Databases
arXiv:cs.DB
Covers database management, datamining, and data processing. Roughly includes material in ACM Subject Classes H.2, H.3, and H.4.
Looking for a broader view? This category is part of:
Covers database management, datamining, and data processing. Roughly includes material in ACM Subject Classes H.2, H.3, and H.4.
Looking for a broader view? This category is part of:
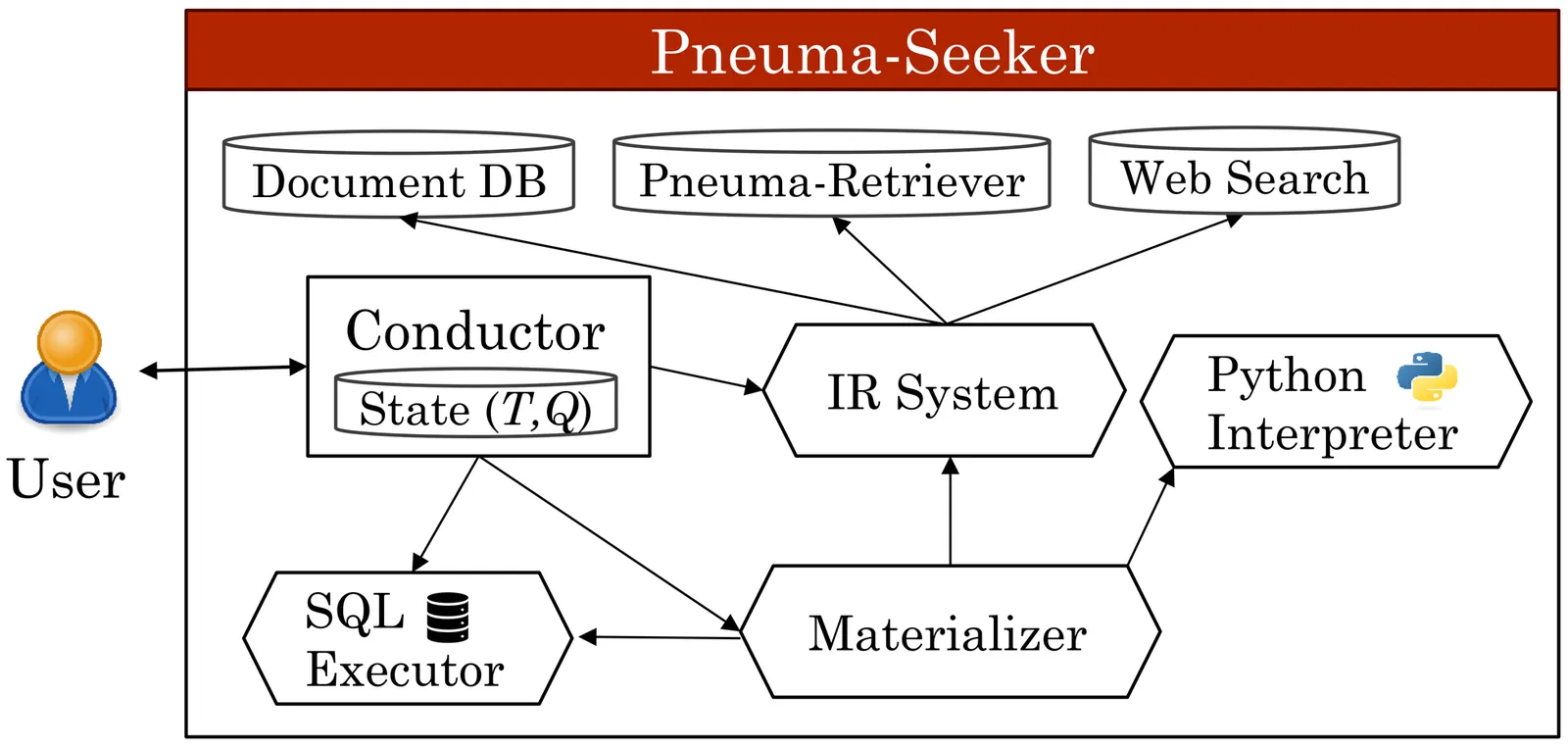
Data discovery and preparation remain persistent bottlenecks in the data management lifecycle, especially when user intent is vague, evolving, or difficult to operationalize. The Pneuma Project introduces Pneuma-Seeker, a system that helps users articulate and fulfill information needs through iterative interaction with a language model-powered platform. The system reifies the user's evolving information need as a relational data model and incrementally converges toward a usable document aligned with that intent. To achieve this, the system combines three architectural ideas: context specialization to reduce LLM burden across subtasks, a conductor-style planner to assemble dynamic execution plans, and a convergence mechanism based on shared state. The system integrates recent advances in retrieval-augmented generation (RAG), agentic frameworks, and structured data preparation to support semi-automatic, language-guided workflows. We evaluate the system through LLM-based user simulations and show that it helps surface latent intent, guide discovery, and produce fit-for-purpose documents. It also acts as an emergent documentation layer, capturing institutional knowledge and supporting organizational memory.
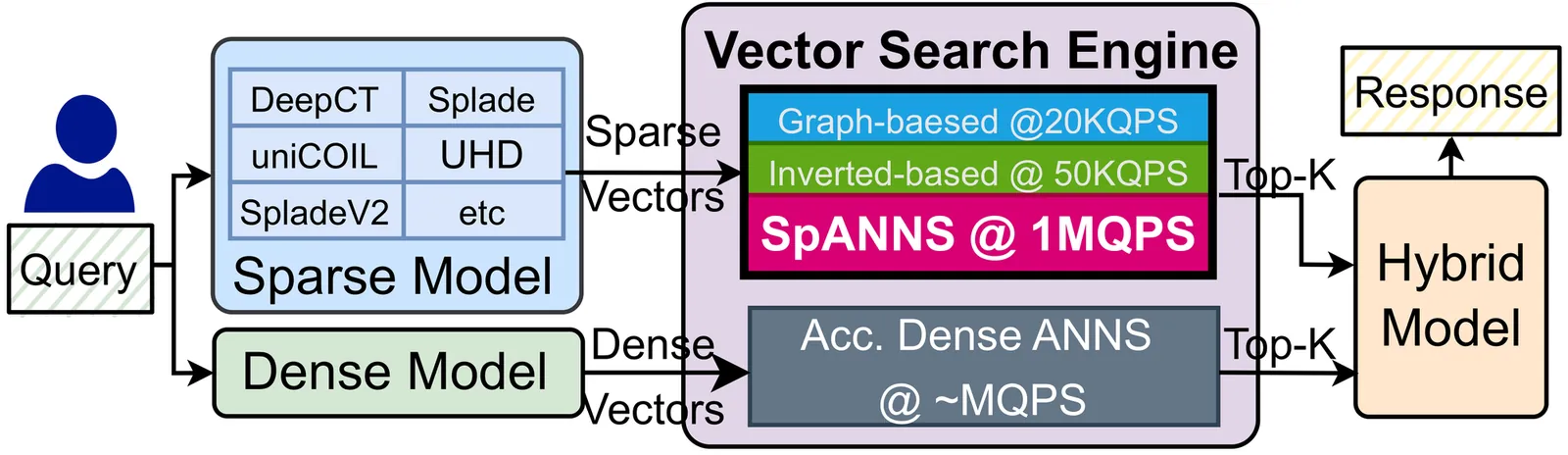
Approximate Nearest Neighbor Search (ANNS) is a fundamental operation in vector databases, enabling efficient similarity search in high-dimensional spaces. While dense ANNS has been optimized using specialized hardware accelerators, sparse ANNS remains limited by CPU-based implementations, hindering scalability. This limitation is increasingly critical as hybrid retrieval systems, combining sparse and dense embeddings, become standard in Information Retrieval (IR) pipelines. We propose SpANNS, a near-memory processing architecture for sparse ANNS. SpANNS combines a hybrid inverted index with efficient query management and runtime optimizations. The architecture is built on a CXL Type-2 near-memory platform, where a specialized controller manages query parsing and cluster filtering, while compute-enabled DIMMs perform index traversal and distance computations close to the data. It achieves 15.2x to 21.6x faster execution over the state-of-the-art CPU baselines, offering scalable and efficient solutions for sparse vector search.

Given a table T in a database and a question Q in natural language, the table question answering (TQA) task aims to return an accurate answer to Q based on the content of T. Recent state-of-the-art solutions leverage large language models (LLMs) to obtain high-quality answers. However, most rely on proprietary, large-scale LLMs with costly API access, posing a significant financial barrier. This paper instead focuses on TQA with smaller, open-weight LLMs that can run on a desktop or laptop. This setting is challenging, as such LLMs typically have weaker capabilities than large proprietary models, leading to substantial performance degradation with existing methods. We observe that a key reason for this degradation is that prior approaches often require the LLM to solve a highly sophisticated task using long, complex prompts, which exceed the capabilities of small open-weight LLMs. Motivated by this observation, we present Orchestra, a multi-agent approach that unlocks the potential of accessible LLMs for high-quality, cost-effective TQA. Orchestra coordinates a group of LLM agents, each responsible for a relatively simple task, through a structured, layered workflow to solve complex TQA problems -- akin to an orchestra. By reducing the prompt complexity faced by each agent, Orchestra significantly improves output reliability. We implement Orchestra on top of AgentScope, an open-source multi-agent framework, and evaluate it on multiple TQA benchmarks using a wide range of open-weight LLMs. Experimental results show that Orchestra achieves strong performance even with small- to medium-sized models. For example, with Qwen2.5-14B, Orchestra reaches 72.1% accuracy on WikiTQ, approaching the best prior result of 75.3% achieved with GPT-4; with larger Qwen, Llama, or DeepSeek models, Orchestra outperforms all prior methods and establishes new state-of-the-art results across all benchmarks.
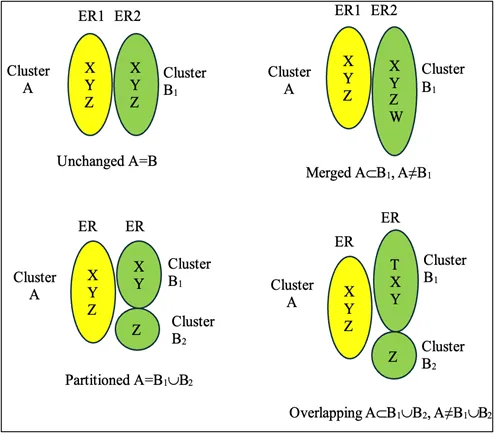
This paper describes a new process and software system, the Case Count Metric System (CCMS), for systematically comparing and analyzing the outcomes of two different ER clustering processes acting on the same dataset when the true linking (labeling) is not known. The CCMS produces a set of counts that describe how the clusters produced by the first process are transformed by the second process based on four possible transformation scenarios. The transformations are that a cluster formed in the first process either remains unchanged, merges into a larger cluster, is partitioned into smaller clusters, or otherwise overlaps with multiple clusters formed in the second process. The CCMS produces a count for each of these cases, accounting for every cluster formed in the first process. In addition, when run in analysis mode, the CCMS program can assist the user in evaluating these changes by displaying the details for all changes or only for certain types of changes. The paper includes a detailed description of the CCMS process and program and examples of how the CCMS has been applied in university and industry research.
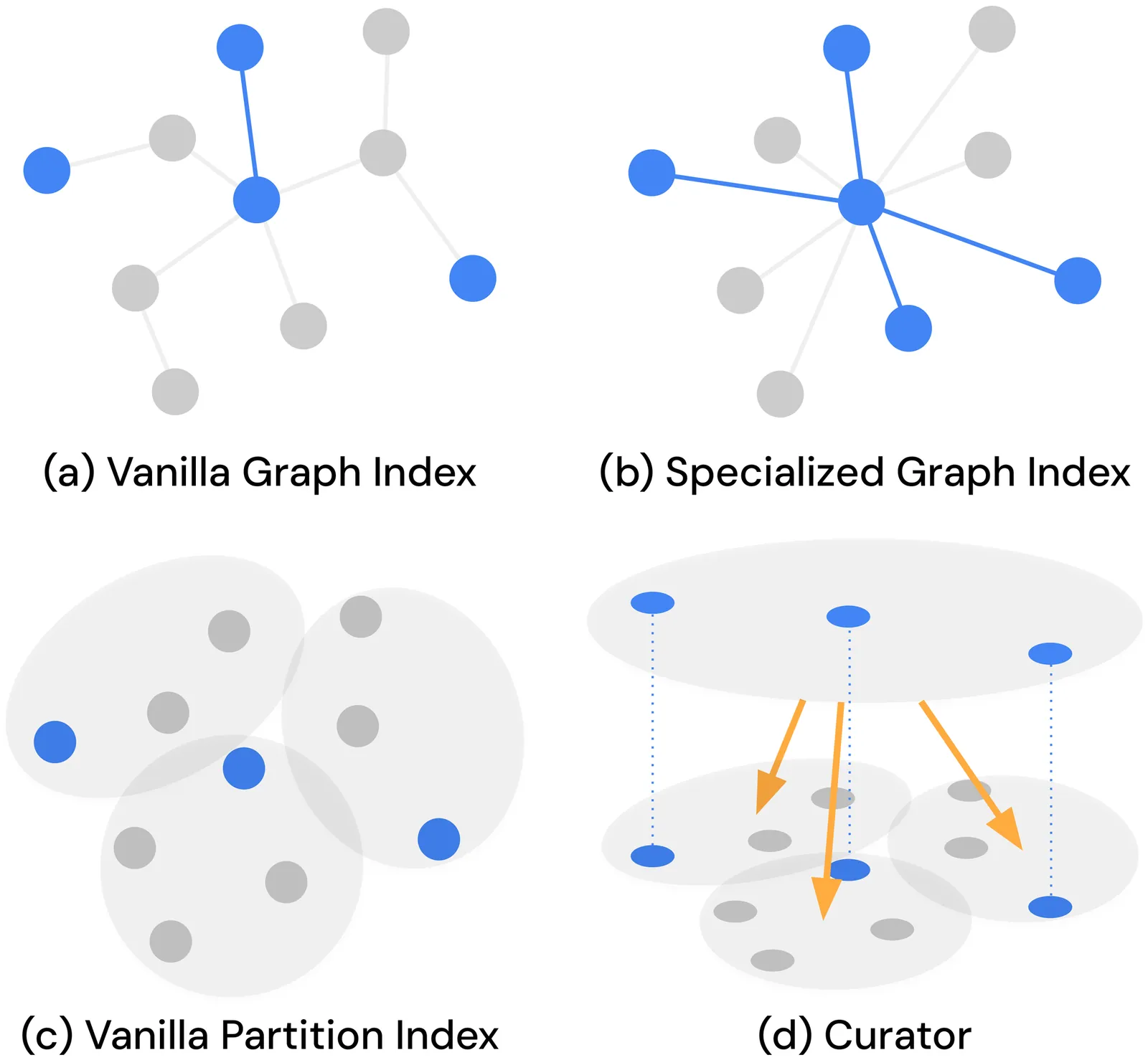
Embedding-based dense retrieval has become the cornerstone of many critical applications, where approximate nearest neighbor search (ANNS) queries are often combined with filters on labels such as dates and price ranges. Graph-based indexes achieve state-of-the-art performance on unfiltered ANNS but encounter connectivity breakdown on low-selectivity filtered queries, where qualifying vectors become sparse and the graph structure among them fragments. Recent research proposes specialized graph indexes that address this issue by expanding graph degree, which incurs prohibitively high construction costs. Given these inherent limitations of graph-based methods, we argue for a dual-index architecture and present Curator, a partition-based index that complements existing graph-based approaches for low-selectivity filtered ANNS. Curator builds specialized indexes for different labels within a shared clustering tree, where each index adapts to the distribution of its qualifying vectors to ensure efficient search while sharing structure to minimize memory overhead. The system also supports incremental updates and handles arbitrary complex predicates beyond single-label filters by efficiently constructing temporary indexes on the fly. Our evaluation demonstrates that integrating Curator with state-of-the-art graph indexes reduces low-selectivity query latency by up to 20.9x compared to pre-filtering fallback, while increasing construction time and memory footprint by only 5.5% and 4.3%, respectively.

