Computational Geometry
arXiv:cs.CG
Roughly includes material in ACM Subject Classes I.3.5 and F.2.2.
Looking for a broader view? This category is part of:
Roughly includes material in ACM Subject Classes I.3.5 and F.2.2.
Looking for a broader view? This category is part of:

We address the Diverse Traveling Salesman Problem (D-TSP), a bi-criteria optimization challenge that seeks a set of $k$ distinct TSP tours. The objective requires every selected tour to have a length at most $c|T^*|$ (where $|T^*|$ is the optimal tour length) while minimizing the average Jaccard similarity across all tour pairs. This formulation is crucial for applications requiring both high solution quality and fault tolerance, such as logistics planning, robotics pathfinding or strategic patrolling. Current methods are limited: traditional heuristics, such as the Niching Memetic Algorithm (NMA) or bi-criteria optimization, incur high computational complexity $O(n^3)$, while modern neural approaches (e.g., RF-MA3S) achieve limited diversity quality and rely on complex, external mechanisms. To overcome these limitations, we propose a novel hybrid framework that decomposes D-TSP into two efficient steps. First, we utilize a simple Graph Pointer Network (GPN), augmented with an approximated sequence entropy loss, to efficiently sample a large, diverse pool of high-quality tours. This simple modification effectively controls the quality-diversity trade-off without complex external mechanisms. Second, we apply a greedy algorithm that yields a 2-approximation for the dispersion problem to select the final $k$ maximally diverse tours from the generated pool. Our results demonstrate state-of-the-art performance. On the Berlin instance, our model achieves an average Jaccard index of $0.015$, significantly outperforming NMA ($0.081$) and RF-MA3S. By leveraging GPU acceleration, our GPN structure achieves a near-linear empirical runtime growth of $O(n)$. While maintaining solution diversity comparable to complex bi-criteria algorithms, our approach is over 360 times faster on large-scale instances (783 cities), delivering high-quality TSP solutions with unprecedented efficiency and simplicity.
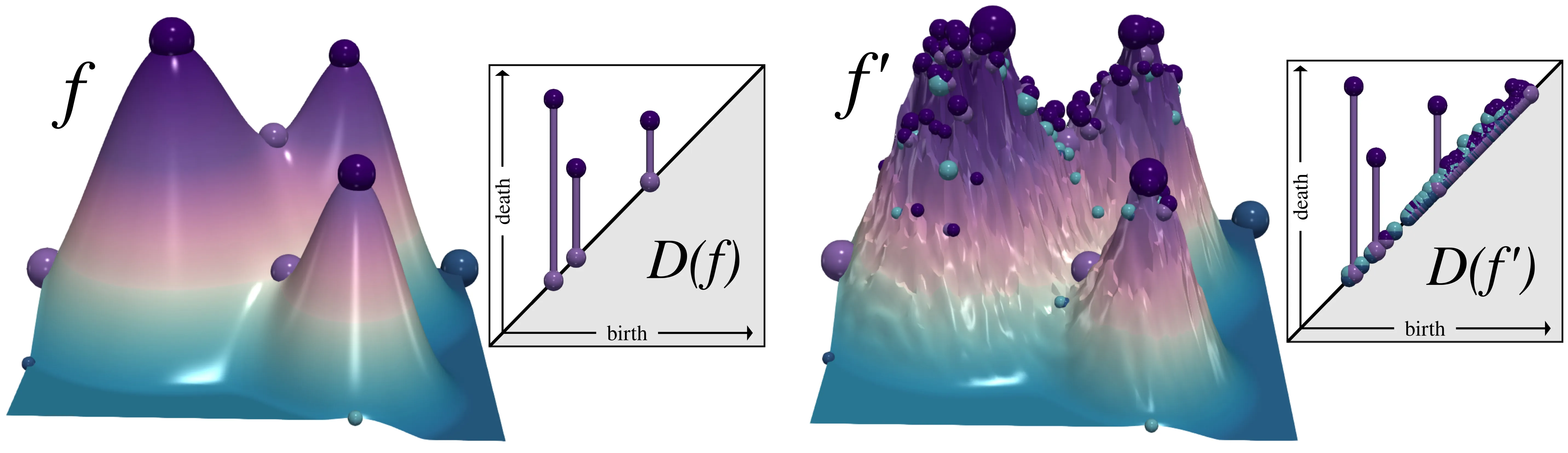
Exterior powers play important roles in persistent homology in computational geometry. In the present paper we study the problem of extracting the $K$ longest intervals of the exterior-power layers of a tame persistence module. We prove a structural decomposition theorem that organizes the exterior-power layers into monotone per-anchor streams with explicit multiplicities, enabling a best-first algorithm. We also show that the Top-$K$ length vector is $2$-Lipschitz under bottleneck perturbations of the input barcode, and prove a comparison-model lower bound. Our experiments confirm the theory, showing speedups over full enumeration in high overlap cases. By enabling efficient extraction of the most prominent features, our approach makes higher-order persistence feasible for large datasets and thus broadly applicable to machine learning, data science, and scientific computing.
We present the Chromatic Persistence Algorithm (CPA), an event-driven method for computing persistent cohomological features of weighted graphs via graphic arrangements, a classical object in computational geometry. We establish rigorous complexity results: CPA is exponential in the worst case, fixed-parameter tractable in treewidth, and nearly linear for common graph families such as trees, cycles, and series-parallel graphs. Finally, we demonstrate its practical applicability through a controlled experiment on molecular-like graph structures.

We consider the problem of searching for rays (or lines) in the half-plane. The given problem turns out to be a very natural extension of the cow-path problem that is lifted into the half-plane and the problem can also directly be motivated by a 1.5-dimensional terrain search problem. We present and analyse an efficient strategy for our setting and guarantee a competitive ratio of less than 9.12725 in the worst case and also prove a lower bound of at least 9.06357 for any strategy. Thus the given strategy is almost optimal, the gap is less than 0.06368. By appropriate adjustments for the terrain search problem we can improve on former results and present geometrically motivated proof arguments. As expected, the terrain itself can only be helpful for the searcher that competes against the unknown shortest path. We somehow extract the core of the problem.

Temporal sequences of terrains arise in various application areas. To analyze them efficiently, one generally needs a suitable abstraction of the data as well as a method to compare and match them over time. In this paper we consider merge trees as a topological descriptor for terrains and the interleaving distance as a method to match and compare them. An interleaving between two merge trees consists of two maps, one in each direction. These maps must satisfy ancestor relations and hence introduce a ''shift'' between points and their image. An optimal interleaving minimizes the maximum shift; the interleaving distance is the value of this shift. However, to study the evolution of merge trees over time, we need not only a number but also a meaningful matching between the two trees. The two maps of an optimal interleaving induce a matching, but due to the bottleneck nature of the interleaving distance, this matching fails to capture local similarities between the trees. In this paper we hence propose a notion of local optimality for interleavings. To do so, we define the residual interleaving distance, a generalization of the interleaving distance that allows additional constraints on the maps. This allows us to define locally correct interleavings, which use a range of shifts across the two merge trees that reflect the local similarity well. We give a constructive proof that a locally correct interleaving always exists.

Implicit Neural Representations (INRs) have been demonstrated to achieve state-of-the-art compression of a broad range of modalities such as images, videos, 3D surfaces, and audio. Most studies have focused on building neural counterparts of traditional implicit representations of 3D geometries, such as signed distance functions. However, the triangle mesh-based representation of geometry remains the most widely used representation in the industry, while building INRs capable of generating them has been sparsely studied. In this paper, we present a method for building compact INRs of zero-genus 3D manifolds. Our method relies on creating a spherical parameterization of a given 3D mesh - mapping the surface of a mesh to that of a unit sphere - then constructing an INR that encodes the displacement vector field defined continuously on its surface that regenerates the original shape. The compactness of our representation can be attributed to its hierarchical structure, wherein it first recovers the coarse structure of the encoded surface before adding high-frequency details to it. Once the INR is computed, 3D meshes of arbitrary resolution/connectivity can be decoded from it. The decoding can be performed in real time while achieving a state-of-the-art trade-off between reconstruction quality and the size of the compressed representations.
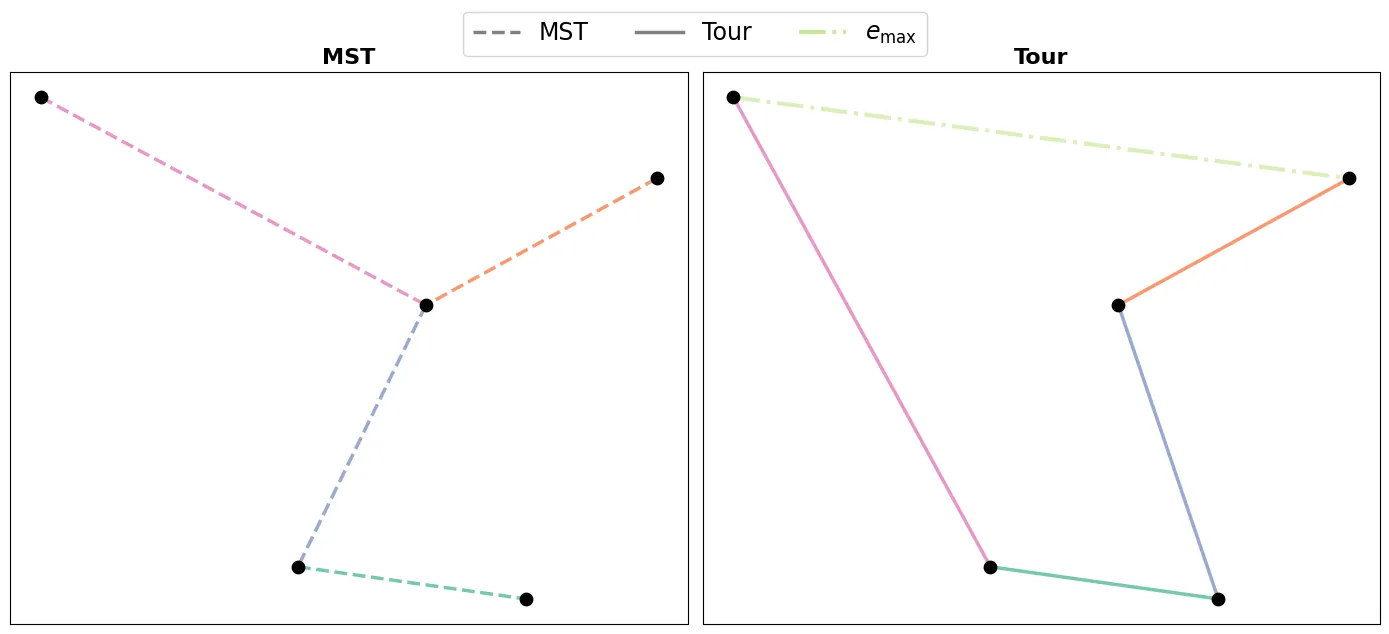
We introduce a topological feedback mechanism for the Travelling Salesman Problem (TSP) by analyzing the divergence between a tour and the minimum spanning tree (MST). Our key contribution is a canonical decomposition theorem that expresses the tour-MST gap as edge-wise topology-divergence gaps from the RTD-Lite barcode. Based on this, we develop a topological guidance for 2-opt and 3-opt heuristics that increases their performance. We carry out experiments with fine-optimization of tours obtained from heatmap-based methods, TSPLIB, and random instances. Experiments demonstrate the topology-guided optimization results in better performance and faster convergence in many cases.
