15,676 papers
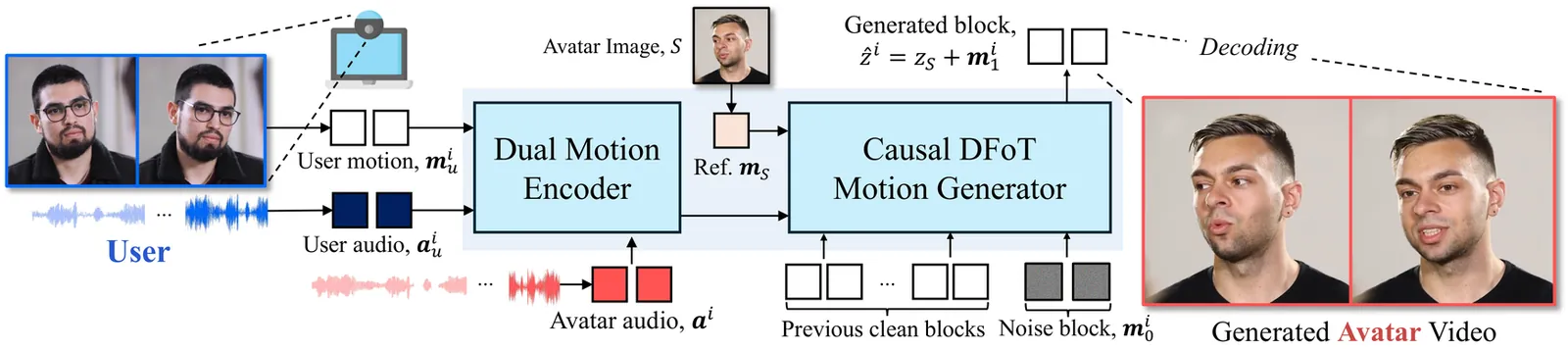
Lightweight Test-Time Adaptation for EMG-Based Gesture Recognition
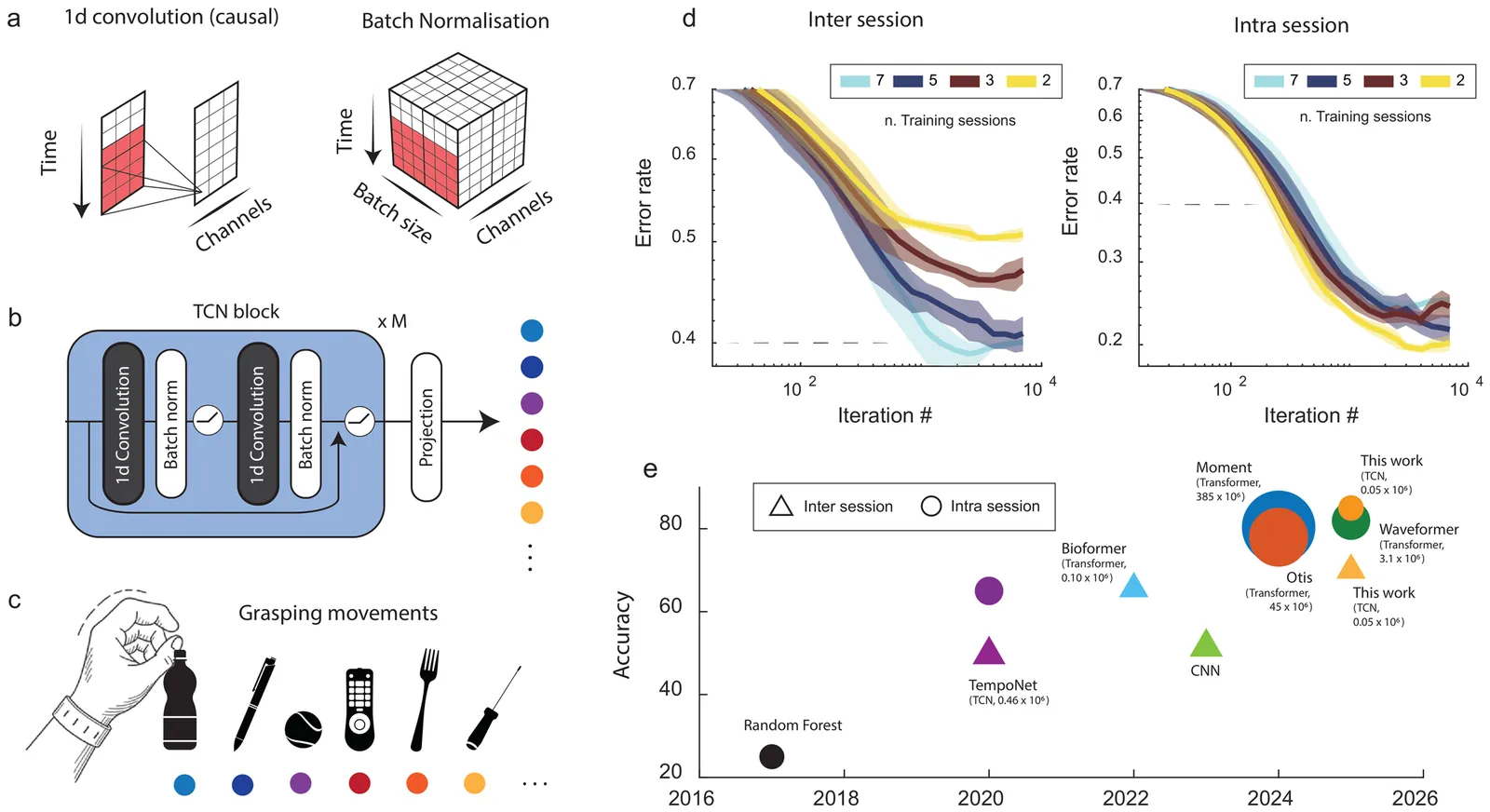
Reliable long-term decoding of surface electromyography (EMG) is hindered by signal drift caused by electrode shifts, muscle fatigue, and posture changes. While state-of-the-art models achieve high intra-session accuracy, their performance often degrades sharply. Existing solutions typically demand large datasets or high-compute pipelines that are impractical for energy-efficient wearables. We propose a lightweight framework for Test-Time Adaptation (TTA) using a Temporal Convolutional Network (TCN) backbone. We introduce three deployment-ready strategies: (i) causal adaptive batch normalization for real-time statistical alignment; (ii) a Gaussian Mixture Model (GMM) alignment with experience replay to prevent forgetting; and (iii) meta-learning for rapid, few-shot calibration. Evaluated on the NinaPro DB6 multi-session dataset, our framework significantly bridges the inter-session accuracy gap with minimal overhead. Our results show that experience-replay updates yield superior stability under limited data, while meta-learning achieves competitive performance in one- and two-shot regimes using only a fraction of the data required by current benchmarks. This work establishes a path toward robust, "plug-and-play" myoelectric control for long-term prosthetic use.
