Operating Systems
arXiv:cs.OS
Covers all aspects of operating systems design and implementation.
Looking for a broader view? This category is part of:
Covers all aspects of operating systems design and implementation.
Looking for a broader view? This category is part of:
Resource-management tasks in modern operating and distributed systems continue to rely primarily on hand-designed heuristics for tasks such as scheduling, caching, or active queue management. Designing performant heuristics is an expensive, time-consuming process that we are forced to continuously go through due to the constant flux of hardware, workloads and environments. We propose a new alternative: synthesizing instance-optimal heuristics -- specialized for the exact workloads and hardware where they will be deployed -- using code-generating large language models (LLMs). To make this synthesis tractable, Vulcan separates policy and mechanism through LLM-friendly, task-agnostic interfaces. With these interfaces, users specify the inputs and objectives of their desired policy, while Vulcan searches for performant policies via evolutionary search over LLM-generated code. This interface is expressive enough to capture a wide range of system policies, yet sufficiently constrained to allow even small, inexpensive LLMs to generate correct and executable code. We use Vulcan to synthesize performant heuristics for cache eviction and memory tiering, and find that these heuristics outperform all human-designed state-of-the-art algorithms by upto 69% and 7.9% in performance for each of these tasks respectively.
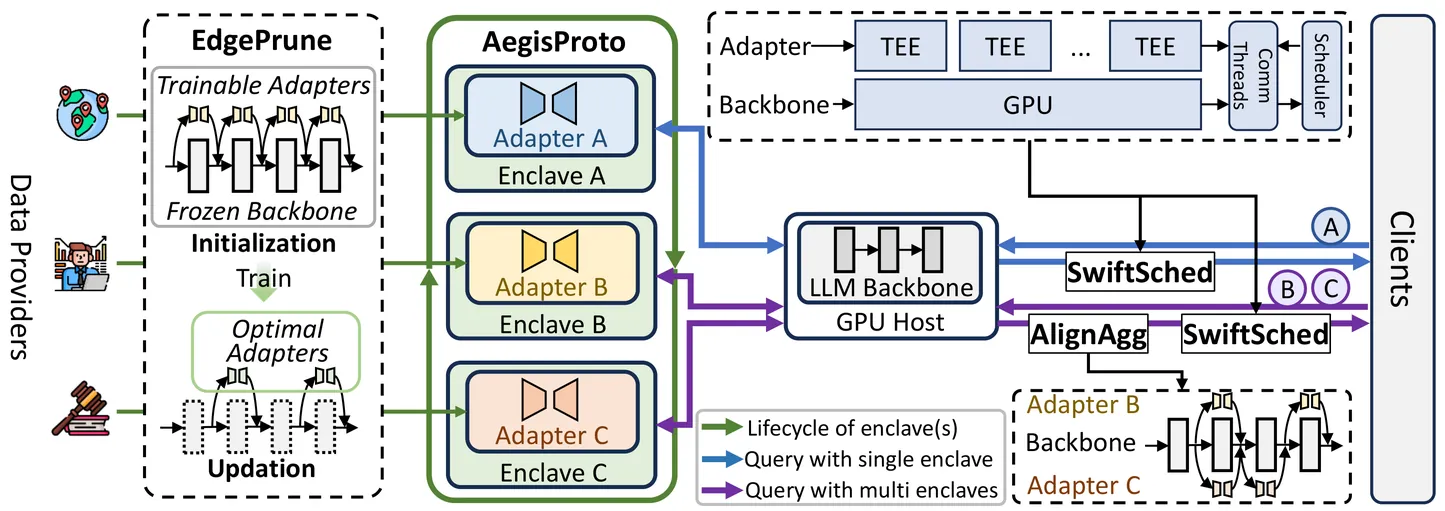
Future improvements in large language model (LLM) services increasingly hinge on access to high-value professional knowledge rather than more generic web data. However, the data providers of this knowledge face a skewed tradeoff between income and risk: they receive little share of downstream value yet retain copyright and privacy liability, making them reluctant to contribute their assets to LLM services. Existing techniques do not offer a trustworthy and controllable way to use professional knowledge, because they keep providers in the dark and combine knowledge parameters with the underlying LLM backbone. In this paper, we present PKUS, the Professional Knowledge Utilization System, which treats professional knowledge as a first-class, separable artifact. PKUS keeps the backbone model on GPUs and encodes each provider's contribution as a compact adapter that executes only inside an attested Trusted Execution Environment (TEE). A hardware-rooted lifecycle protocol, adapter pruning, multi-provider aggregation, and split-execution scheduling together make this design practical at serving time. On SST-2, MNLI, and SQuAD with GPT-2 Large and Llama-3.2-1B, PKUS preserves model utility, matching the accuracy and F1 of full fine-tuning and plain LoRA, while achieving the lowest per-request latency with 8.1-11.9x speedup over CPU-only TEE inference and naive CPU-GPU co-execution.

Reusing KV cache is essential for high efficiency of Large Language Model (LLM) inference systems. With more LLM users, the KV cache footprint can easily exceed GPU memory capacity, so prior work has proposed to either evict KV cache to lower-tier storage devices, or compress KV cache so that more KV cache can be fit in the fast memory. However, prior work misses an important opportunity: jointly optimizing the eviction and compression decisions across all KV caches to minimize average generation latency without hurting quality. We propose EVICPRESS, a KV-cache management system that applies lossy compression and adaptive eviction to KV cache across multiple storage tiers. Specifically, for each KV cache of a context, EVICPRESS considers the effect of compression and eviction of the KV cache on the average generation quality and delay across all contexts as a whole. To achieve this, EVICPRESS proposes a unified utility function that quantifies the effect of quality and delay of the lossy compression or eviction. To this end, EVICPRESS's profiling module periodically updates the utility function scores on all possible eviction-compression configurations for all contexts and places KV caches using a fast heuristic to rearrange KV caches on all storage tiers, with the goal of maximizing the utility function scores on each storage tier. Compared to the baselines that evict KV cache or compress KV cache, EVICPRESS achieves higher KV-cache hit rates on fast devices, i.e., lower delay, while preserving high generation quality by applying conservative compression to contexts that are sensitive to compression errors. Evaluation on 12 datasets and 5 models demonstrates that EVICPRESS achieves up to 2.19x faster time-to-first-token (TTFT) at equivalent generation quality.
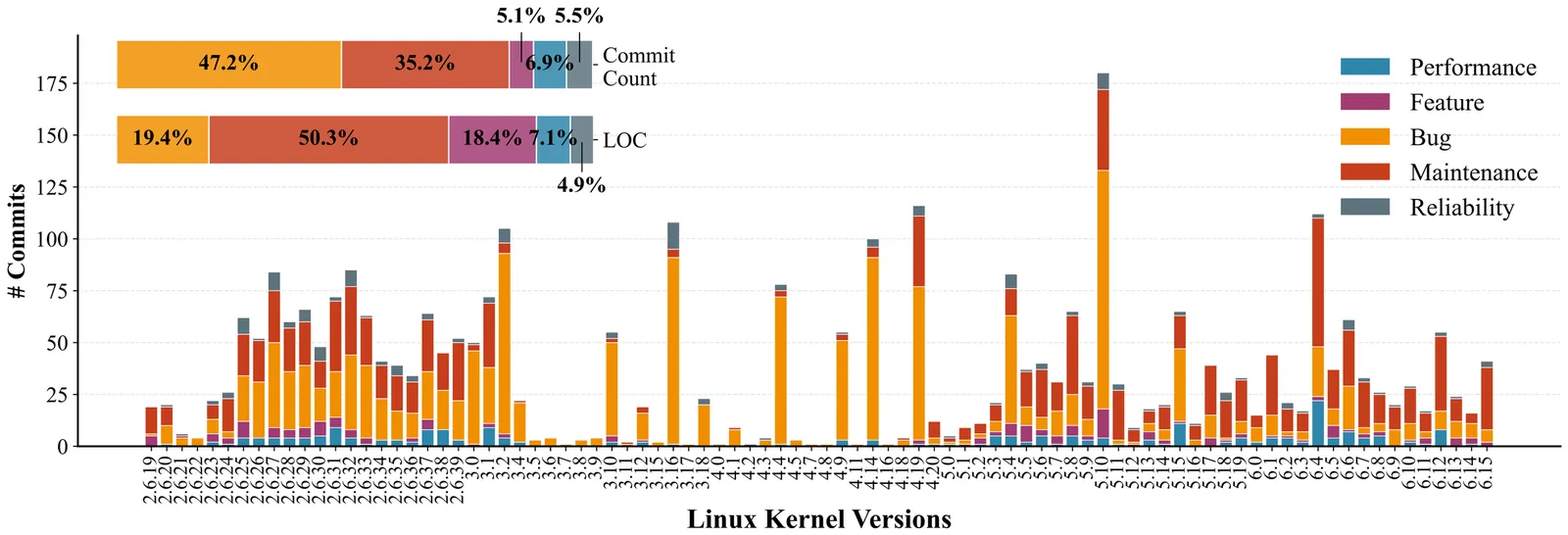
File systems are critical OS components that require constant evolution to support new hardware and emerging application needs. However, the traditional paradigm of developing features, fixing bugs, and maintaining the system incurs significant overhead, especially as systems grow in complexity. This paper proposes a new paradigm, generative file systems, which leverages Large Language Models (LLMs) to generate and evolve a file system from prompts, effectively addressing the need for robust evolution. Despite the widespread success of LLMs in code generation, attempts to create a functional file system have thus far been unsuccessful, mainly due to the ambiguity of natural language prompts. This paper introduces SYSSPEC, a framework for developing generative file systems. Its key insight is to replace ambiguous natural language with principles adapted from formal methods. Instead of imprecise prompts, SYSSPEC employs a multi-part specification that accurately describes a file system's functionality, modularity, and concurrency. The specification acts as an unambiguous blueprint, guiding LLMs to generate expected code flexibly. To manage evolution, we develop a DAG-structured patch that operates on the specification itself, enabling new features to be added without violating existing invariants. Moreover, the SYSSPEC toolchain features a set of LLM-based agents with mechanisms to mitigate hallucination during construction and evolution. We demonstrate our approach by generating SPECFS, a concurrent file system. SPECFS passes hundreds of regression tests, matching a manually-coded baseline. We further confirm its evolvability by seamlessly integrating 10 real-world features from Ext4. Our work shows that a specification-guided approach makes generating and evolving complex systems not only feasible but also highly effective.

Performance in modern GPU-centric systems increasingly depends on resource management policies, including memory placement, scheduling, and observability. However, uniform policies typically yield suboptimal performance across diverse workloads. Existing approaches present a tradeoff: user-space runtimes provide programmability and flexibility but lack cross-tenant visibility and fine-grained control of hardware resources; meanwhile, modifications to the OS kernel introduce significant complexity and safety risks. To address this, we argue that the GPU driver and device layer should provide an extensible OS interface for policy enforcement. While the emerging eBPF technology shows potential, directly applying existing host-side eBPF is insufficient because they lack visibility and control into critical device-side events, and directly embedding policy code into GPU kernels could compromise safety and efficiency. We propose gpu_ext, an eBPF-based runtime that treats the GPU driver and device as a programmable OS subsystem. gpu_ext extends GPU drivers by exposing safe programmable hooks and introduces a device-side eBPF runtime capable of executing verified policy logic within GPU kernels, enabling coherent and transparent policies. Evaluation across realistic workloads including inference, training, and vector search demonstrates that gpu_ext improves throughput by up to 4.8x and reduces tail latency by up to 2x, incurring low overhead, without modifying or restarting applications
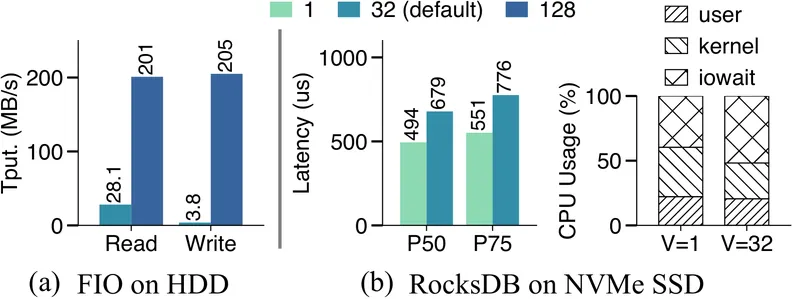
The Linux kernel source code contains numerous constant values that critically influence system performance. Many of these constants, which we term perf-consts, are magic numbers that encode brittle assumptions about hardware and workloads. As systems and workloads evolve, such constants often become suboptimal. Unfortunately, deployed kernels lack support for safe and efficient in-situ tuning of perf-consts without a long and disruptive process of rebuilding and redeploying the kernel image. This paper advocates principled OS performance tunability. We present KernelX, a system that provides a safe, efficient, and programmable interface for in-situ tuning of arbitrary perf-consts on a running kernel. KernelX transforms any perf-const into a tunable knob on demand using a novel mechanism called Scoped Indirect Execution (SIE). SIE precisely identifies the binary boundaries where a perf-const influences system state and redirects execution to synthesized instructions that update the state as if new values were used. KernelX goes beyond version atomicity to guarantee side-effect safety, a property not provided by existing kernel update mechanisms. KernelX also provides a programmable interface that allows policies to incorporate application hints, hardware heuristics, and fine-grained isolation, without modifying kernel source code or disrupting deployed OS kernels. Case studies across multiple kernel subsystems demonstrate that KernelX enables significant performance improvements by making previously untunable perf-consts safely tunable at runtime, while supporting millisecond-scale policy updates.

