Computer Vision
arXiv:cs.CV
Covers image processing, computer vision, pattern recognition, and scene understanding.
Looking for a broader view? This category is part of:
Covers image processing, computer vision, pattern recognition, and scene understanding.
Looking for a broader view? This category is part of:
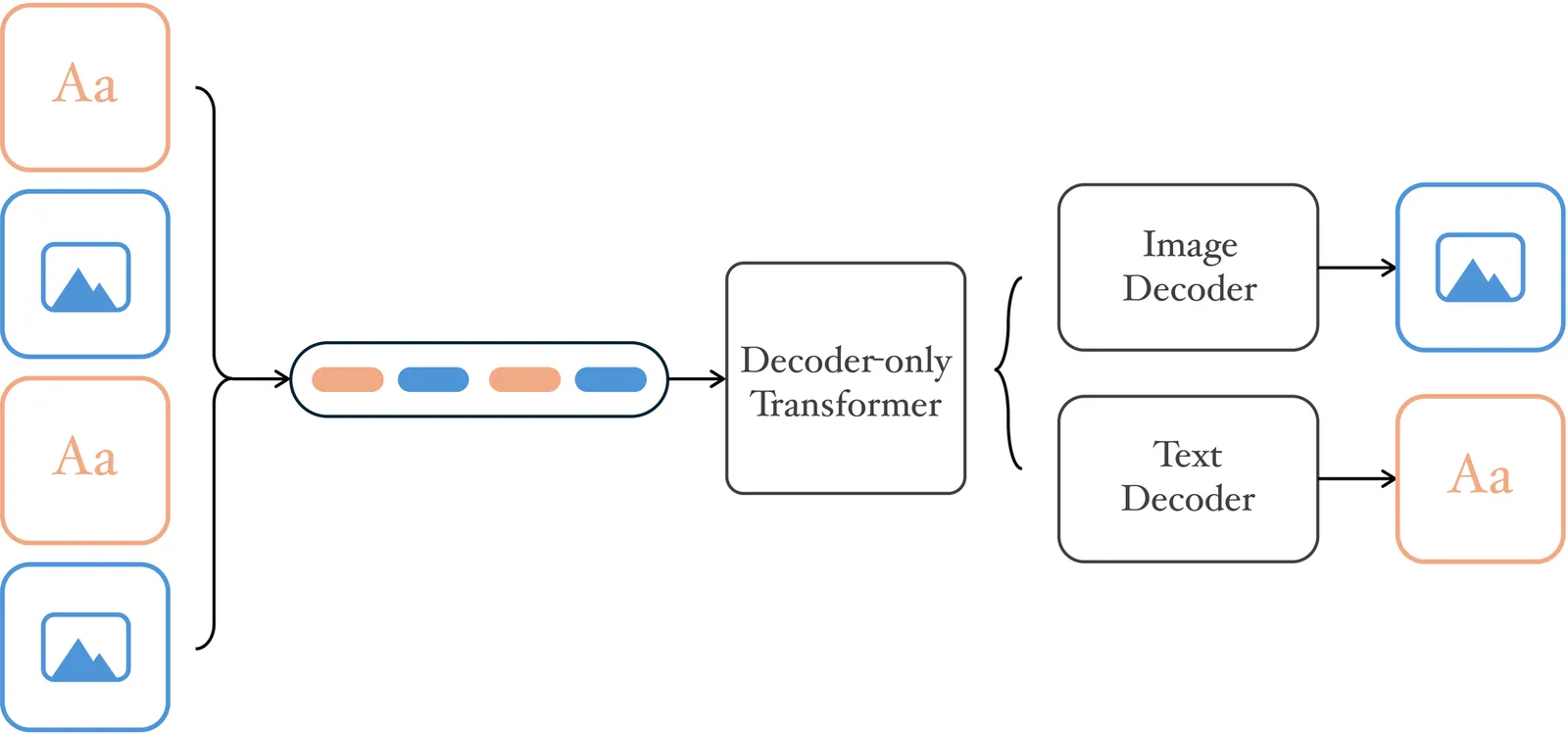
We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
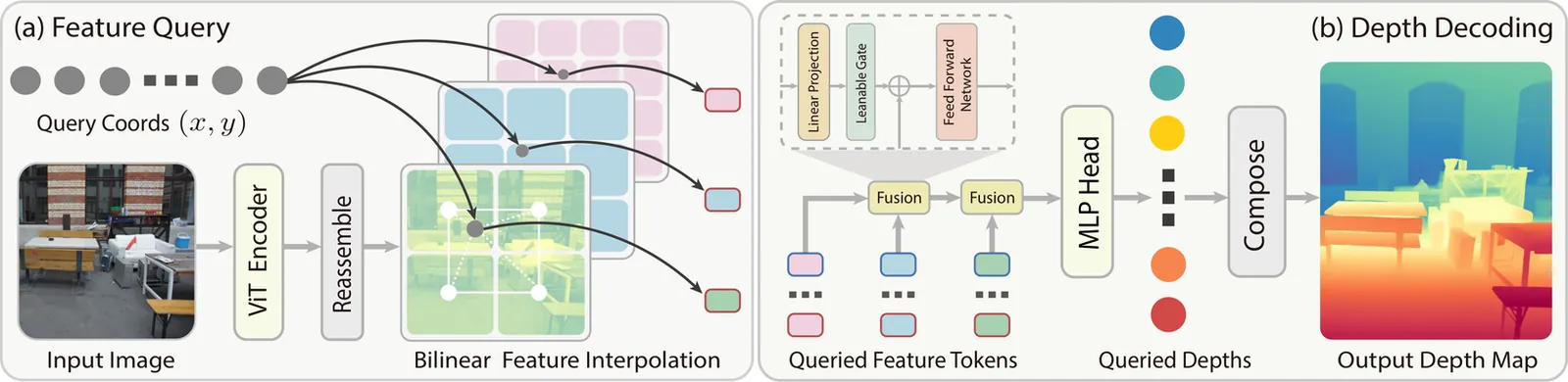
Existing depth estimation methods are fundamentally limited to predicting depth on discrete image grids. Such representations restrict their scalability to arbitrary output resolutions and hinder the geometric detail recovery. This paper introduces InfiniDepth, which represents depth as neural implicit fields. Through a simple yet effective local implicit decoder, we can query depth at continuous 2D coordinates, enabling arbitrary-resolution and fine-grained depth estimation. To better assess our method's capabilities, we curate a high-quality 4K synthetic benchmark from five different games, spanning diverse scenes with rich geometric and appearance details. Extensive experiments demonstrate that InfiniDepth achieves state-of-the-art performance on both synthetic and real-world benchmarks across relative and metric depth estimation tasks, particularly excelling in fine-detail regions. It also benefits the task of novel view synthesis under large viewpoint shifts, producing high-quality results with fewer holes and artifacts.

Dynamic objects in our physical 4D (3D + time) world are constantly evolving, deforming, and interacting with other objects, leading to diverse 4D scene dynamics. In this paper, we present a universal generative pipeline, CHORD, for CHOReographing Dynamic objects and scenes and synthesizing this type of phenomena. Traditional rule-based graphics pipelines to create these dynamics are based on category-specific heuristics, yet are labor-intensive and not scalable. Recent learning-based methods typically demand large-scale datasets, which may not cover all object categories in interest. Our approach instead inherits the universality from the video generative models by proposing a distillation-based pipeline to extract the rich Lagrangian motion information hidden in the Eulerian representations of 2D videos. Our method is universal, versatile, and category-agnostic. We demonstrate its effectiveness by conducting experiments to generate a diverse range of multi-body 4D dynamics, show its advantage compared to existing methods, and demonstrate its applicability in generating robotics manipulation policies. Project page: https://yanzhelyu.github.io/chord
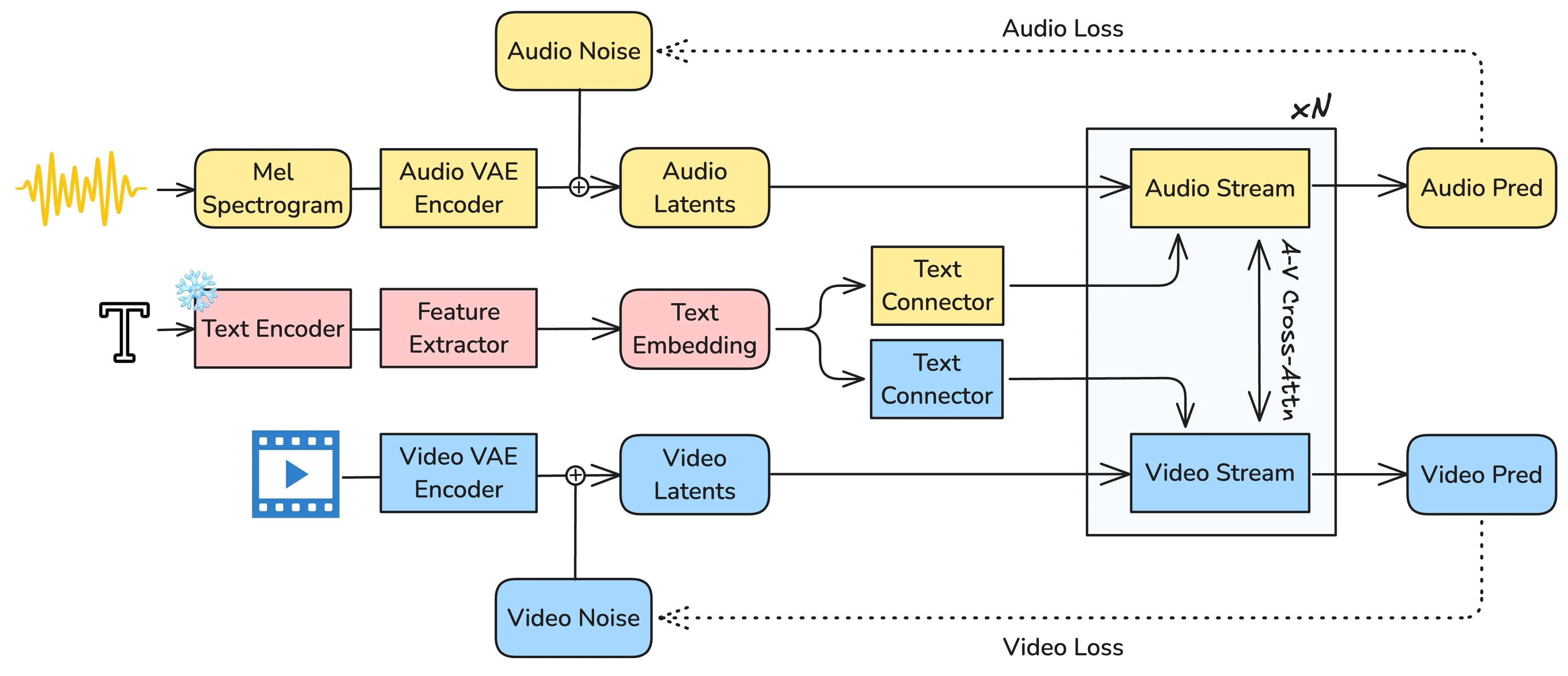
Recent text-to-video diffusion models can generate compelling video sequences, yet they remain silent -- missing the semantic, emotional, and atmospheric cues that audio provides. We introduce LTX-2, an open-source foundational model capable of generating high-quality, temporally synchronized audiovisual content in a unified manner. LTX-2 consists of an asymmetric dual-stream transformer with a 14B-parameter video stream and a 5B-parameter audio stream, coupled through bidirectional audio-video cross-attention layers with temporal positional embeddings and cross-modality AdaLN for shared timestep conditioning. This architecture enables efficient training and inference of a unified audiovisual model while allocating more capacity for video generation than audio generation. We employ a multilingual text encoder for broader prompt understanding and introduce a modality-aware classifier-free guidance (modality-CFG) mechanism for improved audiovisual alignment and controllability. Beyond generating speech, LTX-2 produces rich, coherent audio tracks that follow the characters, environment, style, and emotion of each scene -- complete with natural background and foley elements. In our evaluations, the model achieves state-of-the-art audiovisual quality and prompt adherence among open-source systems, while delivering results comparable to proprietary models at a fraction of their computational cost and inference time. All model weights and code are publicly released.

While Unified Multimodal Models (UMMs) have achieved remarkable success in cross-modal comprehension, a significant gap persists in their ability to leverage such internal knowledge for high-quality generation. We formalize this discrepancy as Conduction Aphasia, a phenomenon where models accurately interpret multimodal inputs but struggle to translate that understanding into faithful and controllable synthesis. To address this, we propose UniCorn, a simple yet elegant self-improvement framework that eliminates the need for external data or teacher supervision. By partitioning a single UMM into three collaborative roles: Proposer, Solver, and Judge, UniCorn generates high-quality interactions via self-play and employs cognitive pattern reconstruction to distill latent understanding into explicit generative signals. To validate the restoration of multimodal coherence, we introduce UniCycle, a cycle-consistency benchmark based on a Text to Image to Text reconstruction loop. Extensive experiments demonstrate that UniCorn achieves comprehensive and substantial improvements over the base model across six general image generation benchmarks. Notably, it achieves SOTA performance on TIIF(73.8), DPG(86.8), CompBench(88.5), and UniCycle while further delivering substantial gains of +5.0 on WISE and +6.5 on OneIG. These results highlight that our method significantly enhances T2I generation while maintaining robust comprehension, demonstrating the scalability of fully self-supervised refinement for unified multimodal intelligence.
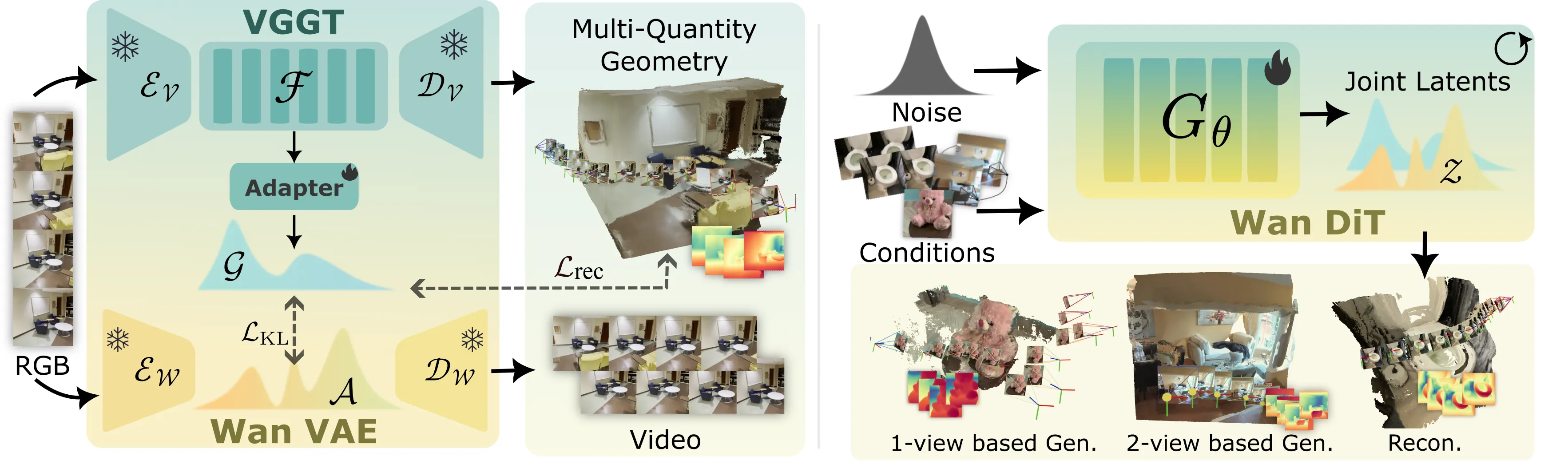
We present Gen3R, a method that bridges the strong priors of foundational reconstruction models and video diffusion models for scene-level 3D generation. We repurpose the VGGT reconstruction model to produce geometric latents by training an adapter on its tokens, which are regularized to align with the appearance latents of pre-trained video diffusion models. By jointly generating these disentangled yet aligned latents, Gen3R produces both RGB videos and corresponding 3D geometry, including camera poses, depth maps, and global point clouds. Experiments demonstrate that our approach achieves state-of-the-art results in single- and multi-image conditioned 3D scene generation. Additionally, our method can enhance the robustness of reconstruction by leveraging generative priors, demonstrating the mutual benefit of tightly coupling reconstruction and generative models.

