9,198 papers
KubePACS: Kubernetes Cluster Using Performant, Highly Available, and Cost Efficient Spot Instances
Cloud users aim to minimize cost while maximizing performance by selecting the most suitable instance types for their workloads. To reduce expenses, spot instances have been widely adopted due to their steep discounts compared to on-demand pricing. However, their use introduces reliability risks due to potential interruptions, and existing research has primarily focused on mitigating this trade-off from a cost or availability perspective alone. Despite the diversity in hardware capabilities among instance types, current provisioning systems tend to ignore performance variation, selecting nodes solely based on minimum resource requirements. In this paper, we present KubePACS, a Kubernetes-native spot instance provisioning system that constructs node pools optimized for both cost and performance while guaranteeing high availability. KubePACS formulates the node selection process as a multi-objective optimization problem, incorporating real-time data such as spot prices, performance benchmarks, and availability scores, including the multi-node Spot Placement Score (SPS). It solves this problem efficiently using an Integer Linear Programming (ILP) approach guided by the Golden Section Search (GSS) algorithm to find the optimal configuration. By integrating with the Karpenter node autoscaler, KubePACS jointly optimizes instance-type selection and node scaling decisions within a standard provisioning workflow. KubePACS also adopts a novel heuristic to support workload-specific preferences by scaling performance metrics for specialized instances. Through extensive evaluation across synthetic and real-world workloads, KubePACS demonstrates on average 55.09% and up to 81.06% higher performance per dollar over state-of-the-art solutions such as Karpenter, SpotVerse, and SpotKube, which only reference the spot instance prices and limited availability data.
2604.24027Apr 2026
ViewClusterFusion++: Expanding Cluster-Level Fusion to Full Transformer-Block Decoding
Large language model (LLM) decoding is latency-sensitive and often bottlenecked by fragmented operator execution and repeated off-chip materialization of intermediate tensors. Prior work expands fusion scope by leveraging thread-block clusters and on-chip inter-block collectives to fuse attention-side operators such as QKV projection, attention, and output projection. We develop ClusterFusion++, a CUDA-level extension that broadens fusion to the full Transformer decoder block for GPT-NeoX/Pythia models: LayerNorm -> QKV -> RoPE -> decode attention -> output projection -> Post-LN -> MLP -> residual. We additionally engineer a CUDA-Graph-compatible execution mode with persistent Tensor Memory Accelerator (TMA) descriptors to reduce per-step overhead. On an NVIDIA RTX 5090-class GPU, ClusterFusion++ improves throughput by 1.34x for Pythia-2.8B and yields similar gains for Pythia-6.9B, while maintaining high output fidelity (near-token-identical generation, with minor non-determinism from FP16 atomics).
2604.23553Apr 2026
View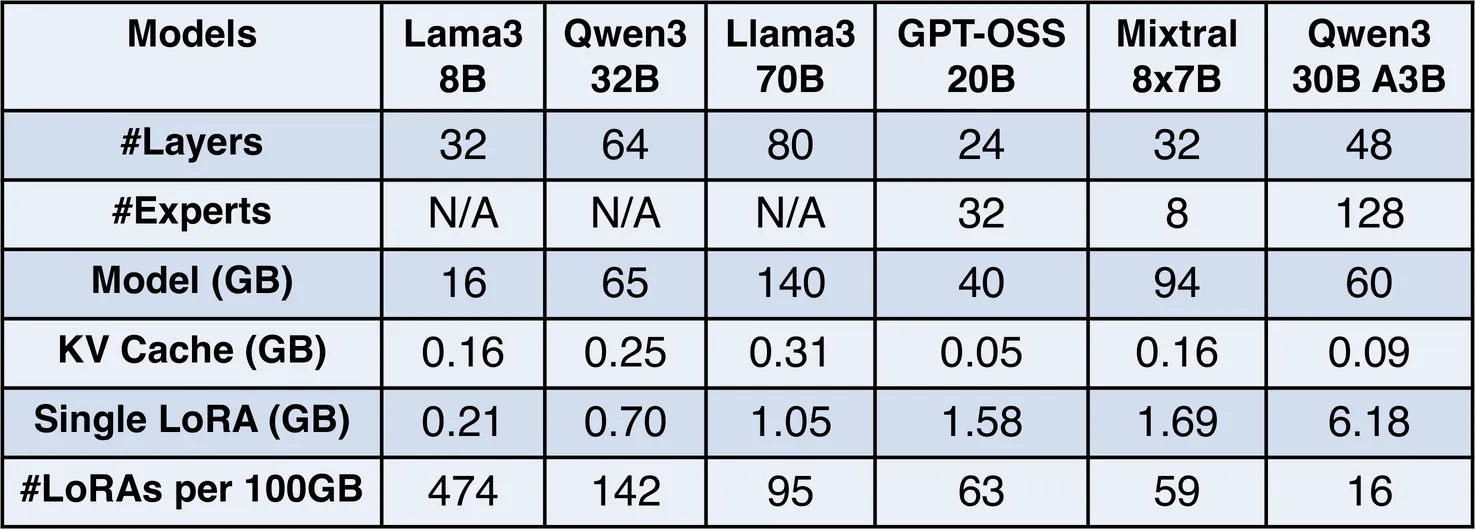
InfiniLoRA: Disaggregated Multi-LoRA Serving for Large Language Models
LoRA enables efficient customization of LLMs and is widely used in multi-tenant and multi-task serving. However, emerging model architectures such as MoE significantly increase LoRA memory cost, making existing coupled LoRA serving designs poorly scalable and prone to tail-latency inflation. We present InfiniLoRA, a disaggregated LoRA serving system that decouples LoRA execution from base-model inference. InfiniLoRA introduces a shared LoRA Server with parallelism-aware execution, SLO-driven provisioning, and critical-path optimizations, including GPU-initiated communication and hardware-specialized LoRA kernels. Experiments show that InfiniLoRA can achieve an average $3.05\times$ increase in serviceable request rate under strict latency SLOs, and improve the percentage of LoRA adapters satisfying the SLO requirement by 54.0\%.
