Hardware Architecture
arXiv:cs.AR
Covers systems organization and hardware architecture. Roughly includes material in ACM Subject Classes C.0, C.1, and C.5.
Covers systems organization and hardware architecture. Roughly includes material in ACM Subject Classes C.0, C.1, and C.5.
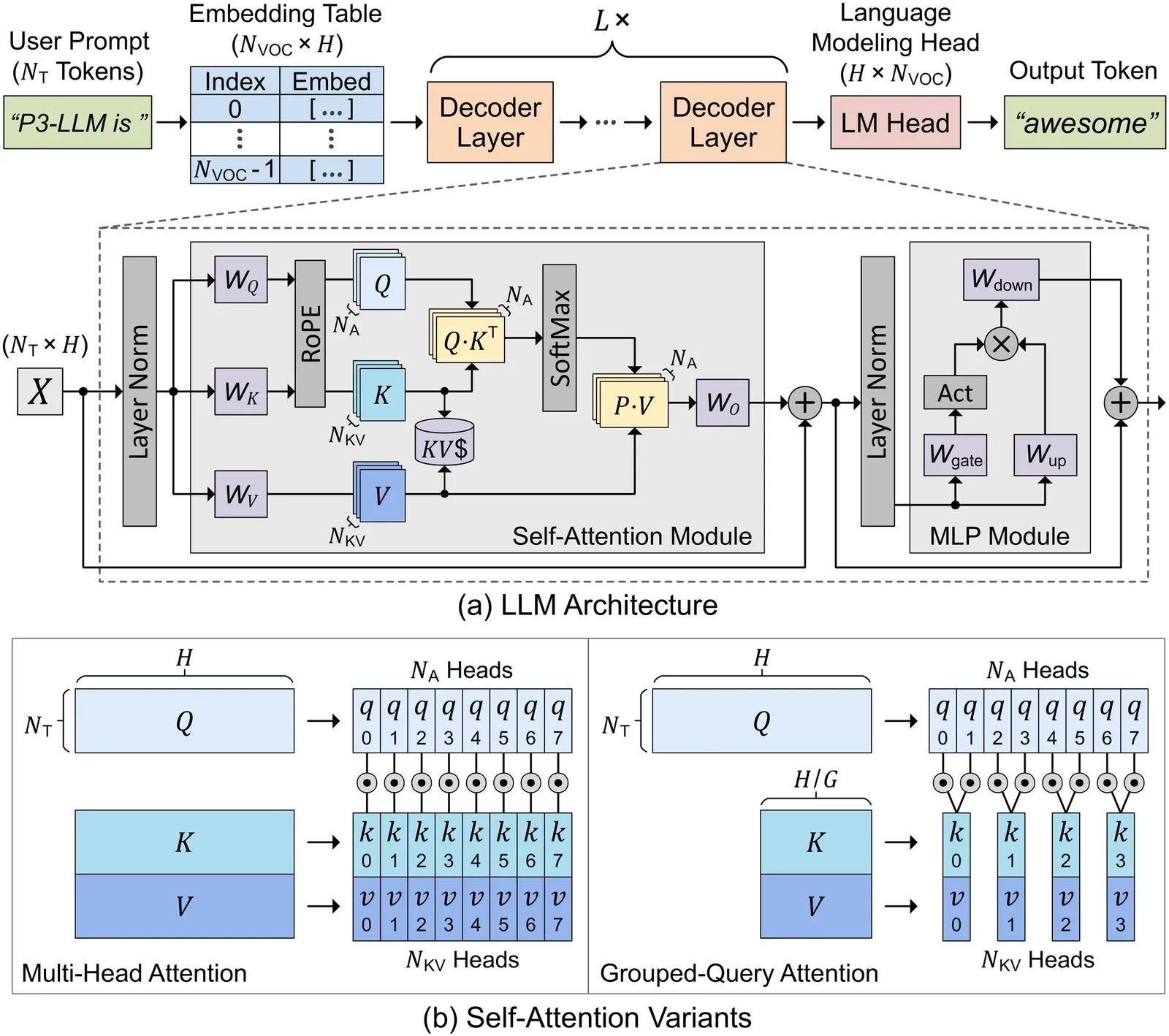
The substantial memory bandwidth and computational demand of large language models (LLMs) present critical challenges for efficient inference. To tackle this, the literature has explored heterogeneous systems that combine neural processing units (NPUs) with DRAM-based processing-in-memory (PIM) for LLM acceleration. However, existing high-precision (e.g., FP16) PIM compute units incur significant area and power overhead in DRAM technology, limiting the effective computation throughput. In this paper, we introduce P3-LLM, a novel NPU-PIM integrated accelerator for LLM inference using hybrid numerical formats. Our approach is threefold: First, we propose a flexible mixed-precision quantization scheme, which leverages hybrid numerical formats to quantize different LLM operands with high compression efficiency and minimal accuracy loss. Second, we architect an efficient PIM accelerator co-design for P3-LLM, featuring lightweight compute units to support our hybrid numerical formats. The enhanced PIM compute units significantly boost the computation throughput under iso-area constraints. Third, we optimize the low-precision dataflow of different LLM modules by applying operator fusion to minimize the overhead of runtime dequantization. Our evaluation on a diverse set of representative LLMs and tasks demonstrates that P3-LLM achieves state-of-the-art quantization accuracy in terms of both KV-cache-only quantization and weight-activation quantization. Combining the proposed quantization scheme with PIM architecture co-design, P3-LLM yields an average of $4.9\times$, $2.0\times$, and $3.4\times$ speedups over the state-of-the-art LLM accelerators HBM-PIM, Ecco, and Pimba, respectively. Our quantization code is available at https://github.com/yc2367/P3-LLM.git
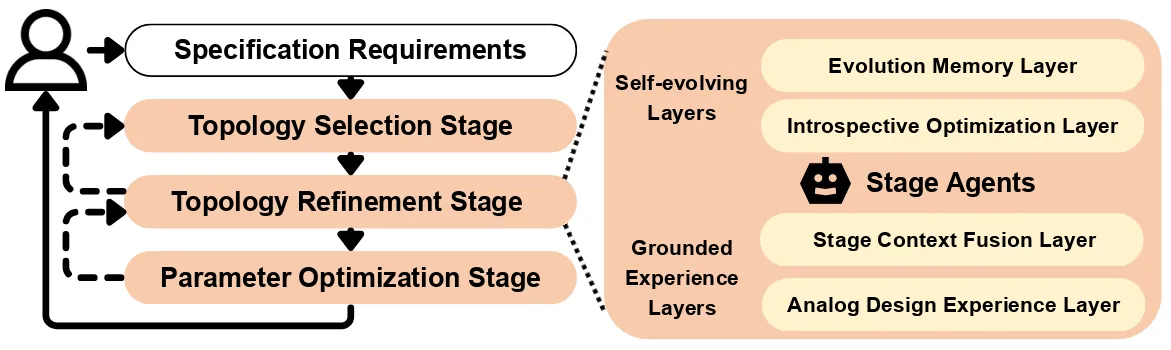
Analog circuit design remains a knowledge- and experience-intensive process that relies heavily on human intuition for topology generation and device parameter tuning. Existing LLM-based approaches typically depend on prompt-driven netlist generation or predefined topology templates, limiting their ability to satisfy complex specification requirements. We propose AnalogSAGE, an open-source self-evolving multi-agent framework that coordinates three-stage agent explorations through four stratified memory layers, enabling iterative refinement with simulation-grounded feedback. To support reproducibility and generality, we release the source code. Our benchmark spans ten specification-driven operational amplifier design problems of varying difficulty, enabling quantitative and cross-task comparison under identical conditions. Evaluated under the open-source SKY130 PDK with ngspice, AnalogSAGE achieves a 10$\times$ overall pass rate, a 48$\times$ Pass@1, and a 4$\times$ reduction in parameter search space compared with existing frameworks, demonstrating that stratified memory and grounded reasoning substantially enhance the reliability and autonomy of analog design automation in practice.
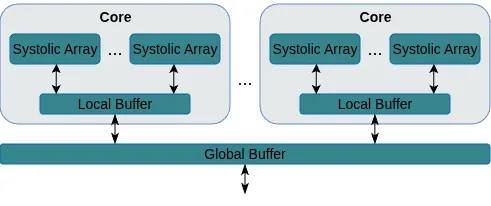
Energy consumption dictates the cost and environmental impact of deploying Large Language Models. This paper investigates the impact of on-chip SRAM size and operating frequency on the energy efficiency and performance of LLM inference, focusing on the distinct behaviors of the compute-bound prefill and memory-bound decode phases. Our simulation methodology combines OpenRAM for energy modeling, LLMCompass for latency simulation, and ScaleSIM for systolic array operational intensity. Our findings show that total energy use is predominantly determined by SRAM size in both phases, with larger buffers significantly increasing static energy due to leakage, which is not offset by corresponding latency benefits. We quantitatively explore the memory-bandwidth bottleneck, demonstrating that while high operating frequencies reduce prefill latency, their positive impact on memory-bound decode latency is capped by the external memory bandwidth. Counter-intuitively, high compute frequency can reduce total energy by reducing execution time and consequently decreasing static energy consumption more than the resulting dynamic power increase. We identify an optimal hardware configuration for the simulated workload: high operating frequencies (1200MHz-1400MHz) and a small local buffer size of 32KB to 64KB. This combination achieves the best energy-delay product, balancing low latency with high energy efficiency. Furthermore, we demonstrate how memory bandwidth acts as a performance ceiling, and that increasing compute frequency only yields performance gains up to the point where the workload becomes memory-bound. This analysis provides concrete architectural insights for designing energy-efficient LLM accelerators, especially for datacenters aiming to minimize their energy overhead.