zkVMs promise general-purpose verifiable computation through ISA-level compatibility with modern programs and toolchains. However, compatibility extends further than just the ISA; modern programs often cannot run or even compile without an operating system and libc. zkVMs attempt to address this by maintaining forks of language-specific runtimes and statically linking them into applications to create self-contained unikernels, but this ad-hoc approach leads to version hell and burdens verifiable applications (vApps) with an unnecessarily large trusted computing base. We solve this problem with ZeroOS, a modular library operating system (libOS) for vApp unikernels; vApp developers can use off-the-shelf toolchains to compile and link only the exact subset of the Linux ABI their vApp needs. Any zkVM team can easily leverage the ZeroOS ecosystem by writing a ZeroOS bootloader for their platform, resulting in a reduced maintainence burden and unifying the entire zkVM ecosystem with consolidated development and audit resources. ZeroOS is free and open-sourced at https://github.com/LayerZero-Labs/ZeroOS.
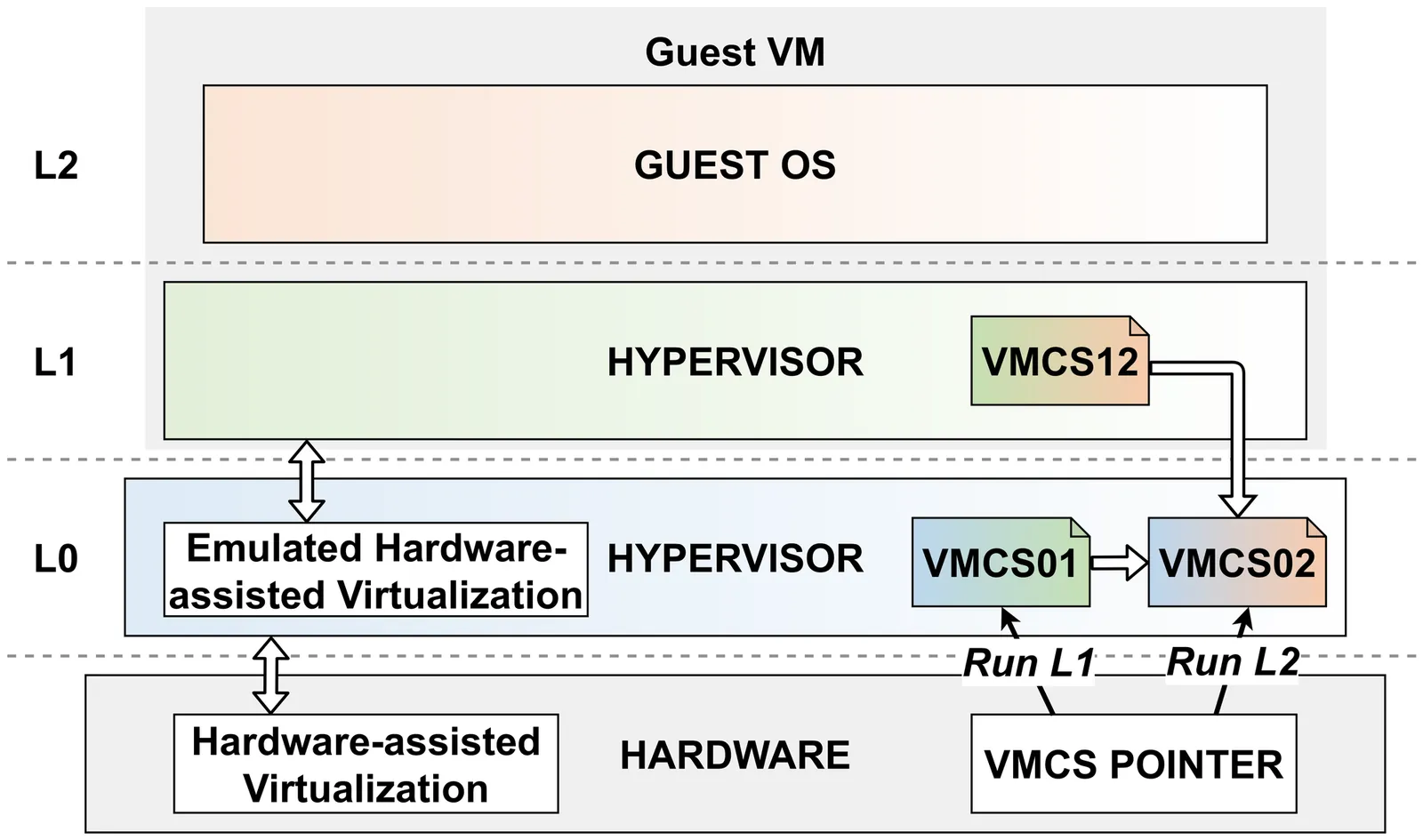
Nested virtualization is now widely supported by major cloud vendors, allowing users to leverage virtualization-based technologies in the cloud. However, supporting nested virtualization significantly increases host hypervisor complexity and introduces a new attack surface in cloud platforms. While many prior studies have explored hypervisor fuzzing, none has explicitly addressed nested virtualization due to the challenge of generating effective virtual machine (VM) instances with a vast state space as fuzzing inputs. We present NecoFuzz, the first fuzzing framework that systematically targets nested virtualization-specific logic in hypervisors. NecoFuzz synthesizes executable fuzz-harness VMs with internal states near the boundary between valid and invalid, guided by an approximate model of hardware-assisted virtualization specifications. Since vulnerabilities in nested virtualization often stem from incorrect handling of unexpected VM states, this specification-guided, boundary-oriented generation significantly improves coverage of security-critical code across different hypervisors. We implemented NecoFuzz on Intel VT-x and AMD-V by extending AFL++ to support fuzz-harness VMs. NecoFuzz achieved 84.7% and 74.2% code coverage for nested virtualization-specific code on Intel VT-x and AMD-V, respectively, and uncovered six previously unknown vulnerabilities across three hypervisors, including two assigned CVEs.
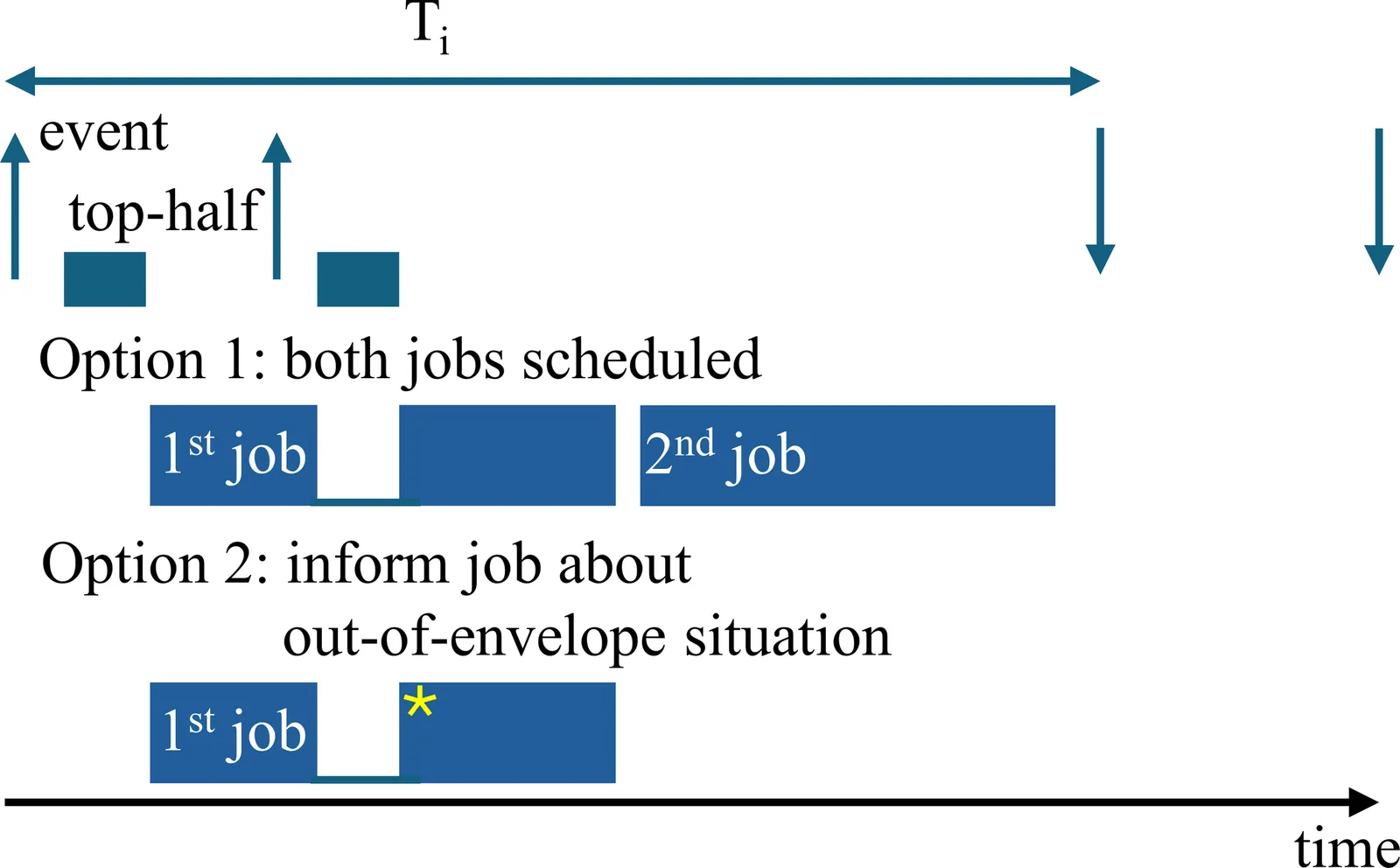
The design of real-time systems is based on assumptions about environmental conditions in which they will operate. We call this their safe operational envelope. Violation of these assumptions, i.e., out-of-envelope environments, can jeopardize timeliness and safety of real-time systems, e.g., by overwhelming them with interrupt storms. A long-lasting debate has been going on over which design paradigm, the time- or event-triggered, is more robust against such behavior. In this work, we investigate the claim that time-triggered systems are immune against out-of-envelope behavior and how event-triggered systems can be constructed to defend against being overwhelmed by interrupt showers. We introduce importance (independently of priority and criticality) as a means to express which tasks should still be scheduled in case environmental design assumptions cease to hold, draw parallels to mixed-criticality scheduling, and demonstrate how event-triggered systems can defend against out-of-envelope behavior.
We present Mirror-Optimized Storage Tiering (MOST), a novel tiering-based approach optimized for modern storage hierarchies. The key idea of MOST is to combine the load balancing advantages of mirroring with the space-efficiency advantages of tiering. Specifically, MOST dynamically mirrors a small amount of hot data across storage tiers to efficiently balance load, avoiding costly migrations. As a result, MOST is as space-efficient as classic tiering while achieving better bandwidth utilization under I/O-intensive workloads. We implement MOST in Cerberus, a user-level storage management layer based on CacheLib. We show the efficacy of Cerberus through a comprehensive empirical study: across a range of static and dynamic workloads, Cerberus achieves better throughput than competing approaches on modern storage hierarchies especially under I/O-intensive and dynamic workloads.
