Trending in Natural Language Processing
Rethinking Reasoning-Intensive Retrieval: Evaluating and Advancing Retrievers in Agentic Search Systems
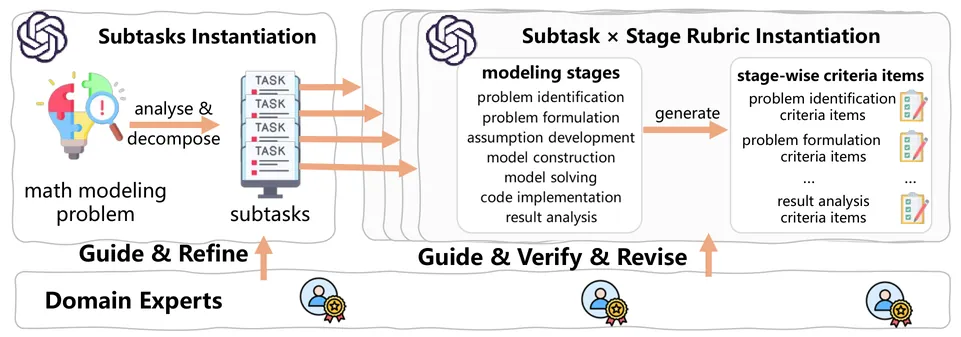
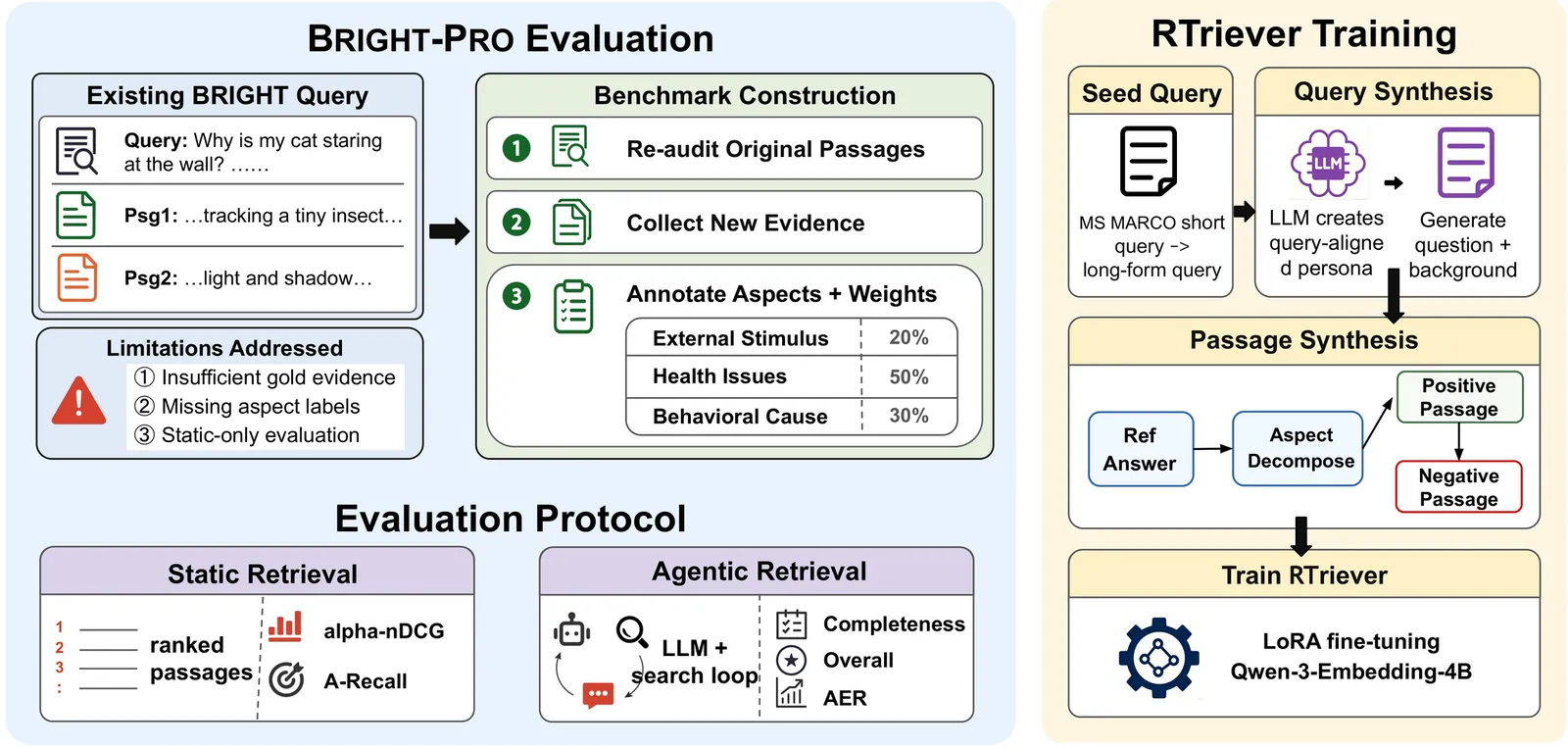
Reasoning-intensive retrieval aims to surface evidence that supports downstream reasoning rather than merely matching topical similarity. This capability is increasingly important for agentic search systems, where retrievers must provide complementary evidence across iterative search and synthesis. However, existing work remains limited on both evaluation and training: benchmarks such as BRIGHT provide narrow gold sets and evaluate retrievers in isolation, while synthetic training corpora often optimize single-passage relevance rather than evidence portfolio construction. We introduce BRIGHT-Pro, an expert-annotated benchmark that expands each query with multi-aspect gold evidence and evaluates retrievers under both static and agentic search protocols. We further construct RTriever-Synth, an aspect-decomposed synthetic corpus that generates complementary positives and positive-conditioned hard negatives, and use it to LoRA fine-tune RTriever-4B from Qwen3-Embedding-4B. Experiments across lexical, general-purpose, and reasoning-intensive retrievers show that aspect-aware and agentic evaluation expose behaviors hidden by standard metrics, while RTriever-4B substantially improves over its base model.
2605.04018
May 2026Computation and Language

Synthetic Data for any Differentiable Target
What are the limits of controlling language models via synthetic training data? We develop a reinforcement learning (RL) primitive, the Dataset Policy Gradient (DPG), which can precisely optimize synthetic data generators to produce a dataset of targeted examples. When used for supervised fine-tuning (SFT) of a target model, these examples cause the target model to do well on a differentiable metric of our choice. Our approach achieves this by taking exact data attribution via higher-order gradients and using those scores as policy gradient rewards. We prove that this procedure closely approximates the true, intractable gradient for the synthetic data generator. To illustrate the potential of DPG, we show that, using only SFT on generated examples, we can cause the target model's LM head weights to (1) embed a QR code, (2) embed the pattern $\texttt{67}$, and (3) have lower $\ell^2$ norm. We additionally show that we can cause the generator to (4) rephrase inputs in a new language and (5) produce a specific UUID, even though neither of these objectives is conveyed in the generator's input prompts. These findings suggest that DPG is a powerful and flexible technique for shaping model properties using only synthetic training examples.
2604.08423
Apr 2026Computation and Language
What do Language Models Learn and When? The Implicit Curriculum Hypothesis
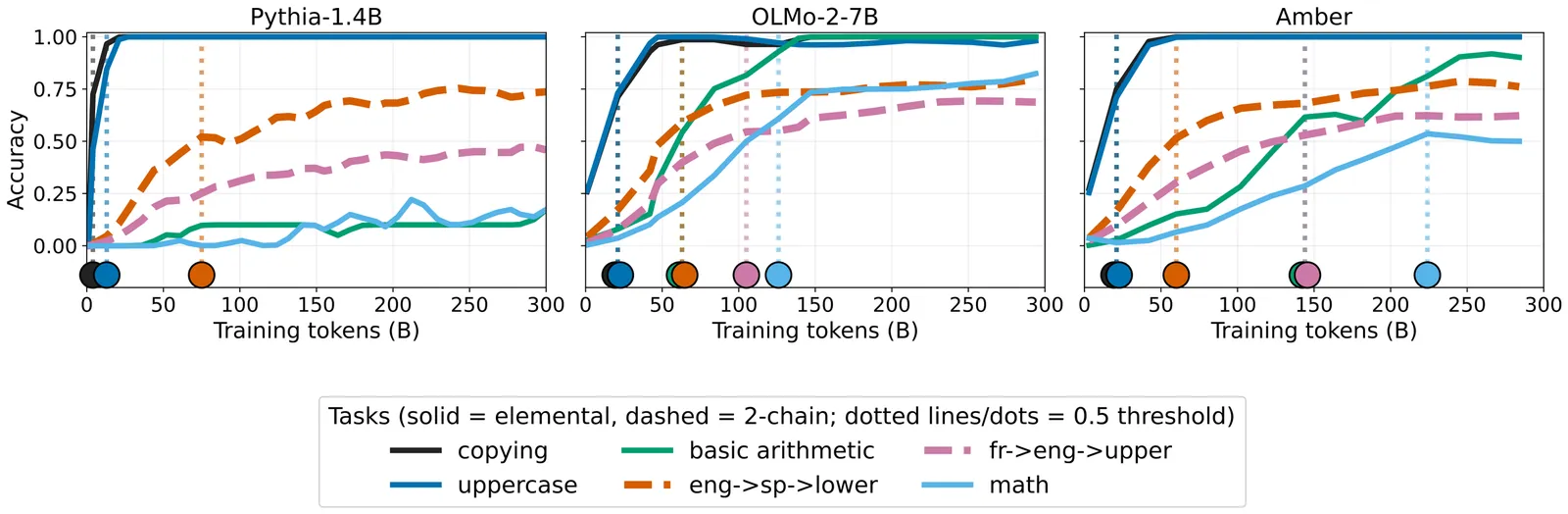
Large language models (LLMs) can perform remarkably complex tasks, yet the fine-grained details of how these capabilities emerge during pretraining remain poorly understood. Scaling laws on validation loss tell us how much a model improves with additional compute, but not what skills it acquires in which order. To remedy this, we propose the Implicit Curriculum Hypothesis: pretraining follows a compositional and predictable curriculum across models and data mixtures. We test this by designing a suite of simple, composable tasks spanning retrieval, morphological transformations, coreference, logical reasoning, and mathematics. Using these tasks, we track emergence points across four model families spanning sizes from 410M-13B parameters. We find that emergence orderings of when models reach fixed accuracy thresholds are strikingly consistent ($ρ= .81$ across 45 model pairs), and that composite tasks most often emerge after their component tasks. Furthermore, we find that this structure is encoded in model representations: tasks with similar function vector representations also tend to follow similar trajectories in training. By using the space of representations derived from our task set, we can effectively predict the training trajectories of simple held-out compositional tasks throughout the course of pretraining ($R^2 = .68$-$.84$ across models) without previously evaluating them. Together, these results suggest that pretraining is more structured than loss curves reveal: skills emerge in a compositional order that is consistent across models and readable from their internals.
