Computational Engineering, Finance, and Science
arXiv:cs.CE
Covers applications of computer science to the mathematical modeling of complex systems in the fields of science, engineering, and finance.
Covers applications of computer science to the mathematical modeling of complex systems in the fields of science, engineering, and finance.

We present PIVONet (Physically-Informed Variational ODE Neural Network), a unified framework that integrates Neural Ordinary Differential Equations (Neuro-ODEs) with Continuous Normalizing Flows (CNFs) for stochastic fluid simulation and visualization. First, we demonstrate that a physically informed model, parameterized by CNF parameters θ, can be trained offline to yield an efficient surrogate simulator for a specific fluid system, eliminating the need to simulate the full dynamics explicitly. Second, by introducing a variational model with parameters φ that captures latent stochasticity in observed fluid trajectories, we model the network output as a variational distribution and optimize a pathwise Evidence Lower Bound (ELBO), enabling stochastic ODE integration that captures turbulence and random fluctuations in fluid motion (advection-diffusion behaviors).
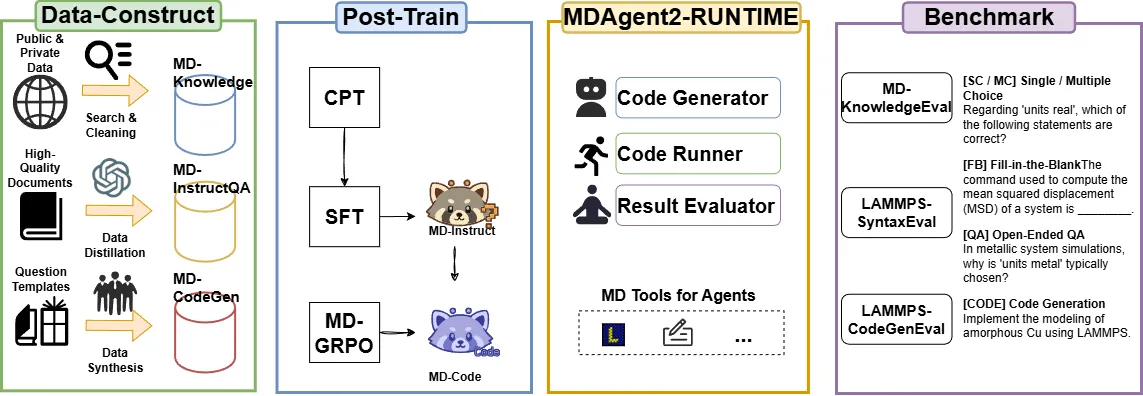
Molecular dynamics (MD) simulations are essential for understanding atomic-scale behaviors in materials science, yet writing LAMMPS scripts remains highly specialized and time-consuming tasks. Although LLMs show promise in code generation and domain-specific question answering, their performance in MD scenarios is limited by scarce domain data, the high deployment cost of state-of-the-art LLMs, and low code executability. Building upon our prior MDAgent, we present MDAgent2, the first end-to-end framework capable of performing both knowledge Q&A and code generation within the MD domain. We construct a domain-specific data-construction pipeline that yields three high-quality datasets spanning MD knowledge, question answering, and code generation. Based on these datasets, we adopt a three stage post-training strategy--continued pre-training (CPT), supervised fine-tuning (SFT), and reinforcement learning (RL)--to train two domain-adapted models, MD-Instruct and MD-Code. Furthermore, we introduce MD-GRPO, a closed-loop RL method that leverages simulation outcomes as reward signals and recycles low-reward trajectories for continual refinement. We further build MDAgent2-RUNTIME, a deployable multi-agent system that integrates code generation, execution, evaluation, and self-correction. Together with MD-EvalBench proposed in this work, the first benchmark for LAMMPS code generation and question answering, our models and system achieve performance surpassing several strong baselines.This work systematically demonstrates the adaptability and generalization capability of large language models in industrial simulation tasks, laying a methodological foundation for automatic code generation in AI for Science and industrial-scale simulations. URL: https://github.com/FredericVAN/PKU_MDAgent2
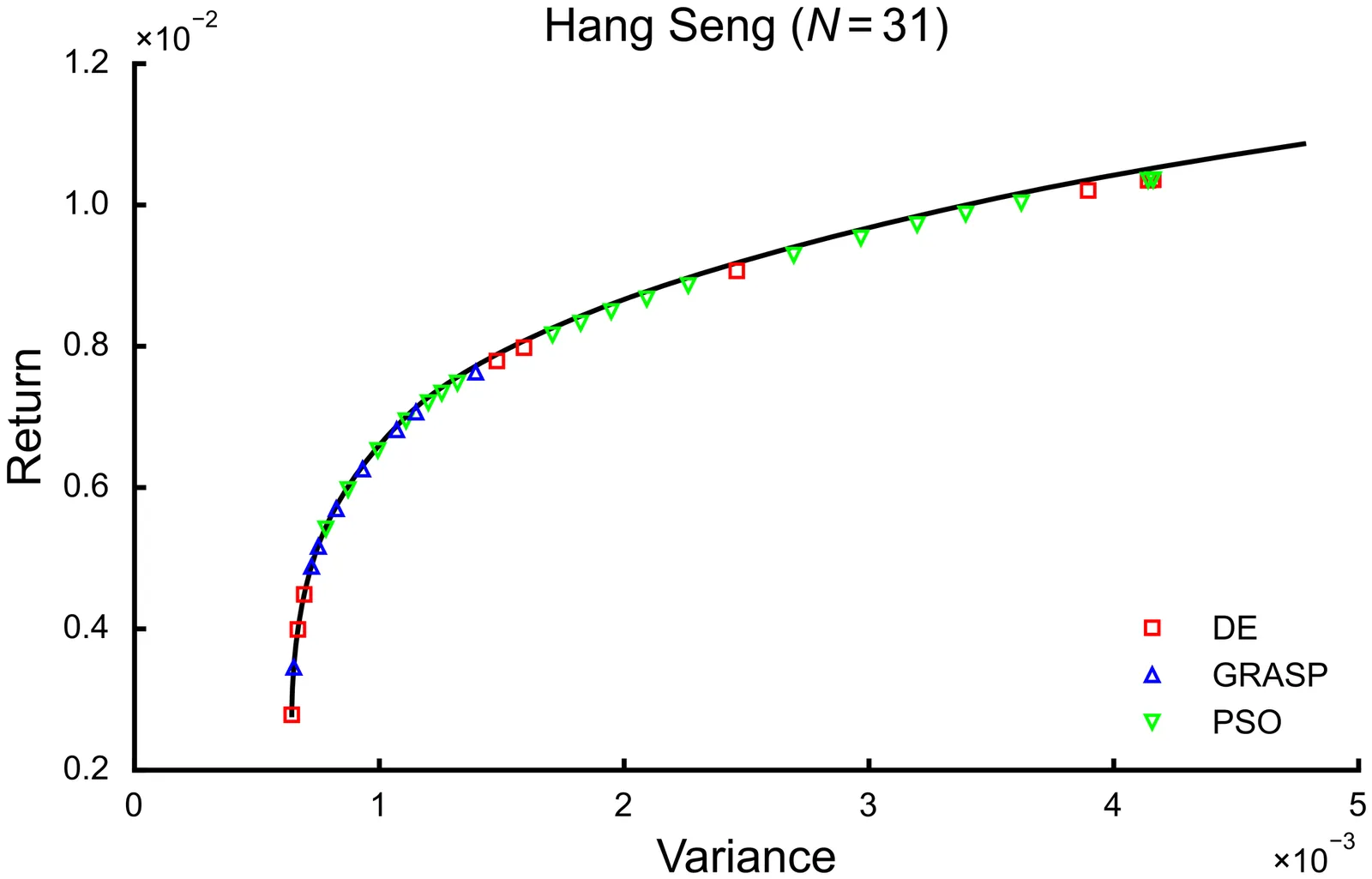
Investment portfolio optimization is a task conducted in all major financial institutions. The Cardinality Constrained Mean-Variance Portfolio Optimization (CCPO) problem formulation is ubiquitous for portfolio optimization. The challenge of this type of portfolio optimization, a mixed-integer quadratic programming (MIQP) problem, arises from the intractability of solutions from exact solvers, where heuristic algorithms are used to find approximate portfolio solutions. CCPO entails many laborious and complex workflows and also requires extensive effort pertaining to heuristic algorithm development, where the combination of pooled heuristic solutions results in improved efficient frontiers. Hence, common approaches are to develop many heuristic algorithms. Agentic frameworks emerge as a promising candidate for many problems within combinatorial optimization, as they have been shown to be equally efficient with regard to automating large workflows and have been shown to be excellent in terms of algorithm development, sometimes surpassing human-level performance. This study implements a novel agentic framework for the CCPO and explores several concrete architectures. In benchmark problems, the implemented agentic framework matches state-of-the-art algorithms. Furthermore, complex workflows and algorithm development efforts are alleviated, while in the worst case, lower but acceptable error is reported.