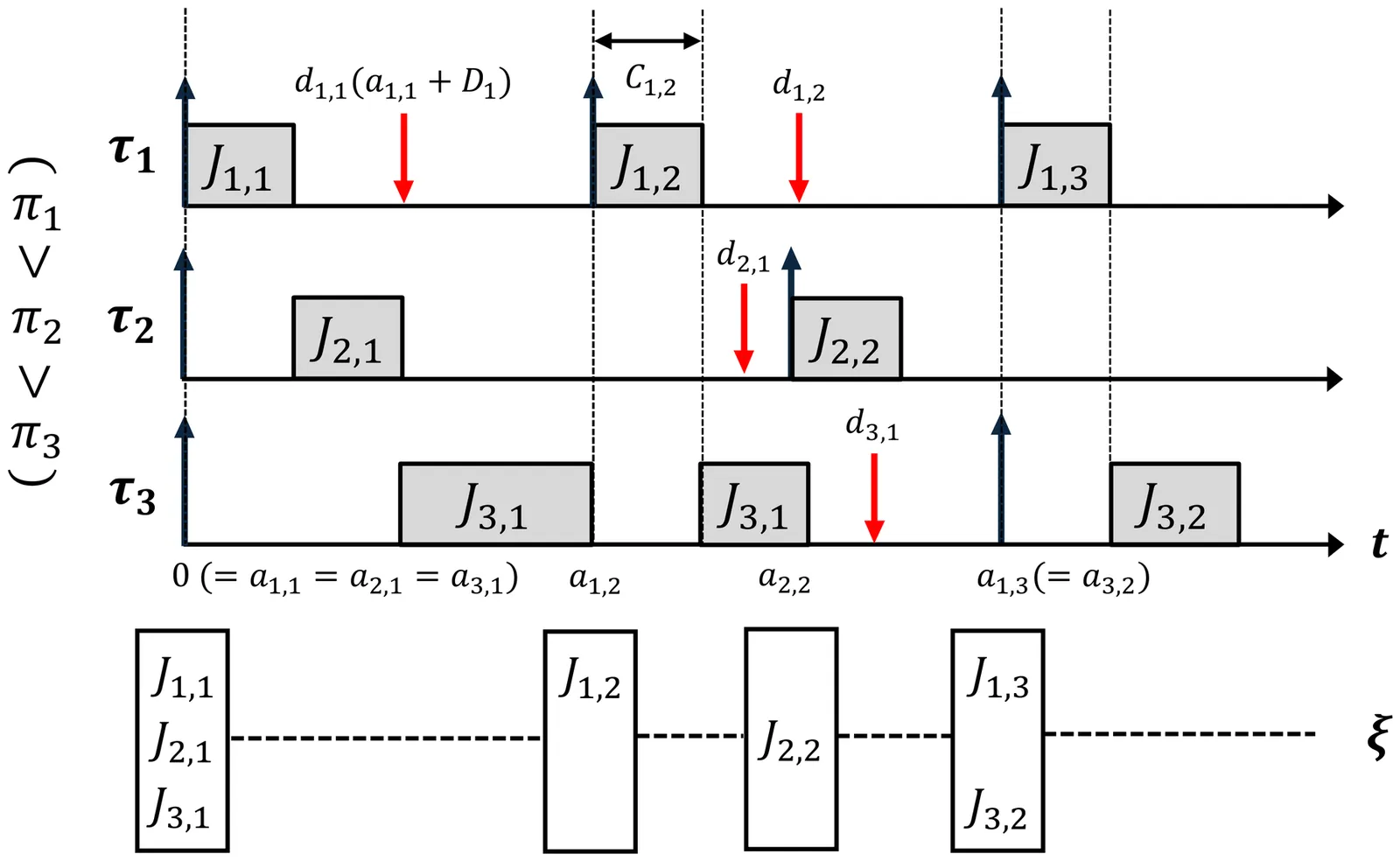
Accurate estimation of the Worst-Case Deadline Failure Probability (WCDFP) has attracted growing attention as a means to provide safety assurances in complex systems such as robotic platforms and autonomous vehicles. WCDFP quantifies the likelihood of deadline misses under the most pessimistic operating conditions, and safe estimation is essential for dependable real-time applications. However, achieving high accuracy in WCDFP estimation often incurs significant computational cost. Recent studies have revealed that the classical assumption of the critical instant, the activation pattern traditionally considered to trigger the worst-case behavior, can lead to underestimation of WCDFP in probabilistic settings. This observation motivates the use of a revised critical instant formulation that more faithfully captures the true worst-case scenario. This paper investigates convolution-based methods for WCDFP estimation under this revised setting and proposes an optimization technique that accelerates convolution by improving the merge order. Extensive experiments with diverse execution-time distributions demonstrate that the proposed optimized Aggregate Convolution reduces computation time by up to an order of magnitude compared to Sequential Convolution, while retaining accurate and safe-sided WCDFP estimates. These results highlight the potential of the approach to provide both efficiency and reliability in probabilistic timing analysis for safety-critical real-time applications.
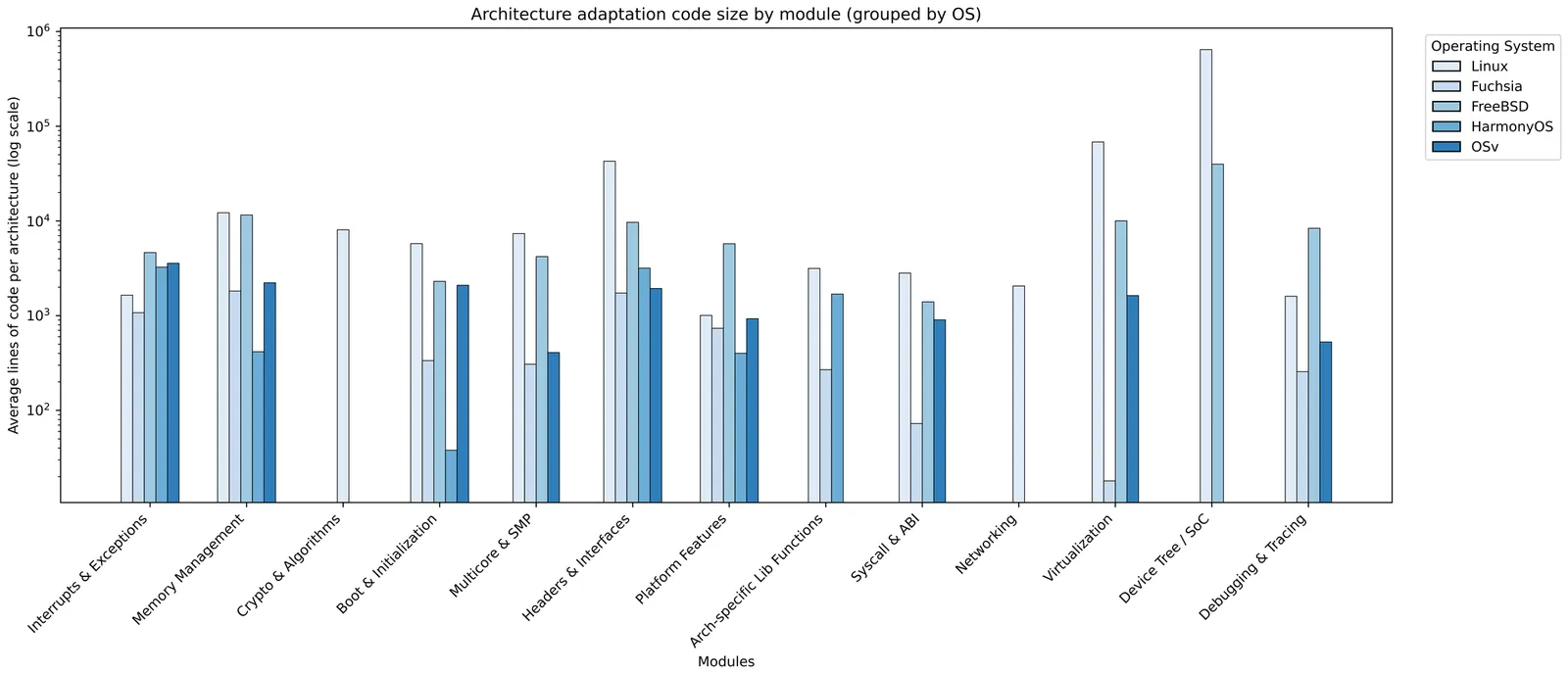
The growing complexity of embedded systems creates tension between rich functionality and strict resource and real-time constraints. Traditional monolithic operating system and hypervisor designs suffer from resource bloat and unpredictable scheduling, making them unsuitable for time-critical workloads where low latency and low jitter are essential. We propose TenonOS, a demand-driven, self-generating, lightweight operating system framework for time-critical embedded systems that rethinks both hypervisor and operating system architectures. TenonOS introduces a LibOS-on-LibOS model that decomposes hypervisor and operating system functionality into fine-grained, reusable micro-libraries. A generative orchestration engine dynamically composes these libraries to synthesize a customized runtime tailored to each application's criticality, timing requirements, and resource profile. TenonOS consists of two core components: Mortise, a minimalist micro-hypervisor, and Tenon, a real-time library operating system. Mortise provides lightweight isolation and removes the usual double-scheduler overhead in virtualized setups, while Tenon provides precise and deterministic task management. By generating only the necessary software stack per workload, TenonOS removes redundant layers, minimizes the trusted computing base, and maximizes responsiveness. Experiments show a 40.28 percent reduction in scheduling latency, an ultra-compact 361 KiB memory footprint, and strong adaptability.
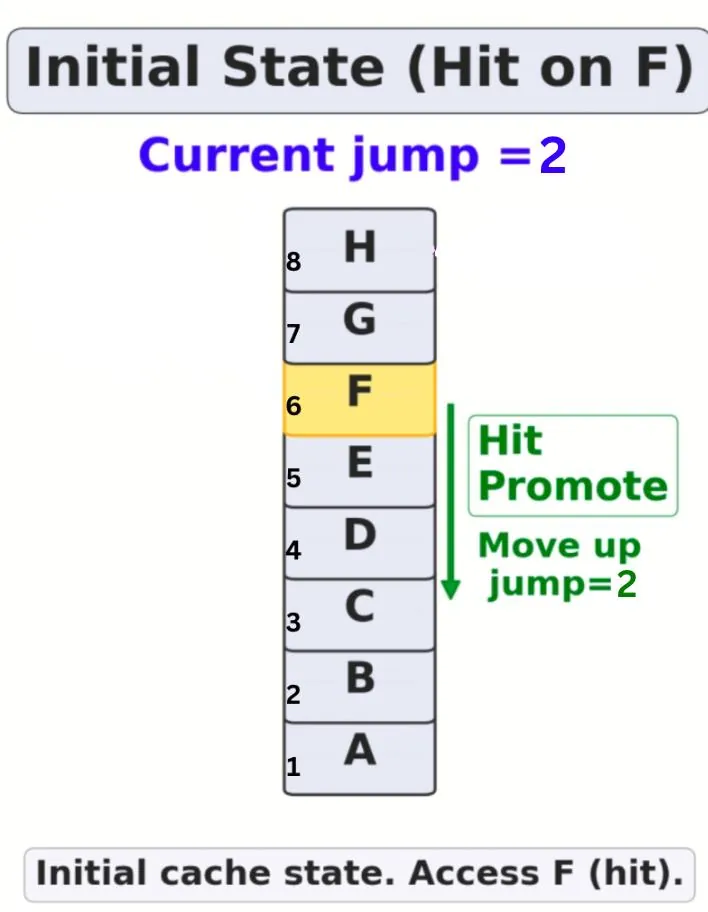
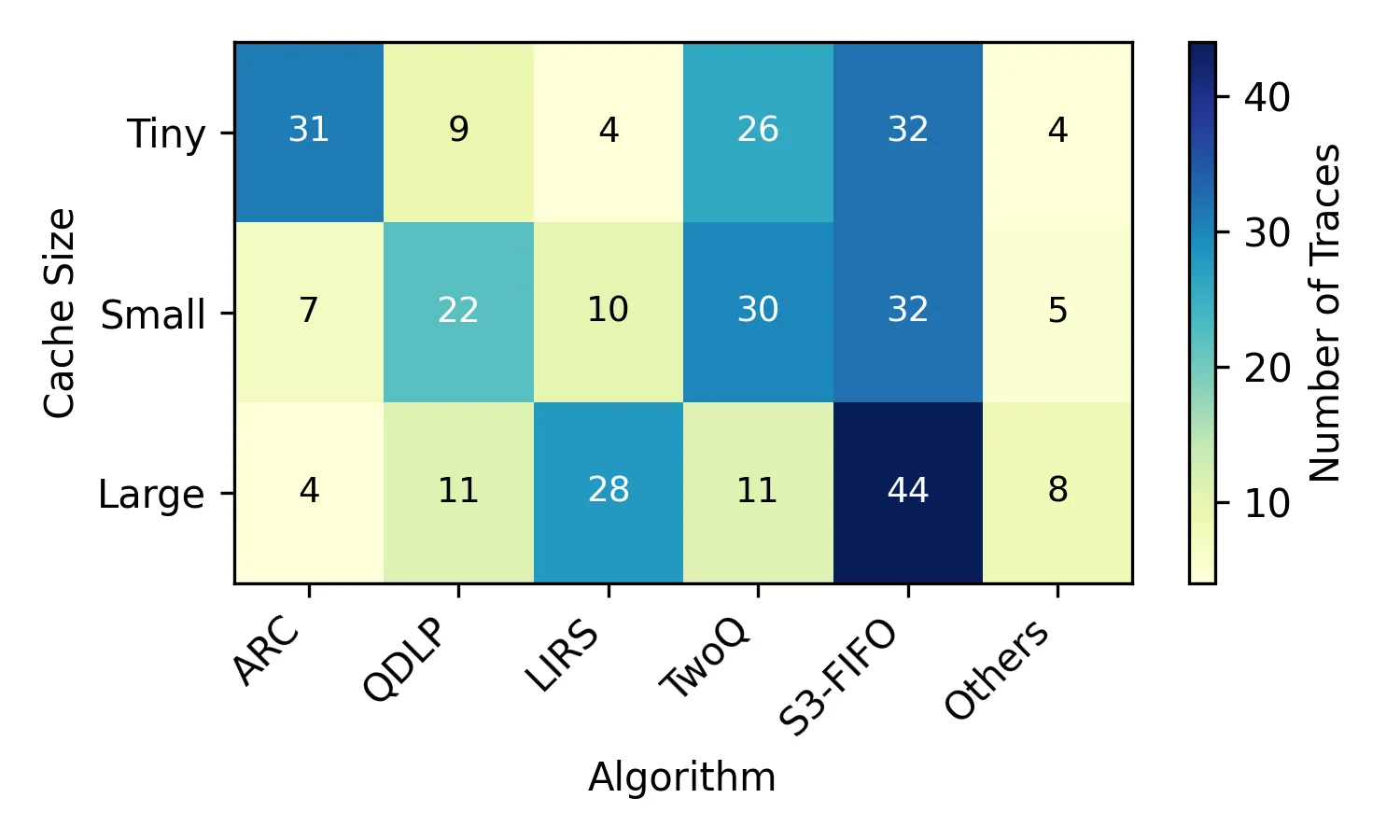
Efficient cache management is critical for optimizing the system performance, and numerous caching mechanisms have been proposed, each exploring various insertion and eviction strategies. In this paper, we present AdaptiveClimb and its extension, DynamicAdaptiveClimb, two novel cache replacement policies that leverage lightweight, cache adaptation to outperform traditional approaches. Unlike classic Least Recently Used (LRU) and Incremental Rank Progress (CLIMB) policies, AdaptiveClimb dynamically adjusts the promotion distance (jump) of the cached objects based on recent hit and miss patterns, requiring only a single tunable parameter and no per-item statistics. This enables rapid adaptation to changing access distributions while maintaining low overhead. Building on this foundation, DynamicAdaptiveClimb further enhances adaptability by automatically tuning the cache size in response to workload demands. Our comprehensive evaluation across a diverse set of real-world traces, including 1067 traces from 6 different datasets, demonstrates that DynamicAdaptiveClimb consistently achieves substantial speedups and higher hit ratios compared to other state-of-the-art algorithms. In particular, our approach achieves up to a 29% improvement in hit ratio and a substantial reduction in miss penalties compared to the FIFO baseline. Furthermore, it outperforms the next-best contenders, AdaptiveClimb and SIEVE [43], by approximately 10% to 15%, especially in environments characterized by fluctuating working set sizes. These results highlight the effectiveness of our approach in delivering efficient performance, making it well-suited for modern, dynamic caching environments.
