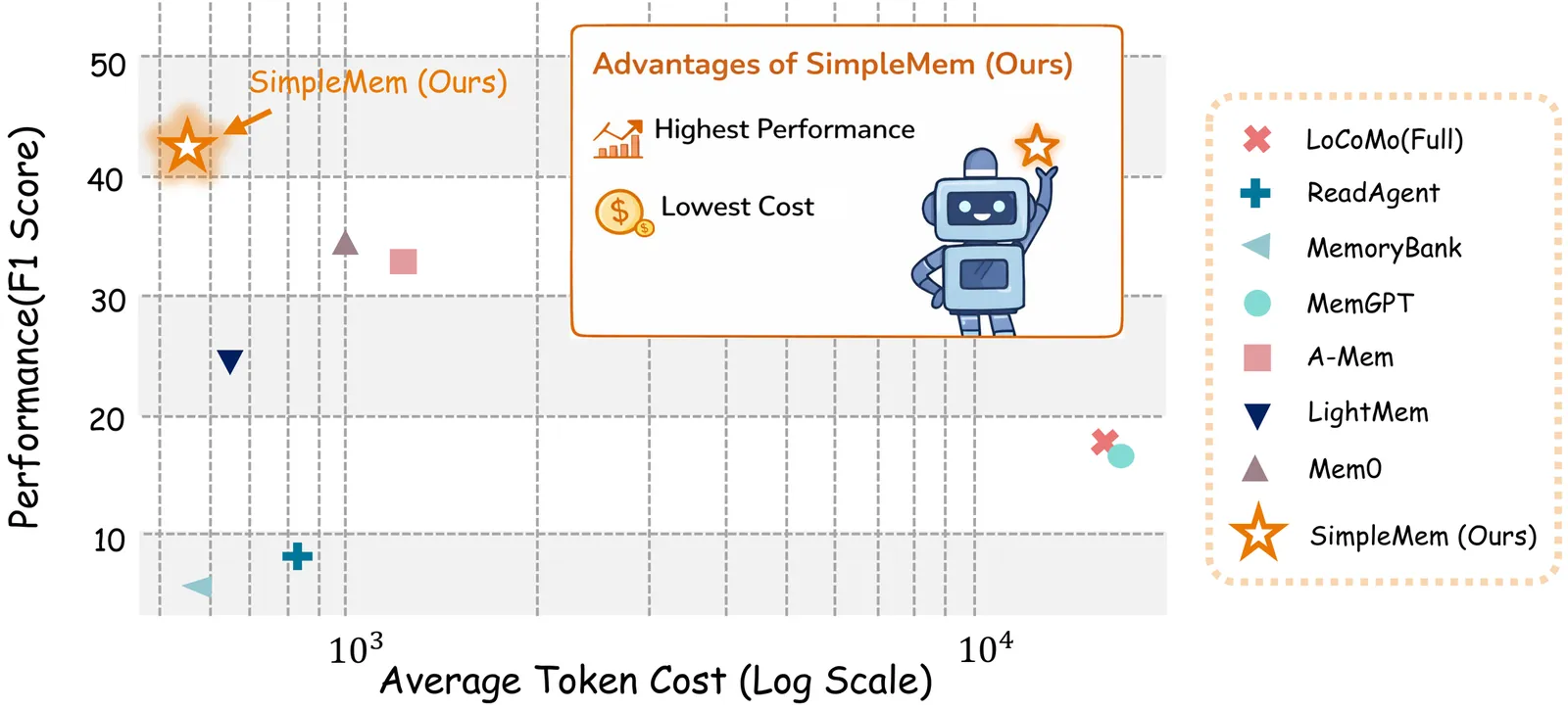
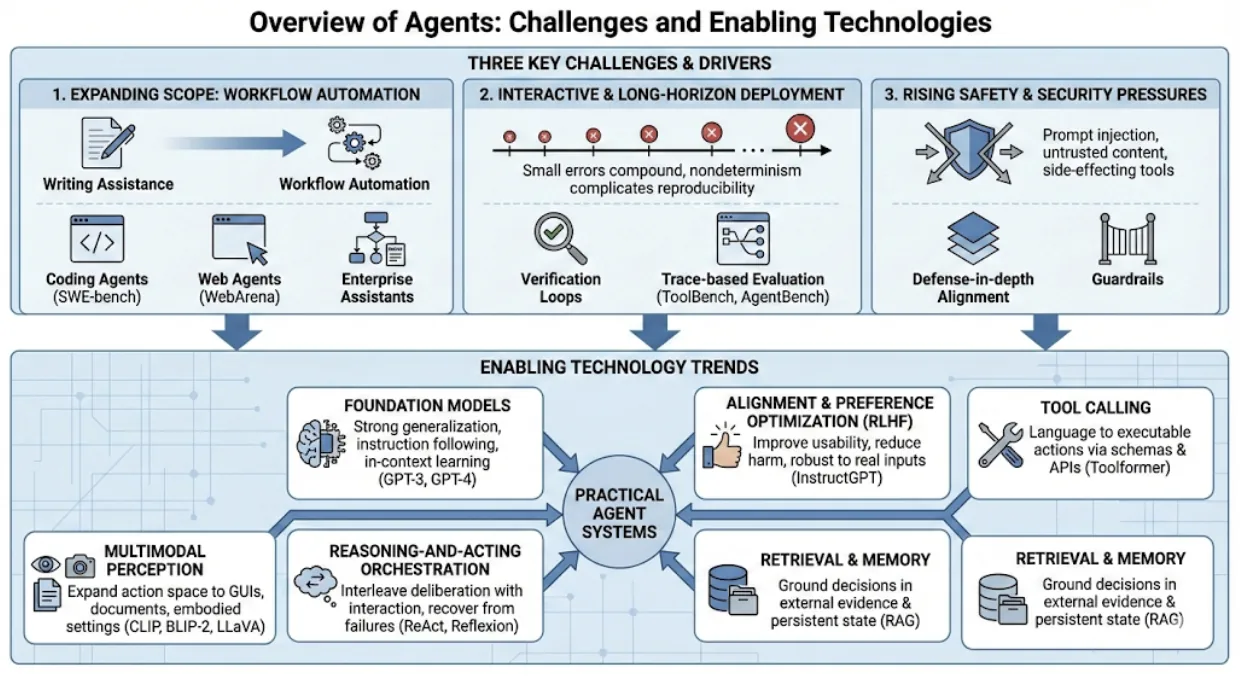
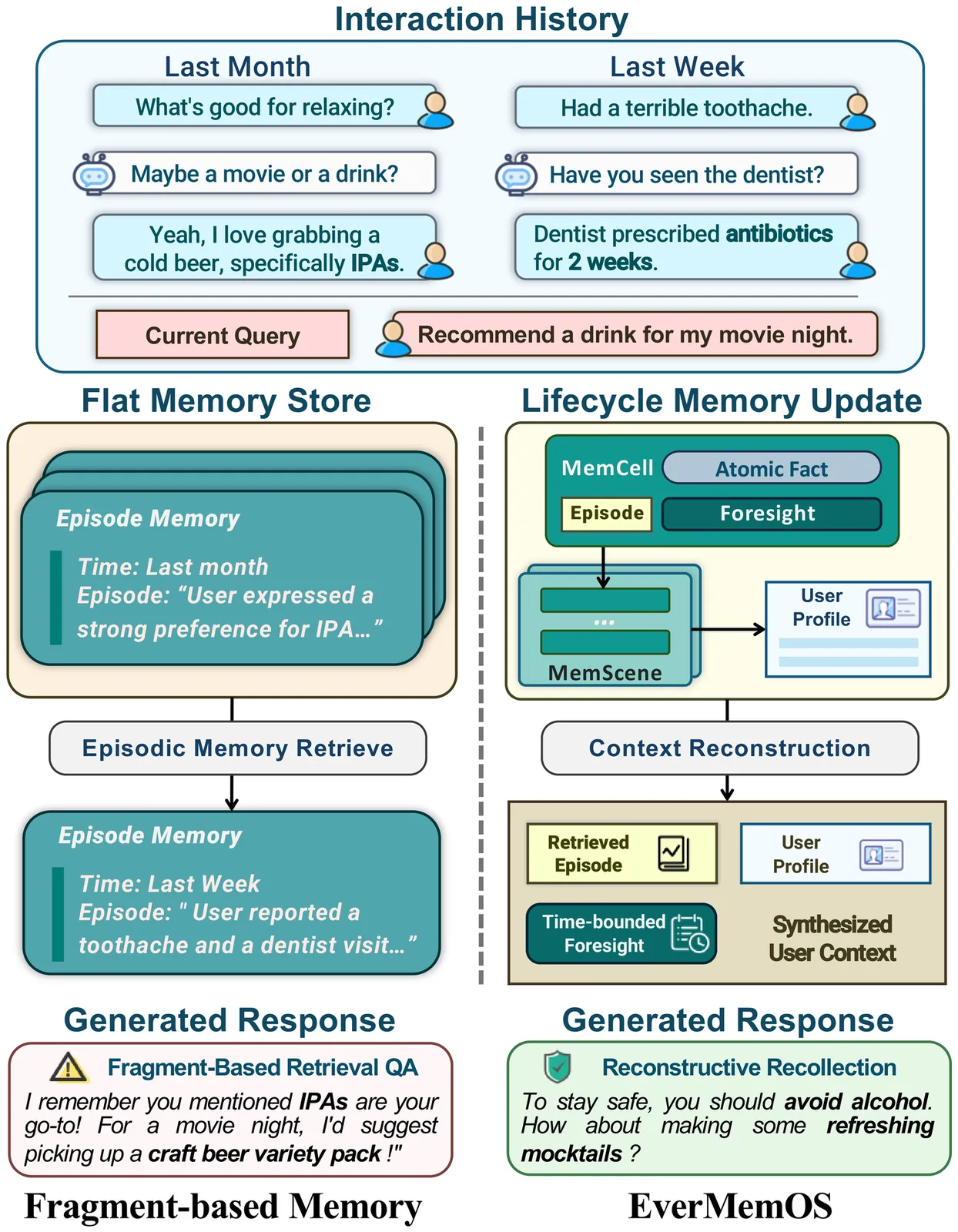
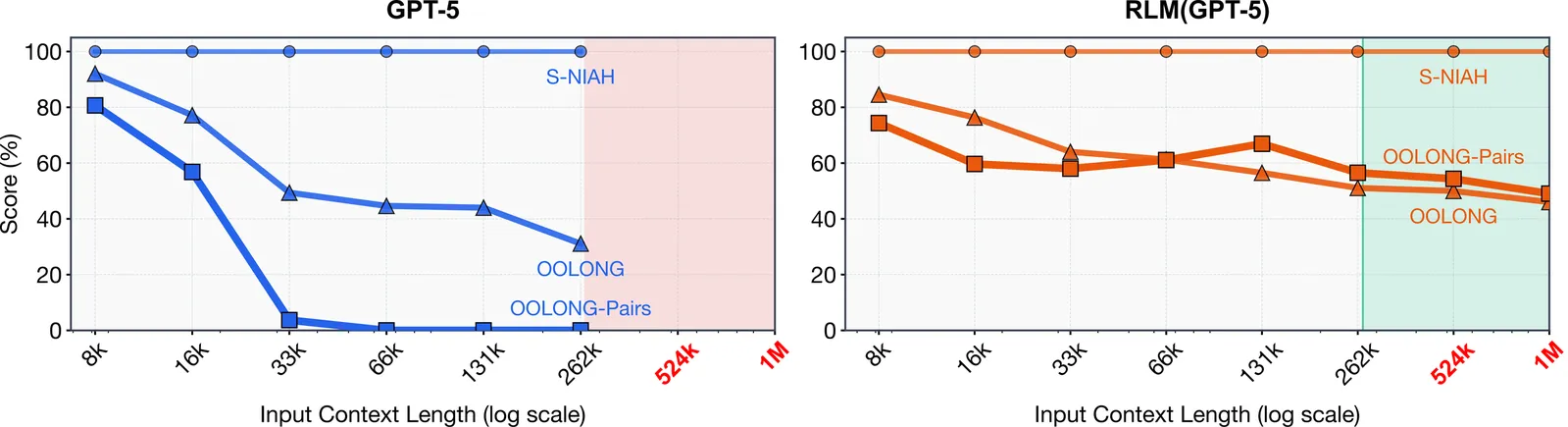
4,959 papers

Agent Drift: Quantifying Behavioral Degradation in Multi-Agent LLM Systems Over Extended Interactions
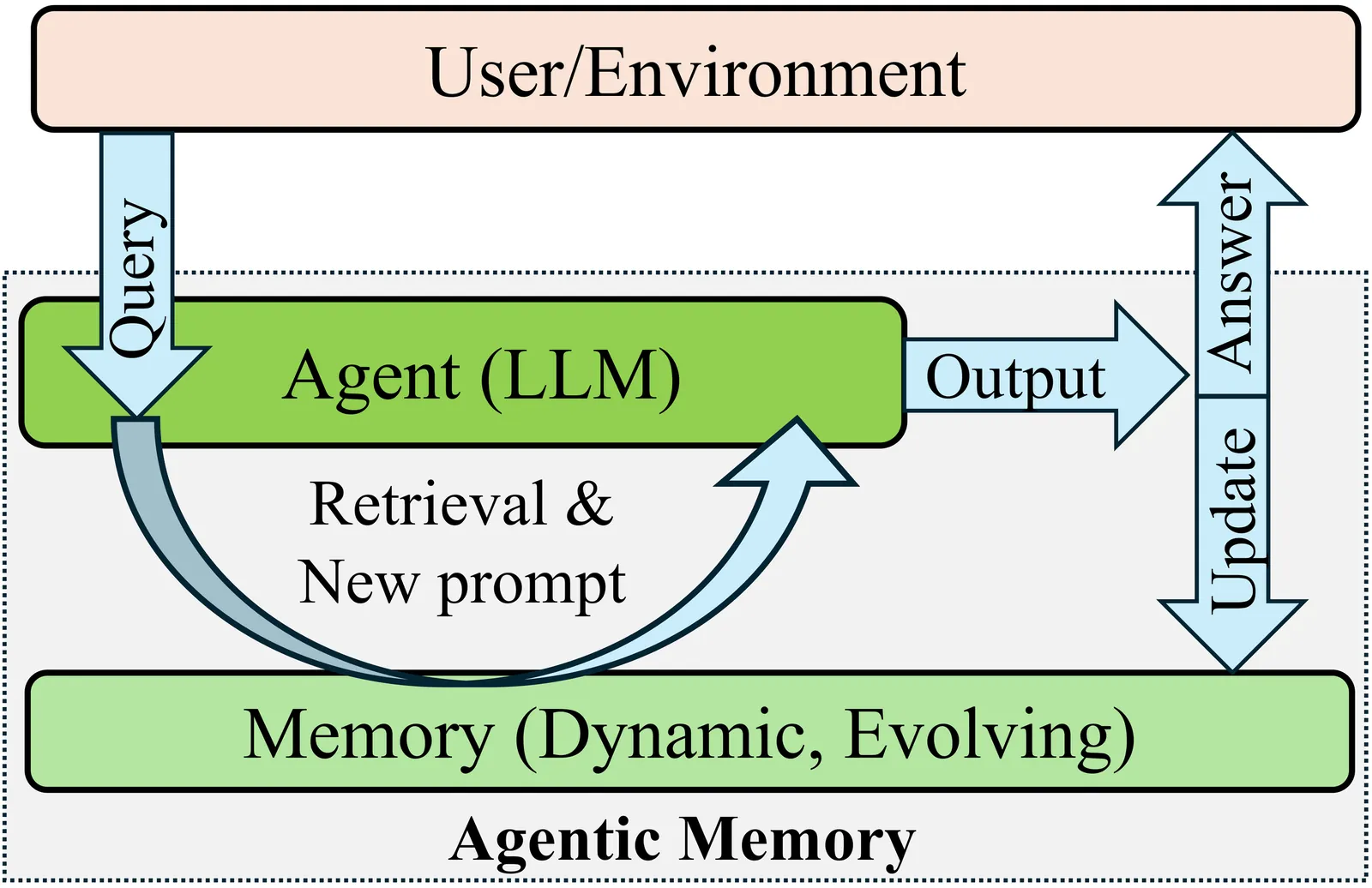
Multi-agent Large Language Model (LLM) systems have emerged as powerful architectures for complex task decomposition and collaborative problem-solving. However, their long-term behavioral stability remains largely unexamined. This study introduces the concept of agent drift, defined as the progressive degradation of agent behavior, decision quality, and inter-agent coherence over extended interaction sequences. We present a comprehensive theoretical framework for understanding drift phenomena, proposing three distinct manifestations: semantic drift (progressive deviation from original intent), coordination drift (breakdown in multi-agent consensus mechanisms), and behavioral drift (emergence of unintended strategies). We introduce the Agent Stability Index (ASI), a novel composite metric framework for quantifying drift across twelve dimensions, including response consistency, tool usage patterns, reasoning pathway stability, and inter-agent agreement rates. Through simulation-based analysis and theoretical modeling, we demonstrate how unchecked agent drift can lead to substantial reductions in task completion accuracy and increased