Trending in Computer Vision
Mamoda2.5: Enhancing Unified Multimodal Model with DiT-MoE
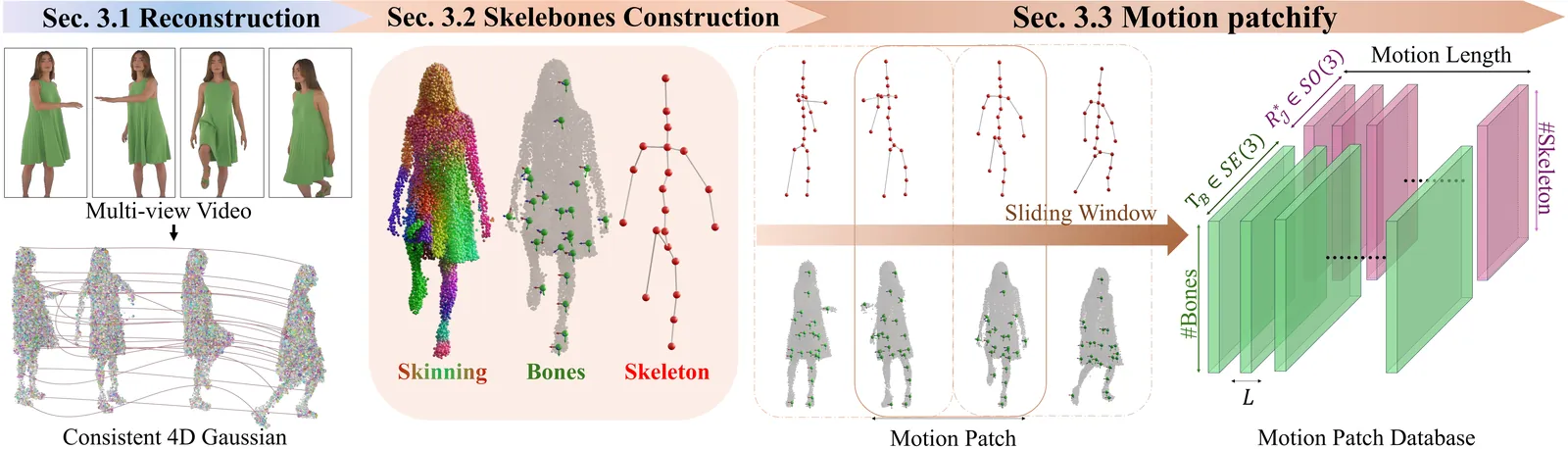
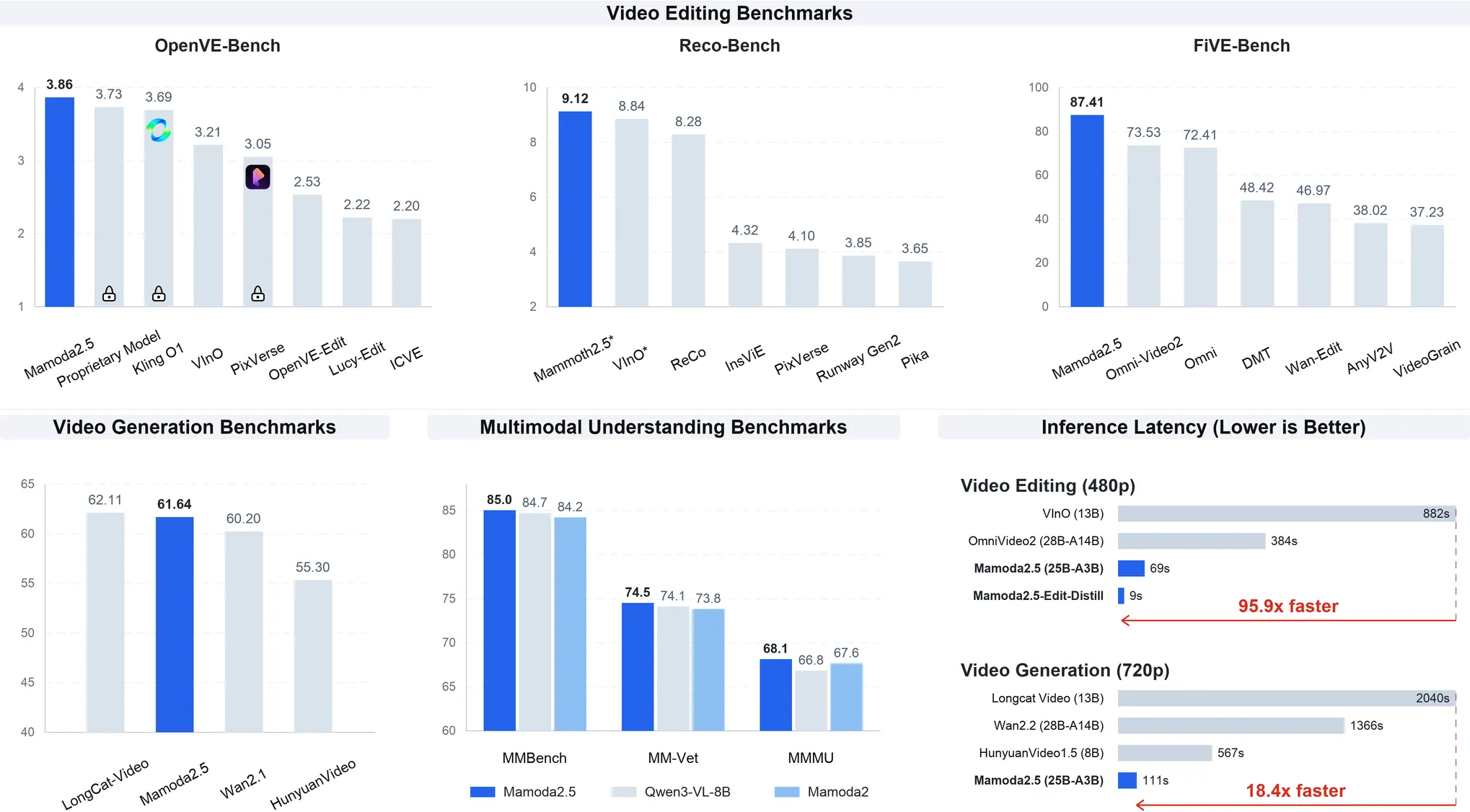
We present Mamoda2.5, a unified AR-Diffusion framework that seamlessly integrates multimodal understanding and generation within a single architecture. To efficiently enhance the model's generation capability, we equip the Diffusion Transformer backbone with a fine-grained Mixture-of-Experts (MoE) design (128 experts, Top-8 routing), yielding a 25B-parameter model that activates only 3B parameters, significantly reducing training costs while scaling up the model capacity. Mamoda2.5 achieves top-tier generation performance on VBench 2.0 and sets a new record in video editing quality, surpassing evaluated open-source models and matching the performance of current top-tier proprietary models, including the Kling O1 on OpenVE-Bench. Furthermore, we introduce a joint few-step distillation and reinforcement learning framework that compresses the 30-step editing model into a 4-step model and greatly accelerates model inference. Compared to open-source baselines, Mamoda2.5 achieves up to $95.9\times$ faster video editing inference. In real-world applications, Mamoda2.5 has been successfully deployed for content moderation and creative restoration tasks in advertising scenarios, achieving a 98% success rate in internal advertising video editing scenario.
2605.02641
May 2026Computer Vision
Audio-Visual Intelligence in Large Foundation Models
Audio-Visual Intelligence (AVI) has emerged as a central frontier in artificial intelligence, bridging auditory and visual modalities to enable machines that can perceive, generate, and interact in the multimodal real world. In the era of large foundation models, joint modeling of audio and vision has become increasingly crucial, i.e., not only for understanding but also for controllable generation and reasoning across dynamic, temporally grounded signals. Recent advances, such as Meta MovieGen and Google Veo-3, highlight the growing industrial and academic focus on unified audio-vision architectures that learn from massive multimodal data. However, despite rapid progress, the literature remains fragmented, spanning diverse tasks, inconsistent taxonomies, and heterogeneous evaluation practices that impede systematic comparison and knowledge integration. This survey provides the first comprehensive review of AVI through the lens of large foundation models. We establish a unified taxonomy covering the broad landscape of AVI tasks, ranging from understanding (e.g., speech recognition, sound localization) to generation (e.g., audio-driven video synthesis, video-to-audio) and interaction (e.g., dialogue, embodied, or agentic interfaces). We synthesize methodological foundations, including modality tokenization, cross-modal fusion, autoregressive and diffusion-based generation, large-scale pretraining, instruction alignment, and preference optimization. Furthermore, we curate representative datasets, benchmarks, and evaluation metrics, offering a structured comparison across task families and identifying open challenges in synchronization, spatial reasoning, controllability, and safety. By consolidating this rapidly expanding field into a coherent framework, this survey aims to serve as a foundational reference for future research on large-scale AVI.
