Computers and Society
arXiv:cs.CY
Covers impact of computers on society, computer ethics, information technology and public policy, legal aspects of computing, computers and education.
Looking for a broader view? This category is part of:
Covers impact of computers on society, computer ethics, information technology and public policy, legal aspects of computing, computers and education.
Looking for a broader view? This category is part of:
Alignment of artificial intelligence (AI) encompasses the normative problem of specifying how AI systems should act and the technical problem of ensuring AI systems comply with those specifications. To date, AI alignment has generally overlooked an important source of knowledge and practice for grappling with these problems: law. In this paper, we aim to fill this gap by exploring how legal rules, principles, and methods can be leveraged to address problems of alignment and inform the design of AI systems that operate safely and ethically. This emerging field -- legal alignment -- focuses on three research directions: (1) designing AI systems to comply with the content of legal rules developed through legitimate institutions and processes, (2) adapting methods from legal interpretation to guide how AI systems reason and make decisions, and (3) harnessing legal concepts as a structural blueprint for confronting challenges of reliability, trust, and cooperation in AI systems. These research directions present new conceptual, empirical, and institutional questions, which include examining the specific set of laws that particular AI systems should follow, creating evaluations to assess their legal compliance in real-world settings, and developing governance frameworks to support the implementation of legal alignment in practice. Tackling these questions requires expertise across law, computer science, and other disciplines, offering these communities the opportunity to collaborate in designing AI for the better.
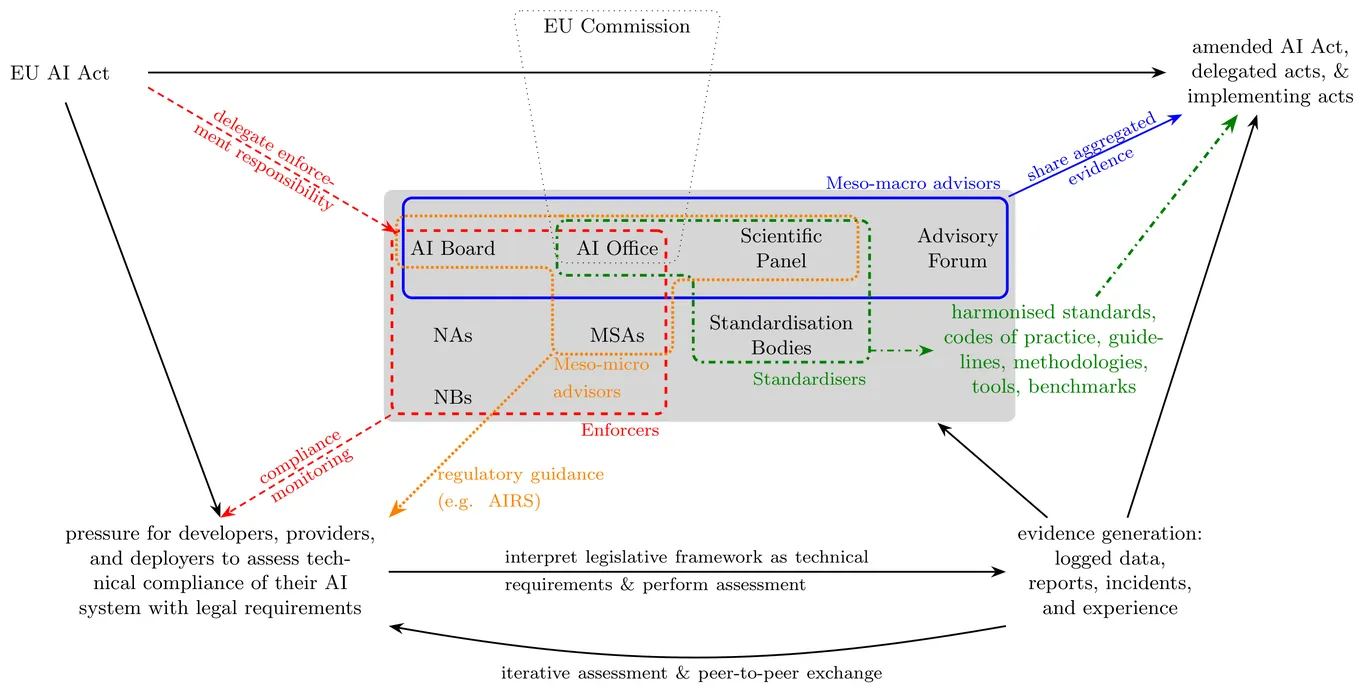
The EU AI Act adopts a horizontal and adaptive approach to govern AI technologies characterised by rapid development and unpredictable emerging capabilities. To maintain relevance, the Act embeds provisions for regulatory learning. However, these provisions operate within a complex network of actors and mechanisms that lack a clearly defined technical basis for scalable information flow. This paper addresses this gap by establishing a theoretical model of regulatory learning space defined by the AI Act, decomposed into micro, meso, and macro levels. Drawing from this functional perspective of this model, we situate the diverse stakeholders - ranging from the EU Commission at the macro level to AI developers at the micro level - within the transitions of enforcement (macro-micro) and evidence aggregation (micro-macro). We identify AI Technical Sandboxes as the essential engine for evidence generation at the micro level, providing the necessary data to drive scalable learning across all levels of the model. By providing an extensive discussion of the requirements and challenges for AITSes to serve as this micro-level evidence generator, we aim to bridge the gap between legislative commands and technical operationalisation, thereby enabling a structured discourse between technical and legal experts.
