4,780 papers
LitXBench: A Benchmark for Extracting Experiments from Scientific Literature
Aggregating experimental data from papers enables materials scientists to build better property prediction models and to facilitate scientific discovery. Recently, interest has grown in extracting not only single material properties but also entire experimental measurements. To support this shift, we introduce LitXBench, a framework for benchmarking methods that extract experiments from literature. We also present LitXAlloy, a dense benchmark comprising 1426 total measurements from 19 alloy papers. By storing the benchmark's entries as Python objects, rather than text-based formats such as CSV or JSON, we improve auditability and enable programmatic data validation. We find that frontier language models, such as Gemini 3.1 Pro Preview, outperform existing multi-turn extraction pipelines by up to 0.37 F1. Our results suggest that this performance gap arises because extraction pipelines associate measurements with compositions rather than the processing steps that define a material.
2604.07649Apr 2026
View
Beyond Hard Negatives: The Importance of Score Distribution in Knowledge Distillation for Dense Retrieval
Transferring knowledge from a cross-encoder teacher via Knowledge Distillation (KD) has become a standard paradigm for training retrieval models. While existing studies have largely focused on mining hard negatives to improve discrimination, the systematic composition of training data and the resulting teacher score distribution have received relatively less attention. In this work, we highlight that focusing solely on hard negatives prevents the student from learning the comprehensive preference structure of the teacher, potentially hampering generalization. To effectively emulate the teacher score distribution, we propose a Stratified Sampling strategy that uniformly covers the entire score spectrum. Experiments on in-domain and out-of-domain benchmarks confirm that Stratified Sampling, which preserves the variance and entropy of teacher scores, serves as a robust baseline, significantly outperforming top-K and random sampling in diverse settings. These findings suggest that the essence of distillation lies in preserving the diverse range of relative scores perceived by the teacher.
2604.04734Apr 2026
View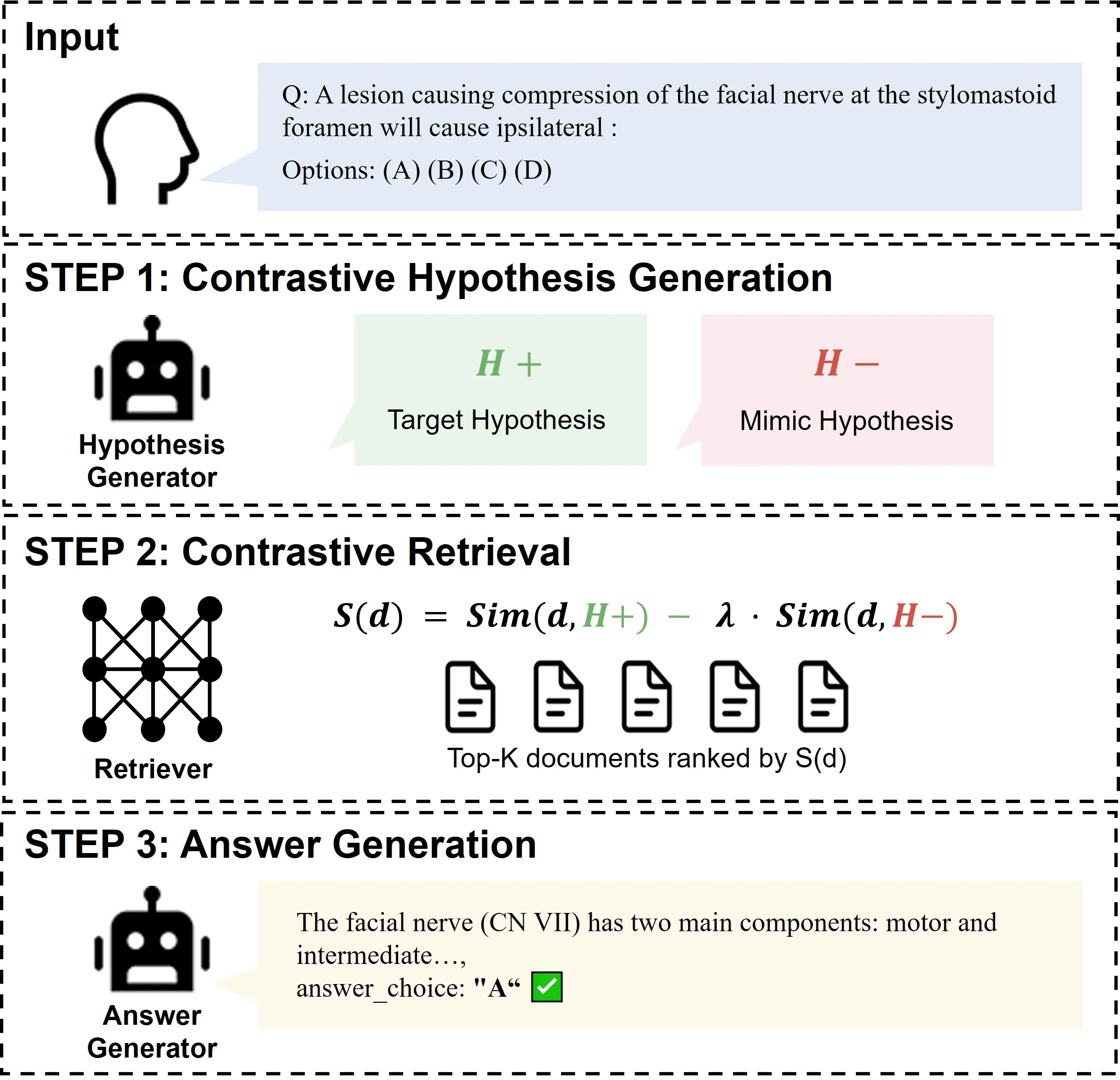
Ruling Out to Rule In: Contrastive Hypothesis Retrieval for Medical Question Answering
Retrieval-augmented generation (RAG) grounds large language models in external medical knowledge, yet standard retrievers frequently surface hard negatives that are semantically close to the query but describe clinically distinct conditions. While existing query-expansion methods improve query representation to mitigate ambiguity, they typically focus on enriching target-relevant semantics without an explicit mechanism to selectively suppress specific, clinically plausible hard negatives. This leaves the system prone to retrieving plausible mimics that overshadow the actual diagnosis, particularly when such mimics are dominant within the corpus. We propose Contrastive Hypothesis Retrieval (CHR), a framework inspired by the process of clinical differential diagnosis. CHR generates a target hypothesis $H^+$ for the likely correct answer and a mimic hypothesis $H^-$ for the most plausible incorrect alternative, then scores documents by promoting $H^+$-aligned evidence while penalizing $H^-$-aligned content. Across three medical QA benchmarks and three answer generators, CHR outperforms all five baselines in every configuration, with improvements of up to 10.4 percentage points over the next-best method. On the $n=587$ pooled cases where CHR answers correctly while embedded hypothetical-document query expansion does not, 85.2\% have no shared documents between the top-5 retrieval lists of CHR and of that baseline, consistent with substantive retrieval redirection rather than light re-ranking of the same candidates. By explicitly modeling what to avoid alongside what to find, CHR bridges clinical reasoning with retrieval mechanism design and offers a practical path to reducing hard-negative contamination in medical RAG systems.
2604.04593Apr 2026
View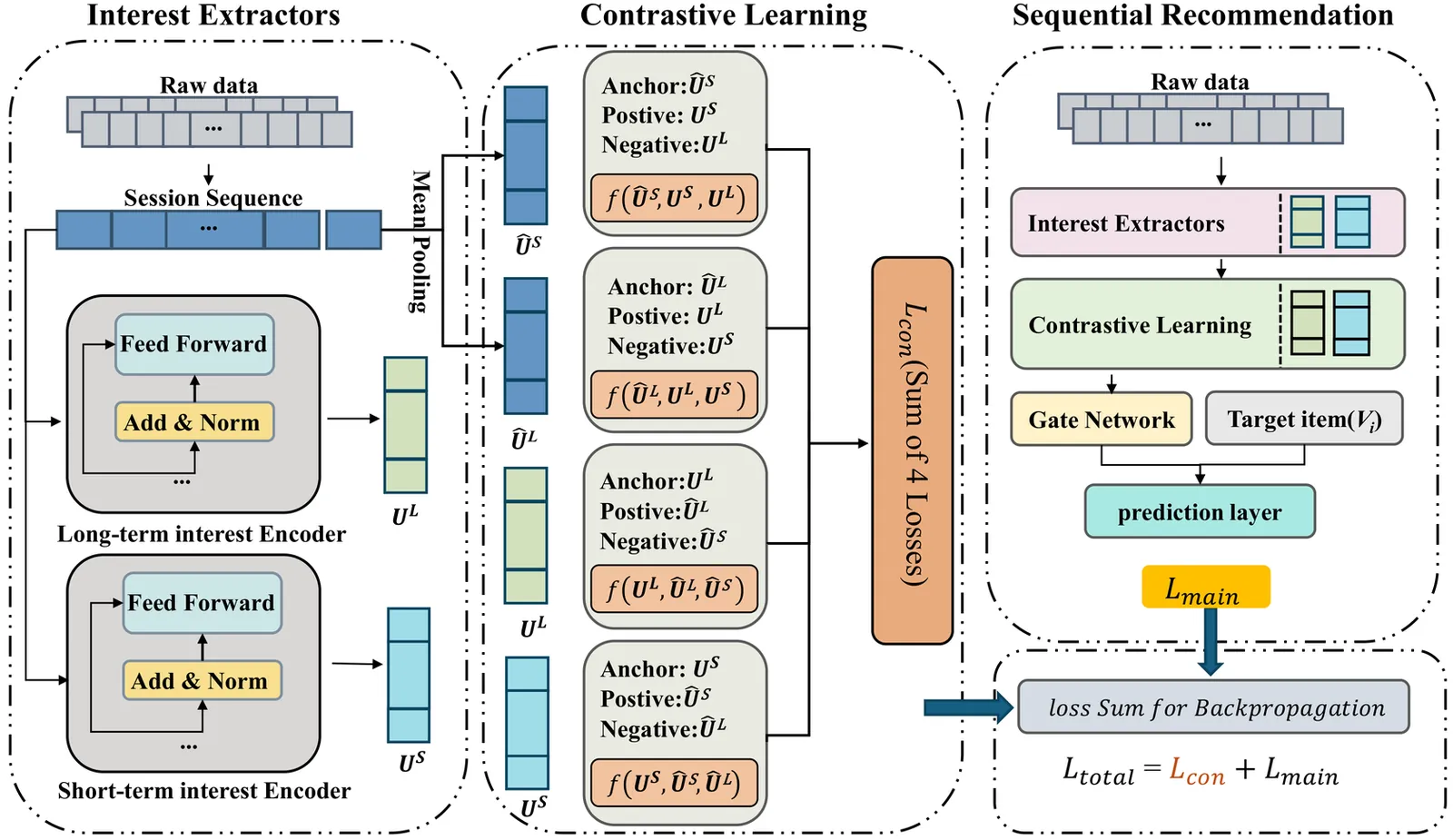
SLSREC: Self-Supervised Contrastive Learning for Adaptive Fusion of Long- and Short-Term User Interests
User interests typically encompass both long-term preferences and short-term intentions, reflecting the dynamic nature of user behaviors across different timeframes. The uneven temporal distribution of user interactions highlights the evolving patterns of interests, making it challenging to accurately capture shifts in interests using comprehensive historical behaviors. To address this, we propose SLSRec, a novel Session-based model with the fusion of Long- and Short-term Recommendations that effectively captures the temporal dynamics of user interests by segmenting historical behaviors over time. Unlike conventional models that combine long- and short-term user interests into a single representation, compromising recommendation accuracy, SLSRec utilizes a self-supervised learning framework to disentangle these two types of interests. A contrastive learning strategy is introduced to ensure accurate calibration of long- and short-term interest representations. Additionally, an attention-based fusion network is designed to adaptively aggregate interest representations, optimizing their integration to enhance recommendation performance. Extensive experiments on three public benchmark datasets demonstrate that SLSRec consistently outperforms state-of-the-art models while exhibiting superior robustness across various scenarios.We will release all source code upon acceptance.