2604.08510
Apr 2026Computation and Language
Towards Real-world Human Behavior Simulation: Benchmarking Large Language Models on Long-horizon, Cross-scenario, Heterogeneous Behavior Traces
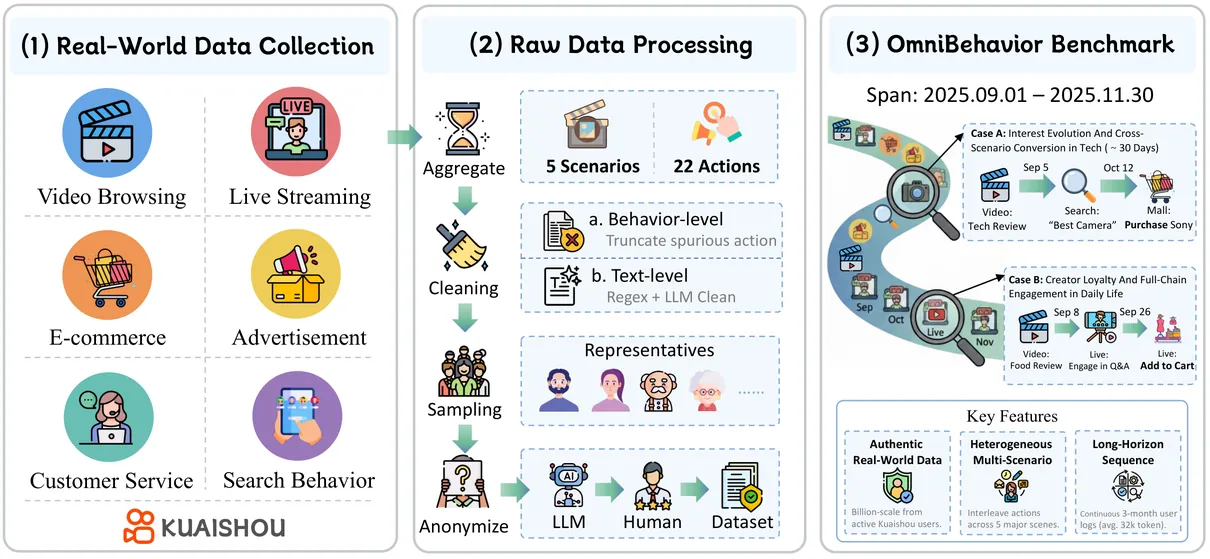
The emergence of Large Language Models (LLMs) has illuminated the potential for a general-purpose user simulator. However, existing benchmarks remain constrained to isolated scenarios, narrow action spaces, or synthetic data, failing to capture the holistic nature of authentic human behavior. To bridge this gap, we introduce OmniBehavior, the first user simulation benchmark constructed entirely from real-world data, integrating long-horizon, cross-scenario, and heterogeneous behavioral patterns into a unified framework. Based on this benchmark, we first provide empirical evidence that previous datasets with isolated scenarios suffer from tunnel vision, whereas real-world decision-making relies on long-term, cross-scenario causal chains. Extensive evaluations of state-of-the-art LLMs reveal that current models struggle to accurately simulate these complex behaviors, with performance plateauing even as context windows expand. Crucially, a systematic comparison between simulated and authentic behaviors uncovers a fundamental structural bias: LLMs tend to converge toward a positive average person, exhibiting hyper-activity, persona homogenization, and a Utopian bias. This results in the loss of individual differences and long-tail behaviors, highlighting critical directions for future high-fidelity simulation research.
2604.08362
Apr 2026Computation and Language
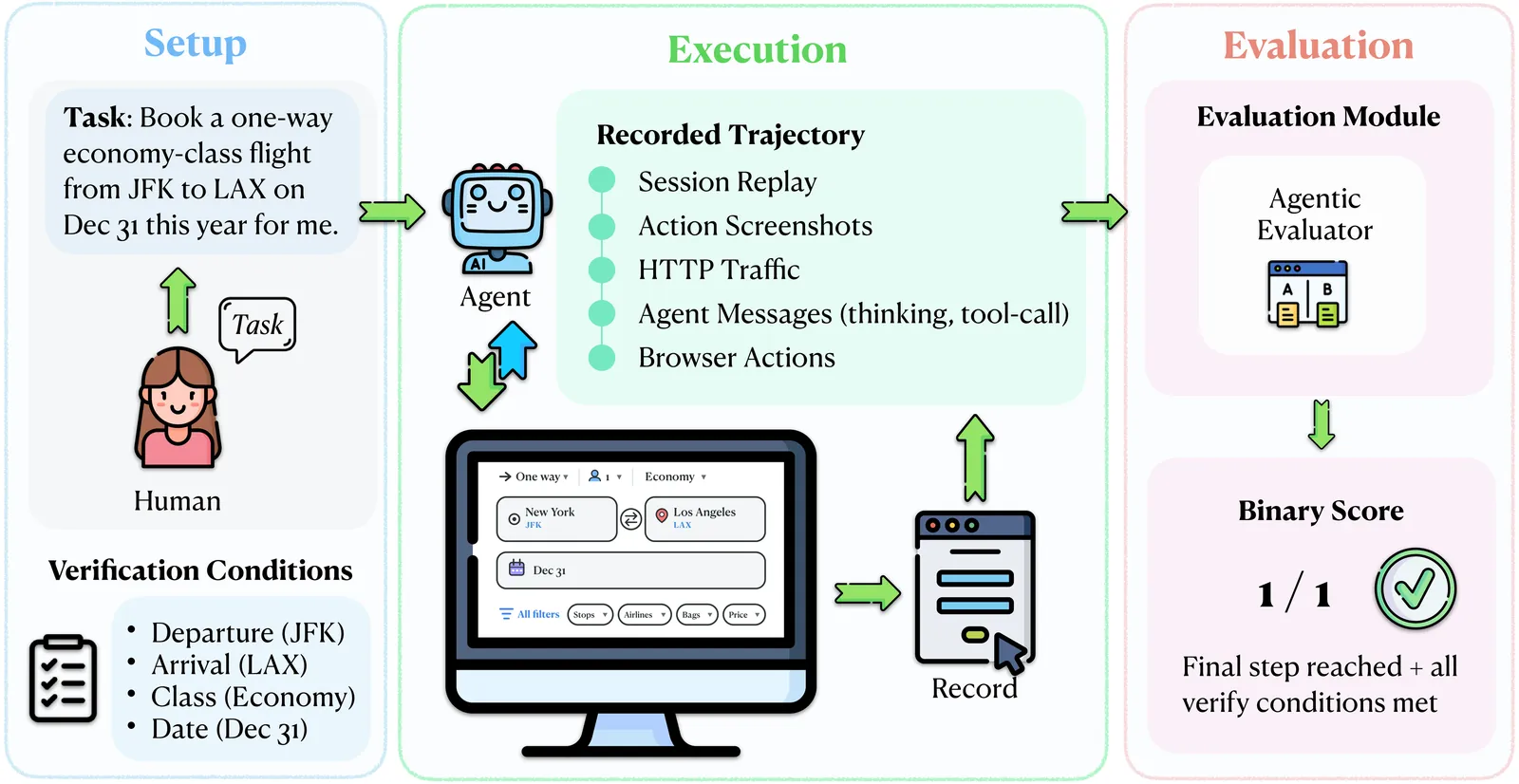
ClawBench: Can AI Agents Complete Everyday Online Tasks?
AI agents may be able to automate your inbox, but can they automate other routine aspects of your life? Everyday online tasks offer a realistic yet unsolved testbed for evaluating the next generation of AI agents. To this end, we introduce ClawBench, an evaluation framework of 153 simple tasks that people need to accomplish regularly in their lives and work, spanning 144 live platforms across 15 categories, from completing purchases and booking appointments to submitting job applications. These tasks require demanding capabilities beyond existing benchmarks, such as obtaining relevant information from user-provided documents, navigating multi-step workflows across diverse platforms, and write-heavy operations like filling in many detailed forms correctly. Unlike existing benchmarks that evaluate agents in offline sandboxes with static pages, ClawBench operates on production websites, preserving the full complexity, dynamic nature, and challenges of real-world web interaction. A lightweight interception layer captures and blocks only the final submission request, ensuring safe evaluation without real-world side effects. Our evaluations of 7 frontier models show that both proprietary and open-source models can complete only a small portion of these tasks. For example, Claude Sonnet 4.6 achieves only 33.3%. Progress on ClawBench brings us closer to AI agents that can function as reliable general-purpose assistants.