2601.04181Jan 2026
View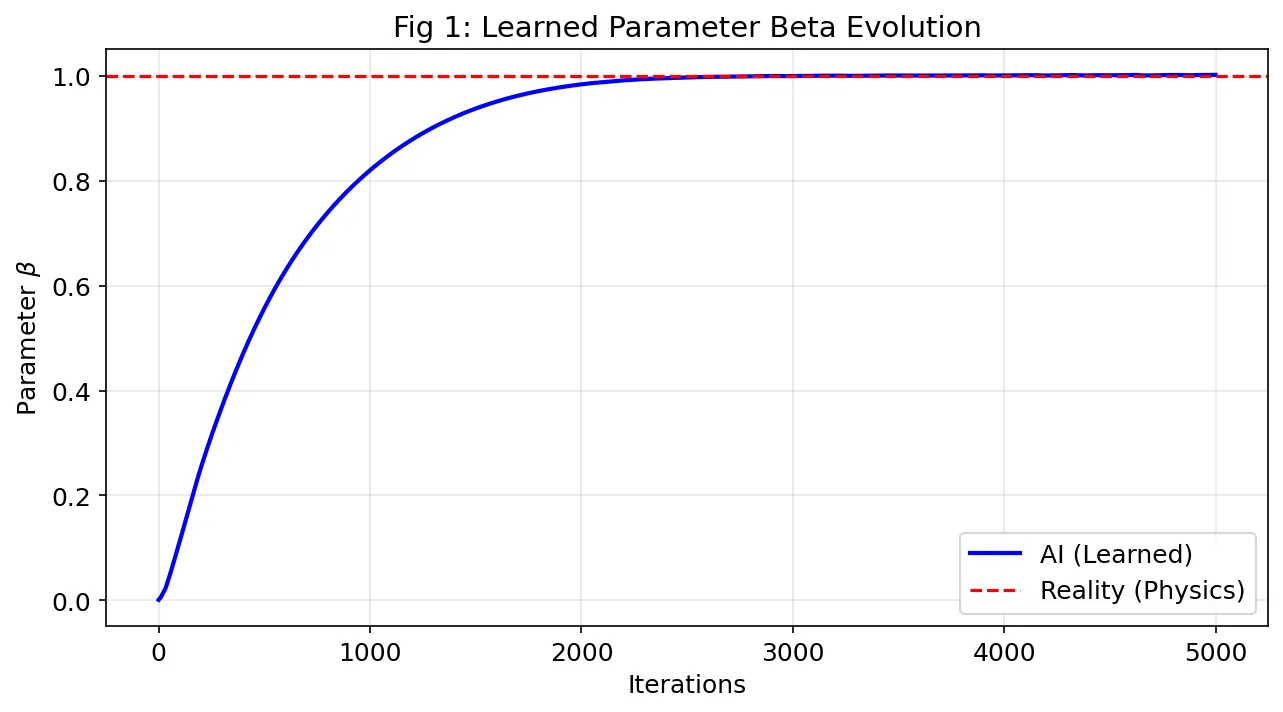
Robust Physics Discovery from Highly Corrupted Data: A PINN Framework Applied to the Nonlinear Schrödinger Equation
We demonstrate a deep learning framework capable of recovering physical parameters from the Nonlinear Schrodinger Equation (NLSE) under severe noise conditions. By integrating Physics-Informed Neural Networks (PINNs) with automatic differentiation, we achieve reconstruction of the nonlinear coefficient beta with less than 0.2 percent relative error using only 500 sparse, randomly sampled data points corrupted by 20 percent additive Gaussian noise, a regime where traditional finite difference methods typically fail due to noise amplification in numerical derivatives. We validate the method's generalization capabilities across different physical regimes (beta between 0.5 and 2.0) and varying data availability (between 100 and 1000 training points), demonstrating consistent sub-1 percent accuracy. Statistical analysis over multiple independent runs confirms robustness (standard deviation less than 0.15 percent for beta equals 1.0). The complete pipeline executes in approximately 80 minutes on modest cloud GPU resources (NVIDIA Tesla T4), making the approach accessible for widespread adoption. Our results indicate that physics-based regularization acts as an effective filter against high measurement uncertainty, positioning PINNs as a viable alternative to traditional optimization methods for inverse problems in spatiotemporal dynamics where experimental data is scarce and noisy. All code is made publicly available to facilitate reproducibility.
2601.04176Jan 2026
View
Agentic Rubrics as Contextual Verifiers for SWE Agents
Verification is critical for improving agents: it provides the reward signal for Reinforcement Learning and enables inference-time gains through Test-Time Scaling (TTS). Despite its importance, verification in software engineering (SWE) agent settings often relies on code execution, which can be difficult to scale due to environment setup overhead. Scalable alternatives such as patch classifiers and heuristic methods exist, but they are less grounded in codebase context and harder to interpret. To this end, we explore Agentic Rubrics: an expert agent interacts with the repository to create a context-grounded rubric checklist, and candidate patches are then scored against it without requiring test execution. On SWE-Bench Verified under parallel TTS evaluation, Agentic Rubrics achieve a score of 54.2% on Qwen3-Coder-30B-A3B and 40.6% on Qwen3-32B, with at least a +3.5 percentage-point gain over the strongest baseline in our comparison set. We further analyze rubric behavior, showing that rubric scores are consistent with ground-truth tests while also flagging issues that tests do not capture. Our ablations show that agentic context gathering is essential for producing codebase-specific, unambiguous criteria. Together, these results suggest that Agentic Rubrics provide an efficient, scalable, and granular verification signal for SWE agents.
2601.04171Jan 2026
View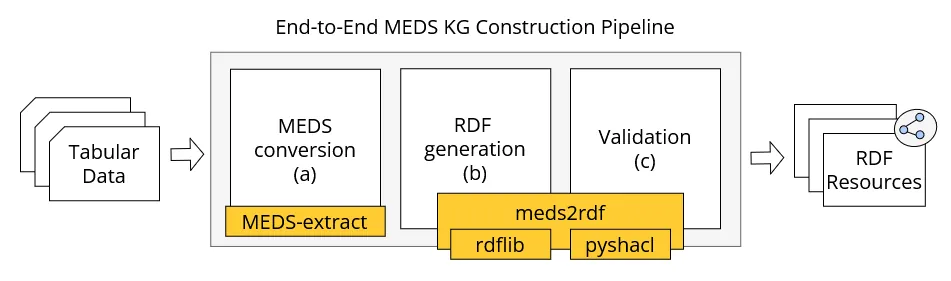
Clinical Data Goes MEDS? Let's OWL make sense of it
The application of machine learning on healthcare data is often hindered by the lack of standardized and semantically explicit representation, leading to limited interoperability and reproducibility across datasets and experiments. The Medical Event Data Standard (MEDS) addresses these issues by introducing a minimal, event-centric data model designed for reproducible machine-learning workflows from health data. However, MEDS is defined as a data-format specification and does not natively provide integration with the Semantic Web ecosystem. In this article, we introduce MEDS-OWL, a lightweight OWL ontology that provides formal concepts and relations to enable representing MEDS datasets as RDF graphs. Additionally, we implemented meds2rdf, a Python conversion library that transforms MEDS events into RDF graphs, ensuring conformance with the ontology. We demonstrate the approach on a synthetic clinical dataset that describes patient care pathways for ruptured intracranial aneurysms and validate the resulting graph using SHACL constraints. The first release of MEDS-OWL comprises 13 classes, 10 object properties, 20 data properties, and 24 OWL axioms. Combined with meds2rdf, it enables data transformation into FAIR-aligned datasets, provenance-aware publishing, and interoperability of event-based clinical data. By bridging MEDS with the Semantic Web, this work contributes a reusable semantic layer for event-based clinical data and establishes a robust foundation for subsequent graph-based analytics.
2601.04164Jan 2026
View
MORPHFED: Federated Learning for Cross-institutional Blood Morphology Analysis
Automated blood morphology analysis can support hematological diagnostics in low- and middle-income countries (LMICs) but remains sensitive to dataset shifts from staining variability, imaging differences, and rare morphologies. Building centralized datasets to capture this diversity is often infeasible due to privacy regulations and data-sharing restrictions. We introduce a federated learning framework for white blood cell morphology analysis that enables collaborative training across institutions without exchanging training data. Using blood films from multiple clinical sites, our federated models learn robust, domain-invariant representations while preserving complete data privacy. Evaluations across convolutional and transformer-based architectures show that federated training achieves strong cross-site performance and improved generalization to unseen institutions compared to centralized training. These findings highlight federated learning as a practical and privacy-preserving approach for developing equitable, scalable, and generalizable medical imaging AI in resource-limited healthcare environments.
