Multimedia
arXiv:cs.MM
Covers all aspects of multimedia information systems.
Covers all aspects of multimedia information systems.
Subjective video quality assessment is crucial for optimizing streaming and compression, yet traditional protocols face limitations in capturing nuanced perceptual differences and ensuring reliable user input. We propose an integrated framework that enhances rater training, enforces attention through real-time scoring, and streamlines pairwise comparisons to recover quality scores with fewer comparisons. Participants first undergo an automated training quiz to learn key video quality indicators (e.g., compression artifacts) and verify their readiness. During the test, a real-time attention scoring mechanism, using "golden" video pairs, monitors and reinforces rater focus by applying penalties for lapses. An efficient chain-based pairwise comparison procedure is then employed, yielding quality scores in Just-Objectionable-Differences (JOD) units. Experiments comparing three groups (no training, training without feedback, and training with feedback) with 80 participants demonstrate that training-quiz significantly improves data quality in terms of golden unit accuracy and reduces tie rate, while real-time feedback further improves data quality and yields the most monotonic quality ratings. The new training, quiz, testing with feedback, 3-phase approach can significantly reduce the non-monotonic cases on the high quality part of the R-Q curve where normal viewer typically prefer the slightly compressed less-grainy content and help train a better objective video quality metric.
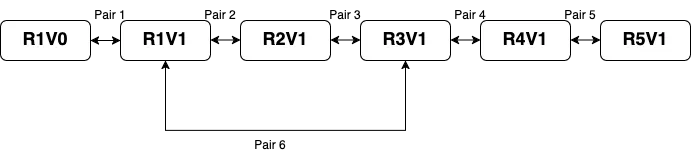
Adaptive streaming of 360-degree video relies on viewport prediction to allocate bandwidth efficiently. Current approaches predominantly use visual saliency or historical gaze patterns, neglecting the role of spatial audio in guiding user attention. This paper presents a self-learning framework for detecting "surprising" auditory events -- moments that deviate from learned temporal expectations -- and demonstrates their utility for viewport prediction. The proposed architecture combines $SE(3)$-equivariant graph neural networks with recurrent temporal modeling, trained via a dual self-supervised objective. A key feature is the natural modeling of temporal attention decay: surprise is high at event onset but diminishes as the listener adapts. Experiments on the AVTrack360 dataset show that integrating audio surprise with visual cues reduces bitrate waste by up to 18% compared to visual-only methods.
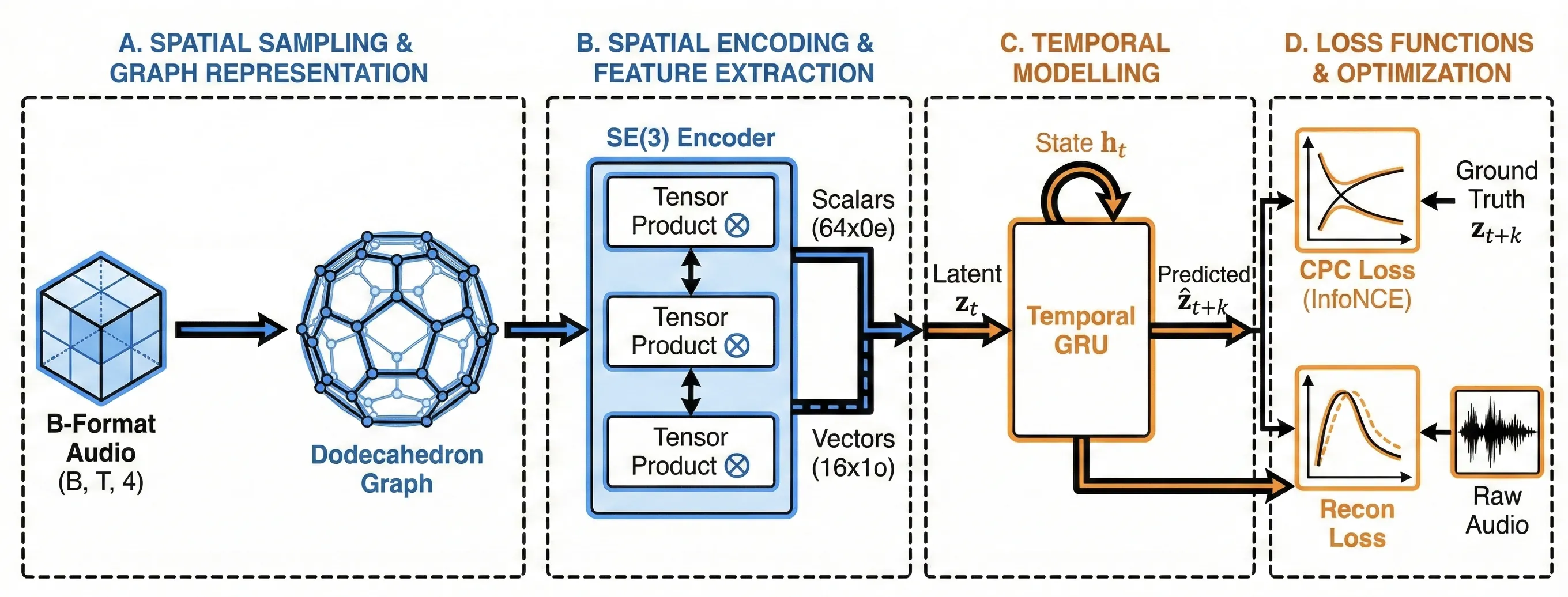
Motion capture remains costly and complex to deploy, limiting use outside specialized laboratories. We present Mesquite, an open-source, low-cost inertial motion-capture system that combines a body-worn network of 15 IMU sensor nodes with a hip-worn Android smartphone for position tracking. A low-power wireless link streams quaternion orientations to a central USB dongle and a browser-based application for real-time visualization and recording. Built on modern web technologies -- WebGL for rendering, WebXR for SLAM, WebSerial and WebSockets for device and network I/O, and Progressive Web Apps for packaging -- the system runs cross-platform entirely in the browser. In benchmarks against a commercial optical system, Mesquite achieves mean joint-angle error of 2-5 degrees while operating at approximately 5% of the cost. The system sustains 30 frames per second with end-to-end latency under 15ms and a packet delivery rate of at least 99.7% in standard indoor environments. By leveraging IoT principles, edge processing, and a web-native stack, Mesquite lowers the barrier to motion capture for applications in entertainment, biomechanics, healthcare monitoring, human-computer interaction, and virtual reality. We release hardware designs, firmware, and software under an open-source license (GNU GPL).
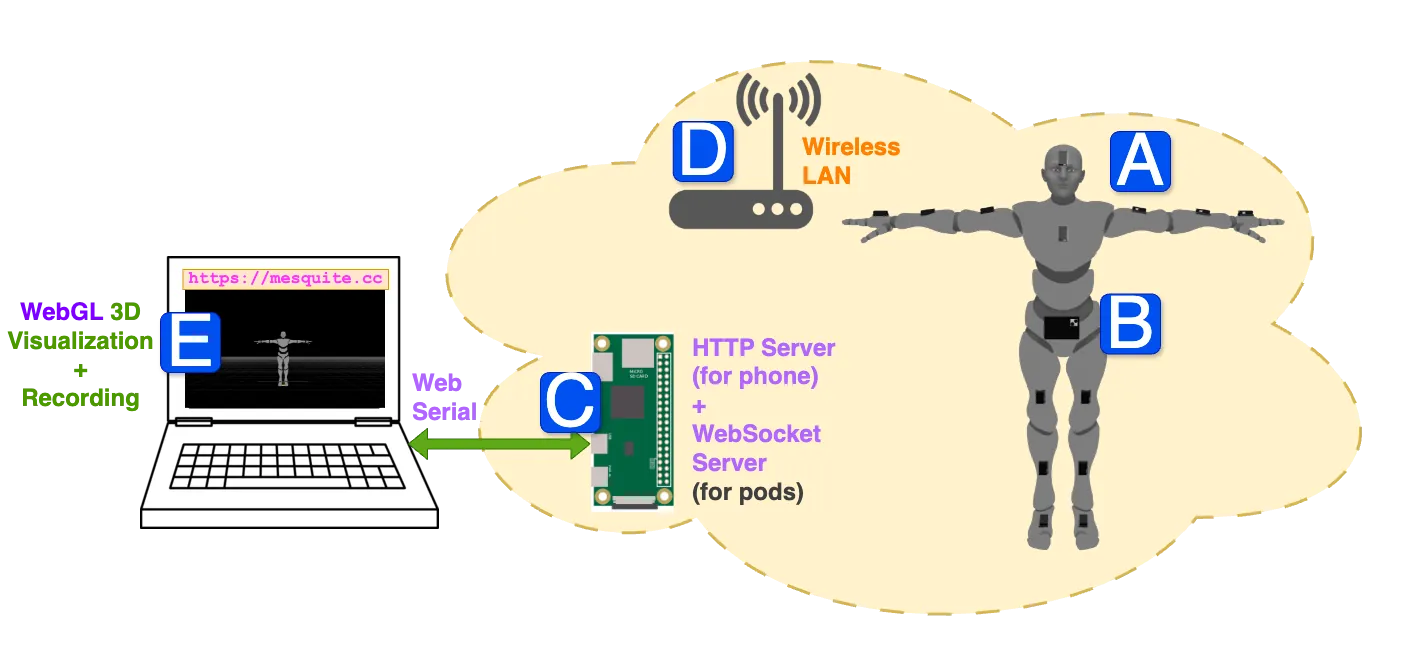
Student engagement is a critical factor influencing academic success and learning outcomes. Accurately predicting student engagement is essential for optimizing teaching strategies and providing personalized interventions. However, most approaches focus on single-dimensional feature analysis and assessing engagement based on individual student factors. In this work, we propose a dual-stream multi-feature fusion model based on hypergraph convolutional networks (DS-HGCN), incorporating social contagion of student engagement. DS-HGCN enables accurate prediction of student engagement states by modeling multi-dimensional features and their propagation mechanisms between students. The framework constructs a hypergraph structure to encode engagement contagion among students and captures the emotional and behavioral differences and commonalities by multi-frequency signals. Furthermore, we introduce a hypergraph attention mechanism to dynamically weigh the influence of each student, accounting for individual differences in the propagation process. Extensive experiments on public benchmark datasets demonstrate that our proposed method achieves superior performance and significantly outperforms existing state-of-the-art approaches.
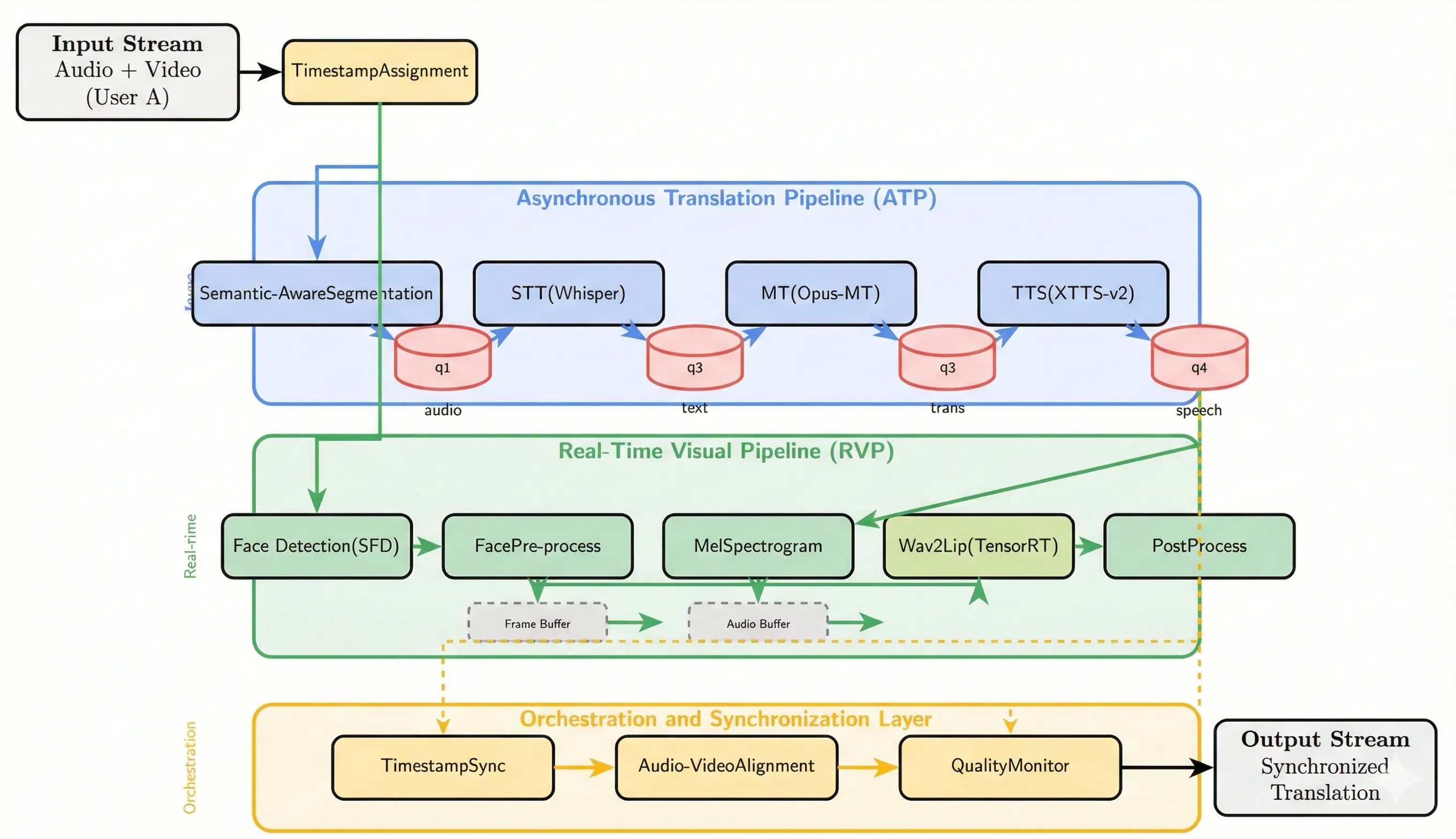
This paper introduces a parallel and asynchronous Transformer framework designed for efficient and accurate multilingual lip synchronization in real-time video conferencing systems. The proposed architecture integrates translation, speech processing, and lip-synchronization modules within a pipeline-parallel design that enables concurrent module execution through message-queue-based decoupling, reducing end-to-end latency by up to 3.1 times compared to sequential approaches. To enhance computational efficiency and throughput, the inference workflow of each module is optimized through low-level graph compilation, mixed-precision quantization, and hardware-accelerated kernel fusion. These optimizations provide substantial gains in efficiency while preserving model accuracy and visual quality. In addition, a context-adaptive silence-detection component segments the input speech stream at semantically coherent boundaries, improving translation consistency and temporal alignment across languages. Experimental results demonstrate that the proposed parallel architecture outperforms conventional sequential pipelines in processing speed, synchronization stability, and resource utilization. The modular, message-oriented design makes this work applicable to resource-constrained IoT communication scenarios including telemedicine, multilingual kiosks, and remote assistance systems. Overall, this work advances the development of low-latency, resource-efficient multimodal communication frameworks for next-generation AIoT systems.
