Graphics
arXiv:cs.GR
Covers all aspects of computer graphics.
Looking for a broader view? This category is part of:
Covers all aspects of computer graphics.
Looking for a broader view? This category is part of:

Realistic visual simulations are omnipresent, yet their creation requires computing time, rendering, and expert animation knowledge. Open-vocabulary visual effects generation from text inputs emerges as a promising solution that can unlock immense creative potential. However, current pipelines lack both physical realism and effective language interfaces, requiring slow offline optimization. In contrast, PhysTalk takes a 3D Gaussian Splatting (3DGS) scene as input and translates arbitrary user prompts into real time, physics based, interactive 4D animations. A large language model (LLM) generates executable code that directly modifies 3DGS parameters through lightweight proxies and particle dynamics. Notably, PhysTalk is the first framework to couple 3DGS directly with a physics simulator without relying on time consuming mesh extraction. While remaining open vocabulary, this design enables interactive 3D Gaussian animation via collision aware, physics based manipulation of arbitrary, multi material objects. Finally, PhysTalk is train-free and computationally lightweight: this makes 4D animation broadly accessible and shifts these workflows from a "render and wait" paradigm toward an interactive dialogue with a modern, physics-informed pipeline.
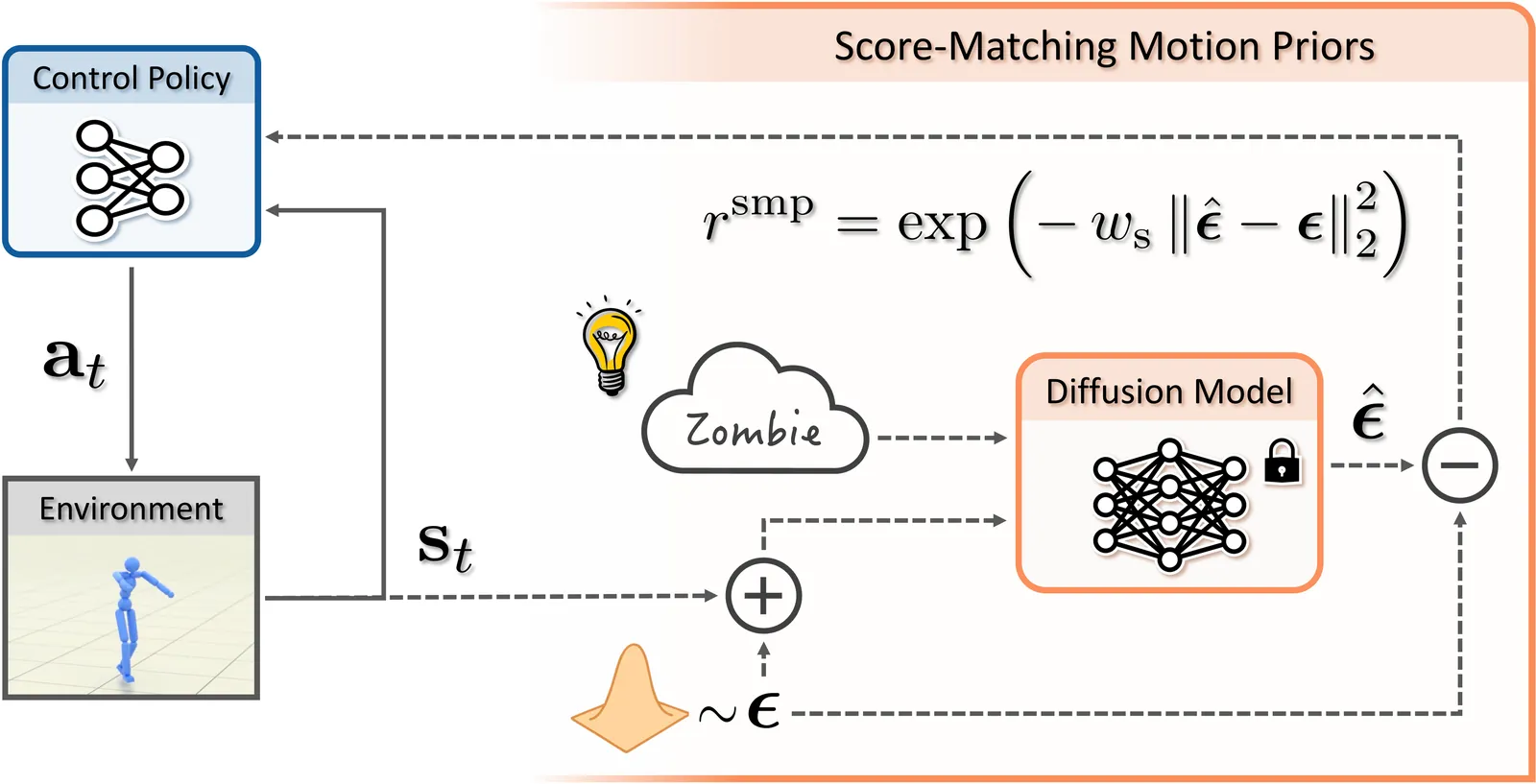
Data-driven motion priors that can guide agents toward producing naturalistic behaviors play a pivotal role in creating life-like virtual characters. Adversarial imitation learning has been a highly effective method for learning motion priors from reference motion data. However, adversarial priors, with few exceptions, need to be retrained for each new controller, thereby limiting their reusability and necessitating the retention of the reference motion data when training on downstream tasks. In this work, we present Score-Matching Motion Priors (SMP), which leverages pre-trained motion diffusion models and score distillation sampling (SDS) to create reusable task-agnostic motion priors. SMPs can be pre-trained on a motion dataset, independent of any control policy or task. Once trained, SMPs can be kept frozen and reused as general-purpose reward functions to train policies to produce naturalistic behaviors for downstream tasks. We show that a general motion prior trained on large-scale datasets can be repurposed into a variety of style-specific priors. Furthermore SMP can compose different styles to synthesize new styles not present in the original dataset. Our method produces high-quality motion comparable to state-of-the-art adversarial imitation learning methods through reusable and modular motion priors. We demonstrate the effectiveness of SMP across a diverse suite of control tasks with physically simulated humanoid characters. Video demo available at https://youtu.be/ravlZJteS20
We introduce radiance meshes, a technique for representing radiance fields with constant density tetrahedral cells produced with a Delaunay tetrahedralization. Unlike a Voronoi diagram, a Delaunay tetrahedralization yields simple triangles that are natively supported by existing hardware. As such, our model is able to perform exact and fast volume rendering using both rasterization and ray-tracing. We introduce a new rasterization method that achieves faster rendering speeds than all prior radiance field representations (assuming an equivalent number of primitives and resolution) across a variety of platforms. Optimizing the positions of Delaunay vertices introduces topological discontinuities (edge flips). To solve this, we use a Zip-NeRF-style backbone which allows us to express a smoothly varying field even when the topology changes. Our rendering method exactly evaluates the volume rendering equation and enables high quality, real-time view synthesis on standard consumer hardware. Our tetrahedral meshes also lend themselves to a variety of exciting applications including fisheye lens distortion, physics-based simulation, editing, and mesh extraction.

We present a novel, regression-based method for artistically styling images. Unlike recent neural style transfer or diffusion-based approaches, our method allows for explicit control over the stroke composition and level of detail in the rendered image through the use of an extensible set of stroke patches. The stroke patch sets are procedurally generated by small programs that control the shape, size, orientation, density, color, and noise level of the strokes in the individual patches. Once trained on a set of stroke patches, a U-Net based regression model can render any input image in a variety of distinct, evocative and customizable styles.
