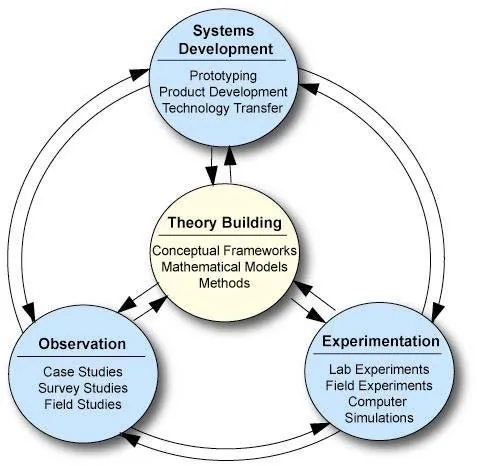
The unprecedented proliferation of digital data presents significant challenges in access, integration, and value creation across all data-intensive sectors. Valuable information is frequently encapsulated within disparate systems, unstructured documents, and heterogeneous formats, creating silos that impede efficient utilization and collaborative decision-making. This paper introduces the Intelligent Knowledge Mining Framework (IKMF), a comprehensive conceptual model designed to bridge the critical gap between dynamic AI-driven analysis and trustworthy long-term preservation. The framework proposes a dual-stream architecture: a horizontal Mining Process that systematically transforms raw data into semantically rich, machine-actionable knowledge, and a parallel Trustworthy Archiving Stream that ensures the integrity, provenance, and computational reproducibility of these assets. By defining a blueprint for this symbiotic relationship, the paper provides a foundational model for transforming static repositories into living ecosystems that facilitate the flow of actionable intelligence from producers to consumers. This paper outlines the motivation, problem statement, and key research questions guiding the research and development of the framework, presents the underlying scientific methodology, and details its conceptual design and modeling.
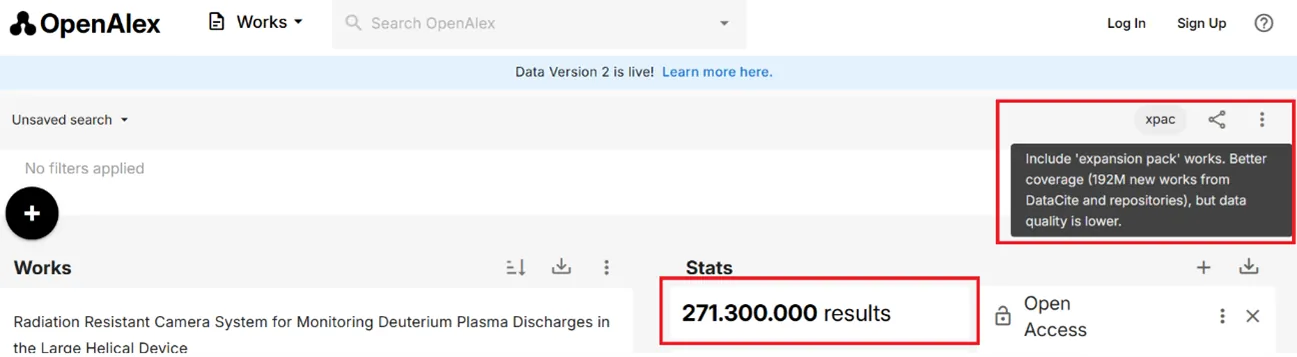
OpenAlex is an open bibliographic database that has been proposed as an alternative to commercial platforms in a context defined by the aim of transforming science evaluation systems into more transparent sources based on open data. This paper analyses its features, information sources, entities, advantages and limitations. The results reveal numerous records lacking abstracts, affiliations and references; deficiencies in identifying document types and languages; and issues with authority control and versioning. Although OpenAlex has been adopted in important initiatives and has yielded results comparable to those obtained with commercial databases, gaps in its metadata and a lack of consistency point to a need for intensive data cleaning, suggesting it should be used with caution. The study concludes by identifying three lines of action to improve data quality: increasing publishers' commitment to completing metadata in primary sources; creating coordination structures to channel the contributions of institutional users; and endowing the project with sufficient human resources and reliable procedures to address internal quality control tasks and user support requests.
Large-scale digitization initiatives have unlocked massive collections of historical newspapers, yet effective computational access remains hindered by OCR corruption, multilingual orthographic variation, and temporal language drift. We develop and evaluate a multilingual Retrieval-Augmented Generation pipeline specifically designed for question answering on noisy historical documents. Our approach integrates: (i) semantic query expansion and multi-query fusion using Reciprocal Rank Fusion to improve retrieval robustness against vocabulary mismatch; (ii) a carefully engineered generation prompt that enforces strict grounding in retrieved evidence and explicit abstention when evidence is insufficient; and (iii) a modular architecture enabling systematic component evaluation. We conduct comprehensive ablation studies on Named Entity Recognition and embedding model selection, demonstrating the importance of syntactic coherence in entity extraction and balanced performance-efficiency trade-offs in dense retrieval. Our end-to-end evaluation framework shows that the pipeline generates faithful answers for well-supported queries while correctly abstaining from unanswerable questions. The hybrid retrieval strategy improves recall stability, particularly benefiting from RRF's ability to smooth performance variance across query formulations. We release our code and configurations at https://anonymous.4open.science/r/RAGs-C5AE/, providing a reproducible foundation for robust historical document question answering.
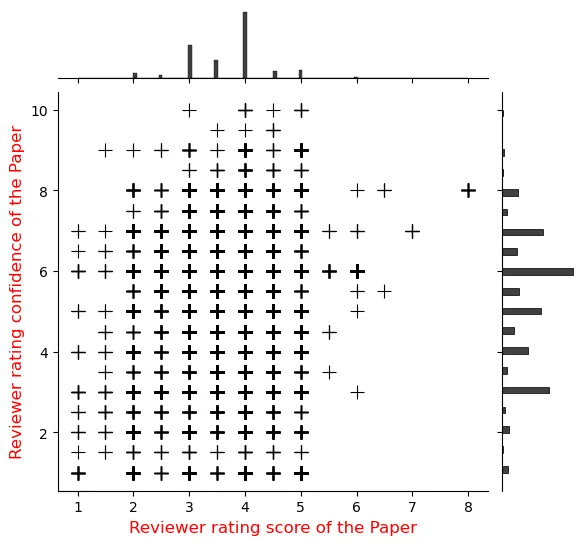
Large Language Models are versatile general-task solvers, and their capabilities can truly assist people with scholarly peer review as \textit{pre-review} agents, if not as fully autonomous \textit{peer-review} agents. While incredibly beneficial, automating academic peer-review, as a concept, raises concerns surrounding safety, research integrity, and the validity of the academic peer-review process. The majority of the studies performing a systematic evaluation of frontier LLMs generating reviews across science disciplines miss the mark on addressing the alignment/misalignment of reviews along with the utility of LLM generated reviews when compared against publication outcomes such as \textbf{Citations}, \textbf{Hit-papers}, \textbf{Novelty}, and \textbf{Disruption}. This paper presents an experimental study in which we gathered ground-truth reviewer ratings from OpenReview and used various frontier open-weight LLMs to generate reviews of papers to gauge the safety and reliability of incorporating LLMs into the scientific review pipeline. Our findings demonstrate the utility of frontier open-weight LLMs as pre-review screening agents despite highlighting fundamental misalignment risks when deployed as autonomous reviewers. Our results show that all models exhibit weak correlation with human peer reviewers (0.15), with systematic overestimation bias of 3-5 points and uniformly high confidence scores (8.0-9.0/10) despite prediction errors. However, we also observed that LLM reviews correlate more strongly with post-publication metrics than with human scores, suggesting potential utility as pre-review screening tools. Our findings highlight the potential and address the pitfalls of automating peer reviews with language models. We open-sourced our dataset $D_{LMRSD}$ to help the research community expand the safety framework of automating scientific reviews.
For scientific knowledge to be findable, accessible, interoperable, and reusable, it needs to be machine-readable. Moving forward from post-publication extraction of knowledge, we adopted a pre-publication approach to write research findings in a machine-readable format at early stages of data analysis. For this purpose, we developed the package dtreg in Python and R. Registered and persistently identified data types, aka schemata, which dtreg applies to describe data analysis in a machine-readable format, cover the most widely used statistical tests and machine learning methods. The package supports (i) downloading a relevant schema as a mutable instance of a Python or R class, (ii) populating the instance object with metadata about data analysis, and (iii) converting the object into a lightweight Linked Data format. This paper outlines the background of our approach, explains the code architecture, and illustrates the functionality of dtreg with a machine-readable description of a t-test on Iris Data. We suggest that the dtreg package can enhance the methodological repertoire of researchers aiming to adhere to the FAIR principles.

We present BookReconciler, an open-source tool for enhancing and clustering book data. BookReconciler allows users to take spreadsheets with minimal metadata, such as book title and author, and automatically 1) add authoritative, persistent identifiers like ISBNs 2) and cluster related Expressions and Manifestations of the same Work, e.g., different translations or editions. This enhancement makes it easier to combine related collections and analyze books at scale. The tool is currently designed as an extension for OpenRefine -- a popular software application -- and connects to major bibliographic services including the Library of Congress, VIAF, OCLC, HathiTrust, Google Books, and Wikidata. Our approach prioritizes human judgment. Through an interactive interface, users can manually evaluate matches and define the contours of a Work (e.g., to include translations or not). We evaluate reconciliation performance on datasets of U.S. prize-winning books and contemporary world fiction. BookReconciler achieves near-perfect accuracy for U.S. works but lower performance for global texts, reflecting structural weaknesses in bibliographic infrastructures for non-English and global literature. Overall, BookReconciler supports the reuse of bibliographic data across domains and applications, contributing to ongoing work in digital libraries and digital humanities.
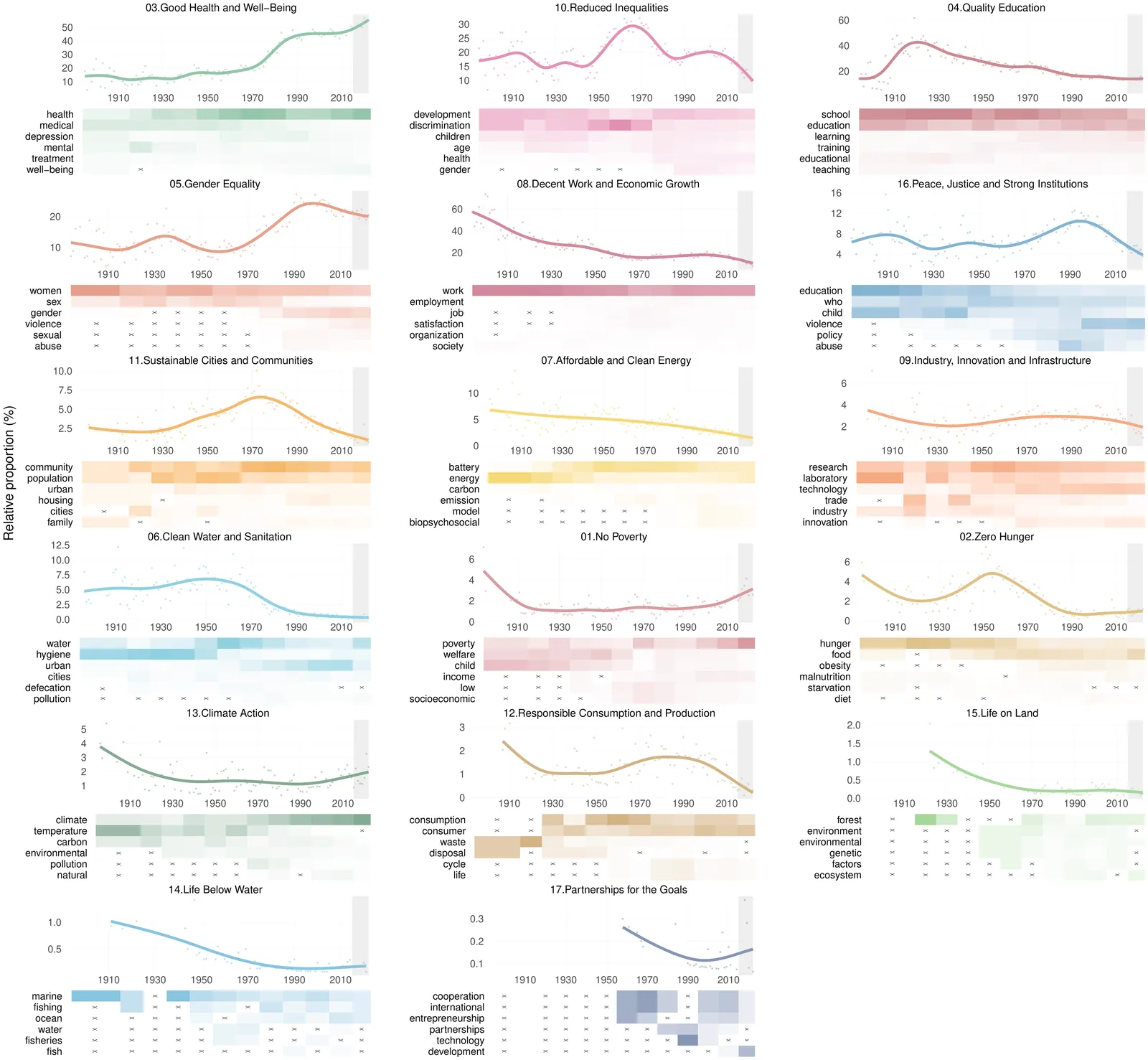
The Sustainable Development Goals (SDGs) offer a lens for tracking societal change, yet contributions from the social and behavioral sciences have rarely been integrated into policy agendas. To take stock and create a baseline and benchmark for the future, we assemble 233,061 psychology publications (1894 -- 2022) and tag them to the 17 SDGs using a query-based classifier. Health, education, work, inequality, and gender dominate the study of SDGs in psychology, shifting from an early focus on work to education and inequality, and since the 1960s, health. United States-based research leads across most goals. Other countries set distinct priorities (e.g., China: education and work; Australia: health). Women comprise about one-third of authors, concentrated in social and health goals, but have been underrepresented in STEM-oriented goals. The 2015 launch of the SDGs marked a turning point: SDG-tagged publications have been receiving more citations than comparable non-SDG work, reversing a pre-2015 deficit. Tracking the SDGs through psychology clarifies long-run engagement with social priorities, identifies evidence gaps, and guides priorities to accelerate the field's contribution to the SDG agenda.