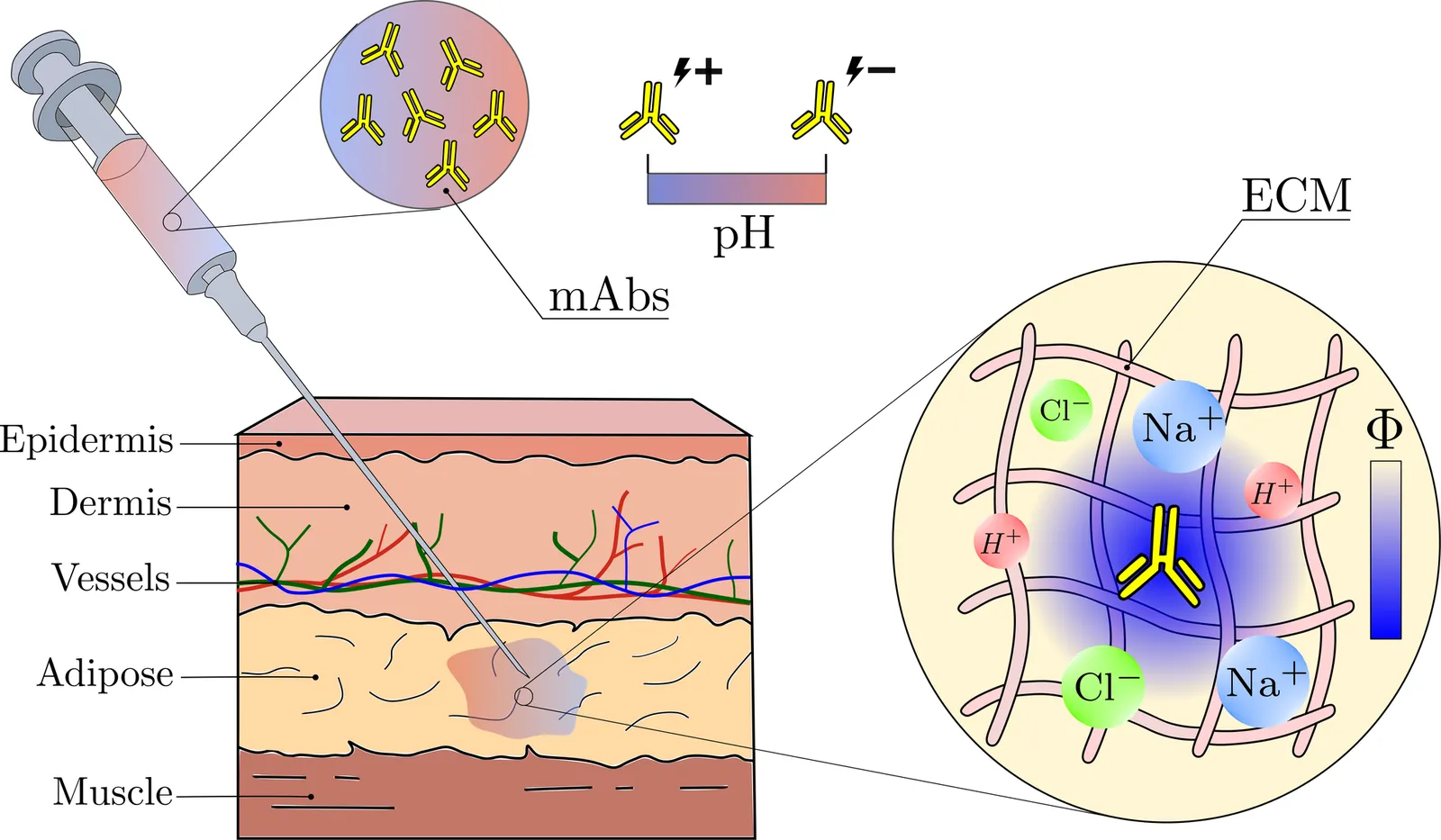
This study explores the effects of electric charge on the dynamics of drug transport and absorption in subcutaneous injections of monoclonal antibodies (mAbs). We develop a novel mathematical and computational model, based on the Nernst-Planck equations and porous media flow theory, to investigate the complex interactions between mAbs and charged species in subcutaneous tissue. The model enables us to study short-term transport dynamics and long-term binding and absorption for two mAbs with different electric properties. We examine the influence of buffer pH, body mass index, injection depth, and formulation concentration on drug distribution and compare our numerical results with experimental data from the literature.

Accurate forecasting of financial markets remains a long-standing challenge due to complex temporal and often latent dependencies, non-linear dynamics, and high volatility. Building on our earlier recurrent neural network framework, we present an enhanced StockBot architecture that systematically evaluates modern attention-based, convolutional, and recurrent time-series forecasting models within a unified experimental setting. While attention-based and transformer-inspired models offer increased modeling flexibility, extensive empirical evaluation reveals that a carefully constructed vanilla LSTM consistently achieves superior predictive accuracy and more stable buy/sell decision-making when trained under a common set of default hyperparameters. These results highlight the robustness and data efficiency of recurrent sequence models for financial time-series forecasting, particularly in the absence of extensive hyperparameter tuning or the availability of sufficient data when discretized to single-day intervals. Additionally, these results underscore the importance of architectural inductive bias in data-limited market prediction tasks.
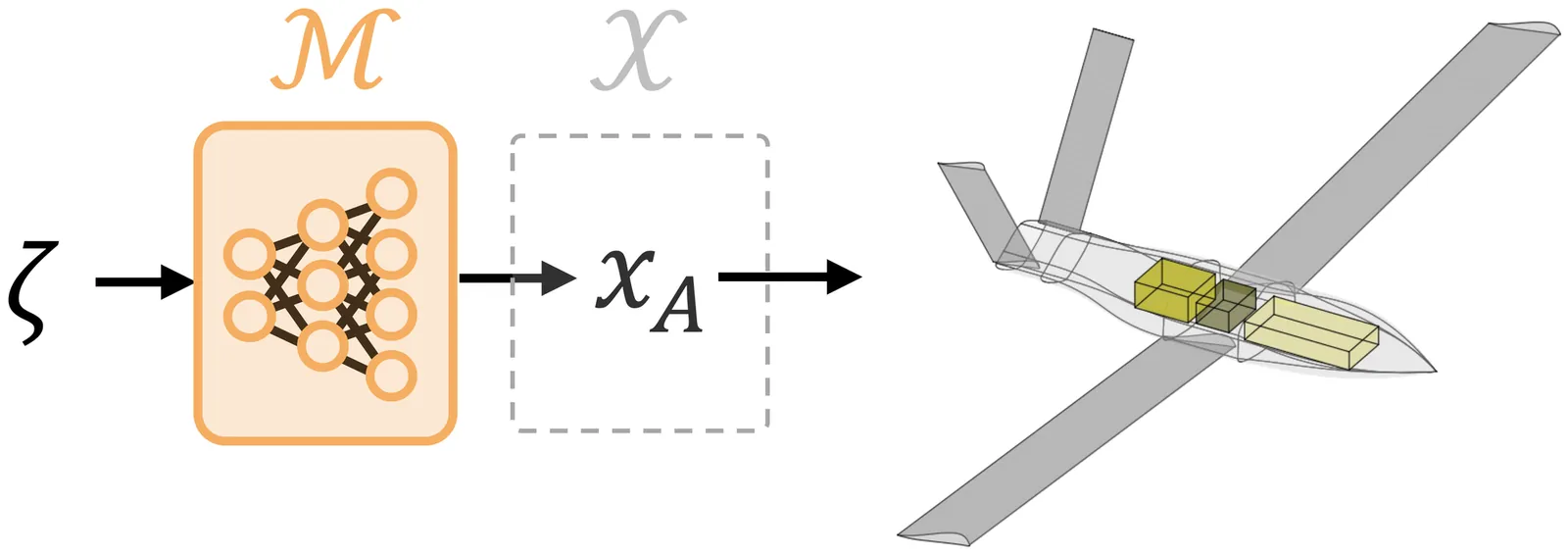
Engineering complex systems (aircraft, buildings, vehicles) requires accounting for geometric and performance couplings across subsystems. As generative models proliferate for specialized domains (wings, structures, engines), a key research gap is how to coordinate frozen, pre-trained submodels to generate full-system designs that are feasible, diverse, and high-performing. We introduce Generative Latent Unification of Expertise-Informed Engineering Models (GLUE), which orchestrates pre-trained, frozen subsystem generators while enforcing system-level feasibility, optimality, and diversity. We propose and benchmark (i) data-driven GLUE models trained on pre-generated system-level designs and (ii) a data-free GLUE model trained online on a differentiable geometry layer. On a UAV design problem with five coupling constraints, we find that data-driven approaches yield diverse, high-performing designs but require large datasets to satisfy constraints reliably. The data-free approach is competitive with Bayesian optimization and gradient-based optimization in performance and feasibility while training a full generative model in only 10 min on a RTX 4090 GPU, requiring more than two orders of magnitude fewer geometry evaluations and FLOPs than the data-driven method. Ablations focused on data-free training show that subsystem output continuity affects coordination, and equality constraints can trigger mode collapse unless mitigated. By integrating unmodified, domain-informed submodels into a modular generative workflow, this work provides a viable path for scaling generative design to complex, real-world engineering systems.

