Trending in Machine Learning
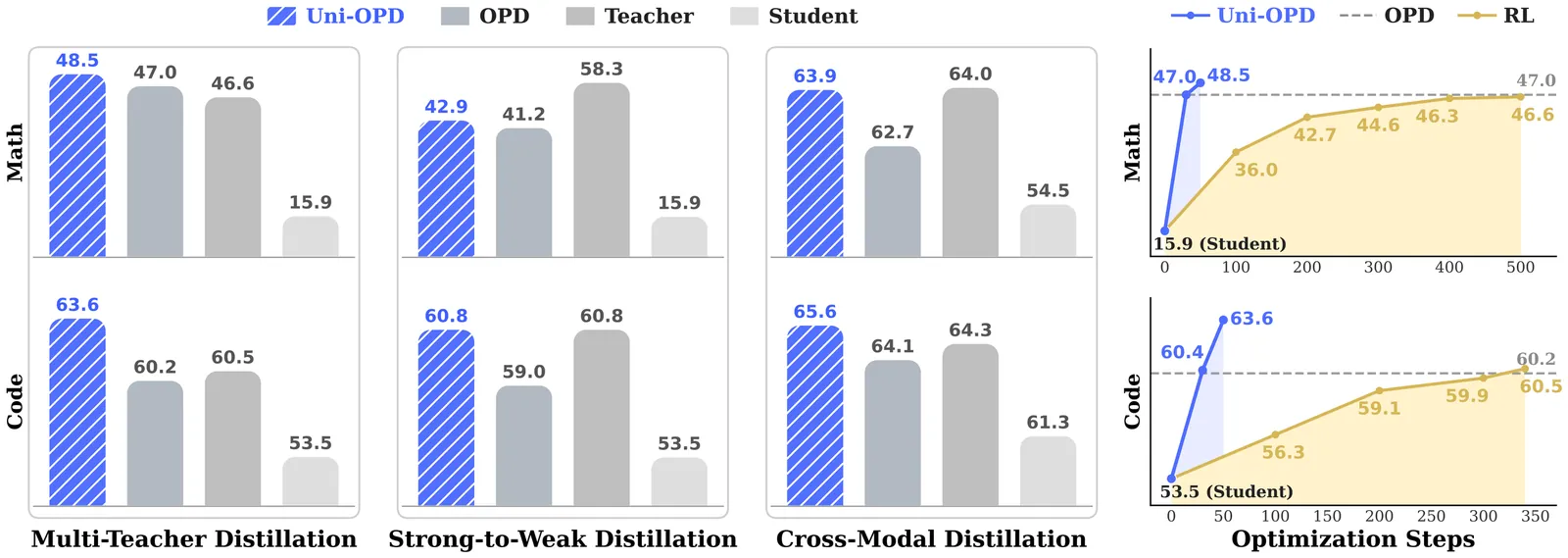
Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe
On-policy distillation (OPD) has recently emerged as an effective post-training paradigm for consolidating the capabilities of specialized expert models into a single student model. Despite its empirical success, the conditions under which OPD yields reliable improvement remain poorly understood. In this work, we identify two fundamental bottlenecks that limit effective OPD: insufficient exploration of informative states and unreliable teacher supervision for student rollouts. Building on this insight, we propose Uni-OPD, a unified OPD framework that generalizes across Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs), centered on a dual-perspective optimization strategy. Specifically, from the student's perspective, we adopt two data balancing strategies to promote exploration of informative student-generated states during training. From the teacher's perspective, we show that reliable supervision hinges on whether aggregated token-level guidance remains order-consistent with the outcome reward. To this end, we develop an outcome-guided margin calibration mechanism to restore order consistency between correct and incorrect trajectories. We conduct extensive experiments on 5 domains and 16 benchmarks covering diverse settings, including single-teacher and multi-teacher distillation across LLMs and MLLMs, strong-to-weak distillation, and cross-modal distillation. Our results verify the effectiveness and versatility of Uni-OPD and provide practical insights into reliable OPD.
2605.03677
May 2026Machine Learning
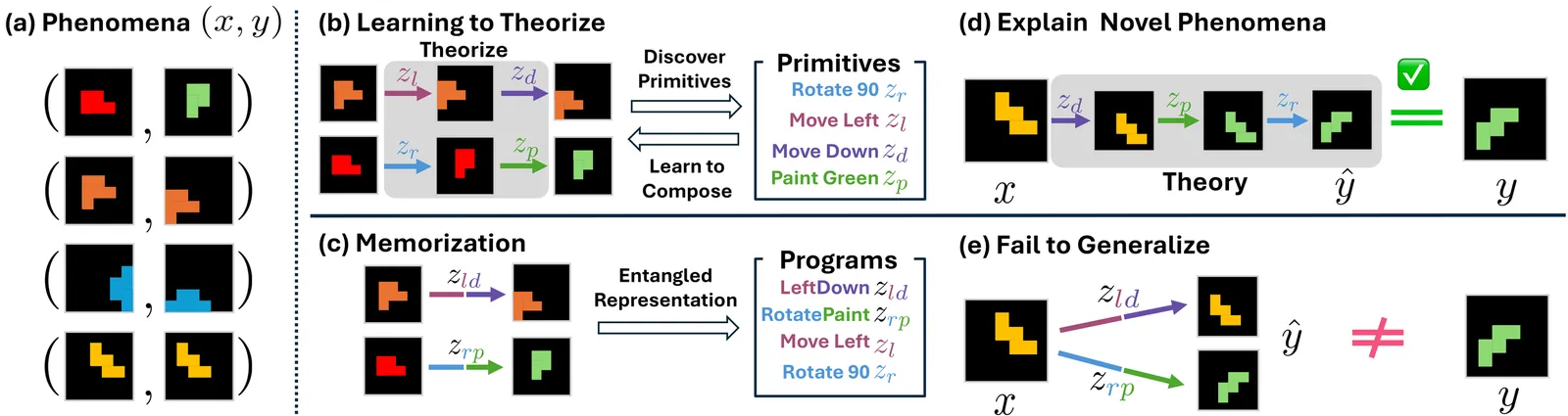
Learning to Theorize the World from Observation
What does it mean to understand the world? Contemporary world models often operationalize understanding as accurate future prediction in latent or observation space. Developmental cognitive science, however, suggests a different view: human understanding emerges through the construction of internal theories of how the world works, even before mature language is acquired. Inspired by this theory-building view of cognition, we introduce Learning-to-Theorize, a learning paradigm for inferring explicit explanatory theories of the world from raw, non-textual observations. We instantiate this paradigm with the Neural Theorizer (NEO), a probabilistic neural model that induces latent programs as a learned Language of Thought and executes them through a shared transition model. In NEO, a theory is represented as an executable, compositional program whose learned primitives can be systematically recombined to explain novel phenomena. Experiments show that this formulation enables explanation-driven generalization, allowing observations to be understood in terms of the programs that generate them.
2605.03413
May 2026Machine Learning
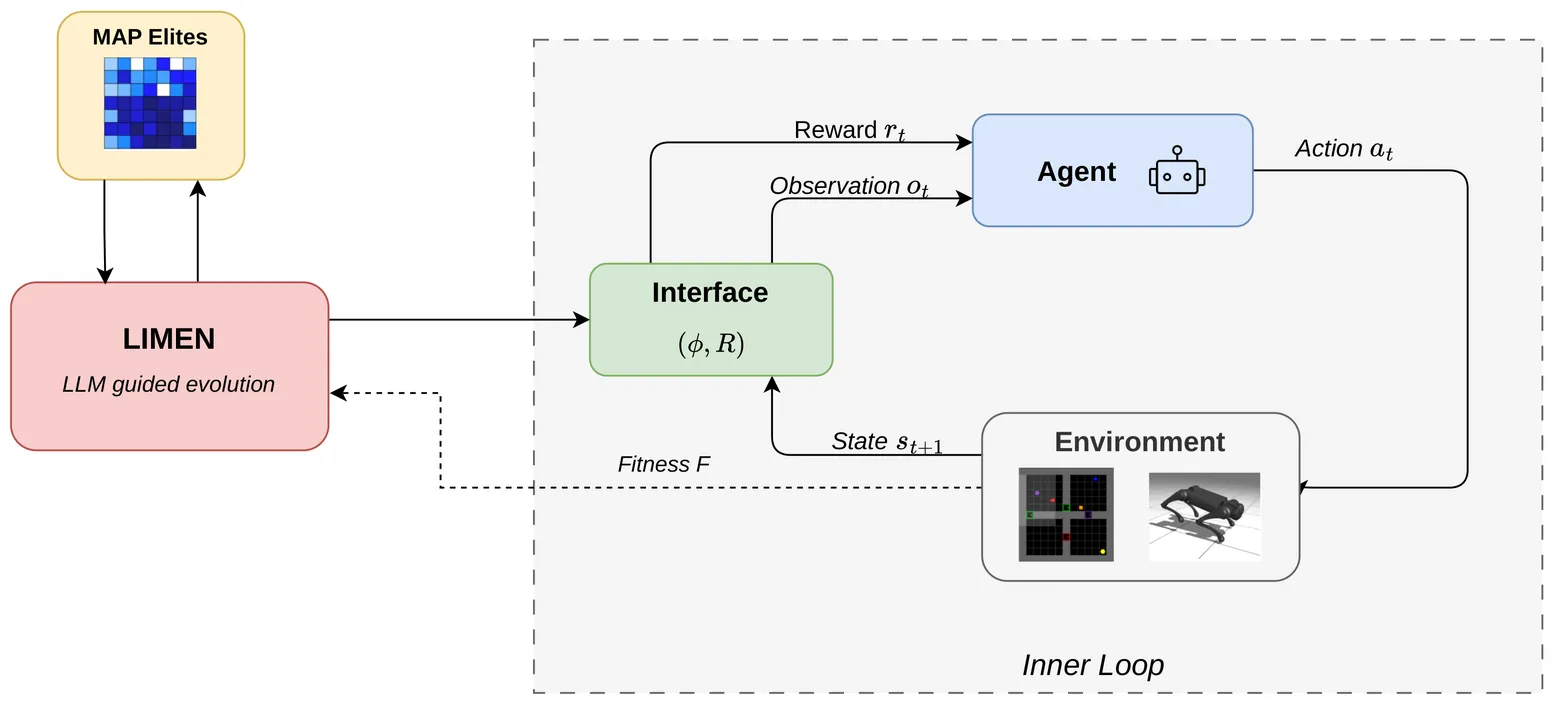
Discovering Reinforcement Learning Interfaces with Large Language Models
Reinforcement learning systems rely on environment interfaces that specify observations and reward functions, yet constructing these interfaces for new tasks often requires substantial manual effort. While recent work has automated reward design using large language models (LLMs), these approaches assume fixed observations and do not address the broader challenge of synthesizing complete task interfaces. We study RL task interface discovery from raw simulator state, where both observation mappings and reward functions must be generated. We propose LIMEN (Code available at https://github.com/Lossfunk/LIMEN), a LLM guided evolutionary framework that produces candidate interfaces as executable programs and iteratively refines them using policy training feedback. Across novel discrete gridworld tasks and continuous control domains spanning locomotion and manipulation, joint evolution of observations and rewards discovers effective interfaces given only a trajectory-level success metric, while optimizing either component alone fails on at least one domain. These results demonstrate that automatic construction of RL interfaces from raw state can substantially reduce manual engineering and that observation and reward components often benefit from co-design, as single-component optimization fails catastrophically on at least one domain in our evaluation suite.