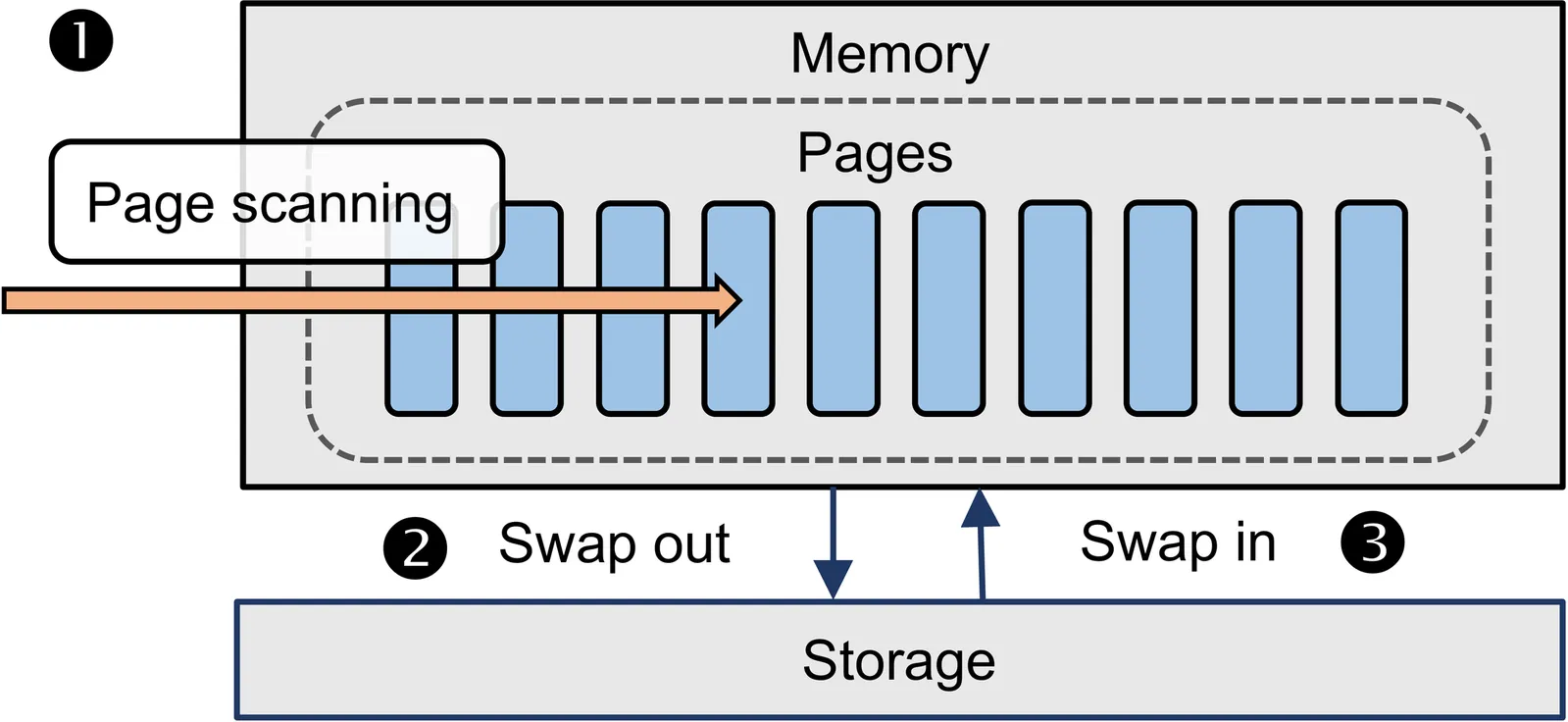
The memory capacity in edge devices is often limited due to constraints on cost, size, and power. Consequently, memory competition leads to inevitable page swapping in memory-constrained mixed-criticality edge devices, causing slow storage I/O and thus performance degradation. In such scenarios, inefficient memory allocation disrupts the balance between application performance, causing soft real-time (soft RT) tasks to miss deadlines or preventing non-real-time (non-RT) applications from optimizing throughput. Meanwhile, we observe unpredictable, long system-level stalls (called long stalls) under high memory and I/O pressure, which further degrade performance. In this work, we propose a Stall-Aware Real-Time Memory Allocator (SARA), which discovers opportunities for performance balance by allocating just enough memory to soft RT tasks to meet deadlines and, at the same time, optimizing the remaining memory for non-RT applications. To minimize the memory usage of soft RT tasks while meeting real-time requirements, SARA leverages our insight into how latency, caused by memory insufficiency and measured by our proposed PSI-based metric, affects the execution time of each soft RT job, where a job runs per period and a soft RT task consists of multiple periods. Moreover, SARA detects long stalls using our definition and proactively drops affected jobs, minimizing stalls in task execution. Experiments show that SARA achieves an average of 97.13% deadline hit ratio for soft RT tasks and improves non-RT application throughput by up to 22.32x over existing approaches, even with memory capacity limited to 60% of peak demand.
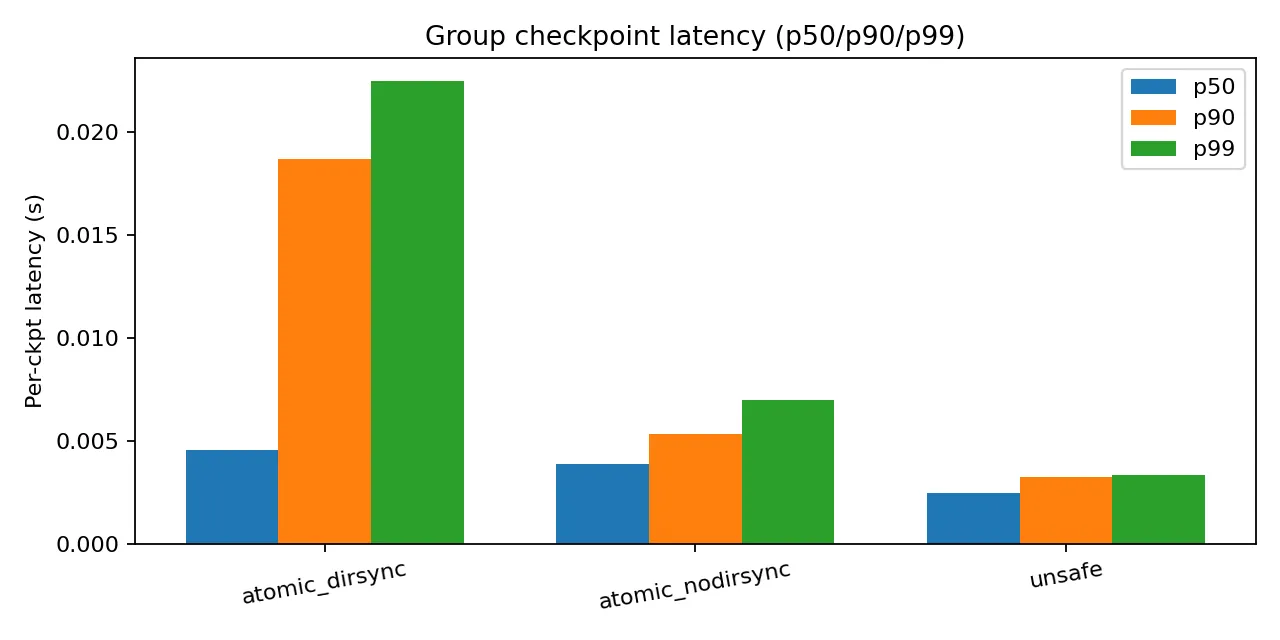
Deep learning training relies on periodic checkpoints to recover from failures, but unsafe checkpoint installation can leave corrupted files on disk. This paper presents an experimental study of checkpoint installation protocols and integrity validation for AI training on macOS/APFS. We implement three write modes with increasing durability guarantees: unsafe (baseline, no fsync), atomic_nodirsync (file-level durability via fsync()), and atomic_dirsync (file + directory durability). We design a format-agnostic integrity guard using SHA-256 checksums with automatic rollback. Through controlled experiments including crash injection (430 unsafe-mode trials) and corruption injection (1,600 atomic-mode trials), we demonstrate that the integrity guard detects 99.8-100% of corruptions with zero false positives. Performance overhead is 56.5-108.4% for atomic_nodirsync and 84.2-570.6% for atomic_dirsync relative to the unsafe baseline. Our findings quantify the reliability-performance trade-offs and provide deployment guidance for production AI infrastructure.
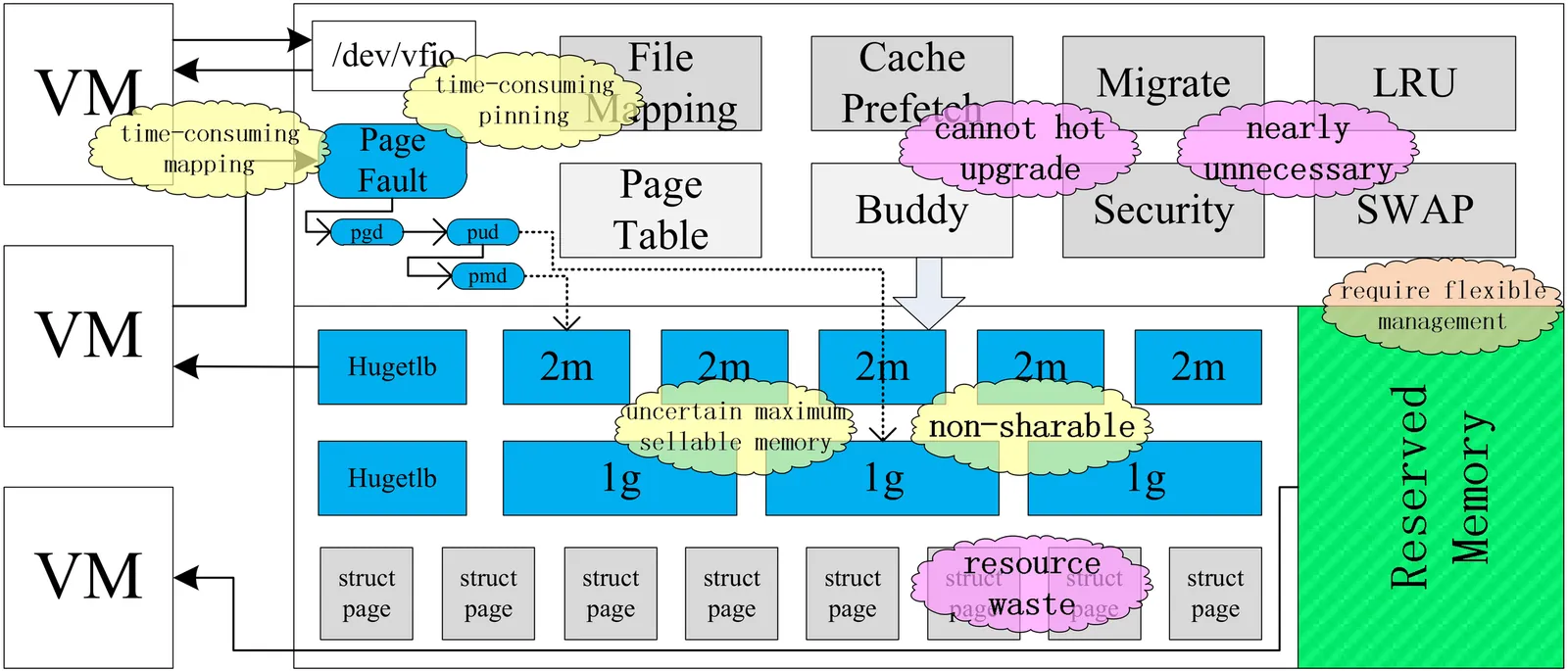
Traditional memory management suffers from metadata overhead, architectural complexity, and stability degradation, problems intensified in cloud environments. Existing software/hardware optimizations are insufficient for cloud computing's dual demands of flexibility and low overhead. This paper presents Vmem, a memory management architecture for in-production cloud environments that enables flexible, efficient cloud server memory utilization through lightweight reserved memory management. Vmem is the first such architecture to support online upgrades, meeting cloud requirements for high stability and rapid iterative evolution. Experiments show Vmem increases sellable memory rate by about 2%, delivers extreme elasticity and performance, achieves over 3x faster boot time for VFIO-based virtual machines (VMs), and improves network performance by about 10% for DPU-accelerated VMs. Vmem has been deployed at large scale for seven years, demonstrating efficiency and stability on over 300,000 cloud servers supporting hundreds of millions of VMs.