2604.04530Apr 2026
View
Retrieval Augmented Conversational Recommendation with Reinforcement Learning
Large language models (LLMs) exhibit enhanced capabilities in language understanding and generation. By utilizing their embedded knowledge, LLMs are increasingly used as conversational recommender systems (CRS), achieving improved performance across diverse scenarios. However, existing LLM-based methods rely on pretrained knowledge without external retrieval mechanisms for novel items. Additionally, the lack of a unified corpus poses challenges for integrating retrieval augmentation into CRS. Motivated by these challenges, we present RAR, a novel two-stage retrieval augmented conversational recommendation framework that aligns retrieval and generation to enhance both performance and factuality. To support this framework and provide a unified corpus, we construct a large-scale movie corpus, comprising over 300k movies with rich metadata, such as titles, casts and plot summaries. Leveraging this data, our primary contribution is RAR, the first framework to departs from standard two-stage CRS by dynamically bridging retrieval and generation. First, a retriever model generates candidate items based on user history; in the subsequent stage, an LLM refines the recommendations by incorporating conversational context with retrieved results. In addition, we introduce a novel reinforcement learning (RL) method that leverages LLM feedback to iteratively update the retriever. By creating a collaborative feedback loop that reinforces sampled candidate sets with higher ranking metrics, RAR effectively mitigates the misalignment between the retrieval and generation stages. Furthermore, grounding the LLM in factual metadata allows our RL-driven approach to capture subtle user intentions and generate context-aware recommendations with reduced hallucinations. We validate our approach through extensive experiments on multiple benchmarks, where RAR consistently outperforms state-of-the-art baseline methods.
2604.04457Apr 2026
View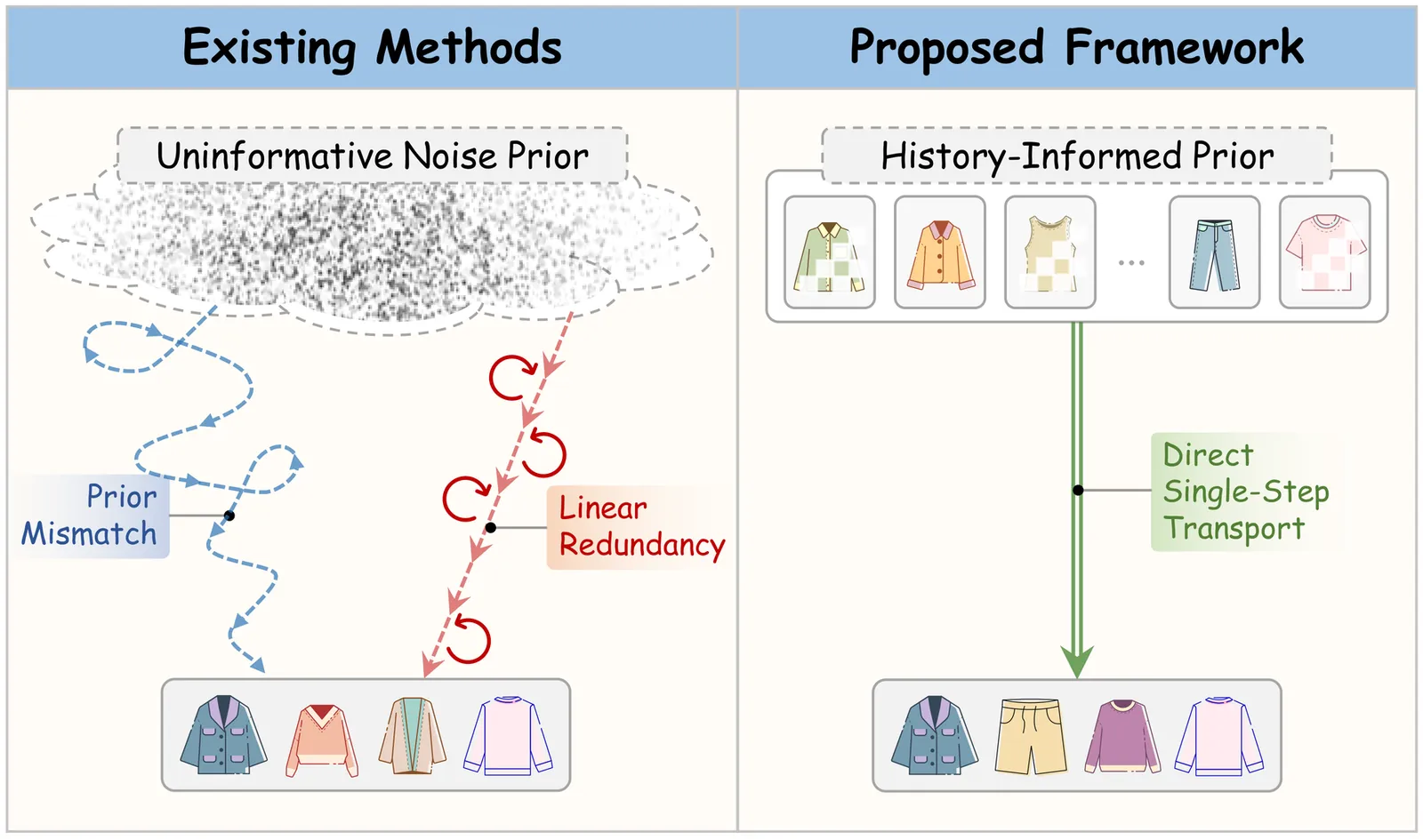
FAVE: Flow-based Average Velocity Establishment for Sequential Recommendation
Generative recommendation has emerged as a transformative paradigm for capturing the dynamic evolution of user intents in sequential recommendation. While flow-based methods improve the efficiency of diffusion models, they remain hindered by the ``Noise-to-Data'' paradigm, which introduces two critical inefficiencies: prior mismatch, where generation starts from uninformative noise, forcing a lengthy recovery trajectory; and linear redundancy, where iterative solvers waste computation on modeling deterministic preference transitions. To address these limitations, we propose a Flow-based Average Velocity Establishment (Fave) framework for one-step generation recommendation that learns a direct trajectory from an informative prior to the target distribution. Fave is structured via a progressive two-stage training strategy. In Stage 1, we establish a stable preference space through dual-end semantic alignment, applying constraints at both the source (user history) and target (next item) to prevent representation collapse. In Stage 2, we directly resolve the efficiency bottlenecks by introducing a semantic anchor prior, which initializes the flow with a masked embedding from the user's interaction history, providing an informative starting point. Then we learn a global average velocity, consolidating the multi-step trajectory into a single displacement vector, and enforce trajectory straightness via a JVP-based consistency constraint to ensure one-step generation. Extensive experiments on three benchmarks demonstrate that Fave not only achieves state-of-the-art recommendation performance but also delivers an order-of-magnitude improvement in inference efficiency, making it practical for latency-sensitive scenarios.
2604.04427Apr 2026
View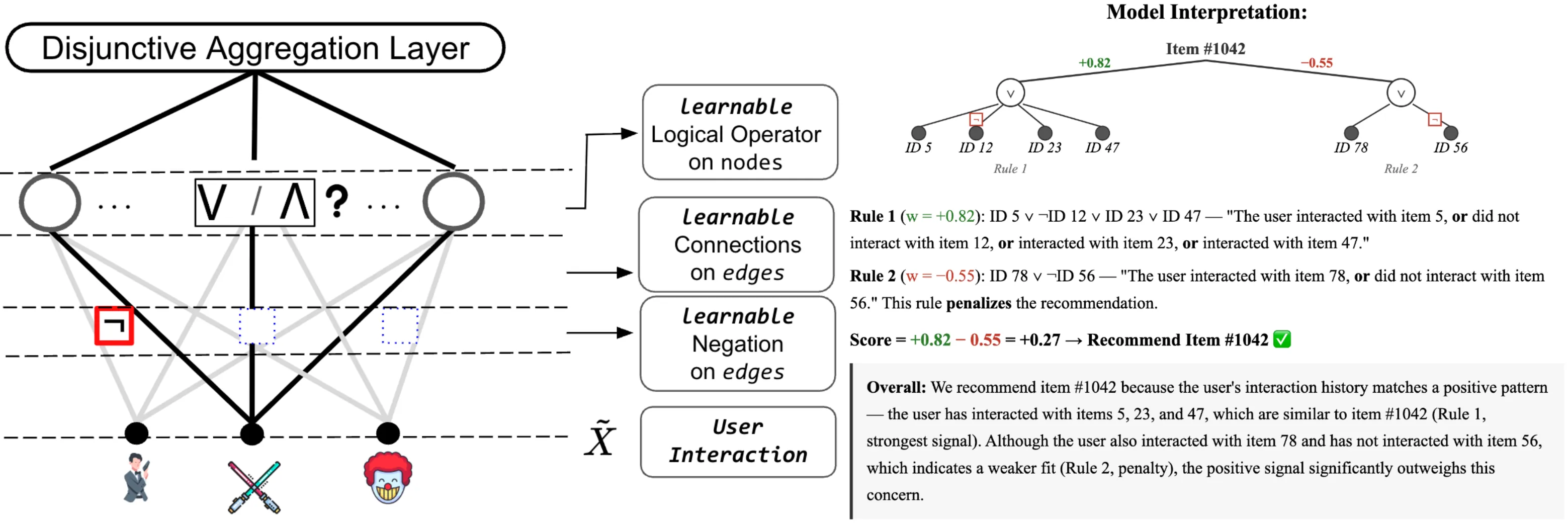
A Logical-Rule Autoencoder for Interpretable Recommendations
Most deep learning recommendation models operate as black boxes, relying on latent representations that obscure their decision process. This lack of intrinsic interpretability raises concerns in applications that require transparency and accountability. In this work, we propose a Logical-rule Interpretable Autoencoder (LIA) for collaborative filtering that is interpretable by design. LIA introduces a learnable logical rule layer in which each rule neuron is equipped with a gate parameter that automatically selects between AND and OR operators during training, enabling the model to discover diverse logical patterns directly from data. To support functional completeness without doubling the input dimensionality, LIA encodes negation through the sign of connection weights, providing a parameter-efficient mechanism for expressing both positive and negated item conditions within each rule. By learning explicit, human-readable reconstruction rules, LIA allows users to directly trace the decision process behind each recommendation. Extensive experiments show that our method achieves improved recommendation performance over traditional baselines while remaining fully interpretable. Code and data are available at https://github.com/weibowen555/LIA.