2605.03408
May 2026Machine Learning
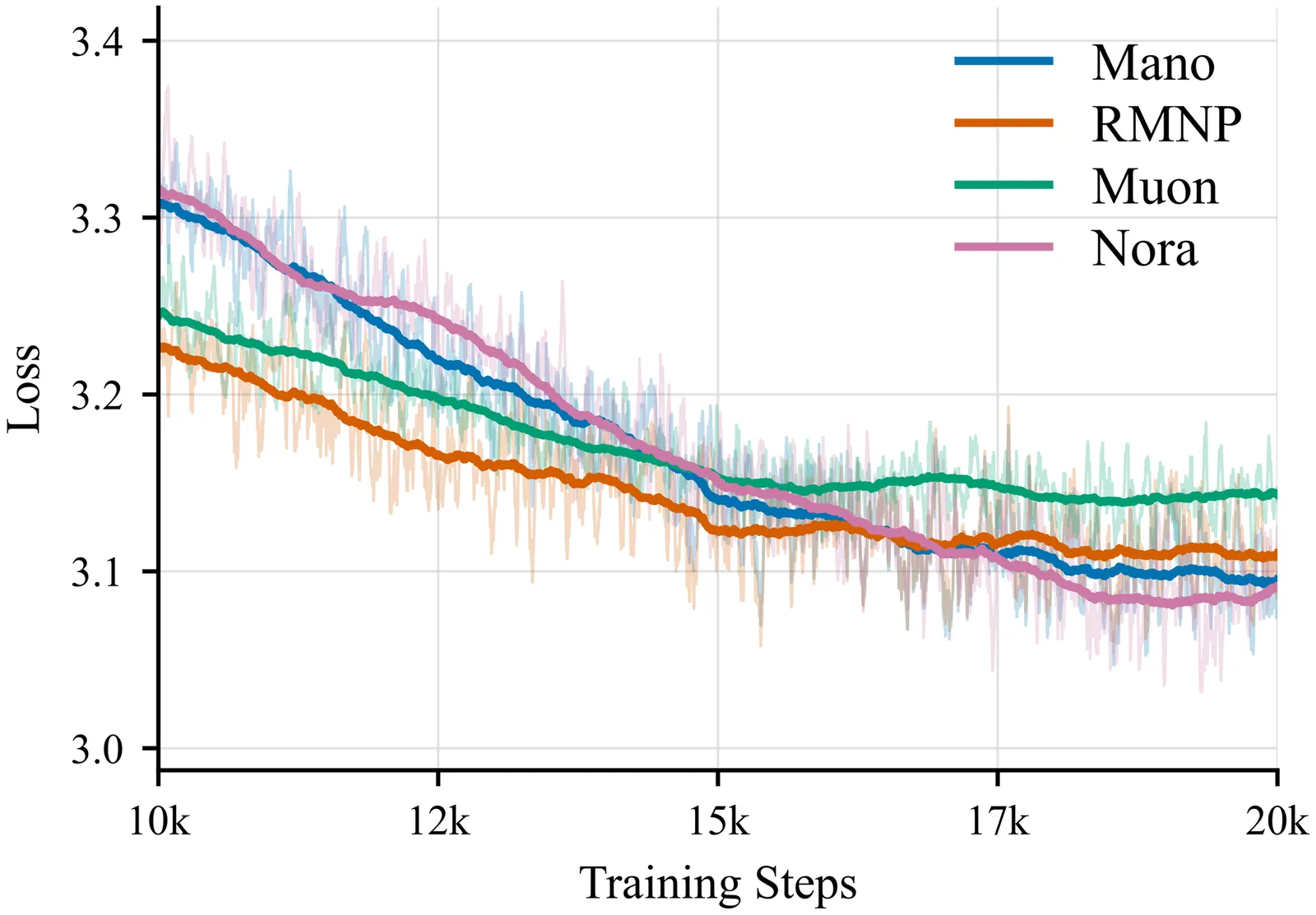
Nora: Normalized Orthogonal Row Alignment for Scalable Matrix Optimizer
Matrix-based optimizers have demonstrated immense potential in training Large Language Models (LLMs), however, designing an ideal optimizer remains a formidable challenge. A superior optimizer must satisfy three core desiderata: efficiency, achieving Muon-like preconditioning to accelerate optimization; stability, strictly adhering to the scale-invariance inherent in neural networks; and speed, minimizing computational overhead. While existing methods address these aspects to varying degrees, they often fail to unify them, either incurring prohibitive computational costs like Muon, or allowing radial jitters that compromise stability like RMNP. To bridge this gap, we propose Nora, an optimizer that rigorously satisfies all three requirements. Nora achieves training stability by explicitly stabilizing weight norms and angular velocities through row-wise momentum projection onto the orthogonal complement of the weights. Simultaneously, by leveraging the block-diagonal dominance of the Transformer Hessian, Nora effectively approximates structured preconditioning while maintaining an optimal computational complexity of $\mathcal{O}(mn)$. Furthermore, we prove that Nora is a scalable optimizer and establish its corresponding scaling theorems. With a streamlined implementation requiring only two lines of code, our preliminary experiments validate Nora as an efficient and highly promising optimizer for large-scale training.
2605.03769
May 2026Machine Learning
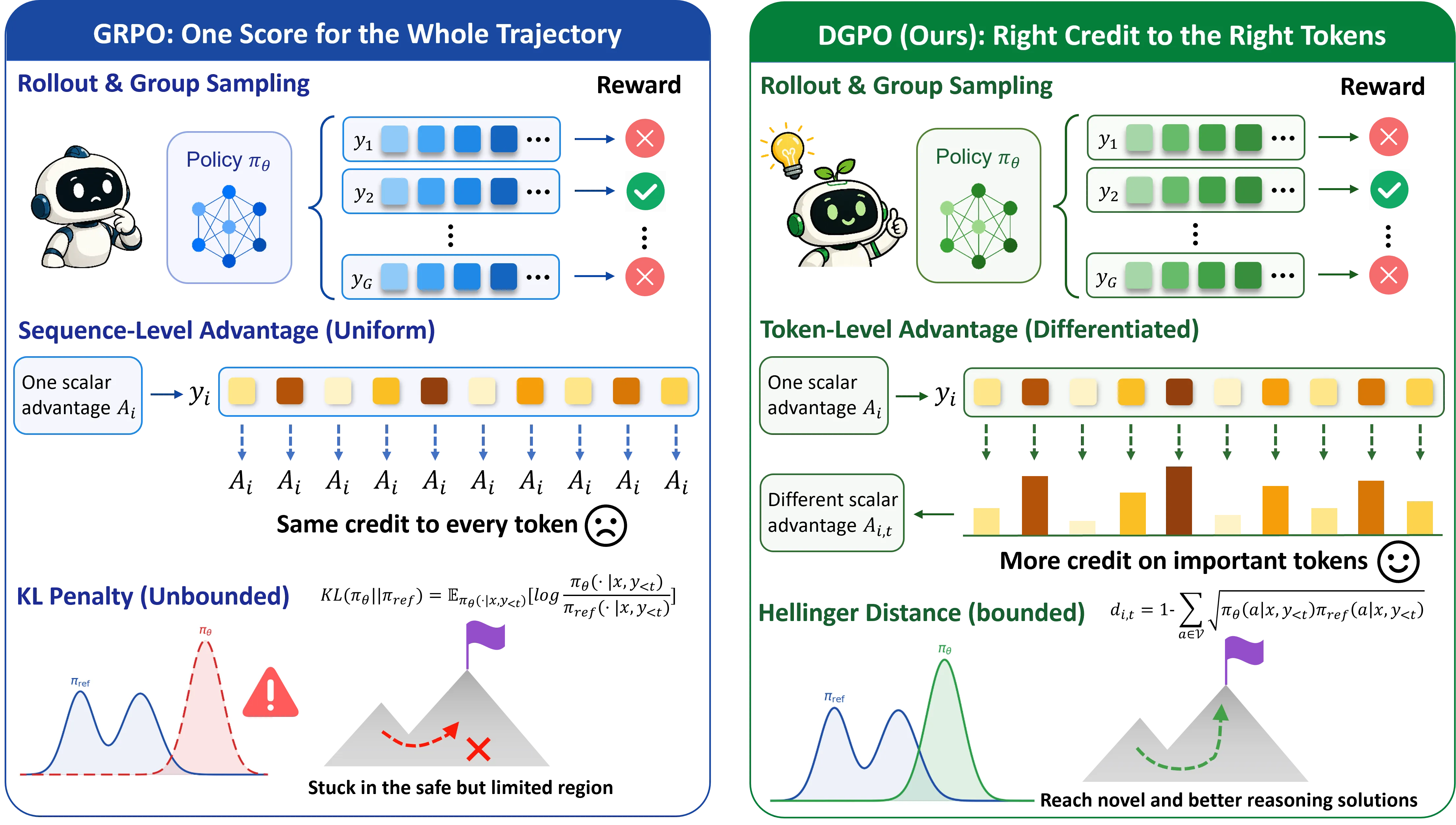
DGPO: Distribution Guided Policy Optimization for Fine Grained Credit Assignment
Reinforcement learning is crucial for aligning large language models to perform complex reasoning tasks. However, current algorithms such as Group Relative Policy Optimization suffer from coarse grained, sequence level credit assignment, which severely struggles to isolate pivotal reasoning steps within long Chain of Thought generations. Furthermore, the standard unbounded Kullback Leibler divergence penalty induces severe gradient instability and mode seeking conservatism, ultimately stifling the discovery of novel reasoning trajectories. To overcome these limitations, we introduce Distribution Guided Policy Optimization, a novel critic free reinforcement learning framework that reinterprets distribution deviation as a guiding signal rather than a rigid penalty.