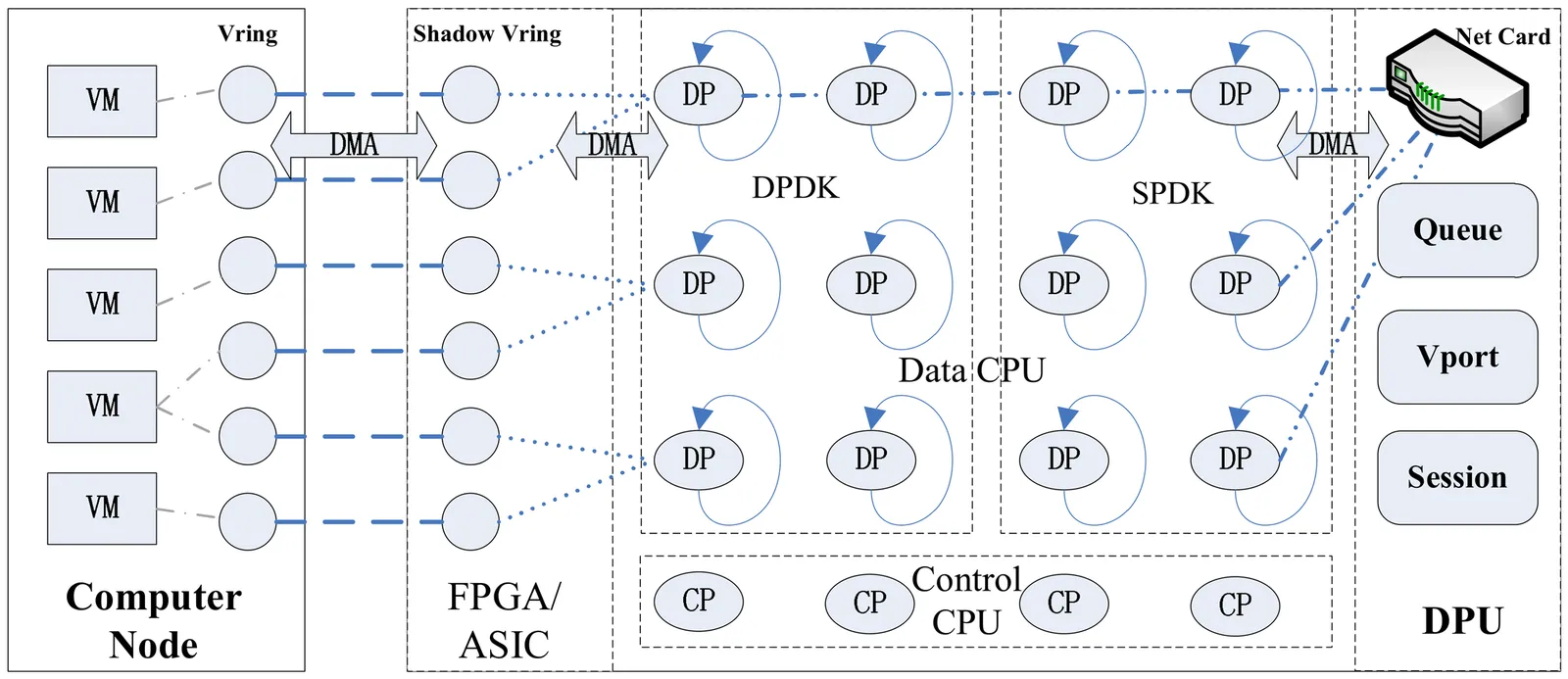
The growth of cloud computing drives data centers toward higher density and efficiency. Data processing units (DPUs) enhance server network and storage performance but face challenges such as long hardware upgrade cycles and limited resources. To address these, we propose Taiji, a resource-elasticity architecture for DPUs. Combining hybrid virtualization with parallel memory swapping, Taiji switches the DPU's operating system (OS) into a guest OS and inserts a lightweight virtualization layer, making nearly all DPU memory swappable. It achieves memory overcommitment for the switched guest OS via high-performance memory elasticity, fully transparent to upper-layer applications, and supports hot-switch and hot-upgrade to meet in-production cloud requirements. Experiments show that Taiji expands DPU memory resources by over 50%, maintains virtualization overhead around 5%, and ensures 90% of swap-ins complete within 10 microseconds. Taiji delivers an efficient, reliable, low-overhead elasticity solution for DPUs and is deployed in large-scale production systems across more than 30,000 servers.
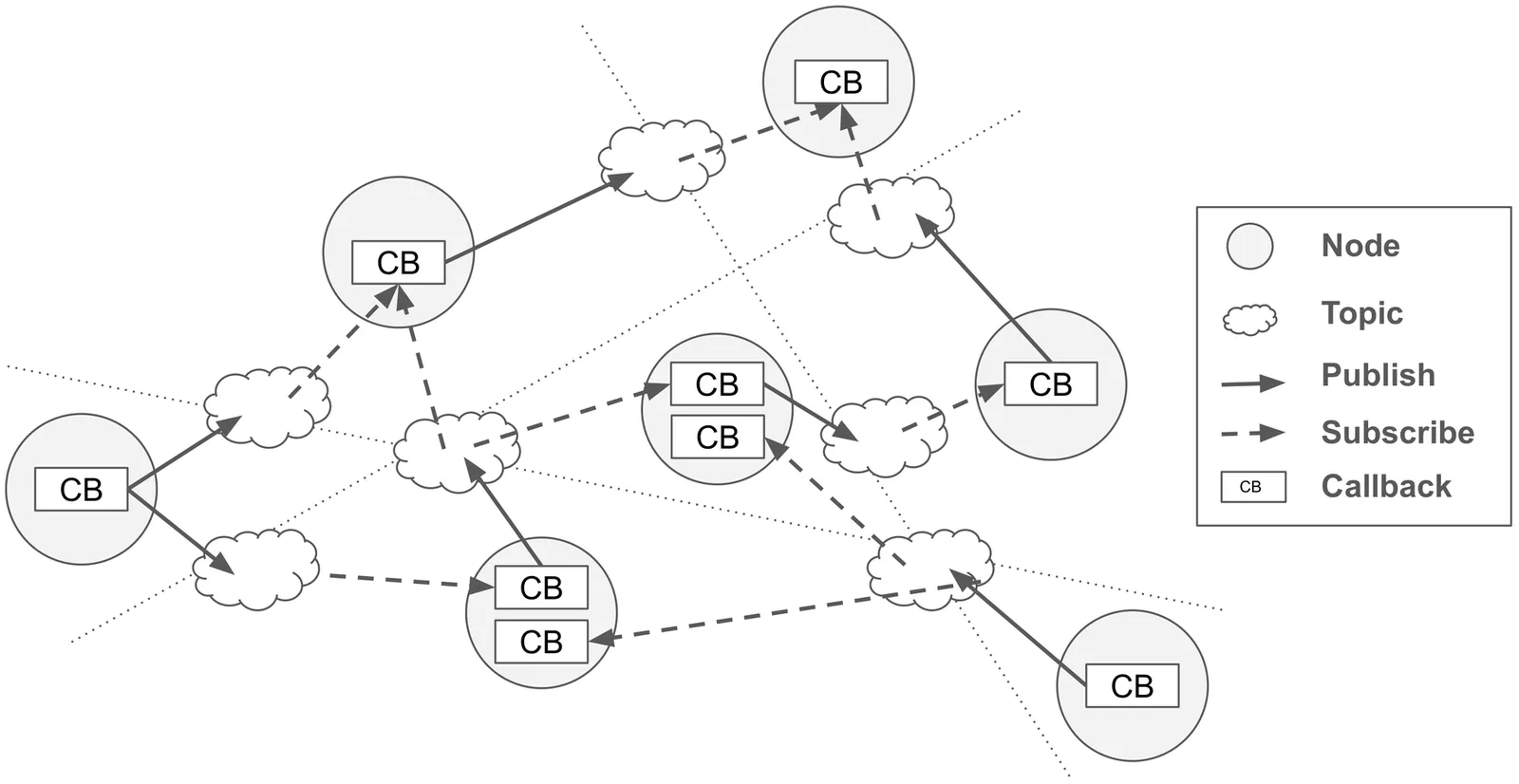
The Directed Acyclic Graph (DAG) task model for real-time scheduling finds its primary practical target in Robot Operating System 2 (ROS 2). However, ROS 2's publish/subscribe API leaves DAG precedence constraints unenforced: a callback may publish mid-execution, and multi-input callbacks let developers choose topic-matching policies. Thus preserving DAG semantics relies on conventions; once violated, the model collapses. We propose the Function-as-Subtask (FasS) API, which expresses each subtask as a function whose arguments/return values are the subtask's incoming/outgoing edges. By minimizing description freedom, DAG semantics is guaranteed at the API rather than by programmer discipline. We implement a DAG-native scheduler using FasS on a Rust-based experimental kernel and evaluate its semantic fidelity, and we outline design guidelines for applying FasS to Linux Linux sched_ext.

The accuracy of large language models (LLMs) improves with increasing model size, but increasing model complexity also poses significant challenges to training stability. Periodic checkpointing is a key mechanism for fault recovery and is widely used in LLM training. However, traditional checkpointing strategies often pause or delay GPU computation during checkpoint saving for checkpoint GPU-CPU transfer, resulting in significant training interruptions and reduced training throughput. To address this issue, we propose GoCkpt, a method to overlap checkpoint saving with multiple training steps and restore the final checkpoint on the CPU. We transfer the checkpoint across multiple steps, each step transfers part of the checkpoint state, and we transfer some of the gradient data used for parameter updates. After the transfer is complete, each partial checkpoint state is updated to a consistent version on the CPU, thus avoiding the checkpoint state inconsistency problem caused by transferring checkpoints across multiple steps. Furthermore, we introduce a transfer optimization strategy to maximize GPU-CPU bandwidth utilization and SSD persistence throughput. This dual optimization overlapping saves across steps and maximizing I/O efficiency significantly reduces invalid training time. Experimental results show that GoCkpt can increase training throughput by up to 38.4% compared to traditional asynchronous checkpoint solutions in the industry. We also find that GoCkpt can reduce training interruption time by 86.7% compared to the state-of-the-art checkpoint transfer methods, which results in a 4.8% throughput improvement.