Conforming hexahedral (hex) meshes are favored in simulation for their superior numerical properties, yet automatically decomposing a general 3D volume into a conforming hex mesh remains a formidable challenge. Among existing approaches, methods that construct an adaptive Cartesian grid and subsequently convert it into a conforming mesh stand out for their robustness. However, the topological schemes enabling this conversion require strict compatibility conditions among grid elements, which inevitably refine the initial grid and increase element count. Developing more relaxed conditions to minimize this overhead has been a persistent research focus. State-of-the-art 2-refinement octree methods employ a weakly-balanced condition combined with a generalized pairing condition, using a dual transformation to yield exceptionally low element counts. Yet this approach suffers from critical limitations: information stored on primal cells, such as signed distance fields or triangle index sets, is lost after dualization, and the resulting dual cells often exhibit poor minimum scaled Jacobian (min SJ) with non-planar quadrilateral (quad) faces. Alternatively, 3-refinement 27-tree methods can directly generate conforming hex meshes through template-based replacement of primal cells, producing higher-quality elements with planar quad faces. However, previous 3-refinement techniques impose conditions far more strict than 2-refinement counterparts, severely over-refining grids by factors of ten to one hundred, creating a major bottleneck in simulation pipelines. This article introduces a novel 3-refinement approach that transforms an adaptive 3-refinement grid into a conforming grid using a moderately-balanced condition, slightly stronger than the weakly-balanced condition but substantially more relaxed than prior 3-refinement requirements...... (check PDF for the full abstract)

We study the Heilbronn triangle problem, which involves placing n points in the unit square such that the minimum area of any triangle formed by these points is maximized. A straightforward maximin formulation of this problem is highly non-linear and non-convex due to the existence of bilinear terms and absolute value equations. We propose two mixed-integer quadratically constrained programming (MIQCP) and one QCP formulation, which can be readily solved by any global optimization solver. We develop several formulation enhancements in the form of bound tightening and symmetry breaking inequalities that are prevalent in the global optimization literature in addition to other enhancements that exploit the problem structure. With the help of these enhancements, our models reproduce proven optimal values for instances up to n = 8 points with certified optimality in the order of seconds. In the case of n = 9 points, for which no analytical proof is known, we establish a certified optimal value by a computational effort of one day. This is a significant improvement over the previous benchmark established in 31 days of computations by Chen et al. (2017).
The 3SUM problem represents a class of problems conjectured to require $Ω(n^2)$ time to solve, where $n$ is the size of the input. Given two polygons $P$ and $Q$ in the plane, we show that some variants of the decision problem, whether there exists a transformation of $P$ that makes it contained in $Q$, are 3SUM-Hard. In the first variant $P$ and $Q$ are any simple polygons and the allowed transformations are translations only; in the second and third variants both polygons are convex and we allow either rotations only or any rigid motion. We also show that finding the translation in the plane that minimizes the Hausdorff distance between two segment sets is 3SUM-Hard.
We present a new algorithm for computing the first discrete homology group of a graph. By testing the algorithm on different data sets of random graphs, we find that it significantly outperforms other known algorithms.
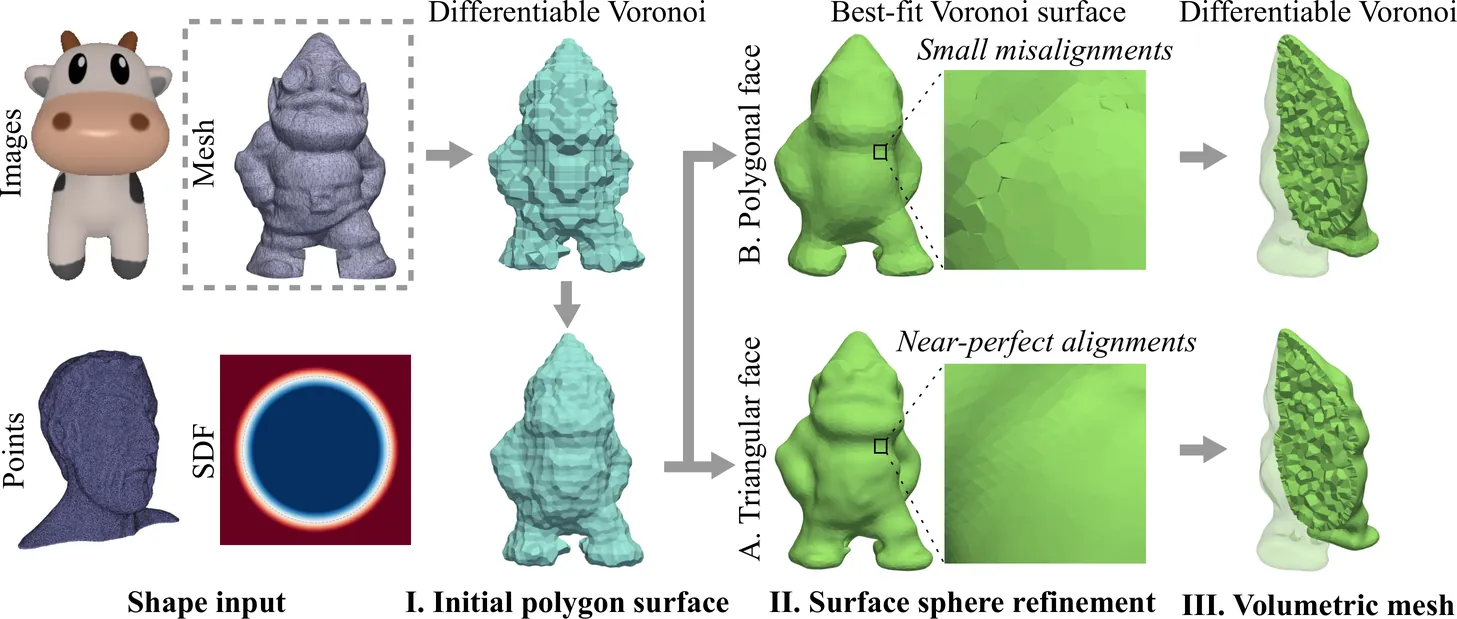
We present VoroLight, a differentiable framework for 3D shape reconstruction based on Voronoi meshing. Our approach generates smooth, watertight surfaces and topologically consistent volumetric meshes directly from diverse inputs, including images, implicit shape level-set fields, point clouds and meshes. VoroLight operates in three stages: it first initializes a surface using a differentiable Voronoi formulation, then refines surface quality through a polygon-face sphere training stage, and finally reuses the differentiable Voronoi formulation for volumetric optimization with additional interior generator points. Project page: https://jiayinlu19960224.github.io/vorolight/
We introduce the Continuous Edit Distance (CED), a geodesic and elastic distance for time-varying persistence diagrams (TVPDs). The CED extends edit-distance ideas to TVPDs by combining local substitution costs with penalized deletions/insertions, controlled by two parameters: \(α\) (trade-off between temporal misalignment and diagram discrepancy) and \(β\) (gap penalty). We also provide an explicit construction of CED-geodesics. Building on these ingredients, we present two practical barycenter solvers, one stochastic and one greedy, that monotonically decrease the CED Frechet energy. Empirically, the CED is robust to additive perturbations (both temporal and spatial), recovers temporal shifts, and supports temporal pattern search. On real-life datasets, the CED achieves clustering performance comparable or better than standard elastic dissimilarities, while our clustering based on CED-barycenters yields superior classification results. Overall, the CED equips TVPD analysis with a principled distance, interpretable geodesics, and practical barycenters, enabling alignment, comparison, averaging, and clustering directly in the space of TVPDs. A C++ implementation is provided for reproducibility at the following address https://github.com/sebastien-tchitchek/ContinuousEditDistance.
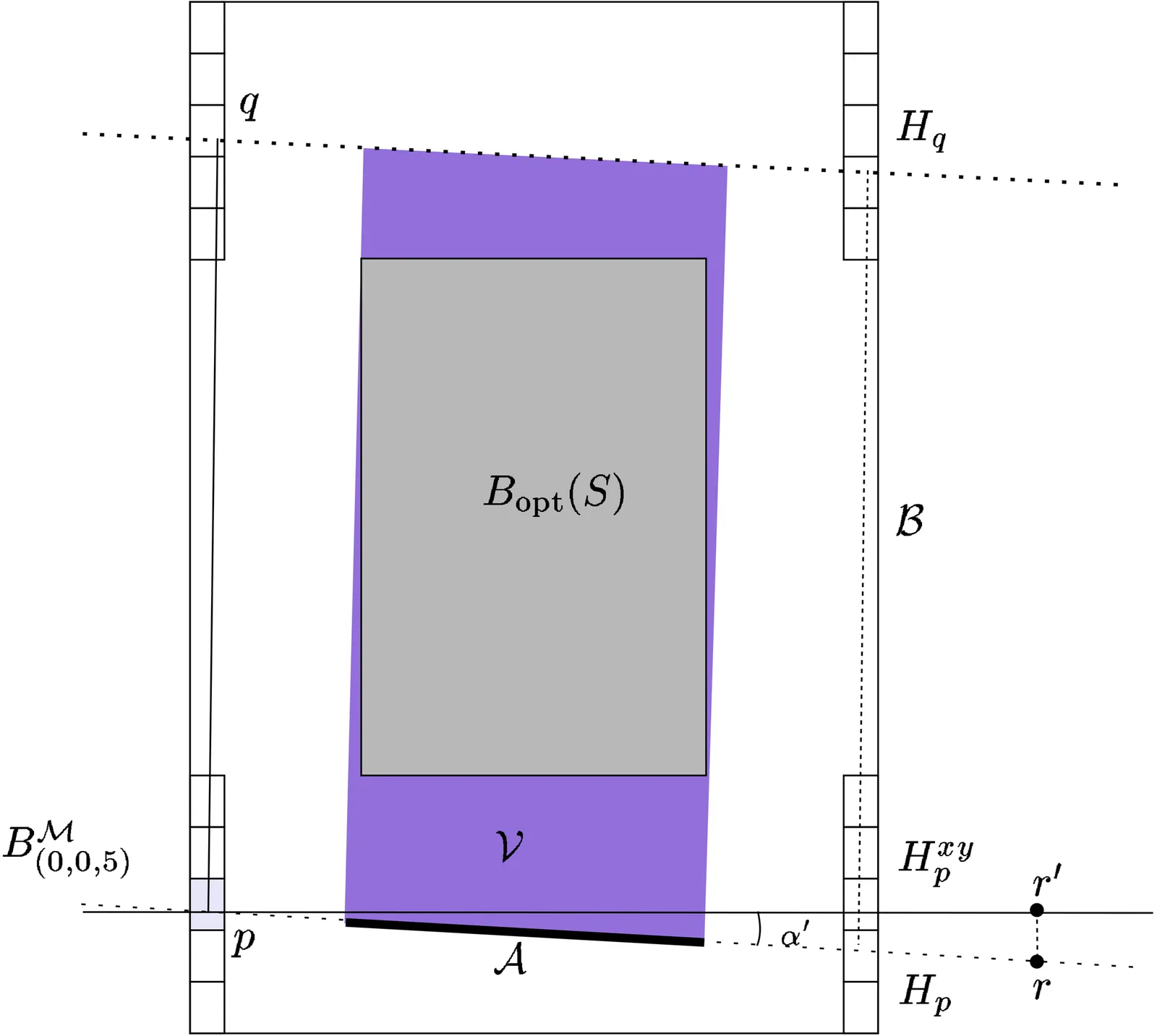
$\renewcommand{\Re}{\mathbb{R}}$We present an efficient $O (n + 1/\varepsilon^{4.5})$-time algorithm for computing a $(1+\varepsilon$)-approximation of the minimum-volume bounding box of $n$ points in $\Re^3$. We also present a simpler algorithm (for the same purpose) whose running time is $O (n \log{n} + n / \varepsilon^3)$. We give some experimental results with implementations of various variants of the second algorithm. The implementation of the algorithm described in this paper is available online https://github.com/sarielhp/MVBB.