2605.03327
May 2026Machine Learning
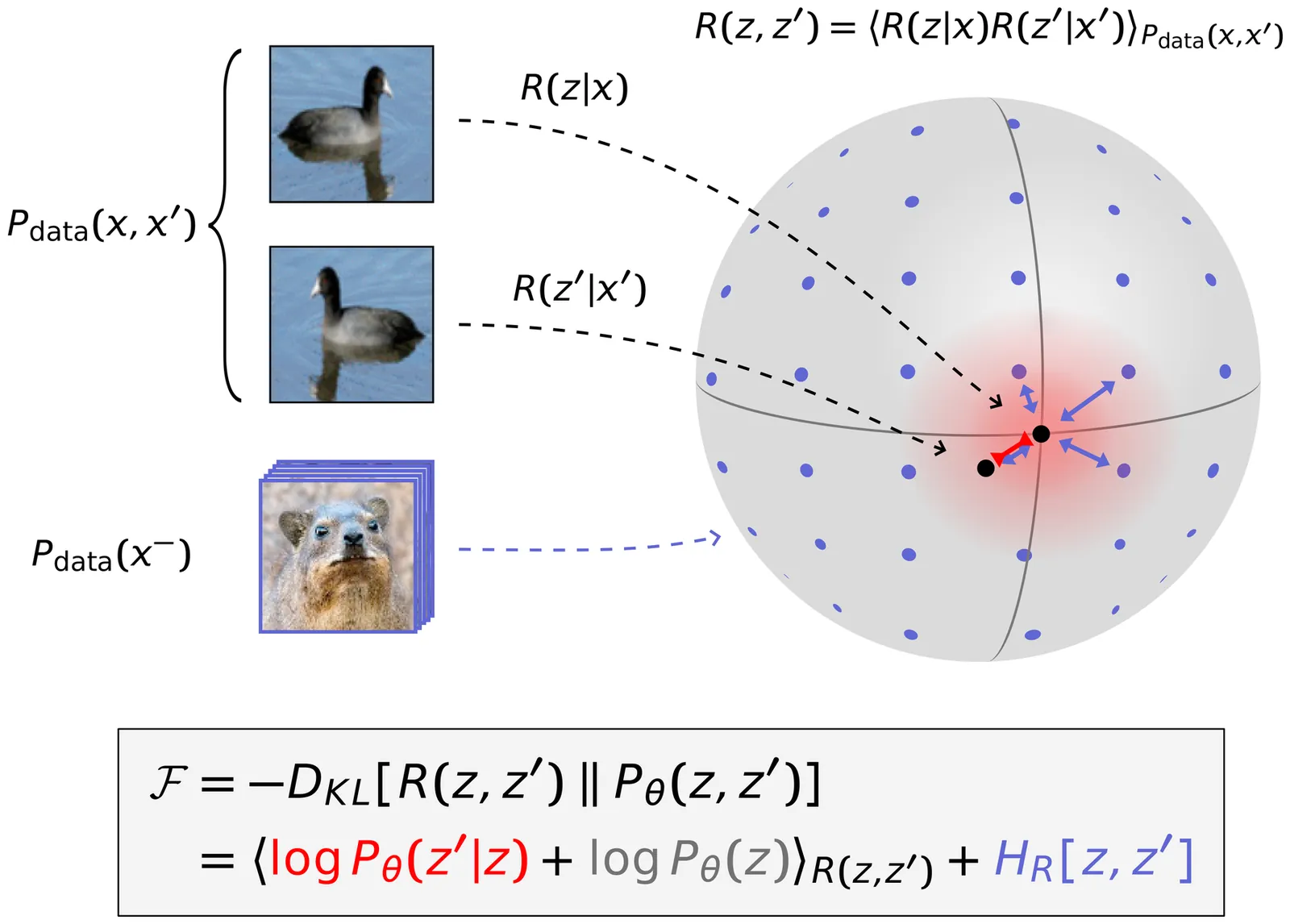
Understanding Self-Supervised Learning via Latent Distribution Matching
Self-supervised learning (SSL) excels at finding general-purpose latent representations from complex data, yet lacks a unifying theoretical framework that explains the diverse existing methods and guides the design of new ones. We cast SSL as latent distribution matching (LDM): learning representations that maximize their log-probability under an assumed latent model (alignment), while maximizing latent entropy to prevent collapse (uniformity). This view unifies independent component analysis with contrastive, non-contrastive, and predictive SSL methods, including stop gradient approaches. Leveraging LDM, we derive a nonlinear, sampling-free Bayesian filtering model with a Kalman-based predictor for high-dimensional timeseries. We further prove that predictive LDM yields identifiable latent representations under mild assumptions, even with nonlinear predictors. Overall, LDM clarifies the assumptions behind established SSL methods and provides principled guidance for developing new approaches.
2605.03517
May 2026Machine Learning
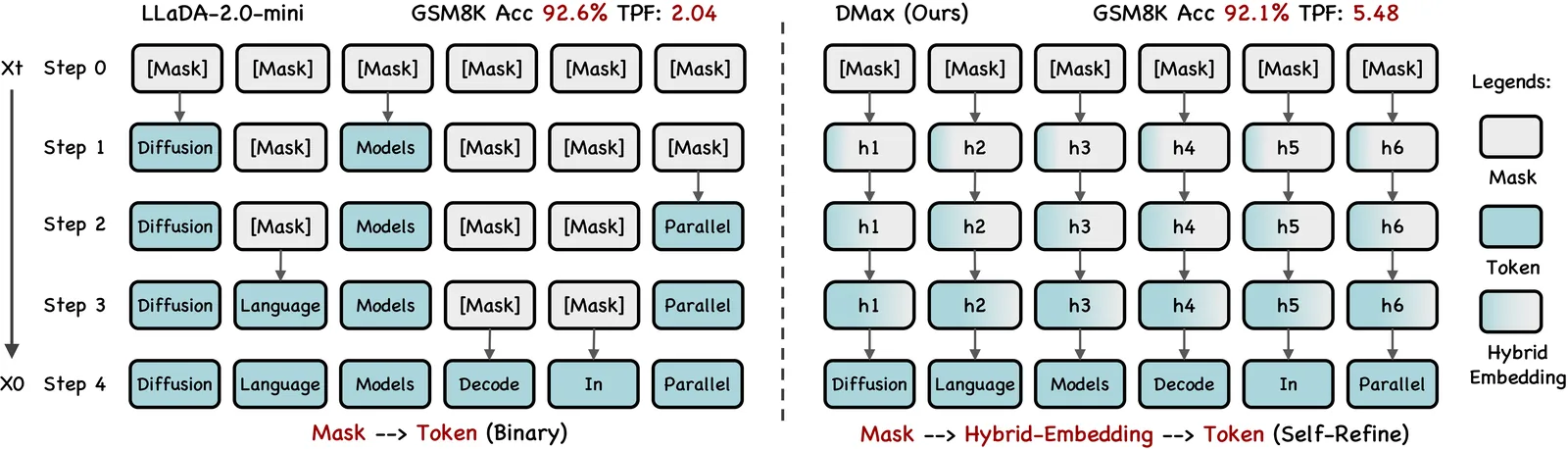
DMax: Aggressive Parallel Decoding for dLLMs
We present DMax, a new paradigm for efficient diffusion language models (dLLMs). It mitigates error accumulation in parallel decoding, enabling aggressive decoding parallelism while preserving generation quality. Unlike conventional masked dLLMs that decode through a binary mask-to-token transition, DMax reformulates decoding as a progressive self-refinement from mask embeddings to token embeddings. At the core of our approach is On-Policy Uniform Training, a novel training strategy that efficiently unifies masked and uniform dLLMs, equipping the model to recover clean tokens from both masked inputs and its own erroneous predictions. Building on this foundation, we further propose Soft Parallel Decoding. We represent each intermediate decoding state as an interpolation between the predicted token embedding and the mask embedding, enabling iterative self-revising in embedding space. Extensive experiments across a variety of benchmarks demonstrate the effectiveness of DMax. Compared with the original LLaDA-2.0-mini, our method improves TPF on GSM8K from 2.04 to 5.47 while preserving accuracy. On MBPP, it increases TPF from 2.71 to 5.86 while maintaining comparable performance. On two H200 GPUs, our model achieves an average of 1,338 TPS at batch size 1. Code is available at: https://github.com/czg1225/DMax
2604.08302
Apr 2026Machine Learning
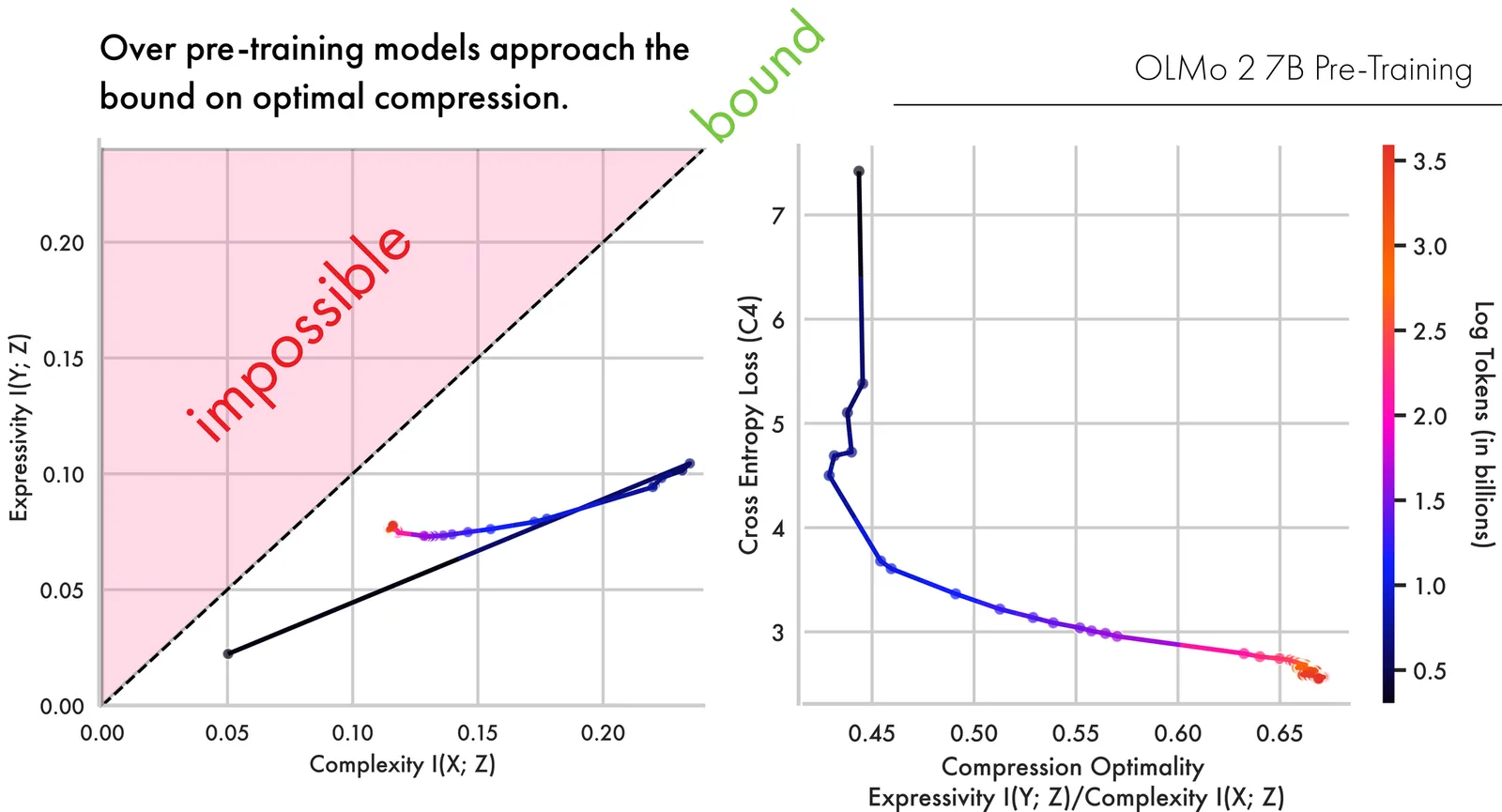
Learning is Forgetting: LLM Training As Lossy Compression
Despite the increasing prevalence of large language models (LLMs), we still have a limited understanding of how their representational spaces are structured. This limits our ability to interpret how and what they learn or relate them to learning in humans. We argue LLMs are best seen as an instance of lossy compression, where over training they learn by retaining only information in their training data relevant to their objective(s). We show pre-training results in models that are optimally compressed for next-sequence prediction, approaching the Information Bottleneck bound on compression. Across an array of open weights models, each compresses differently, likely due to differences in the data and training recipes used. However even across different families of LLMs the optimality of a model's compression, and the information present in it, can predict downstream performance on across a wide array of benchmarks, letting us directly link representational structure to actionable insights about model performance. In the general case the work presented here offers a unified Information-Theoretic framing for how these models learn that is deployable at scale.