human intervention requirements. We propose three mitigation strategies: episodic memory consolidation, drift-aware routing protocols, and adaptive behavioral anchoring. Theoretical analysis suggests these approaches can significantly reduce drift-related errors while maintaining system throughput. This work establishes a foundational methodology for monitoring, measuring, and mitigating agent drift in production agentic AI systems, with direct implications for enterprise deployment reliability and AI safety research.
2601.04170Jan 2026
View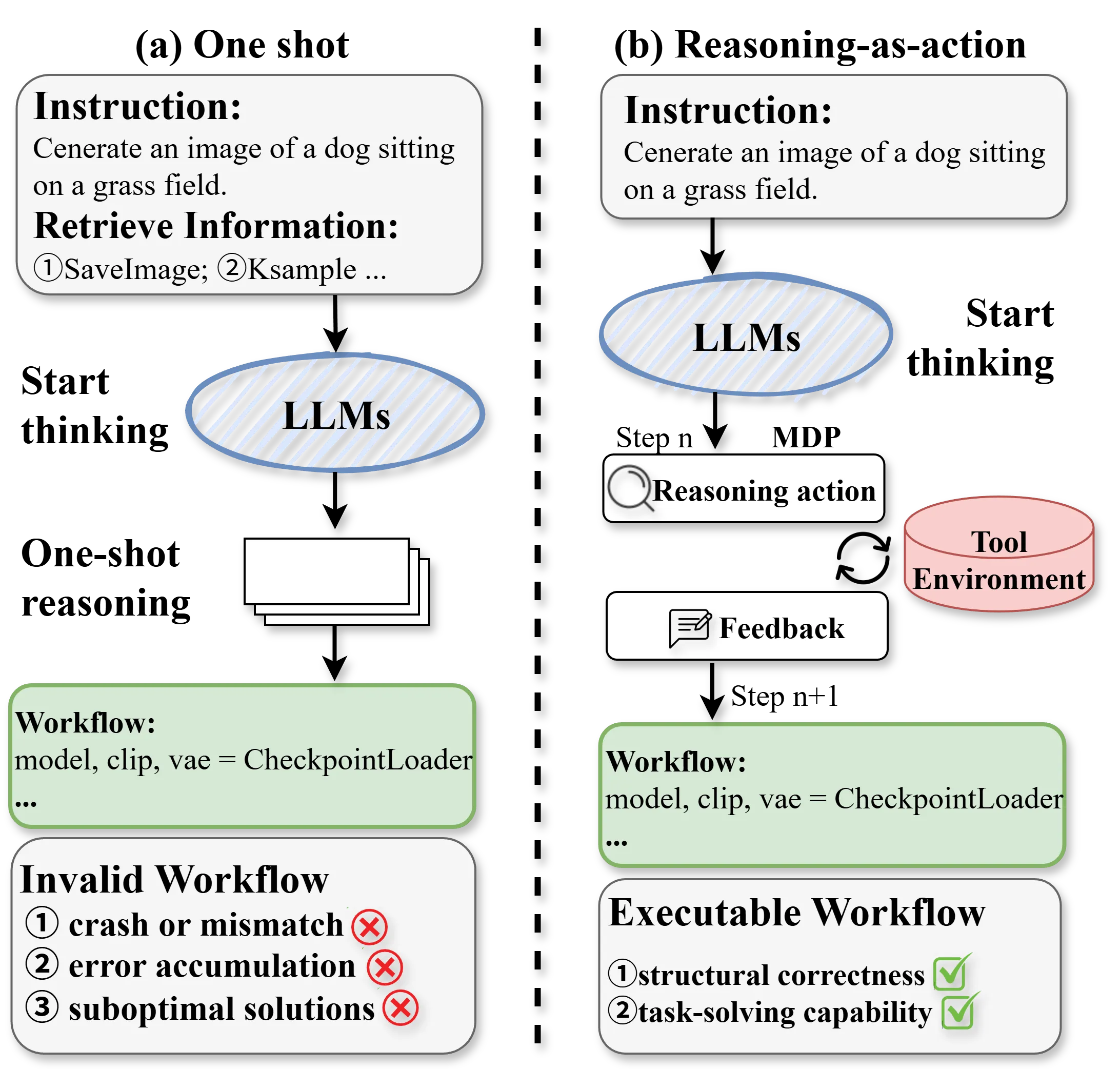
ComfySearch: Autonomous Exploration and Reasoning for ComfyUI Workflows
AI-generated content has progressed from monolithic models to modular workflows, especially on platforms like ComfyUI, allowing users to customize complex creative pipelines. However, the large number of components in ComfyUI and the difficulty of maintaining long-horizon structural consistency under strict graph constraints frequently lead to low pass rates and workflows of limited quality. To tackle these limitations, we present ComfySearch, an agentic framework that can effectively explore the component space and generate functional ComfyUI pipelines via validation-guided workflow construction. Experiments demonstrate that ComfySearch substantially outperforms existing methods on complex and creative tasks, achieving higher executability (pass) rates, higher solution rates, and stronger generalization.