Cloud storage has become the backbone of modern data infrastructure, yet privacy and efficient data retrieval remain significant challenges. Traditional privacy-preserving approaches primarily focus on enhancing database security but fail to address the automatic identification of sensitive information before encryption. This can dramatically reduce query processing time and mitigate errors during manual identification of sensitive information, thereby reducing potential privacy risks. To address this limitation, this research proposes an intelligent privacy-preserving query optimization framework that integrates Named Entity Recognition (NER) to detect sensitive information in queries, utilizing secure data encryption and query optimization techniques for both sensitive and non-sensitive data in parallel, thereby enabling efficient database optimization. Combined deep learning algorithms and transformer-based models to detect and classify sensitive entities with high precision, and the Advanced Encryption Standard (AES) algorithm to encrypt, with blind indexing to secure search functionality of the sensitive data, whereas non-sensitive data was divided into groups using the K-means algorithm, along with a rank search for optimization. Among all NER models, the Deep Belief Network combined with Long Short-Term Memory (DBN-LSTM) delivers the best performance, with an accuracy of 93% and precision (94%), recall, and F1 score of 93%, and 93%, respectively. Besides, encrypted search achieved considerably faster results with the help of blind indexing, and non-sensitive data fetching also outperformed traditional clustering-based searches. By integrating sensitive data detection, encryption, and query optimization, this work advances the state of privacy-preserving computation in modern cloud infrastructures.
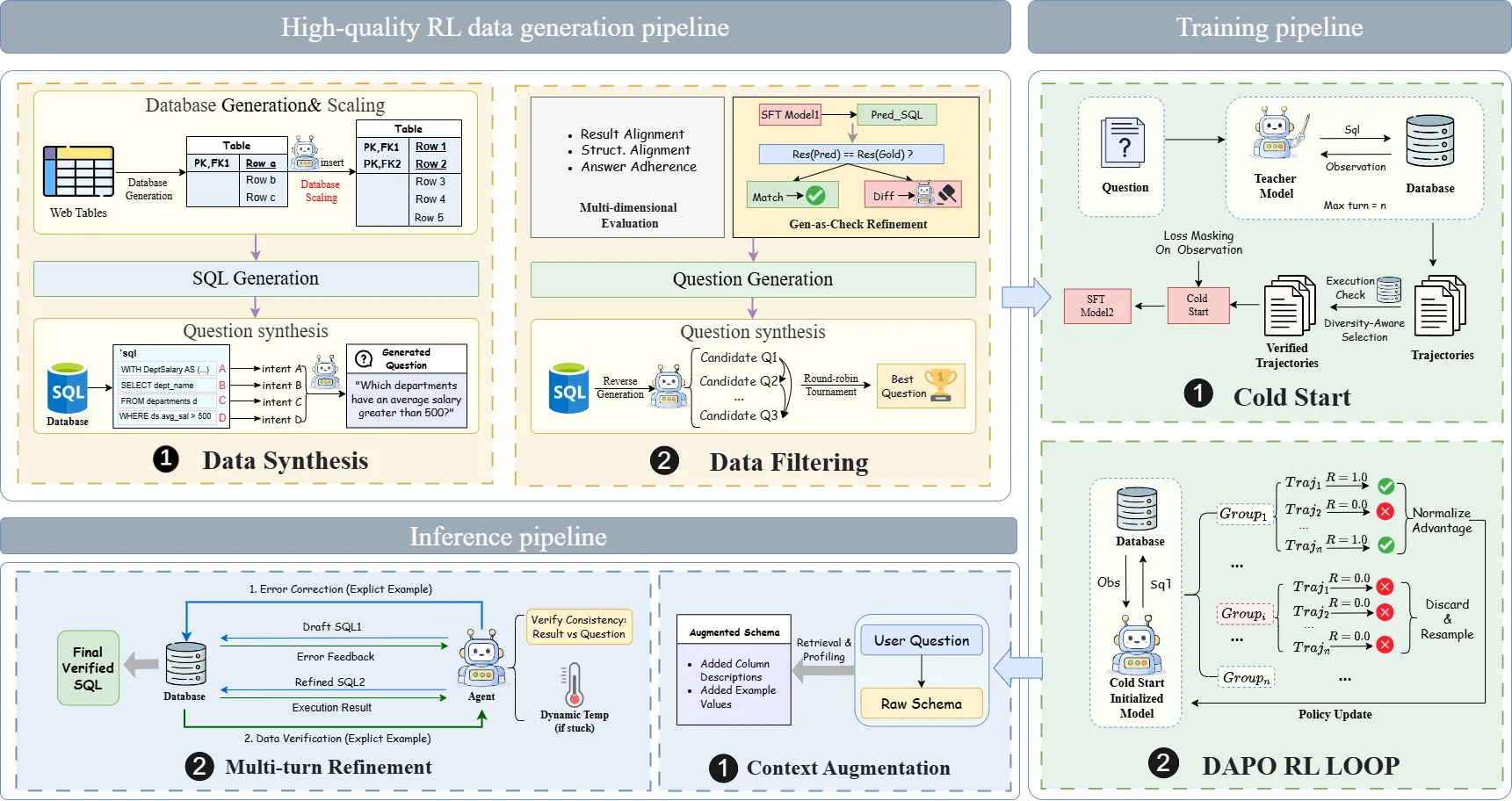
The advancement of Text-to-SQL systems is currently hindered by the scarcity of high-quality training data and the limited reasoning capabilities of models in complex scenarios. In this paper, we propose a holistic framework that addresses these issues through a dual-centric approach. From a Data-Centric perspective, we construct an iterative data factory that synthesizes RL-ready data characterized by high correctness and precise semantic-logic alignment, ensured by strict verification. From a Model-Centric perspective, we introduce a novel Agentic Reinforcement Learning framework. This framework employs a Diversity-Aware Cold Start stage to initialize a robust policy, followed by Group Relative Policy Optimization (GRPO) to refine the agent's reasoning via environmental feedback. Extensive experiments on BIRD and Spider benchmarks demonstrate that our synergistic approach achieves state-of-the-art performance among single-model methods.
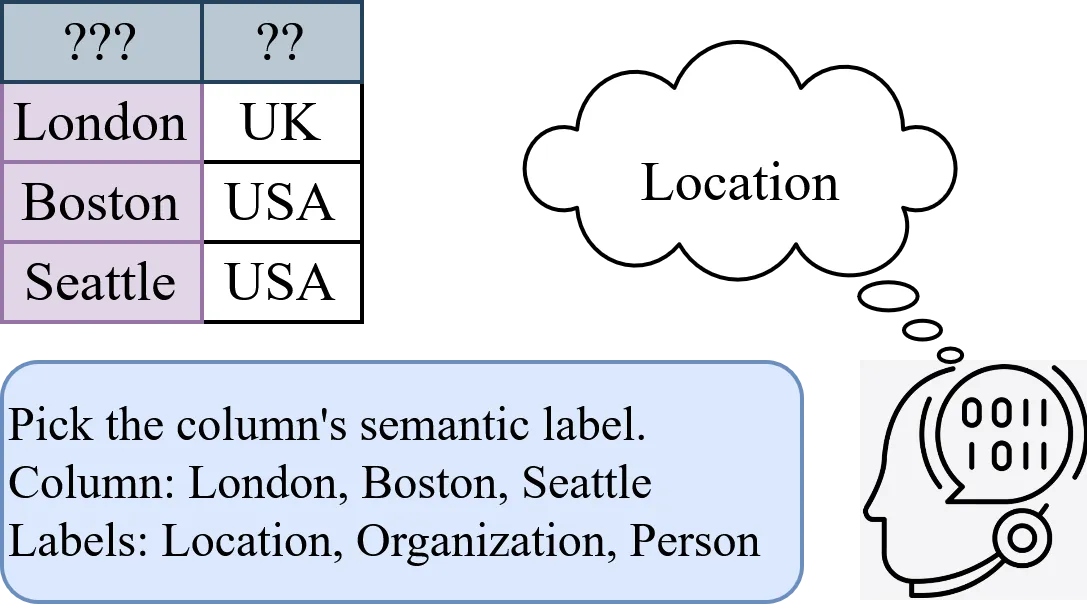
Column Type Annotation (CTA) is a fundamental step towards enabling schema alignment and semantic understanding of tabular data. Existing encoder-only language models achieve high accuracy when fine-tuned on labeled columns, but their applicability is limited to in-domain settings, as distribution shifts in tables or label spaces require costly re-training from scratch. Recent work has explored prompting generative large language models (LLMs) by framing CTA as a multiple-choice task, but these approaches face two key challenges: (1) model performance is highly sensitive to subtle changes in prompt wording and structure, and (2) annotation F1 scores remain modest. A natural extension is to fine-tune large language models. However, fully fine-tuning these models incurs prohibitive computational costs due to their scale, and the sensitivity to prompts is not eliminated. In this paper, we present a parameter-efficient framework for CTA that trains models over prompt-augmented data via Low-Rank Adaptation (LoRA). Our approach mitigates sensitivity to prompt variations while drastically reducing the number of necessary trainable parameters, achieving robust performance across datasets and templates. Experimental results on recent benchmarks demonstrate that models fine-tuned with our prompt augmentation strategy maintain stable performance across diverse prompt patterns during inference and yield higher weighted F1 scores than those fine-tuned on a single prompt template. These results highlight the effectiveness of parameter-efficient training and augmentation strategies in developing practical and adaptable CTA systems.

Text-to-SQL systems powered by Large Language Models (LLMs) achieve high accuracy on standard benchmarks, yet existing efficiency metrics such as the Valid Efficiency Score (VES) measure execution time rather than the consumption-based costs of cloud data warehouses. This paper presents the first systematic evaluation of cloud compute costs for LLM-generated SQL queries. We evaluate six state-of-the-art LLMs across 180 query executions on Google BigQuery using the StackOverflow dataset (230GB), measuring bytes processed, slot utilization, and estimated cost. Our analysis yields three key findings: (1) reasoning models process 44.5% fewer bytes than standard models while maintaining equivalent correctness (96.7%-100%); (2) execution time correlates weakly with query cost (r=0.16), indicating that speed optimization does not imply cost optimization; and (3) models exhibit up to 3.4x cost variance, with standard models producing outliers exceeding 36GB per query. We identify prevalent inefficiency patterns including missing partition filters and unnecessary full-table scans, and provide deployment guidelines for cost-sensitive enterprise environments.
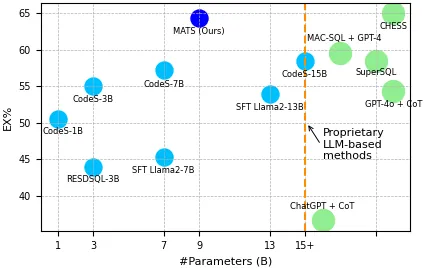
Text2SQL, the task of generating SQL queries from natural language text, is a critical challenge in data engineering. Recently, Large Language Models (LLMs) have demonstrated superior performance for this task due to their advanced comprehension and generation capabilities. However, privacy and cost considerations prevent companies from using Text2SQL solutions based on external LLMs offered as a service. Rather, small LLMs (SLMs) that are openly available and can hosted in-house are adopted. These SLMs, in turn, lack the generalization capabilities of larger LLMs, which impairs their effectiveness for complex tasks such as Text2SQL. To address these limitations, we propose MATS, a novel Text2SQL framework designed specifically for SLMs. MATS uses a multi-agent mechanism that assigns specialized roles to auxiliary agents, reducing individual workloads and fostering interaction. A training scheme based on reinforcement learning aligns these agents using feedback obtained during execution, thereby maintaining competitive performance despite a limited LLM size. Evaluation results using on benchmark datasets show that MATS, deployed on a single- GPU server, yields accuracy that are on-par with large-scale LLMs when using significantly fewer parameters. Our source code and data are available at https://github.com/thanhdath/mats-sql.
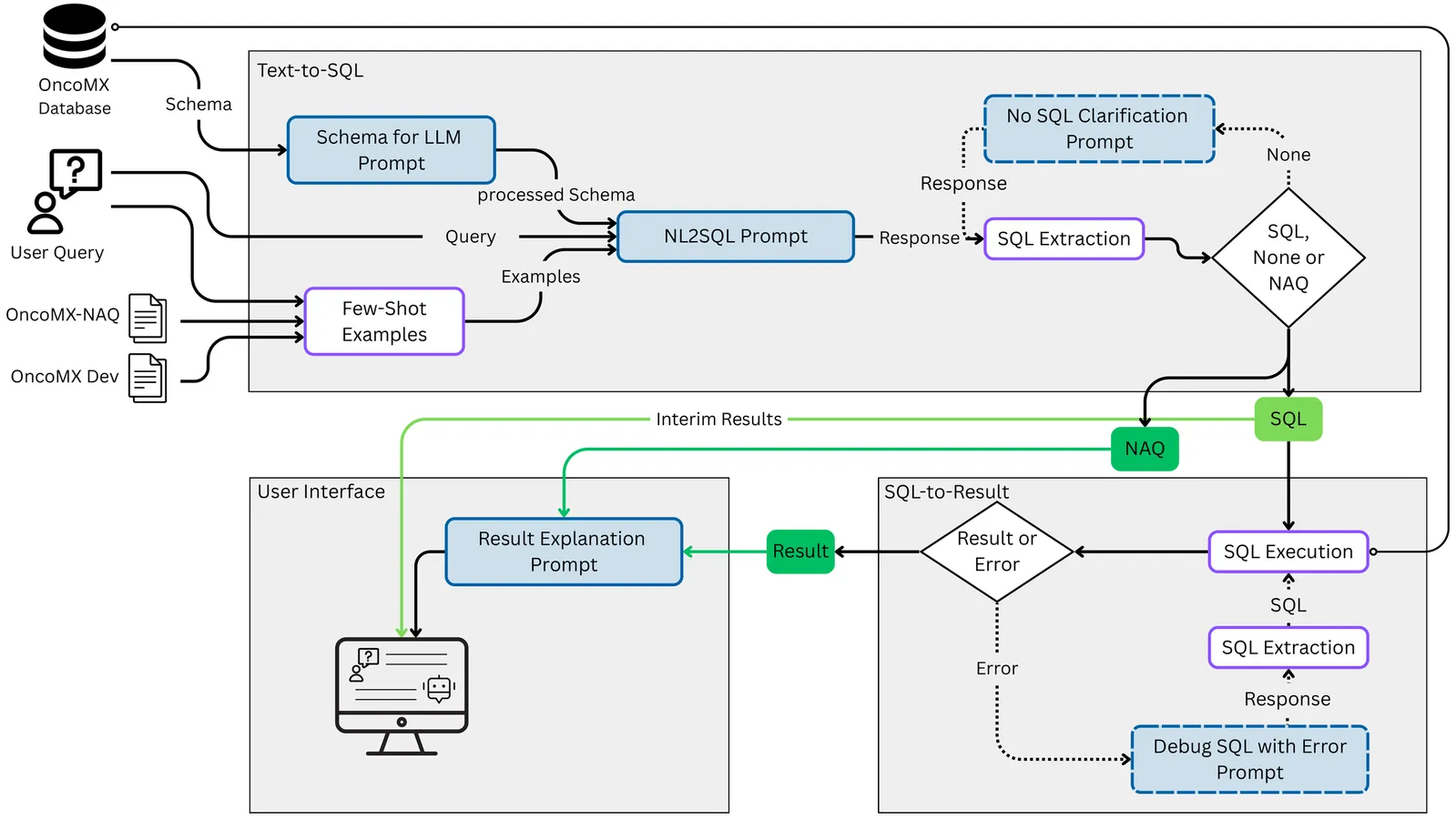
Text-to-SQL systems allow non-SQL experts to interact with relational databases using natural language. However, their tendency to generate executable SQL for ambiguous, out-of-scope, or unanswerable queries introduces a hidden risk, as outputs may be misinterpreted as correct. This risk is especially serious in biomedical contexts, where precision is critical. We therefore present Query Carefully, a pipeline that integrates LLM-based SQL generation with explicit detection and handling of unanswerable inputs. Building on the OncoMX component of ScienceBenchmark, we construct OncoMX-NAQ (No-Answer Questions), a set of 80 no-answer questions spanning 8 categories (non-SQL, out-of-schema/domain, and multiple ambiguity types). Our approach employs llama3.3:70b with schema-aware prompts, explicit No-Answer Rules (NAR), and few-shot examples drawn from both answerable and unanswerable questions. We evaluate SQL exact match, result accuracy, and unanswerable-detection accuracy. On the OncoMX dev split, few-shot prompting with answerable examples increases result accuracy, and adding unanswerable examples does not degrade performance. On OncoMX-NAQ, balanced prompting achieves the highest unanswerable-detection accuracy (0.8), with near-perfect results for structurally defined categories (non-SQL, missing columns, out-of-domain) but persistent challenges for missing-value queries (0.5) and column ambiguity (0.3). A lightweight user interface surfaces interim SQL, execution results, and abstentions, supporting transparent and reliable text-to-SQL in biomedical applications.