2604.04270Apr 2026
View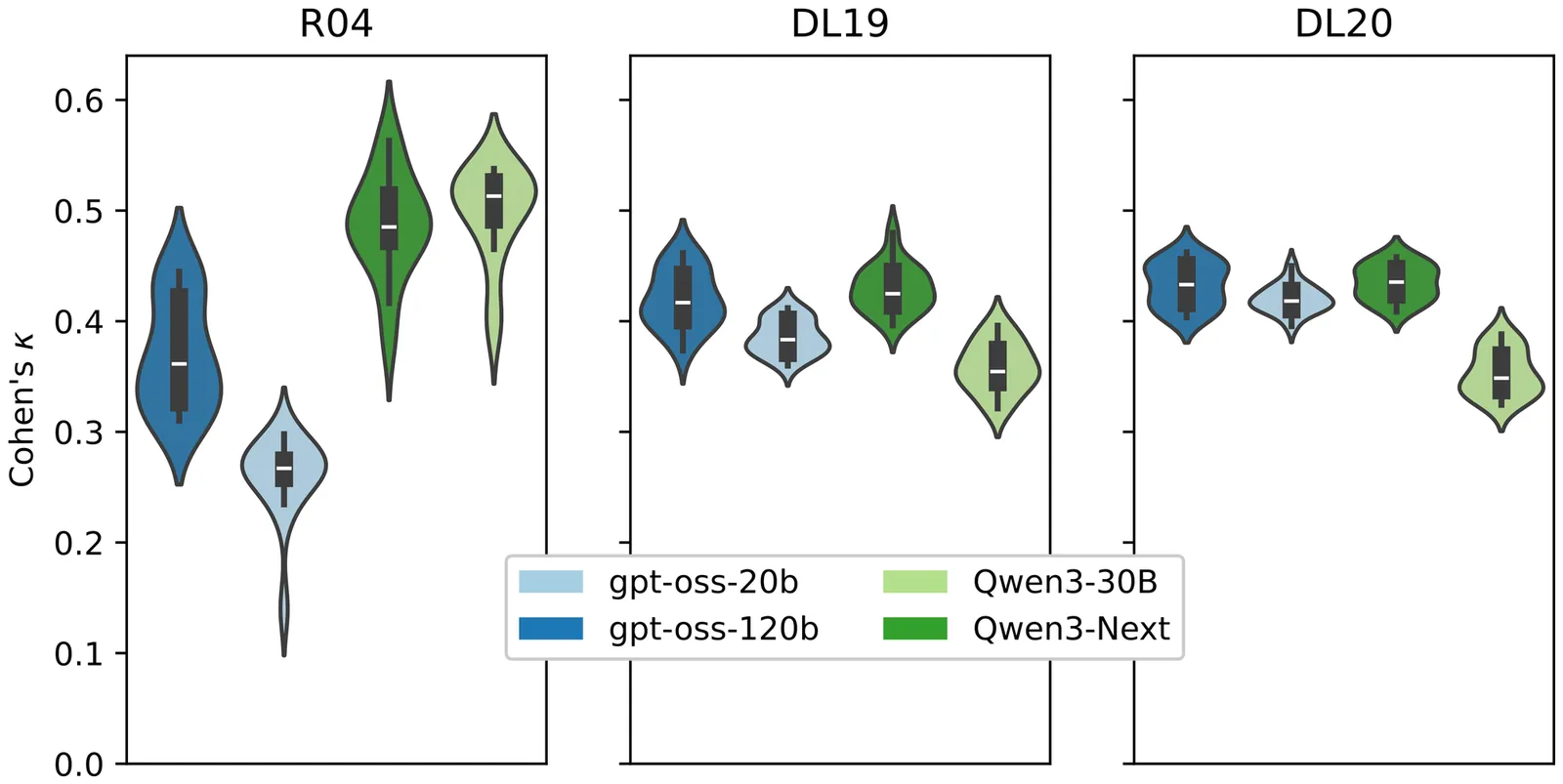
Formalized Information Needs Improve Large-Language-Model Relevance Judgments
Cranfield-style retrieval evaluations with too few or too many relevant documents or with low inter-assessor agreement on relevance can reduce the reliability of observations. In evaluations with human assessors, information needs are often formalized as retrieval topics to avoid an excessive number of relevant documents while maintaining good agreement. However, emerging evaluation setups that use Large Language Models (LLMs) as relevance assessors often use only queries, potentially decreasing the reliability. To study whether LLM relevance assessors benefit from formalized information needs, we synthetically formalize information needs with LLMs into topics that follow the established structure from previous human relevance assessments (i.e., descriptions and narratives). We compare assessors using synthetically formalized topics against the LLM-default query-only assessor on Robust04 and the 2019/2020 editions of TREC Deep Learning. We find that assessors without formalization judge many more documents relevant and have a lower agreement, leading to reduced reliability in retrieval evaluations. Furthermore, we show that the formalized topics improve agreement between human and LLM relevance judgments, even when the topics are not highly similar to their human counterparts. Our findings indicate that LLM relevance assessors should use formalized information needs, as is standard for human assessment, and synthetically formalize topics when no human formalization exists to improve evaluation reliability.
2604.04140Apr 2026
View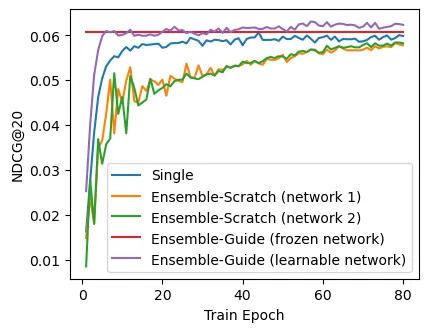
FLAME: Condensing Ensemble Diversity into a Single Network for Efficient Sequential Recommendation
Sequential recommendation requires capturing diverse user behaviors, which a single network often fails to capture. While ensemble methods mitigate this by leveraging multiple networks, training them all from scratch leads to high computational cost and instability from noisy mutual supervision. We propose {\bf F}rozen and {\bf L}earnable networks with {\bf A}ligned {\bf M}odular {\bf E}nsemble ({\bf FLAME}), a novel framework that condenses ensemble-level diversity into a single network for efficient sequential recommendation. During training, FLAME simulates exponential diversity using only two networks via {\it modular ensemble}. By decomposing each network into sub-modules (e.g., layers or blocks) and dynamically combining them, FLAME generates a rich space of diverse representation patterns. To stabilize this process, we pretrain and freeze one network to serve as a semantic anchor and employ {\it guided mutual learning}. This aligns the diverse representations into the space of the remaining learnable network, ensuring robust optimization. Consequently, at inference, FLAME utilizes only the learnable network, achieving ensemble-level performance with zero overhead compared to a single network. Experiments on six datasets show that FLAME outperforms state-of-the-art baselines, achieving up to 7.69$\times$ faster convergence and 9.70\% improvement in NDCG@20. We provide the source code of FLAME at https://github.com/woo-joo/FLAME_SIGIR26.