2604.07173Apr 2026
View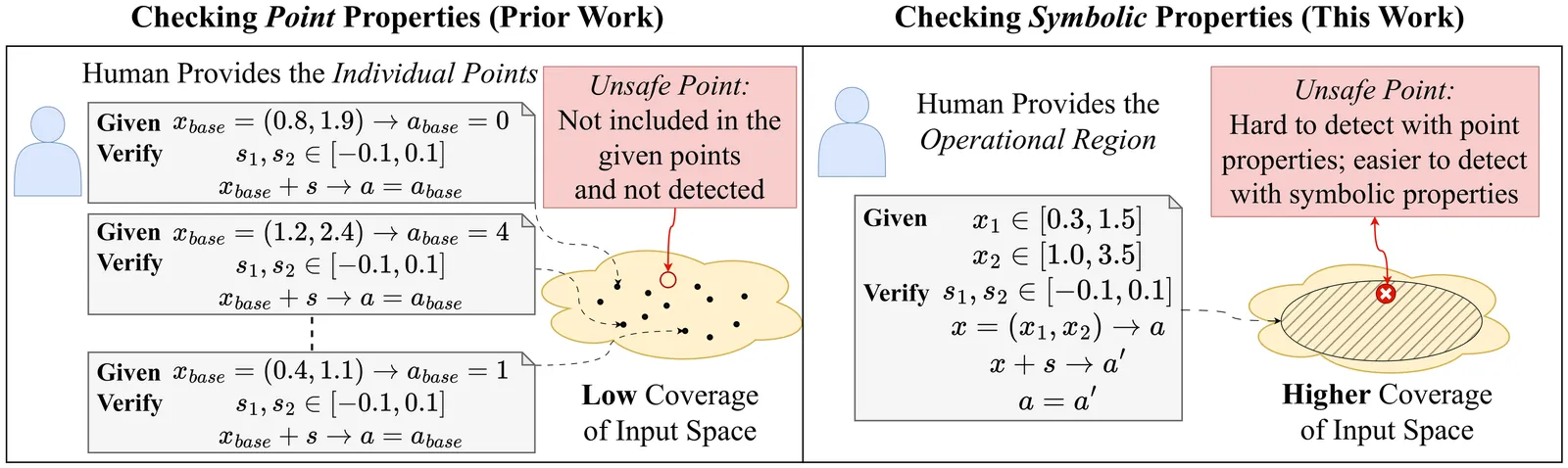
Analyzing Symbolic Properties for DRL Agents in Systems and Networking
Deep reinforcement learning (DRL) has shown remarkable performance on complex control problems in systems and networking, including adaptive video streaming, wireless resource management, and congestion control. For safe deployment, however, it is critical to reason about how agents behave across the range of system states they encounter in practice. Existing verification-based methods in this domain primarily focus on point properties, defined around fixed input states, which offer limited coverage and require substantial manual effort to identify relevant input-output pairs for analysis. In this paper, we study symbolic properties, that specify expected behavior over ranges of input states, for DRL agents in systems and networking. We present a generic formulation for symbolic properties, with monotonicity and robustness as concrete examples, and show how they can be analyzed using existing DNN verification engines. Our approach encodes symbolic properties as comparisons between related executions of the same policy and decomposes them into practically tractable sub-properties. These techniques serve as practical enablers for applying existing verification tools to symbolic analysis. Using our framework, diffRL, we conduct an extensive empirical study across three DRL-based control systems, adaptive video streaming, wireless resource management, and congestion control. Through these case studies, we analyze symbolic properties over broad input ranges, examine how property satisfaction evolves during training, study the impact of model size on verifiability, and compare multiple verification backends. Our results show that symbolic properties provide substantially broader coverage than point properties and can uncover non-obvious, operationally meaningful counterexamples, while also revealing practical solver trade-offs and limitations.
2604.04914Apr 2026
View
Query Optimization and Evaluation via Information Theory: A Tutorial
Database theory is exciting because it studies highly general and practically useful abstractions. Conjunctive query (CQ) evaluation is a prime example: it simultaneously generalizes graph pattern matching, constraint satisfaction, and statistical inference, among others. This generality is both the strength and the central challenge of the field. The query optimization and evaluation problem is fundamentally a "meta-algorithm" problem: given a query $Q$ and statistics $\cal S$ about the input database, how should one best answer $Q$? Because the problem is so general, it is often impossible for such a meta-algorithm to match the runtimes of specialized algorithms designed for a fixed query -- or so it seemed. The past fifteen years have witnessed an exciting development in database theory: a general framework, called PANDA, that emerged from advances in database theory, constraint satisfaction problems (CSP), and graph algorithms, for evaluating conjunctive queries given input data statistics. The key idea is to derive information-theoretically tight upper bounds on the cardinalities of intermediate relations produced during query evaluation. These bounds determine the costs of query plans, and crucially, the query plans themselves are derived directly from the mathematical proof of the upper bound. This tight coupling of proof and algorithm is what makes PANDA both principled and powerful. Remarkably, this generic algorithm matches -- and in some cases subsumes -- the runtimes of specialized algorithms for the same problems, including algorithms that exploit fast matrix multiplication. This paper is a tutorial on the PANDA framework. We illustrate the key ideas through concrete examples, conveying the main intuitions behind the theory.
2604.04893Apr 2026
View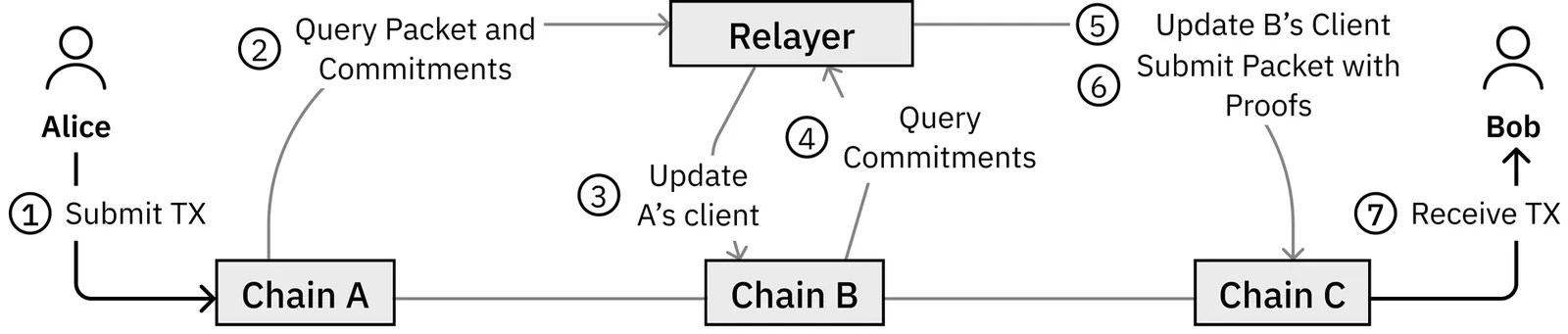
Towards Policy-Enabled Multi-Hop Routing for Cross-Chain Message Delivery
Blockchain ecosystems face a significant issue with liquidity fragmentation, as applications and assets are distributed across many public chains with each only accessible by subset of users. Cross-chain communication was designed to address this by allowing chains to interoperate, but existing solutions limit communication to directly connected chains or route traffic through hubs that create bottlenecks and centralization risks. In this paper, we introduce xRoute, a cross-chain routing and message-delivery framework inspired by traditional networks. Our design brings routing, name resolution, and policy-based delivery to the blockchain setting. It allows applications to specify routing policies, enables destination chains to verify that selected routes satisfy security requirements, and uses a decentralized relayer network to compute routes and deliver messages without introducing a trusted hub. Experiments on the chains supporting the Inter-Blockchain Communication (IBC) protocol show that our approach improves connectivity, decentralization, and scalability compared to hub-based designs, particularly under heavy load.