2604.08523
Apr 2026Computation and Language
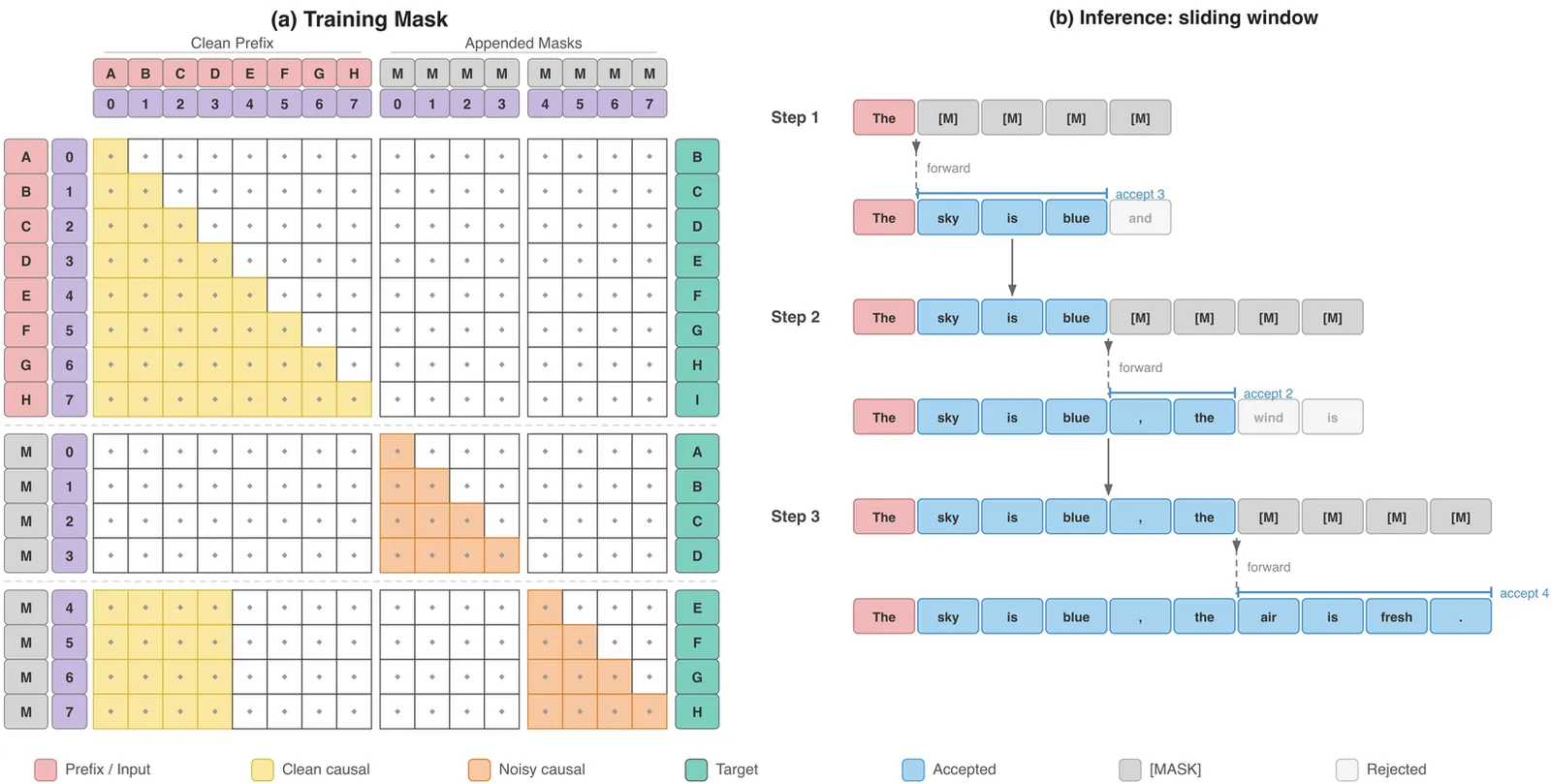
MARS: Enabling Autoregressive Models Multi-Token Generation
Autoregressive (AR) language models generate text one token at a time, even when consecutive tokens are highly predictable given earlier context. We introduce MARS (Mask AutoRegreSsion), a lightweight fine-tuning method that teaches an instruction-tuned AR model to predict multiple tokens per forward pass. MARS adds no architectural modifications, no extra parameters, and produces a single model that can still be called exactly like the original AR model with no performance degradation. Unlike speculative decoding, which maintains a separate draft model alongside the target, or multi-head approaches such as Medusa, which attach additional prediction heads, MARS requires only continued training on existing instruction data. When generating one token per forward pass, MARS matches or exceeds the AR baseline on six standard benchmarks. When allowed to accept multiple tokens per step, it maintains baseline-level accuracy while achieving 1.5-1.7x throughput. We further develop a block-level KV caching strategy for batch inference, achieving up to 1.71x wall-clock speedup over AR with KV cache on Qwen2.5-7B. Finally, MARS supports real-time speed adjustment via confidence thresholding: under high request load, the serving system can increase throughput on the fly without swapping models or restarting, providing a practical latency-quality knob for deployment.
2604.07023
Apr 2026Computation and Language
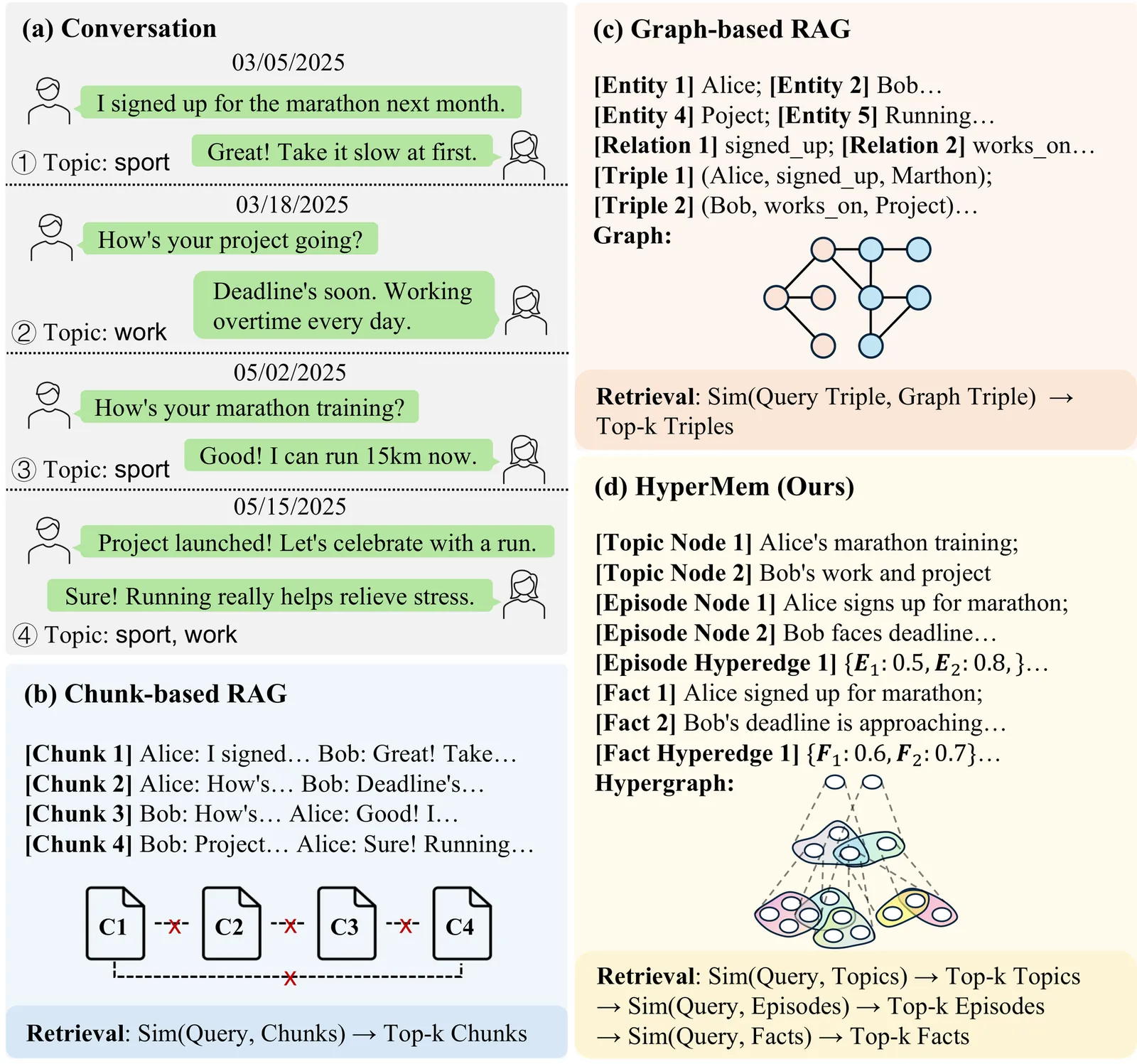
HyperMem: Hypergraph Memory for Long-Term Conversations
Long-term memory is essential for conversational agents to maintain coherence, track persistent tasks, and provide personalized interactions across extended dialogues. However, existing approaches as Retrieval-Augmented Generation (RAG) and graph-based memory mostly rely on pairwise relations, which can hardly capture high-order associations, i.e., joint dependencies among multiple elements, causing fragmented retrieval. To this end, we propose HyperMem, a hypergraph-based hierarchical memory architecture that explicitly models such associations using hyperedges. Particularly, HyperMem structures memory into three levels: topics, episodes, and facts, and groups related episodes and their facts via hyperedges, unifying scattered content into coherent units. Leveraging this structure, we design a hybrid lexical-semantic index and a coarse-to-fine retrieval strategy, supporting accurate and efficient retrieval of high-order associations. Experiments on the LoCoMo benchmark show that HyperMem achieves state-of-the-art performance with 92.73% LLM-as-a-judge accuracy, demonstrating the effectiveness of HyperMem for long-term conversations.