We propose a pressure-robust enriched Galerkin (EG) finite element method for the incompressible Navier-Stokes and heat equations in the Boussinesq regime. For the Navier-Stokes equations, the EG formulation combines continuous Lagrange elements with a discontinuous enrichment vector per element in the velocity space and a piecewise constant pressure space, and it can be implemented efficiently within standard finite element frameworks. To enforce pressure robustness, we construct velocity reconstruction operators that map the discrete EG velocity field into exactly divergence-free, H(div)-conforming fields. In particular, we develop reconstructions based on Arbogast-Correa (AC) mixed finite element spaces on quadrilateral meshes and demonstrate that the resulting schemes remain stable and accurate even on highly distorted grids. The nonlinearity of the coupled Navier-Stokes-Boussinesq system is treated with several iterative strategies, including Picard iterations and Anderson-accelerated iterations; our numerical study shows that Anderson acceleration yields robust and efficient convergence for high Rayleigh number flows within the proposed framework. The performance of the method is assessed on a set of benchmark problems and application-driven test cases. These numerical experiments highlight the potential of pressure-robust EG methods as flexible and accurate tools for coupled flow and heat transport in complex geometries.

Reliable forward uncertainty quantification in engineering requires methods that account for aleatory and epistemic uncertainties. In many applications, epistemic effects arising from uncertain parameters and model form dominate prediction error and strongly influence engineering decisions. Because distinguishing and representing each source separately is often infeasible, their combined effect is typically analyzed using a unified model-error framework. Model error directly affects model credibility and predictive reliability; yet its characterization remains challenging. To address this need, we introduce a bootstrap-based stochastic subspace model for characterizing model error in the stochastic reduced-order modeling framework. Given a snapshot matrix of state vectors, the method leverages the empirical data distribution to induce a sampling distribution over principal subspaces for reduced order modeling. The resulting stochastic model enables improved characterization of model error in computational mechanics compared with existing approaches. The method offers several advantages: (1) it is assumption-free and leverages the empirical data distribution; (2) it enforces linear constraints (such as boundary conditions) by construction; (3) it requires only one hyperparameter, significantly simplifying the training process; and (4) its algorithm is straightforward to implement. We evaluate the method's performance against existing approaches using numerical examples in computational mechanics and structural dynamics.
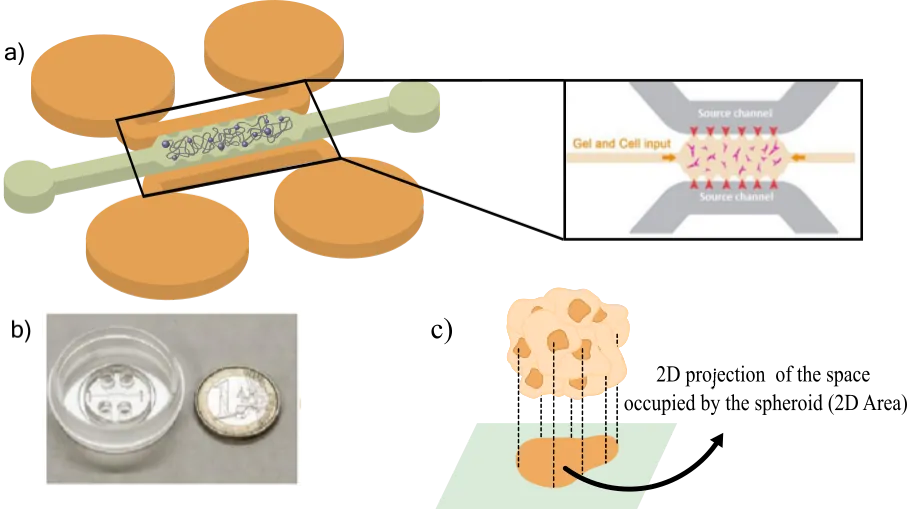
Cancer research has shifted from a purely gene-centric view to a more holistic understanding that recognizes the critical role of the tumour microenvironment, where mechanics and metabolism are key drivers of disease progression. However, the intricate interplay between these multifactorial mechanisms remains poorly understood. To address this gap, we present an agent-based computational model (ABM) that integrates tumour metabolism and mechanics to study 3D cancer spheroid growth. Our approach unifies the metabolism and mechanical aspects of tumour development within an integral model for cancer spheroid formation and growth. In addition to that, we performed a computational calibration of the parameters and tested the model versatility to reproduce different cellular behaviours. Our model reproduced qualitatively and quantitatively the experimental results of spheroid growth obtained in the lab and also allowed to discern different dynamics that cancer cells can present under the same conditions, providing insight into the potential factors contributing to the variability in the size of spheroids. Furthermore, it also showed its adaptability to reproduce diferent cell lines and behaviours by tuning its parameters. This study highlights the significant potential and versatility of integrative modelling approaches in the field of cancer research, not only as a tool to complement in vitro studies, but also as independent tools to derive conclusions from the physical reality.
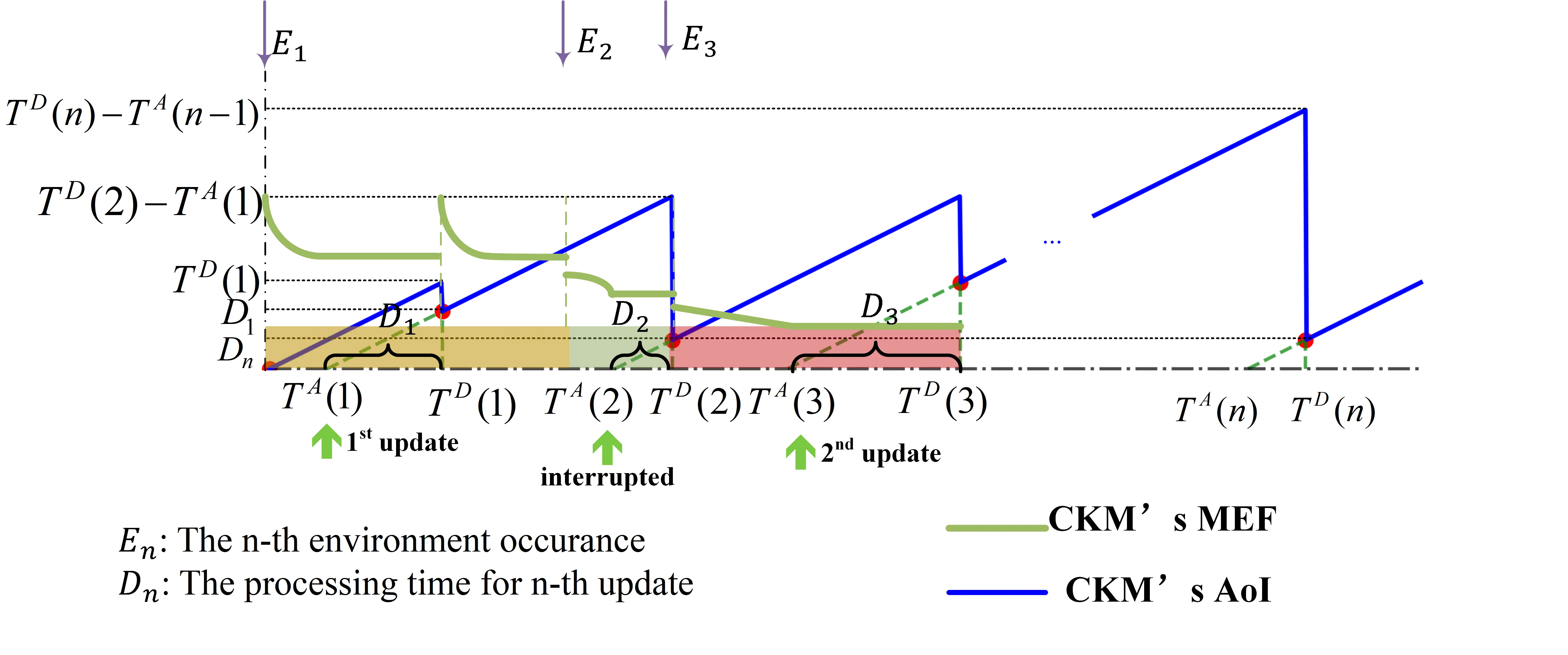
The Channel Knowledge Map (CKM) maps position information to channel state information, leveraging environmental knowledge to reduce signaling overhead in sixth-generation networks. However, constructing a reliable CKM demands substantial data and computation, and in dynamic environments, a pre-built CKM becomes outdated, degrading performance. Frequent retraining restores accuracy but incurs significant waste, creating a fundamental trade-off between CKM efficacy and update overhead. To address this, we introduce a Map Efficacy Function (MEF) capturing both gradual aging and abrupt environmental transitions, and formulate the update scheduling problem as fractional programming. We develop two Dinkelbach-based algorithms: Delta-P guarantees global optimality, while Delta-L achieves near-optimal performance with near-linear complexity. For unpredictable environments, we derive a threshold-based policy: immediate updates are optimal when the environmental degradation rate exceeds the resource consumption acceleration; otherwise, delay is preferable. For predictable environments, long-term strategies strategically relax these myopic rules to maximize global performance. Across this regime, the policy reveals that stronger entry loss and faster decay favor immediate updates, while weaker entry loss and slower decay favor delayed updates.