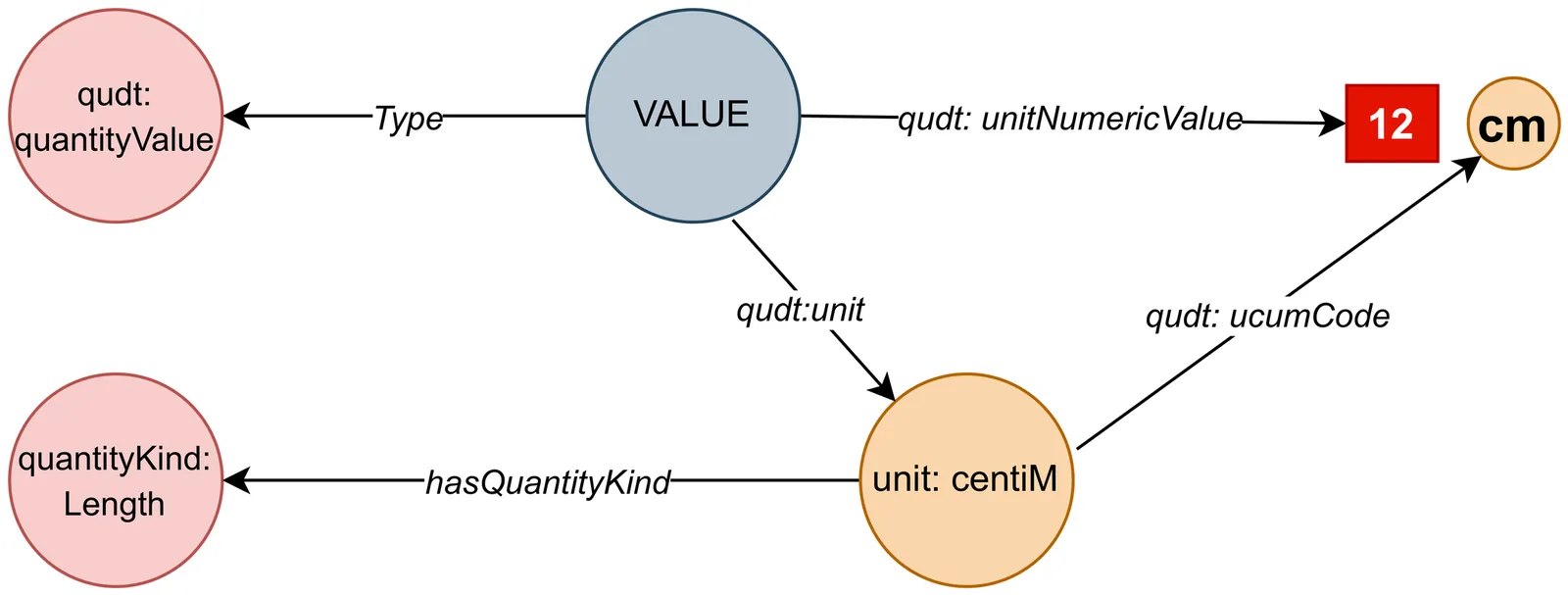
Scientists have always used the studies and research of other researchers to achieve new objectives and perspectives. In particular, employing and operating the measured data in previous studies is so practical. Searching the content of other scientists' articles is a challenge that researchers have always struggled with. Nowadays, the use of knowledge graphs as a semantic database has helped a lot in saving and retrieving scholarly knowledge. Such technologies are crucial to upgrading traditional search systems to smart knowledge retrieval, which is crucial to getting the most relevant answers for a user query, especially in information and knowledge management. However, in most cases, only the metadata of a paper is searchable, and it is still cumbersome for scientists to have access to the content of the papers. In this paper, we present a novel method of faceted search \emph{structured content} for comparing and filtering measured data in scholarly knowledge graphs while different units of measurement are used in different studies. This search system proposes applicable units as facets to the user and would dynamically integrate content from further remote knowledge graphs to materialize the scholarly knowledge graph and achieve a higher order of exploration usability on scholarly content, which can be filtered to better satisfy the user's information needs. The state of the art is that, by using our faceted search system, users can not only search the contents of scientific articles, but also compare and filter heterogeneous data.
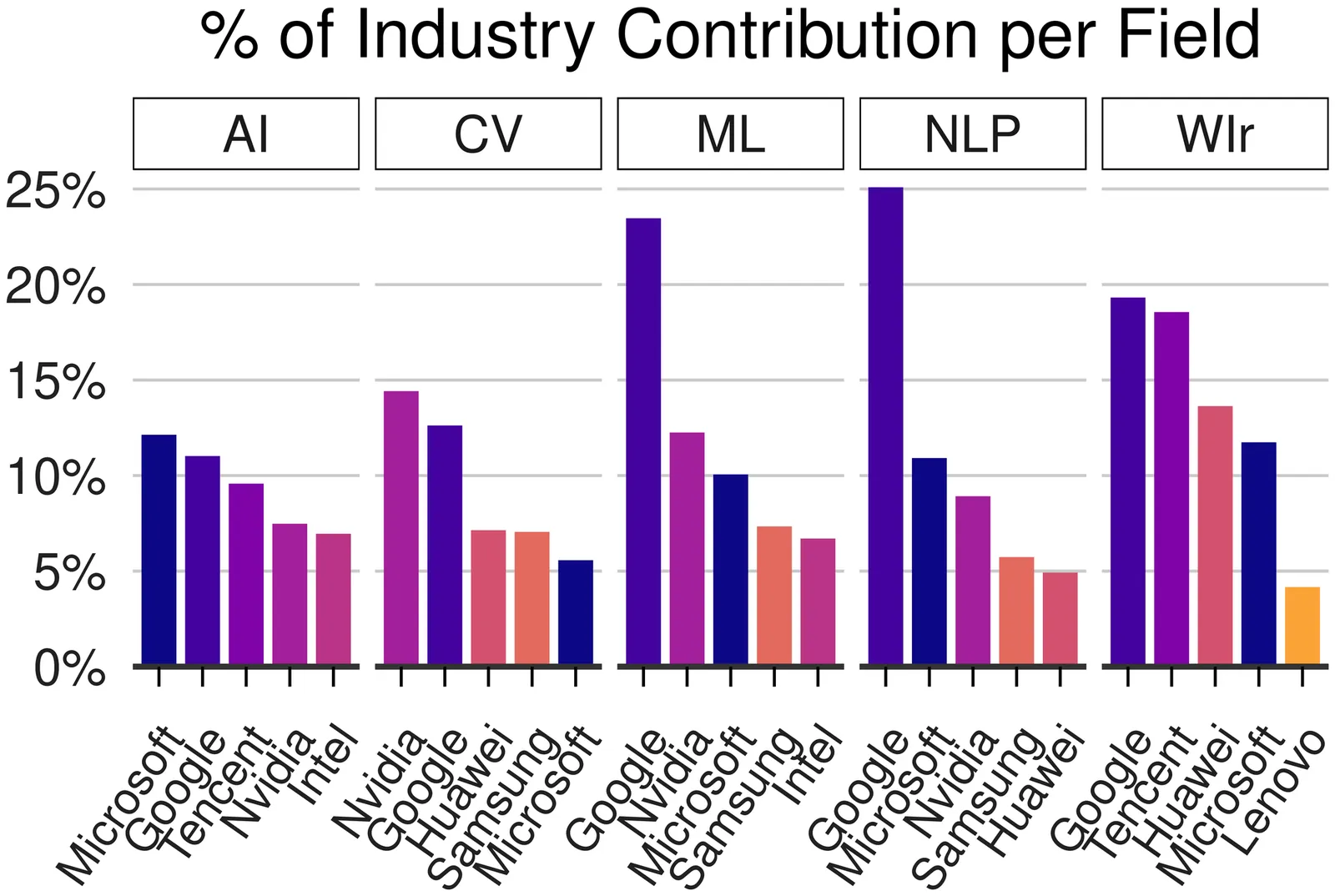
Over the past four decades, artificial intelligence (AI) research has flourished at the nexus of academia and industry. However, Big Tech companies have increasingly acquired the edge in computational resources, big data, and talent. So far, it has been largely unclear how many papers the industry funds, how their citation impact compares to non-funded papers, and what drives industry interest. This study fills that gap by quantifying the number of industry-funded papers at 10 top AI conferences (e.g., ICLR, CVPR, AAAI, ACL) and their citation influence. We analyze about 49.8K papers, about 1.8M citations from AI papers to other papers, and about 2.3M citations from other papers to AI papers from 1998-2022 in Scopus. Through seven research questions, we examine the volume and evolution of industry funding in AI research, the citation impact of funded papers, the diversity and temporal range of their citations, and the subfields in which industry predominantly acts. Our findings reveal that industry presence has grown markedly since 2015, from less than 2 percent to more than 11 percent in 2020. Between 2018 and 2022, 12 percent of industry-funded papers achieved high citation rates as measured by the h5-index, compared to 4 percent of non-industry-funded papers and 2 percent of non-funded papers. Top AI conferences engage more with industry-funded research than non-funded research, as measured by our newly proposed metric, the Citation Preference Ratio (CPR). We show that industry-funded research is increasingly insular, citing predominantly other industry-funded papers while referencing fewer non-funded papers. These findings reveal new trends in AI research funding, including a shift towards more industry-funded papers and their growing citation impact, greater insularity of industry-funded work than non-funded work, and a preference of industry-funded research to cite recent work.
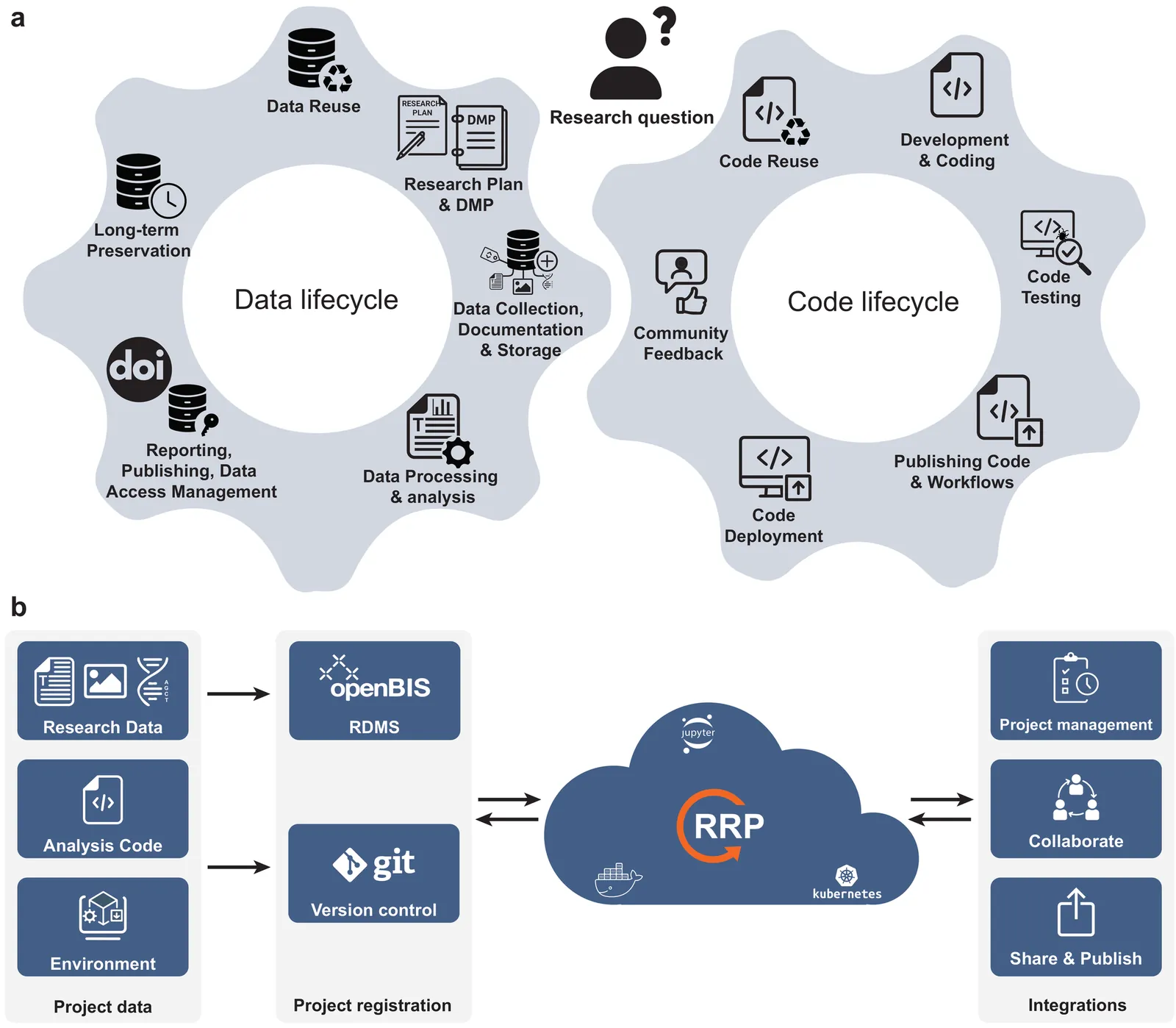
Many research groups aspire to make data and code FAIR and reproducible, yet struggle because the data and code life cycles are disconnected, executable environments are often missing from published work, and technical skill requirements hinder adoption. Existing approaches rarely enable researchers to keep using their preferred tools or support seamless execution across domains. To close this gap, we developed the open-source Reproducible Research Platform (RRP), which unifies research data management with version-controlled, containerized computational environments in modular, shareable projects. RRP enables anyone to execute, reuse, and publish fully documented, FAIR research workflows without manual retrieval or platform-specific setup. We demonstrate RRP's impact by reproducing results from diverse published studies, including work over a decade old, showing sustained reproducibility and usability. With a minimal graphical interface focused on core tasks, modular tool installation, and compatibility with institutional servers or local computers, RRP makes reproducible science broadly accessible across scientific domains.