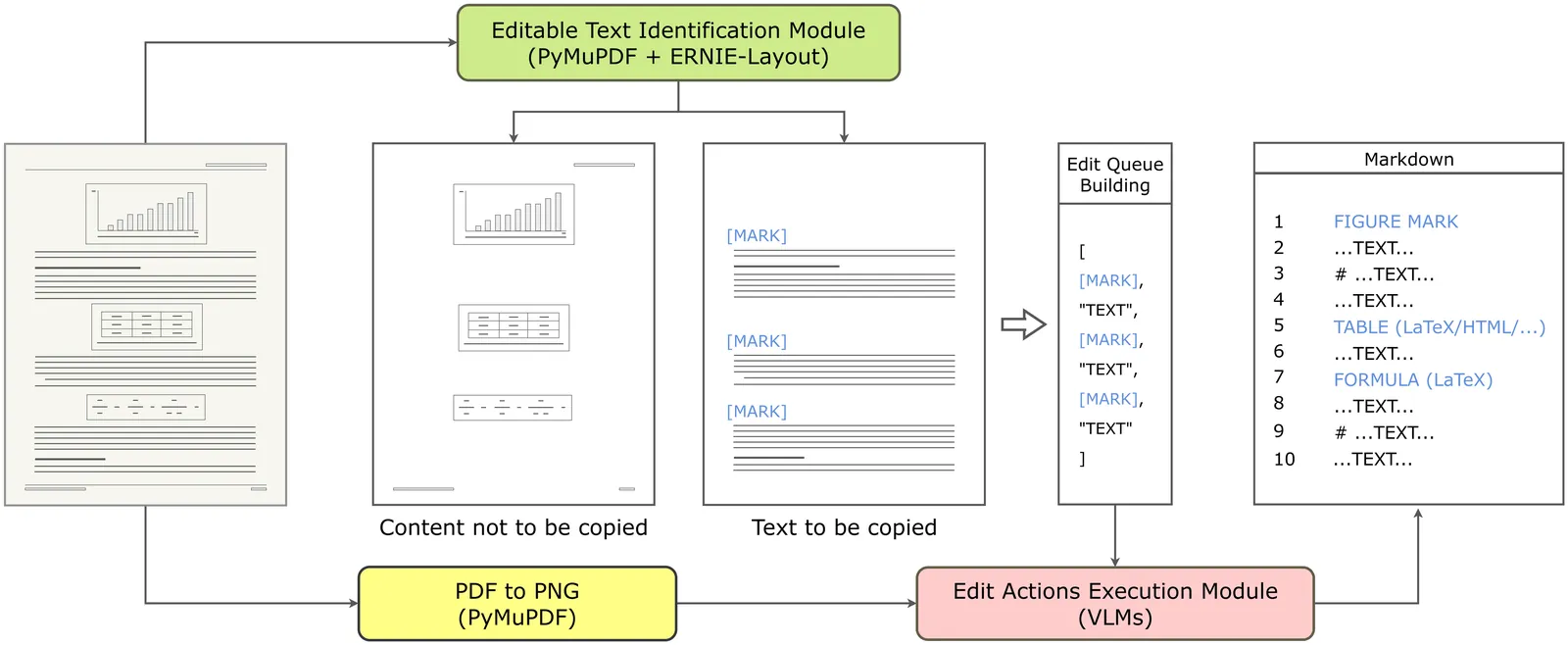
Academic documents stored in PDF format can be transformed into plain text structured markup languages to enhance accessibility and enable scalable digital library workflows. Markup languages allow for easier updates and customization, making academic content more adaptable and accessible to diverse usage, such as linguistic corpus compilation. Such documents, typically delivered in PDF format, contain complex elements including mathematical formulas, figures, headers, and tables, as well as densely layouted text. Existing end-to-end decoder transformer models can transform screenshots of documents into markup language. However, these models exhibit significant inefficiencies; their token-by-token decoding from scratch wastes a lot of inference steps in regenerating dense text that could be directly copied from PDF files. To solve this problem, we introduce EditTrans, a hybrid editing-generation model whose features allow identifying a queue of to-be-edited text from a PDF before starting to generate markup language. EditTrans contains a lightweight classifier fine-tuned from a Document Layout Analysis model on 162,127 pages of documents from arXiv. In our evaluations, EditTrans reduced the transformation latency up to 44.5% compared to end-to-end decoder transformer models, while maintaining transformation quality. Our code and reproducible dataset production scripts are open-sourced.
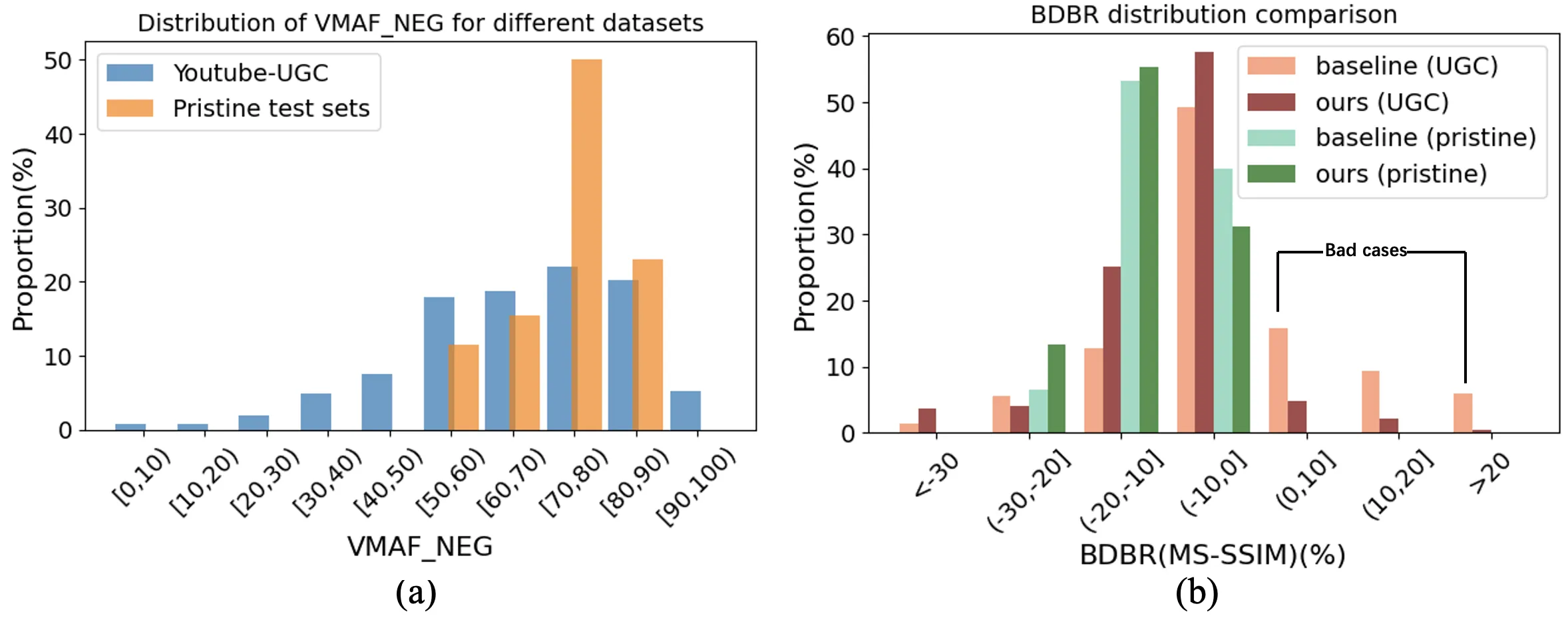
In recent years, user generated content (UGC) has become the dominant force in internet traffic. However, UGC videos exhibit a higher degree of variability and diverse characteristics compared to traditional encoding test videos. This variance challenges the effectiveness of data-driven machine learning algorithms for optimizing encoding in the broader context of UGC scenarios. To address this issue, we propose a Tri-Dynamic Preprocessing framework for UGC. Firstly, we employ an adaptive factor to regulate preprocessing intensity. Secondly, an adaptive quantization level is employed to fine-tune the codec simulator. Thirdly, we utilize an adaptive lambda tradeoff to adjust the rate-distortion loss function. Experimental results on large-scale test sets demonstrate that our method attains exceptional performance.
Gamification is widely used in digital learning. However, most systems neglect age-related differences. This paper investigates how gamification can be designed in an age-aware way to address learners' diverse motivational and cognitive needs. Based on a targeted literature review, we present a mapping of age groups, mechanics, and effects. Furthermore, we derive five design principles for age-specific gamification and identify three technical patterns for implementation in multimedia learning environments. The results indicate that gamification is not universally effective, but rather requires a differentiated design to support engagement and inclusivity across the lifespan.
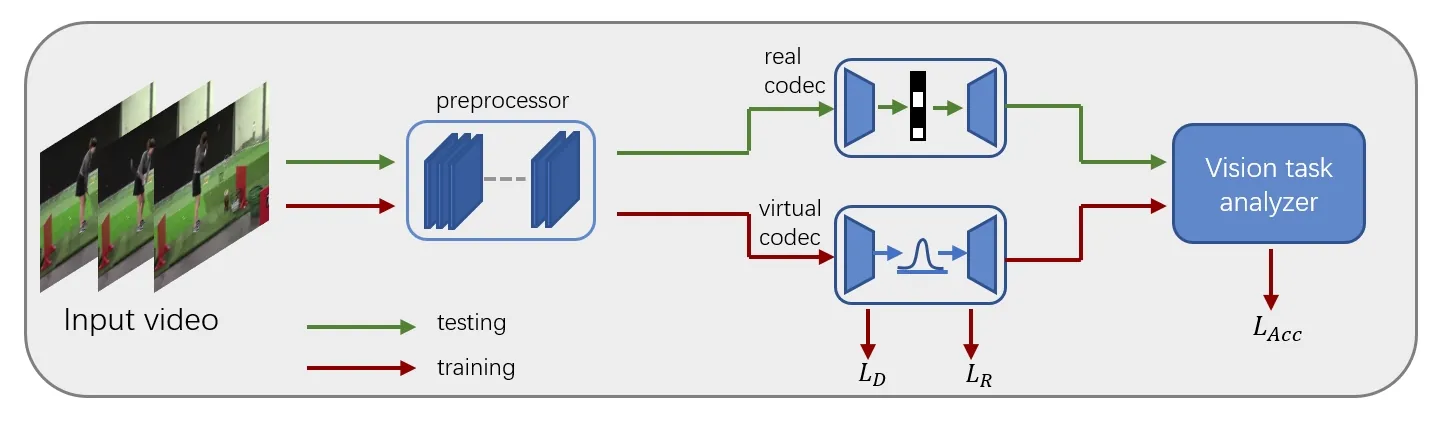
There has been a growing trend in compressing and transmitting videos from terminals for machine vision tasks. Nevertheless, most video coding optimization method focus on minimizing distortion according to human perceptual metrics, overlooking the heightened demands posed by machine vision systems. In this paper, we propose a video preprocessing framework tailored for machine vision tasks to address this challenge. The proposed method incorporates a neural preprocessor which retaining crucial information for subsequent tasks, resulting in the boosting of rate-accuracy performance. We further introduce a differentiable virtual codec to provide constraints on rate and distortion during the training stage. We directly apply widely used standard codecs for testing. Therefore, our solution can be easily applied to real-world scenarios. We conducted extensive experiments evaluating our compression method on two typical downstream tasks with various backbone networks. The experimental results indicate that our approach can save over 15% of bitrate compared to using only the standard codec anchor version.
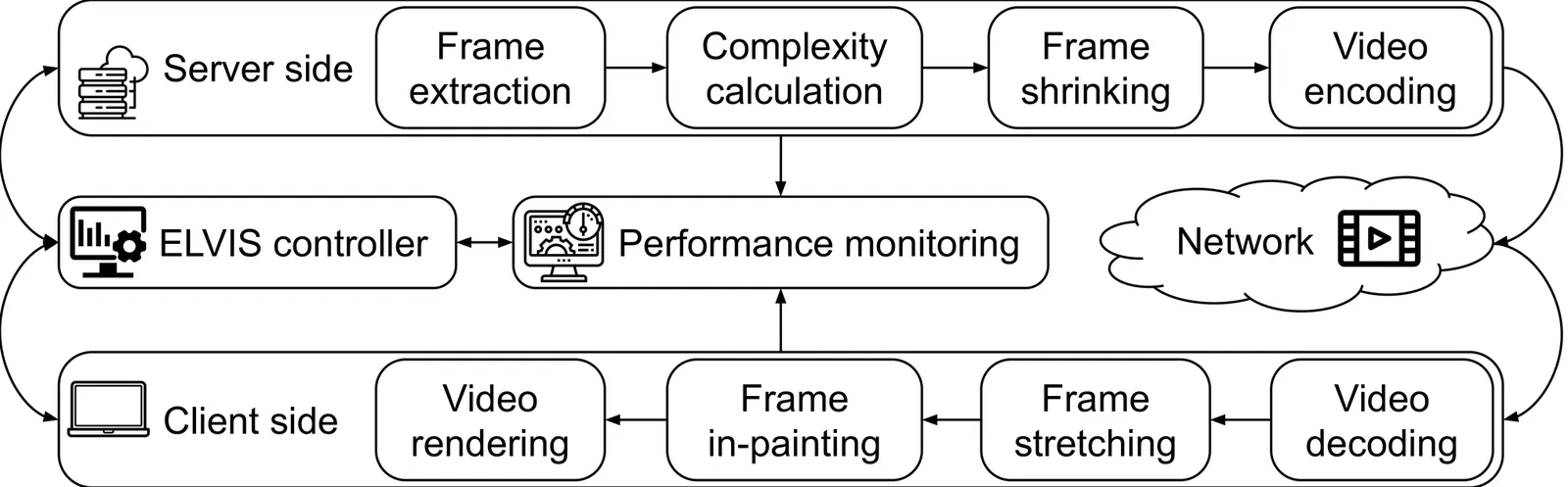
The primary challenge of video streaming is to balance high video quality with smooth playback. Traditional codecs are well tuned for this trade-off, yet their inability to use context means they must encode the entire video data and transmit it to the client. This paper introduces ELVIS (End-to-end Learning-based VIdeo Streaming Enhancement Pipeline), an end-to-end architecture that combines server-side encoding optimizations with client-side generative in-painting to remove and reconstruct redundant video data. Its modular design allows ELVIS to integrate different codecs, inpainting models, and quality metrics, making it adaptable to future innovations. Our results show that current technologies achieve improvements of up to 11 VMAF points over baseline benchmarks, though challenges remain for real-time applications due to computational demands. ELVIS represents a foundational step toward incorporating generative AI into video streaming pipelines, enabling higher quality experiences without increased bandwidth requirements.