Subset sampling (also known as Poisson sampling), where the decision to include any specific element in the sample is made independently of all others, is a fundamental primitive in data analytics, enabling efficient approximation by processing representative subsets rather than massive datasets. While sampling from explicit lists is well-understood, modern applications -- such as machine learning over relational data -- often require sampling from a set defined implicitly by a relational join. In this paper, we study the problem of \emph{subset sampling over joins}: drawing a random subset from the join results, where each join result is included independently with some probability. We address the general setting where the probability is derived from input tuple weights via decomposable functions (e.g., product, sum, min, max). Since the join size can be exponentially larger than the input, the naive approach of materializing all join results to perform subset sampling is computationally infeasible. We propose the first efficient algorithms for subset sampling over acyclic joins: (1) a \emph{static index} for generating multiple (independent) subset samples over joins; (2) a \emph{one-shot} algorithm for generating a single subset sample over joins; (3) a \emph{dynamic index} that can support tuple insertions, while maintaining a one-shot sample or generating multiple (independent) samples. Our techniques achieve near-optimal time and space complexity with respect to the input size and the expected sample size.
Analyzing flow of objects or data at different granularities of space and time can unveil interesting insights or trends. For example, transportation companies, by aggregating passenger travel data (e.g., counting passengers traveling from one region to another), can analyze movement behavior. In this paper, we study the problem of finding important trends in passenger movements between regions at different granularities. We define Origin (O), Destination (D), and Time (T ) patterns (ODT patterns) and propose a bottom-up algorithm that enumerates them. We suggest and employ optimizations that greatly reduce the search space and the computational cost of pattern enumeration. We also propose pattern variants (constrained patterns and top-k patterns) that could be useful to different applications scenarios. Finally, we propose an approximate solution that fast identifies ODT patterns of specific sizes, following a generate-and-test approach. We evaluate the efficiency and effectiveness of our methods on three real datasets and showcase interesting ODT flow patterns in them.
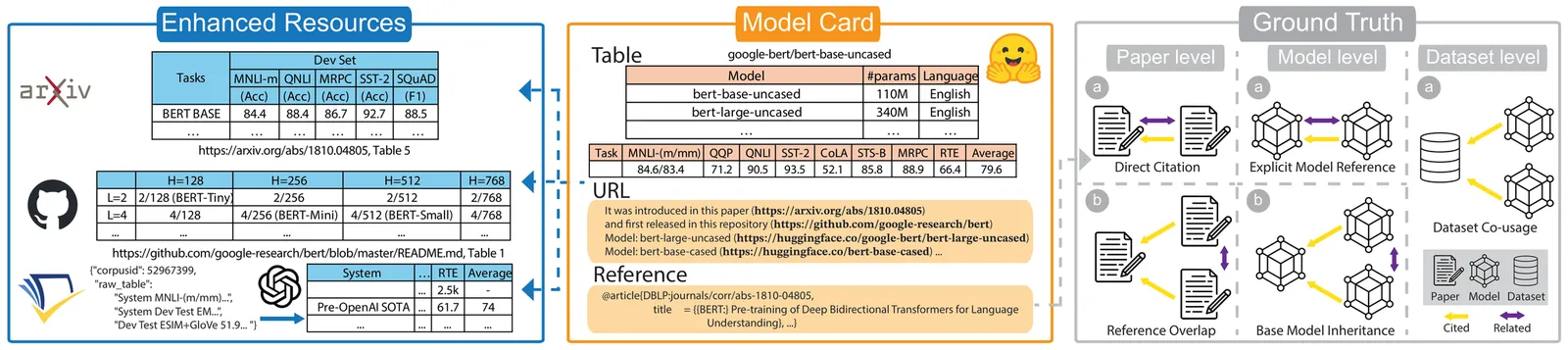
We present ModelTables, a benchmark of tables in Model Lakes that captures the structured semantics of performance and configuration tables often overlooked by text only retrieval. The corpus is built from Hugging Face model cards, GitHub READMEs, and referenced papers, linking each table to its surrounding model and publication context. Compared with open data lake tables, model tables are smaller yet exhibit denser inter table relationships, reflecting tightly coupled model and benchmark evolution. The current release covers over 60K models and 90K tables. To evaluate model and table relatedness, we construct a multi source ground truth using three complementary signals: (1) paper citation links, (2) explicit model card links and inheritance, and (3) shared training datasets. We present one extensive empirical use case for the benchmark which is table search. We compare canonical Data Lake search operators (unionable, joinable, keyword) and Information Retrieval baselines (dense, sparse, hybrid retrieval) on this benchmark. Union based semantic table retrieval attains 54.8 % P@1 overall (54.6 % on citation, 31.3 % on inheritance, 30.6 % on shared dataset signals); table based dense retrieval reaches 66.5 % P@1, and metadata hybrid retrieval achieves 54.1 %. This evaluation indicates clear room for developing better table search methods. By releasing ModelTables and its creation protocol, we provide the first large scale benchmark of structured data describing AI model. Our use case of table discovery in Model Lakes, provides intuition and evidence for developing more accurate semantic retrieval, structured comparison, and principled organization of structured model knowledge. Source code, data, and other artifacts have been made available at https://github.com/RJMillerLab/ModelTables.
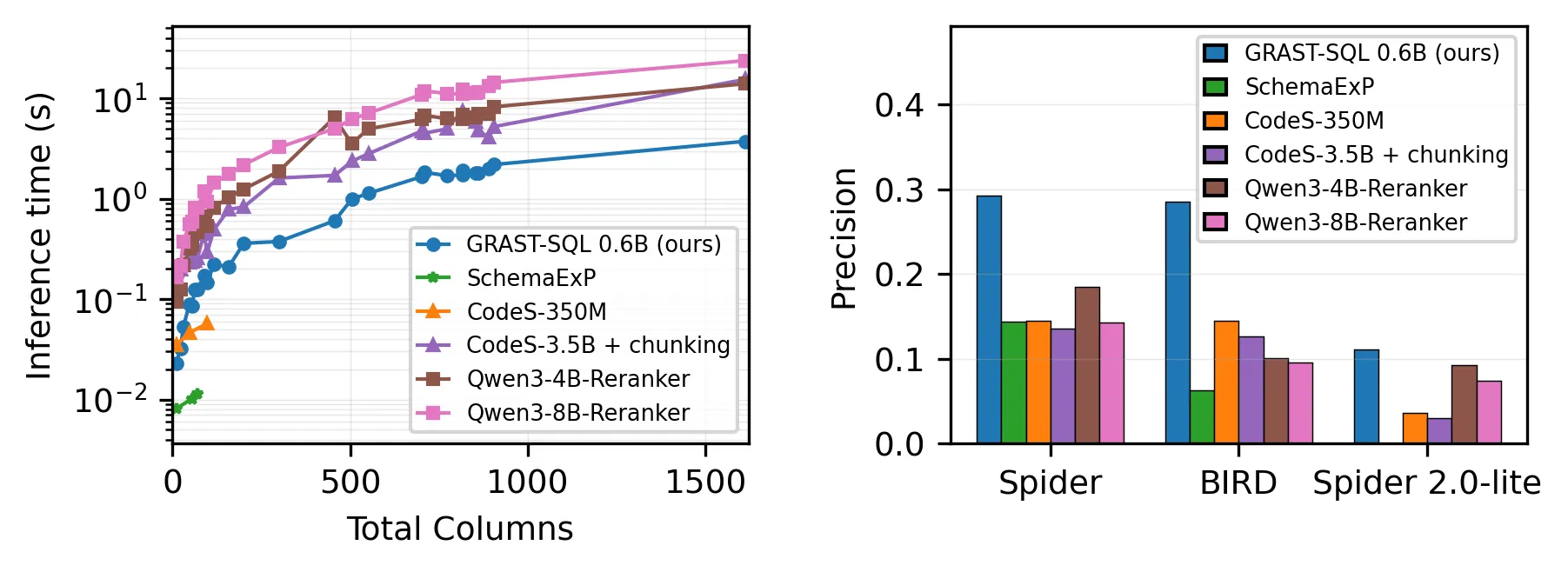
Most modern Text2SQL systems prompt large language models (LLMs) with entire schemas -- mostly column information -- alongside the user's question. While effective on small databases, this approach fails on real-world schemas that exceed LLM context limits, even for commercial models. The recent Spider 2.0 benchmark exemplifies this with hundreds of tables and tens of thousands of columns, where existing systems often break. Current mitigations either rely on costly multi-step prompting pipelines or filter columns by ranking them against user's question independently, ignoring inter-column structure. To scale existing systems, we introduce \toolname, an open-source, LLM-efficient schema filtering framework that compacts Text2SQL prompts by (i) ranking columns with a query-aware LLM encoder enriched with values and metadata, (ii) reranking inter-connected columns via a lightweight graph transformer over functional dependencies, and (iii) selecting a connectivity-preserving sub-schema with a Steiner-tree heuristic. Experiments on real datasets show that \toolname achieves near-perfect recall and higher precision than CodeS, SchemaExP, Qwen rerankers, and embedding retrievers, while maintaining sub-second median latency and scaling to schemas with 23,000+ columns. Our source code is available at https://github.com/thanhdath/grast-sql.
Data sharing in large consortia, such as research collaborations or industry partnerships, requires addressing both organizational and technical challenges. A common platform is essential to promote collaboration, facilitate exchange of findings, and ensure secure access to sensitive data. Key technical challenges include creating a scalable architecture, a user-friendly interface, and robust security and access control. The BIG-MAP Archive is a cloud-based, disciplinary, private repository designed to address these challenges. Built on InvenioRDM, it leverages platform functionalities to meet consortium-specific needs, providing a tailored solution compared to general repositories. Access can be restricted to members of specific communities or open to the entire consortium, such as the BATTERY 2030+, a consortium accelerating advanced battery technologies. Uploaded data and metadata are controlled via fine grained permissions, allowing access to individual project members or the full initiative. The formalized upload process ensures data are formatted and ready for publication in open repositories when needed. This paper reviews the repository's key features, showing how the BIG-MAP Archive enables secure, controlled data sharing within large consortia. It ensures data confidentiality while supporting flexible, permissions-based access and can be easily redeployed for other consortia, including MaterialsCommons4.eu and RAISE (Resource for AI Science in Europe).
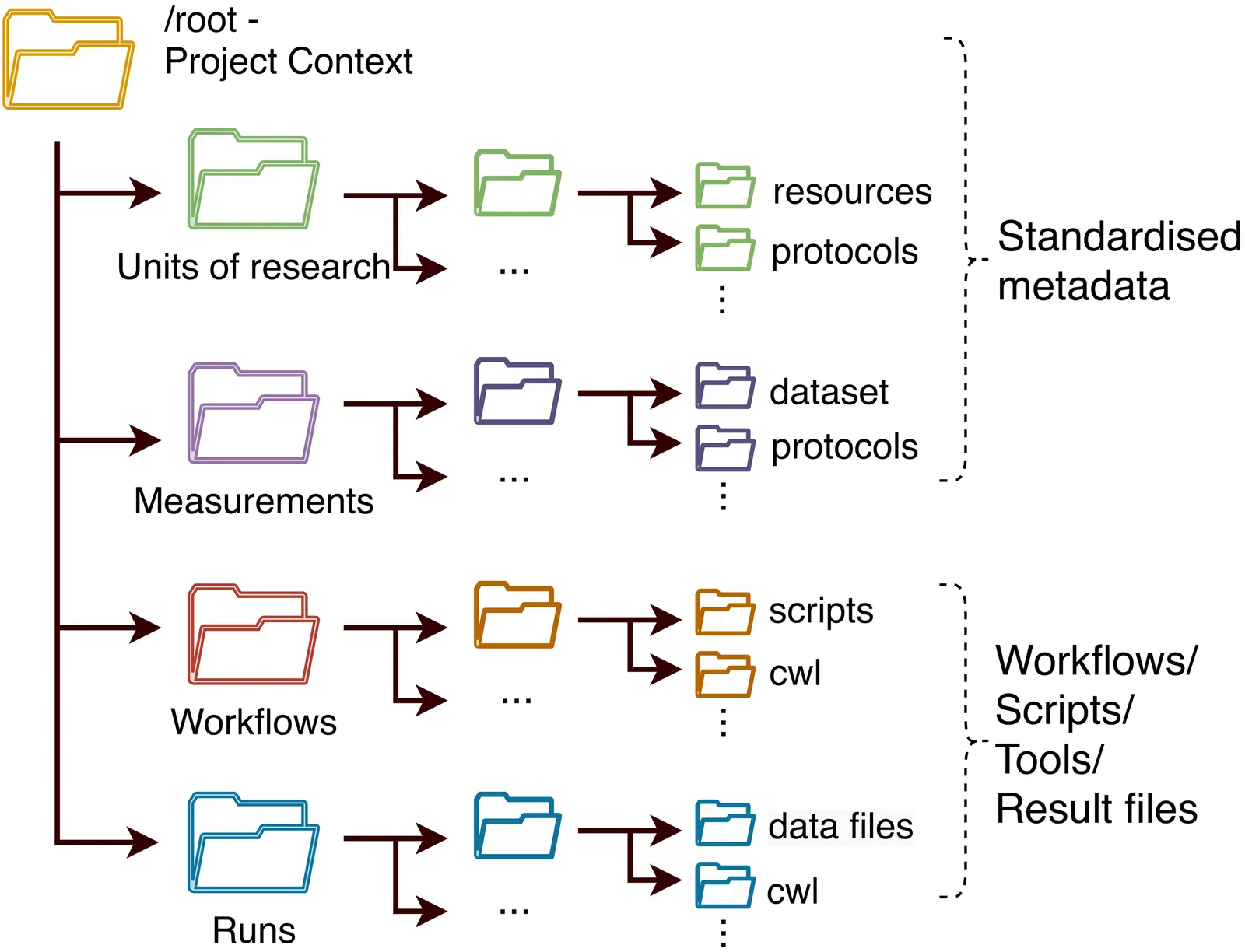
Traditional search applications within Research Data Management (RDM) ecosystems are crucial in helping users discover and explore the structured metadata from the research datasets. Typically, text search engines require users to submit keyword-based queries rather than using natural language. However, using Large Language Models (LLMs) trained on domain-specific content for specialized natural language processing (NLP) tasks is becoming increasingly common. We present ArcBERT, an LLM-based system designed for integrated metadata exploration. ArcBERT understands natural language queries and relies on semantic matching, unlike traditional search applications. Notably, ArcBERT also understands the structure and hierarchies within the metadata, enabling it to handle diverse user querying patterns effectively.