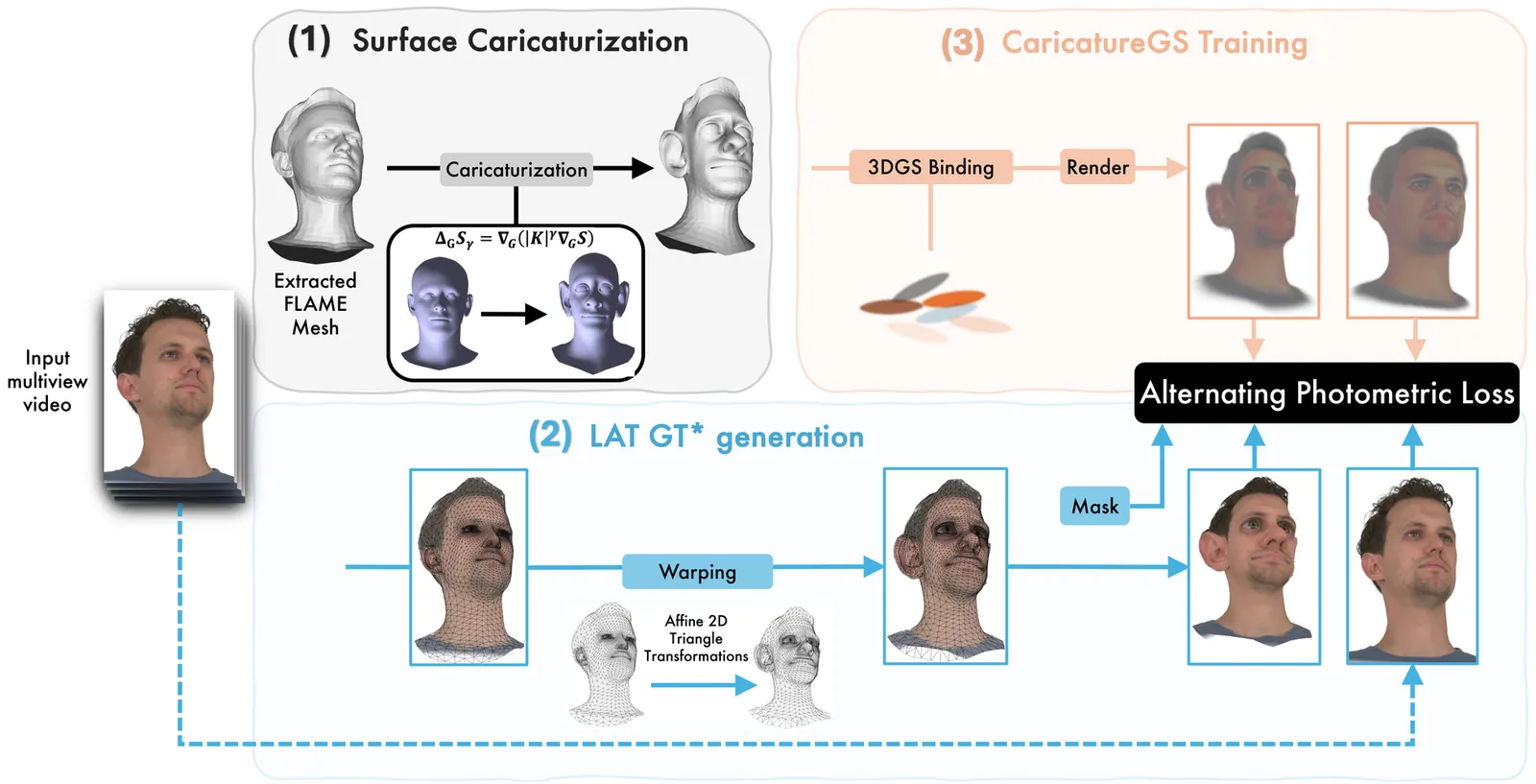
A photorealistic and controllable 3D caricaturization framework for faces is introduced. We start with an intrinsic Gaussian curvature-based surface exaggeration technique, which, when coupled with texture, tends to produce over-smoothed renders. To address this, we resort to 3D Gaussian Splatting (3DGS), which has recently been shown to produce realistic free-viewpoint avatars. Given a multiview sequence, we extract a FLAME mesh, solve a curvature-weighted Poisson equation, and obtain its exaggerated form. However, directly deforming the Gaussians yields poor results, necessitating the synthesis of pseudo-ground-truth caricature images by warping each frame to its exaggerated 2D representation using local affine transformations. We then devise a training scheme that alternates real and synthesized supervision, enabling a single Gaussian collection to represent both natural and exaggerated avatars. This scheme improves fidelity, supports local edits, and allows continuous control over the intensity of the caricature. In order to achieve real-time deformations, an efficient interpolation between the original and exaggerated surfaces is introduced. We further analyze and show that it has a bounded deviation from closed-form solutions. In both quantitative and qualitative evaluations, our results outperform prior work, delivering photorealistic, geometry-controlled caricature avatars.
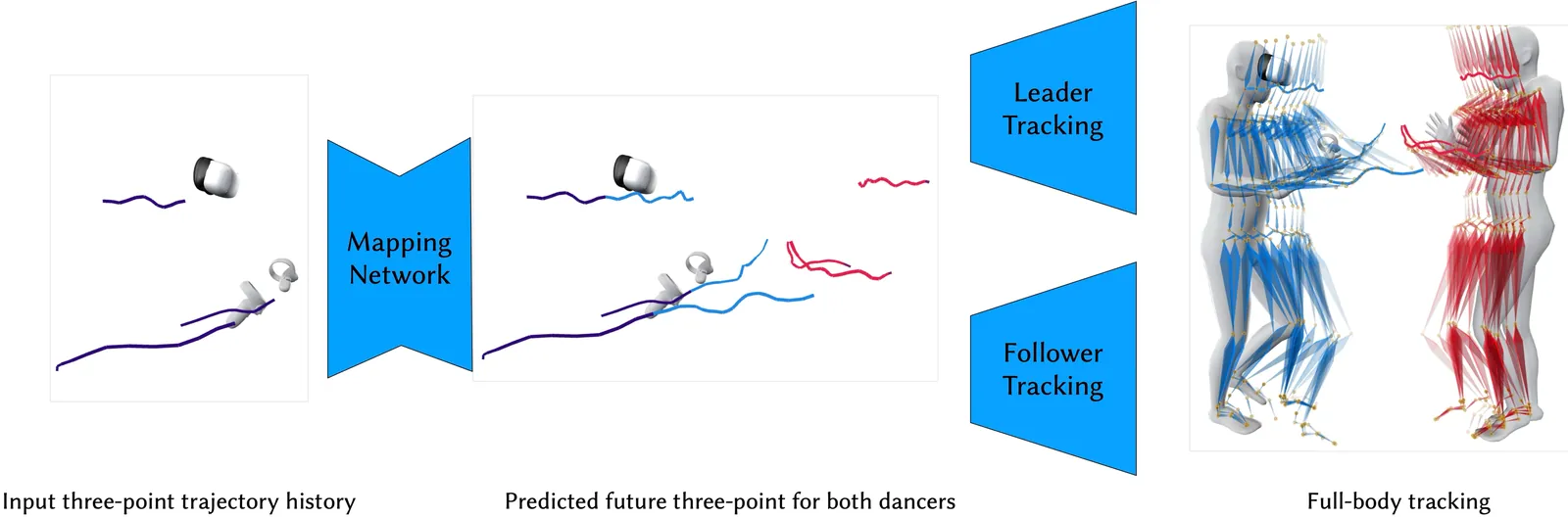
Ballroom dancing is a structured yet expressive motion category. Its highly diverse movement and complex interactions between leader and follower dancers make the understanding and synthesis challenging. We demonstrate that the three-point trajectory available from a virtual reality (VR) device can effectively serve as a dancer's motion descriptor, simplifying the modeling and synthesis of interplay between dancers' full-body motions down to sparse trajectories. Thanks to the low dimensionality, we can employ an efficient MLP network to predict the follower's three-point trajectory directly from the leader's three-point input for certain types of ballroom dancing, addressing the challenge of modeling high-dimensional full-body interaction. It also prevents our method from overfitting thanks to its compact yet explicit representation. By leveraging the inherent structure of the movements and carefully planning the autoregressive procedure, we show a deterministic neural network is able to translate three-point trajectories into a virtual embodied avatar, which is typically considered under-constrained and requires generative models for common motions. In addition, we demonstrate this deterministic approach generalizes beyond small, structured datasets like ballroom dancing, and performs robustly on larger, more diverse datasets such as LaFAN. Our method provides a computationally- and data-efficient solution, opening new possibilities for immersive paired dancing applications. Code and pre-trained models for this paper are available at https://peizhuoli.github.io/dancing-points.
