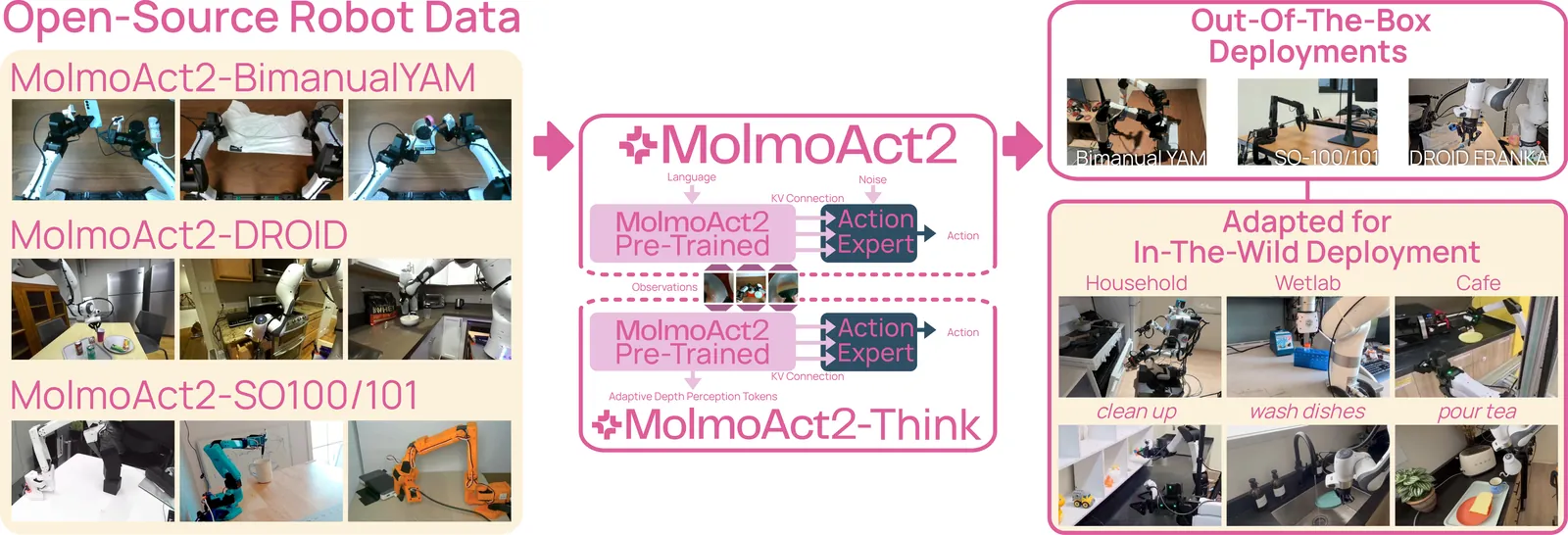
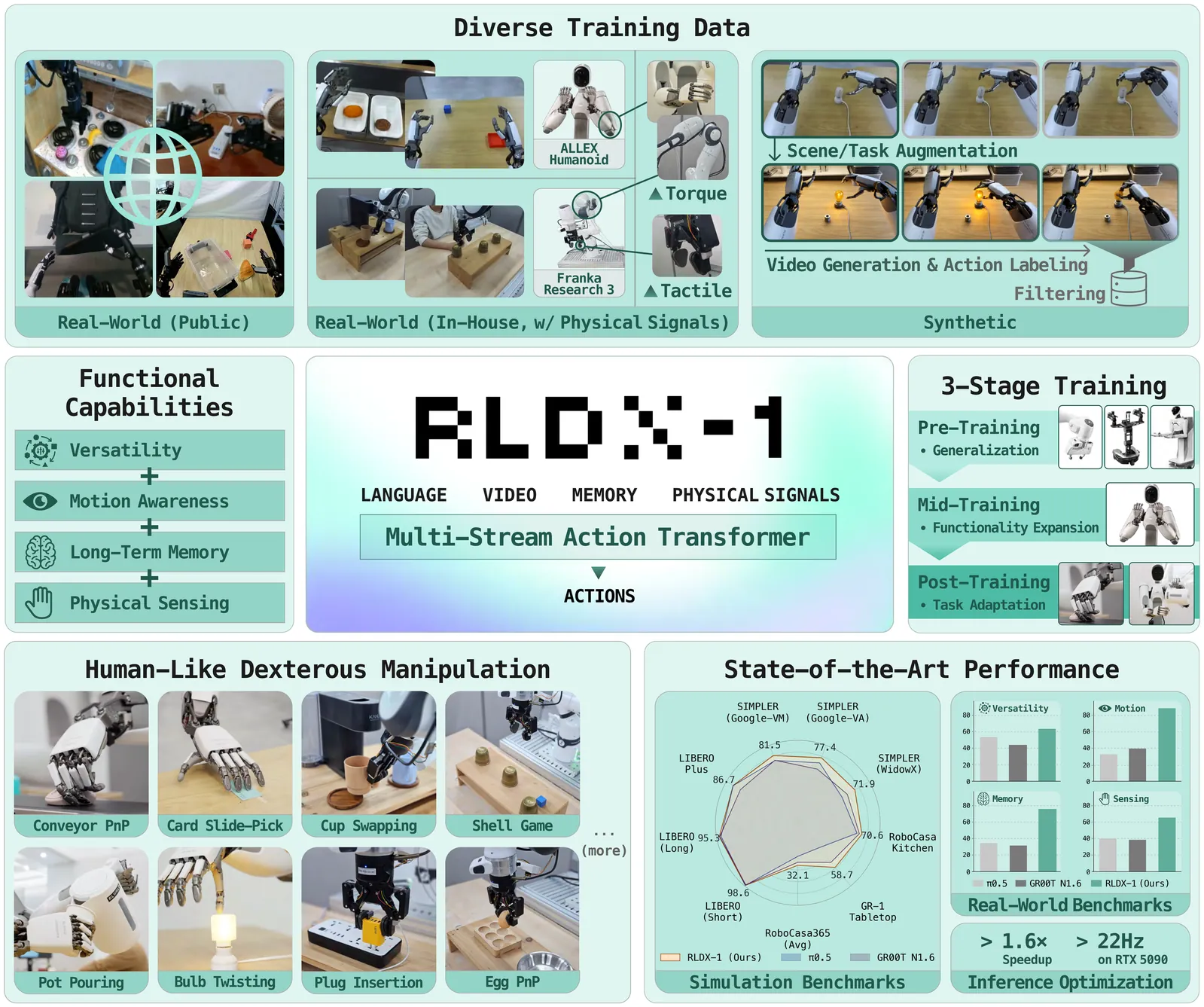
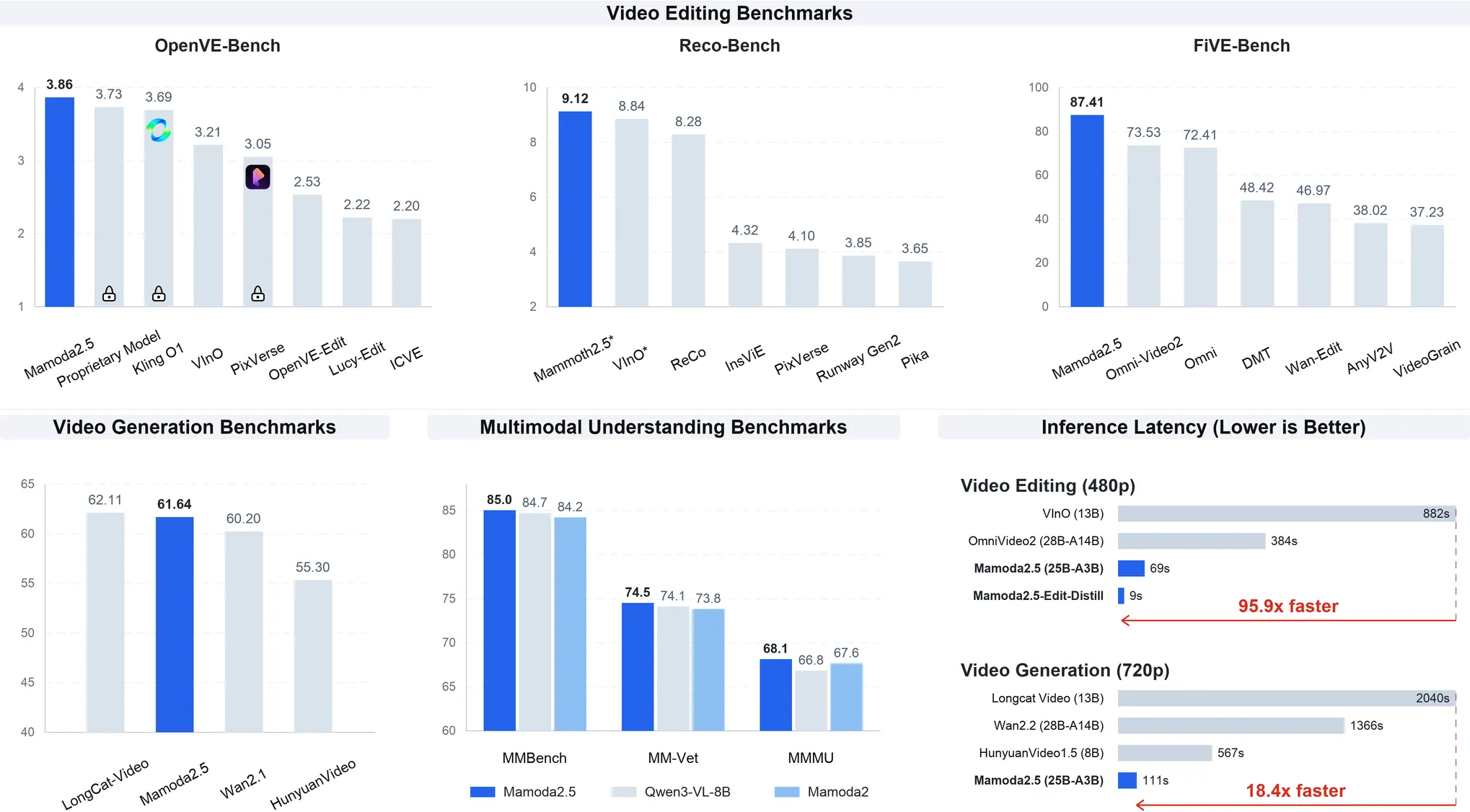