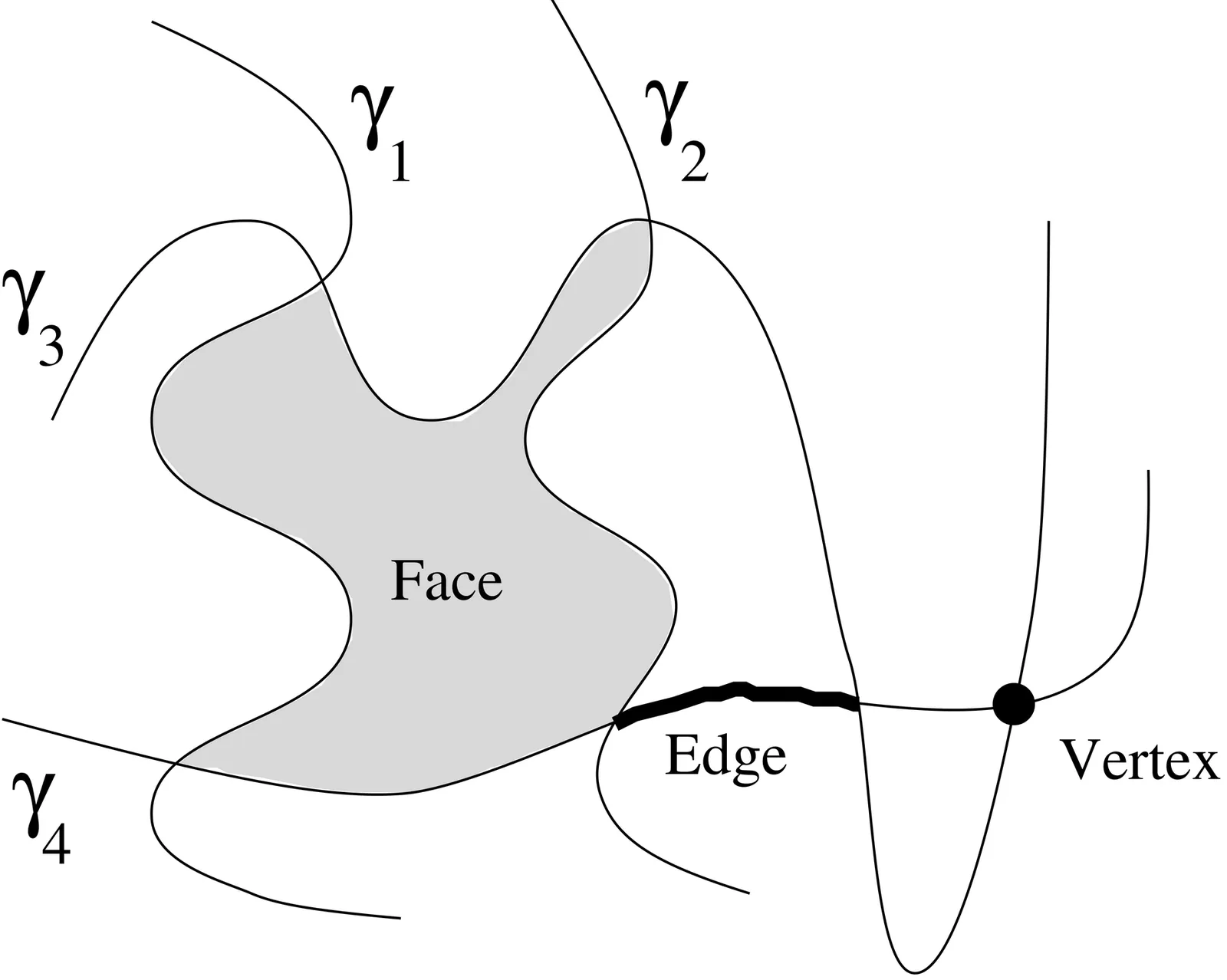
We present an extension of the Combination Lemma of [GSS89] that expresses the complexity of one or several faces in the overlay of many arrangements, as a function of the number of arrangements, the number of faces, and the complexities of these faces in the separate arrangements. Several applications of the new Combination Lemma are presented: We first show that the complexity of a single face in an arrangement of $k$ simple polygons with a total of $n$ sides is $Θ(n α(k) )$, where $α(\cdot)$ is the inverse of Ackermann's function. We also give a new and simpler proof of the bound $O \left( \sqrt{m} λ_{s+2}( n ) \right)$ on the total number of edges of $m$ faces in an arrangement of $n$ Jordan arcs, each pair of which intersect in at most $s$ points, where $λ_{s}(n)$ is the maximum length of a Davenport-Schinzel sequence of order $s$ with $n$ symbols. We extend this result, showing that the total number of edges of $m$ faces in a sparse arrangement of $n$ Jordan arcs is $O \left( (n + \sqrt{m}\sqrt{w}) \frac{λ_{s+2}(n)}{n} \right)$, where $w$ is the total complexity of the arrangement. Several other applications and variants of the Combination Lemma are also presented.
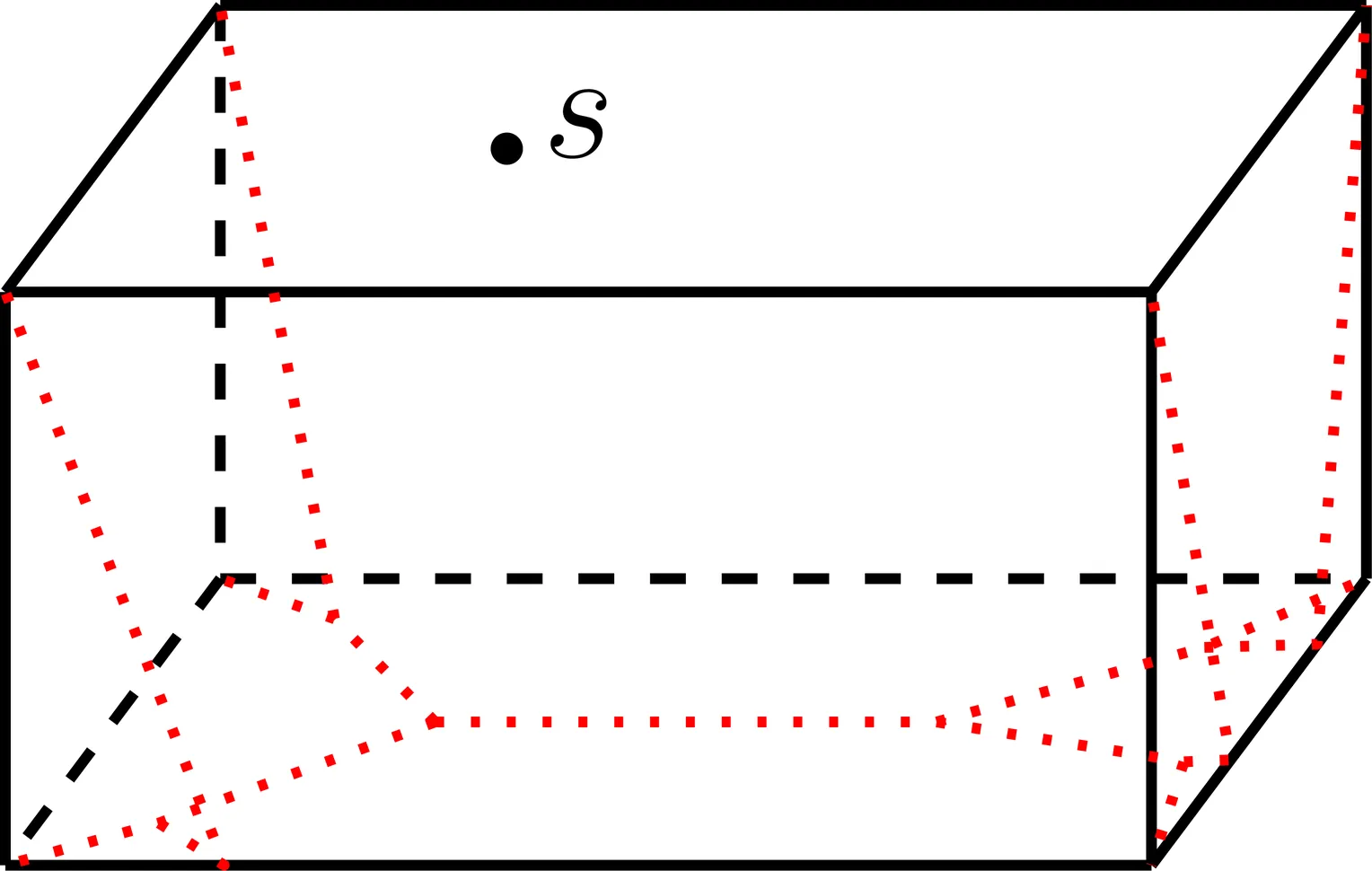
Let $\mathcal{P}$ be the surface of a convex polyhedron with $n$ vertices. We consider the two-point shortest path query problem for $\mathcal{P}$: Constructing a data structure so that given any two query points $s$ and $t$ on $\mathcal{P}$, a shortest path from $s$ to $t$ on $\mathcal{P}$ can be computed efficiently. To achieve $O(\log n)$ query time (for computing the shortest path length), the previously best result uses $O(n^{8+ε})$ preprocessing time and space [Aggarwal, Aronov, O'Rourke, and Schevon, SICOMP 1997], where $ε$ is an arbitrarily small positive constant. In this paper, we present a new data structure of $O(n^{6+ε})$ preprocessing time and space, with $O(\log n)$ query time. For a special case where one query point is required to lie on one of the edges of $\mathcal{P}$, the previously best work uses $O(n^{6+ε})$ preprocessing time and space to achieve $O(\log n)$ query time. We improve the preprocessing time and space to $O(n^{5+ε})$, with $O(\log n)$ query time. Furthermore, we present a new algorithm to compute the exact set of shortest path edge sequences of $\mathcal{P}$, which are known to be $Θ(n^4)$ in number and have a total complexity of $Θ(n^5)$ in the worst case. The previously best algorithm for the problem takes roughly $O(n^6\log n\log^*n)$ time, while our new algorithm runs in $O(n^{5+ε})$ time.