We present VINO, a unified visual generator that performs image and video generation and editing within a single framework. Instead of relying on task-specific models or independent modules for each modality, VINO uses a shared diffusion backbone that conditions on text, images and videos, enabling a broad range of visual creation and editing tasks under one model. Specifically, VINO couples a vision-language model (VLM) with a Multimodal Diffusion Transformer (MMDiT), where multimodal inputs are encoded as interleaved conditioning tokens, and then used to guide the diffusion process. This design supports multi-reference grounding, long-form instruction following, and coherent identity preservation across static and dynamic content, while avoiding modality-specific architectural components. To train such a unified system, we introduce a multi-stage training pipeline that progressively expands a video generation base model into a unified, multi-task generator capable of both image and video input and output. Across diverse generation and editing benchmarks, VINO demonstrates strong visual quality, faithful instruction following, improved reference and attribute preservation, and more controllable multi-identity edits. Our results highlight a practical path toward scalable unified visual generation, and the promise of interleaved, in-context computation as a foundation for general-purpose visual creation.
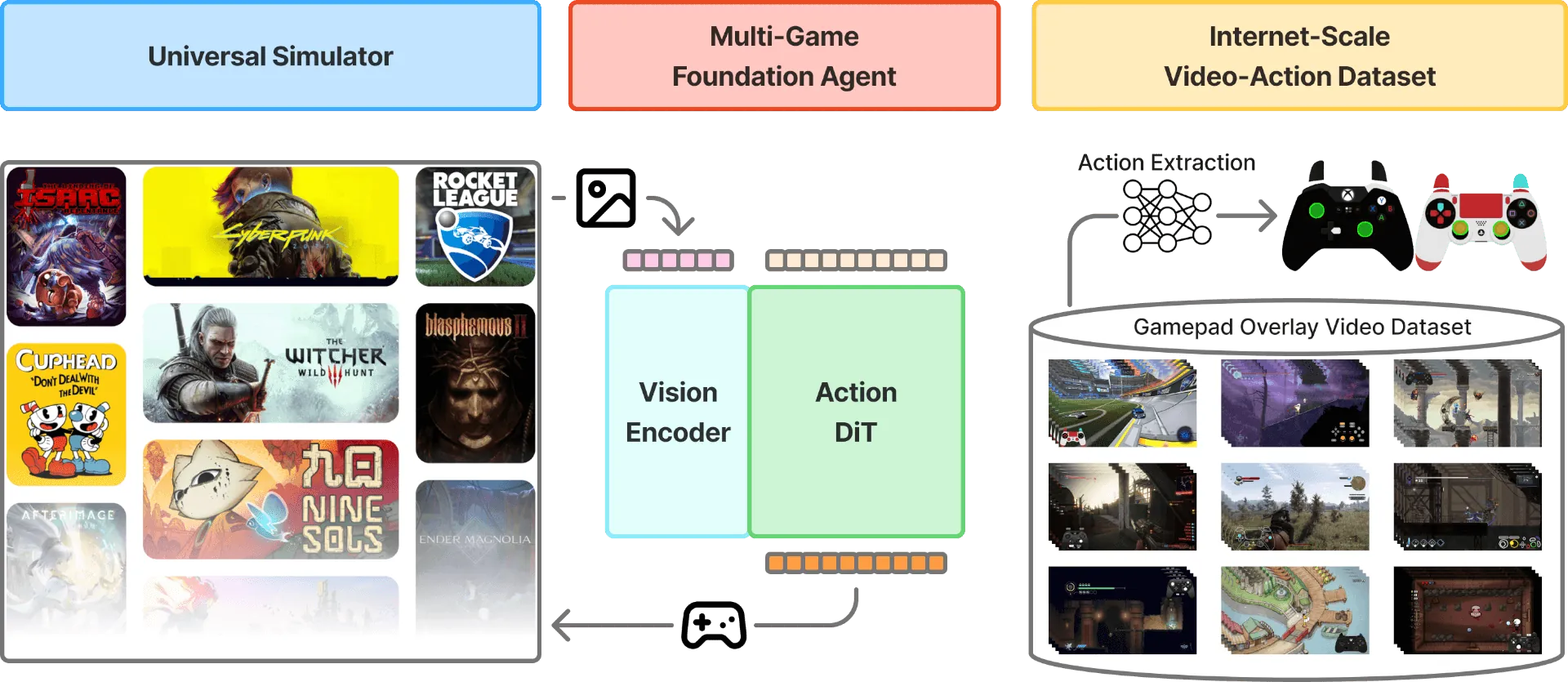
We introduce NitroGen, a vision-action foundation model for generalist gaming agents that is trained on 40,000 hours of gameplay videos across more than 1,000 games. We incorporate three key ingredients: 1) an internet-scale video-action dataset constructed by automatically extracting player actions from publicly available gameplay videos, 2) a multi-game benchmark environment that can measure cross-game generalization, and 3) a unified vision-action model trained with large-scale behavior cloning. NitroGen exhibits strong competence across diverse domains, including combat encounters in 3D action games, high-precision control in 2D platformers, and exploration in procedurally generated worlds. It transfers effectively to unseen games, achieving up to 52% relative improvement in task success rates over models trained from scratch. We release the dataset, evaluation suite, and model weights to advance research on generalist embodied agents.
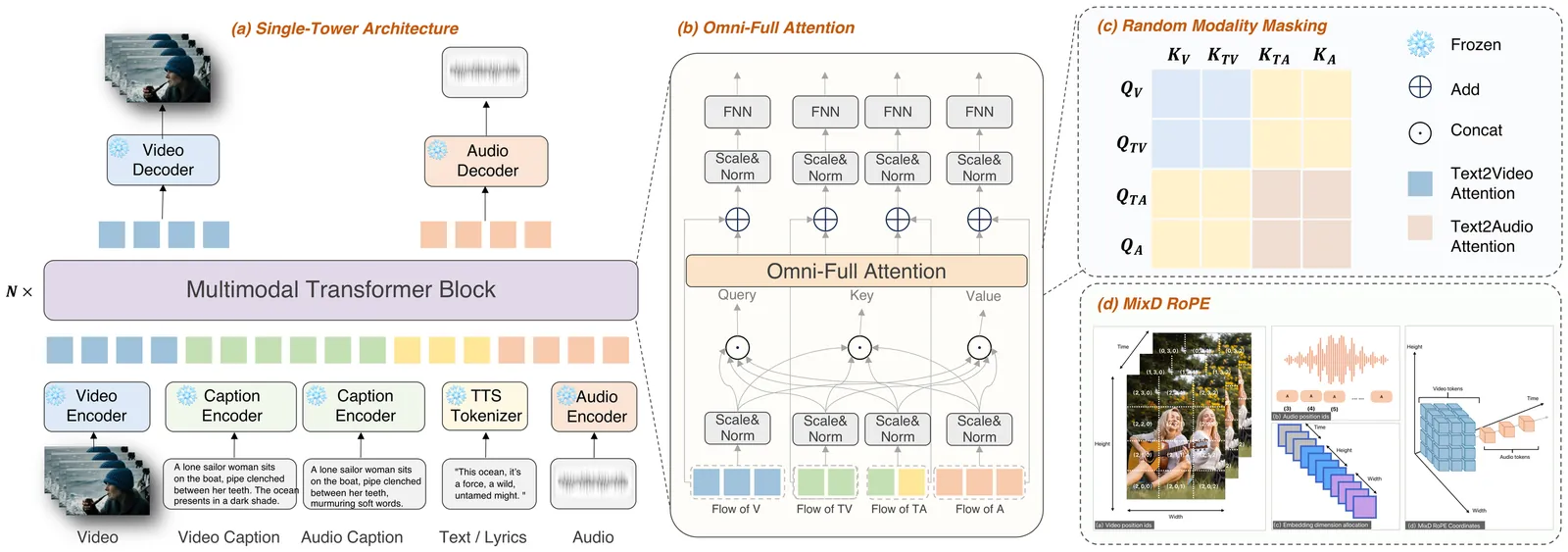
Audio-video joint generation has progressed rapidly, yet substantial challenges still remain. Non-commercial approaches still suffer audio-visual asynchrony, poor lip-speech alignment, and unimodal degradation, which can be stemmed from weak audio-visual correspondence modeling, limited generalization, and scarce high-quality dense-caption data. To address these issues, we introduce Klear and delve into three axes--model architecture, training strategy, and data curation. Architecturally, we adopt a single-tower design with unified DiT blocks and an Omni-Full Attention mechanism, achieving tight audio-visual alignment and strong scalability. Training-wise, we adopt a progressive multitask regime--random modality masking to joint optimization across tasks, and a multistage curriculum, yielding robust representations, strengthening A-V aligned world knowledge, and preventing unimodal collapse. For datasets, we present the first large-scale audio-video dataset with dense captions, and introduce a novel automated data-construction pipeline which annotates and filters millions of diverse, high-quality, strictly aligned audio-video-caption triplets. Building on this, Klear scales to large datasets, delivering high-fidelity, semantically and temporally aligned, instruction-following generation in both joint and unimodal settings while generalizing robustly to out-of-distribution scenarios. Across tasks, it substantially outperforms prior methods by a large margin and achieves performance comparable to Veo 3, offering a unified, scalable path toward next-generation audio-video synthesis.
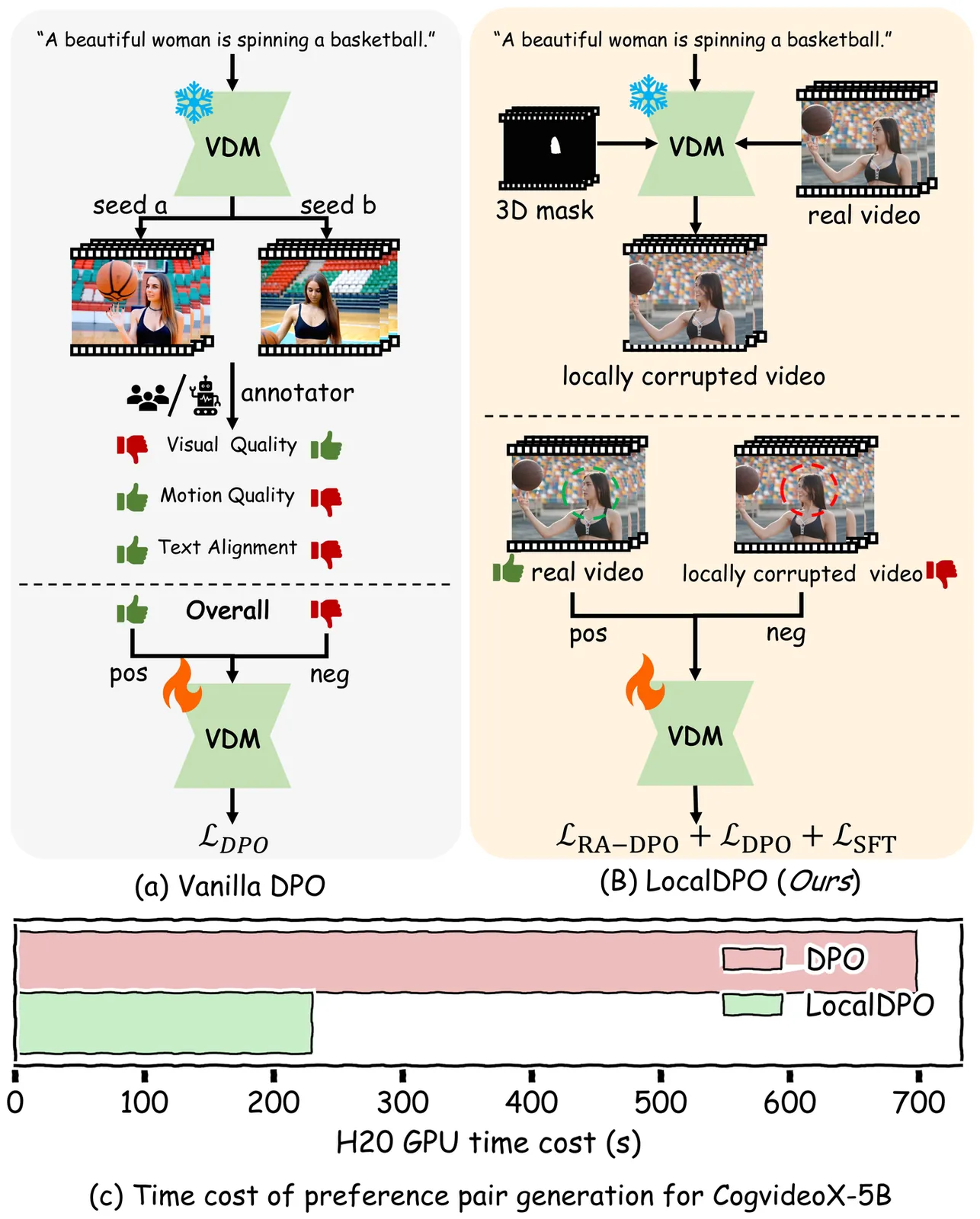
Aligning text-to-video diffusion models with human preferences is crucial for generating high-quality videos. Existing Direct Preference Otimization (DPO) methods rely on multi-sample ranking and task-specific critic models, which is inefficient and often yields ambiguous global supervision. To address these limitations, we propose LocalDPO, a novel post-training framework that constructs localized preference pairs from real videos and optimizes alignment at the spatio-temporal region level. We design an automated pipeline to efficiently collect preference pair data that generates preference pairs with a single inference per prompt, eliminating the need for external critic models or manual annotation. Specifically, we treat high-quality real videos as positive samples and generate corresponding negatives by locally corrupting them with random spatio-temporal masks and restoring only the masked regions using the frozen base model. During training, we introduce a region-aware DPO loss that restricts preference learning to corrupted areas for rapid convergence. Experiments on Wan2.1 and CogVideoX demonstrate that LocalDPO consistently improves video fidelity, temporal coherence and human preference scores over other post-training approaches, establishing a more efficient and fine-grained paradigm for video generator alignment.