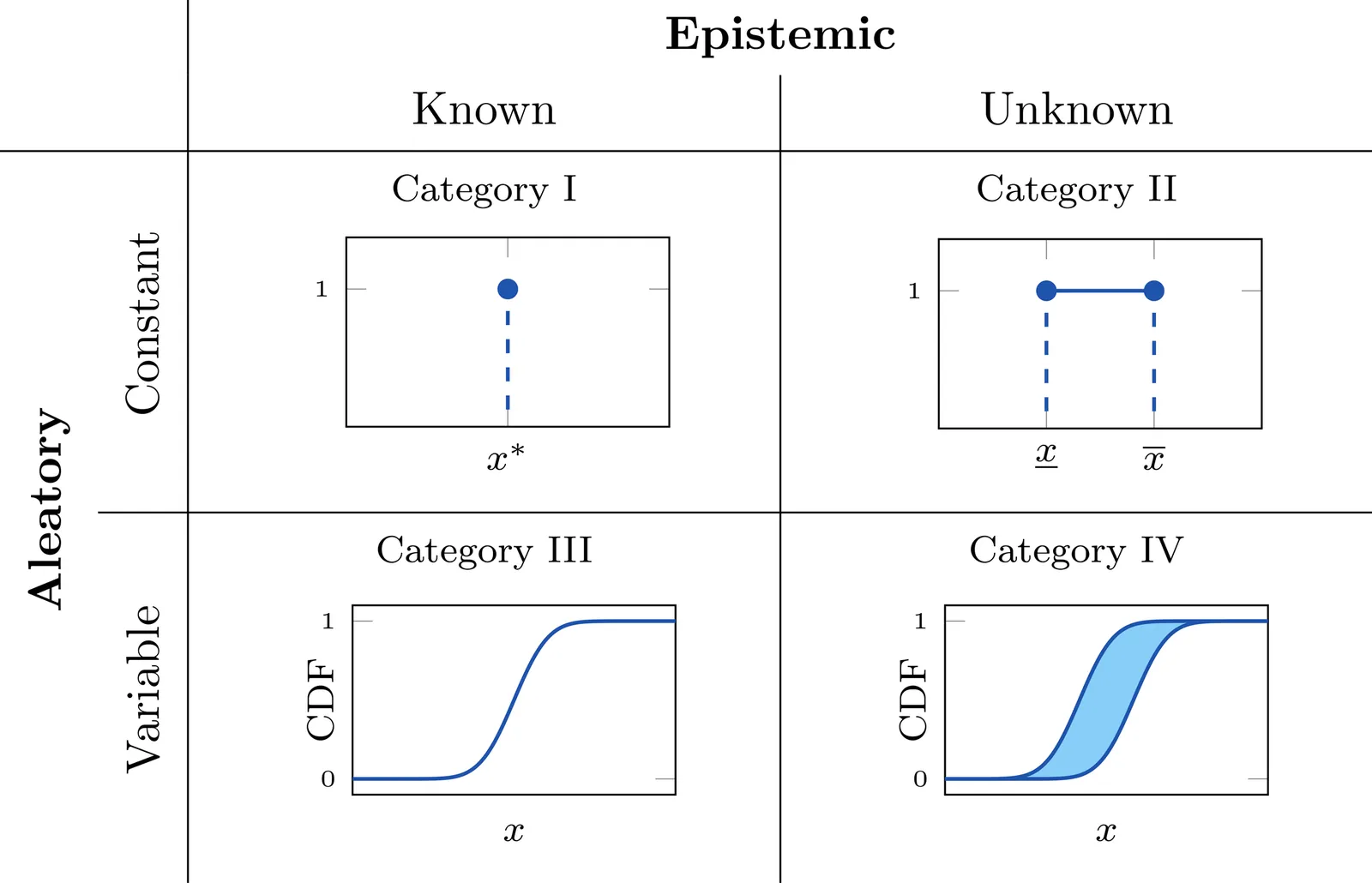
Accurate modeling of bacterial biofilm growth is essential for understanding their complex dynamics in biomedical, environmental, and industrial settings. These dynamics are shaped by a variety of environmental influences, including the presence of antibiotics, nutrient availability, and inter-species interactions, all of which affect species-specific growth rates. However, capturing this behavior in computational models is challenging due to the presence of hybrid uncertainties, a combination of epistemic uncertainty (stemming from incomplete knowledge about model parameters) and aleatory uncertainty (reflecting inherent biological variability and stochastic environmental conditions). In this work, we present a Bayesian model updating (BMU) framework to calibrate a recently introduced multi-species biofilm growth model. To enable efficient inference in the presence of hybrid uncertainties, we construct a reduced-order model (ROM) derived using the Time-Separated Stochastic Mechanics (TSM) approach. TSM allows for an efficient propagation of aleatory uncertainty, which enables single-loop Bayesian inference, thereby avoiding the computationally expensive nested (double-loop) schemes typically required in hybrid uncertainty quantification. The BMU framework employs a likelihood function constructed from the mean and variance of stochastic model outputs, enabling robust parameter calibration even under sparse and noisy data. We validate our approach through two case studies: a two-species and a four-species biofilm model. Both demonstrate that our method not only accurately recovers the underlying model parameters but also provides predictive responses consistent with the synthetic data.
