Information Retrieval
arXiv:cs.IR
Covers indexing, dictionaries, retrieval, content and analysis. Roughly includes material in ACM Subject Classes H.3.0-3, H.3.4-5.
Looking for a broader view? This category is part of:
Covers indexing, dictionaries, retrieval, content and analysis. Roughly includes material in ACM Subject Classes H.3.0-3, H.3.4-5.
Looking for a broader view? This category is part of:
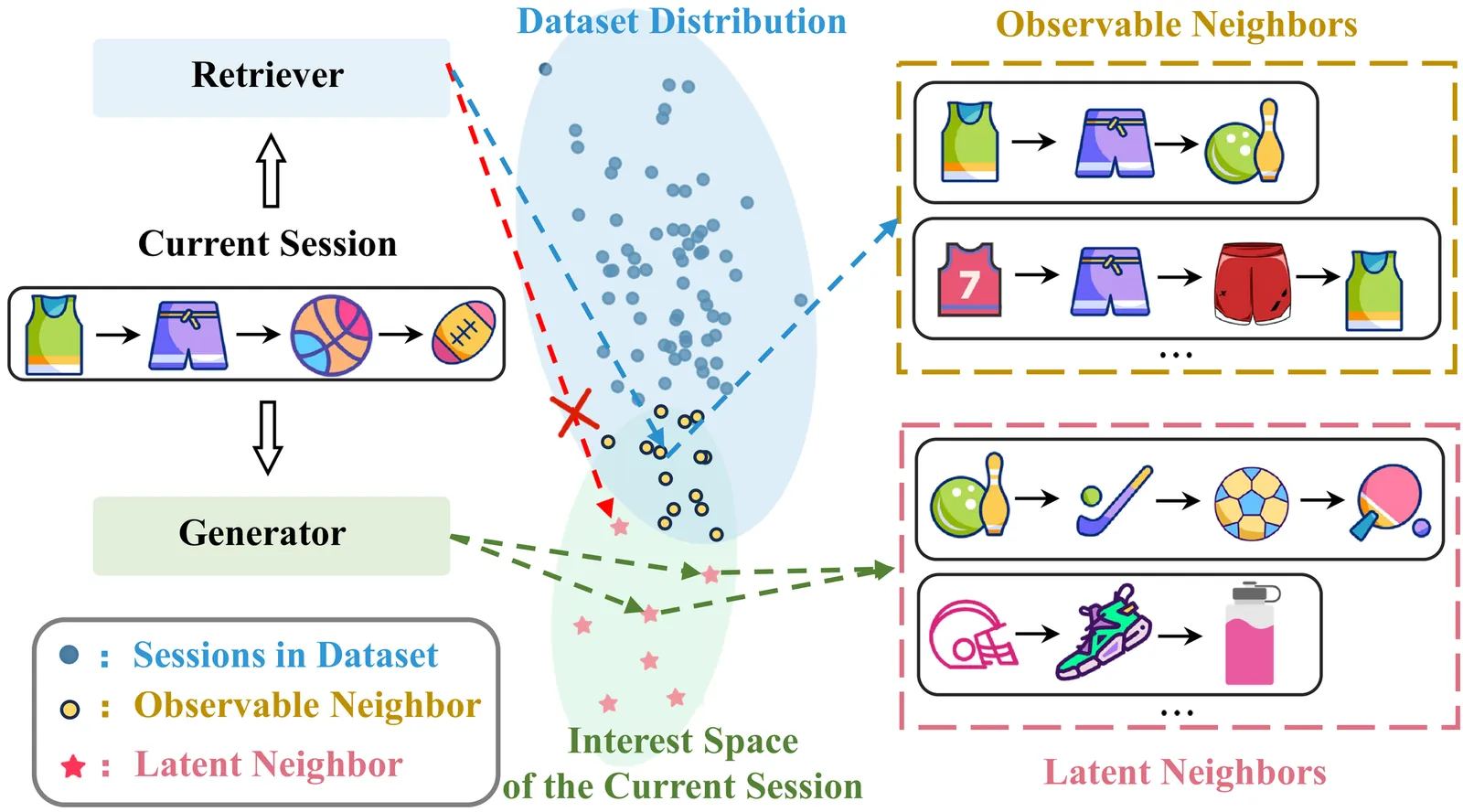
Session-based recommendation aims to predict the next item that anonymous users may be interested in, based on their current session interactions. Recent studies have demonstrated that retrieving neighbor sessions to augment the current session can effectively alleviate the data sparsity issue and improve recommendation performance. However, existing methods typically rely on explicitly observed session data, neglecting latent neighbors - not directly observed but potentially relevant within the interest space - thereby failing to fully exploit the potential of neighbor sessions in recommendation. To address the above limitation, we propose a novel model of diffusion-based latent neighbor generation for session-based recommendation, named DiffSBR. Specifically, DiffSBR leverages two diffusion modules, including retrieval-augmented diffusion and self-augmented diffusion, to generate high-quality latent neighbors. In the retrieval-augmented diffusion module, we leverage retrieved neighbors as guiding signals to constrain and reconstruct the distribution of latent neighbors. Meanwhile, we adopt a training strategy that enables the retriever to learn from the feedback provided by the generator. In the self-augmented diffusion module, we explicitly guide the generation of latent neighbors by injecting the current session's multi-modal signals through contrastive learning. After obtaining the generated latent neighbors, we utilize them to enhance session representations for improving session-based recommendation. Extensive experiments on four public datasets show that DiffSBR generates effective latent neighbors and improves recommendation performance against state-of-the-art baselines.
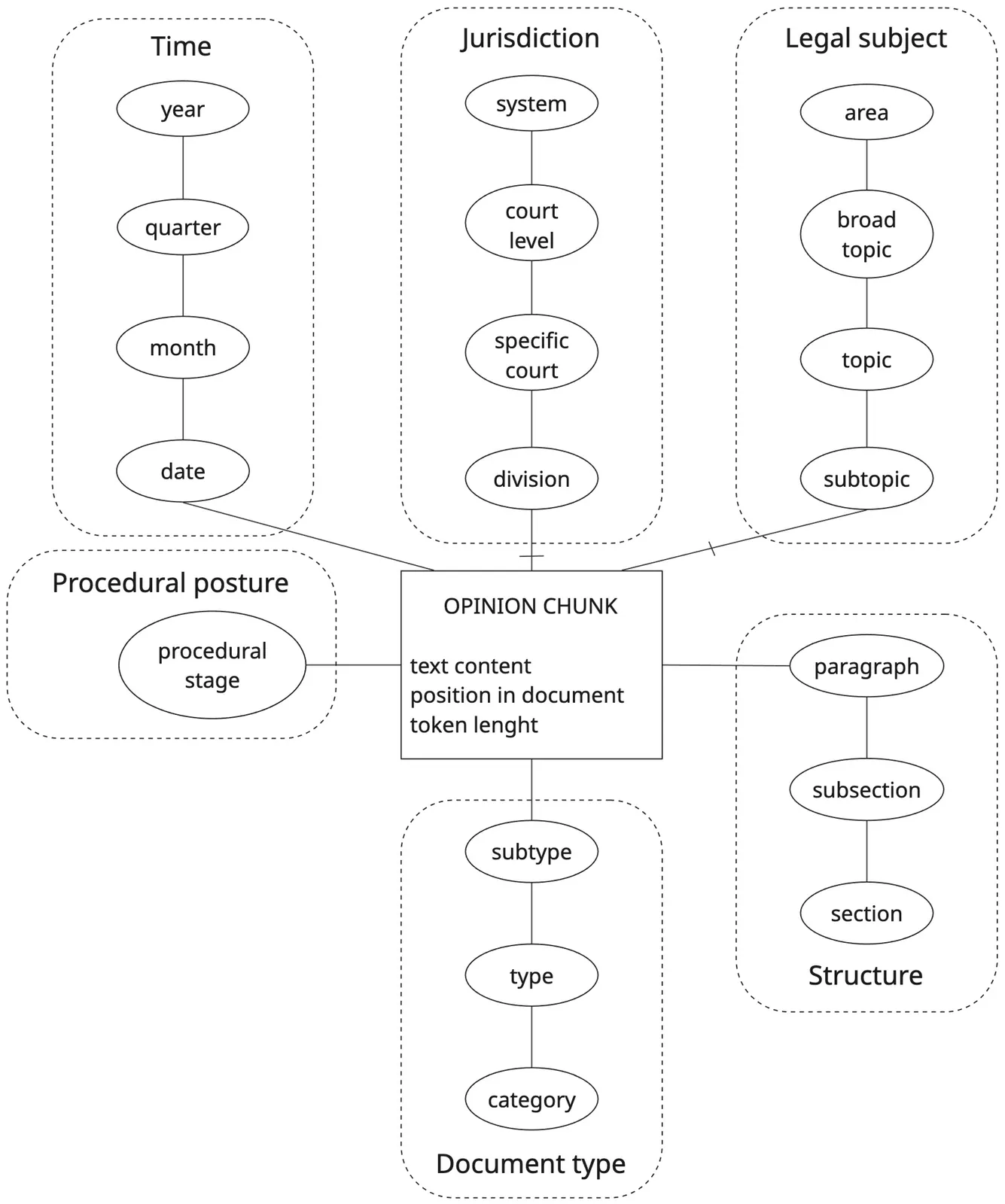
Retrieval-Augmented Generation (RAG) systems are increasingly deployed on large-scale document collections, often comprising millions of documents and tens of millions of text chunks. In industrial-scale retrieval platforms, scalability is typically addressed through horizontal sharding and a combination of Approximate Nearest-Neighbor search, hybrid indexing, and optimized metadata filtering. Although effective from an efficiency perspective, these mechanisms rely on bottom-up, similarity-driven organization and lack a conceptual rationale for corpus partitioning. In this paper, we claim that the design of large-scale RAG systems may benefit from the combination of two orthogonal strategies: semantic clustering, which optimizes locality in embedding space, and multidimensional partitioning, which governs where retrieval should occur based on conceptual dimensions such as time and organizational context. Although such dimensions are already implicitly present in current systems, they are used in an ad hoc and poorly structured manner. We propose the Dimensional Fact Model (DFM) as a conceptual framework to guide the design of multidimensional partitions for RAG corpora. The DFM provides a principled way to reason about facts, dimensions, hierarchies, and granularity in retrieval-oriented settings. This framework naturally supports hierarchical routing and controlled fallback strategies, ensuring that retrieval remains robust even in the presence of incomplete metadata, while transforming the search process from a 'black-box' similarity matching into a governable and deterministic workflow. This work is intended as a position paper; its goal is to bridge the gap between OLAP-style multidimensional modeling and modern RAG architectures, and to stimulate further research on principled, explainable, and governable retrieval strategies at scale.