2604.04890Apr 2026
View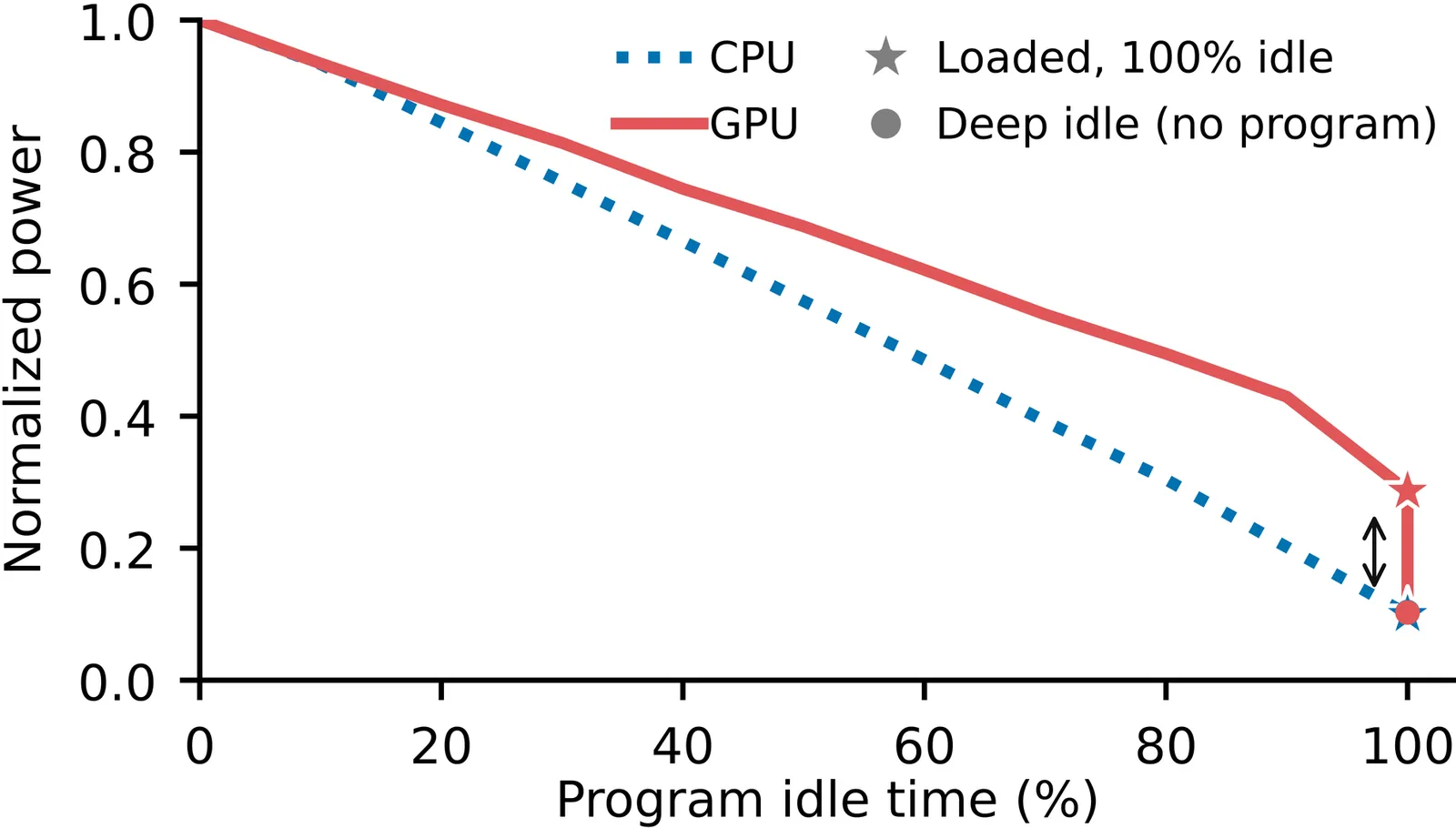
The Energy Cost of Execution-Idle in GPU Clusters
GPUs are becoming a major contributor to data center power, yet unlike CPUs, they can remain at high power even when visible activity is near zero. We call this state execution-idle. Using per-second telemetry from a large academic AI cluster, we characterize execution-idle as a recurring low-activity yet high-power state in real deployments. Across diverse workloads and multiple GPU generations, it accounts for 19.7% of in-execution time and 10.7% of energy. This suggests a need to both reduce the cost of execution-idle and reduce exposure to it. We therefore build two prototypes: one uses automatic downscaling during execution-idle, and the other uses load imbalance to reduce exposure, both with performance trade-offs. These findings suggest that future energy-efficient GPU systems should treat execution-idle as a first-class operating state.
2604.04745Apr 2026
View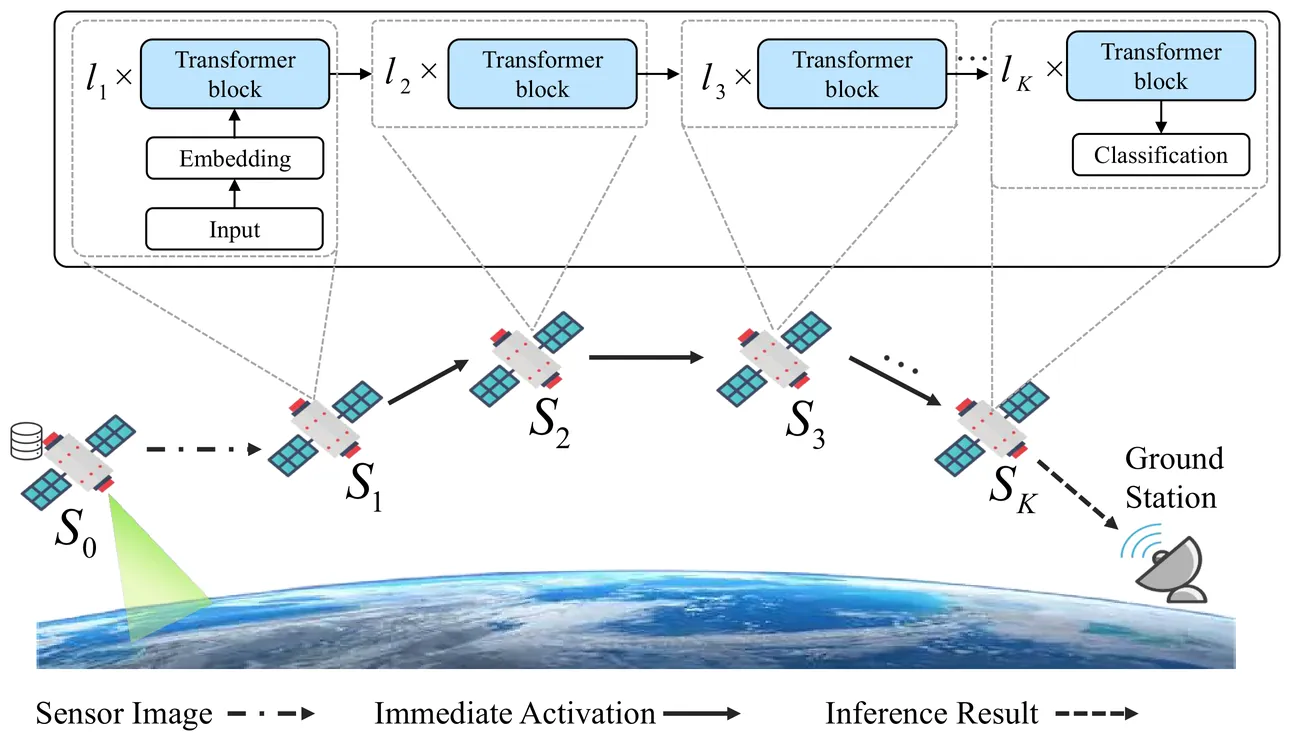
Communication-Efficient Collaborative LLM Inference over LEO Satellite Networks
Low Earth orbit (LEO) satellites play an essential role in intelligent Earth observation by leveraging artificial intelligence models. However, limited onboard memory and excessive inference delay prevent the practical deployment of large language models (LLMs) on a single satellite. In this paper, we propose a communication-efficient collaborative LLM inference scheme for LEO satellite networks. Specifically, the entire LLM is split into multiple sub-models, with each deployed on a satellite, thereby enabling collaborative LLM inference via exchanging intermediate activations between satellites. The proposed scheme also leverages the pipeline parallelism mechanism that overlaps sub-model inference with intermediate activation transmission, thereby reducing LLM inference delay. An adaptive activation compression scheme is designed to mitigate cumulative errors from multi-stage model splitting while preserving inference accuracy. Furthermore, we formulate the LLM inference delay minimization problem by jointly optimizing model splitting and compression ratios under onboard memory and inference accuracy constraints. The problem is transformed into a shortest-path search problem over a directed acyclic graph that edge weights explicitly quantify the inference delay induced by model splitting and compression strategies, which is solved via a modified A Star-based search algorithm. Extensive simulation results indicate that the proposed solution can reduce inference delay by up to 42% and communication overhead by up to 71% compared to state-of-the-art benchmarks, while maintaining the inference accuracy loss of less than 1%.