2604.07569
Apr 2026Machine Learning

FP4 Explore, BF16 Train: Diffusion Reinforcement Learning via Efficient Rollout Scaling
Reinforcement-Learning-based post-training has recently emerged as a promising paradigm for aligning text-to-image diffusion models with human preferences. In recent studies, increasing the rollout group size yields pronounced performance improvements, indicating substantial room for further alignment gains. However, scaling rollouts on large-scale foundational diffusion models (e.g., FLUX.1-12B) imposes a heavy computational burden. To alleviate this bottleneck, we explore the integration of FP4 quantization into Diffusion RL rollouts. Yet, we identify that naive quantized pipelines inherently introduce risks of performance degradation. To overcome this dilemma between efficiency and training integrity, we propose Sol-RL (Speed-of-light RL), a novel FP4-empowered Two-stage Reinforcement Learning framework. First, we utilize high-throughput NVFP4 rollouts to generate a massive candidate pool and extract a highly contrastive subset. Second, we regenerate these selected samples in BF16 precision and optimize the policy exclusively on them. By decoupling candidate exploration from policy optimization, Sol-RL integrates the algorithmic mechanisms of rollout scaling with the system-level throughput gains of NVFP4. This synergistic algorithm-hardware design effectively accelerates the rollout phase while reserving high-fidelity samples for optimization. We empirically demonstrate that our framework maintains the training integrity of BF16 precision pipeline while fully exploiting the throughput gains enabled by FP4 arithmetic. Extensive experiments across SANA, FLUX.1, and SD3.5-L substantiate that our approach delivers superior alignment performance across multiple metrics while accelerating training convergence by up to $4.64\times$, unlocking the power of massive rollout scaling at a fraction of the cost.
2604.06916
Apr 2026Machine Learning
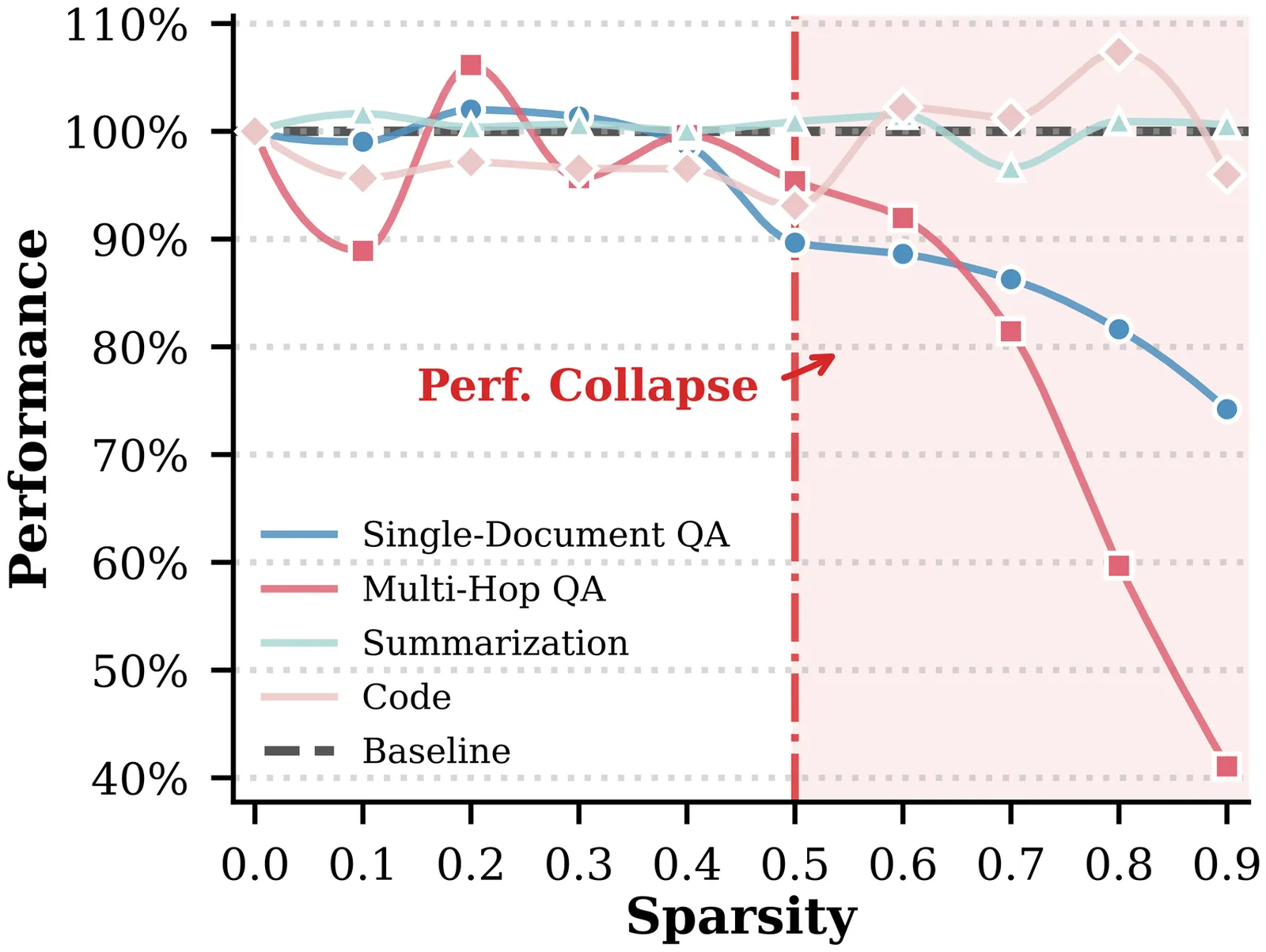
Flux Attention: Context-Aware Hybrid Attention for Efficient LLMs Inference
The quadratic computational complexity of standard attention mechanisms presents a severe scalability bottleneck for LLMs in long-context scenarios. While hybrid attention mechanisms combining Full Attention (FA) and Sparse Attention (SA) offer a potential solution, existing methods typically rely on static allocation ratios that fail to accommodate the variable retrieval demands of different tasks. Furthermore, head-level dynamic sparsity often introduces severe computational load imbalance and synchronization long-tails, which hinder hardware acceleration during autoregressive decoding. To bridge this gap, we introduce Flux Attention, a context-aware framework that dynamically optimizes attention computation at the layer level. By integrating a lightweight Layer Router into frozen pretrained LLMs, the proposed method adaptively routes each layer to FA or SA based on the input context. This layer-wise routing preserves high-fidelity information retrieval while ensuring contiguous memory access, translating theoretical computational reductions into practical wall-clock speedups. As a parameter-efficient approach, our framework requires only 12 hours of training on 8$\times$A800 GPUs. Extensive experiments across multiple long-context and mathematical reasoning benchmarks demonstrate that Flux Attention achieves a superior trade-off between performance and inference speed compared with baseline models, with speed improvements of up to $2.8\times$ and $2.0\times$ in the prefill and decode stages.