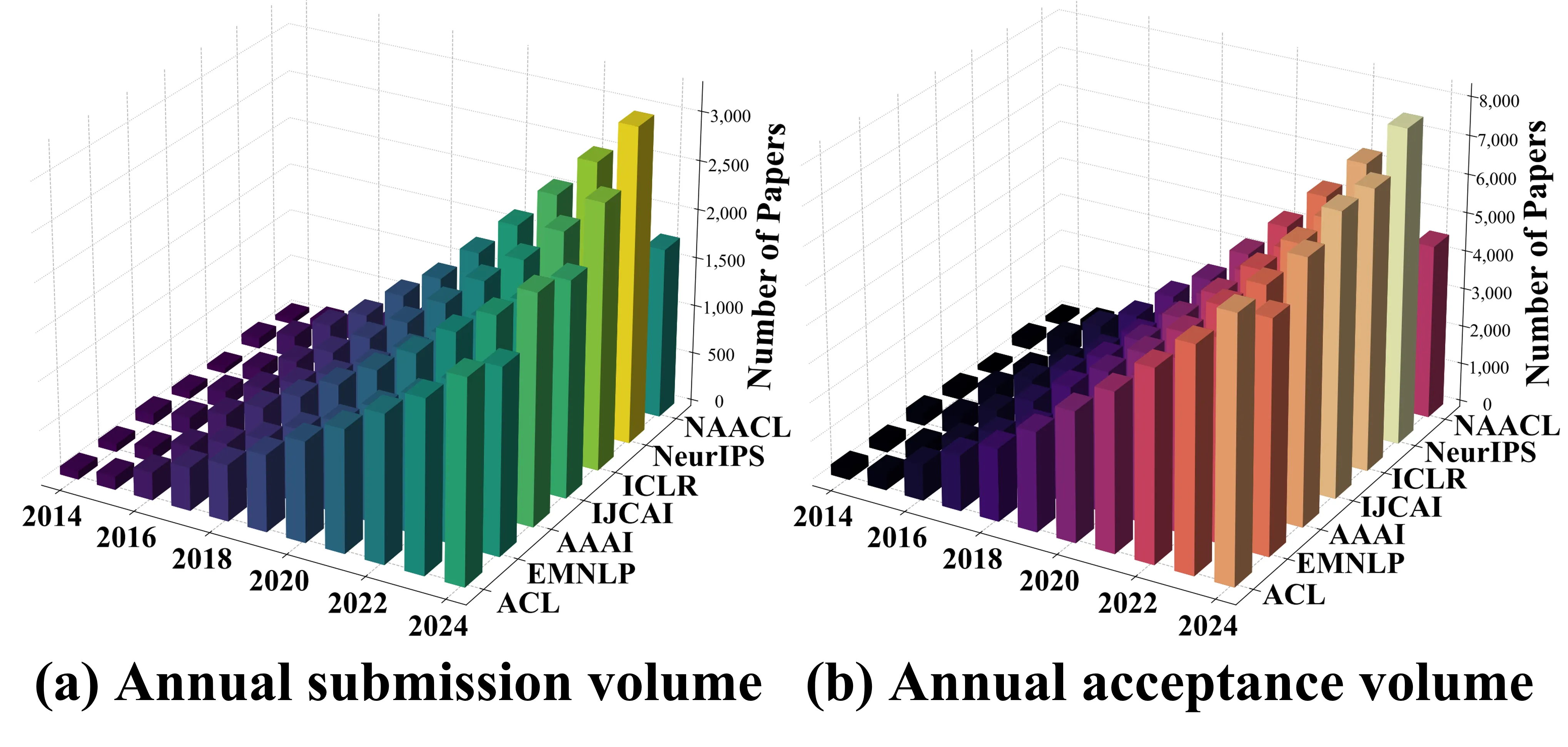
The recent surge of language models has rapidly expanded NLP research, driving an exponential rise in submissions and acceptances at major conferences. Yet this growth has been shadowed by escalating concerns over conference quality, e.g., plagiarism, reviewer inexperience and collusive bidding. However, existing studies rely largely on qualitative accounts (e.g., expert interviews, social media discussions, etc.), lacking longitudinal empirical evidence. To fill this gap, we conduct a ten year empirical study spanning seven leading conferences. We build a four dimensional bibliometric framework covering conference scale, core citation statistics,impact dispersion, cross venue and journal influence, etc. Notably, we further propose a metric Quality Quantity Elasticity, which measures the elasticity of citation growth relative to acceptance growth. Our findings show that ML venues sustain dominant and stable impact, NLP venues undergo widening stratification with mixed expansion efficiency, and AI venues exhibit structural decline. This study provides the first decade-long, cross-venue empirical evidence on the evolution of major conferences.
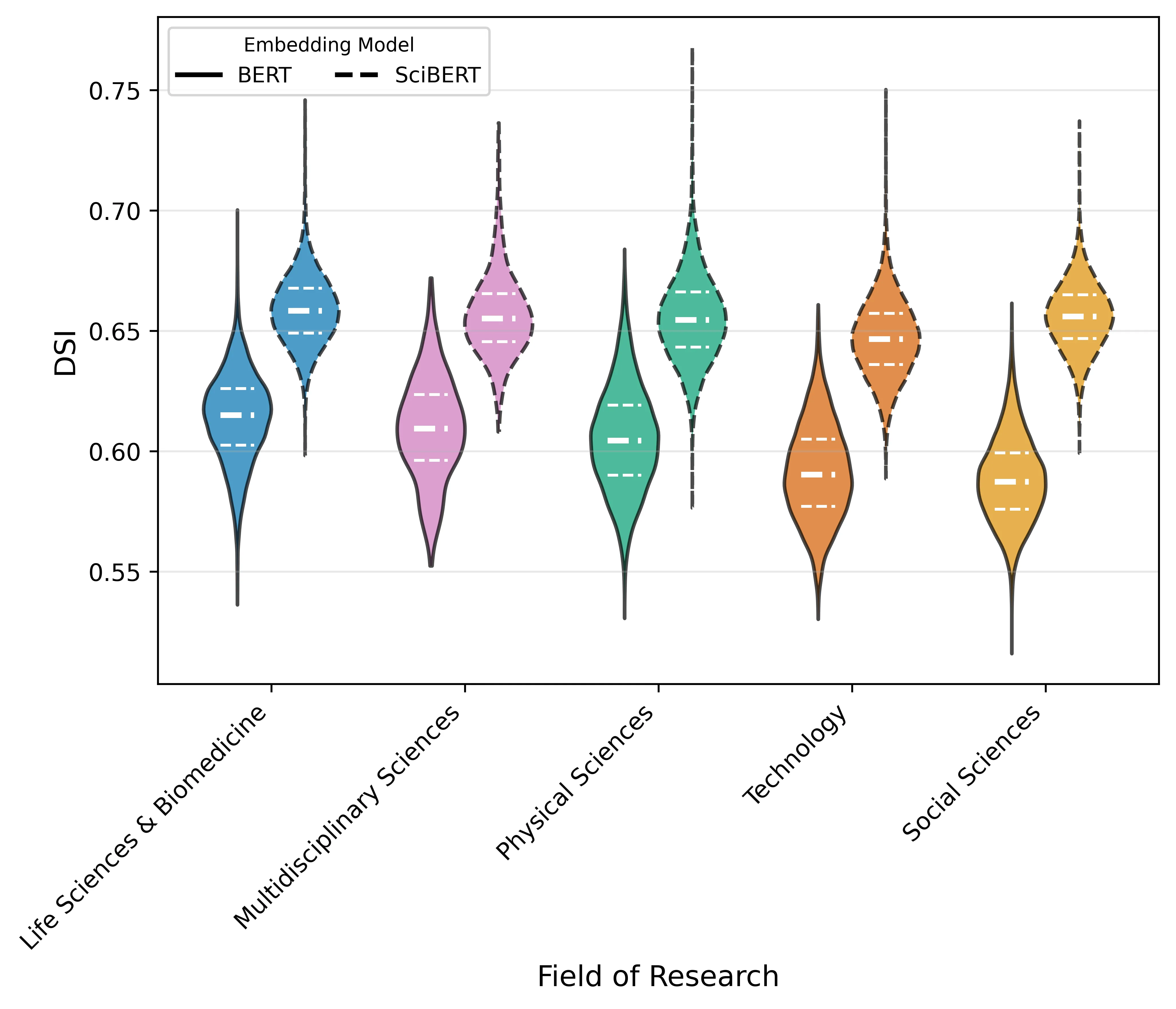
The study of creativity in science has long sought quantitative metrics capable of capturing the originality of the scientific insights contained within articles and other scientific works. In recent years, the field has witnessed a substantial expansion of research activity, enabled by advances in natural language processing and network analysis, and has utilised both macro- and micro-scale approaches with success. However, they often do not examine the text itself for evidence of originality. In this paper, we apply a computational measure correlating with originality from creativity science, Divergent Semantic Integration (DSI), to a set of 51,200 scientific abstracts and titles sourced from the Web of Science. To adapt DSI for application to scientific texts, we advance the original BERT method by incorporating SciBERT (a model trained on scientific corpora) into the computation of DSI. In our study, we observe that DSI plays a more pronounced role in the accrual of early citations for papers with fewer authors, varies substantially across subjects and research fields, and exhibits a declining correlation with citation counts over time. Furthermore, by modelling SciBERT- and BERT-DSI as predictors of the logarithm of 5-year citation counts alongside field, publication year, and the logarithm of author count, we find statistically significant relationships, with adjusted R-squared of 0.103 and 0.101 for BERT-DSI and SciBERT-DSI. Because existing scientometric measures rarely assess the originality expressed in textual content, DSI provides a valuable means of directly quantifying the conceptual originality embedded in scientific writing.
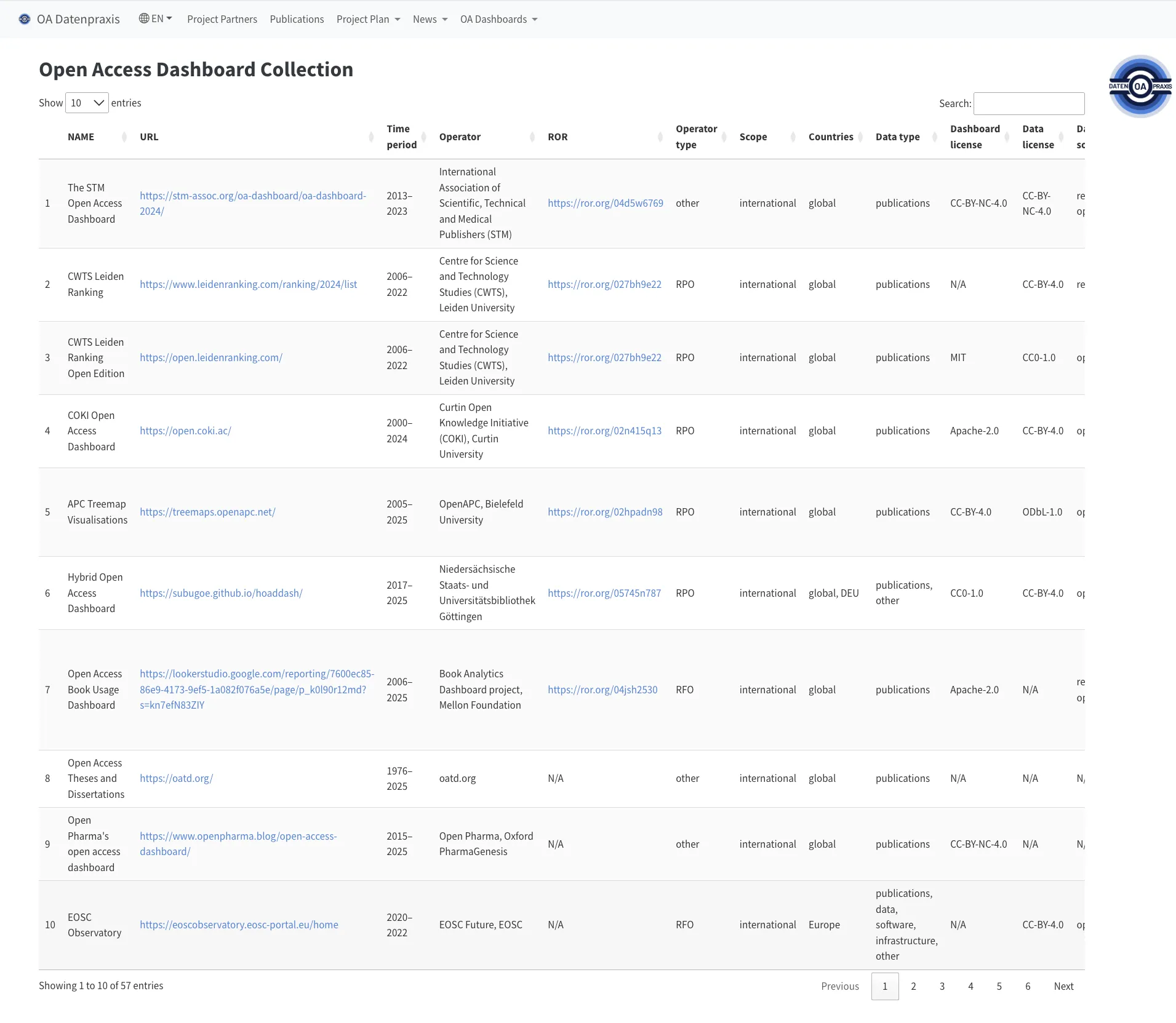
As Open Access continues to gain importance in science policy, understanding the proportion of Open Access publications relative to the total research output of research-performing organizations, individual countries, or even globally has become increasingly relevant. In response, dashboards are being developed to capture and communicate progress in this area. To provide an overview of these dashboards and their characteristics, an extensive survey was conducted, resulting in the identification of nearly 60 dashboards. To support a detailed and structured description, a dedicated metadata schema was developed, and the identified dashboards were systematically indexed accordingly. To foster community engagement and ensure ongoing development, a participatory process was launched, allowing interested stakeholders to contribute to the dataset. The dataset is particularly relevant for researchers in Library and Information Science (LIS) and Science and Technology Studies (STS), supporting both empirical analyses of Open Access and the methodological refinement of indicators and policy instruments in the context of Open Science.

Peer-review venues have increasingly adopted open reviewing policies that publicly release anonymized reviews and permit public commenting. Venues have adopted a variety of policies, and there is still ongoing debate about the benefits and drawbacks of decisions. To inform this debate, we surveyed 2,385 reviewers, authors, and other peer-review participants in machine learning to understand their experiences and opinions. Our key findings are: (a) Preferences: Over 80% of respondents support releasing reviews for accepted papers and allowing public comments. However, only 27.1% support releasing rejected manuscripts. (b) Benefits: Respondents cite improved public understanding (75.3%) and reviewer education (57.8%), increased fairness (56.6%), and stronger incentives for high-quality reviews (48.0%). (c) Challenges: The top concern is resubmission bias, where rejection history biases future reviewers (ranked top impact of open reviewing by 41% of respondents, and mentioned in over 50% of free responses). Other challenges include fear of reviewer de-anonymization (33.2%) and potential commenting abuse. (d) AI and open peer review: Participants believe open policies deter "AI slop" submissions (71.9%) and AI-generated reviews (38.9%). Respondents are split regarding peer-review venues generating official AI reviews, with 56.0% opposed and 44.0% supportive. Finally, we use AI to annotate 4,244 reviews from ICLR (fully open) and NeurIPS (partially open). We find that the fully open venue (ICLR) has higher levels of correctness and completeness than the partially open venue (NeurIPS). The effect size is small for correctness and very small for completeness, and both are statistically significant. We also find that there is no statistically significant difference in the level of substantiation. We release the full dataset at https://github.com/justinpayan/OpenReviewAnalysis.