2601.04121Jan 2026
View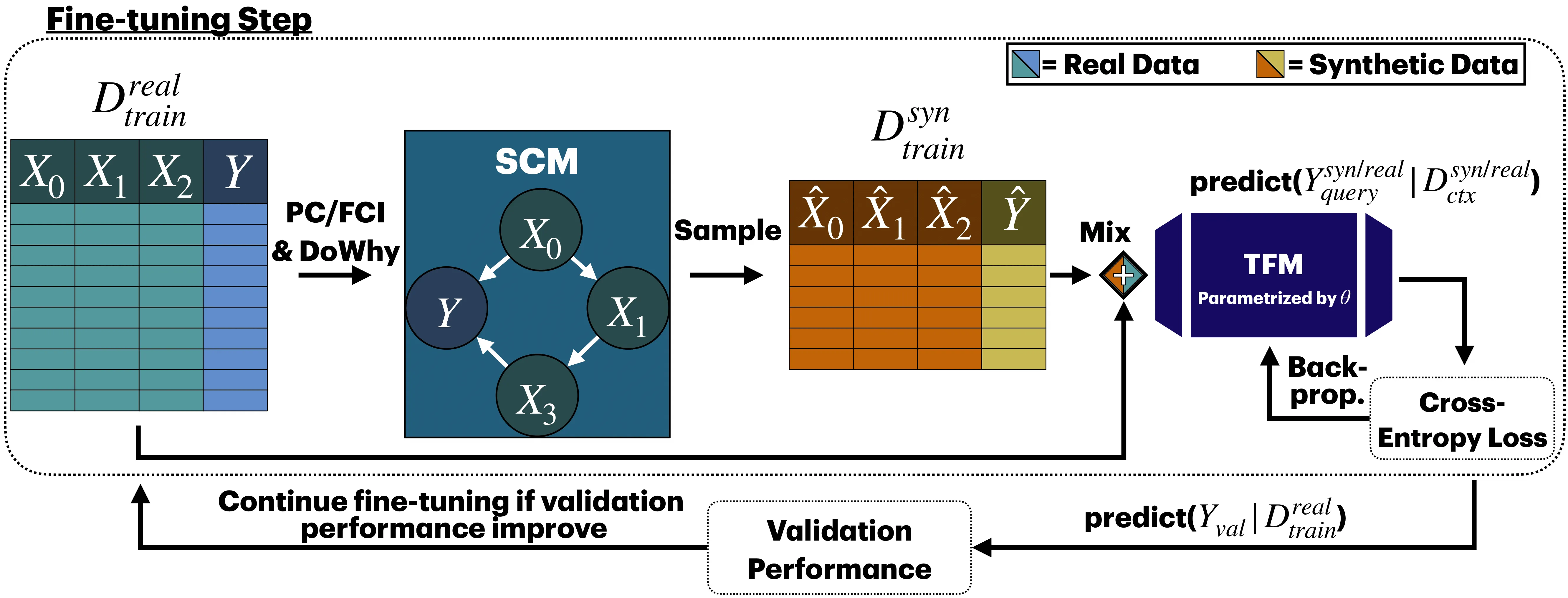
Causal Data Augmentation for Robust Fine-Tuning of Tabular Foundation Models
Fine-tuning tabular foundation models (TFMs) under data scarcity is challenging, as early stopping on even scarcer validation data often fails to capture true generalization performance. We propose CausalMixFT, a method that enhances fine-tuning robustness and downstream performance by generating structurally consistent synthetic samples using Structural Causal Models (SCMs) fitted on the target dataset. This approach augments limited real data with causally informed synthetic examples, preserving feature dependencies while expanding training diversity. Evaluated across 33 classification datasets from TabArena and over 2300 fine-tuning runs, our CausalMixFT method consistently improves median normalized ROC-AUC from 0.10 (standard fine-tuning) to 0.12, outperforming purely statistical generators such as CTGAN (-0.01), TabEBM (-0.04), and TableAugment (-0.09). Moreover, it narrows the median validation-test performance correlation gap from 0.67 to 0.30, enabling more reliable validation-based early stopping, a key step toward improving fine-tuning stability under data scarcity. These results demonstrate that incorporating causal structure into data augmentation provides an effective and principled route to fine-tuning tabular foundation models in low-data regimes.
2601.04110Jan 2026
View
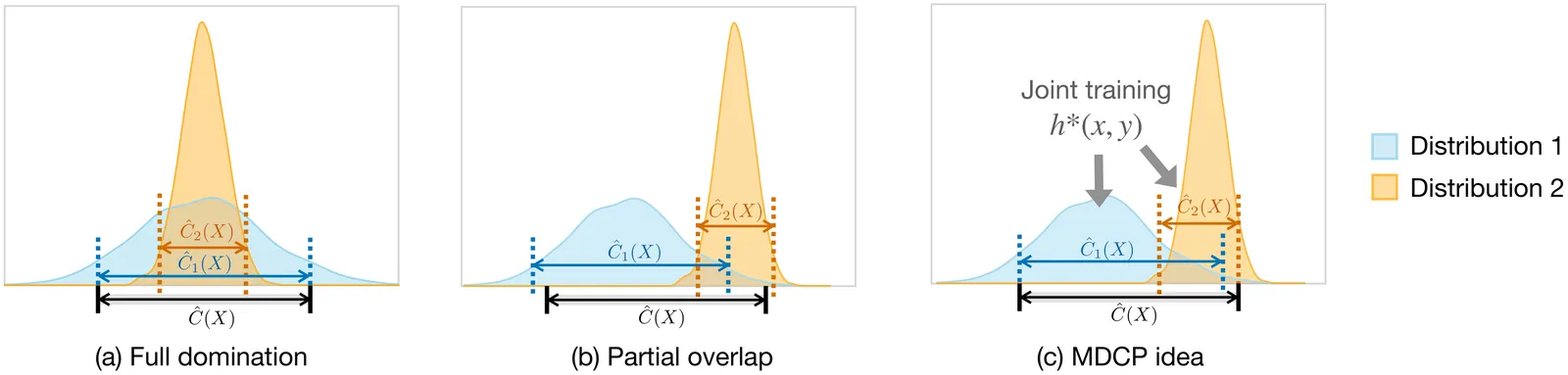
Minimum distance classification for nonlinear dynamical systems
We address the problem of classifying trajectory data generated by some nonlinear dynamics, where each class corresponds to a distinct dynamical system. We propose Dynafit, a kernel-based method for learning a distance metric between training trajectories and the underlying dynamics. New observations are assigned to the class with the most similar dynamics according to the learned metric. The learning algorithm approximates the Koopman operator which globally linearizes the dynamics in a (potentially infinite) feature space associated with a kernel function. The distance metric is computed in feature space independently of its dimensionality by using the kernel trick common in machine learning. We also show that the kernel function can be tailored to incorporate partial knowledge of the dynamics when available. Dynafit is applicable to various classification tasks involving nonlinear dynamical systems and sensors. We illustrate its effectiveness on three examples: chaos detection with the logistic map, recognition of handwritten dynamics and of visual dynamic textures.