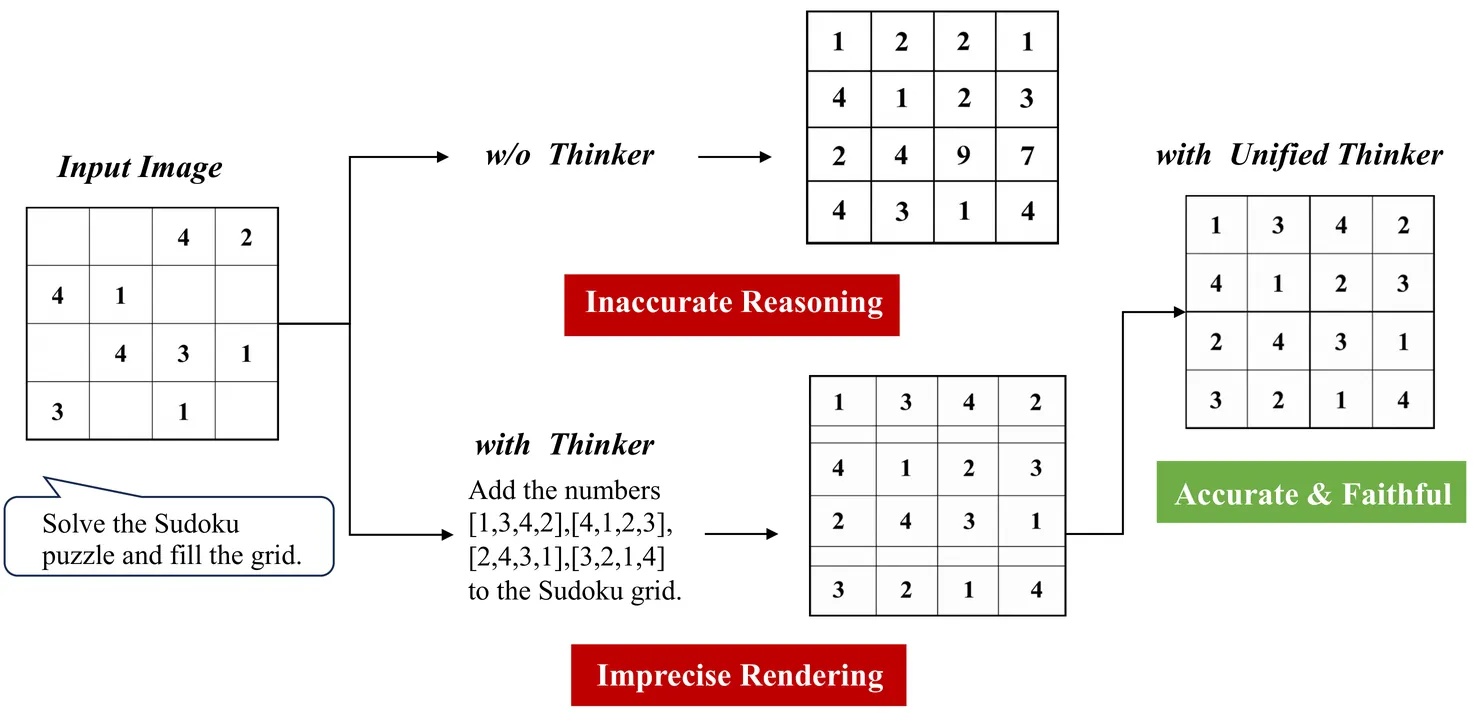
Despite impressive progress in high-fidelity image synthesis, generative models still struggle with logic-intensive instruction following, exposing a persistent reasoning--execution gap. Meanwhile, closed-source systems (e.g., Nano Banana) have demonstrated strong reasoning-driven image generation, highlighting a substantial gap to current open-source models. We argue that closing this gap requires not merely better visual generators, but executable reasoning: decomposing high-level intents into grounded, verifiable plans that directly steer the generative process. To this end, we propose Unified Thinker, a task-agnostic reasoning architecture for general image generation, designed as a unified planning core that can plug into diverse generators and workflows. Unified Thinker decouples a dedicated Thinker from the image Generator, enabling modular upgrades of reasoning without retraining the entire generative model. We further introduce a two-stage training paradigm: we first build a structured planning interface for the Thinker, then apply reinforcement learning to ground its policy in pixel-level feedback, encouraging plans that optimize visual correctness over textual plausibility. Extensive experiments on text-to-image generation and image editing show that Unified Thinker substantially improves image reasoning and generation quality.
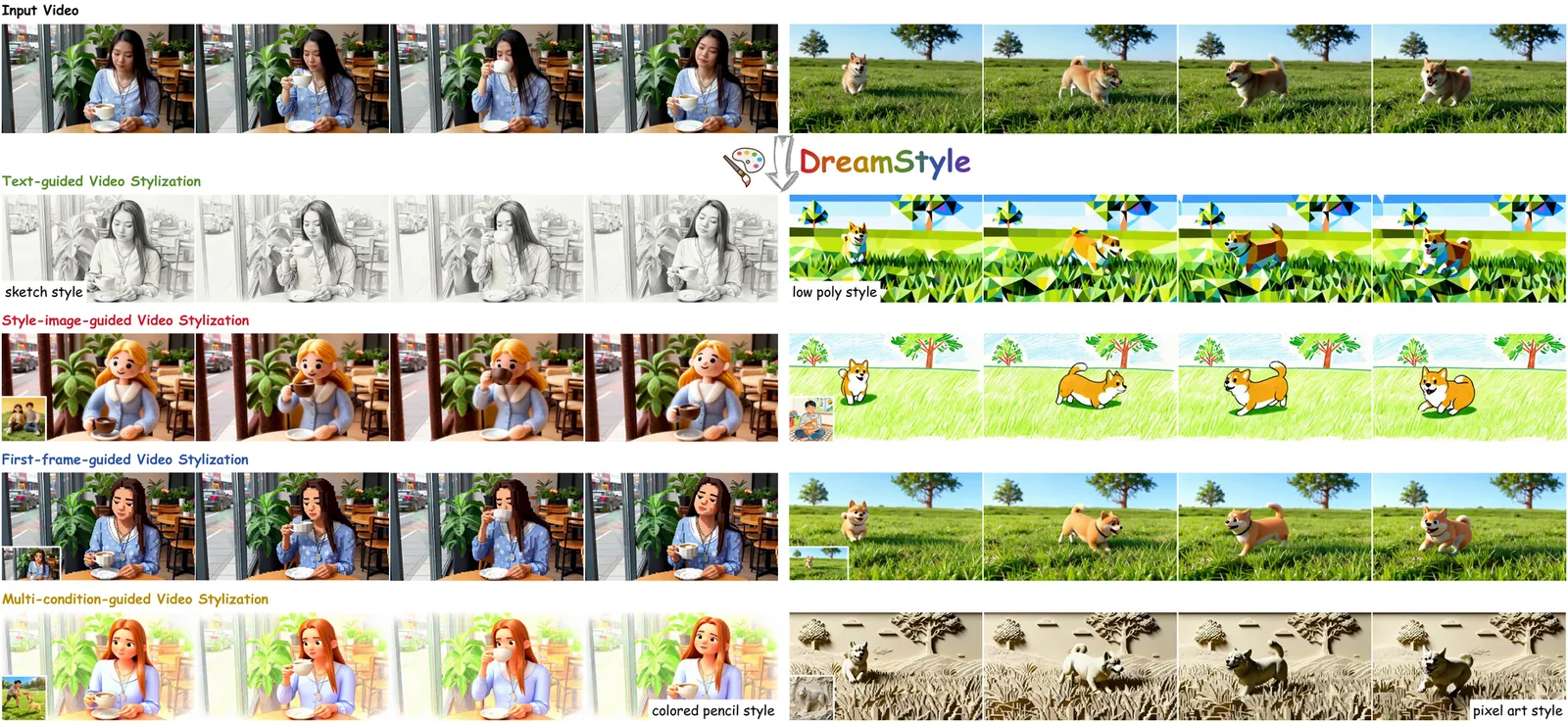
Video stylization, an important downstream task of video generation models, has not yet been thoroughly explored. Its input style conditions typically include text, style image, and stylized first frame. Each condition has a characteristic advantage: text is more flexible, style image provides a more accurate visual anchor, and stylized first frame makes long-video stylization feasible. However, existing methods are largely confined to a single type of style condition, which limits their scope of application. Additionally, their lack of high-quality datasets leads to style inconsistency and temporal flicker. To address these limitations, we introduce DreamStyle, a unified framework for video stylization, supporting (1) text-guided, (2) style-image-guided, and (3) first-frame-guided video stylization, accompanied by a well-designed data curation pipeline to acquire high-quality paired video data. DreamStyle is built on a vanilla Image-to-Video (I2V) model and trained using a Low-Rank Adaptation (LoRA) with token-specific up matrices that reduces the confusion among different condition tokens. Both qualitative and quantitative evaluations demonstrate that DreamStyle is competent in all three video stylization tasks, and outperforms the competitors in style consistency and video quality.
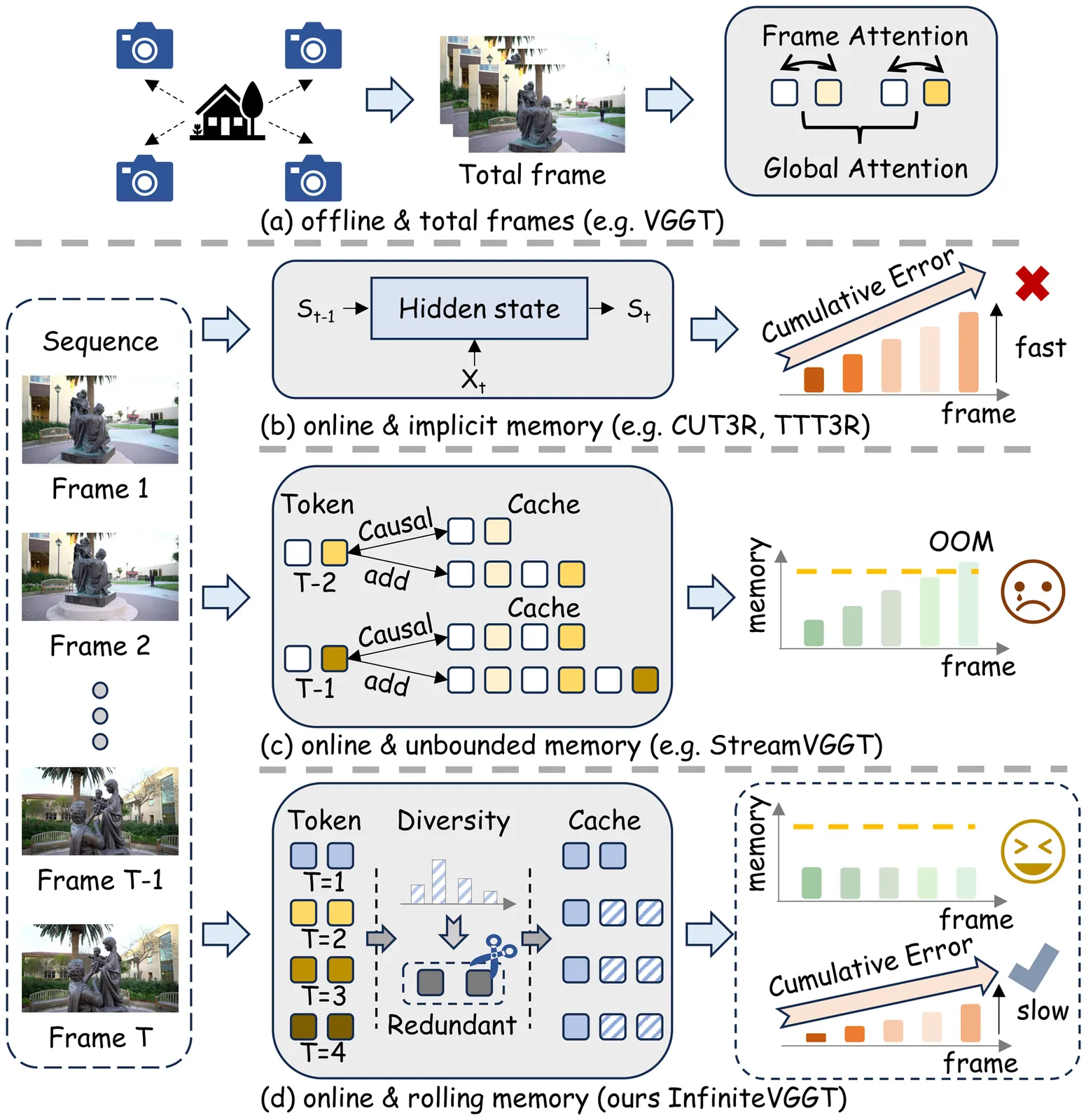
The grand vision of enabling persistent, large-scale 3D visual geometry understanding is shackled by the irreconcilable demands of scalability and long-term stability. While offline models like VGGT achieve inspiring geometry capability, their batch-based nature renders them irrelevant for live systems. Streaming architectures, though the intended solution for live operation, have proven inadequate. Existing methods either fail to support truly infinite-horizon inputs or suffer from catastrophic drift over long sequences. We shatter this long-standing dilemma with InfiniteVGGT, a causal visual geometry transformer that operationalizes the concept of a rolling memory through a bounded yet adaptive and perpetually expressive KV cache. Capitalizing on this, we devise a training-free, attention-agnostic pruning strategy that intelligently discards obsolete information, effectively ``rolling'' the memory forward with each new frame. Fully compatible with FlashAttention, InfiniteVGGT finally alleviates the compromise, enabling infinite-horizon streaming while outperforming existing streaming methods in long-term stability. The ultimate test for such a system is its performance over a truly infinite horizon, a capability that has been impossible to rigorously validate due to the lack of extremely long-term, continuous benchmarks. To address this critical gap, we introduce the Long3D benchmark, which, for the first time, enables a rigorous evaluation of continuous 3D geometry estimation on sequences about 10,000 frames. This provides the definitive evaluation platform for future research in long-term 3D geometry understanding. Code is available at: https://github.com/AutoLab-SAI-SJTU/InfiniteVGGT
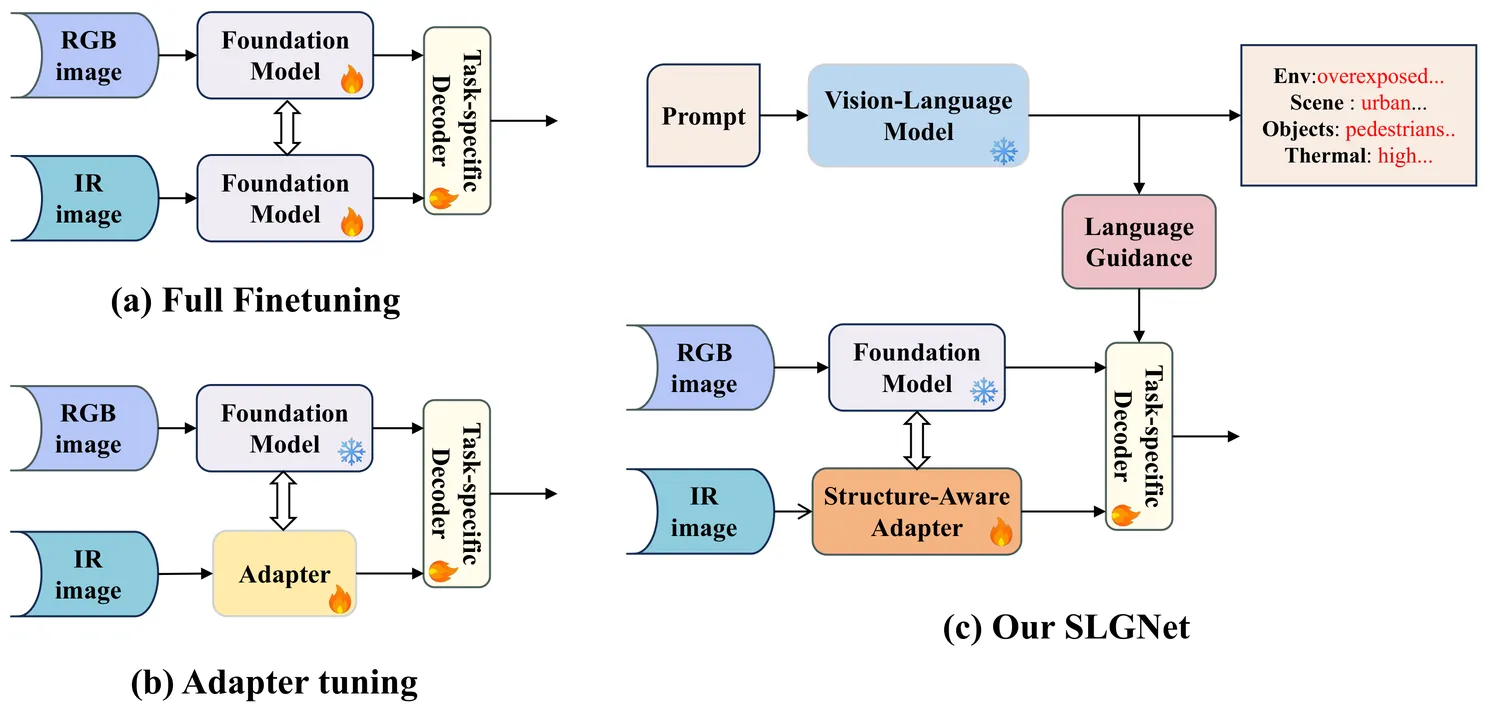
Multimodal object detection leveraging RGB and Infrared (IR) images is pivotal for robust perception in all-weather scenarios. While recent adapter-based approaches efficiently transfer RGB-pretrained foundation models to this task, they often prioritize model efficiency at the expense of cross-modal structural consistency. Consequently, critical structural cues are frequently lost when significant domain gaps arise, such as in high-contrast or nighttime environments. Moreover, conventional static multimodal fusion mechanisms typically lack environmental awareness, resulting in suboptimal adaptation and constrained detection performance under complex, dynamic scene variations. To address these limitations, we propose SLGNet, a parameter-efficient framework that synergizes hierarchical structural priors and language-guided modulation within a frozen Vision Transformer (ViT)-based foundation model. Specifically, we design a Structure-Aware Adapter to extract hierarchical structural representations from both modalities and dynamically inject them into the ViT to compensate for structural degradation inherent in ViT-based backbones. Furthermore, we propose a Language-Guided Modulation module that exploits VLM-driven structured captions to dynamically recalibrate visual features, thereby endowing the model with robust environmental awareness. Extensive experiments on the LLVIP, FLIR, KAIST, and DroneVehicle datasets demonstrate that SLGNet establishes new state-of-the-art performance. Notably, on the LLVIP benchmark, our method achieves an mAP of 66.1, while reducing trainable parameters by approximately 87% compared to traditional full fine-tuning. This confirms SLGNet as a robust and efficient solution for multimodal perception.