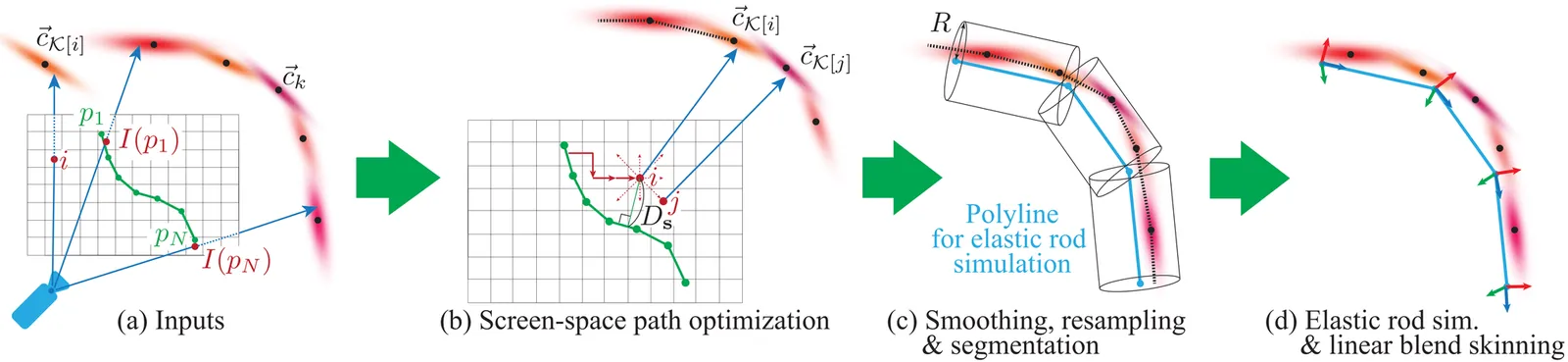
Physics simulation of slender elastic objects often requires discretization as a polyline. However, constructing a polyline from Gaussian splatting is challenging as Gaussian splatting lacks connectivity information and the configuration of Gaussian primitives contains much noise. This paper presents a method to extract a polyline representation of the slender part of the objects in a Gaussian splatting scene from the user's sketching input. Our method robustly constructs a polyline mesh that represents the slender parts using the screen-space shortest path analysis that can be efficiently solved using dynamic programming. We demonstrate the effectiveness of our approach in several in-the-wild examples.
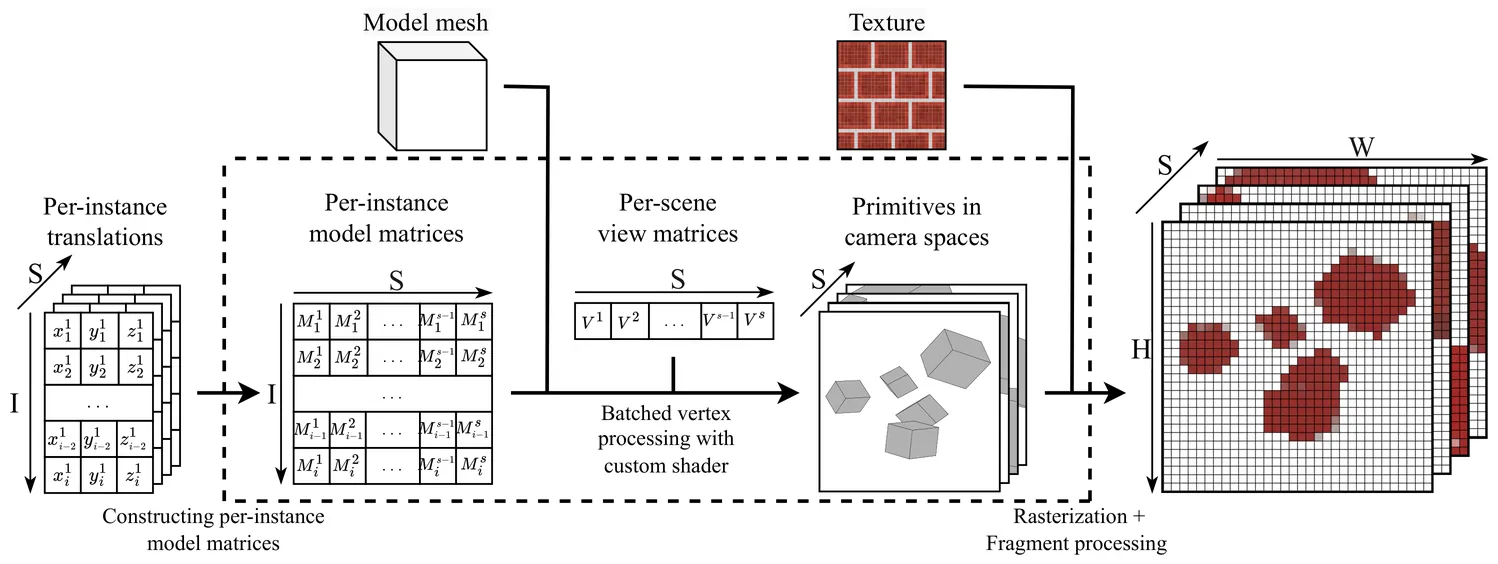
Reinforcement learning from pixels is often bottlenecked by the performance and complexity of 3D rendered environments. Researchers face a trade-off between high-speed, low-level engines and slower, more accessible Python frameworks. To address this, we introduce PyBatchRender, a Python library for high-throughput, batched 3D rendering that achieves over 1 million FPS on simple scenes. Built on the Panda3D game engine, it utilizes its mature ecosystem while enhancing performance through optimized batched rendering for up to 1000X speedups. Designed as a physics-agnostic renderer for reinforcement learning from pixels, PyBatchRender offers greater flexibility than dedicated libraries, simpler setup than typical game-engine wrappers, and speeds rivaling state-of-the-art C++ engines like Madrona. Users can create custom scenes entirely in Python with tens of lines of code, enabling rapid prototyping for scalable AI training. Open-source and easy to integrate, it serves to democratize high-performance 3D simulation for researchers and developers. The library is available at https://github.com/dolphin-in-a-coma/PyBatchRender.
Realistic visual simulations are omnipresent, yet their creation requires computing time, rendering, and expert animation knowledge. Open-vocabulary visual effects generation from text inputs emerges as a promising solution that can unlock immense creative potential. However, current pipelines lack both physical realism and effective language interfaces, requiring slow offline optimization. In contrast, PhysTalk takes a 3D Gaussian Splatting (3DGS) scene as input and translates arbitrary user prompts into real time, physics based, interactive 4D animations. A large language model (LLM) generates executable code that directly modifies 3DGS parameters through lightweight proxies and particle dynamics. Notably, PhysTalk is the first framework to couple 3DGS directly with a physics simulator without relying on time consuming mesh extraction. While remaining open vocabulary, this design enables interactive 3D Gaussian animation via collision aware, physics based manipulation of arbitrary, multi material objects. Finally, PhysTalk is train-free and computationally lightweight: this makes 4D animation broadly accessible and shifts these workflows from a "render and wait" paradigm toward an interactive dialogue with a modern, physics-informed pipeline.