2604.04654Apr 2026
View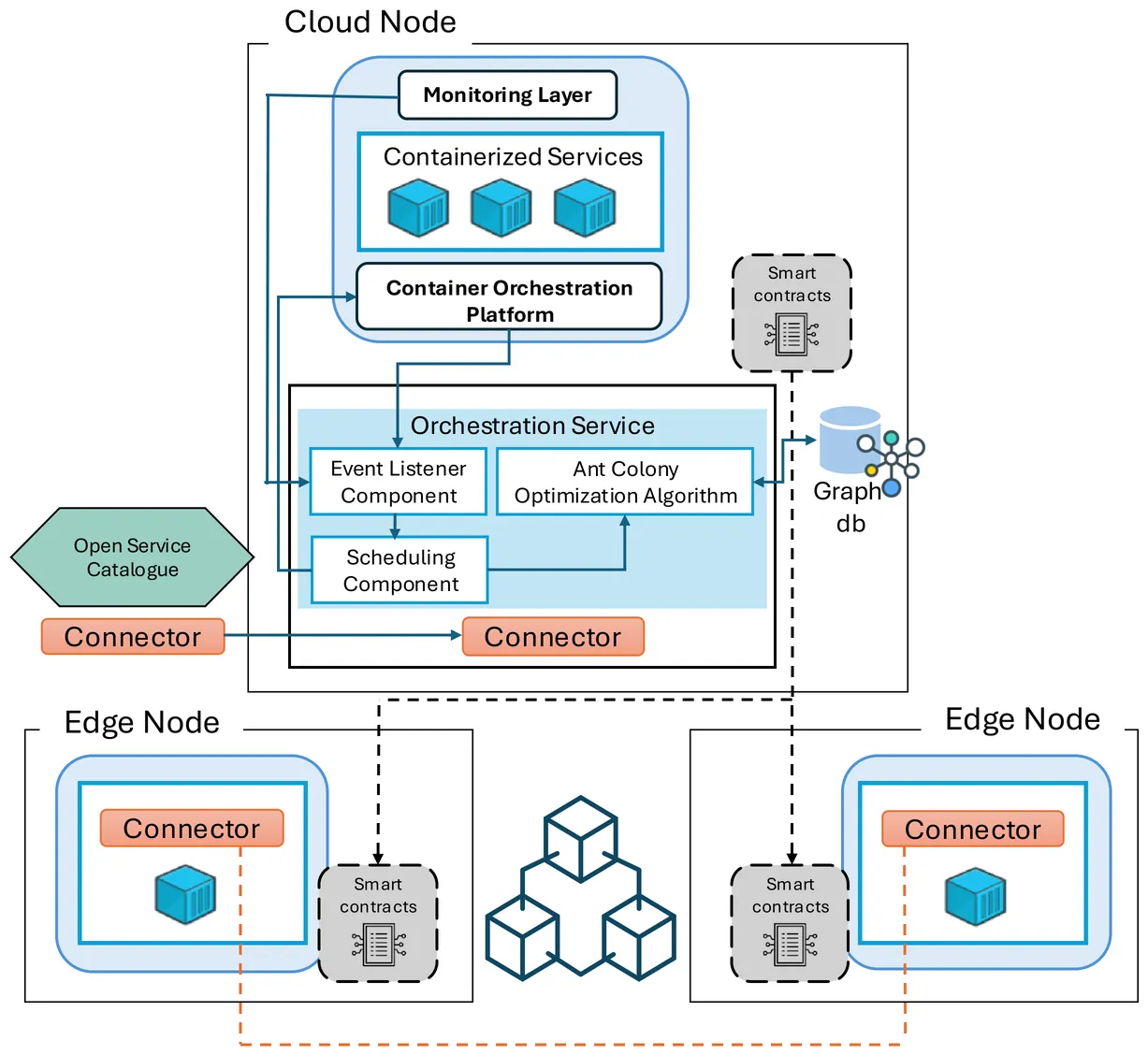
Edge-Oriented Orchestration of Energy Services Using Graph-Driven Swarm Intelligence
As smart grids increasingly depend on IoT devices and distributed energy management, they require decentralized, low latency orchestration of energy services. We address this with a unified framework for edge fog cloud infrastructures tailored to smart energy systems. It features a graph based data model that captures infrastructure and workload, enabling efficient topology exploration and task placement. Leveraging this model, a swarm-based heuristic algorithm handles task offloading in a resource-aware, latency sensitive manner. Our framework ensures data interoperability via energy data space compliance and guarantees traceability using blockchain based workload notarization. We validate our approach with a real-world KubeEdge deployment, demonstrating zero downtime service migration under dynamic workloads while maintaining service continuity.
2604.04645Apr 2026
View
Tight Bounds on Window Size and Time for Single-Agent Graph Exploration under T-Interval Connectivity
We study deterministic exploration by a single agent in $T$-interval-connected graphs, a standard model of dynamic networks in which, for every time window of length $T$, the intersection of the graphs within the window is connected. The agent does not know the window size $T$, nor the number of nodes $n$ or edges $m$, and must visit all nodes of the graph. We consider two visibility models, $KT_0$ and $KT_1$, depending on whether the agent can observe the identifiers of neighboring nodes. We investigate two fundamental questions: the minimum window size that guarantees exploration, and the optimal exploration time under sufficiently large window size. For both models, we show that a window size $T = Ω(m)$ is necessary. We also present deterministic algorithms whose required window size is $O(ε(n,m)\cdot m + n \log^2 n)$, where $ε(n,m) = \frac{\ln n}{1 + \ln m - \ln n}$. These bounds are tight for a wide range of $m$, in particular when $m = n^{1+Θ(1)}$. The same algorithms also yield optimal or near-optimal exploration time: we prove lower bounds of $Ω((m - n + 1)n)$ in the $KT_0$ model and $Ω(m)$ in the $KT_1$ model, and show that our algorithms match these bounds up to a polylogarithmic factor, while being fully time-optimal when $m = n^{1+Θ(1)}$. This yields tight bounds when parameterized solely by $n$: $Θ(n^3)$ for $KT_0$ and $Θ(n^2)$ for $KT_1$.