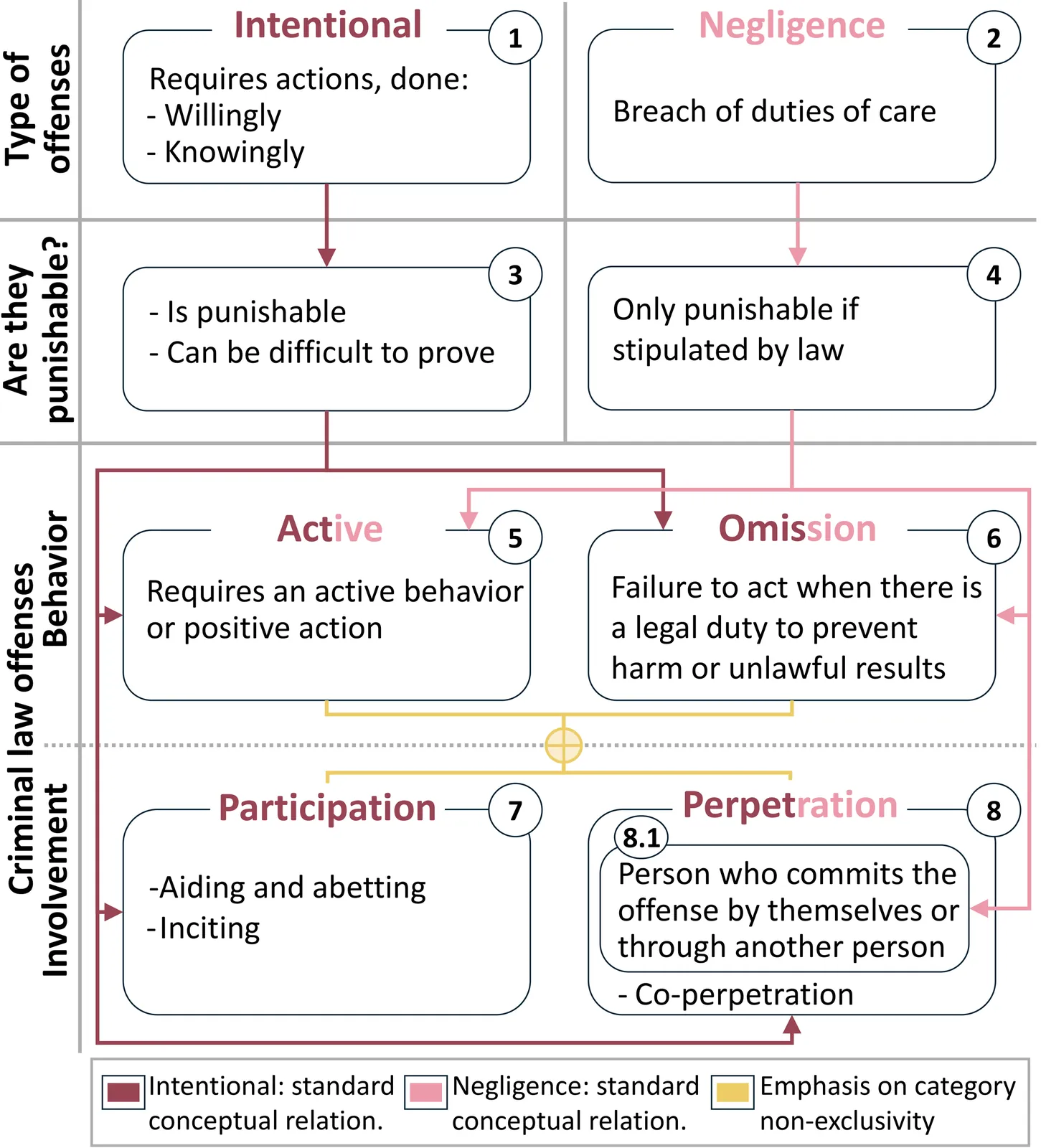
The development of more powerful Generative Artificial Intelligence (GenAI) has expanded its capabilities and the variety of outputs. This has introduced significant legal challenges, including gray areas in various legal systems, such as the assessment of criminal liability for those responsible for these models. Therefore, we conducted a multidisciplinary study utilizing the statutory interpretation of relevant German laws, which, in conjunction with scenarios, provides a perspective on the different properties of GenAI in the context of Child Sexual Abuse Material (CSAM) generation. We found that generating CSAM with GenAI may have criminal and legal consequences not only for the user committing the primary offense but also for individuals responsible for the models, such as independent software developers, researchers, and company representatives. Additionally, the assessment of criminal liability may be affected by contextual and technical factors, including the type of generated image, content moderation policies, and the model's intended purpose. Based on our findings, we discussed the implications for different roles, as well as the requirements when developing such systems.
As artificial intelligence rapidly advances, society is increasingly captivated by promises of superhuman machines and seamless digital futures. Yet these visions often obscure mounting social, ethical, and psychological concerns tied to pervasive digital technologies - from surveillance to mental health crises. This article argues that a guiding ethos is urgently needed to navigate these transformations. Inspired by the lasting influence of the biblical Ten Commandments, a European interdisciplinary group has proposed "Ten Rules for the Digital World" - a novel ethical framework to help individuals and societies make prudent, human-centered decisions in the age of "supercharged" technology.

Engineering education faces a double disruption: traditional apprenticeship models that cultivated judgment and tacit skill are eroding, just as generative AI emerges as an informal coaching partner. This convergence rekindles long-standing questions in the philosophy of AI and cognition about the limits of computation, the nature of embodied rationality, and the distinction between information processing and wisdom. Building on this rich intellectual tradition, this paper examines whether AI chatbots can provide coaching that fosters mastery rather than merely delivering information. We synthesize critical perspectives from decades of scholarship on expertise, tacit knowledge, and human-machine interaction, situating them within the context of contemporary AI-driven education. Empirically, we report findings from a mixed-methods study (N = 75 students, N = 7 faculty) exploring the use of a coaching chatbot in engineering education. Results reveal a consistent boundary: participants accept AI for technical problem solving (convergent tasks; M = 3.84 on a 1-5 Likert scale) but remain skeptical of its capacity for moral, emotional, and contextual judgment (divergent tasks). Faculty express stronger concerns over risk (M = 4.71 vs. M = 4.14, p = 0.003), and privacy emerges as a key requirement, with 64-71 percent of participants demanding strict confidentiality. Our findings suggest that while generative AI can democratize access to cognitive and procedural support, it cannot replicate the embodied, value-laden dimensions of human mentorship. We propose a multiplex coaching framework that integrates human wisdom within expert-in-the-loop models, preserving the depth of apprenticeship while leveraging AI scalability to enrich the next generation of engineering education.

Intelligent tutoring systems have long enabled automated immediate feedback on student work when it is presented in a tightly structured format and when problems are very constrained, but reliably assessing free-form mathematical reasoning remains challenging. We present a system that processes free-form natural language input, handles a wide range of edge cases, and comments competently not only on the technical correctness of submitted proofs, but also on style and presentation issues. We discuss the advantages and disadvantages of various approaches to the evaluation of such a system, and show that by the metrics we evaluate, the quality of the feedback generated is comparable to that produced by human experts when assessing early undergraduate homework. We stress-test our system with a small set of more advanced and unusual questions, and report both significant gaps and encouraging successes in that more challenging setting. Our system uses large language models in a modular workflow. The workflow configuration is human-readable and editable without programming knowledge, and allows some intermediate steps to be precomputed or injected by the instructor. A version of our tool is deployed on the Imperial mathematics homework platform Lambdafeedback. We report also on the integration of our tool into this platform.
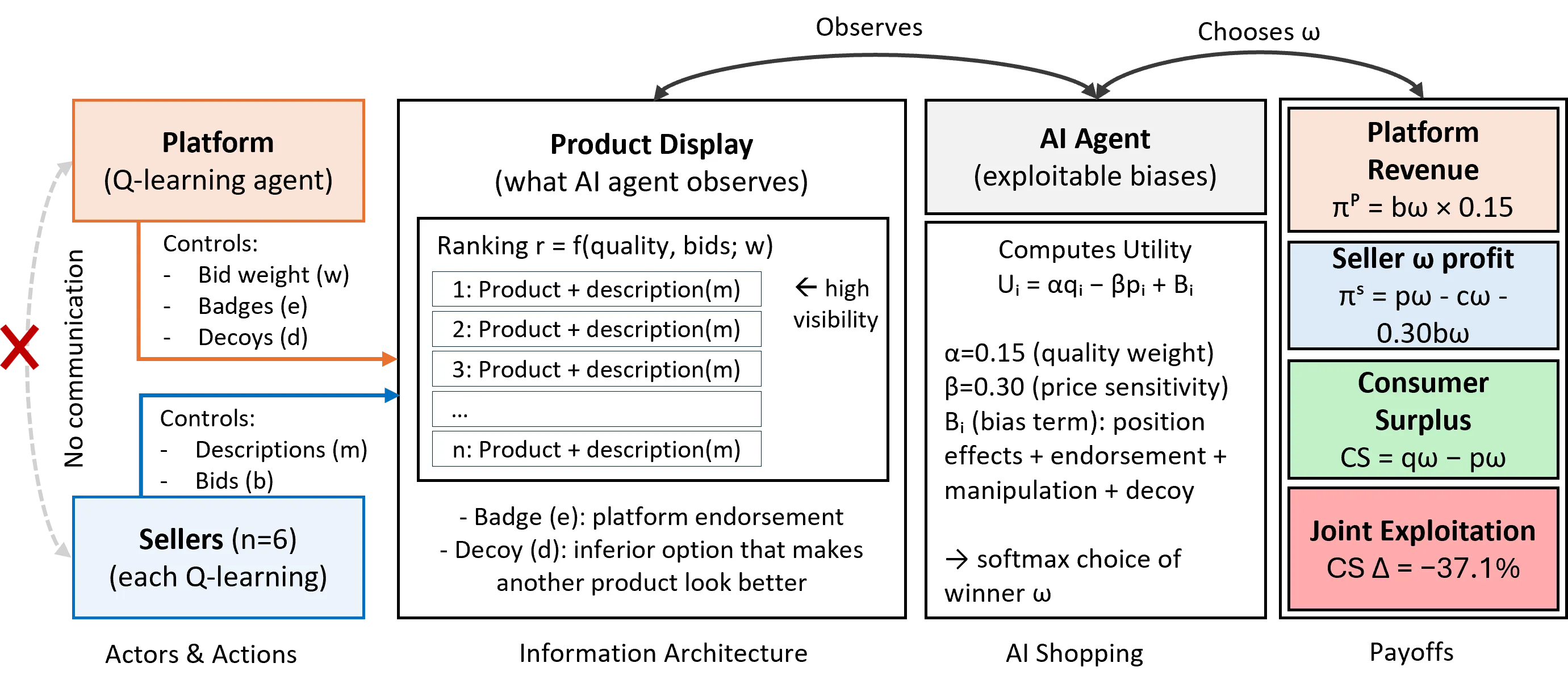
AI shopping agents are being deployed to hundreds of millions of consumers, creating a new intermediary between platforms, sellers, and buyers. We identify a novel market failure: vertical tacit collusion, where platforms controlling rankings and sellers controlling product descriptions independently learn to exploit documented AI cognitive biases. Using multi-agent simulation calibrated to empirical measurements of large language model biases, we show that joint exploitation produces consumer harm more than double what would occur if strategies were independent. This super-additive harm arises because platform ranking determines which products occupy bias-triggering positions while seller manipulation determines conversion rates. Unlike horizontal algorithmic collusion, vertical tacit collusion requires no coordination and evades antitrust detection because harm emerges from aligned incentives rather than agreement. Our findings identify an urgent regulatory gap as AI shopping agents reach mainstream adoption.