2601.04058Jan 2026
View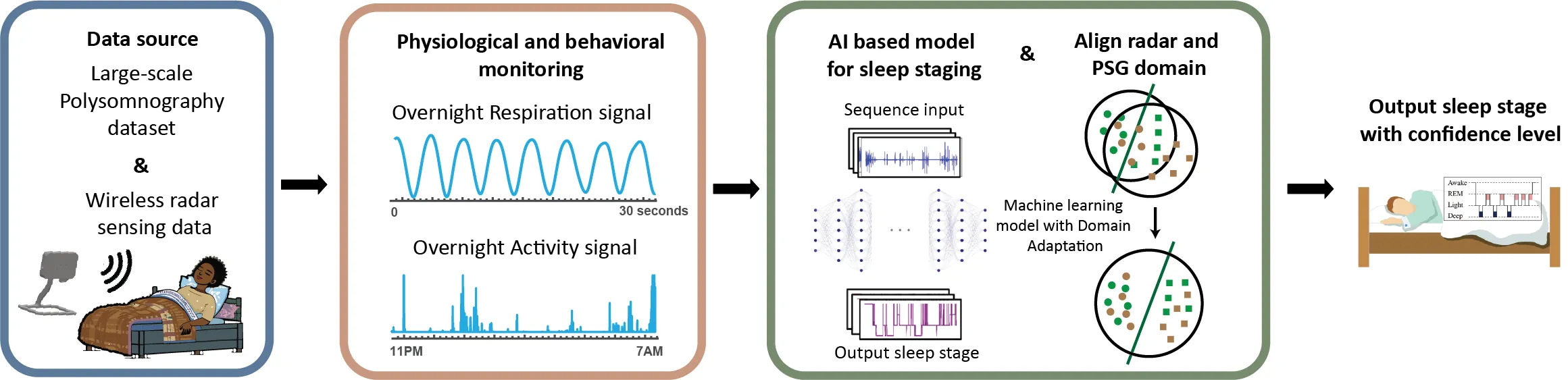
Using Legacy Polysomnography Data to Train a Radar System to Quantify Sleep in Older Adults and People living with Dementia
Objective: Ultra-wideband radar technology offers a promising solution for unobtrusive and cost-effective in-home sleep monitoring. However, the limited availability of radar sleep data poses challenges in building robust models that generalize across diverse cohorts and environments. This study proposes a novel deep transfer learning framework to enhance sleep stage classification using radar data. Methods: An end-to-end neural network was developed to classify sleep stages based on nocturnal respiratory and motion signals. The network was trained using a combination of large-scale polysomnography (PSG) datasets and radar data. A domain adaptation approach employing adversarial learning was utilized to bridge the knowledge gap between PSG and radar signals. Validation was performed on a radar dataset of 47 older adults (mean age: 71.2), including 18 participants with prodromal or mild Alzheimer disease. Results: The proposed network structure achieves an accuracy of 79.5% with a Kappa value of 0.65 when classifying wakefulness, rapid eye movement, light sleep and deep sleep. Experimental results confirm that our deep transfer learning approach significantly enhances automatic sleep staging performance in the target domain. Conclusion: This method effectively addresses challenges associated with data variability and limited sample size, substantially improving the reliability of automatic sleep staging models, especially in contexts where radar data is limited. Significance: The findings underscore the viability of UWB radar as a nonintrusive, forward-looking sleep assessment tool that could significantly benefit care for older people and people with neurodegenerative disorders.
2601.04057Jan 2026
View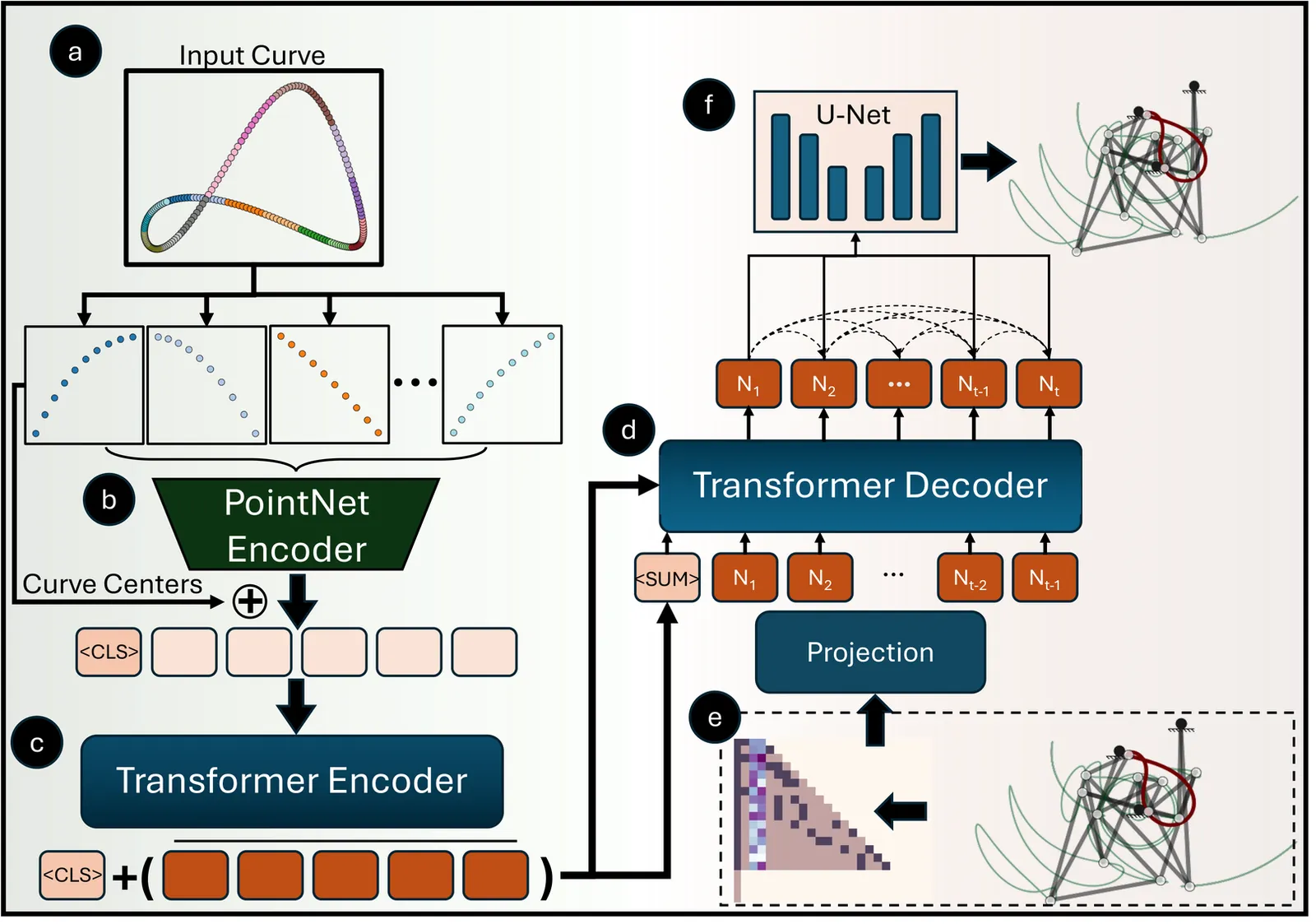
LinkD: AutoRegressive Diffusion Model for Mechanical Linkage Synthesis
Designing mechanical linkages to achieve target end-effector trajectories presents a fundamental challenge due to the intricate coupling between continuous node placements, discrete topological configurations, and nonlinear kinematic constraints. The highly nonlinear motion-to-configuration relationship means small perturbations in joint positions drastically alter trajectories, while the combinatorially expanding design space renders conventional optimization and heuristic methods computationally intractable. We introduce an autoregressive diffusion framework that exploits the dyadic nature of linkage assembly by representing mechanisms as sequentially constructed graphs, where nodes correspond to joints and edges to rigid links. Our approach combines a causal transformer with a Denoising Diffusion Probabilistic Model (DDPM), both conditioned on target trajectories encoded via a transformer encoder. The causal transformer autoregressively predicts discrete topology node-by-node, while the DDPM refines each node's spatial coordinates and edge connectivity to previously generated nodes. This sequential generation enables adaptive trial-and-error synthesis where problematic nodes exhibiting kinematic locking or collisions can be selectively regenerated, allowing autonomous correction of degenerate configurations during design. Our graph-based, data-driven methodology surpasses traditional optimization approaches, enabling scalable inverse design that generalizes to mechanisms with arbitrary node counts. We demonstrate successful synthesis of linkage systems containing up to 20 nodes with extensibility to N-node architectures. This work advances autoregressive graph generation methodologies and computational kinematic synthesis, establishing new paradigms for scalable inverse design of complex mechanical systems.
2601.04054Jan 2026
View
Symbolic Regression for Shared Expressions: Introducing Partial Parameter Sharing
Symbolic Regression aims to find symbolic expressions that describe datasets. Due to better interpretability, it is a machine learning paradigm particularly powerful for scientific discovery. In recent years, several works have expanded the concept to allow the description of similar phenomena using a single expression with varying sets of parameters, thereby introducing categorical variables. Some previous works allow only "non-shared" (category-value-specific) parameters, and others also incorporate "shared" (category-value-agnostic) parameters. We expand upon those efforts by considering multiple categorical variables, and introducing intermediate levels of parameter sharing. With two categorical variables, an intermediate level of parameter sharing emerges, i.e., parameters which are shared across either category but change across the other. The new approach potentially decreases the number of parameters, while revealing additional information about the problem. Using a synthetic, fitting-only example, we test the limits of this setup in terms of data requirement reduction and transfer learning. As a real-world symbolic regression example, we demonstrate the benefits of the proposed approach on an astrophysics dataset used in a previous study, which considered only one categorical variable. We achieve a similar fit quality but require significantly fewer individual parameters, and extract additional information about the problem.