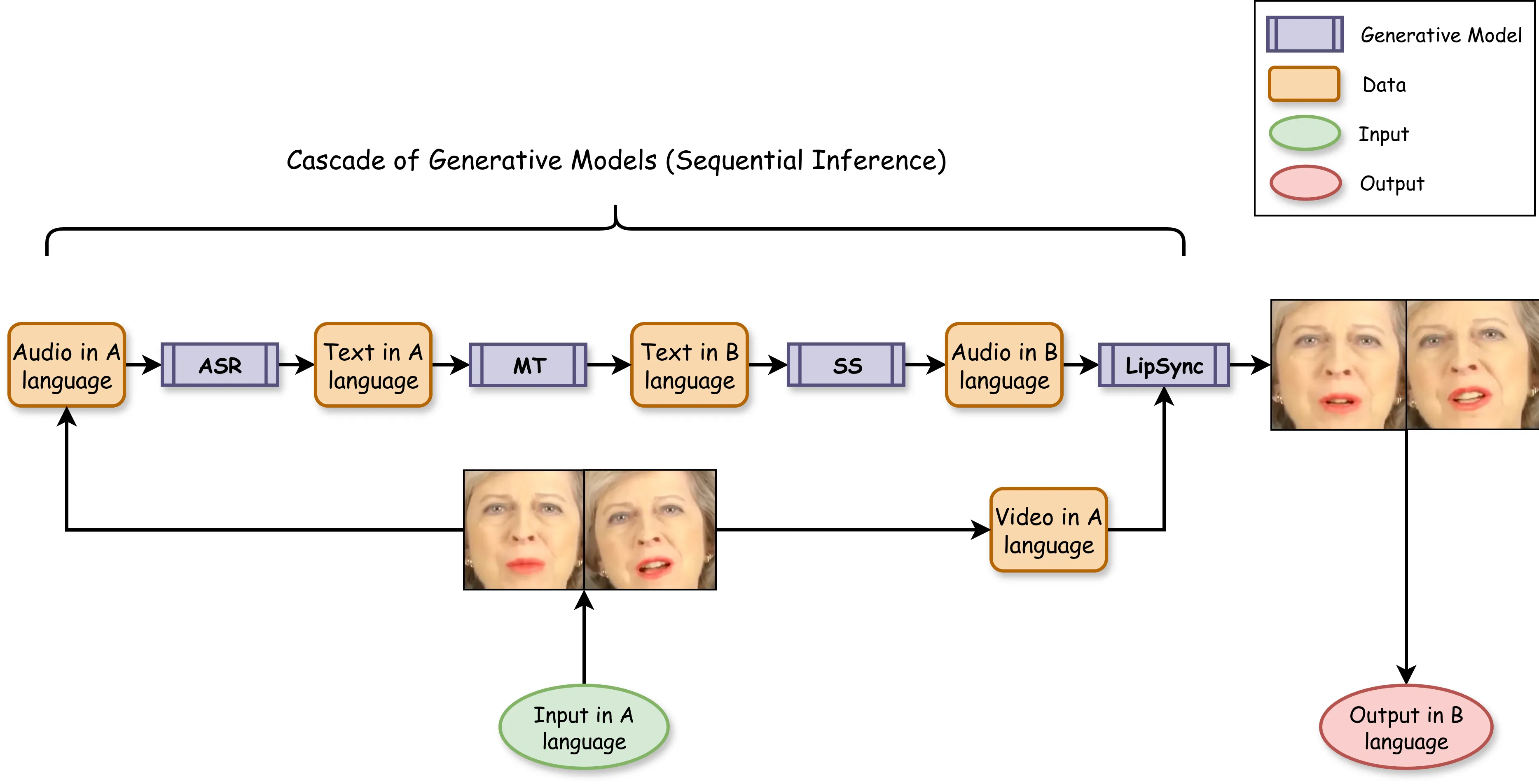
The real-time deployment of cascaded generative AI pipelines for applications like video translation is constrained by significant system-level challenges. These include the cumulative latency of sequential model inference and the quadratic ($\mathcal{O}(N^2)$) computational complexity that renders multi-user video conferencing applications unscalable. This paper proposes and evaluates a practical system-level framework designed to mitigate these critical bottlenecks. The proposed architecture incorporates a turn-taking mechanism to reduce computational complexity from quadratic to linear in multi-user scenarios, and a segmented processing protocol to manage inference latency for a perceptually real-time experience. We implement a proof-of-concept pipeline and conduct a rigorous performance analysis across a multi-tiered hardware setup, including commodity (NVIDIA RTX 4060), cloud (NVIDIA T4), and enterprise (NVIDIA A100) GPUs. Our objective evaluation demonstrates that the system achieves real-time throughput ($τ< 1.0$) on modern hardware. A subjective user study further validates the approach, showing that a predictable, initial processing delay is highly acceptable to users in exchange for a smooth, uninterrupted playback experience. The work presents a validated, end-to-end system design that offers a practical roadmap for deploying scalable, real-time generative AI applications in multilingual communication platforms.
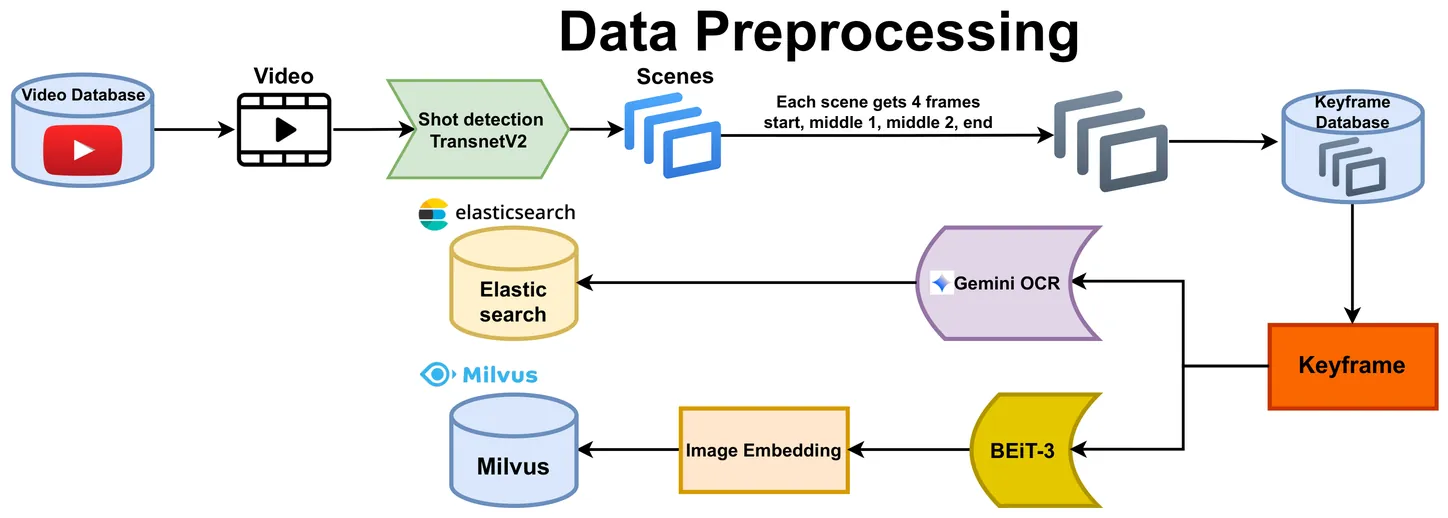
The growing volume of video data and the introduction of complex retrieval challenges, such as the Temporal Retrieval and Alignment of Key Events (TRAKE) task at the Ho Chi Minh City AI Challenge 2025, expose critical limitations in existing systems. Many methodologies lack scalable, holistic architectures and rely on "frozen" embedding models that fail on out-of-knowledge (OOK) or real-world queries. This paper introduces the comprehensive video retrieval framework developed by team AIO\_Owlgorithms to address these gaps. Our system features an architecture integrating TransNetV2 for scene segmentation, BEiT-3 for visual embeddings in Milvus, and Gemini OCR for metadata in Elasticsearch. We propose two components: (1) \textbf{QUEST} (Query Understanding and External Search for Out-of-Knowledge Tasks), a two-branch framework that leverages a Large Language Model (LLM) for query rewriting and an external image search pathway to resolve OOK queries; and (2) \textbf{DANTE} (Dynamic Alignment of Narrative Temporal Events), a dynamic programming algorithm that efficiently solves the temporally-incoherent TRAKE task. These contributions form a robust and intelligent system that significantly advances the state-of-the-art in handling complex, real-world video search queries.

Understanding videos inherently requires reasoning over both visual and auditory information. To properly evaluate Omni-Large Language Models (Omni-LLMs), which are capable of processing multi-modal information including vision and audio, an effective benchmark must comprehensively cover three key aspects: (1) multi-modal dependency (i.e., questions that cannot be answered using vision or audio alone), (2) diverse audio information types (e.g., speech, sound events), and (3) varying scene spans. However, existing datasets fall short in one or more of these dimensions, limiting strict and comprehensive evaluation. To address this gap, we introduce JointAVBench, a novel benchmark with strict audio-video correlation, spanning five cognitive dimensions, four audio information types (speech, sound events, music, vocal traits), and three scene spans (single-, cross-, and full-scene). Given the high cost of manual annotation, we propose an automated pipeline that leverages state-of-the-art vision-LLMs, audio-LLMs, and general-purpose LLMs to synthesize questions and answers that strictly require joint audio-visual understanding. We evaluate leading vision-only, audio-only, and Omni-LLMs on our dataset. Results show that even the best-performing Omni-LLM achieves an average accuracy of only 62.6\%, outperforming uni-modal baselines but revealing substantial room for improvement, especially in cross-scene reasoning.

Music-to-Video (M2V) generation for full-length songs faces significant challenges. Existing methods produce short, disjointed clips, failing to align visuals with musical structure, beats, or lyrics, and lack temporal consistency. We propose AutoMV, a multi-agent system that generates full music videos (MVs) directly from a song. AutoMV first applies music processing tools to extract musical attributes, such as structure, vocal tracks, and time-aligned lyrics, and constructs these features as contextual inputs for following agents. The screenwriter Agent and director Agent then use this information to design short script, define character profiles in a shared external bank, and specify camera instructions. Subsequently, these agents call the image generator for keyframes and different video generators for "story" or "singer" scenes. A Verifier Agent evaluates their output, enabling multi-agent collaboration to produce a coherent longform MV. To evaluate M2V generation, we further propose a benchmark with four high-level categories (Music Content, Technical, Post-production, Art) and twelve ine-grained criteria. This benchmark was applied to compare commercial products, AutoMV, and human-directed MVs with expert human raters: AutoMV outperforms current baselines significantly across all four categories, narrowing the gap to professional MVs. Finally, we investigate using large multimodal models as automatic MV judges; while promising, they still lag behind human expert, highlighting room for future work.

In recommendation-driven online media, creators increasingly suffer from semantic mutation, where malicious secondary edits preserve visual fidelity while altering the intended meaning. Detecting these mutations requires modeling a creator's unique semantic manifold. However, training robust detector models for individual creators is challenged by data scarcity, as a distinct blogger may typically have fewer than 50 representative samples available for training. We propose quantum-enhanced blogger anomaly recognition (Q-BAR), a hybrid quantum-classical framework that leverages the high expressivity and parameter efficiency of variational quantum circuits to detect semantic anomalies in low-data regimes. Unlike classical deep anomaly detectors that often struggle to generalize from sparse data, our method employs a parameter-efficient quantum anomaly detection strategy to map multimodal features into a Hilbert space hypersphere. On a curated dataset of 100 creators, our quantum-enhanced approach achieves robust detection performance with significantly fewer trainable parameters compared to classical baselines. By utilizing only hundreds of quantum parameters, the model effectively mitigates overfitting, demonstrating the potential of quantum machine learning for personalized media forensics.
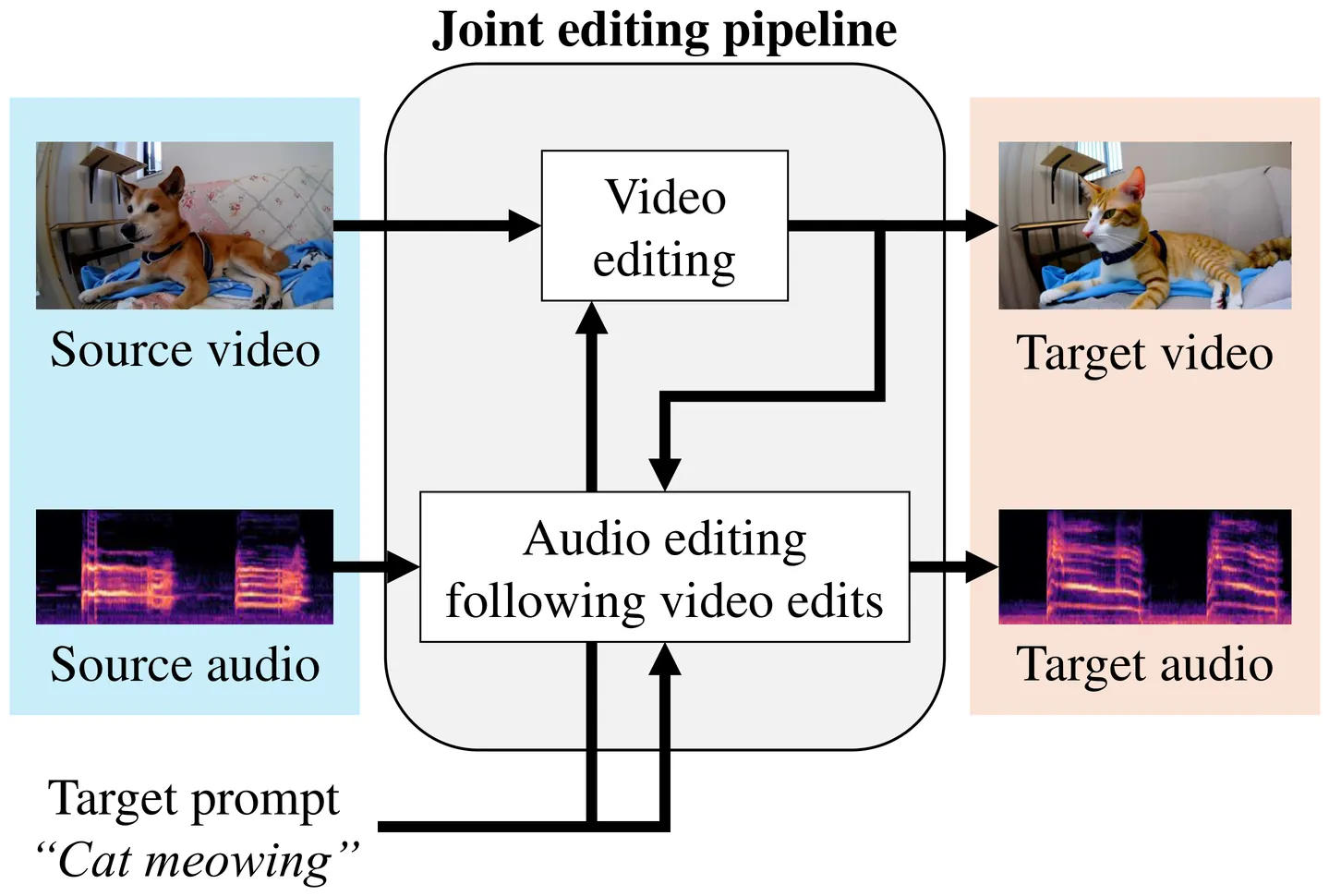
We introduce a novel pipeline for joint audio-visual editing that enhances the coherence between edited video and its accompanying audio. Our approach first applies state-of-the-art video editing techniques to produce the target video, then performs audio editing to align with the visual changes. To achieve this, we present a new video-to-audio generation model that conditions on the source audio, target video, and a text prompt. We extend the model architecture to incorporate conditional audio input and propose a data augmentation strategy that improves training efficiency. Furthermore, our model dynamically adjusts the influence of the source audio based on the complexity of the edits, preserving the original audio structure where possible. Experimental results demonstrate that our method outperforms existing approaches in maintaining audio-visual alignment and content integrity.