2604.04619Apr 2026
View
nascTime: A Full-Stack 5G-TSN Bridge Simulation Framework with SDAP-Based QoS Mapping and IEEE 802.1AS Transparent Clock
The integration of 5G with IEEE 802.1 Time-Sensitive Networking (TSN) is essential for enabling flexible and mobile deterministic communication in industrial automation. The 3GPP Release 16 specification defines a bridge architecture where the 5G system operates as a transparent TSN bridge, incorporating Network-side and Device-side TSN Translators (NW-TT, DS-TT), a TSN Application Function, and QoS mapping between TSN Priority Code Points and 5G QoS Flow Identifiers. However, existing simulation frameworks model only subsets of this architecture, either QoS mapping without time synchronization, or time synchronization without data plane traffic, and none implements the complete QoS pipeline through the 3GPP SDAP layer with per-flow Data Radio Bearer selection. We present nascTime[20], an open simulation framework built on OMNeT 6.3, INET 4.6, and Simu5G that implements the complete 3GPP Release 16 5G-TSN bridge model. The framework provides end-to-end QoS mapping from TSN PCP through to 5G QFI via the SDAP/DRB pipeline, IEEE 802.1AS transparent clock behavior with measured residence time correction through L2-in-GTP-U gPTP transport, and multi-endpoint scaling with bidirectional traffic. The bridge ports integrate with INET's LayeredEthernetInterface and streaming PHY for compatibility with TSN features including Time-Aware Shaping and frame preemption. We validate nascTime with a three-endpoint factory scenario demonstrating near-perfect packet delivery across two traffic classes, correct gPTP synchronization with residence time correction, and zero packet loss. nascTime is the first simulation framework to model the full 5G-TSN bridge data path with SDAP-based QoS differentiation and measured IEEE 802.1AS transparent clock behavior in a multi-endpoint topology.
2604.04616Apr 2026
View
Cardinality Estimation for High Dimensional Similarity Queries with Adaptive Bucket Probing
In this work, we address the problem of cardinality estimation for similarity search in high-dimensional spaces. Our goal is to design a framework that is lightweight, easy to construct, and capable of providing accurate estimates with satisfying online efficiency. We leverage locality-sensitive hashing (LSH) to partition the vector space while preserving distance proximity. Building on this, we adopt the principles of classical multi-probe LSH to adaptively explore neighboring buckets, accounting for distance thresholds of varying magnitudes. To improve online efficiency, we employ progressive sampling to reduce the number of distance computations and utilize asymmetric distance computation in product quantization to accelerate distance calculations in high-dimensional spaces. In addition to handling static datasets, our framework includes updating algorithm designed to efficiently support large-scale dynamic scenarios of data updates.Experiments demonstrate that our methods can accurately estimate the cardinality of similarity queries, yielding satisfying efficiency.
2604.04603Apr 2026
View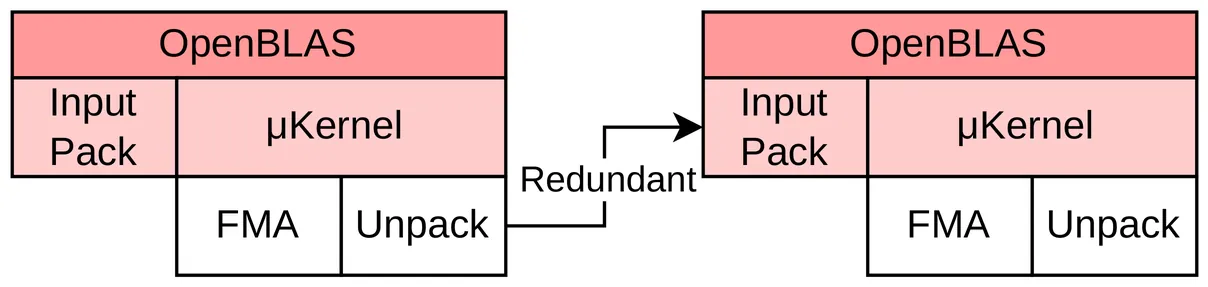
LP-GEMM: Integrating Layout Propagation into GEMM Operations
In Scientific Computing and modern Machine Learning (ML) workloads, sequences of dependent General Matrix Multiplications (GEMMs) often dominate execution time. While state-of-the-art BLAS libraries aggressively optimize individual GEMM calls, they remain constrained by the BLAS API, which requires each call to independently pack input matrices and restore outputs to a canonical memory layout. In sequential GEMMs, these constraints cause redundant packing and unpacking, wasting valuable computational resources. This paper introduces LP-GEMM, a decomposition of the GEMM kernel that enables packing-layout propagation across sequential GEMM operations. This approach eliminates unnecessary data repacking while preserving full BLAS semantic correctness at the boundaries. We evaluate LP-GEMM on x86 (AVX-512) and RISC-V (RVV 1.0) architectures across MLP-like and Attention-like workloads. Our results show average speedups of 2.25x over OpenBLAS on Intel x86 for sequential GEMMs and competitive gains relative to vendor-optimized libraries such as Intel MKL. We demonstrate the practicality of the approach beyond microbenchmarks by implementing a standalone C++ version of the Llama-3.2 inference path using exclusively BLAS-level GEMM calls. These results confirm that leveraging data layout propagation between operations can significantly boost performance.