2601.04060Jan 2026
View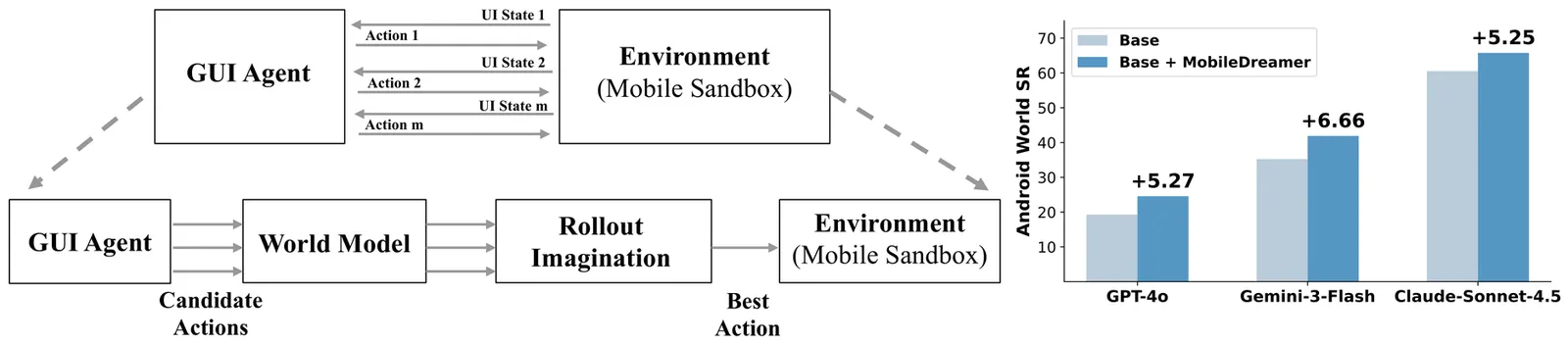
MobileDreamer: Generative Sketch World Model for GUI Agent
Mobile GUI agents have shown strong potential in real-world automation and practical applications. However, most existing agents remain reactive, making decisions mainly from current screen, which limits their performance on long-horizon tasks. Building a world model from repeated interactions enables forecasting action outcomes and supports better decision making for mobile GUI agents. This is challenging because the model must predict post-action states with spatial awareness while remaining efficient enough for practical deployment. In this paper, we propose MobileDreamer, an efficient world-model-based lookahead framework to equip the GUI agents based on the future imagination provided by the world model. It consists of textual sketch world model and rollout imagination for GUI agent. Textual sketch world model forecasts post-action states through a learning process to transform digital images into key task-related sketches, and designs a novel order-invariant learning strategy to preserve the spatial information of GUI elements. The rollout imagination strategy for GUI agent optimizes the action-selection process by leveraging the prediction capability of world model. Experiments on Android World show that MobileDreamer achieves state-of-the-art performance and improves task success by 5.25%. World model evaluations further verify that our textual sketch modeling accurately forecasts key GUI elements.
2601.04035Jan 2026
View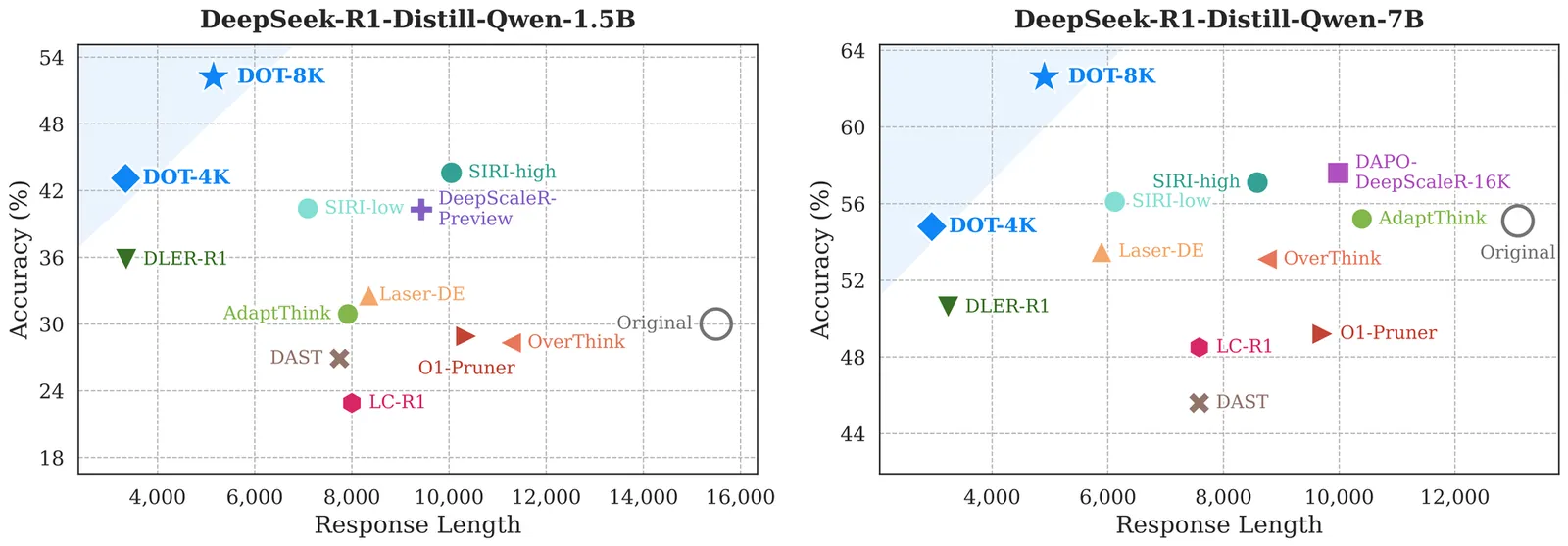
Anti-Length Shift: Dynamic Outlier Truncation for Training Efficient Reasoning Models
Large reasoning models enhanced by reinforcement learning with verifiable rewards have achieved significant performance gains by extending their chain-of-thought. However, this paradigm incurs substantial deployment costs as models often exhibit excessive verbosity on simple queries. Existing efficient reasoning methods relying on explicit length penalties often introduce optimization conflicts and leave the generative mechanisms driving overthinking largely unexamined. In this paper, we identify a phenomenon termed length shift where models increasingly generate unnecessary reasoning on trivial inputs during training. To address this, we introduce Dynamic Outlier Truncation (DOT), a training-time intervention that selectively suppresses redundant tokens. This method targets only the extreme tail of response lengths within fully correct rollout groups while preserving long-horizon reasoning capabilities for complex problems. To complement this intervention and ensure stable convergence, we further incorporate auxiliary KL regularization and predictive dynamic sampling. Experimental results across multiple model scales demonstrate that our approach significantly pushes the efficiency-performance Pareto frontier outward. Notably, on the AIME-24, our method reduces inference token usage by 78% while simultaneously increasing accuracy compared to the initial policy and surpassing state-of-the-art efficient reasoning methods.