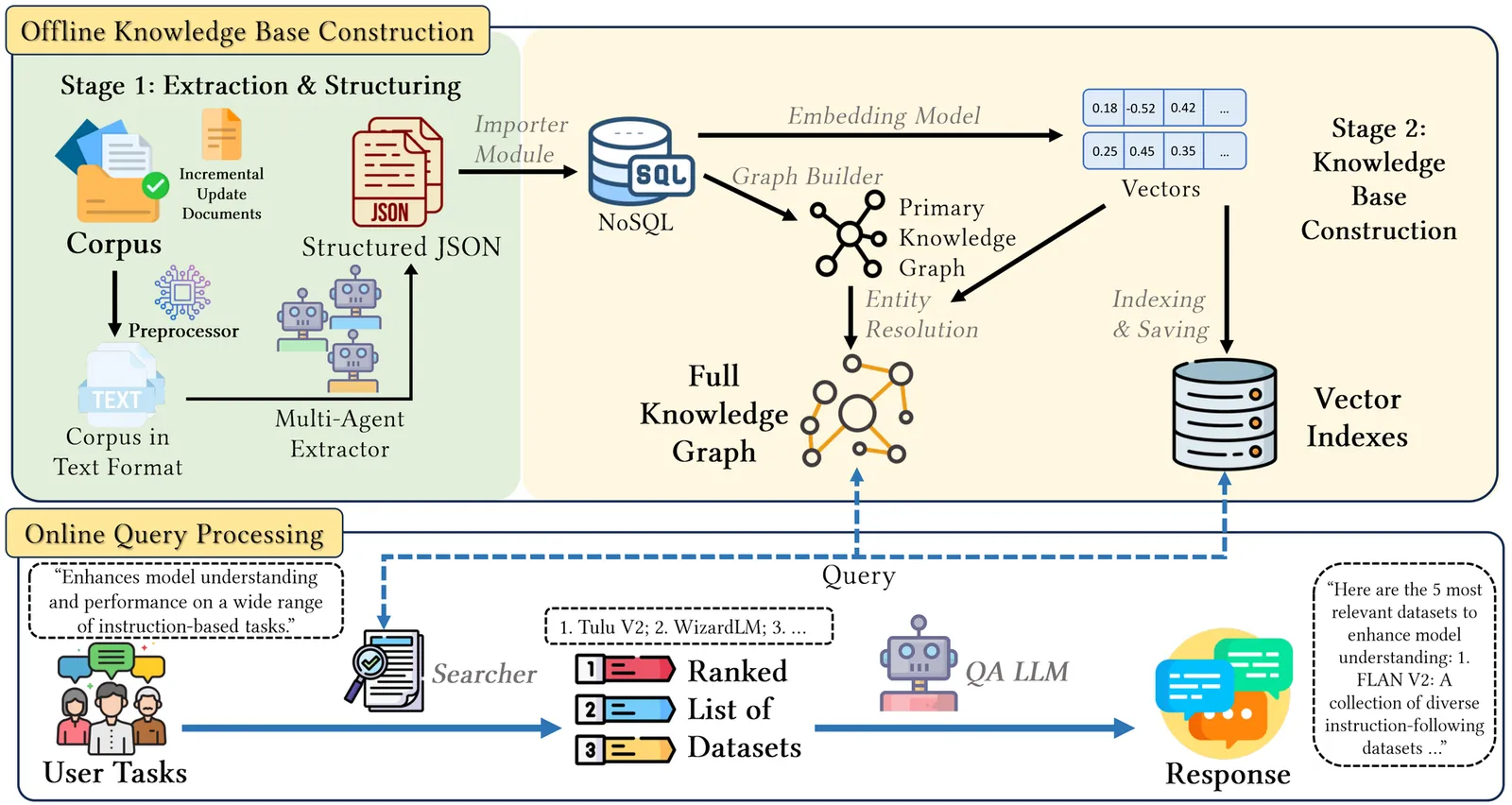
The search for suitable datasets is the critical "first step" in data-driven research, but it remains a great challenge. Researchers often need to search for datasets based on high-level task descriptions. However, existing search systems struggle with this task due to ambiguous user intent, task-to-dataset mapping and benchmark gaps, and entity ambiguity. To address these challenges, we introduce KATS, a novel end-to-end system for task-oriented dataset search from unstructured scientific literature. KATS consists of two key components, i.e., offline knowledge base construction and online query processing. The sophisticated offline pipeline automatically constructs a high-quality, dynamically updatable task-dataset knowledge graph by employing a collaborative multi-agent framework for information extraction, thereby filling the task-to-dataset mapping gap. To further address the challenge of entity ambiguity, a unique semantic-based mechanism is used for task entity linking and dataset entity resolution. For online retrieval, KATS utilizes a specialized hybrid query engine that combines vector search with graph-based ranking to generate highly relevant results. Additionally, we introduce CS-TDS, a tailored benchmark suite for evaluating task-oriented dataset search systems, addressing the critical gap in standardized evaluation. Experiments on our benchmark suite show that KATS significantly outperforms state-of-the-art retrieval-augmented generation frameworks in both effectiveness and efficiency, providing a robust blueprint for the next generation of dataset discovery systems.
We introduce graph pattern-based association rules (GPARs) for directed labeled multigraphs such as RDF graphs. GPARs support both generative tasks, where a graph is extended, and evaluative tasks, where the plausibility of a graph is assessed. The framework goes beyond related formalisms such as graph functional dependencies, graph entity dependencies, relational association rules, graph association rules, multi-relation and path association rules, and Horn rules. Given a collection of graphs, we evaluate graph patterns under no-repeated-anything semantics, which allows the topology of a graph to be taken into account more effectively. We define a probability space and derive confidence, lift, leverage, and conviction in a probabilistic setting. We further analyze how these metrics relate to their classical itemset-based counterparts and identify conditions under which their characteristic properties are preserved.
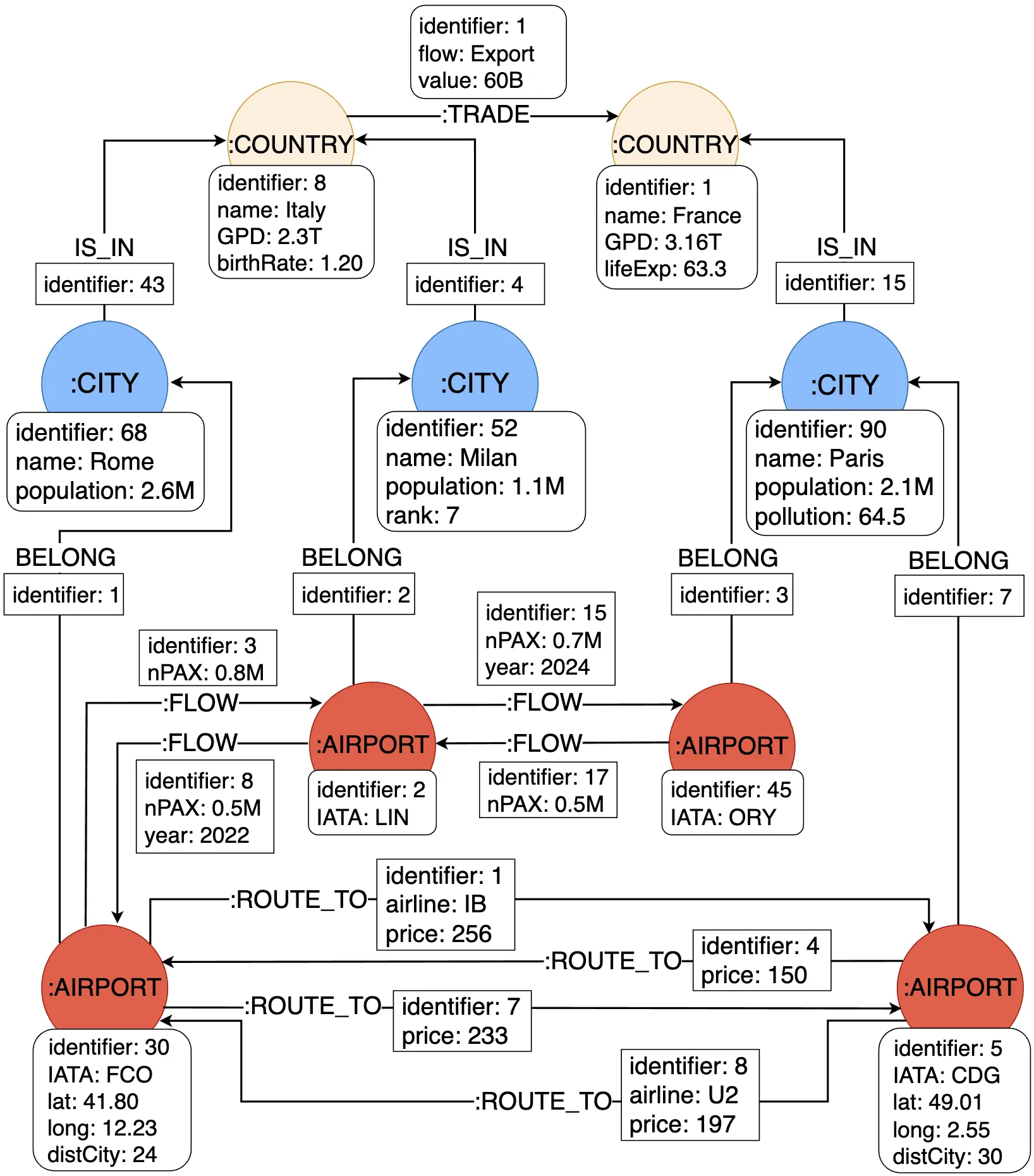
While scoring nodes in graphs to understand their importance (e.g., in terms of centrality) has been investigated for decades, comparing nodes in property graphs based on their properties has not, to our knowledge, yet been addressed. In this paper, we propose an approach to automatically extract comparison of nodes in property graphs, to support the interactive exploratory analysis of said graphs. We first present a way of devising comparison indicators using the context of nodes to be compared. Then, we formally define the problem of using these indicators to group the nodes so that the comparisons extracted are both significant and not straightforward. We propose various heuristics for solving this problem. Our tests on real property graph databases show that simple heuristics can be used to obtain insights within minutes while slower heuristics are needed to obtain insights of higher quality.
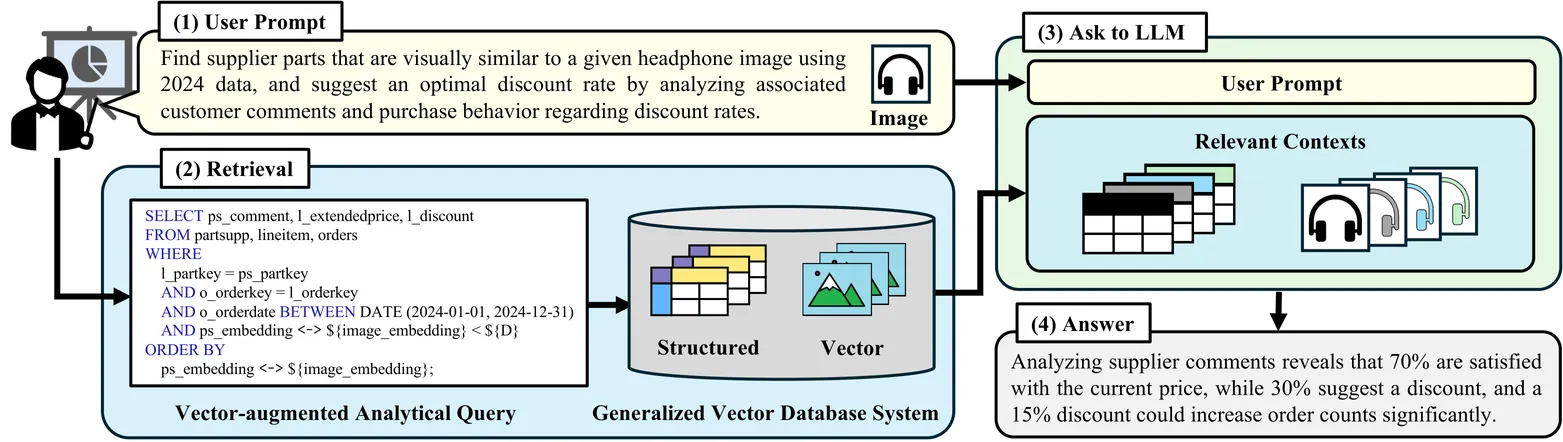
Vector similarity search is becoming increasingly important for data science pipelines, particularly in Retrieval-Augmented Generation (RAG), where it enhances large language model inference by enabling efficient retrieval of relevant external knowledge. As RAG expands with table-augmented generation to incorporate structured data, workloads integrating table and vector search are becoming more prevalent. However, efficiently executing such queries remains challenging due to inaccurate cardinality estimation for vector search components, leading to suboptimal query plans. In this paper, we propose Exqutor, an extended query optimizer for vector-augmented analytical queries. Exqutor is a pluggable cardinality estimation framework designed to address this issue, leveraging exact cardinality query optimization techniques to enhance estimation accuracy when vector indexes (e.g., HNSW, IVF) are available. In scenarios lacking these indexes, we employ a sampling-based approach with adaptive sampling size adjustment, dynamically tuning the sample size to balance estimation accuracy and sampling overhead. This allows Exqutor to efficiently approximate vector search cardinalities while minimizing computational costs. We integrate our framework into pgvector, VBASE, and DuckDB, demonstrating performance improvements of up to four orders of magnitude on vector-augmented analytical queries.
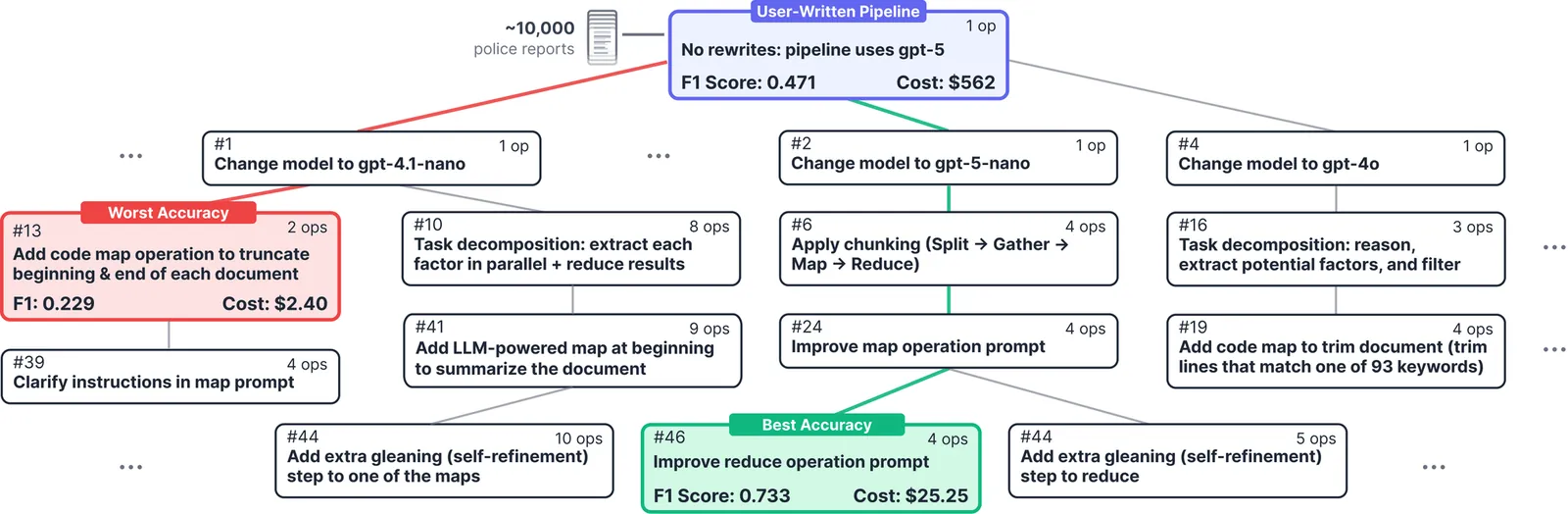
One year ago, we open-sourced DocETL, a declarative system for LLM-powered data processing that, as of November 2025, has 3.2K GitHub stars and users across domains (e.g., journalism, law, medicine, policy, finance, and urban planning). In DocETL, users build pipelines by composing operators described in natural language, also known as semantic operators, with an LLM executing each operator's logic. However, due to complexity in the operator or the data it operates on, LLMs often give inaccurate results. To address this challenge, DocETL introduced rewrite directives, or abstract rules that guide LLM agents in rewriting pipelines by decomposing operators or data. For example, decomposing a single filter("is this email sent from an executive and discussing fraud?") into the conjunction of two separate semantic filters may improve accuracy. However, DocETL only optimizes for accuracy, not cost. How do we optimize for both? We present MOAR (Multi-Objective Agentic Rewrites), a new optimizer for DocETL. To target cost optimization, we introduce two new categories of directives and extend all three existing categories with new ones, bringing the total to over 30 directives -- more than doubling what DocETL originally had. Moreover, since operators can interact with each other unpredictably due to LLM behavior, optimizing operators or sub-pipelines individually can yield suboptimal overall plans. Recognizing this, we design a new global search algorithm that explores rewrites in the context of entire pipelines. Since the space of rewrites is infinite -- pipelines can be rewritten in many ways, and each rewritten pipeline can itself be rewritten -- our algorithm adapts a multi-armed bandit framework to prioritize which pipelines to rewrite. Across six workloads, MOAR achieves 27% higher accuracy than ABACUS, the next-best optimizer, while matching its best accuracy at 55% of its cost.

Outlier detection and cleaning are essential steps in data preprocessing to ensure the integrity and validity of data analyses. This paper focuses on outlier points within individual trajectories, i.e., points that deviate significantly inside a single trajectory. We experiment with ten open-source libraries to comprehensively evaluate available tools, comparing their efficiency and accuracy in identifying and cleaning outliers. This experiment considers the libraries as they are offered to end users, with real-world applicability. We compare existing outlier detection libraries, introduce a method for establishing ground-truth, and aim to guide users in choosing the most appropriate tool for their specific outlier detection needs. Furthermore, we survey the state-of-the-art algorithms for outlier detection and classify them into five types: Statistic-based methods, Sliding window algorithms, Clustering-based methods, Graph-based methods, and Heuristic-based methods. Our research provides insights into these libraries' performance and contributes to developing data preprocessing and outlier detection methodologies.