Multimodal Emotion Recognition in Conversation (MERC) aims to predict speakers' emotions by integrating textual, acoustic, and visual cues. Existing approaches either struggle to capture complex cross-modal interactions or experience gradient conflicts and unstable training when using deeper architectures. To address these issues, we propose Cross-Space Synergy (CSS), which couples a representation component with an optimization component. Synergistic Polynomial Fusion (SPF) serves the representation role, leveraging low-rank tensor factorization to efficiently capture high-order cross-modal interactions. Pareto Gradient Modulator (PGM) serves the optimization role, steering updates along Pareto-optimal directions across competing objectives to alleviate gradient conflicts and improve stability. Experiments show that CSS outperforms existing representative methods on IEMOCAP and MELD in both accuracy and training stability, demonstrating its effectiveness in complex multimodal scenarios.
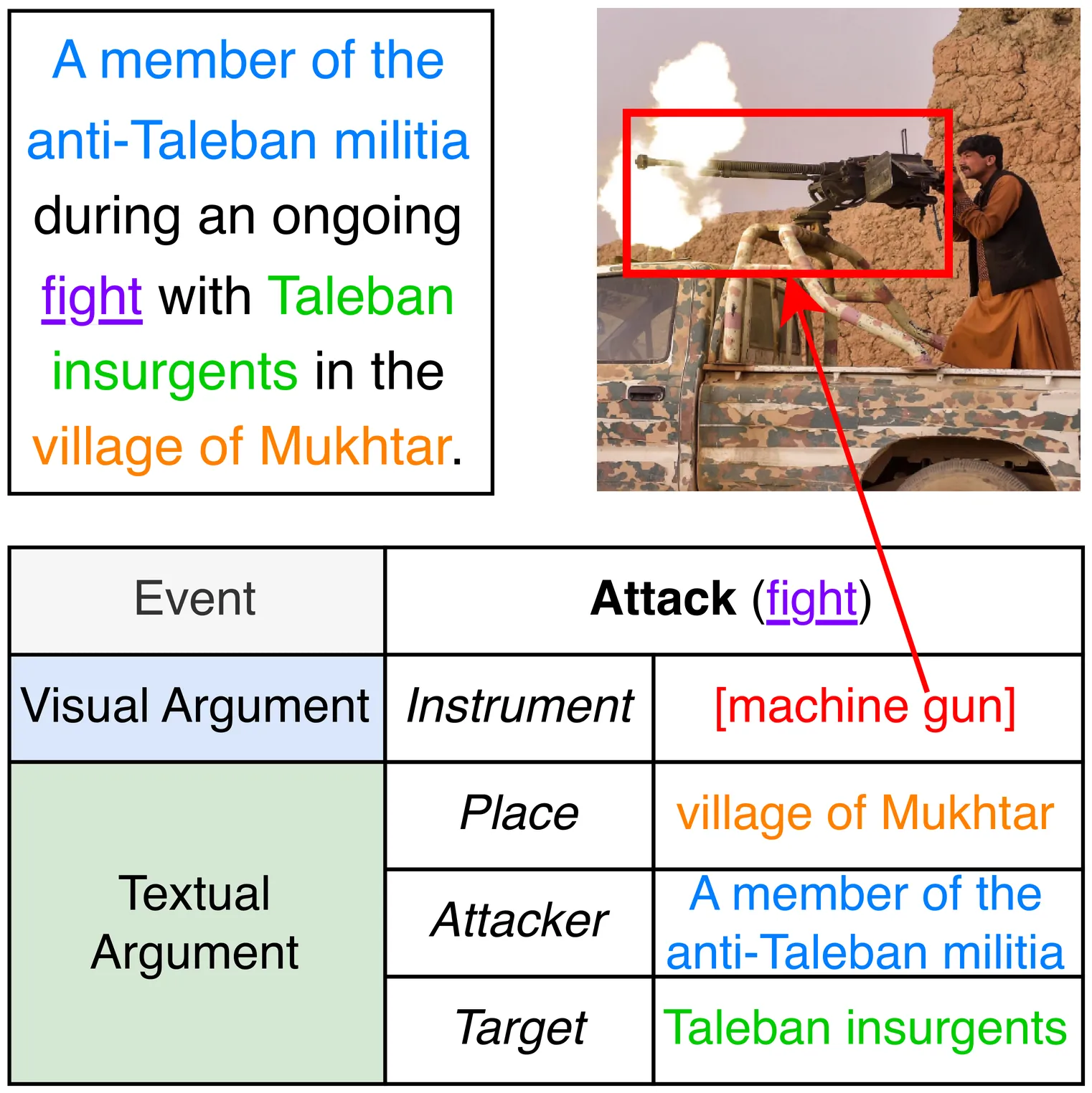
Multimedia Event Extraction (MEE) has become an important task in information extraction research as news today increasingly prefers to contain multimedia content. Current MEE works mainly face two challenges: (1) Inadequate extraction framework modeling for handling complex and flexible multimedia event structure; (2) The absence of multimodal-aligned training data for effective knowledge transfer to MEE task. In this work, we propose a Stepwise Schema-Guided Prompting Framework (SSGPF) using Multimodal Large Language Model (MLLM) as backbone for adaptive structure capturing to solve MEE task. At the initial step of SSGPF, we design Event Type Schema Guided Prompting (ETSGP) for event detection, then we devise Argument Role Schema Guided Prompting (ARSGP) that contains multi-step prompts with text-bridged grounding technique for argument extraction. We construct a weakly-aligned multimodal event labeled dataset based on existing unimodal event annotations, then conduct parameter efficient instruction tuning with LoRA on LLaVA-v1.5-7B under SSGPF. Experiments on the M2E2 benchmark demonstrate that SSGPF significantly outperforms current SOTA baselines by 5.8 percent F1 on event detection and 8.4 percent F1 on argument extraction.
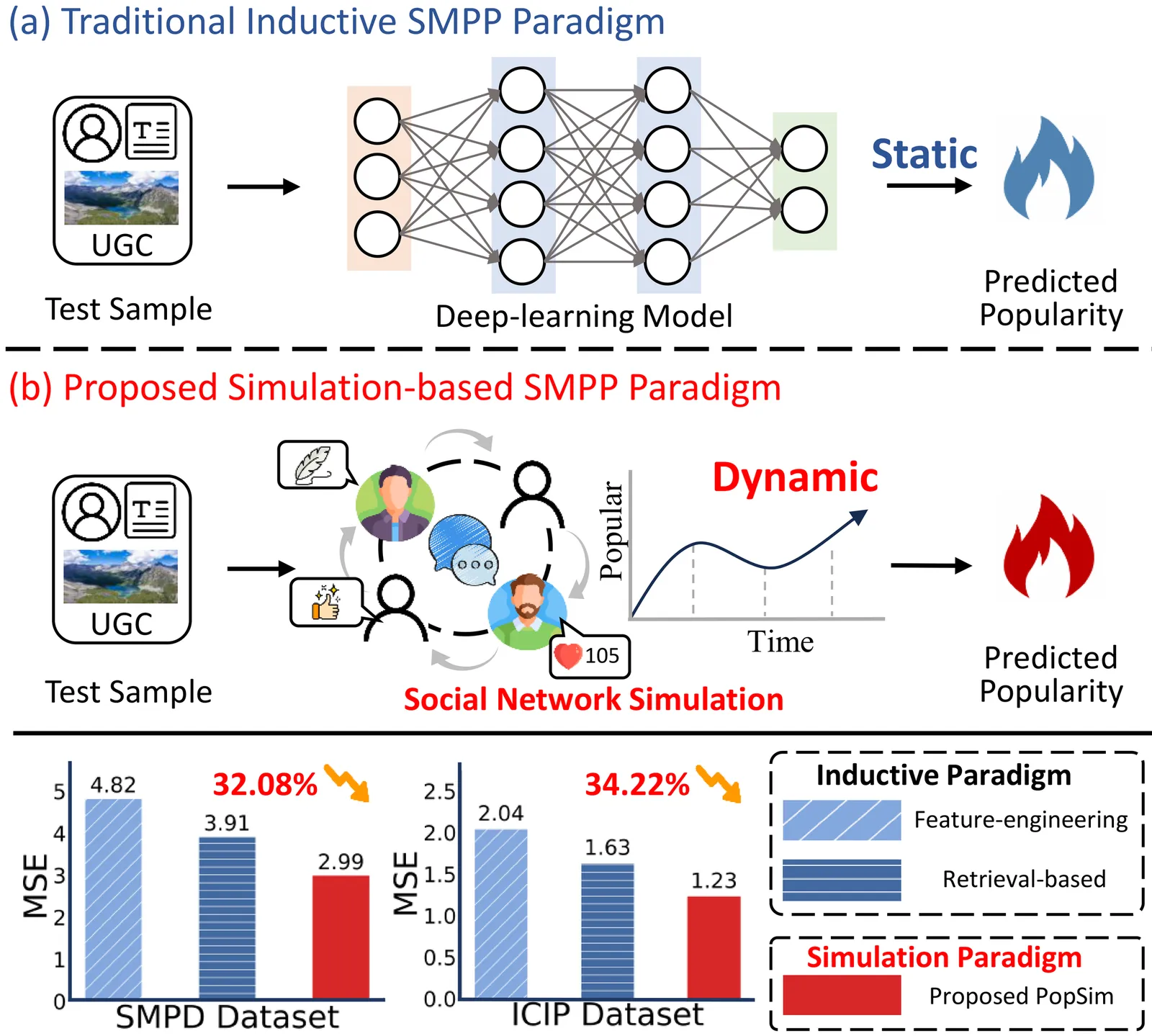
Accurately predicting the popularity of user-generated content (UGC) is essential for advancing social media analytics and recommendation systems. Existing approaches typically follow an inductive paradigm, where researchers train static models on historical data for popularity prediction. However, the UGC propagation is inherently a dynamic process, and static modeling based on historical features fails to capture the complex interactions and nonlinear evolution. In this paper, we propose PopSim, a novel simulation-based paradigm for social media popularity prediction (SMPP). Unlike the inductive paradigm, PopSim leverages the large language models (LLMs)-based multi-agent social network sandbox to simulate UGC propagation dynamics for popularity prediction. Specifically, to effectively model the UGC propagation process in the network, we design a social-mean-field-based agent interaction mechanism, which models the dual-channel and bidirectional individual-population interactions, enhancing agents' global perception and decision-making capabilities. In addition, we propose a multi-source information aggregation module that transforms heterogeneous social metadata into a uniform formulation for LLMs. Finally, propagation dynamics with multimodal information are fused to provide comprehensive popularity prediction. Extensive experiments on real-world datasets demonstrate that SimPop consistently outperforms the state-of-the-art methods, reducing prediction error by an average of 8.82%, offering a new perspective for research on the SMPP task.
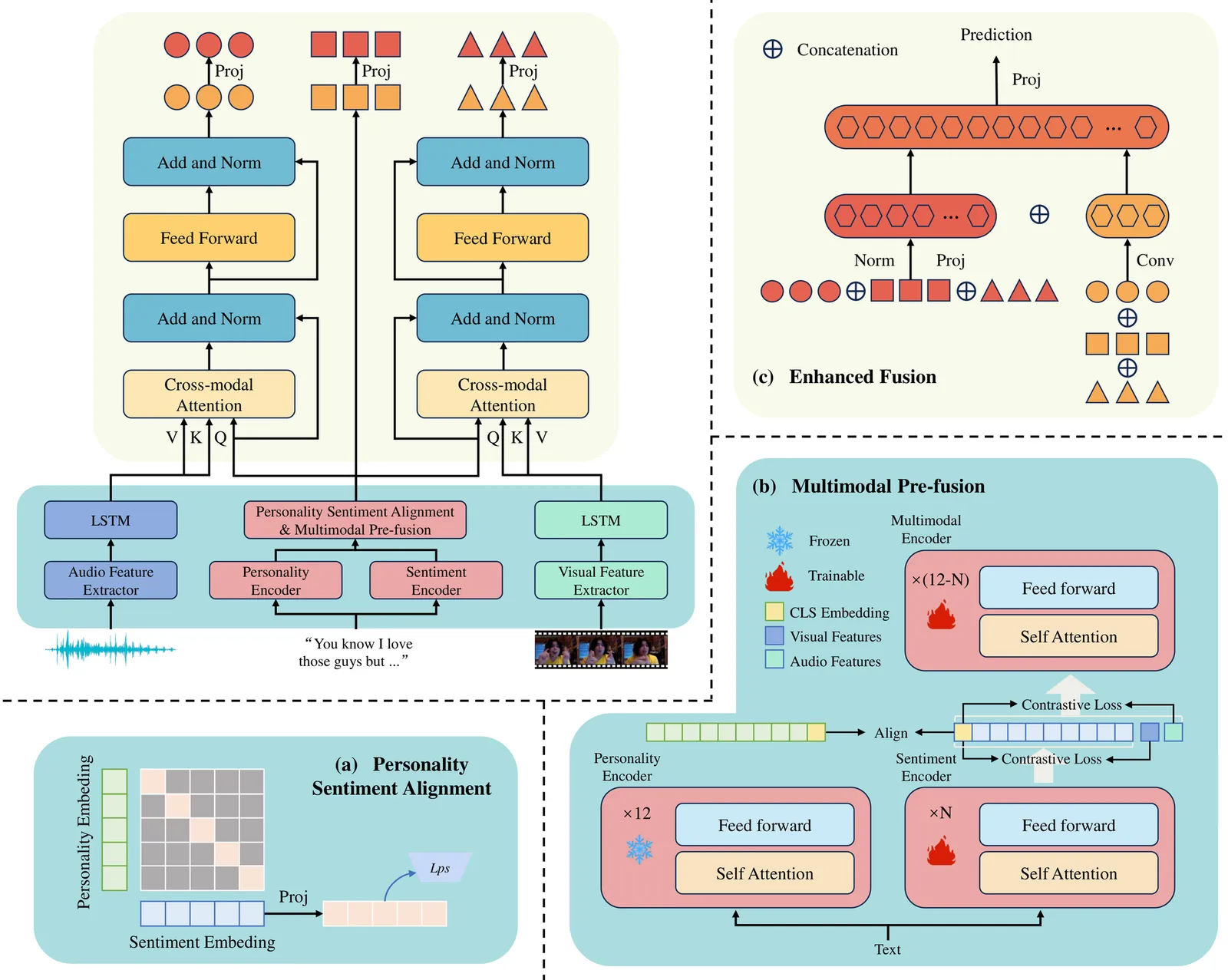
Multimodal sentiment analysis (MSA) is a research field that recognizes human sentiments by combining textual, visual, and audio modalities. The main challenge lies in integrating sentiment-related information from different modalities, which typically arises during the unimodal feature extraction phase and the multimodal feature fusion phase. Existing methods extract only shallow information from unimodal features during the extraction phase, neglecting sentimental differences across different personalities. During the fusion phase, they directly merge the feature information from each modality without considering differences at the feature level. This ultimately affects the model's recognition performance. To address this problem, we propose a personality-sentiment aligned multi-level fusion framework. We introduce personality traits during the feature extraction phase and propose a novel personality-sentiment alignment method to obtain personalized sentiment embeddings from the textual modality for the first time. In the fusion phase, we introduce a novel multi-level fusion method. This method gradually integrates sentimental information from textual, visual, and audio modalities through multimodal pre-fusion and a multi-level enhanced fusion strategy. Our method has been evaluated through multiple experiments on two commonly used datasets, achieving state-of-the-art results.