2604.04599Apr 2026
View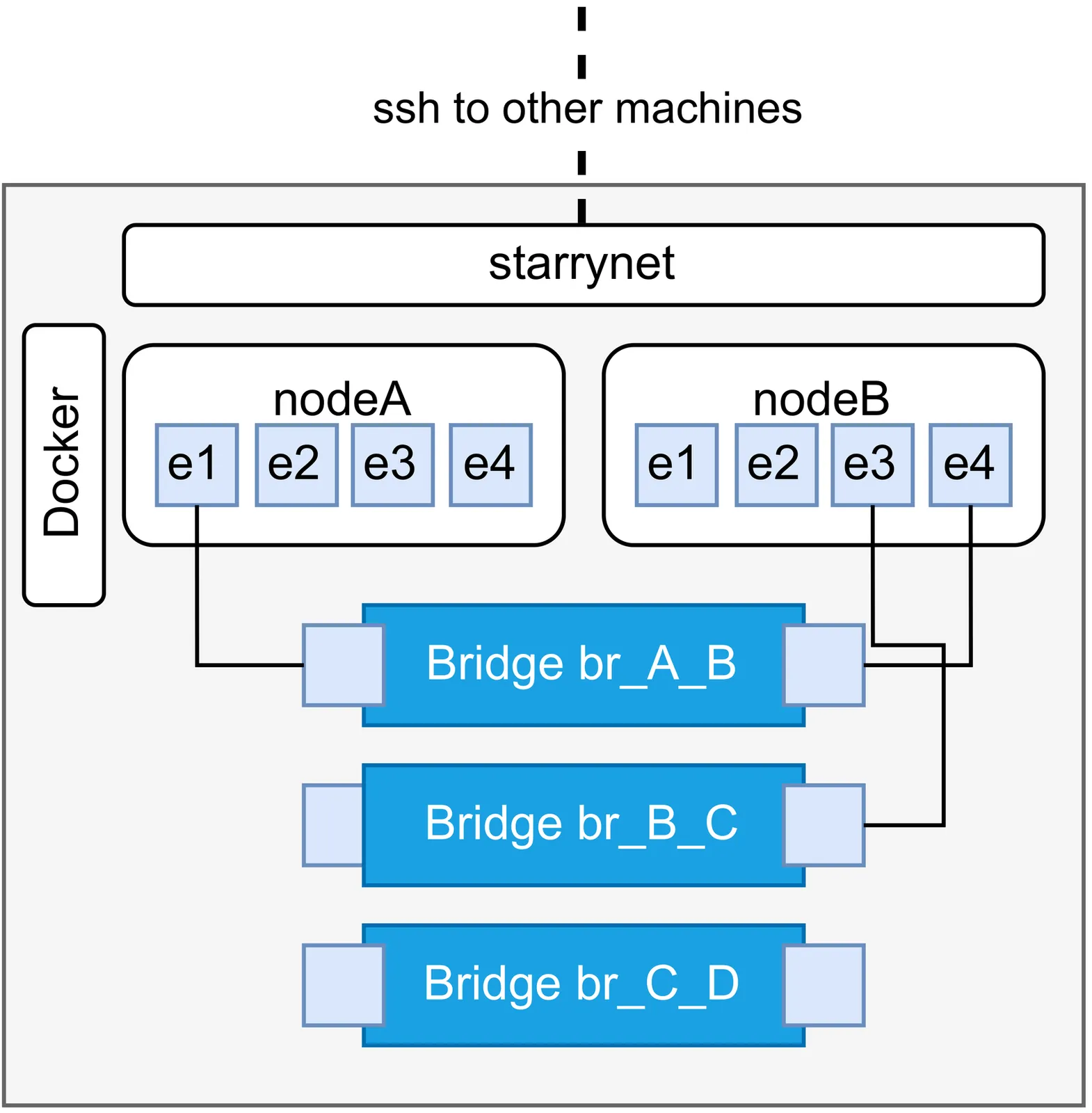
An experimental evaluation of satellite constellation emulators
Satellite emulation software is essential for research due to the lack of access to physical testbeds. To be useful, emulators must generate observations that are well-aligned with real-world ones, and they must have acceptable resource overheads for setting up and running experiments. This study provides an in-depth evaluation of three open-source emulators: StarryNet, OpenSN, and Celestial. Running them side-by-side and comparing them with real-world measurements from the WetLinks study identifies shortcomings of current satellite emulation techniques as well as promising avenues for research and development.
2604.04498Apr 2026
ViewTraining Transformers in Cosine Coefficient Space
We parameterize the weight matrices of a transformer in the two-dimensional discrete cosine transform (DCT) domain, retaining only the lowest-frequency coefficients. At each forward pass the full weight matrix is reconstructed via the inverse DCT; gradients propagate through the reconstruction to update the spectral coefficients directly. On character-level language modeling (Shakespeare, 1M characters), a 4-layer transformer trained from scratch in this representation matches the perplexity of the standard parameterization (6.1 vs.\ 6.1) while storing 52\% of the parameters. At 4$\times$ compression (29\% of parameters), the model reaches perplexity 6.9 -- outperforming a low-rank baseline (perplexity 8.8 at 21\% of parameters) at a comparable reduction. The method requires no architectural changes, no pre-trained checkpoint, and no auxiliary loss. It reduces to replacing each \texttt{nn.Linear} with a drop-in spectral layer that stores $K$ DCT coefficients instead of $n \times m$ weights.
2604.04440Apr 2026
View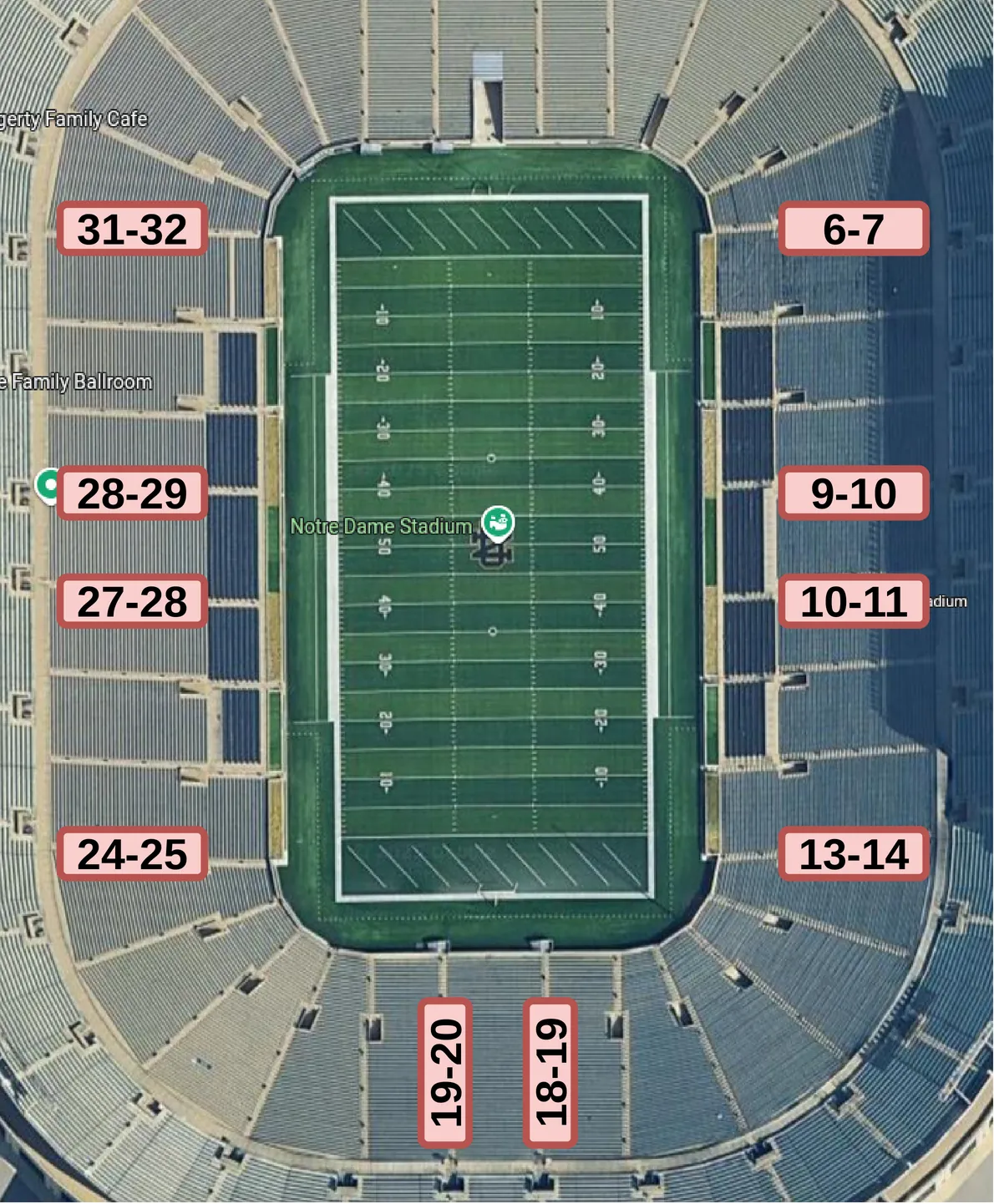
Comprehensive Analysis of Cellular Uplink Performance in a Dense Stadium Deployment
Uplink performance remains a critical limitation in modern 5G networks, where UEs have to balance limited transmission power against propagation challenges. We conducted extensive measurements in the University of Notre Dame's football stadium, which has a seating capacity of 80,000 spectators, evaluating network behavior under both unloaded (pregame) and severely congested (game day) conditions, with a focus on uplink performance. Analyzing PHY-layer metrics captured via the Rohde & Schwarz QualiPoc, we show that high-frequency TDD bands in the uplink are severely bottlenecked in both the spectral and temporal domains. Despite transmitting near maximum 