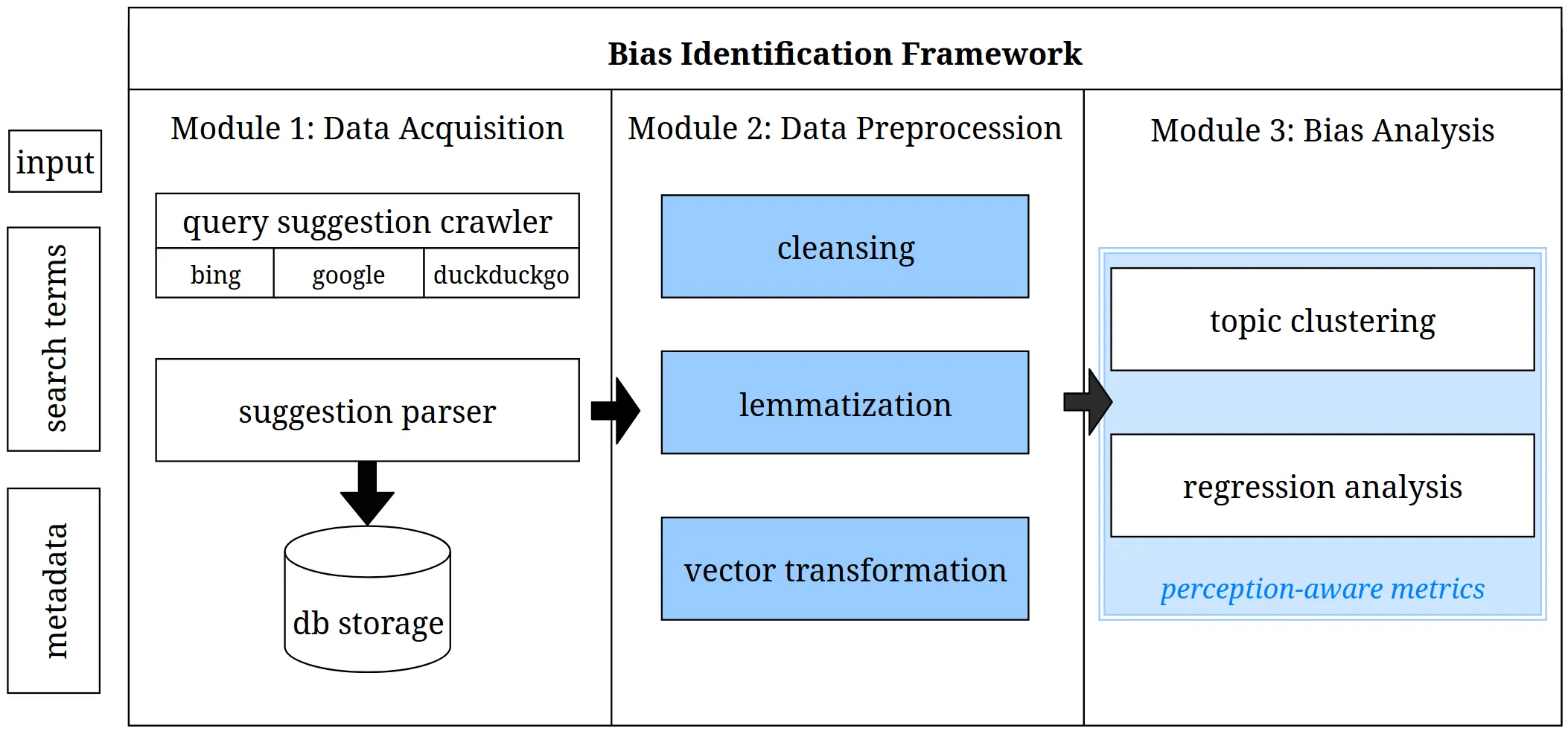
Bias in web search has been in the spotlight of bias detection research for quite a while. At the same time, little attention has been paid to query suggestions in this regard. Awareness of the problem of biased query suggestions has been raised. Likewise, there is a rising need for automatic bias detection approaches. This paper adds on the bias detection pipeline for bias detection in query suggestions of person-related search developed by Bonart et al. \cite{Bonart_2019a}. The sparseness and lack of contextual metadata of query suggestions make them a difficult subject for bias detection. Furthermore, query suggestions are perceived very briefly and subliminally. To overcome these issues, perception-aware metrics are introduced. Consequently, the enhanced pipeline is able to better detect systematic topical bias in search engine query suggestions for person-related searches. The results of an analysis performed with the developed pipeline confirm this assumption. Due to the perception-aware bias detection metrics, findings produced by the pipeline can be assumed to reflect bias that users would discern.
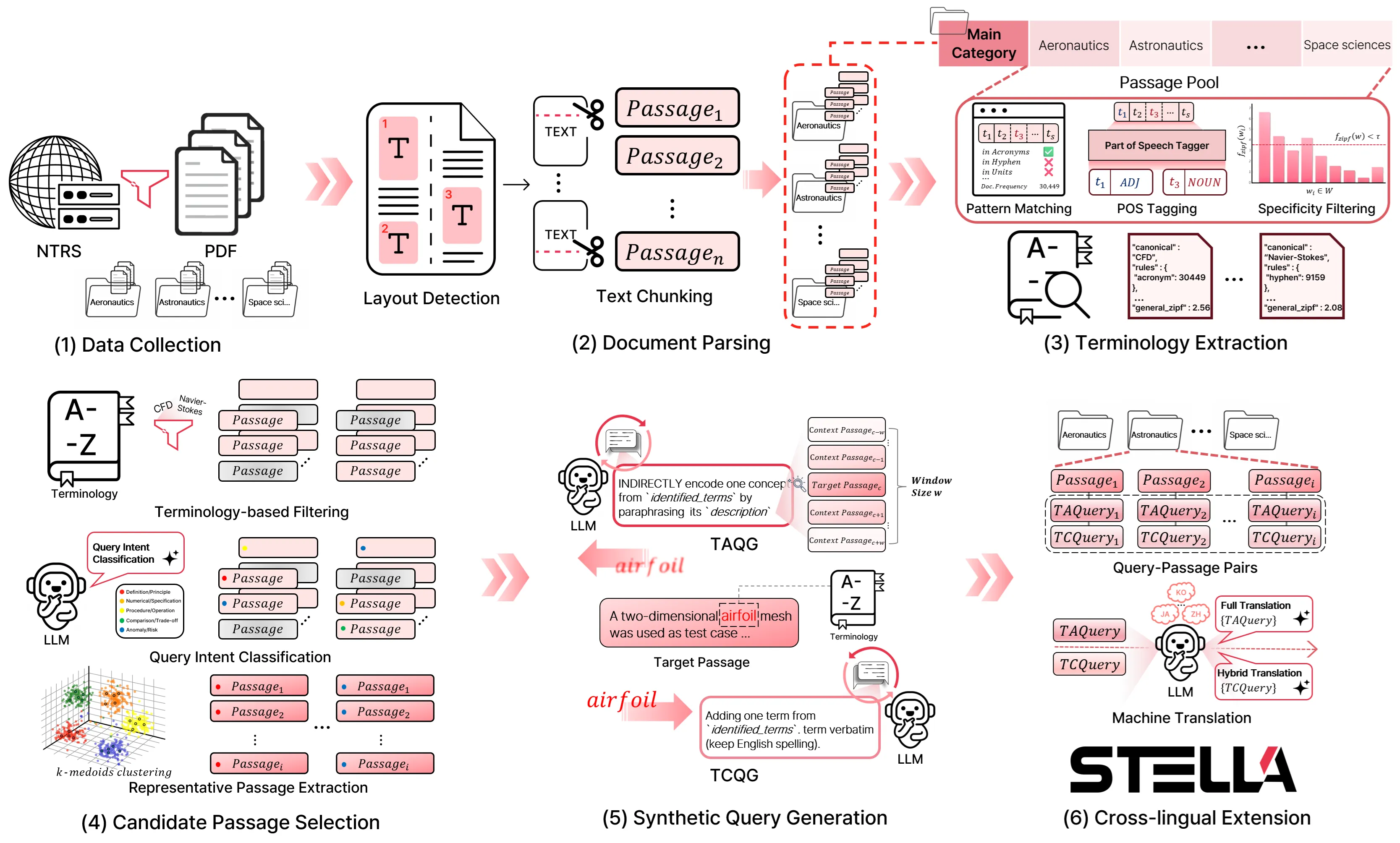
Tasks in the aerospace industry heavily rely on searching and reusing large volumes of technical documents, yet there is no public information retrieval (IR) benchmark that reflects the terminology- and query-intent characteristics of this domain. To address this gap, this paper proposes the STELLA (Self-Reflective TErminoLogy-Aware Framework for BuiLding an Aerospace Information Retrieval Benchmark) framework. Using this framework, we introduce the STELLA benchmark, an aerospace-specific IR evaluation set constructed from NASA Technical Reports Server (NTRS) documents via a systematic pipeline that comprises document layout detection, passage chunking, terminology dictionary construction, synthetic query generation, and cross-lingual extension. The framework generates two types of queries: the Terminology Concordant Query (TCQ), which includes the terminology verbatim to evaluate lexical matching, and the Terminology Agnostic Query (TAQ), which utilizes the terminology's description to assess semantic matching. This enables a disentangled evaluation of the lexical and semantic matching capabilities of embedding models. In addition, we combine Chain-of-Density (CoD) and the Self-Reflection method with query generation to improve quality and implement a hybrid cross-lingual extension that reflects real user querying practices. Evaluation of seven embedding models on the STELLA benchmark shows that large decoder-based embedding models exhibit the strongest semantic understanding, while lexical matching methods such as BM25 remain highly competitive in domains where exact lexical matching technical term is crucial. The STELLA benchmark provides a reproducible foundation for reliable performance evaluation and improvement of embedding models in aerospace-domain IR tasks. The STELLA benchmark can be found in https://huggingface.co/datasets/telepix/STELLA.
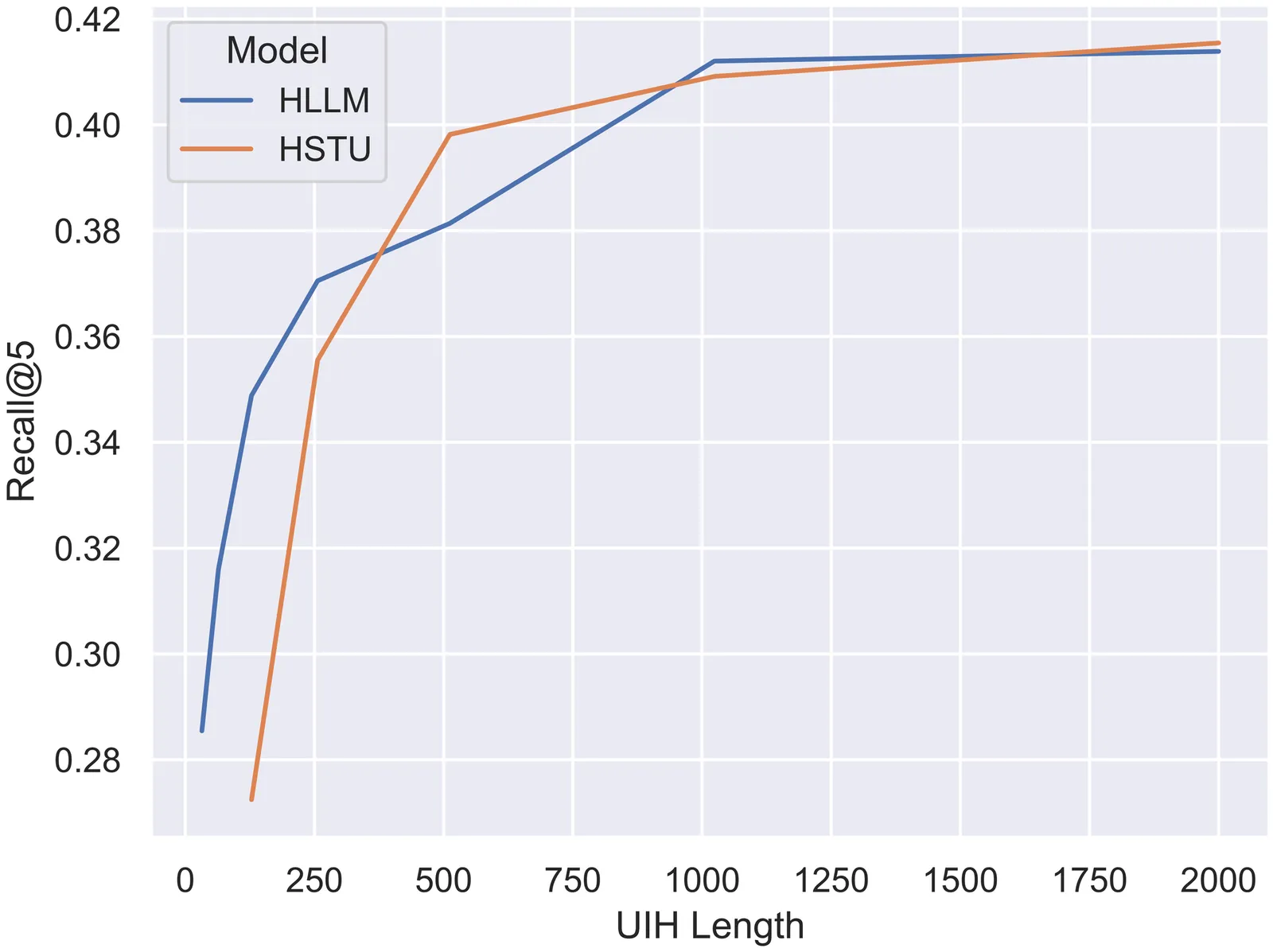
Recent years have witnessed success of sequential modeling, generative recommender, and large language model for recommendation. Though the scaling law has been validated for sequential models, it showed inefficiency in computational capacity when considering real-world applications like recommendation, due to the non-linear(quadratic) increasing nature of the transformer model. To improve the efficiency of the sequential model, we introduced a novel approach to sequential recommendation that leverages personalization techniques to enhance efficiency and performance. Our method compresses long user interaction histories into learnable tokens, which are then combined with recent interactions to generate recommendations. This approach significantly reduces computational costs while maintaining high recommendation accuracy. Our method could be applied to existing transformer based recommendation models, e.g., HSTU and HLLM. Extensive experiments on multiple sequential models demonstrate its versatility and effectiveness. Source code is available at \href{https://github.com/facebookresearch/PerSRec}{https://github.com/facebookresearch/PerSRec}.