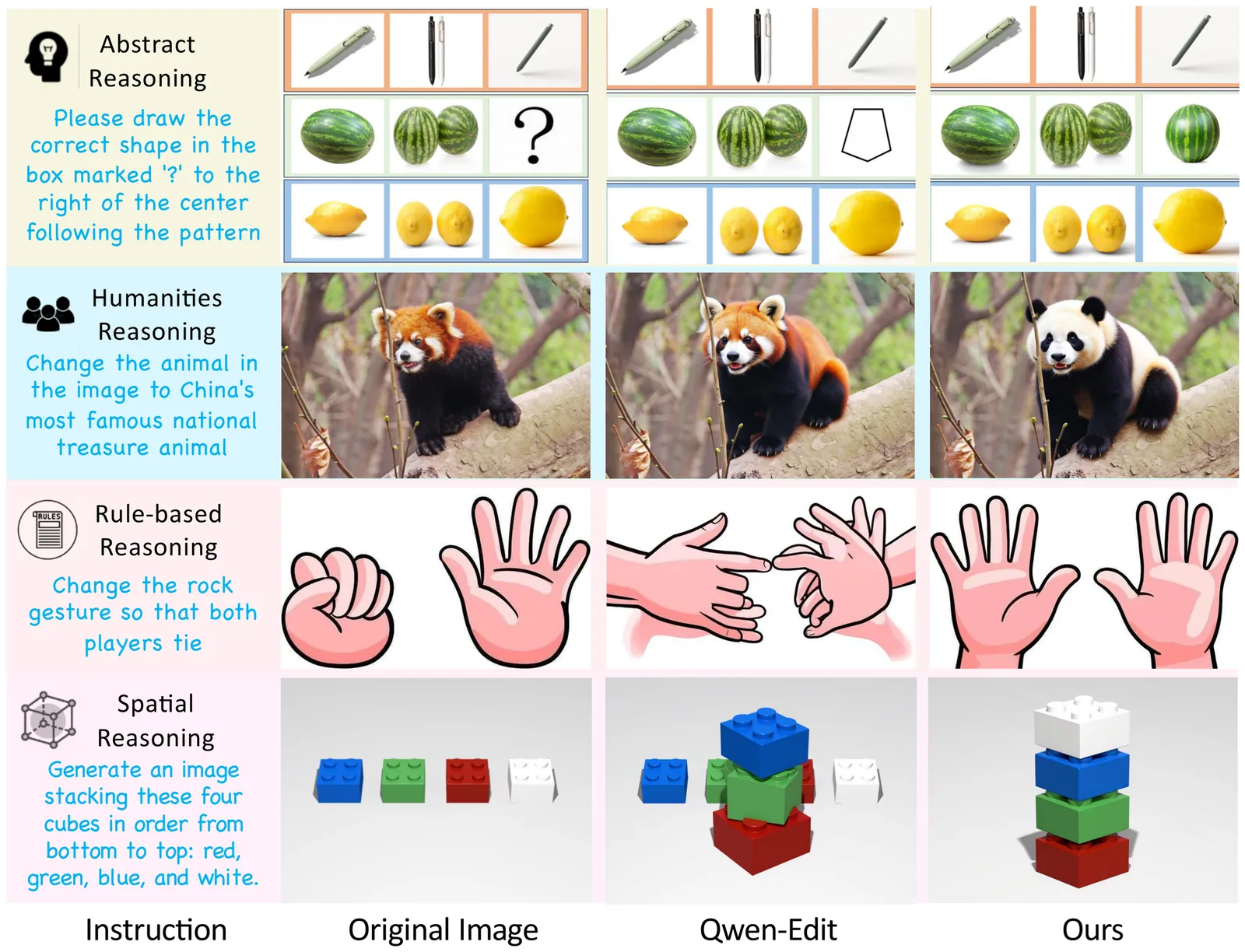
Instruction-driven image editing with unified multimodal generative models has advanced rapidly, yet their underlying visual reasoning remains limited, leading to suboptimal performance on reasoning-centric edits. Reinforcement learning (RL) has been investigated for improving the quality of image editing, but it faces three key challenges: (1) limited reasoning exploration confined to denoising stochasticity, (2) biased reward fusion, and (3) unstable VLM-based instruction rewards. In this work, we propose ThinkRL-Edit, a reasoning-centric RL framework that decouples visual reasoning from image synthesis and expands reasoning exploration beyond denoising. To the end, we introduce Chain-of-Thought (CoT)-based reasoning sampling with planning and reflection stages prior to generation in online sampling, compelling the model to explore multiple semantic hypotheses and validate their plausibility before committing to a visual outcome. To avoid the failures of weighted aggregation, we propose an unbiased chain preference grouping strategy across multiple reward dimensions. Moreover, we replace interval-based VLM scores with a binary checklist, yielding more precise, lower-variance, and interpretable rewards for complex reasoning. Experiments show our method significantly outperforms prior work on reasoning-centric image editing, producing instruction-faithful, visually coherent, and semantically grounded edits.
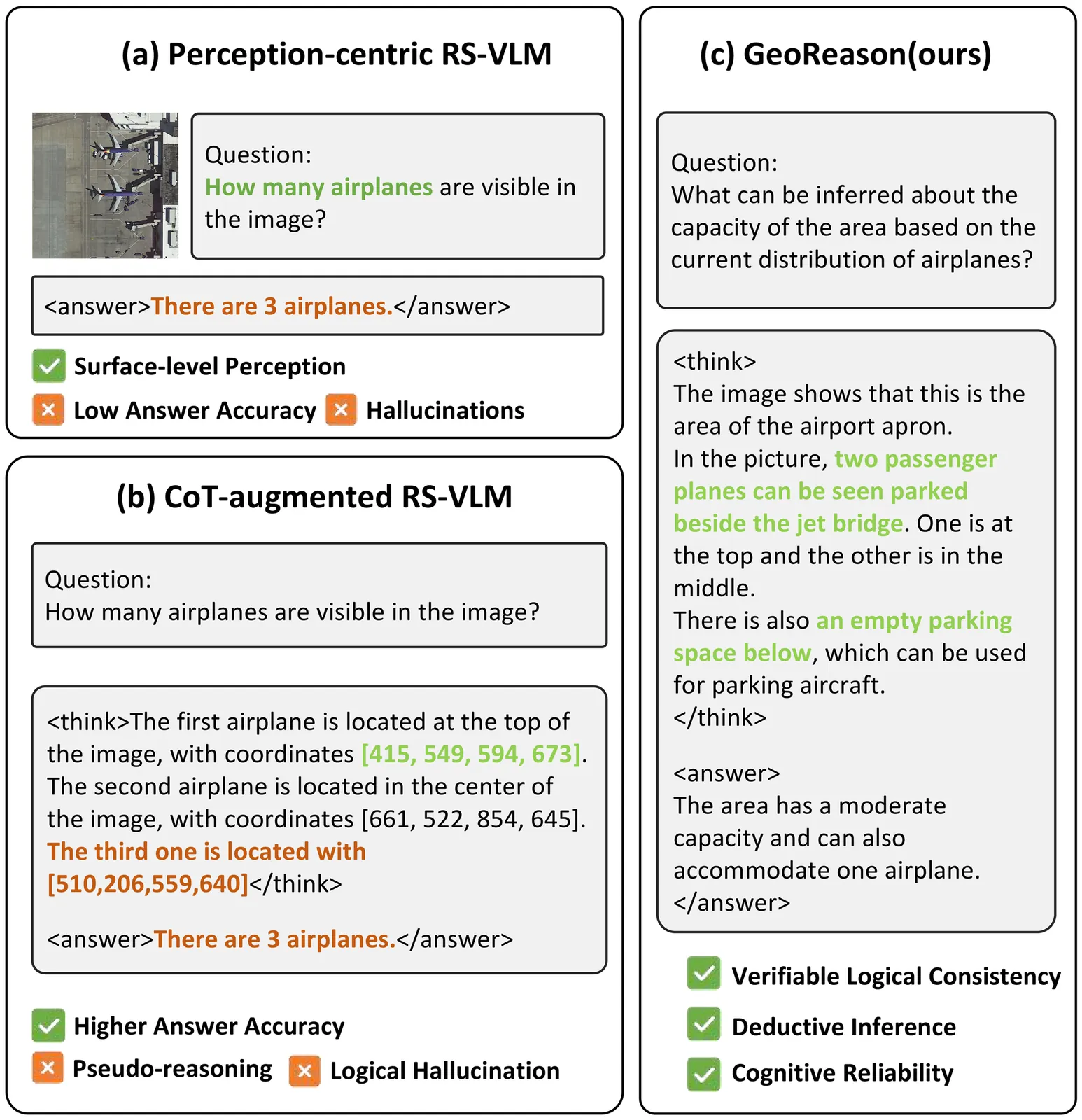
The evolution of Remote Sensing Vision-Language Models(RS-VLMs) emphasizes the importance of transitioning from perception-centric recognition toward high-level deductive reasoning to enhance cognitive reliability in complex spatial tasks. However, current models often suffer from logical hallucinations, where correct answers are derived from flawed reasoning chains or rely on positional shortcuts rather than spatial logic. This decoupling undermines reliability in strategic spatial decision-making. To address this, we present GeoReason, a framework designed to synchronize internal thinking with final decisions. We first construct GeoReason-Bench, a logic-driven dataset containing 4,000 reasoning trajectories synthesized from geometric primitives and expert knowledge. We then formulate a two-stage training strategy: (1) Supervised Knowledge Initialization to equip the model with reasoning syntax and domain expertise, and (2) Consistency-Aware Reinforcement Learning to refine deductive reliability. This second stage integrates a novel Logical Consistency Reward, which penalizes logical drift via an option permutation strategy to anchor decisions in verifiable reasoning traces. Experimental results demonstrate that our framework significantly enhances the cognitive reliability and interpretability of RS-VLMs, achieving state-of-the-art performance compared to other advanced methods.

Maintaining consistent characters, props, and environments across multiple shots is a central challenge in narrative video generation. Existing models can produce high-quality short clips but often fail to preserve entity identity and appearance when scenes change or when entities reappear after long temporal gaps. We present VideoMemory, an entity-centric framework that integrates narrative planning with visual generation through a Dynamic Memory Bank. Given a structured script, a multi-agent system decomposes the narrative into shots, retrieves entity representations from memory, and synthesizes keyframes and videos conditioned on these retrieved states. The Dynamic Memory Bank stores explicit visual and semantic descriptors for characters, props, and backgrounds, and is updated after each shot to reflect story-driven changes while preserving identity. This retrieval-update mechanism enables consistent portrayal of entities across distant shots and supports coherent long-form generation. To evaluate this setting, we construct a 54-case multi-shot consistency benchmark covering character-, prop-, and background-persistent scenarios. Extensive experiments show that VideoMemory achieves strong entity-level coherence and high perceptual quality across diverse narrative sequences.