2604.08256
Apr 2026Computation and Language
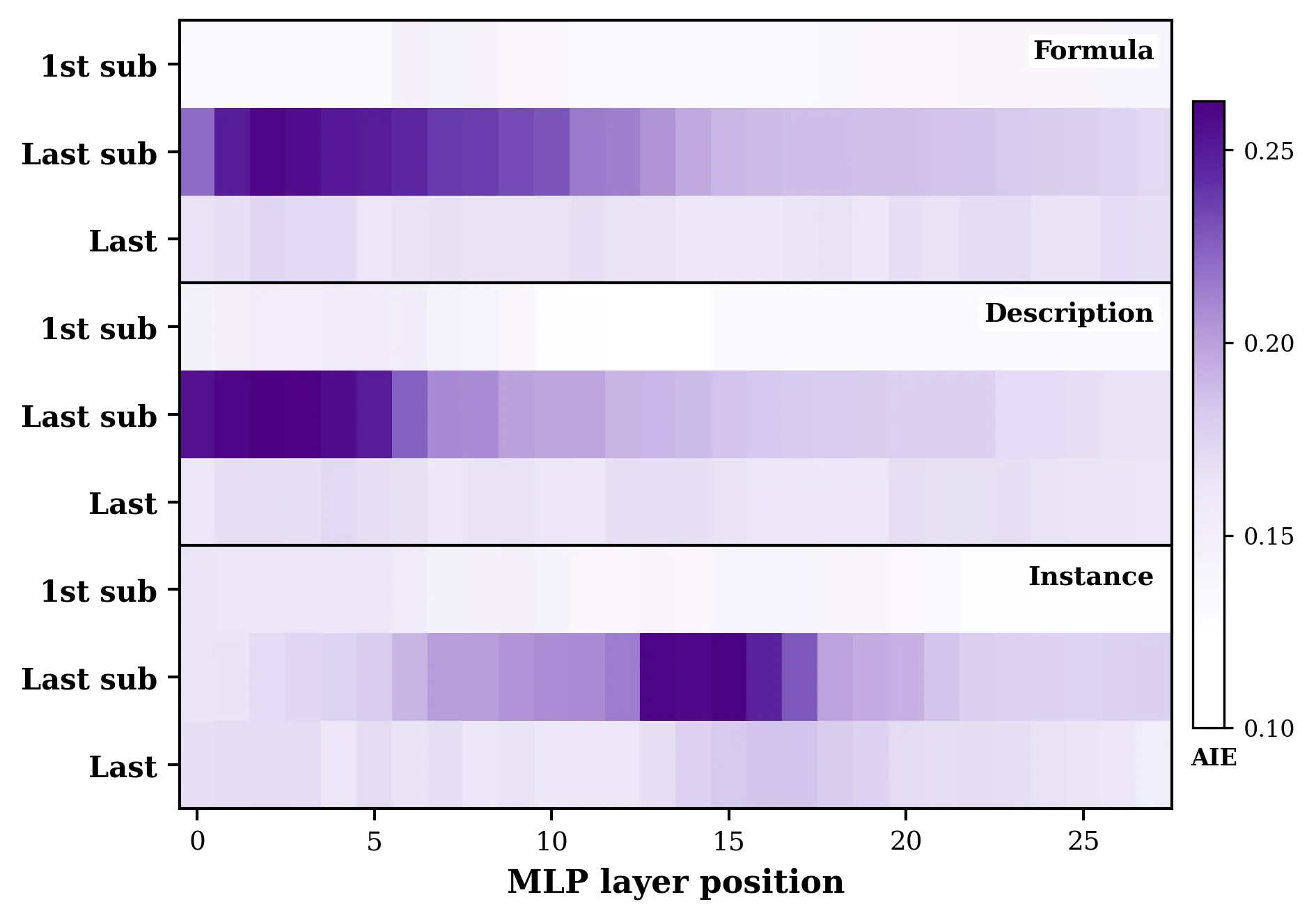
Distributed Multi-Layer Editing for Rule-Level Knowledge in Large Language Models
Large language models store not only isolated facts but also rules that support reasoning across symbolic expressions, natural language explanations, and concrete instances. Yet most model editing methods are built for fact-level knowledge, assuming that a target edit can be achieved through a localized intervention. This assumption does not hold for rule-level knowledge, where a single rule must remain consistent across multiple interdependent forms. We investigate this problem through a mechanistic study of rule-level knowledge editing. To support this study, we extend the RuleEdit benchmark from 80 to 200 manually verified rules spanning mathematics and physics. Fine-grained causal tracing reveals a form-specific organization of rule knowledge in transformer layers: formulas and descriptions are concentrated in earlier layers, while instances are more associated with middle layers. These results suggest that rule knowledge is not uniformly localized, and therefore cannot be reliably edited by a single-layer or contiguous-block intervention. Based on this insight, we propose Distributed Multi-Layer Editing (DMLE), which applies a shared early-layer update to formulas and descriptions and a separate middle-layer update to instances. While remaining competitive on standard editing metrics, DMLE achieves substantially stronger rule-level editing performance. On average, it improves instance portability and rule understanding by 13.91 and 50.19 percentage points, respectively, over the strongest baseline across GPT-J-6B, Qwen2.5-7B, Qwen2-7B, and LLaMA-3-8B. The code is available at https://github.com/Pepper66/DMLE.
2604.08284
Apr 2026Computation and Language
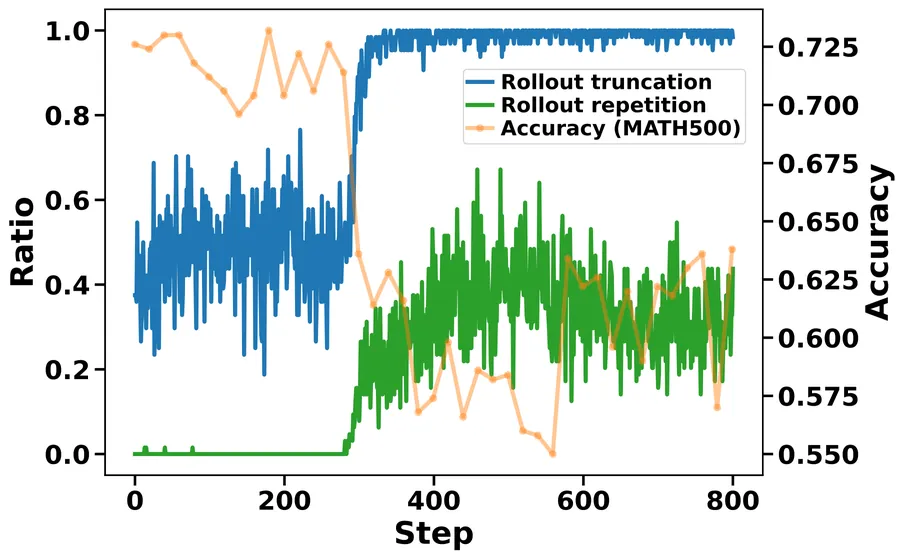
Demystifying OPD: Length Inflation and Stabilization Strategies for Large Language Models
On-policy distillation (OPD) trains student models under their own induced distribution while leveraging supervision from stronger teachers. We identify a failure mode of OPD: as training progresses, on-policy rollouts can undergo abrupt length inflation, causing truncated trajectories to dominate the training data. This truncation collapse coincides with abrupt repetition saturation and induces biased gradient signals, leading to severe training instability and sharp degradation in validation performance. We attribute this problem to the interaction between student-induced data collection and the distillation objective, which implicitly favors long and repetitive rollouts. To address this issue, we propose StableOPD, a stabilized OPD framework that combines a reference-based divergence constraint with rollout mixture distillation. These together mitigate repetition-induced length inflation and further stabilize OPD training. Across multiple math reasoning datasets, our approach prevents truncation collapse, stabilizes training dynamics, and improves performance by 7.2% on average.
2604.08527
Apr 2026Computation and Language
PRBench: End-to-end Paper Reproduction in Physics Research
AI agents powered by large language models exhibit strong reasoning and problem-solving capabilities, enabling them to assist scientific research tasks such as formula derivation and code generation. However, whether these agents can reliably perform end-to-end reproduction from real scientific papers remains an open question. We introduce PRBench, a benchmark of 30 expert-curated tasks spanning 11 subfields of physics. Each task requires an agent to comprehend the methodology of a published paper, implement the corresponding algorithms from scratch, and produce quantitative results matching the original publication. Agents are provided only with the task instruction and paper content, and operate in a sandboxed execution environment. All tasks are contributed by domain experts from over 20 research groups at the School of Physics, Peking University, each grounded in a real published paper and validated through end-to-end reproduction with verified ground-truth results and detailed scoring rubrics. Using an agentified assessment pipeline, we evaluate a set of coding agents on PRBench and analyze their capabilities across key dimensions of scientific reasoning and execution. The best-performing agent, OpenAI Codex powered by GPT-5.3-Codex, achieves a mean overall score of 34%. All agents exhibit a zero end-to-end callback success rate, with particularly poor performance in data accuracy and code correctness. We further identify systematic failure modes, including errors in formula implementation, inability to debug numerical simulations, and fabrication of output data. Overall, PRBench provides a rigorous benchmark for evaluating progress toward autonomous scientific research.