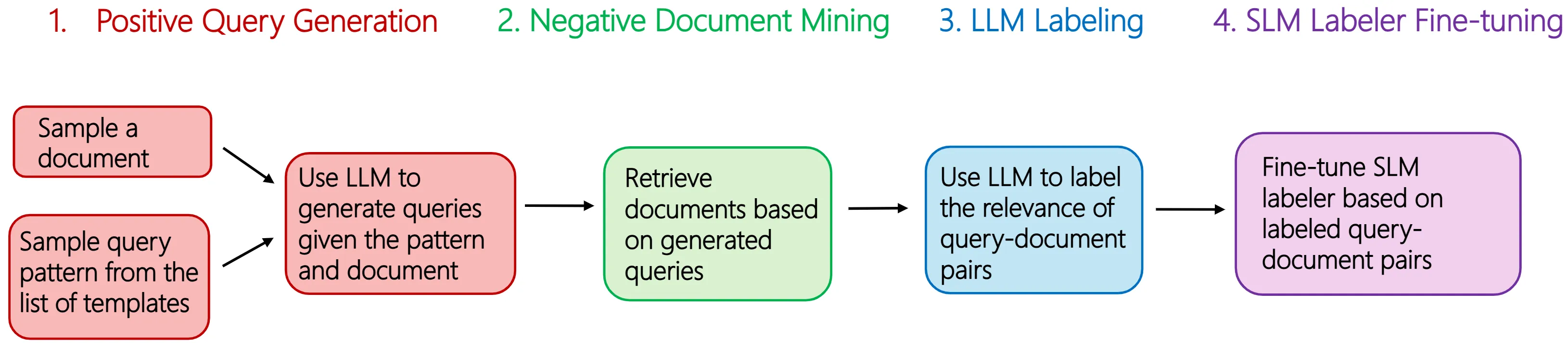
In enterprise search, building high-quality datasets at scale remains a central challenge due to the difficulty of acquiring labeled data. To resolve this challenge, we propose an efficient approach to fine-tune small language models (SLMs) for accurate relevance labeling, enabling high-throughput, domain-specific labeling comparable or even better in quality to that of state-of-the-art large language models (LLMs). To overcome the lack of high-quality and accessible datasets in the enterprise domain, our method leverages on synthetic data generation. Specifically, we employ an LLM to synthesize realistic enterprise queries from a seed document, apply BM25 to retrieve hard negatives, and use a teacher LLM to assign relevance scores. The resulting dataset is then distilled into an SLM, producing a compact relevance labeler. We evaluate our approach on a high-quality benchmark consisting of 923 enterprise query-document pairs annotated by trained human annotators, and show that the distilled SLM achieves agreement with human judgments on par with or better than the teacher LLM. Furthermore, our fine-tuned labeler substantially improves throughput, achieving 17 times increase while also being 19 times more cost-effective. This approach enables scalable and cost-effective relevance labeling for enterprise-scale retrieval applications, supporting rapid offline evaluation and iteration in real-world settings.
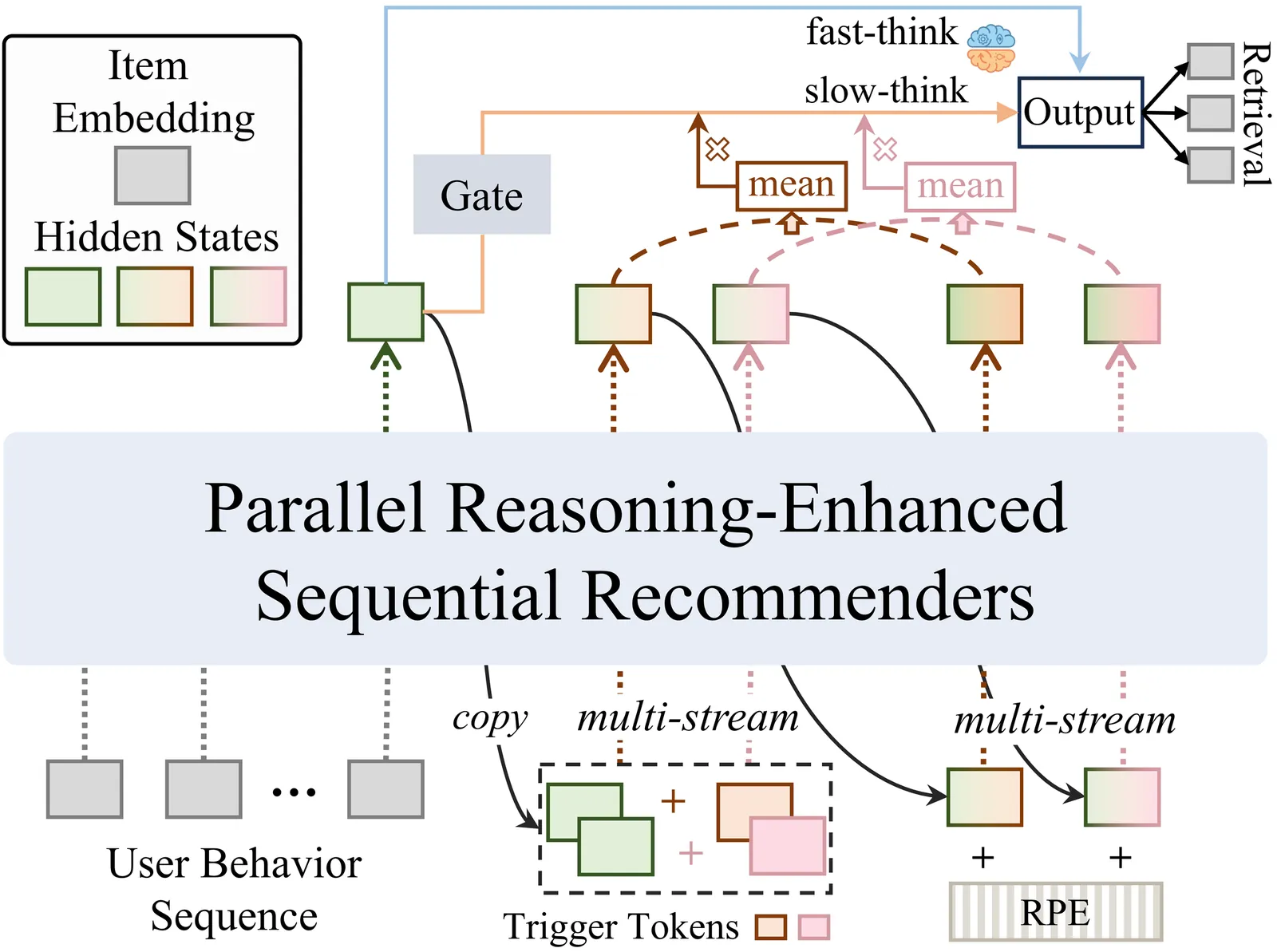
Capturing complex user preferences from sparse behavioral sequences remains a fundamental challenge in sequential recommendation. Recent latent reasoning methods have shown promise by extending test-time computation through multi-step reasoning, yet they exclusively rely on depth-level scaling along a single trajectory, suffering from diminishing returns as reasoning depth increases. To address this limitation, we propose \textbf{Parallel Latent Reasoning (PLR)}, a novel framework that pioneers width-level computational scaling by exploring multiple diverse reasoning trajectories simultaneously. PLR constructs parallel reasoning streams through learnable trigger tokens in continuous latent space, preserves diversity across streams via global reasoning regularization, and adaptively synthesizes multi-stream outputs through mixture-of-reasoning-streams aggregation. Extensive experiments on three real-world datasets demonstrate that PLR substantially outperforms state-of-the-art baselines while maintaining real-time inference efficiency. Theoretical analysis further validates the effectiveness of parallel reasoning in improving generalization capability. Our work opens new avenues for enhancing reasoning capacity in sequential recommendation beyond existing depth scaling.
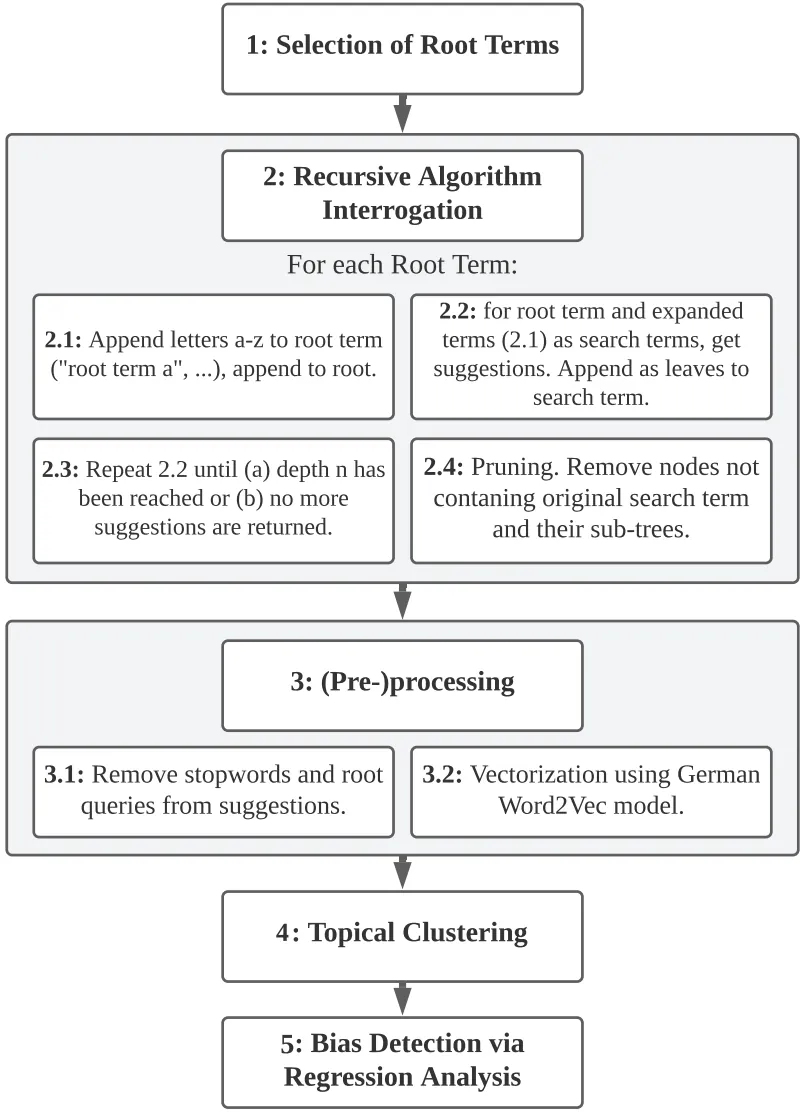
Despite their important role in online information search, search query suggestions have not been researched as much as most other aspects of search engines. Although reasons for this are multi-faceted, the sparseness of context and the limited data basis of up to ten suggestions per search query pose the most significant problem in identifying bias in search query suggestions. The most proven method to reduce sparseness and improve the validity of bias identification of search query suggestions so far is to consider suggestions from subsequent searches over time for the same query. This work presents a new, alternative approach to search query bias identification that includes less high-level suggestions to deepen the data basis of bias analyses. We employ recursive algorithm interrogation techniques and create suggestion trees that enable access to more subliminal search query suggestions. Based on these suggestions, we investigate topical group bias in person-related searches in the political domain.