In recent years, user generated content (UGC) has become the dominant force in internet traffic. However, UGC videos exhibit a higher degree of variability and diverse characteristics compared to traditional encoding test videos. This variance challenges the effectiveness of data-driven machine learning algorithms for optimizing encoding in the broader context of UGC scenarios. To address this issue, we propose a Tri-Dynamic Preprocessing framework for UGC. Firstly, we employ an adaptive factor to regulate preprocessing intensity. Secondly, an adaptive quantization level is employed to fine-tune the codec simulator. Thirdly, we utilize an adaptive lambda tradeoff to adjust the rate-distortion loss function. Experimental results on large-scale test sets demonstrate that our method attains exceptional performance.
There has been a growing trend in compressing and transmitting videos from terminals for machine vision tasks. Nevertheless, most video coding optimization method focus on minimizing distortion according to human perceptual metrics, overlooking the heightened demands posed by machine vision systems. In this paper, we propose a video preprocessing framework tailored for machine vision tasks to address this challenge. The proposed method incorporates a neural preprocessor which retaining crucial information for subsequent tasks, resulting in the boosting of rate-accuracy performance. We further introduce a differentiable virtual codec to provide constraints on rate and distortion during the training stage. We directly apply widely used standard codecs for testing. Therefore, our solution can be easily applied to real-world scenarios. We conducted extensive experiments evaluating our compression method on two typical downstream tasks with various backbone networks. The experimental results indicate that our approach can save over 15% of bitrate compared to using only the standard codec anchor version.
The primary challenge of video streaming is to balance high video quality with smooth playback. Traditional codecs are well tuned for this trade-off, yet their inability to use context means they must encode the entire video data and transmit it to the client. This paper introduces ELVIS (End-to-end Learning-based VIdeo Streaming Enhancement Pipeline), an end-to-end architecture that combines server-side encoding optimizations with client-side generative in-painting to remove and reconstruct redundant video data. Its modular design allows ELVIS to integrate different codecs, inpainting models, and quality metrics, making it adaptable to future innovations. Our results show that current technologies achieve improvements of up to 11 VMAF points over baseline benchmarks, though challenges remain for real-time applications due to computational demands. ELVIS represents a foundational step toward incorporating generative AI into video streaming pipelines, enabling higher quality experiences without increased bandwidth requirements.

The future of digital marketing lies in the convergence of human creativity and generative AI, where insight, strategy, and storytelling are co-authored by intelligent systems. We present MindFuse, a brave new explainable generative AI framework designed to act as a strategic partner in the marketing process. Unlike conventional LLM applications that stop at content generation, MindFuse fuses CTR-based content AI-guided co-creation with large language models to extract, interpret, and iterate on communication narratives grounded in real advertising data. MindFuse operates across the full marketing lifecycle: from distilling content pillars and customer personas from competitor campaigns to recommending in-flight optimizations based on live performance telemetry. It uses attention-based explainability to diagnose ad effectiveness and guide content iteration, while aligning messaging with strategic goals through dynamic narrative construction and storytelling. We introduce a new paradigm in GenAI for marketing, where LLMs not only generate content but reason through it, adapt campaigns in real time, and learn from audience engagement patterns. Our results, validated in agency deployments, demonstrate up to 12 times efficiency gains, setting the stage for future integration with empirical audience data (e.g., GWI, Nielsen) and full-funnel attribution modeling. MindFuse redefines AI not just as a tool, but as a collaborative agent in the creative and strategic fabric of modern marketing.
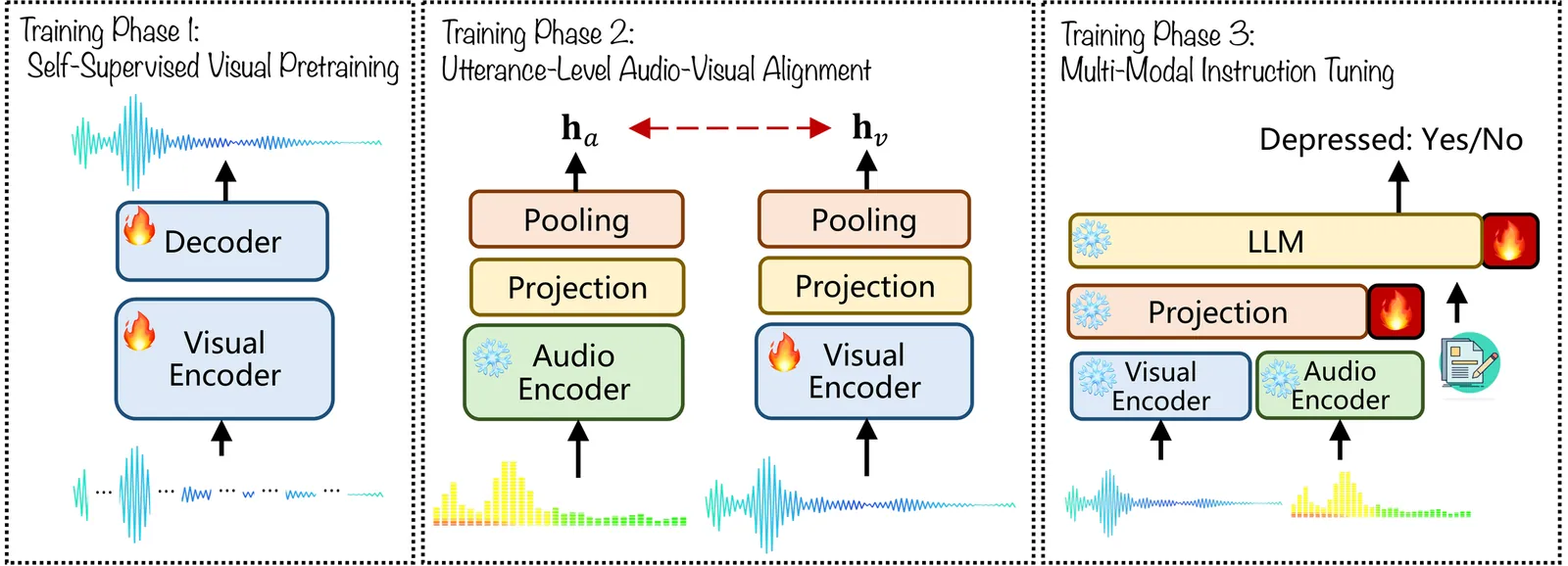
Depression is one of the most prevalent mental health disorders globally. In recent years, multi-modal data, such as speech, video, and transcripts, has been increasingly used to develop AI-assisted depression assessment systems. Large language models have further advanced this field due to their strong language understanding and generalization capabilities. However, conventional LLMs remain text-centric and cannot process the rich non-verbal cues found in audio and visual modalities, which are critical components in mental health evaluation. While multi-modal LLMs offer a promising direction, few are tailored for psychological applications. In this study, we propose a novel multi-modal LLM framework for depression detection. Our approach augments an audio language model with visual understanding and aligns audio-visual features at the timestamp level. This fine-grained alignment improves modeling of temporal dynamics across modalities while reducing the need for extensive training data and computational resources. Experiments on the DAIC-WoZ dataset demonstrate that our model outperforms both single-modality approaches and previous multi-modal methods. Moreover, the proposed framework can be extended to incorporate additional physiological signals, paving the way for broader clinical applications beyond mental health.
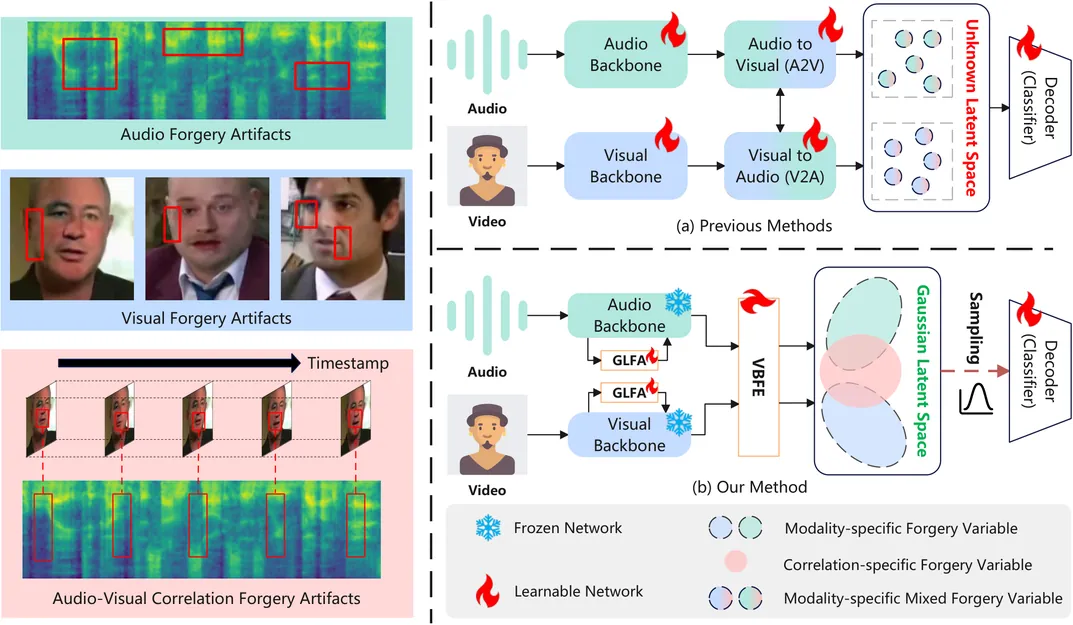
The widespread application of AIGC contents has brought not only unprecedented opportunities, but also potential security concerns, e.g., audio-visual deepfakes. Therefore, it is of great importance to develop an effective and generalizable method for multi-modal deepfake detection. Typically, the audio-visual correlation learning could expose subtle cross-modal inconsistencies, e.g., audio-visual misalignment, which serve as crucial clues in deepfake detection. In this paper, we reformulate the correlation learning with variational Bayesian estimation, where audio-visual correlation is approximated as a Gaussian distributed latent variable, and thus develop a novel framework for deepfake detection, i.e., Forgery-aware Audio-Visual Adaptation with Variational Bayes (FoVB). Specifically, given the prior knowledge of pre-trained backbones, we adopt two core designs to estimate audio-visual correlations effectively. First, we exploit various difference convolutions and a high-pass filter to discern local and global forgery traces from both modalities. Second, with the extracted forgery-aware features, we estimate the latent Gaussian variable of audio-visual correlation via variational Bayes. Then, we factorize the variable into modality-specific and correlation-specific ones with orthogonality constraint, allowing them to better learn intra-modal and cross-modal forgery traces with less entanglement. Extensive experiments demonstrate that our FoVB outperforms other state-of-the-art methods in various benchmarks.
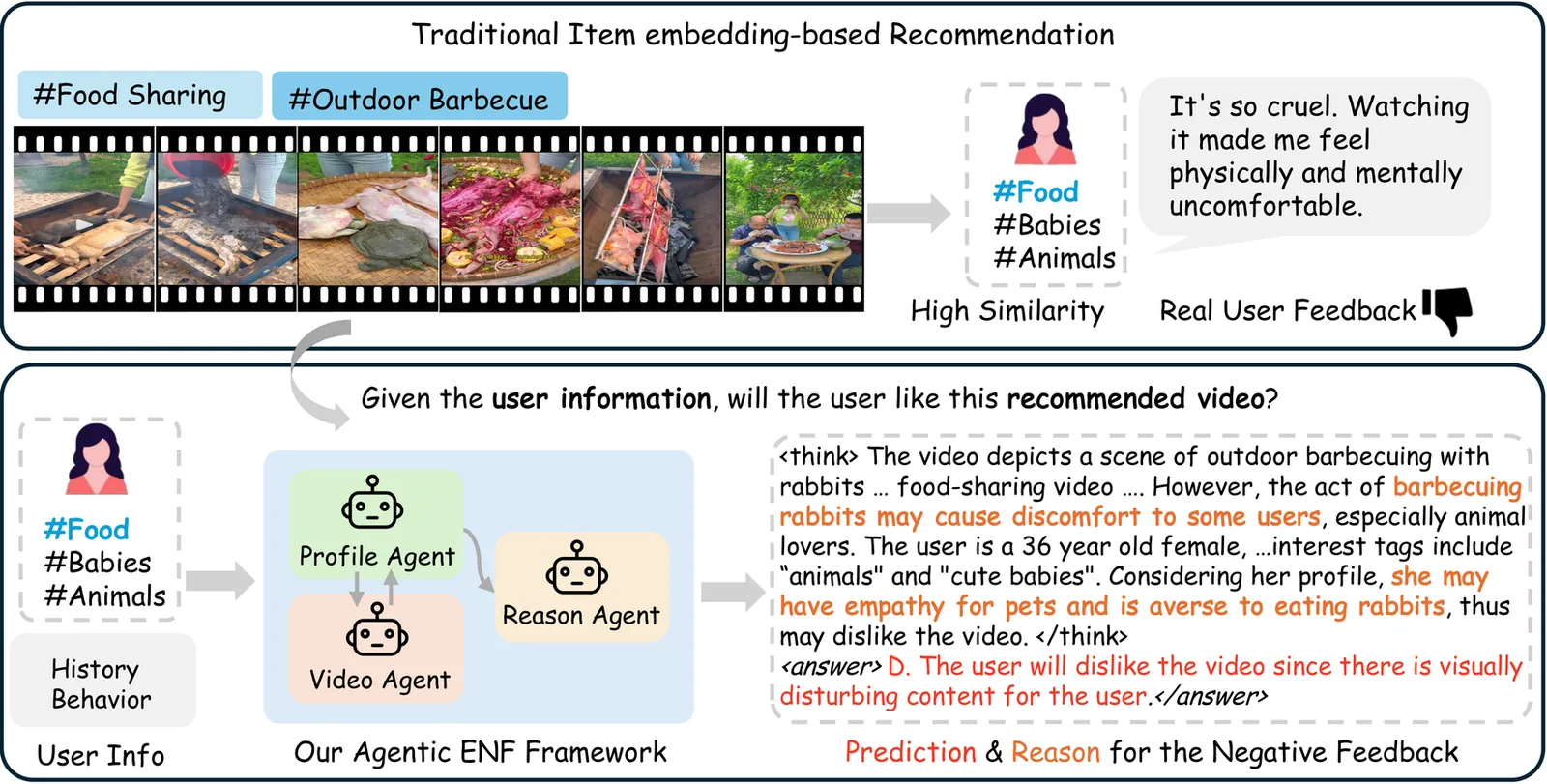
Existing video recommendation systems, relying mainly on ID-based embedding mapping and collaborative filtering, often fail to capture in-depth video content semantics. Moreover, most struggle to address biased user behaviors (e.g., accidental clicks, fast skips), leading to inaccurate interest modeling and frequent negative feedback in top recommendations with unclear causes. To tackle this issue, we collect real-world user video-watching sequences, annotate the reasons for users' dislikes, and construct a benchmark dataset for personalized explanations. We then introduce the Agentic Explainable Negative Feedback (ENF) framework, which integrates three core components: (1) the Profile Agent, extracting behavioral cues from users' historical data to derive psychological and personality profiles; (2) the Video Agent, performing comprehensive multimodal video analysis; and (3) the Reason Agent, synthesizing information from the other two agents to predict user engagement and generate explanations. Additionally, we propose the S-GRPO algorithm, enabling the model to progressively address complex tasks during reinforcement fine-tuning. Experimental results on the collected dataset show that our method significantly outperforms state-of-the-art baselines in negative feedback prediction and reason explanation. Notably, it achieves an 8.6% improvement over GPT-4o in reason classification. Deployment on the business platform further validates its benefits: increasing average user watch time by 6.2%, reducing the fast-skip rate by 9.4%, and significantly enhancing user satisfaction.