2604.04038Apr 2026
View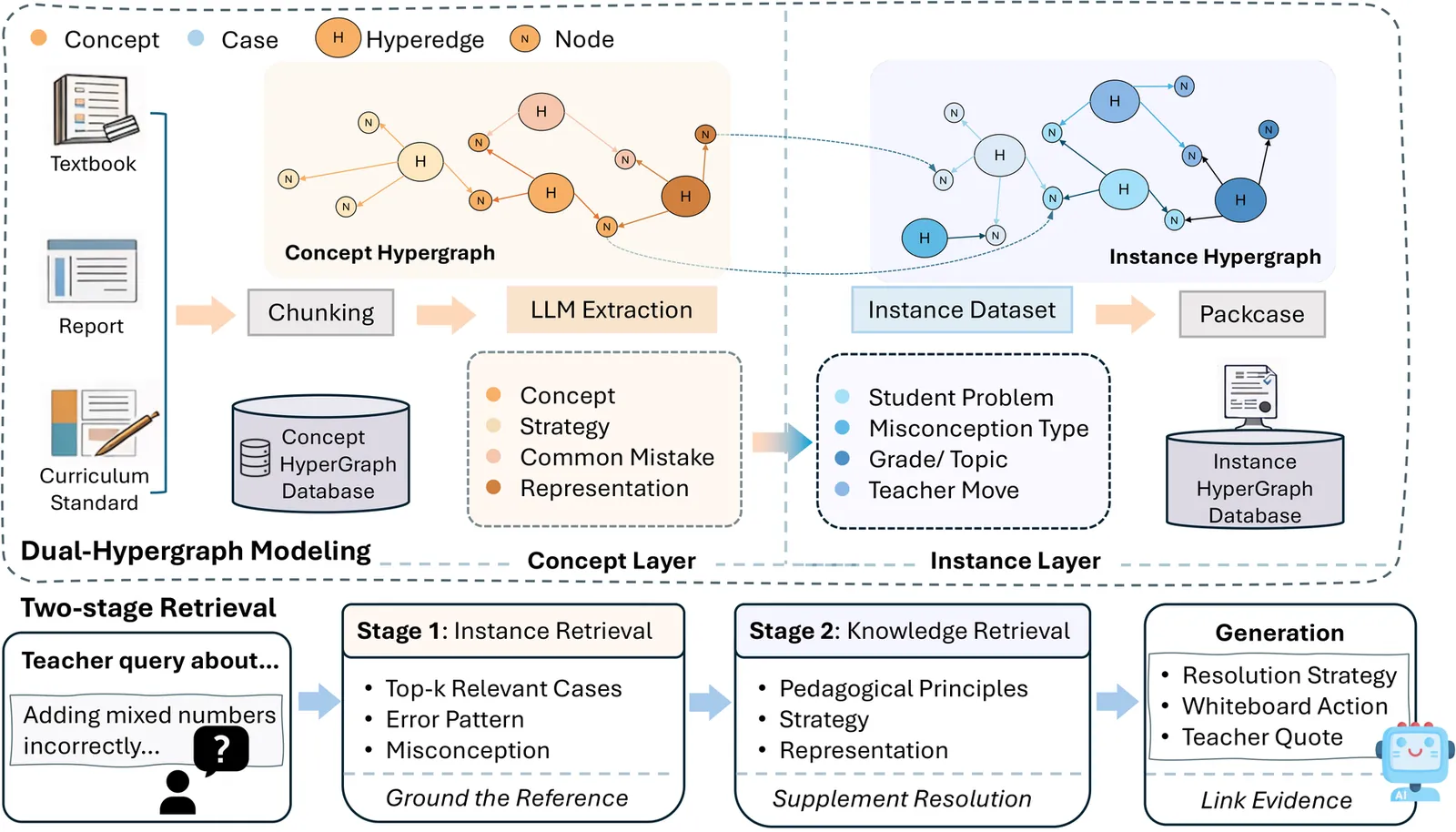
MisEdu-RAG: A Misconception-Aware Dual-Hypergraph RAG for Novice Math Teachers
Novice math teachers often encounter students' mistakes that are difficult to diagnose and remediate. Misconceptions are especially challenging because teachers must explain what went wrong and how to solve them. Although many existing large language model (LLM) platforms can assist in generating instructional feedback, these LLMs loosely connect pedagogical knowledge and student mistakes, which might make the guidance less actionable for teachers. To address this gap, we propose MisEdu-RAG, a dual-hypergraph-based retrieval-augmented generation (RAG) framework that organizes pedagogical knowledge as a concept hypergraph and real student mistake cases as an instance hypergraph. Given a query, MisEdu-RAG performs a two-stage retrieval to gather connected evidence from both layers and generates a response grounded in the retrieved cases and pedagogical principles. We evaluate on \textit{MisstepMath}, a dataset of math mistakes paired with teacher solutions, as a benchmark for misconception-aware retrieval and response generation across topics and error types. Evaluation results on \textit{MisstepMath} show that, compared with baseline models, MisEdu-RAG improves token-F1 by 10.95\% and yields up to 15.3\% higher five-dimension response quality, with the largest gains on \textit{Diversity} and \textit{Empowerment}. To verify its applicability in practical use, we further conduct a pilot study through a questionnaire survey of 221 teachers and interviews with 6 novices. The findings suggest that MisEdu-RAG provides diagnosis results and concrete teaching moves for high-demand misconception scenarios. Overall, MisEdu-RAG demonstrates strong potential for scalable teacher training and AI-assisted instruction for misconception handling. Our code is available on GitHub: https://github.com/GEMLab-HKU/MisEdu-RAG.
2604.04036Apr 2026
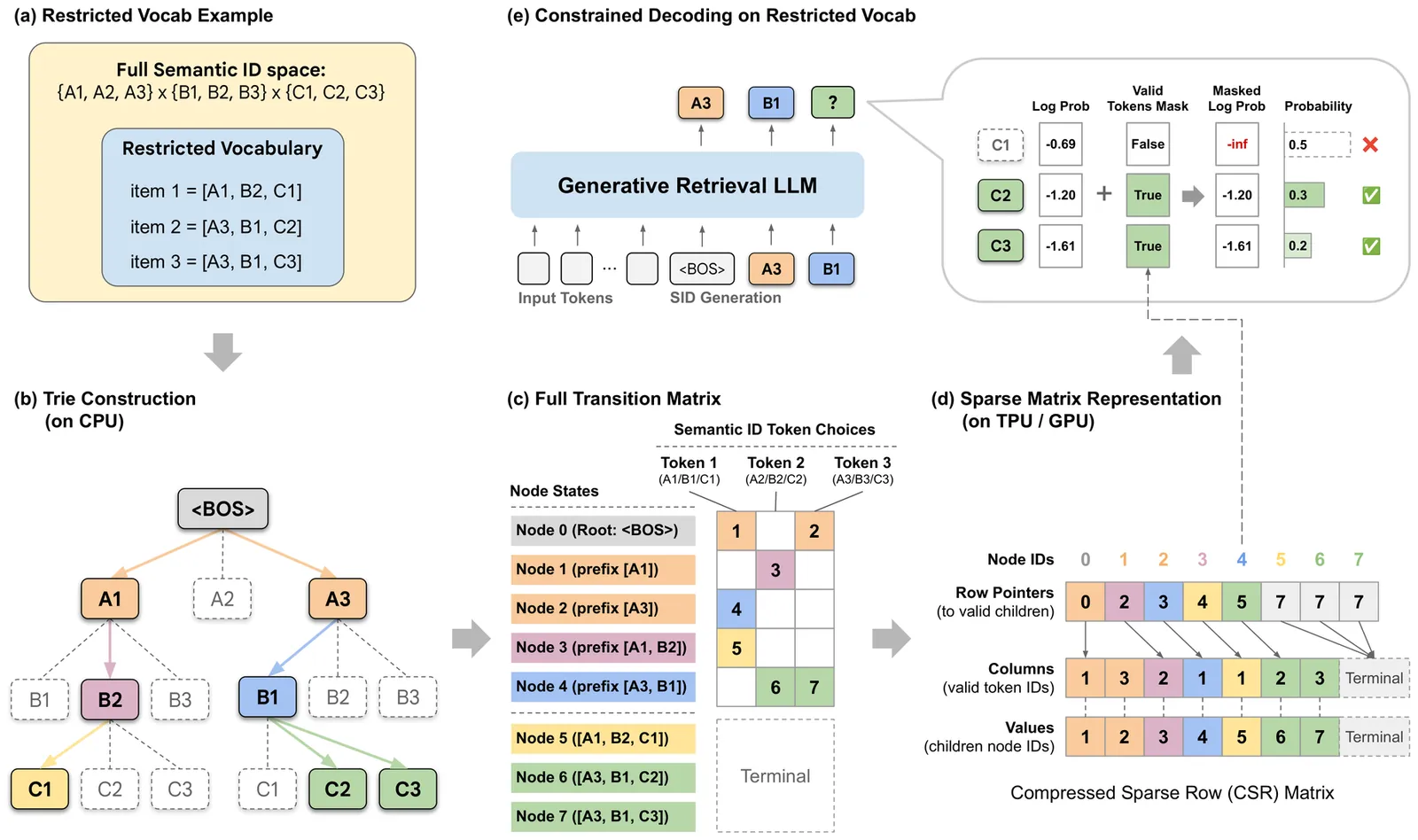
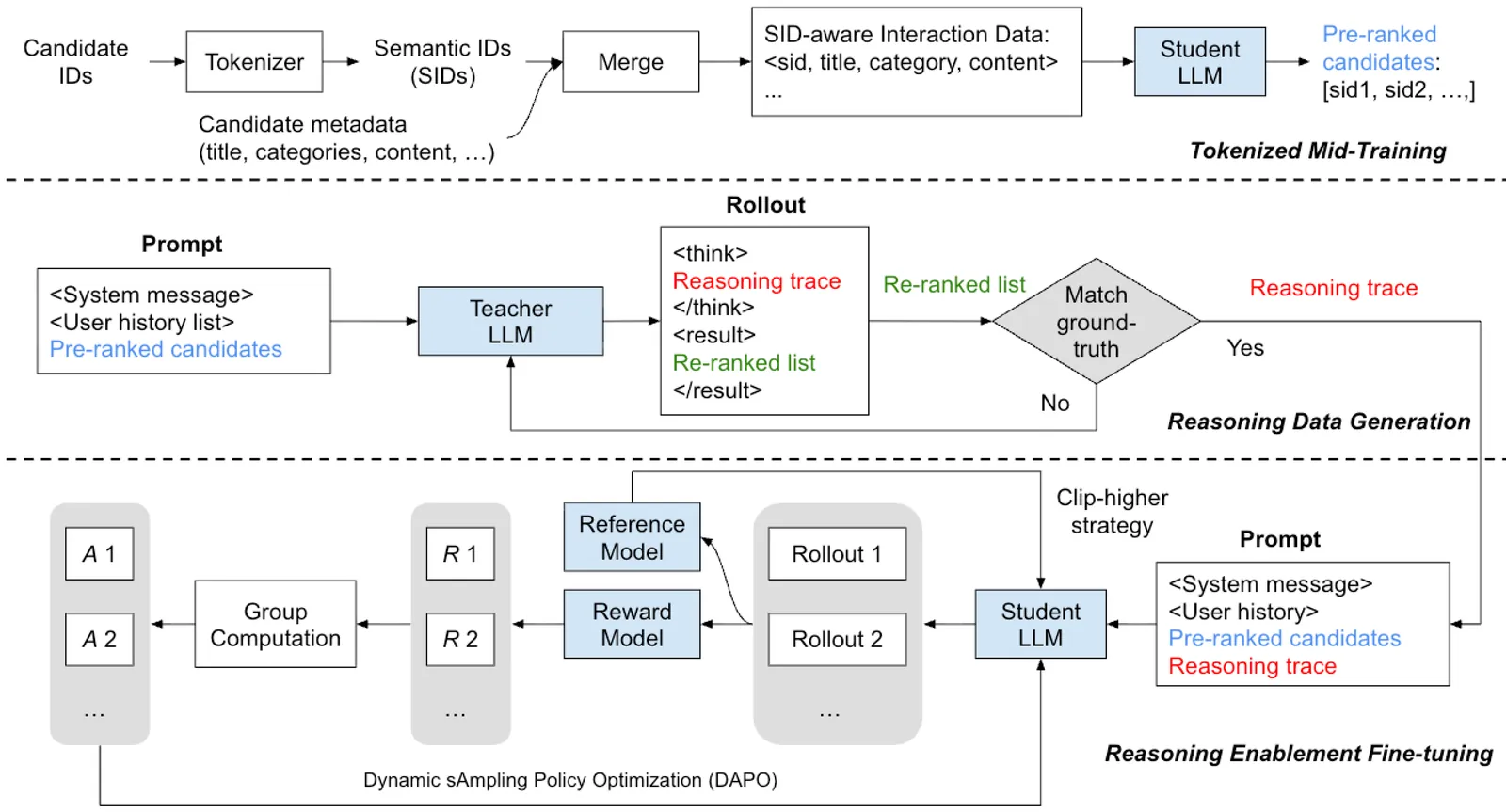
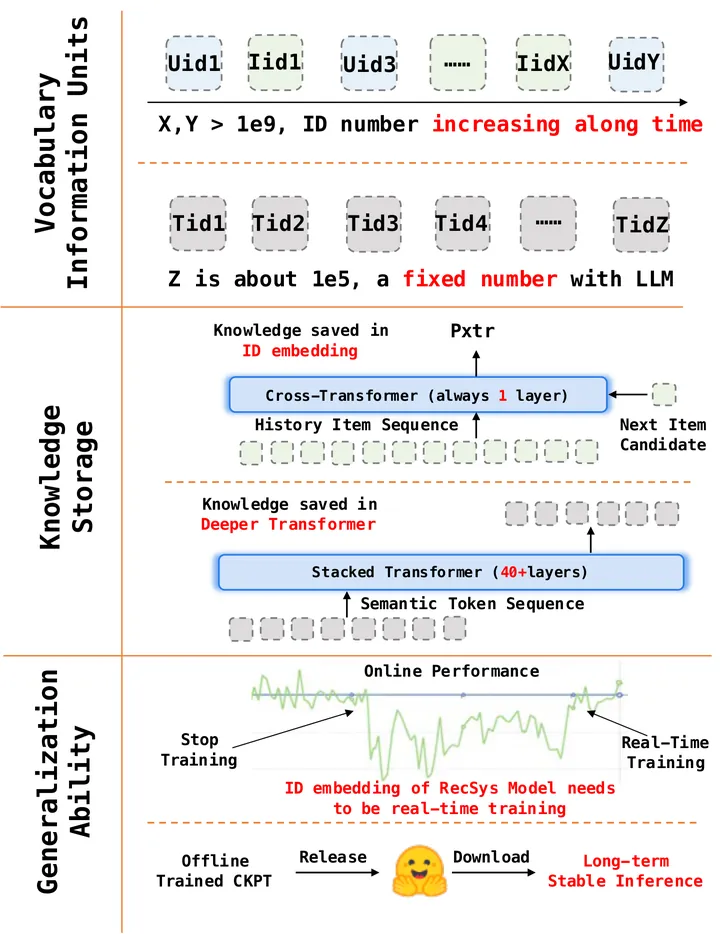
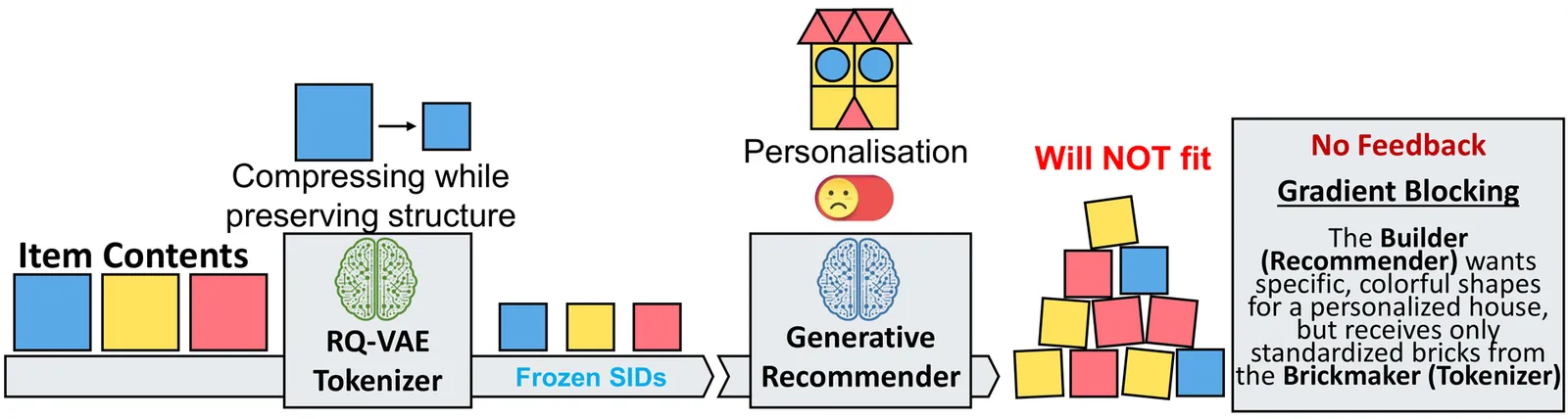
ViewSemantic IDs for Recommender Systems at Snapchat: Use Cases, Technical Challenges, and Design Choices
Effective item identifiers (IDs) are an important component for recommender systems (RecSys) in practice, and are commonly adopted in many use cases such as retrieval and ranking. IDs can encode collaborative filtering signals within training data, such that RecSys models can extrapolate during the inference and personalize the prediction based on users' behavioral histories. Recently, Semantic IDs (SIDs) have become a trending