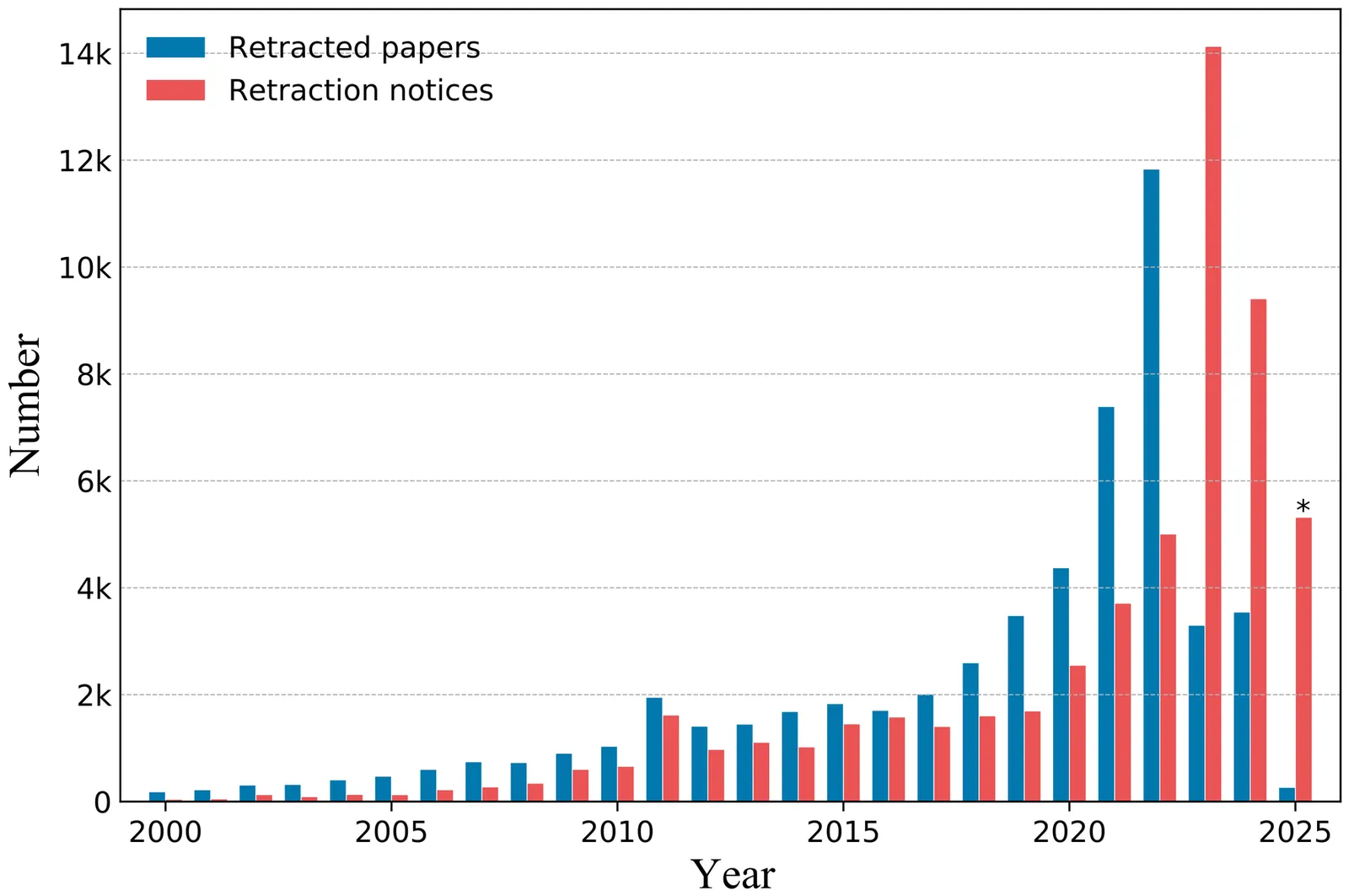
Scientific publications form the cornerstone of innovation and have maintained a stable growth trend over the years. However, in recent years, there has been a significant surge in retractions, driven largely by the proliferation of low-quality and fraudulent papers. This study aims to examine retractions and their evolving trends through a topic lens. Our analysis of global retraction data reveals that the numbers of retraction have remained alarmingly high in recent years, with the growth rate of retracted papers significantly outpacing that of overall global publications. While retractions are observed across various fields, their distribution is not uniform. In disciplines characterized by high retraction rates, certain topics may only encounter minor issues, whereas in fields with lower retraction rates, some topics can experience substantial challenges. Moreover, an unexpected surge in publications has been observed in specific topics that also display abnormally high retraction rates. This study underscores several indicators that can assist the scientific community in pinpointing key fields that require rigorous scrutiny for potential low-quality and fraudulent research. Ultimately, our findings could serve as a benchmark for examining scientific integrity across diverse topics and offer crucial insights for developing tailored governance policies to enhance research integrity in each field.
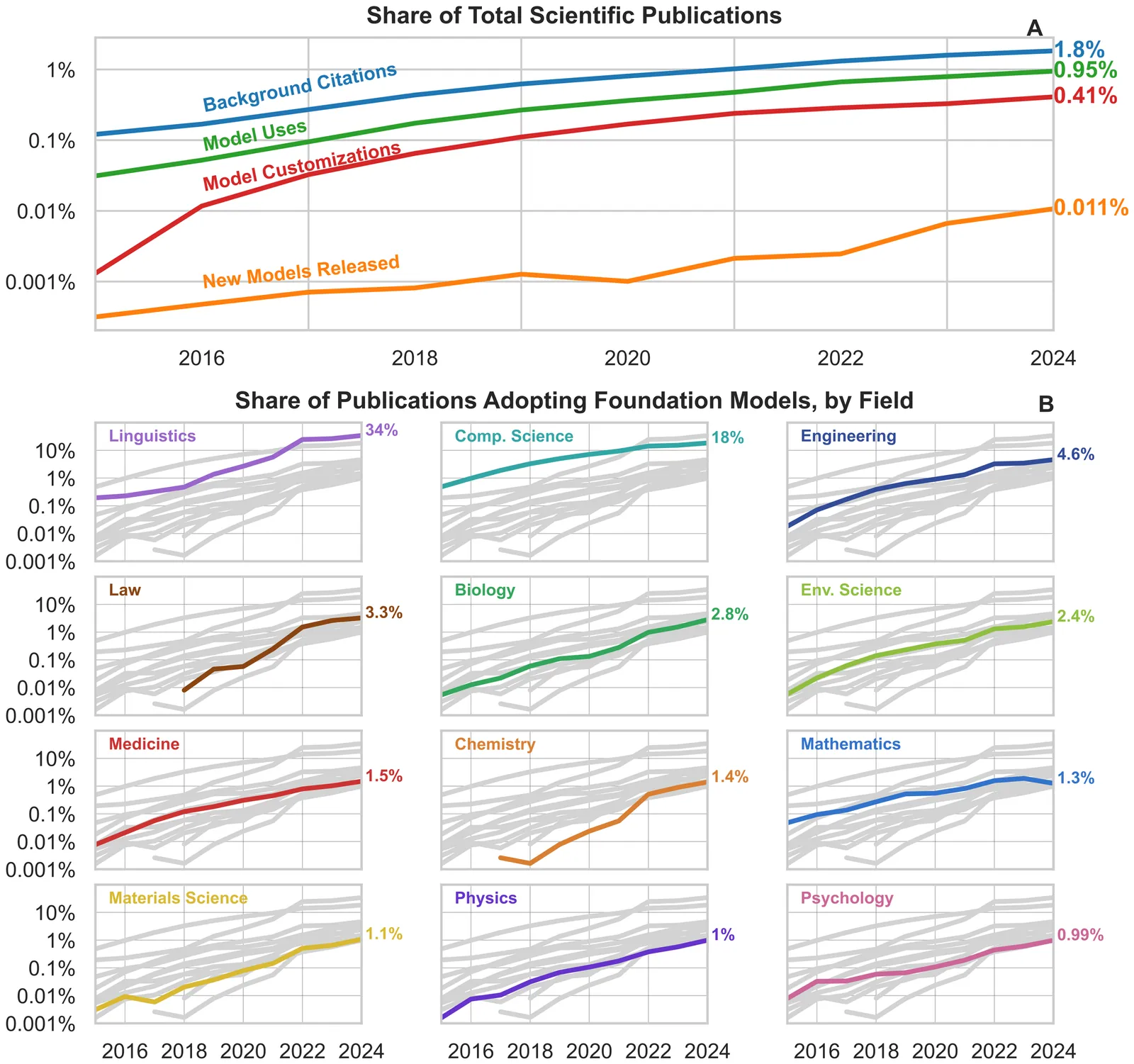
We present the first large-scale analysis of AI foundation model usage in science - not just citations or keywords. We find that adoption has grown rapidly, at nearly-exponential rates, with the highest uptake in Linguistics, Computer Science, and Engineering. Vision models are the most used foundation models in science, although language models' share is growing. Open-weight models dominate. As AI builders increase the parameter counts of their models, scientists have followed suit but at a much slower rate: in 2013, the median foundation model built was 7.7x larger than the median one adopted in science, by 2024 this had jumped to 26x. We also present suggestive evidence that scientists' use of these smaller models may be limiting them from getting the full benefits of AI-enabled science, as papers that use larger models appear in higher-impact journals and accrue more citations.
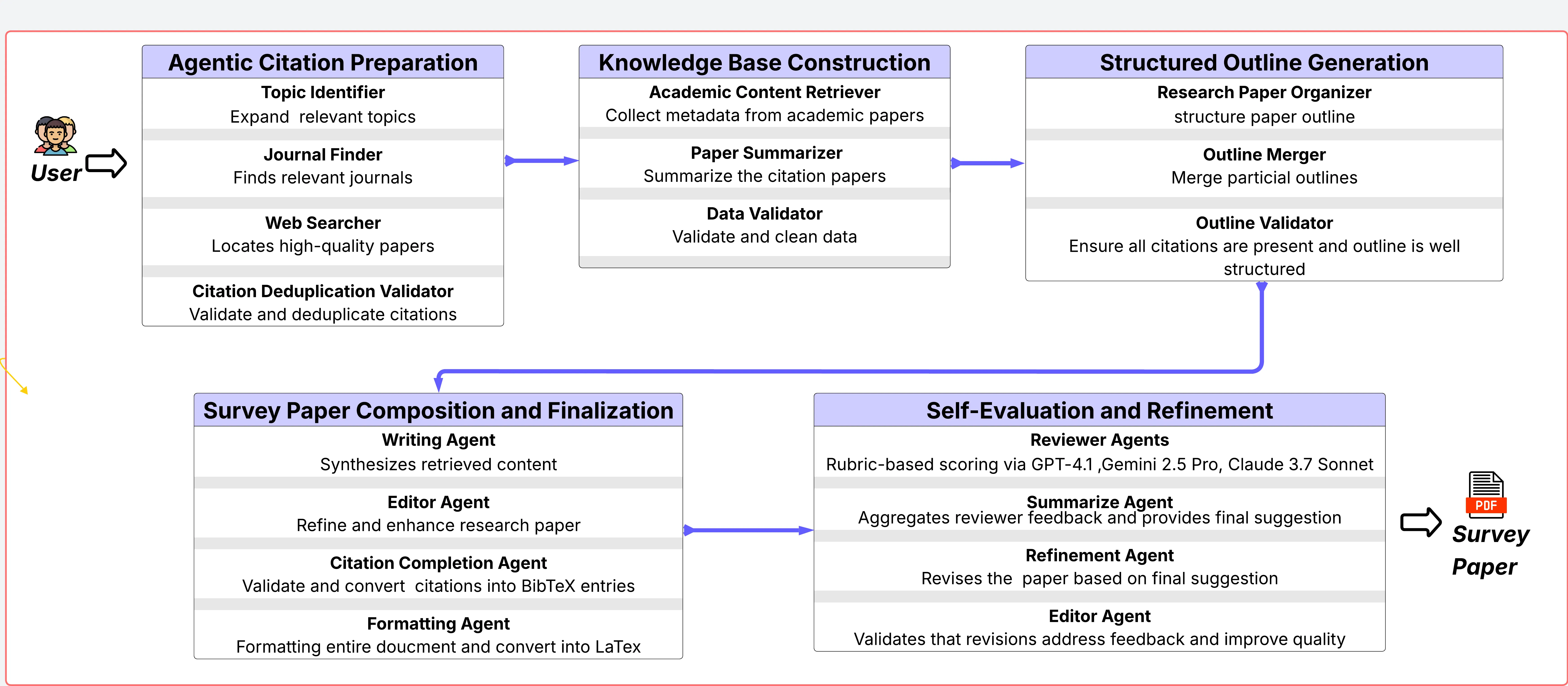
The rapid expansion of scholarly literature presents significant challenges in synthesizing comprehensive, high-quality academic surveys. Recent advancements in agentic systems offer considerable promise for automating tasks that traditionally require human expertise, including literature review, synthesis, and iterative refinement. However, existing automated survey-generation solutions often suffer from inadequate quality control, poor formatting, and limited adaptability to iterative feedback, which are core elements intrinsic to scholarly writing. To address these limitations, we introduce ARISE, an Agentic Rubric-guided Iterative Survey Engine designed for automated generation and continuous refinement of academic survey papers. ARISE employs a modular architecture composed of specialized large language model agents, each mirroring distinct scholarly roles such as topic expansion, citation curation, literature summarization, manuscript drafting, and peer-review-based evaluation. Central to ARISE is a rubric-guided iterative refinement loop in which multiple reviewer agents independently assess manuscript drafts using a structured, behaviorally anchored rubric, systematically enhancing the content through synthesized feedback. Evaluating ARISE against state-of-the-art automated systems and recent human-written surveys, our experimental results demonstrate superior performance, achieving an average rubric-aligned quality score of 92.48. ARISE consistently surpasses baseline methods across metrics of comprehensiveness, accuracy, formatting, and overall scholarly rigor. All code, evaluation rubrics, and generated outputs are provided openly at https://github.com/ziwang11112/ARISE
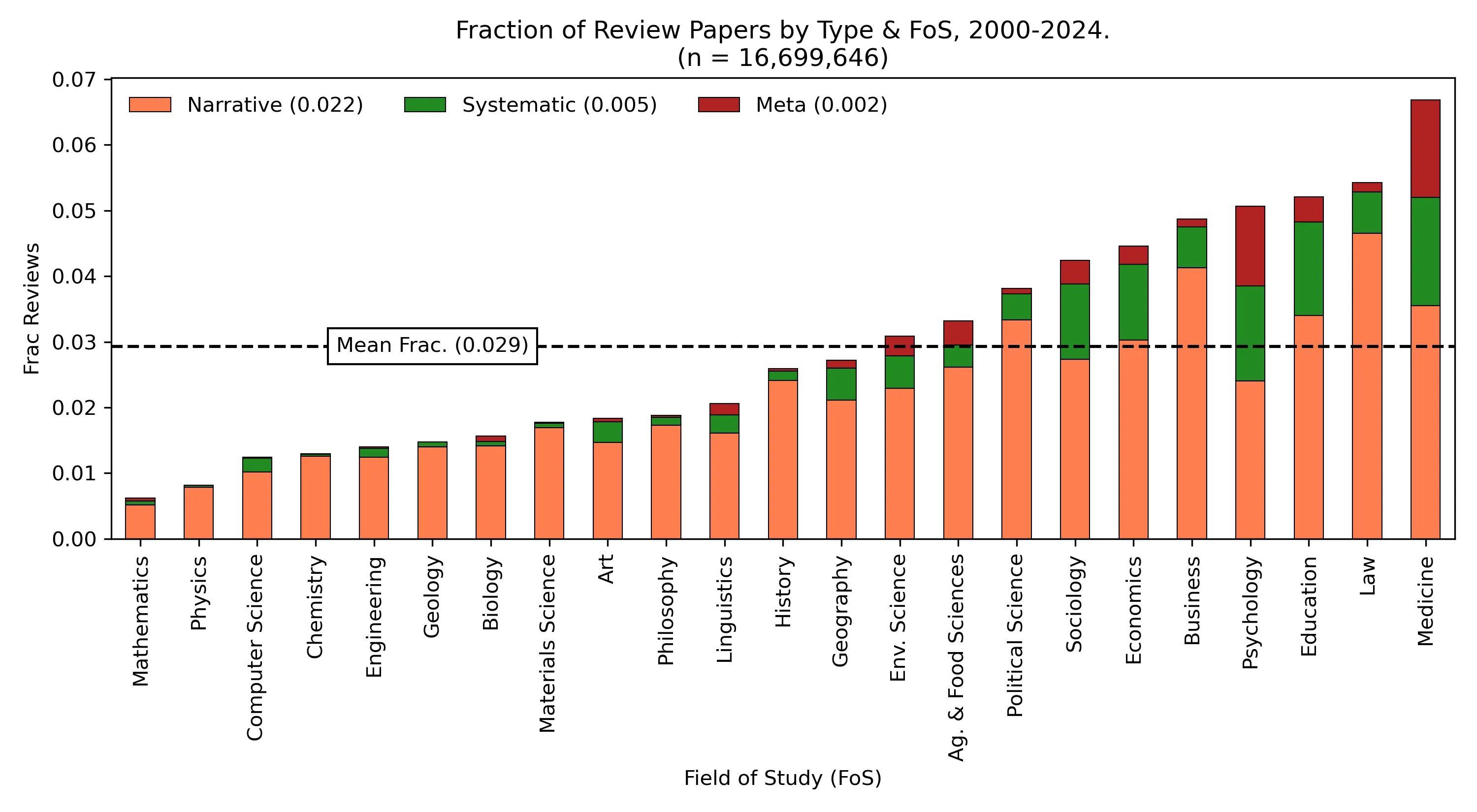
Review papers have traditionally enjoyed a high status in academic publishing because of the important role they can play in summarising and synthesising a field of research. They can also attract significantly more citations than primary research papers presenting original research, making them attractive to authors. There has been a dramatic increase in the publication of review papers in recent years, both in raw numbers and as a proportion of overall publication output. In this paper we demonstrate this increase across a wide range of fields of study. We quantify the citation dividend associated with review papers, but also demonstrate that it is declining and discuss the reasons for this decline. We further show that, since the arrival of GenAI tools in 2022 there is evidence of widespread use of GenAI in research paper writing, and we present evidence for a stronger AI signal among review papers compared to primary research papers. We suggest that the potential for GenAI to accelerate and even automate the production review papers will have a further significant impact on their status.