Recommendation for live-streaming e-commerce is gaining increasing attention due to the explosive growth of the live streaming economy. Different from traditional e-commerce, live-streaming e-commerce shifts the focus from products to streamers, which requires ranking mechanism to balance both purchases and user-streamer interactions for long-term ecology. To trade off multiple objectives, a popular solution is to build an ensemble model to integrate multi-objective scores into a unified score. The ensemble model is usually supervised by multiple independent binary classification losses of all objectives. However, this paradigm suffers from two inherent limitations. First, the optimization direction of the binary classification task is misaligned with the ranking task (evaluated by AUC). Second, this paradigm overlooks the alignment between objectives, e.g., comment and buy behaviors are partially dependent which can be revealed in labels correlations. The model can achieve better trade-offs if it learns the aligned parts of ranking abilities among different objectives. To mitigate these limitations, we propose a novel multi-objective ensemble framework HarmonRank to fulfill both alignment to the ranking task and alignment among objectives. For alignment to ranking, we formulate ranking metric AUC as a rank-sum problem and utilize differentiable ranking techniques for ranking-oriented optimization. For inter-objective alignment, we change the original one-step ensemble paradigm to a two-step relation-aware ensemble scheme. Extensive offline experiments results on two industrial datasets and online experiments demonstrate that our approach significantly outperforms existing state-of-the-art methods. The proposed method has been fully deployed in Kuaishou's live-streaming e-commerce recommendation platform with 400 million DAUs, contributing over 2% purchase gain.
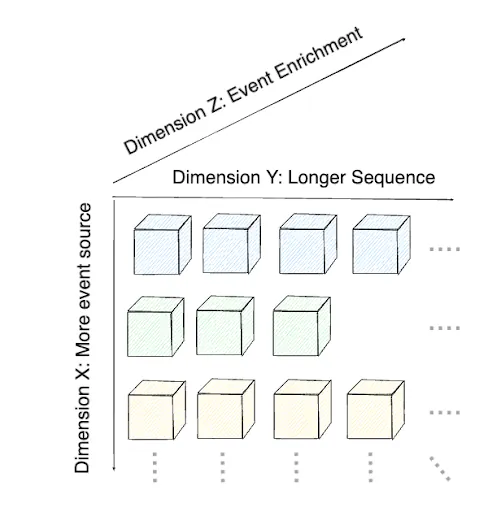
Diverse and enriched data sources are essential for commercial ads-recommendation models to accurately assess user interest both before and after engagement with content. While extended user-engagement histories can improve the prediction of user interests, it is equally important to embed activity sequences from multiple sources to ensure freshness of user and ad-representations, following scaling law principles. In this paper, we present a novel three-dimensional framework for enhancing user-ad representations without increasing model inference or serving complexity. The first dimension examines the impact of incorporating diverse event sources, the second considers the benefits of longer user histories, and the third focuses on enriching data with additional event attributes and multi-modal embeddings. We assess the return on investment (ROI) of our source enrichment framework by comparing organic user engagement sources, such as content viewing, with ad-impression sources. The proposed method can boost the area under curve (AUC) and the slope of scaling curves for ad-impression sources by 1.56 to 2 times compared to organic usage sources even for short online-sequence lengths of 100 to 10K. Additionally, click-through rate (CTR) prediction improves by 0.56% AUC over the baseline production ad-recommendation system when using enriched ad-impression event sources, leading to improved sequence scaling resolutions for longer and offline user-ad representations.

Large language models (LLMs) have demonstrated success in various applications of user recommendation and personalization across e-commerce and entertainment. On many entertainment platforms such as Netflix, users typically interact with a wide range of titles, each represented by an artwork. Since users have diverse preferences, an artwork that appeals to one type of user may not resonate with another with different preferences. Given this user heterogeneity, our work explores the novel problem of personalized artwork recommendations according to diverse user preferences. Similar to the multi-dimensional nature of users' tastes, titles contain different themes and tones that may appeal to different viewers. For example, the same title might feature both heartfelt family drama and intense action scenes. Users who prefer romantic content may like the artwork emphasizing emotional warmth between the characters, while those who prefer action thrillers may find high-intensity action scenes more intriguing. Rather than a one-size-fits-all approach, we conduct post-training of pre-trained LLMs to make personalized artwork recommendations, selecting the most preferred visual representation of a title for each user and thereby improving user satisfaction and engagement. Our experimental results with Llama 3.1 8B models (trained on a dataset of 110K data points and evaluated on 5K held-out user-title pairs) show that the post-trained LLMs achieve 3-5\% improvements over the Netflix production model, suggesting a promising direction for granular personalized recommendations using LLMs.
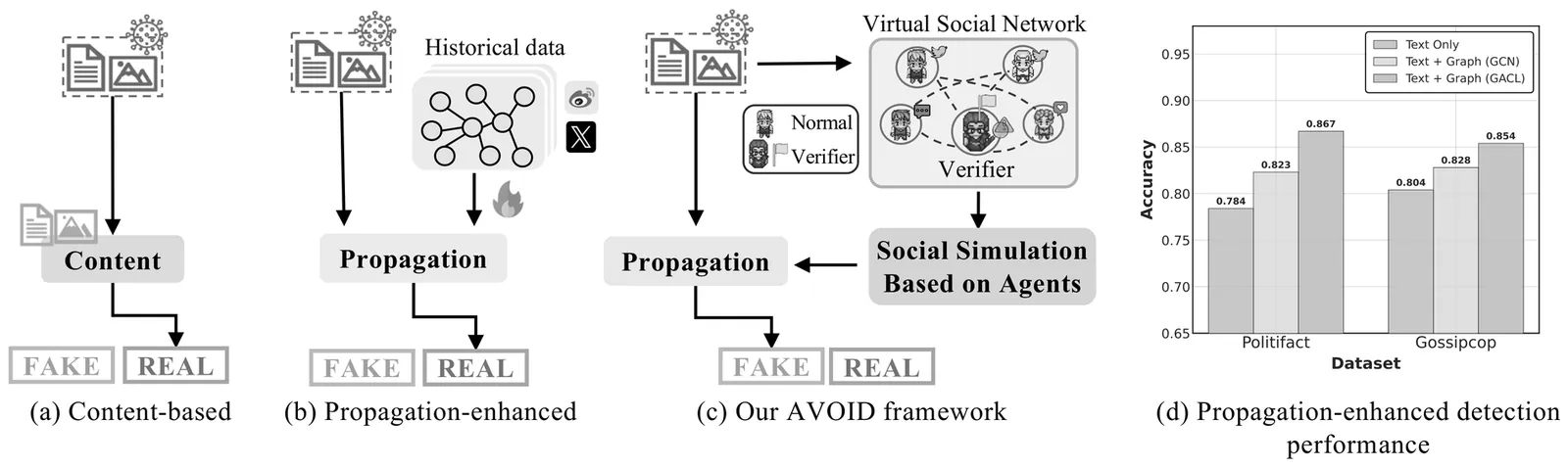
Early detection of fake news is critical for mitigating its rapid dissemination on social media, which can severely undermine public trust and social stability. Recent advancements show that incorporating propagation dynamics can significantly enhance detection performance compared to previous content-only approaches. However, this remains challenging at early stages due to the absence of observable propagation signals. To address this limitation, we propose AVOID, an \underline{a}gent-driven \underline{v}irtual pr\underline{o}pagat\underline{i}on for early fake news \underline{d}etection. AVOID reformulates early detection as a new paradigm of evidence generation, where propagation signals are actively simulated rather than passively observed. Leveraging LLM-powered agents with differentiated roles and data-driven personas, AVOID realistically constructs early-stage diffusion behaviors without requiring real propagation data. The resulting virtual trajectories provide complementary social evidence that enriches content-based detection, while a denoising-guided fusion strategy aligns simulated propagation with content semantics. Extensive experiments on benchmark datasets demonstrate that AVOID consistently outperforms state-of-the-art baselines, highlighting the effectiveness and practical value of virtual propagation augmentation for early fake news detection. The code and data are available at https://github.com/Ironychen/AVOID.

Information retrieval (IR) in dynamic data streams is emerging as a challenging task, as shifts in data distribution degrade the performance of AI-powered IR systems. To mitigate this issue, memory-based continual learning has been widely adopted for IR. However, existing methods rely on a fixed set of queries with ground-truth relevant documents, which limits generalization to unseen queries and documents, making them impractical for real-world applications. To enable more effective learning with unseen topics of a new corpus without ground-truth labels, we propose CREAM, a self-supervised framework for memory-based continual retrieval. CREAM captures the evolving semantics of streaming queries and documents into dynamically structured soft memory and leverages it to adapt to both seen and unseen topics in an unsupervised setting. We realize this through three key techniques: fine-grained similarity estimation, regularized cluster prototyping, and stratified coreset sampling. Experiments on two benchmark datasets demonstrate that CREAM exhibits superior adaptability and retrieval accuracy, outperforming the strongest method in a label-free setting by 27.79\% in Success@5 and 44.5\% in Recall@10 on average, and achieving performance comparable to or even exceeding that of supervised methods.

Large Language Models (LLMs) are increasingly applied in recommendation scenarios due to their strong natural language understanding and generation capabilities. However, they are trained on vast corpora whose contents are not publicly disclosed, raising concerns about data leakage. Recent work has shown that the MovieLens-1M dataset is memorized by both the LLaMA and OpenAI model families, but the extraction of such memorized data has so far relied exclusively on manual prompt engineering. In this paper, we pose three main questions: Is it possible to enhance manual prompting? Can LLM memorization be detected through methods beyond manual prompting? And can the detection of data leakage be automated? To address these questions, we evaluate three approaches: (i) jailbreak prompt engineering; (ii) unsupervised latent knowledge discovery, probing internal activations via Contrast-Consistent Search (CCS) and Cluster-Norm; and (iii) Automatic Prompt Engineering (APE), which frames prompt discovery as a meta-learning process that iteratively refines candidate instructions. Experiments on MovieLens-1M using LLaMA models show that jailbreak prompting does not improve the retrieval of memorized items and remains inconsistent; CCS reliably distinguishes genuine from fabricated movie titles but fails on numerical user and rating data; and APE retrieves item-level information with moderate success yet struggles to recover numerical interactions. These findings suggest that automatically optimizing prompts is the most promising strategy for extracting memorized samples.
ChatGPT has emerged as a versatile tool, demonstrating capabilities across diverse domains. Given these successes, the Recommender Systems (RSs) community has begun investigating its applications within recommendation scenarios primarily focusing on accuracy. While the integration of ChatGPT into RSs has garnered significant attention, a comprehensive analysis of its performance across various dimensions remains largely unexplored. Specifically, the capabilities of providing diverse and novel recommendations or exploring potential biases such as popularity bias have not been thoroughly examined. As the use of these models continues to expand, understanding these aspects is crucial for enhancing user satisfaction and achieving long-term personalization. This study investigates the recommendations provided by ChatGPT-3.5 and ChatGPT-4 by assessing ChatGPT's capabilities in terms of diversity, novelty, and popularity bias. We evaluate these models on three distinct datasets and assess their performance in Top-N recommendation and cold-start scenarios. The findings reveal that ChatGPT-4 matches or surpasses traditional recommenders, demonstrating the ability to balance novelty and diversity in recommendations. Furthermore, in the cold-start scenario, ChatGPT models exhibit superior performance in both accuracy and novelty, suggesting they can be particularly beneficial for new users. This research highlights the strengths and limitations of ChatGPT's recommendations, offering new perspectives on the capacity of these models to provide recommendations beyond accuracy-focused metrics.
