Trending in Computer Graphics
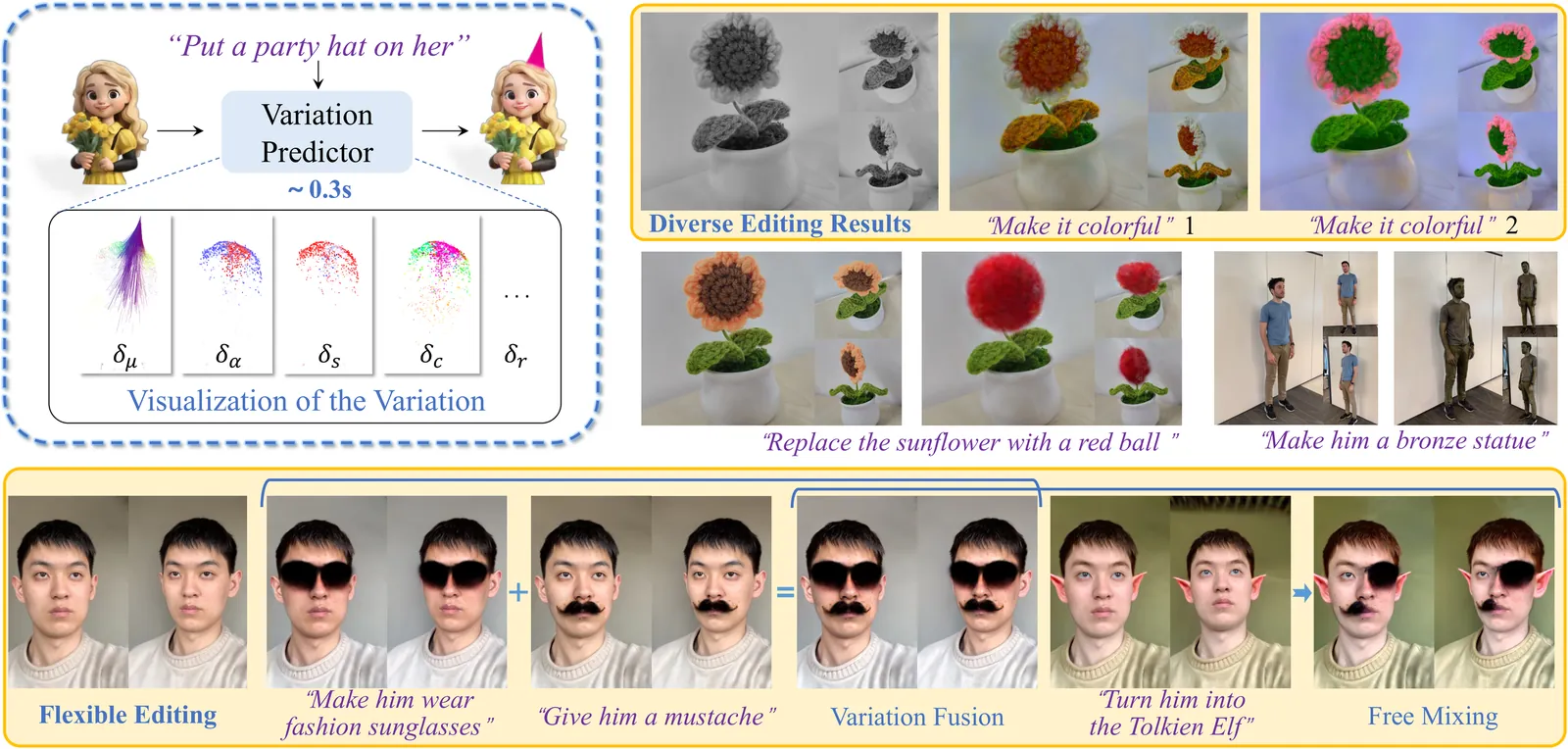
Variation-aware Flexible 3D Gaussian Editing
Indirect editing methods for 3D Gaussian Splatting (3DGS) have recently witnessed significant advancements. These approaches operate by first applying edits in the rendered 2D space and subsequently projecting the modifications back into 3D. However, this paradigm inevitably introduces cross-view inconsistencies and constrains both the flexibility and efficiency of the editing process. To address these challenges, we present VF-Editor, which enables native editing of Gaussian primitives by predicting attribute variations in a feedforward manner. To accurately and efficiently estimate these variations, we design a novel variation predictor distilled from 2D editing knowledge. The predictor encodes the input to generate a variation field and employs two learnable, parallel decoding functions to iteratively infer attribute changes for each 3D Gaussian. Thanks to its unified design, VF-Editor can seamlessly distill editing knowledge from diverse 2D editors and strategies into a single predictor, allowing for flexible and effective knowledge transfer into the 3D domain. Extensive experiments on both public and private datasets reveal the inherent limitations of indirect editing pipelines and validate the effectiveness and flexibility of our approach.