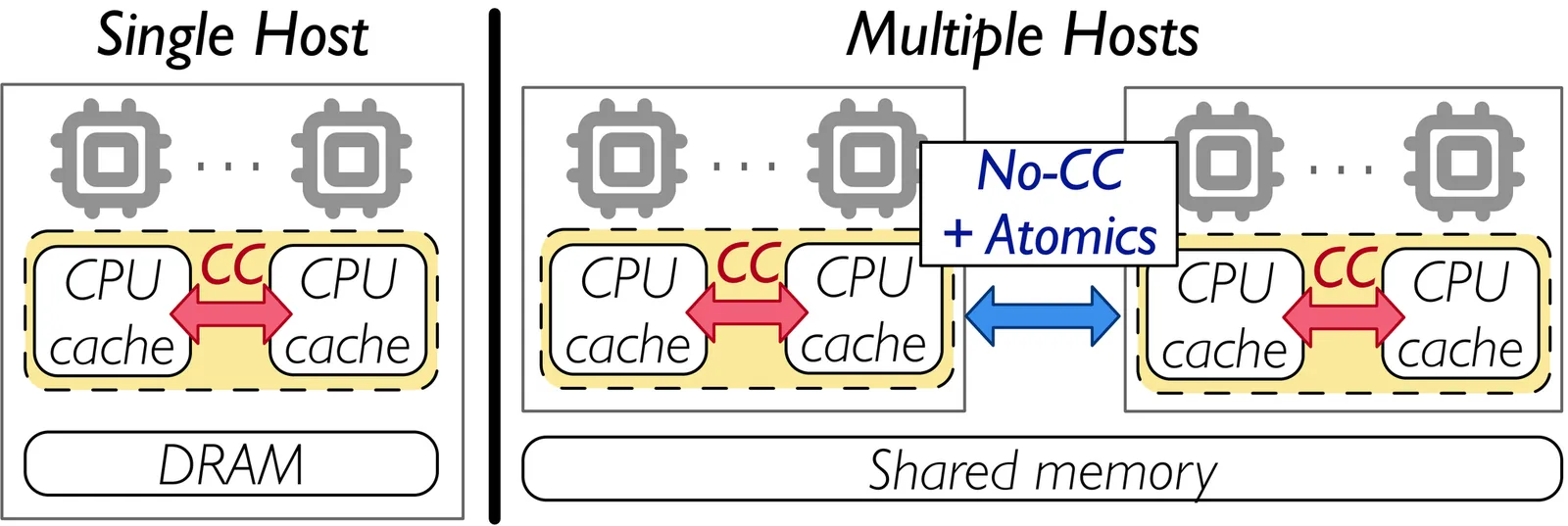
The \emph{Partial Cache-Coherence (PCC)} model maintains hardware cache coherence only within subsets of cores, enabling large-scale memory sharing with emerging memory interconnect technologies like Compute Express Link (CXL). However, PCC's relaxation of global cache coherence compromises the correctness of existing single-machine software. This paper focuses on building consistent and efficient indexes on PCC platforms. We present that existing indexes designed for cache-coherent platforms can be made consistent on PCC platforms following SP guidelines, i.e., we identify \emph{sync-data} and \emph{protected-data} according to the index's concurrency control mechanisms, and synchronize them accordingly. However, conversion with SP guidelines introduces performance overhead. To mitigate the overhead, we identify several unique performance bottlenecks on PCC platforms, and propose P$^3$ guidelines (i.e., using Out-of-\underline{P}lace update, Re\underline{P}licated shared variable, S\underline{P}eculative Reading) to improve the efficiency of converted indexes on PCC platforms. With SP and P$^3$ guidelines, we convert and optimize two indexes (CLevelHash and BwTree) for PCC platforms. Evaluation shows that converted indexes' throughput improves up to 16$\times$ following P$^3$ guidelines, and the optimized indexes outperform their message-passing-based and disaggregated-memory-based counterparts by up to 16$\times$ and 19$\times$.
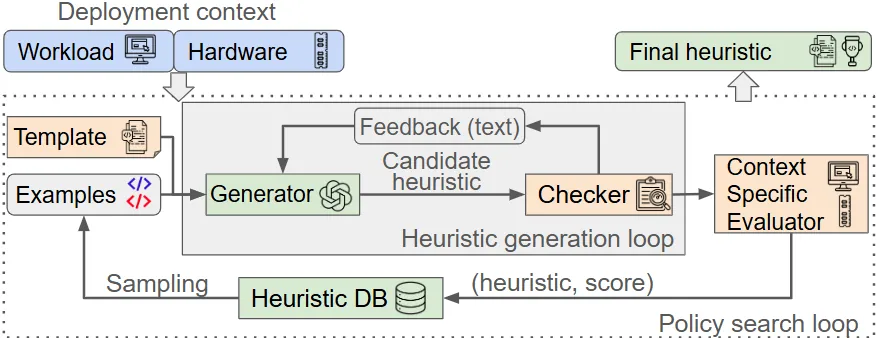
Policy design for various systems controllers has conventionally been a manual process, with domain experts carefully tailoring heuristics for the specific instance in which the policy will be deployed. In this paper, we re-imagine policy design via a novel automated search technique fueled by recent advances in generative models, specifically Large Language Model (LLM)-driven code generation. We outline the design and implementation of PolicySmith, a framework that applies LLMs to synthesize instance-optimal heuristics. We apply PolicySmith to two long-standing systems policies - web caching and congestion control, highlighting the opportunities unraveled by this LLM-driven heuristic search. For caching, PolicySmith discovers heuristics that outperform established baselines on standard open-source traces. For congestion control, we show that PolicySmith can generate safe policies that integrate directly into the Linux kernel.
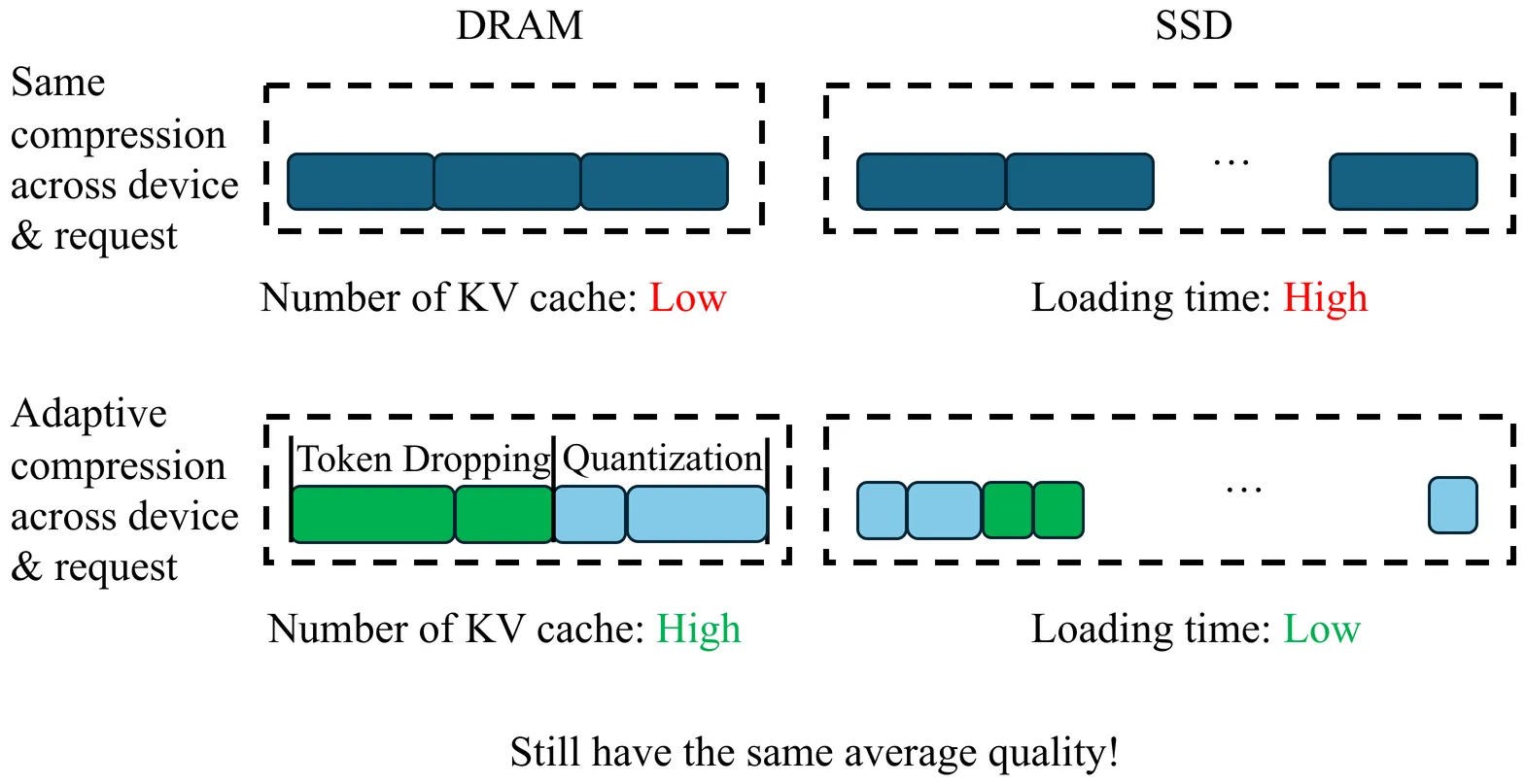
Large language model (LLM) applications often reuse previously processed context, such as chat history and documents, which introduces significant redundant computation. Existing LLM serving systems address such redundant computation by storing the KV caches of processed context and loading the corresponding KV cache when a new request reuses the context. Further, as these LLM applications scale, the total size of KV caches becomes excessively large and requires both DRAM and SSD for full storage. However, prior work that stores KV caches in DRAM and SSD suffers from high loading delays, as most KV cache hits come from SSD, which is slow to load. To increase the KV cache hit rate on DRAM, we identify lossy KV cache compression as a promising approach. We design a lossy compression system that decides the compression algorithm, compression rate and device placement for each KV cache entry to maximise DRAM hits and minimise loading delay without significantly degrading generation quality. Compared to various static compression baselines across three tasks, our system AdaptCache achieves 1.43--2.4 x delay savings at the same quality and 6--55% quality improvements at the same delay.
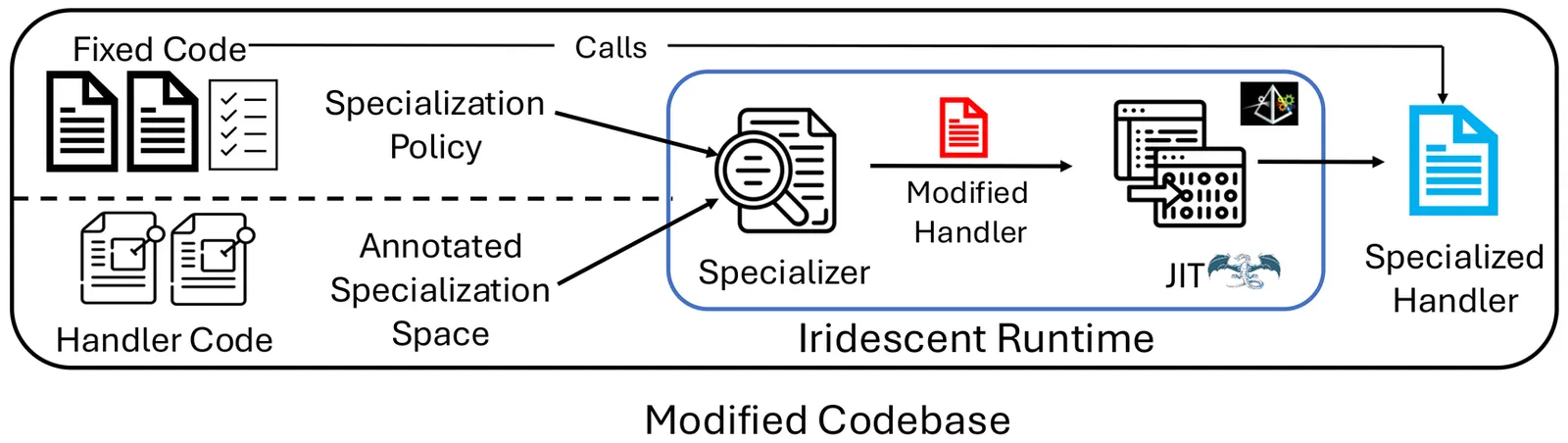
Specializing systems to specifics of the workload they serve and platform they are running on often significantly improves performance. However, specializing systems is difficult in practice because of compounding challenges: i) complexity for the developers to determine and implement optimal specialization; ii) inherent loss of generality of the resulting implementation, and iii) difficulty in identifying and implementing a single optimal specialized configuration for the messy reality of modern systems. To address this, we introduce Iridescent, a framework for automated online system specialization guided by observed overall system performance. Iridescent lets developers specify a space of possible specialization choices, and then at runtime generates and runs different specialization choices through JIT compilation as the system runs. By using overall system performance metrics to guide this search, developers can use Iridescent to find optimal system specializations for the hardware and workload conditions at a given time. We demonstrate feasibility, effectivity, and ease of use.

Modern software infrastructure increasingly relies on LLM agents for development and maintenance, such as Claude Code and Gemini-cli. However, these AI agents differ fundamentally from traditional deterministic software, posing a significant challenge to conventional monitoring and debugging. This creates a critical semantic gap: existing tools observe either an agent's high-level intent (via LLM prompts) or its low-level actions (e.g., system calls), but cannot correlate these two views. This blindness makes it difficult to distinguish between benign operations, malicious attacks, and costly failures. We introduce AgentSight, an AgentOps observability framework that bridges this semantic gap using a hybrid approach. Our approach, boundary tracing, monitors agents from outside their application code at stable system interfaces using eBPF. AgentSight intercepts TLS-encrypted LLM traffic to extract semantic intent, monitors kernel events to observe system-wide effects, and causally correlates these two streams across process boundaries using a real-time engine and secondary LLM analysis. This instrumentation-free technique is framework-agnostic, resilient to rapid API changes, and incurs less than 3% performance overhead. Our evaluation shows AgentSight detects prompt injection attacks, identifies resource-wasting reasoning loops, and reveals hidden coordination bottlenecks in multi-agent systems. AgentSight is released as an open-source project at https://github.com/agent-sight/agentsight.