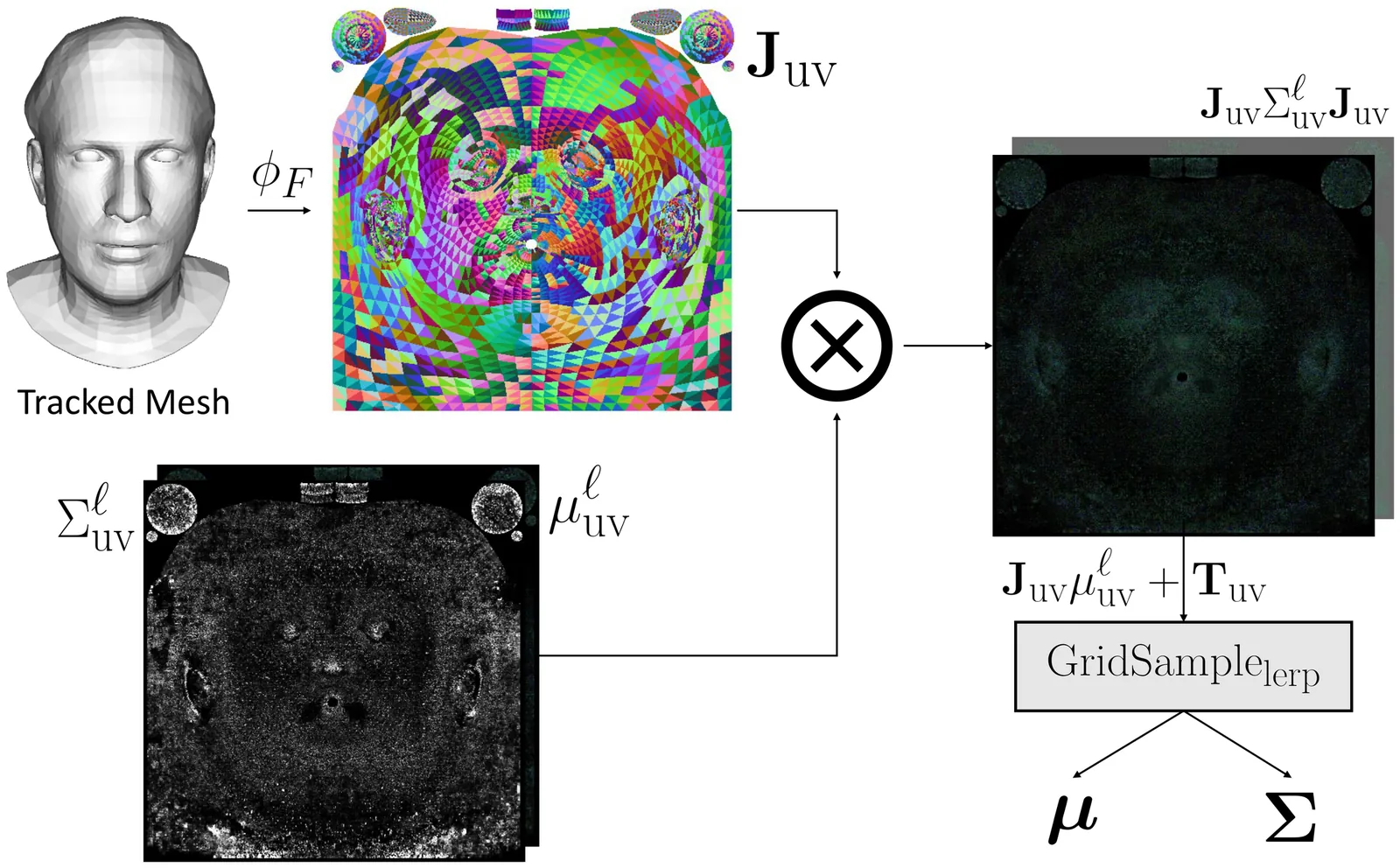
Constructing drivable and photorealistic 3D head avatars has become a central task in AR/XR, enabling immersive and expressive user experiences. With the emergence of high-fidelity and efficient representations such as 3D Gaussians, recent works have pushed toward ultra-detailed head avatars. Existing approaches typically fall into two categories: rule-based analytic rigging or neural network-based deformation fields. While effective in constrained settings, both approaches often fail to generalize to unseen expressions and poses, particularly in extreme reenactment scenarios. Other methods constrain Gaussians to the global texel space of 3DMMs to reduce rendering complexity. However, these texel-based avatars tend to underutilize the underlying mesh structure. They apply minimal analytic deformation and rely heavily on neural regressors and heuristic regularization in UV space, which weakens geometric consistency and limits extrapolation to complex, out-of-distribution deformations. To address these limitations, we introduce TexAvatars, a hybrid avatar representation that combines the explicit geometric grounding of analytic rigging with the spatial continuity of texel space. Our approach predicts local geometric attributes in UV space via CNNs, but drives 3D deformation through mesh-aware Jacobians, enabling smooth and semantically meaningful transitions across triangle boundaries. This hybrid design separates semantic modeling from geometric control, resulting in improved generalization, interpretability, and stability. Furthermore, TexAvatars captures fine-grained expression effects, including muscle-induced wrinkles, glabellar lines, and realistic mouth cavity geometry, with high fidelity. Our method achieves state-of-the-art performance under extreme pose and expression variations, demonstrating strong generalization in challenging head reenactment settings.

Free-viewpoint video (FVV) enables immersive viewing experiences by allowing users to view scenes from arbitrary perspectives. As a prominent reconstruction technique for FVV generation, 4D Gaussian Splatting (4DGS) models dynamic scenes with time-varying 3D Gaussian ellipsoids and achieves high-quality rendering via fast rasterization. However, existing 4DGS approaches suffer from quality degradation over long sequences and impose substantial bandwidth and storage overhead, limiting their applicability in real-time and wide-scale deployments. Therefore, we present AirGS, a streaming-optimized 4DGS framework that rearchitects the training and delivery pipeline to enable high-quality, low-latency FVV experiences. AirGS converts Gaussian video streams into multi-channel 2D formats and intelligently identifies keyframes to enhance frame reconstruction quality. It further combines temporal coherence with inflation loss to reduce training time and representation size. To support communication-efficient transmission, AirGS models 4DGS delivery as an integer linear programming problem and design a lightweight pruning level selection algorithm to adaptively prune the Gaussian updates to be transmitted, balancing reconstruction quality and bandwidth consumption. Extensive experiments demonstrate that AirGS reduces quality deviation in PSNR by more than 20% when scene changes, maintains frame-level PSNR consistently above 30, accelerates training by 6 times, reduces per-frame transmission size by nearly 50% compared to the SOTA 4DGS approaches.

Density plots effectively summarize large numbers of points, which would otherwise lead to severe overplotting in, for example, a scatter plot. However, when applied to line-based datasets, such as trajectories or time series, density plots alone are insufficient, as they disrupt path continuity, obscuring smooth trends and rare anomalies. We propose a bin-based illumination model that decouples structure from density to enhance flow and reveal sparse outliers while preserving the original colormap. We introduce a bin-based outlierness metric to rank trajectories. Guided by this ranking, we construct a structural normal map and apply locally-adaptive lighting in the luminance channel to highlight chosen patterns -- from dominant trends to atypical paths -- with acceptable color distortion. Our interactive method enables analysts to prioritize main trends, focus on outliers, or strike a balance between the two. We demonstrate our method on several real-world datasets, showing it reveals details missed by simpler alternatives, achieves significantly lower CIEDE2000 color distortion than standard shading, and supports interactive updates for up to 10,000 lines.
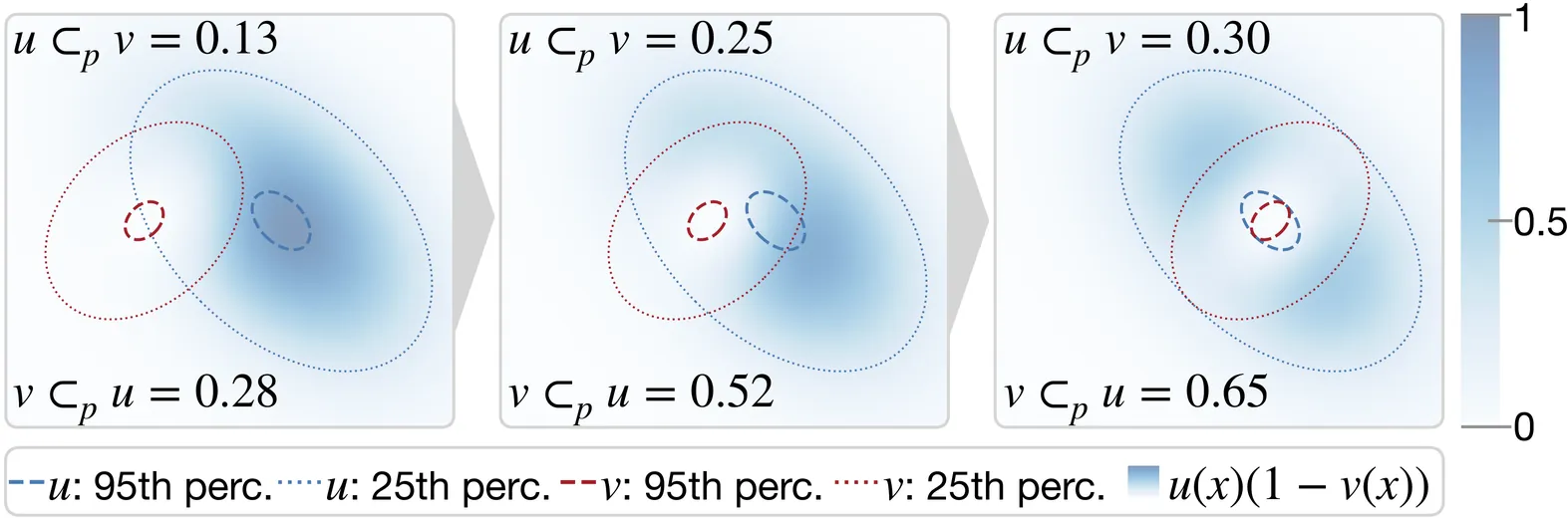
We propose Probabilistic Inclusion Depth (PID) for the ensemble visualization of scalar fields. By introducing a probabilistic inclusion operator $\subset_{\!p}$, our method is a general data depth model supporting ensembles of fuzzy contours, such as soft masks from modern segmentation methods, and conventional ensembles of binary contours. We also advocate to extend contour extraction in scalar field ensembles to become a fuzzy decision by considering the probabilistic distribution of an isovalue to encode the sensitivity information. To reduce the complexity of the data depth computation, an efficient approximation using the mean probabilistic contour is devised. Furthermore, an order of magnitude reduction in computational time is achieved with an efficient parallel algorithm on the GPU. Our new method enables the computation of contour boxplots for ensembles of probabilistic masks, ensembles defined on various types of grids, and large 3D ensembles that are not studied by existing methods. The effectiveness of our method is evaluated with numerical comparisons to existing techniques on synthetic datasets, through examples of real-world ensemble datasets, and expert feedback.