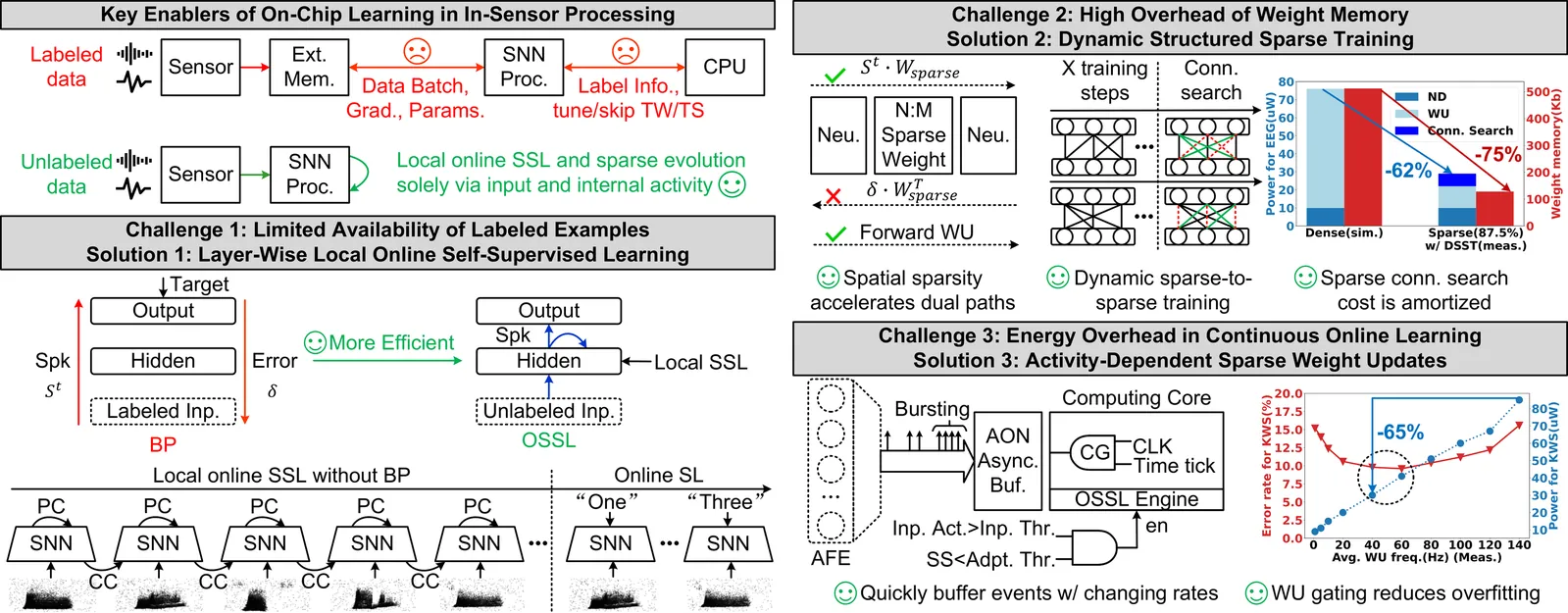
In this paper, we present ElfCore, a 28nm digital spiking neural network processor tailored for event-driven sensory signal processing. ElfCore is the first to efficiently integrate: (1) a local online self-supervised learning engine that enables multi-layer temporal learning without labeled inputs; (2) a dynamic structured sparse training engine that supports high-accuracy sparse-to-sparse learning; and (3) an activity-dependent sparse weight update mechanism that selectively updates weights based solely on input activity and network dynamics. Demonstrated on tasks including gesture recognition, speech, and biomedical signal processing, ElfCore outperforms state-of-the-art solutions with up to 16X lower power consumption, 3.8X reduced on-chip memory requirements, and 5.9X greater network capacity efficiency.
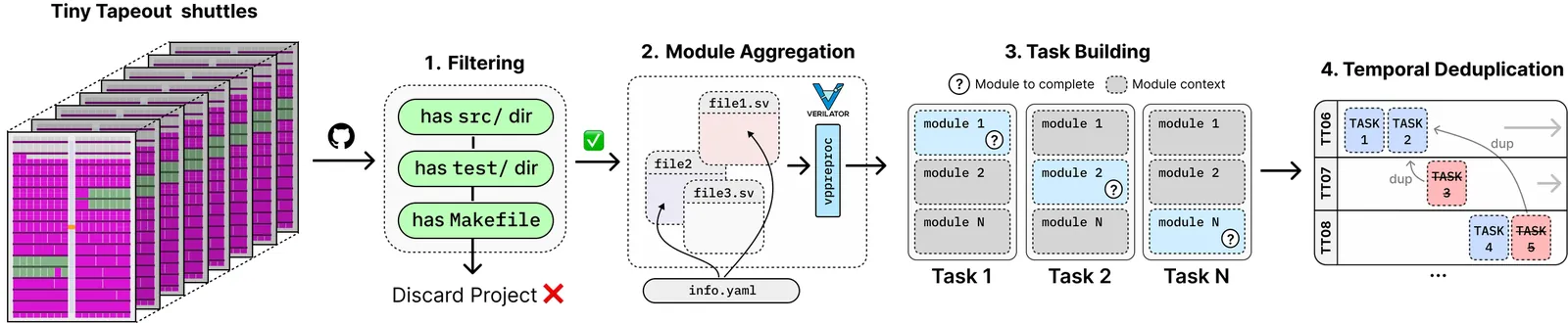
LLMs have shown early promise in generating RTL code, yet evaluating their capabilities in realistic setups remains a challenge. So far, RTL benchmarks have been limited in scale, skewed toward trivial designs, offering minimal verification rigor, and remaining vulnerable to data contamination. To overcome these limitations and to push the field forward, this paper introduces NotSoTiny, a benchmark that assesses LLM on the generation of structurally rich and context-aware RTL. Built from hundreds of actual hardware designs produced by the Tiny Tapeout community, our automated pipeline removes duplicates, verifies correctness and periodically incorporates new designs to mitigate contamination, matching Tiny Tapeout release schedule. Evaluation results show that NotSoTiny tasks are more challenging than prior benchmarks, emphasizing its effectiveness in overcoming current limitations of LLMs applied to hardware design, and in guiding the improvement of such promising technology.
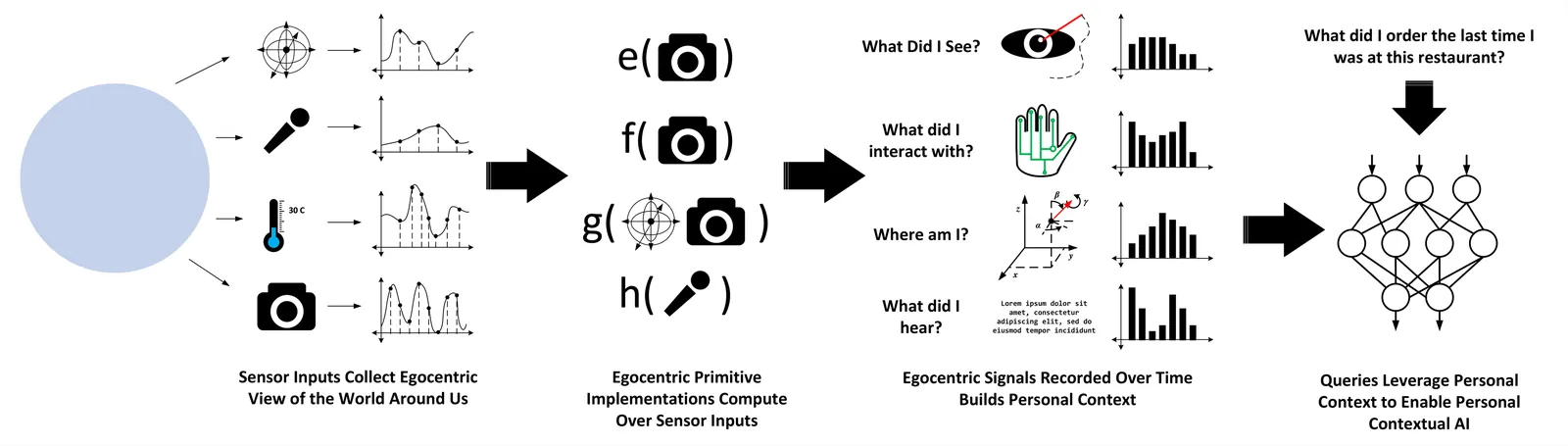
The next generation of human-oriented computing will require always-on, spatially-aware wearable devices to capture egocentric vision and functional primitives (e.g., Where am I? What am I looking at?, etc.). These devices will sense an egocentric view of the world around us to observe all human-relevant signals across space and time to construct and maintain a user's personal context. This personal context, combined with advanced generative AI, will unlock a powerful new generation of contextual AI personal assistants and applications. However, designing a wearable system to support contextual AI is a daunting task because of the system's complexity and stringent power constraints due to weight and battery restrictions. To understand how to guide design for such systems, this work provides the first complete system architecture view of one such wearable contextual AI system (Aria2), along with the lessons we have learned through the system modeling and design space exploration process. We show that an end-to-end full system model view of such systems is vitally important, as no single component or category overwhelmingly dominates system power. This means long-range design decisions and power optimizations need to be made in the full system context to avoid running into limits caused by other system bottlenecks (i.e., Amdahl's law as applied to power) or as bottlenecks change. Finally, we reflect on lessons and insights for the road ahead, which will be important toward eventually enabling all-day, wearable, contextual AI systems.