2604.07394
Apr 2026Machine Learning
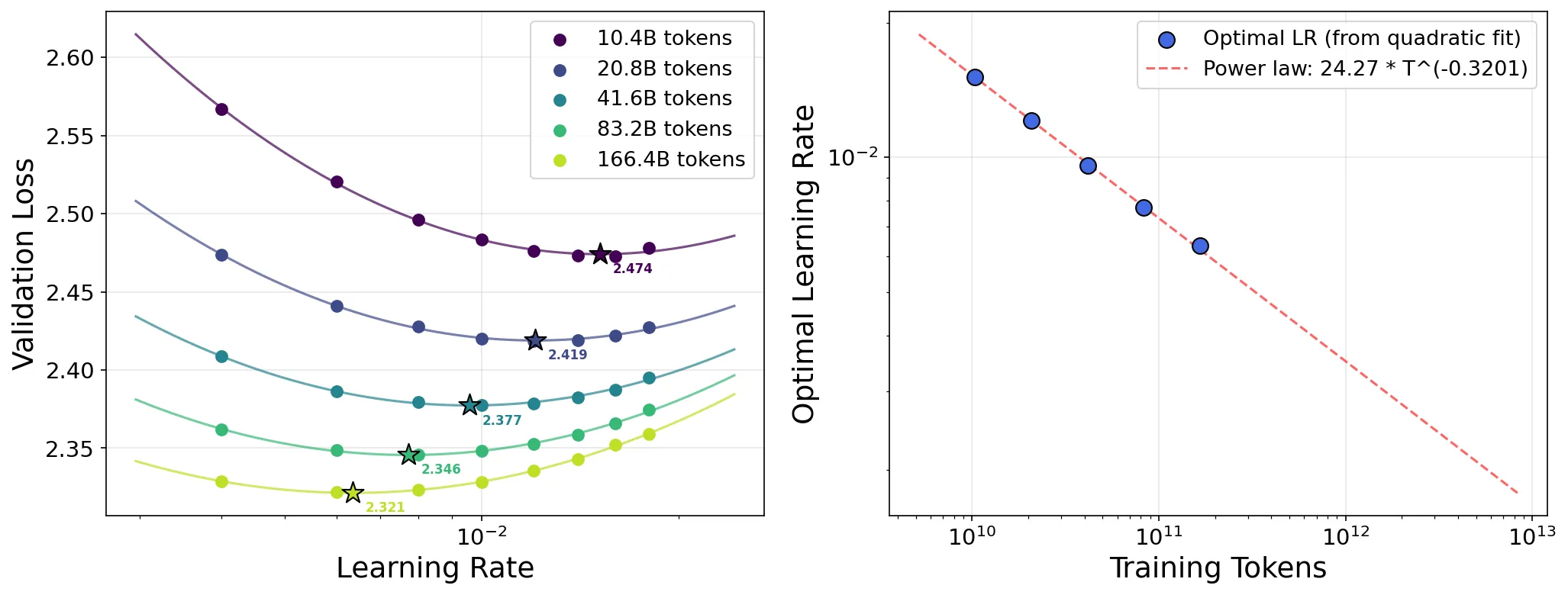
Rethinking Language Model Scaling under Transferable Hypersphere Optimization
Scaling laws for large language models depend critically on the optimizer and parameterization. Existing hyperparameter transfer laws are mainly developed for first-order optimizers, and they do not structurally prevent training instability at scale. Recent hypersphere optimization methods constrain weight matrices to a fixed-norm hypersphere, offering a promising alternative for more stable scaling. We introduce HyperP (Hypersphere Parameterization), the first framework for transferring optimal learning rates across model width, depth, training tokens, and Mixture-of-Experts (MoE) granularity under the Frobenius-sphere constraint with the Muon optimizer. We prove that weight decay is a first-order no-op on the Frobenius sphere, show that Depth-$μ$P remains necessary, and find that the optimal learning rate follows the same data-scaling power law with the "magic exponent" 0.32 previously observed for AdamW. A single base learning rate tuned at the smallest scale transfers across all compute budgets under HyperP, yielding $1.58\times$ compute efficiency over a strong Muon baseline at $6\times10^{21}$ FLOPs. Moreover, HyperP delivers transferable stability: all monitored instability indicators, including $Z$-values, output RMS, and activation outliers, remain bounded and non-increasing under training FLOPs scaling. We also propose SqrtGate, an MoE gating mechanism derived from the hypersphere constraint that preserves output RMS across MoE granularities for improved granularity scaling, and show that hypersphere optimization enables substantially larger auxiliary load-balancing weights, yielding both strong performance and good expert balance. We release our training codebase at https://github.com/microsoft/ArchScale.
2603.28743
Mar 2026Machine Learning
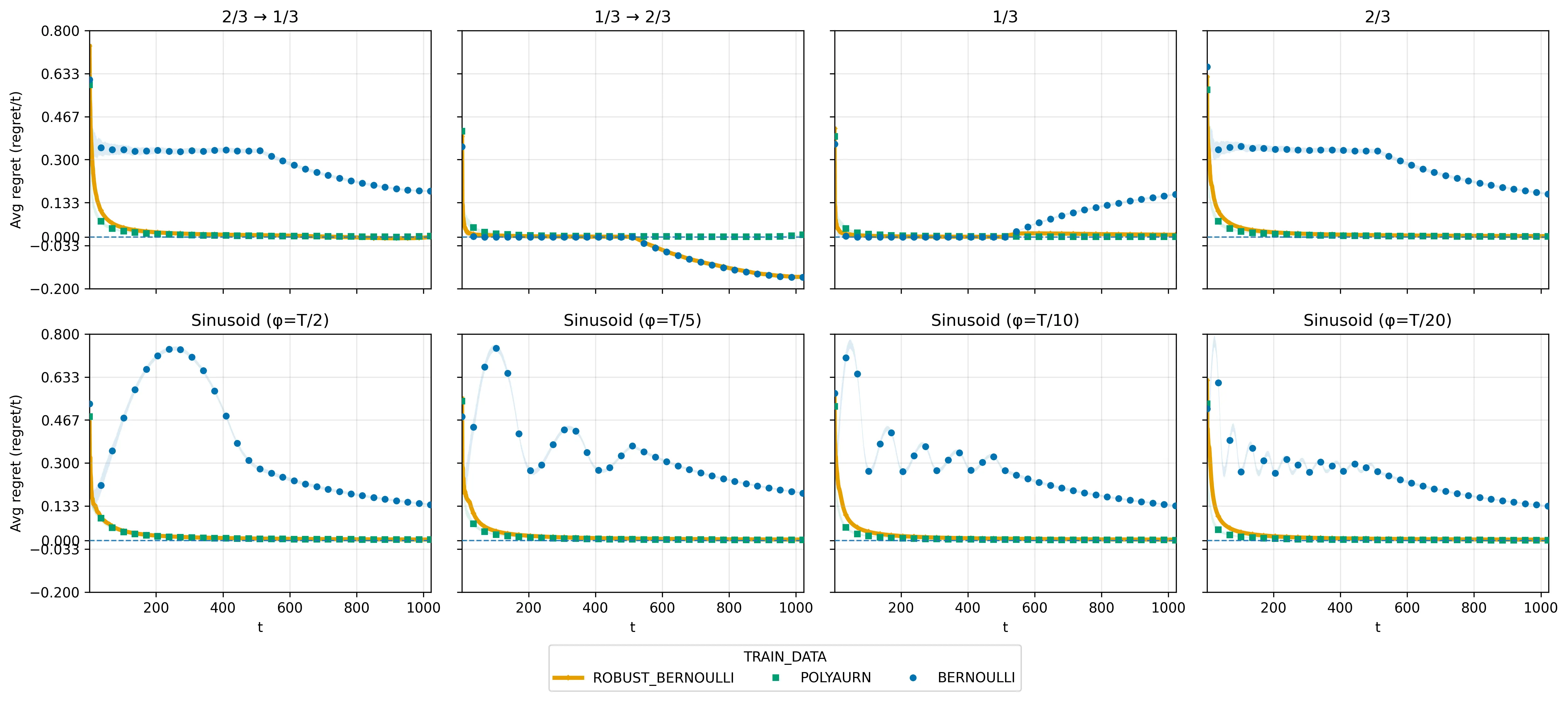
Next-Token Prediction and Regret Minimization
We consider the question of how to employ next-token prediction algorithms in adversarial online decision-making environments. Specifically, if we train a next-token prediction model on a distribution $\mathcal{D}$ over sequences of opponent actions, when is it the case that the induced online decision-making algorithm (by approximately best responding to the model's predictions) has low adversarial regret (i.e., when is $\mathcal{D}$ a \emph{low-regret distribution})? For unbounded context windows (where the prediction made by the model can depend on all the actions taken by the adversary thus far), we show that although not every distribution $\mathcal{D}$ is a low-regret distribution, every distribution $\mathcal{D}$ is exponentially close (in TV distance) to one low-regret distribution, and hence sublinear regret can always be achieved at negligible cost to the accuracy of the original next-token prediction model. In contrast to this, for bounded context windows (where the prediction made by the model can depend only on the past $w$ actions taken by the adversary, as may be the case in modern transformer architectures), we show that there are some distributions $\mathcal{D}$ of opponent play that are $Θ(1)$-far from any low-regret distribution $\mathcal{D'}$ (even when $w = Ω(T)$ and such distributions exist). Finally, we complement these results by showing that the unbounded context robustification procedure can be implemented by layers of a standard transformer architecture, and provide empirical evidence that transformer models can be efficiently trained to represent these new low-regret distributions.