2601.03969Jan 2026
View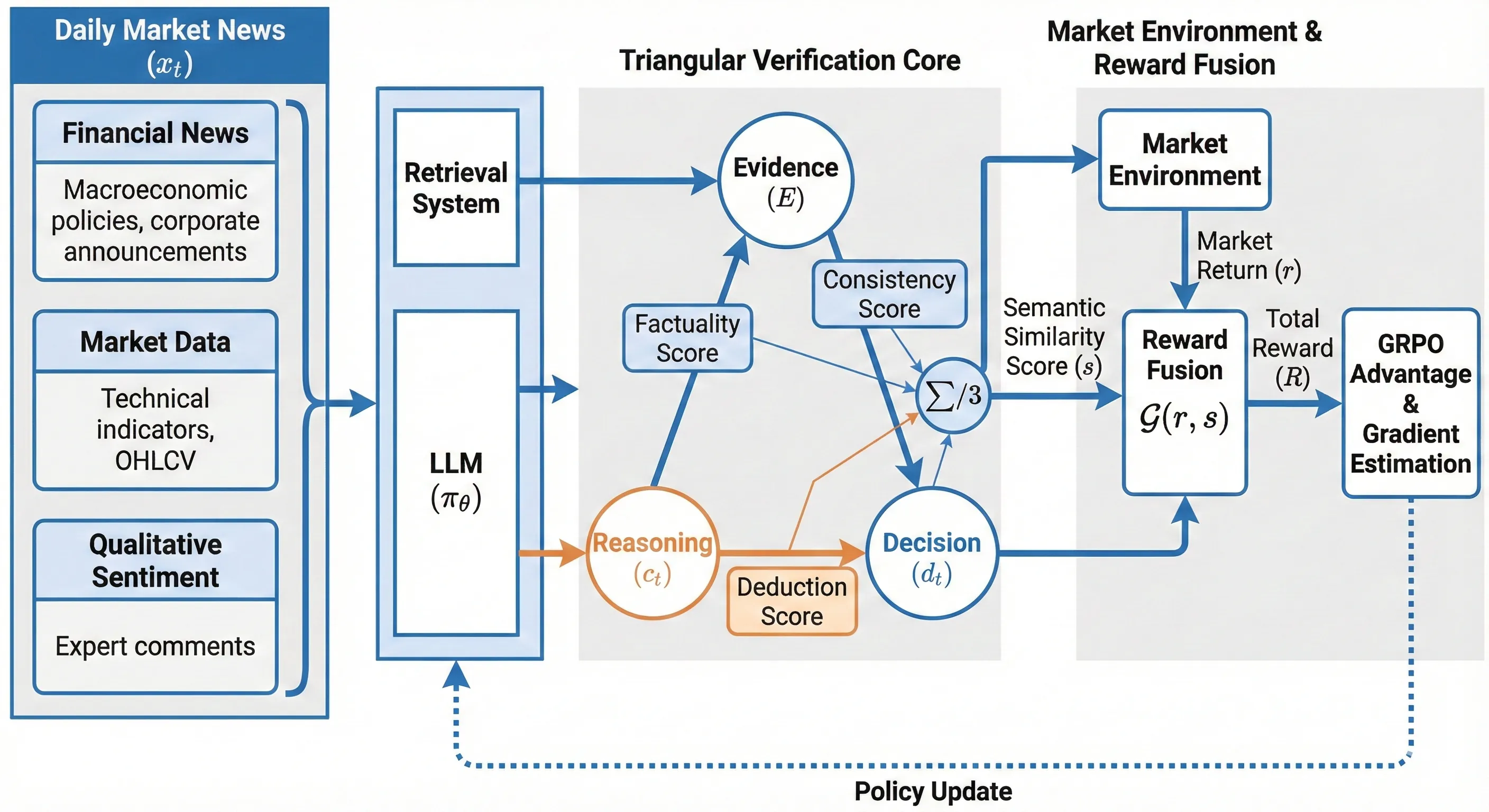
Trade-R1: Bridging Verifiable Rewards to Stochastic Environments via Process-Level Reasoning Verification
Reinforcement Learning (RL) has enabled Large Language Models (LLMs) to achieve remarkable reasoning in domains like mathematics and coding, where verifiable rewards provide clear signals. However, extending this paradigm to financial decision is challenged by the market's stochastic nature: rewards are verifiable but inherently noisy, causing standard RL to degenerate into reward hacking. To address this, we propose Trade-R1, a model training framework that bridges verifiable rewards to stochastic environments via process-level reasoning verification. Our key innovation is a verification method that transforms the problem of evaluating reasoning over lengthy financial documents into a structured Retrieval-Augmented Generation (RAG) task. We construct a triangular consistency metric, assessing pairwise alignment between retrieved evidence, reasoning chains, and decisions to serve as a validity filter for noisy market returns. We explore two reward integration strategies: Fixed-effect Semantic Reward (FSR) for stable alignment signals, and Dynamic-effect Semantic Reward (DSR) for coupled magnitude optimization. Experiments on different country asset selection demonstrate that our paradigm reduces reward hacking, with DSR achieving superior cross-market generalization while maintaining the highest reasoning consistency.
2601.03948Jan 2026
View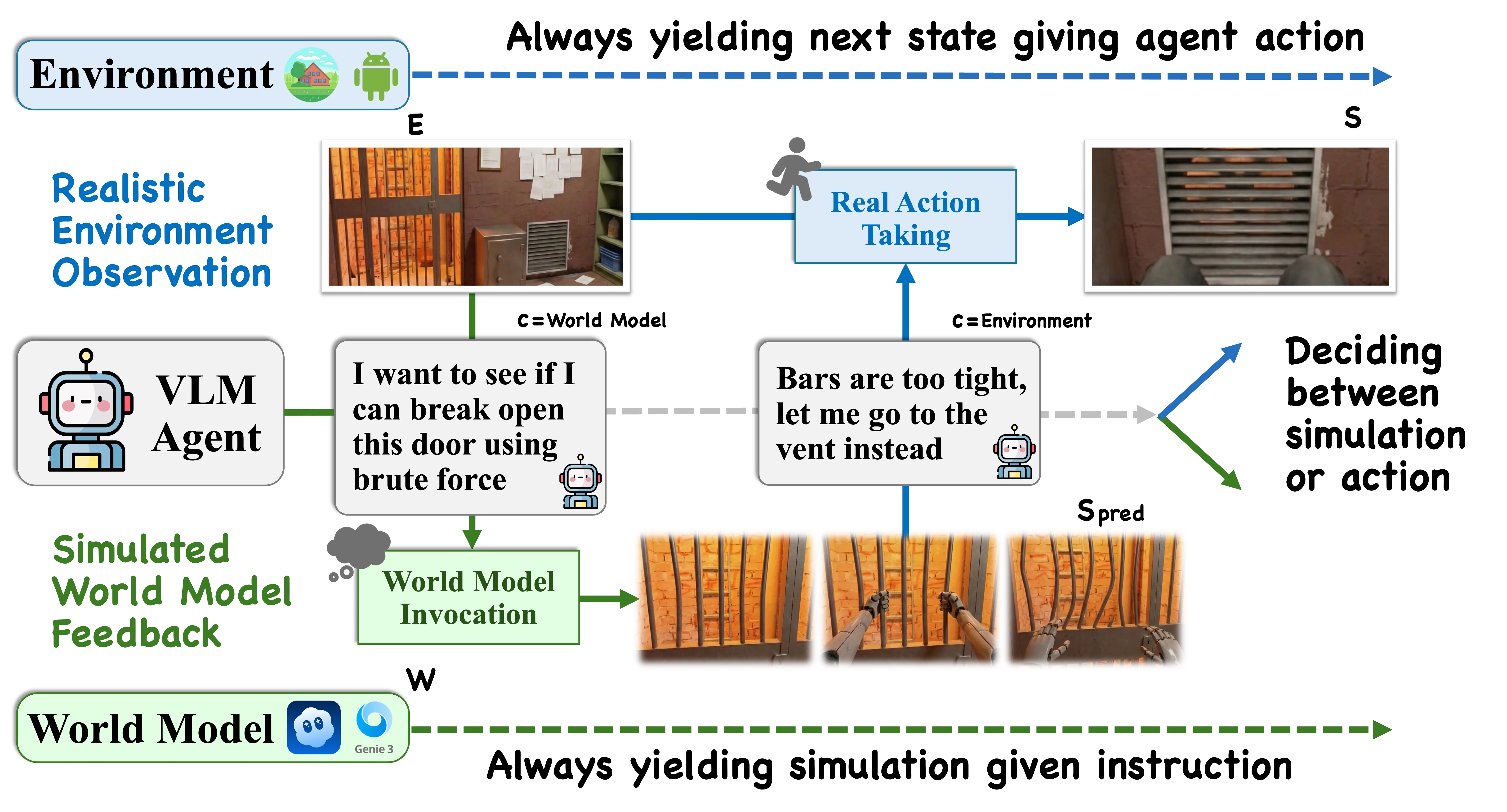
Current Agents Fail to Leverage World Model as Tool for Foresight
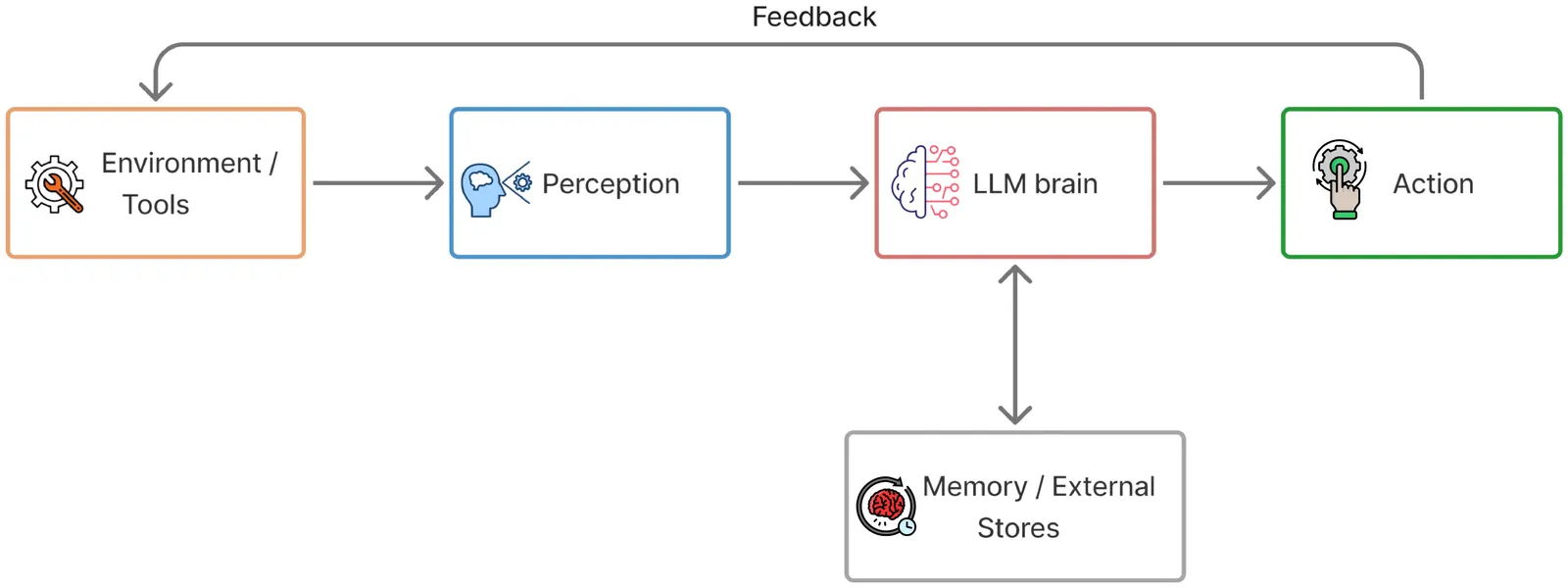
Agents built on vision-language models increasingly face tasks that demand anticipating future states rather than relying on short-horizon reasoning. Generative world models offer a promising remedy: agents could use them as external simulators to foresee outcomes before acting. This paper empirically examines whether current agents can leverage such world models as tools to enhance their cognition. Across diverse agentic and visual question answering tasks, we observe that some agents rarely invoke simulation (fewer than 1%), frequently misuse predicted rollouts (approximately 15%), and often exhibit inconsistent or even degraded performance (up to 5%) when simulation is available or enforced. Attribution analysis further indicates that the primary bottleneck lies in the agents' capacity to decide when to simulate, how to interpret predicted outcomes, and how to integrate foresight into downstream reasoning. These findings underscore the need for mechanisms that foster calibrated, strategic interaction with world models, paving the way toward more reliable anticipatory cognition in future agent systems.