2605.04045
May 2026Computer Vision
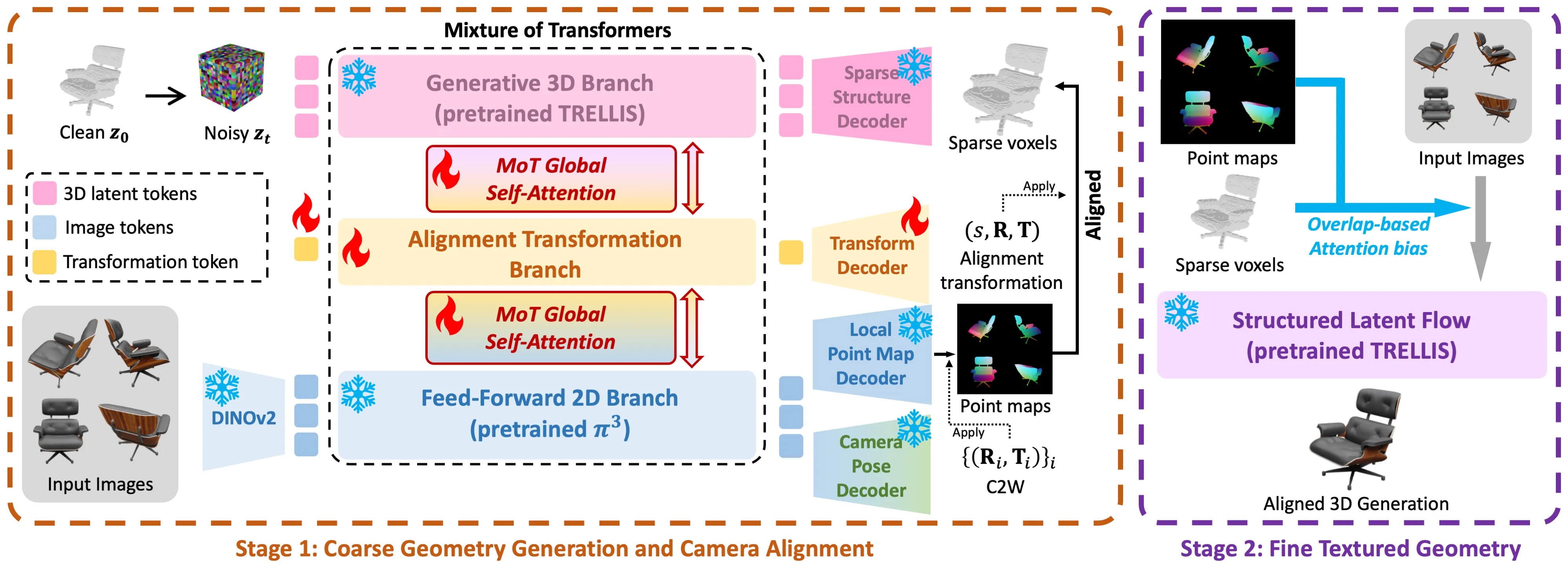
Mix3R: Mixing Feed-forward Reconstruction and Generative 3D Priors for Joint Multi-view Aligned 3D Reconstruction and Pose Estimation
Recent trends in sparse-view 3D reconstruction have taken two different paths: feed-forward reconstruction that predicts pixel-aligned point maps without a complete geometry, and generative 3D reconstruction that generates complete geometry but often with poor input-alignment. We present Mix3R, a novel generative 3D reconstruction method which mixes feed-forward reconstruction and 3D generation into a single framework in an aligned manner. Mix3R generates a 3D shape in two stages: a sparse voxel generation stage and a textured geometry generation stage. Unlike pure generative methods, our first-stage generation jointly produces a coarse 3D structure (sparse voxels), per-view point maps and camera parameters aligned to that 3D structure. This is made possible by introducing a Mixture-of-Transformers architecture that inserts global self-attentions to a feed-forward reconstruction model and a 3D generative model, both pretrained on large-scale data. This design effectively retains the pretrained priors but enables better 2D-3D alignment. Based on the initial aligned generations of sparse 3D voxels and point maps, we compute an overlap-based attention bias that is directly added to another pretrained textured geometry generation model, enabling it to correctly place input textures onto generated shapes in a training-free manner. Our design brings mutual benefits to both feed-forward reconstruction and 3D generation: The feed-forward branch learns to ground its predictions to a generative 3D prior, and conversely, the 3D generation branch is conditioned on geometrically informative features from the feed-forward branch. As a result, our method produces 3D shapes with better input alignment compared with pure 3D generative methods, together with camera pose estimations more accurate than previous feed-forward reconstruction methods. Our project page is at https://jsnln.github.io/mix3r/
2605.03359
May 2026Computer Vision

Perceptual Flow Network for Visually Grounded Reasoning
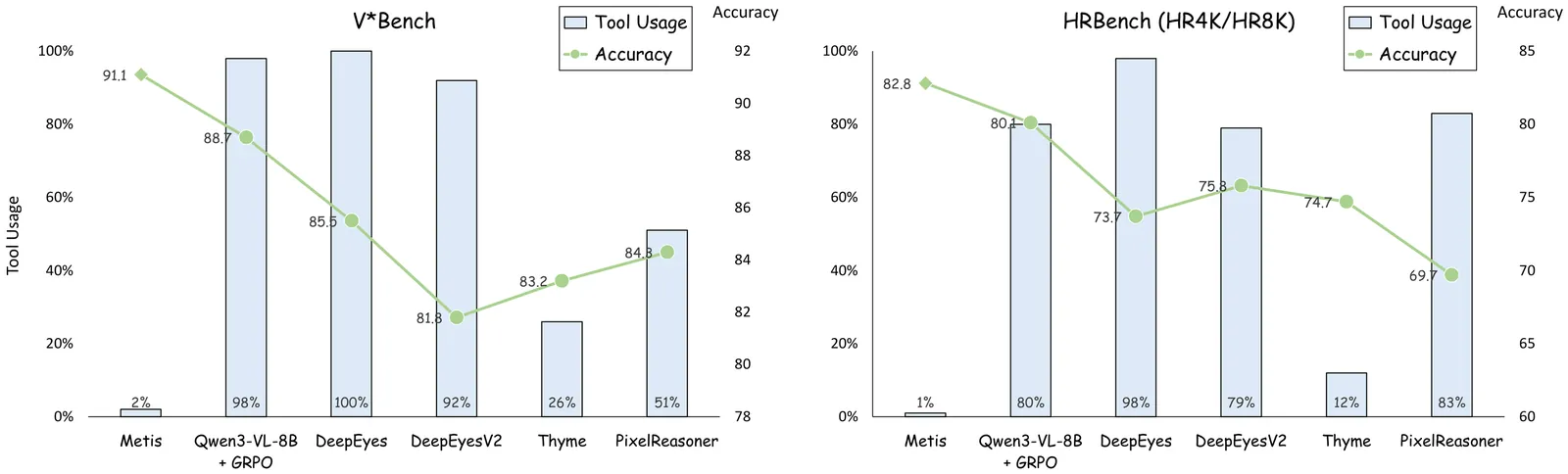
Despite the success of Large-Vision Language Models (LVLMs), general optimization objectives (e.g., standard MLE) fail to constrain visual trajectories, leading to language bias and hallucination. To mitigate this, current methods introduce geometric priors from visual experts as additional supervision. However, we observe that such supervision is typically suboptimal: it is biased toward geometric precision and offers limited reasoning utility. To bridge this gap, we propose Perceptual Flow Network (PFlowNet), which eschews rigid alignment with the expert priors and achieves interpretable yet more effective visual reasoning. Specifically, PFlowNet decouples perception from reasoning to establish a self-conditioned generation process. Based on this, it integrates multi-dimensional rewards with vicinal geometric shaping via variational reinforcement learning, thereby facilitating reasoning-oriented perceptual behaviors while preserving visual reliability. PFlowNet delivers a provable performance guarantee and competitive empirical results, particularly setting new SOTA records on V* Bench (90.6%) and MME-RealWorld-lite (67.0%).
2605.02730
May 2026Computer Vision
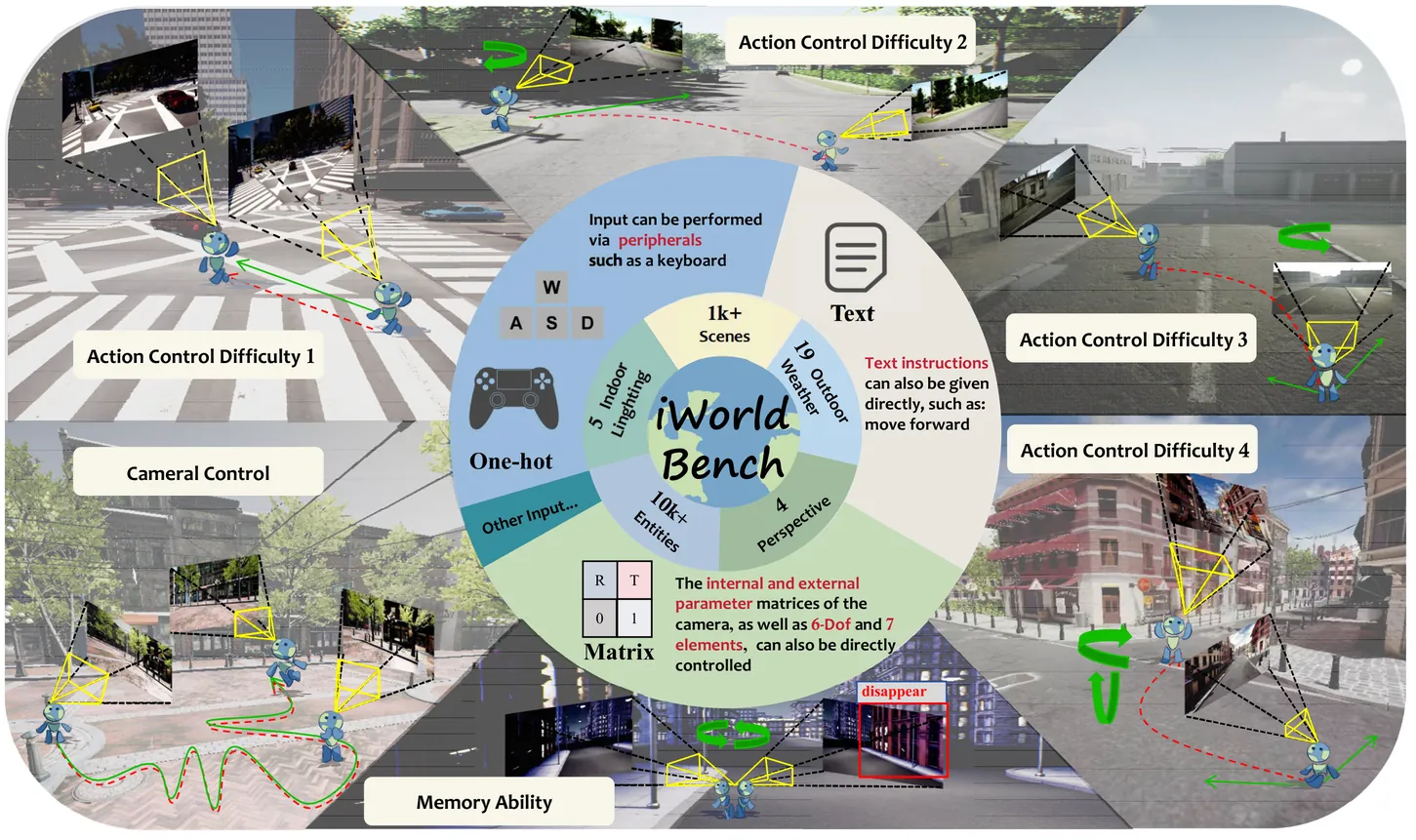
iWorld-Bench: A Benchmark for Interactive World Models with a Unified Action Generation Framework
Achieving Artificial General Intelligence (AGI) requires agents that learn and interact adaptively, with interactive world models providing scalable environments for perception, reasoning, and action. Yet current research still lacks large-scale datasets and unified benchmarks to evaluate their physical interaction capabilities. To address this, we propose iWorld-Bench, a comprehensive benchmark for training and testing world models on interaction-related abilities such as distance perception and memory. We construct a diverse dataset with 330k video clips and select 2.1k high-quality samples covering varied perspectives, weather, and scenes. As existing world models differ in interaction modalities, we introduce an Action Generation Framework to unify evaluation and design six task types, generating 4.9k test samples. These tasks jointly assess model performance across visual generation, trajectory following, and memory. Evaluating 14 representative world models, we identify key limitations and provide insights for future research. The iWorld-Bench model leaderboard is publicly available at iWorld-Bench.com.