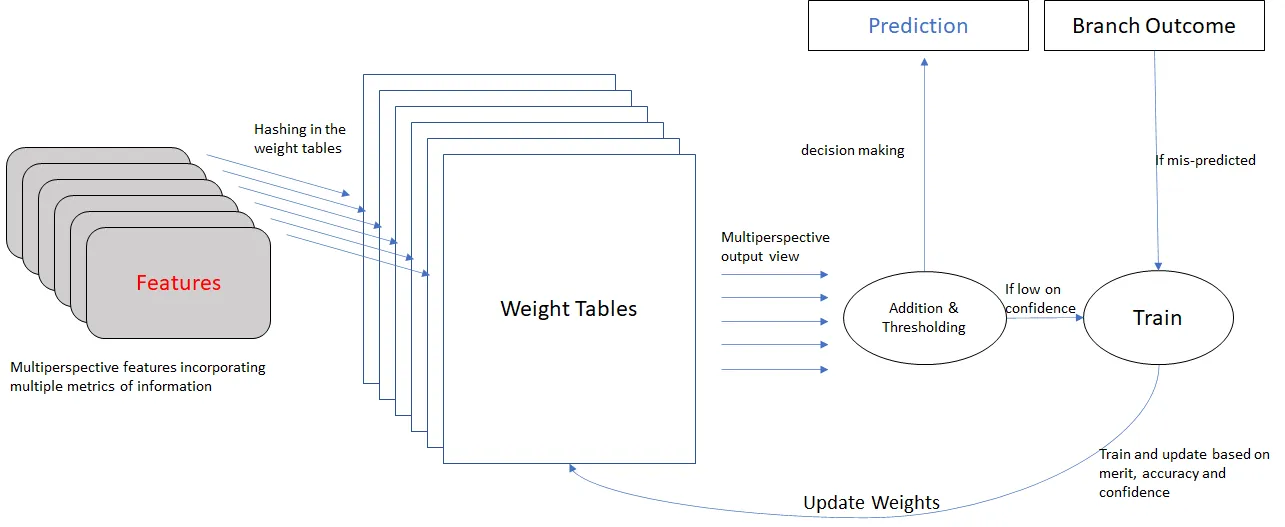
Conditional branch prediction predicts the likely direction of a conditional branch instruction to support ILP extraction. Branch prediction is a pattern recognition problem that learns mappings between a context to the branch outcome. An accurate predictor reduces the number of instructions executed on the wrong path resulting in an improvement of performance and energy consumption. In this paper, we present a workload characterization methodology for branch prediction. We propose two new workload-driven branch prediction accuracy identifiers -- branch working set size and branch predictability. These parameters are highly correlated with misprediction rates of modern branch prediction schemes (e.g. TAGE and perceptron). We define the branch working set of a trace as a group of most frequently occurring branch contexts, i.e. the 3-part tuple of branch address, and associated global and local history. We analyze the branch working set's size and predictability on a per-trace basis to study its relationship with a modern branch predictor's accuracy. We have characterized 2,451 workload traces into seven branch working set size and nine predictability categories after analyzing their branch behavior. We present further insights into the source of prediction accuracy and favored workload categories for modern branch predictors.
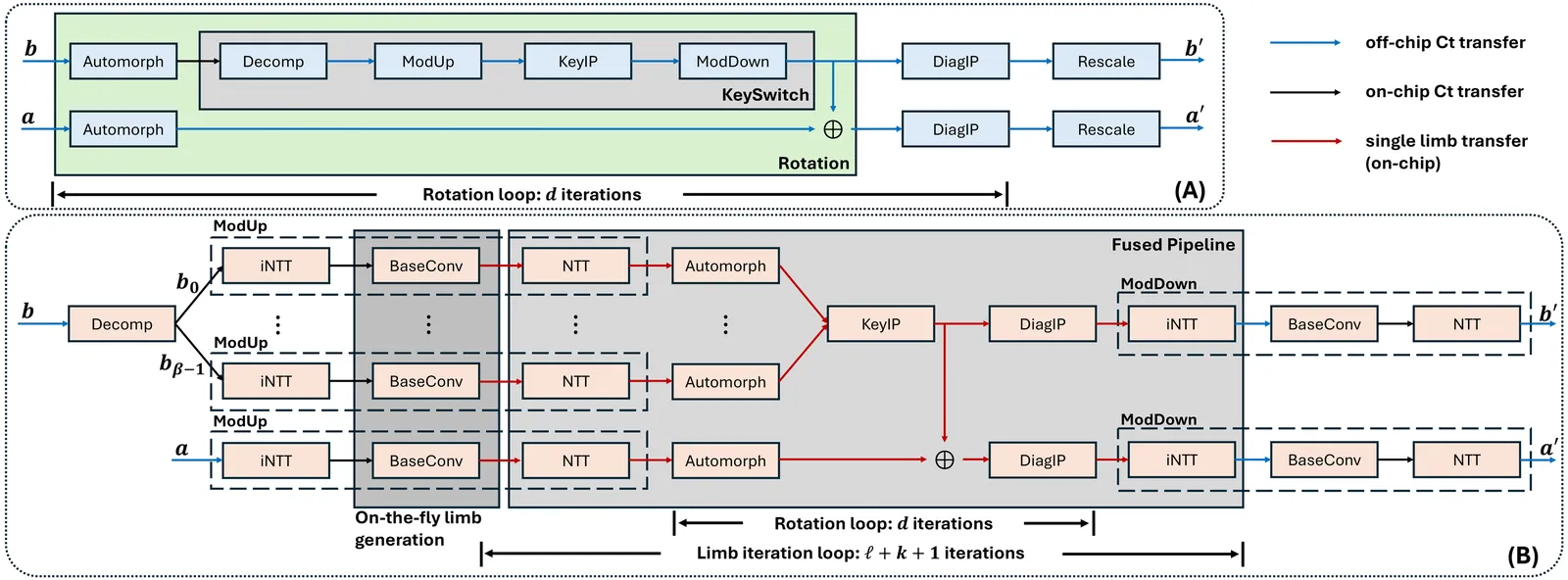
Homomorphic Encryption (HE) enables secure computation on encrypted data, addressing privacy concerns in cloud computing. However, the high computational cost of HE operations, particularly matrix multiplication (MM), remains a major barrier to its practical deployment. Accelerating homomorphic encrypted MM (HE MM) is therefore crucial for applications such as privacy-preserving machine learning. In this paper, we present a bandwidth-efficient FPGA implementation of HE MM. We first develop a cost model to evaluate the on-chip memory requirements for a given set of HE parameters and input matrix sizes. Our analysis shows that optimizing on-chip memory usage is critical for scalable and efficient HE MM. To this end, we design a novel datapath for Homomorphic Linear Transformation (HLT), the primary bottleneck in HE MM. The proposed datapath significantly reduces off-chip memory traffic and on-chip memory demand by enabling fine-grained data reuse. Leveraging this datapath, we introduce FAME, the first FPGA-based accelerator specifically tailored for HE MM. FAME supports arbitrary matrix shapes and is configurable across a wide range of HE parameter sets. We implement FAME on an Alveo U280 FPGA and evaluate its performance across diverse matrix sizes and shapes. Experimental results show that FAME achieves an average speedup of 221x over state-of-the-art CPU-based implementations, demonstrating its scalability and practicality for large-scale consecutive HE MM and real-world workloads.
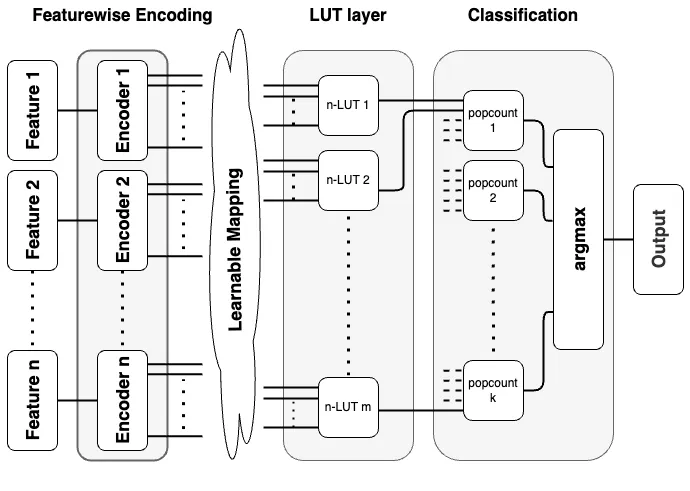
Fully parallel neural network accelerators on field-programmable gate arrays (FPGAs) offer high throughput for latency-critical applications but face hardware resource constraints. Weightless neural networks (WNNs) efficiently replace arithmetic with logic-based inference. Differential weightless neural networks (DWN) further optimize resource usage by learning connections between encoders and LUT layers via gradient-based training. However, DWNs rely on thermometer encoding, and the associated hardware cost has not been fully evaluated. We present a DWN hardware generator that includes thermometer encoding explicitly. Experiments on the Jet Substructure Classification (JSC) task show that encoding can increase LUT usage by up to 3.20$\times$, dominating costs in small networks and highlighting the need for encoding-aware hardware design in DWN accelerators.