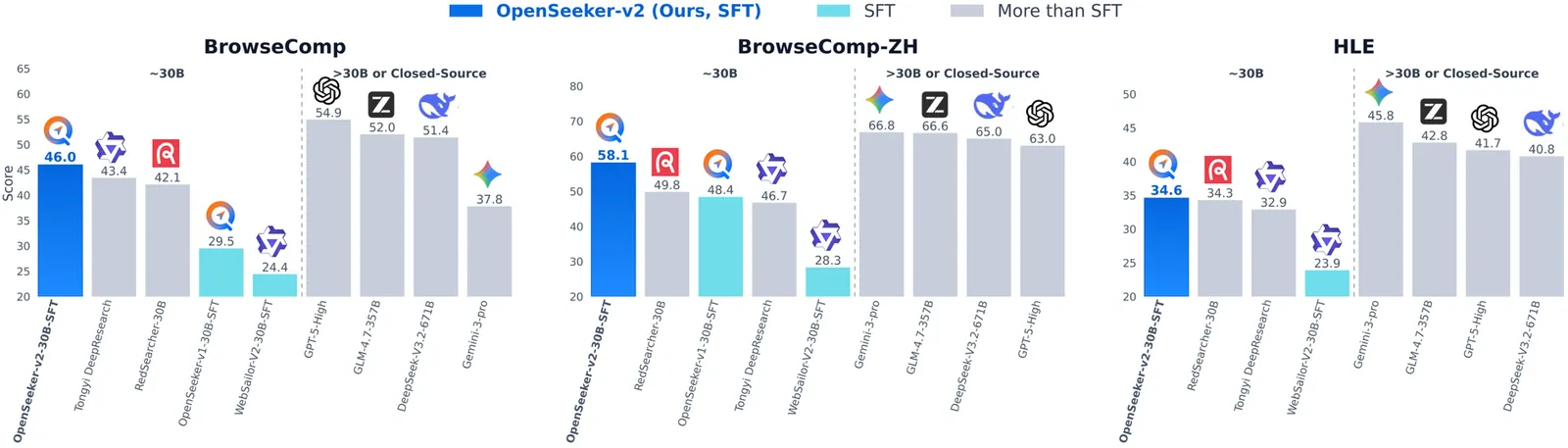
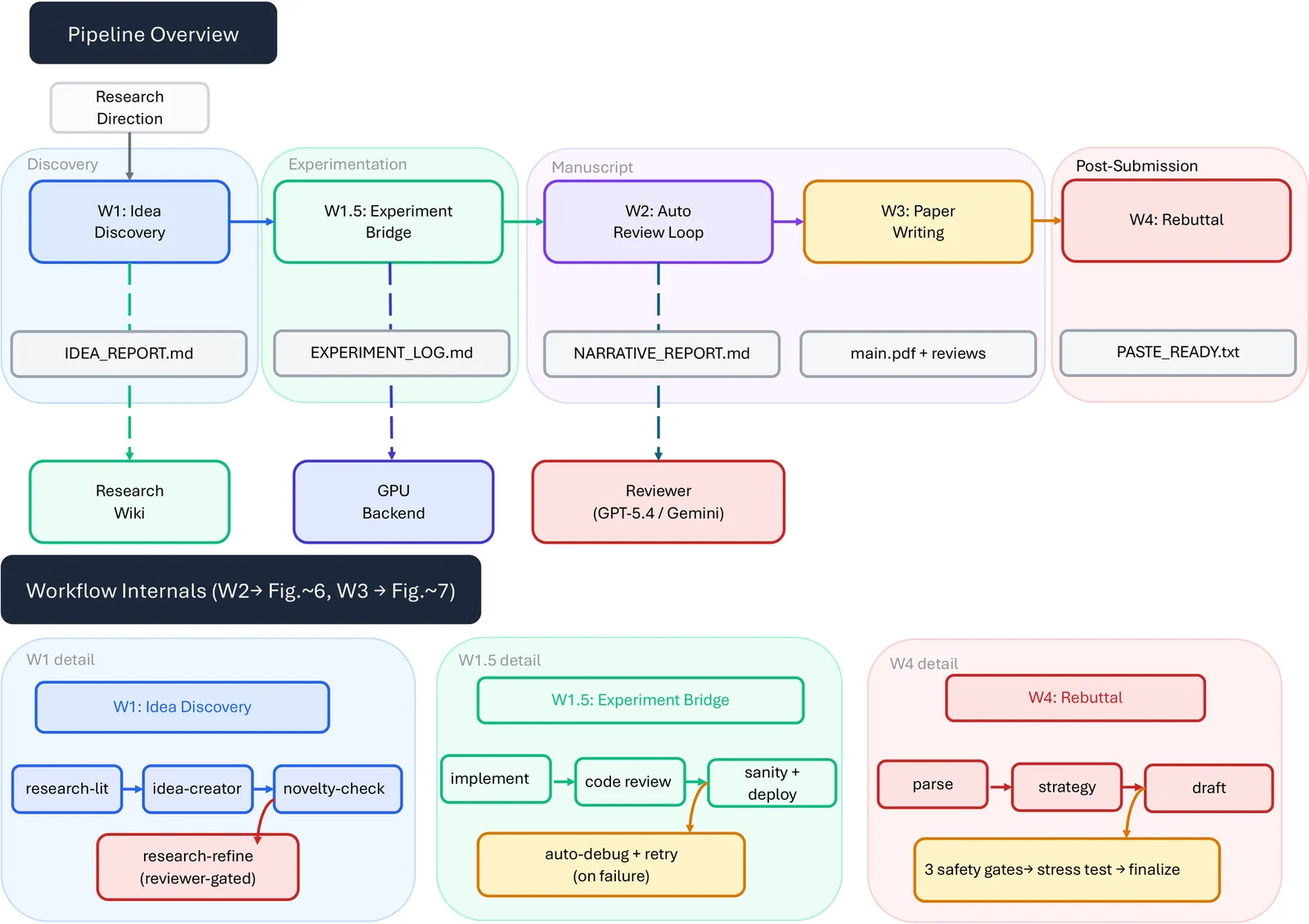