The probability folder of Mathlib, Lean's mathematical library, makes a heavy use of Markov kernels. We present their definition and properties and describe the formalization of the disintegration theorem for Markov kernels. That theorem is used to define conditional probability distributions of random variables as well as posterior distributions. We then explain how Markov kernels are used in a more unusual way to get a common definition of independence and conditional independence and, following the same principles, to define sub-Gaussian random variables. Finally, we also discuss the role of kernels in our formalization of entropy and Kullback-Leibler divergence.
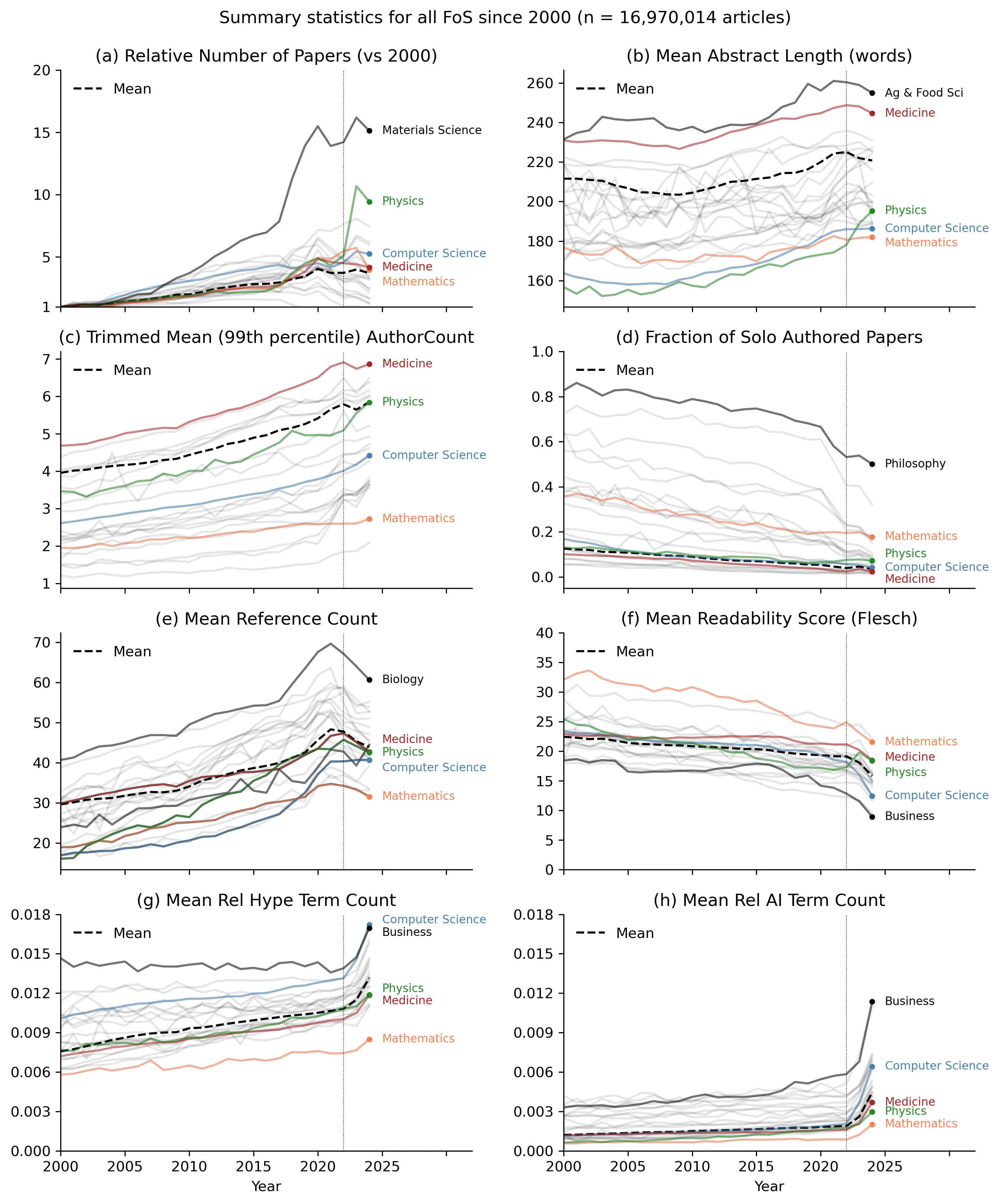
Academic and scientific publishing practices have changed significantly in recent years. This paper presents an analysis of 17 million research papers published since 2000 to explore changes in authorship and content practices. It shows a clear trend towards more authors, more references and longer abstracts. While increased authorship has been reported elsewhere, the present analysis shows that it is pervasive across many major fields of study. We also identify a decline in author productivity which suggests that `gift' authorship (the inclusion of authors who have not contributed significantly to a work) may be a significant factor. We further report on a tendency for authors to use more hyperbole, perhaps exaggerating their contributions to compete for the limited attention of reviewers, and often at the expense of readability. This has been especially acute since 2023, as AI has been increasingly used across many fields of study, but particularly in fields such as Computer Science, Engineering and Business. In summary, many of these changes are causes of significant concern. Increased authorship counts and gift authorship have the potential to distort impact metrics such as field-weighted citation impact andh-index, while increased AI usage may compromise readability and objectivity.

Large, open datasets can accelerate ecological research, particularly by enabling researchers to develop new insights by reusing datasets from multiple sources. However, to find the most suitable datasets to combine and integrate, researchers must navigate diverse ecological and environmental data provider platforms with varying metadata availability and standards. To overcome this obstacle, we have developed a large language model (LLM)-based metadata harvester that flexibly extracts metadata from any dataset's landing page, and converts these to a user-defined, unified format using existing metadata standards. We validate that our tool is able to extract both structured and unstructured metadata with equal accuracy, aided by our LLM post-processing protocol. Furthermore, we utilise LLMs to identify links between datasets, both by calculating embedding similarity and by unifying the formats of extracted metadata to enable rule-based processing. Our tool, which flexibly links the metadata of different datasets, can therefore be used for ontology creation or graph-based queries, for example, to find relevant ecological and environmental datasets in a virtual research environment.
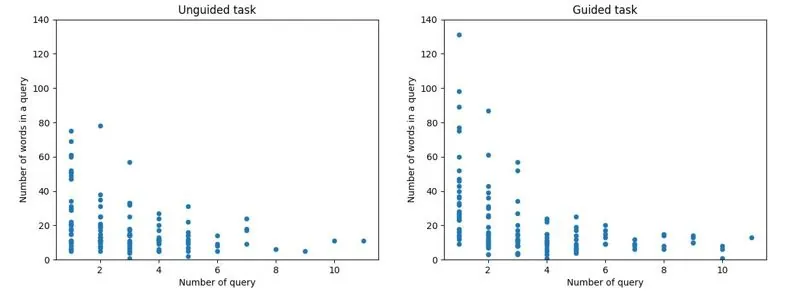
Data search for scientific research is more complex than a simple web search. The emergence of large language models (LLMs) and their applicability for scientific tasks offers new opportunities for researchers who are looking for data, e.g., to freely express their data needs instead of fitting them into restrictions of data catalogues and portals. However, this also creates uncertainty about whether LLMs are suitable for this task. To answer this question, we conducted a user study with 32 researchers. We qualitatively and quantitively analysed participants' information interaction behaviour while searching for data using LLMs in two data search tasks, one in which we prompted the LLM to behave as a persona. We found that participants interact with LLMs in natural language, but LLMs remain a tool for them rather than an equal conversational partner. This changes slightly when the LLM is prompted to behave as a persona, but the prompting only affects participants' user experience when they are already experienced in LLM use.
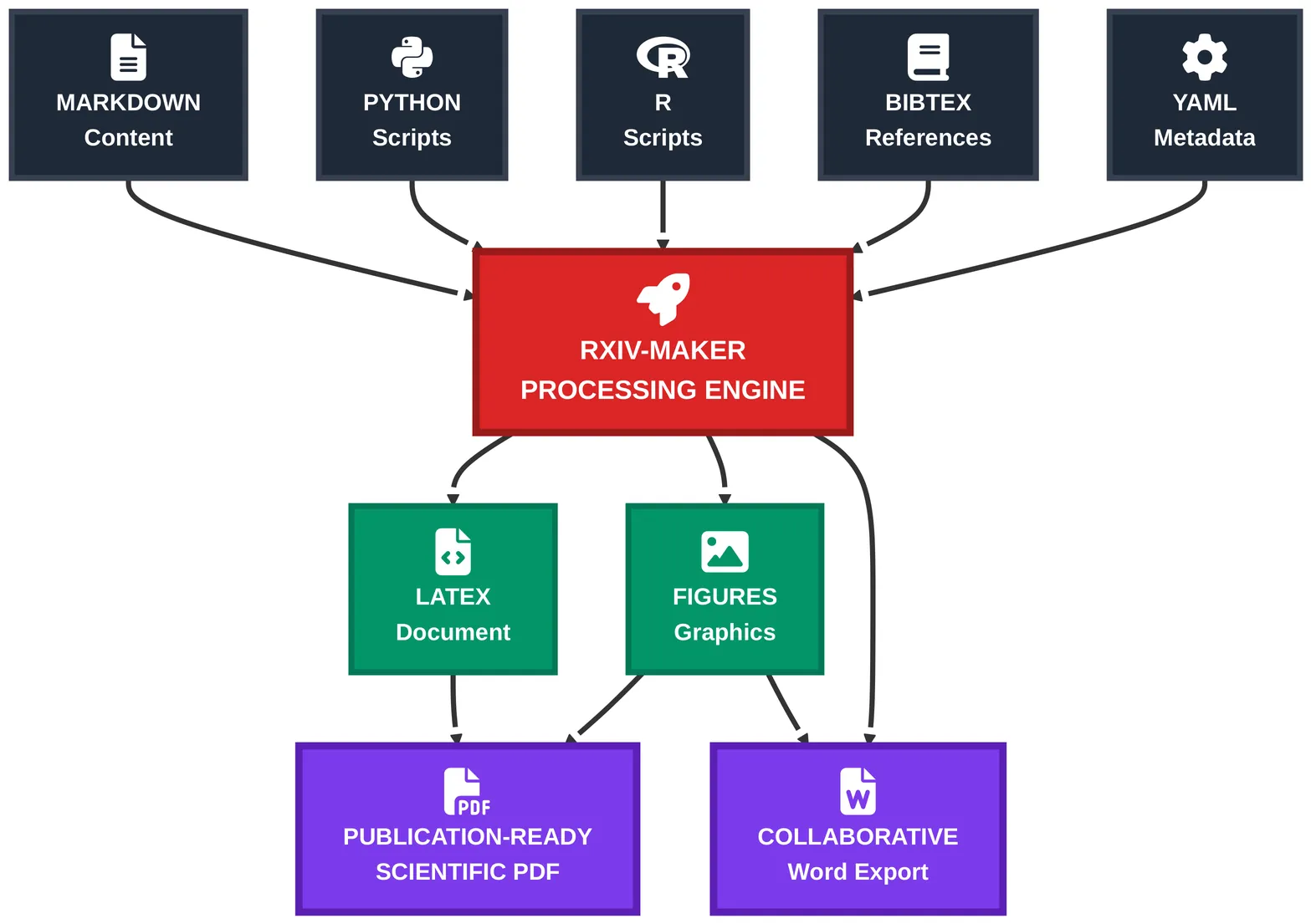
The rapid growth of preprint servers has accelerated scientific dissemination but has also shifted the technical burden of manuscript preparation to authors. This challenge is particularly acute in computational research, where manuscripts must remain synchronised with evolving data and code. We present Rxiv-Maker, a framework that resolves this by converting simple Markdown files into professionally typeset, publication-ready PDFs. Its core feature is the ability to execute embedded code, creating a self-updating manuscript where figures and statistical values are generated directly from source data during compilation. This ensures that the final document is always current and fully reproducible. By integrating with standard tools like Git and Visual Studio (VS) Code, Rxiv-Maker provides an efficient, transparent, and collaborative authoring experience, applying principles of software engineering to academic writing to foster open and verifiable science.