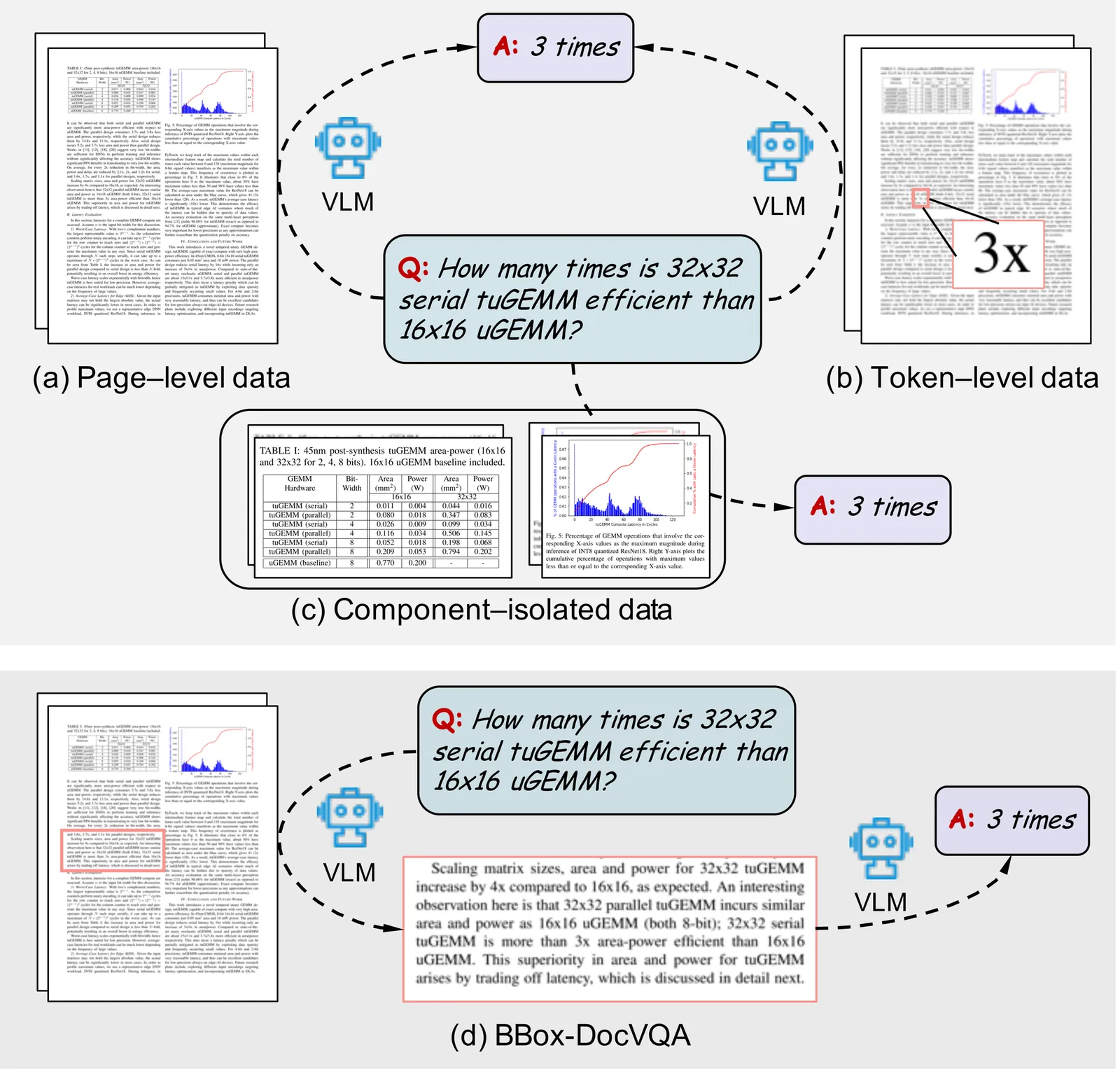
Document Visual Question Answering (DocVQA) is a fundamental task for multimodal document understanding and a key testbed for vision language reasoning. However, most existing DocVQA datasets are limited to the page level and lack fine grained spatial grounding, constraining the interpretability and reasoning capability of Vision Language Models (VLMs). To address this gap, we introduce BBox DocVQA a large scale, bounding box grounded dataset designed to enhance spatial reasoning and evidence localization in visual documents. We further present an automated construction pipeline, Segment Judge and Generate, which integrates a segment model for region segmentation, a VLM for semantic judgment, and another advanced VLM for question answer generation, followed by human verification for quality assurance. The resulting dataset contains 3.6 K diverse documents and 32 K QA pairs, encompassing single and multi region as well as single and multi page scenarios. Each QA instance is grounded on explicit bounding boxes, enabling fine grained evaluation of spatial semantic alignment. Benchmarking multiple state of the art VLMs (e.g., GPT 5, Qwen2.5 VL, and InternVL) on BBox DocVQA reveals persistent challenges in spatial grounding and reasoning accuracy. Furthermore, fine tuning on BBox DocVQA substantially improves both bounding box localization and answer generation, validating its effectiveness for enhancing the reasoning ability of VLMs. Our dataset and code will be publicly released to advance research on interpretable and spatially grounded vision language reasoning.

Vector search has been widely employed in recommender system and retrieval-augmented-generation pipelines, commonly performed with vector indexes to efficiently find similar items in large datasets. Recent growths in both data and task complexity have motivated placing vector indexes onto remote storage -- cloud-native vector search, which cloud providers have recently introduced services for. Yet, despite varying workload characteristics and various available vector index forms, providers default to using cluster-based indexes, which on paper do adapt well to differences between disk and cloud-based environment: their fetch granularities and lack of notable intra-query dependencies aligns with the large optimal fetch sizes and minimizes costly round-trips (i.e., as opposed to graph-based indexes) to remote storage, respectively. This paper systematically studies cloud-native vector search: What and how should indexes be built and used for on-cloud vector search? We analyze bottlenecks of two common index classes, cluster and graph indexes, on remote storage, and show that despite current standardized adoption of cluster indexes on the cloud, graph indexes are favored in workloads requiring high concurrency and recall, or operating on high-dimensional data or large datatypes. We further find that on-cloud search demands significantly different indexing and search parameterizations versus on-disk search for optimal performance. Finally, we incorporate existing cloud-based caching setups into vector search and find that certain index optimizations work against caching, and study how this can be mitigated to maximize gains under various available cache sizes.

Ranging from batch scripts to computational notebooks, modern data science tools rely on massive and evolving object graphs that represent structured data, models, plots, and more. Persisting these objects is critical, not only to enhance system robustness against unexpected failures but also to support continuous, non-linear data exploration via versioning. Existing object persistence mechanisms (e.g., Pickle, Dill) rely on complete snapshotting, often redundantly storing unchanged objects during execution and exploration, resulting in significant inefficiency in both time and storage. Unlike DBMSs, data science systems lack centralized buffer managers that track dirty objects. Worse, object states span various locations such as memory heaps, shared memory, GPUs, and remote machines, making dirty object identification fundamentally more challenging. In this work, we propose a graph-based object store, named Chipmink, that acts like the centralized buffer manager. Unlike static pages in DBMSs, persistence units in Chipmink are dynamically induced by partitioning objects into appropriate subgroups (called pods), minimizing expected persistence costs based on object sizes and reference structure. These pods effectively isolate dirty objects, enabling efficient partial persistence. Our experiments show that Chipmink is general, supporting libraries that rely on shared memory, GPUs, and remote objects. Moreover, Chipmink achieves up to 36.5x smaller storage sizes and 12.4x faster persistence than the best baselines in real-world notebooks and scripts.
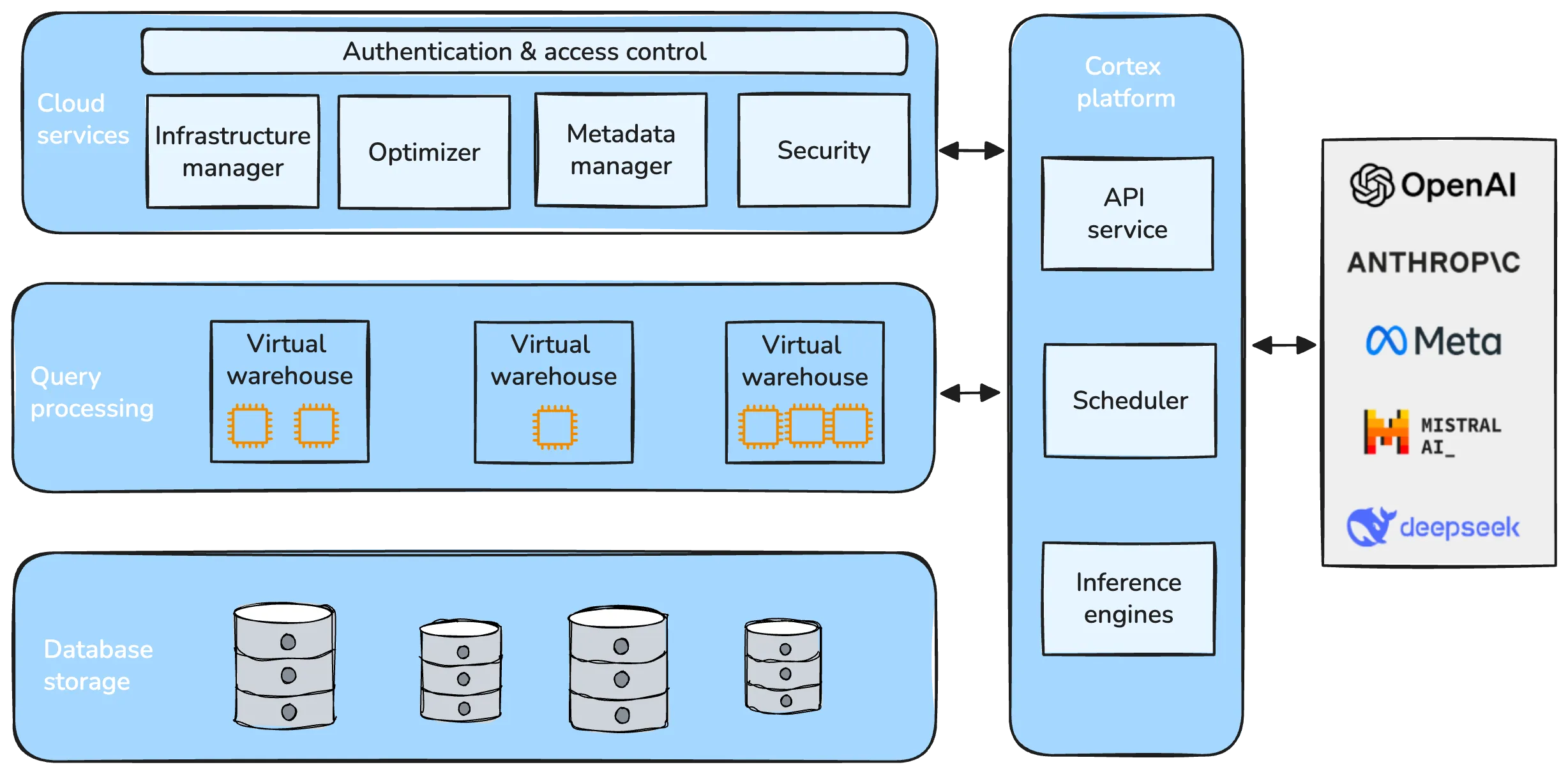
Snowflake's Cortex AISQL is a production SQL engine that integrates native semantic operations directly into SQL. This integration allows users to write declarative queries that combine relational operations with semantic reasoning, enabling them to query both structured and unstructured data effortlessly. However, making semantic operations efficient at production scale poses fundamental challenges. Semantic operations are more expensive than traditional SQL operations, possess distinct latency and throughput characteristics, and their cost and selectivity are unknown during query compilation. Furthermore, existing query engines are not designed to optimize semantic operations. The AISQL query execution engine addresses these challenges through three novel techniques informed by production deployment data from Snowflake customers. First, AI-aware query optimization treats AI inference cost as a first-class optimization objective, reasoning about large language model (LLM) cost directly during query planning to achieve 2-8$\times$ speedups. Second, adaptive model cascades reduce inference costs by routing most rows through a fast proxy model while escalating uncertain cases to a powerful oracle model, achieving 2-6$\times$ speedups while maintaining 90-95% of oracle model quality. Third, semantic join query rewriting lowers the quadratic time complexity of join operations to linear through reformulation as multi-label classification tasks, achieving 15-70$\times$ speedups with often improved prediction quality. AISQL is deployed in production at Snowflake, where it powers diverse customer workloads across analytics, search, and content understanding.
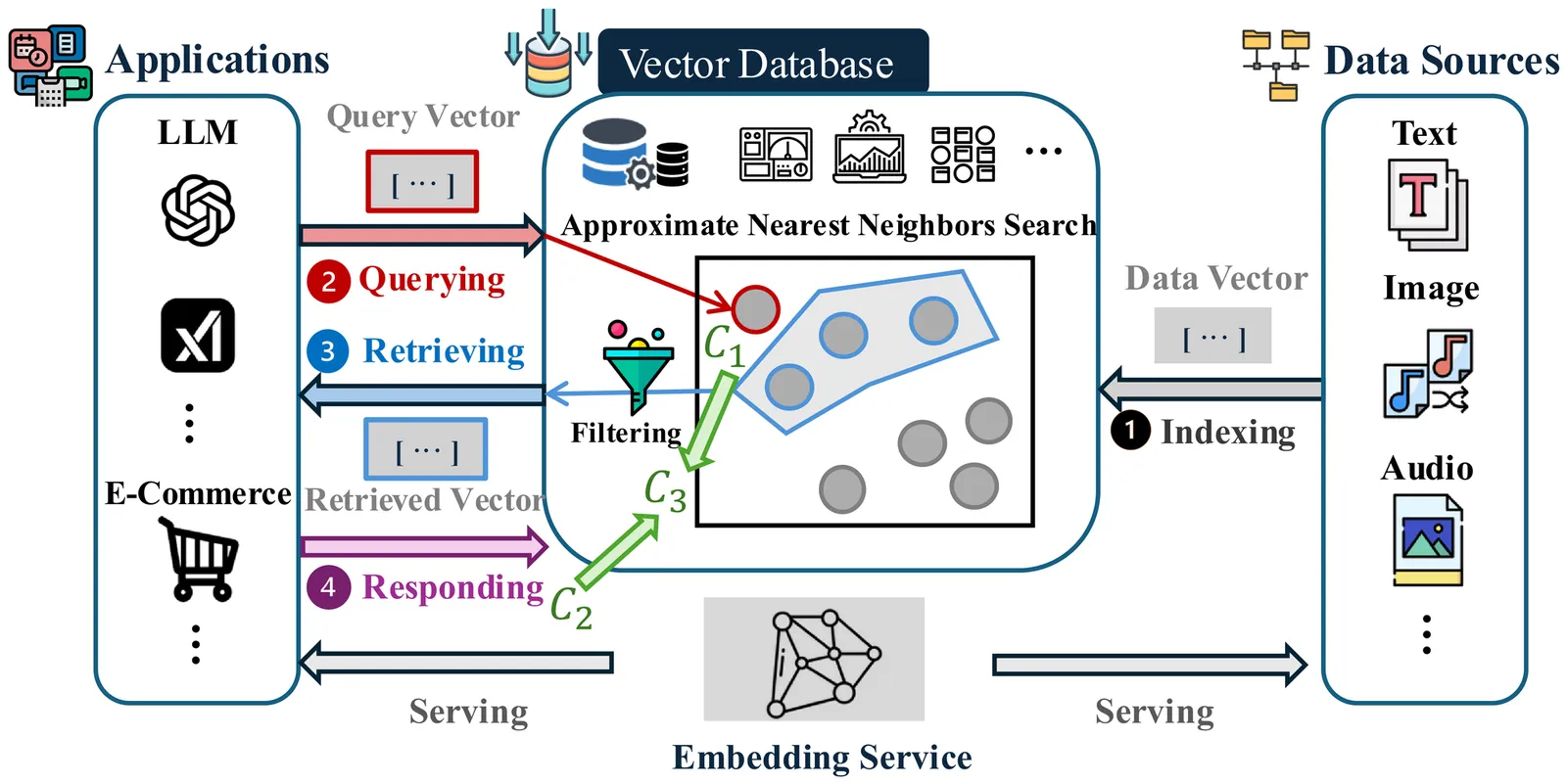
Vector data trading is essential for cross-domain learning with vector databases, yet it remains largely unexplored. We study this problem under online learning, where sellers face uncertain retrieval costs and buyers provide stochastic feedback to posted prices. Three main challenges arise: (1) heterogeneous and partial feedback in configuration learning, (2) variable and complex feedback in pricing learning, and (3) inherent coupling between configuration and pricing decisions. We propose a hierarchical bandit framework that jointly optimizes retrieval configurations and pricing. Stage I employs contextual clustering with confidence-based exploration to learn effective configurations with logarithmic regret. Stage II adopts interval-based price selection with local Taylor approximation to estimate buyer responses and achieve sublinear regret. We establish theoretical guarantees with polynomial time complexity and validate the framework on four real-world datasets, demonstrating consistent improvements in cumulative reward and regret reduction compared with existing methods.