2603.27646
Mar 2026Computation and Language
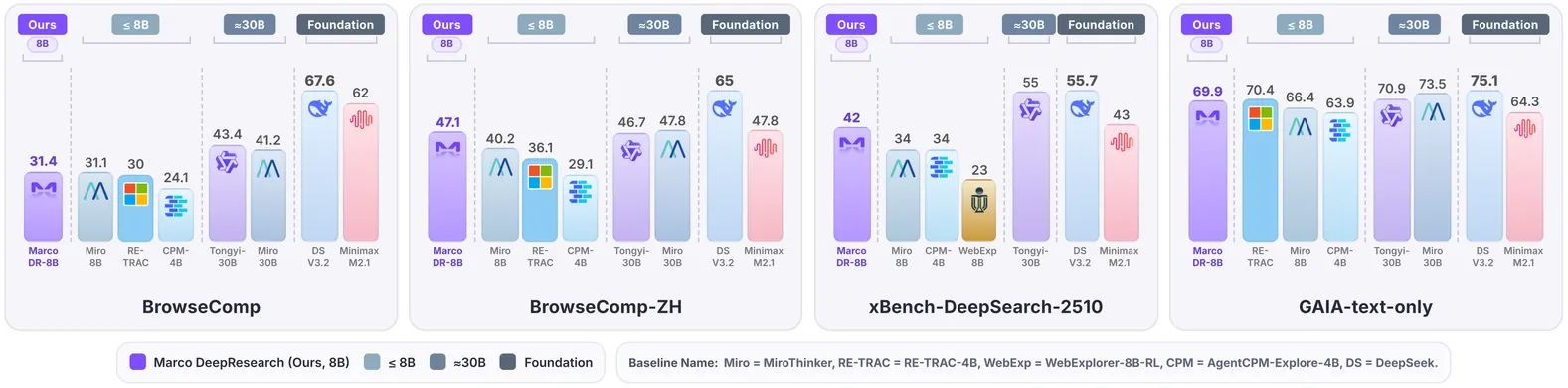
Marco DeepResearch: Unlocking Efficient Deep Research Agents via Verification-Centric Design
Deep research agents autonomously conduct open-ended investigations, integrating complex information retrieval with multi-step reasoning across diverse sources to solve real-world problems. To sustain this capability on long-horizon tasks, reliable verification is critical during both training and inference. A major bottleneck in existing paradigms stems from the lack of explicit verification mechanisms in QA data synthesis, trajectory construction, and test-time scaling. Errors introduced at each stage propagate downstream and degrade the overall agent performance. To address this, we present Marco DeepResearch, a deep research agent optimized with a verification-centric framework design at three levels: \textbf{(1)~QA Data Synthesis:} We introduce verification mechanisms to graph-based and agent-based QA synthesis to control question difficulty while ensuring answers are unique and correct; \textbf{(2)~Trajectory Construction:} We design a verification-driven trajectory synthesis method that injects explicit verification patterns into training trajectories; and \textbf{(3)~Test-time scaling:} We use Marco DeepResearch itself as a verifier at inference time and effectively improve performance on challenging questions. Extensive experimental results demonstrate that our proposed Marco DeepResearch agent significantly outperforms 8B-scale deep research agents on most challenging benchmarks, such as BrowseComp and BrowseComp-ZH. Crucially, under a maximum budget of 600 tool calls, Marco DeepResearch even surpasses or approaches several 30B-scale agents, like Tongyi DeepResearch-30B.
2603.28376
Mar 2026Computation and Language
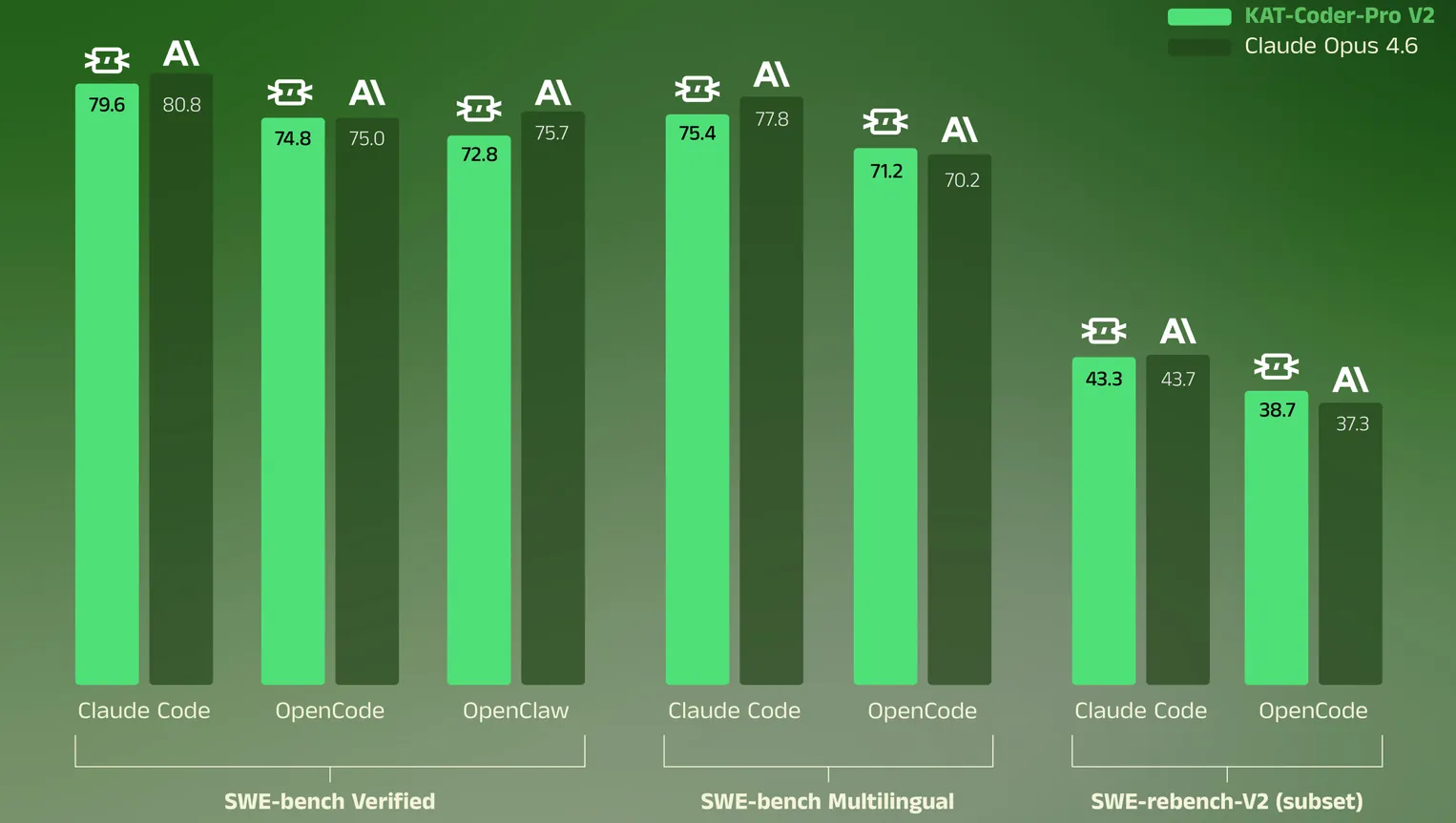
KAT-Coder-V2 Technical Report
We present KAT-Coder-V2, an agentic coding model developed by the KwaiKAT team at Kuaishou. KAT-Coder-V2 adopts a "Specialize-then-Unify" paradigm that decomposes agentic coding into five expert domains - SWE, WebCoding, Terminal, WebSearch, and General - each undergoing independent supervised fine-tuning and reinforcement learning, before being consolidated into a single model via on-policy distillation. We develop KwaiEnv, a modular infrastructure sustaining tens of thousands of concurrent sandbox instances, and scale RL training along task complexity, intent alignment, and scaffold generalization. We further propose MCLA for stabilizing MoE RL training and Tree Training for eliminating redundant computation over tree-structured trajectories with up to 6.2x speedup. KAT-Coder-V2 achieves 79.6% on SWE-bench Verified (vs. Claude Opus 4.6 at 80.8%), 88.7 on PinchBench (surpassing GLM-5 and MiniMax M2.7), ranks first across all three frontend aesthetics scenarios, and maintains strong generalist scores on Terminal-Bench Hard (46.8) and tau^2-Bench (93.9). Our model is publicly available at https://streamlake.com/product/kat-coder.