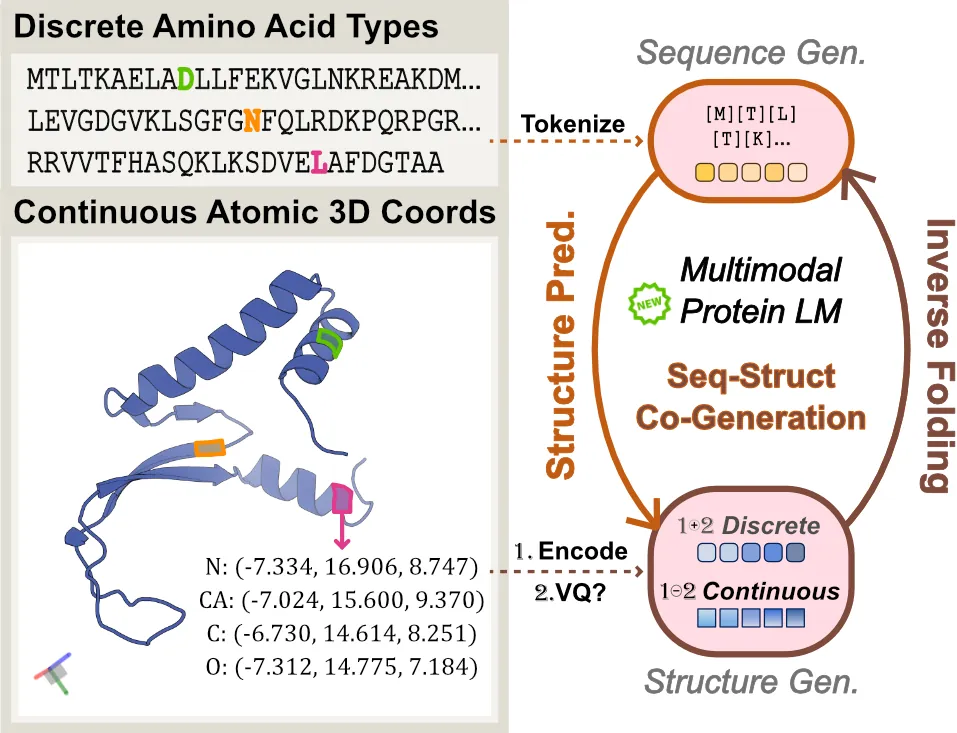
Proteins inherently possess a consistent sequence-structure duality. The abundance of protein sequence data, which can be readily represented as discrete tokens, has driven fruitful developments in protein language models (pLMs). A key remaining challenge, however, is how to effectively integrate continuous structural knowledge into pLMs. Current methods often discretize protein structures to accommodate the language modeling framework, which inevitably results in the loss of fine-grained information and limits the performance potential of multimodal pLMs. In this paper, we argue that such concerns can be circumvented: a sequence-based pLM can be extended to incorporate the structure modality through continuous tokens, i.e., high-fidelity protein structure latents that avoid vector quantization. Specifically, we propose a hybrid diffusion protein language model, HD-Prot, which embeds a continuous-valued diffusion head atop a discrete pLM, enabling seamless operation with both discrete and continuous tokens for joint sequence-structure modeling. It captures inter-token dependencies across modalities through a unified absorbing diffusion process, and estimates per-token distributions via categorical prediction for sequences and continuous diffusion for structures. Extensive empirical results show that HD-Prot achieves competitive performance in unconditional sequence-structure co-generation, motif-scaffolding, protein structure prediction, and inverse folding tasks, performing on par with state-of-the-art multimodal pLMs despite being developed under limited computational resources. It highlights the viability of simultaneously estimating categorical and continuous distributions within a unified language model architecture, offering a promising alternative direction for multimodal pLMs.
Artificial intelligence is beginning to ease long-standing bottlenecks in the CAD-to-mesh pipeline. This survey reviews recent advances where machine learning aids part classification, mesh quality prediction, and defeaturing. We explore methods that improve unstructured and block-structured meshing, support volumetric parameterizations, and accelerate parallel mesh generation. We also examine emerging tools for scripting automation, including reinforcement learning and large language models. Across these efforts, AI acts as an assistive technology, extending the capabilities of traditional geometry and meshing tools. The survey highlights representative methods, practical deployments, and key research challenges that will shape the next generation of data-driven meshing workflows.
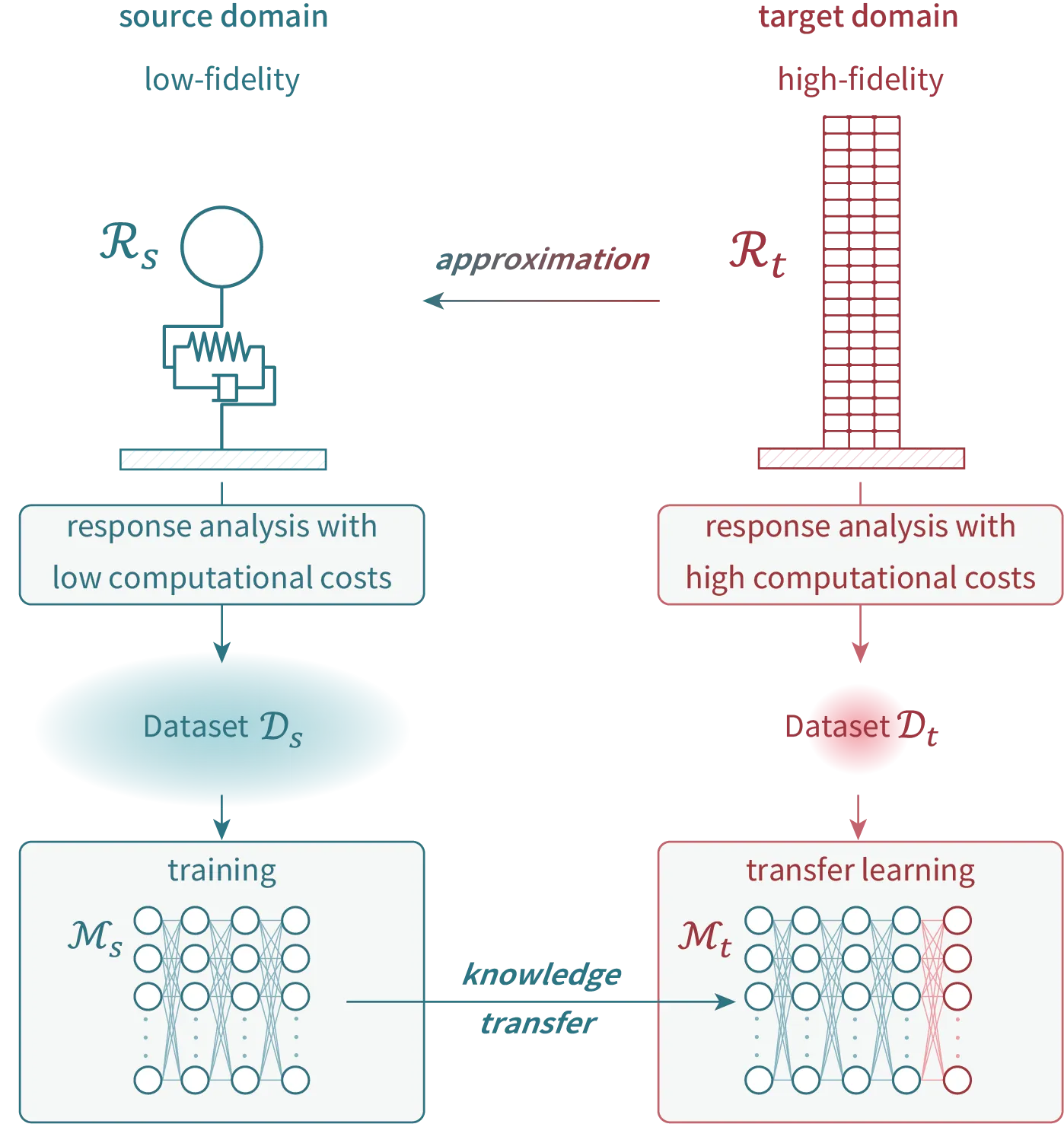
In a performance based earthquake engineering (PBEE) framework, nonlinear time-history response analysis (NLTHA) for numerous ground motions are required to assess the seismic risk of buildings or civil engineering structures. However, such numerical simulations are computationally expensive, limiting the real-world practical application of the framework. To address this issue, previous studies have used machine learning to predict the structural responses to ground motions with low computational costs. These studies typically conduct NLTHAs for a few hundreds ground motions and use the results to train and validate surrogate models. However, most of the previous studies focused on computationally-inexpensive response analysis models such as single degree of freedom. Surrogate models of high-fidelity response analysis are required to enrich the quantity and diversity of information used for damage assessment in PBEE. Notably, the computational cost of creating training and validation datasets increases if the fidelity of response analysis model becomes higher. Therefore, methods that enable surrogate modeling of high-fidelity response analysis without a large number of training samples are needed. This study proposes a framework that uses transfer learning to construct the surrogate model of a high-fidelity response analysis model. This framework uses a surrogate model of low-fidelity response analysis as the pretrained model and transfers its knowledge to construct surrogate models for high-fidelity response analysis with substantially reduced computational cost. As a case study, surrogate models that predict responses of a 20-story steel moment frame were constructed with only 20 samples as the training dataset. The responses to the ground motions predicted by constructed surrogate model were consistent with a site-specific time-based hazard.

The patterns of different financial data sources vary substantially, and accordingly, investors exhibit heterogeneous cognition behavior in information processing. To capture different patterns, we propose a novel approach called the two-stage dynamic stacking ensemble model based on investor knowledge representations, which aims to effectively extract and integrate the features from multi-source financial data. In the first stage, we identify different financial data property from global stock market indices, industrial indices, and financial news based on the perspective of investors. And then, we design appropriate neural network architectures tailored to these properties to generate effective feature representations. Based on learned feature representations, we design multiple meta-classifiers and dynamically select the optimal one for each time window, enabling the model to effectively capture and learn the distinct patterns that emerge across different temporal periods. To evaluate the performance of the proposed model, we apply it to predicting the daily movement of Shanghai Securities Composite index, SZSE Component index and Growth Enterprise index in Chinese stock market. The experimental results demonstrate the effectiveness of our model in improving the prediction performance. In terms of accuracy metric, our approach outperforms the best competing models by 1.42%, 7.94%, and 7.73% on the SSEC, SZEC, and GEI indices, respectively. In addition, we design a trading strategy based on the proposed model. The economic results show that compared to the competing trading strategies, our strategy delivers a superior performance in terms of the accumulated return and Sharpe ratio.