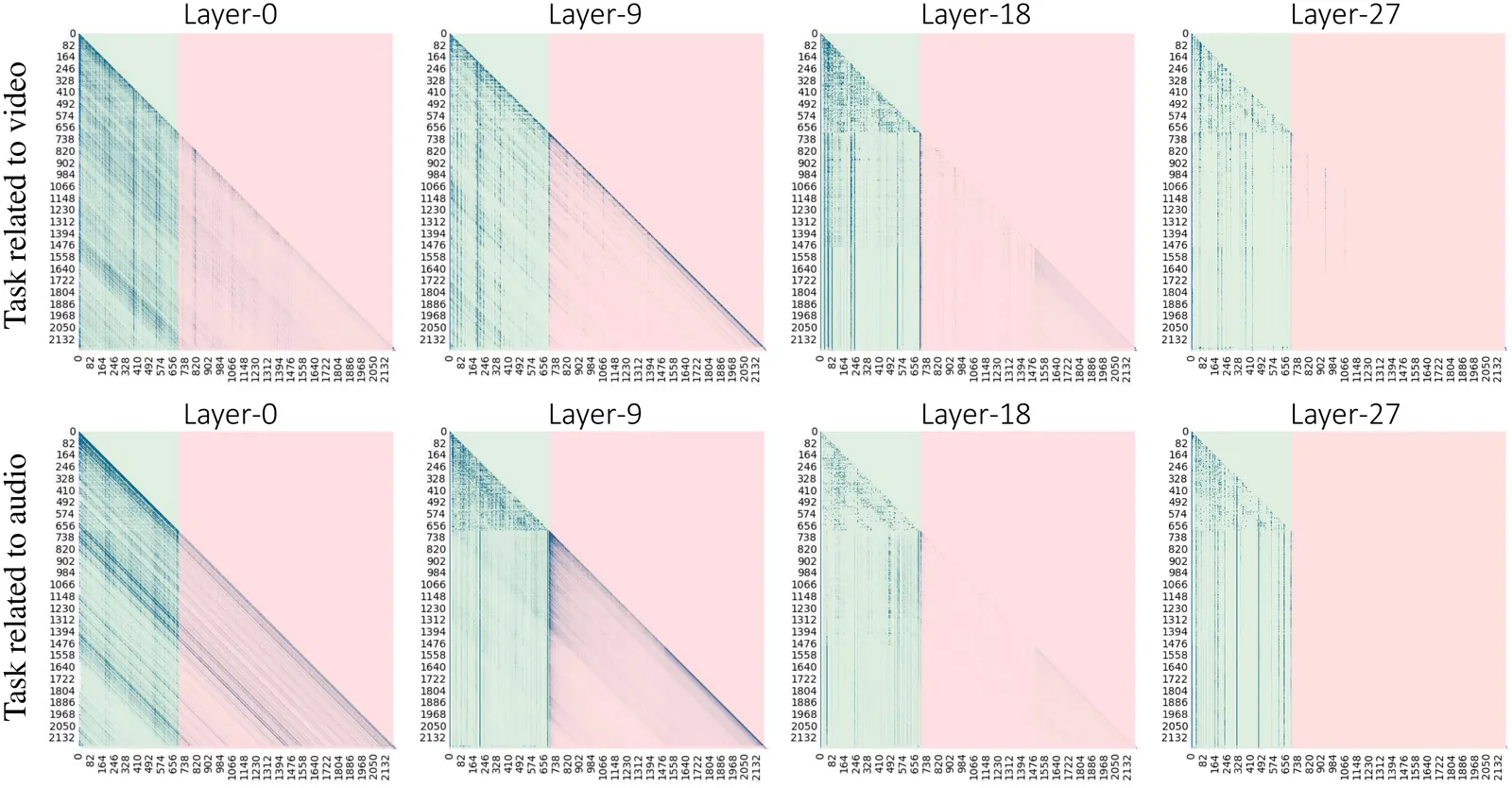
Recent advancements in Audio-Video Large Language Models (AV-LLMs) have enhanced their capabilities in tasks like audio-visual question answering and multimodal dialog systems. Video and audio introduce an extended temporal dimension, resulting in a larger key-value (KV) cache compared to static image embedding. A naive optimization strategy is to selectively focus on and retain KV caches of audio or video based on task. However, in the experiment, we observed that the attention of AV-LLMs to various modalities in the high layers is not strictly dependent on the task. In higher layers, the attention of AV-LLMs shifts more towards the video modality. In addition, we also found that directly integrating temporal KV of audio and spatial-temporal KV of video may lead to information confusion and significant performance degradation of AV-LLMs. If audio and video are processed indiscriminately, it may also lead to excessive compression or reservation of a certain modality, thereby disrupting the alignment between modalities. To address these challenges, we propose AccKV, an Adaptive-Focusing and Cross-Calibration KV cache optimization framework designed specifically for efficient AV-LLMs inference. Our method is based on layer adaptive focusing technology, selectively focusing on key modalities according to the characteristics of different layers, and enhances the recognition of heavy hitter tokens through attention redistribution. In addition, we propose a Cross-Calibration technique that first integrates inefficient KV caches within the audio and video modalities, and then aligns low-priority modalities with high-priority modalities to selectively evict KV cache of low-priority modalities. The experimental results show that AccKV can significantly improve the computational efficiency of AV-LLMs while maintaining accuracy.
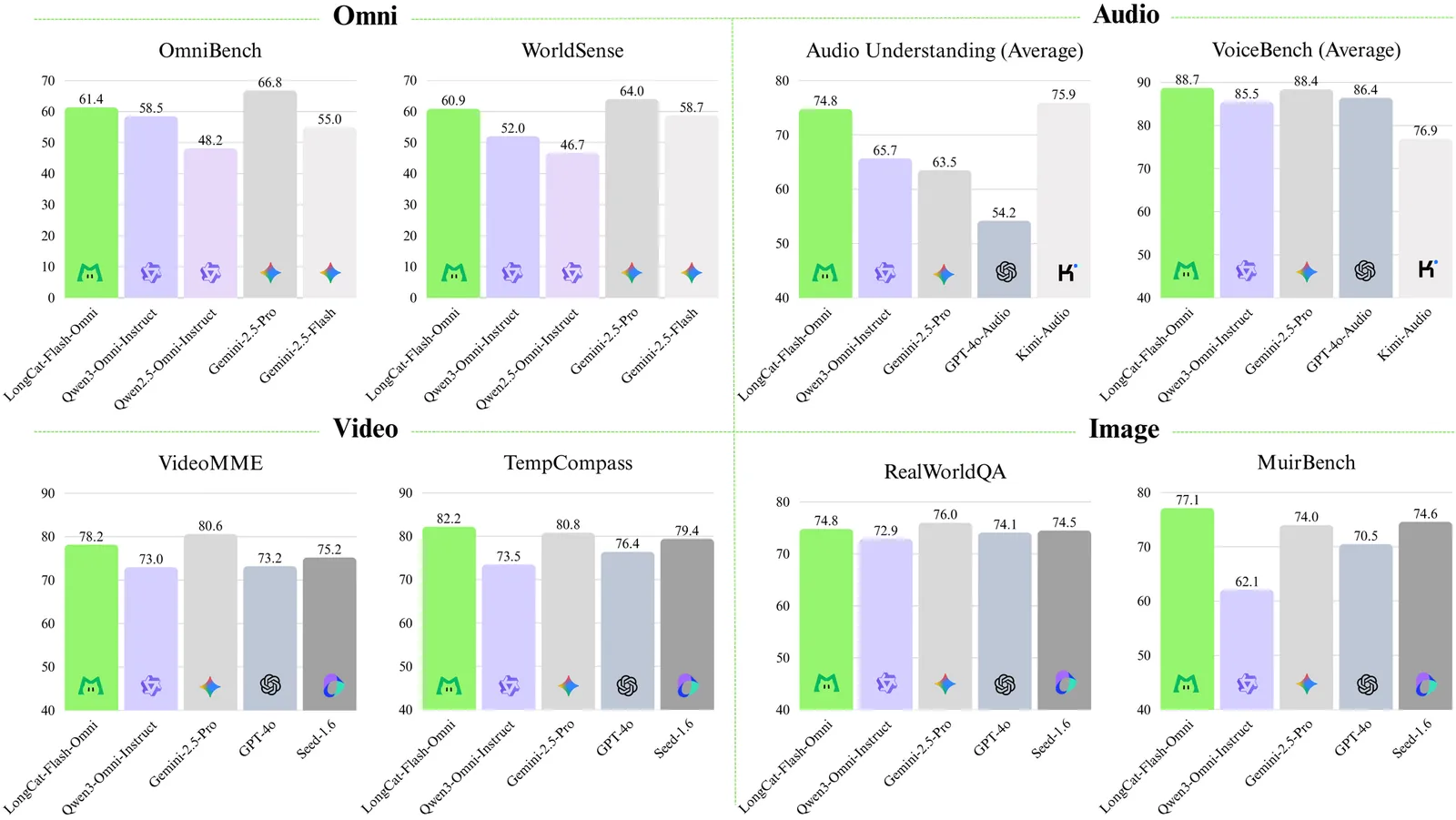
We introduce LongCat-Flash-Omni, a state-of-the-art open-source omni-modal model with 560 billion parameters, excelling at real-time audio-visual interaction. By adopting a curriculum-inspired progressive training strategy that transitions from simpler to increasingly complex modality sequence modeling tasks, LongCat-Flash-Omni attains comprehensive multimodal capabilities while maintaining strong unimodal capability. Building upon LongCat-Flash, which adopts a high-performance Shortcut-connected Mixture-of-Experts (MoE) architecture with zero-computation experts, LongCat-Flash-Omni integrates efficient multimodal perception and speech reconstruction modules. Despite its immense size of 560B parameters (with 27B activated), LongCat-Flash-Omni achieves low-latency real-time audio-visual interaction. For training infrastructure, we developed a modality-decoupled parallelism scheme specifically designed to manage the data and model heterogeneity inherent in large-scale multimodal training. This innovative approach demonstrates exceptional efficiency by sustaining over 90% of the throughput achieved by text-only training. Extensive evaluations show that LongCat-Flash-Omni achieves state-of-the-art performance on omni-modal benchmarks among open-source models. Furthermore, it delivers highly competitive results across a wide range of modality-specific tasks, including text, image, and video understanding, as well as audio understanding and generation. We provide a comprehensive overview of the model architecture design, training procedures, and data strategies, and open-source the model to foster future research and development in the community.
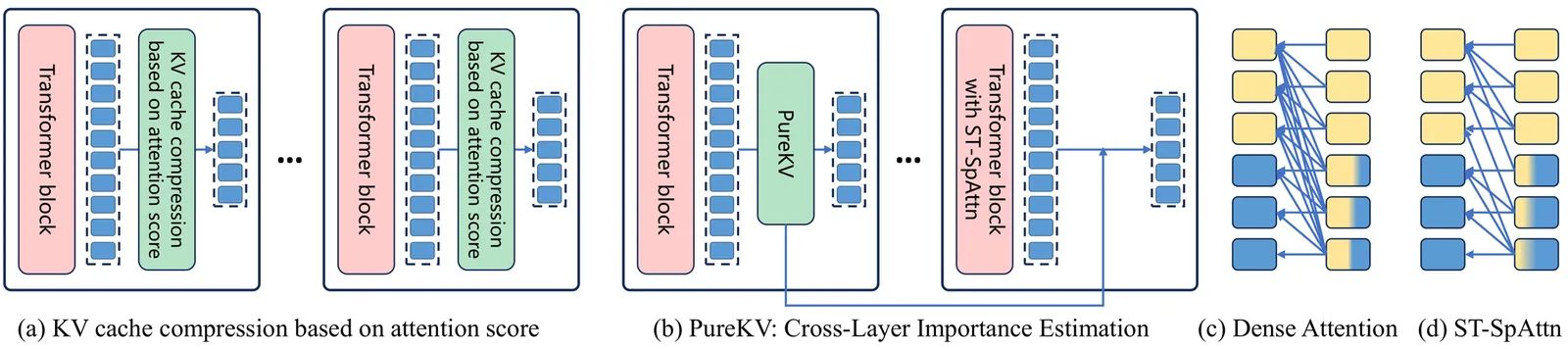
Vision-Language Large Models (VLLMs) face significant efficiency challenges when processing high-resolution inputs. The quadratic complexity in attention and autoregressive generation, as well as the constantly growing key value (KV) cache size, severely hinder the prefilling and decoding stages. Recent efforts have attempted to compress KV cache by identifying and pruning KV cache of less important tokens, but these methods typically rely on attention scores to estimate token importance, making them incompatible with efficient attention mechanisms such as FlashAttention and Sparse Attention, which do not explicitly compute attention matrices. Moreover, existing methods overlook how sparse attention, while accelerating the prefilling stage, alters the information structure of the KV cache, thereby compromising the effectiveness of downstream KV cache compression strategies. To address this issue, we propose PureKV, a plug-and-play framework for joint optimization of sparse attention and KV cache compression. We first introduce a KV cache compression strategy that is fully compatible with efficient attention accelerators. Our method utilizes lower layer attention scores to estimate the importance of high layers' KV cache, enabling active pruning without compromising accuracy. In addition, we have designed a Spatial-Temporal Sparse Attention (ST-SpAttn) module specifically tailored for video KV cache compression algorithms. This module combines spatial and temporal attention sparsity to improve the compression efficiency of KV cache optimization algorithms by purifying spatial noise and temporal redundancy in KV cache. At the same time, ST-SpAttn also accelerated the prefilling stage of VLLMs. Extensive experiments on VLLMs (VideoLLaMA2, Qwen2.5-VL) have shown that PureKV achieves 5.0 times KV cache compression and 3.16 times prefill acceleration, with negligible quality degradation.