Automated vehicles present unique opportunities and challenges, with progress and adoption limited, in part, by policy and regulatory barriers. Underrepresented groups, including individuals with mobility impairments, sensory disabilities, and cognitive conditions, who may benefit most from automation, are often overlooked in crucial discussions on system design, implementation, and usability. Despite the high potential benefits of automated vehicles, the needs of Persons with Disabilities are frequently an afterthought, considered only in terms of secondary accommodations rather than foundational design elements. We aim to shift automated vehicle research and discourse away from this reactive model and toward a proactive and inclusive approach. We first present an overview of the current state of automated vehicle systems. Regarding their adoption, we examine social and technical barriers and advantages for Persons with Disabilities. We analyze existing regulations and policies concerning automated vehicles and Persons with Disabilities, identifying gaps that hinder accessibility. To address these deficiencies, we introduce a scoring rubric intended for use by manufacturers and vehicle designers. The rubric fosters direct collaboration throughout the design process, moving beyond an `afterthought` approach and towards intentional, inclusive innovation. This work was created by authors with varying degrees of personal experience within the realm of disability.
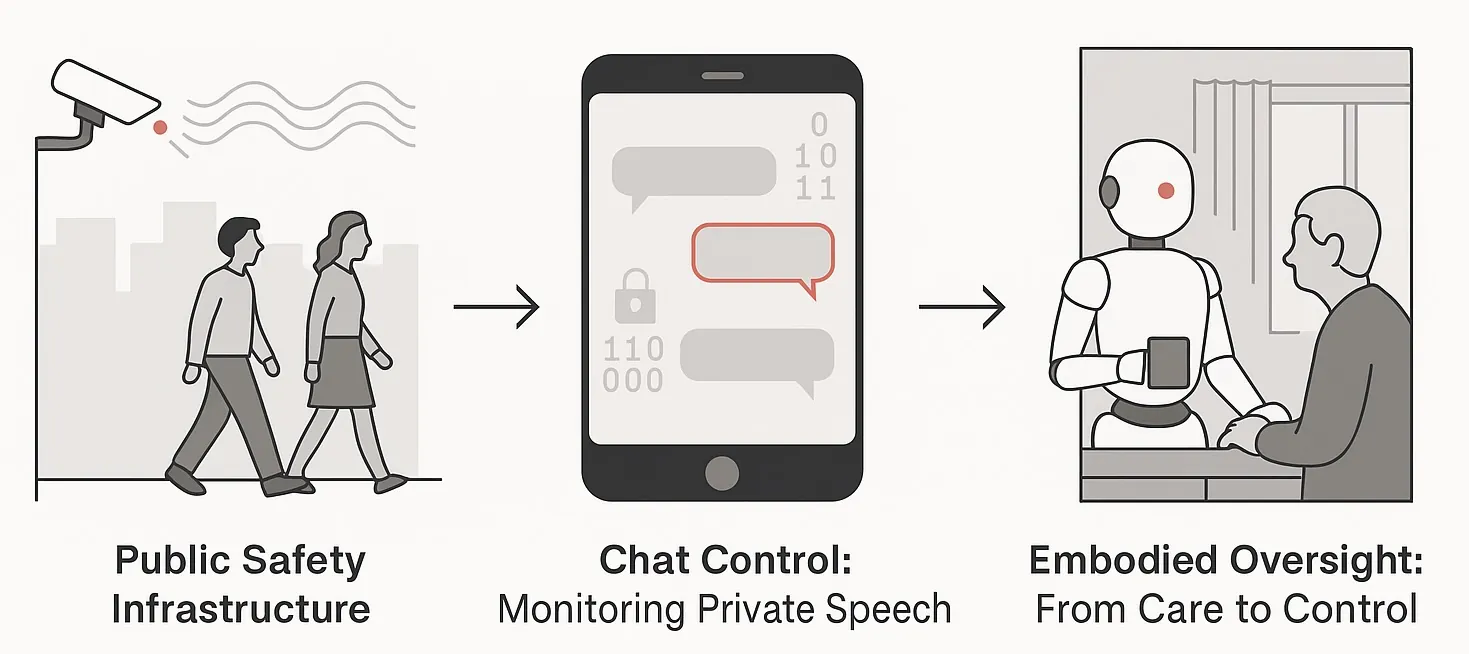
This paper explores how a recent European Union proposal, the so-called Chat Control law, which creates regulatory incentives for providers to implement content detection and communication scanning, could transform the foundations of human-robot interaction (HRI). As robots increasingly act as interpersonal communication channels in care, education, and telepresence, they convey not only speech but also gesture, emotion, and contextual cues. We argue that extending digital surveillance laws to such embodied systems would entail continuous monitoring, embedding observation into the very design of everyday robots. This regulation blurs the line between protection and control, turning companions into potential informants. At the same time, monitoring mechanisms that undermine end-to-end encryption function as de facto backdoors, expanding the attack surface and allowing adversaries to exploit legally induced monitoring infrastructures. This creates a paradox of safety through insecurity: systems introduced to protect users may instead compromise their privacy, autonomy, and trust. This work does not aim to predict the future, but to raise awareness and help prevent certain futures from materialising.