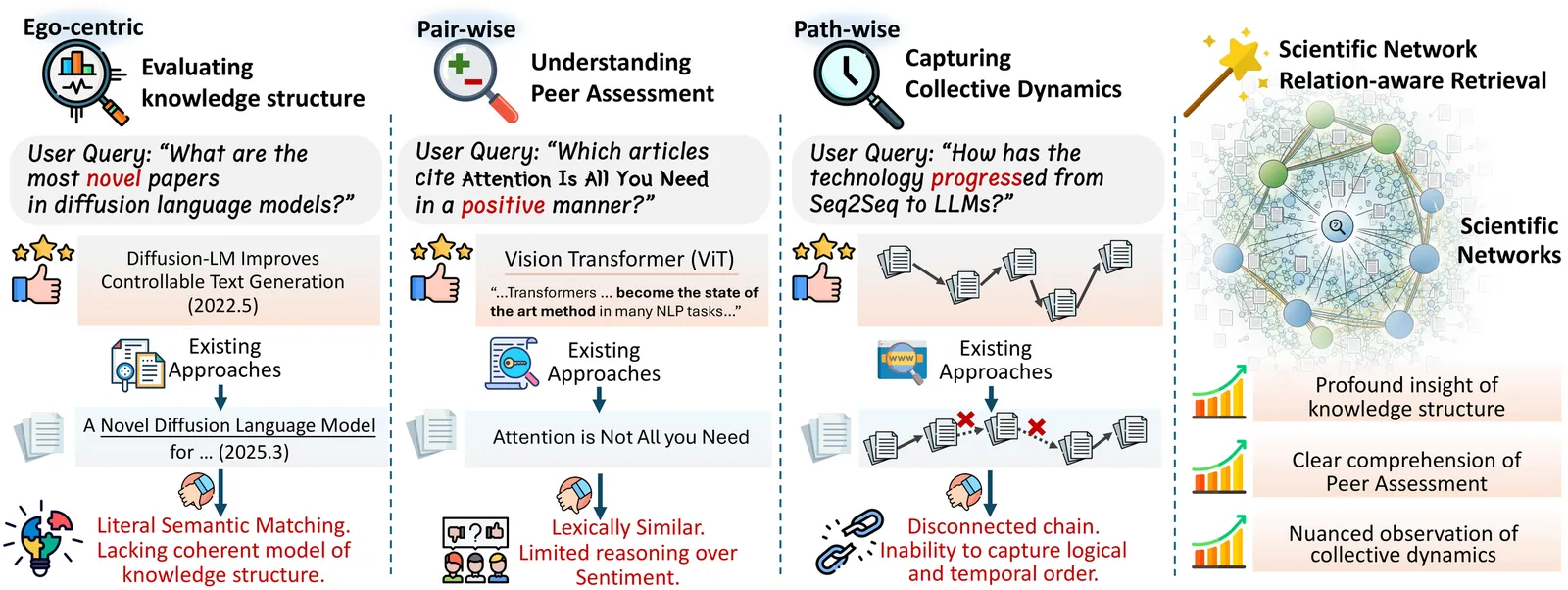
The rapid development of AI agent has spurred the development of advanced research tools, such as Deep Research. Achieving this require a nuanced understanding of the relations within scientific literature, surpasses the scope of keyword-based or embedding-based retrieval. Existing retrieval agents mainly focus on the content-level similarities and are unable to decode critical relational dynamics, such as identifying corroborating or conflicting studies or tracing technological lineages, all of which are essential for a comprehensive literature review. Consequently, this fundamental limitation often results in a fragmented knowledge structure, misleading sentiment interpretation, and inadequate modeling of collective scientific progress. To investigate relation-aware retrieval more deeply, we propose SciNetBench, the first Scientific Network Relation-aware Benchmark for literature retrieval agents. Constructed from a corpus of over 18 million AI papers, our benchmark systematically evaluates three levels of relations: ego-centric retrieval of papers with novel knowledge structures, pair-wise identification of scholarly relationships, and path-wise reconstruction of scientific evolutionary trajectories. Through extensive evaluation of three categories of retrieval agents, we find that their accuracy on relation-aware retrieval tasks often falls below 20%, revealing a core shortcoming of current retrieval paradigms. Notably, further experiments on the literature review tasks demonstrate that providing agents with relational ground truth leads to a substantial 23.4% performance improvement in the review quality, validating the critical importance of relation-aware retrieval. We publicly release our benchmark at https://anonymous.4open.science/r/SciNetBench/ to support future research on advanced retrieval systems.
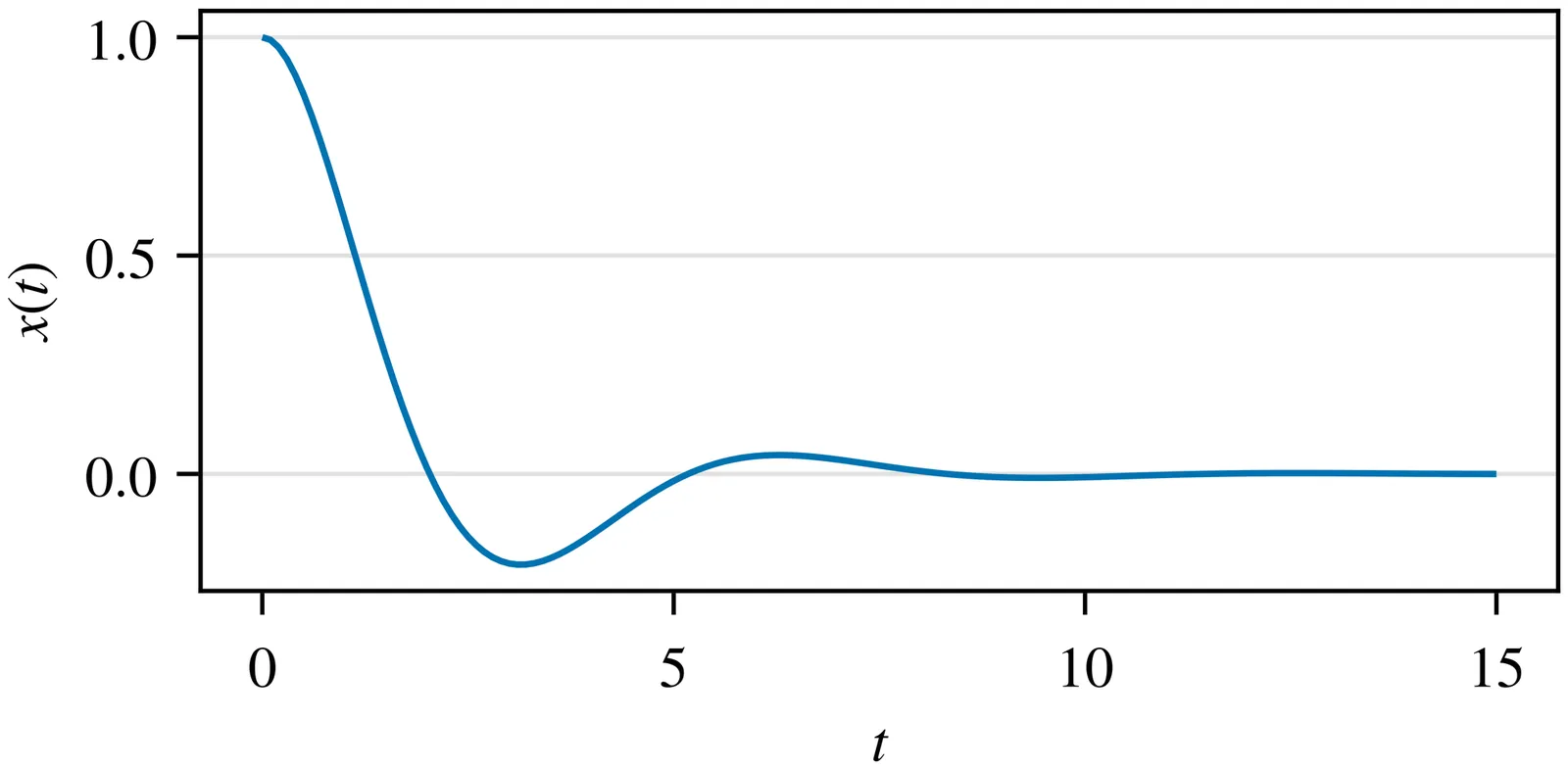
When two simulation units in a continuous-time co-simulation are connected via some variable $q$, and both simulation units have an internal state which represents the time integral of $q$, there will generally be a discrepancy between those states due to extrapolation errors. Normally, such extrapolation errors diminish if the macro time step size is reduced. Here we show that, under certain circumstances, step size changes can cause such discrepancies to increase even when the change is towards smaller steps.