2605.03941
May 2026Computer Vision

Linearizing Vision Transformer with Test-Time Training
While linear-complexity attention mechanisms offer a promising alternative to Softmax attention for overcoming the quadratic bottleneck, training such models from scratch remains prohibitively expensive. Inheriting weights from pretrained Transformers provides an appealing shortcut, yet the fundamental representational gap between Softmax and linear attention prevents effective weight transfer. In this work, we address this conversion challenge from two perspectives: architectural alignment and representational alignment. We identify Test-Time Training (TTT) as a linear-complexity architecture whose two-layer dynamic formulation is structurally aligned with Softmax attention, enabling direct inheritance of pretrained attention weights. To further align representational properties, including key shift-invariance and locality, we introduce key instance normalization and a lightweight locality enhancement module. We validate our approach by linearizing Stable Diffusion 3.5 and introduce SD3.5-T$^5$ (Transformer To Test Time Training). With only 1 hour of fine-tuning on 4$\times$H20 GPUs, SD3.5-T$^5$ achieves comparable text-to-image quality to the fine-tuned Softmax model, while accelerating inference by 1.32$\times$ and 1.47$\times$ at 1K and 2K resolutions.
2605.02772
May 2026Computer Vision
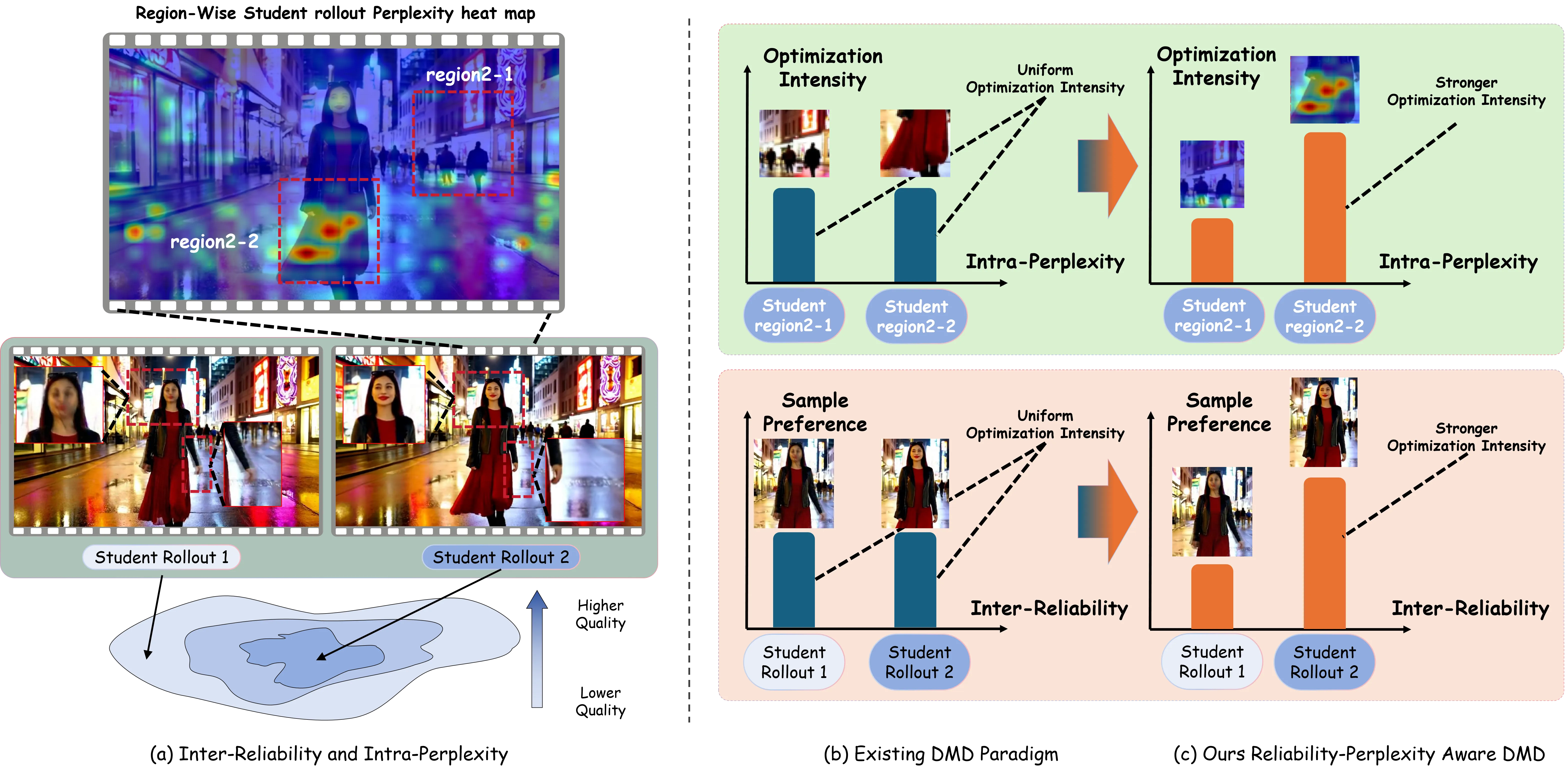
Stream-R1: Reliability-Perplexity Aware Reward Distillation for Streaming Video Generation
Distillation-based acceleration has become foundational for making autoregressive streaming video diffusion models practical, with distribution matching distillation (DMD) as the de facto choice. Existing methods, however, train the student to match the teacher's output indiscriminately, treating every rollout, frame, and pixel as equally reliable supervision. We argue that this caps distilled quality, since it overlooks two complementary axes of variance in DMD supervision: Inter-Reliability across student rollouts whose supervision varies in reliability, and Intra-Perplexity across spatial regions and temporal frames that contribute unequally to where quality can still be improved. The objective thus conflates two questions under a uniform weight: whether to learn from each rollout, and where to concentrate optimization within it. To address this, we propose Stream-R1, a Reliability-Perplexity Aware Reward Distillation framework that adaptively reweights the distillation objective at both rollout and spatiotemporal-element levels through a single shared reward-guided mechanism. At the Inter-Reliability level, Stream-R1 rescales each rollout's loss by an exponential of a pretrained video reward score, so that rollouts with reliable supervision dominate optimization. At the Intra-Perplexity level, it back-propagates the same reward model to extract per-pixel gradient saliency, which is factored into spatial and temporal weights that concentrate optimization pressure on regions and frames where refinement yields the largest expected gain. An adaptive balancing mechanism prevents any single quality axis from dominating across visual quality, motion quality, and text alignment. Stream-R1 attains consistent improvements on all three dimensions over distillation baselines on standard streaming video generation benchmarks, without architectural modification or additional inference cost.
2605.03849
May 2026Computer Vision

AniMatrix: An Anime Video Generation Model that Thinks in Art, Not Physics
Video generation models internalize physical realism as their prior. Anime deliberately violates physics: smears, impact frames, chibi shifts; and its thousands of coexisting artistic conventions yield no single "physics of anime" a model can absorb. Physics-biased models therefore flatten the artistry that defines the medium or collapse under its stylistic variance. We present AniMatrix, a video generation model that targets artistic rather than physical correctness through a dual-channel conditioning mechanism and a three-step transition: redefine correctness, override the physics prior, and distinguish art from failure. First, a Production Knowledge System encodes anime as a structured taxonomy of controllable production variables (Style, Motion, Camera, VFX), and AniCaption infers these variables from pixels as directorial directives. A trainable tag encoder preserves the field-value structure of this taxonomy while a frozen T5 encoder handles free-form narrative; dual-path injection (cross-attention for fine-grained control, AdaLN modulation for global enforcement) ensures categorical directives are never diluted by open-ended text. Second, a style-motion-deformation curriculum transitions the model from near-physical motion to full anime expressiveness. Third, deformation-aware preference optimization with a domain-specific reward model separates intentional artistry from pathological collapse. On an anime-specific human evaluation with five production dimensions scored by professional animators, AniMatrix ranks first on four of five, with the largest gains over Seedance-Pro 1.0 on Prompt Understanding (+0.70, +22.4 percent) and Artistic Motion (+0.55, +16.9 percent). We will publicly release the AniMatrix model weights and inference code.