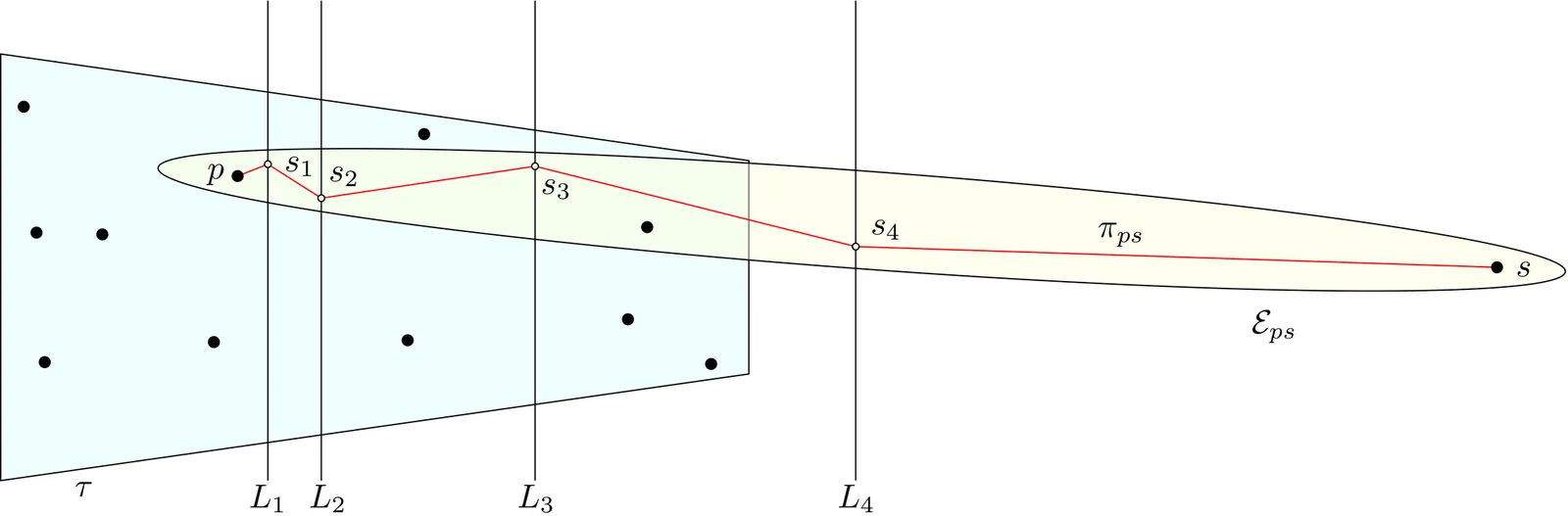
For a weighted graph $G = (V, E, w)$ and a designated source vertex $s \in V$, a spanning tree that simultaneously approximates a shortest-path tree w.r.t. source $s$ and a minimum spanning tree is called a shallow-light tree (SLT). Specifically, an $(α, β)$-SLT of $G$ w.r.t. $s \in V$ is a spanning tree of $G$ with root-stretch $α$ (preserving all distances between $s$ and the other vertices up to a factor of $α$) and lightness $β$ (its weight is at most $β$ times the weight of a minimum spanning tree of $G$). Despite the large body of work on SLTs, the basic question of whether a better approximation algorithm exists was left untouched to date, and this holds in any graph family. This paper makes a first nontrivial step towards this question by presenting two bicriteria approximation algorithms. For any $ε>0$, a set $P$ of $n$ points in constant-dimensional Euclidean space and a source $s\in P$, our first (respectively, second) algorithm returns, in $O(n \log n \cdot {\rm polylog}(1/ε))$ time, a non-Steiner (resp., Steiner) tree with root-stretch $1+O(ε\log ε^{-1})$ and weight at most $O(\mathrm{opt}_ε\cdot \log^2 ε^{-1})$ (resp., $O(\mathrm{opt}_ε\cdot \log ε^{-1})$), where $\mathrm{opt}_ε$ denotes the minimum weight of a non-Steiner (resp., Steiner) tree with root-stretch $1+ε$.
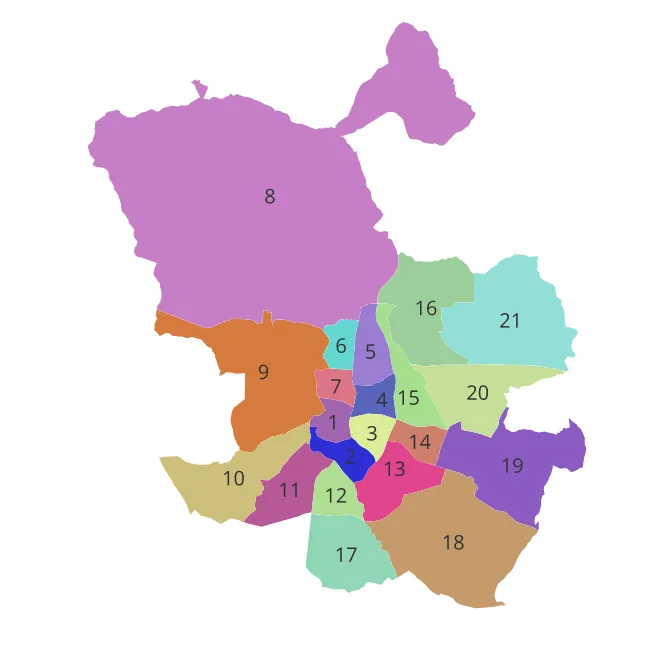
Gentrification is the process by which wealthier individuals move into a previously lower-income neighbourhood. Among the effects of this multi-faceted phenomenon are rising living costs, cultural and social changes-where local traditions, businesses, and community networks are replaced or diluted by new, more affluent lifestyles-and population displacement, where long-term, lower-income residents are priced out by rising rents and property taxes. Despite its relevance, quantifying displacement presents difficulties stemming from lack of information on motives for relocation and from the fact that a long time-span must be analysed: displacement is a gradual process (leases end or conditions change at different times), impossible to capture in one data snapshot. We introduce a novel tool to overcome these difficulties. Using only publicly available address change data, we construct four cubical complexes which simultaneously incorporate geographical and temporal information of people moving, and then analyse them building on Topological Data Analysis tools. Finally, we demonstrate the potential of this method through a 20-year case study of Madrid, Spain. The results reveal its ability to capture population displacement and to identify the specific neighbourhoods and years affected--patterns that cannot be inferred from raw address change data.
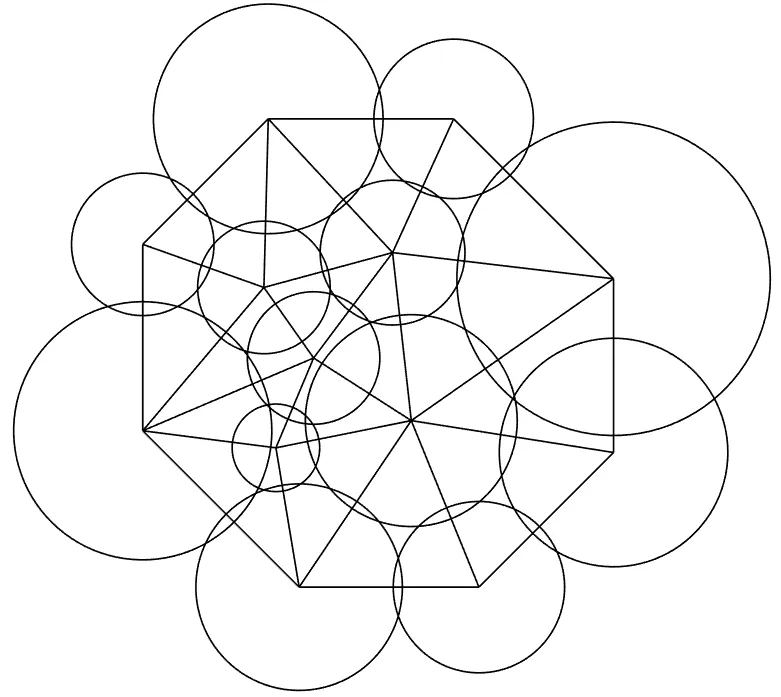
This paper presents a new algorithm for generating planar circle patterns. The algorithm employs gradient descent and conjugate gradient method to compute circle radii and centers separately. Compared with existing algorithms, the proposed method is more efficient in computing centers of circles and is applicable for realizing circle patterns with possible obtuse overlap angles.
A \emph{disk graph} is the intersection graph of (closed) disks in the plane. We consider the classic problem of finding a maximum clique in a disk graph. For general disk graphs, the complexity of this problem is still open, but for unit disk graphs, it is well known to be in P. The currently fastest algorithm runs in time $O(n^{7/3+ o(1)})$, where $n$ denotes the number of disks~\cite{EspenantKM23, keil_et_al:LIPIcs.SoCG.2025.63}. Moreover, for the case of disk graphs with $t$ distinct radii, the problem has also recently been shown to be in XP. More specifically, it is solvable in time $O^*(n^{2t})$~\cite{keil_et_al:LIPIcs.SoCG.2025.63}. In this paper, we present algorithms with improved running times by allowing for approximate solutions and by using randomization: (i) for unit disk graphs, we give an algorithm that, with constant success probability, computes a $(1-\varepsilon)$-approximate maximum clique in expected time $\tilde{O}(n/\varepsilon^2)$; and (ii) for disk graphs with $t$ distinct radii, we give a parameterized approximation scheme that, with a constant success probability, computes a $(1-\varepsilon)$-approximate maximum clique in expected time $\tilde{O}(f(t)\cdot (1/\varepsilon)^{O(t)} \cdot n)$.
The 3SUM problem represents a class of problems conjectured to require $Ω(n^2)$ time to solve, where $n$ is the size of the input. Given two polygons $P$ and $Q$ in the plane, we show that some variants of the decision problem, whether there exists a transformation of $P$ that makes it contained in $Q$, are 3SUM-Hard. In the first variant $P$ and $Q$ are any simple polygons and the allowed transformations are translations only; in the second and third variants both polygons are convex and we allow either rotations only or any rigid motion. We also show that finding the translation in the plane that minimizes the Hausdorff distance between two segment sets is 3SUM-Hard.
$\renewcommand{\Re}{\mathbb{R}}$We present an efficient $O (n + 1/\varepsilon^{4.5})$-time algorithm for computing a $(1+\varepsilon$)-approximation of the minimum-volume bounding box of $n$ points in $\Re^3$. We also present a simpler algorithm (for the same purpose) whose running time is $O (n \log{n} + n / \varepsilon^3)$. We give some experimental results with implementations of various variants of the second algorithm. The implementation of the algorithm described in this paper is available online https://github.com/sarielhp/MVBB.