2603.27703
Mar 2026Computation and Language
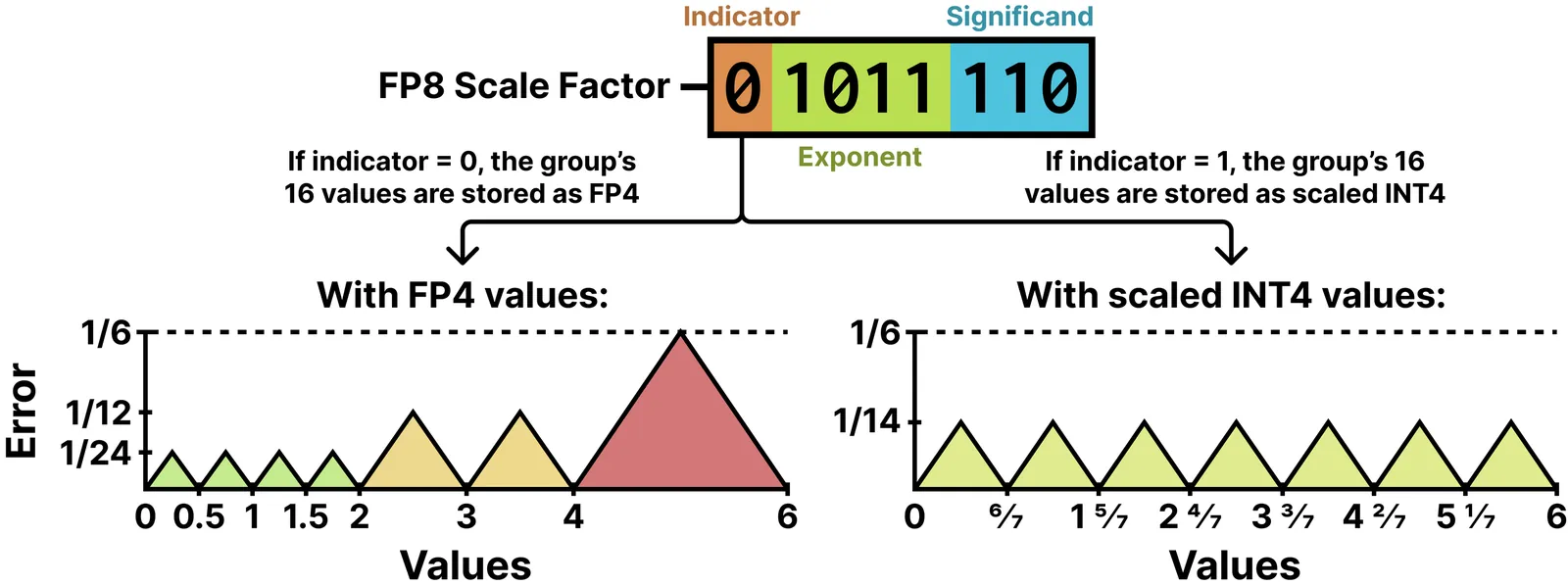
Adaptive Block-Scaled Data Types
NVFP4 has grown increasingly popular as a 4-bit format for quantizing large language models due to its hardware support and its ability to retain useful information with relatively few bits per parameter. However, the format is not without limitations: recent work has shown that NVFP4 suffers from its error distribution, resulting in large amounts of quantization error on near-maximal values in each group of 16 values. In this work, we leverage this insight to design new Adaptive Block-Scaled Data Types that can adapt to the distribution of their input values. For four-bit quantization, our proposed IF4 (Int/Float 4) data type selects between FP4 and INT4 representations for each group of 16 values, which are then scaled by an E4M3 scale factor as is done with NVFP4. The selected data type is denoted using the scale factor's sign bit, which is currently unused in NVFP4, and we apply the same insight to design formats for other bit-widths, including IF3 and IF6. When used to quantize language models, we find that IF4 outperforms existing 4-bit block-scaled formats, achieving lower loss during quantized training and achieving higher accuracy on many tasks in post-training quantization. We additionally design and evaluate an IF4 Multiply-Accumulate (MAC) unit to demonstrate that IF4 can be implemented efficiently in next-generation hardware accelerators. Our code is available at https://github.com/mit-han-lab/fouroversix.
2603.28765
Mar 2026Computation and Language
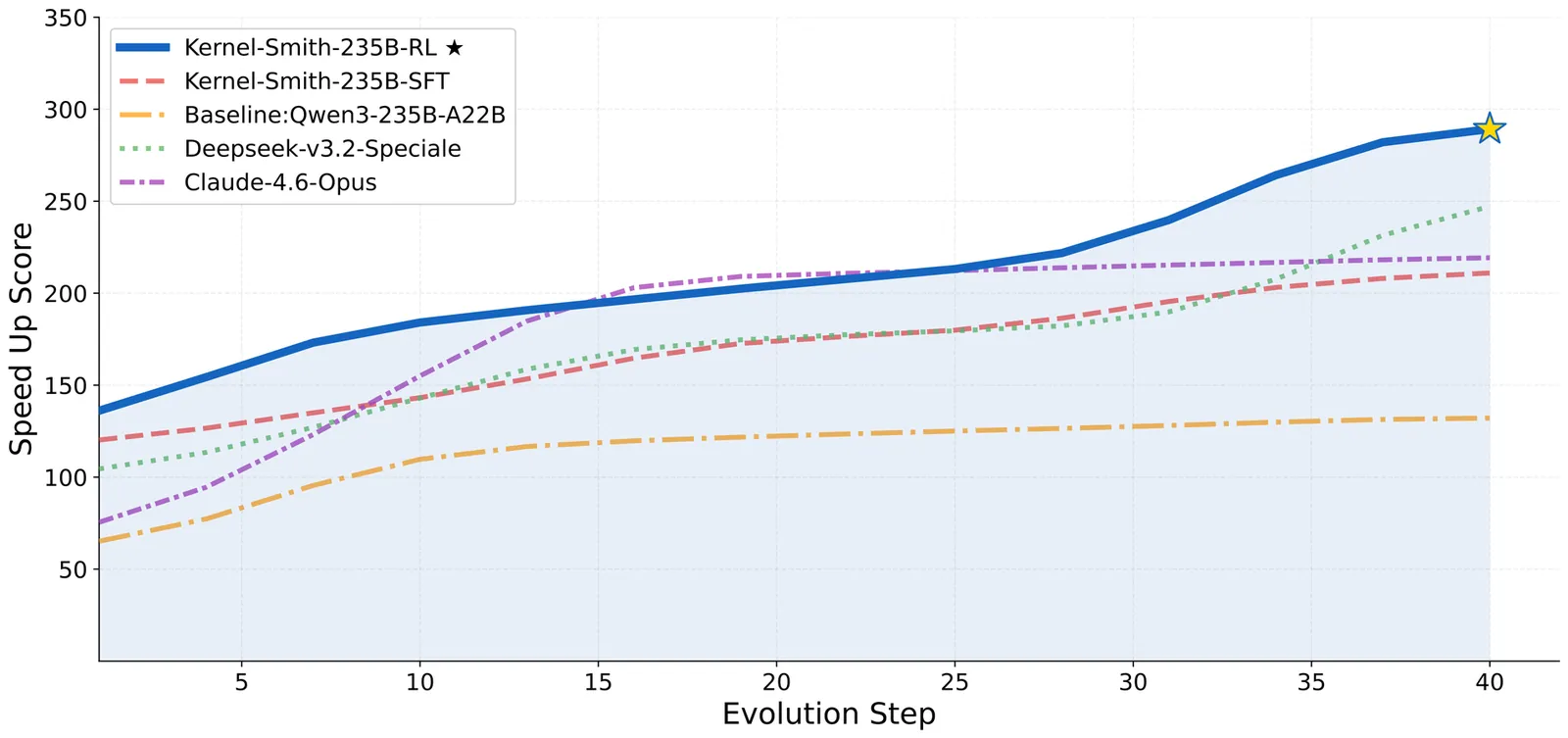
Kernel-Smith: A Unified Recipe for Evolutionary Kernel Optimization
We present Kernel-Smith, a framework for high-performance GPU kernel and operator generation that combines a stable evaluation-driven evolutionary agent with an evolution-oriented post-training recipe. On the agent side, Kernel-Smith maintains a population of executable candidates and iteratively improves them using an archive of top-performing and diverse programs together with structured execution feedback on compilation, correctness, and speedup. To make this search reliable, we build backend-specific evaluation services for Triton on NVIDIA GPUs and Maca on MetaX GPUs. On the training side, we convert long-horizon evolution trajectories into step-centric supervision and reinforcement learning signals by retaining correctness-preserving, high-gain revisions, so that the model is optimized as a strong local improver inside the evolutionary loop rather than as a one-shot generator. Under a unified evolutionary protocol, Kernel-Smith-235B-RL achieves state-of-the-art overall performance on KernelBench with Nvidia Triton backend, attaining the best average speedup ratio and outperforming frontier proprietary models including Gemini-3.0-pro and Claude-4.6-opus. We further validate the framework on the MetaX MACA backend, where our Kernel-Smith-MACA-30B surpasses large-scale counterparts such as DeepSeek-V3.2-think and Qwen3-235B-2507-think, highlighting potential for seamless adaptation across heterogeneous platforms. Beyond benchmark results, the same workflow produces upstream contributions to production systems including SGLang and LMDeploy, demonstrating that LLM-driven kernel optimization can transfer from controlled evaluation to practical deployment.
2603.28342
Mar 2026Computation and Language

Attention Residuals
Residual connections with PreNorm are standard in modern LLMs, yet they accumulate all layer outputs with fixed unit weights. This uniform aggregation causes uncontrolled hidden-state growth with depth, progressively diluting each layer's contribution. We propose Attention Residuals (AttnRes), which replaces this fixed accumulation with softmax attention over preceding layer outputs, allowing each layer to selectively aggregate earlier representations with learned, input-dependent weights. To address the memory and communication overhead of attending over all preceding layer outputs for large-scale model training, we introduce Block AttnRes, which partitions layers into blocks and attends over block-level representations, reducing the memory footprint while preserving most of the gains of full AttnRes. Combined with cache-based pipeline communication and a two-phase computation strategy, Block AttnRes becomes a practical drop-in replacement for standard residual connections with minimal overhead. Scaling law experiments confirm that the improvement is consistent across model sizes, and ablations validate the benefit of content-dependent depth-wise selection. We further integrate AttnRes into the Kimi Linear architecture (48B total / 3B activated parameters) and pre-train on 1.4T tokens, where AttnRes mitigates PreNorm dilution, yielding more uniform output magnitudes and gradient distribution across depth, and improves downstream performance across all evaluated tasks.