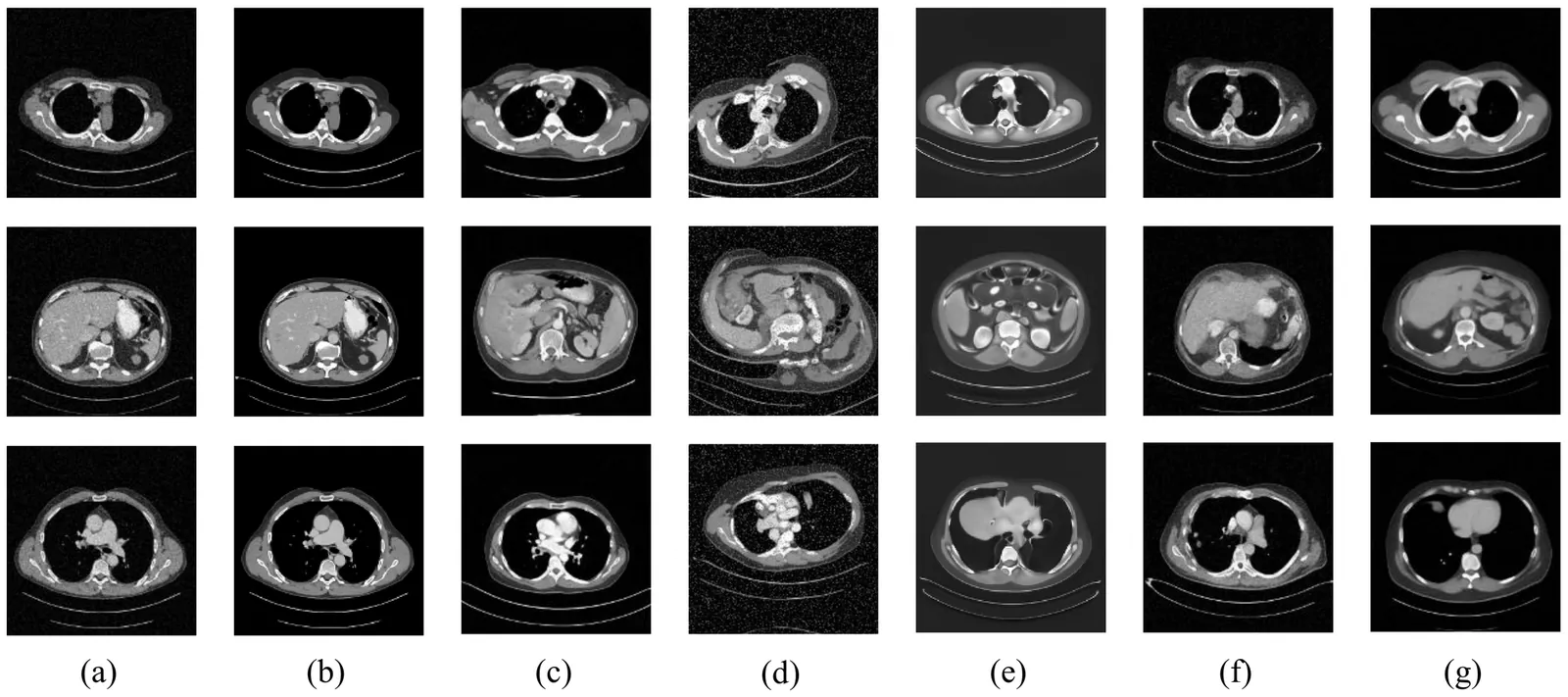
Task-based measures of image quality (IQ) are critical for evaluating medical imaging systems, which must account for randomness including anatomical variability. Stochastic object models (SOMs) provide a statistical description of such variability, but conventional mathematical SOMs fail to capture realistic anatomy, while data-driven approaches typically require clean data rarely available in clinical tasks. To address this challenge, we propose AMID, an unsupervised Ambient Measurement-Integrated Diffusion with noise decoupling, which establishes clean SOMs directly from noisy measurements. AMID introduces a measurement-integrated strategy aligning measurement noise with the diffusion trajectory, and explicitly models coupling between measurement and diffusion noise across steps, an ambient loss is thus designed base on it to learn clean SOMs. Experiments on real CT and mammography datasets show that AMID outperforms existing methods in generation fidelity and yields more reliable task-based IQ evaluation, demonstrating its potential for unsupervised medical imaging analysis.
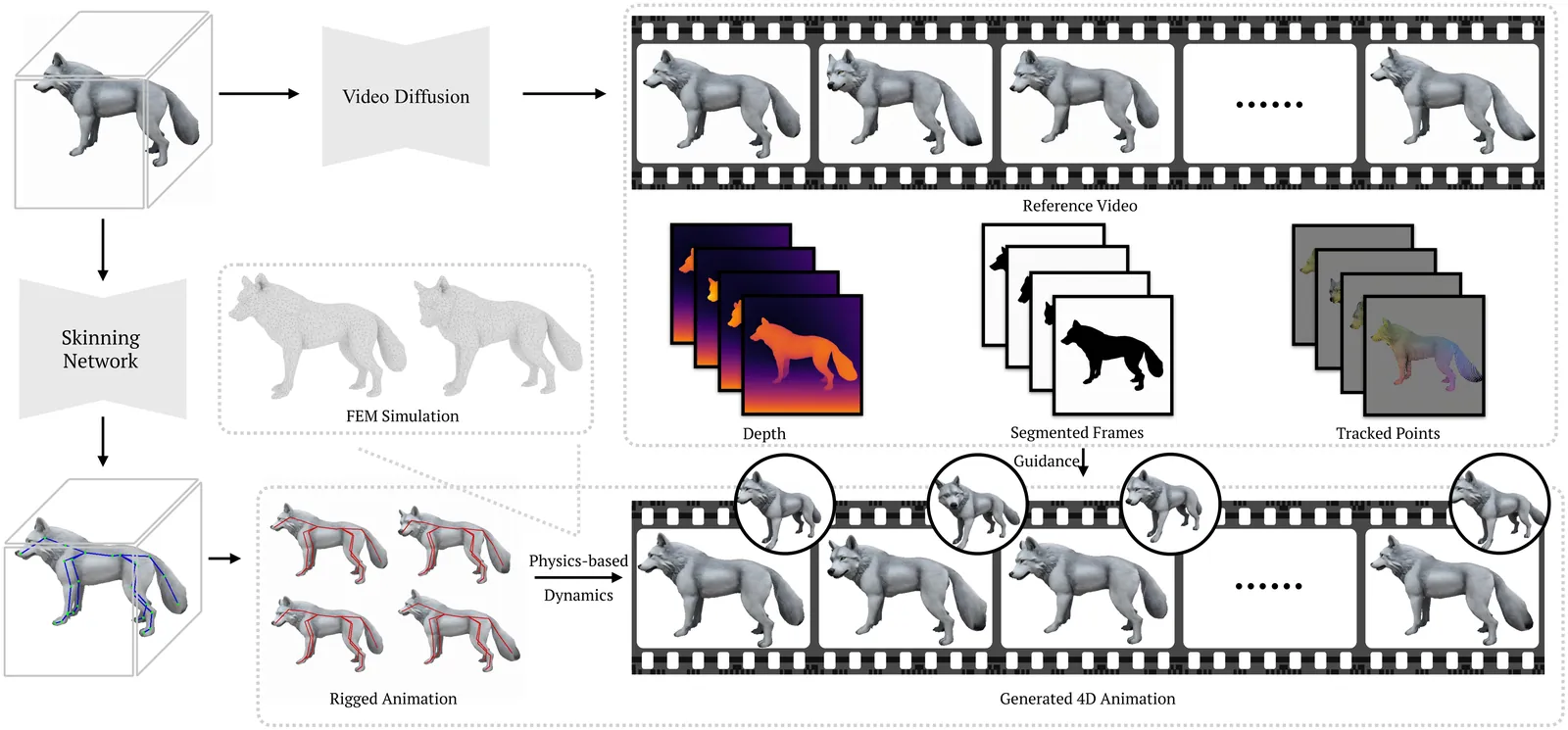
Creating realistic 3D animation remains a time-consuming and expertise-dependent process, requiring manual rigging, keyframing, and fine-tuning of complex motions. Meanwhile, video diffusion models have recently demonstrated remarkable motion imagination in 2D, generating dynamic and visually coherent motion from text or image prompts. However, their results lack explicit 3D structure and cannot be directly used for animation or simulation. We present AnimaMimic, a framework that animates static 3D meshes using motion priors learned from video diffusion models. Starting from an input mesh, AnimaMimic synthesizes a monocular animation video, automatically constructs a skeleton with skinning weights, and refines joint parameters through differentiable rendering and video-based supervision. To further enhance realism, we integrate a differentiable simulation module that refines mesh deformation through physically grounded soft-tissue dynamics. Our method bridges the creativity of video diffusion and the structural control of 3D rigged animation, producing physically plausible, temporally coherent, and artist-editable motion sequences that integrate seamlessly into standard animation pipelines. Our project page is at: https://xpandora.github.io/AnimaMimic/
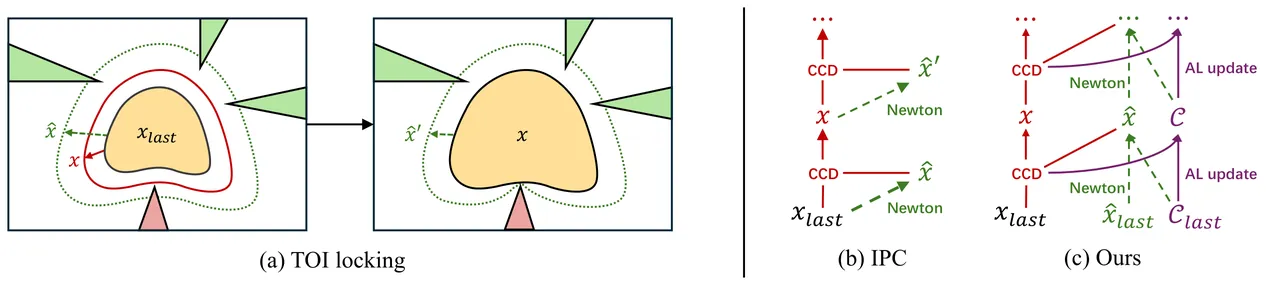