3GPP power limits, propagation loss inherent to high-frequency bands restricts UEs to low MCS indices and low PRB allocations, even in unloaded networks. This inability to achieve wideband allocation is further compounded by the significantly smaller number of uplink slots compared to downlink slots in TDD frames. Consequently, we observe a severe disparity between uplink and downlink: while high-frequency TDD bands carry the majority of downlink throughput, the network relies heavily on lower-frequency FDD bands for uplink. Additional measurements under favorable propagation conditions around a Verizon COW deployment located in the stadium parking lot also show that this limitation is not solely propagation-driven; rather, the duplexing scheme itself also plays a significant role. Even when TDD bands achieve higher or comparable MCS, FDD bands have a performance edge in the uplink due to the restrictive, downlink-heavy TDD architecture. These findings emphasize the indispensable role of low-frequency FDD spectrum in sustaining uplink capacity, providing insights that will help guide the design of next-generation wireless networks.
2604.04371Apr 2026
View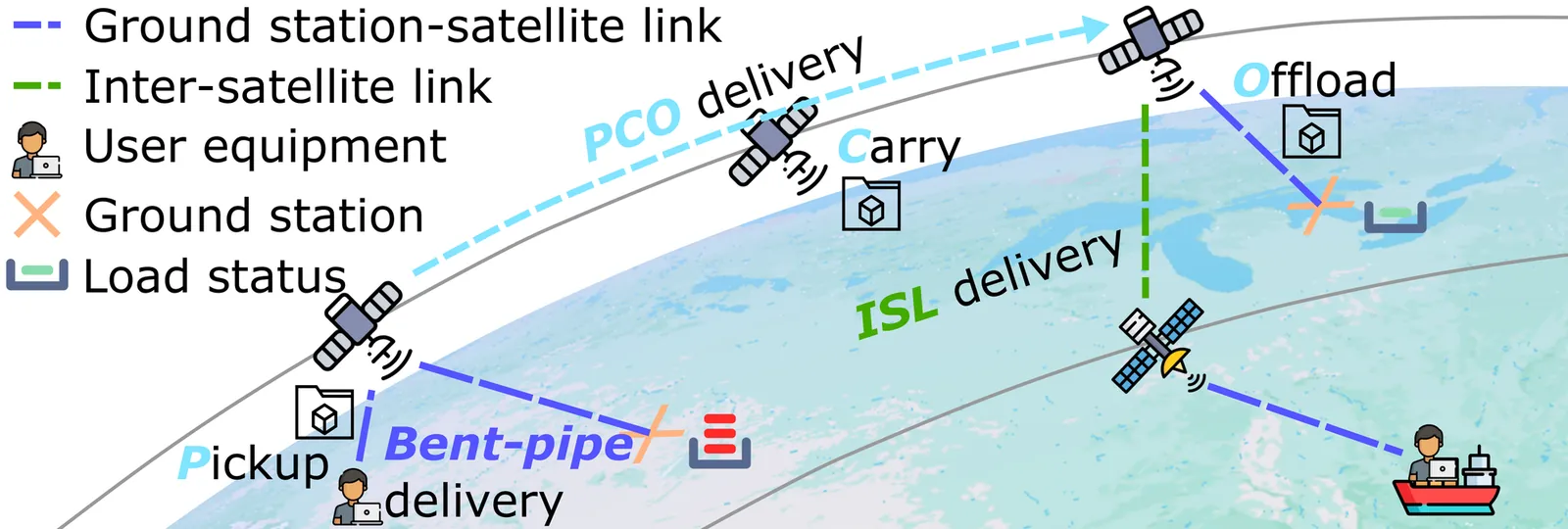
OrbitTransit: Traffic Delivery and Diffusion for Earth Observation via Satellite Mobility
The emerging demand for Earth observation (EO) to address environmental challenges has driven unprecedented growth in its primary carrier, Low Earth Orbit satellites, in recent years. Ground stations (GSs), the egress points of these networks, are congested due to the massive volume of EO traffic, and their deployment is constrained by geographic, political, and budgetary factors. Although inter-satellite links (ISLs) can partially relieve this congestion by forwarding traffic to alternative GSs, existing ISL-based approaches can hardly address traffic contention caused by biased GS distribution and may also raise sustainability concerns due to prolonged ISL paths. In this paper, we propose OrbitTransit, a pickup-carry-offload (PCO) approach that leverages satellite mobility for data \textit{delivery} and integrates ISLs for traffic \textit{diffusion} to alleviate the resource contention inherent in PCO delivery. The proposed orbit-as-node framework and contention-avoidant delivery jointly determine the optimal hybrid PCO-ISL path, minimizing energy consumption and balancing GS traffic. Extensive experiments show that OrbitTransit reduces battery consumption by $47.16\%$, decreases task failures by $1.09\times$, and improves GS load balancing compared with state-of-the-art GS selection and routing algorithms.