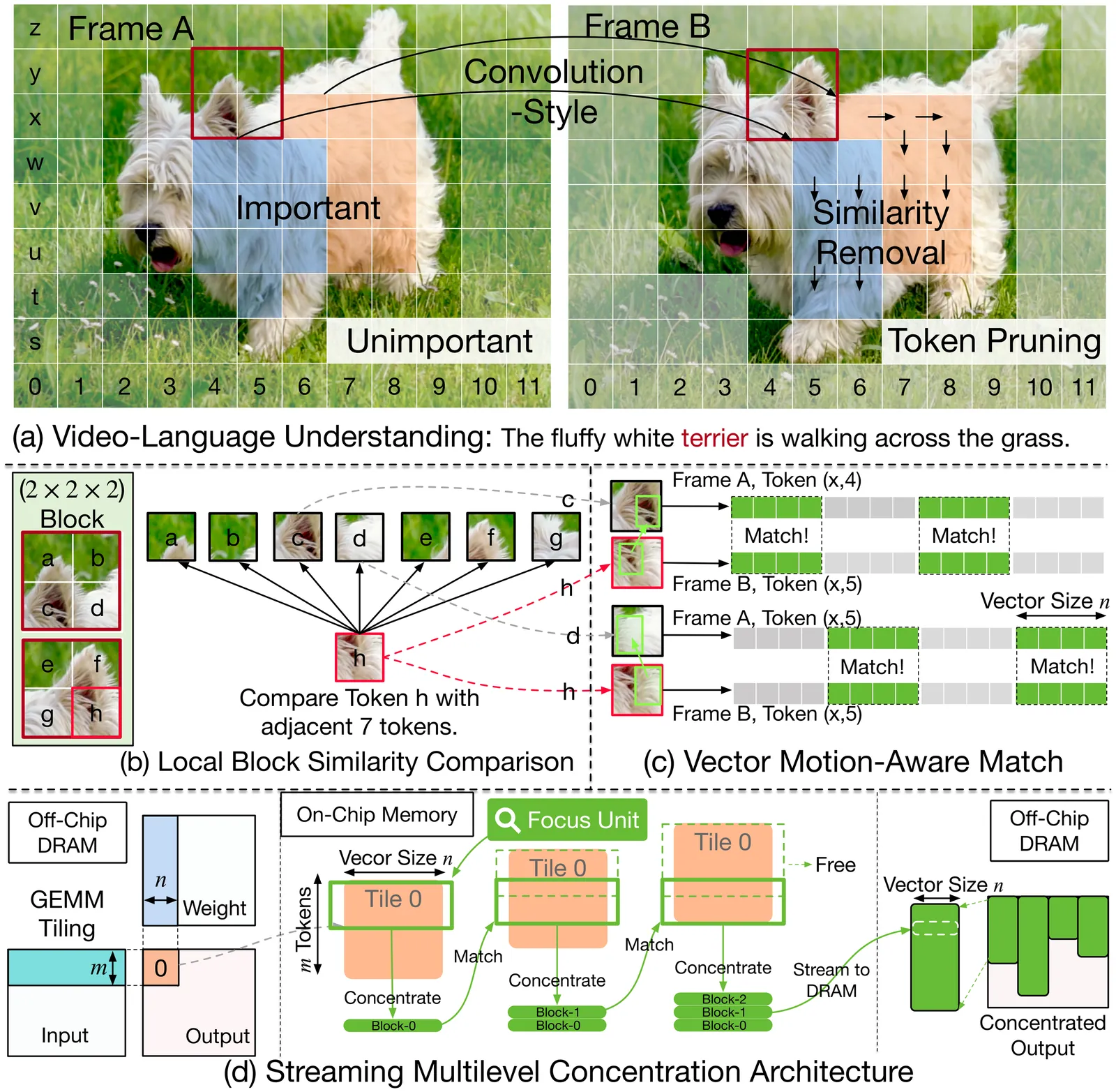
Vision-Language Models (VLMs) have demonstrated strong performance on tasks such as video captioning and visual question answering. However, their growing scale and video-level inputs lead to significant computational and memory overhead, posing challenges for real-time deployment on hardware accelerators. While prior work attempts to reduce redundancy via token pruning or merging, these methods typically operate at coarse granularity and incur high runtime overhead due to global token-level operations. In this study, we propose Focus, a Streaming Concentration Architecture that efficiently accelerates VLM inference through progressive, fine-grained redundancy elimination. Focus introduces a multilevel concentration paradigm that hierarchically compresses vision-language inputs at three levels: (1) semantic-guided token pruning based on textual prompts, (2) spatial-temporal block-level concentration using localized comparisons, and (3) vector-level redundancy removal via motion-aware matching. All concentration steps are tightly co-designed with the architecture to support streaming-friendly, on-chip execution. Focus leverages GEMM tiling, convolution-style layout, and cross-modal attention to minimize off-chip access while enabling high throughput. Implemented as a modular unit within a systolic-array accelerator, Focus achieves a 2.4x speedup and 3.3x reduction in energy, significantly outperforming state-of-the-art accelerators in both performance and energy efficiency. Full-stack implementation of Focus is open-sourced at https://github.com/dubcyfor3/Focus.
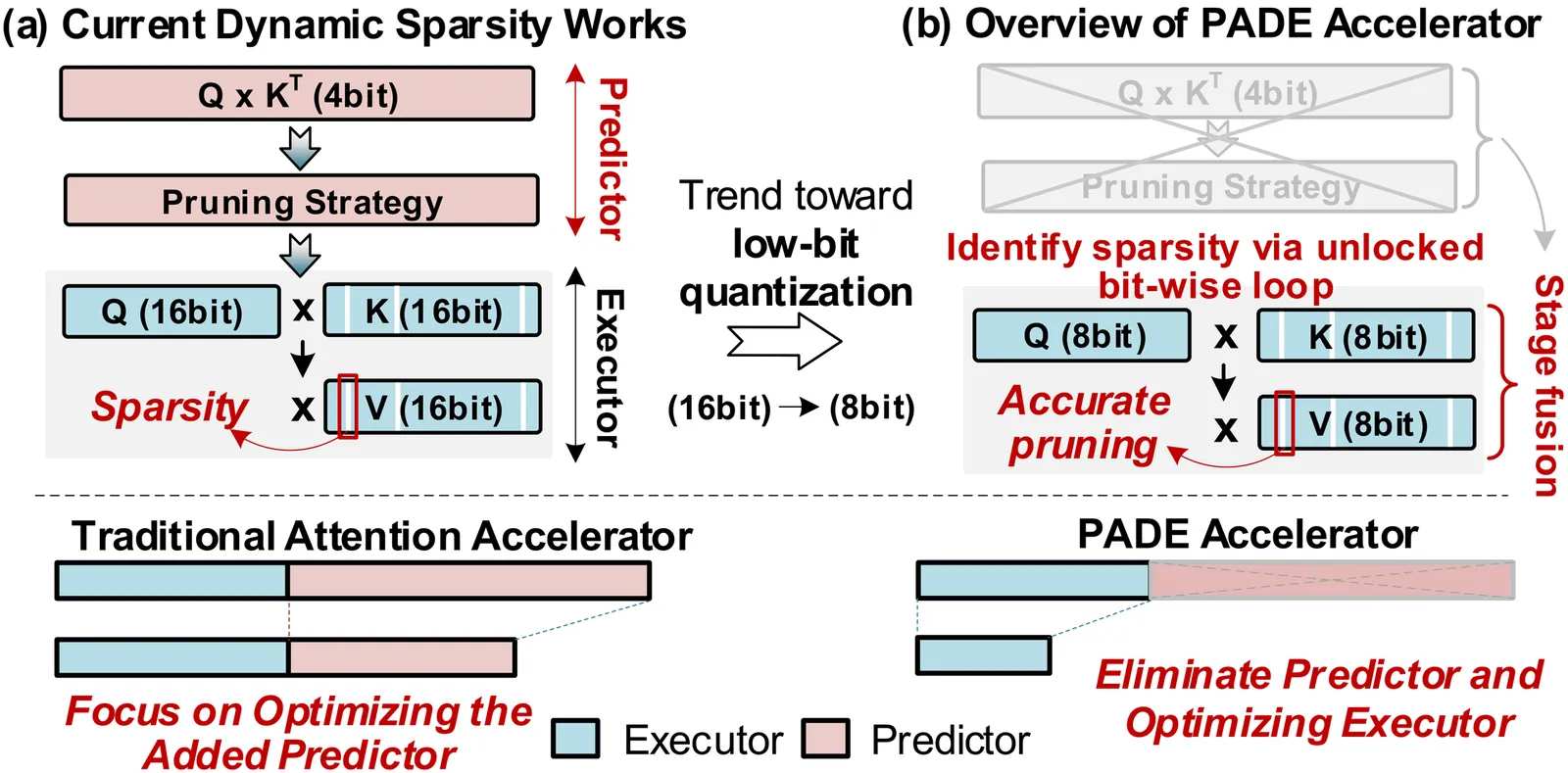
Attention-based models have revolutionized AI, but the quadratic cost of self-attention incurs severe computational and memory overhead. Sparse attention methods alleviate this by skipping low-relevance token pairs. However, current approaches lack practicality due to the heavy expense of added sparsity predictor, which severely drops their hardware efficiency. This paper advances the state-of-the-art (SOTA) by proposing a bit-serial enable stage-fusion (BSF) mechanism, which eliminates the need for a separate predictor. However, it faces key challenges: 1) Inaccurate bit-sliced sparsity speculation leads to incorrect pruning; 2) Hardware under-utilization due to fine-grained and imbalanced bit-level workloads. 3) Tiling difficulty caused by the row-wise dependency in sparsity pruning criteria. We propose PADE, a predictor-free algorithm-hardware co-design for dynamic sparse attention acceleration. PADE features three key innovations: 1) Bit-wise uncertainty interval-enabled guard filtering (BUI-GF) strategy to accurately identify trivial tokens during each bit round; 2) Bidirectional sparsity-based out-of-order execution (BS-OOE) to improve hardware utilization; 3) Interleaving-based sparsity-tiled attention (ISTA) to reduce both I/O and computational complexity. These techniques, combined with custom accelerator designs, enable practical sparsity acceleration without relying on an added sparsity predictor. Extensive experiments on 22 benchmarks show that PADE achieves 7.43x speed up and 31.1x higher energy efficiency than Nvidia H100 GPU. Compared to SOTA accelerators, PADE achieves 5.1x, 4.3x and 3.4x energy saving than Sanger, DOTA and SOFA.