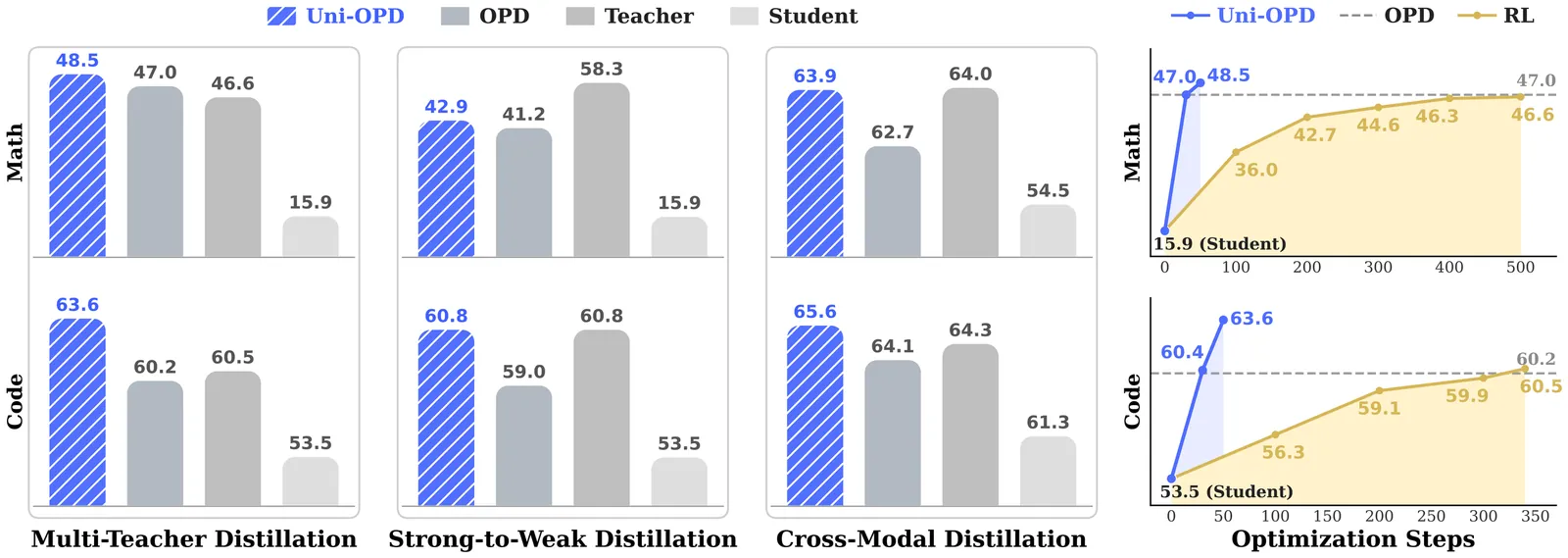
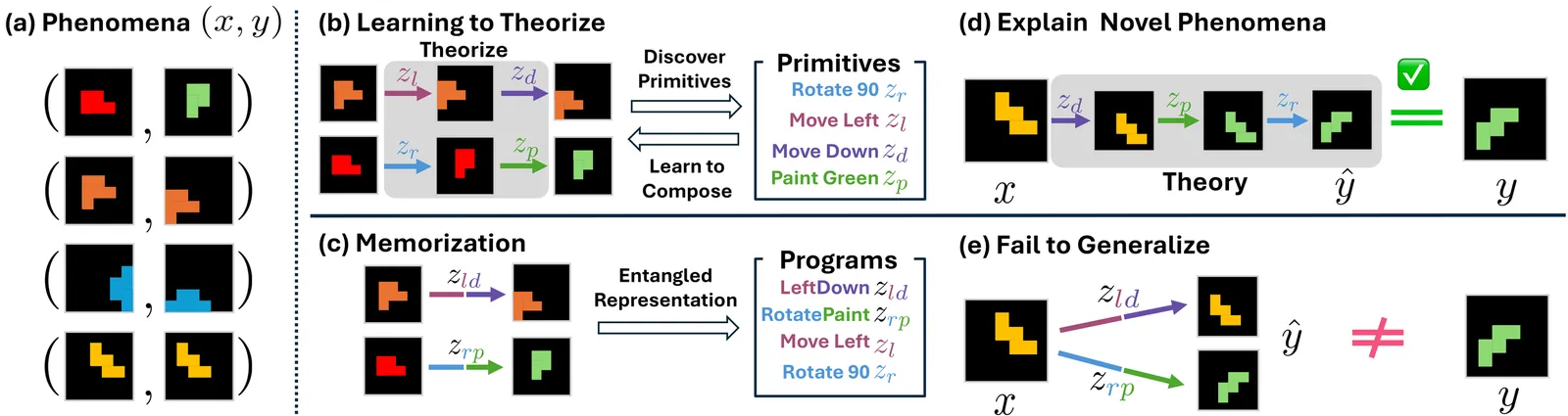
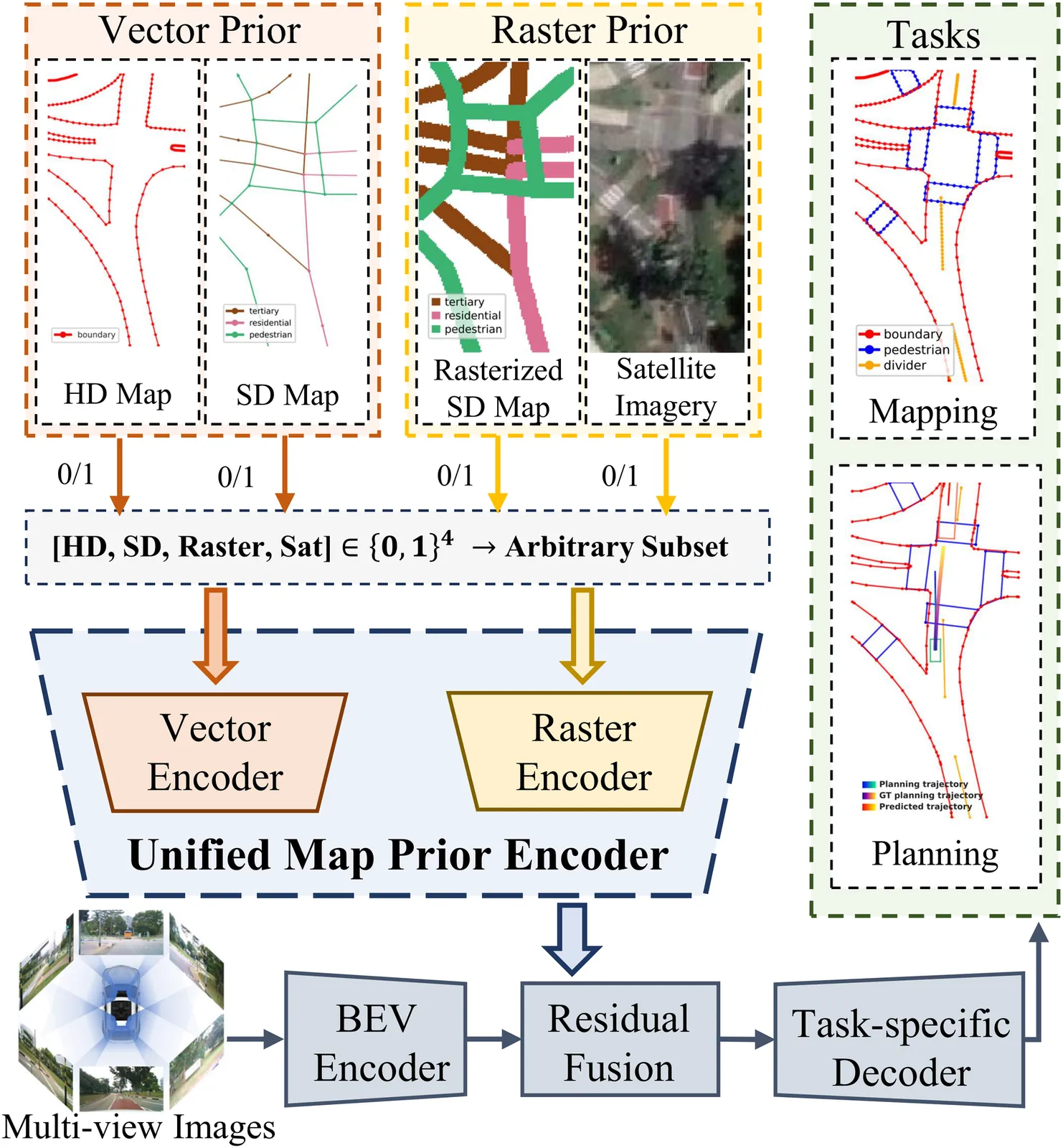