2601.04051Jan 2026
View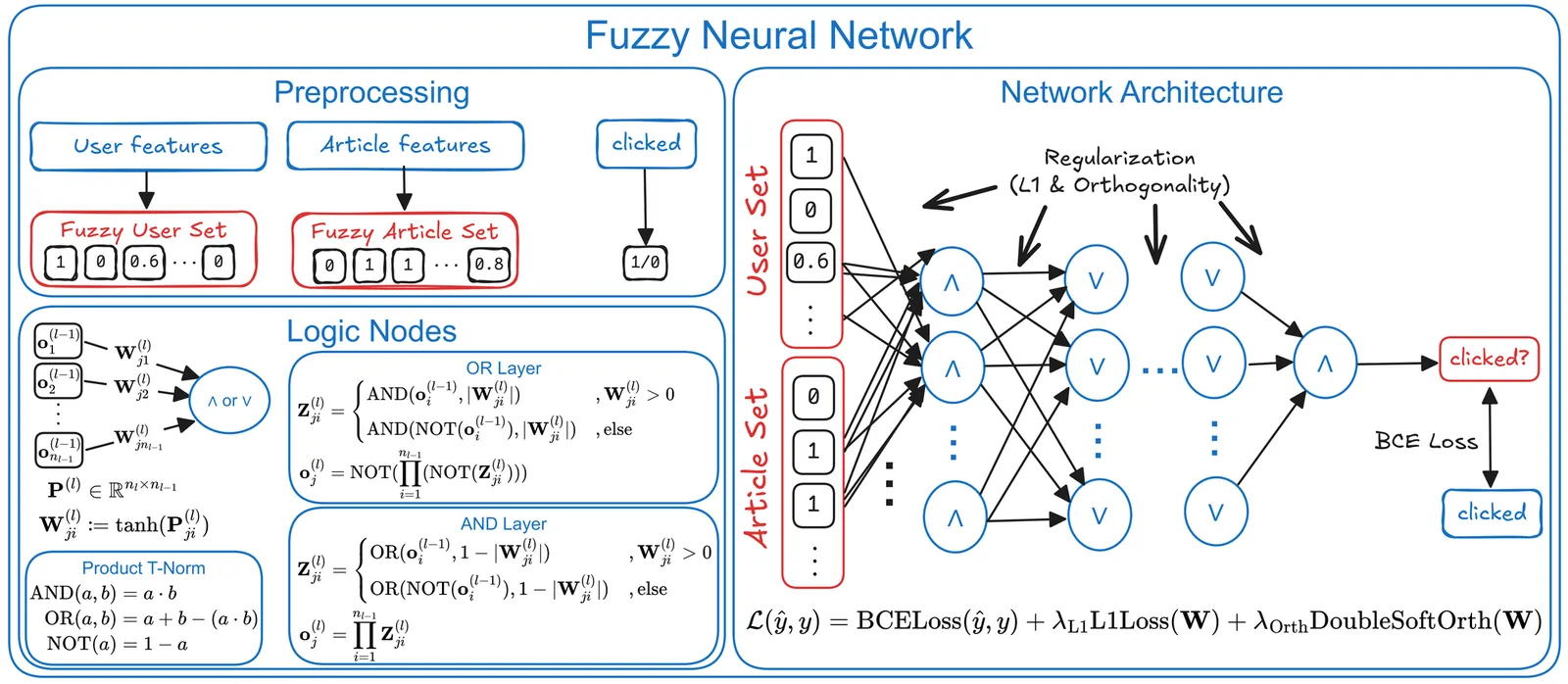
Modeling Behavioral Patterns in News Recommendations Using Fuzzy Neural Networks
News recommender systems are increasingly driven by black-box models, offering little transparency for editorial decision-making. In this work, we introduce a transparent recommender system that uses fuzzy neural networks to learn human-readable rules from behavioral data for predicting article clicks. By extracting the rules at configurable thresholds, we can control rule complexity and thus, the level of interpretability. We evaluate our approach on two publicly available news datasets (i.e., MIND and EB-NeRD) and show that we can accurately predict click behavior compared to several established baselines, while learning human-readable rules. Furthermore, we show that the learned rules reveal news consumption patterns, enabling editors to align content curation goals with target audience behavior.
2601.04019Jan 2026
View
Stage-specific cancer survival prediction enriched by explainable machine learning
Despite the fact that cancer survivability rates vary greatly between stages, traditional survival prediction models have frequently been trained and assessed using examples from all combined phases of the disease. This method may result in an overestimation of performance and ignore the stage-specific variations. Using the SEER dataset, we created and verified explainable machine learning (ML) models to predict stage-specific cancer survivability in colorectal, stomach, and liver cancers. ML-based cancer survival analysis has been a long-standing topic in the literature; however, studies involving the explainability and transparency of ML survivability models are limited. Our use of explainability techniques, including SHapley Additive exPlanations (SHAP) and Local Interpretable Model-agnostic Explanations (LIME), enabled us to illustrate significant feature-cancer stage interactions that would have remained hidden in traditional black-box models. We identified how certain demographic and clinical variables influenced survival differently across cancer stages and types. These insights provide not only transparency but also clinical relevance, supporting personalized treatment planning. By focusing on stage-specific models, this study provides new insights into the most important factors at each stage of cancer, offering transparency and potential clinical relevance to support personalized treatment planning.
2601.03977Jan 2026
View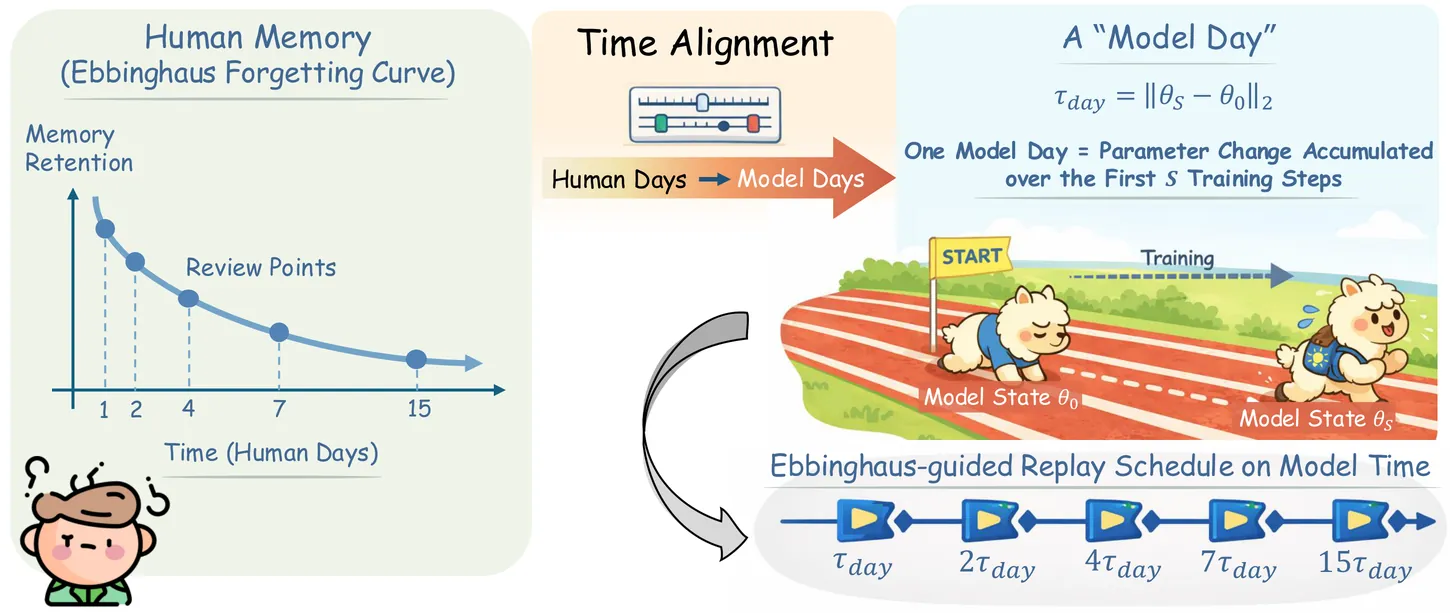
FOREVER: Forgetting Curve-Inspired Memory Replay for Language Model Continual Learning
Continual learning (CL) for large language models (LLMs) aims to enable sequential knowledge acquisition without catastrophic forgetting. Memory replay methods are widely used for their practicality and effectiveness, but most rely on fixed, step-based heuristics that often misalign with the model's actual learning progress, since identical training steps can result in varying degrees of parameter change. Motivated by recent findings that LLM forgetting mirrors the Ebbinghaus human forgetting curve, we propose FOREVER (FORgEtting curVe-inspired mEmory Replay), a novel CL framework that aligns replay schedules with a model-centric notion of time. FOREVER defines model time using the magnitude of optimizer updates, allowing forgetting curve-inspired replay intervals to align with the model's internal evolution rather than raw training steps. Building on this approach, FOREVER incorporates a forgetting curve-based replay scheduler to determine when to replay and an intensity-aware regularization mechanism to adaptively control how to replay. Extensive experiments on three CL benchmarks and models ranging from 0.6B to 13B parameters demonstrate that FOREVER consistently mitigates catastrophic forgetting.