We present a benchmark targeting a novel class of systems: semantic query processing engines. Those systems rely inherently on generative and reasoning capabilities of state-of-the-art large language models (LLMs). They extend SQL with semantic operators, configured by natural language instructions, that are evaluated via LLMs and enable users to perform various operations on multimodal data. Our benchmark introduces diversity across three key dimensions: scenarios, modalities, and operators. Included are scenarios ranging from movie review analysis to medical question-answering. Within these scenarios, we cover different data modalities, including images, audio, and text. Finally, the queries involve a diverse set of operators, including semantic filters, joins, mappings, ranking, and classification operators. We evaluated our benchmark on three academic systems (LOTUS, Palimpzest, and ThalamusDB) and one industrial system, Google BigQuery. Although these results reflect a snapshot of systems under continuous development, our study offers crucial insights into their current strengths and weaknesses, illuminating promising directions for future research.
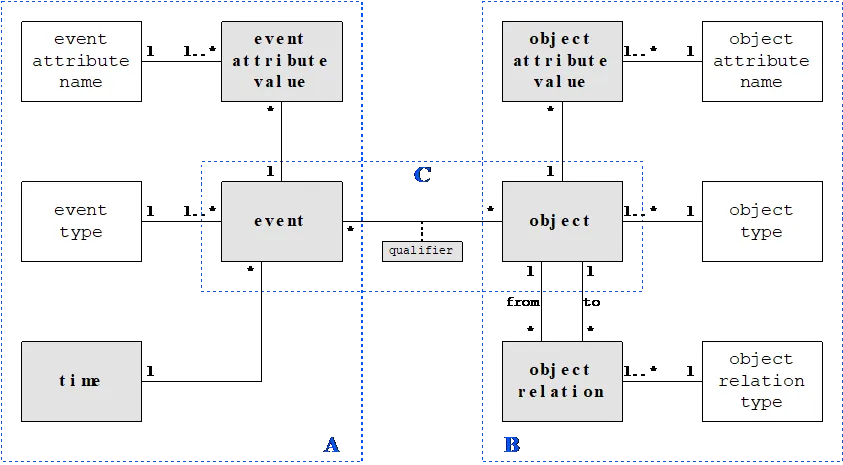
Object Centric Event Data (OCED) has gained attention in recent years within the field of process mining. However, there are still many challenges, such as connecting the XES format to object-centric approaches to enable more insightful analysis. It is important for a process miner to understand the insights and dependencies of events in the event log to see what is going on in our processes. In previous standards, the dependencies of event logs are only used to show events, but not their dependencies among each other and actions in detail as described in OCEDO. There is more information in the event log when it is revealed using the OCEDO model. It becomes more understandable and easier to grasp the concepts and deal with the processes. This paper proposes the use of Object-Centric Event Data Ontology (OCEDO) to overcome the limitations of the XES standard in event logs for process mining. We demonstrate how the OCEDO approach, integrated with SPARQL queries, can be applied to the BPIC 2013 dataset to make the relationships between events and objects more explicit. It describes dealing with the meta descriptions of the OCEDO model on a business process challenge as an event log. It improves the completeness and readability of process data, suggesting that object-centric modeling allows for richer analyses than traditional approaches.
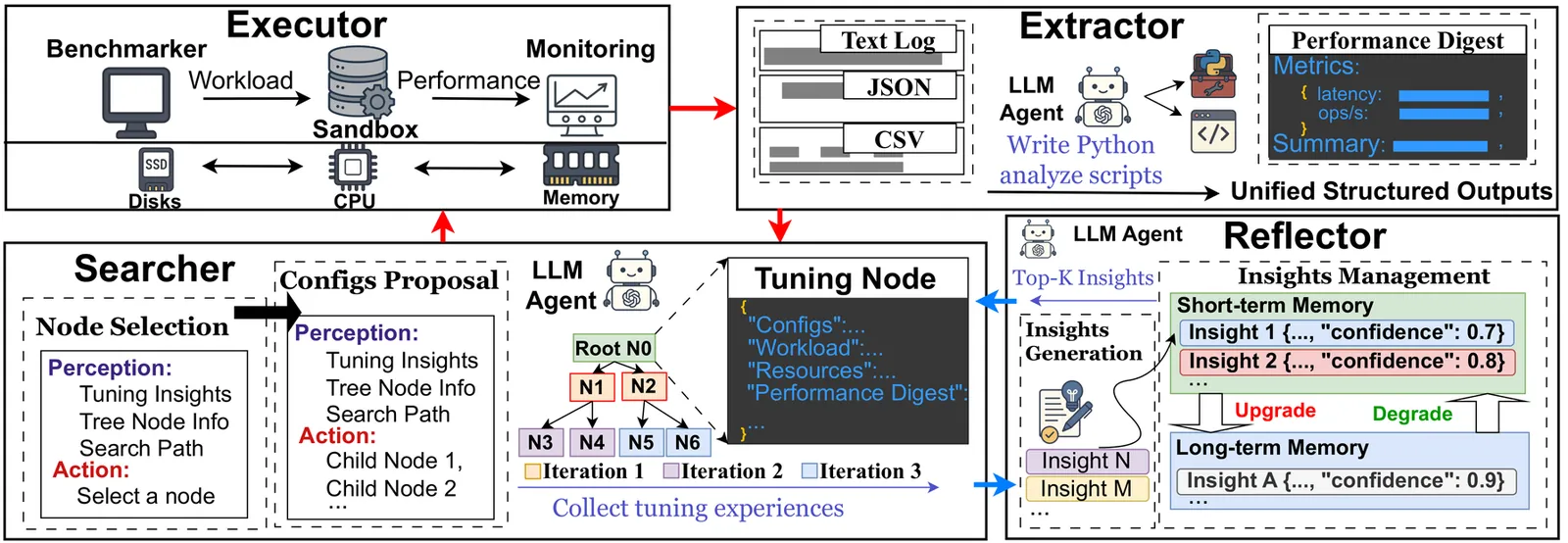
Automatically configuring storage systems is hard: parameter spaces are large and conditions vary across workloads, deployments, and versions. Heuristic and ML tuners are often system specific, require manual glue, and degrade under changes. Recent LLM-based approaches help but usually treat tuning as a single-shot, system-specific task, which limits cross-system reuse, constrains exploration, and weakens validation. We present StorageXTuner, an LLM agent-driven auto-tuning framework for heterogeneous storage engines. StorageXTuner separates concerns across four agents - Executor (sandboxed benchmarking), Extractor (performance digest), Searcher (insight-guided configuration exploration), and Reflector (insight generation and management). The design couples an insight-driven tree search with layered memory that promotes empirically validated insights and employs lightweight checkers to guard against unsafe actions. We implement a prototype and evaluate it on RocksDB, LevelDB, CacheLib, and MySQL InnoDB with YCSB, MixGraph, and TPC-H/C. Relative to out-of-the-box settings and to ELMo-Tune, StorageXTuner reaches up to 575% and 111% higher throughput, reduces p99 latency by as much as 88% and 56%, and converges with fewer trials.
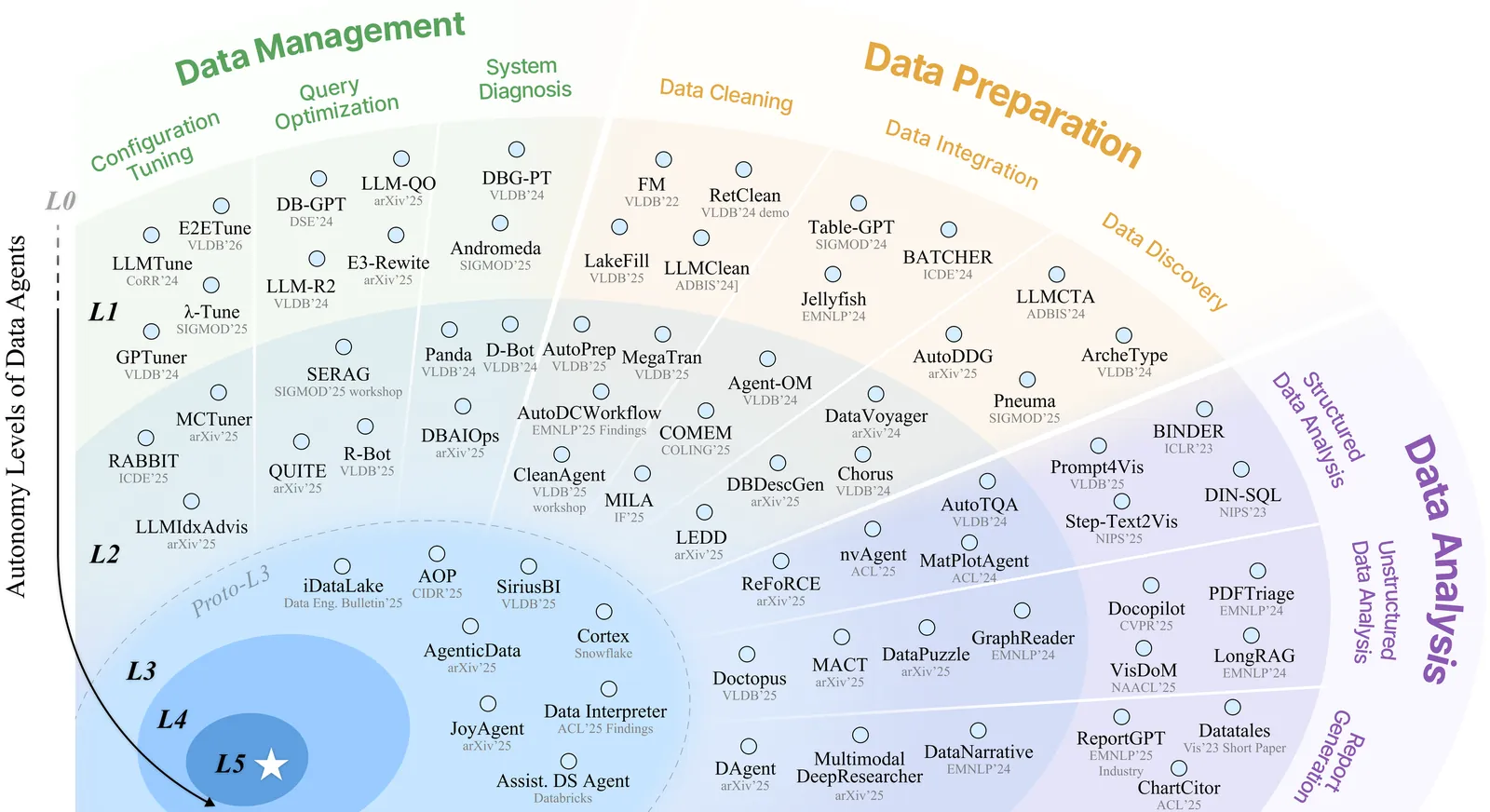
The rapid advancement of large language models (LLMs) has spurred the emergence of data agents--autonomous systems designed to orchestrate Data + AI ecosystems for tackling complex data-related tasks. However, the term "data agent" currently suffers from terminological ambiguity and inconsistent adoption, conflating simple query responders with sophisticated autonomous architectures. This terminological ambiguity fosters mismatched user expectations, accountability challenges, and barriers to industry growth. Inspired by the SAE J3016 standard for driving automation, this survey introduces the first systematic hierarchical taxonomy for data agents, comprising six levels that delineate and trace progressive shifts in autonomy, from manual operations (L0) to a vision of generative, fully autonomous data agents (L5), thereby clarifying capability boundaries and responsibility allocation. Through this lens, we offer a structured review of existing research arranged by increasing autonomy, encompassing specialized data agents for data management, preparation, and analysis, alongside emerging efforts toward versatile, comprehensive systems with enhanced autonomy. We further analyze critical evolutionary leaps and technical gaps for advancing data agents, especially the ongoing L2-to-L3 transition, where data agents evolve from procedural execution to autonomous orchestration. Finally, we conclude with a forward-looking roadmap, envisioning the advent of proactive, generative data agents.
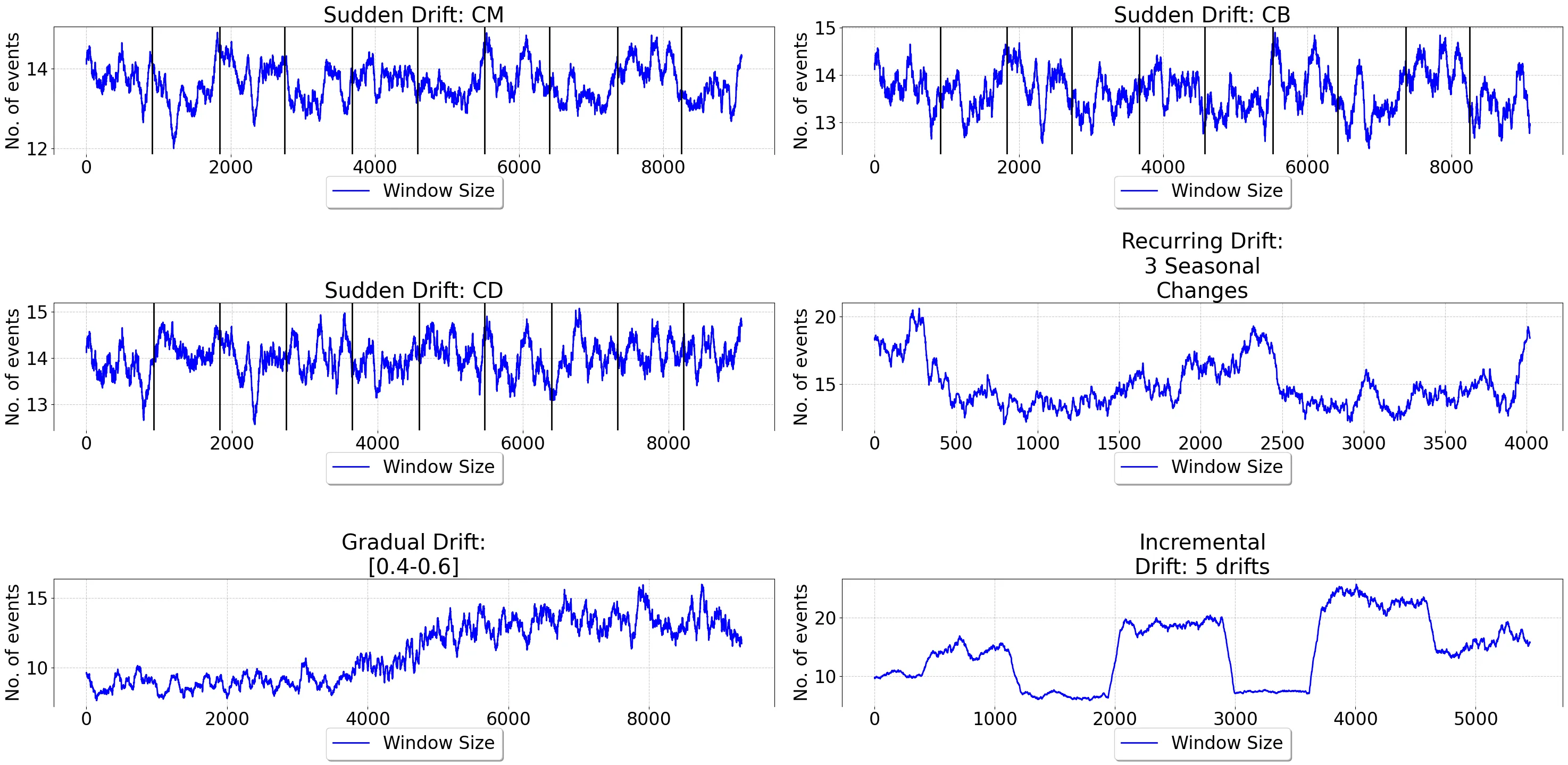
Streaming process mining deals with the real-time analysis of event streams. A common approach for it is to adopt windowing mechanisms that select event data from a stream for subsequent analysis. However, the size of these windows denotes a crucial parameter, as it influences the representativeness of the window content and, by extension, of the analysis results. Given that process dynamics are subject to changes and potential concept drift, a static, fixed window size leads to inaccurate representations that introduce bias in the analysis. In this work, we present a novel approach for streaming process mining that addresses these limitations by adjusting window sizes. Specifically, we dynamically determine suitable window sizes based on estimators for the representativeness of samples as developed for species estimation in biodiversity research. Evaluation results on real-world data sets show improvements over existing approaches that adopt static window sizes in terms of accuracy and robustness to concept drifts.