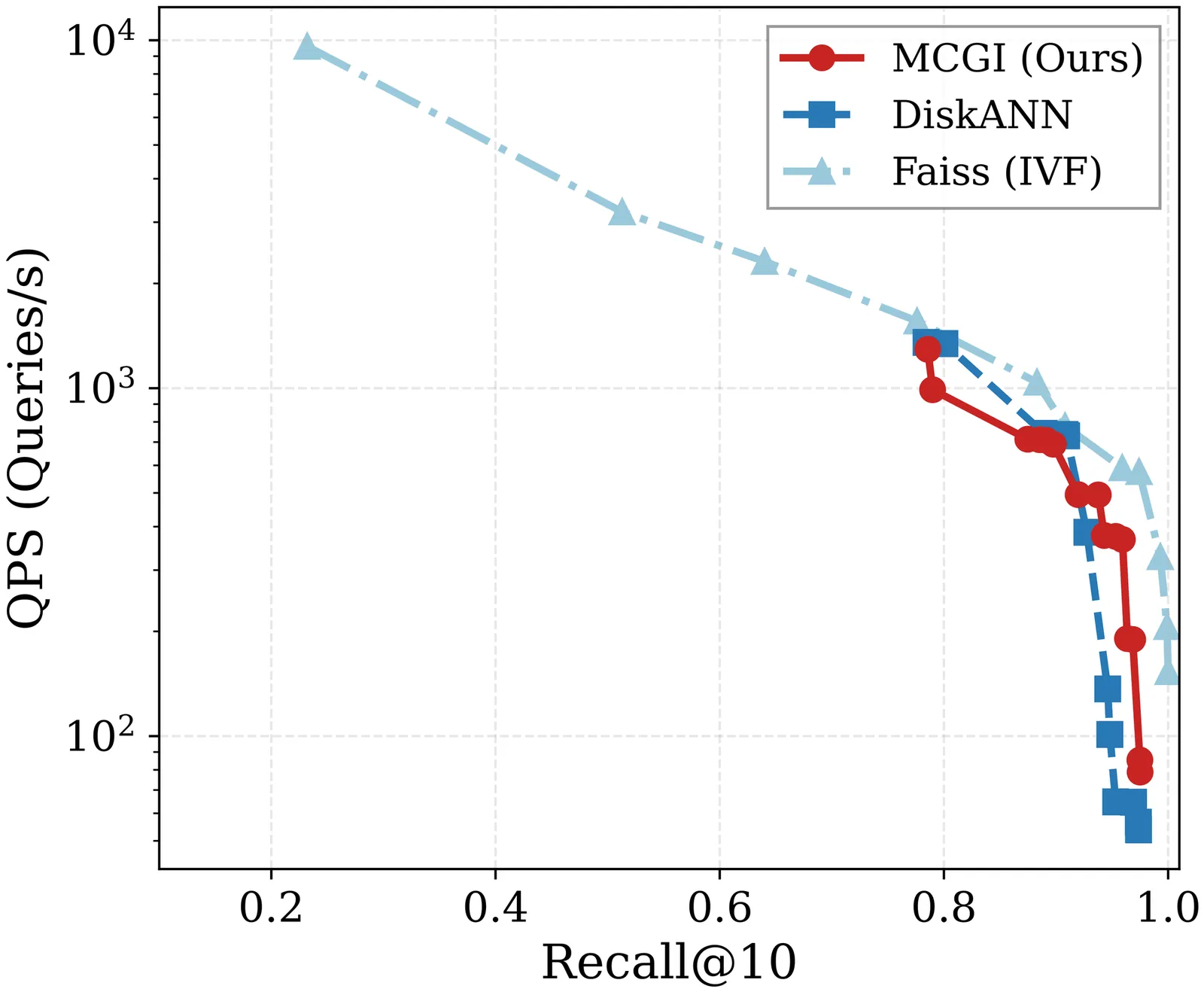
Graph-based Approximate Nearest Neighbor (ANN) search often suffers from performance degradation in high-dimensional spaces due to the ``Euclidean-Geodesic mismatch,'' where greedy routing diverges from the underlying data manifold. To address this, we propose Manifold-Consistent Graph Indexing (MCGI), a geometry-aware and disk-resident indexing method that leverages Local Intrinsic Dimensionality (LID) to dynamically adapt search strategies to the data's intrinsic geometry. Unlike standard algorithms that treat dimensions uniformly, MCGI modulates its beam search budget based on in situ geometric analysis, eliminating dependency on static hyperparameters. Theoretical analysis confirms that MCGI enables improved approximation guarantees by preserving manifold-consistent topological connectivity. Empirically, MCGI achieves 5.8$\times$ higher throughput at 95\% recall on high-dimensional GIST1M compared to state-of-the-art DiskANN. On the billion-scale SIFT1B dataset, MCGI further validates its scalability by reducing high-recall query latency by 3$\times$, while maintaining performance parity on standard lower-dimensional datasets.

Retrieval-Augmented Generation (RAG) systems often rely on fixed top-k document selection mechanisms that ignore downstream generation quality and impose computational overheads. We propose SRAS (Sparse Reward-Aware Selector), a lightweight document selector trained via reinforcement learning (RL) for edge-native RAG deployment. Unlike prior RL-based retrievers that assume large memory and latency budgets, SRAS learns a compact (~0.76MB) policy using Proximal Policy Optimization (PPO), guided by a hybrid reward signal combining Relaxed F1 and BERTScore. Our method operates under tight token and compute constraints, maintaining <1s latency on CPU. SRAS outperforms supervised and random selectors on a synthetic QA benchmark, and generalizes to real-world data, achieving BERTScore F1 of 0.8546 on SQuAD v2 without domain-specific tuning. This work is the first to demonstrate that RL-based document selection can be made ultra-lightweight, latency-aware, and effective for on-device RAG pipelines.

Modern recommender systems trained on domain-specific data often struggle to generalize across multiple domains. Cross-domain sequential recommendation has emerged as a promising research direction to address this challenge; however, existing approaches face fundamental limitations, such as reliance on overlapping users or items across domains, or unrealistic assumptions that ignore privacy constraints. In this work, we propose a new framework, MergeRec, based on model merging under a new and realistic problem setting termed data-isolated cross-domain sequential recommendation, where raw user interaction data cannot be shared across domains. MergeRec consists of three key components: (1) merging initialization, (2) pseudo-user data construction, and (3) collaborative merging optimization. First, we initialize a merged model using training-free merging techniques. Next, we construct pseudo-user data by treating each item as a virtual sequence in each domain, enabling the synthesis of meaningful training samples without relying on real user interactions. Finally, we optimize domain-specific merging weights through a joint objective that combines a recommendation loss, which encourages the merged model to identify relevant items, and a distillation loss, which transfers collaborative filtering signals from the fine-tuned source models. Extensive experiments demonstrate that MergeRec not only preserves the strengths of the original models but also significantly enhances generalizability to unseen domains. Compared to conventional model merging methods, MergeRec consistently achieves superior performance, with average improvements of up to 17.21% in Recall@10, highlighting the potential of model merging as a scalable and effective approach for building universal recommender systems. The source code is available at https://github.com/DIALLab-SKKU/MergeRec.
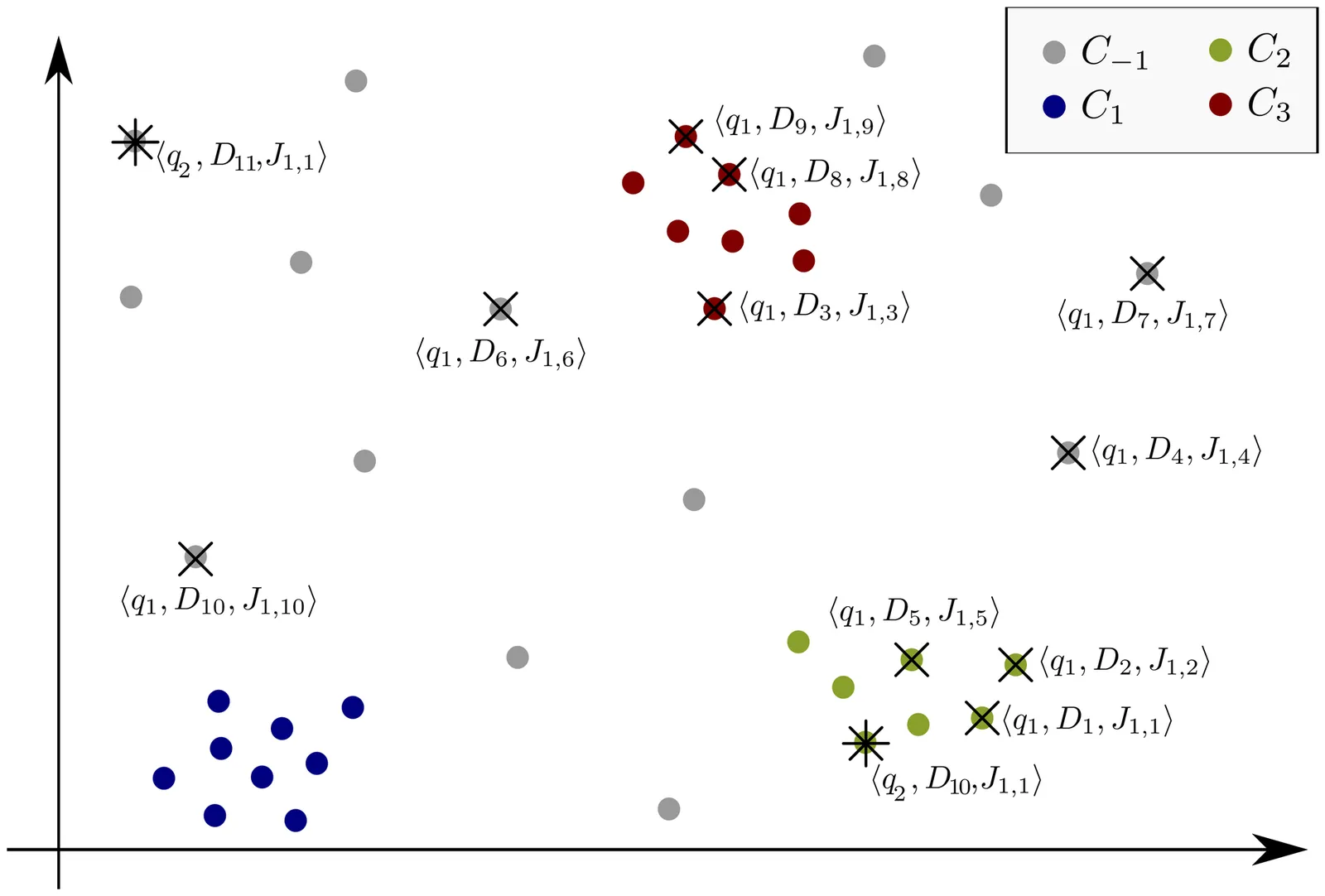
Large Language Models (LLMs) have been used as relevance assessors for Information Retrieval (IR) evaluation collection creation due to reduced cost and increased scalability as compared to human assessors. While previous research has looked at the reliability of LLMs as compared to human assessors, in this work, we aim to understand if LLMs make systematic mistakes when judging relevance, rather than just understanding how good they are on average. To this aim, we propose a novel representational method for queries and documents that allows us to analyze relevance label distributions and compare LLM and human labels to identify patterns of disagreement and localize systematic areas of disagreement. We introduce a clustering-based framework that embeds query-document (Q-D) pairs into a joint semantic space, treating relevance as a relational property. Experiments on TREC Deep Learning 2019 and 2020 show that systematic disagreement between humans and LLMs is concentrated in specific semantic clusters rather than distributed randomly. Query-level analyses reveal recurring failures, most often in definition-seeking, policy-related, or ambiguous contexts. Queries with large variation in agreement across their clusters emerge as disagreement hotspots, where LLMs tend to under-recall relevant content or over-include irrelevant material. This framework links global diagnostics with localized clustering to uncover hidden weaknesses in LLM judgments, enabling bias-aware and more reliable IR evaluation.