2601.03938Jan 2026
View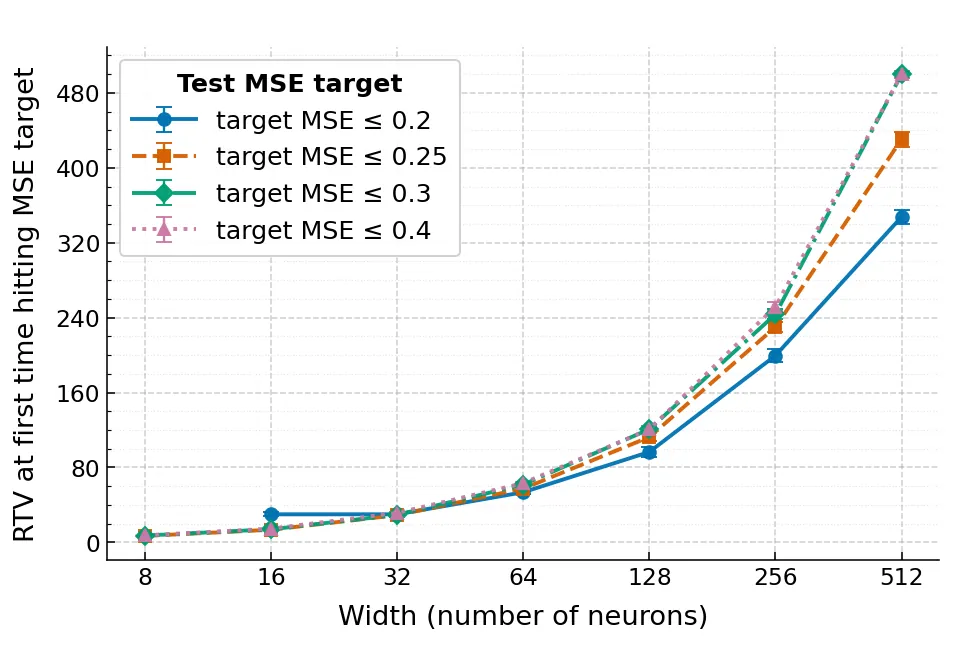
A Gap Between Decision Trees and Neural Networks
We study when geometric simplicity of decision boundaries, used here as a notion of interpretability, can conflict with accurate approximation of axis-aligned decision trees by shallow neural networks. Decision trees induce rule-based, axis-aligned decision regions (finite unions of boxes), whereas shallow ReLU networks are typically trained as score models whose predictions are obtained by thresholding. We analyze the infinite-width, bounded-norm, single-hidden-layer ReLU class through the Radon total variation ($\mathrm{R}\mathrm{TV}$) seminorm, which controls the geometric complexity of level sets. We first show that the hard tree indicator $1_A$ has infinite $\mathrm{R}\mathrm{TV}$. Moreover, two natural split-wise continuous surrogates--piecewise-linear ramp smoothing and sigmoidal (logistic) smoothing--also have infinite $\mathrm{R}\mathrm{TV}$ in dimensions $d>1$, while Gaussian convolution yields finite $\mathrm{R}\mathrm{TV}$ but with an explicit exponential dependence on $d$. We then separate two goals that are often conflated: classification after thresholding (recovering the decision set) versus score learning (learning a calibrated score close to $1_A$). For classification, we construct a smooth barrier score $S_A$ with finite $\mathrm{R}\mathrm{TV}$ whose fixed threshold $τ=1$ exactly recovers the box. Under a mild tube-mass condition near $\partial A$, we prove an $L_1(P)$ calibration bound that decays polynomially in a sharpness parameter, along with an explicit $\mathrm{R}\mathrm{TV}$ upper bound in terms of face measures. Experiments on synthetic unions of rectangles illustrate the resulting accuracy--complexity tradeoff and how threshold selection shifts where training lands along it.
2601.03919Jan 2026
View
Adaptive-Boundary-Clipping GRPO: Ensuring Bounded Ratios for Stable and Generalizable Training
Group Relative Policy Optimization (GRPO) has emerged as a popular algorithm for reinforcement learning with large language models (LLMs). However, upon analyzing its clipping mechanism, we argue that it is suboptimal in certain scenarios. With appropriate modifications, GRPO can be significantly enhanced to improve both flexibility and generalization. To this end, we propose Adaptive-Boundary-Clipping GRPO (ABC-GRPO), an asymmetric and adaptive refinement of the original GRPO framework. We demonstrate that ABC-GRPO achieves superior performance over standard GRPO on mathematical reasoning tasks using the Qwen3 LLMs. Moreover, ABC-GRPO maintains substantially higher entropy throughout training, thereby preserving the model's exploration capacity and mitigating premature convergence. The implementation code is available online to ease reproducibility https://github.com/chi2liu/ABC-GRPO.
2601.03895Jan 2026
View
Spectral Manifold Regularization for Stable and Modular Routing in Deep MoE Architectures
Mixture of Experts (MoE) architectures enable efficient scaling of neural networks but suffer from expert collapse, where routing converges to a few dominant experts. This reduces model capacity and causes catastrophic interference during adaptation. We propose the Spectrally-Regularized Mixture of Experts (SR-MoE), which imposes geometric constraints on the routing manifold to enforce structural modularity. Our method uses dual regularization: spectral norm constraints bound routing function Lipschitz continuity, while stable rank penalties preserve high-dimensional feature diversity in expert selection. We evaluate SR-MoE across architectural scales and dataset complexities using modular one-shot adaptation tasks. Results show that traditional linear gating fails with increasing depth (accuracy drops up to 4.72% due to expert entanglement), while SR-MoE maintains structural integrity (mean interference -0.32%). Our spectral constraints facilitate positive knowledge transfer, enabling localized expert updates without global performance decay. SR-MoE provides a general solution for building high-capacity, modular networks capable of stable lifelong learning.