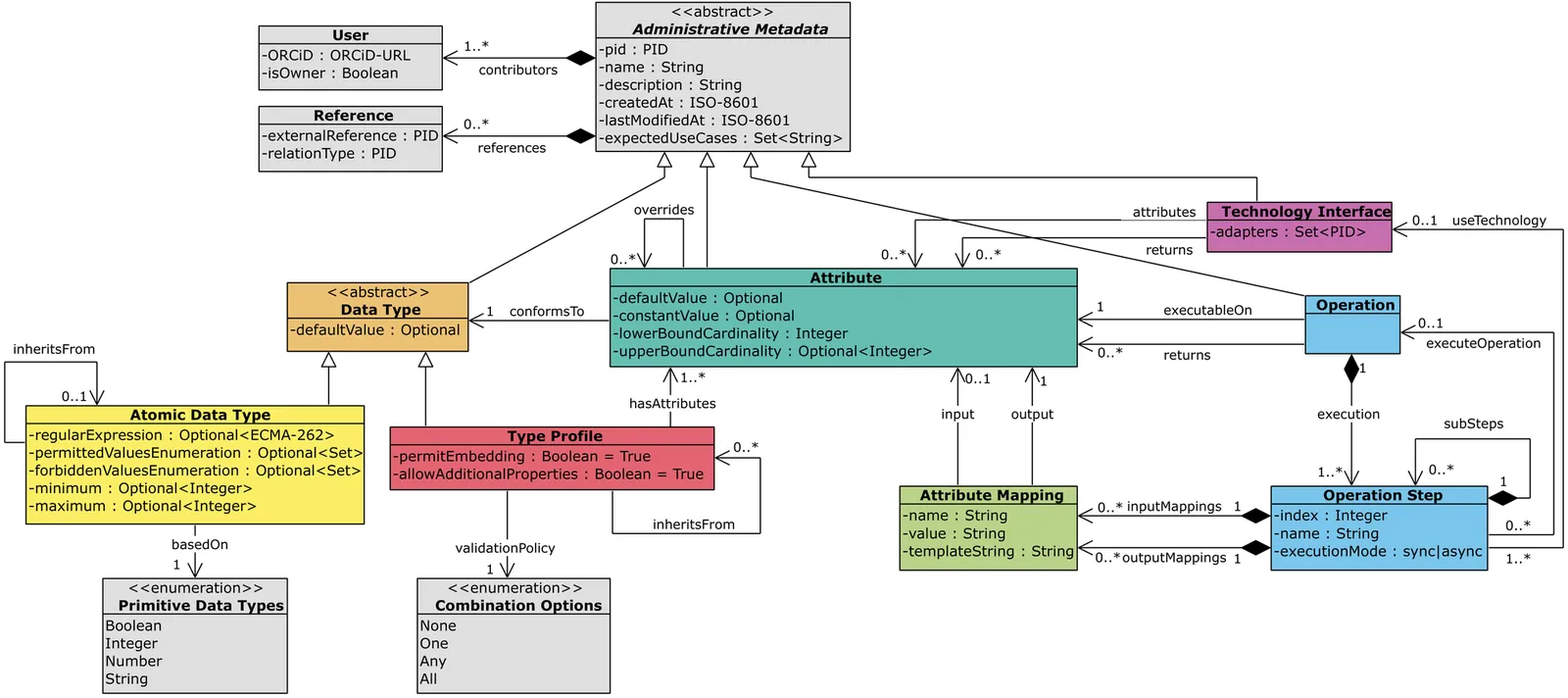
FAIR Digital Objects support research data management aligned with the FAIR principles. To be machine-actionable, they must support operations that interact with their contents. This can be achieved by associating operations with FAIR-DO data types. However, current typing models and Data Type Registries lack support for type-associated operations. In this work, we introduce a typing model that describes type-associated and technology-agnostic FAIR Digital Object Operations in a machine-actionable way, building and improving on the existing concepts. In addition, we introduce the Integrated Data Type and Operations Registry with Inheritance System, a prototypical implementation of this model that integrates inheritance mechanisms for data types, a rule-based validation system, and the computation of type-operation associations. Our approach significantly improves the machine-actionability of FAIR Digital Objects, paving the way towards dynamic, interoperable, and reproducible research workflows.
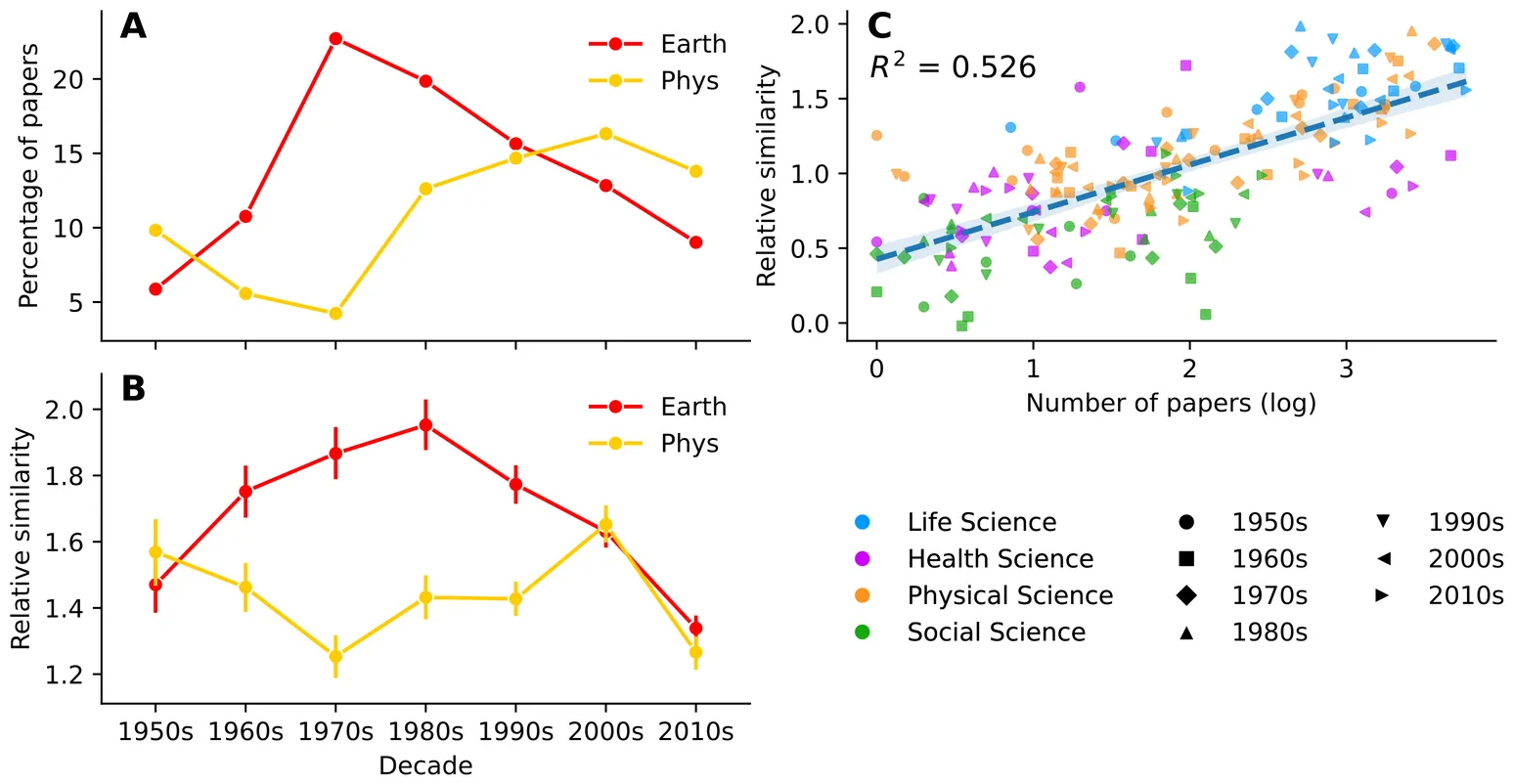
Understanding the changing structure of science over time is essential to elucidating how science evolves. We develop diachronic embeddings of scholarly periodicals to quantify "semantic changes" of periodicals across decades, allowing us to track the evolution of research topics and identify rapidly developing fields. By mapping periodicals within a physical-life-health triangle, we reveal an evolving interdisciplinary science landscape, finding an overall trend toward specialization for most periodicals but increasing interdisciplinarity for bioscience periodicals. Analyzing a periodical's trajectory within this triangle over time allows us to visualize how its research focus shifts. Furthermore, by monitoring the formation of local clusters of periodicals, we can identify emerging research topics such as AIDS research and nanotechnology in the 1980s. Our work offers novel quantification in the science of science and provides a quantitative lens to examine the evolution of science, which may facilitate future investigations into the emergence and development of research fields.
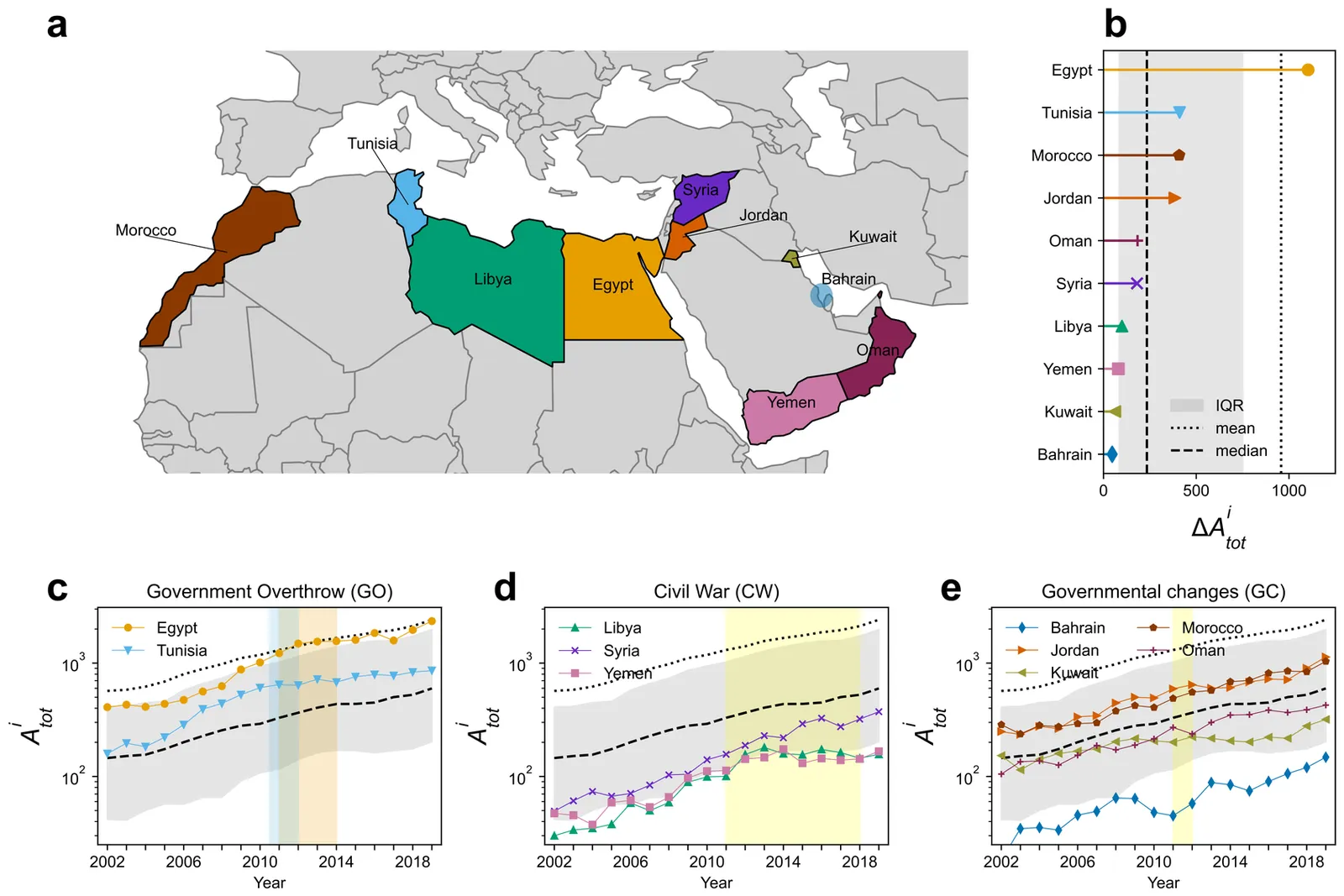
The 2010-2011 Arab Spring reverberated far beyond politics, reshaping how the Middle East and North Africa region (MENA) is studied. Analyzing 3.7 million Scopus-indexed articles published between 2002 and 2019, we find that mentions of ten of these countries in titles or abstracts rose significantly after 2011 relative to the global baseline, with Egypt receiving the greatest attention in the region. We link this surge to two intertwined mechanisms: an increase in research funding directed at the MENA region and the emigration of researchers who continued publishing on their countries of origin. Our analysis reveals that Saudi Arabia has emerged as a regional hub for studying the affected countries, attracting funding and scholars, and thereby playing a significant role in shaping the scientific narrative on the region. These findings demonstrate how political upheaval can reshape global knowledge flows by altering who studies whom, with what resources, and in which disciplines.
The rapid growth of submissions to top-tier Artificial Intelligence (AI) and Machine Learning (ML) conferences has prompted many venues to transition from closed to open review platforms. Some have fully embraced open peer reviews, allowing public visibility throughout the process, while others adopt hybrid approaches, such as releasing reviews only after final decisions or keeping reviews private despite using open peer review systems. In this work, we analyze the strengths and limitations of these models, highlighting the growing community interest in transparent peer review. To support this discussion, we examine insights from Paper Copilot, a website launched two years ago to aggregate and analyze AI / ML conference data while engaging a global audience. The site has attracted over 200,000 early-career researchers, particularly those aged 18-34 from 177 countries, many of whom are actively engaged in the peer review process. Drawing on our findings, this position paper advocates for a more transparent, open, and well-regulated peer review aiming to foster greater community involvement and propel advancements in the field.