2603.15031
Mar 2026Computation and Language
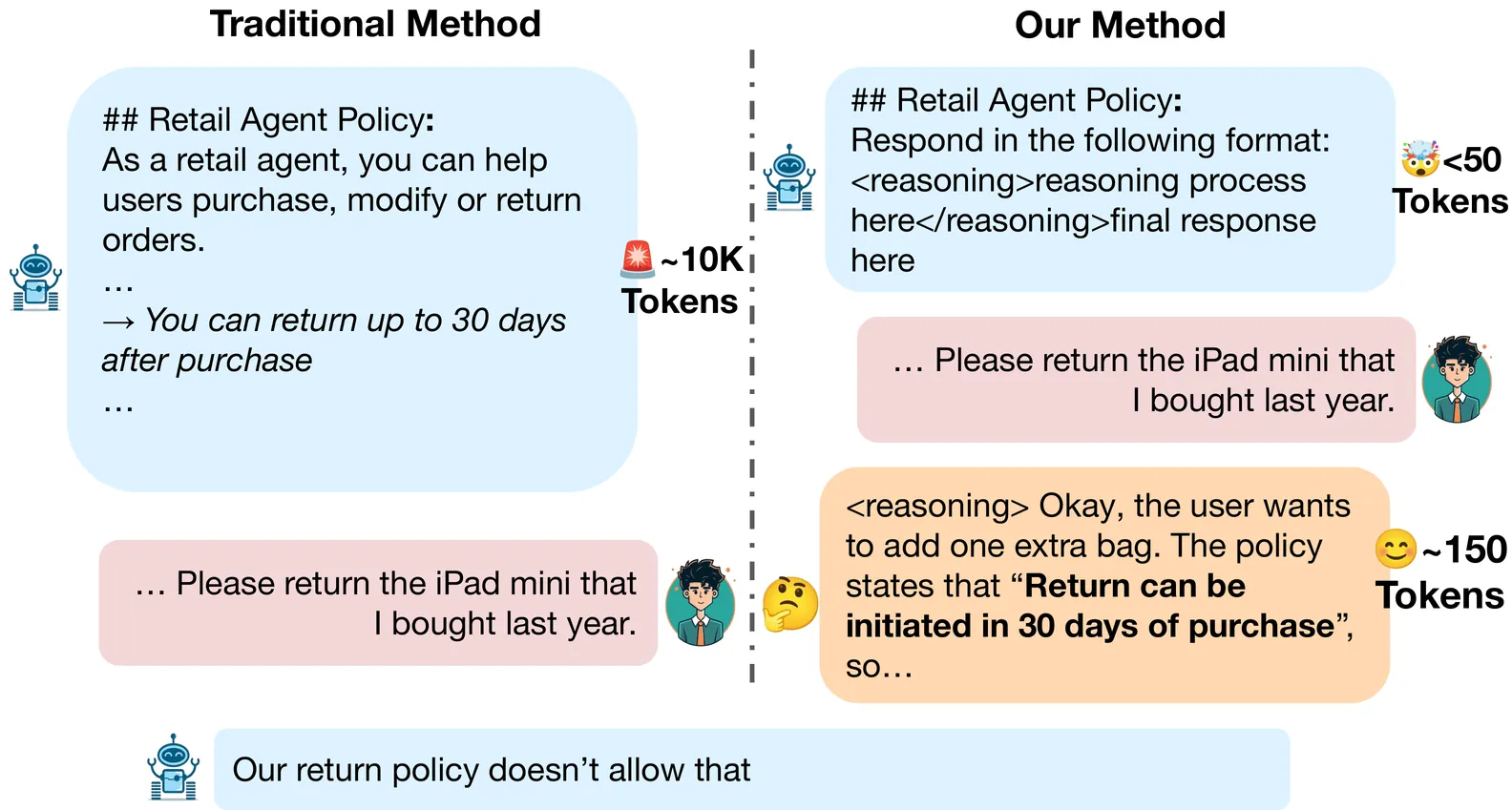
$PA^3$: $\textbf{P}$olicy-$\textbf{A}$ware $\textbf{A}$gent $\textbf{A}$lignment through Chain-of-Thought
Conversational assistants powered by large language models (LLMs) excel at tool-use tasks but struggle with adhering to complex, business-specific rules. While models can reason over business rules provided in context, including all policies for every query introduces high latency and wastes compute. Furthermore, these lengthy prompts lead to long contexts, harming overall performance due to the "needle-in-the-haystack" problem. To address these challenges, we propose a multi-stage alignment method that teaches models to recall and apply relevant business policies during chain-of-thought reasoning at inference time, without including the full business policy in-context. Furthermore, we introduce a novel PolicyRecall reward based on the Jaccard score and a Hallucination Penalty for GRPO training. Altogether, our best model outperforms the baseline by 16 points and surpasses comparable in-context baselines of similar model size by 3 points, while using 40% fewer words.
2603.14602
Mar 2026Computation and Language
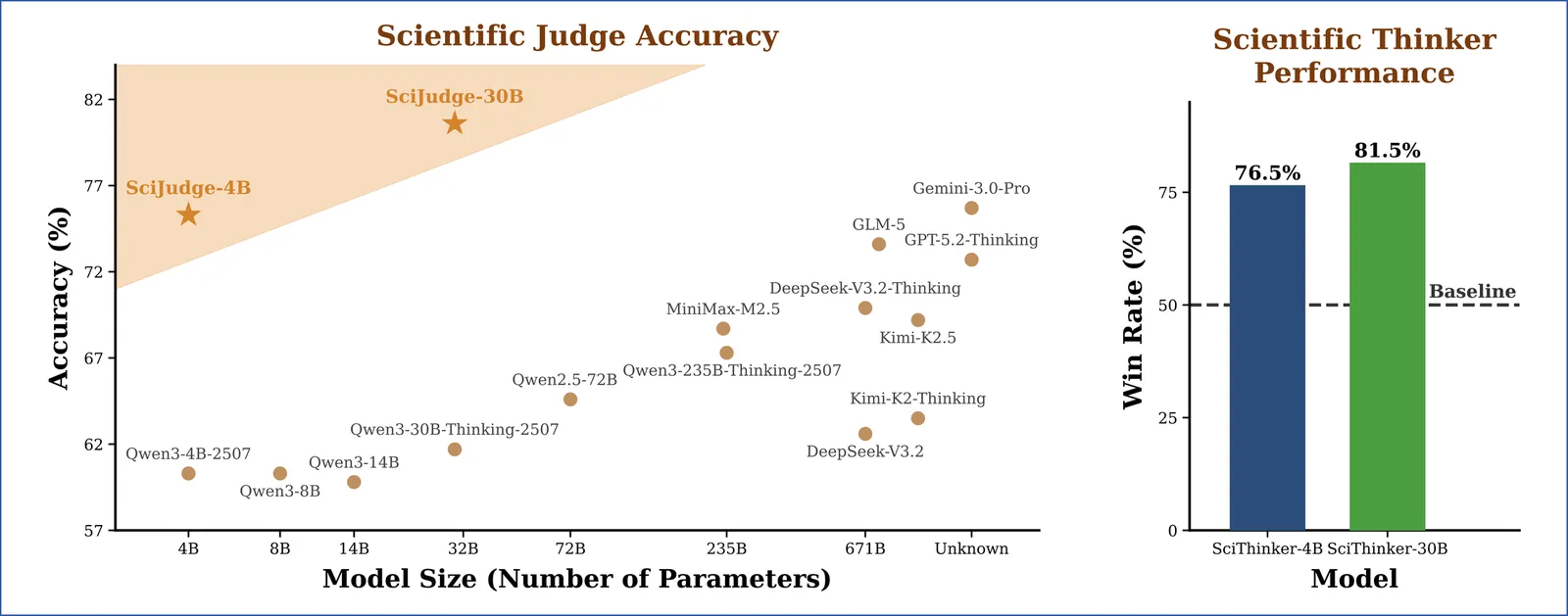
AI Can Learn Scientific Taste
Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potential impact. However, most relative research focuses on improving an AI scientist's executive capability, while enhancing an AI's scientific taste remains underexplored. In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem. For preference modeling, we train Scientific Judge on 700K field- and time-matched pairs of high- vs. low-citation papers to judge ideas. For preference alignment, using Scientific Judge as a reward model, we train a policy model, Scientific Thinker, to propose research ideas with high potential impact. Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference. Furthermore, Scientific Thinker proposes research ideas with higher potential impact than baselines. Our findings show that AI can learn scientific taste, marking a key step toward reaching human-level AI scientists.