paradigm for RecSys. In comparison to the conventional atomic ID, an SID is an ordered list of codes, derived from tokenizers such as residual quantization, applied to semantic representations commonly extracted from foundation models or collaborative signals. SIDs have drastically smaller cardinality than the atomic counterpart, and induce semantic clustering in the ID space. At Snapchat, we apply SIDs as auxiliary features for ranking models, and also explore SIDs as additional retrieval sources in different ML applications. In this paper, we discuss practical technical challenges we encountered while applying SIDs, experiments we have conducted, and design choices we have iterated to mitigate these challenges. Backed by promising offline results on both internal data and academic benchmarks as well as online A/B studies, SID variants have been launched in multiple production models with positive metrics impact.
2604.03949Apr 2026
View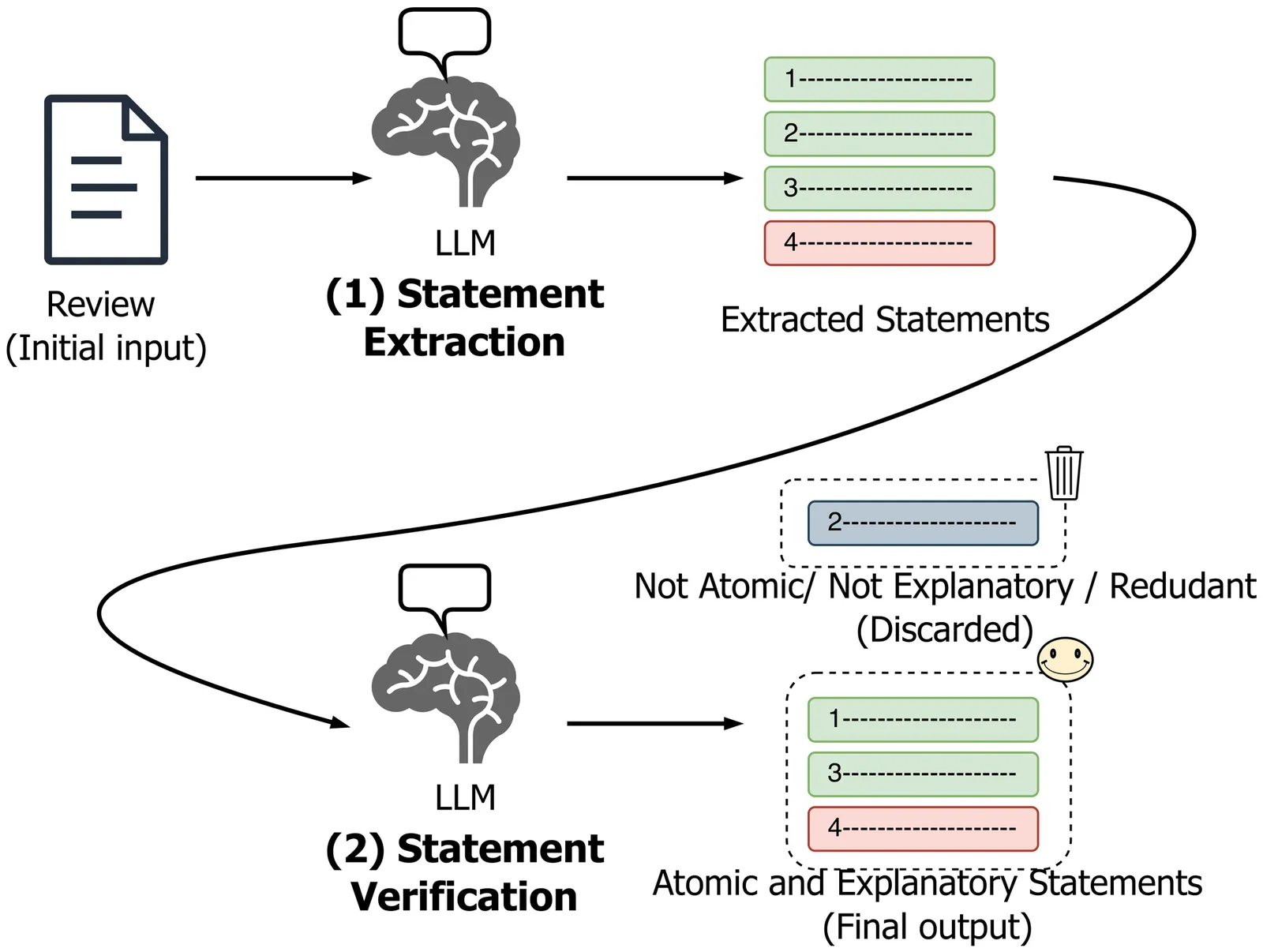
Rank, Don't Generate: Statement-level Ranking for Explainable Recommendation
Textual explanations, generated with large language models (LLMs), are increasingly used to justify recommendations. Yet, evaluating these explanations remains a critical challenge. We advocate a shift in objective: rank, don't generate. We formalize explainable recommendation as a statement-level ranking problem, where systems rank candidate explanatory statements derived from reviews and return the top-k as explanation. This formulation mitigates hallucination by construction and enables fine-grained factual analysis. It also models factor importance through relevance scores and supports standardized, reproducible evaluation with established ranking metrics. Meaningful assessment, however, requires each statement to be explanatory (item facts affecting user experience), atomic (one opinion about one aspect), and unique (paraphrases consolidated), which is challenging to obtain from noisy reviews. We address this with (i) an LLM-based extraction pipeline producing explanatory and atomic statements, and (ii) a scalable, semantic clustering method consolidating paraphrases to enforce uniqueness. Building on this pipeline, we introduce StaR, a benchmark for statement ranking in explainable recommendation, constructed from four Amazon Reviews 2014 product categories. We evaluate popularity-based baselines and state-of-the-art models under global-level (all statements) and item-level (target item statements) ranking. Popularity baselines are competitive in global-level ranking but outperform state-of-the-art models on average in item-level ranking, exposing critical limitations in personalized explanation ranking.