2601.03905Jan 2026
View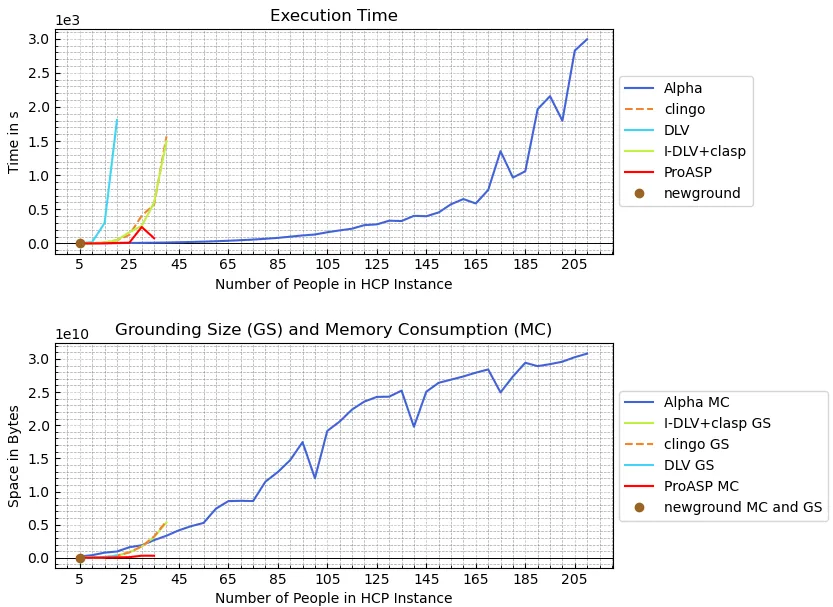
Investigating the Grounding Bottleneck for a Large-Scale Configuration Problem: Existing Tools and Constraint-Aware Guessing
Answer set programming (ASP) aims to realize the AI vision: The user specifies the problem, and the computer solves it. Indeed, ASP has made this vision true in many application domains. However, will current ASP solving techniques scale up for large configuration problems? As a benchmark for such problems, we investigated the configuration of electronic systems, which may comprise more than 30,000 components. We show the potential and limits of current ASP technology, focusing on methods that address the so-called grounding bottleneck, i.e., the sharp increase of memory demands in the size of the problem instances. To push the limits, we investigated the incremental solving approach, which proved effective in practice. However, even in the incremental approach, memory demands impose significant limits. Based on an analysis of grounding, we developed the method constraint-aware guessing, which significantly reduced the memory need.
2601.03850Jan 2026
View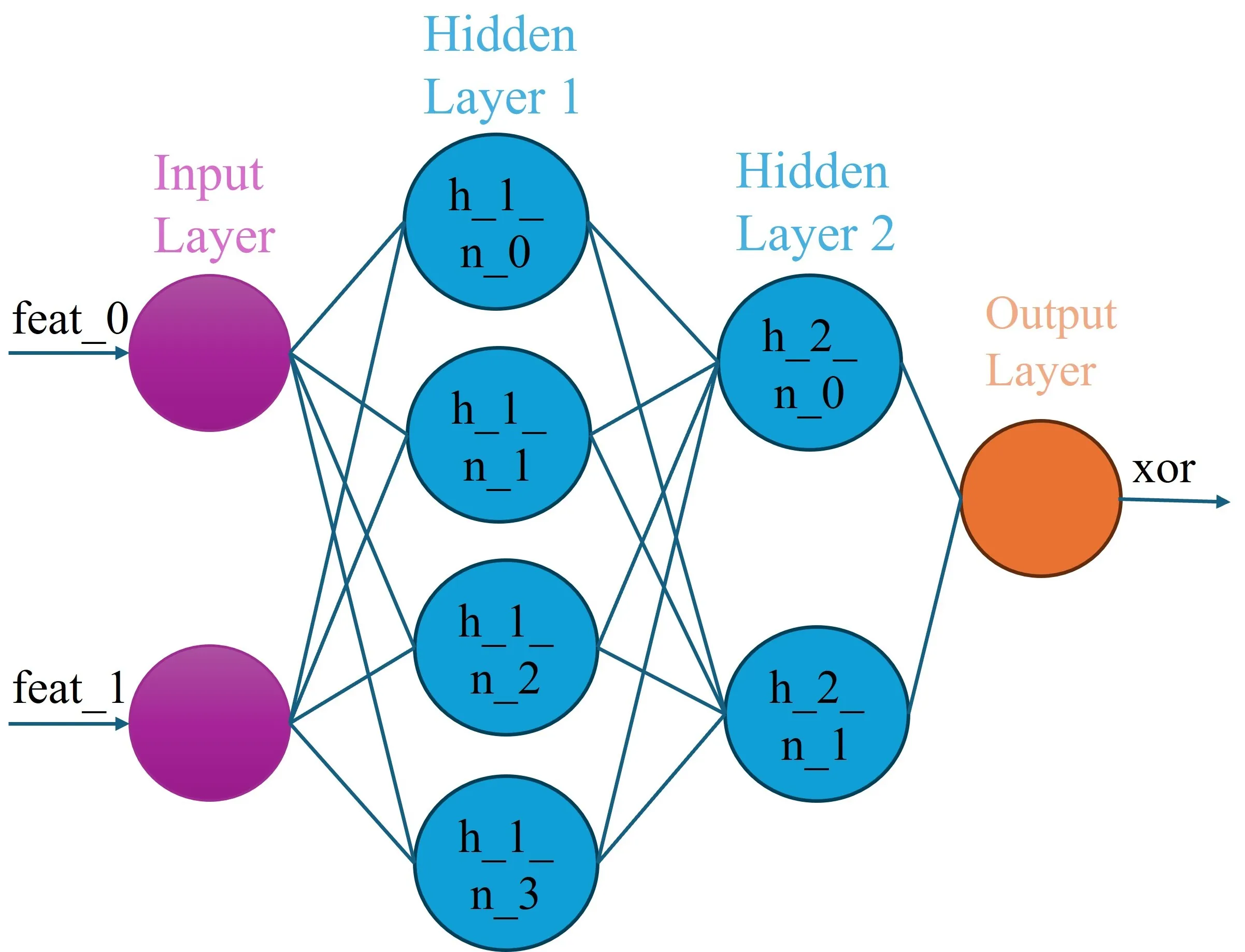
xDNN(ASP): Explanation Generation System for Deep Neural Networks powered by Answer Set Programming
Explainable artificial intelligence (xAI) has gained significant attention in recent years. Among other things, explainablility for deep neural networks has been a topic of intensive research due to the meteoric rise in prominence of deep neural networks and their "black-box" nature. xAI approaches can be characterized along different dimensions such as their scope (global versus local explanations) or underlying methodologies (statistic-based versus rule-based strategies). Methods generating global explanations aim to provide reasoning process applicable to all possible output classes while local explanation methods focus only on a single, specific class. SHAP (SHapley Additive exPlanations), a well-known statistical technique, identifies important features of a network. Deep neural network rule extraction method constructs IF-THEN rules that link input conditions to a class. Another approach focuses on generating counterfactuals which help explain how small changes to an input can affect the model's predictions. However, these techniques primarily focus on the input-output relationship and thus neglect the structure of the network in explanation generation. In this work, we propose xDNN(ASP), an explanation generation system for deep neural networks that provides global explanations. Given a neural network model and its training data, xDNN(ASP) extracts a logic program under answer set semantics that-in the ideal case-represents the trained model, i.e., answer sets of the extracted program correspond one-to-one to input-output pairs of the network. We demonstrate experimentally, using two synthetic datasets, that not only the extracted logic program maintains a high-level of accuracy in the prediction task, but it also provides valuable information for the understanding of the model such as the importance of features as well as the impact of hidden nodes on the prediction. The latter can be used as a guide for reducing the number of nodes used in hidden layers, i.e., providing a means for optimizing the network.
2601.03847Jan 2026
View
Formally Explaining Decision Tree Models with Answer Set Programming
Decision tree models, including random forests and gradient-boosted decision trees, are widely used in machine learning due to their high predictive performance. However, their complex structures often make them difficult to interpret, especially in safety-critical applications where model decisions require formal justification. Recent work has demonstrated that logical and abductive explanations can be derived through automated reasoning techniques. In this paper, we propose a method for generating various types of explanations, namely, sufficient, contrastive, majority, and tree-specific explanations, using Answer Set Programming (ASP). Compared to SAT-based approaches, our ASP-based method offers greater flexibility in encoding user preferences and supports enumeration of all possible explanations. We empirically evaluate the approach on a diverse set of datasets and demonstrate its effectiveness and limitations compared to existing methods.