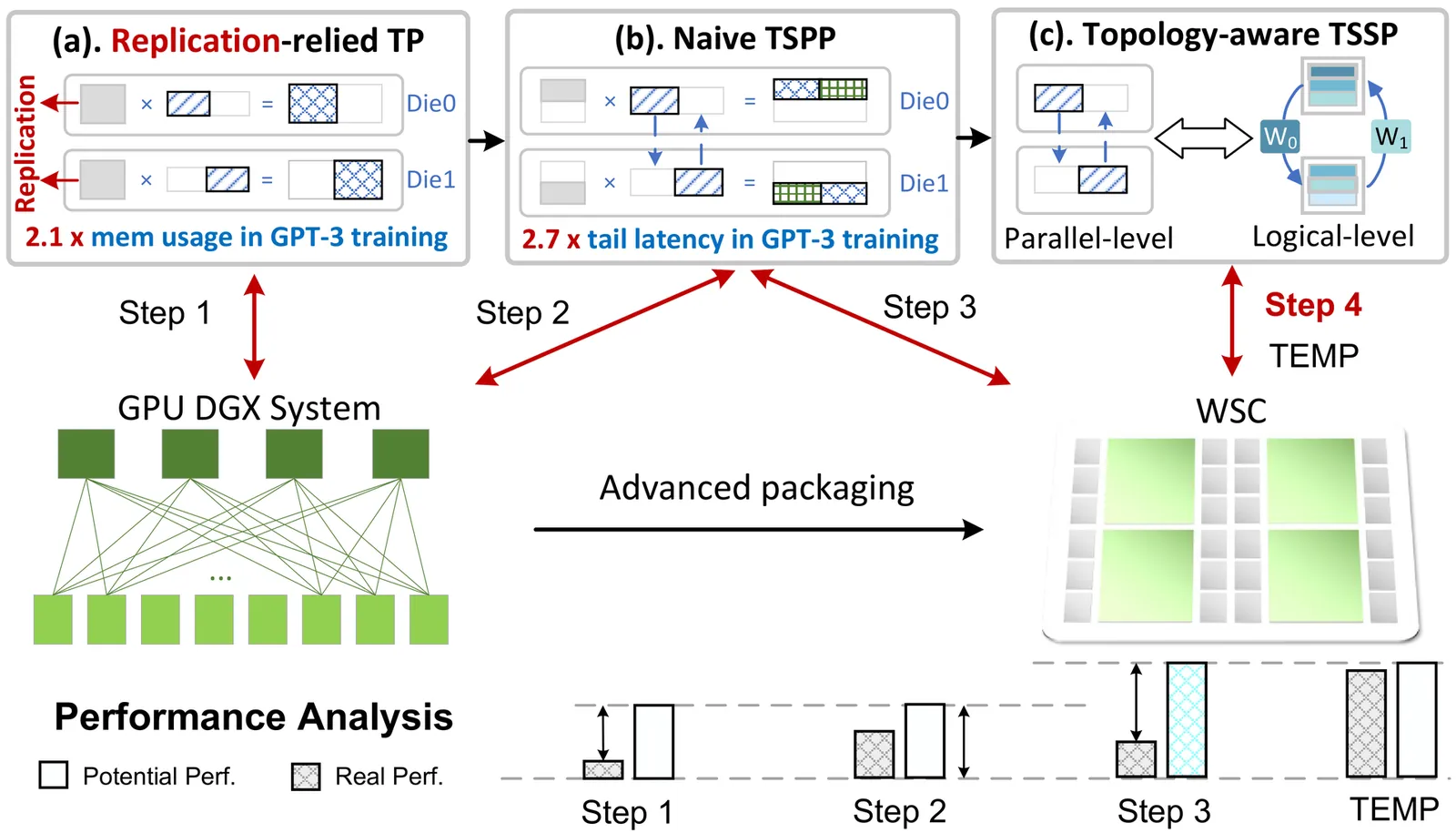
Large language models (LLMs) demand significant memory and computation resources. Wafer-scale chips (WSCs) provide high computation power and die-to-die (D2D) bandwidth but face a unique trade-off between on-chip memory and compute resources due to limited wafer area. Therefore, tensor parallelism strategies for wafer should leverage communication advantages while maintaining memory efficiency to maximize WSC performance. However, existing approaches fail to address these challenges. To address these challenges, we propose the tensor stream partition paradigm (TSPP), which reveals an opportunity to leverage WSCs' abundant communication bandwidth to alleviate stringent on-chip memory constraints. However, the 2D mesh topology of WSCs lacks long-distance and flexible interconnects, leading to three challenges: 1) severe tail latency, 2) prohibitive D2D traffic contention, and 3) intractable search time for optimal design. We present TEMP, a framework for LLM training on WSCs that leverages topology-aware tensor-stream partition, traffic-conscious mapping, and dual-level wafer solving to overcome hardware constraints and parallelism challenges. These integrated approaches optimize memory efficiency and throughput, unlocking TSPP's full potential on WSCs. Evaluations show TEMP achieves 1.7x average throughput improvement over state-of-the-art LLM training systems across various models.
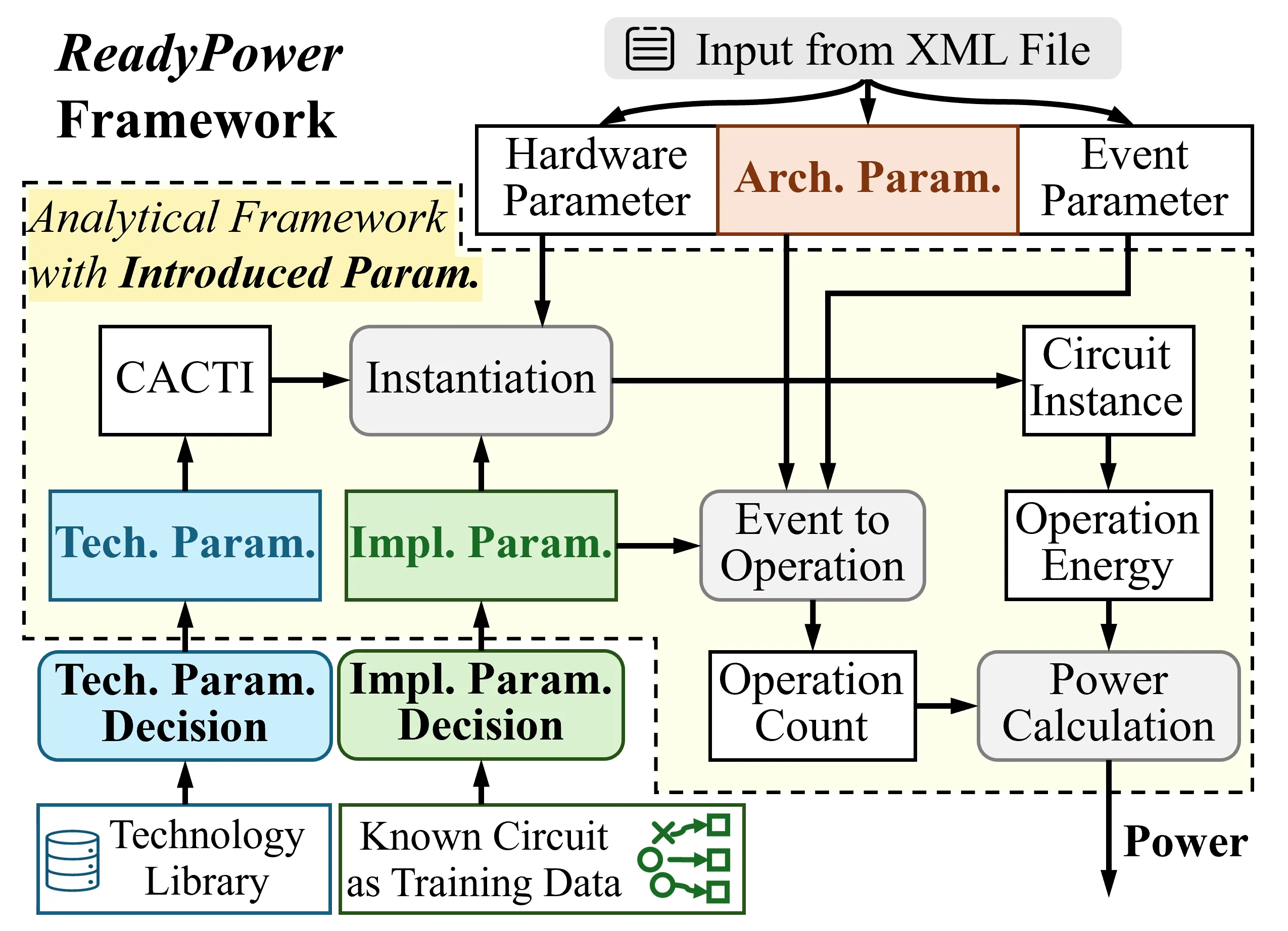
Power is a primary objective in modern processor design, requiring accurate yet efficient power modeling techniques. Architecture-level power models are necessary for early power optimization and design space exploration. However, classical analytical architecture-level power models (e.g., McPAT) suffer from significant inaccuracies. Emerging machine learning (ML)-based power models, despite their superior accuracy in research papers, are not widely adopted in the industry. In this work, we point out three inherent limitations of ML-based power models: unreliability, limited interpretability, and difficulty in usage. This work proposes a new analytical power modeling framework named ReadyPower, which is ready-for-use by being reliable, interpretable, and handy. We observe that the root cause of the low accuracy of classical analytical power models is the discrepancies between the real processor implementation and the processor's analytical model. To bridge the discrepancies, we introduce architecture-level, implementation-level, and technology-level parameters into the widely adopted McPAT analytical model to build ReadyPower. The parameters at three different levels are decided in different ways. In our experiment, averaged across different training scenarios, ReadyPower achieves >20% lower mean absolute percentage error (MAPE) and >0.2 higher correlation coefficient R compared with the ML-based baselines, on both BOOM and XiangShan CPU architectures.baselines, on both BOOM and XiangShan CPU architectures.