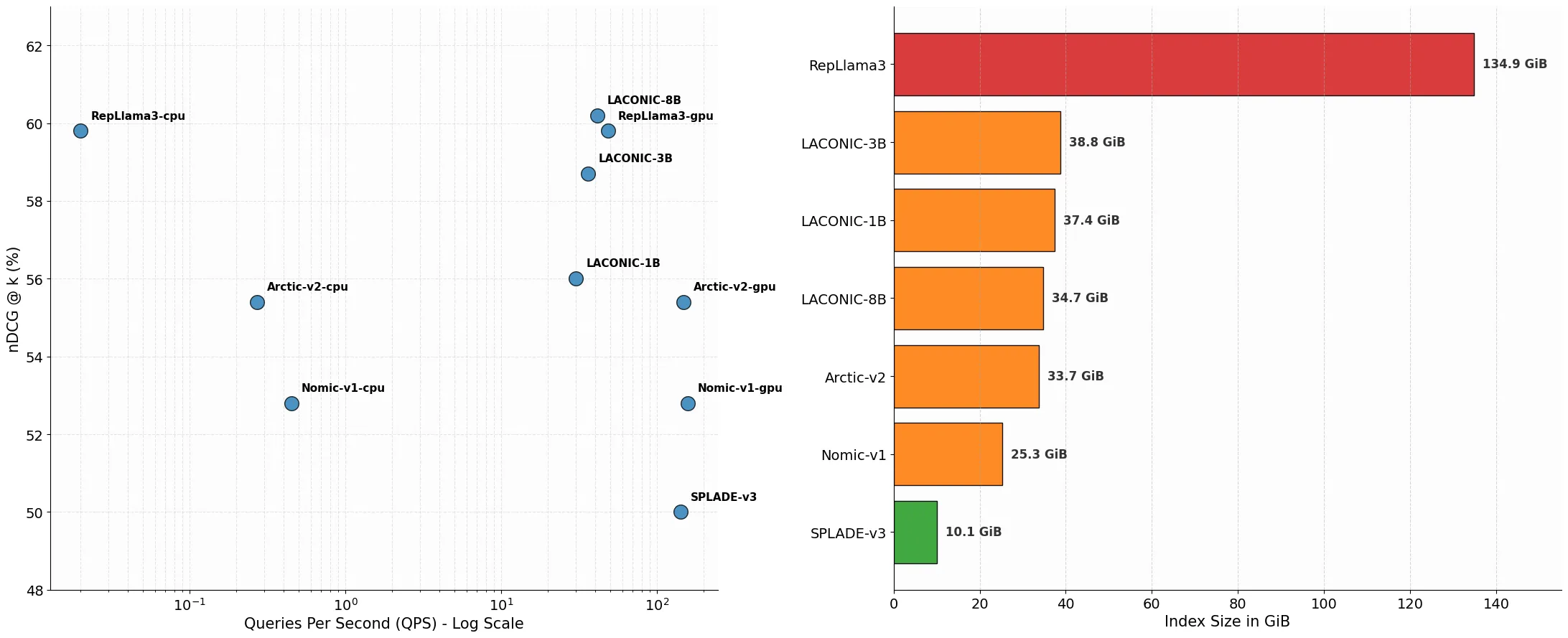
While dense retrieval models have become the standard for state-of-the-art information retrieval, their deployment is often constrained by high memory requirements and reliance on GPU accelerators for vector similarity search. Learned sparse retrieval offers a compelling alternative by enabling efficient search via inverted indices, yet it has historically received less attention than dense approaches. In this report, we introduce LACONIC, a family of learned sparse retrievers based on the Llama-3 architecture (1B, 3B, and 8B). We propose a streamlined two-phase training curriculum consisting of (1) weakly supervised pre-finetuning to adapt causal LLMs for bidirectional contextualization and (2) high-signal finetuning using curated hard negatives. Our results demonstrate that LACONIC effectively bridges the performance gap with dense models: the 8B variant achieves a state-of-the-art 60.2 nDCG on the MTEB Retrieval benchmark, ranking 15th on the leaderboard as of January 1, 2026, while utilizing 71\% less index memory than an equivalent dense model. By delivering high retrieval effectiveness on commodity CPU hardware with a fraction of the compute budget required by competing models, LACONIC provides a scalable and efficient solution for real-world search applications.
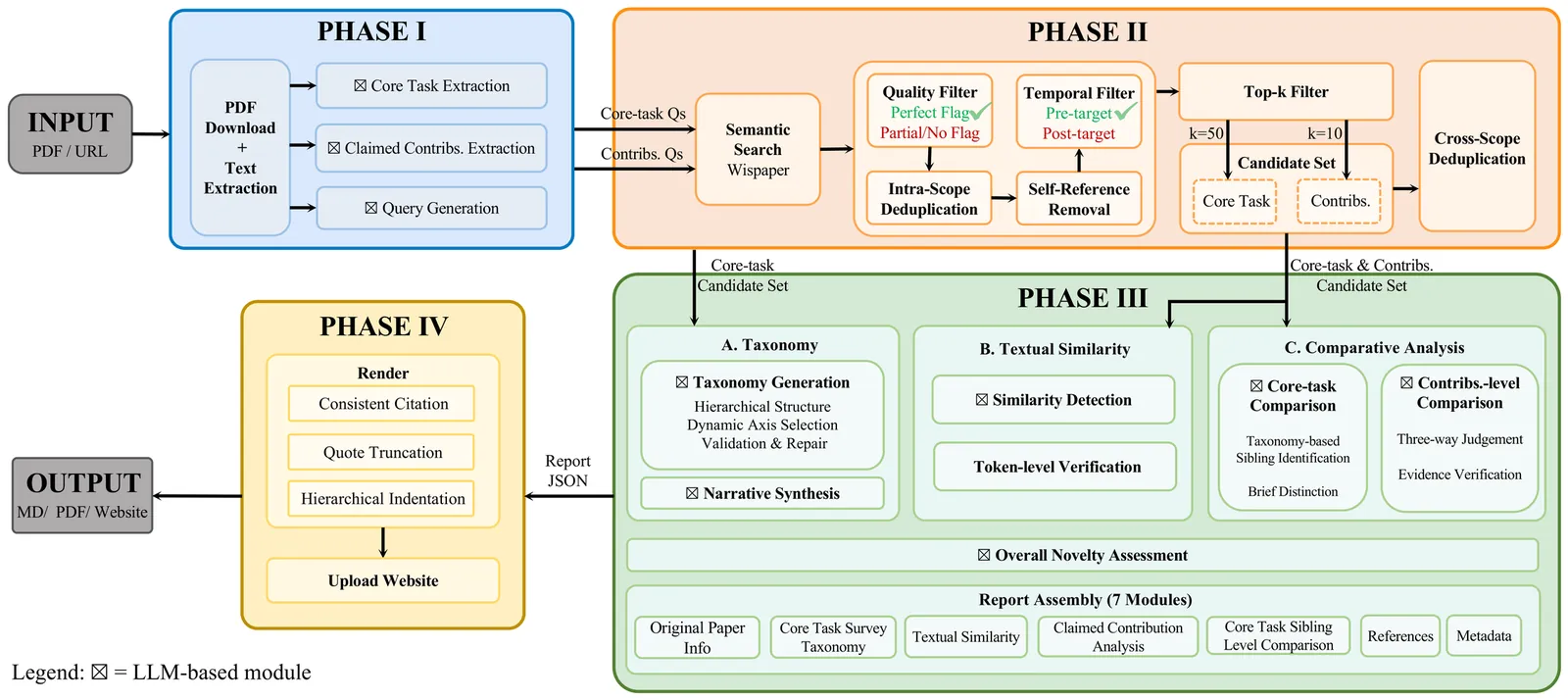
Evaluating novelty is critical yet challenging in peer review, as reviewers must assess submissions against a vast, rapidly evolving literature. This report presents OpenNovelty, an LLM-powered agentic system for transparent, evidence-based novelty analysis. The system operates through four phases: (1) extracting the core task and contribution claims to generate retrieval queries; (2) retrieving relevant prior work based on extracted queries via semantic search engine; (3) constructing a hierarchical taxonomy of core-task-related work and performing contribution-level full-text comparisons against each contribution; and (4) synthesizing all analyses into a structured novelty report with explicit citations and evidence snippets. Unlike naive LLM-based approaches, \textsc{OpenNovelty} grounds all assessments in retrieved real papers, ensuring verifiable judgments. We deploy our system on 500+ ICLR 2026 submissions with all reports publicly available on our website, and preliminary analysis suggests it can identify relevant prior work, including closely related papers that authors may overlook. OpenNovelty aims to empower the research community with a scalable tool that promotes fair, consistent, and evidence-backed peer review.
Capturing complex user preferences from sparse behavioral sequences remains a fundamental challenge in sequential recommendation. Recent latent reasoning methods have shown promise by extending test-time computation through multi-step reasoning, yet they exclusively rely on depth-level scaling along a single trajectory, suffering from diminishing returns as reasoning depth increases. To address this limitation, we propose \textbf{Parallel Latent Reasoning (PLR)}, a novel framework that pioneers width-level computational scaling by exploring multiple diverse reasoning trajectories simultaneously. PLR constructs parallel reasoning streams through learnable trigger tokens in continuous latent space, preserves diversity across streams via global reasoning regularization, and adaptively synthesizes multi-stream outputs through mixture-of-reasoning-streams aggregation. Extensive experiments on three real-world datasets demonstrate that PLR substantially outperforms state-of-the-art baselines while maintaining real-time inference efficiency. Theoretical analysis further validates the effectiveness of parallel reasoning in improving generalization capability. Our work opens new avenues for enhancing reasoning capacity in sequential recommendation beyond existing depth scaling.
In enterprise search, building high-quality datasets at scale remains a central challenge due to the difficulty of acquiring labeled data. To resolve this challenge, we propose an efficient approach to fine-tune small language models (SLMs) for accurate relevance labeling, enabling high-throughput, domain-specific labeling comparable or even better in quality to that of state-of-the-art large language models (LLMs). To overcome the lack of high-quality and accessible datasets in the enterprise domain, our method leverages on synthetic data generation. Specifically, we employ an LLM to synthesize realistic enterprise queries from a seed document, apply BM25 to retrieve hard negatives, and use a teacher LLM to assign relevance scores. The resulting dataset is then distilled into an SLM, producing a compact relevance labeler. We evaluate our approach on a high-quality benchmark consisting of 923 enterprise query-document pairs annotated by trained human annotators, and show that the distilled SLM achieves agreement with human judgments on par with or better than the teacher LLM. Furthermore, our fine-tuned labeler substantially improves throughput, achieving 17 times increase while also being 19 times more cost-effective. This approach enables scalable and cost-effective relevance labeling for enterprise-scale retrieval applications, supporting rapid offline evaluation and iteration in real-world settings.
Recent years have witnessed success of sequential modeling, generative recommender, and large language model for recommendation. Though the scaling law has been validated for sequential models, it showed inefficiency in computational capacity when considering real-world applications like recommendation, due to the non-linear(quadratic) increasing nature of the transformer model. To improve the efficiency of the sequential model, we introduced a novel approach to sequential recommendation that leverages personalization techniques to enhance efficiency and performance. Our method compresses long user interaction histories into learnable tokens, which are then combined with recent interactions to generate recommendations. This approach significantly reduces computational costs while maintaining high recommendation accuracy. Our method could be applied to existing transformer based recommendation models, e.g., HSTU and HLLM. Extensive experiments on multiple sequential models demonstrate its versatility and effectiveness. Source code is available at \href{https://github.com/facebookresearch/PerSRec}{https://github.com/facebookresearch/PerSRec}.