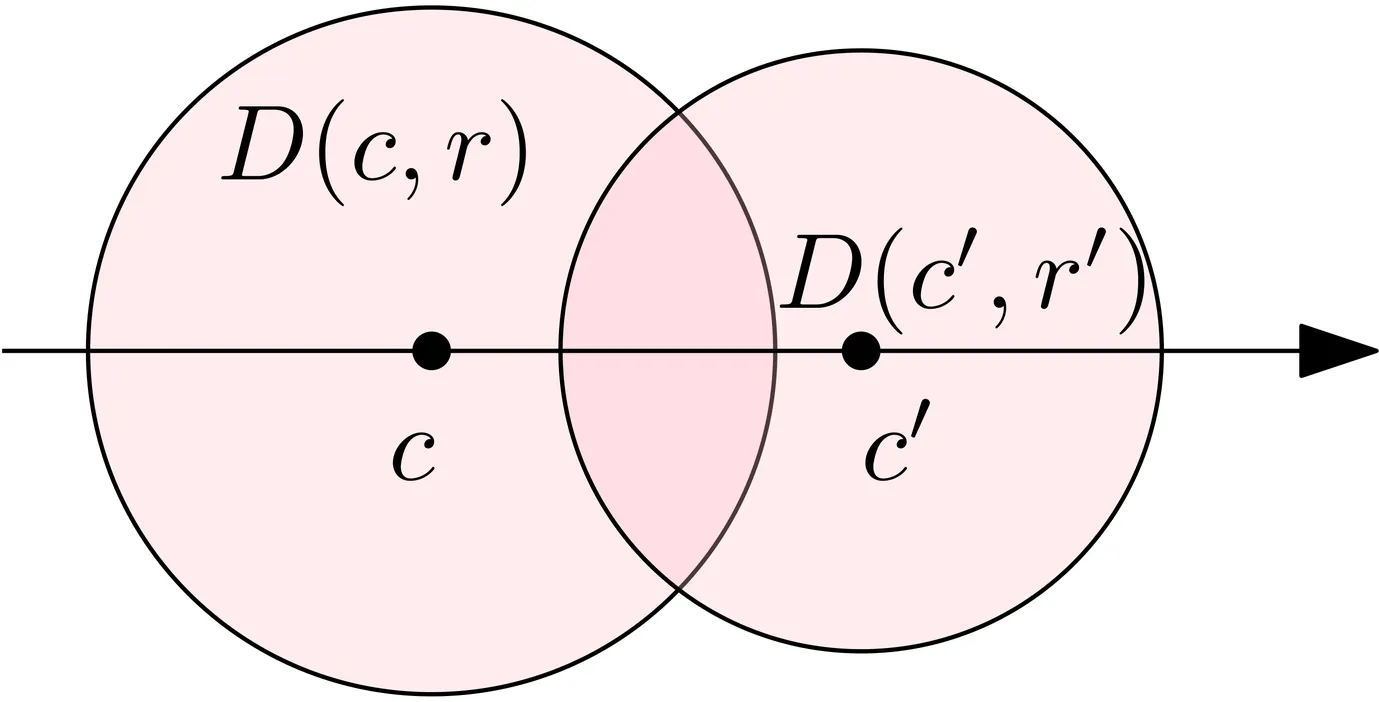
$\renewcommand{\Re}{\mathbb{R}}$We present a new optimal construction of a semi-separated pair decomposition (i.e., SSPD) for a set of $n$ points in $\Re^d$. In the new construction each point participates in a few pairs, and it extends easily to spaces with low doubling dimension. This is the first optimal construction with these properties. As an application of the new construction, for a fixed $t>1$, we present a new construction of a $t$-spanner with $O(n)$ edges and maximum degree $O(\log^2 n)$ that has a separator of size $O\pth{n^{1-1/d}}$.
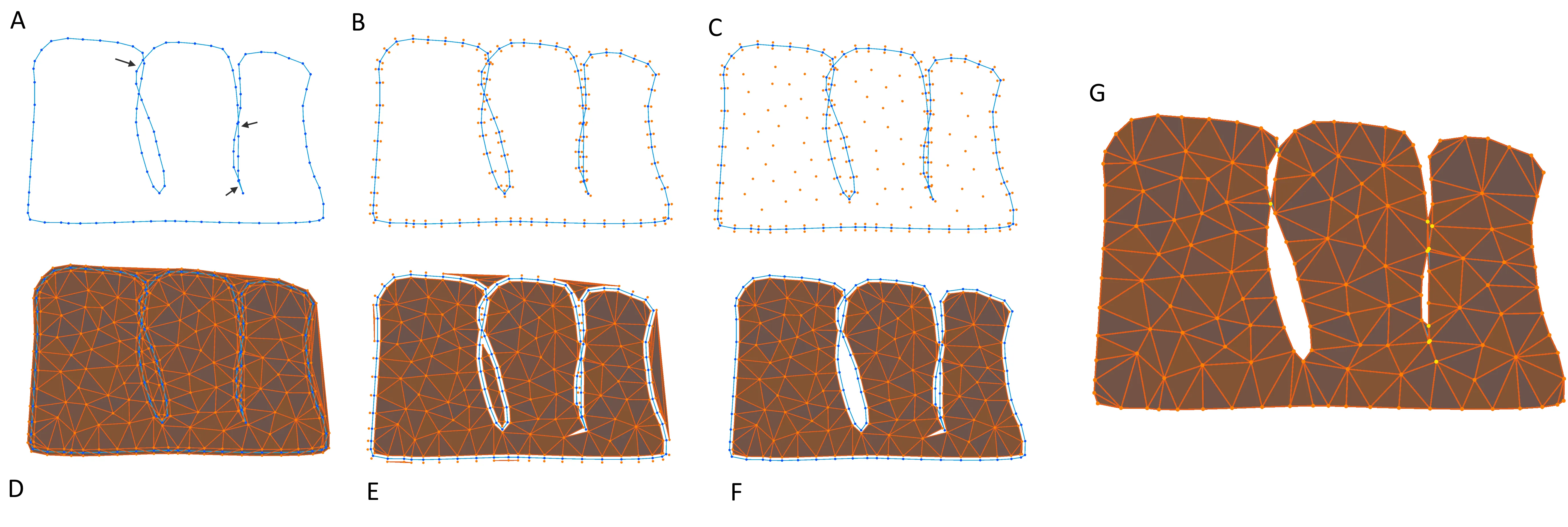
A prerequisite for many biomechanical simulation techniques is discretizing a bounded volume into a tetrahedral mesh. In certain contexts, such as cortical surface simulations, preserving input surface connectivity is critical. However, automated surface extraction often yields meshes containing self-intersections, small holes, and faulty geometry, which prevents existing constrained and unconstrained meshers from preserving this connectivity. We address this issue by developing a novel tetrahedralization method that maintains input surface connectivity in the presence of such defects. We also present a metric to quantify the preservation of surface connectivity and demonstrate that our method correctly maintains connectivity compared to existing solutions.
The continuous Frechet distance between two polygonal curves is classically computed by exploring their free space diagram. Recently, Har-Peled, Raichel, and Robson [SoCG'25] proposed a radically different approach: instead of directly traversing the continuous free space, they approximate the distance by computing paths in a discrete graph derived from the discrete free space, recursively bisecting edges until the discrete distance converges to the continuous Frechet distance. They implement this so-called frog-based technique and report substantial practical speedups over the state of the art. We revisit the frog-based approach and address three of its limitations. First, the method does not compute the Frechet distance exactly. Second, the recursive bisection procedure only introduces the monotonicity events required to realise the Frechet distance asymptotically, that is, only in the limit. Third, the applied simplification technique is heuristic. Motivated by theoretical considerations, we develop new techniques that guarantee exactness, polynomial-time convergence, and near-optimal lossless simplifications. We provide an open-source C++ implementation of our variant. Our primary contribution is an extensive empirical evaluation. As expected, exact computation introduces overhead and increases the median running time. Yet, our method is often faster in the worst case, the slowest ten percent of instances, or even on average due to its convergence guarantees. More surprisingly, in our experiments, the implementation of Bringmann, Kuennemann, and Nusser [SoCG'19] consistently outperforms all frog-based approaches in practice. This appears to contrast published claims of the efficiency of the frog-based techniques. These results thereby provide nuanced perspective on frogs: highlighting both the theoretical appeal, but also the practical limitations.
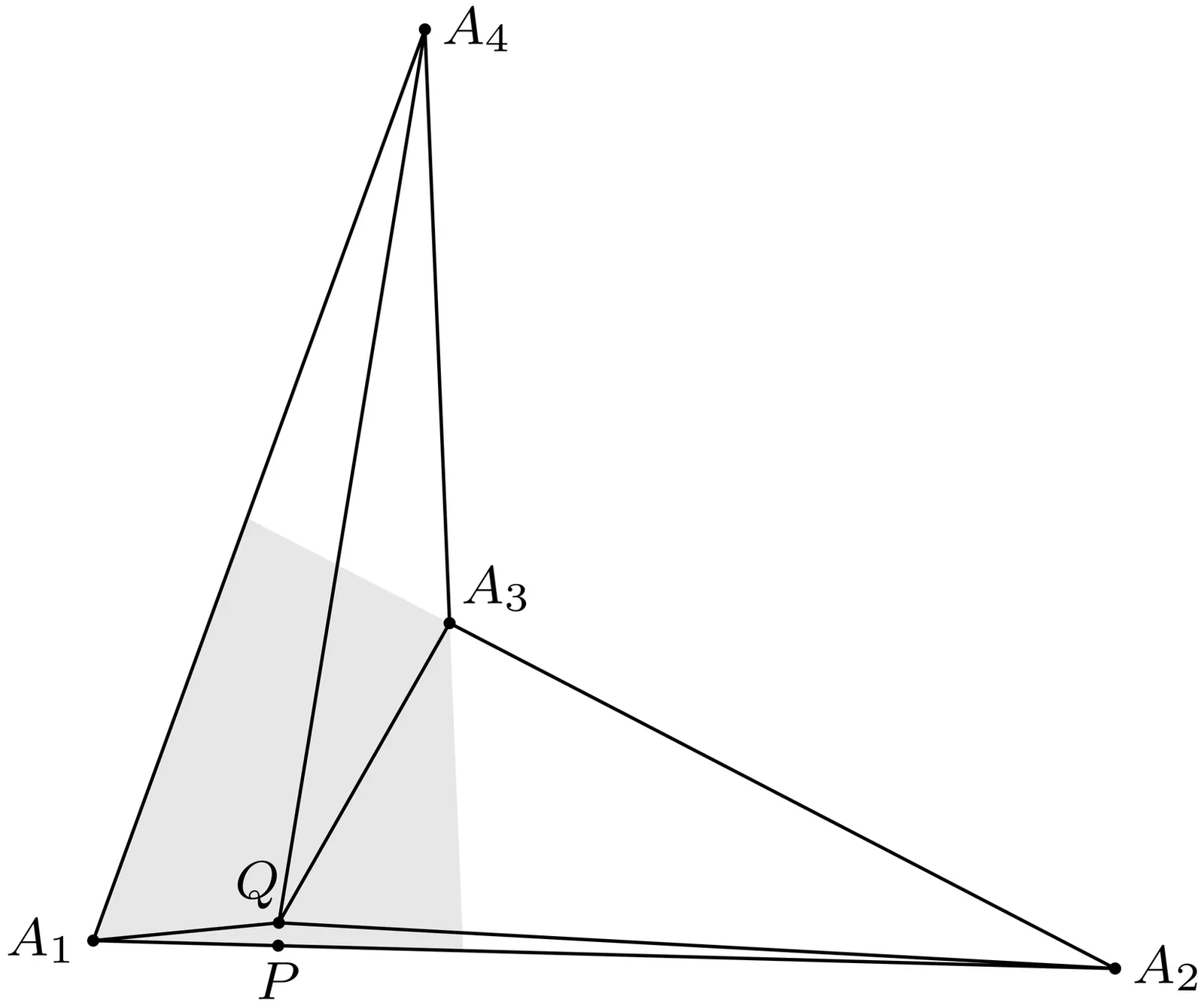
We exactly settle the complexity of graph realization, graph rigidity, and graph global rigidity as applied to three types of graphs: "globally noncrossing" graphs, which avoid crossings in all of their configurations; matchstick graphs, with unit-length edges and where only noncrossing configurations are considered; and unrestricted graphs (crossings allowed) with unit edge lengths (or in the global rigidity case, edge lengths in $\{1,2\}$). We show that all nine of these questions are complete for the class $\exists\mathbb{R}$, defined by the Existential Theory of the Reals, or its complement $\forall\mathbb{R}$; in particular, each problem is (co)NP-hard. One of these nine results--that realization of unit-distance graphs is $\exists\mathbb{R}$-complete--was shown previously by Schaefer (2013), but the other eight are new. We strengthen several prior results. Matchstick graph realization was known to be NP-hard (Eades \& Wormald 1990, or Cabello et al.\ 2007), but its membership in NP remained open; we show it is complete for the (possibly) larger class $\exists\mathbb{R}$. Global rigidity of graphs with edge lengths in $\{1,2\}$ was known to be coNP-hard (Saxe 1979); we show it is $\forall\mathbb{R}$-complete. The majority of the paper is devoted to proving an analog of Kempe's Universality Theorem--informally, "there is a linkage to sign your name"--for globally noncrossing linkages. In particular, we show that any polynomial curve $φ(x,y)=0$ can be traced by a noncrossing linkage, settling an open problem from 2004. More generally, we show that the regions in the plane that may be traced by a noncrossing linkage are precisely the compact semialgebraic regions (plus the trivial case of the entire plane). Thus, no drawing power is lost by restricting to noncrossing linkages. We prove analogous results for matchstick linkages and unit-distance linkages as well.