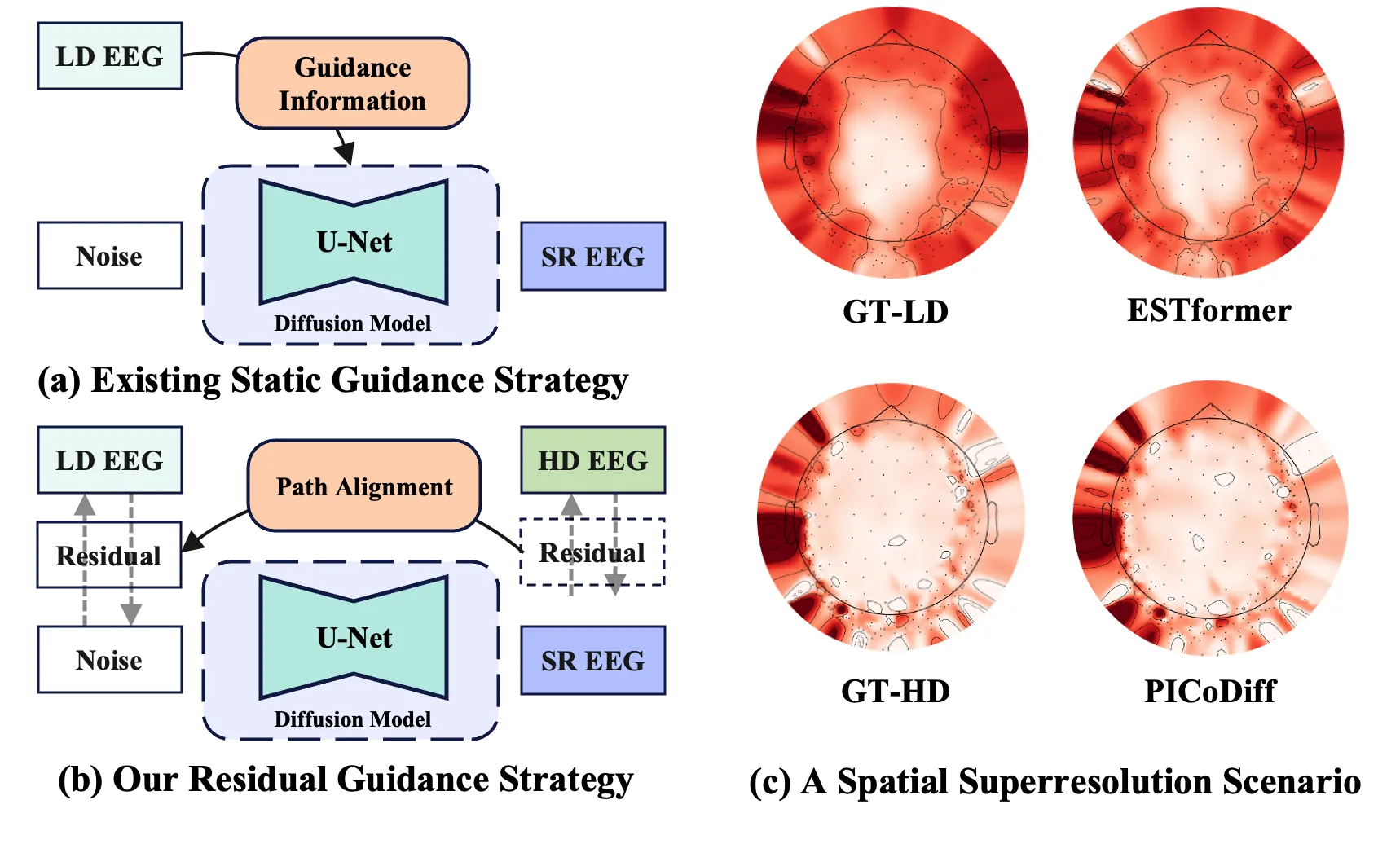
For real-world BCI applications, lightweight Electroencephalography (EEG) systems offer the best cost-deployment balance. However, such spatial sparsity of EEG limits spatial fidelity, hurting learning and introducing bias. EEG spatial super-resolution methods aim to recover high-density EEG signals from sparse measurements, yet is often hindered by distribution shift and signal distortion and thus reducing fidelity and usability for EEG analysis and visualization. To overcome these challenges, we introduce SRGDiff, a step-aware residual-guided diffusion model that formulates EEG spatial super-resolution as dynamic conditional generation. Our key idea is to learn a dynamic residual condition from the low-density input that predicts the step-wise temporal and spatial details to add and uses the evolving cue to steer the denoising process toward high-density reconstructions. At each denoising step, the proposed residual condition is additively fused with the previous denoiser feature maps, then a step-dependent affine modulation scales and shifts the activation to produce the current features. This iterative procedure dynamically extracts step-wise temporal rhythms and spatial-topographic cues to steer high-density recovery and maintain a fidelity-consistency balance. We adopt a comprehensive evaluation protocol spanning signal-, feature-, and downstream-level metrics across SEED, SEED-IV, and Localize-MI and multiple upsampling scales. SRGDiff achieves consistent gains of up to 40% over strong baselines, proving its superiority in the task of EEG spatial super-resolution. Moreover, topographic visualizations comparison and substantial EEG-FID gains jointly indicate that our SR EEG mitigates the spatial-spectral shift between low- and high-density recordings.
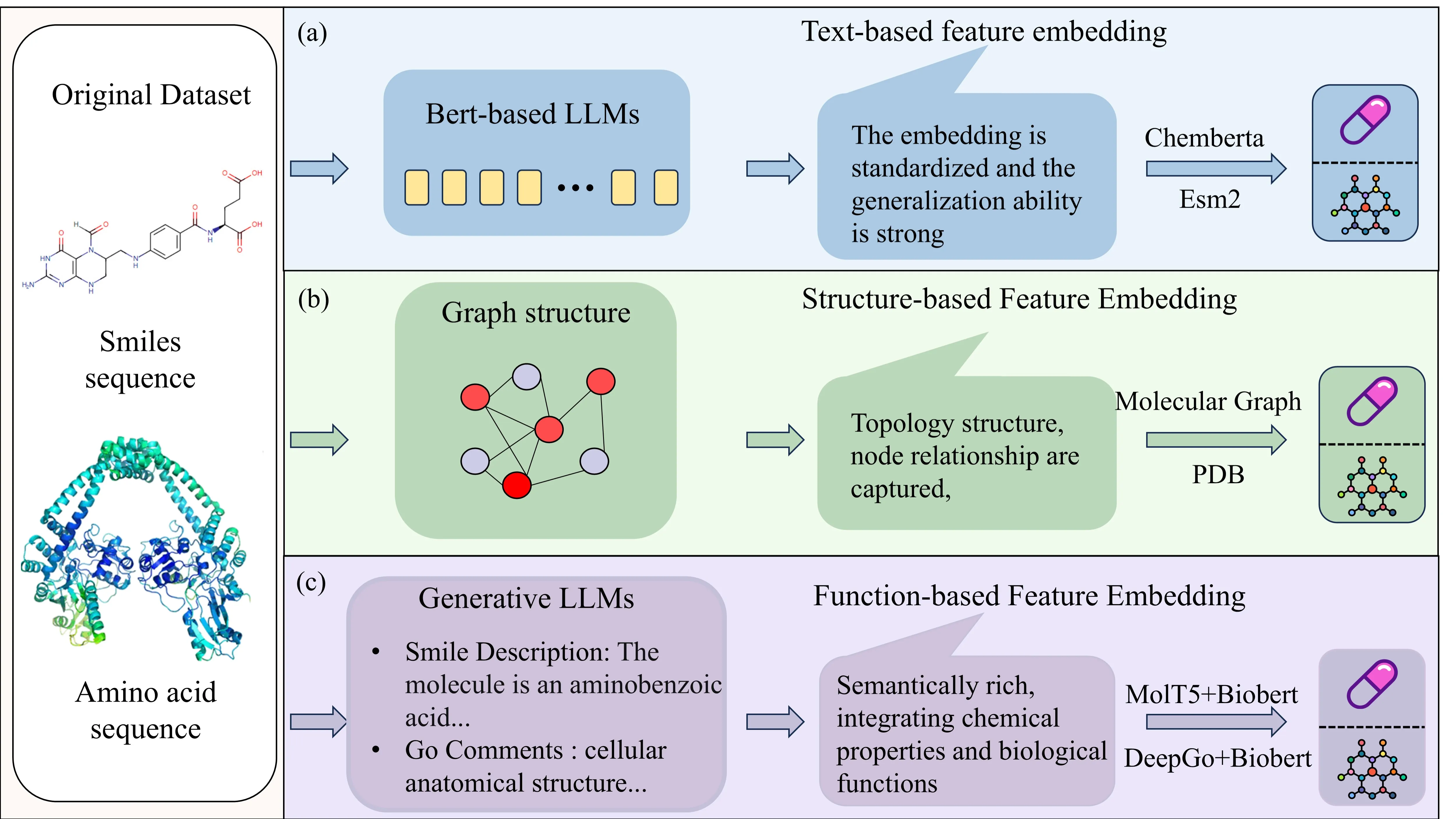
Accurate prediction of drug-target interactions (DTI) is pivotal in drug discovery. However, existing approaches often fail to capture deep intra-modal feature interactions or achieve effective cross-modal alignment, limiting predictive performance and generalization. To address these challenges, we propose M3ST-DTI, a multi-task learning model that enables multi-stage integration and alignment of multi modal features for DTI prediction. M3ST-DTI incorporates three types of features-textual, structural, and functional and enhances intra-modal representations using self-attention mechanisms and a hybrid pooling graph attention module. For early-stage feature alignment and fusion, the model in tegrates MCA with Gram loss as a structural constraint. In the later stage, a BCA module captures fine-grained interactions between drugs and targets within each modality, while a deep orthogonal fusion module mitigates feature redundancy.Extensive evaluations on benchmark datasets demonstrate that M3ST-DTI consistently outperforms state-of-the art methods across diverse metrics

Emotions conveyed through voice and face shape engagement and context in human-AI interaction. Despite rapid progress in omni-modal large language models (LLMs), the holistic evaluation of emotional reasoning with audiovisual cues remains limited. To address this gap, we introduce AV-EMO-Reasoning, a benchmark designed to systematically assess emotional coherence in LLMs. The framework leverages a curated, single- and multi-turn synthetic audiovisual corpus with a real-world set and is assessed under continuous, categorical, and perceptual metrics. Experiments with leading LLMs show that visual cues reliably improve emotional coherence over audio-only baselines. Moreover, LLMs can leverage audio-visual cues to generate more emotion-aware speech. Models exhibit complementary strengths across metric families, indicating that automatic scores capture facets distinct from perceptual judgments. By releasing a systematic evaluation benchmark, AV-EMO-Reasoning offers a reproducible standard for evaluating emotion-aware dialogue and advances toward more natural, adaptive human-AI interaction.
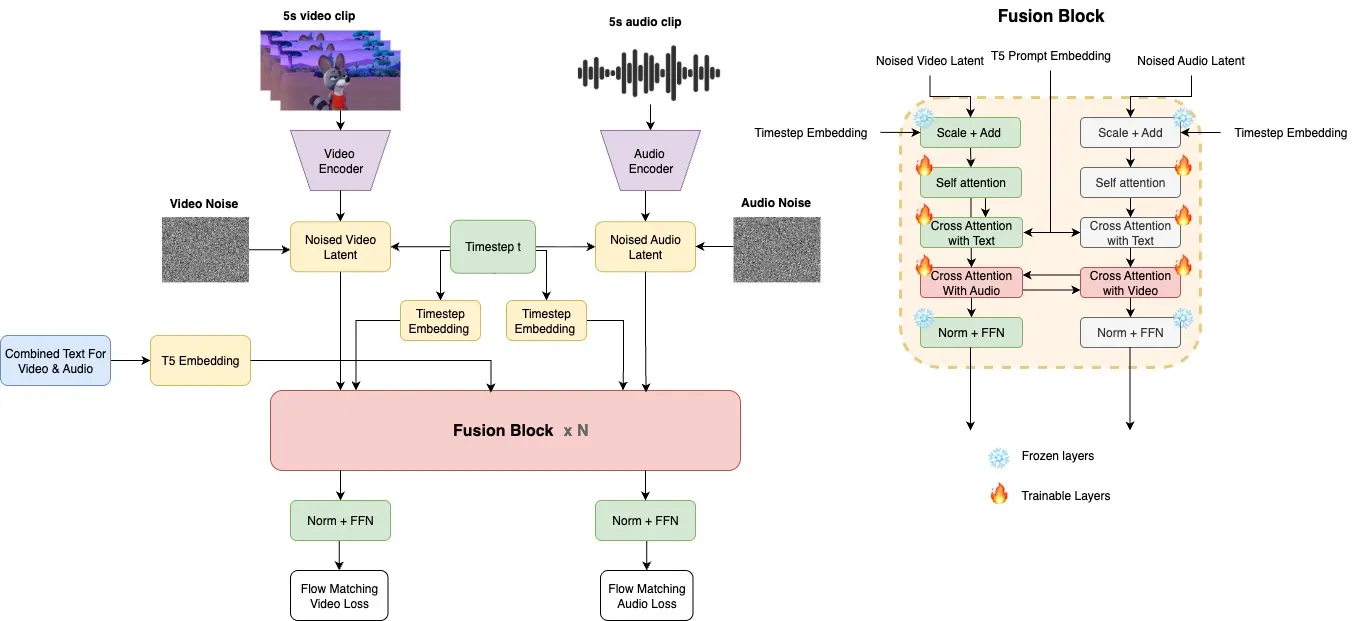
Audio-video generation has often relied on complex multi-stage architectures or sequential synthesis of sound and visuals. We introduce Ovi, a unified paradigm for audio-video generation that models the two modalities as a single generative process. By using blockwise cross-modal fusion of twin-DiT modules, Ovi achieves natural synchronization and removes the need for separate pipelines or post hoc alignment. To facilitate fine-grained multimodal fusion modeling, we initialize an audio tower with an architecture identical to that of a strong pretrained video model. Trained from scratch on hundreds of thousands of hours of raw audio, the audio tower learns to generate realistic sound effects, as well as speech that conveys rich speaker identity and emotion. Fusion is obtained by jointly training the identical video and audio towers via blockwise exchange of timing (via scaled-RoPE embeddings) and semantics (through bidirectional cross-attention) on a vast video corpus. Our model enables cinematic storytelling with natural speech and accurate, context-matched sound effects, producing movie-grade video clips. All the demos, code and model weights are published at https://aaxwaz.github.io/Ovi

There is a high demand for audio-visual editing in video post-production and the film making field. While numerous models have explored audio and video editing, they struggle with object-level audio-visual operations. Specifically, object-level audio-visual editing requires the ability to perform object addition, replacement, and removal across both audio and visual modalities, while preserving the structural information of the source instances during the editing process. In this paper, we present \textbf{Object-AVEdit}, achieving the object-level audio-visual editing based on the inversion-regeneration paradigm. To achieve the object-level controllability during editing, we develop a word-to-sounding-object well-aligned audio generation model, bridging the gap in object-controllability between audio and current video generation models. Meanwhile, to achieve the better structural information preservation and object-level editing effect, we propose an inversion-regeneration holistically-optimized editing algorithm, ensuring both information retention during the inversion and better regeneration effect. Extensive experiments demonstrate that our editing model achieved advanced results in both audio-video object-level editing tasks with fine audio-visual semantic alignment. In addition, our developed audio generation model also achieved advanced performance. More results on our project page: https://gewu-lab.github.io/Object_AVEdit-website/.