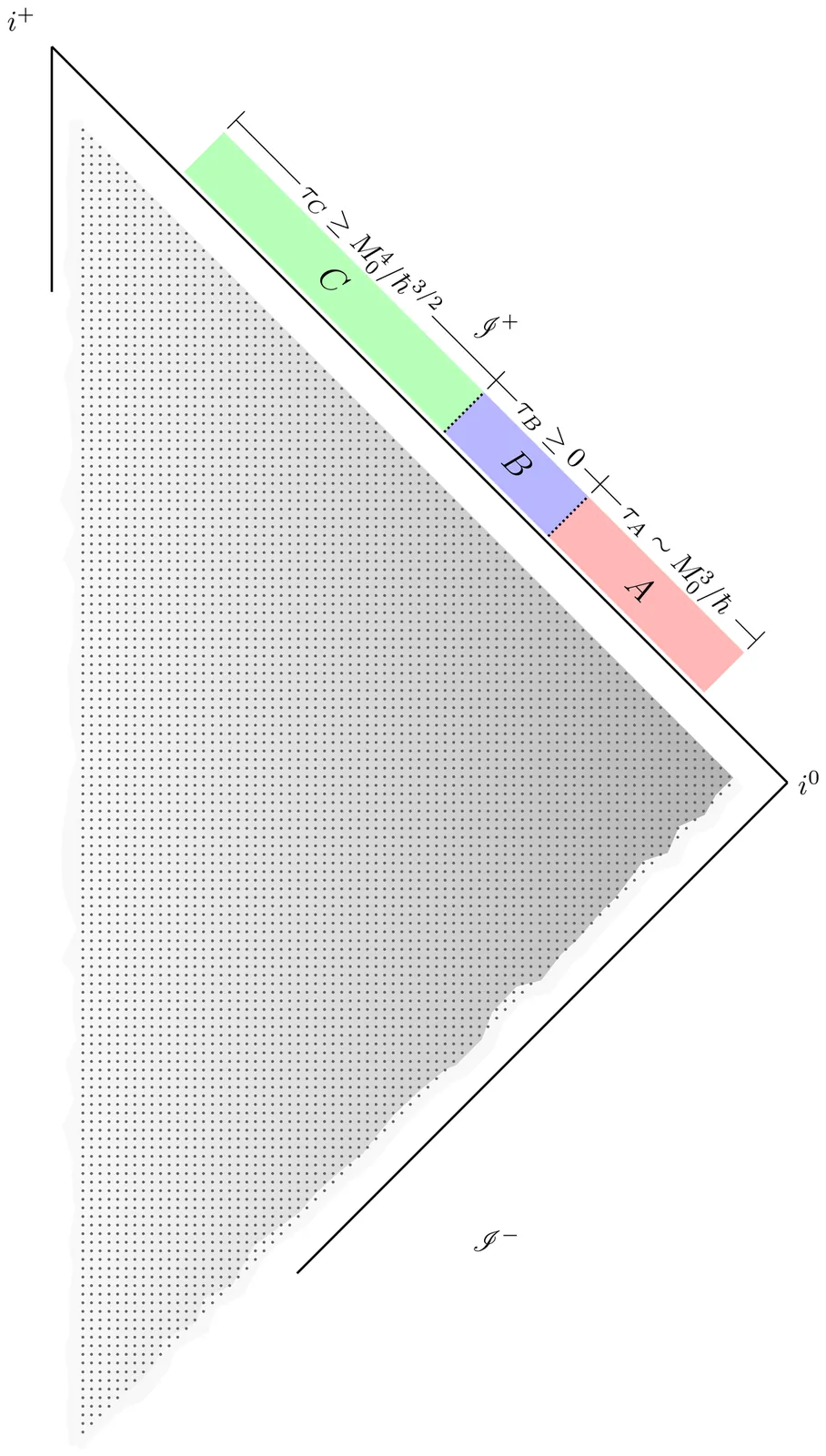
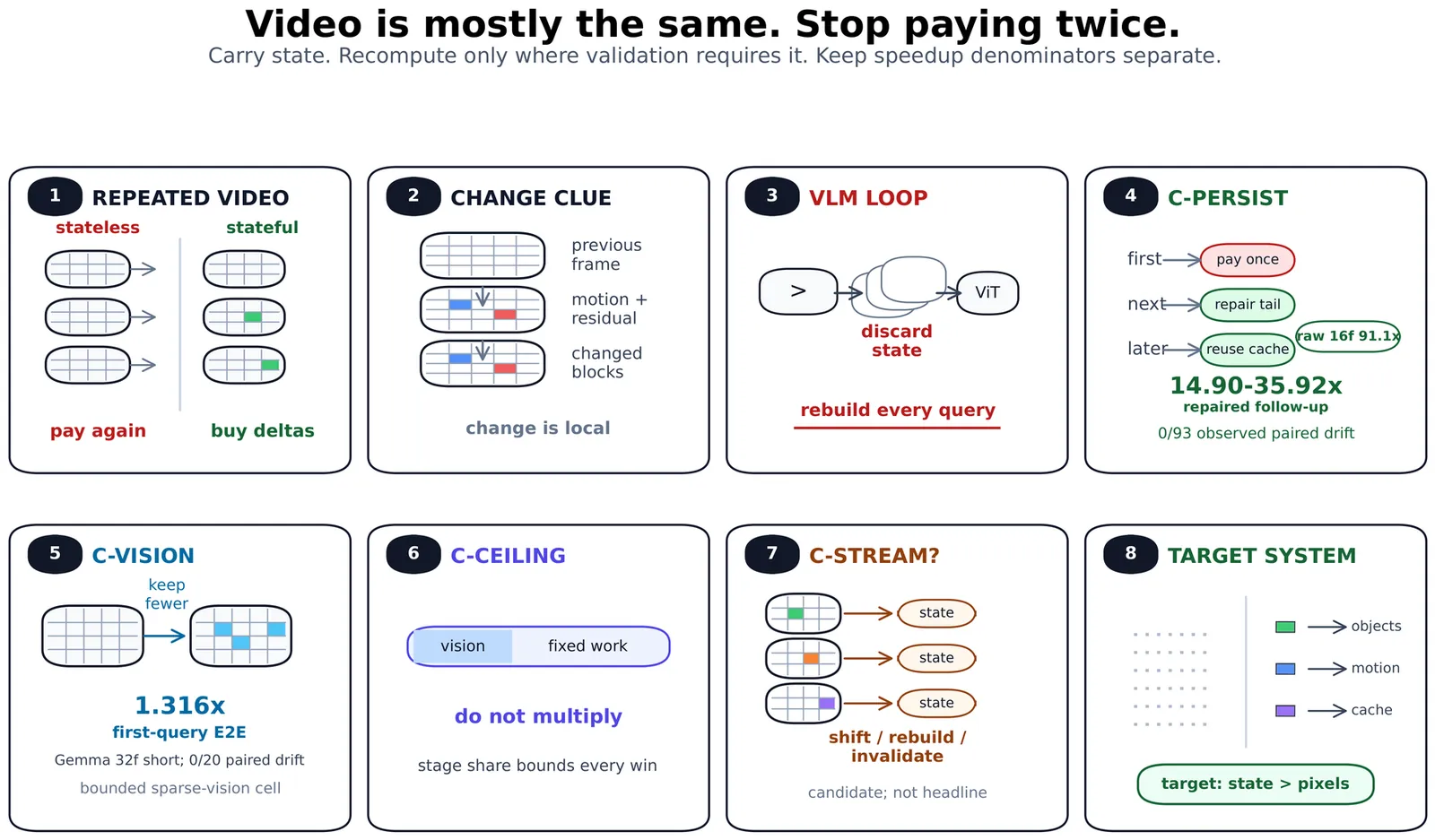
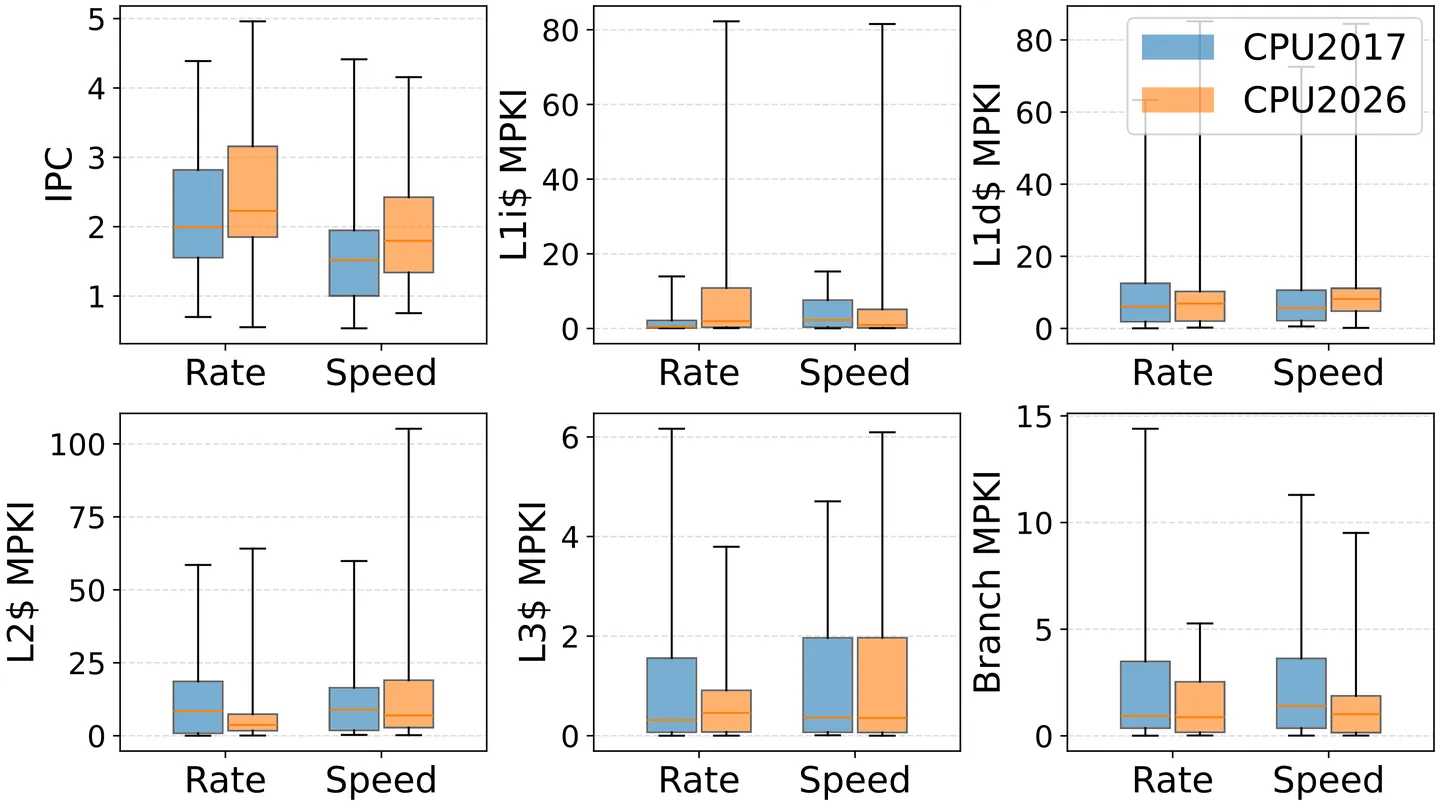