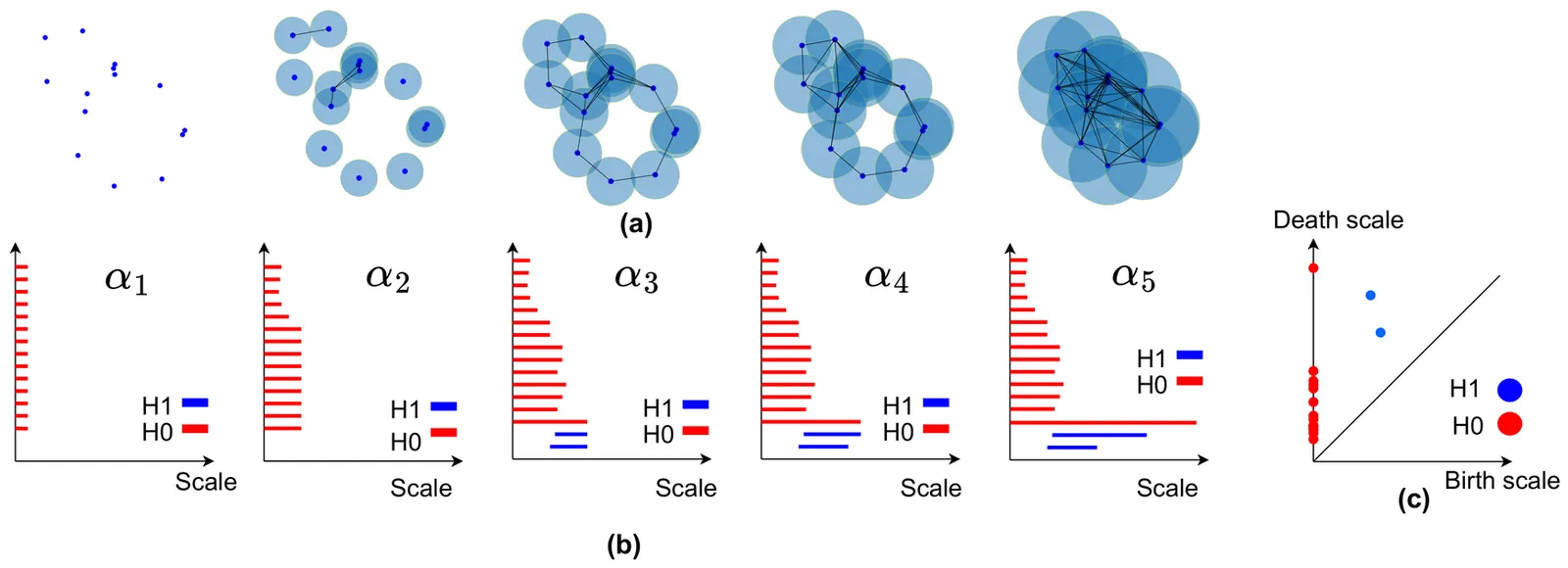
We introduce ellipsoidal filtration, a novel method for persistent homology, and demonstrate its effectiveness in denoising recurrent signals. Unlike standard Rips filtrations, which use isotropic neighbourhoods and ignore the signal's direction of evolution, our approach constructs ellipsoids aligned with local gradients to capture trajectory flow. The death scale of the most persistent H_1 feature defines a data-driven neighbourhood for averaging. Experiments on synthetic signals show that our method achieves better noise reduction than both topological and moving-average filters, especially for low-amplitude components.
We present Instant Skinned Gaussian Avatars, a real-time and cross-platform 3D avatar system. Many approaches have been proposed to animate Gaussian Splatting, but they often require camera arrays, long preprocessing times, or high-end GPUs. Some methods attempt to convert Gaussian Splatting into mesh-based representations, achieving lightweight performance but sacrificing visual fidelity. In contrast, our system efficiently animates Gaussian Splatting by leveraging parallel splat-wise processing to dynamically follow the underlying skinned mesh in real time while preserving high visual fidelity. From smartphone-based 3D scanning to on-device preprocessing, the entire process takes just around five minutes, with the avatar generation step itself completed in only about 30 seconds. Our system enables users to instantly transform their real-world appearance into a 3D avatar, making it ideal for seamless integration with social media and metaverse applications. Website: https://gaussian-vrm.github.io/
We introduce a scalable witness-based persistent homology pipeline for full-brain MRI volumes that couples density-aware landmark selection with a GPU-ready witness filtration. Candidates are scored by a hybrid metric that balances geometric coverage against inverse kernel density, yielding landmark sets that shrink mean pairwise distances by 30-60% over random or density-only baselines while preserving topological features. Benchmarks on BrainWeb, IXI, and synthetic manifolds execute in under ten seconds on a single NVIDIA RTX 4090 GPU, avoiding the combinatorial blow-up of Cech, Vietoris-Rips, and alpha filtrations. The package is distributed on PyPI as whale-tda (installable via pip); source and issues are hosted at https://github.com/jorgeLRW/whale. The release also exposes a fast preset (mri_deep_dive_fast) for exploratory sweeps, and ships with reproducibility-focused scripts and artifacts for drop-in use in medical imaging workflows.
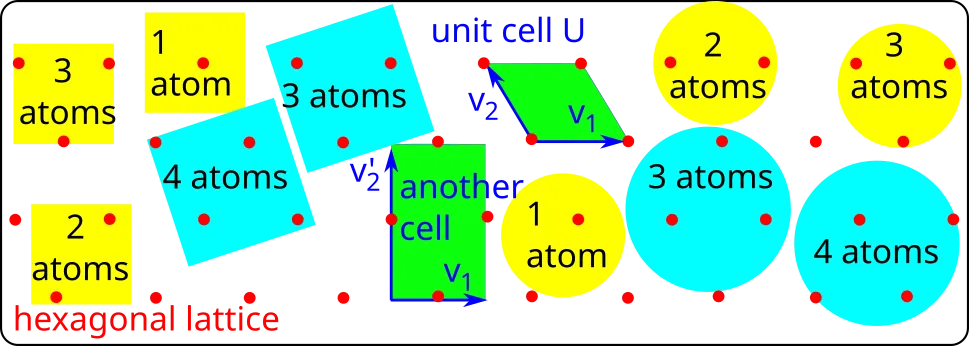
Periodic point sets model all solid crystalline materials (crystals) whose atoms can be considered zero-sized points with or without atomic types. This paper addresses the fundamental problem of checking whether claimed crystals are novel, not noisy perturbations of known materials obtained by unrealistic atomic replacements. Such near-duplicates have skewed ground-truth because past comparisons relied on unstable cells and symmetries. The proposed Lipschitz continuity under noise is a new essential requirement for machine learning on any data objects that have ambiguous representations and live in continuous spaces. For periodic point sets under isometry (any distance-preserving transformation), we designed invariants that distinguish all known counter-examples to the completeness of past descriptors and detect thousands of (near-)duplicates in large high-profile databases of crystals within two days on a modest desktop computer.
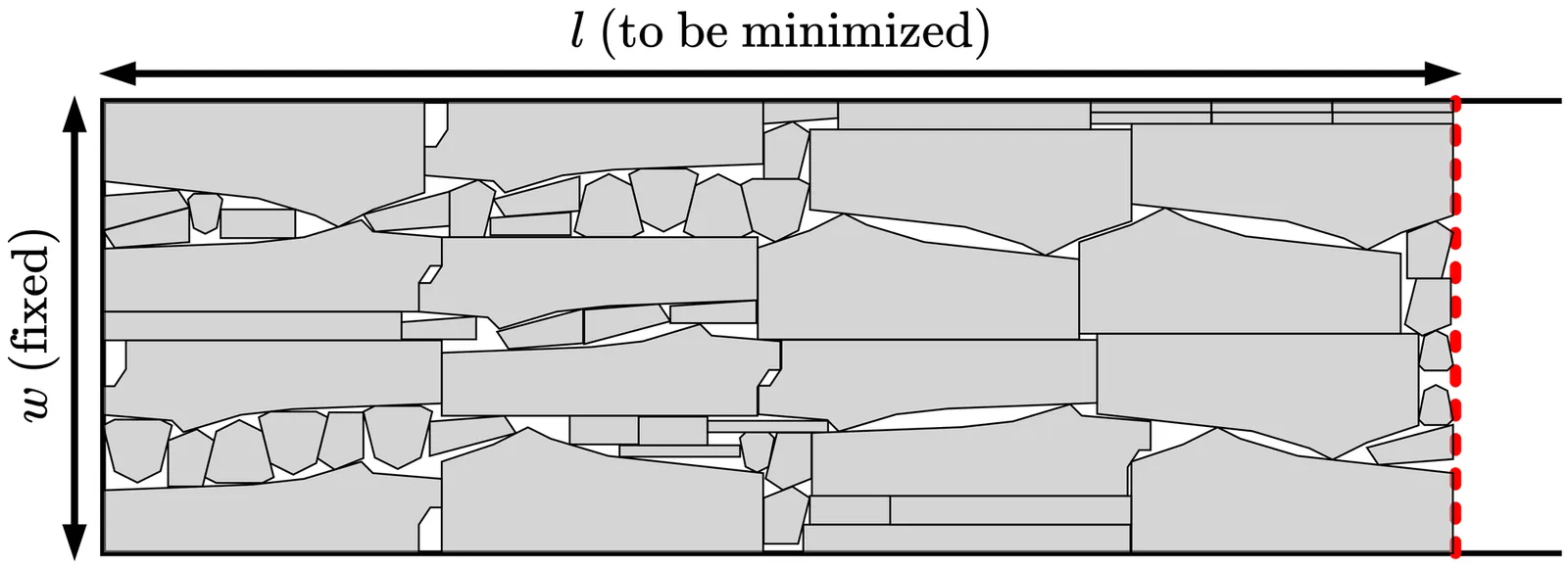
2D nesting problems rank among the most challenging cutting and packing problems. Yet, despite their practical relevance, research over the past decade has seen remarkably little progress. One reasonable explanation could be that nesting problems are already solved to near optimality, leaving little room for improvement. However, as our paper demonstrates, we are not at the limit after all. This paper presents $\texttt{sparrow}$, an open-source heuristic approach to solving 2D irregular strip packing problems, along with ten new real-world instances for benchmarking. Our approach decomposes the optimization problem into a sequence of feasibility problems, where collisions between items are gradually resolved. $\texttt{sparrow}$ consistently outperforms the state of the art - in some cases by an unexpectedly wide margin. We are therefore convinced that the aforementioned stagnation is better explained by both a high barrier to entry and a widespread lack of reproducibility. By releasing $\texttt{sparrow}$'s source code, we directly address both issues. At the same time, we are confident there remains significant room for further algorithmic improvement. The ultimate aim of this paper is not only to take a single step forward, but to reboot the research culture in the domain and enable continued, reproducible progress.