We introduce a barrier-free optimization framework for non-penetration elastodynamic simulation that matches the robustness of Incremental Potential Contact (IPC) while overcoming its two primary efficiency bottlenecks: (1) reliance on logarithmic barrier functions to enforce non-penetration constraints, which leads to ill-conditioned systems and significantly slows down the convergence of iterative linear solvers; and (2) the time-of-impact (TOI) locking issue, which restricts active-set exploration in collision-intensive scenes and requires a large number of Newton iterations. We propose a novel second-order constrained optimization framework featuring a custom augmented Lagrangian solver that avoids TOI locking by immediately incorporating all requisite contact pairs detected via CCD, enabling more efficient active-set exploration and leading to significantly fewer Newton iterations. By adaptively updating Lagrange multipliers rather than increasing penalty stiffness, our method prevents stagnation at zero TOI while maintaining a well-conditioned system. We further introduce a constraint filtering and decay mechanism to keep the active set compact and stable, along with a theoretical justification of our method's finite-step termination and first-order time integration accuracy under a cumulative TOI-based termination criterion. A comprehensive set of experiments demonstrates the efficiency, robustness, and accuracy of our method. With a GPU-optimized simulator design, our method achieves an up to 103x speedup over GIPC on challenging, contact-rich benchmarks - scenarios that were previously tractable only with barrier-based methods. Our code and data will be open-sourced.
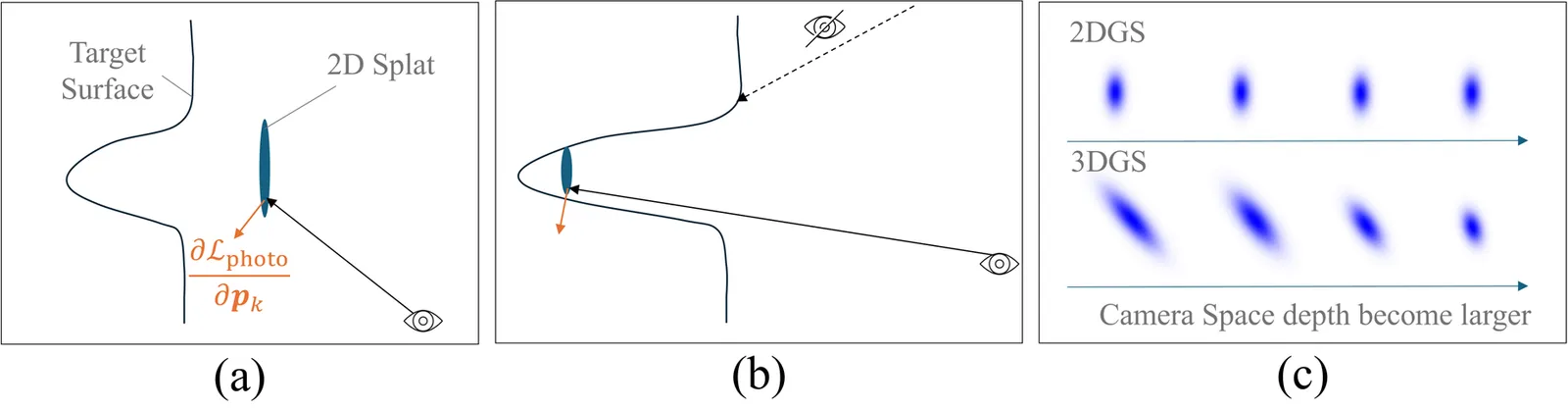
We propose DeMapGS, a structured Gaussian Splatting framework that jointly optimizes deformable surfaces and surface-attached 2D Gaussian splats. By anchoring splats to a deformable template mesh, our method overcomes topological inconsistencies and enhances editing flexibility, addressing limitations of prior Gaussian Splatting methods that treat points independently. The unified representation in our method supports extraction of high-fidelity diffuse, normal, and displacement maps, enabling the reconstructed mesh to inherit the photorealistic rendering quality of Gaussian Splatting. To support robust optimization, we introduce a gradient diffusion strategy that propagates supervision across the surface, along with an alternating 2D/3D rendering scheme to handle concave regions. Experiments demonstrate that DeMapGS achieves state-of-the-art mesh reconstruction quality and enables downstream applications for Gaussian splats such as editing and cross-object manipulation through a shared parametric surface.