2601.03845Jan 2026
View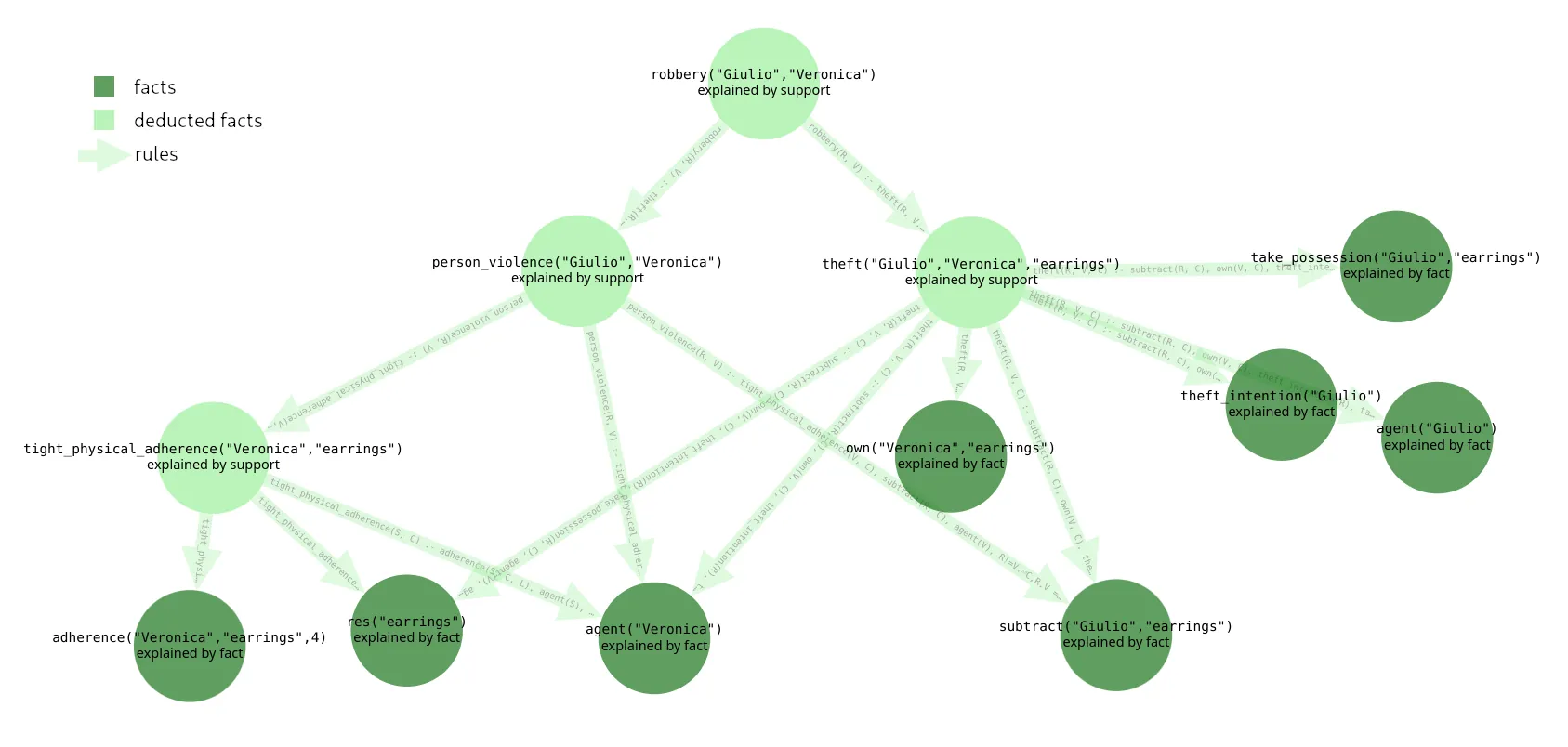
XAI-LAW: A Logic Programming Tool for Modeling, Explaining, and Learning Legal Decisions
We propose an approach to model articles of the Italian Criminal Code (ICC), using Answer Set Programming (ASP), and to semi-automatically learn legal rules from examples based on prior judicial decisions. The developed tool is intended to support legal experts during the criminal trial phase by providing reasoning and possible legal outcomes. The methodology involves analyzing and encoding articles of the ICC in ASP, including "crimes against the person" and property offenses. The resulting model is validated on a set of previous verdicts and refined as necessary. During the encoding process, contradictions may arise; these are properly handled by the system, which also generates possible decisions for new cases and provides explanations through a tool that leverages the "supportedness" of stable models. The automatic explainability offered by the tool can also be used to clarify the logic behind judicial decisions, making the decision-making process more interpretable. Furthermore, the tool integrates an inductive logic programming system for ASP, which is employed to generalize legal rules from case examples.
2601.03844Jan 2026
View
Defeasible Conditionals using Answer Set Programming
Defeasible entailment is concerned with drawing plausible conclusions from incomplete information. A foundational framework for modelling defeasible entailment is the KLM framework. Introduced by Kraus, Lehmann, and Magidor, the KLM framework outlines several key properties for defeasible entailment. One of the most prominent algorithms within this framework is Rational Closure (RC). This paper presents a declarative definition for computing RC using Answer Set Programming (ASP). Our approach enables the automatic construction of the minimal ranked model from a given knowledge base and supports entailment checking for specified queries. We formally prove the correctness of our ASP encoding and conduct empirical evaluations to compare the performance of our implementation with that of existing imperative implementations, specifically the InfOCF solver. The results demonstrate that our ASP-based approach adheres to RC's theoretical foundations and offers improved computational efficiency.
2601.03840Jan 2026
View
ROI-Reasoning: Rational Optimization for Inference via Pre-Computation Meta-Cognition
Large language models (LLMs) can achieve strong reasoning performance with sufficient computation, but they do not inherently know how much computation a task requires. We study budgeted inference-time reasoning for multiple tasks under a strict global token constraint and formalize it as a Ordered Stochastic Multiple-Choice Knapsack Problem(OS-MCKP). This perspective highlights a meta-cognitive requirement -- anticipating task difficulty, estimating return over investment (ROI), and allocating computation strategically. We propose ROI-Reasoning, a two-stage framework that endows LLMs with intrinsic, budget-aware rationality. In the first stage, Meta-Cognitive Fine-Tuning teaches models to predict reasoning cost and expected utility before generation, enabling explicit solve-or-skip decisions. Next, Rationality-Aware Reinforcement Learning optimizes sequential decision making under a hard token budget, allowing models to learn long-horizon allocation strategies. Across budgeted mathematical reasoning benchmarks, ROI-Reasoning consistently improves overall score while substantially reducing regret under tight computation budgets.
2601.03822Jan 2026
View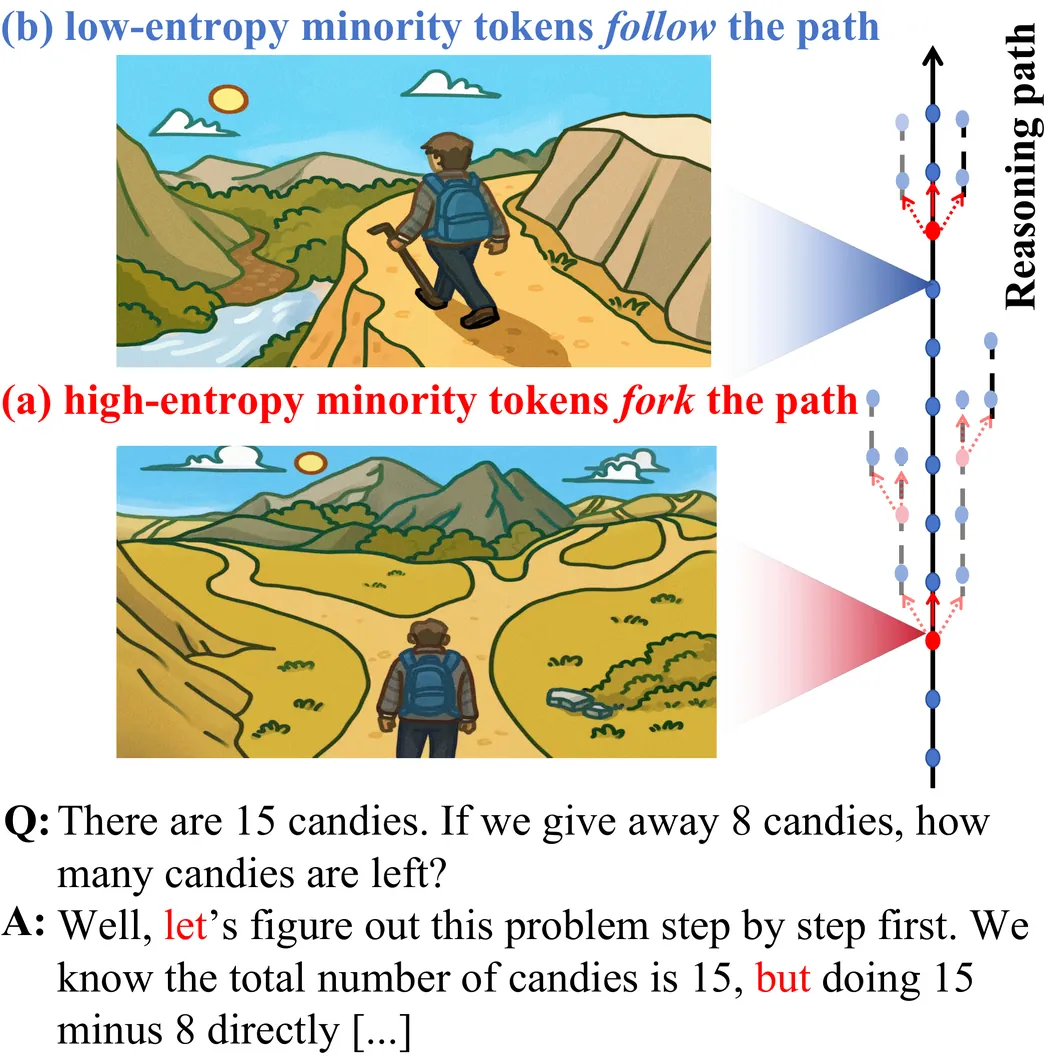
EntroCoT: Enhancing Chain-of-Thought via Adaptive Entropy-Guided Segmentation
Chain-of-Thought (CoT) prompting has significantly enhanced the mathematical reasoning capabilities of Large Language Models. We find existing fine-tuning datasets frequently suffer from the "answer right but reasoning wrong" probelm, where correct final answers are derived from hallucinated, redundant, or logically invalid intermediate steps. This paper proposes EntroCoT, a unified framework for automatically identifying and refining low-quality CoT supervision traces. EntroCoT first proposes an entropy-based mechanism to segment the reasoning trace into multiple steps at uncertain junctures, and then introduces a Monte Carlo rollout-based mechanism to evaluate the marginal contribution of each step. By accurately filtering deceptive reasoning samples, EntroCoT constructs a high-quality dataset where every intermediate step in each reasoning trace facilitates the final answer. Extensive experiments on mathematical benchmarks demonstrate that fine-tuning on the subset constructed by EntroCoT consistently outperforms the baseslines of full-dataset supervision.