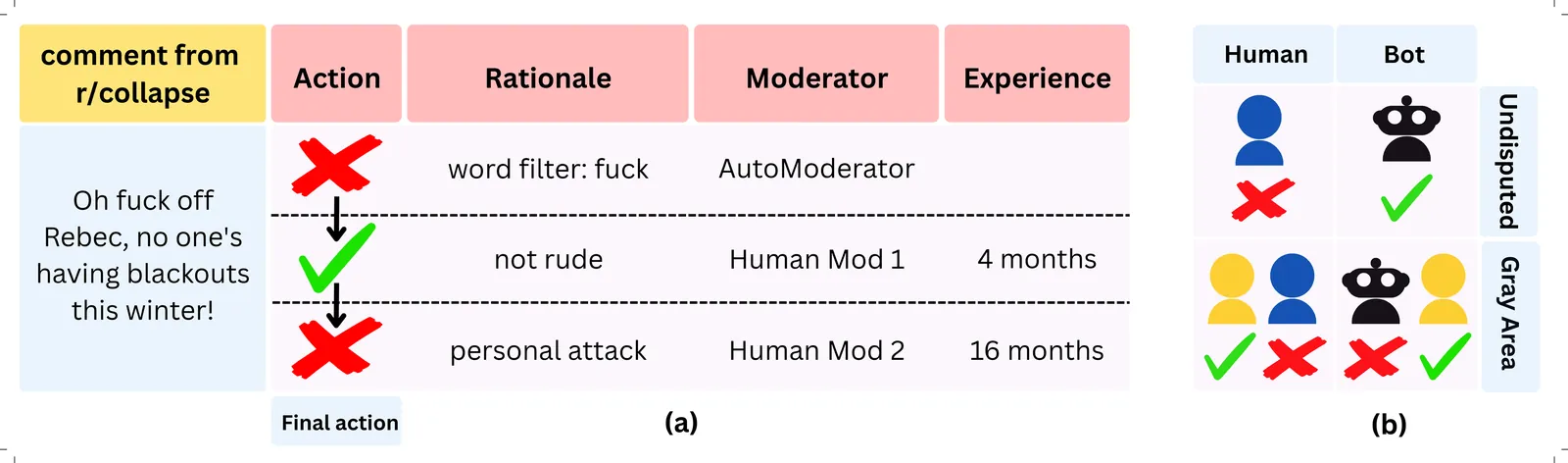
Volunteer moderators play a crucial role in sustaining online dialogue, but they often disagree about what should or should not be allowed. In this paper, we study the complexity of content moderation with a focus on disagreements between moderators, which we term the ``gray area'' of moderation. Leveraging 5 years and 4.3 million moderation log entries from 24 subreddits of different topics and sizes, we characterize how gray area, or disputed cases, differ from undisputed cases. We show that one-in-seven moderation cases are disputed among moderators, often addressing transgressions where users' intent is not directly legible, such as in trolling and brigading, as well as tensions around community governance. This is concerning, as almost half of all gray area cases involved automated moderation decisions. Through information-theoretic evaluations, we demonstrate that gray area cases are inherently harder to adjudicate than undisputed cases and show that state-of-the-art language models struggle to adjudicate them. We highlight the key role of expert human moderators in overseeing the moderation process and provide insights about the challenges of current moderation processes and tools.
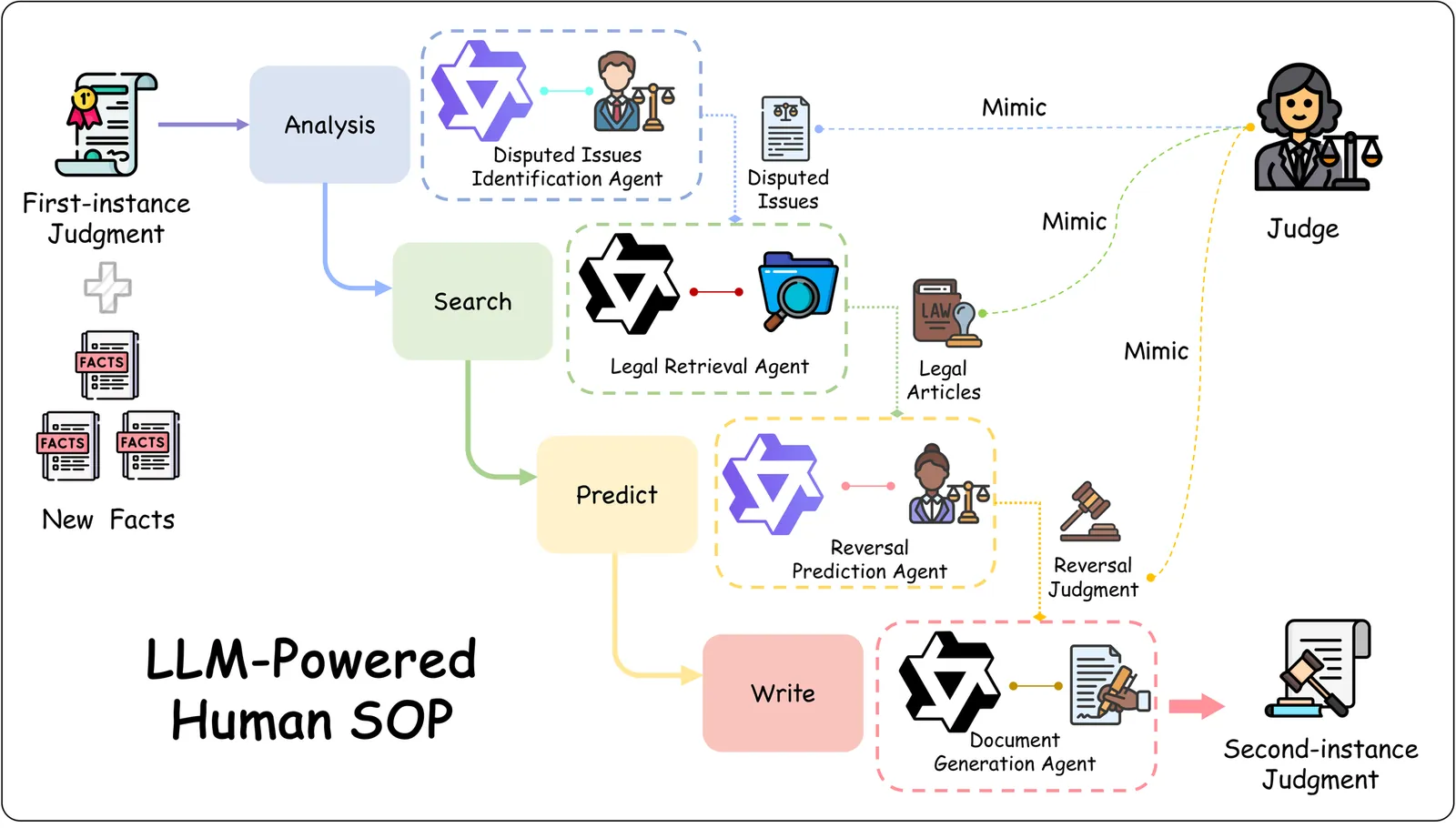
Legal judgment generation is a critical task in legal intelligence. However, existing research in legal judgment generation has predominantly focused on first-instance trials, relying on static fact-to-verdict mappings while neglecting the dialectical nature of appellate (second-instance) review. To address this, we introduce AppellateGen, a benchmark for second-instance legal judgment generation comprising 7,351 case pairs. The task requires models to draft legally binding judgments by reasoning over the initial verdict and evidentiary updates, thereby modeling the causal dependency between trial stages. We further propose a judicial Standard Operating Procedure (SOP)-based Legal Multi-Agent System (SLMAS) to simulate judicial workflows, which decomposes the generation process into discrete stages of issue identification, retrieval, and drafting. Experimental results indicate that while SLMAS improves logical consistency, the complexity of appellate reasoning remains a substantial challenge for current LLMs. The dataset and code are publicly available at: https://anonymous.4open.science/r/AppellateGen-5763.