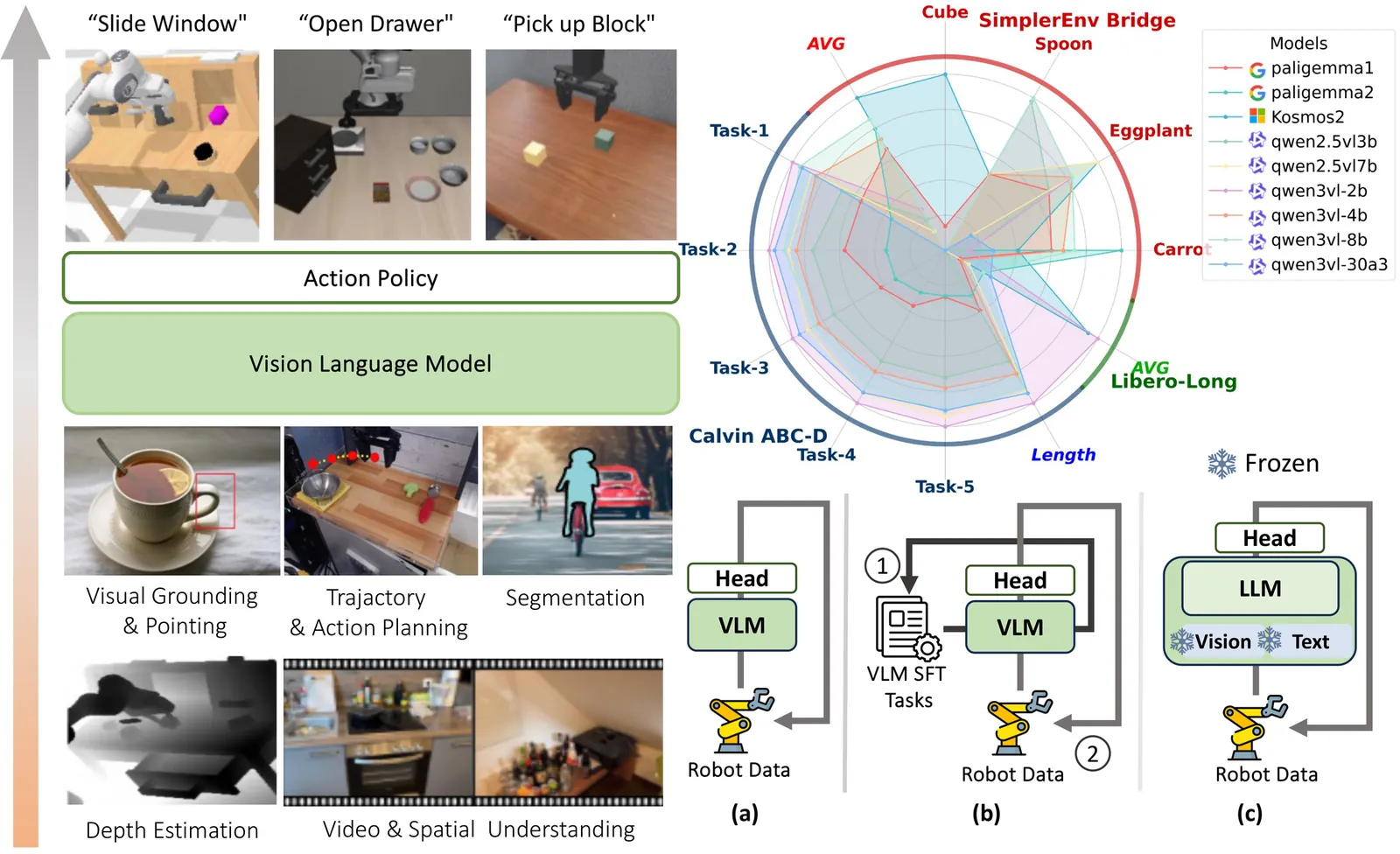
Vision-Language-Action (VLA) models, which integrate pretrained large Vision-Language Models (VLM) into their policy backbone, are gaining significant attention for their promising generalization capabilities. This paper revisits a fundamental yet seldom systematically studied question: how VLM choice and competence translate to downstream VLA policies performance? We introduce VLM4VLA, a minimal adaptation pipeline that converts general-purpose VLMs into VLA policies using only a small set of new learnable parameters for fair and efficient comparison. Despite its simplicity, VLM4VLA proves surprisingly competitive with more sophisticated network designs. Through extensive empirical studies on various downstream tasks across three benchmarks, we find that while VLM initialization offers a consistent benefit over training from scratch, a VLM's general capabilities are poor predictors of its downstream task performance. This challenges common assumptions, indicating that standard VLM competence is necessary but insufficient for effective embodied control. We further investigate the impact of specific embodied capabilities by fine-tuning VLMs on seven auxiliary embodied tasks (e.g., embodied QA, visual pointing, depth estimation). Contrary to intuition, improving a VLM's performance on specific embodied skills does not guarantee better downstream control performance. Finally, modality-level ablations identify the visual module in VLM, rather than the language component, as the primary performance bottleneck. We demonstrate that injecting control-relevant supervision into the vision encoder of the VLM yields consistent gains, even when the encoder remains frozen during downstream fine-tuning. This isolates a persistent domain gap between current VLM pretraining objectives and the requirements of embodied action-planning.

Monocular depth estimation aims to recover the depth information of 3D scenes from 2D images. Recent work has made significant progress, but its reliance on large-scale datasets and complex decoders has limited its efficiency and generalization ability. In this paper, we propose a lightweight and data-centric framework for zero-shot monocular depth estimation. We first adopt DINOv3 as the visual encoder to obtain high-quality dense features. Secondly, to address the inherent drawbacks of the complex structure of the DPT, we design the Simple Depth Transformer (SDT), a compact transformer-based decoder. Compared to the DPT, it uses a single-path feature fusion and upsampling process to reduce the computational overhead of cross-scale feature fusion, achieving higher accuracy while reducing the number of parameters by approximately 85%-89%. Furthermore, we propose a quality-based filtering strategy to filter out harmful samples, thereby reducing dataset size while improving overall training quality. Extensive experiments on five benchmarks demonstrate that our framework surpasses the DPT in accuracy. This work highlights the importance of balancing model design and data quality for achieving efficient and generalizable zero-shot depth estimation. Code: https://github.com/AIGeeksGroup/AnyDepth. Website: https://aigeeksgroup.github.io/AnyDepth.
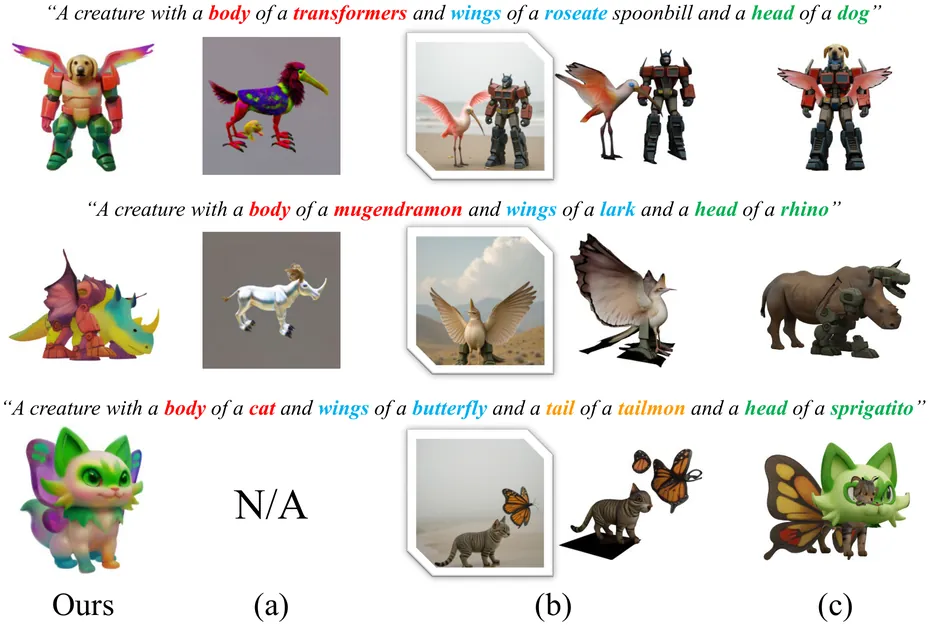
We present Muses, the first training-free method for fantastic 3D creature generation in a feed-forward paradigm. Previous methods, which rely on part-aware optimization, manual assembly, or 2D image generation, often produce unrealistic or incoherent 3D assets due to the challenges of intricate part-level manipulation and limited out-of-domain generation. In contrast, Muses leverages the 3D skeleton, a fundamental representation of biological forms, to explicitly and rationally compose diverse elements. This skeletal foundation formalizes 3D content creation as a structure-aware pipeline of design, composition, and generation. Muses begins by constructing a creatively composed 3D skeleton with coherent layout and scale through graph-constrained reasoning. This skeleton then guides a voxel-based assembly process within a structured latent space, integrating regions from different objects. Finally, image-guided appearance modeling under skeletal conditions is applied to generate a style-consistent and harmonious texture for the assembled shape. Extensive experiments establish Muses' state-of-the-art performance in terms of visual fidelity and alignment with textual descriptions, and potential on flexible 3D object editing. Project page: https://luhexiao.github.io/Muses.github.io/.
Dynamic objects in our physical 4D (3D + time) world are constantly evolving, deforming, and interacting with other objects, leading to diverse 4D scene dynamics. In this paper, we present a universal generative pipeline, CHORD, for CHOReographing Dynamic objects and scenes and synthesizing this type of phenomena. Traditional rule-based graphics pipelines to create these dynamics are based on category-specific heuristics, yet are labor-intensive and not scalable. Recent learning-based methods typically demand large-scale datasets, which may not cover all object categories in interest. Our approach instead inherits the universality from the video generative models by proposing a distillation-based pipeline to extract the rich Lagrangian motion information hidden in the Eulerian representations of 2D videos. Our method is universal, versatile, and category-agnostic. We demonstrate its effectiveness by conducting experiments to generate a diverse range of multi-body 4D dynamics, show its advantage compared to existing methods, and demonstrate its applicability in generating robotics manipulation policies. Project page: https://yanzhelyu.github.io/chord
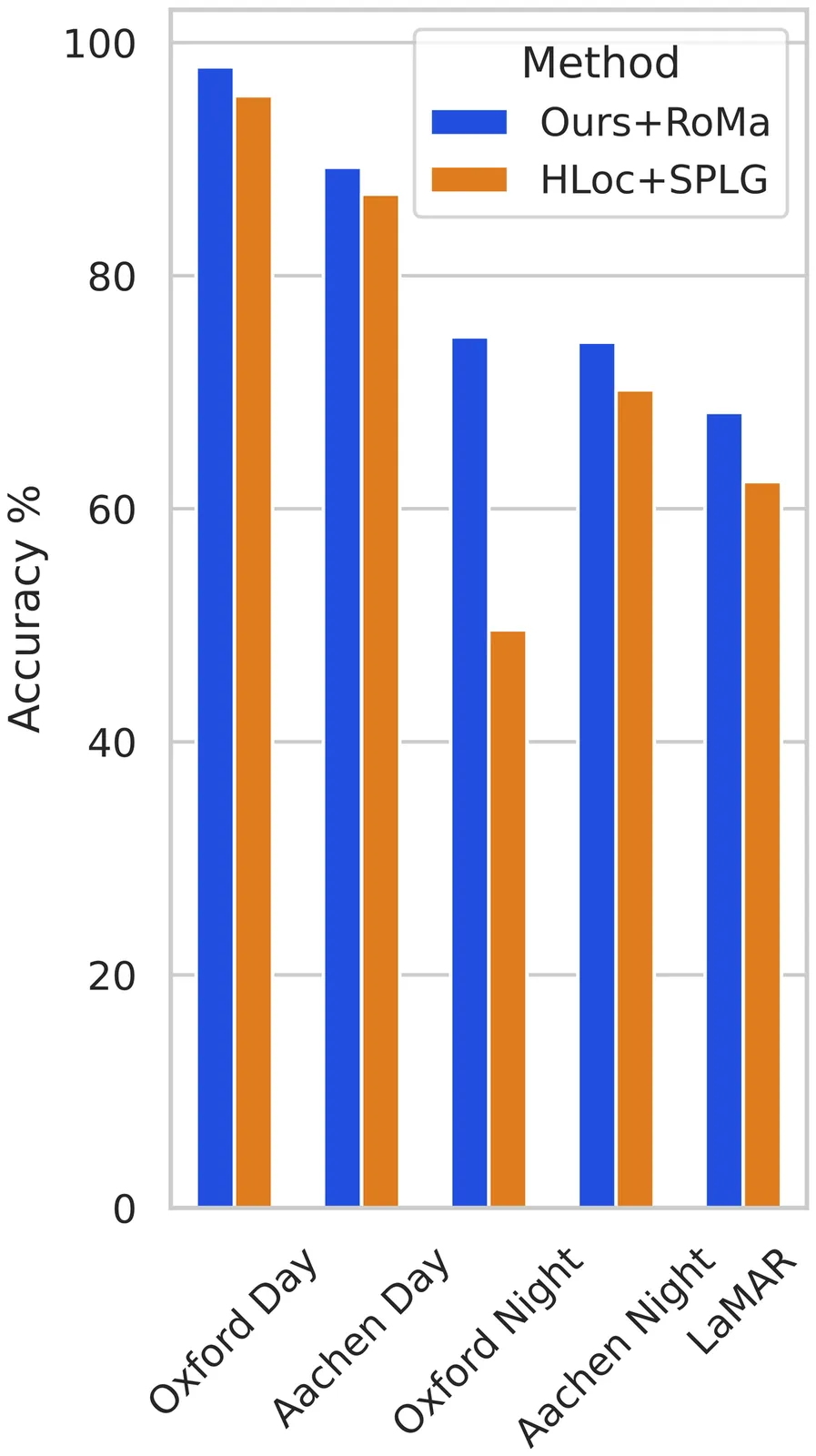
Existing visual localization methods are typically either 2D image-based, which are easy to build and maintain but limited in effective geometric reasoning, or 3D structure-based, which achieve high accuracy but require a centralized reconstruction and are difficult to update. In this work, we revisit visual localization with a 2D image-based representation and propose to augment each image with estimated depth maps to capture the geometric structure. Supported by the effective use of dense matchers, this representation is not only easy to build and maintain, but achieves highest accuracy in challenging conditions. With compact compression and a GPU-accelerated LO-RANSAC implementation, the whole pipeline is efficient in both storage and computation and allows for a flexible trade-off between accuracy and highest memory efficiency. Our method achieves a new state-of-the-art accuracy on various standard benchmarks and outperforms existing memory-efficient methods at comparable map sizes. Code will be available at https://github.com/cvg/Hierarchical-Localization.

Direct Preference Optimization (DPO) has recently improved Text-to-Video (T2V) generation by enhancing visual fidelity and text alignment. However, current methods rely on non-differentiable preference signals from human annotations or learned reward models. This reliance makes training label-intensive, bias-prone, and easy-to-game, which often triggers reward hacking and unstable training. We propose Diffusion-DRF, a differentiable reward flow for fine-tuning video diffusion models using a frozen, off-the-shelf Vision-Language Model (VLM) as a training-free critic. Diffusion-DRF directly backpropagates VLM feedback through the diffusion denoising chain, converting logit-level responses into token-aware gradients for optimization. We propose an automated, aspect-structured prompting pipeline to obtain reliable multi-dimensional VLM feedback, while gradient checkpointing enables efficient updates through the final denoising steps. Diffusion-DRF improves video quality and semantic alignment while mitigating reward hacking and collapse -- without additional reward models or preference datasets. It is model-agnostic and readily generalizes to other diffusion-based generative tasks.
Audio-video joint generation has progressed rapidly, yet substantial challenges still remain. Non-commercial approaches still suffer audio-visual asynchrony, poor lip-speech alignment, and unimodal degradation, which can be stemmed from weak audio-visual correspondence modeling, limited generalization, and scarce high-quality dense-caption data. To address these issues, we introduce Klear and delve into three axes--model architecture, training strategy, and data curation. Architecturally, we adopt a single-tower design with unified DiT blocks and an Omni-Full Attention mechanism, achieving tight audio-visual alignment and strong scalability. Training-wise, we adopt a progressive multitask regime--random modality masking to joint optimization across tasks, and a multistage curriculum, yielding robust representations, strengthening A-V aligned world knowledge, and preventing unimodal collapse. For datasets, we present the first large-scale audio-video dataset with dense captions, and introduce a novel automated data-construction pipeline which annotates and filters millions of diverse, high-quality, strictly aligned audio-video-caption triplets. Building on this, Klear scales to large datasets, delivering high-fidelity, semantically and temporally aligned, instruction-following generation in both joint and unimodal settings while generalizing robustly to out-of-distribution scenarios. Across tasks, it substantially outperforms prior methods by a large margin and achieves performance comparable to Veo 3, offering a unified, scalable path toward next-generation audio-video synthesis.