2603.28499
Mar 2026Machine Learning
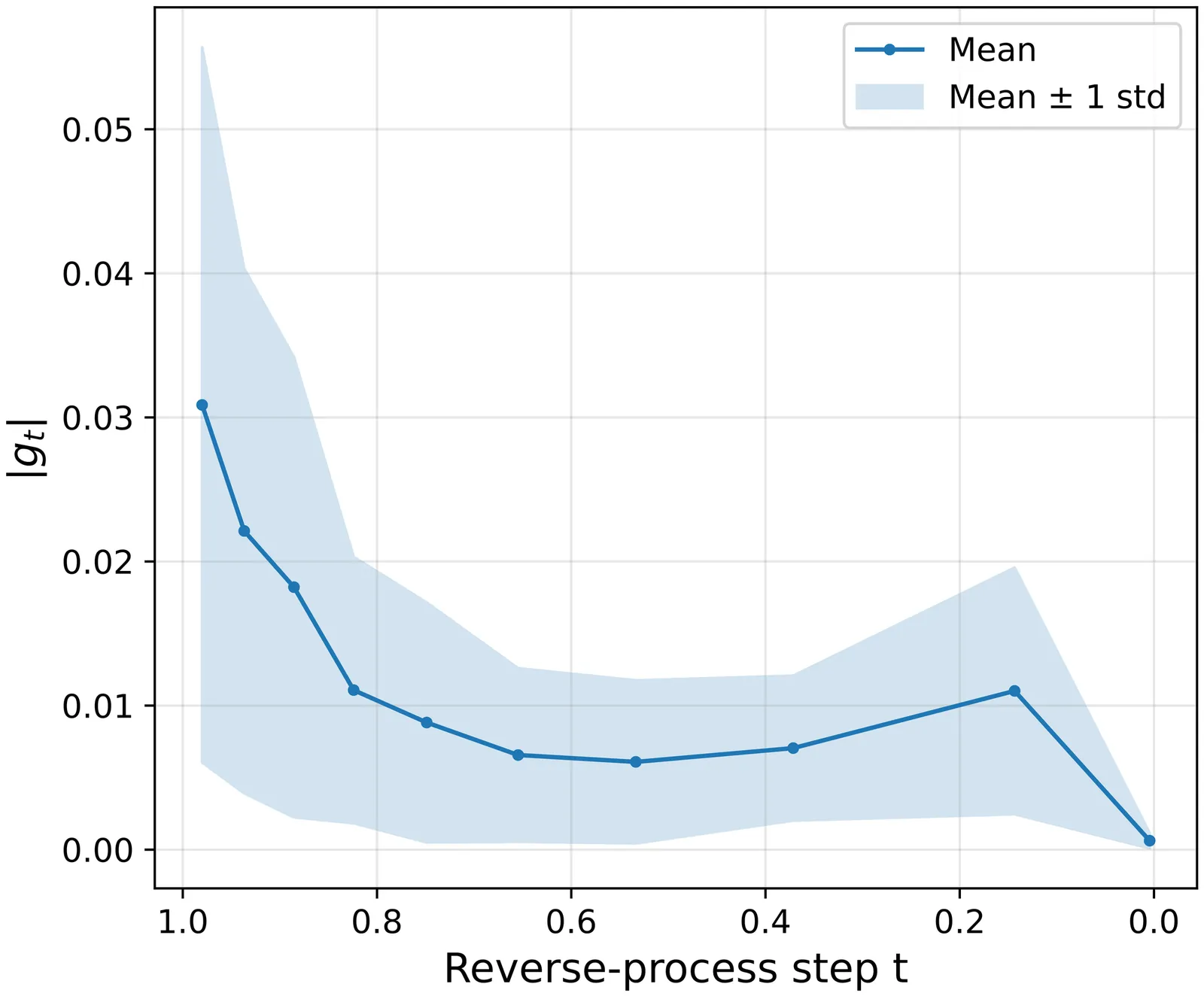
Stepwise Credit Assignment for GRPO on Flow-Matching Models
Flow-GRPO successfully applies reinforcement learning to flow models, but uses uniform credit assignment across all steps. This ignores the temporal structure of diffusion generation: early steps determine composition and content (low-frequency structure), while late steps resolve details and textures (high-frequency details). Moreover, assigning uniform credit based solely on the final image can inadvertently reward suboptimal intermediate steps, especially when errors are corrected later in the diffusion trajectory. We propose Stepwise-Flow-GRPO, which assigns credit based on each step's reward improvement. By leveraging Tweedie's formula to obtain intermediate reward estimates and introducing gain-based advantages, our method achieves superior sample efficiency and faster convergence. We also introduce a DDIM-inspired SDE that improves reward quality while preserving stochasticity for policy gradients.
2603.28718
Mar 2026Machine Learning
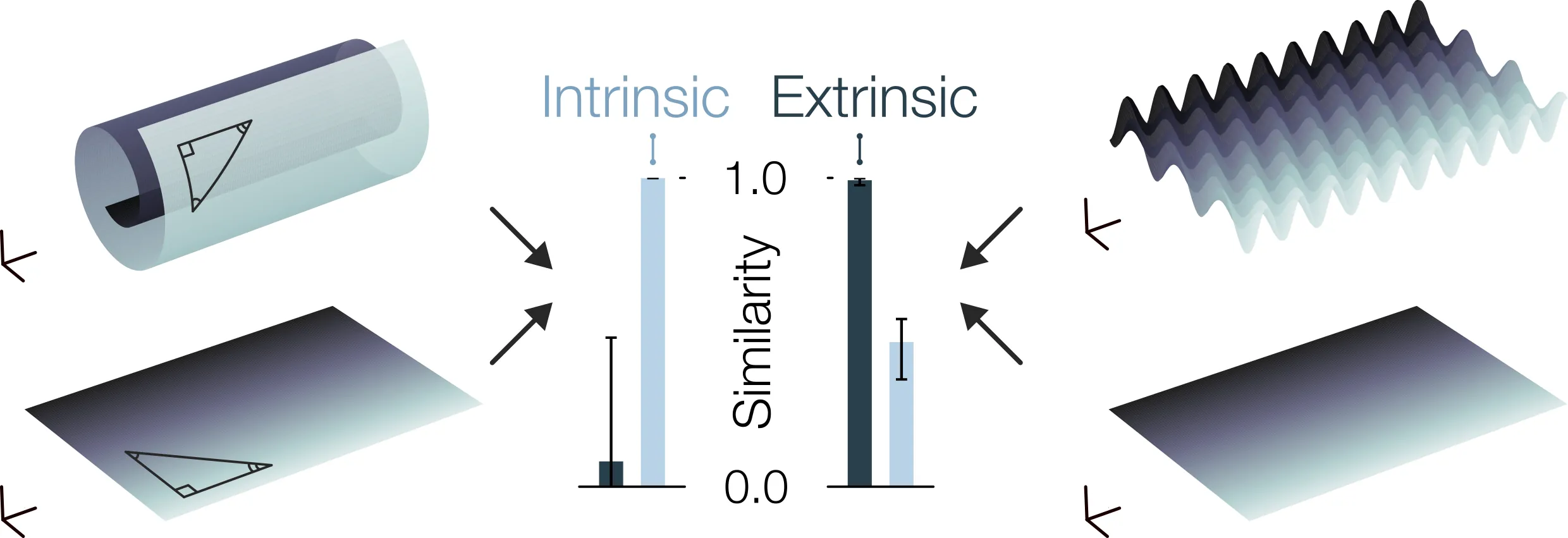
Geometry-aware similarity metrics for neural representations on Riemannian and statistical manifolds
Similarity measures are widely used to interpret the representational geometries used by neural networks to solve tasks. Yet, because existing methods compare the extrinsic geometry of representations in state space, rather than their intrinsic geometry, they may fail to capture subtle yet crucial distinctions between fundamentally different neural network solutions. Here, we introduce metric similarity analysis (MSA), a novel method which leverages tools from Riemannian geometry to compare the intrinsic geometry of neural representations under the manifold hypothesis. We show that MSA can be used to i) disentangle features of neural computations in deep networks with different learning regimes, ii) compare nonlinear dynamics, and iii) investigate diffusion models. Hence, we introduce a mathematically grounded and broadly applicable framework to understand the mechanisms behind neural computations by comparing their intrinsic geometries.
2603.28764
Mar 2026Machine Learning
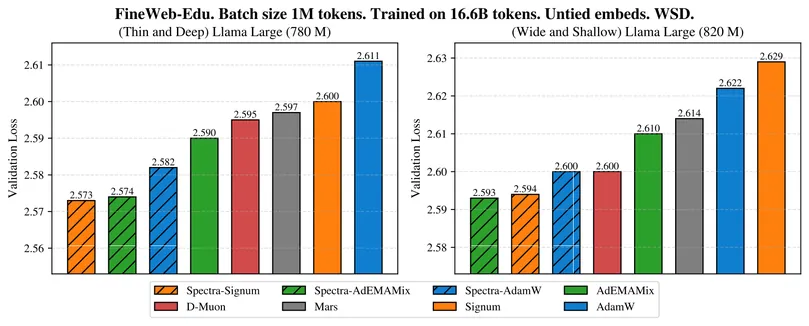
Enhancing LLM Training via Spectral Clipping
While spectral-based optimizers like Muon operate directly on the spectrum of updates, standard adaptive methods such as AdamW do not account for the global spectral structure of weights and gradients, leaving them vulnerable to two empirical issues in large language model (LLM) training: (i) the optimizer updates can have large spectral norms, potentially destabilizing training and degrading generalization; (ii) stochastic gradient noise can exhibit sparse spectral spikes, with a few dominant singular values much larger than the rest. We propose SPECTRA, a general framework addressing these by (i) post-spectral clipping of updates to enforce spectral-norm constraints; (ii) optional pre-spectral clipping of gradients to suppress spectral noise spikes. We prove that post-clipping constitutes a Composite Frank-Wolfe method with spectral-norm constraints and weight regularization, recovering Frobenius and $\ell_{\infty}$-norm regularization with SGD-based and sign-based methods. We further analyze how pre-clipping mitigates sparse spectral spikes. We propose efficient soft spectral clipping via Newton-Schulz iterations, avoiding expensive SVD. Experiments on LLM pretraining show SPECTRA uniformly improves validation loss for various optimizers, including AdamW, Signum, and AdEMAMix, with the best-performing variants achieving state-of-the-art results. Models trained with SPECTRA exhibit smaller weight norms, confirming the link between spectral clipping and regularization.