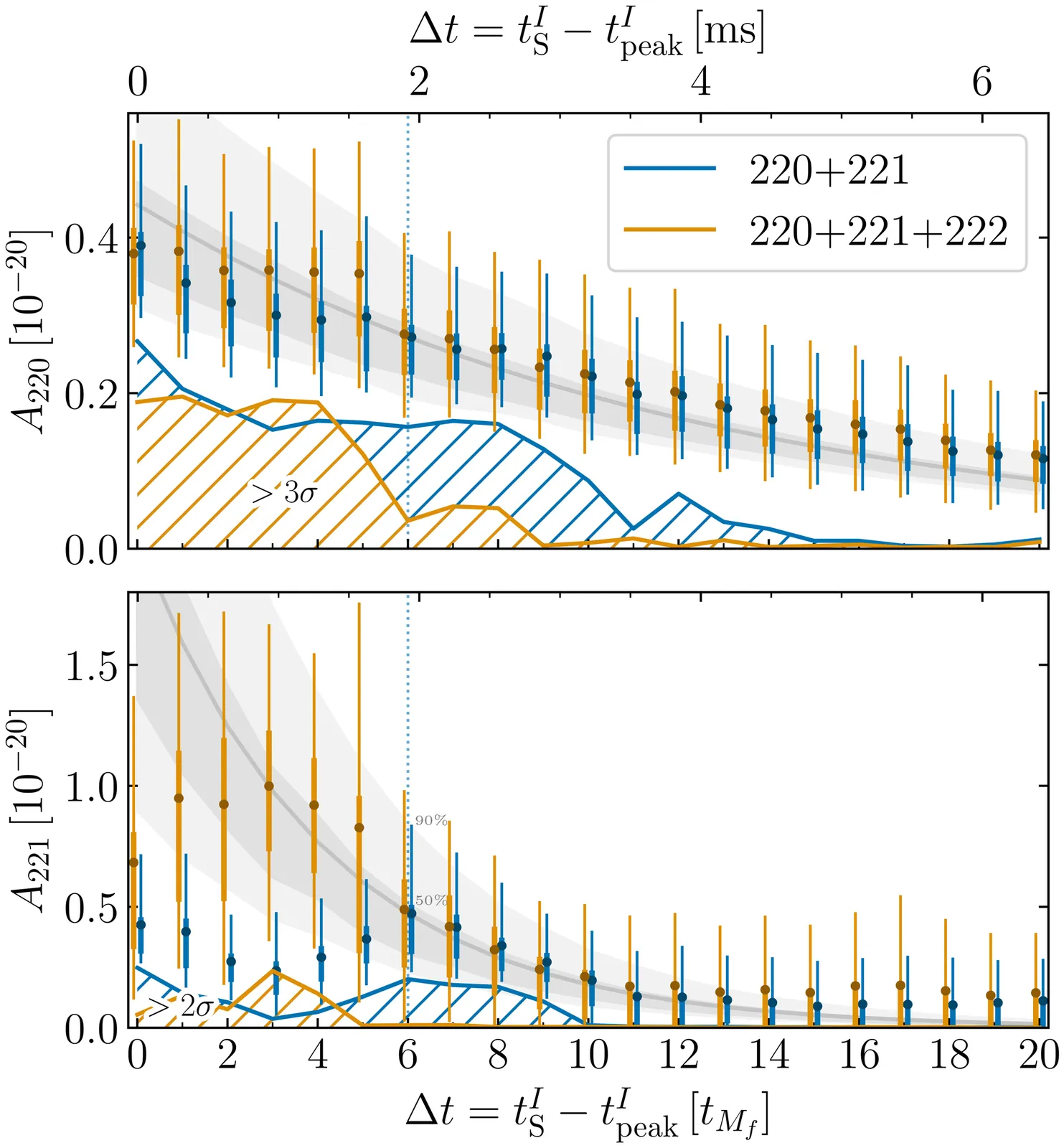
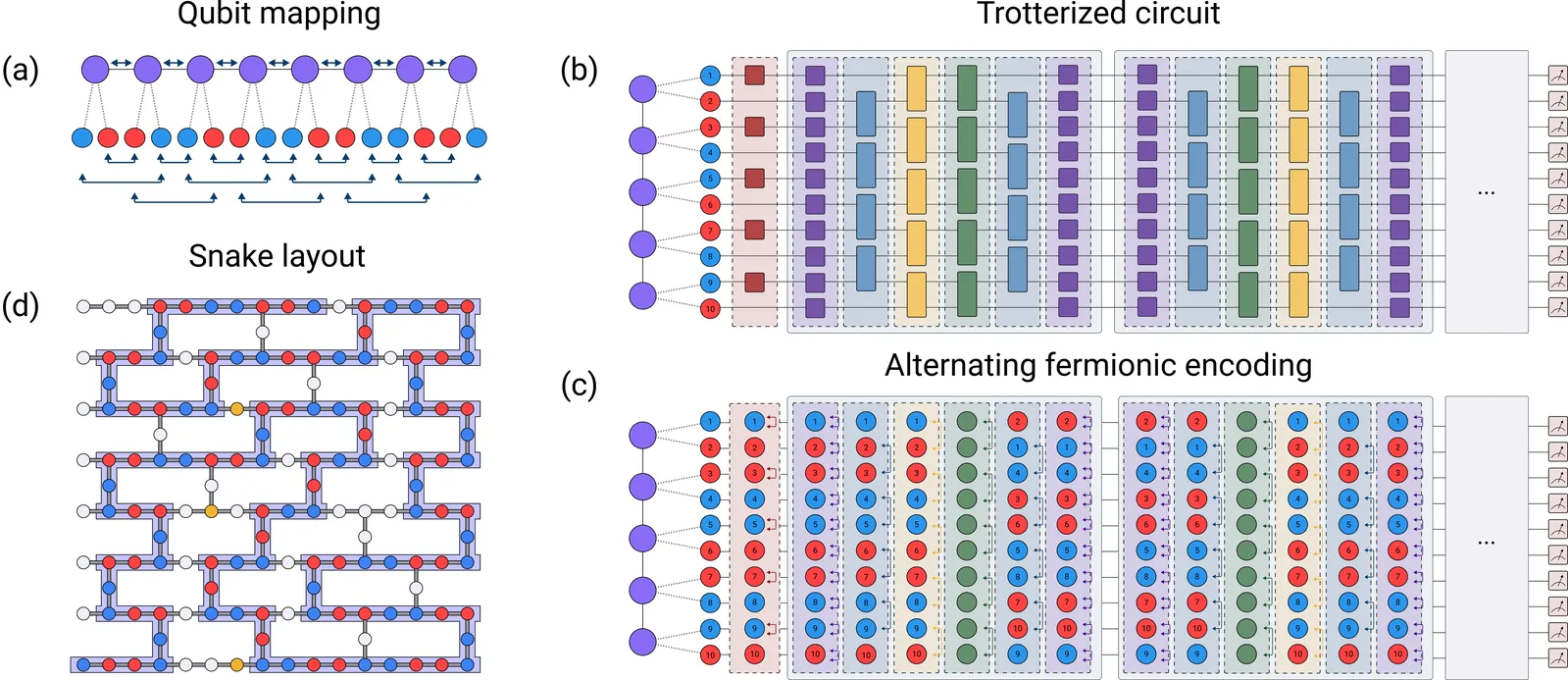
Papers As Code
Query papers like a database. Extract sections, tables, figures, equations. Structured answers, insanely fast.