2605.03652
May 2026Computer Vision
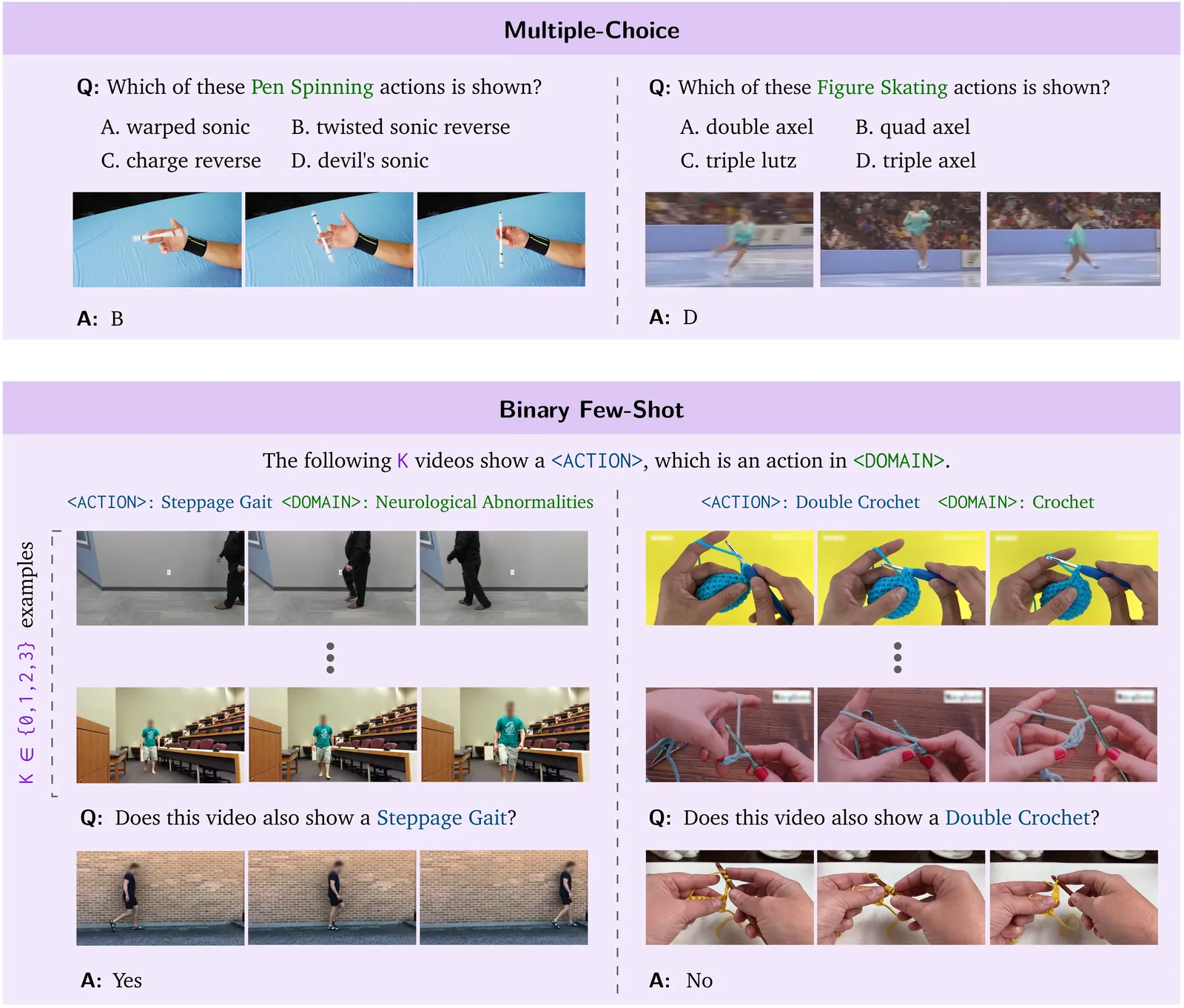
VideoNet: A Large-Scale Dataset for Domain-Specific Action Recognition
Videos are unique in their ability to capture actions which transcend multiple frames. Accordingly, for many years action recognition was the quintessential task for video understanding. Unfortunately, due to a lack of sufficiently diverse and challenging data, modern vision-language models (VLMs) are no longer evaluated on their action recognition capabilities. To revitalize action recognition in the era of VLMs, we advocate for a returned focus on domain-specific actions. To this end, we introduce VideoNet, a domain-specific action recognition benchmark covering 1,000 distinct actions from 37 domains. We begin with a multiple-choice evaluation setting, where the difference between closed and open models is stark: Gemini 3.1 Pro attains 69.9% accuracy while Qwen3-VL-8B gets a mere 45.0%. To understand why VLMs struggle on VideoNet, we relax the questions into a binary setting, where random chance is 50%. Still, Qwen achieves only 59.2% accuracy. Further relaxing the evaluation setup, we provide $k\in\{1,2,3\}$ in-context examples of the action. Some models excel in the few-shot setting, while others falter; Qwen improves $+7.0\%$, while Gemini declines $-4.8\%$. Notably, these gains fall short of the $+13.6\%$ improvement in non-expert humans when given few-shot examples. Finding that VLMs struggle to fully exploit in-context examples, we shift from test-time improvements to the training side. We collect the first large-scale training dataset for domain-specific actions, totaling nearly 500k video question-answer pairs. Fine-tuning a Molmo2-4B model on our data, we surpass all open-weight 8B models on the VideoNet benchmark.
2605.02834
May 2026Computer Vision

UniCorrn: Unified Correspondence Transformer Across 2D and 3D
Visual correspondence across image-to-image (2D-2D), image-to-point cloud (2D-3D), and point cloud-to-point cloud (3D-3D) geometric matching forms the foundation for numerous 3D vision tasks. Despite sharing a similar problem structure, current methods use task-specific designs with separate models for each modality combination. We present UniCorrn, the first correspondence model with shared weights that unifies geometric matching across all three tasks. Our key insight is that Transformer attention naturally captures cross-modal feature similarity. We propose a dual-stream decoder that maintains separate appearance and positional feature streams. This design enables end-to-end learning through stack-able layers while supporting flexible query-based correspondence estimation across heterogeneous modalities. Our architecture employs modality-specific backbones followed by shared encoder and decoder components, trained jointly on diverse data combining pseudo point clouds from depth maps with real 3D correspondence annotations. UniCorrn achieves competitive performance on 2D-2D matching and surpasses prior state-of-the-art by 8% on 7Scenes (2D-3D) and 10% on 3DLoMatch (3D-3D) in registration recall. Project website: https://neu-vi.github.io/UniCorrn
2605.04044
May 2026Computer Vision
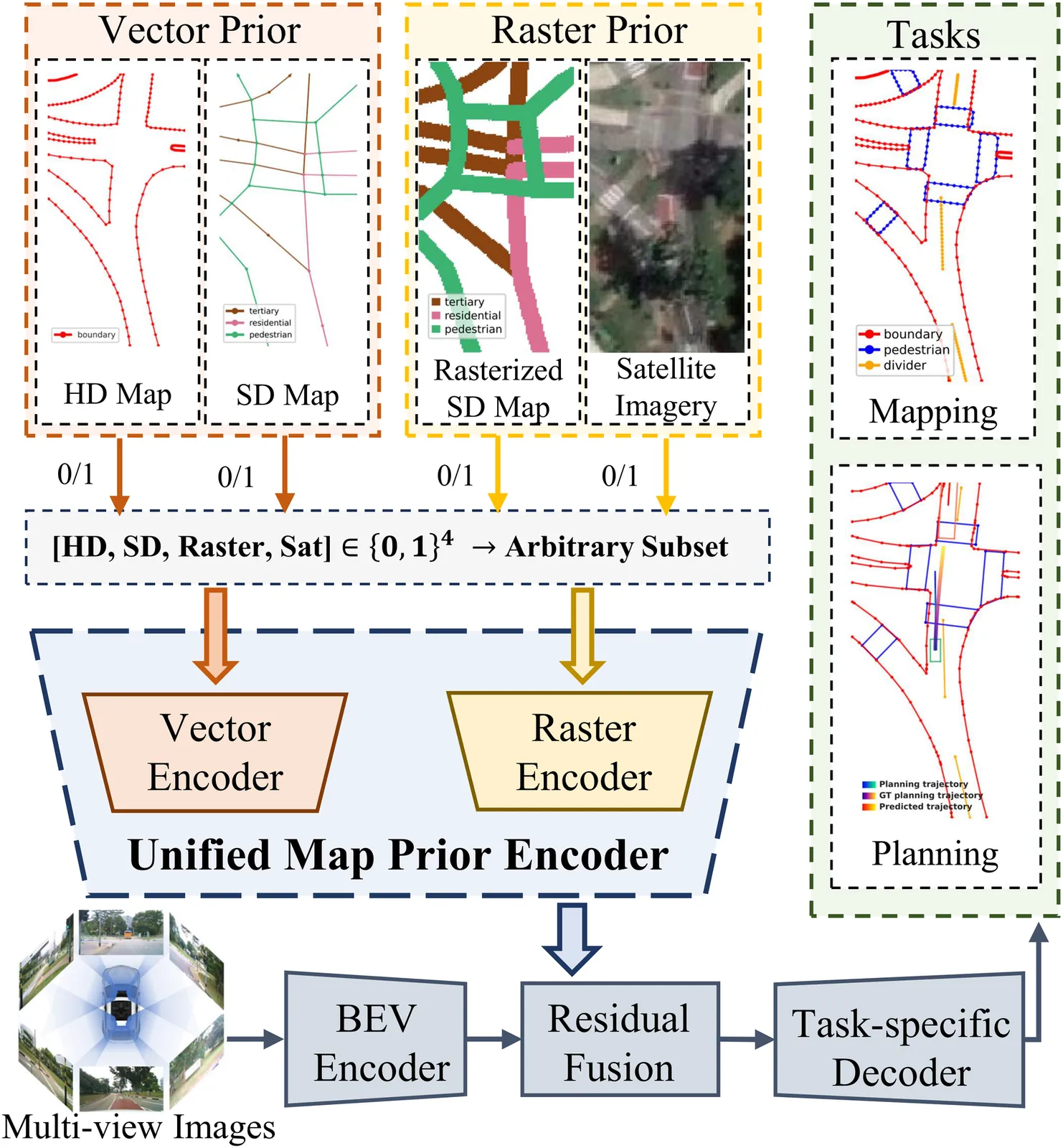
Unified Map Prior Encoder for Mapping and Planning
Online mapping and end-to-end (E2E) planning in autonomous driving remain largely sensor-centric, leaving rich map priors, including HD/SD vector maps, rasterized SD maps, and satellite imagery, underused because of heterogeneity, pose drift, and inconsistent availability at test time. We present UMPE, a Unified Map Prior Encoder that can ingest any subset of four priors and fuse them with BEV features for both mapping and planning. UMPE has two branches. The vector encoder pre-aligns HD/SD polylines with a frame-wise SE(2) correction, encodes points via multi-frequency sinusoidal features, and produces polyline tokens with confidence scores. BEV queries then apply cross-attention with confidence bias, followed by normalized channel-wise gating to avoid length imbalance and softly down-weight uncertain sources. The raster encoder shares a ResNet-18 backbone conditioned by FiLM with scaling and shift at every stage, performs SE(2) micro-alignment, and injects priors through zero-initialized residual fusion, so the network starts from a do-no-harm baseline and learns to add only useful prior evidence. A vector-then-raster fusion order reflects the inductive bias of geometry first, appearance second. On nuScenes mapping, UMPE lifts MapTRv2 from 61.5 to 67.4 mAP (+5.9) and MapQR from 66.4 to 71.7 mAP (+5.3). On Argoverse2, UMPE adds +4.1 mAP over strong baselines. UMPE is compositional: when trained with all priors, it outperforms single-prior models even when only one prior is available at test time, demonstrating powerset robustness. For E2E planning with the VAD backbone on nuScenes, UMPE reduces trajectory error from 0.72 to 0.42 m L2 on average (-0.30 m) and collision rate from 0.22% to 0.12% (-0.10%), surpassing recent prior-injection methods. These results show that a unified, alignment-aware treatment of heterogeneous map priors yields better mapping and better planning.