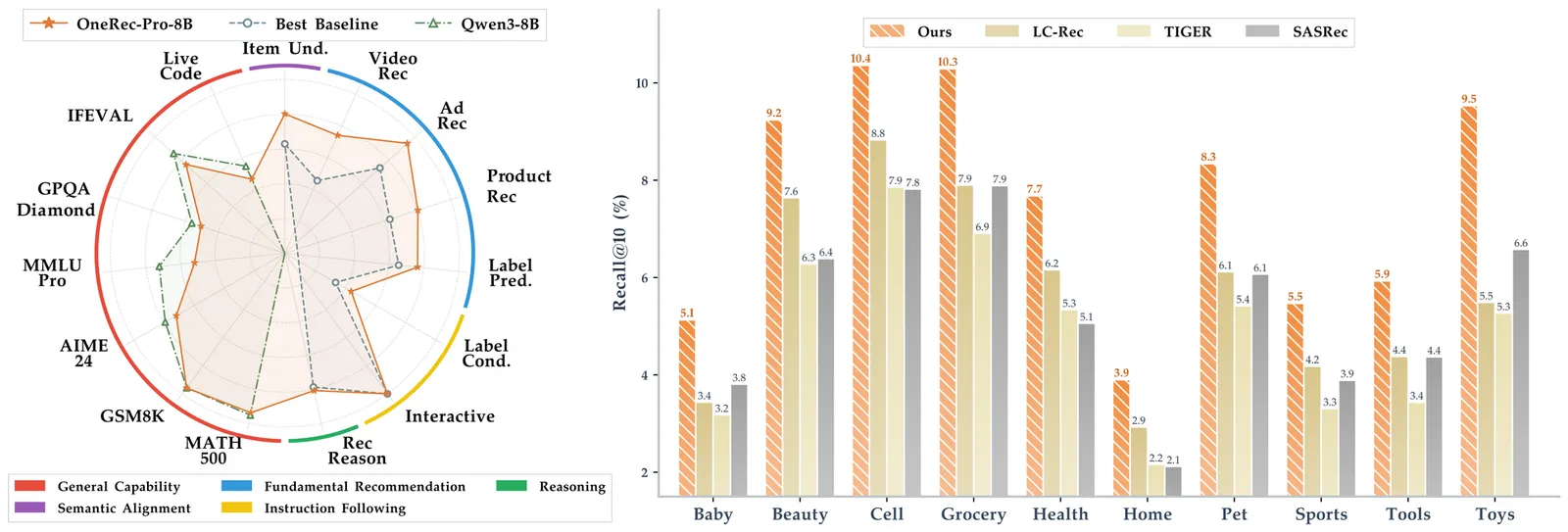
While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
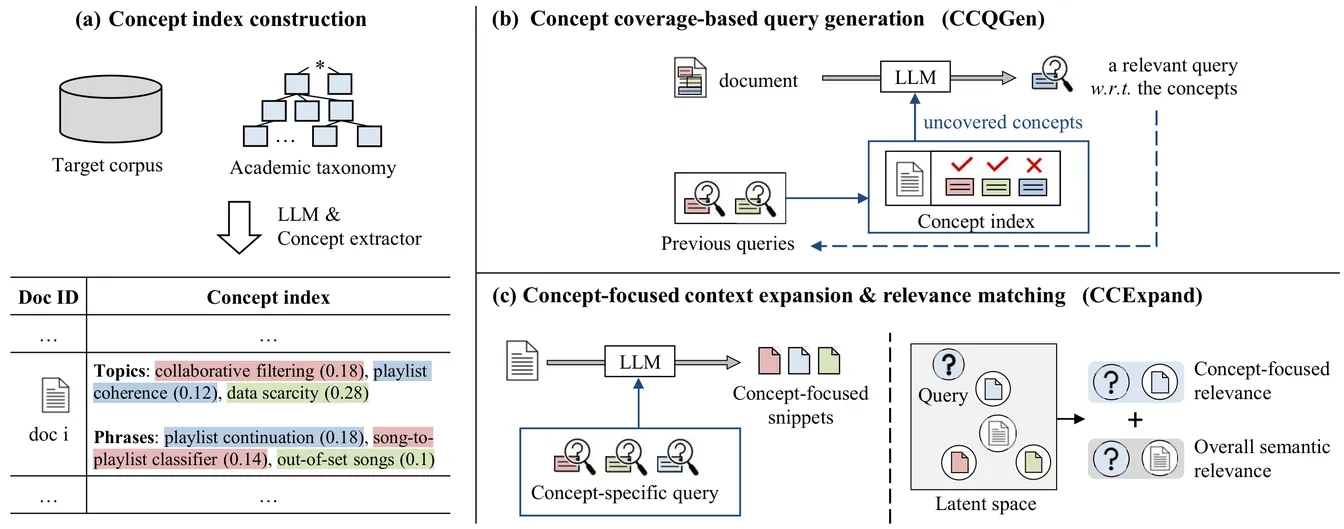
Adapting general-domain retrievers to scientific domains is challenging due to the scarcity of large-scale domain-specific relevance annotations and the substantial mismatch in vocabulary and information needs. Recent approaches address these issues through two independent directions that leverage large language models (LLMs): (1) generating synthetic queries for fine-tuning, and (2) generating auxiliary contexts to support relevance matching. However, both directions overlook the diverse academic concepts embedded within scientific documents, often producing redundant or conceptually narrow queries and contexts. To address this limitation, we introduce an academic concept index, which extracts key concepts from papers and organizes them guided by an academic taxonomy. This structured index serves as a foundation for improving both directions. First, we enhance the synthetic query generation with concept coverage-based generation (CCQGen), which adaptively conditions LLMs on uncovered concepts to generate complementary queries with broader concept coverage. Second, we strengthen the context augmentation with concept-focused auxiliary contexts (CCExpand), which leverages a set of document snippets that serve as concise responses to the concept-aware CCQGen queries. Extensive experiments show that incorporating the academic concept index into both query generation and context augmentation leads to higher-quality queries, better conceptual alignment, and improved retrieval performance.
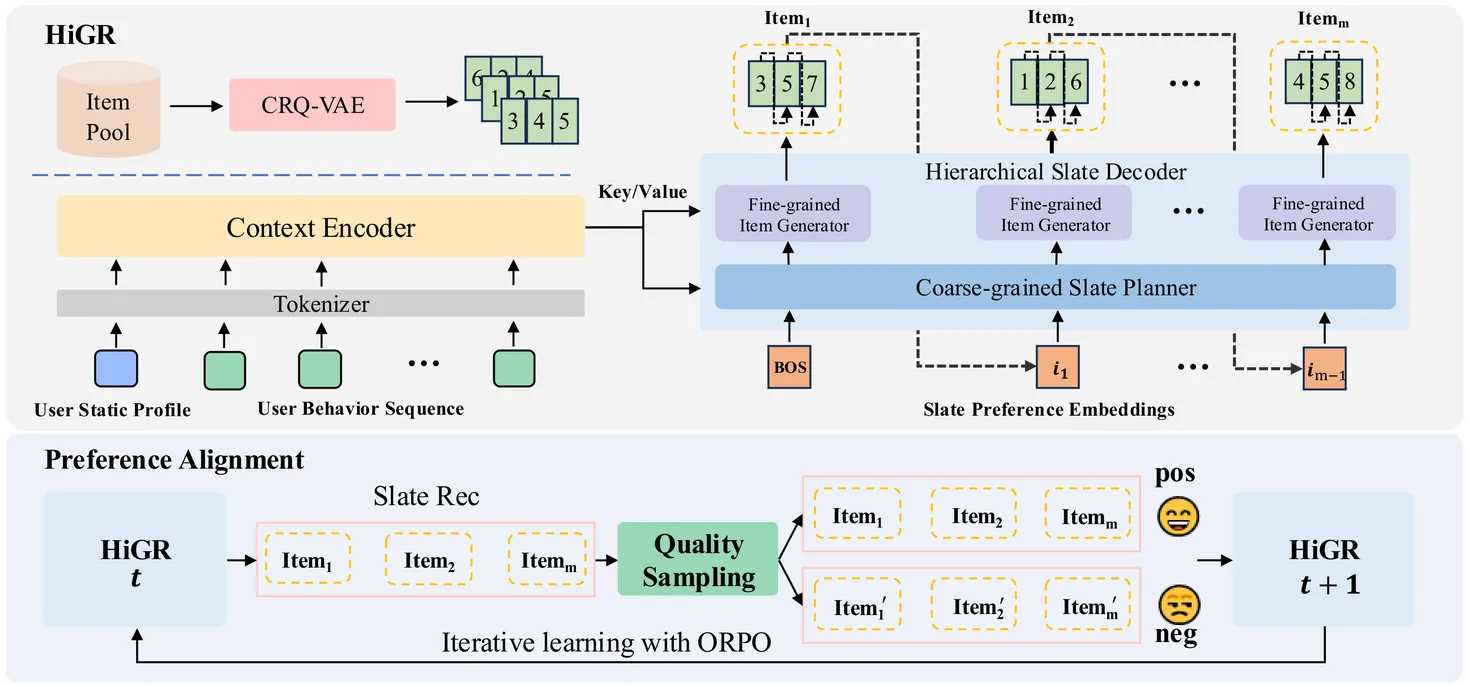
Slate recommendation, where users are presented with a ranked list of items simultaneously, is widely adopted in online platforms. Recent advances in generative models have shown promise in slate recommendation by modeling sequences of discrete semantic IDs autoregressively. However, existing autoregressive approaches suffer from semantically entangled item tokenization and inefficient sequential decoding that lacks holistic slate planning. To address these limitations, we propose HiGR, an efficient generative slate recommendation framework that integrates hierarchical planning with listwise preference alignment. First, we propose an auto-encoder utilizing residual quantization and contrastive constraints to tokenize items into semantically structured IDs for controllable generation. Second, HiGR decouples generation into a list-level planning stage for global slate intent, followed by an item-level decoding stage for specific item selection. Third, we introduce a listwise preference alignment objective to directly optimize slate quality using implicit user feedback. Experiments on our large-scale commercial media platform demonstrate that HiGR delivers consistent improvements in both offline evaluations and online deployment. Specifically, it outperforms state-of-the-art methods by over 10% in offline recommendation quality with a 5x inference speedup, while further achieving a 1.22% and 1.73% increase in Average Watch Time and Average Video Views in online A/B tests.
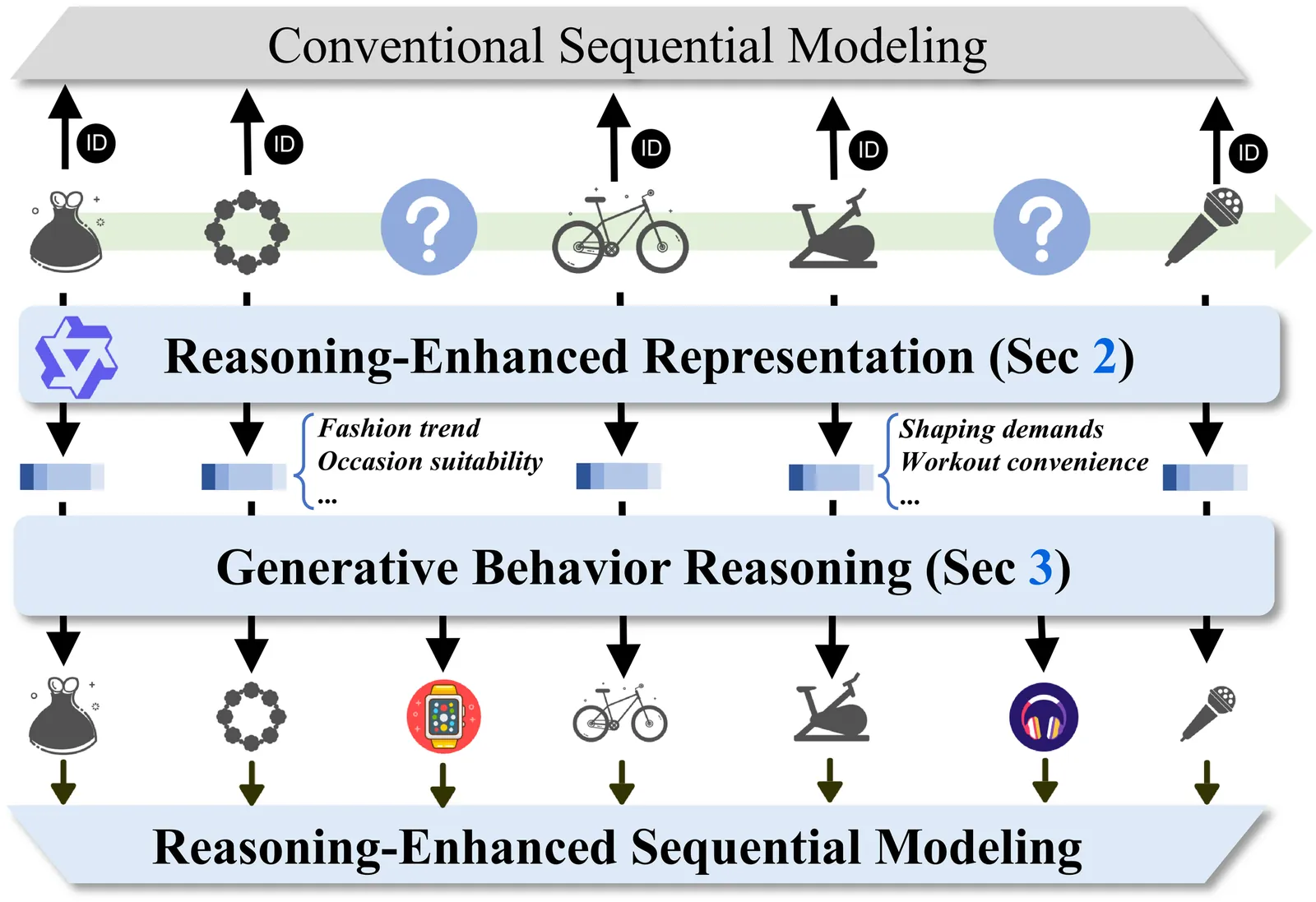
Industrial recommender systems face two fundamental limitations under the log-driven paradigm: (1) knowledge poverty in ID-based item representations that causes brittle interest modeling under data sparsity, and (2) systemic blindness to beyond-log user interests that constrains model performance within platform boundaries. These limitations stem from an over-reliance on shallow interaction statistics and close-looped feedback while neglecting the rich world knowledge about product semantics and cross-domain behavioral patterns that Large Language Models have learned from vast corpora. To address these challenges, we introduce ReaSeq, a reasoning-enhanced framework that leverages world knowledge in Large Language Models to address both limitations through explicit and implicit reasoning. Specifically, ReaSeq employs explicit Chain-of-Thought reasoning via multi-agent collaboration to distill structured product knowledge into semantically enriched item representations, and latent reasoning via Diffusion Large Language Models to infer plausible beyond-log behaviors. Deployed on Taobao's ranking system serving hundreds of millions of users, ReaSeq achieves substantial gains: >6.0% in IPV and CTR, >2.9% in Orders, and >2.5% in GMV, validating the effectiveness of world-knowledge-enhanced reasoning over purely log-driven approaches.