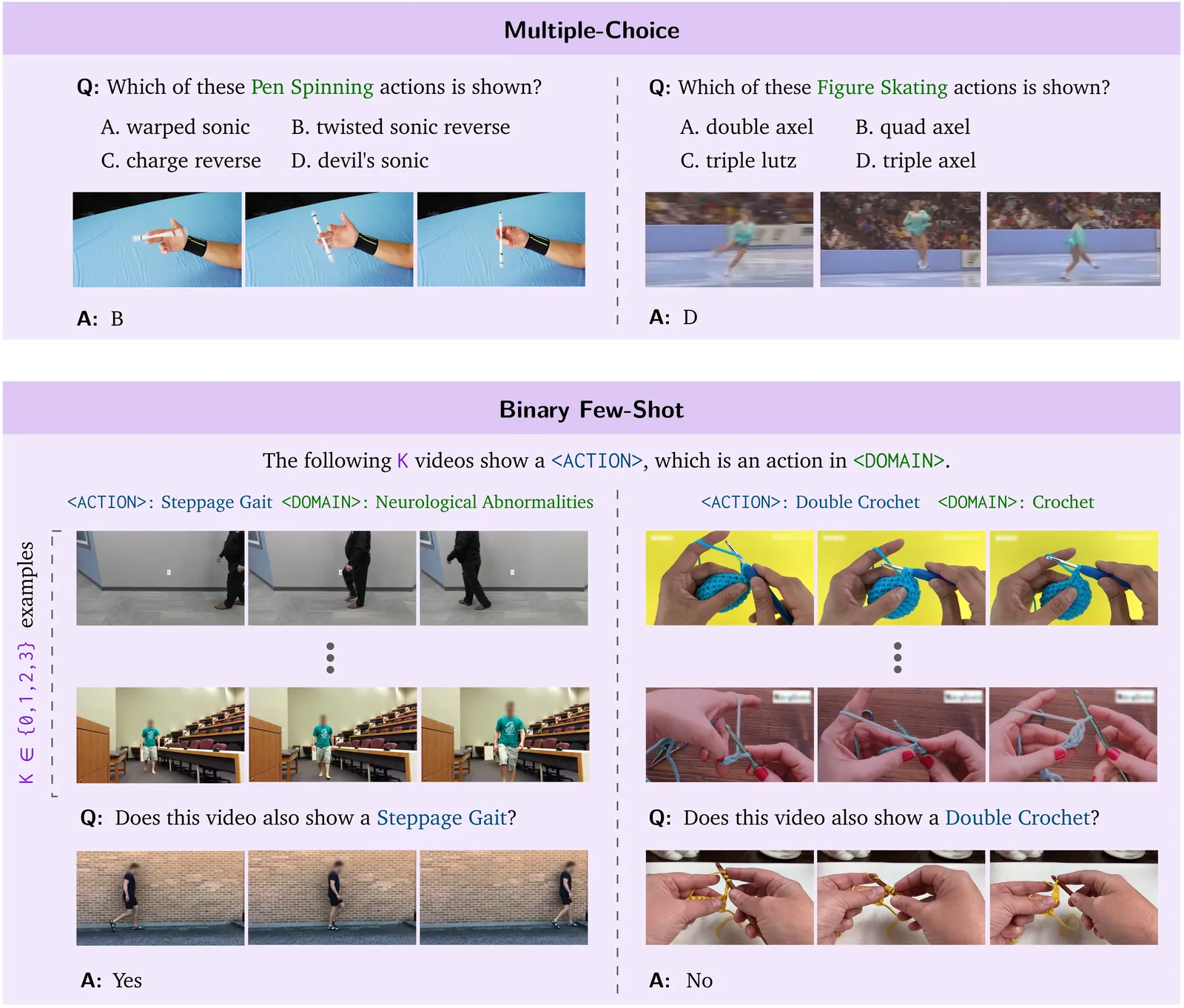
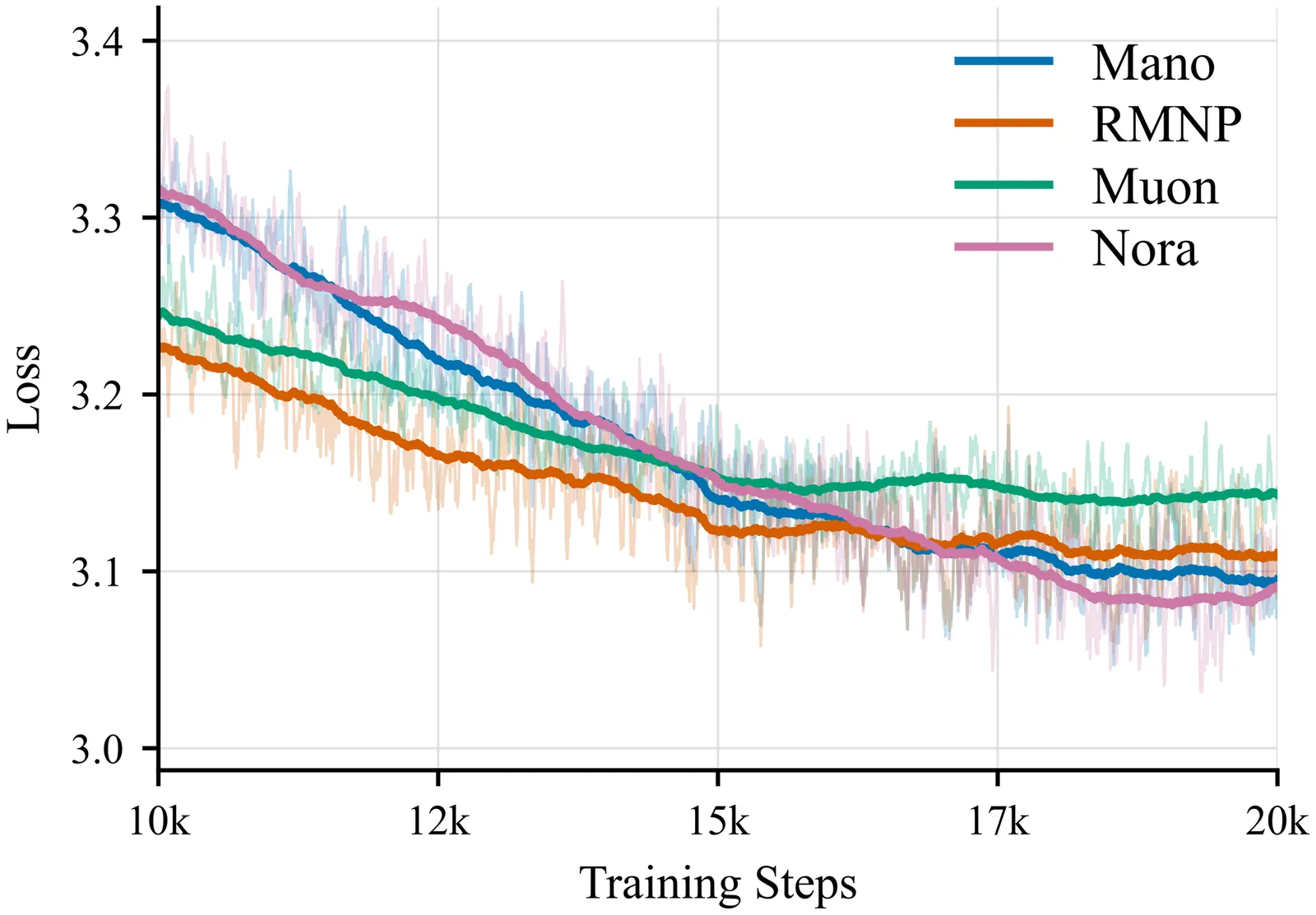
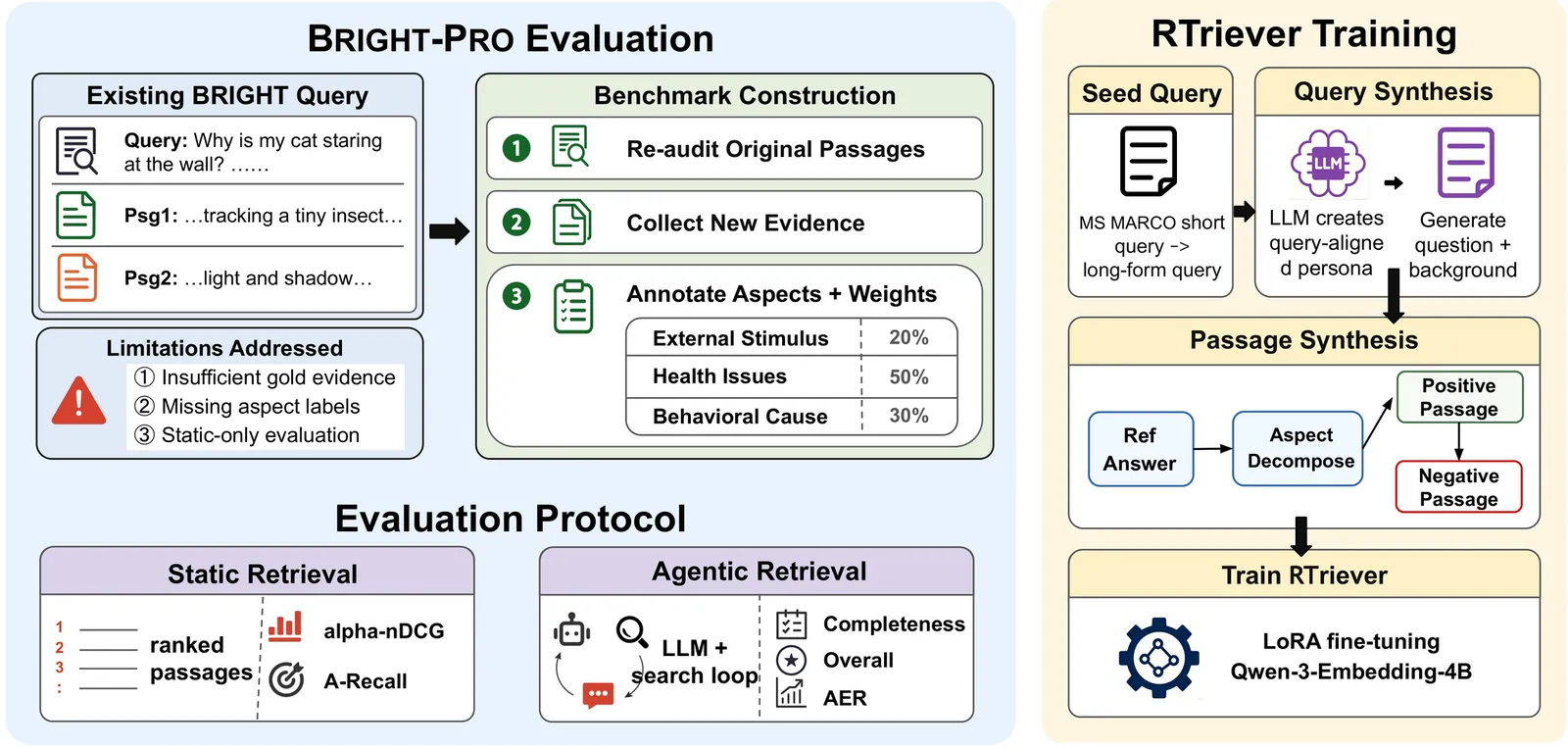
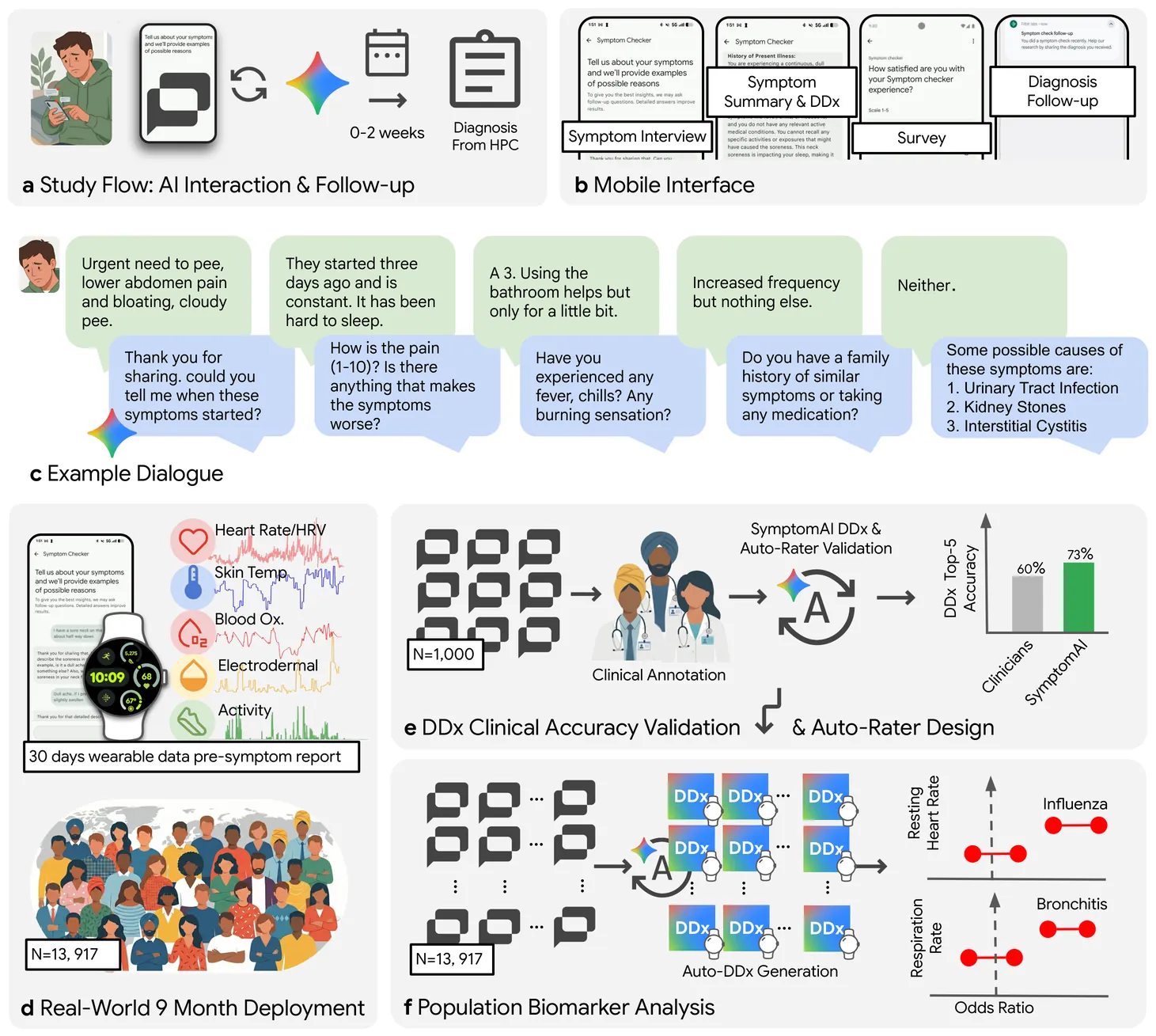
Trending Today
Browse by Field
Machine Learning
3 arXiv categories
Neural networks, deep learning, statistical learning, and optimization methods
Artificial Intelligence
2 arXiv categories
Knowledge representation, reasoning, planning, and multi-agent systems
Natural Language Processing
1 arXiv category
Language models, text understanding, machine translation, and speech
Computer Vision
1 arXiv category
Image recognition, object detection, video understanding, and 3D vision
Computer Graphics
2 arXiv categories
Rendering, simulation, computational geometry, and visual effects
Robotics
2 arXiv categories
Robot perception, control, manipulation, and autonomous systems
Systems & Networking
5 arXiv categories
Distributed systems, databases, networking, operating systems, and performance
Security & Cryptography
1 arXiv category
Cryptography, network security, privacy, and secure systems
Theory & Algorithms
5 arXiv categories
Computational complexity, data structures, algorithms, and game theory
Programming Languages
2 arXiv categories
Language design, compilers, program analysis, and software engineering
Human-Computer Interaction
3 arXiv categories
User interfaces, interaction design, accessibility, and social computing
Information Retrieval
1 arXiv category
Search engines, recommender systems, and web mining