2604.03724Apr 2026
View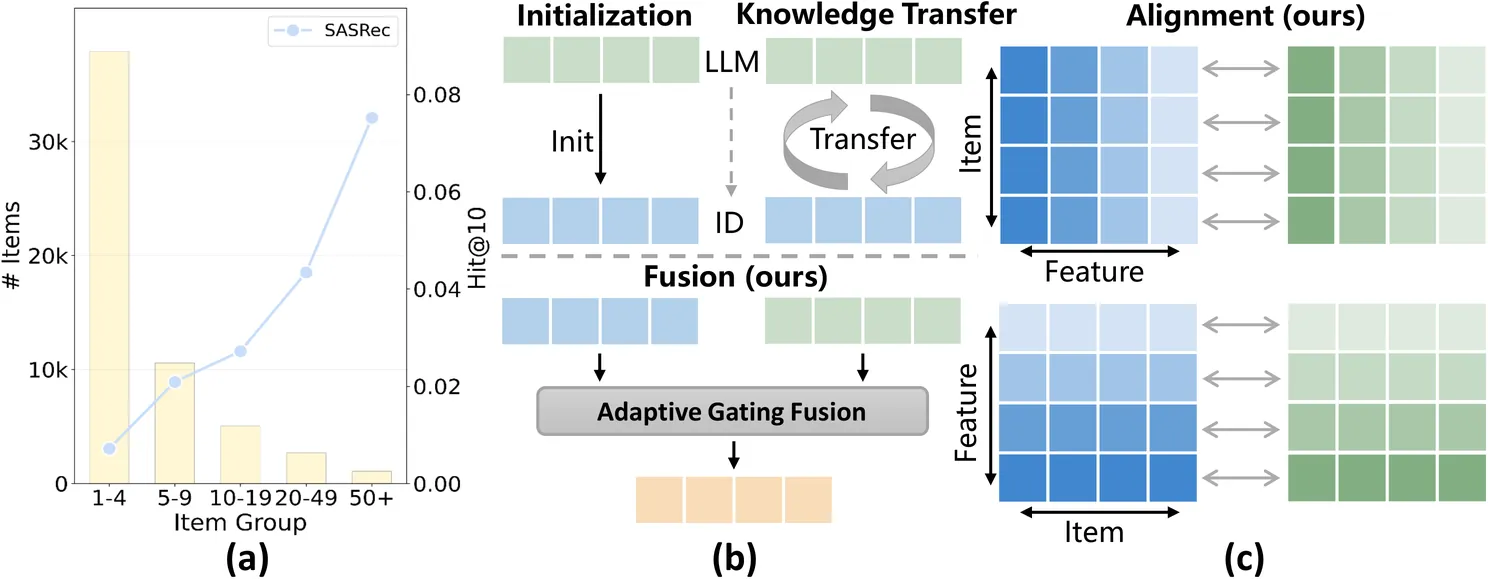
Fusion and Alignment Enhancement with Large Language Models for Tail-item Sequential Recommendation
Sequential Recommendation (SR) learns user preferences from their historical interaction sequences and provides personalized suggestions. In real-world scenarios, most items exhibit sparse interactions, known as the tail-item problem. This issue limits the model's ability to accurately capture item transition patterns. To tackle this, large language models (LLMs) offer a promising solution by capturing semantic relationships between items. Despite previous efforts to leverage LLM-derived embeddings for enriching tail items, they still face the following limitations: 1) They struggle to effectively fuse collaborative signals with semantic knowledge, leading to suboptimal item embedding quality. 2) Existing methods overlook the structural inconsistency between the ID and LLM embedding spaces, causing conflicting signals that degrade recommendation accuracy. In this work, we propose a Fusion and Alignment Enhancement framework with LLMs for Tail-item Sequential Recommendation (FAERec), which improves item representations by generating coherently-fused and structurally consistent embeddings. For the information fusion challenge, we design an adaptive gating mechanism that dynamically fuses ID and LLM embeddings. Then, we propose a dual-level alignment approach to mitigate structural inconsistency. The item-level alignment establishes correspondences between ID and LLM embeddings of the same item through contrastive learning, while the feature-level alignment constrains the correlation patterns between corresponding dimensions across the two embedding spaces. Furthermore, the weights of the two alignments are adjusted by a curriculum learning scheduler to avoid premature optimization of the complex feature-level objective. Extensive experiments across three widely used datasets with multiple representative SR backbones demonstrate the effectiveness and generalizability of our framework.
2604.03688Apr 2026
View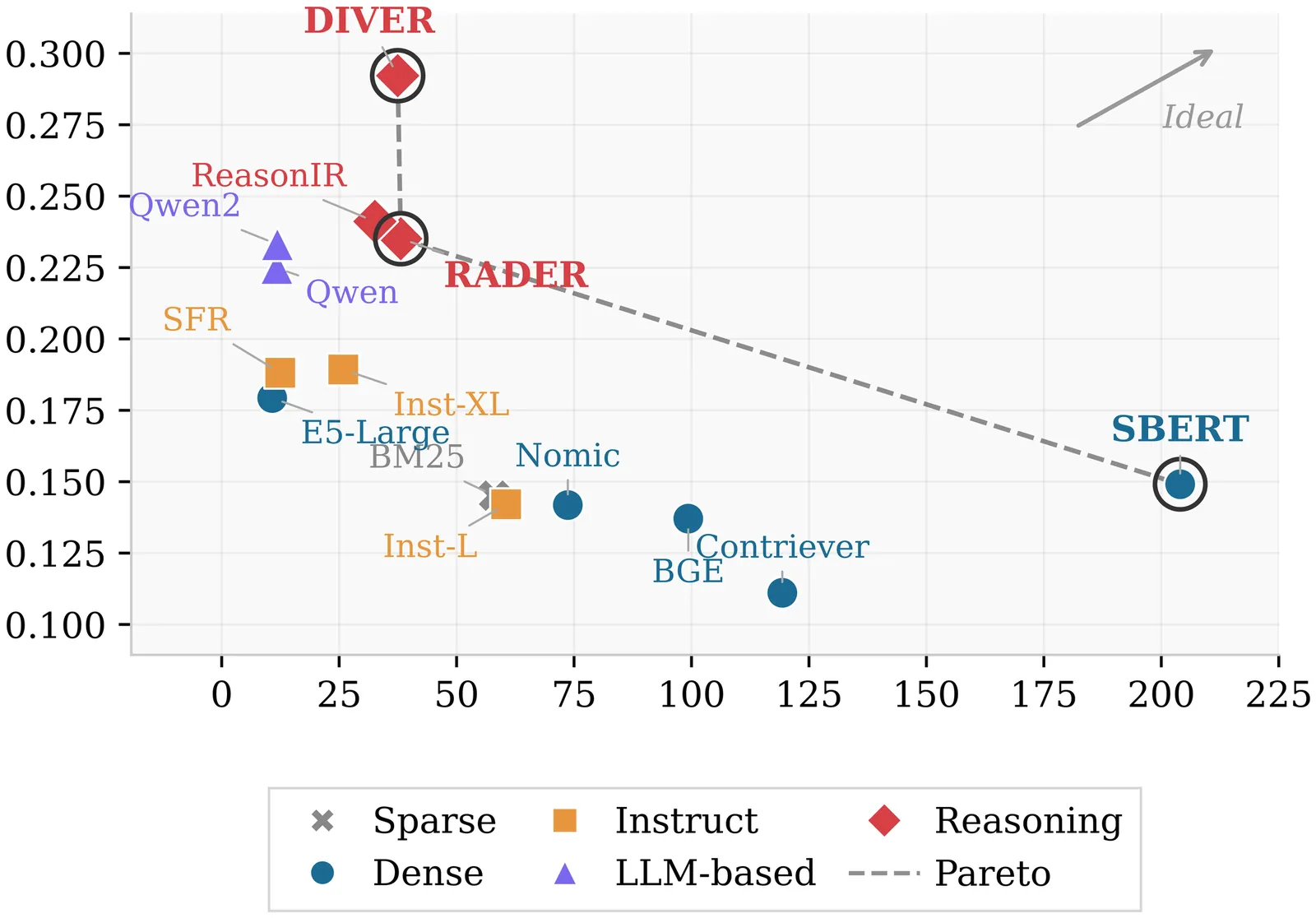
Are LLM-Based Retrievers Worth Their Cost? An Empirical Study of Efficiency, Robustness, and Reasoning Overhead
Large language model retrievers improve performance on complex queries, but their practical value depends on efficiency, robustness, and reliable confidence signals in addition to accuracy. We reproduce a reasoning-intensive retrieval benchmark (BRIGHT) across 12 tasks and 14 retrievers, and extend evaluation with cold-start indexing cost, query latency distributions and throughput, corpus scaling, robustness to controlled query perturbations, and confidence use (AUROC) for predicting query success. We also quantify \emph{reasoning overhead} by comparing standard queries to five provided reasoning-augmented variants, measuring accuracy gains relative to added latency. We find that some reasoning-specialized retrievers achieve strong effectiveness while remaining competitive in throughput, whereas several large LLM-based bi-encoders incur substantial latency for modest gains. Reasoning augmentation incurs minimal latency for sub-1B encoders but exhibits diminishing returns for top retrievers and may reduce performance on formal math/code domains. Confidence calibration is consistently weak across model families, indicating that raw retrieval scores are unreliable for downstream routing without additional calibration. We release all code and artifacts for reproducibility.