Satellites continuously generate massive volumes of data, particularly for Earth observation, including satellite image time series (SITS). However, most deep learning models are designed to process either entire images or complete time series sequences to extract meaningful features for downstream tasks. In this study, we propose a novel multimodal approach that leverages pixel-wise two-dimensional (2D) representations to encode visual property variations from SITS more effectively. Specifically, we generate recurrence plots from pixel-based vegetation index time series (NDVI, EVI, and SAVI) as an alternative to using raw pixel values, creating more informative representations. Additionally, we introduce PIxel-wise Multimodal Contrastive (PIMC), a new multimodal self-supervision approach that produces effective encoders based on two-dimensional pixel time series representations and remote sensing imagery (RSI). To validate our approach, we assess its performance on three downstream tasks: pixel-level forecasting and classification using the PASTIS dataset, and land cover classification on the EuroSAT dataset. Moreover, we compare our results to state-of-the-art (SOTA) methods on all downstream tasks. Our experimental results show that the use of 2D representations significantly enhances feature extraction from SITS, while contrastive learning improves the quality of representations for both pixel time series and RSI. These findings suggest that our multimodal method outperforms existing models in various Earth observation tasks, establishing it as a robust self-supervision framework for processing both SITS and RSI. Code avaliable on
The evolution of Remote Sensing Vision-Language Models(RS-VLMs) emphasizes the importance of transitioning from perception-centric recognition toward high-level deductive reasoning to enhance cognitive reliability in complex spatial tasks. However, current models often suffer from logical hallucinations, where correct answers are derived from flawed reasoning chains or rely on positional shortcuts rather than spatial logic. This decoupling undermines reliability in strategic spatial decision-making. To address this, we present GeoReason, a framework designed to synchronize internal thinking with final decisions. We first construct GeoReason-Bench, a logic-driven dataset containing 4,000 reasoning trajectories synthesized from geometric primitives and expert knowledge. We then formulate a two-stage training strategy: (1) Supervised Knowledge Initialization to equip the model with reasoning syntax and domain expertise, and (2) Consistency-Aware Reinforcement Learning to refine deductive reliability. This second stage integrates a novel Logical Consistency Reward, which penalizes logical drift via an option permutation strategy to anchor decisions in verifiable reasoning traces. Experimental results demonstrate that our framework significantly enhances the cognitive reliability and interpretability of RS-VLMs, achieving state-of-the-art performance compared to other advanced methods.
We present Gen3R, a method that bridges the strong priors of foundational reconstruction models and video diffusion models for scene-level 3D generation. We repurpose the VGGT reconstruction model to produce geometric latents by training an adapter on its tokens, which are regularized to align with the appearance latents of pre-trained video diffusion models. By jointly generating these disentangled yet aligned latents, Gen3R produces both RGB videos and corresponding 3D geometry, including camera poses, depth maps, and global point clouds. Experiments demonstrate that our approach achieves state-of-the-art results in single- and multi-image conditioned 3D scene generation. Additionally, our method can enhance the robustness of reconstruction by leveraging generative priors, demonstrating the mutual benefit of tightly coupling reconstruction and generative models.
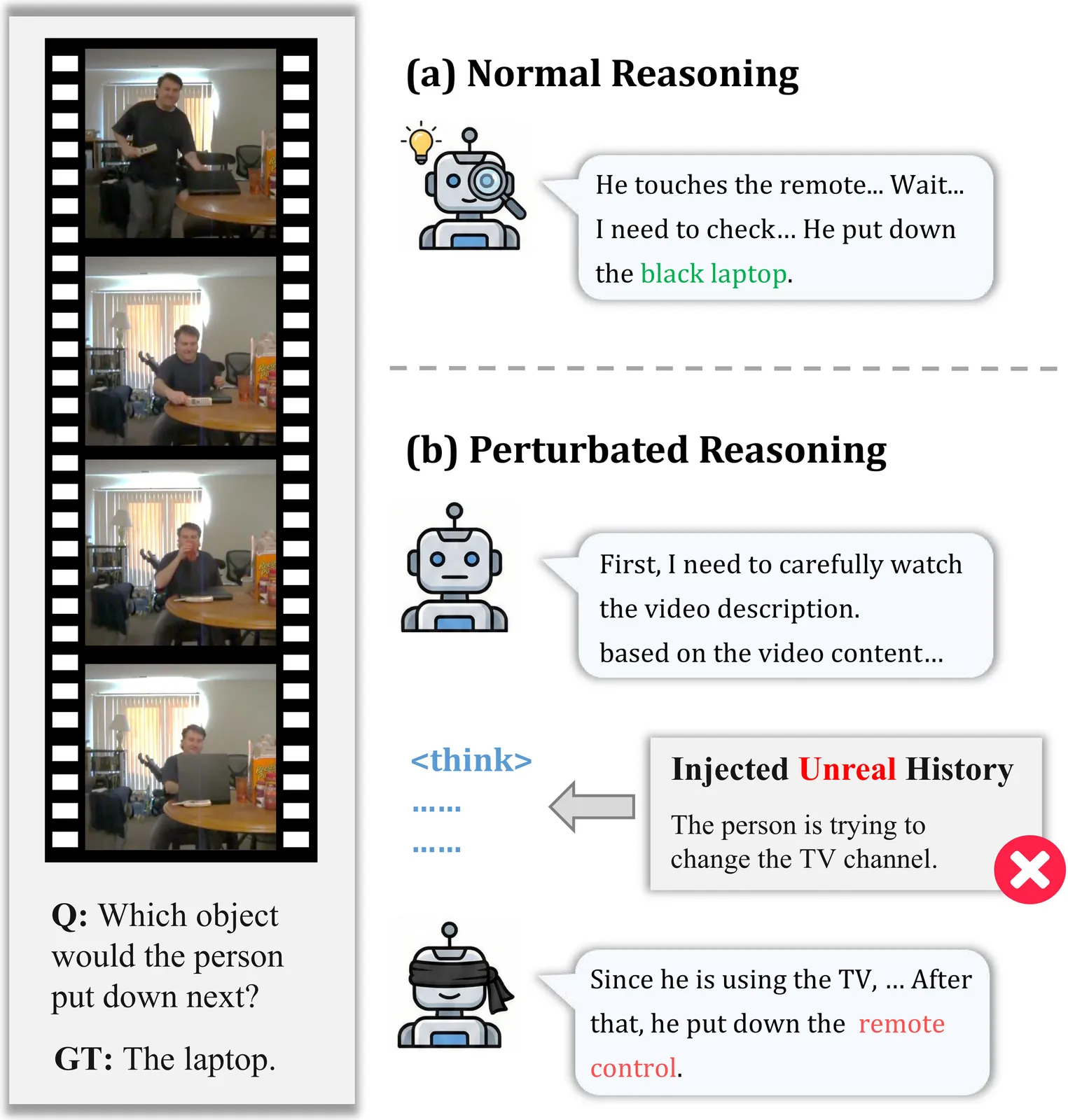
Large Multimodal Models (LMMs) have demonstrated impressive capabilities in video reasoning via Chain-of-Thought (CoT). However, the robustness of their reasoning chains remains questionable. In this paper, we identify a critical failure mode termed textual inertia, where once a textual hallucination occurs in the thinking process, models tend to blindly adhere to the erroneous text while neglecting conflicting visual evidence. To systematically investigate this, we propose the LogicGraph Perturbation Protocol that structurally injects perturbations into the reasoning chains of diverse LMMs spanning both native reasoning architectures and prompt-driven paradigms to evaluate their self-reflection capabilities. The results reveal that models successfully self-correct in less than 10% of cases and predominantly succumb to blind textual error propagation. To mitigate this, we introduce Active Visual-Context Refinement, a training-free inference paradigm which orchestrates an active visual re-grounding mechanism to enforce fine-grained verification coupled with an adaptive context refinement strategy to summarize and denoise the reasoning history. Experiments demonstrate that our approach significantly stifles hallucination propagation and enhances reasoning robustness.
Aligning text-to-video diffusion models with human preferences is crucial for generating high-quality videos. Existing Direct Preference Otimization (DPO) methods rely on multi-sample ranking and task-specific critic models, which is inefficient and often yields ambiguous global supervision. To address these limitations, we propose LocalDPO, a novel post-training framework that constructs localized preference pairs from real videos and optimizes alignment at the spatio-temporal region level. We design an automated pipeline to efficiently collect preference pair data that generates preference pairs with a single inference per prompt, eliminating the need for external critic models or manual annotation. Specifically, we treat high-quality real videos as positive samples and generate corresponding negatives by locally corrupting them with random spatio-temporal masks and restoring only the masked regions using the frozen base model. During training, we introduce a region-aware DPO loss that restricts preference learning to corrupted areas for rapid convergence. Experiments on Wan2.1 and CogVideoX demonstrate that LocalDPO consistently improves video fidelity, temporal coherence and human preference scores over other post-training approaches, establishing a more efficient and fine-grained paradigm for video generator alignment.
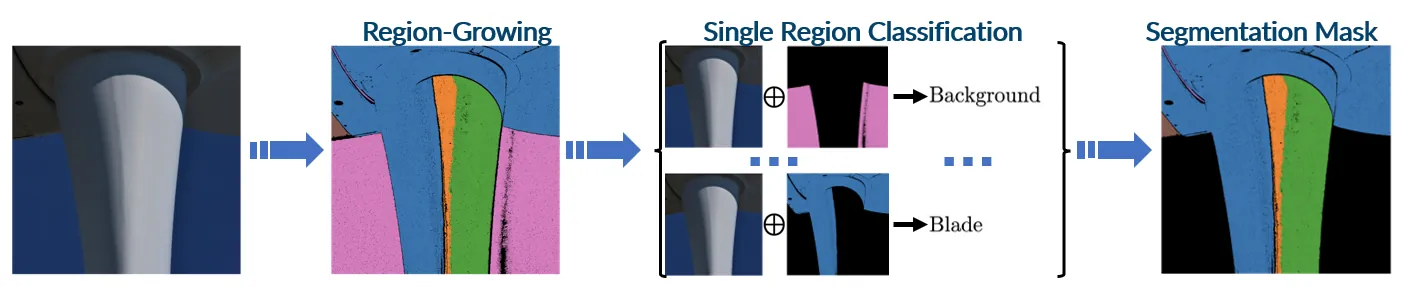
Reliable operation of wind turbines requires frequent inspections, as even minor surface damages can degrade aerodynamic performance, reduce energy output, and accelerate blade wear. Central to automating these inspections is the accurate segmentation of turbine blades from visual data. This task is traditionally addressed through dense, pixel-wise deep learning models. However, such methods demand extensive annotated datasets, posing scalability challenges. In this work, we introduce an annotation-efficient segmentation approach that reframes the pixel-level task into a binary region classification problem. Image regions are generated using a fully unsupervised, interpretable Modular Adaptive Region Growing technique, guided by image-specific Adaptive Thresholding and enhanced by a Region Merging process that consolidates fragmented areas into coherent segments. To improve generalization and classification robustness, we introduce RegionMix, an augmentation strategy that synthesizes new training samples by combining distinct regions. Our framework demonstrates state-of-the-art segmentation accuracy and strong cross-site generalization by consistently segmenting turbine blades across distinct windfarms.

Recent advances in video reward models and post-training strategies have improved text-to-video (T2V) generation. While these models typically assess visual quality, motion quality, and text alignment, they often overlook key structural distortions, such as abnormal object appearances and interactions, which can degrade the overall quality of the generative video. To address this gap, we introduce REACT, a frame-level reward model designed specifically for structural distortions evaluation in generative videos. REACT assigns point-wise scores and attribution labels by reasoning over video frames, focusing on recognizing distortions. To support this, we construct a large-scale human preference dataset, annotated based on our proposed taxonomy of structural distortions, and generate additional data using a efficient Chain-of-Thought (CoT) synthesis pipeline. REACT is trained with a two-stage framework: ((1) supervised fine-tuning with masked loss for domain knowledge injection, followed by (2) reinforcement learning with Group Relative Policy Optimization (GRPO) and pairwise rewards to enhance reasoning capability and align output scores with human preferences. During inference, a dynamic sampling mechanism is introduced to focus on frames most likely to exhibit distortion. We also present REACT-Bench, a benchmark for generative video distortion evaluation. Experimental results demonstrate that REACT complements existing reward models in assessing structutal distortion, achieving both accurate quantitative evaluations and interpretable attribution analysis.
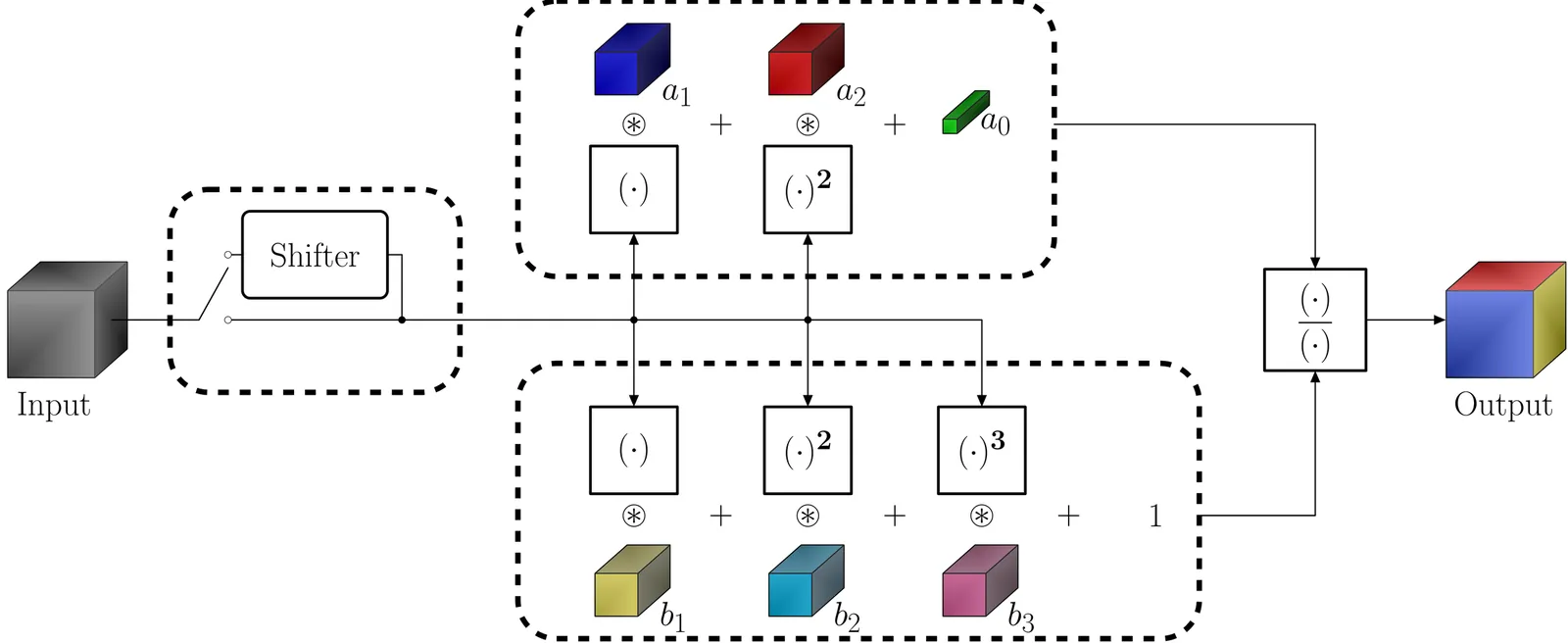
Neural networks commonly employ the McCulloch-Pitts neuron model, which is a linear model followed by a point-wise non-linear activation. Various researchers have already advanced inherently non-linear neuron models, such as quadratic neurons, generalized operational neurons, generative neurons, and super neurons, which offer stronger non-linearity compared to point-wise activation functions. In this paper, we introduce a novel and better non-linear neuron model called Padé neurons (Paons), inspired by Padé approximants. Paons offer several advantages, such as diversity of non-linearity, since each Paon learns a different non-linear function of its inputs, and layer efficiency, since Paons provide stronger non-linearity in much fewer layers compared to piecewise linear approximation. Furthermore, Paons include all previously proposed neuron models as special cases, thus any neuron model in any network can be replaced by Paons. We note that there has been a proposal to employ the Padé approximation as a generalized point-wise activation function, which is fundamentally different from our model. To validate the efficacy of Paons, in our experiments, we replace classic neurons in some well-known neural image super-resolution, compression, and classification models based on the ResNet architecture with Paons. Our comprehensive experimental results and analyses demonstrate that neural models built by Paons provide better or equal performance than their classic counterparts with a smaller number of layers. The PyTorch implementation code for Paon is open-sourced at https://github.com/onur-keles/Paon.