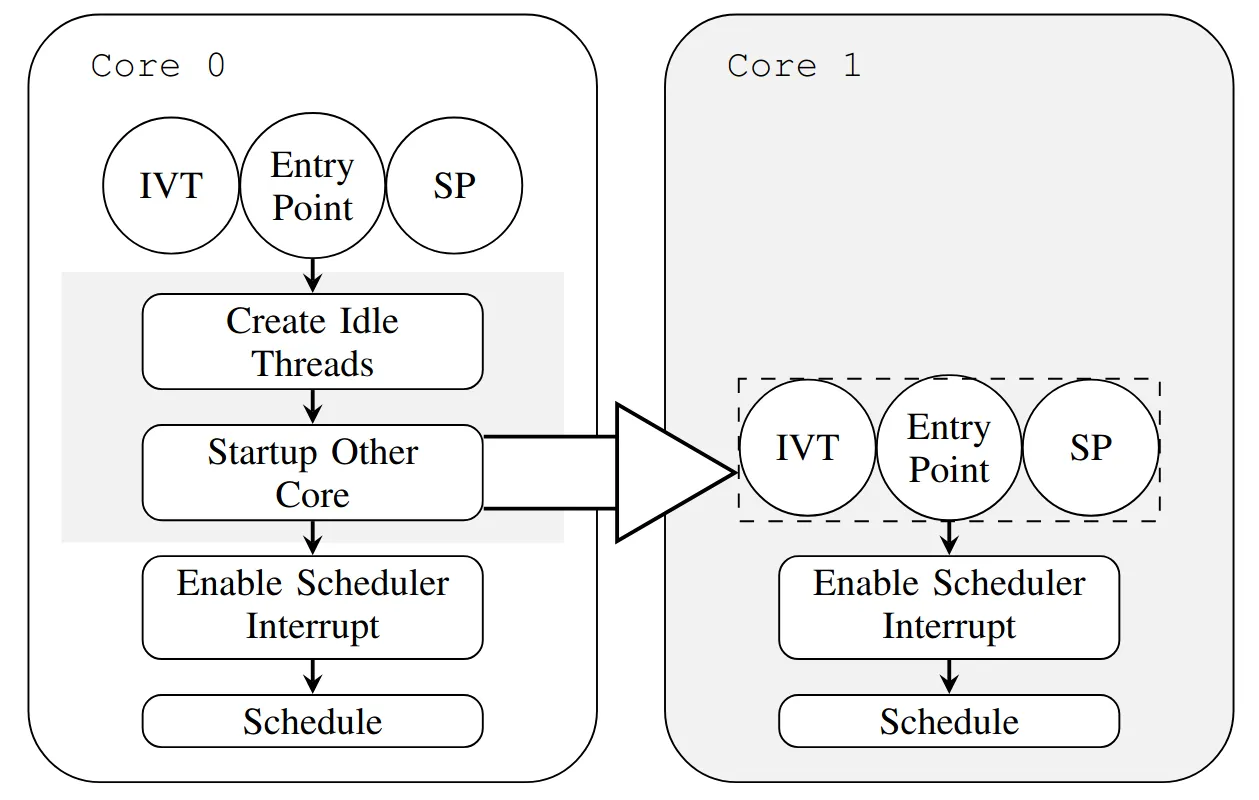
Large swaths of low-level system software building blocks originally implemented in C/C++ are currently being swapped for equivalent rewrites in Rust, a relatively more secure and dependable programming language. So far, however, no embedded OS in Rust supports multicore preemptive scheduling on microcontrollers. In this paper, we thus fill this gap with a new operating system: Ariel OS. We describe its design, we provide the source code of its implementation, and we perform micro-benchmarks on the main 32-bit microcontroller architectures: ARM Cortex-M, RISC-V and Espressif Xtensa. We show how our scheduler takes advantage of several cores, while incurring only small overhead on single-core hardware. As such, Ariel OS provides a convenient embedded software platform for small networked devices, for both research and industry practitioners.
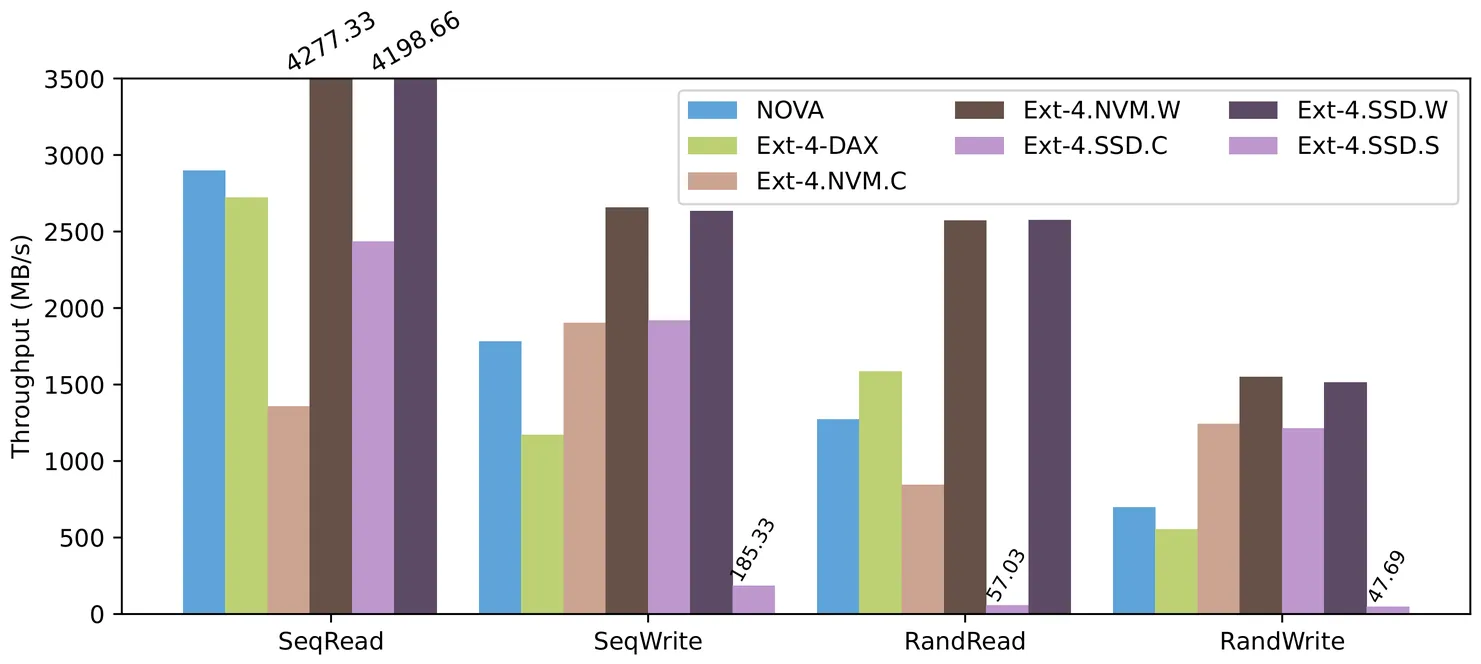
We propose NVLog, an NVM-based write-ahead log for disk file systems, designed to transparently harness the high performance of NVM within the legacy storage stack. NVLog provides on-demand byte-granularity sync absorption, reserving the fast DRAM path for asynchronous operations, meanwhile occupying NVM space only temporarily. To accomplish this, we designed a highly efficient log structure, developed mechanisms to address heterogeneous crash consistency, optimized for small writes, and implemented robust crash recovery and garbage collection methods. Compared to previous solutions, NVLog is lighter, more stable, and delivers higher performance, all while leveraging the mature kernel software stack and avoiding data migration overhead. Experimental results demonstrate that NVLog can accelerate disk file systems by up to 15.09x and outperform NOVA and SPFS in various scenarios by up to 3.72x and 324.11x, respectively.
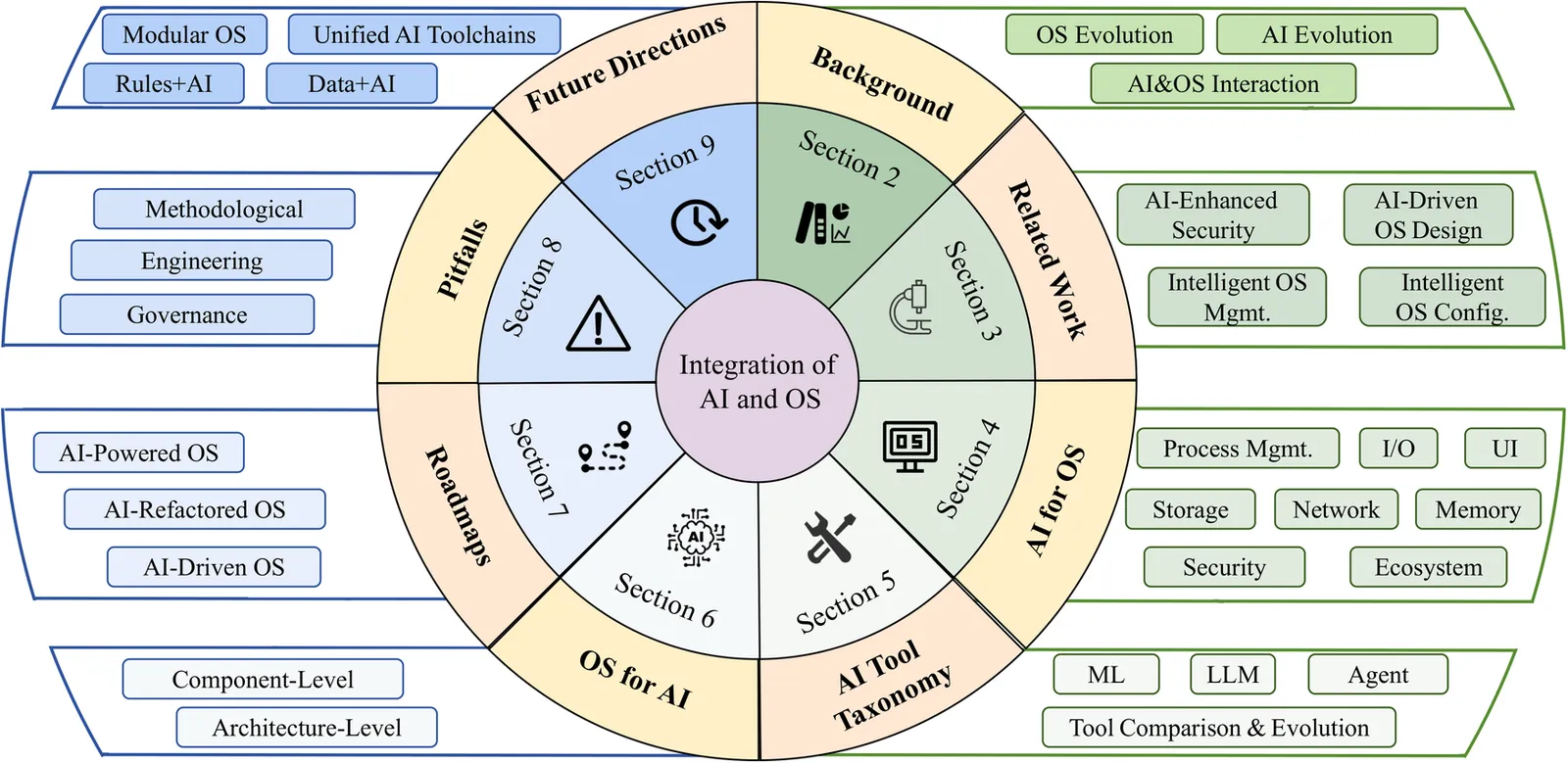
Heterogeneous hardware and dynamic workloads worsen long-standing OS bottlenecks in scalability, adaptability, and manageability. At the same time, advances in machine learning (ML), large language models (LLMs), and agent-based methods enable automation and self-optimization, but current efforts lack a unifying view. This survey reviews techniques, architectures, applications, challenges, and future directions at the AI-OS intersection. We chart the shift from heuristic- and rule-based designs to AI-enhanced systems, outlining the strengths of ML, LLMs, and agents across the OS stack. We summarize progress in AI for OS (core components and the wider ecosystem) and in OS for AI (component- and architecture-level support for short- and long-context inference, distributed training, and edge inference). For practice, we consolidate evaluation dimensions, methodological pipelines, and patterns that balance real-time constraints with predictive accuracy. We identify key challenges, such as complexity, overhead, model drift, limited explainability, and privacy and safety risks, and recommend modular, AI-ready kernel interfaces; unified toolchains and benchmarks; hybrid rules-plus-AI decisions with guardrails; and verifiable in-kernel inference. Finally, we propose a three-stage roadmap including AI-powered, AI-refactored, and AI-driven OSs, to bridge prototypes and production and to enable scalable, reliable AI deployment.
LLM-based intelligent agents face significant deployment challenges, particularly related to resource management. Allowing unrestricted access to LLM or tool resources can lead to inefficient or even potentially harmful resource allocation and utilization for agents. Furthermore, the absence of proper scheduling and resource management mechanisms in current agent designs hinders concurrent processing and limits overall system efficiency. To address these challenges, this paper proposes the architecture of AIOS (LLM-based AI Agent Operating System) under the context of managing LLM-based agents. It introduces a novel architecture for serving LLM-based agents by isolating resources and LLM-specific services from agent applications into an AIOS kernel. This AIOS kernel provides fundamental services (e.g., scheduling, context management, memory management, storage management, access control) for runtime agents. To enhance usability, AIOS also includes an AIOS SDK, a comprehensive suite of APIs designed for utilizing functionalities provided by the AIOS kernel. Experimental results demonstrate that using AIOS can achieve up to 2.1x faster execution for serving agents built by various agent frameworks. The source code is available at https://github.com/agiresearch/AIOS.