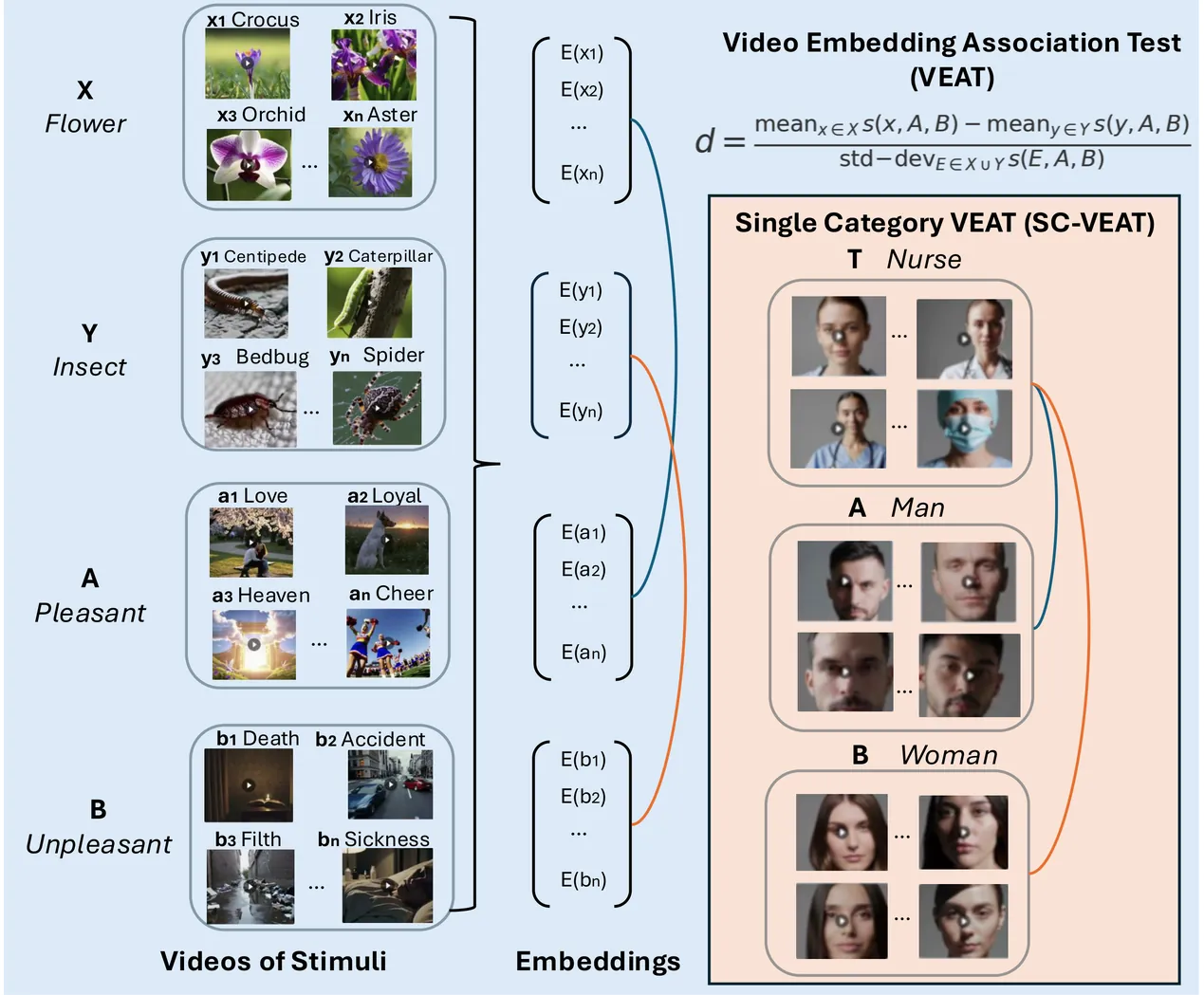
Text-to-Video (T2V) generators such as Sora raise concerns about whether generated content reflects societal bias. We extend embedding-association tests from words and images to video by introducing the Video Embedding Association Test (VEAT) and Single-Category VEAT (SC-VEAT). We validate these methods by reproducing the direction and magnitude of associations from widely used baselines, including Implicit Association Test (IAT) scenarios and OASIS image categories. We then quantify race (African American vs. European American) and gender (women vs. men) associations with valence (pleasant vs. unpleasant) across 17 occupations and 7 awards. Sora videos associate European Americans and women more with pleasantness (both d>0.8). Effect sizes correlate with real-world demographic distributions: percent men and White in occupations (r=0.93, r=0.83) and percent male and non-Black among award recipients (r=0.88, r=0.99). Applying explicit debiasing prompts generally reduces effect-size magnitudes, but can backfire: two Black-associated occupations (janitor, postal service) become more Black-associated after debiasing. Together, these results reveal that easily accessible T2V generators can actually amplify representational harms if not rigorously evaluated and responsibly deployed.

Generative AI (GenAI) now produces text, images, audio, and video that can be perceptually convincing at scale and at negligible marginal cost. While public debate often frames the associated harms as "deepfakes" or incremental extensions of misinformation and fraud, this view misses a broader socio-technical shift: GenAI enables synthetic realities; coherent, interactive, and potentially personalized information environments in which content, identity, and social interaction are jointly manufactured and mutually reinforcing. We argue that the most consequential risk is not merely the production of isolated synthetic artifacts, but the progressive erosion of shared epistemic ground and institutional verification practices as synthetic content, synthetic identity, and synthetic interaction become easy to generate and hard to audit. This paper (i) formalizes synthetic reality as a layered stack (content, identity, interaction, institutions), (ii) expands a taxonomy of GenAI harms spanning personal, economic, informational, and socio-technical risks, (iii) articulates the qualitative shifts introduced by GenAI (cost collapse, throughput, customization, micro-segmentation, provenance gaps, and trust erosion), and (iv) synthesizes recent risk realizations (2023-2025) into a compact case bank illustrating how these mechanisms manifest in fraud, elections, harassment, documentation, and supply-chain compromise. We then propose a mitigation stack that treats provenance infrastructure, platform governance, institutional workflow redesign, and public resilience as complementary rather than substitutable, and outline a research agenda focused on measuring epistemic security. We conclude with the Generative AI Paradox: as synthetic media becomes ubiquitous, societies may rationally discount digital evidence altogether.