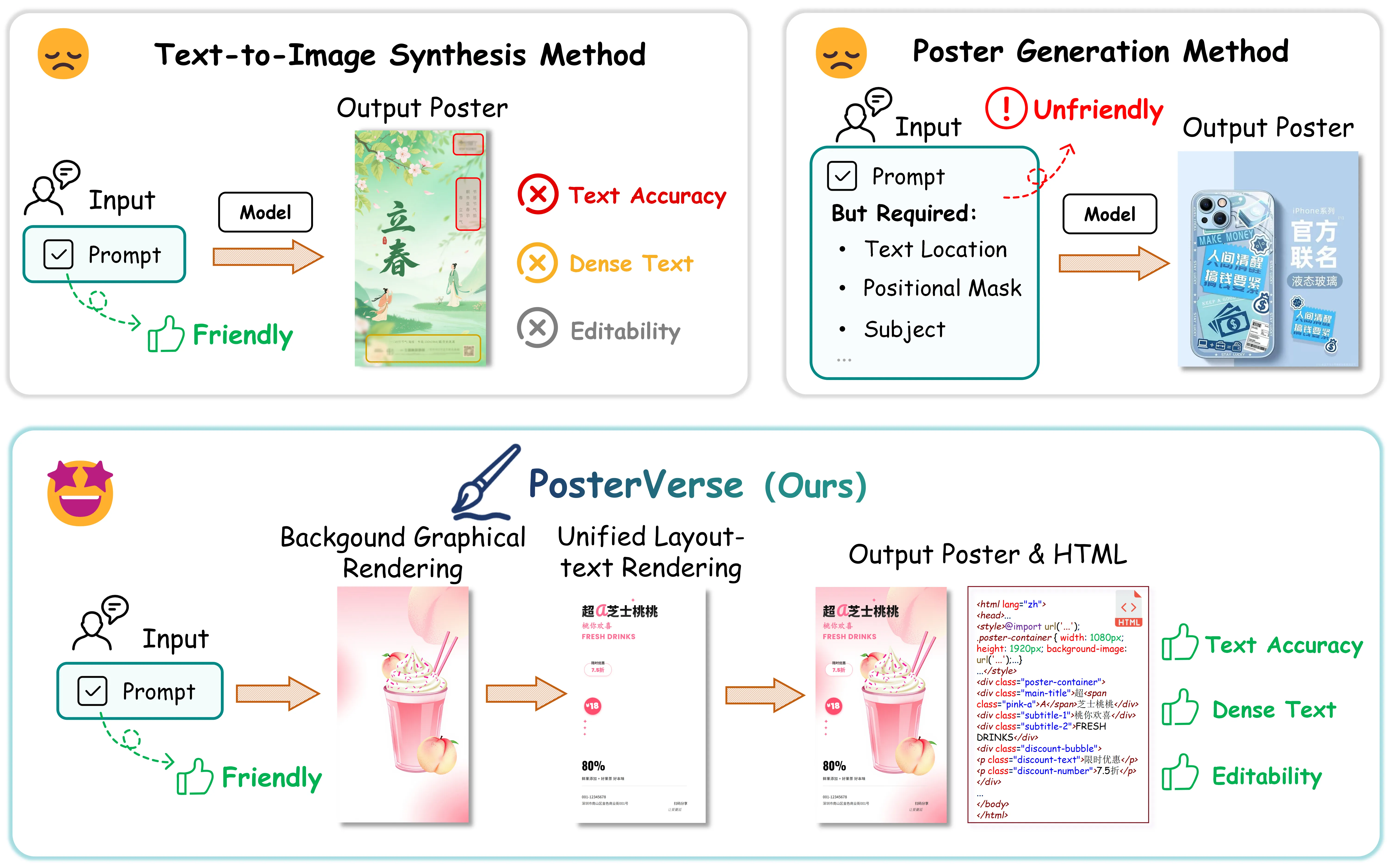
Commercial-grade poster design demands the seamless integration of aesthetic appeal with precise, informative content delivery. Current automated poster generation systems face significant limitations, including incomplete design workflows, poor text rendering accuracy, and insufficient flexibility for commercial applications. To address these challenges, we propose PosterVerse, a full-workflow, commercial-grade poster generation method that seamlessly automates the entire design process while delivering high-density and scalable text rendering. PosterVerse replicates professional design through three key stages: (1) blueprint creation using fine-tuned LLMs to extract key design elements from user requirements, (2) graphical background generation via customized diffusion models to create visually appealing imagery, and (3) unified layout-text rendering with an MLLM-powered HTML engine to guarantee high text accuracy and flexible customization. In addition, we introduce PosterDNA, a commercial-grade, HTML-based dataset tailored for training and validating poster design models. To the best of our knowledge, PosterDNA is the first Chinese poster generation dataset to introduce HTML typography files, enabling scalable text rendering and fundamentally solving the challenges of rendering small and high-density text. Experimental results demonstrate that PosterVerse consistently produces commercial-grade posters with appealing visuals, accurate text alignment, and customizable layouts, making it a promising solution for automating commercial poster design. The code and model are available at https://github.com/wuhaer/PosterVerse.
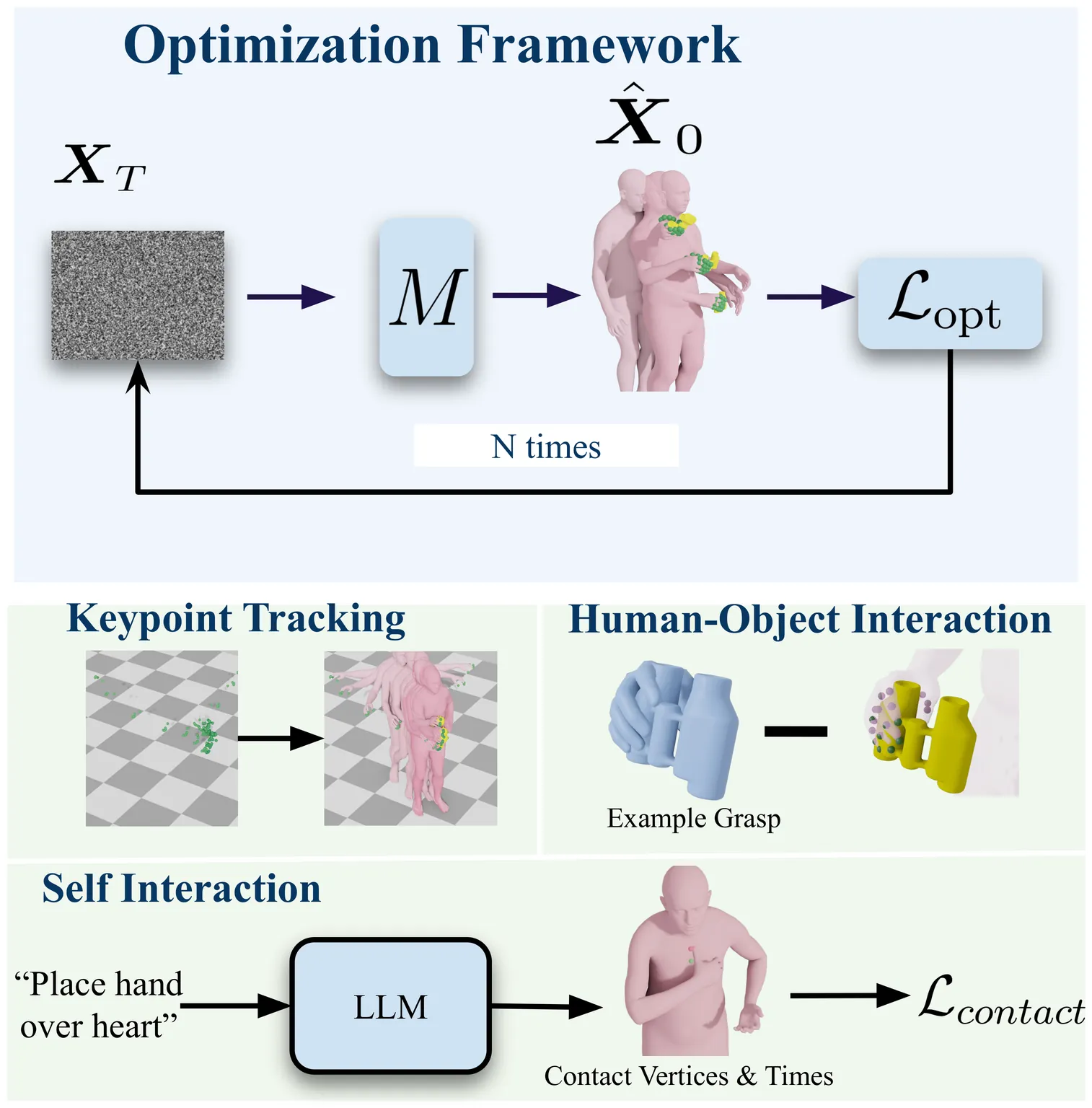
Hands are central to interacting with our surroundings and conveying gestures, making their inclusion essential for full-body motion synthesis. Despite this, existing human motion synthesis methods fall short: some ignore hand motions entirely, while others generate full-body motions only for narrowly scoped tasks under highly constrained settings. A key obstacle is the lack of large-scale datasets that jointly capture diverse full-body motion with detailed hand articulation. While some datasets capture both, they are limited in scale and diversity. Conversely, large-scale datasets typically focus either on body motion without hands or on hand motions without the body. To overcome this, we curate and unify existing hand motion datasets with large-scale body motion data to generate full-body sequences that capture both hand and body. We then propose the first diffusion-based unconditional full-body motion prior, FUSION, which jointly models body and hand motion. Despite using a pose-based motion representation, FUSION surpasses state-of-the-art skeletal control models on the Keypoint Tracking task in the HumanML3D dataset and achieves superior motion naturalness. Beyond standard benchmarks, we demonstrate that FUSION can go beyond typical uses of motion priors through two applications: (1) generating detailed full-body motion including fingers during interaction given the motion of an object, and (2) generating Self-Interaction motions using an LLM to transform natural language cues into actionable motion constraints. For these applications, we develop an optimization pipeline that refines the latent space of our diffusion model to generate task-specific motions. Experiments on these tasks highlight precise control over hand motion while maintaining plausible full-body coordination. The code will be public.
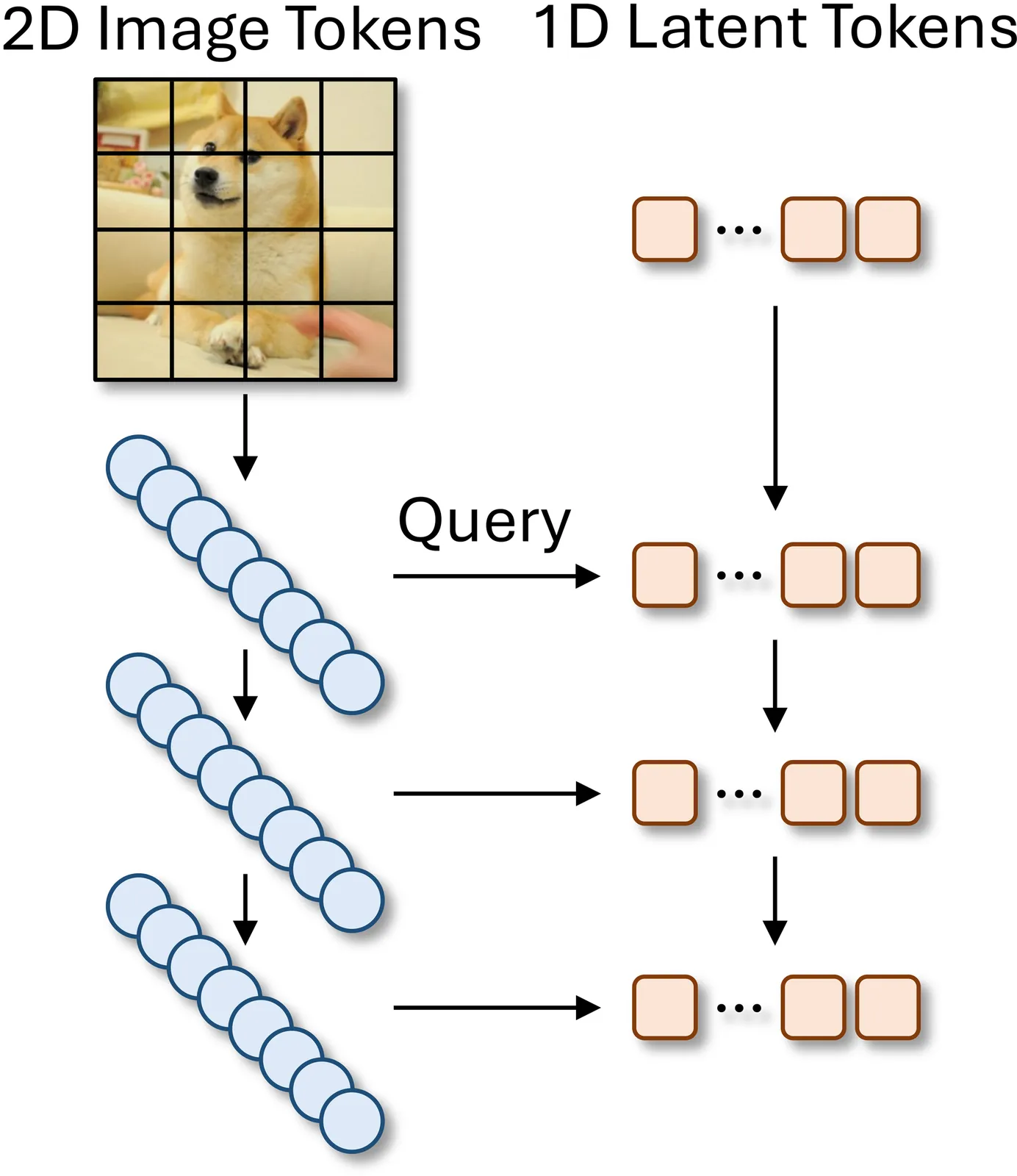
Existing 1D visual tokenizers for autoregressive (AR) generation largely follow the design principles of language modeling, as they are built directly upon transformers whose priors originate in language, yielding single-hierarchy latent tokens and treating visual data as flat sequential token streams. However, this language-like formulation overlooks key properties of vision, particularly the hierarchical and residual network designs that have long been essential for convergence and efficiency in visual models. To bring "vision" back to vision, we propose the Residual Tokenizer (ResTok), a 1D visual tokenizer that builds hierarchical residuals for both image tokens and latent tokens. The hierarchical representations obtained through progressively merging enable cross-level feature fusion at each layer, substantially enhancing representational capacity. Meanwhile, the semantic residuals between hierarchies prevent information overlap, yielding more concentrated latent distributions that are easier for AR modeling. Cross-level bindings consequently emerge without any explicit constraints. To accelerate the generation process, we further introduce a hierarchical AR generator that substantially reduces sampling steps by predicting an entire level of latent tokens at once rather than generating them strictly token-by-token. Extensive experiments demonstrate that restoring hierarchical residual priors in visual tokenization significantly improves AR image generation, achieving a gFID of 2.34 on ImageNet-256 with only 9 sampling steps. Code is available at https://github.com/Kwai-Kolors/ResTok.