2601.03769Jan 2026
View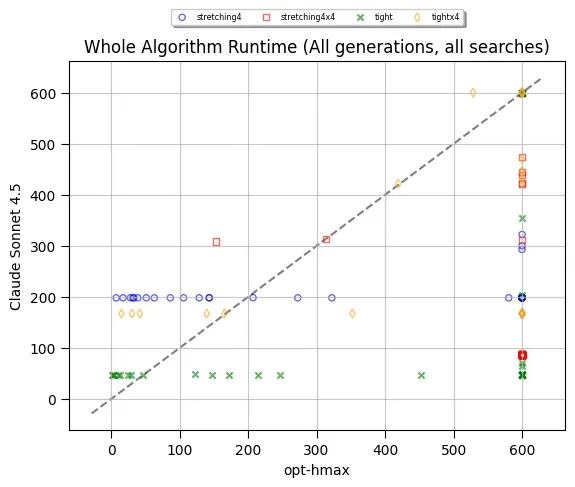
Personalized Medication Planning via Direct Domain Modeling and LLM-Generated Heuristics
Personalized medication planning involves selecting medications and determining a dosing schedule to achieve medical goals specific to each individual patient. Previous work successfully demonstrated that automated planners, using general domain-independent heuristics, are able to generate personalized treatments, when the domain and problems are modeled using a general domain description language (\pddlp). Unfortunately, this process was limited in practice to consider no more than seven medications. In clinical terms, this is a non-starter. In this paper, we explore the use of automatically-generated domain- and problem-specific heuristics to be used with general search, as a method of scaling up medication planning to levels allowing closer work with clinicians. Specifically, we specify the domain programmatically (specifying an initial state and a successor generation procedure), and use an LLM to generate a problem specific heuristic that can be used by a fixed search algorithm (GBFS). The results indicate dramatic improvements in coverage and planning time, scaling up the number of medications to at least 28, and bringing medication planning one step closer to practical applications.
2601.03687Jan 2026
View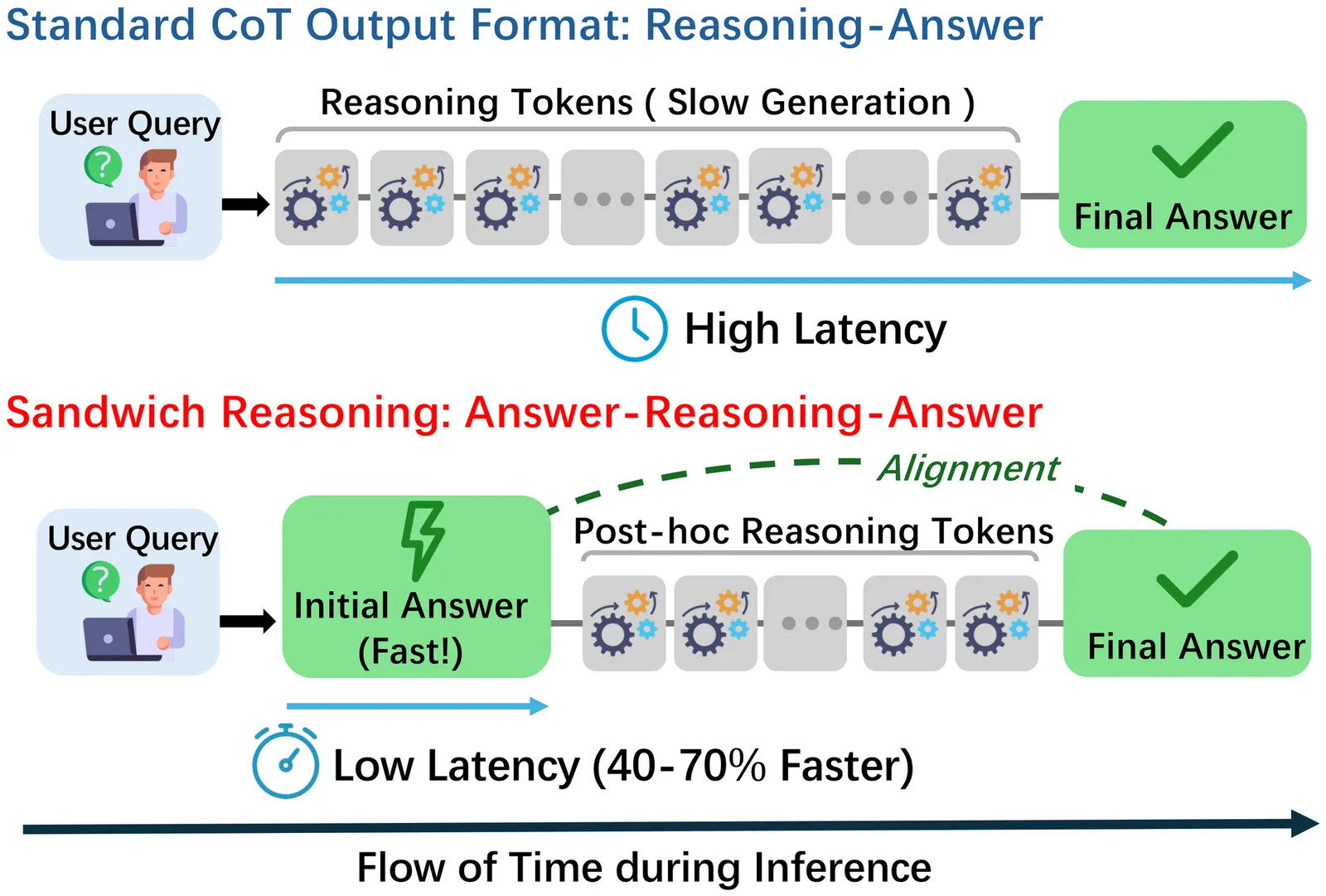
Sandwich Reasoning: An Answer-Reasoning-Answer Approach for Low-Latency Query Correction
Query correction is a critical entry point in modern search pipelines, demanding high accuracy strictly within real-time latency constraints. Chain-of-Thought (CoT) reasoning improves accuracy but incurs prohibitive latency for real-time query correction. A potential solution is to output an answer before reasoning to reduce latency; however, under autoregressive decoding, the early answer is independent of subsequent reasoning, preventing the model from leveraging its reasoning capability to improve accuracy. To address this issue, we propose Sandwich Reasoning (SandwichR), a novel approach that explicitly aligns a fast initial answer with post-hoc reasoning, enabling low-latency query correction without sacrificing reasoning-aware accuracy. SandwichR follows an Answer-Reasoning-Answer paradigm, producing an initial correction, an explicit reasoning process, and a final refined correction. To align the initial answer with post-reasoning insights, we design a consistency-aware reinforcement learning (RL) strategy: a dedicated consistency reward enforces alignment between the initial and final corrections, while margin-based rejection sampling prioritizes borderline samples where reasoning drives the most impactful corrective gains. Additionally, we construct a high-quality query correction dataset, addressing the lack of specialized benchmarks for complex query correction. Experimental results demonstrate that SandwichR achieves SOTA accuracy comparable to standard CoT while delivering a 40-70% latency reduction, resolving the latency-accuracy trade-off in online search.
2601.03672Jan 2026
View
How Does the Thinking Step Influence Model Safety? An Entropy-based Safety Reminder for LRMs
Large Reasoning Models (LRMs) achieve remarkable success through explicit thinking steps, yet the thinking steps introduce a novel risk by potentially amplifying unsafe behaviors. Despite this vulnerability, conventional defense mechanisms remain ineffective as they overlook the unique reasoning dynamics of LRMs. In this work, we find that the emergence of safe-reminding phrases within thinking steps plays a pivotal role in ensuring LRM safety. Motivated by this finding, we propose SafeRemind, a decoding-time defense method that dynamically injects safe-reminding phrases into thinking steps. By leveraging entropy triggers to intervene at decision-locking points, SafeRemind redirects potentially harmful trajectories toward safer outcomes without requiring any parameter updates. Extensive evaluations across five LRMs and six benchmarks demonstrate that SafeRemind substantially enhances safety, achieving improvements of up to 45.5%p while preserving core reasoning utility.
2601.03662Jan 2026
View
Architecting Agentic Communities using Design Patterns
The rapid evolution of Large Language Models (LLM) and subsequent Agentic AI technologies requires systematic architectural guidance for building sophisticated, production-grade systems. This paper presents an approach for architecting such systems using design patterns derived from enterprise distributed systems standards, formal methods, and industry practice. We classify these patterns into three tiers: LLM Agents (task-specific automation), Agentic AI (adaptive goal-seekers), and Agentic Communities (organizational frameworks where AI agents and human participants coordinate through formal roles, protocols, and governance structures). We focus on Agentic Communities - coordination frameworks encompassing LLM Agents, Agentic AI entities, and humans - most relevant for enterprise and industrial applications. Drawing on established coordination principles from distributed systems, we ground these patterns in a formal framework that specifies collaboration agreements where AI agents and humans fill roles within governed ecosystems. This approach provides both practical guidance and formal verification capabilities, enabling expression of organizational, legal, and ethical rules through accountability mechanisms that ensure operational and verifiable governance of inter-agent communication, negotiation, and intent modeling. We validate this framework through a clinical trial matching case study. Our goal is to provide actionable guidance to practitioners while maintaining the formal rigor essential for enterprise deployment in dynamic, multi-agent ecosystems.