2603.14315
Mar 2026Machine Learning
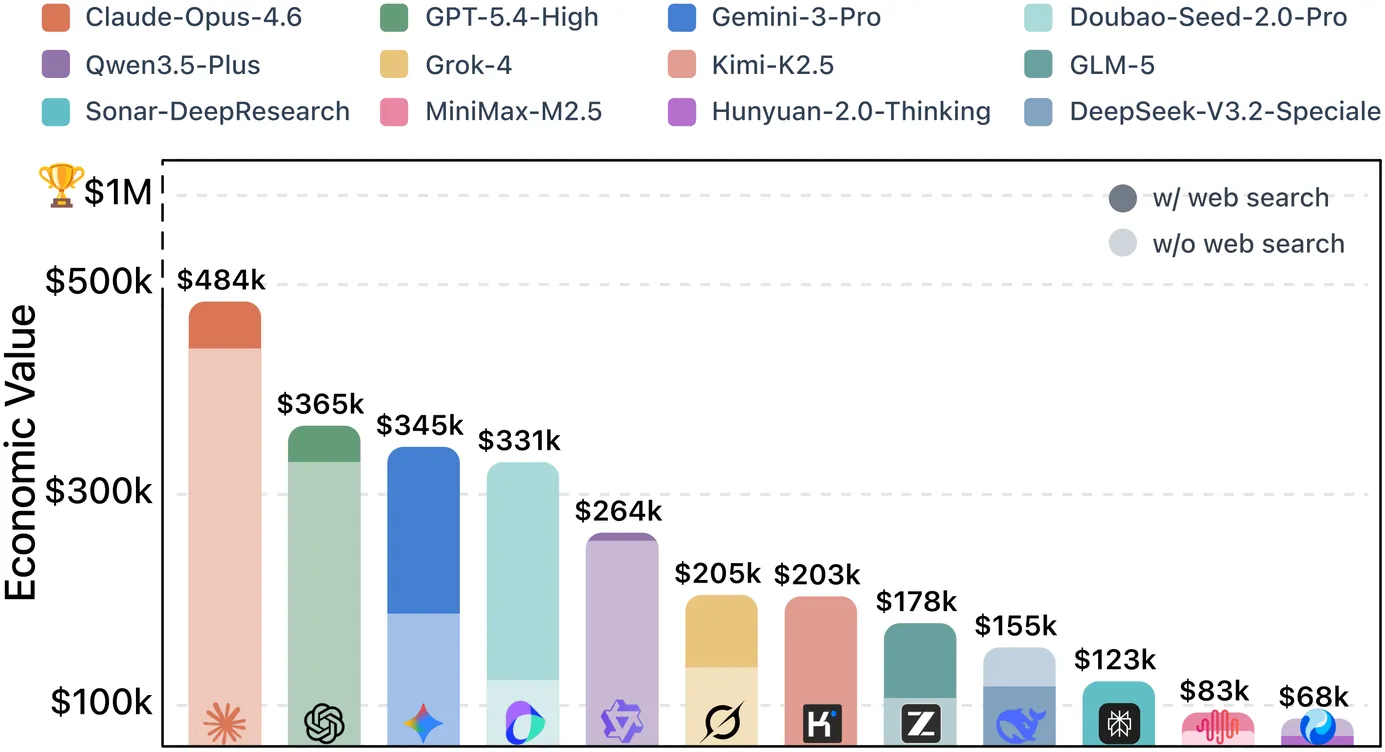
\$OneMillion-Bench: How Far are Language Agents from Human Experts?
As language models (LMs) evolve from chat assistants to long-horizon agents capable of multi-step reasoning and tool use, existing benchmarks remain largely confined to structured or exam-style tasks that fall short of real-world professional demands. To this end, we introduce \$OneMillion-Bench \$OneMillion-Bench, a benchmark of 400 expert-curated tasks spanning Law, Finance, Industry, Healthcare, and Natural Science, built to evaluate agents across economically consequential scenarios. Unlike prior work, the benchmark requires retrieving authoritative sources, resolving conflicting evidence, applying domain-specific rules, and making constraint decisions, where correctness depends as much on the reasoning process as the final answer. We adopt a rubric-based evaluation protocol scoring factual accuracy, logical coherence, practical feasibility, and professional compliance, focused on expert-level problems to ensure meaningful differentiation across agents. Together, \$OneMillion-Bench provides a unified testbed for assessing agentic reliability, professional depth, and practical readiness in domain-intensive scenarios.
2603.07980
Mar 2026Machine Learning
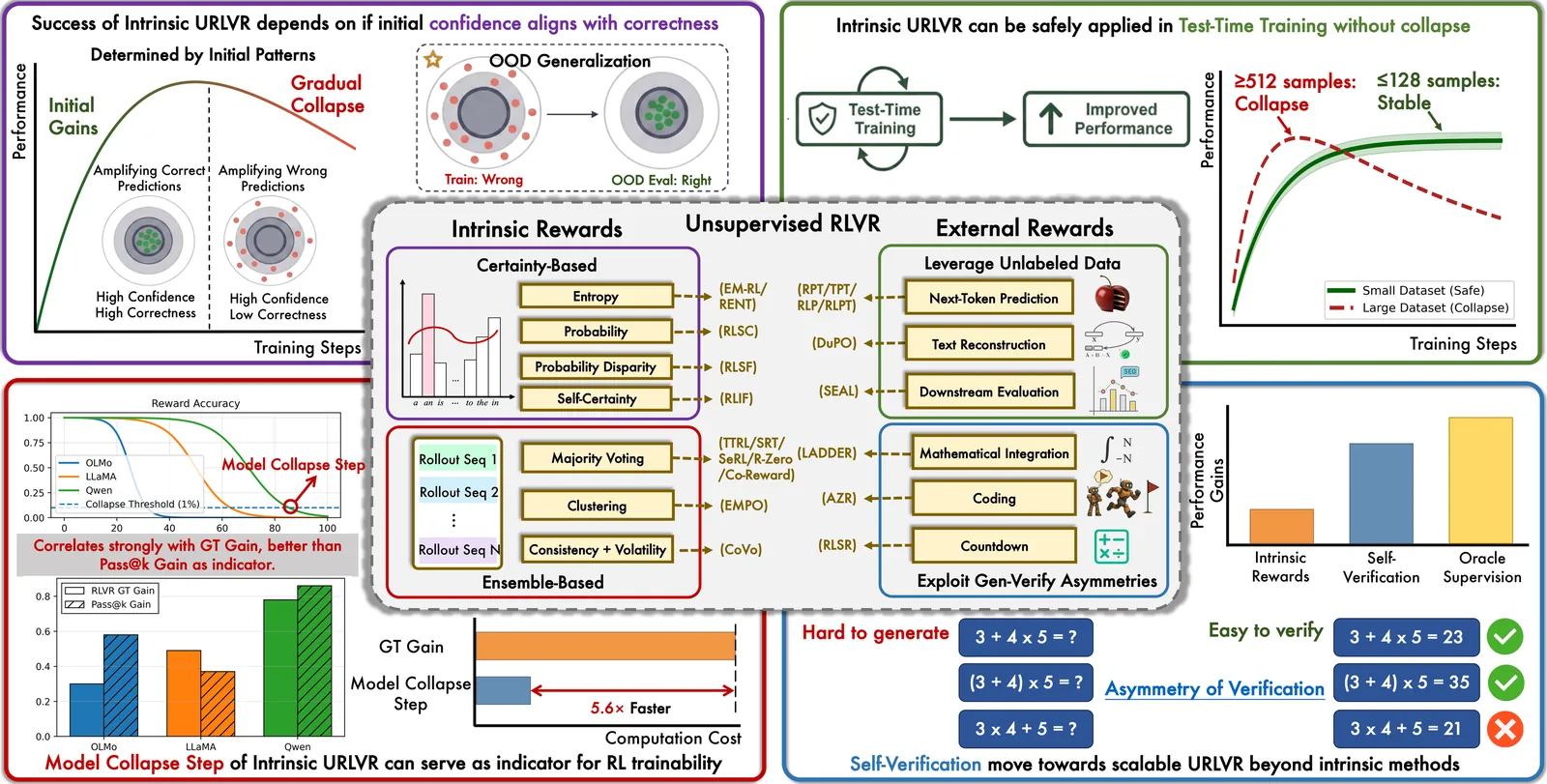
How Far Can Unsupervised RLVR Scale LLM Training?
Unsupervised reinforcement learning with verifiable rewards (URLVR) offers a pathway to scale LLM training beyond the supervision bottleneck by deriving rewards without ground truth labels. Recent works leverage model intrinsic signals, showing promising early gains, yet their potential and limitations remain unclear. In this work, we revisit URLVR and provide a comprehensive analysis spanning taxonomy, theory and extensive experiments. We first classify URLVR methods into intrinsic versus external based on reward sources, then establish a unified theoretical framework revealing that all intrinsic methods converge toward sharpening the model's initial distribution This sharpening mechanism succeeds when initial confidence aligns with correctness but fails catastrophically when misaligned. Through systematic experiments, we show intrinsic rewards consistently follow a rise-then-fall pattern across methods, with collapse timing determined by model prior rather than engineering choices. Despite these scaling limits, we find intrinsic rewards remain valuable in test-time training on small datasets, and propose Model Collapse Step to measure model prior, serving as a practical indicator for RL trainability. Finally, we explore external reward methods that ground verification in computational asymmetries, showing preliminary evidence they may escape the confidence-correctness ceiling. Our findings chart boundaries for intrinsic URLVR while motivating paths toward scalable alternatives.