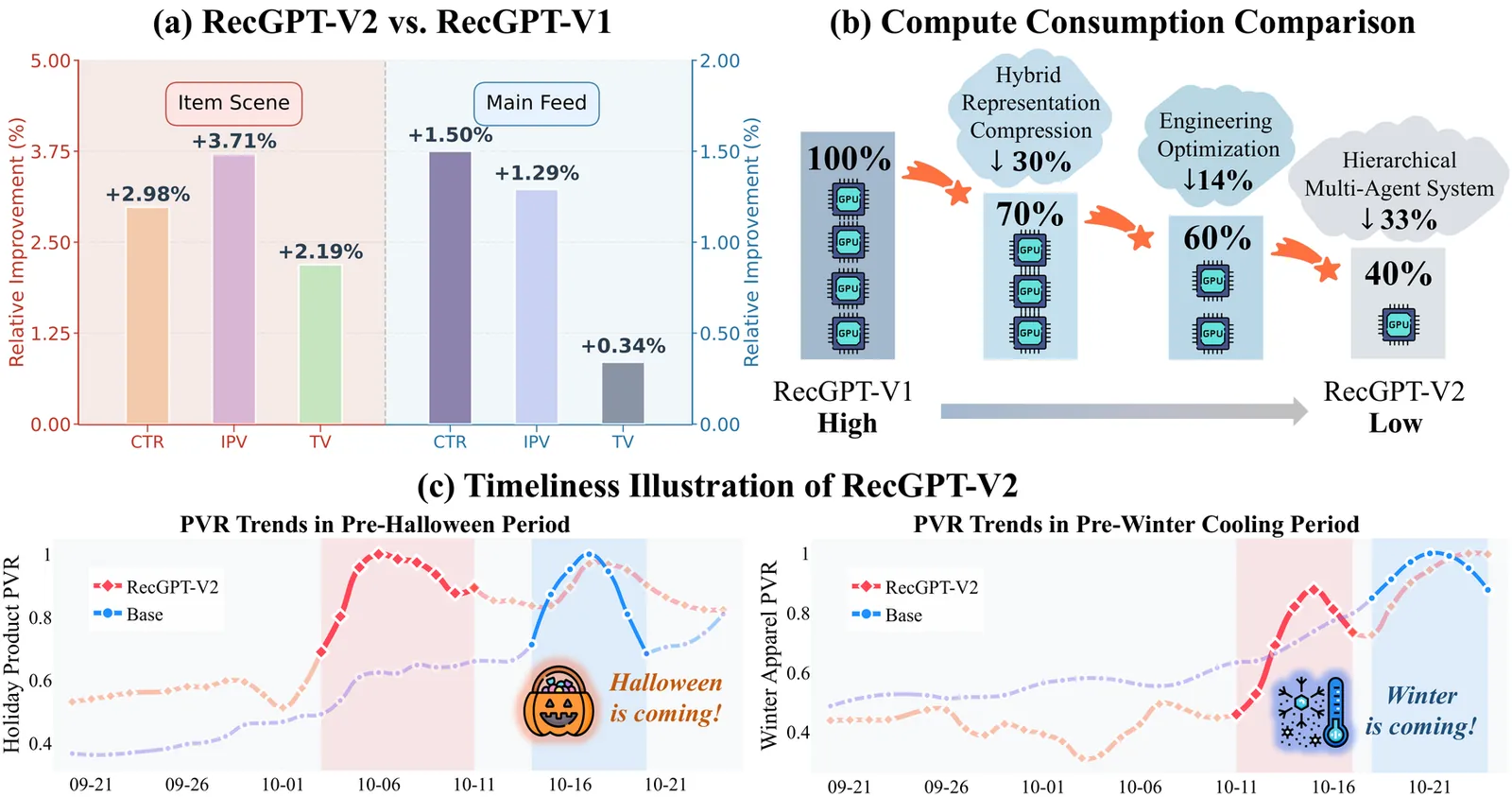
Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.
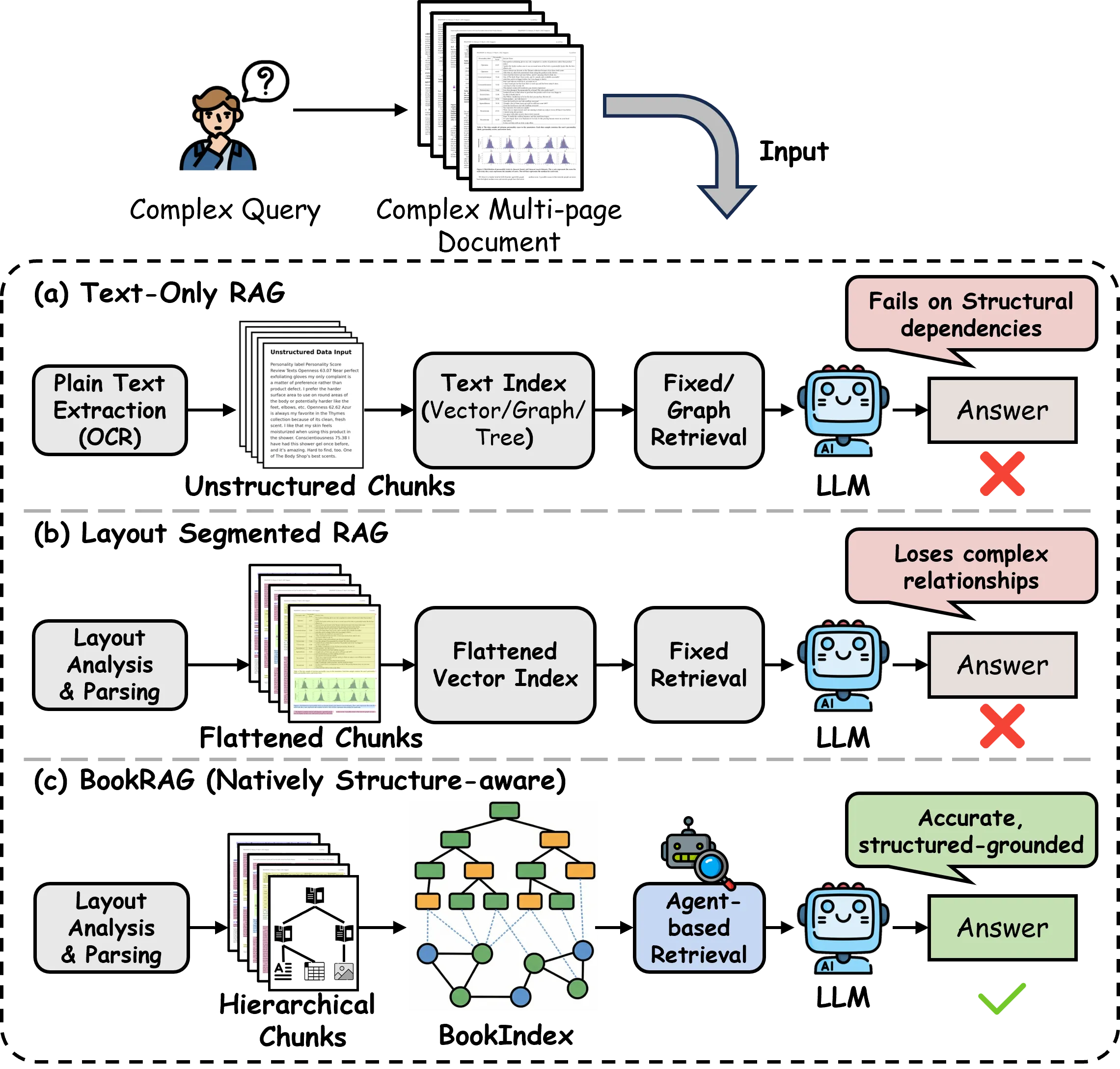
As an effective method to boost the performance of Large Language Models (LLMs) on the question answering (QA) task, Retrieval-Augmented Generation (RAG), which queries highly relevant information from external complex documents, has attracted tremendous attention from both industry and academia. Existing RAG approaches often focus on general documents, and they overlook the fact that many real-world documents (such as books, booklets, handbooks, etc.) have a hierarchical structure, which organizes their content from different granularity levels, leading to poor performance for the QA task. To address these limitations, we introduce BookRAG, a novel RAG approach targeted for documents with a hierarchical structure, which exploits logical hierarchies and traces entity relations to query the highly relevant information. Specifically, we build a novel index structure, called BookIndex, by extracting a hierarchical tree from the document, which serves as the role of its table of contents, using a graph to capture the intricate relationships between entities, and mapping entities to tree nodes. Leveraging the BookIndex, we then propose an agent-based query method inspired by the Information Foraging Theory, which dynamically classifies queries and employs a tailored retrieval workflow. Extensive experiments on three widely adopted benchmarks demonstrate that BookRAG achieves state-of-the-art performance, significantly outperforming baselines in both retrieval recall and QA accuracy while maintaining competitive efficiency.
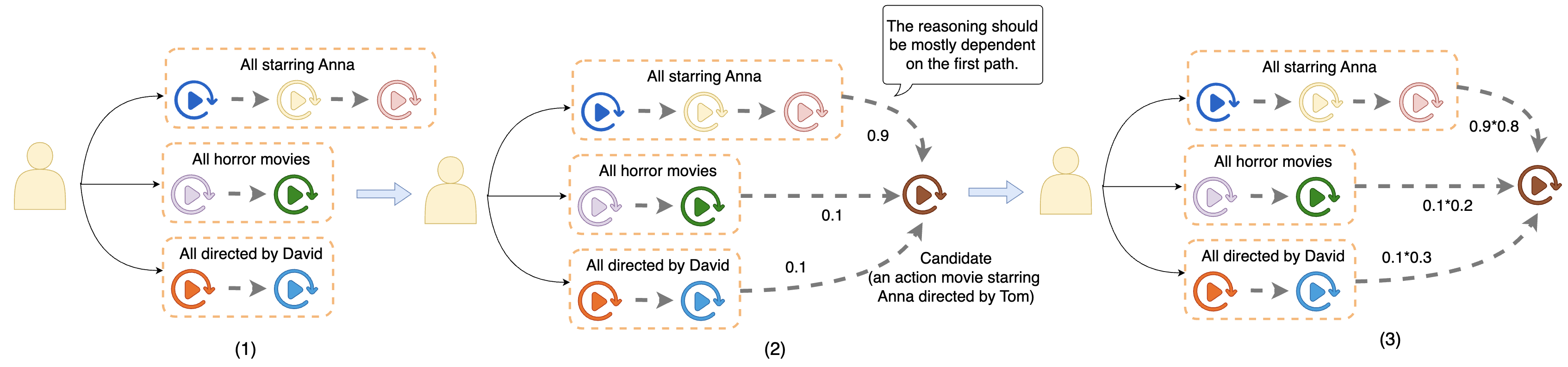
Large Language Models (LLMs) have shown significant potential for improving recommendation systems through their inherent reasoning capabilities and extensive knowledge base. Yet, existing studies predominantly address warm-start scenarios with abundant user-item interaction data, leaving the more challenging cold-start scenarios, where sparse interactions hinder traditional collaborative filtering methods, underexplored. To address this limitation, we propose novel reasoning strategies designed for cold-start item recommendations within the Netflix domain. Our method utilizes the advanced reasoning capabilities of LLMs to effectively infer user preferences, particularly for newly introduced or rarely interacted items. We systematically evaluate supervised fine-tuning, reinforcement learning-based fine-tuning, and hybrid approaches that combine both methods to optimize recommendation performance. Extensive experiments on real-world data demonstrate significant improvements in both methodological efficacy and practical performance in cold-start recommendation contexts. Remarkably, our reasoning-based fine-tuned models outperform Netflix's production ranking model by up to 8% in certain cases.