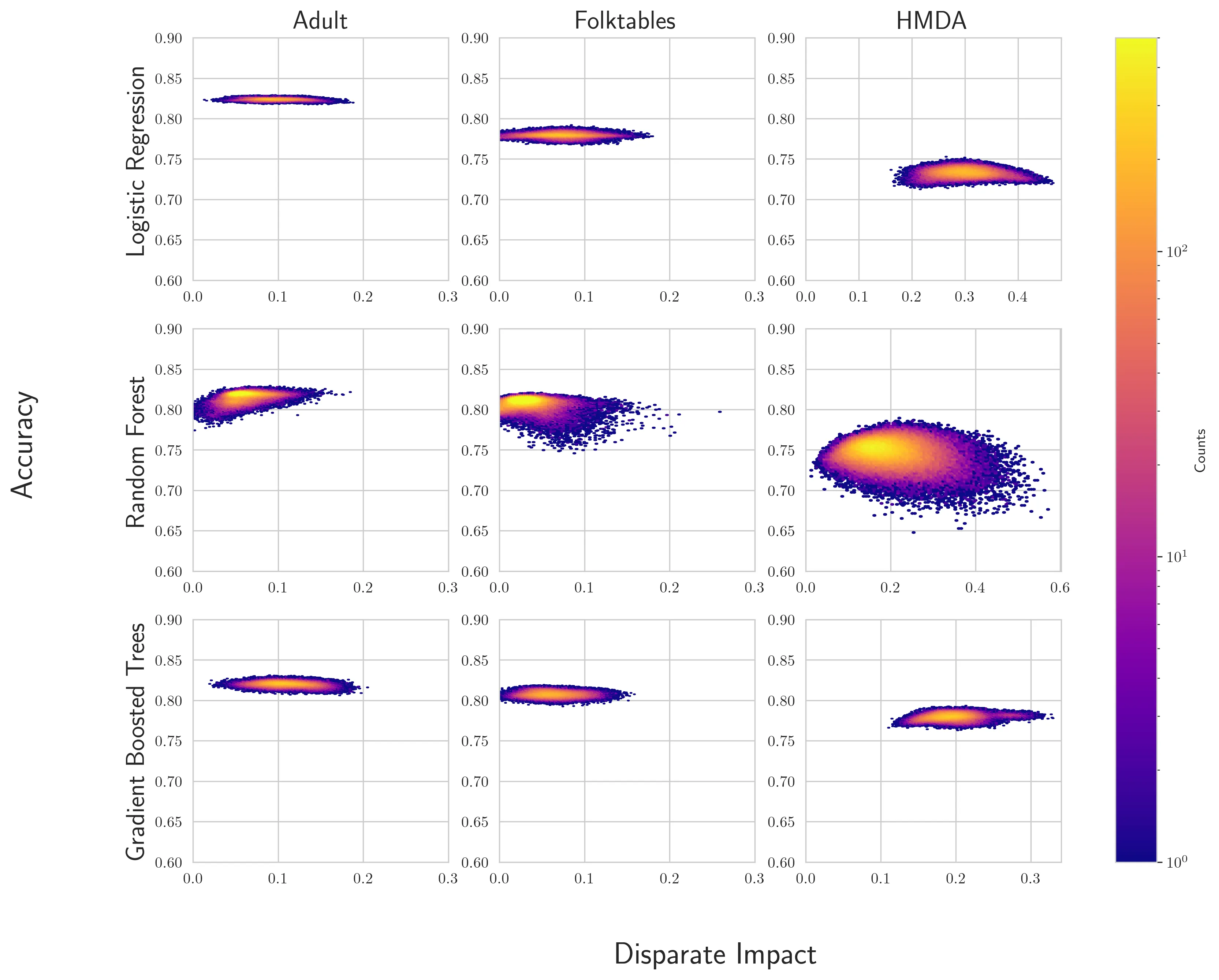
Recent scholarship has argued that firms building data-driven decision systems in high-stakes domains like employment, credit, and housing should search for "less discriminatory algorithms" (LDAs) (Black et al., 2024). That is, for a given decision problem, firms considering deploying a model should make a good-faith effort to find equally performant models with lower disparate impact across social groups. Evidence from the literature on model multiplicity shows that randomness in training pipelines can lead to multiple models with the same performance, but meaningful variations in disparate impact. This suggests that developers can find LDAs simply by randomly retraining models. Firms cannot continue retraining forever, though, which raises the question: What constitutes a good-faith effort? In this paper, we formalize LDA search via model multiplicity as an optimal stopping problem, where a model developer with limited information wants to produce strong evidence that they have sufficiently explored the space of models. Our primary contribution is an adaptive stopping algorithm that yields a high-probability upper bound on the gains achievable from a continued search, allowing the developer to certify (e.g., to a court) that their search was sufficient. We provide a framework under which developers can impose stronger assumptions about the distribution of models, yielding correspondingly stronger bounds. We validate the method on real-world credit, employment and housing datasets.
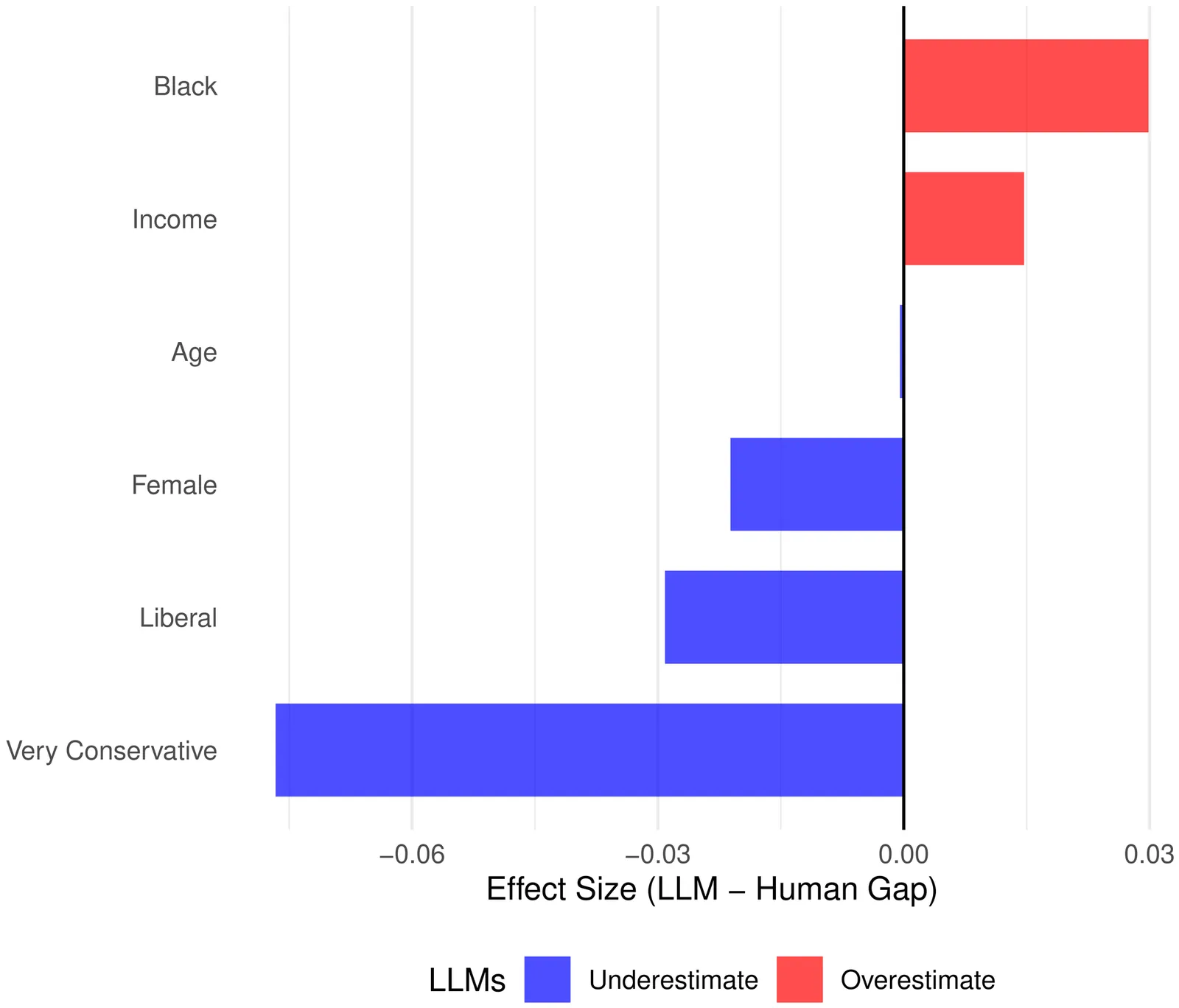
Federal agencies and researchers increasingly use large language models to analyze and simulate public opinion. When AI mediates between the public and policymakers, accuracy across intersecting identities becomes consequential; inaccurate group-level estimates can mislead outreach, consultation, and policy design. While research examines intersectionality in LLM outputs, no study has compared these outputs against real human responses across intersecting identities. Climate policy is one such domain, and this is particularly urgent for climate change, where opinion is contested and diverse. We investigate how LLMs represent intersectional patterns in U.S. climate opinions. We prompted six LLMs with profiles of 978 respondents from a nationally representative U.S. climate opinion survey and compared AI-generated responses to actual human answers across 20 questions. We find that LLMs appear to compress the diversity of American climate opinions, predicting less-concerned groups as more concerned and vice versa. This compression is intersectional: LLMs apply uniform gender assumptions that match reality for White and Hispanic Americans but misrepresent Black Americans, where actual gender patterns differ. These patterns, which may be invisible to standard auditing approaches, could undermine equitable climate governance.