2605.02762
May 2026Computer Vision
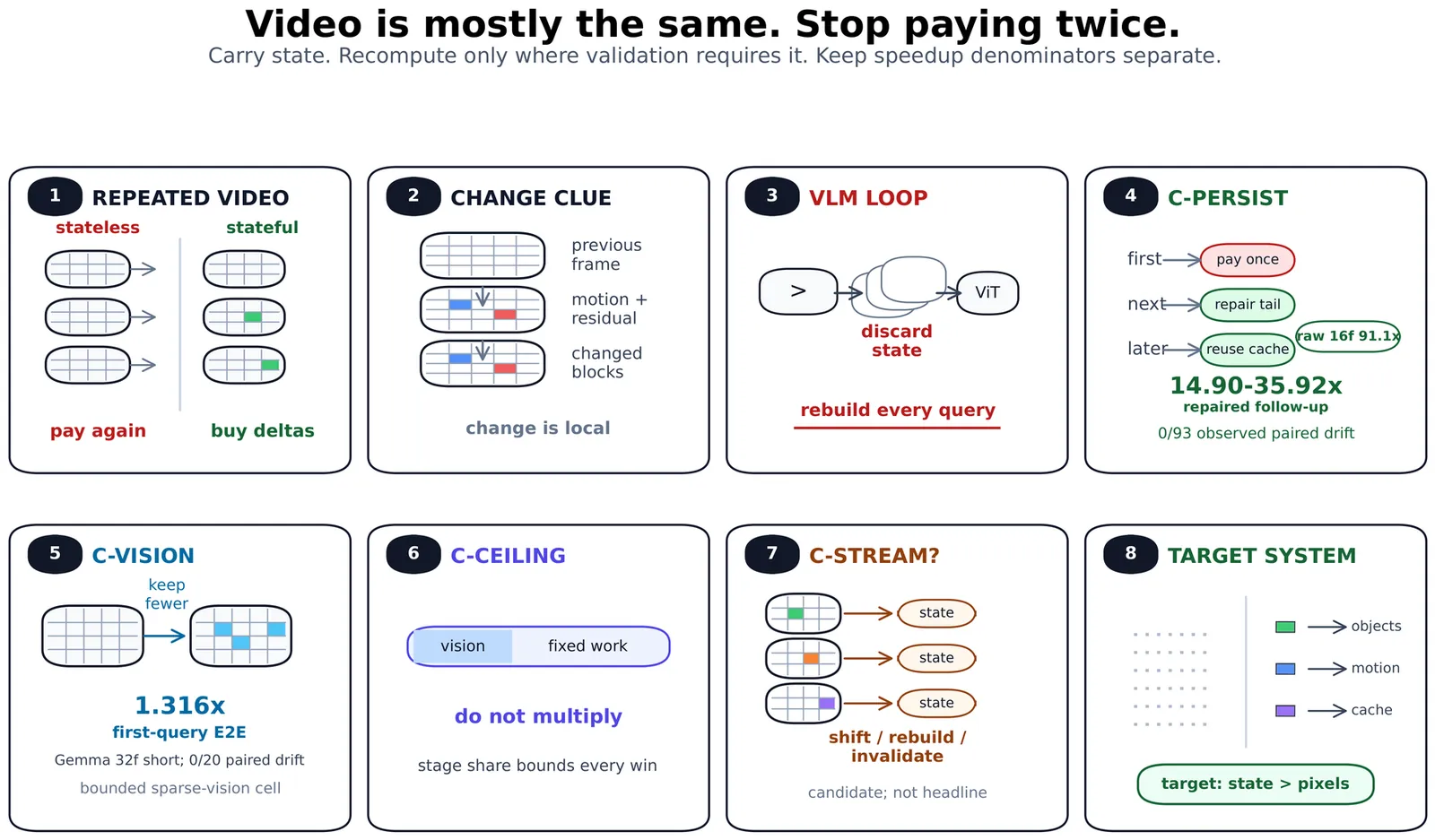
VLMaxxing through FrameMogging Training-Free Anti-Recomputation for Video Vision-Language Models
Video vision-language models (VLMs) keep paying for visual state the stream already told us was stable. The factory wall did not move, but most VLM pipelines still hand the model dense RGB frames or a fresh prefix again. We study that waste as training-free anti-recomputation: reuse state when validation says it survives, and buy fresh evidence when the scene, query, or cache topology requires it. The largest measured win is after ingest. On frozen Qwen2.5-VL-7B-Instruct-4bit, adaptive same-video follow-up reuse preserves paired choices and correctness on a 93-query VideoMME breadth setting while reducing follow-up latency by 14.90-35.92x. The first query is still cold; the win starts when later questions reuse the same video state. Stress tests bound the result: repeated-question schedules hold through 50 turns, while dense-answer-anchored prompt variation separates conservative fixed K=1 repair from faster aggressive policies that drift. Fresh-video pruning is smaller but real. C-VISION skips timed vision-tower work before the first answer is generated. On Gemma 4-E4B-4bit, the clean 32f short cell reaches 1.316x first-query speedup with no paired drift or parse failures on 20 items; Qwen shows the fidelity/speed boundary. Stage-share ceiling (C-CEILING) is the accounting guardrail: a component speedup becomes an end-to-end speedup only in proportion to the wall-clock share it accelerates, so C-VISION and after-ingest follow-up reuse do not multiply. Candidate C-STREAM remains a native-rate target, not a headline result here. The broader direction is VLM-native media that expose change, motion, uncertainty, object state, sensor time, and active tiles directly, so models do not have to rediscover the world from dense RGB every frame.
2605.03351
May 2026Computer Vision
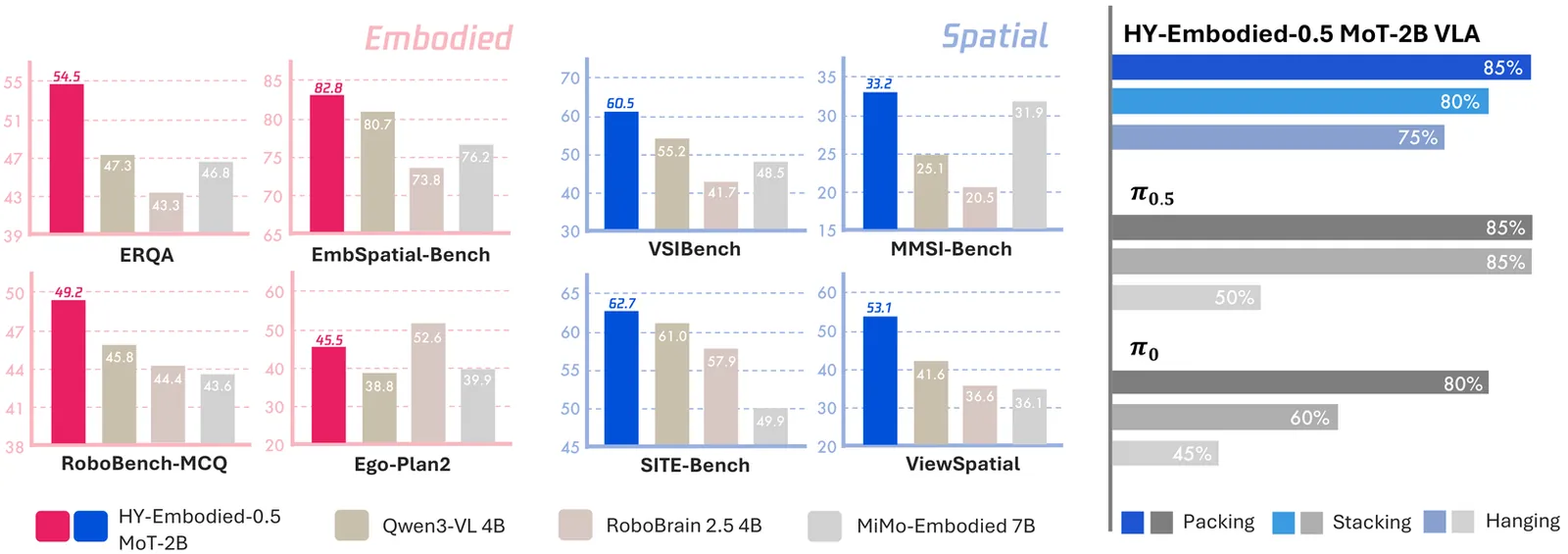
HY-Embodied-0.5: Embodied Foundation Models for Real-World Agents
We introduce HY-Embodied-0.5, a family of foundation models specifically designed for real-world embodied agents. To bridge the gap between general Vision-Language Models (VLMs) and the demands of embodied agents, our models are developed to enhance the core capabilities required by embodied intelligence: spatial and temporal visual perception, alongside advanced embodied reasoning for prediction, interaction, and planning. The HY-Embodied-0.5 suite comprises two primary variants: an efficient model with 2B activated parameters designed for edge deployment, and a powerful model with 32B activated parameters targeted for complex reasoning. To support the fine-grained visual perception essential for embodied tasks, we adopt a Mixture-of-Transformers (MoT) architecture to enable modality-specific computing. By incorporating latent tokens, this design effectively enhances the perceptual representation of the models. To improve reasoning capabilities, we introduce an iterative, self-evolving post-training paradigm. Furthermore, we employ on-policy distillation to transfer the advanced capabilities of the large model to the smaller variant, thereby maximizing the performance potential of the compact model. Extensive evaluations across 22 benchmarks, spanning visual perception, spatial reasoning, and embodied understanding, demonstrate the effectiveness of our approach. Our MoT-2B model outperforms similarly sized state-of-the-art models on 16 benchmarks, while the 32B variant achieves performance comparable to frontier models such as Gemini 3.0 Pro. In downstream robot control experiments, we leverage our robust VLM foundation to train an effective Vision-Language-Action (VLA) model, achieving compelling results in real-world physical evaluations. Code and models are open-sourced at https://github.com/Tencent-Hunyuan/HY-Embodied.