2604.04368Apr 2026
View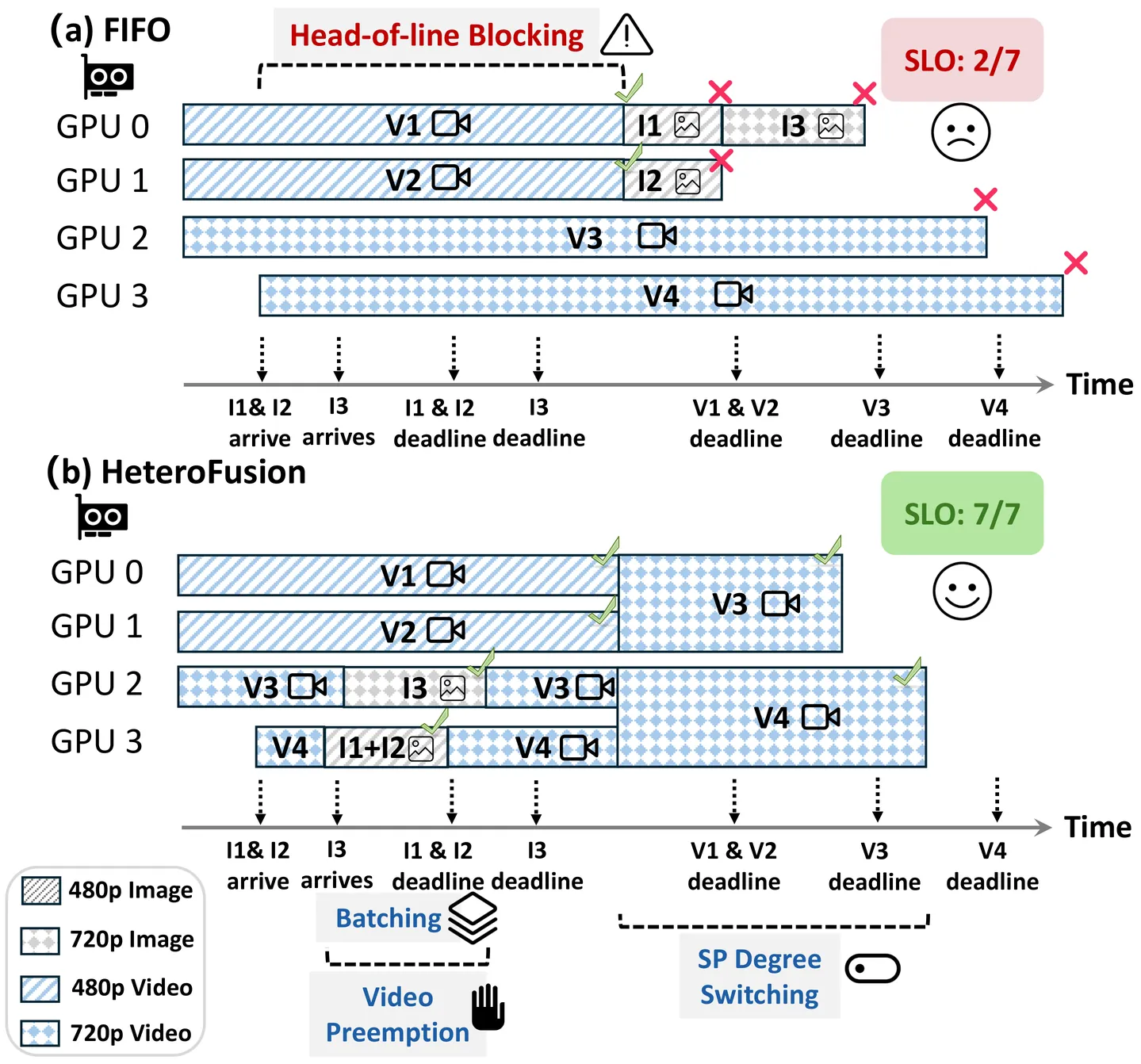
GENSERVE: Efficient Co-Serving of Heterogeneous Diffusion Model Workloads
Diffusion models have emerged as the prevailing approach for text-to-image (T2I) and text-to-video (T2V) generation, yet production platforms must increasingly serve both modalities on shared GPU clusters while meeting stringent latency SLOs. Co-serving such heterogeneous workloads is challenging: T2I and T2V requests exhibit vastly different compute demands, parallelism characteristics, and latency requirements, leading to significant SLO violations in existing serving systems. We present GENSERVE, a co-serving system that leverages the inherent predictability of the diffusion process to optimize serving efficiency. A central insight is that diffusion inference proceeds in discrete, predictable steps and is naturally preemptible at step boundaries, opening a new design space for heterogeneity-aware resource management. GENSERVE introduces step-level resource adaptation through three coordinated mechanisms: intelligent video preemption, elastic sequence parallelism with dynamic batching, and an SLO-aware scheduler that jointly optimizes resource allocation across all concurrent requests. Experimental results show that GENSERVE improves the SLO attainment rate by up to 44% over the strongest baseline across diverse configurations.
2604.04335Apr 2026
View
Shortest-Path FFT: Optimal SIMD Instruction Scheduling via Graph Search
An $N$-point FFT admits many valid implementations that differ in radix choice, stage ordering, and register-blocking strategy. These alternatives use different SIMD instruction mixes with different latencies, yet produce the same mathematical result. We show that finding the fastest implementation is a shortest-path problem on a directed acyclic graph. We formalize two variants of this graph. In the \emph{context-free} model, nodes represent computation stages and edge weights are independently measured instruction costs. In the \emph{context-aware} model, nodes are expanded to encode the \emph{predecessor edge type}, so that edge weights capture inter-operation correlations such as cache warming -- the cost of operation~B depends on which operation~A preceded it. This addresses a limitation identified but deliberately bypassed by FFTW \citep{FrigoJohnson1998}: that optimal-substructure assumptions break down ``because of the different states of the cache.'' Applied to Apple M1 NEON, the context-free Dijkstra finds an arrangement at 22.1~GFLOPS (74\% of optimal). The context-aware Dijkstra discovers $\text{R4} \to \text{R2} \to \text{R4} \to \text{R4} \to \text{Fused-8}$ at 29.8~GFLOPS -- a $5.2\times$ improvement over pure radix-2 and 34\% faster than the context-free result. This arrangement includes a radix-2 pass \emph{sandwiched between} radix-4 passes, exploiting cache residuals that only exist in context. No context-free search can discover this.
2604.04311Apr 2026
View
A Family of Open Time-Series Foundation Models for the Radio Access Network
The Radio Access Network (RAN) is evolving into a programmable and disaggregated infrastructure that increasingly relies on AI-native algorithms for optimization and closed-loop control. However, current RAN intelligence is still largely built from task-specific models tailored to individual functions, resulting in model fragmentation, limited knowledge sharing across tasks, poor generalization, and increased system complexity. To address these limitations, we introduce TimeRAN, a unified multi-task learning framework for time-series modeling in the RAN. TimeRAN leverages a lightweight time-series foundation model with few task-specific heads to learn transferable representations that can be efficiently adapted across diverse tasks with limited supervision. To enable large-scale pretraining, we further curate and open-source TimeRAN DataPile, the largest time-series corpus for RAN analytics to date, comprising over 355K time series and 0.56B measurements across diverse telemetry sources, protocol layers, and deployment scenarios. We evaluate TimeRAN across a comprehensive set of RAN analytics tasks, including anomaly detection, classification, forecasting, and imputation, and show that it achieves state-of-the-art performance with minimal or no task-specific fine-tuning. Finally, we integrate TimeRAN into a proof-of-concept 5G testbed and demonstrate that it operates efficiently with limited resource requirements in real-world scenarios.
2604.04271Apr 2026
ViewPage 1 of 460