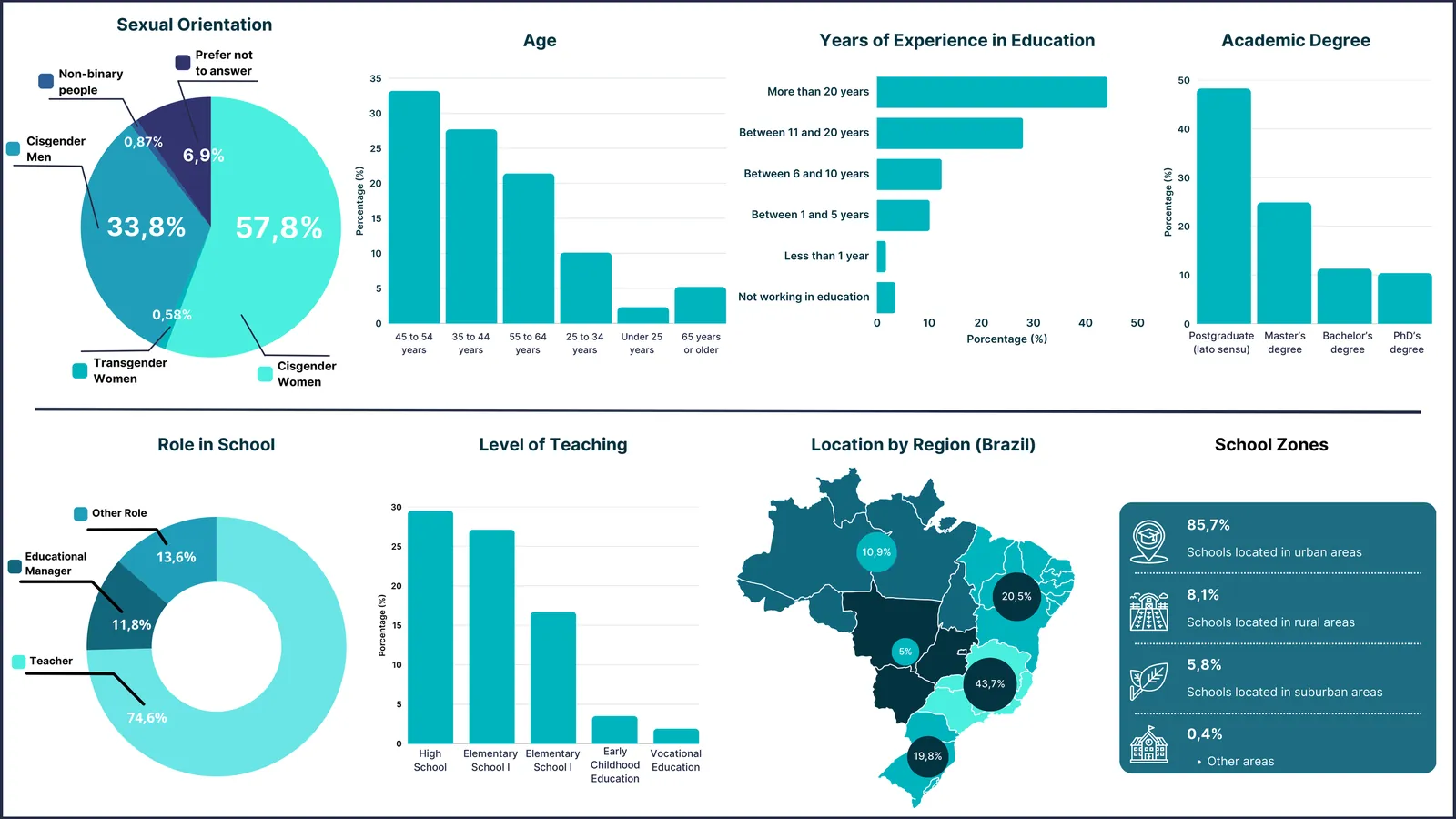
This study examines the perceptions of Brazilian K-12 education teachers regarding the use of AI in education, specifically General Purpose AI. This investigation employs a quantitative analysis approach, extracting information from a questionnaire completed by 346 educators from various regions of Brazil regarding their AI literacy and use. Educators vary in their educational level, years of experience, and type of educational institution. The analysis of the questionnaires shows that although most educators had only basic or limited knowledge of AI (80.3\%), they showed a strong interest in its application, particularly for the creation of interactive content (80.6%), lesson planning (80.2%), and personalized assessment (68.6%). The potential of AI to promote inclusion and personalized learning is also widely recognized (65.5%). The participants emphasized the importance of discussing ethics and digital citizenship, reflecting on technological dependence, biases, transparency, and responsible use of AI, aligning with critical education and the development of conscious students. Despite enthusiasm for the pedagogical potential of AI, significant structural challenges were identified, including a lack of training (43.4%), technical support (41.9%), and limitations of infrastructure, such as low access to computers, reliable Internet connections, and multimedia resources in schools. The study shows that Brazil is still in a bottom-up model for AI integration, missing official curricula to guide its implementation and structured training for teachers and students. Furthermore, effective implementation of AI depends on integrated public policies, adequate teacher training, and equitable access to technology, promoting ethical, inclusive, and contextually grounded adoption of AI in Brazilian K-12 education.