2603.08660
Mar 2026Machine Learning
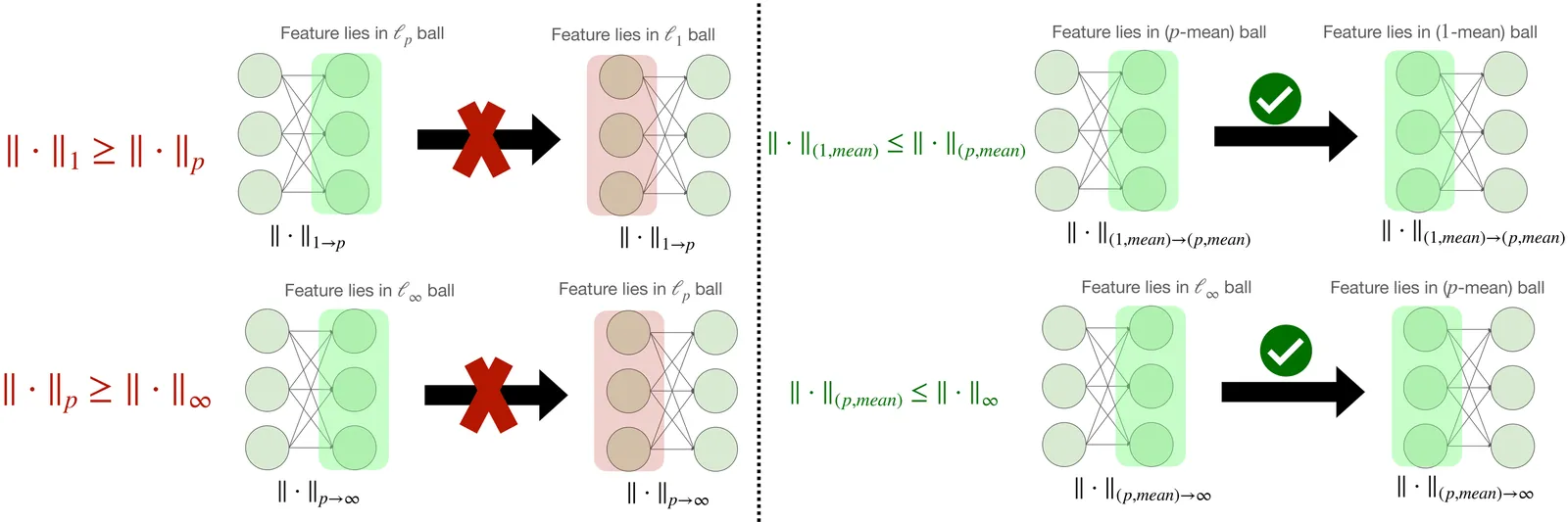
On the Width Scaling of Neural Optimizers Under Matrix Operator Norms I: Row/Column Normalization and Hyperparameter Transfer
A central question in modern deep learning is how to design optimizers whose behavior remains stable as the network width $w$ increases. We address this question by interpreting several widely used neural-network optimizers, including \textrm{AdamW} and \textrm{Muon}, as instances of steepest descent under matrix operator norms. This perspective links optimizer geometry with the Lipschitz structure of the network forward map, and enables width-independent control of both Lipschitz and smoothness constants. However, steepest-descent rules induced by standard $p \to q$ operator norms lack layerwise composability and therefore cannot provide width-independent bounds in deep architectures. We overcome this limitation by introducing a family of mean-normalized operator norms, denoted $\pmean \to \qmean$, that admit layerwise composability, yield width-independent smoothness bounds, and give rise to practical optimizers such as \emph{rescaled} \textrm{AdamW}, row normalization, and column normalization. The resulting learning rate width-aware scaling rules recover $μ$P scaling~\cite{yang2021tensor} as a special case and provide a principled mechanism for cross-width learning-rate transfer across a broad class of optimizers. We further show that \textrm{Muon} can suffer an $\mathcal{O}(\sqrt{w})$ worst-case growth in the smoothness constant, whereas a new family of row-normalized optimizers we propose achieves width-independent smoothness guarantees. Based on the observations, we propose MOGA (Matrix Operator Geometry Aware), a width-aware optimizer based only on row/column-wise normalization that enables stable learning-rate transfer across model widths. Large-scale pre-training on GPT-2 and LLaMA shows that MOGA, especially with row normalization, is competitive with Muon while being notably faster in large-token and low-loss regimes.
2603.09952
Mar 2026Machine Learning
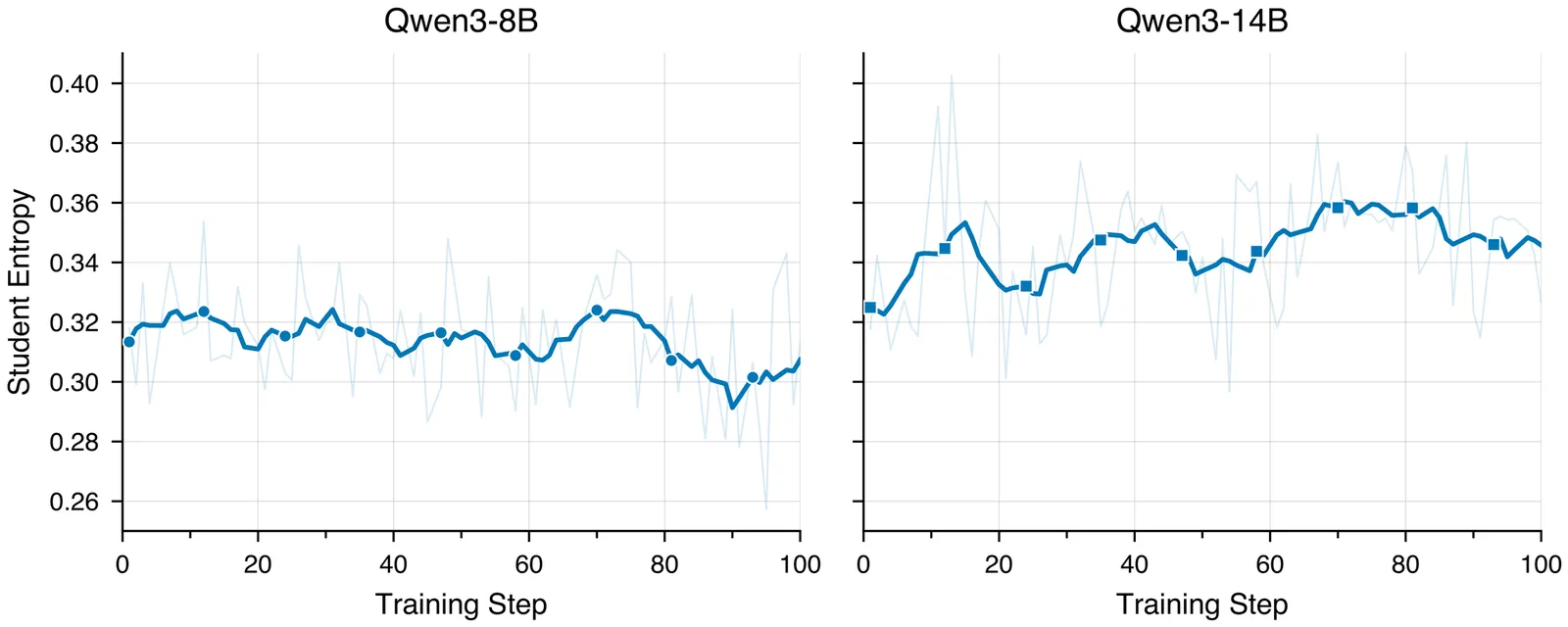
On-Policy Self-Distillation for Reasoning Compression
Reasoning models think out loud, but much of what they say is noise. We introduce OPSDC (On-Policy Self-Distillation for Reasoning Compression), a method that teaches models to reason more concisely by distilling their own concise behavior back into themselves. The entire approach reduces to one idea: condition the same model on a "be concise" instruction to obtain teacher logits, and minimize per-token reverse KL on the student's own rollouts. No ground-truth answers, no token budgets, no difficulty estimators. Just self-distillation. Yet this simplicity belies surprising sophistication: OPSDC automatically compresses easy problems aggressively while preserving the deliberation needed for hard ones. On Qwen3-8B and Qwen3-14B, we achieve 57-59% token reduction on MATH-500 while improving accuracy by 9-16 points absolute. On AIME 2024, the 14B model gains 10 points with 41% compression. The secret? Much of what reasoning models produce is not just redundant-it is actively harmful, compounding errors with every unnecessary token.
2603.05433
Mar 2026Machine Learning
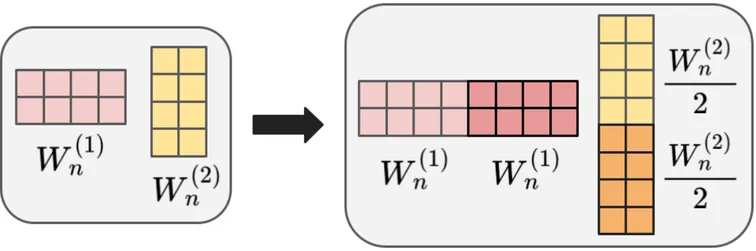
Grow, Don't Overwrite: Fine-tuning Without Forgetting
Adapting pre-trained models to specialized tasks often leads to catastrophic forgetting, where new knowledge overwrites foundational capabilities. Existing methods either compromise performance on the new task or struggle to balance training stability with efficient reuse of pre-trained knowledge. We introduce a novel function-preserving expansion method that resolves this dilemma. Our technique expands model capacity by replicating pre-trained parameters within transformer submodules and applying a scaling correction that guarantees the expanded model is mathematically identical to the original at initialization, enabling stable training while exploiting existing knowledge. Empirically, our method eliminates the trade-off between plasticity and stability, matching the performance of full fine-tuning on downstream tasks without any degradation of the model's original capabilities. Furthermore, we demonstrate the modularity of our approach, showing that by selectively expanding a small subset of layers we can achieve the same performance as full fine-tuning at a fraction of the computational cost.
2603.08647
Mar 2026Machine Learning