2601.03624Jan 2026
View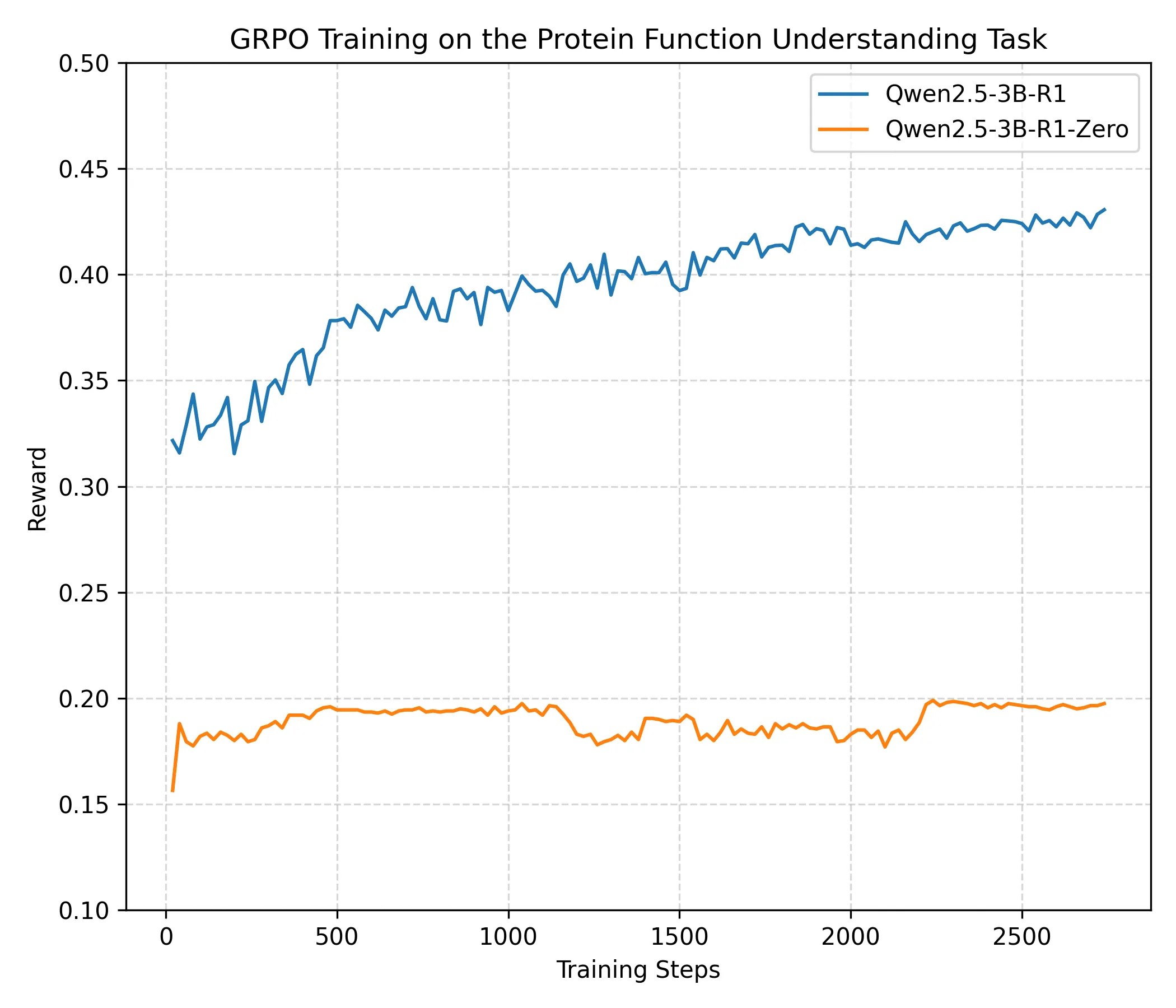
Interleaved Tool-Call Reasoning for Protein Function Understanding
Recent advances in large language models (LLMs) have highlighted the effectiveness of chain-of-thought reasoning in symbolic domains such as mathematics and programming. However, our study shows that directly transferring such text-based reasoning paradigms to protein function understanding is ineffective: reinforcement learning mainly amplifies superficial keyword patterns while failing to introduce new biological knowledge, resulting in limited generalization. We argue that protein function prediction is a knowledge-intensive scientific task that fundamentally relies on external biological priors and computational tools rather than purely internal reasoning. To address this gap, we propose PFUA, a tool-augmented protein reasoning agent that unifies problem decomposition, tool invocation, and grounded answer generation. Instead of relying on long unconstrained reasoning traces, PFUA integrates domain-specific tools to produce verifiable intermediate evidence. Experiments on four benchmarks demonstrate that PFUA consistently outperforms text-only reasoning models with an average performance improvement of 103%.
2601.03604Jan 2026
View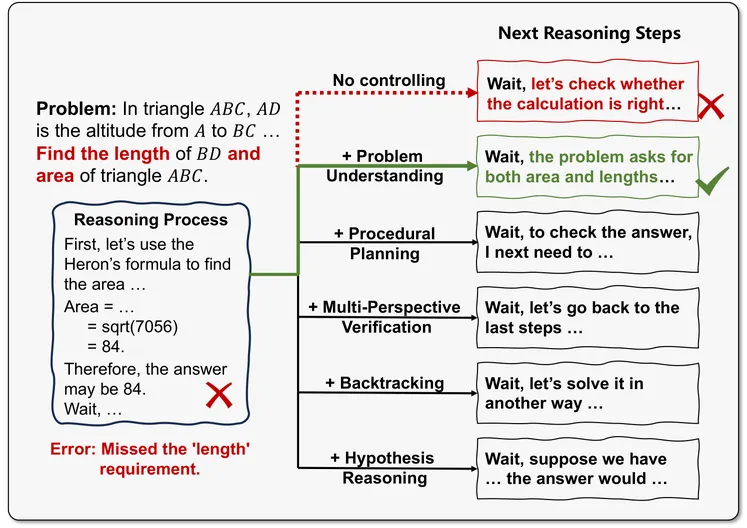
Controllable LLM Reasoning via Sparse Autoencoder-Based Steering
Large Reasoning Models (LRMs) exhibit human-like cognitive reasoning strategies (e.g. backtracking, cross-verification) during reasoning process, which improves their performance on complex tasks. Currently, reasoning strategies are autonomously selected by LRMs themselves. However, such autonomous selection often produces inefficient or even erroneous reasoning paths. To make reasoning more reliable and flexible, it is important to develop methods for controlling reasoning strategies. Existing methods struggle to control fine-grained reasoning strategies due to conceptual entanglement in LRMs' hidden states. To address this, we leverage Sparse Autoencoders (SAEs) to decompose strategy-entangled hidden states into a disentangled feature space. To identify the few strategy-specific features from the vast pool of SAE features, we propose SAE-Steering, an efficient two-stage feature identification pipeline. SAE-Steering first recalls features that amplify the logits of strategy-specific keywords, filtering out over 99\% of features, and then ranks the remaining features by their control effectiveness. Using the identified strategy-specific features as control vectors, SAE-Steering outperforms existing methods by over 15\% in control effectiveness. Furthermore, controlling reasoning strategies can redirect LRMs from erroneous paths to correct ones, achieving a 7\% absolute accuracy improvement.
2601.03595Jan 2026
View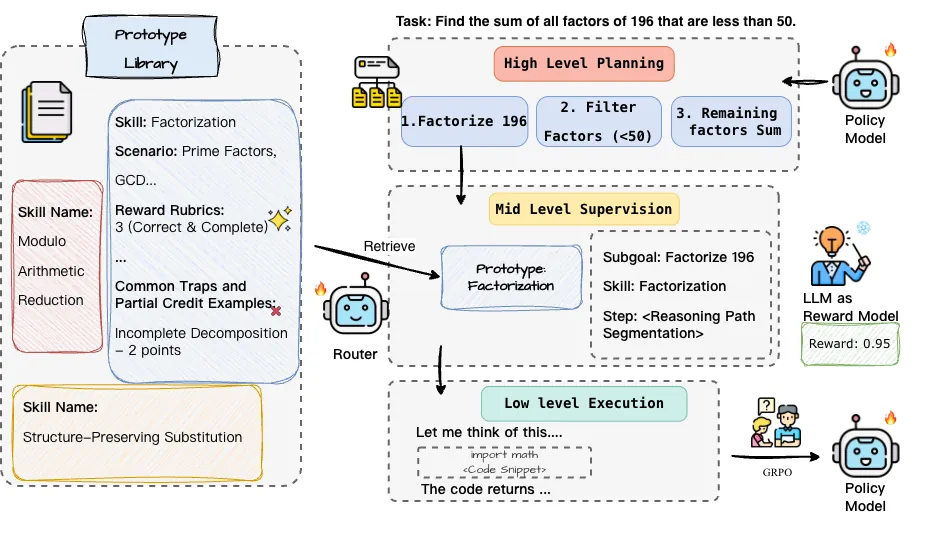
SCRIBE: Structured Mid-Level Supervision for Tool-Using Language Models
Training reliable tool-augmented agents remains a significant challenge, largely due to the difficulty of credit assignment in multi-step reasoning. While process-level reward models offer a promising direction, existing LLM-based judges often produce noisy and inconsistent signals because they lack fine-grained, task-specific rubrics to distinguish high-level planning from low-level execution. In this work, we introduce SCRIBE (Skill-Conditioned Reward with Intermediate Behavioral Evaluation), a reinforcement learning framework that intervenes at a novel mid-level abstraction. SCRIBE grounds reward modeling in a curated library of skill prototypes, transforming open-ended LLM evaluation into a constrained verification problem. By routing each subgoal to a corresponding prototype, the reward model is equipped with precise, structured rubrics that substantially reduce reward variance. Experimental results show that SCRIBE achieves state-of-the-art performance across a range of reasoning and tool-use benchmarks. In particular, it improves the AIME25 accuracy of a Qwen3-4B model from 43.3% to 63.3%, and significantly increases success rates in complex multi-turn tool interactions. Further analysis of training dynamics reveals a co-evolution across abstraction levels, where mastery of mid-level skills consistently precedes the emergence of effective high-level planning behaviors. Finally, we demonstrate that SCRIBE is additive to low-level tool optimizations, providing a scalable and complementary pathway toward more autonomous and reliable tool-using agents.
2601.03555Jan 2026
ViewPage 1 of 248