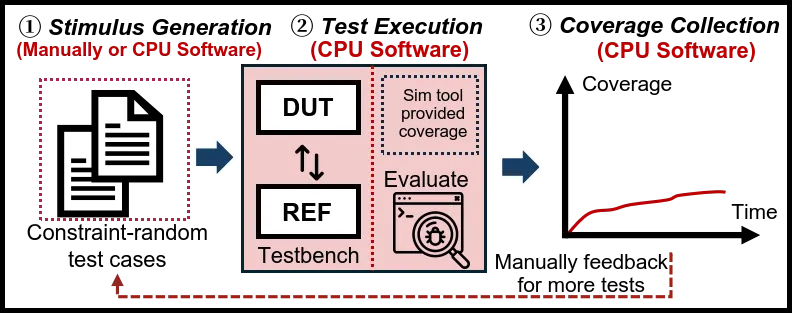
As processor designs grow more complex, verification remains bottlenecked by slow software simulation and low-quality random test stimuli. Recent research has applied software fuzzers to hardware verification, but these rely on semantically blind random mutations that may generate shallow, low-quality stimuli unable to explore complex behaviors. These limitations result in slow coverage convergence and prohibitively high verification costs. In this paper, we present Lyra, a heterogeneous RISC-V verification framework that addresses both challenges by pairing hardware-accelerated verification with an ISA-aware generative model. Lyra executes the DUT and reference model concurrently on an FPGA SoC, enabling high-throughput differential checking and hardware-level coverage collection. Instead of creating verification stimuli randomly or through simple mutations, we train a domain-specialized generative model, LyraGen, with inherent semantic awareness to generate high-quality, semantically rich instruction sequences. Empirical results show Lyra achieves up to $1.27\times$ higher coverage and accelerates end-to-end verification by up to $107\times$ to $3343\times$ compared to state-of-the-art software fuzzers, while consistently demonstrating lower convergence difficulty.

Reproducibility in simulation-based computer architecture research requires coordinating artifacts like disk images, kernels, and benchmarks, but existing workflows are inconsistent. We improve gem5, an open-source simulator with over 1600 forks, and gem5 Resources, a centralized repository of over 2000 pre-packaged artifacts, to address these issues. While gem5 Resources enables artifact sharing, researchers still face challenges. Creating custom disk images is complex and time-consuming, with no standardized process across ISAs, making it difficult to extend and share images. gem5 provides limited guest-host communication features through a set of predefined exit events that restrict researchers' ability to dynamically control and monitor simulations. Lastly, running simulations with multiple workloads requires researchers to write custom external scripts to coordinate multiple gem5 simulations which creates error-prone and hard-to-reproduce workflows. To overcome this, we introduce several features in gem5 and gem5 Resources. We standardize disk-image creation across x86, ARM, and RISC-V using Packer, and provide validated base images with pre-annotated benchmark suites (NPB, GAPBS). We provide 12 new disk images, 6 new kernels, and over 200 workloads across three ISAs. We refactor the exit event system to a class-based model and introduce hypercalls for enhanced guest-host communication that allows researchers to define custom behavior for their exit events. We also provide a utility to remotely monitor simulations and the gem5-bridge driver for user-space m5 operations. Additionally, we implemented Suites and MultiSim to enable parallel full-system simulations from gem5 configuration scripts, eliminating the need for external scripting. These features reduce setup complexity and provide extensible, validated resources that improve reproducibility and standardization.
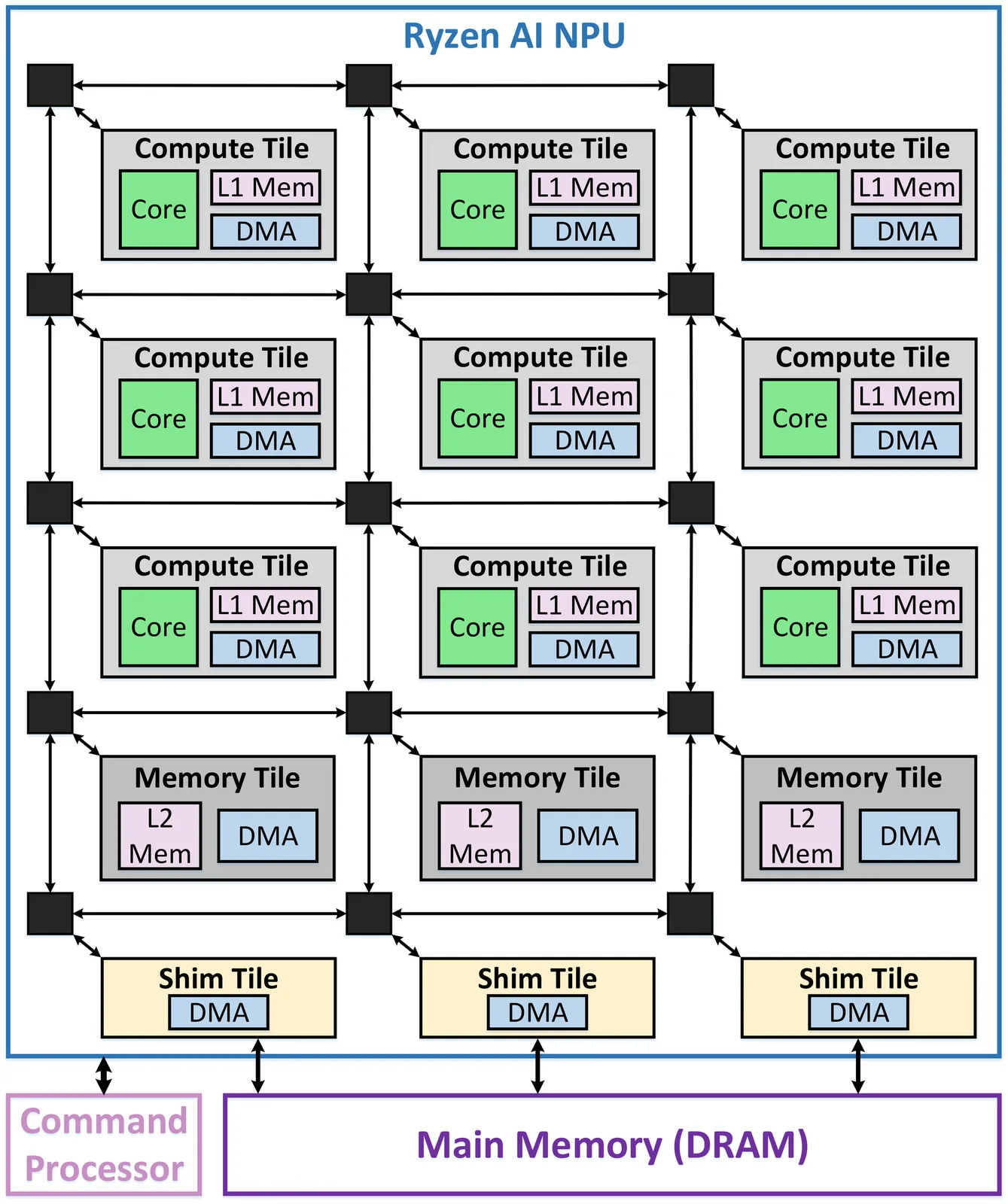
The high computational and memory demands of modern deep learning (DL) workloads have led to the development of specialized hardware devices from cloud to edge, such as AMD's Ryzen AI XDNA NPUs. Optimizing general matrix multiplication (GEMM) algorithms for these architectures is critical for improving DL workload performance. To this end, this paper presents a common systematic methodology to optimize GEMM workloads across the two current NPU generations, namely XDNA and XDNA2. Our implementations exploit the unique architectural features of AMD's NPUs and address key performance bottlenecks at the system level. End-to-end performance evaluation across various GEMM sizes demonstrates state-of-the-art throughput of up to 6.76 TOPS (XDNA) and 38.05 TOPS (XDNA2) for 8-bit integer (int8) precision. Similarly, for brain floating-point (bf16) precision, our GEMM implementations attain up to 3.14 TOPS (XDNA) and 14.71 TOPS (XDNA2). This work provides significant insights into key performance aspects of optimizing GEMM workloads on Ryzen AI NPUs.