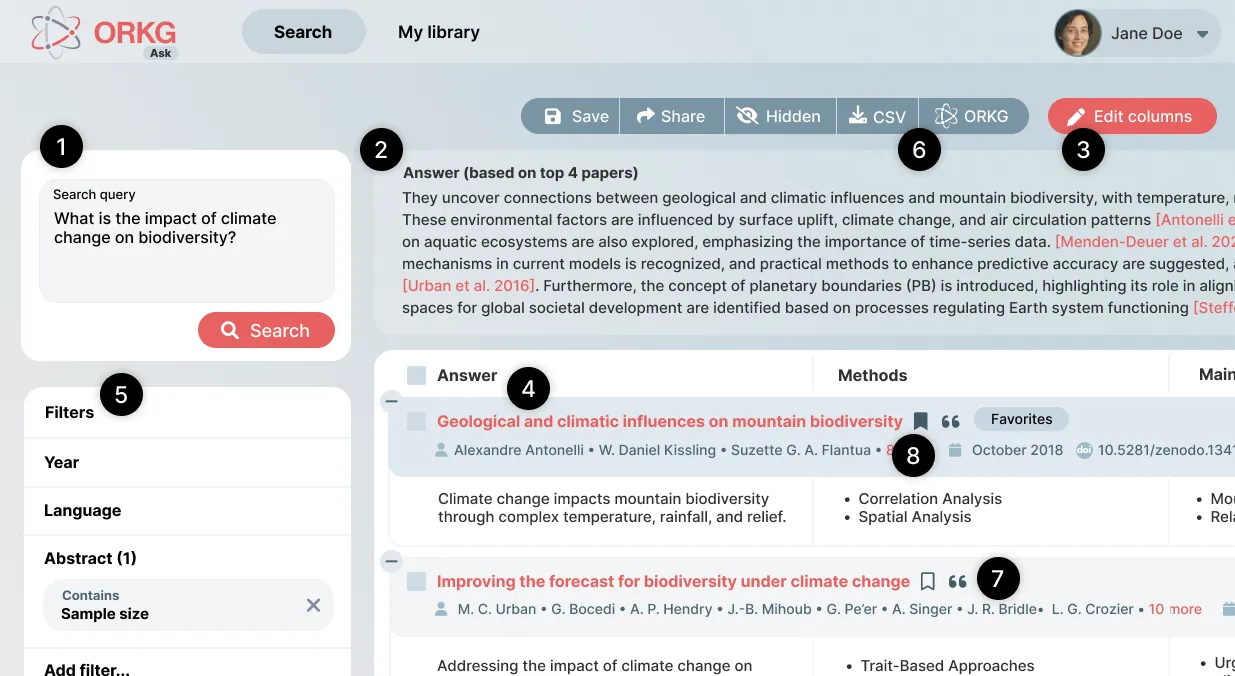
Purpose: Finding scholarly articles is a time-consuming and cumbersome activity, yet crucial for conducting science. Due to the growing number of scholarly articles, new scholarly search systems are needed to effectively assist researchers in finding relevant literature. Methodology: We take a neuro-symbolic approach to scholarly search and exploration by leveraging state-of-the-art components, including semantic search, Large Language Models (LLMs), and Knowledge Graphs (KGs). The semantic search component composes a set of relevant articles. From this set of articles, information is extracted and presented to the user. Findings: The presented system, called ORKG ASK (Assistant for Scientific Knowledge), provides a production-ready search and exploration system. Our preliminary evaluation indicates that our proposed approach is indeed suitable for the task of scholarly information retrieval. Value: With ORKG ASK, we present a next-generation scholarly search and exploration system and make it available online. Additionally, the system components are open source with a permissive license.
Since generative artificial intelligence (AI) tools such as OpenAI's ChatGPT became widely available, researchers have used them in the writing process. The consensus of the academic publishing community is that such usage must be declared in the published article. Academ-AI documents examples of suspected undeclared AI usage in the academic literature, discernible primarily due to the appearance in research papers of idiosyncratic verbiage characteristic of large language model (LLM)-based chatbots. This analysis of the first 768 examples collected reveals that the problem is widespread, penetrating the journals, conference proceedings, and textbooks of highly respected publishers. Undeclared AI seems to appear in journals with higher citation metrics and higher article processing charges (APCs), precisely those outlets that should theoretically have the resources and expertise to avoid such oversights. An extremely small minority of cases are corrected post publication, and the corrections are often insufficient to rectify the problem. The 768 examples analyzed here likely represent a small fraction of the undeclared AI present in the academic literature, much of which may be undetectable. Publishers must enforce their policies against undeclared AI usage in cases that are detectable; this is the best defense currently available to the academic publishing community against the proliferation of undisclosed AI. This is an updated version of a previous preprint.
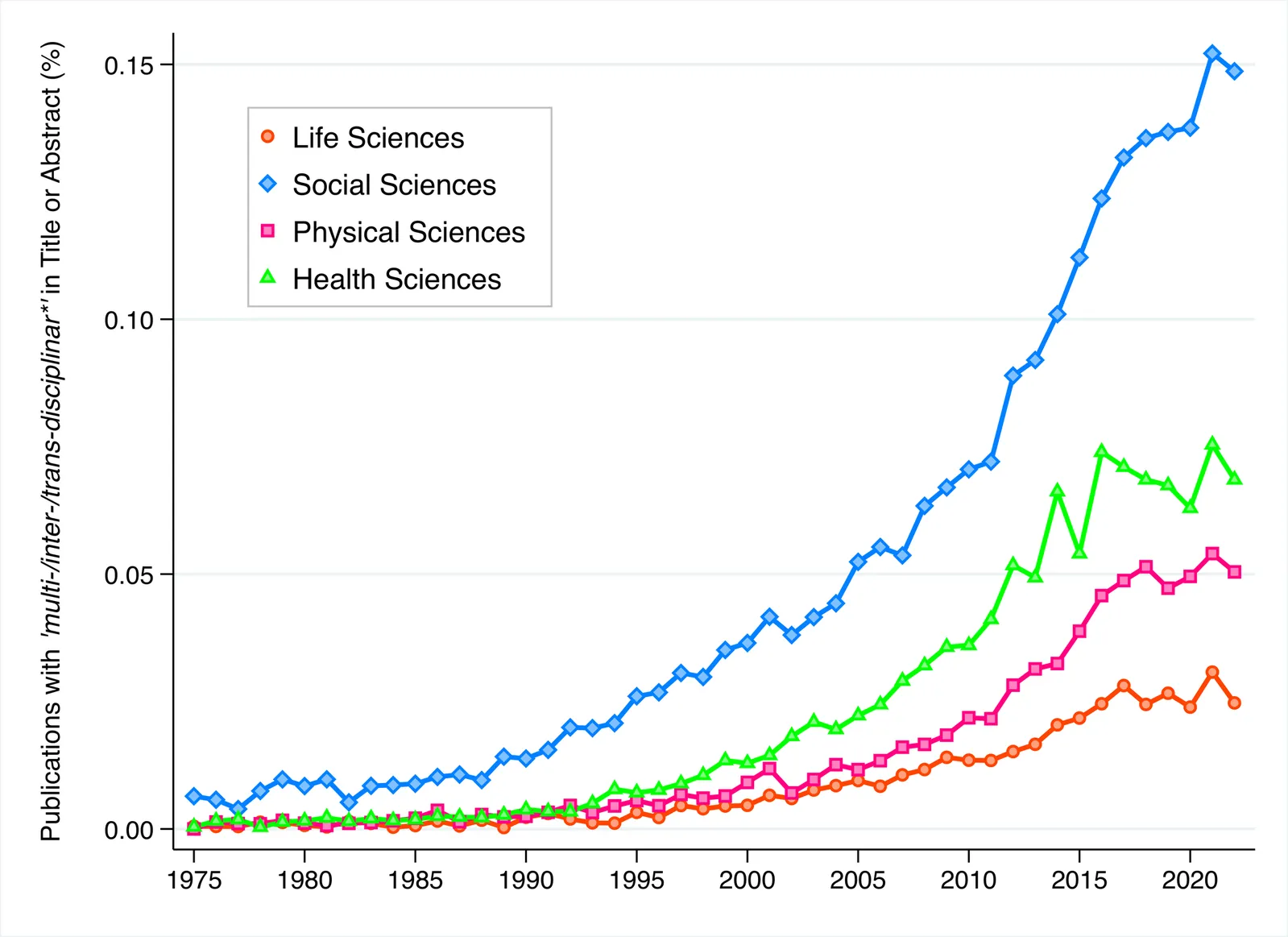
Addressing global societal challenges necessitates insights and expertise that transcend the boundaries of individual disciplines. In recent decades, interdisciplinary collaboration has been recognised as a vital driver of innovation and effective problem-solving, with the potential to profoundly influence policy and practice worldwide. However, quantitative evidence remains limited regarding how cross-disciplinary efforts contribute to societal challenges, as well as the evolving roles and relevance of specific disciplines in addressing these issues. To fill this gap, this study examines the long-term evolution of interdisciplinary contributions to the United Nations' Sustainable Development Goals (SDGs), drawing on extensive bibliometric data from OpenAlex. By analysing publication and citation trends across 19 research fields from 1970 to 2022, we reveal how the relative presence of different disciplines in addressing particular SDGs has shifted over time. Our results also provide unique evidence of the increasing interconnection between fields since the 2000s, coinciding with the United Nations' initiative to tackle global societal challenges through interdisciplinary efforts. These insights will benefit policymakers and practitioners as they reflect on past progress and plan for future action, particularly with the SDG target deadline approaching in the next five years.

Authorship attribution in natural language processing traditionally struggles to distinguish genuine stylistic signals from topical confounds. While contrastive learning approaches have addressed this by maximizing semantic overlap between positive pairs, creating large-scale datasets under strict topic constraints remains challenging. We introduce HALvest, a 17-billion-token multilingual corpus harvested from 778k open-access academic papers, and HALvest-Contrastive, a derived dataset designed to isolate stylometric signals through controlled topic variation. Unlike prior work that minimizes lexical overlap, we exploit natural topic drift between papers by the same author, treating residual lexical patterns as authorial fingerprints rather than noise. Comparing lexical baselines (BM25) against neural models trained on unrestricted (topic-rich) versus base (topic-decoupled) triplets, we demonstrate that models trained exclusively on topic-decoupled data achieve superior performance across all test conditions, outperforming both retrieval baselines and models exposed to topic-rich training data. Our analysis reveals that while lexical signals provide substantial performance gains for keyword-driven methods, neural architectures learn robust stylometric representations that plateau with moderate context length, suggesting they capture distributional style beyond surface-level tokens. Both datasets and code are publicly available.

The advancement of artificial intelligence (AI) hinges on the quality and accessibility of data, yet the current fragmentation and variability of data sources hinder efficient data utilization. The dispersion of data sources and diversity of data formats often lead to inefficiencies in data retrieval and processing, significantly impeding the progress of AI research and applications. To address these challenges, this paper introduces OpenDataLab, a platform designed to bridge the gap between diverse data sources and the need for unified data processing. OpenDataLab integrates a wide range of open-source AI datasets and enhances data acquisition efficiency through intelligent querying and high-speed downloading services. The platform employs a next-generation AI Data Set Description Language (DSDL), which standardizes the representation of multimodal and multi-format data, improving interoperability and reusability. Additionally, OpenDataLab optimizes data processing through tools that complement DSDL. By integrating data with unified data descriptions and smart data toolchains, OpenDataLab can improve data preparation efficiency by 30\%. We anticipate that OpenDataLab will significantly boost artificial general intelligence (AGI) research and facilitate advancements in related AI fields. For more detailed information, please visit the platform's official website: https://opendatalab.com.
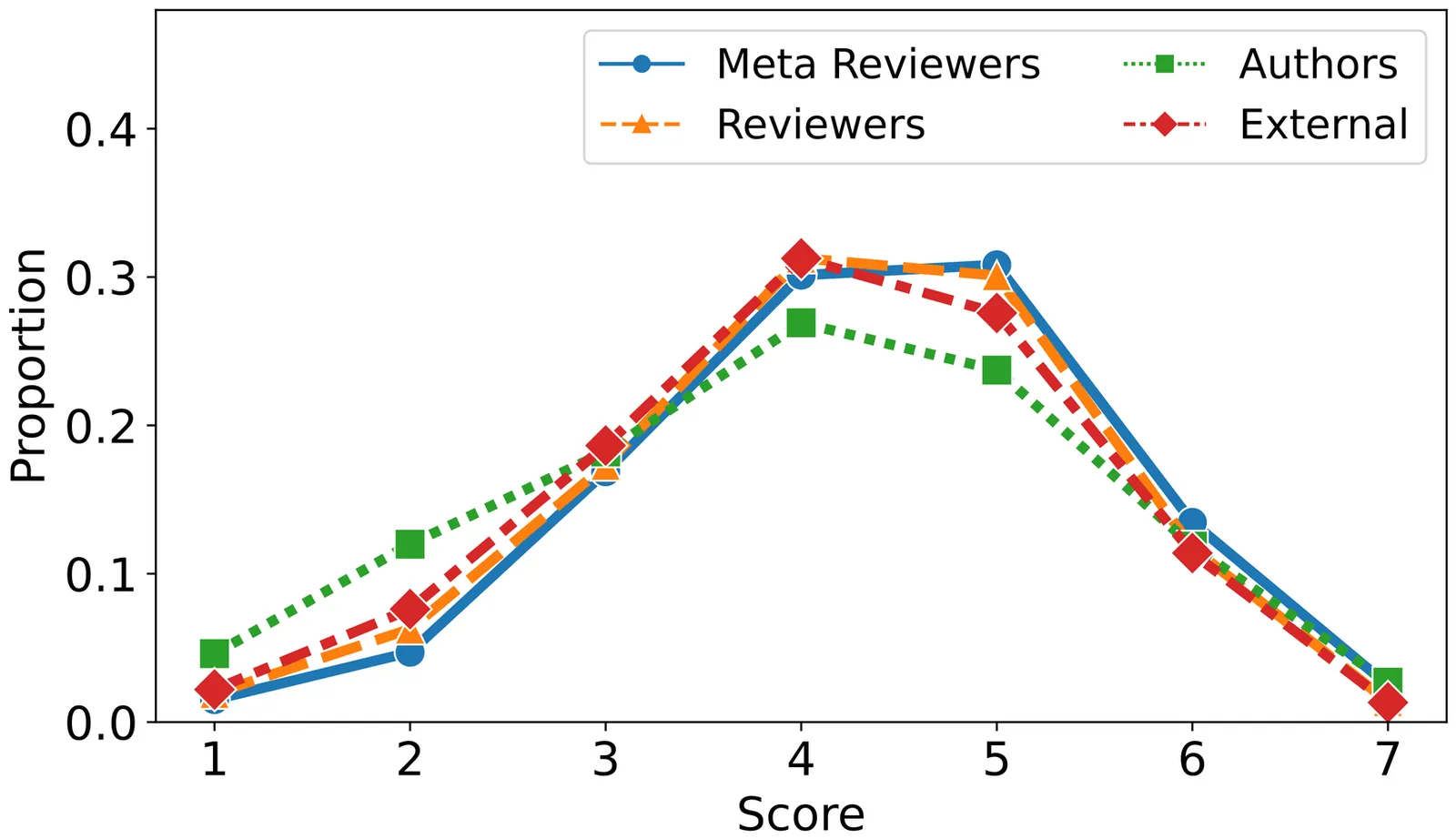
Is it possible to reliably evaluate the quality of peer reviews? We study this question driven by two primary motivations -- incentivizing high-quality reviewing using assessed quality of reviews and measuring changes to review quality in experiments. We conduct a large scale study at the NeurIPS 2022 conference, a top-tier conference in machine learning, in which we invited (meta)-reviewers and authors to evaluate reviews given to submitted papers. First, we conduct a RCT to examine bias due to the length of reviews. We generate elongated versions of reviews by adding substantial amounts of non-informative content. Participants in the control group evaluate the original reviews, whereas participants in the experimental group evaluate the artificially lengthened versions. We find that lengthened reviews are scored (statistically significantly) higher quality than the original reviews. In analysis of observational data we find that authors are positively biased towards reviews recommending acceptance of their own papers, even after controlling for confounders of review length, quality, and different numbers of papers per author. We also measure disagreement rates between multiple evaluations of the same review of 28%-32%, which is comparable to that of paper reviewers at NeurIPS. Further, we assess the amount of miscalibration of evaluators of reviews using a linear model of quality scores and find that it is similar to estimates of miscalibration of paper reviewers at NeurIPS. Finally, we estimate the amount of variability in subjective opinions around how to map individual criteria to overall scores of review quality and find that it is roughly the same as that in the review of papers. Our results suggest that the various problems that exist in reviews of papers -- inconsistency, bias towards irrelevant factors, miscalibration, subjectivity -- also arise in reviewing of reviews.