2601.03889Jan 2026
View
Feature-Aware One-Shot Federated Learning via Hierarchical Token Sequences
One-shot federated learning (OSFL) reduces the communication cost and privacy risks of iterative federated learning by constructing a global model with a single round of communication. However, most existing methods struggle to achieve robust performance on real-world domains such as medical imaging, or are inefficient when handling non-IID (Independent and Identically Distributed) data. To address these limitations, we introduce FALCON, a framework that enhances the effectiveness of OSFL over non-IID image data. The core idea of FALCON is to leverage the feature-aware hierarchical token sequences generation and knowledge distillation into OSFL. First, each client leverages a pretrained visual encoder with hierarchical scale encoding to compress images into hierarchical token sequences, which capture multi-scale semantics. Second, a multi-scale autoregressive transformer generator is used to model the distribution of these token sequences and generate the synthetic sequences. Third, clients upload the synthetic sequences along with the local classifier trained on the real token sequences to the server. Finally, the server incorporates knowledge distillation into global training to reduce reliance on precise distribution modeling. Experiments on medical and natural image datasets validate the effectiveness of FALCON in diverse non-IID scenarios, outperforming the best OSFL baselines by 9.58% in average accuracy.
2601.03882Jan 2026
View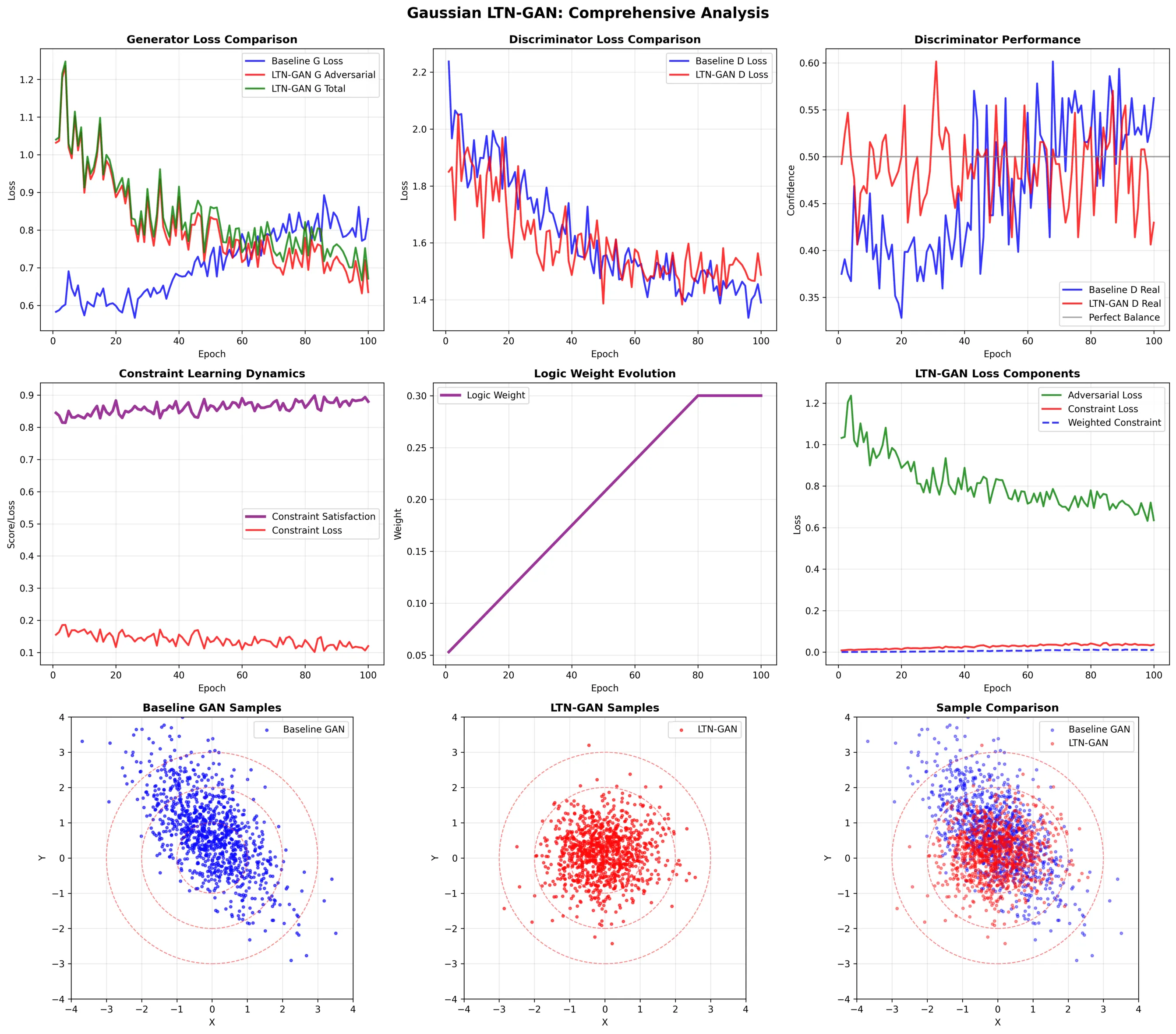
Logic Tensor Network-Enhanced Generative Adversarial Network
In this paper, we introduce Logic Tensor Network-Enhanced Generative Adversarial Network (LTN-GAN), a novel framework that enhances Generative Adversarial Networks (GANs) by incorporating Logic Tensor Networks (LTNs) to enforce domain-specific logical constraints during the sample generation process. Although GANs have shown remarkable success in generating realistic data, they often lack mechanisms to incorporate prior knowledge or enforce logical consistency, limiting their applicability in domains requiring rule adherence. LTNs provide a principled way to integrate first-order logic with neural networks, enabling models to reason over and satisfy logical constraints. By combining the strengths of GANs for realistic data synthesis with LTNs for logical reasoning, we gain valuable insights into how logical constraints influence the generative process while improving both the diversity and logical consistency of the generated samples. We evaluate LTN-GAN across multiple datasets, including synthetic datasets (gaussian, grid, rings) and the MNIST dataset, demonstrating that our model significantly outperforms traditional GANs in terms of adherence to predefined logical constraints while maintaining the quality and diversity of generated samples. This work highlights the potential of neuro-symbolic approaches to enhance generative modeling in knowledge-intensive domains.