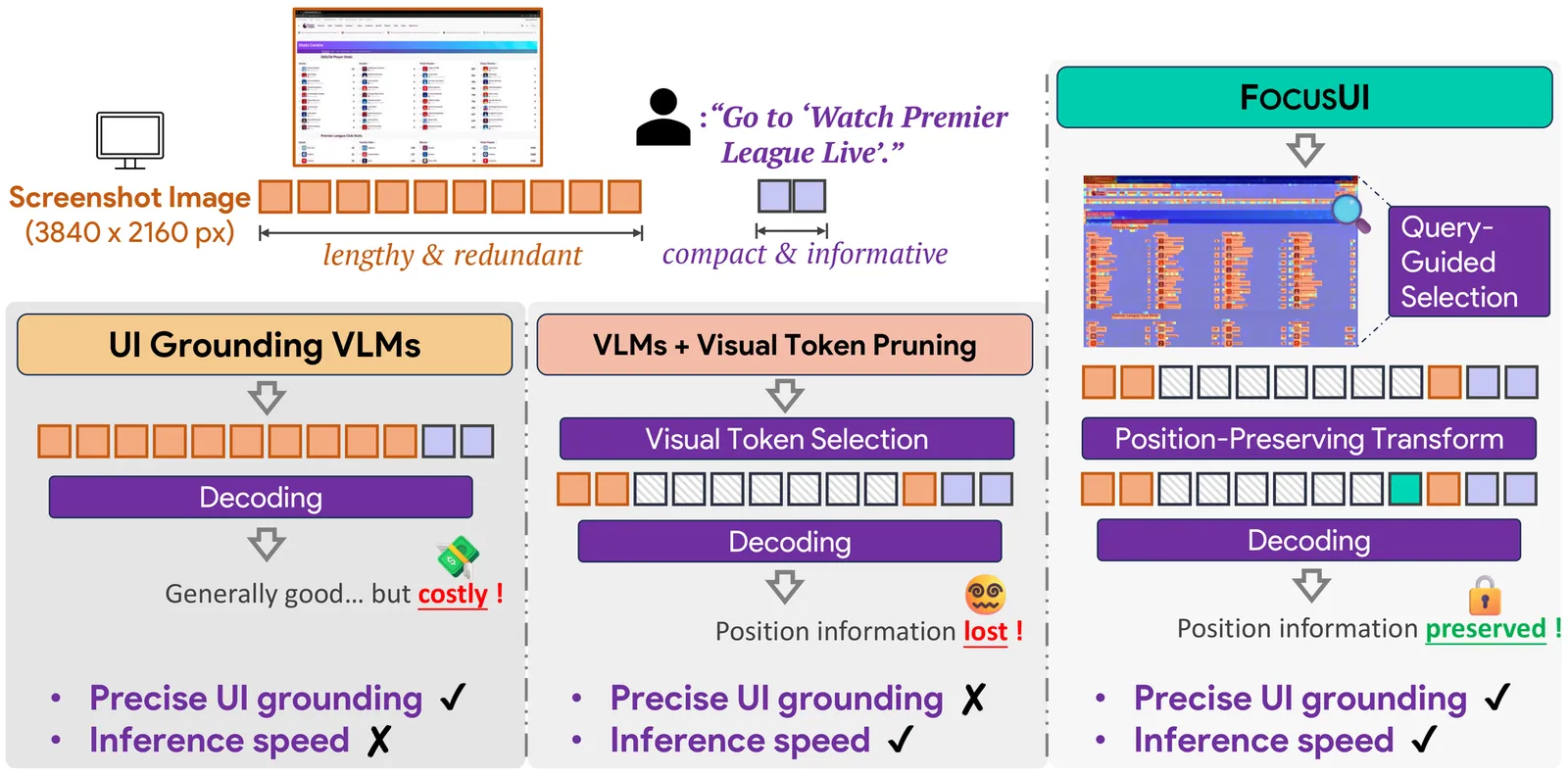
Vision-Language Models (VLMs) have shown remarkable performance in User Interface (UI) grounding tasks, driven by their ability to process increasingly high-resolution screenshots. However, screenshots are tokenized into thousands of visual tokens (e.g., about 4700 for 2K resolution), incurring significant computational overhead and diluting attention. In contrast, humans typically focus on regions of interest when interacting with UI. In this work, we pioneer the task of efficient UI grounding. Guided by practical analysis of the task's characteristics and challenges, we propose FocusUI, an efficient UI grounding framework that selects patches most relevant to the instruction while preserving positional continuity for precise grounding. FocusUI addresses two key challenges: (1) Eliminating redundant tokens in visual encoding. We construct patch-level supervision by fusing an instruction-conditioned score with a rule-based UI-graph score that down-weights large homogeneous regions to select distinct and instruction-relevant visual tokens. (2) Preserving positional continuity during visual token selection. We find that general visual token pruning methods suffer from severe accuracy degradation on UI grounding tasks due to broken positional information. We introduce a novel PosPad strategy, which compresses each contiguous sequence of dropped visual tokens into a single special marker placed at the sequence's last index to preserve positional continuity. Comprehensive experiments on four grounding benchmarks demonstrate that FocusUI surpasses GUI-specific baselines. On the ScreenSpot-Pro benchmark, FocusUI-7B achieves a performance improvement of 3.7% over GUI-Actor-7B. Even with only 30% visual token retention, FocusUI-7B drops by only 3.2% while achieving up to 1.44x faster inference and 17% lower peak GPU memory.
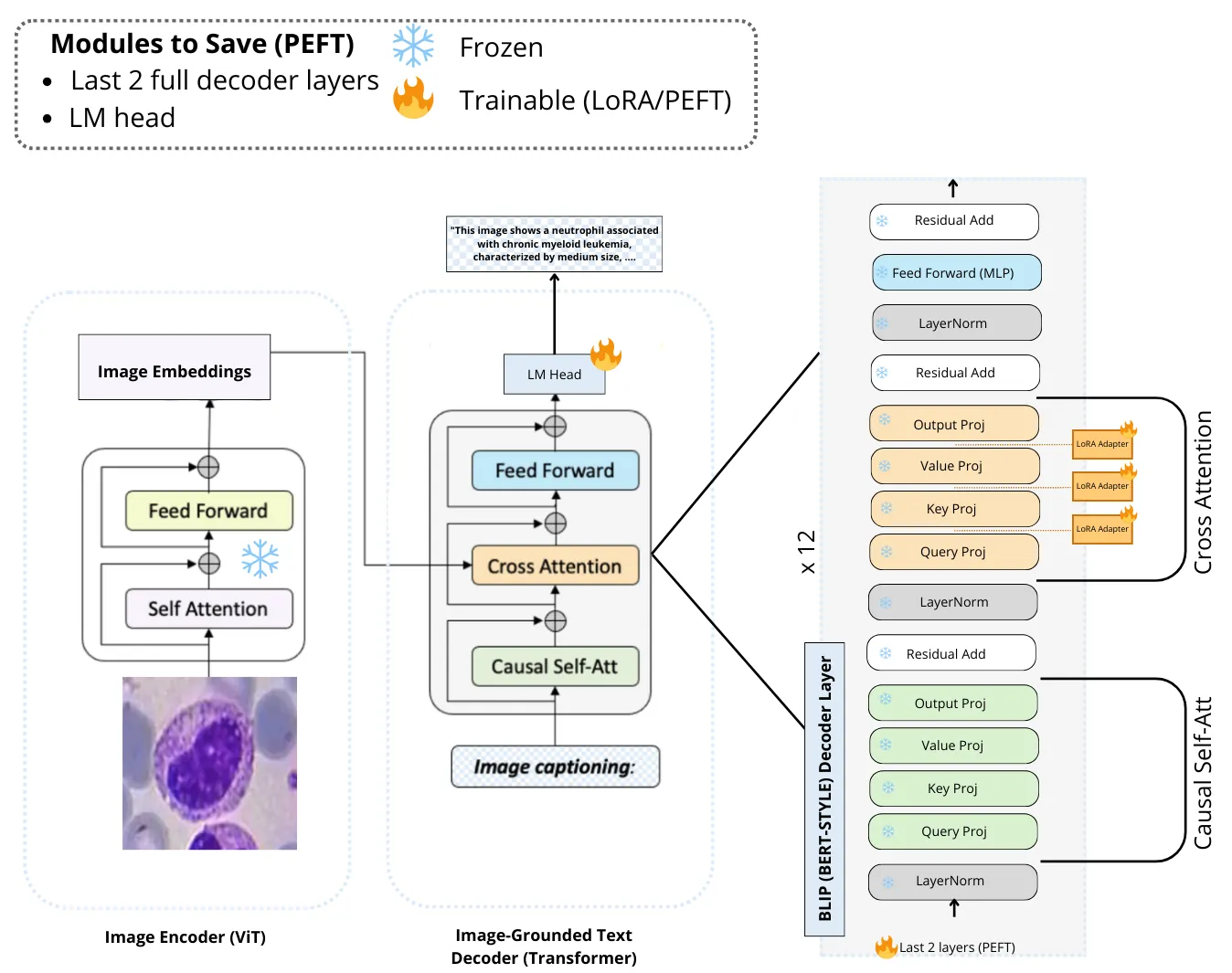
Microscopic evaluation of white blood cell morphology is central to leukemia diagnosis, yet current deep learning models often act as black boxes, limiting clinical trust and adoption. We introduce HemBLIP, a vision language model designed to generate interpretable, morphology aware descriptions of peripheral blood cells. Using a newly constructed dataset of 14k healthy and leukemic cells paired with expert-derived attribute captions, we adapt a general-purpose VLM via both full fine-tuning and LoRA based parameter efficient training, and benchmark against the biomedical foundation model MedGEMMA. HemBLIP achieves higher caption quality and morphological accuracy, while LoRA adaptation provides further gains with significantly reduced computational cost. These results highlight the promise of vision language models for transparent and scalable hematological diagnostics.

Distributing government relief efforts after a flood is challenging. In India, the crops are widely affected by floods; therefore, making rapid and accurate crop damage assessment is crucial for effective post-disaster agricultural management. Traditional manual surveys are slow and biased, while current satellite-based methods face challenges like cloud cover and low spatial resolution. Therefore, to bridge this gap, this paper introduced FLNet, a novel deep learning based architecture that used super-resolution to enhance the 10 m spatial resolution of Sentinel-2 satellite images into 3 m resolution before classifying damage. We tested our model on the Bihar Flood Impacted Croplands Dataset (BFCD-22), and the results showed an improved critical "Full Damage" F1-score from 0.83 to 0.89, nearly matching the 0.89 score of commercial high-resolution imagery. This work presented a cost-effective and scalable solution, paving the way for a nationwide shift from manual to automated, high-fidelity damage assessment.

Monocular depth estimation has applications in many fields, such as autonomous navigation and extended reality, making it an essential computer vision task. However, current methods often produce smooth depth maps that lack the fine geometric detail needed for accurate scene understanding. We propose MDENeRF, an iterative framework that refines monocular depth estimates using depth information from Neural Radiance Fields (NeRFs). MDENeRF consists of three components: (1) an initial monocular estimate for global structure, (2) a NeRF trained on perturbed viewpoints, with per-pixel uncertainty, and (3) Bayesian fusion of the noisy monocular and NeRF depths. We derive NeRF uncertainty from the volume rendering process to iteratively inject high-frequency fine details. Meanwhile, our monocular prior maintains global structure. We demonstrate superior performance on key metrics and experiments using indoor scenes from the SUN RGB-D dataset.
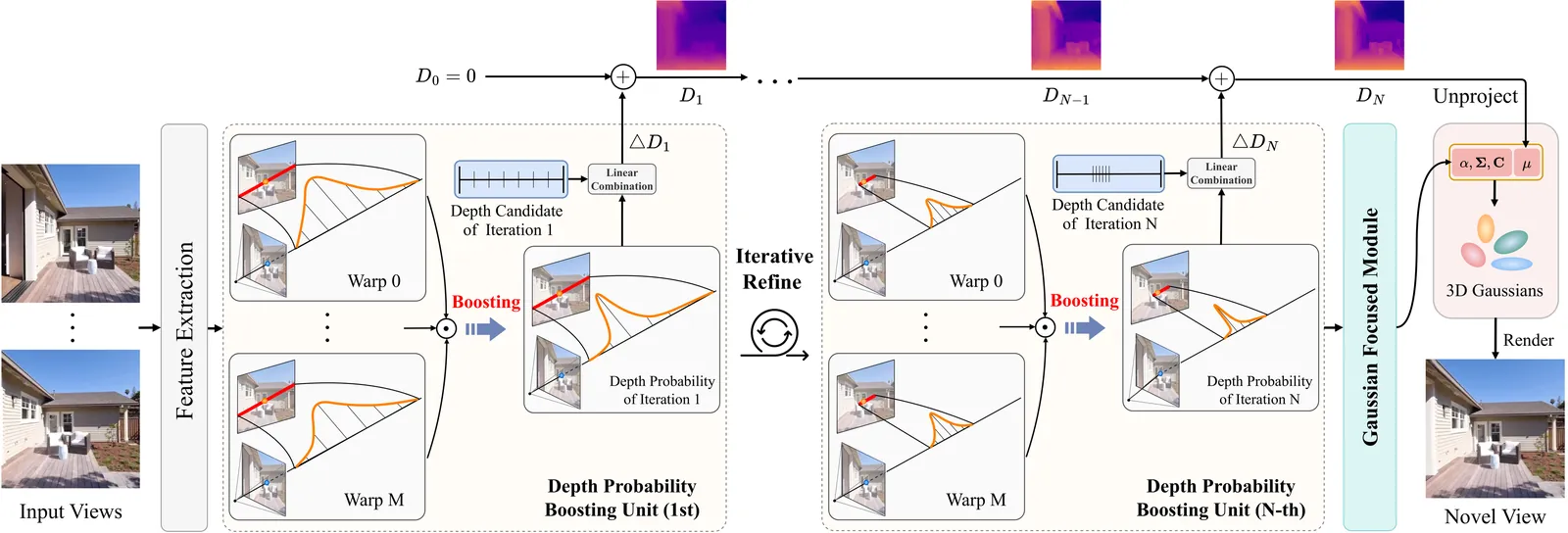
Generalizable 3D Gaussian Splatting aims to directly predict Gaussian parameters using a feed-forward network for scene reconstruction. Among these parameters, Gaussian means are particularly difficult to predict, so depth is usually estimated first and then unprojected to obtain the Gaussian sphere centers. Existing methods typically rely solely on a single warp to estimate depth probability, which hinders their ability to fully leverage cross-view geometric cues, resulting in unstable and coarse depth maps. To address this limitation, we propose IDESplat, which iteratively applies warp operations to boost depth probability estimation for accurate Gaussian mean prediction. First, to eliminate the inherent instability of a single warp, we introduce a Depth Probability Boosting Unit (DPBU) that integrates epipolar attention maps produced by cascading warp operations in a multiplicative manner. Next, we construct an iterative depth estimation process by stacking multiple DPBUs, progressively identifying potential depth candidates with high likelihood. As IDESplat iteratively boosts depth probability estimates and updates the depth candidates, the depth map is gradually refined, resulting in accurate Gaussian means. We conduct experiments on RealEstate10K, ACID, and DL3DV. IDESplat achieves outstanding reconstruction quality and state-of-the-art performance with real-time efficiency. On RE10K, it outperforms DepthSplat by 0.33 dB in PSNR, using only 10.7% of the parameters and 70% of the memory. Additionally, our IDESplat improves PSNR by 2.95 dB over DepthSplat on the DTU dataset in cross-dataset experiments, demonstrating its strong generalization ability.