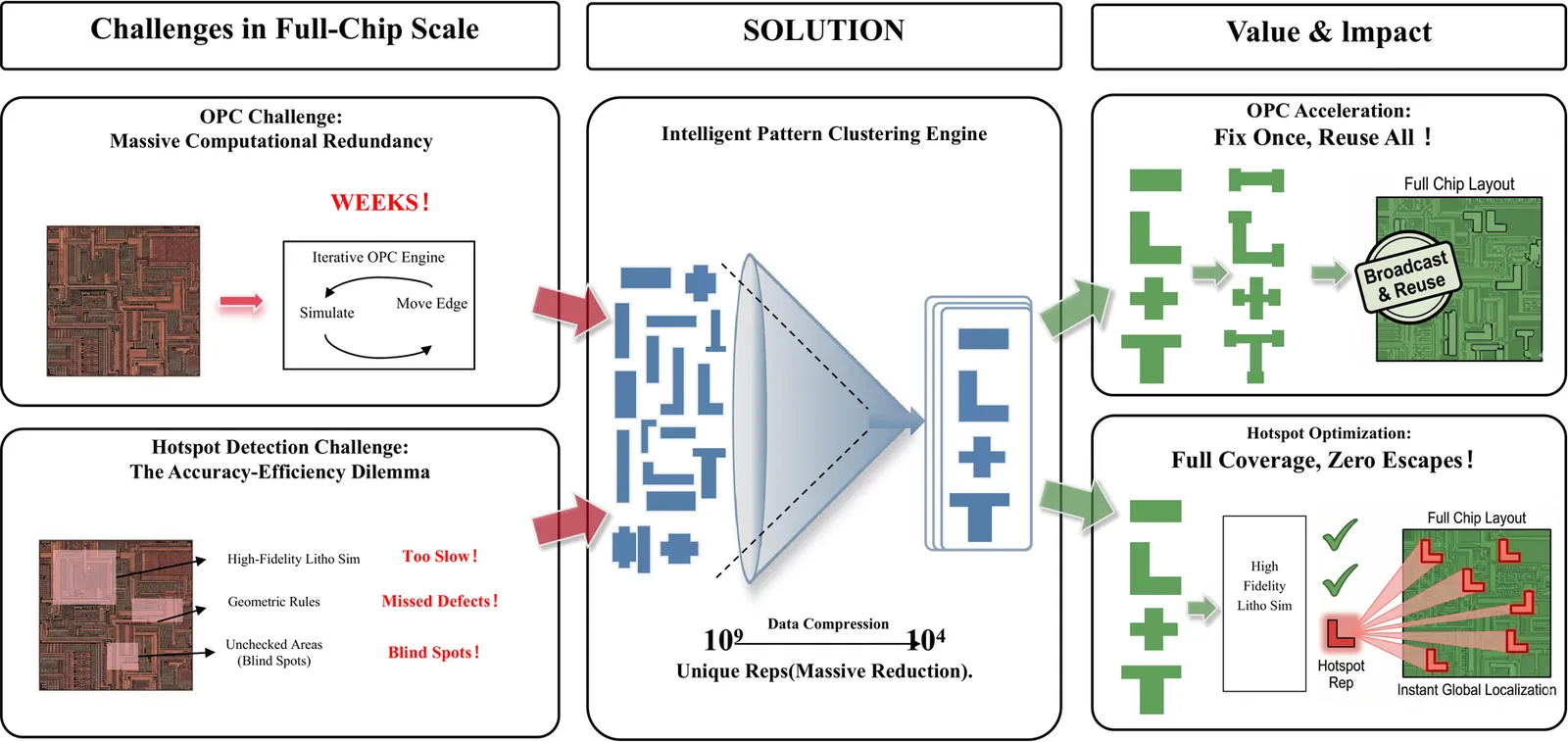
With the aggressive scaling of VLSI technology, the explosion of layout patterns creates a critical bottleneck for DFM applications like OPC. Pattern clustering is essential to reduce data complexity, yet existing methods struggle with computational prohibitiveness ($O(N^2)$ comparisons), sub-optimal discrete sampling for center alignment, and difficult speed-quality trade-offs. To address these, we propose an Optimal Alignment-Driven Iterative Closed-Loop Convergence Framework. First, to resolve alignment ambiguity, we introduce a hybrid suite of high-performance algorithms: an FFT-based Phase Correlation method for cosine similarity constraints, and a Robust Geometric Min-Max strategy for edge displacement constraints that analytically solves for the global optimum. Second, we model clustering as a Set Cover Problem (SCP) using a Surprisal-Based Lazy Greedy heuristic within a coarse-to-fine iterative refinement loop to ensure convergence. Additionally, a multi-stage pruning mechanism filters over 99% of redundant computations. Experimental results on the 2025 China Postgraduate EDA Elite Challenge benchmark demonstrate a 93.4% compression ratio relative to raw inputs and an over 100x speedup compared to the official baseline, effectively handling tens of thousands of patterns in seconds. Securing First Place among 77 teams, this approach proves its superiority in solving the NP-Hard layout clustering problem with an optimal balance of scalability and precision.
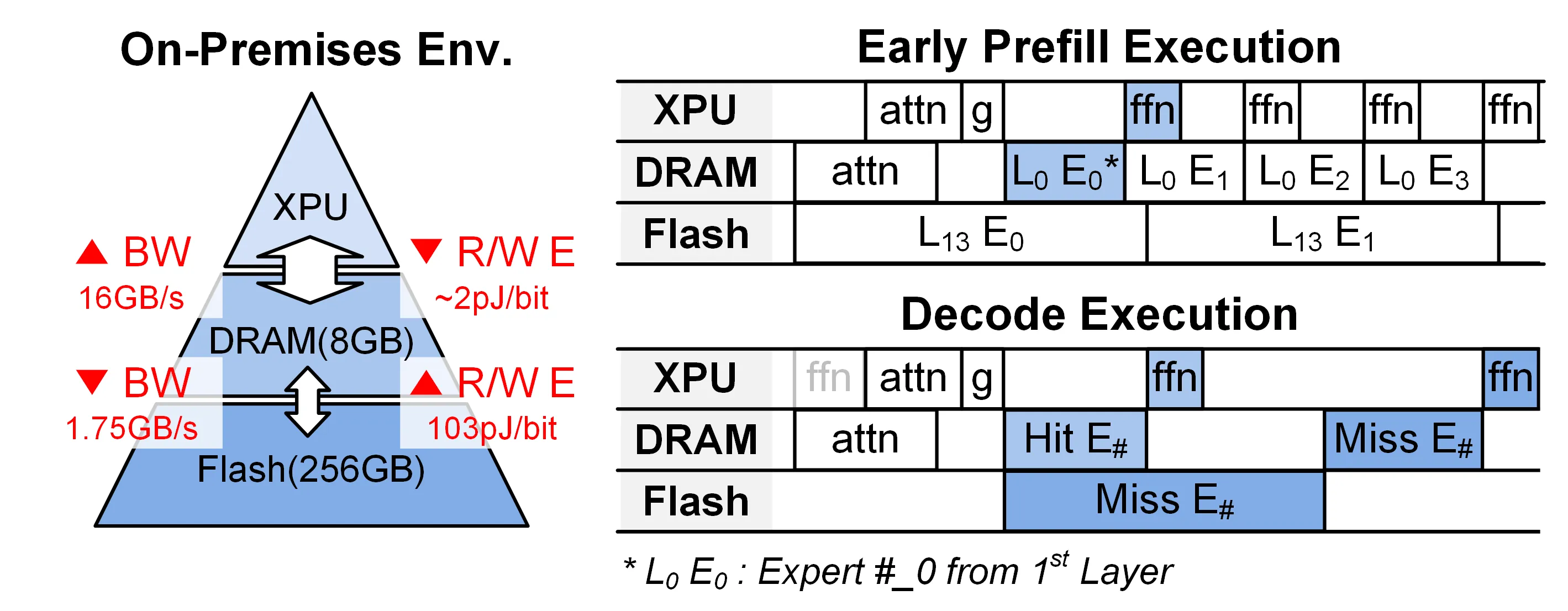
MoE models offer efficient scaling through conditional computation, but their large parameter size and expensive expert offloading make on-device deployment challenging. Existing acceleration techniques such as prefetching or expert clustering often increase energy usage or reduce expert diversity. We present SliceMoE, an energy-efficient MoE inference framework for miss-rate-constrained deployment. SliceMoE introduces Dynamic Bit-Sliced Caching (DBSC), which caches experts at slice-level granularity and assigns precision on demand to expand effective expert capacity. To support mixed-precision experts without memory duplication, we propose Calibration-Free Asymmetric Matryoshka Quantization (AMAT), a truncation-based scheme that maintains compatibility between low-bit and high-bit slices. We further introduce Predictive Cache Warmup (PCW) to reduce early-decode cold misses by reshaping cache contents during prefill. Evaluated on DeepSeek-V2-Lite and Qwen1.5-MoE-A2.7B, SliceMoE reduces decode-stage energy consumption by up to 2.37x and 2.85x, respectively, and improves decode latency by up to 1.81x and 1.64x, while preserving near-high-bit accuracy. These results demonstrate that slice-level caching enables an efficient on-device MoE deployment.