2602.11638
Feb 2026Graphics

PhysTalk: Language-driven Real-time Physics in 3D Gaussian Scenes
Realistic visual simulations are omnipresent, yet their creation requires computing time, rendering, and expert animation knowledge. Open-vocabulary visual effects generation from text inputs emerges as a promising solution that can unlock immense creative potential. However, current pipelines lack both physical realism and effective language interfaces, requiring slow offline optimization. In contrast, PhysTalk takes a 3D Gaussian Splatting (3DGS) scene as input and translates arbitrary user prompts into real time, physics based, interactive 4D animations. A large language model (LLM) generates executable code that directly modifies 3DGS parameters through lightweight proxies and particle dynamics. Notably, PhysTalk is the first framework to couple 3DGS directly with a physics simulator without relying on time consuming mesh extraction. While remaining open vocabulary, this design enables interactive 3D Gaussian animation via collision aware, physics based manipulation of arbitrary, multi material objects. Finally, PhysTalk is train-free and computationally lightweight: this makes 4D animation broadly accessible and shifts these workflows from a "render and wait" paradigm toward an interactive dialogue with a modern, physics-informed pipeline.
2512.24986
Dec 2025Graphics
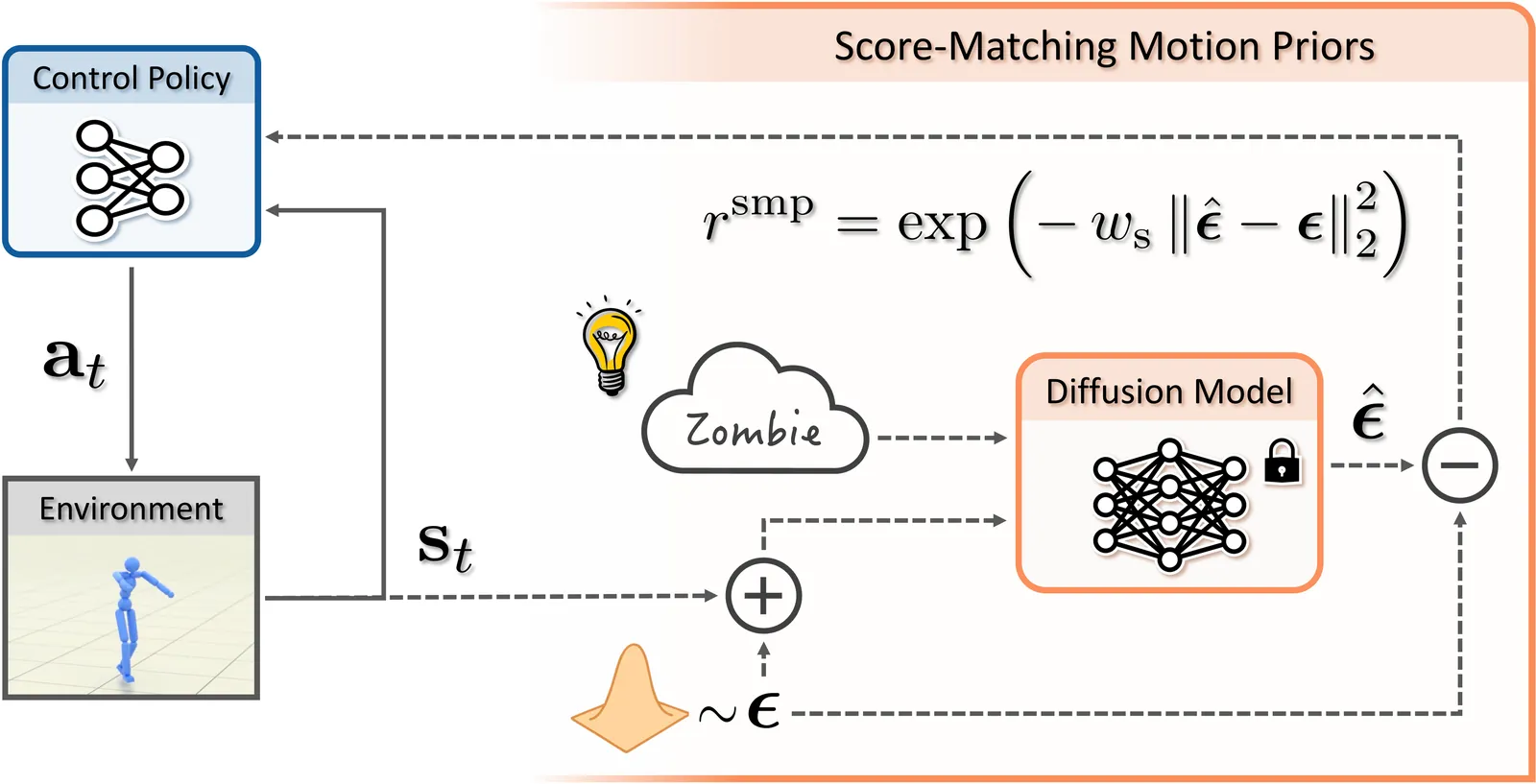
SMP: Reusable Score-Matching Motion Priors for Physics-Based Character Control
Data-driven motion priors that can guide agents toward producing naturalistic behaviors play a pivotal role in creating life-like virtual characters. Adversarial imitation learning has been a highly effective method for learning motion priors from reference motion data. However, adversarial priors, with few exceptions, need to be retrained for each new controller, thereby limiting their reusability and necessitating the retention of the reference motion data when training on downstream tasks. In this work, we present Score-Matching Motion Priors (SMP), which leverages pre-trained motion diffusion models and score distillation sampling (SDS) to create reusable task-agnostic motion priors. SMPs can be pre-trained on a motion dataset, independent of any control policy or task. Once trained, SMPs can be kept frozen and reused as general-purpose reward functions to train policies to produce naturalistic behaviors for downstream tasks. We show that a general motion prior trained on large-scale datasets can be repurposed into a variety of style-specific priors. Furthermore SMP can compose different styles to synthesize new styles not present in the original dataset. Our method produces high-quality motion comparable to state-of-the-art adversarial imitation learning methods through reusable and modular motion priors. We demonstrate the effectiveness of SMP across a diverse suite of control tasks with physically simulated humanoid characters. Video demo available at https://youtu.be/ravlZJteS20
2512.03028
Dec 2025Graphics
Radiance Meshes for Volumetric Reconstruction
We introduce radiance meshes, a technique for representing radiance fields with constant density tetrahedral cells produced with a Delaunay tetrahedralization. Unlike a Voronoi diagram, a Delaunay tetrahedralization yields simple triangles that are natively supported by existing hardware. As such, our model is able to perform exact and fast volume rendering using both rasterization and ray-tracing. We introduce a new rasterization method that achieves faster rendering speeds than all prior radiance field representations (assuming an equivalent number of primitives and resolution) across a variety of platforms. Optimizing the positions of Delaunay vertices introduces topological discontinuities (edge flips). To solve this, we use a Zip-NeRF-style backbone which allows us to express a smoothly varying field even when the topology changes. Our rendering method exactly evaluates the volume rendering equation and enables high quality, real-time view synthesis on standard consumer hardware. Our tetrahedral meshes also lend themselves to a variety of exciting applications including fisheye lens distortion, physics-based simulation, editing, and mesh extraction.
2512.04076
Dec 2025Graphics