2603.14473
Mar 2026Computation and Language
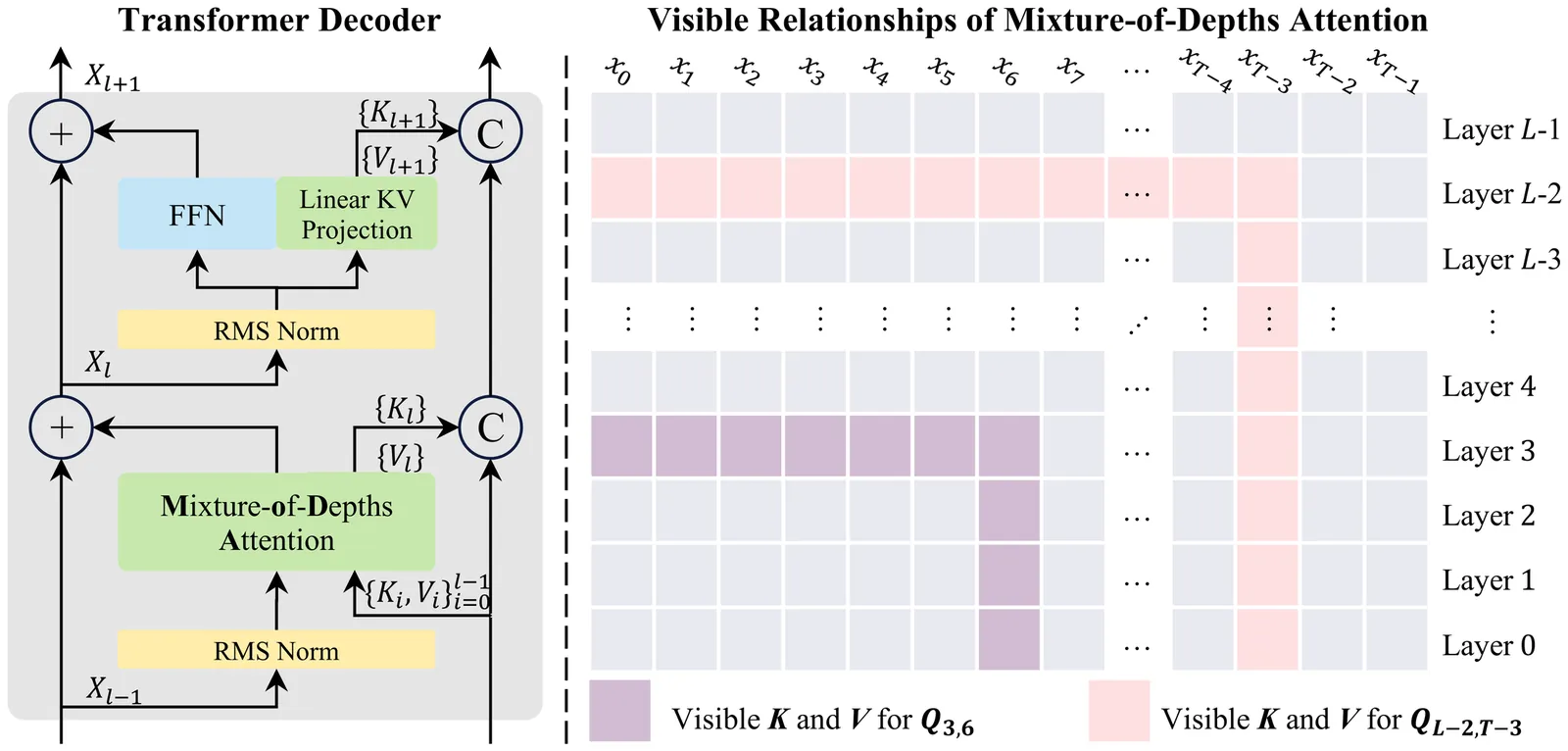
Mixture-of-Depths Attention
Scaling depth is a key driver for large language models (LLMs). Yet, as LLMs become deeper, they often suffer from signal degradation: informative features formed in shallow layers are gradually diluted by repeated residual updates, making them harder to recover in deeper layers. We introduce mixture-of-depths attention (MoDA), a mechanism that allows each attention head to attend to sequence KV pairs at the current layer and depth KV pairs from preceding layers. We further describe a hardware-efficient algorithm for MoDA that resolves non-contiguous memory-access patterns, achieving 97.3% of FlashAttention-2's efficiency at a sequence length of 64K. Experiments on 1.5B-parameter models demonstrate that MoDA consistently outperforms strong baselines. Notably, it improves average perplexity by 0.2 across 10 validation benchmarks and increases average performance by 2.11% on 10 downstream tasks, with a negligible 3.7% FLOPs computational overhead. We also find that combining MoDA with post-norm yields better performance than using it with pre-norm. These results suggest that MoDA is a promising primitive for depth scaling. Code is released at https://github.com/hustvl/MoDA .
2603.15619
Mar 2026Computation and Language
When Does Sparsity Mitigate the Curse of Depth in LLMs
Recent work has demonstrated the curse of depth in large language models (LLMs), where later layers contribute less to learning and representation than earlier layers. Such under-utilization is linked to the accumulated growth of variance in Pre-Layer Normalization, which can push deep blocks toward near-identity behavior. In this paper, we demonstrate that, sparsity, beyond enabling efficiency, acts as a regulator of variance propagation and thereby improves depth utilization. Our investigation covers two sources of sparsity: (i) implicit sparsity, which emerges from training and data conditions, including weight sparsity induced by weight decay and attention sparsity induced by long context inputs; and (ii) explicit sparsity, which is enforced by architectural design, including key/value-sharing sparsity in Grouped-Query Attention and expert-activation sparsity in Mixtureof-Experts. Our claim is thoroughly supported by controlled depth-scaling experiments and targeted layer effectiveness interventions. Across settings, we observe a consistent relationship: sparsity improves layer utilization by reducing output variance and promoting functional differentiation. We eventually distill our findings into a practical rule-of-thumb recipe for training deptheffective LLMs, yielding a notable 4.6% accuracy improvement on downstream tasks. Our results reveal sparsity, arising naturally from standard design choices, as a key yet previously overlooked mechanism for effective depth scaling in LLMs. Code is available at https://github.com/pUmpKin-Co/SparsityAndCoD.
2603.15389
Mar 2026Computation and Language
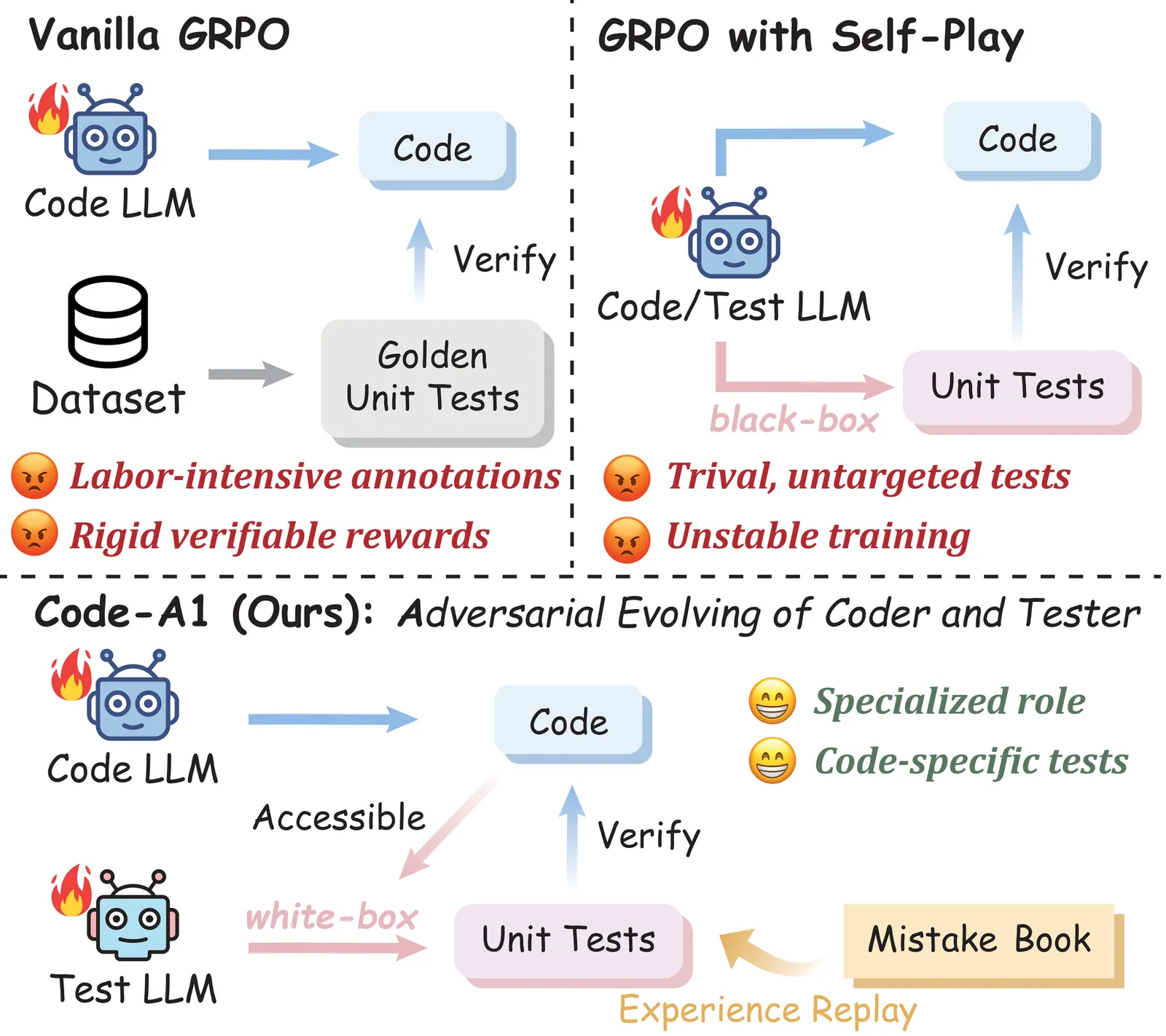
Code-A1: Adversarial Evolving of Code LLM and Test LLM via Reinforcement Learning
Reinforcement learning for code generation relies on verifiable rewards from unit test pass rates. Yet high-quality test suites are scarce, existing datasets offer limited coverage, and static rewards fail to adapt as models improve. Recent self-play methods unify code and test generation in a single model, but face a inherent dilemma: white-box access leads to self-collusion where the model produces trivial tests for easy rewards, yet black-box restriction yields generic tests that miss implementation-specific bugs. We introduce Code-A1, an adversarial co-evolution framework that jointly optimizes a Code LLM and a Test LLM with opposing objectives. The Code LLM is rewarded for passing more tests, while the Test LLM is rewarded for exposing more defects. This architectural separation eliminates self-collusion risks and safely enables white-box test generation, where the Test LLM can inspect candidate code to craft targeted adversarial tests. We further introduce a Mistake Book mechanism for experience replay and a composite reward balancing test validity with adversarial difficulty. Experiments on Qwen2.5-Coder models demonstrate that Code-A1 achieves code generation performance matching or exceeding models trained on human-annotated tests, while significantly improving test generation capability.
2603.15611
Mar 2026Computation and Language