2604.07430
Apr 2026Computer Vision
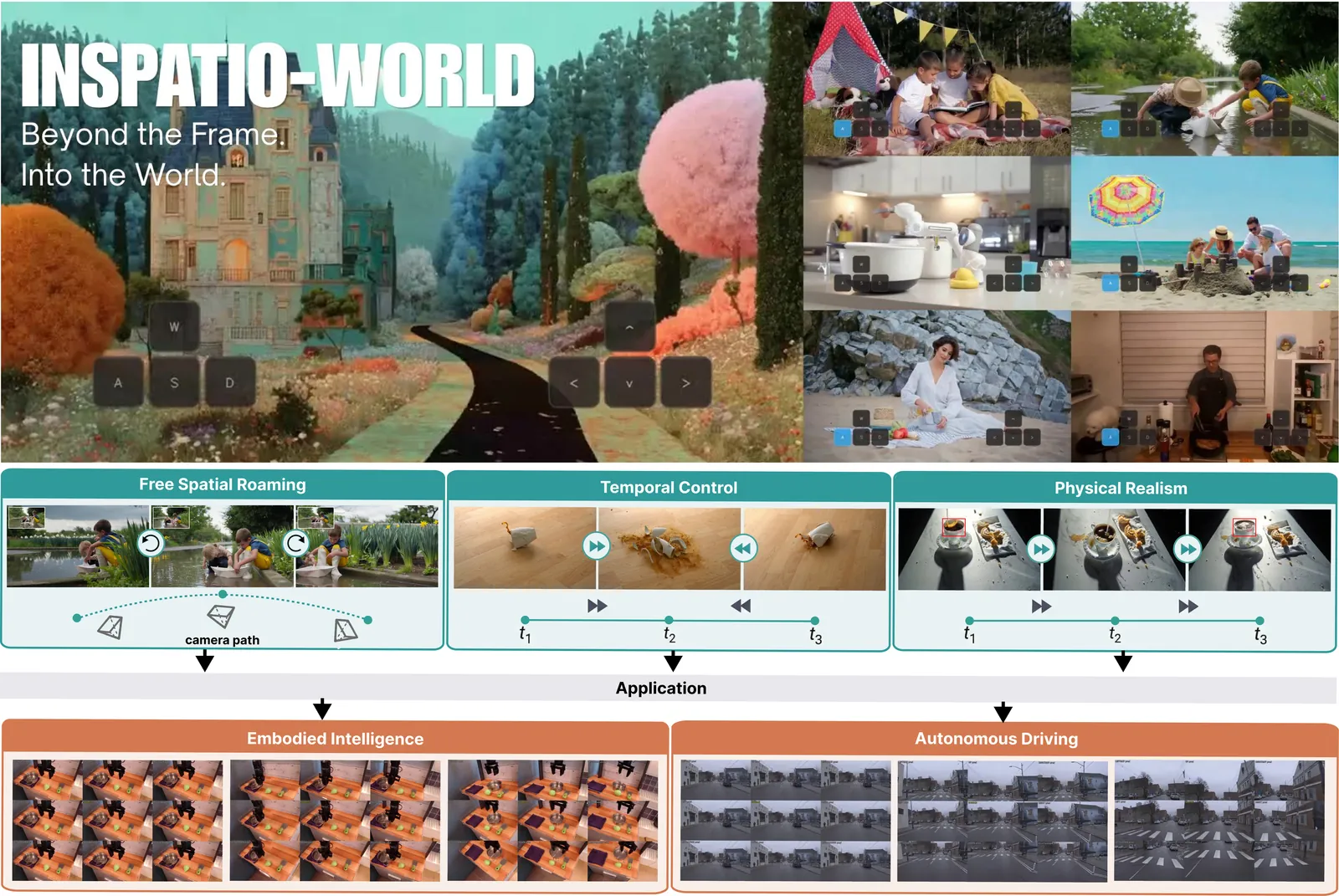
INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
Building world models with spatial consistency and real-time interactivity remains a fundamental challenge in computer vision. Current video generation paradigms often struggle with a lack of spatial persistence and insufficient visual realism, making it difficult to support seamless navigation in complex environments. To address these challenges, we propose INSPATIO-WORLD, a novel real-time framework capable of recovering and generating high-fidelity, dynamic interactive scenes from a single reference video. At the core of our approach is a Spatiotemporal Autoregressive (STAR) architecture, which enables consistent and controllable scene evolution through two tightly coupled components: Implicit Spatiotemporal Cache aggregates reference and historical observations into a latent world representation, ensuring global consistency during long-horizon navigation; Explicit Spatial Constraint Module enforces geometric structure and translates user interactions into precise and physically plausible camera trajectories. Furthermore, we introduce Joint Distribution Matching Distillation (JDMD). By using real-world data distributions as a regularizing guide, JDMD effectively overcomes the fidelity degradation typically caused by over-reliance on synthetic data. Extensive experiments demonstrate that INSPATIO-WORLD significantly outperforms existing state-of-the-art (SOTA) models in spatial consistency and interaction precision, ranking first among real-time interactive methods on the WorldScore-Dynamic benchmark, and establishing a practical pipeline for navigating 4D environments reconstructed from monocular videos.
2604.07209
Apr 2026Computer Vision

LPM 1.0: Video-based Character Performance Model
Performance, the externalization of intent, emotion, and personality through visual, vocal, and temporal behavior, is what makes a character alive. Learning such performance from video is a promising alternative to traditional 3D pipelines. However, existing video models struggle to jointly achieve high expressiveness, real-time inference, and long-horizon identity stability, a tension we call the performance trilemma. Conversation is the most comprehensive performance scenario, as characters simultaneously speak, listen, react, and emote while maintaining identity over time. To address this, we present LPM 1.0 (Large Performance Model), focusing on single-person full-duplex audio-visual conversational performance. Concretely, we build a multimodal human-centric dataset through strict filtering, speaking-listening audio-video pairing, performance understanding, and identity-aware multi-reference extraction; train a 17B-parameter Diffusion Transformer (Base LPM) for highly controllable, identity-consistent performance through multimodal conditioning; and distill it into a causal streaming generator (Online LPM) for low-latency, infinite-length interaction. At inference, given a character image with identity-aware references, LPM 1.0 generates listening videos from user audio and speaking videos from synthesized audio, with text prompts for motion control, all at real-time speed with identity-stable, infinite-length generation. LPM 1.0 thus serves as a visual engine for conversational agents, live streaming characters, and game NPCs. To systematically evaluate this setting, we propose LPM-Bench, the first benchmark for interactive character performance. LPM 1.0 achieves state-of-the-art results across all evaluated dimensions while maintaining real-time inference.
2604.07823
Apr 2026Computer Vision
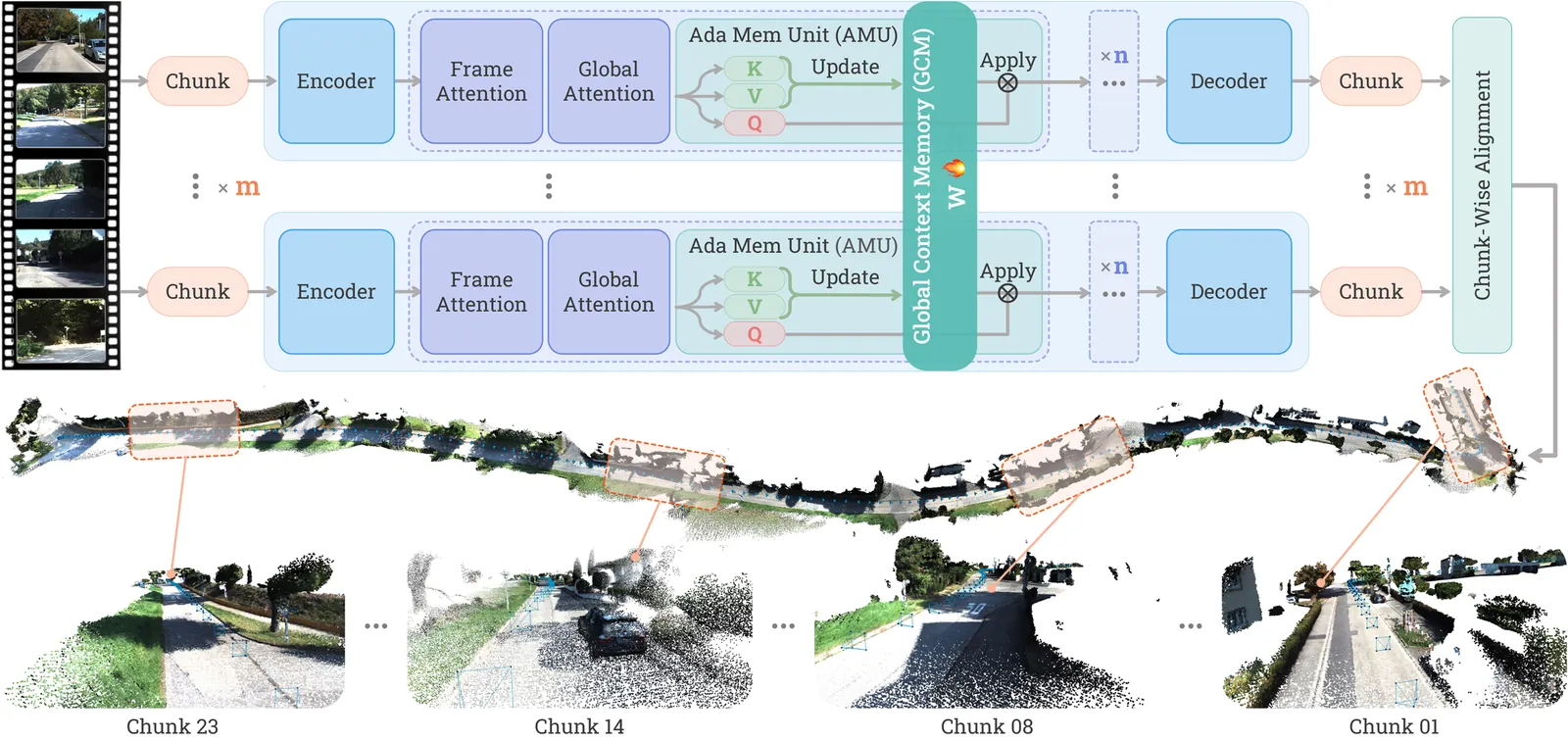
Scal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction
This paper addresses the task of large-scale 3D scene reconstruction from long video sequences. Recent feed-forward reconstruction models have shown promising results by directly regressing 3D geometry from RGB images without explicit 3D priors or geometric constraints. However, these methods often struggle to maintain reconstruction accuracy and consistency over long sequences due to limited memory capacity and the inability to effectively capture global contextual cues. In contrast, humans can naturally exploit the global understanding of the scene to inform local perception. Motivated by this, we propose a novel neural global context representation that efficiently compresses and retains long-range scene information, enabling the model to leverage extensive contextual cues for enhanced reconstruction accuracy and consistency. The context representation is realized through a set of lightweight neural sub-networks that are rapidly adapted during test time via self-supervised objectives, which substantially increases memory capacity without incurring significant computational overhead. The experiments on multiple large-scale benchmarks, including the KITTI Odometry~\cite{Geiger2012CVPR} and Oxford Spires~\cite{tao2025spires} datasets, demonstrate the effectiveness of our approach in handling ultra-large scenes, achieving leading pose accuracy and state-of-the-art 3D reconstruction accuracy while maintaining efficiency. Code is available at https://zju3dv.github.io/scal3r.