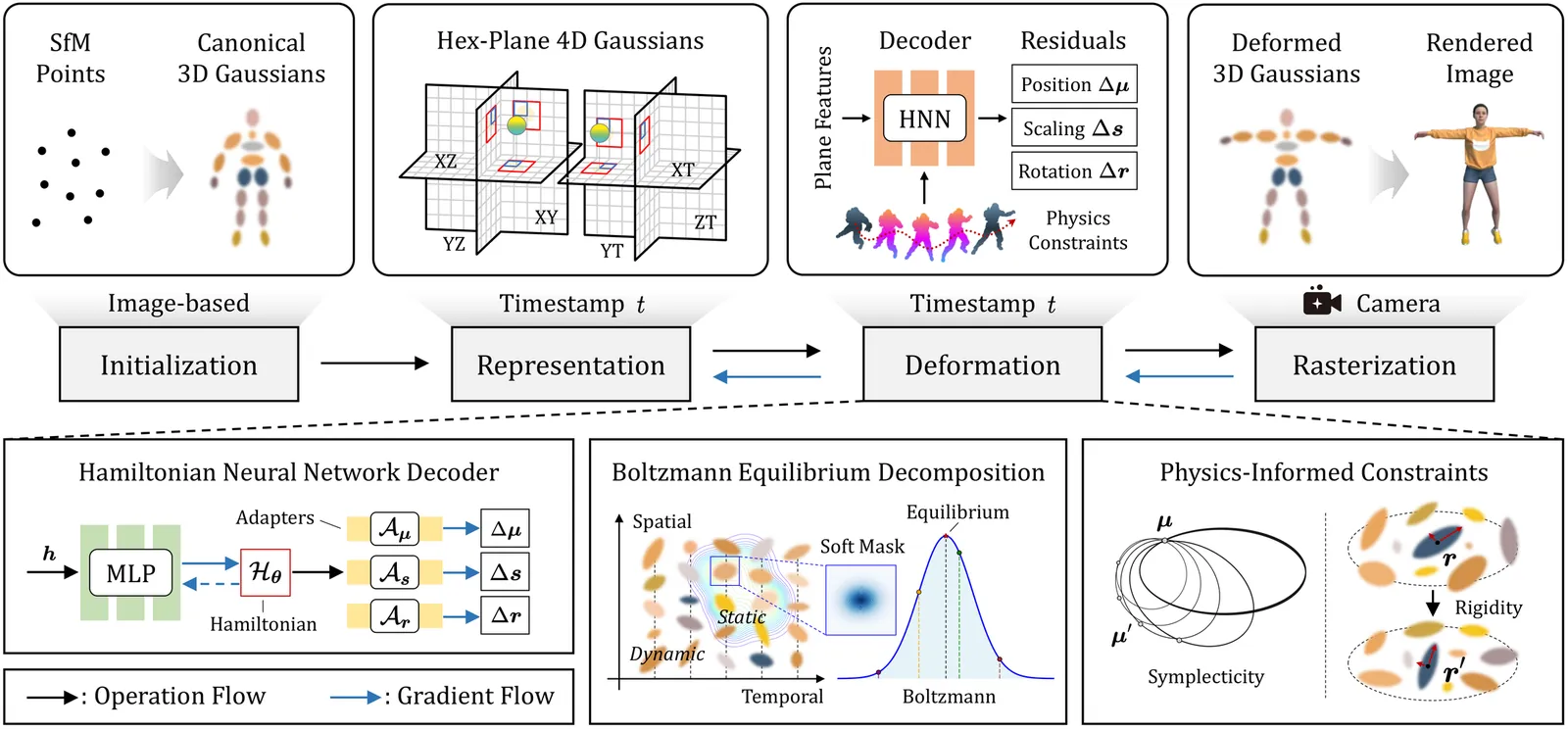
Representing and rendering dynamic scenes with complex motions remains challenging in computer vision and graphics. Recent dynamic view synthesis methods achieve high-quality rendering but often produce physically implausible motions. We introduce NeHaD, a neural deformation field for dynamic Gaussian Splatting governed by Hamiltonian mechanics. Our key observation is that existing methods using MLPs to predict deformation fields introduce inevitable biases, resulting in unnatural dynamics. By incorporating physics priors, we achieve robust and realistic dynamic scene rendering. Hamiltonian mechanics provides an ideal framework for modeling Gaussian deformation fields due to their shared phase-space structure, where primitives evolve along energy-conserving trajectories. We employ Hamiltonian neural networks to implicitly learn underlying physical laws governing deformation. Meanwhile, we introduce Boltzmann equilibrium decomposition, an energy-aware mechanism that adaptively separates static and dynamic Gaussians based on their spatial-temporal energy states for flexible rendering. To handle real-world dissipation, we employ second-order symplectic integration and local rigidity regularization as physics-informed constraints for robust dynamics modeling. Additionally, we extend NeHaD to adaptive streaming through scale-aware mipmapping and progressive optimization. Extensive experiments demonstrate that NeHaD achieves physically plausible results with a rendering quality-efficiency trade-off. To our knowledge, this is the first exploration leveraging Hamiltonian mechanics for neural Gaussian deformation, enabling physically realistic dynamic scene rendering with streaming capabilities.

We introduce a framework for converting 3D shapes into compact and editable assemblies of analytic primitives, directly addressing the persistent trade-off between reconstruction fidelity and parsimony. Our approach combines two key contributions: a novel primitive, termed SuperFrustum, and an iterative fiting algorithm, Residual Primitive Fitting (ResFit). SuperFrustum is an analytical primitive that is simultaneously (1) expressive, being able to model various common solids such as cylinders, spheres, cones & their tapered and bent forms, (2) editable, being compactly parameterized with 8 parameters, and (3) optimizable, with a sign distance field differentiable w.r.t. its parameters almost everywhere. ResFit is an unsupervised procedure that interleaves global shape analysis with local optimization, iteratively fitting primitives to the unexplained residual of a shape to discover a parsimonious yet accurate decompositions for each input shape. On diverse 3D benchmarks, our method achieves state-of-the-art results, improving IoU by over 9 points while using nearly half as many primitives as prior work. The resulting assemblies bridge the gap between dense 3D data and human-controllable design, producing high-fidelity and editable shape programs.
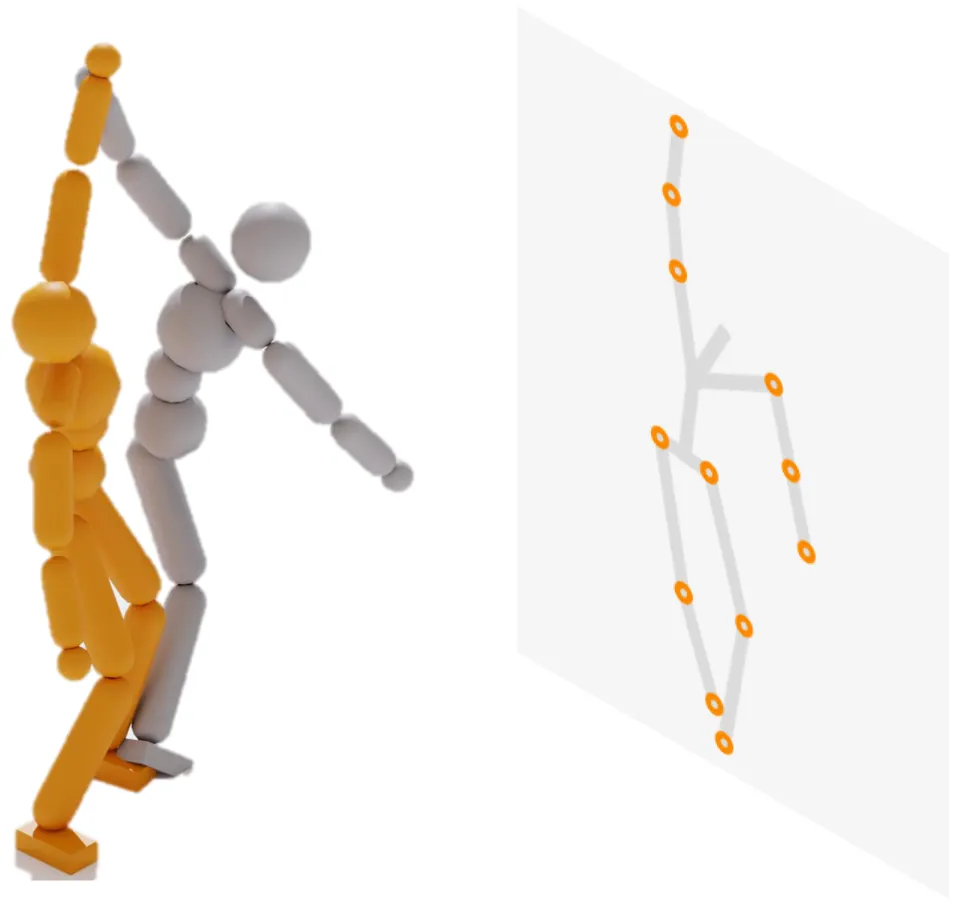
Video data is more cost-effective than motion capture data for learning 3D character motion controllers, yet synthesizing realistic and diverse behaviors directly from videos remains challenging. Previous approaches typically rely on off-the-shelf motion reconstruction techniques to obtain 3D trajectories for physics-based imitation. These reconstruction methods struggle with generalizability, as they either require 3D training data (potentially scarce) or fail to produce physically plausible poses, hindering their application to challenging scenarios like human-object interaction (HOI) or non-human characters. We tackle this challenge by introducing Mimic2DM, a novel motion imitation framework that learns the control policy directly and solely from widely available 2D keypoint trajectories extracted from videos. By minimizing the reprojection error, we train a general single-view 2D motion tracking policy capable of following arbitrary 2D reference motions in physics simulation, using only 2D motion data. The policy, when trained on diverse 2D motions captured from different or slightly different viewpoints, can further acquire 3D motion tracking capabilities by aggregating multiple views. Moreover, we develop a transformer-based autoregressive 2D motion generator and integrate it into a hierarchical control framework, where the generator produces high-quality 2D reference trajectories to guide the tracking policy. We show that the proposed approach is versatile and can effectively learn to synthesize physically plausible and diverse motions across a range of domains, including dancing, soccer dribbling, and animal movements, without any reliance on explicit 3D motion data. Project Website: https://jiann-li.github.io/mimic2dm/

Generating realistic human geometry animations remains a challenging task, as it requires modeling natural clothing dynamics with fine-grained geometric details under limited data. To address these challenges, we propose two novel designs. First, we propose a compact distribution-based latent representation that enables efficient and high-quality geometry generation. We improve upon previous work by establishing a more uniform mapping between SMPL and avatar geometries. Second, we introduce a generative animation model that fully exploits the diversity of limited motion data. We focus on short-term transitions while maintaining long-term consistency through an identity-conditioned design. These two designs formulate our method as a two-stage framework: the first stage learns a latent space, while the second learns to generate animations within this latent space. We conducted experiments on both our latent space and animation model. We demonstrate that our latent space produces high-fidelity human geometry surpassing previous methods ($90\%$ lower Chamfer Dist.). The animation model synthesizes diverse animations with detailed and natural dynamics ($2.2 \times$ higher user study score), achieving the best results across all evaluation metrics.