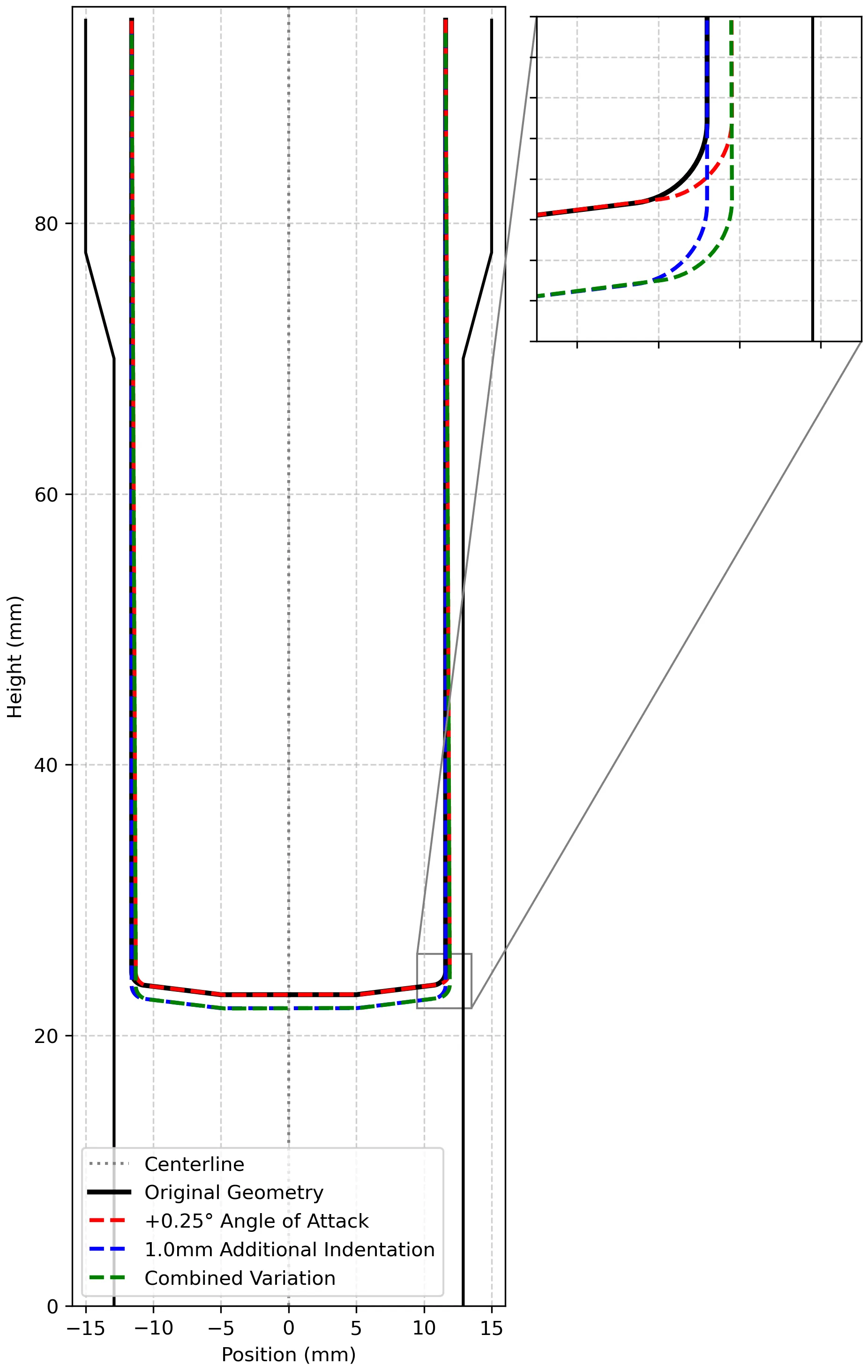
Scatter in properties resulting from manufacturing is a great challenge in lightweight design, requiring consideration of not only the average mechanical performance but also the variance which is done e.g., by conservative safety factors. One contributor to this variance is the inherent geometric variability in the formed part. To isolate and quantify this effect, we present a probabilistic numerical study, aiming to assess the impact of geometric variance on the resulting part performance. By modelling geometric deviations stochastically, we aim to establish a correlation between the variance in geometry with the resulting variance in performance. The study is done on the example of an airbag pressure bin, where a better understanding of this correlation is crucial, as it allows for the design of a lighter part without changing the manufacturing process. Instead, we aim to implement more targeted and effective quality assurance, informed by the performance impact of geometric deviations.
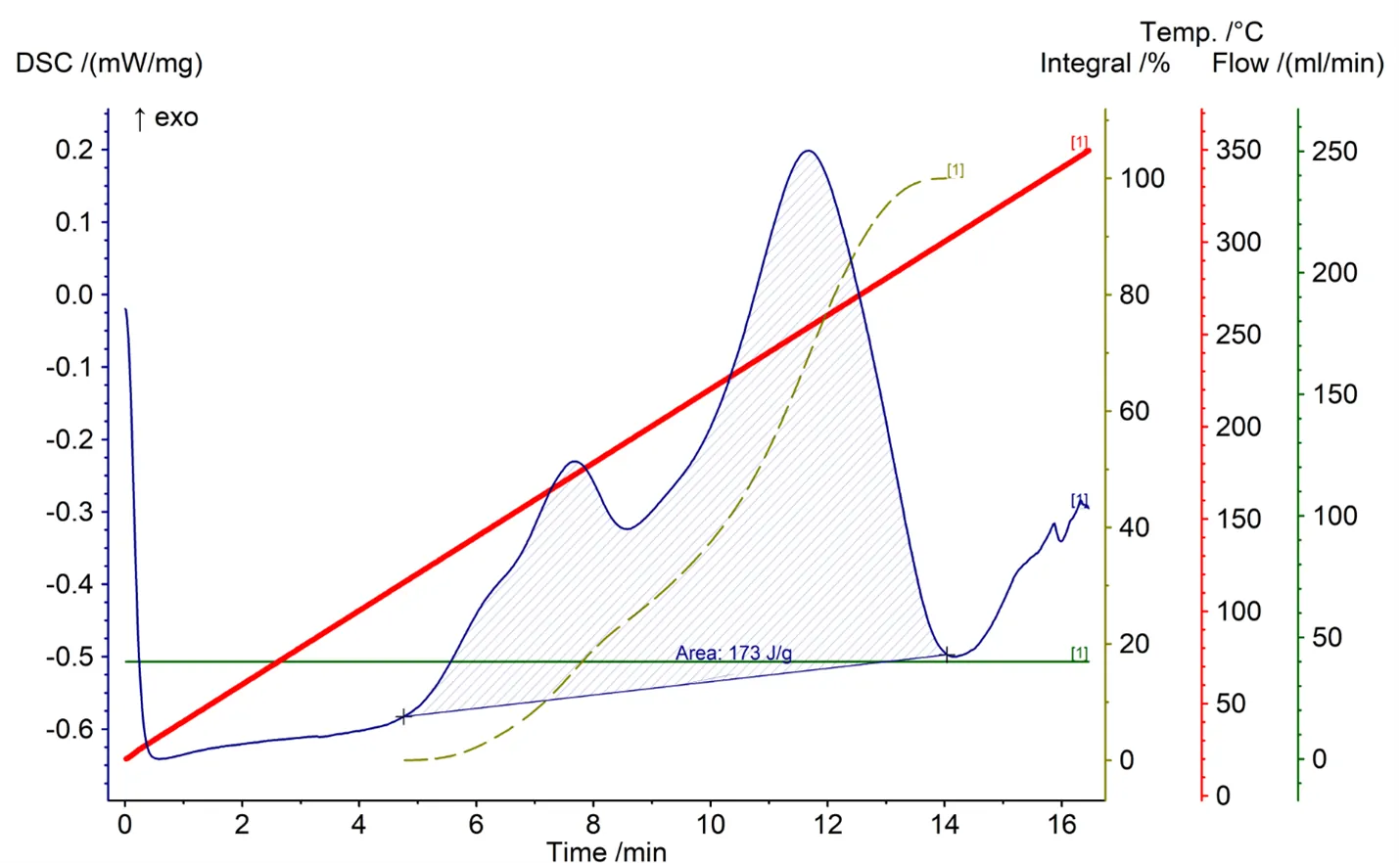
Fiber reinforcement and polymer matrix respond differently to manufacturing conditions due to mismatch in coefficient of thermal expansion and matrix shrinkage during curing of thermosets. These heterogeneities generate residual stresses over multiple length scales, whose partial release leads to process-induced deformation (PID), requiring accurate prediction and mitigation via optimized non-isothermal cure cycles. This study considers a unidirectional AS4 carbon fiber/amine bi-functional epoxy prepreg and models PID using a two-mechanism framework that accounts for thermal expansion/shrinkage and cure shrinkage. The model is validated against manufacturing trials to identify initial and boundary conditions, then used to generate PID responses for a diverse set of non-isothermal cure cycles (time-temperature profiles). Building on this physics-based foundation, we develop a data-driven surrogate based on Deep Operator Networks (DeepONets). A DeepONet is trained on a dataset combining high-fidelity simulations with targeted experimental measurements of PID. We extend this to a Feature-wise Linear Modulation (FiLM) DeepONet, where branch-network features are modulated by external parameters, including the initial degree of cure, enabling prediction of time histories of degree of cure, viscosity, and deformation. Because experimental data are available only at limited time instances (for example, final deformation), we use transfer learning: simulation-trained trunk and branch networks are fixed and only the final layer is updated using measured final deformation. Finally, we augment the framework with Ensemble Kalman Inversion (EKI) to quantify uncertainty under experimental conditions and to support optimization of cure schedules for reduced PID in composites.