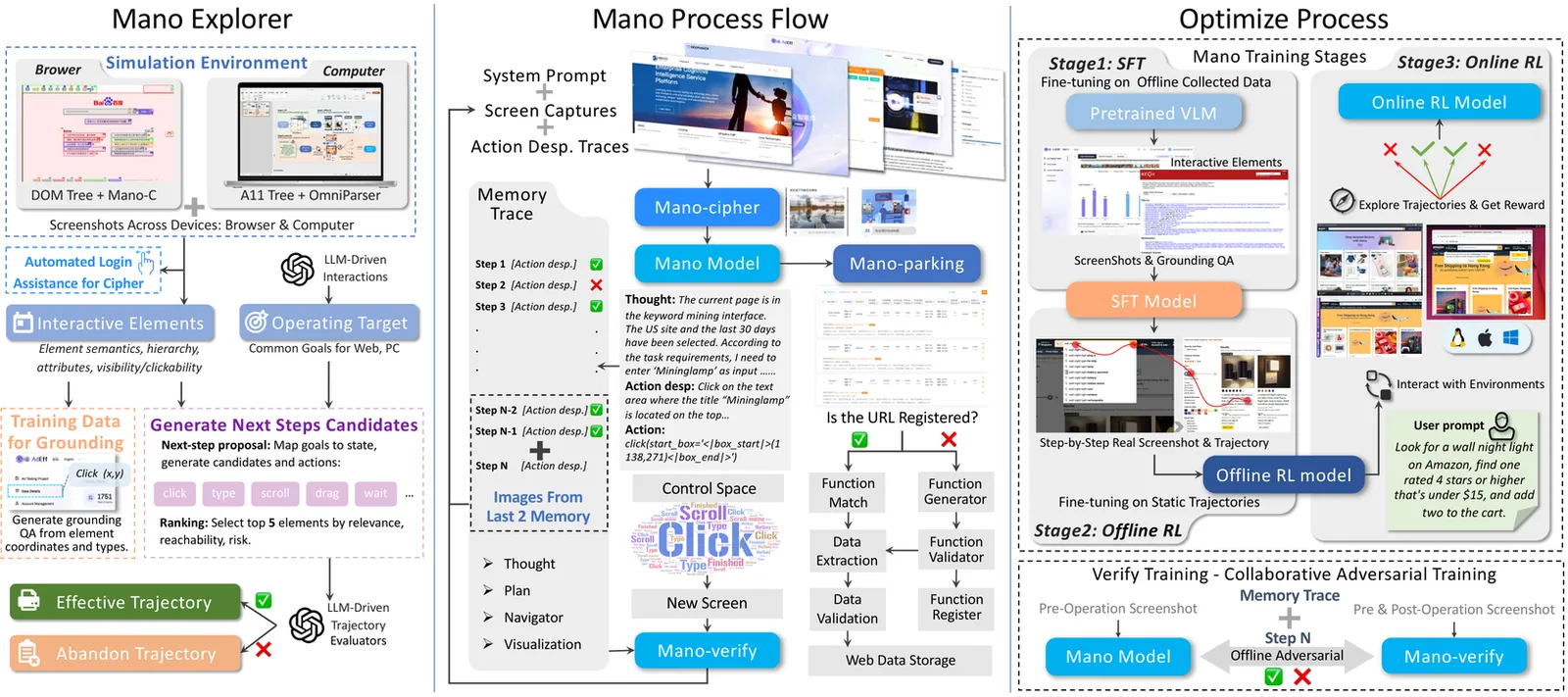
Graphical user interfaces (GUIs) are the primary medium for human-computer interaction, yet automating GUI interactions remains challenging due to the complexity of visual elements, dynamic environments, and the need for multi-step reasoning. Existing methods based on vision-language models (VLMs) often suffer from limited resolution, domain mismatch, and insufficient sequential decisionmaking capability. To address these issues, we propose Mano, a robust GUI agent built upon a multi-modal foundation model pre-trained on extensive web and computer system data. Our approach integrates a novel simulated environment for high-fidelity data generation, a three-stage training pipeline (supervised fine-tuning, offline reinforcement learning, and online reinforcement learning), and a verification module for error recovery. Mano demonstrates state-of-the-art performance on multiple GUI benchmarks, including Mind2Web and OSWorld, achieving significant improvements in success rate and operational accuracy. Our work provides new insights into the effective integration of reinforcement learning with VLMs for practical GUI agent deployment, highlighting the importance of domain-specific data, iterative training, and holistic reward design.
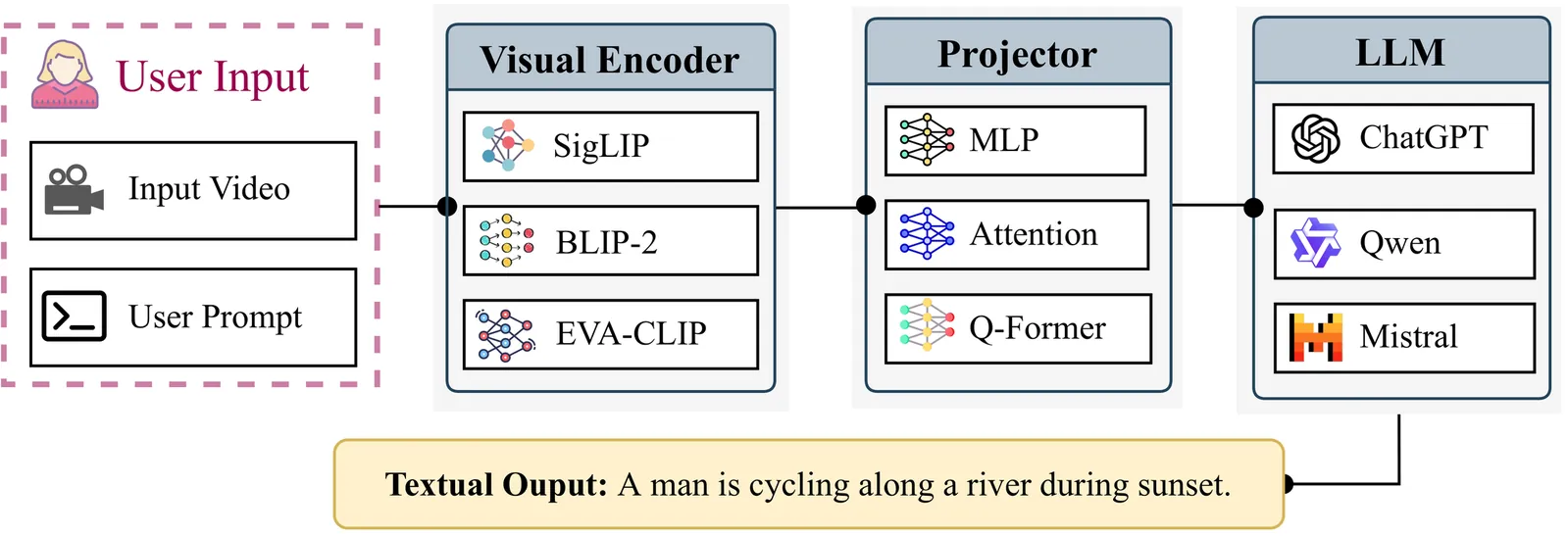
Video Large Language Models (VideoLLMs) are increasingly deployed on numerous critical applications, where users rely on auto-generated summaries while casually skimming the video stream. We show that this interaction hides a critical safety gap: if harmful content is embedded in a video, either as full-frame inserts or as small corner patches, state-of-the-art VideoLLMs rarely mention the harmful content in the output, despite its clear visibility to human viewers. A root-cause analysis reveals three compounding design flaws: (1) insufficient temporal coverage resulting from the sparse, uniformly spaced frame sampling used by most leading VideoLLMs, (2) spatial information loss introduced by aggressive token downsampling within sampled frames, and (3) encoder-decoder disconnection, whereby visual cues are only weakly utilized during text generation. Leveraging these insights, we craft three zero-query black-box attacks, aligning with these flaws in the processing pipeline. Our large-scale evaluation across five leading VideoLLMs shows that the harmfulness omission rate exceeds 90% in most cases. Even when harmful content is clearly present in all frames, these models consistently fail to identify it. These results underscore a fundamental vulnerability in current VideoLLMs' designs and highlight the urgent need for sampling strategies, token compression, and decoding mechanisms that guarantee semantic coverage rather than speed alone.
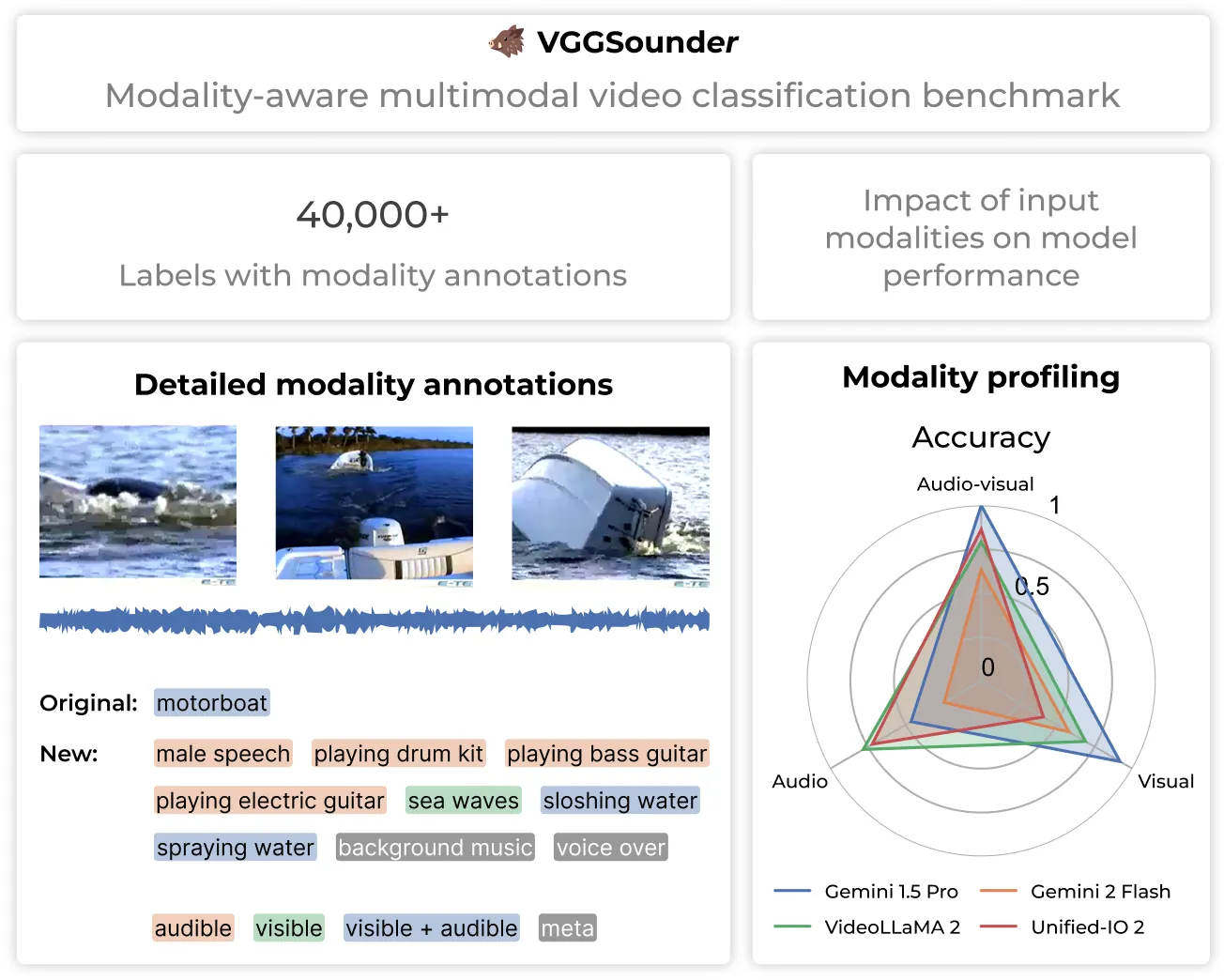
The emergence of audio-visual foundation models underscores the importance of reliably assessing their multi-modal understanding. The VGGSound dataset is commonly used as a benchmark for evaluation audio-visual classification. However, our analysis identifies several limitations of VGGSound, including incomplete labelling, partially overlapping classes, and misaligned modalities. These lead to distorted evaluations of auditory and visual capabilities. To address these limitations, we introduce VGGSounder, a comprehensively re-annotated, multi-label test set that extends VGGSound and is specifically designed to evaluate audio-visual foundation models. VGGSounder features detailed modality annotations, enabling precise analyses of modality-specific performance. Furthermore, we reveal model limitations by analysing performance degradation when adding another input modality with our new modality confusion metric.

The multi-modal long-context document question-answering task aims to locate and integrate multi-modal evidences (such as texts, tables, charts, images, and layouts) distributed across multiple pages, for question understanding and answer generation. The existing methods can be categorized into Large Vision-Language Model (LVLM)-based and Retrieval-Augmented Generation (RAG)-based methods. However, the former were susceptible to hallucinations, while the latter struggled for inter-modal disconnection and cross-page fragmentation. To address these challenges, a novel multi-modal RAG model, named MHier-RAG, was proposed, leveraging both textual and visual information across long-range pages to facilitate accurate question answering for visual-rich documents. A hierarchical indexing method with the integration of flattened in-page chunks and topological cross-page chunks was designed to jointly establish in-page multi-modal associations and long-distance cross-page dependencies. By means of joint similarity evaluation and large language model (LLM)-based re-ranking, a multi-granularity semantic retrieval method, including the page-level parent page retrieval and document-level summary retrieval, was proposed to foster multi-modal evidence connection and long-distance evidence integration and reasoning. Experimental results performed on public datasets, MMLongBench-Doc and LongDocURL, demonstrated the superiority of our MHier-RAG method in understanding and answering modality-rich and multi-page documents.

Owing to powerful natural language processing and generative capabilities, large language model (LLM) agents have emerged as a promising solution for enhancing recommendation systems via user simulation. However, in the realm of video recommendation, existing studies predominantly resort to prompt-based simulation using frozen LLMs and encounter the intricate challenge of multimodal content understanding. This frequently results in suboptimal item modeling and user preference learning, thereby ultimately constraining recommendation performance. To address these challenges, we introduce VRAgent-R1, a novel agent-based paradigm that incorporates human-like intelligence in user simulation. Specifically, VRAgent-R1 comprises two distinct agents: the Item Perception (IP) Agent and the User Simulation (US) Agent, designed for interactive user-item modeling. Firstly, the IP Agent emulates human-like progressive thinking based on MLLMs, effectively capturing hidden recommendation semantics in videos. With a more comprehensive multimodal content understanding provided by the IP Agent, the video recommendation system is equipped to provide higher-quality candidate items. Subsequently, the US Agent refines the recommended video sets based on in-depth chain-of-thought (CoT) reasoning and achieves better alignment with real user preferences through reinforcement learning. Experimental results on a large-scale video recommendation benchmark have demonstrated the effectiveness of our proposed VRAgent-R1 method, e.g., the IP Agent achieves a 6.0\% improvement in NDCG@10 on the MicroLens-100k dataset, while the US Agent shows approximately 45.0\% higher accuracy in user decision simulation compared to state-of-the-art baselines.