2604.08542
Apr 2026Computer Vision
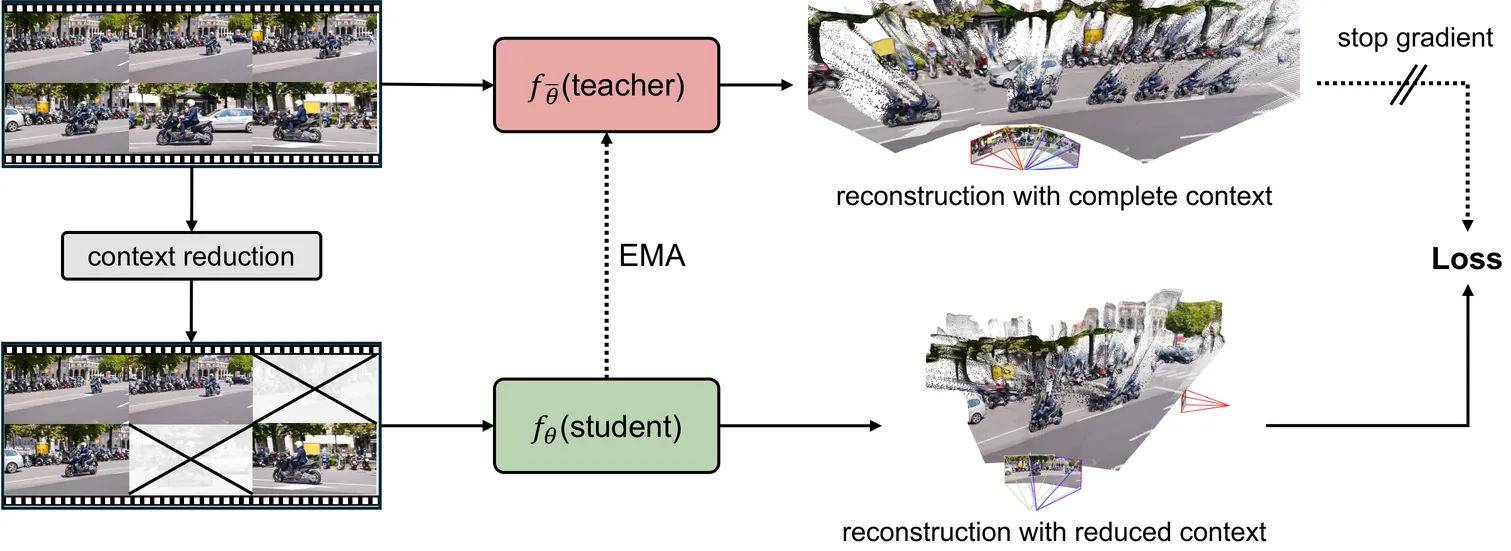
Self-Improving 4D Perception via Self-Distillation
Large-scale multi-view reconstruction models have made remarkable progress, but most existing approaches still rely on fully supervised training with ground-truth 3D/4D annotations. Such annotations are expensive and particularly scarce for dynamic scenes, limiting scalability. We propose SelfEvo, a self-improving framework that continually improves pretrained multi-view reconstruction models using unlabeled videos. SelfEvo introduces a self-distillation scheme using spatiotemporal context asymmetry, enabling self-improvement for learning-based 4D perception without external annotations. We systematically study design choices that make self-improvement effective, including loss signals, forms of asymmetry, and other training strategies. Across eight benchmarks spanning diverse datasets and domains, SelfEvo consistently improves pretrained baselines and generalizes across base models (e.g. VGGT and $π^3$), with significant gains on dynamic scenes. Overall, SelfEvo achieves up to 36.5% relative improvement in video depth estimation and 20.1% in camera estimation, without using any labeled data. Project Page: https://self-evo.github.io/.
2604.08532
Apr 2026Computer Vision
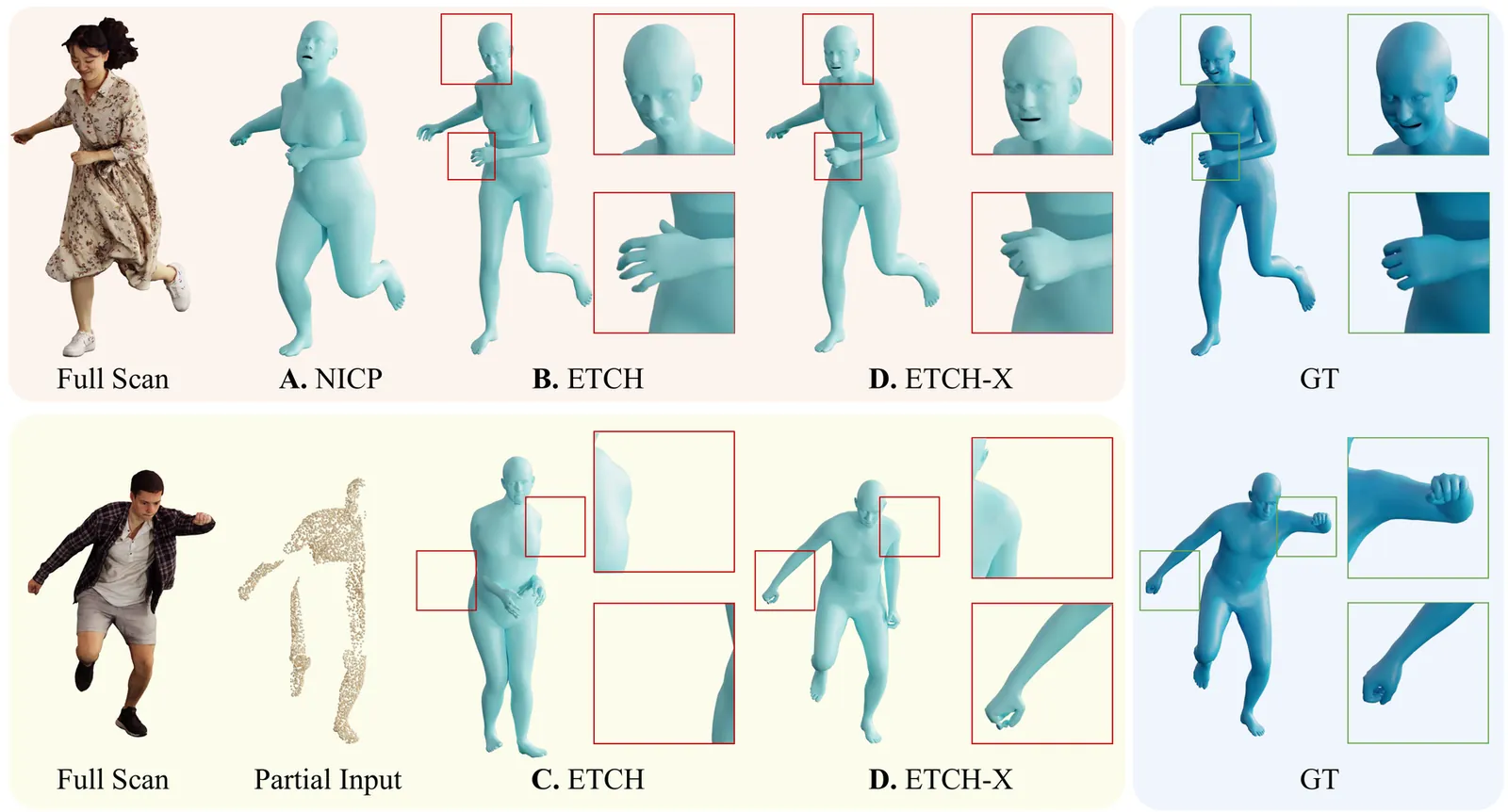
ETCH-X: Robustify Expressive Body Fitting to Clothed Humans with Composable Datasets
Human body fitting, which aligns parametric body models such as SMPL to raw 3D point clouds of clothed humans, serves as a crucial first step for downstream tasks like animation and texturing. An effective fitting method should be both locally expressive-capturing fine details such as hands and facial features-and globally robust to handle real-world challenges, including clothing dynamics, pose variations, and noisy or partial inputs. Existing approaches typically excel in only one aspect, lacking an all-in-one solution.We upgrade ETCH to ETCH-X, which leverages a tightness-aware fitting paradigm to filter out clothing dynamics ("undress"), extends expressiveness with SMPL-X, and replaces explicit sparse markers (which are highly sensitive to partial data) with implicit dense correspondences ("dense fit") for more robust and fine-grained body fitting. Our disentangled "undress" and "dense fit" modular stages enable separate and scalable training on composable data sources, including diverse simulated garments (CLOTH3D), large-scale full-body motions (AMASS), and fine-grained hand gestures (InterHand2.6M), improving outfit generalization and pose robustness of both bodies and hands. Our approach achieves robust and expressive fitting across diverse clothing, poses, and levels of input completeness, delivering a substantial performance improvement over ETCH on both: 1) seen data, such as 4D-Dress (MPJPE-All, 33.0% ) and CAPE (V2V-Hands, 35.8% ), and 2) unseen data, such as BEDLAM2.0 (MPJPE-All, 80.8% ; V2V-All, 80.5% ). Code and models will be released at https://xiaobenli00.github.io/ETCH-X/.