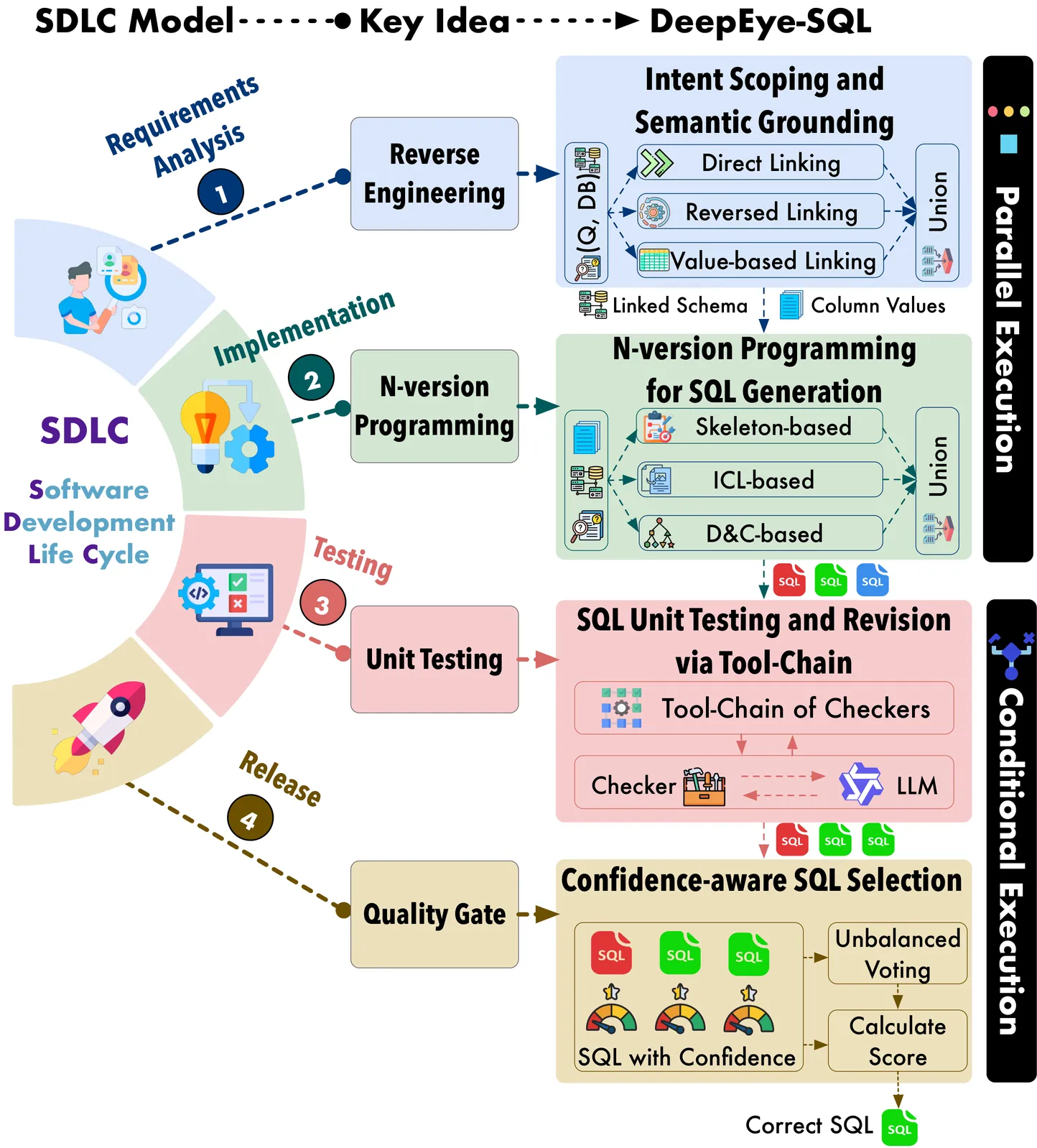
Large language models (LLMs) have advanced Text-to-SQL, yet existing solutions still fall short of system-level reliability. The limitation is not merely in individual modules - e.g., schema linking, reasoning, and verification - but more critically in the lack of structured orchestration that enforces correctness across the entire workflow. This gap motivates a paradigm shift: treating Text-to-SQL not as free-form language generation but as a software-engineering problem that demands structured, verifiable orchestration. We present DeepEye-SQL, a software-engineering-inspired framework that reframes Text-to-SQL as the development of a small software program, executed through a verifiable process guided by the Software Development Life Cycle (SDLC). DeepEye-SQL integrates four synergistic stages: it grounds ambiguous user intent through semantic value retrieval and robust schema linking; enhances fault tolerance with N-version SQL generation using diverse reasoning paradigms; ensures deterministic verification via a tool-chain of unit tests and targeted LLM-guided revision; and introduces confidence-aware selection that clusters execution results to estimate confidence and then takes a high-confidence shortcut or runs unbalanced pairwise adjudication in low-confidence cases, yielding a calibrated, quality-gated output. This SDLC-aligned workflow transforms ad hoc query generation into a disciplined engineering process. Using ~30B open-source LLMs without any fine-tuning, DeepEye-SQL achieves 73.5% execution accuracy on BIRD-Dev and 89.8% on Spider-Test, outperforming state-of-the-art solutions. This highlights that principled orchestration, rather than LLM scaling alone, is key to achieving system-level reliability in Text-to-SQL.
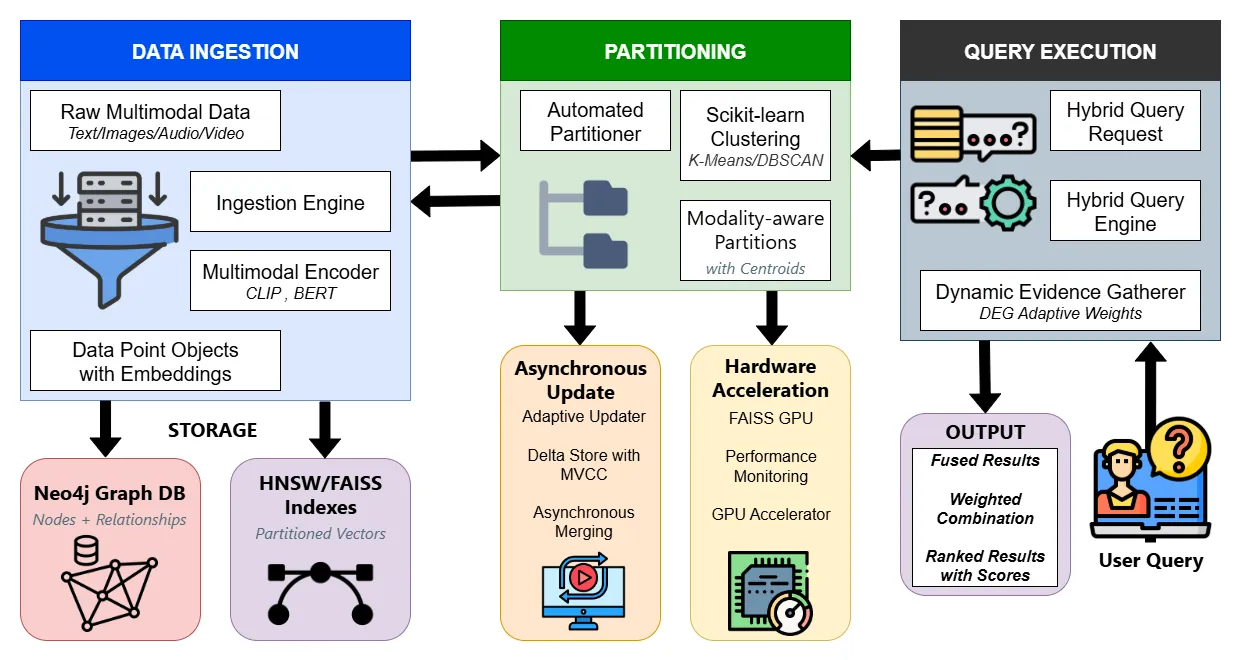
The proliferation of complex, multimodal datasets has exposed a critical gap between the capabilities of specialized vector databases and traditional graph databases. While vector databases excel at semantic similarity search, they lack the capacity for deep relational querying. Conversely, graph databases master complex traversals but are not natively optimized for high-dimensional vector search. This paper introduces the Hybrid Multimodal Graph Index (HMGI), a novel framework designed to bridge this gap by creating a unified system for efficient, hybrid queries on multimodal data. HMGI leverages the native graph database architecture and integrated vector search capabilities, exemplified by platforms like Neo4j, to combine Approximate Nearest Neighbor Search (ANNS) with expressive graph traversal queries. Key innovations of the HMGI framework include modality-aware partitioning of embeddings to optimize index structure and query performance, and a system for adaptive, low-overhead index updates to support dynamic data ingestion, drawing inspiration from the architectural principles of systems like TigerVector. By integrating semantic similarity search directly with relational context, HMGI aims to outperform pure vector databases like Milvus in complex, relationship-heavy query scenarios and achieve sub-linear query times for hybrid tasks.
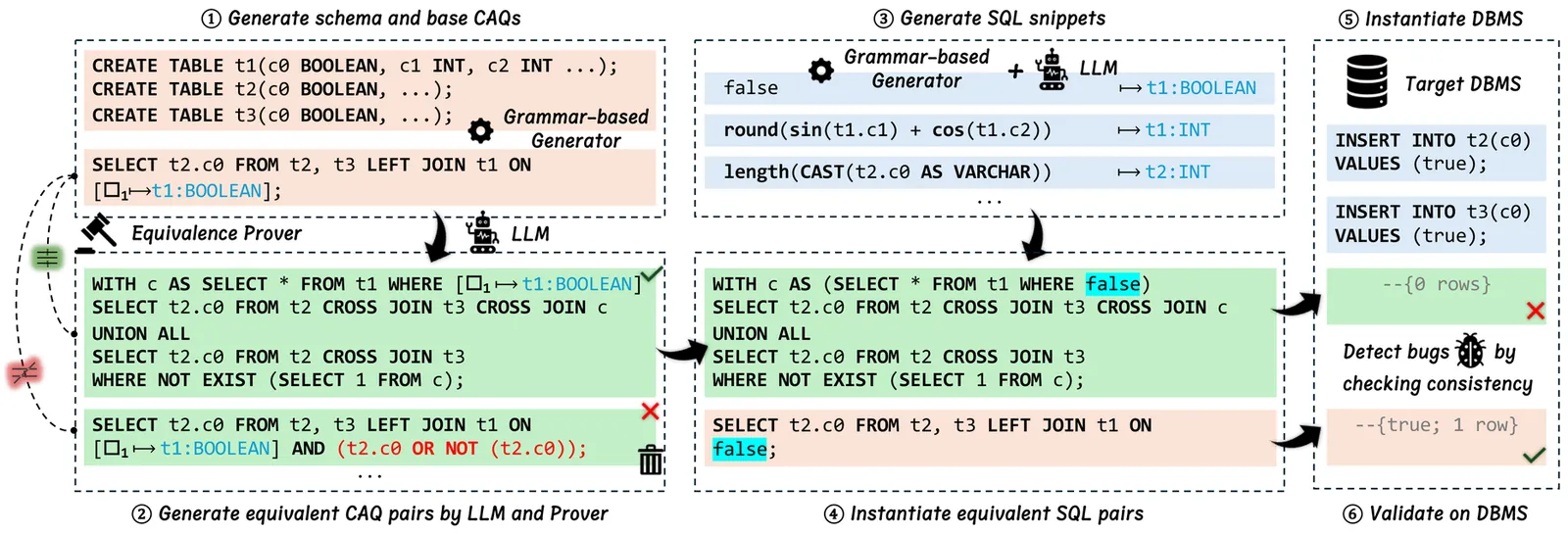
Since 2020, automated testing for Database Management Systems (DBMSs) has flourished, uncovering hundreds of bugs in widely-used systems. A cornerstone of these techniques is test oracle, which typically implements a mechanism to generate equivalent query pairs, thereby identifying bugs by checking the consistency between their results. However, while applying these oracles can be automated, their design remains a fundamentally manual endeavor. This paper explores the use of large language models (LLMs) to automate the discovery and instantiation of test oracles, addressing a long-standing bottleneck towards fully automated DBMS testing. Although LLMs demonstrate impressive creativity, they are prone to hallucinations that can produce numerous false positive bug reports. Furthermore, their significant monetary cost and latency mean that LLM invocations should be limited to ensure that bug detection is efficient and economical. To this end, we introduce Argus, a novel framework built upon the core concept of the Constrained Abstract Query - a SQL skeleton containing placeholders and their associated instantiation conditions (e.g., requiring a placeholder to be filled by a boolean column). Argus uses LLMs to generate pairs of these skeletons that are asserted to be semantically equivalent. This equivalence is then formally proven using a SQL equivalence solver to ensure soundness. Finally, the placeholders within the verified skeletons are instantiated with concrete, reusable SQL snippets that are also synthesized by LLMs to efficiently produce complex test cases. We implemented Argus and evaluated it on five extensively tested DBMSs, discovering 40 previously unknown bugs, 35 of which are logic bugs, with 36 confirmed and 26 already fixed by the developers.