Given in the plane a set $S$ of $n$ points and a set of disks centered at these points, the disk graph $G(S)$ induced by these disks has vertex set $S$ and an edge between two vertices if their disks intersect. Note that the disks may have different radii. We consider the problem of computing shortest paths from a source point $s\in S$ to all vertices in $G(S)$ where the length of a path in $G(S)$ is defined as the number of edges in the path. The previously best algorithm solves the problem in $O(n\log^2 n)$ time. A lower bound of $Ω(n\log n)$ is also known for this problem under the algebraic decision tree model. In this paper, we present an $O(n\log n)$ time algorithm, which matches the lower bound and thus is optimal. Another virtue of our algorithm is that it is quite simple.

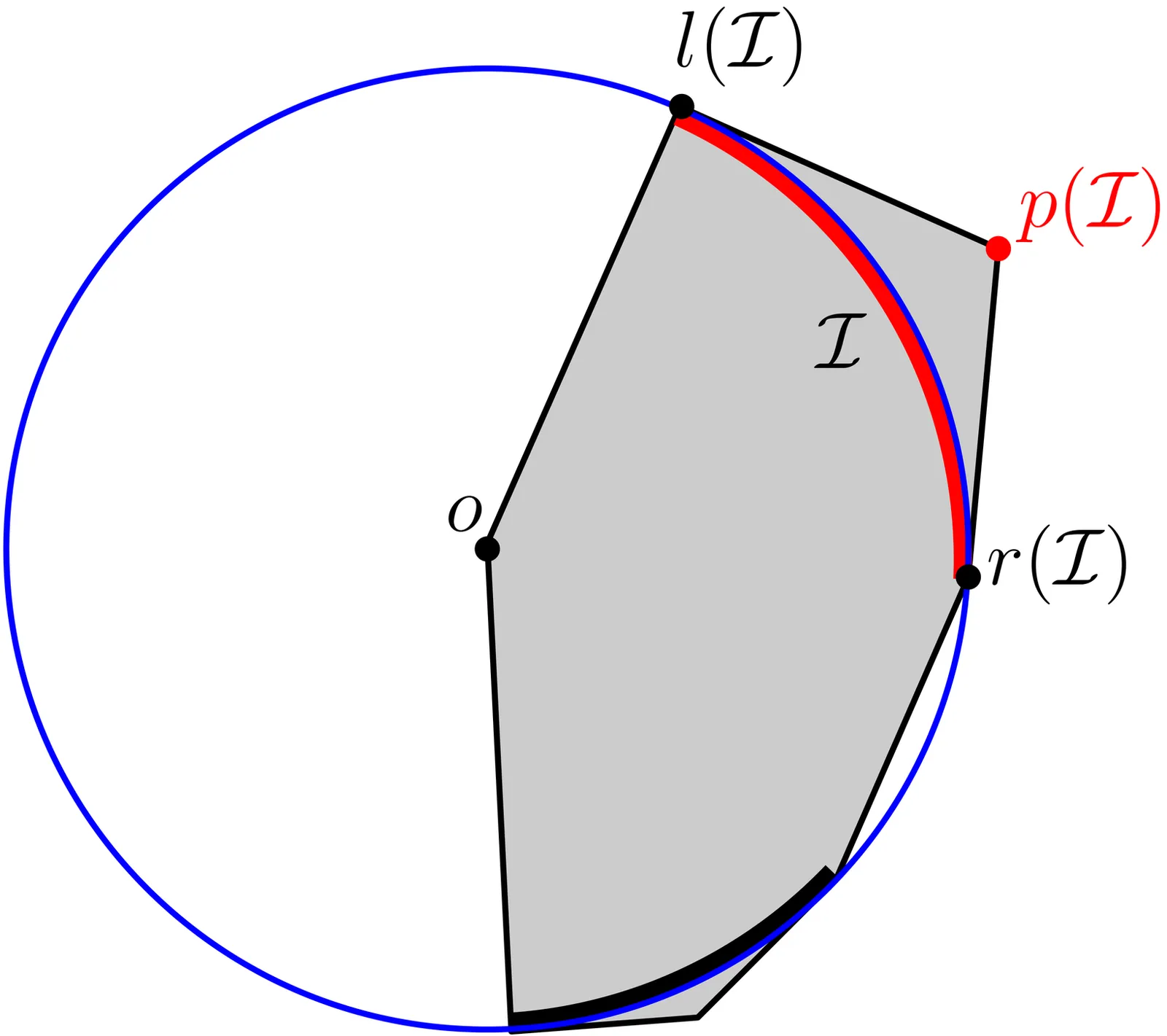
A set is star-shaped if there is a point in the set that can see every other point in the set in the sense that the line-segment connecting the points lies within the set. We show that testing whether a non-empty compact smooth region is star-shaped is $\forall\mathbb{R}$-complete. Since the obvious definition of star-shapedness has logical form $\exists\forall$, this is a somewhat surprising result, based on Krasnosel'skiĭ's theorem from convex geometry; we study several related complexity classifications in the real hierarchy based on other results from convex geometry.

In this work we introduce a triangular Delaunay mesh generator that can be trained using reinforcement learning to maximize a given mesh quality metric. Our mesh generator consists of a graph neural network that distributes and modifies vertices, and a standard Delaunay algorithm to triangulate the vertices. We explore various design choices and evaluate our mesh generator on various tasks including mesh generation, mesh improvement, and producing variable resolution meshes. The learned mesh generator outputs meshes that are comparable to those produced by Triangle and DistMesh, two popular Delaunay-based mesh generators.

This paper presents a novel topology-aware dimensionality reduction approach aiming at accurately visualizing the cyclic patterns present in high dimensional data. To that end, we build on the Topological Autoencoders (TopoAE) formulation. First, we provide a novel theoretical analysis of its associated loss and show that a zero loss indeed induces identical persistence pairs (in high and low dimensions) for the $0$-dimensional persistent homology (PH$^0$) of the Rips filtration. We also provide a counter example showing that this property no longer holds for a naive extension of TopoAE to PH$^d$ for $d\ge 1$. Based on this observation, we introduce a novel generalization of TopoAE to $1$-dimensional persistent homology (PH$^1$), called TopoAE++, for the accurate generation of cycle-aware planar embeddings, addressing the above failure case. This generalization is based on the notion of cascade distortion, a new penalty term favoring an isometric embedding of the $2$-chains filling persistent $1$-cycles, hence resulting in more faithful geometrical reconstructions of the $1$-cycles in the plane. We further introduce a novel, fast algorithm for the exact computation of PH for Rips filtrations in the plane, yielding improved runtimes over previously documented topology-aware methods. Our method also achieves a better balance between the topological accuracy, as measured by the Wasserstein distance, and the visual preservation of the cycles in low dimensions. Our C++ implementation is available at https://github.com/MClemot/TopologicalAutoencodersPlusPlus.
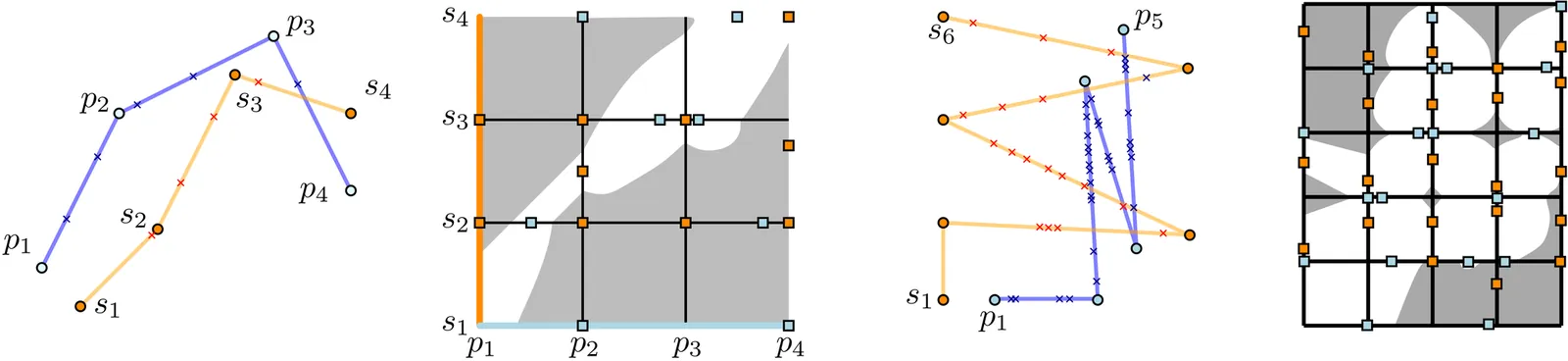
Standard sweep algorithms require an order of discrete points in Euclidean space, and rely on the property that, at a given point, all points in the halfspace below come earlier in this order. We are motivated by the problem of reconstructing a graph in $\mathbb{R}^d$ from vertex locations and degree information, which was addressed using standard sweep algorithms by Fasy et al. We generalize this to the reconstruction of general simplicial complexes. As our main ingredient, we introduce a generalized \emph{sweeping order} on $i$-simplices, maintaining the property that, at a given $i$-simplex $σ$, all $(i+1)$-dimensional cofaces of $σ$ in the halfspace below $σ$ have an $i$-dimensional face that appeared earlier in the order ("below" with respect to some direction perpendicular to $σ$). We then go on to incorporate computing such sweeping orders to reconstruct an unknown simplicial complex $K$, starting with only its vertex locations, i.e., its $0$-skeleton. Specifically, once we have found the $i$-skeleton of $K$, we compute a sweeping order for the $i$-simplices, and use it to reconstruct the $(i+1)$-skeleton of $K$ by querying the \emph{indegree}, or the number of $(i+1)$-simplices incident to and below a given $i$-simplex. In addition to generalizing the algorithm by Fasy et al. to simplicial complexes, we improve upon the running time of their central subroutine of radially finding edges above a vertex.
One of the questions in Rigidity Theory is whether a realization of the vertices of a graph in the plane is flexible, namely, if it allows a continuous deformation preserving the edge lengths. A flexible realization of a connected graph in the plane exists if and only if the graph has a NAC-coloring, which is a surjective edge coloring by two colors such that for each cycle, either all the edges have the same color, or there are at least two edges of each color. The question whether a graph has a NAC-coloring, and hence also the existence of a flexible realization, has been proven to be NP-complete. We show that this question is also NP-complete on graphs with maximum degree five and on graphs with the average degree at most $4+\varepsilon$ for every fixed $\varepsilon >0$. We also show that NAC-colorings can be counted in linear time for graphs with bounded treewidth. Since the only existing implementation of checking the existence of a NAC-coloring is rather naive, we propose new algorithms along with their implementation, which is significantly faster. We also focus on searching all NAC-colorings of a graph, since they provide useful information about its possible flexible realizations.