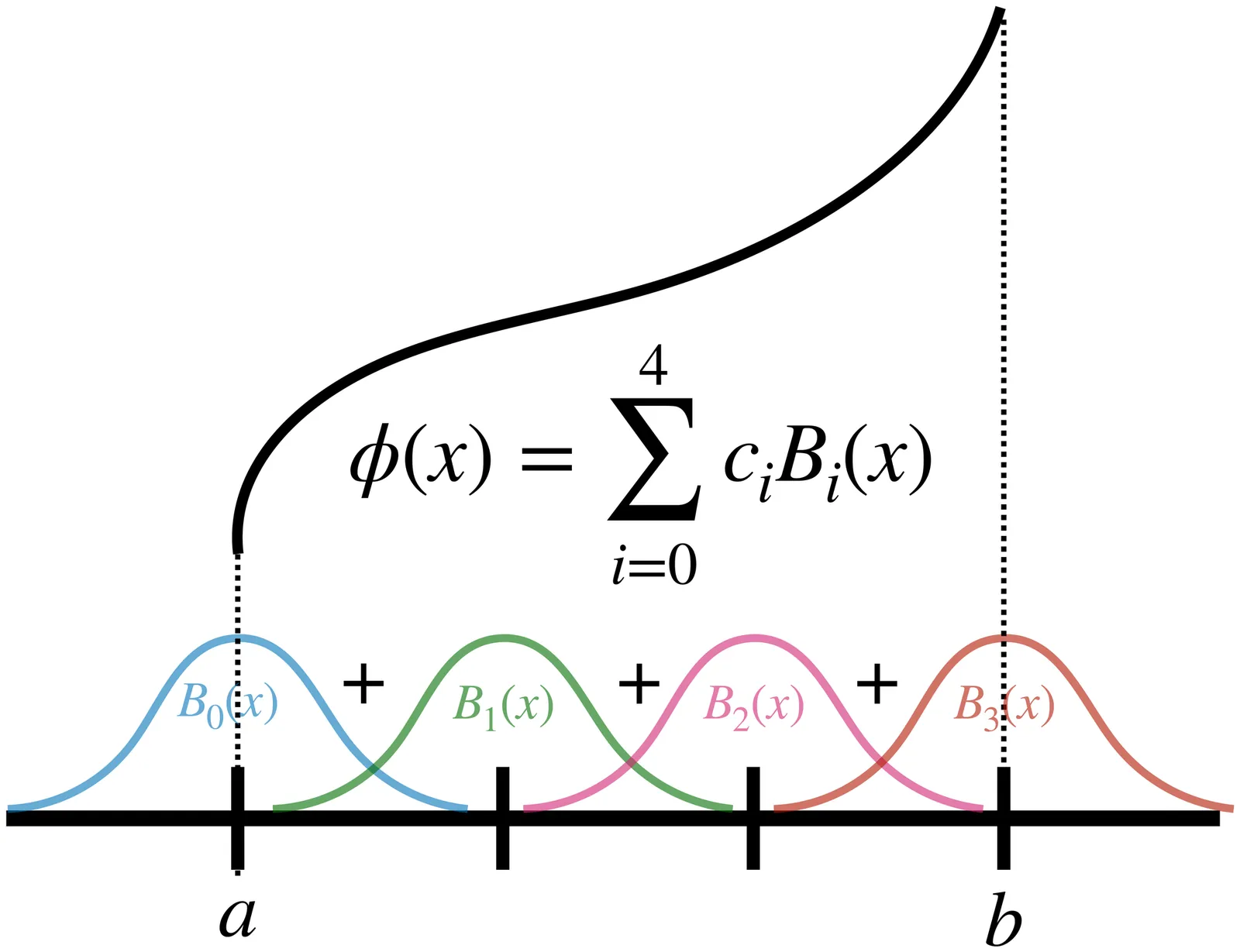
Low-latency, resource-efficient neural network inference on FPGAs is essential for applications demanding real-time capability and low power. Lookup table (LUT)-based neural networks are a common solution, combining strong representational power with efficient FPGA implementation. In this work, we introduce KANELÉ, a framework that exploits the unique properties of Kolmogorov-Arnold Networks (KANs) for FPGA deployment. Unlike traditional multilayer perceptrons (MLPs), KANs employ learnable one-dimensional splines with fixed domains as edge activations, a structure naturally suited to discretization and efficient LUT mapping. We present the first systematic design flow for implementing KANs on FPGAs, co-optimizing training with quantization and pruning to enable compact, high-throughput, and low-latency KAN architectures. Our results demonstrate up to a 2700x speedup and orders of magnitude resource savings compared to prior KAN-on-FPGA approaches. Moreover, KANELÉ matches or surpasses other LUT-based architectures on widely used benchmarks, particularly for tasks involving symbolic or physical formulas, while balancing resource usage across FPGA hardware. Finally, we showcase the versatility of the framework by extending it to real-time, power-efficient control systems.

We introduce a high-throughput neural network accelerator that embeds most network layers directly in hardware, minimizing data transfer and memory usage while preserving a degree of flexibility via a small neural processing unit for the final classification layer. By leveraging power-of-two (Po2) quantization for weights, we replace multiplications with simple rewiring, effectively reducing each convolution to a series of additions. This streamlined approach offers high-throughput, energy-efficient processing, making it highly suitable for applications where model parameters remain stable, such as continuous sensing tasks at the edge or large-scale data center deployments. Furthermore, by including a strategically chosen reprogrammable final layer, our design achieves high throughput without sacrificing fine-tuning capabilities. We implement this accelerator in a 7nm ASIC flow using MobileNetV2 as a baseline and report throughput, area, accuracy, and sensitivity to quantization and pruning - demonstrating both the advantages and potential trade-offs of the proposed architecture. We find that for MobileNetV2, we can improve inference throughput by 20x over fully programmable GPUs, processing 1.21 million images per second through a full forward pass while retaining fine-tuning flexibility. If absolutely no post-deployment fine tuning is required, this advantage increases to 67x at 4 million images per second.
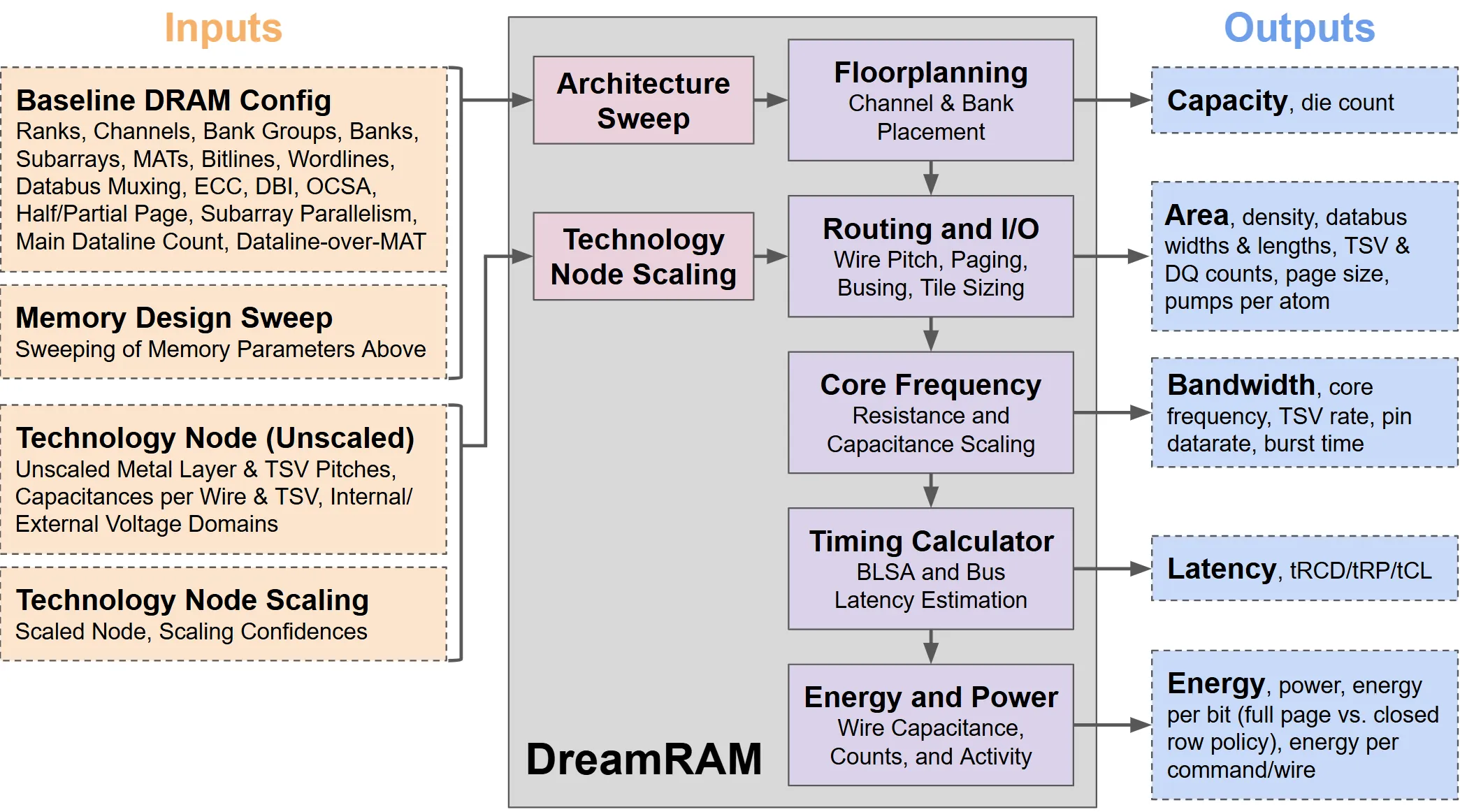
3D die-stacked DRAM has emerged as a key technology for delivering high bandwidth and high density for applications such as high-performance computing, graphics, and machine learning. However, different applications place diverse and sometimes diverging demands on power, performance, and area that cannot be universally satisfied with fixed commodity DRAM designs. Die stacking creates the opportunity for a large DRAM design space through 3D integration and expanded total die area. To open and navigate this expansive design space of customized memory architectures that cater to application-specific needs, we introduce DreamRAM, a configurable bandwidth, capacity, energy, latency, and area modeling tool for custom 3D die-stacked DRAM designs. DreamRAM exposes fine-grained design customization parameters at the MAT, subarray, bank, and inter-bank levels, including extensions of partial page and subarray parallelism proposals found in the literature, to open a large previously-unexplored design space. DreamRAM analytically models wire pitch, width, length, capacitance, and scaling parameters to capture the performance tradeoffs of physical layout and routing design choices. Routing awareness enables DreamRAM to model a custom MAT-level routing scheme, Dataline-Over-MAT (DLOMAT), to facilitate better bandwidth tradeoffs. DreamRAM is calibrated and validated against published industry HBM3 and HBM2E designs. Within DreamRAM's rich design space, we identify designs that achieve each of 66% higher bandwidth, 100% higher capacity, and 45% lower power and energy per bit compared to the baseline design, each on an iso-bandwidth, iso-capacity, and iso-power basis.