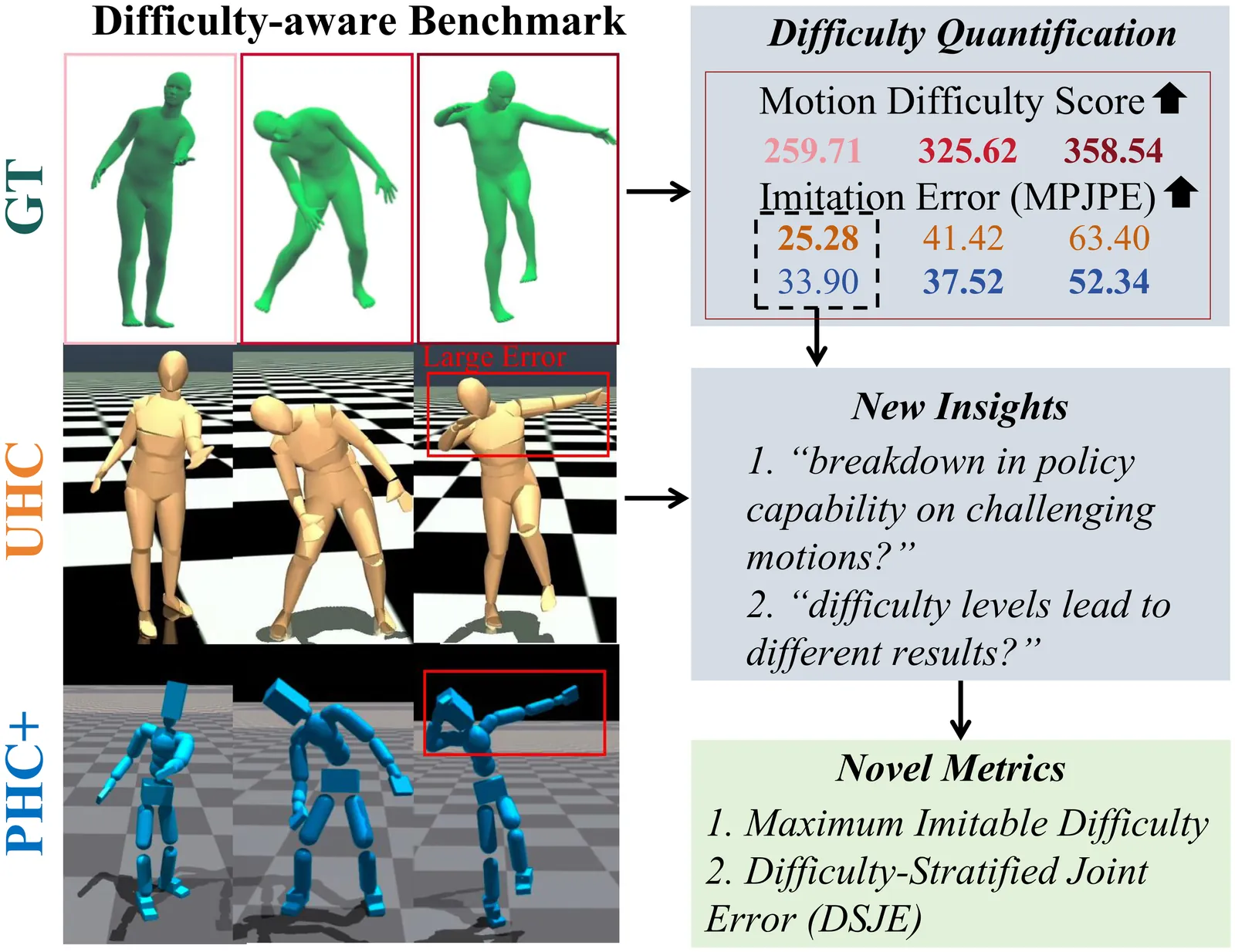
Physics-based motion imitation is central to humanoid control, yet current evaluation metrics (e.g., joint position error) only measure how well a policy imitates but not how difficult the motion itself is. This conflates policy performance with motion difficulty, obscuring whether failures stem from poor learning or inherently challenging motions. In this work, we address this gap with Motion Difficulty Score (MDS), a novel metric that defines and quantifies imitation difficulty independent of policy performance. Grounded in rigid-body dynamics, MDS interprets difficulty as the torque variation induced by small pose perturbations: larger torque-to-pose variation yields flatter reward landscapes and thus higher learning difficulty. MDS captures this through three properties of the perturbation-induced torque space: volume, variance, and temporal variability. We also use it to construct MD-AMASS, a difficulty-aware repartitioning of the AMASS dataset. Empirically, we rigorously validate MDS by demonstrating its explanatory power on the performance of state-of-the-art motion imitation policies. We further demonstrate the utility of MDS through two new MDS-based metrics: Maximum Imitable Difficulty (MID) and Difficulty-Stratified Joint Error (DSJE), providing fresh insights into imitation learning.
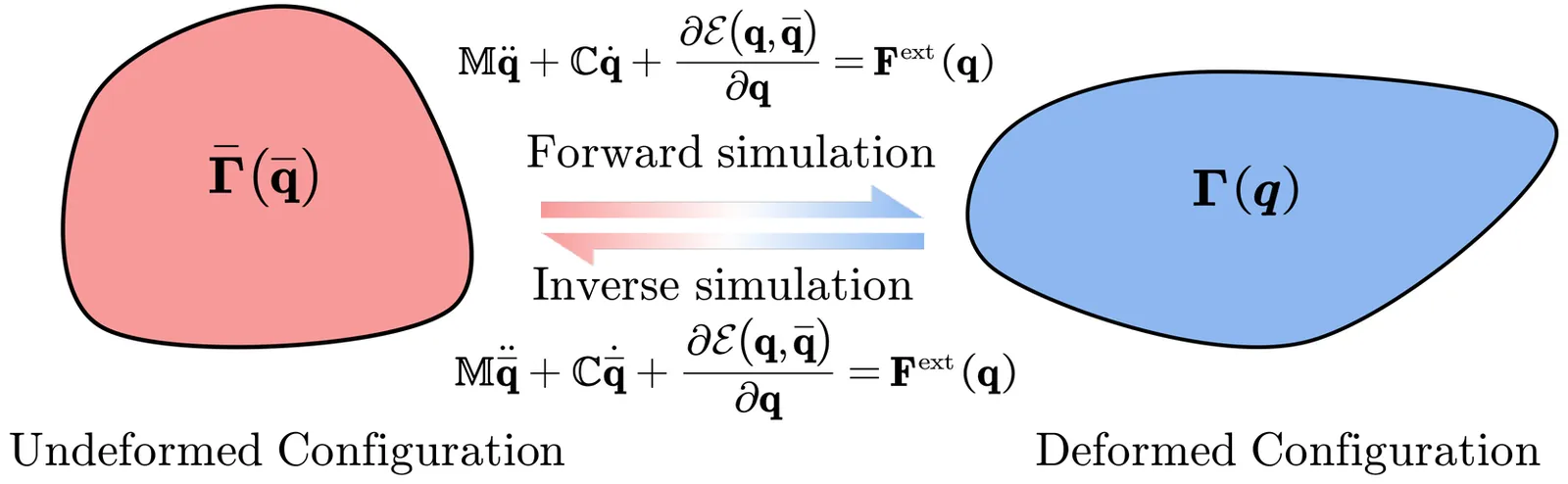
Inverse design of slender elastic structures underlies a wide range of applications in computer graphics, flexible electronics, biomedical devices, and soft robotics. Traditional optimization-based approaches, however, are often orders of magnitude slower than forward dynamic simulations and typically impose restrictive boundary conditions. In this work, we present an inverse discrete elastic rods (inverse-DER) method that enables efficient and accurate inverse design under general loading and boundary conditions. By reformulating the inverse problem as a static equilibrium in the reference configuration, our method attains computational efficiency comparable to forward simulations while preserving high fidelity. This framework allows rapid determination of undeformed geometries for elastic fabrication structures that naturally deform into desired target shapes upon actuation or loading. We validate the approach through both physical prototypes and forward simulations, demonstrating its accuracy, robustness, and potential for real-world design applications.