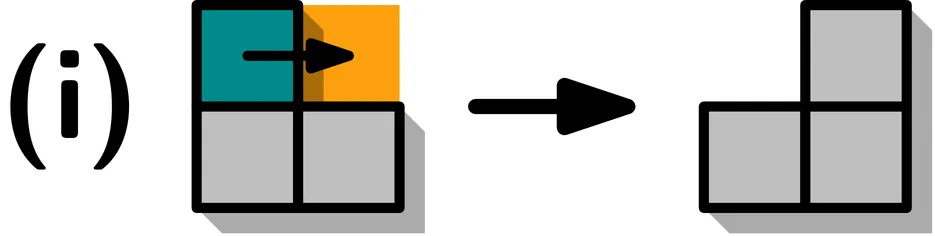
We consider algorithmic problems motivated by modular robotic reconfiguration in the sliding square model, in which we are given $n$ square-shaped modules in a (labeled or unlabeled) start configuration and need to find a schedule of sliding moves to transform it into a desired goal configuration, maintaining connectivity of the configuration at all times. Recent work has aimed at minimizing the total number of moves, resulting in fully sequential schedules that perform reconfiguration in $\mathcal{O}(nP)$ moves for arrangements of bounding box perimeter size $P$, or a number of moves linear in the sum of module coordinates in the start and target arrangements. We extend the model to leverage the possibility of parallel motion, thereby reducing worst-case makespans by a factor linear in $n$. Our work presents tight results both in terms of complexity and algorithms: We show that deciding the existence of a single parallel reconfiguration step that solves an instance is NP-complete for unlabeled modules, but can be solved efficiently in the labeled setting. Nevertheless, deciding whether a labeled instance can be solved in two parallel steps is NP-complete. Finally, we describe an algorithm to perform in-place reconfiguration in worst-case optimal $\mathcal{O}(P)$ parallel steps for the unlabeled setting. This algorithm has a straight-forward extension to the labeled setting with slight relaxations to either the reconfiguration time or space constraint.
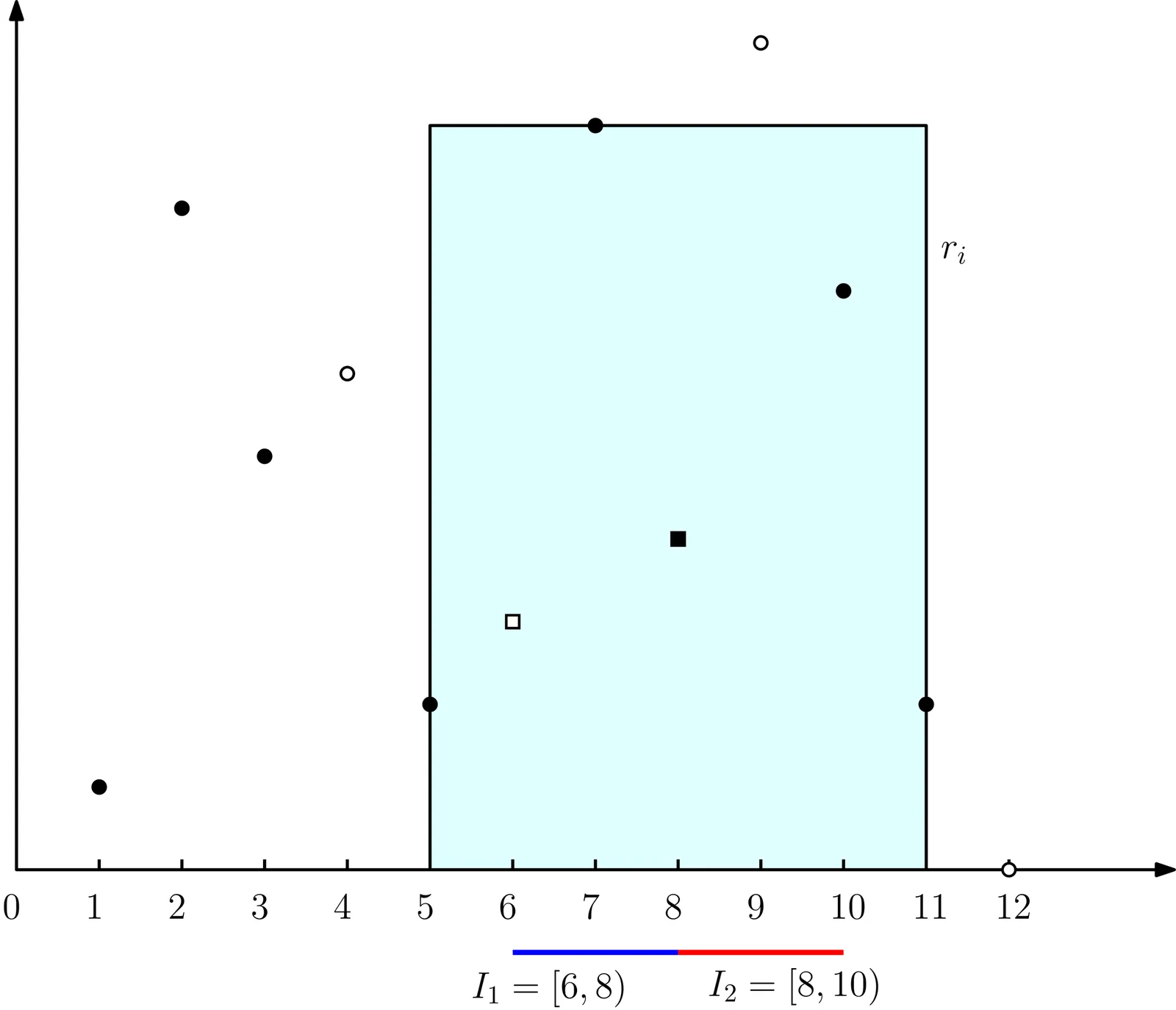
We present algorithms for the online minimum hitting set problem in geometric range spaces: given a set $P$ of $n$ points in the plane and a sequence of geometric objects that arrive one-by-one, we need to maintain a hitting set at all times by making irrevocable decisions. For disks of radii in the interval $[1,M]$, we present an $O(\log M \log n)$-competitive algorithm. This result generalizes from disks to positive homothets of any convex body in the plane with scaling factors in the interval $[1,M]$. As a main technical tool, we reduce the problem to the online hitting set problem for a finite subset of integer points and geometric objects with the lowest point property, introduced in this paper, which behave similarly to bottomless rectangles. Specifically, for a given $N>1$, we present an $O(\log N)$-competitive algorithm for the variant where $P$ is a subset of an $N\times N$ section of the integer lattice, and the geometric objects have the lowest point property.

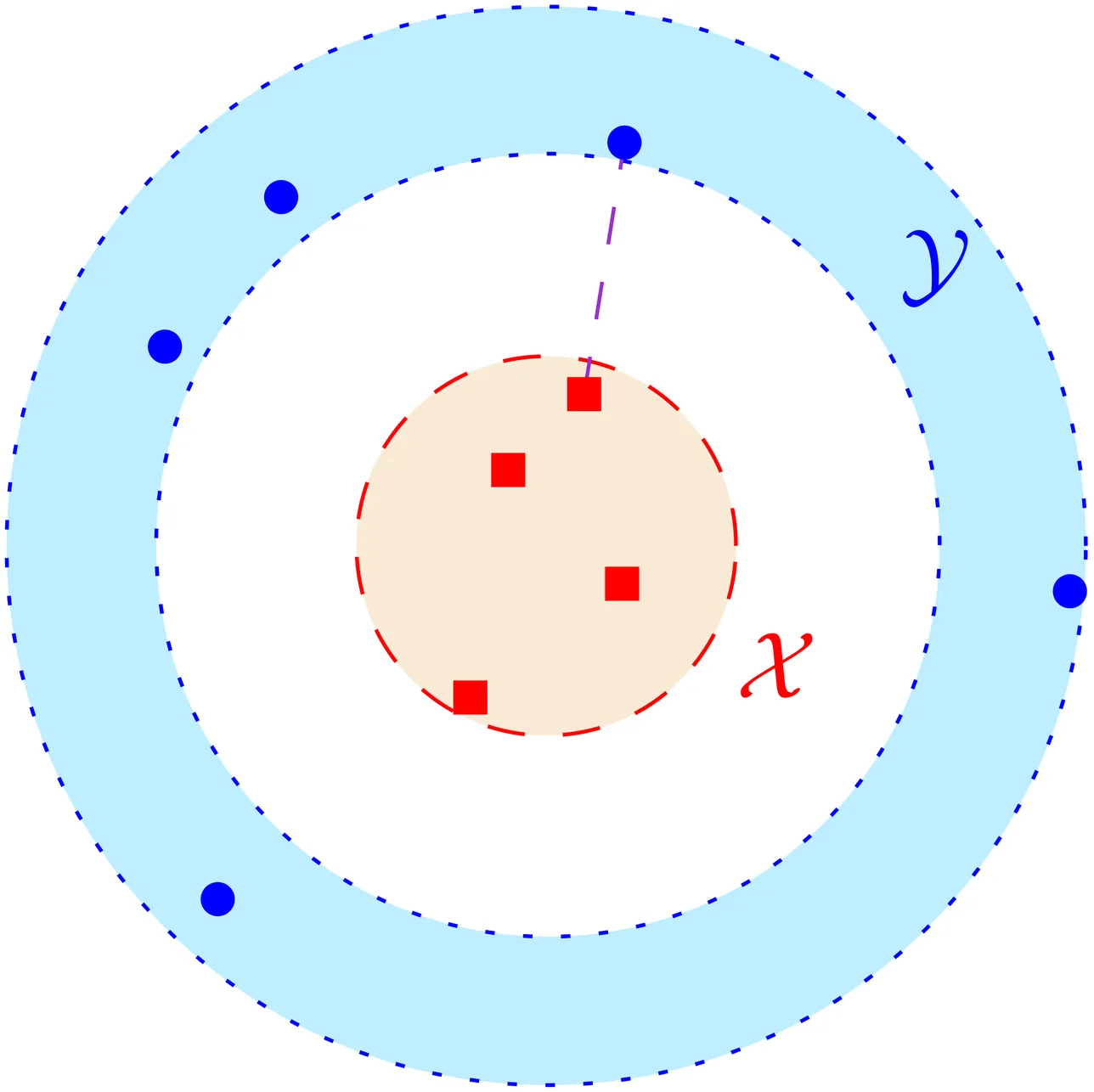
Low density graphs are considered to be a realistic graph class for modelling road networks. It has advantages over other popular graph classes for road networks, such as planar graphs, bounded highway dimension graphs, and spanners. We believe that low density graphs have the potential to be a useful graph class for road networks, but until now, its usefulness is limited by a lack of available tools. In this paper, we develop two fundamental tools for low density graphs, that is, a well-separated pair decomposition and an approximate distance oracle. We believe that by expanding the algorithmic toolbox for low density graphs, we can help provide a useful and realistic graph class for road networks, which in turn, may help explain the many efficient and practical heuristics available for road networks.