International research collaboration among global scientific powerhouses has exhibited a discernible trend towards convergence in recent decades. Notably, the US and China have significantly fortified their collaboration across diverse scientific disciplines, solidifying their status as a national-level duopoly in global scientific knowledge production. However, recent reports hint at a potential decline in collaboration between these two giants, even amidst the backdrop of advancing global convergence. Understanding the intricate interplay between cooperation and disparity within the US-China relationship is vital for both academia and policy leaders, as it provides invaluable insights into the potential future trajectory of global science collaboration. Despite its significance, there remains a noticeable dearth of quantitative evidence that adequately encapsulates the dynamism across disciplines and over time. To bridge this knowledge gap, this study delves into the evolving landscape of interaction between the US and China over recent decades. This investigation employs two approaches, one based on paper identifiers and the other on researcher identifiers, both obtained from bibliometric data sourced from OpenAlex. From both approaches, our findings unveil the unique and dynamic nature of the US-China relationship, characterised by a collaboration pattern initially marked by rapid convergence, followed by a recent phase of divergence.
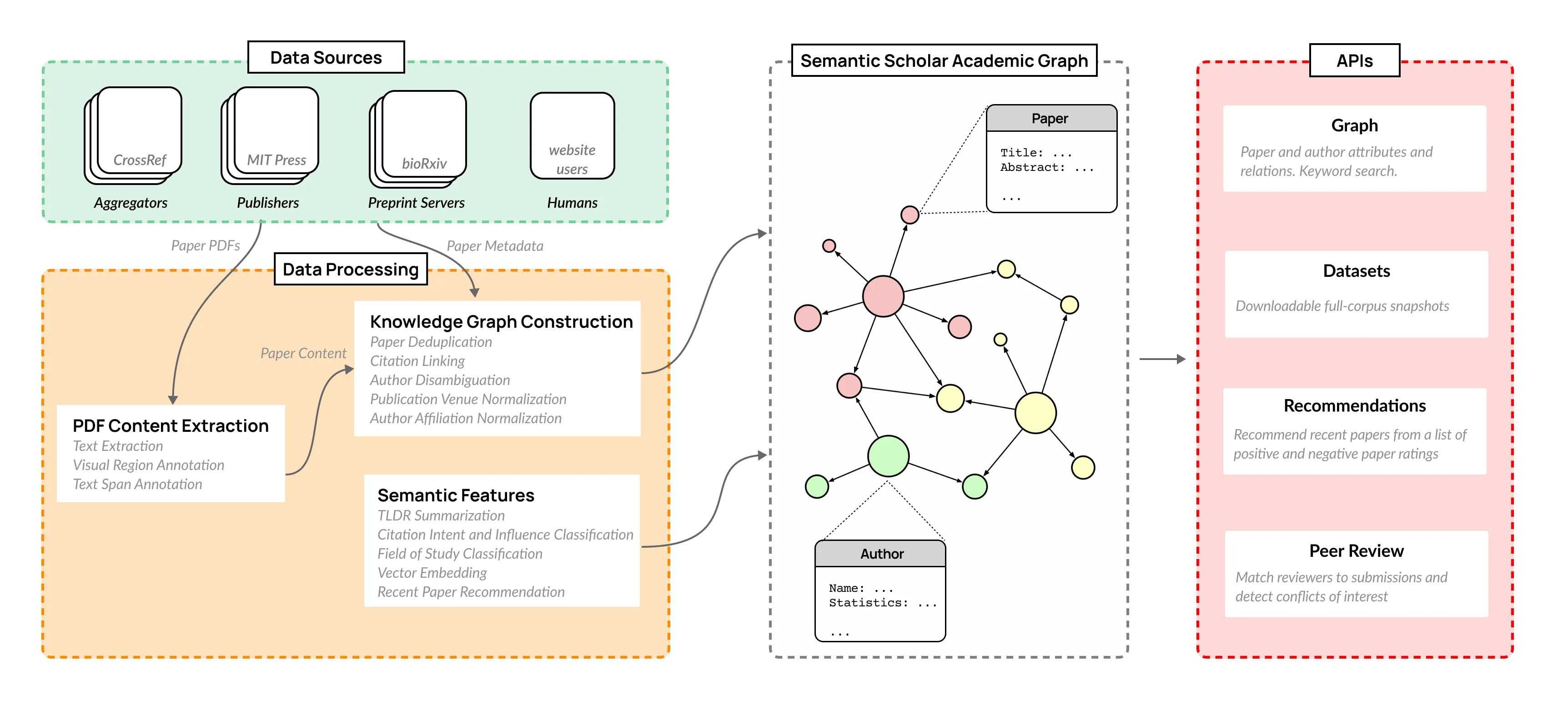
The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
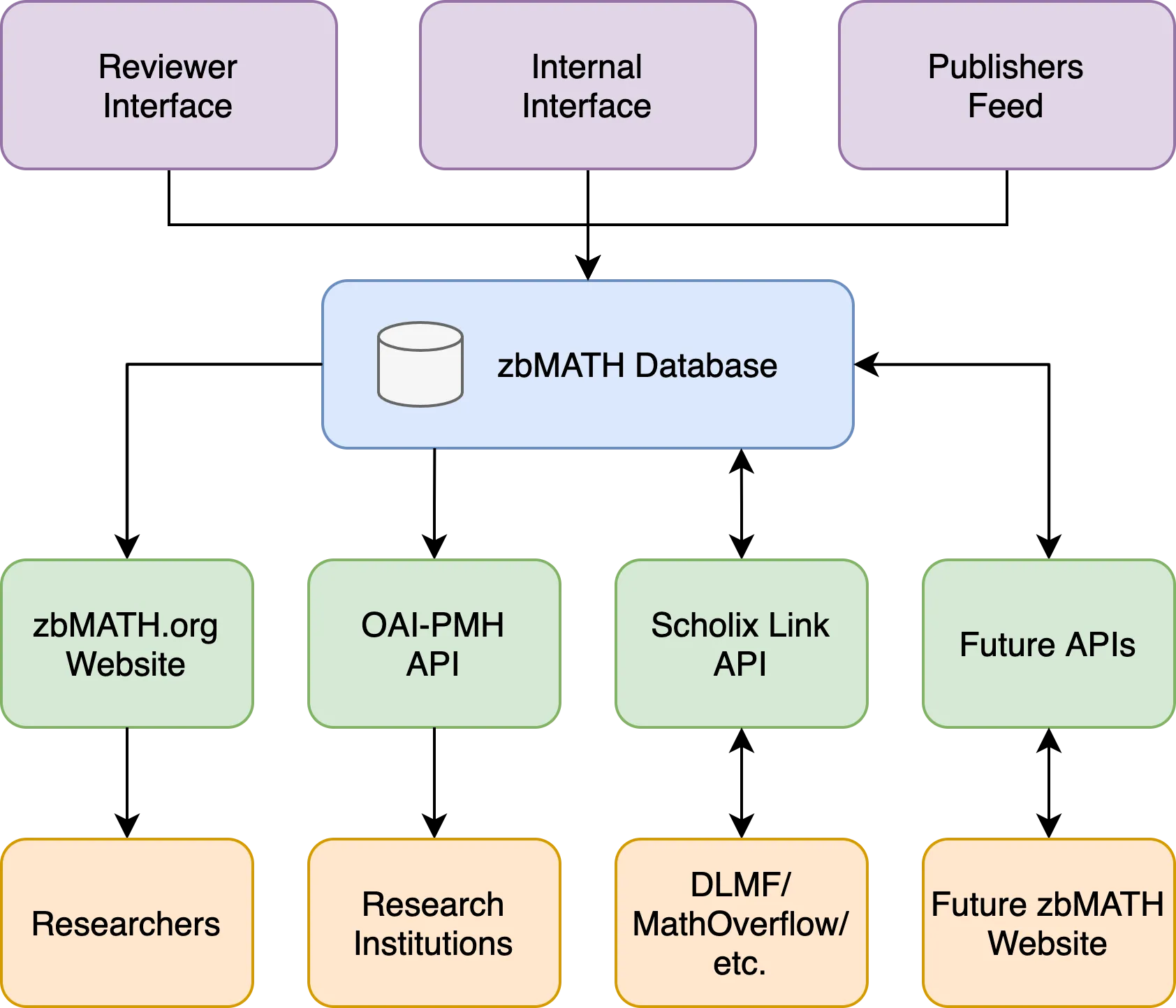
We present zbMATH Open, the most comprehensive collection of reviews and bibliographic metadata of scholarly literature in mathematics. Besides our website https://zbMATH.org which is openly accessible since the beginning of this year, we provide API endpoints to offer our data. The API improves interoperability with others, i.e., digital libraries, and allows using our data for research purposes. In this article, we (1) illustrate the current and future overview of the services offered by zbMATH; (2) present the initial version of the zbMATH links API; (3) analyze potentials and limitations of the links API based on the example of the NIST Digital Library of Mathematical Functions; (4) and finally, present the zbMATH Open dataset as a research resource and discuss connected open research problems.
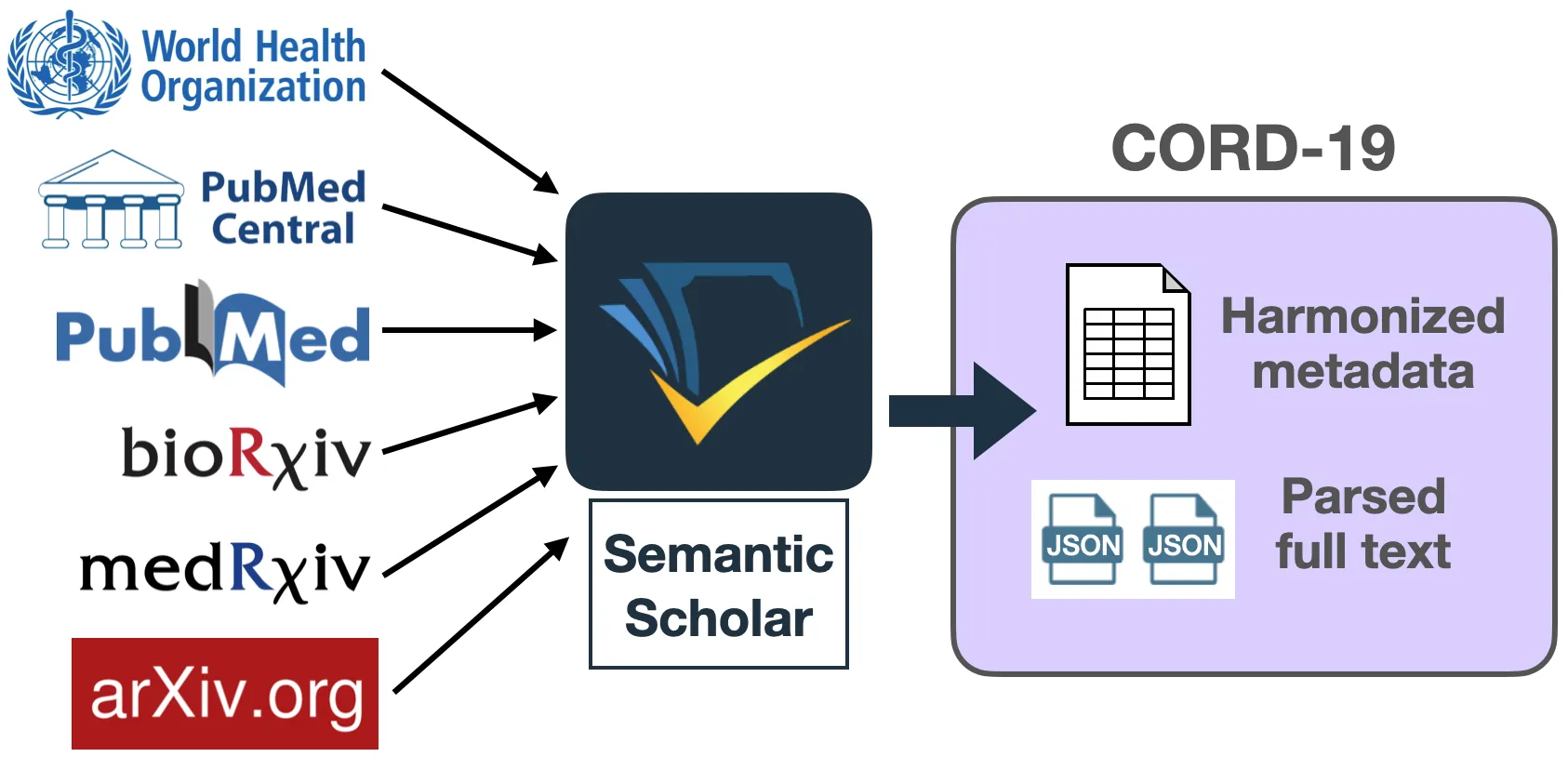
The COVID-19 Open Research Dataset (CORD-19) is a growing resource of scientific papers on COVID-19 and related historical coronavirus research. CORD-19 is designed to facilitate the development of text mining and information retrieval systems over its rich collection of metadata and structured full text papers. Since its release, CORD-19 has been downloaded over 200K times and has served as the basis of many COVID-19 text mining and discovery systems. In this article, we describe the mechanics of dataset construction, highlighting challenges and key design decisions, provide an overview of how CORD-19 has been used, and describe several shared tasks built around the dataset. We hope this resource will continue to bring together the computing community, biomedical experts, and policy makers in the search for effective treatments and management policies for COVID-19.