2604.03676Apr 2026
View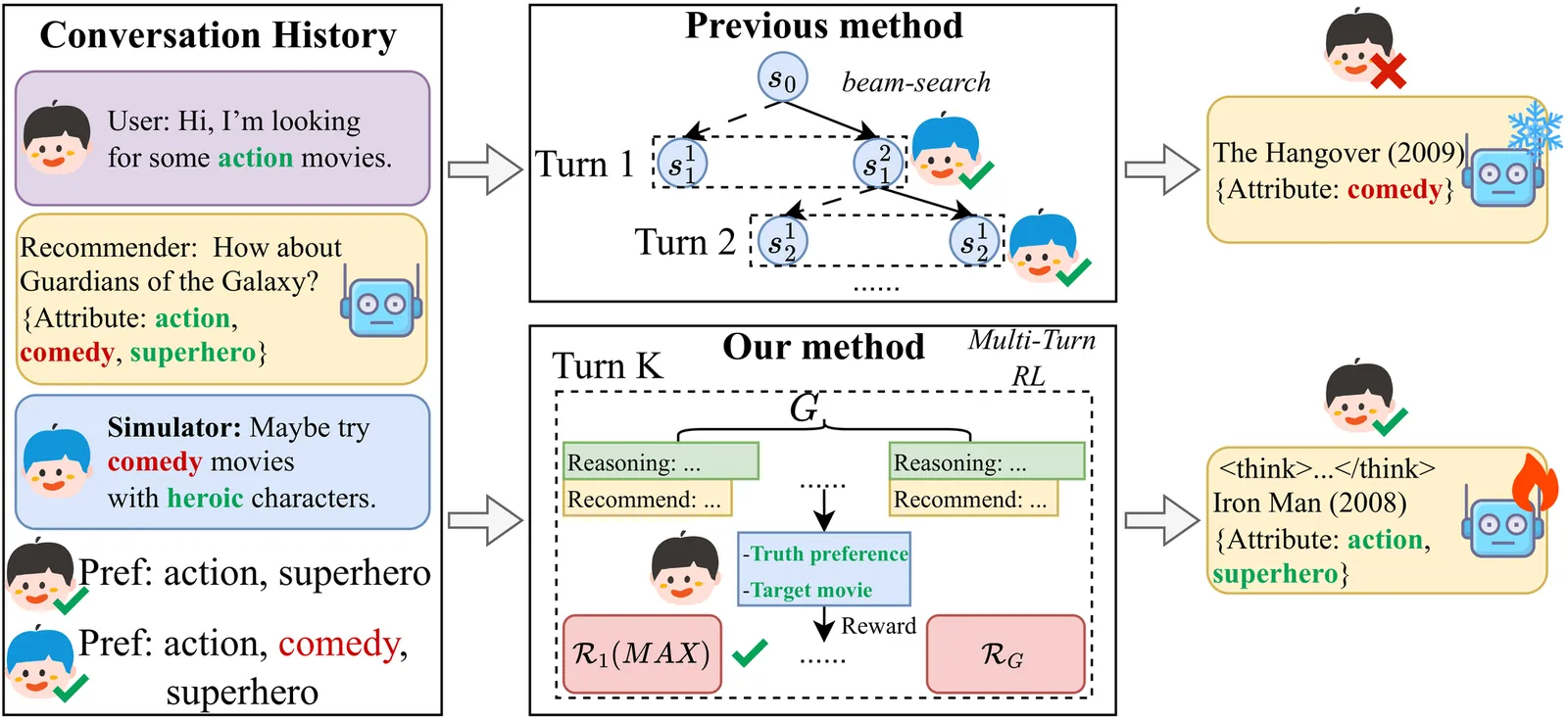
User Simulator-Guided Multi-Turn Preference Optimization for Reasoning LLM-based Conversational Recommendation
Conversational Recommender Systems (CRSs) leverage natural language interactions for personalized recommendation, yet information-scarce dialogue histories and single-turn recommendation paradigms may severely hinder accurate modeling of complex user preferences. To alleviate this issue, recent studies have introduced LLM-based user simulators, which generate natural language feedback and perform simulated multi-turn interactions to assist recommendation. Nevertheless, since simulators cannot access true user preference labels during inference, their feedback may deviate from actual user interests, causing errors to accumulate over multiple interactions and severely affecting the generalization of the recommender. Inspired by the multi-step reasoning capabilities of LLMs and the effectiveness of reinforcement learning in policy optimization, we propose SMTPO, a user simulator-guided multi-turn preference optimization conversational recommendation framework. To align simulator-generated feedback with true user preferences in the absence of explicit labels, we enhance feedback quality via multi-task supervised fine-tuning (SFT), enabling the simulator to better reflect users' complex and diverse needs. To address the challenge of biased feedback destabilizing multi-turn optimization, we first allow the reasoning LLM-based recommender to learn preference reasoning and recommendation patterns through SFT and then employ reinforcement learning with fine-grained reward design to progressively align with true user preferences, improving recommendation performance. Extensive experiments on public datasets demonstrate the effectiveness and transferability of our method.
2604.03671Apr 2026
View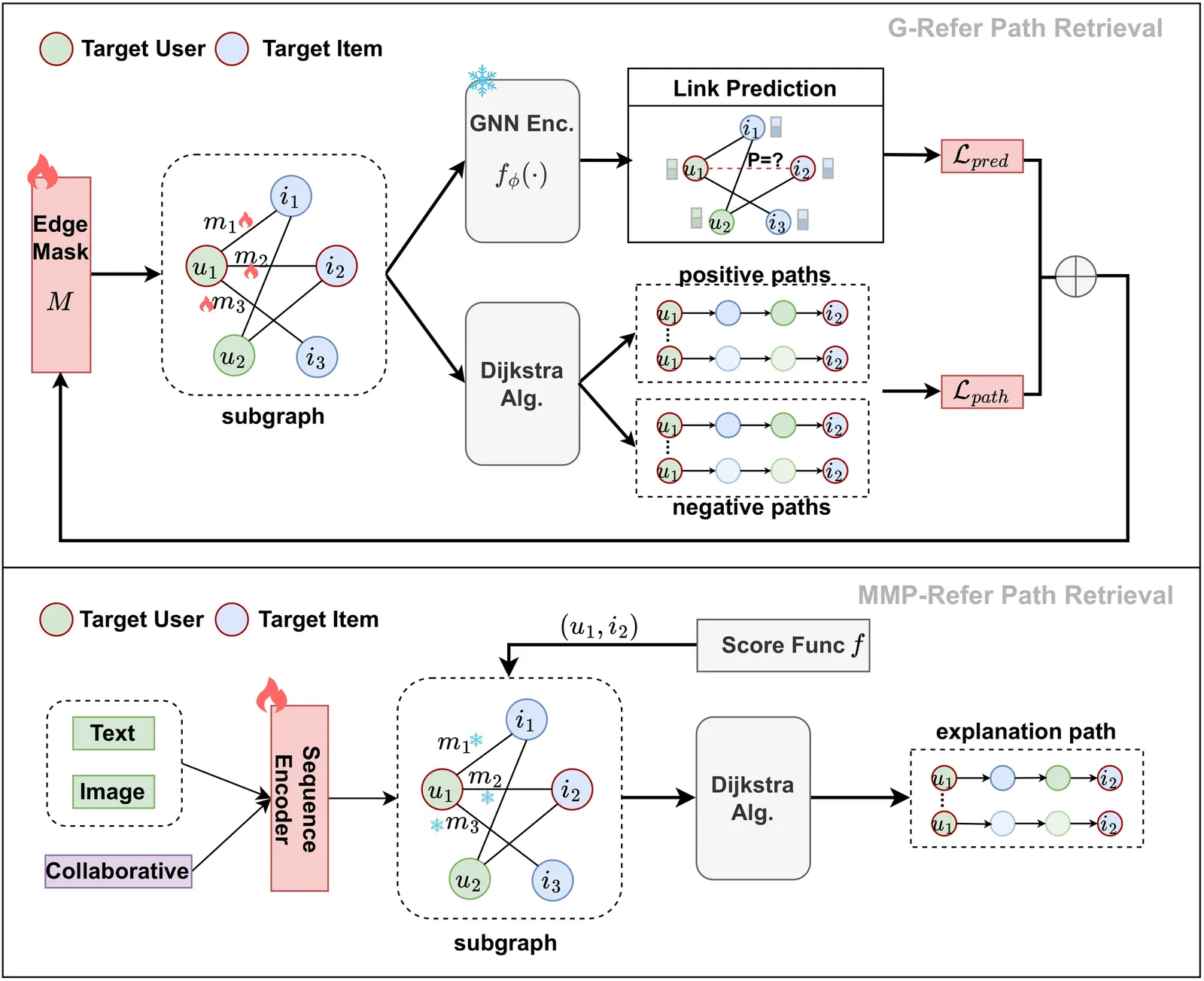
MMP-Refer: Multimodal Path Retrieval-augmented LLMs For Explainable Recommendation
Explainable recommendations help improve the transparency and credibility of recommendation systems, and play an important role in personalized recommendation scenarios. At present, methods for explainable recommendation based on large language models(LLMs) often consider introducing collaborative information to enhance the personalization and accuracy of the model, but ignore the multimodal information in the recommendation dataset; In addition, collaborative information needs to be aligned with the semantic space of LLM. Introducing collaborative signals through retrieval paths is a good choice, but most of the existing retrieval path collection schemes use the existing Explainable GNN algorithms. Although these methods are effective, they are relatively unexplainable and not be suitable for the recommendation field. To address the above challenges, we propose MMP-Refer, a framework using \textbf{M}ulti\textbf{M}odal Retrieval \textbf{P}aths with \textbf{Re}trieval-augmented LLM \textbf{F}or \textbf{E}xplainable \textbf{R}ecommendation. We use a sequential recommendation model based on joint residual coding to obtain multimodal embeddings, and design a heuristic search algorithm to obtain retrieval paths by multimodal embeddings; In the generation phase, we integrated a trainable lightweight collaborative adapter to map the graph encoding of interaction subgraphs to the semantic space of the LLM, as soft prompts to enhance the understanding of interaction information by the LLM. Extensive experiments have demonstrated the effectiveness of our approach. Codes and data are available at https://github.com/pxcstart/MMP-Refer.