2604.08548
Apr 2026Computer Vision
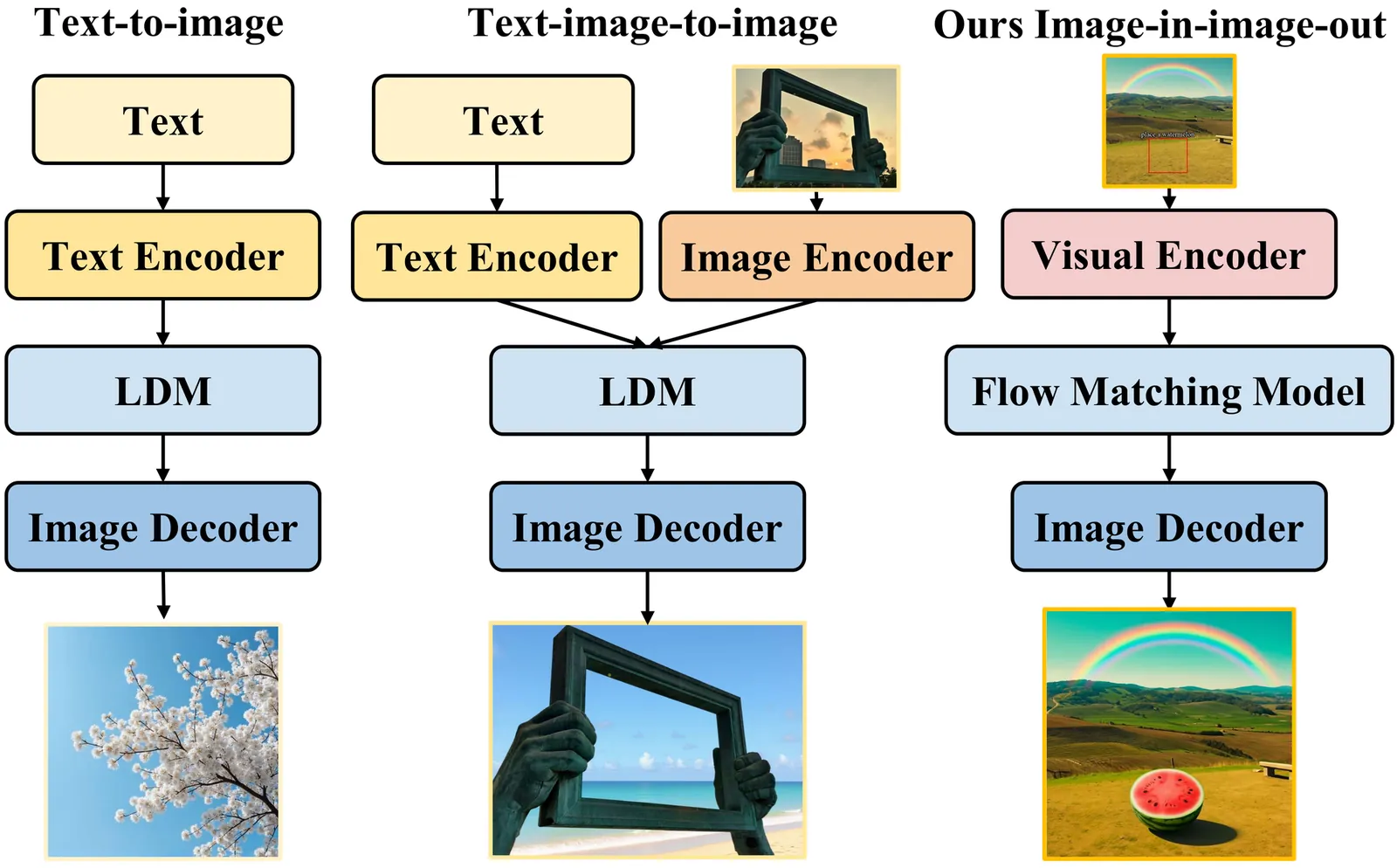
FlowInOne:Unifying Multimodal Generation as Image-in, Image-out Flow Matching
Multimodal generation has long been dominated by text-driven pipelines where language dictates vision but cannot reason or create within it. We challenge this paradigm by asking whether all modalities, including textual descriptions, spatial layouts, and editing instructions, can be unified into a single visual representation. We present FlowInOne, a framework that reformulates multimodal generation as a purely visual flow, converting all inputs into visual prompts and enabling a clean image-in, image-out pipeline governed by a single flow matching model. This vision-centric formulation naturally eliminates cross-modal alignment bottlenecks, noise scheduling, and task-specific architectural branches, unifying text-to-image generation, layout-guided editing, and visual instruction following under one coherent paradigm. To support this, we introduce VisPrompt-5M, a large-scale dataset of 5 million visual prompt pairs spanning diverse tasks including physics-aware force dynamics and trajectory prediction, alongside VP-Bench, a rigorously curated benchmark assessing instruction faithfulness, spatial precision, visual realism, and content consistency. Extensive experiments demonstrate that FlowInOne achieves state-of-the-art performance across all unified generation tasks, surpassing both open-source models and competitive commercial systems, establishing a new foundation for fully vision-centric generative modeling where perception and creation coexist within a single continuous visual space.
2604.06757
Apr 2026Computer Vision
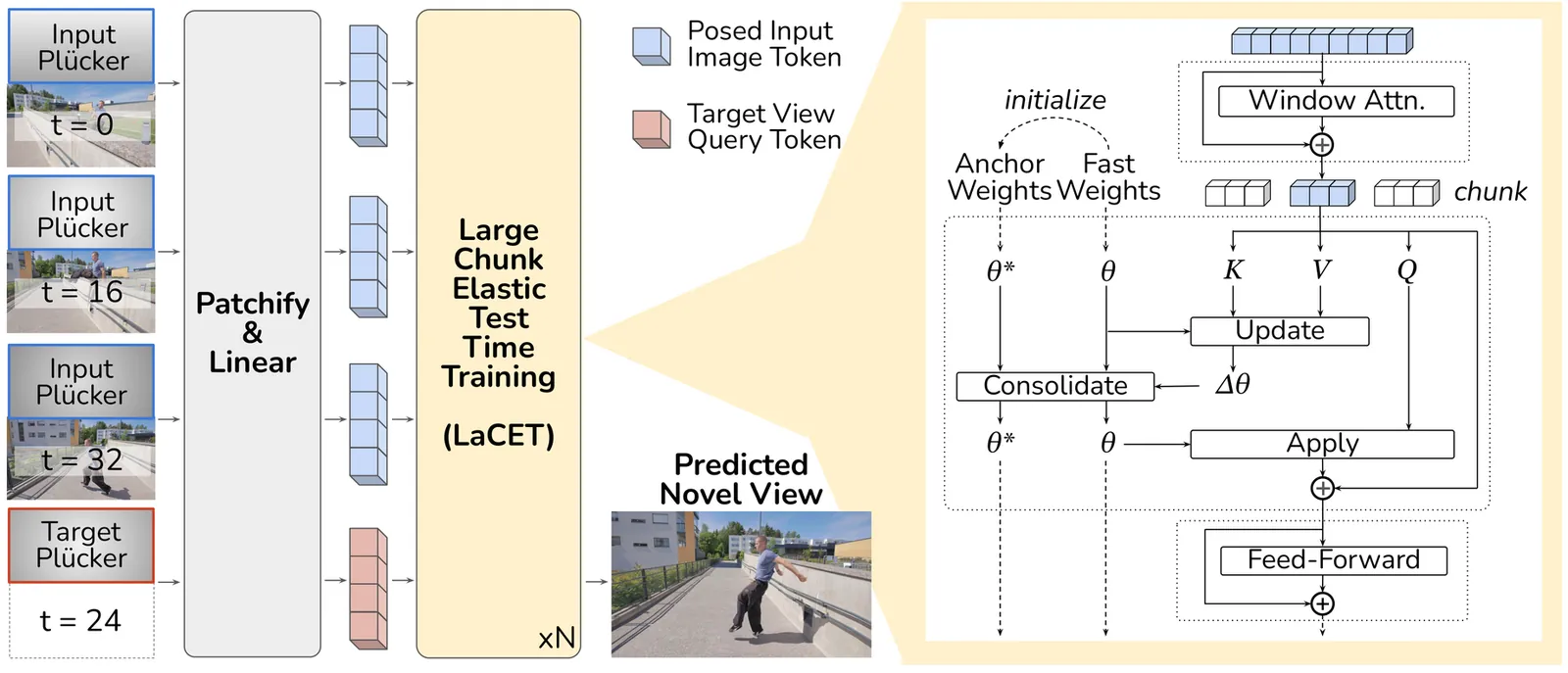
Fast Spatial Memory with Elastic Test-Time Training
Large Chunk Test-Time Training (LaCT) has shown strong performance on long-context 3D reconstruction, but its fully plastic inference-time updates remain vulnerable to catastrophic forgetting and overfitting. As a result, LaCT is typically instantiated with a single large chunk spanning the full input sequence, falling short of the broader goal of handling arbitrarily long sequences in a single pass. We propose Elastic Test-Time Training inspired by elastic weight consolidation, that stabilizes LaCT fast-weight updates with a Fisher-weighted elastic prior around a maintained anchor state. The anchor evolves as an exponential moving average of past fast weights to balance stability and plasticity. Based on this updated architecture, we introduce Fast Spatial Memory (FSM), an efficient and scalable model for 4D reconstruction that learns spatiotemporal representations from long observation sequences and renders novel view-time combinations. We pre-trained FSM on large-scale curated 3D/4D data to capture the dynamics and semantics of complex spatial environments. Extensive experiments show that FSM supports fast adaptation over long sequences and delivers high-quality 3D/4D reconstruction with smaller chunks and mitigating the camera-interpolation shortcut. Overall, we hope to advance LaCT beyond the bounded single-chunk setting toward robust multi-chunk adaptation, a necessary step for generalization to genuinely longer sequences, while substantially alleviating the activation-memory bottleneck.
2604.07350
Apr 2026Computer Vision