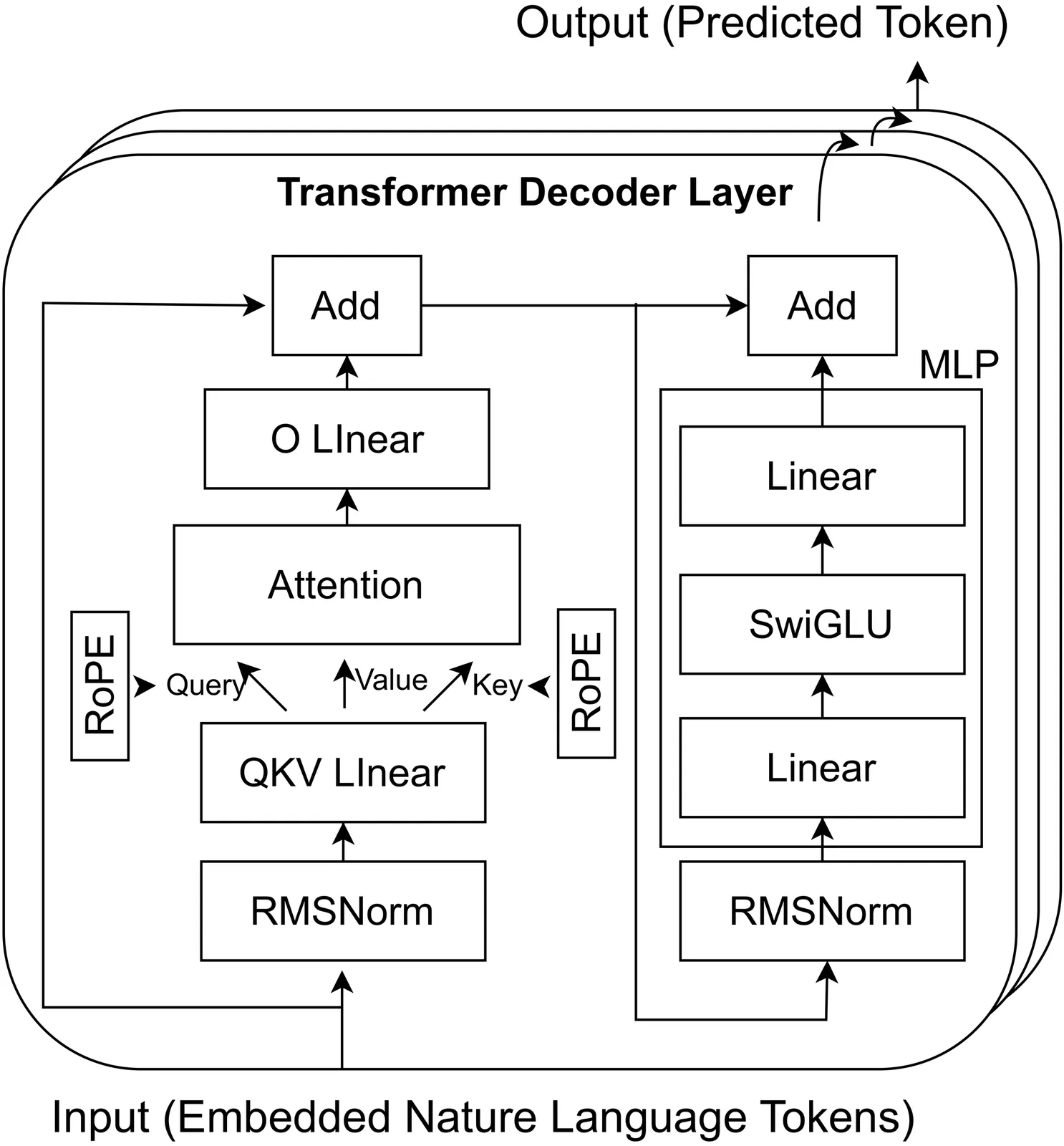
Being more powerful and intrusive into user-device interactions, LLMs are eager for on-device execution to better preserve user privacy. In this work, we propose a new paradigm of mobile AI: LLM as a system service on mobile devices (LLMaaS). Unlike traditional DNNs that execute in a stateless manner, such a system service is stateful: LLMs execution often needs to maintain persistent states (mainly KV cache) across multiple invocations. To minimize the LLM context switching overhead under tight device memory budget, this work presents LLMS, which decouples the memory management of app and LLM contexts with a key idea of fine-grained, chunk-wise, globally-optimized KV cache compression and swapping. By fully leveraging KV cache's unique characteristics, it proposes three novel techniques: (1) Tolerance-Aware Compression: it compresses chunks based on their measured accuracy tolerance to compression. (2) IO-Recompute Pipelined Loading: it introduces recompute to swapping-in for acceleration. (3) Chunk Lifecycle Management: it optimizes the memory activities of chunks with an ahead-of-time swapping-out and an LCTRU (Least Compression-Tolerable and Recently-Used) queue based eviction. In evaluations conducted on well-established traces and various edge devices, \sys reduces context switching latency by up to 2 orders of magnitude when compared to competitive baseline solutions.

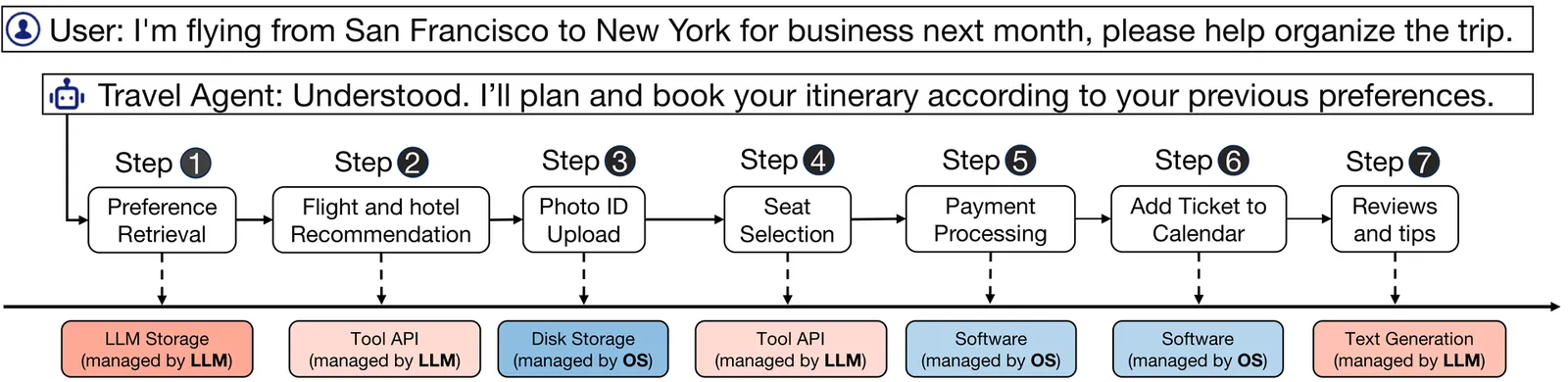
This paper envisions a revolutionary AIOS-Agent ecosystem, where Large Language Model (LLM) serves as the (Artificial) Intelligent Operating System (IOS, or AIOS)--an operating system "with soul". Upon this foundation, a diverse range of LLM-based AI Agent Applications (Agents, or AAPs) are developed, enriching the AIOS-Agent ecosystem and signaling a paradigm shift from the traditional OS-APP ecosystem. We envision that LLM's impact will not be limited to the AI application level, instead, it will in turn revolutionize the design and implementation of computer system, architecture, software, and programming language, featured by several main concepts: LLM as OS (system-level), Agents as Applications (application-level), Natural Language as Programming Interface (user-level), and Tools as Devices/Libraries (hardware/middleware-level). We begin by introducing the architecture of traditional OS. Then we formalize a conceptual framework for AIOS through "LLM as OS (LLMOS)", drawing analogies between AIOS and traditional OS: LLM is likened to OS kernel, context window to memory, external storage to file system, hardware tools to peripheral devices, software tools to programming libraries, and user prompts to user commands. Subsequently, we introduce the new AIOS-Agent Ecosystem, where users can easily program Agent Applications (AAPs) using natural language, democratizing the development of software, which is different from the traditional OS-APP ecosystem. Following this, we explore the diverse scope of Agent Applications. We delve into both single-agent and multi-agent systems, as well as human-agent interaction. Lastly, drawing on the insights from traditional OS-APP ecosystem, we propose a roadmap for the evolution of the AIOS-Agent ecosystem. This roadmap is designed to guide the future research and development, suggesting systematic progresses of AIOS and its Agent applications.
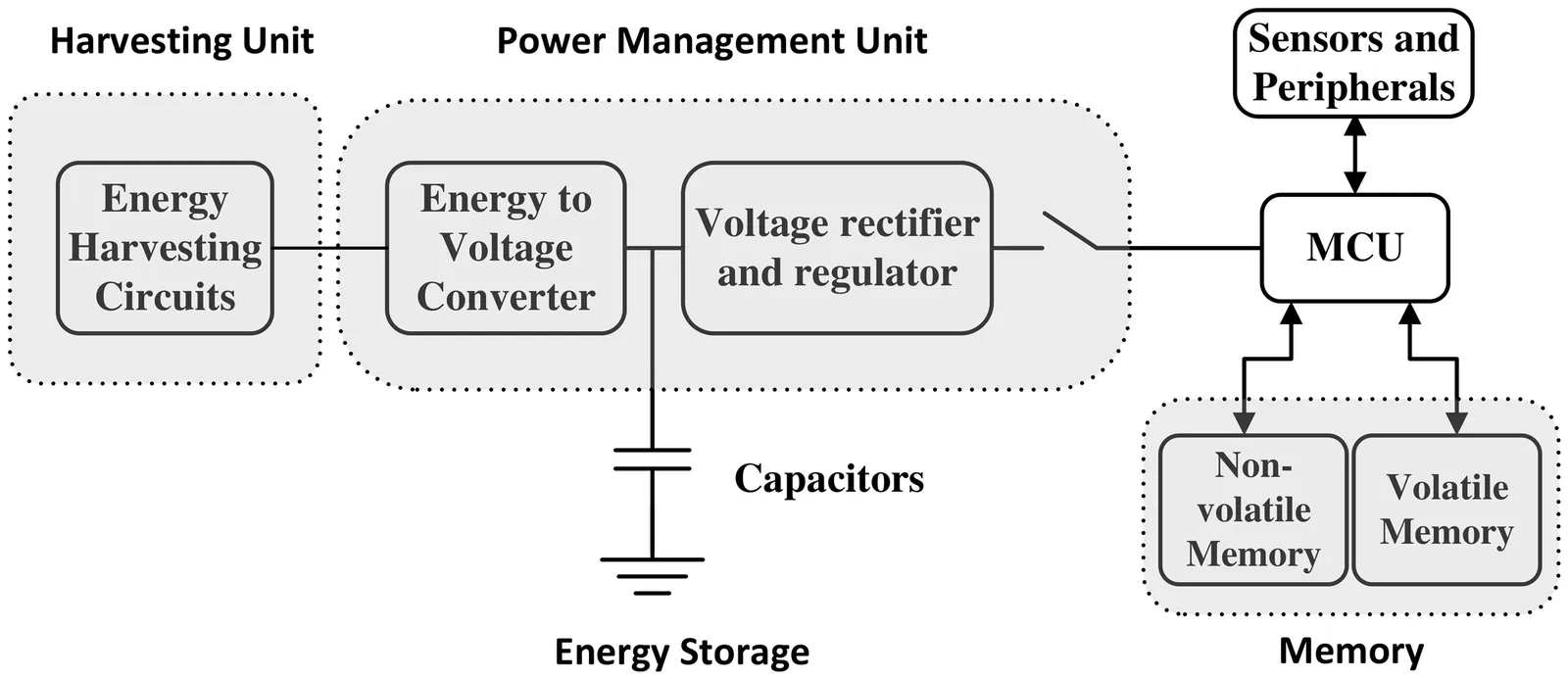
This paper presents CARTOS, a charging-aware real-time operating system designed to enhance the functionality of intermittently-powered batteryless devices (IPDs) for various Internet of Things (IoT) applications. While IPDs offer significant advantages such as extended lifespan and operability in extreme environments, they pose unique challenges, including the need to ensure forward progress of program execution amidst variable energy availability and maintaining reliable real-time time behavior during power disruptions. To address these challenges, CARTOS introduces a mixed-preemption scheduling model that classifies tasks into computational and peripheral tasks, and ensures their efficient and timely execution by adopting just-in-time checkpointing for divisible computation tasks and uninterrupted execution for indivisible peripheral tasks. CARTOS also supports processing chains of tasks with precedence constraints and adapts its scheduling in response to environmental changes to offer continuous execution under diverse conditions. CARTOS is implemented with new APIs and components added to FreeRTOS but is designed for portability to other embedded RTOSs. Through real hardware experiments and simulations, CARTOS exhibits superior performance over state-of-the-art methods, demonstrating that it can serve as a practical platform for developing resilient, real-time sensing applications on IPDs.