2601.03839Jan 2026
View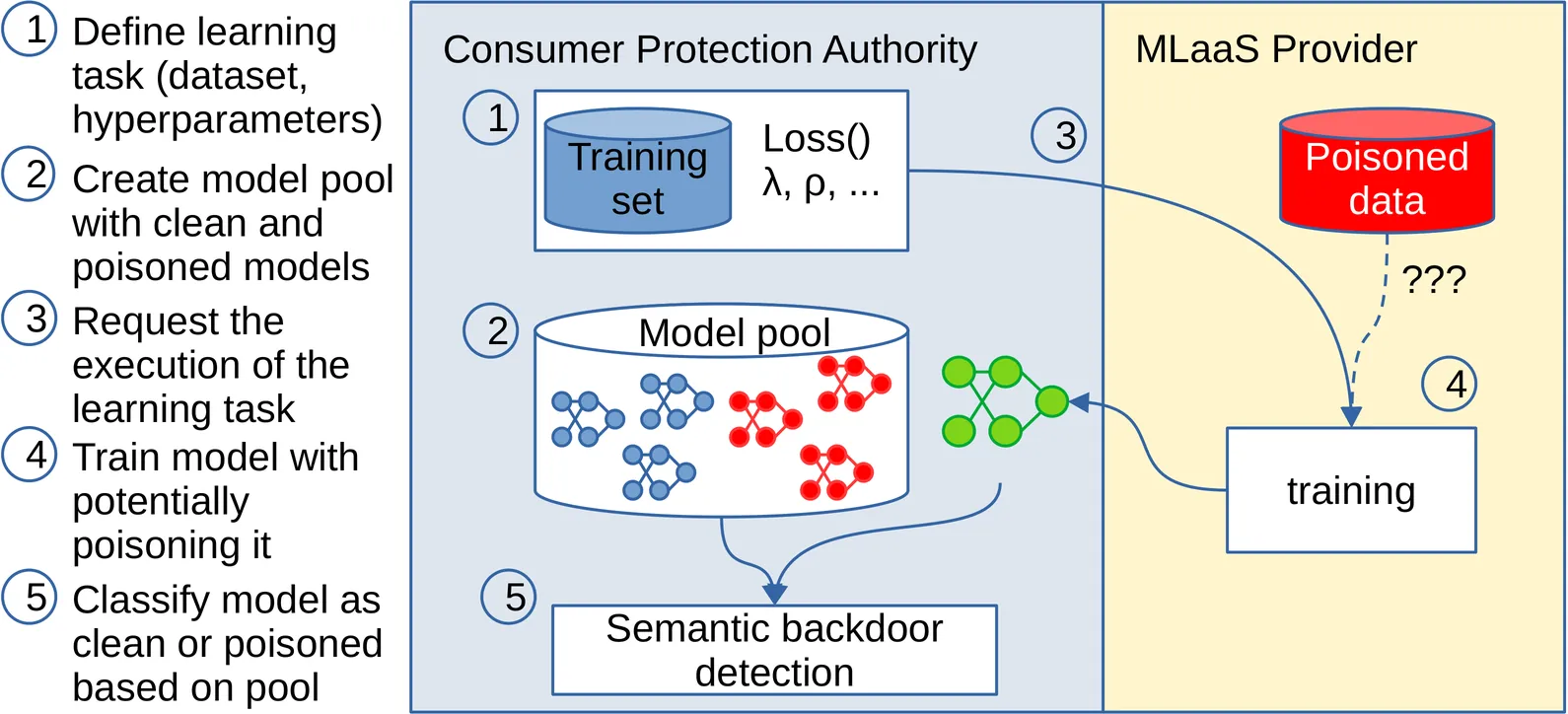
Detecting Semantic Backdoors in a Mystery Shopping Scenario
Detecting semantic backdoors in classification models--where some classes can be activated by certain natural, but out-of-distribution inputs--is an important problem that has received relatively little attention. Semantic backdoors are significantly harder to detect than backdoors that are based on trigger patterns due to the lack of such clearly identifiable patterns. We tackle this problem under the assumption that the clean training dataset and the training recipe of the model are both known. These assumptions are motivated by a consumer protection scenario, in which the responsible authority performs mystery shopping to test a machine learning service provider. In this scenario, the authority uses the provider's resources and tools to train a model on a given dataset and tests whether the provider included a backdoor. In our proposed approach, the authority creates a reference model pool by training a small number of clean and poisoned models using trusted infrastructure, and calibrates a model distance threshold to identify clean models. We propose and experimentally analyze a number of approaches to compute model distances and we also test a scenario where the provider performs an adaptive attack to avoid detection. The most reliable method is based on requesting adversarial training from the provider. The model distance is best measured using a set of input samples generated by inverting the models in such a way as to maximize the distance from clean samples. With these settings, our method can often completely separate clean and poisoned models, and it proves to be superior to state-of-the-art backdoor detectors as well.
2601.03805Jan 2026
View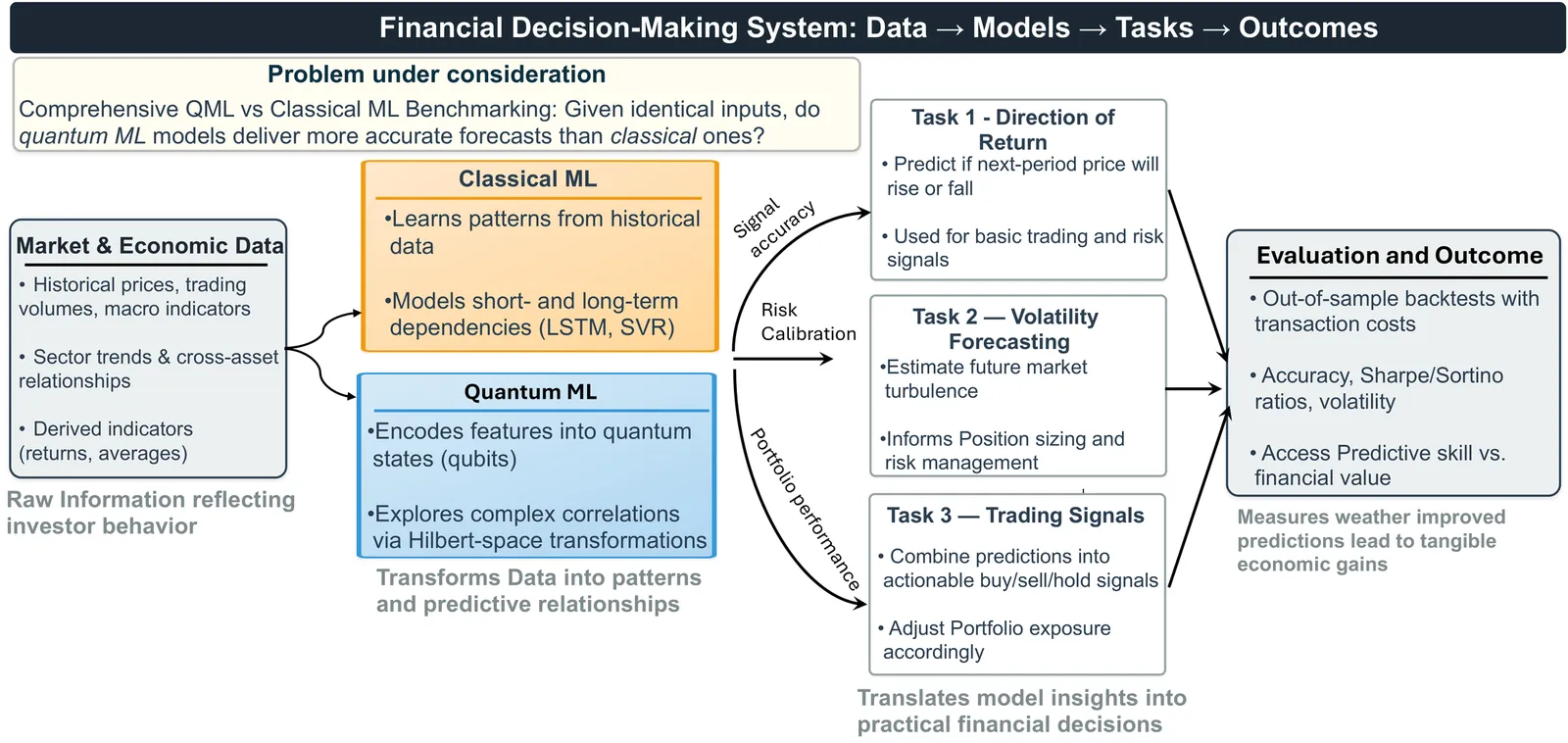
Quantum vs. Classical Machine Learning: A Benchmark Study for Financial Prediction
In this paper, we present a reproducible benchmarking framework that systematically compares QML models with architecture-matched classical counterparts across three financial tasks: (i) directional return prediction on U.S. and Turkish equities, (ii) live-trading simulation with Quantum LSTMs versus classical LSTMs on the S\&P 500, and (iii) realized volatility forecasting using Quantum Support Vector Regression. By standardizing data splits, features, and evaluation metrics, our study provides a fair assessment of when current-generation QML models can match or exceed classical methods. Our results reveal that quantum approaches show performance gains when data structure and circuit design are well aligned. In directional classification, hybrid quantum neural networks surpass the parameter-matched ANN by \textbf{+3.8 AUC} and \textbf{+3.4 accuracy points} on \texttt{AAPL} stock and by \textbf{+4.9 AUC} and \textbf{+3.6 accuracy points} on Turkish stock \texttt{KCHOL}. In live trading, the QLSTM achieves higher risk-adjusted returns in \textbf{two of four} S\&P~500 regimes. For volatility forecasting, an angle-encoded QSVR attains the \textbf{lowest QLIKE} on \texttt{KCHOL} and remains within $\sim$0.02-0.04 QLIKE of the best classical kernels on \texttt{S\&P~500} and \texttt{AAPL}. Our benchmarking framework clearly identifies the scenarios where current QML architectures offer tangible improvements and where established classical methods continue to dominate.
2601.03802Jan 2026
ViewPage 1 of 784