2604.03666Apr 2026
View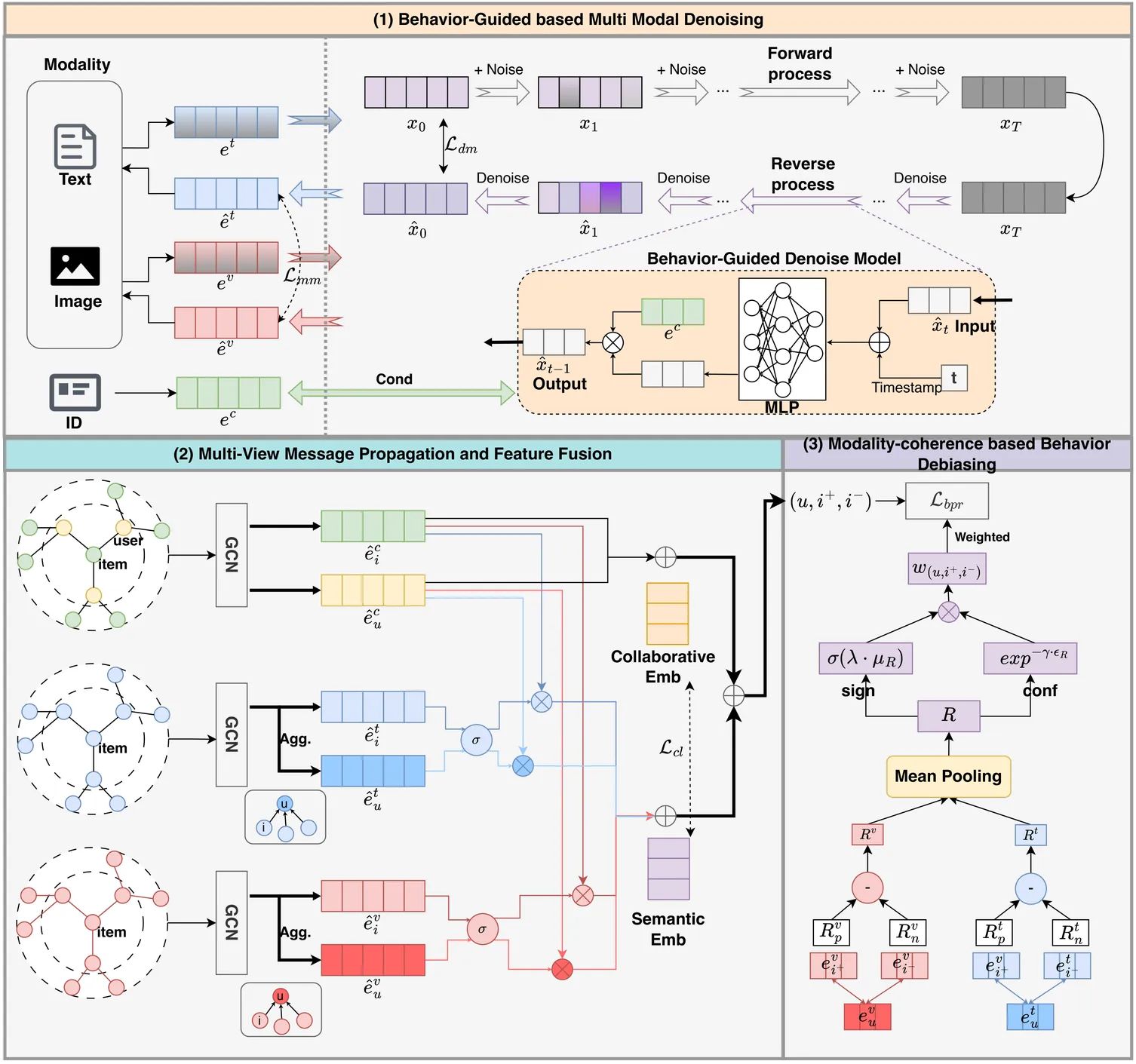
Joint Behavior-guided and Modality-coherence Conditional Graph Diffusion Denoising for Multi Modal Recommendation
In recent years, multimodal recommendation has received significant attention and achieved remarkable success in GCN-based recommendation methods. However, there are two key challenges here: (1) There is a significant amount of redundant information in multimodal features that is unrelated to user preferences. Directly injecting multimodal features into the interaction graph can affect the collaborative feature learning between users and items. (2) There are false negative and false positive behaviors caused by system errors such as accidental clicks and non-exposure. This feedback bias can affect the ranking accuracy of training sample pairs, thereby reducing the recommendation accuracy of the model. To address these challenges, this work proposes a Joint Behavior-guided and Modal-consistent Conditional Graph Diffusion Model (JBM-Diff) for joint denoising of multimodal features and user feedback. We design a diffusion model conditioned on collaborative features for each modal feature to remove preference-irrelevant information, and enhance the alignment between collaborative features and modal semantic information through multi-view message propagation and feature fusion. Finally, we detect the partial order consistency of sample pairs from a behavioral perspective based on learned modal preferences, set the credibility for sample pairs, and achieve data augmentation. Extensive experiments on three public datasets demonstrate the effectiveness of this work. Codes are available at https://github.com/pxcstart/JBMDiff.
2604.03654Apr 2026
View
LLM-based Listwise Reranking under the Effect of Positional Bias
LLM-based listwise passage reranking has attracted attention for its effectiveness in ranking candidate passages. However, these models suffer from positional bias, where passages positioned towards the end of the input are less likely to be moved to top positions in the ranking. We hypothesize that there are two primary sources of positional bias: (1) architectural bias inherent in LLMs and (2) the imbalanced positioning of relevant documents. To address this, we propose DebiasFirst, a method that integrates positional calibration and position-aware data augmentation during fine-tuning. Positional calibration uses inverse propensity scoring to adjust for positional bias by re-weighting the contributions of different positions in the loss function when training. Position-aware augmentation augments training data to ensure that each passage appears equally across varied positions in the input list. This approach markedly enhances both effectiveness and robustness to the original ranking across diverse first-stage retrievers, reducing the dependence of NDCG@10 performance on the position of relevant documents. DebiasFirst also complements the inference-stage debiasing methods, offering a practical solution for mitigating positional bias in reranking.
2604.03642Apr 2026
ViewLightweight Query Routing for Adaptive RAG: A Baseline Study on RAGRouter-Bench
Retrieval-Augmented Generation pipelines span a wide range of retrieval strategies that differ substantially in token cost and capability. Selecting the right strategy per query is a practical efficiency problem, yet no routing classifiers have been trained on RAGRouter-Bench \citep{wang2026ragrouterbench}, a recently released benchmark of $7,727$ queries spanning four knowledge domains, each annotated with one of three canonical query types: factual, reasoning, and summarization. We present the first systematic evaluation of lightweight classifier-based routing on this benchmark. Five classical classifiers are evaluated under three feature regimes, namely, TF-IDF, MiniLM sentence embeddings \citep{reimers2019sbert}, and hand-crafted structural features, yielding 15 classifier feature combinations. Our best configuration, TF-IDF with an SVM, achieves a macro-averaged F1 of $\mathbf{0.928}$ and an accuracy of $\mathbf{93.2\%}$, while simulating $\mathbf{28.1\%}$ token savings relative to always using the most expensive paradigm. Lexical TF-IDF features outperform semantic sentence embeddings by $3.1$ macro-F1 points, suggesting that surface keyword patterns are strong predictors of query-type complexity. Domain-level analysis reveals that medical queries are hardest to route and legal queries most tractable. These results establish a reproducible query-side baseline and highlight the gap that corpus-aware routing must close.
2604.03455Apr 2026
View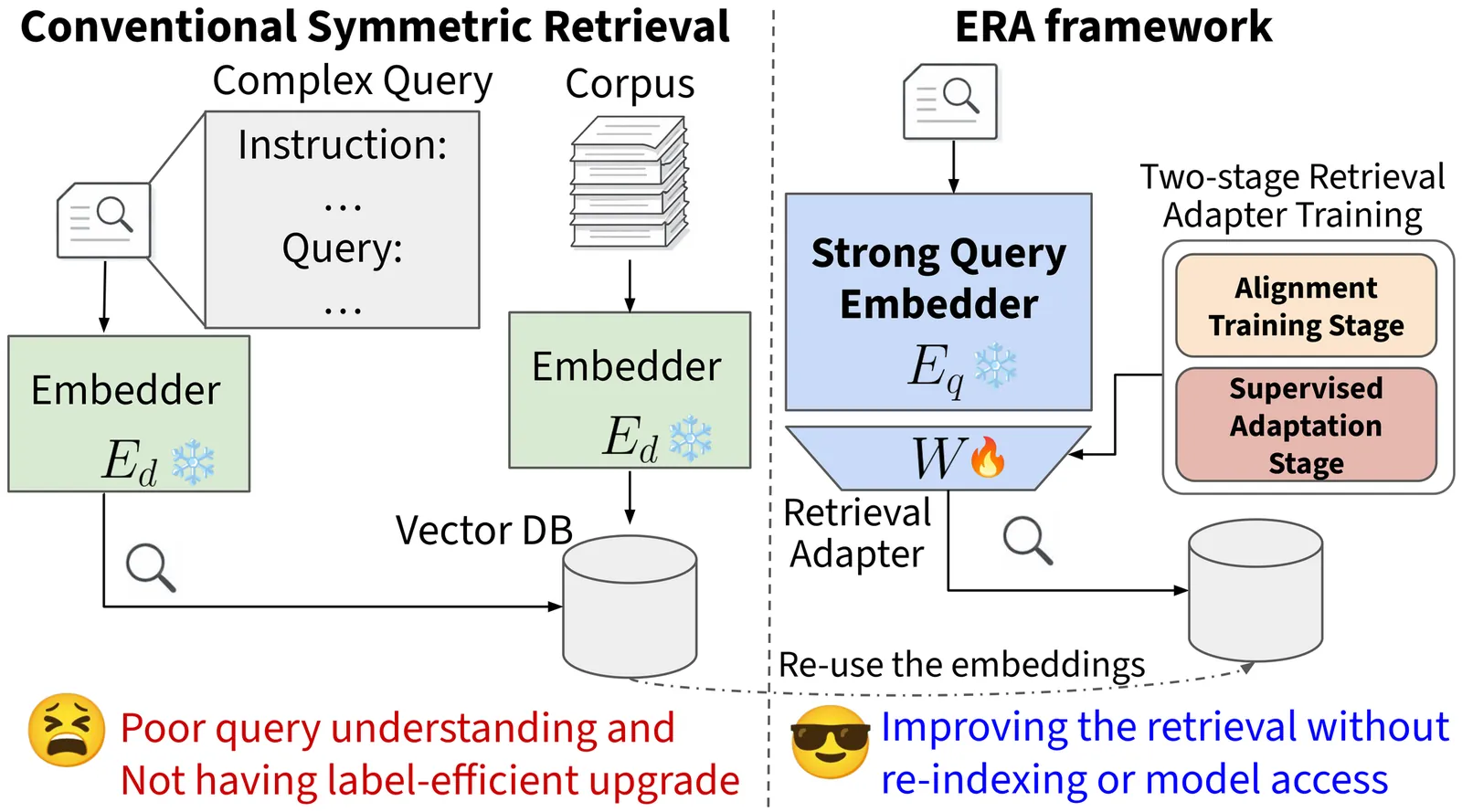
Align then Train: Efficient Retrieval Adapter Learning
Dense retrieval systems increasingly need to handle complex queries. In many realistic settings, users express intent through long instructions or task-specific descriptions, while target documents remain relatively simple and static. This asymmetry creates a retrieval mismatch: understanding queries may require strong reasoning and instruction-following, whereas efficient document indexing favors lightweight encoders. Existing retrieval systems often address this mismatch by directly improving the embedding model, but fine-tuning large embedding models to better follow such instructions is computationally expensive, memory-intensive, and operationally burdensome. To address this challenge, we propose Efficient Retrieval Adapter (ERA), a label-efficient framework that trains retrieval adapters in two stages: self-supervised alignment and supervised adaptation. Inspired by the pre-training and supervised fine-tuning stages of LLMs, ERA first aligns the embedding spaces of a large query embedder and a lightweight document embedder, and then uses limited labeled data to adapt the query-side representation, bridging both the representation gap between embedding models and the semantic gap between complex queries and simple documents without re-indexing the corpus. Experiments on the MAIR benchmark, spanning 126 retrieval tasks across 6 domains, show that ERA improves retrieval in low-label settings, outperforms methods that rely on larger amounts of labeled data, and effectively combines stronger query embedders with weaker document embedders across domains.
2604.03403Apr 2026
ViewPage 1 of 239