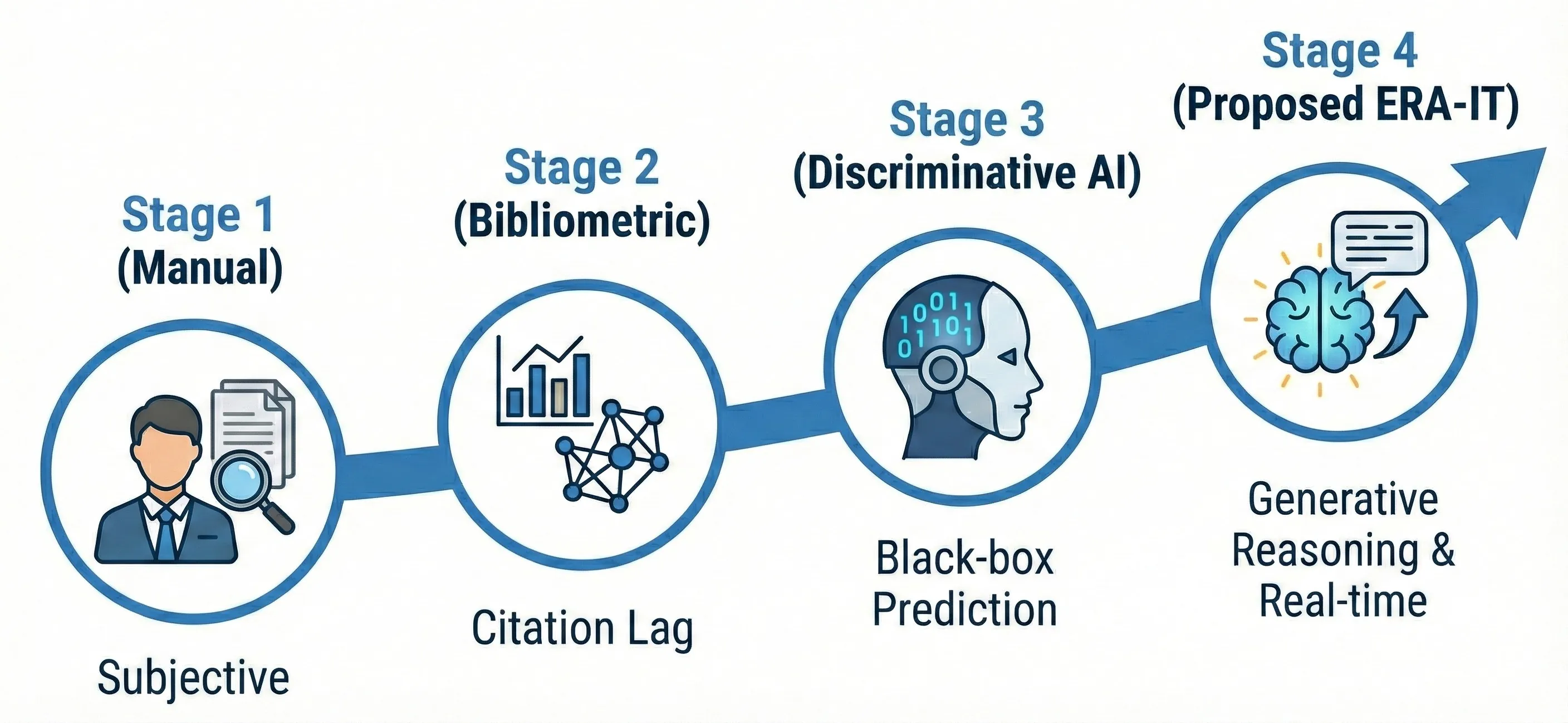
Valuing intangible assets under uncertainty remains a critical challenge in the strategic management of technological innovation due to the information asymmetry inherent in high-dimensional technical specifications. Traditional bibliometric indicators, such as citation counts, fail to address this friction in a timely manner due to the systemic latency inherent in data accumulation. To bridge this gap, this study proposes the Economic Reasoning Alignment via Instruction Tuning (ERA-IT) framework. We theoretically conceptualize patent renewal history as a revealed economic preference and leverage it as an objective supervisory signal to align the generative reasoning of Large Language Models (LLMs) with market realities, a process we term Eco-Semantic Alignment. Using a randomly sampled dataset of 10,000 European Patent Office patents across diverse technological domains, we trained the model not only to predict value tiers but also to reverse-engineer the Economic Chain-of-Thought from unstructured text. Empirical results demonstrate that ERA-IT significantly outperforms both conventional econometric models and zero-shot LLMs in predictive accuracy. More importantly, by generating explicit, logically grounded rationales for valuation, the framework serves as a transparent cognitive scaffold for decision-makers, reducing the opacity of black-box AI in high-stakes intellectual property management.
Investment portfolio optimization is a task conducted in all major financial institutions. The Cardinality Constrained Mean-Variance Portfolio Optimization (CCPO) problem formulation is ubiquitous for portfolio optimization. The challenge of this type of portfolio optimization, a mixed-integer quadratic programming (MIQP) problem, arises from the intractability of solutions from exact solvers, where heuristic algorithms are used to find approximate portfolio solutions. CCPO entails many laborious and complex workflows and also requires extensive effort pertaining to heuristic algorithm development, where the combination of pooled heuristic solutions results in improved efficient frontiers. Hence, common approaches are to develop many heuristic algorithms. Agentic frameworks emerge as a promising candidate for many problems within combinatorial optimization, as they have been shown to be equally efficient with regard to automating large workflows and have been shown to be excellent in terms of algorithm development, sometimes surpassing human-level performance. This study implements a novel agentic framework for the CCPO and explores several concrete architectures. In benchmark problems, the implemented agentic framework matches state-of-the-art algorithms. Furthermore, complex workflows and algorithm development efforts are alleviated, while in the worst case, lower but acceptable error is reported.
Accurate forecasting of financial markets remains a long-standing challenge due to complex temporal and often latent dependencies, non-linear dynamics, and high volatility. Building on our earlier recurrent neural network framework, we present an enhanced StockBot architecture that systematically evaluates modern attention-based, convolutional, and recurrent time-series forecasting models within a unified experimental setting. While attention-based and transformer-inspired models offer increased modeling flexibility, extensive empirical evaluation reveals that a carefully constructed vanilla LSTM consistently achieves superior predictive accuracy and more stable buy/sell decision-making when trained under a common set of default hyperparameters. These results highlight the robustness and data efficiency of recurrent sequence models for financial time-series forecasting, particularly in the absence of extensive hyperparameter tuning or the availability of sufficient data when discretized to single-day intervals. Additionally, these results underscore the importance of architectural inductive bias in data-limited market prediction tasks.