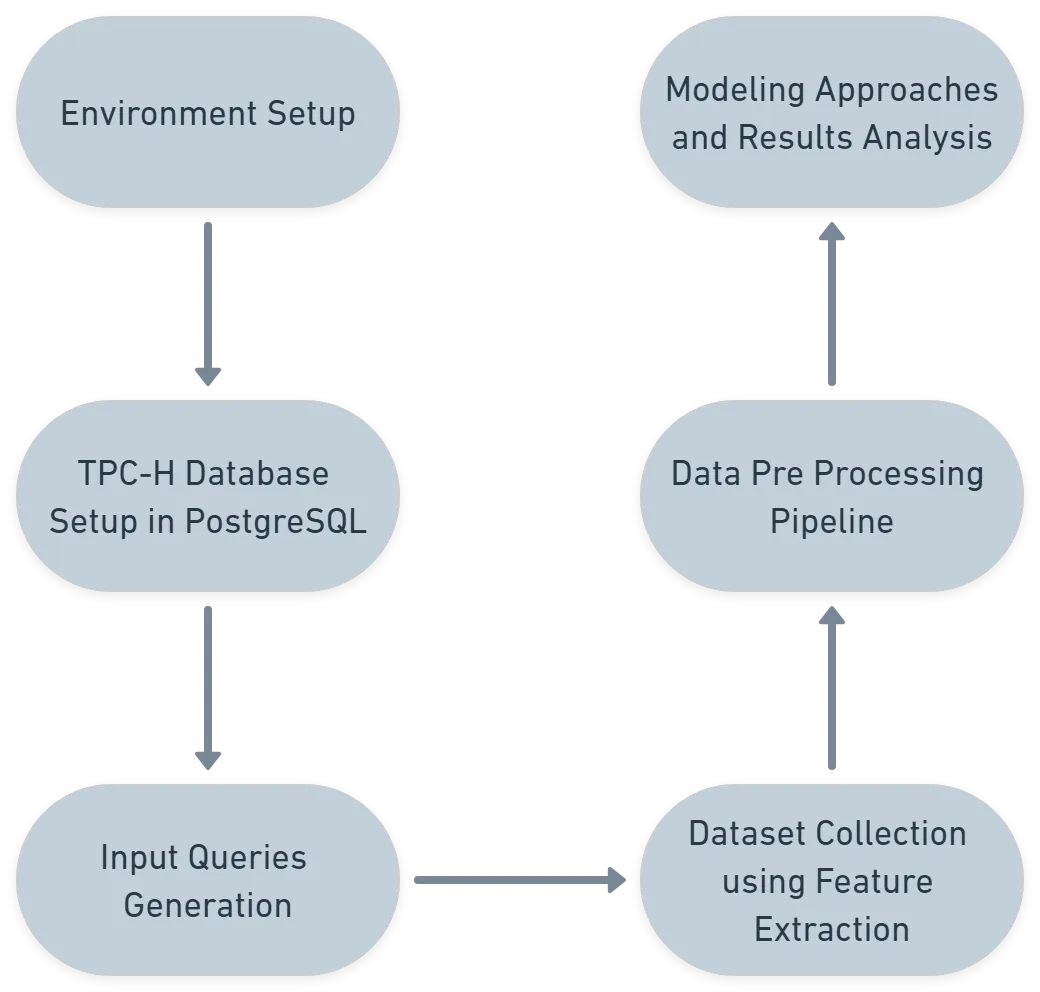
Accurate query runtime prediction is a critical component of effective query optimization in modern database systems. Traditional cost models, such as those used in PostgreSQL, rely on static heuristics that often fail to reflect actual query performance under complex and evolving workloads. This remains an active area of research, with recent work exploring machine learning techniques to replace or augment traditional cost estimators. In this paper, we present a machine learning-based framework for predicting SQL query runtimes using execution plan features extracted from PostgreSQL. Our approach integrates scalar and structural features from execution plans and semantic representations of SQL queries to train predictive models. We construct an automated pipeline for data collection and feature extraction using parameterized TPC-H queries, enabling systematic evaluation of multiple modeling techniques. Unlike prior efforts that focus either on cardinality estimation or on synthetic cost metrics, we model the actual runtimes using fine-grained plan statistics and query embeddings derived from execution traces, to improve the model accuracy. We compare baseline regressors, a refined XGBoost model, and a sequential LSTM-based model to assess their effectiveness in runtime prediction. Our dataset includes over 1000 queries generated from TPC-H query templates executed in PostgreSQL with EXPLAIN ANALYZE. Experimental results show that the XGBoost model significantly outperforms others, achieving a mean squared error of 0.3002 and prediction accuracy within 10% of the true runtime in over 65% of cases. The findings highlight the potential of tree-based learning combined with execution plan features for improving cost estimation in query optimizers.
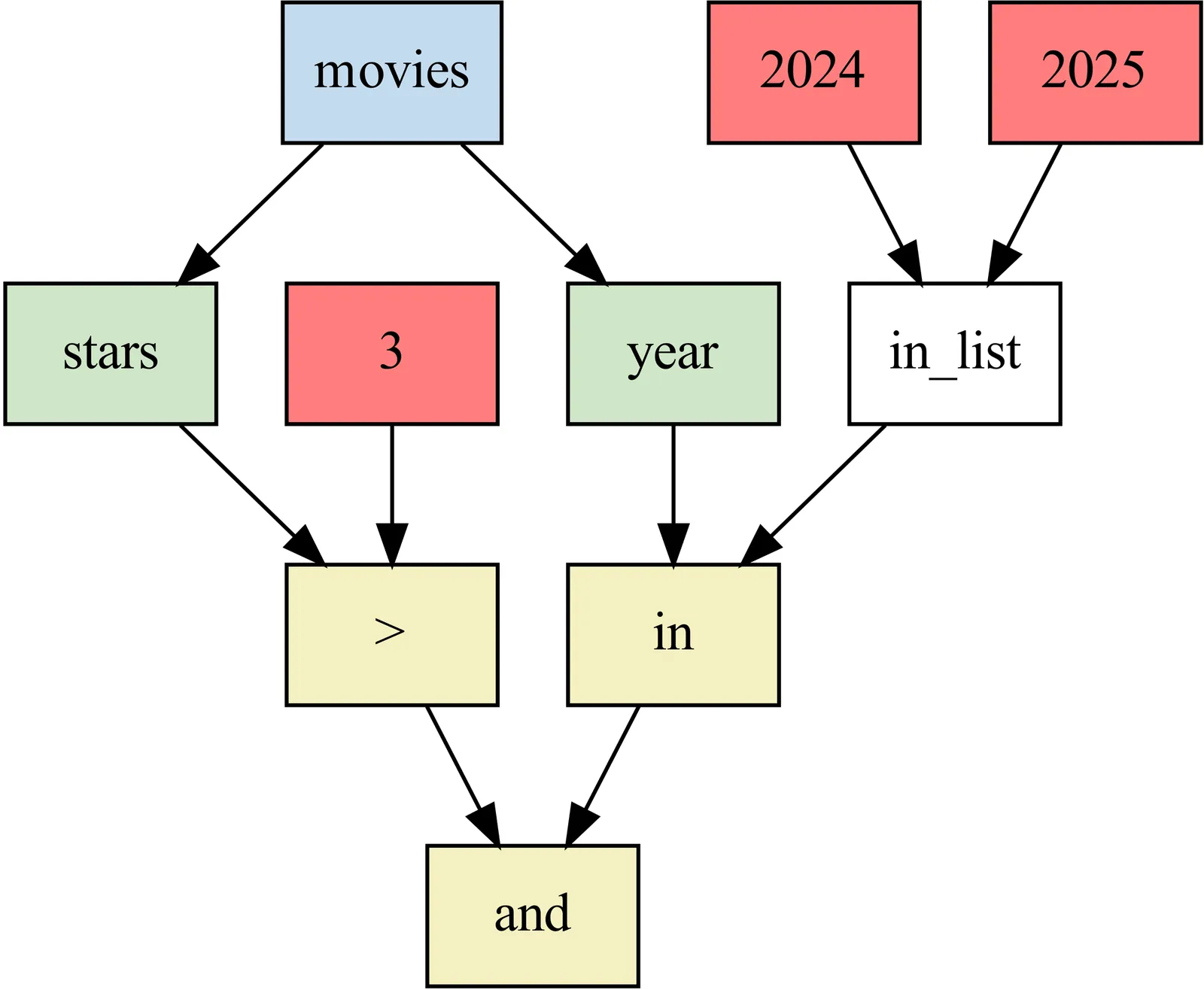
DB engines produce efficient query execution plans by relying on cost models. Practical implementations estimate cardinality of queries using heuristics, with magic numbers tuned to improve average performance on benchmarks. Empirically, estimation error significantly grows with query complexity. Alternatively, learning-based estimators offer improved accuracy, but add operational complexity preventing their adoption in-practice. Recognizing that query workloads contain highly repetitive subquery patterns, we learn many simple regressors online, each localized to a pattern. The regressor corresponding to a pattern can be randomly-accessed using hash of graph structure of the subquery. Our method has negligible overhead and competes with SoTA learning-based approaches on error metrics. Further, amending PostgreSQL with our method achieves notable accuracy and runtime improvements over traditional methods and drastically reduces operational costs compared to other learned cardinality estimators, thereby offering the most practical and efficient solution on the Pareto frontier. Concretely, simulating JOB-lite workload on IMDb speeds-up execution by 7.5 minutes (>30%) while incurring only 37 seconds overhead for online learning.
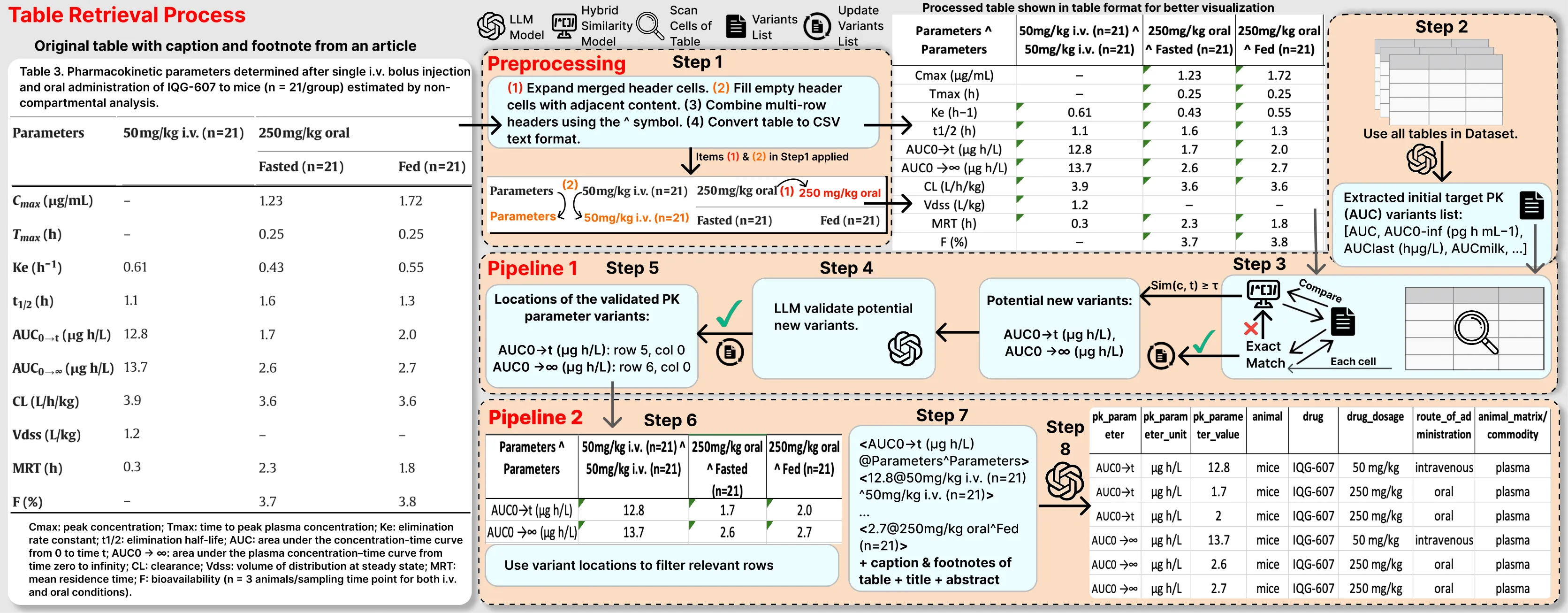
Pharmacokinetics (PK) plays a critical role in drug development and regulatory decision-making for human and veterinary medicine, directly affecting public health through drug safety and efficacy assessments. However, PK data are often embedded in complex, heterogeneous tables with variable structures and inconsistent terminologies, posing significant challenges for automated PK data retrieval and standardization. AutoPK, a novel two-stage framework for accurate and scalable extraction of PK data from complex scientific tables. In the first stage, AutoPK identifies and extracts PK parameter variants using large language models (LLMs), a hybrid similarity metric, and LLM-based validation. The second stage filters relevant rows, converts the table into a key-value text format, and uses an LLM to reconstruct a standardized table. Evaluated on a real-world dataset of 605 PK tables, including captions and footnotes, AutoPK shows significant improvements in precision and recall over direct LLM baselines. For instance, AutoPK with LLaMA 3.1-70B achieved an F1-score of 0.92 on half-life and 0.91 on clearance parameters, outperforming direct use of LLaMA 3.1-70B by margins of 0.10 and 0.21, respectively. Smaller models such as Gemma 3-27B and Phi 3-12B with AutoPK achieved 2-7 fold F1 gains over their direct use, with Gemma's hallucination rates reduced from 60-95% down to 8-14%. Notably, AutoPK enabled open-source models like Gemma 3-27B to outperform commercial systems such as GPT-4o Mini on several PK parameters. AutoPK enables scalable and high-confidence PK data extraction, making it well-suited for critical applications in veterinary pharmacology, drug safety monitoring, and public health decision-making, while addressing heterogeneous table structures and terminology and demonstrating generalizability across key PK parameters. Code and data: https://github.com/hosseinsholehrasa/AutoPK
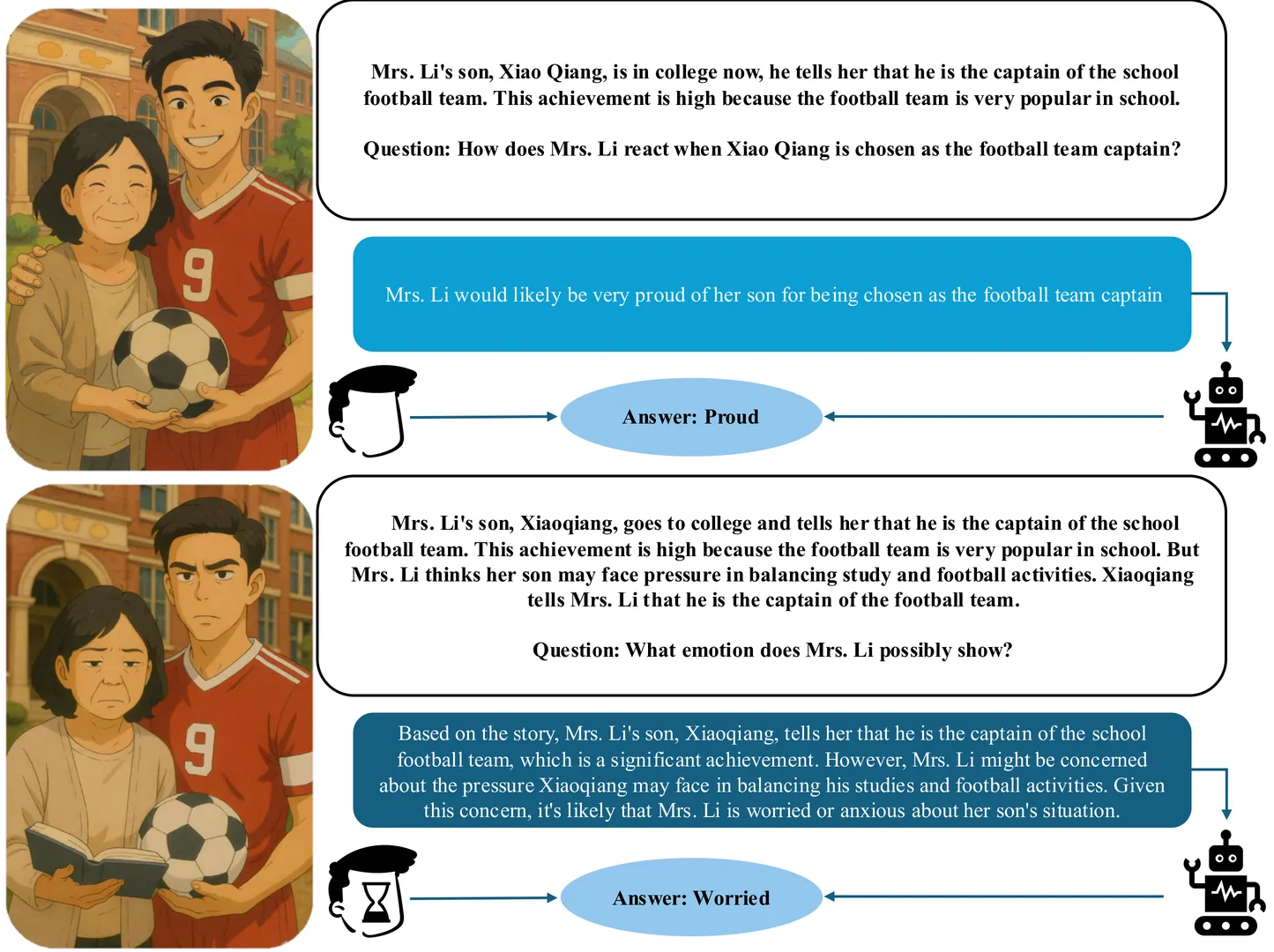
Large Language Models show promise in emotion understanding, social reasoning, and empathy, yet they struggle with psychologically grounded tasks that require inferring implicit mental states in context-rich, ambiguous settings. These limitations arise from the absence of theory-aligned supervision and the difficulty of capturing nuanced mental processes in real-world narratives. To address this gap, we leverage expert-labeled, psychologically rich scenarios and propose a trajectory-aware reinforcement learning framework that explicitly imitates expert psychological thought patterns. By integrating real-world stimuli with structured reasoning guidance, our approach enables compact models to internalize social-cognitive principles, perform nuanced psychological inference, and support continual self-improvement. Comprehensive experiments across multiple benchmarks further demonstrate that our models achieve expert-level interpretive capabilities, exhibiting strong out-of-distribution generalization and robust continual learning across diverse, challenging, and psychologically grounded tasks.