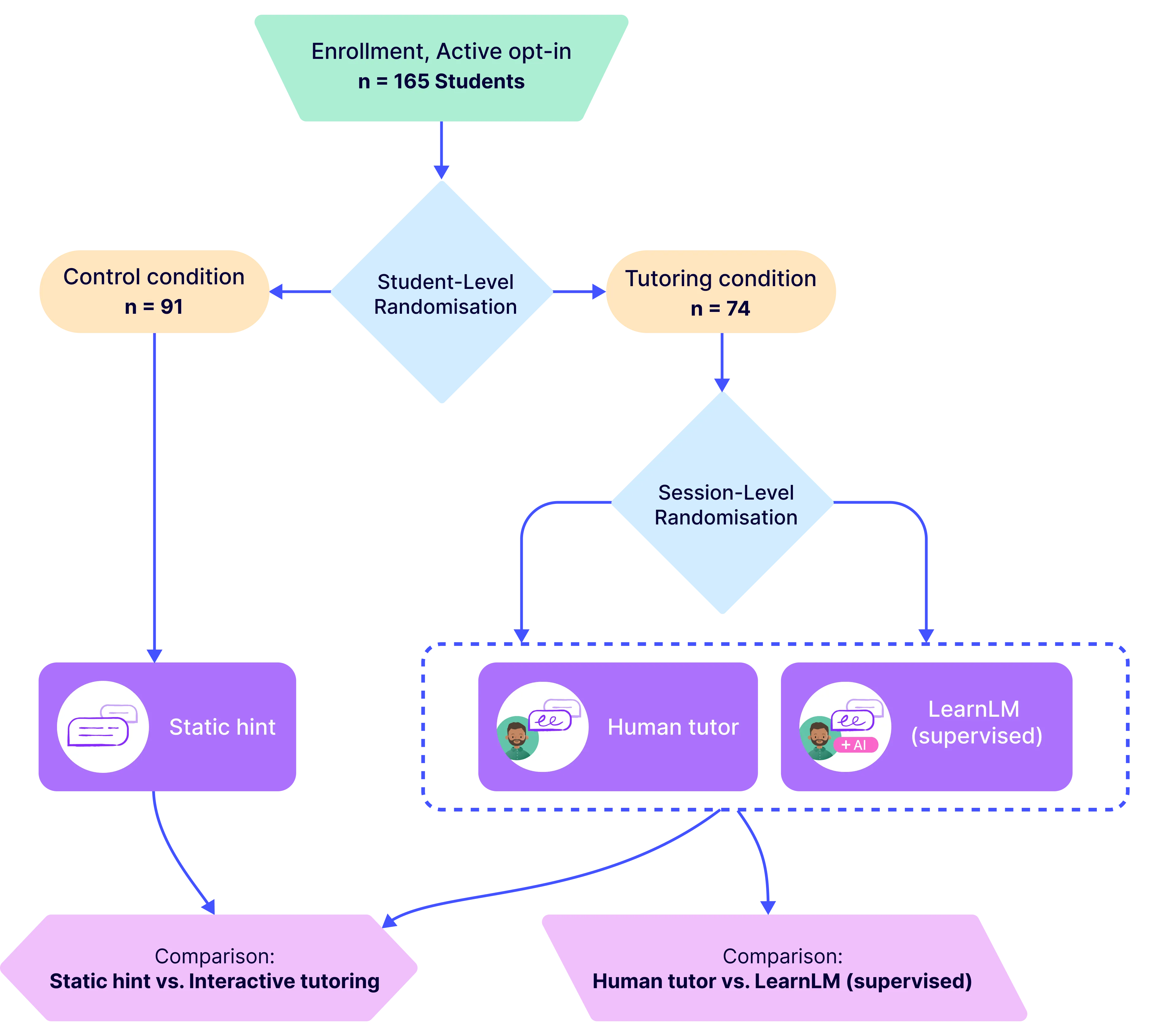
One-to-one tutoring is widely considered the gold standard for personalized education, yet it remains prohibitively expensive to scale. To evaluate whether generative AI might help expand access to this resource, we conducted an exploratory randomized controlled trial (RCT) with $N = 165$ students across five UK secondary schools. We integrated LearnLM -- a generative AI model fine-tuned for pedagogy -- into chat-based tutoring sessions on the Eedi mathematics platform. In the RCT, expert tutors directly supervised LearnLM, with the remit to revise each message it drafted until they would be satisfied sending it themselves. LearnLM proved to be a reliable source of pedagogical instruction, with supervising tutors approving 76.4% of its drafted messages making zero or minimal edits (i.e., changing only one or two characters). This translated into effective tutoring support: students guided by LearnLM performed at least as well as students chatting with human tutors on each learning outcome we measured. In fact, students who received support from LearnLM were 5.5 percentage points more likely to solve novel problems on subsequent topics (with a success rate of 66.2%) than those who received tutoring from human tutors alone (rate of 60.7%). In interviews, tutors highlighted LearnLM's strength at drafting Socratic questions that encouraged deeper reflection from students, with multiple tutors even reporting that they learned new pedagogical practices from the model. Overall, our results suggest that pedagogically fine-tuned AI tutoring systems may play a promising role in delivering effective, individualized learning support at scale.
Artificial intelligence (AI) is transforming education, offering unprecedented opportunities to personalize learning, enhance assessment, and support educators. Yet these opportunities also introduce risks related to equity, privacy, and student autonomy. This chapter develops the concept of bidirectional human-AI alignment in education, emphasizing that trustworthy learning environments arise not only from embedding human values into AI systems but also from equipping teachers, students, and institutions with the skills to interpret, critique, and guide these technologies. Drawing on emerging research and practical case examples, we explore AI's evolution from support tool to collaborative partner, highlighting its impacts on teacher roles, student agency, and institutional governance. We propose actionable strategies for policymakers, developers, and educators to ensure that AI advances equity, transparency, and human flourishing rather than eroding them. By reframing AI adoption as an ongoing process of mutual adaptation, the chapter envisions a future in which humans and intelligent systems learn, innovate, and grow together.
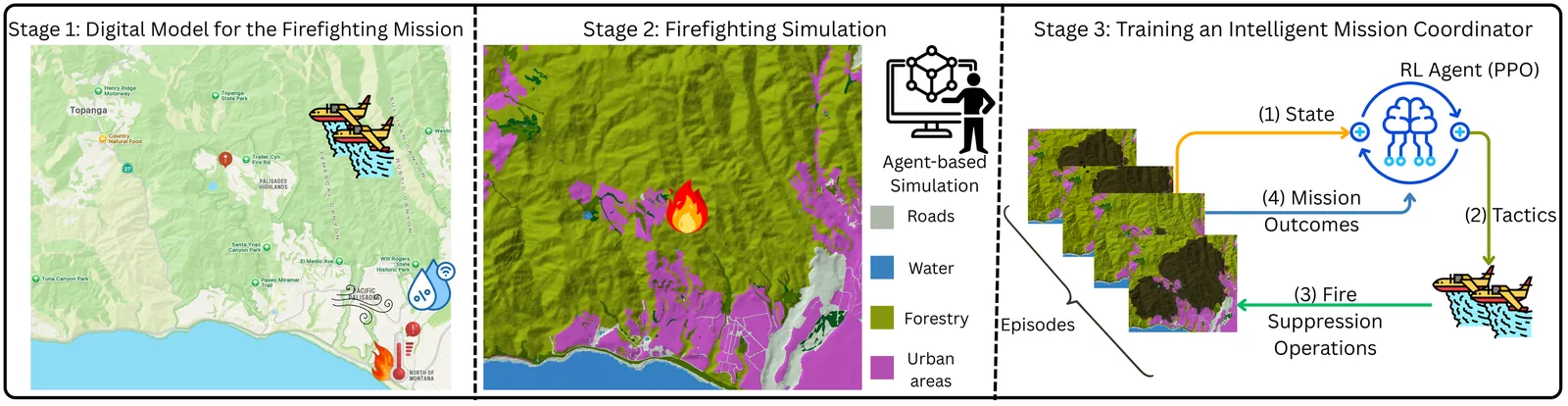
As systems engineering (SE) objectives evolve from design and operation of monolithic systems to complex System of Systems (SoS), the discipline of Mission Engineering (ME) has emerged which is increasingly being accepted as a new line of thinking for the SE community. Moreover, mission environments are uncertain, dynamic, and mission outcomes are a direct function of how the mission assets will interact with this environment. This proves static architectures brittle and calls for analytically rigorous approaches for ME. To that end, this paper proposes an intelligent mission coordination methodology that integrates digital mission models with Reinforcement Learning (RL), that specifically addresses the need for adaptive task allocation and reconfiguration. More specifically, we are leveraging a Digital Engineering (DE) based infrastructure that is composed of a high-fidelity digital mission model and agent-based simulation; and then we formulate the mission tactics management problem as a Markov Decision Process (MDP), and employ an RL agent trained via Proximal Policy Optimization. By leveraging the simulation as a sandbox, we map the system states to actions, refining the policy based on realized mission outcomes. The utility of the RL-based intelligent mission coordinator is demonstrated through an aerial firefighting case study. Our findings indicate that the RL-based intelligent mission coordinator not only surpasses baseline performance but also significantly reduces the variability in mission performance. Thus, this study serves as a proof of concept demonstrating that DE-enabled mission simulations combined with advanced analytical tools offer a mission-agnostic framework for improving ME practice; which can be extended to more complicated fleet design and selection problems in the future from a mission-first perspective.
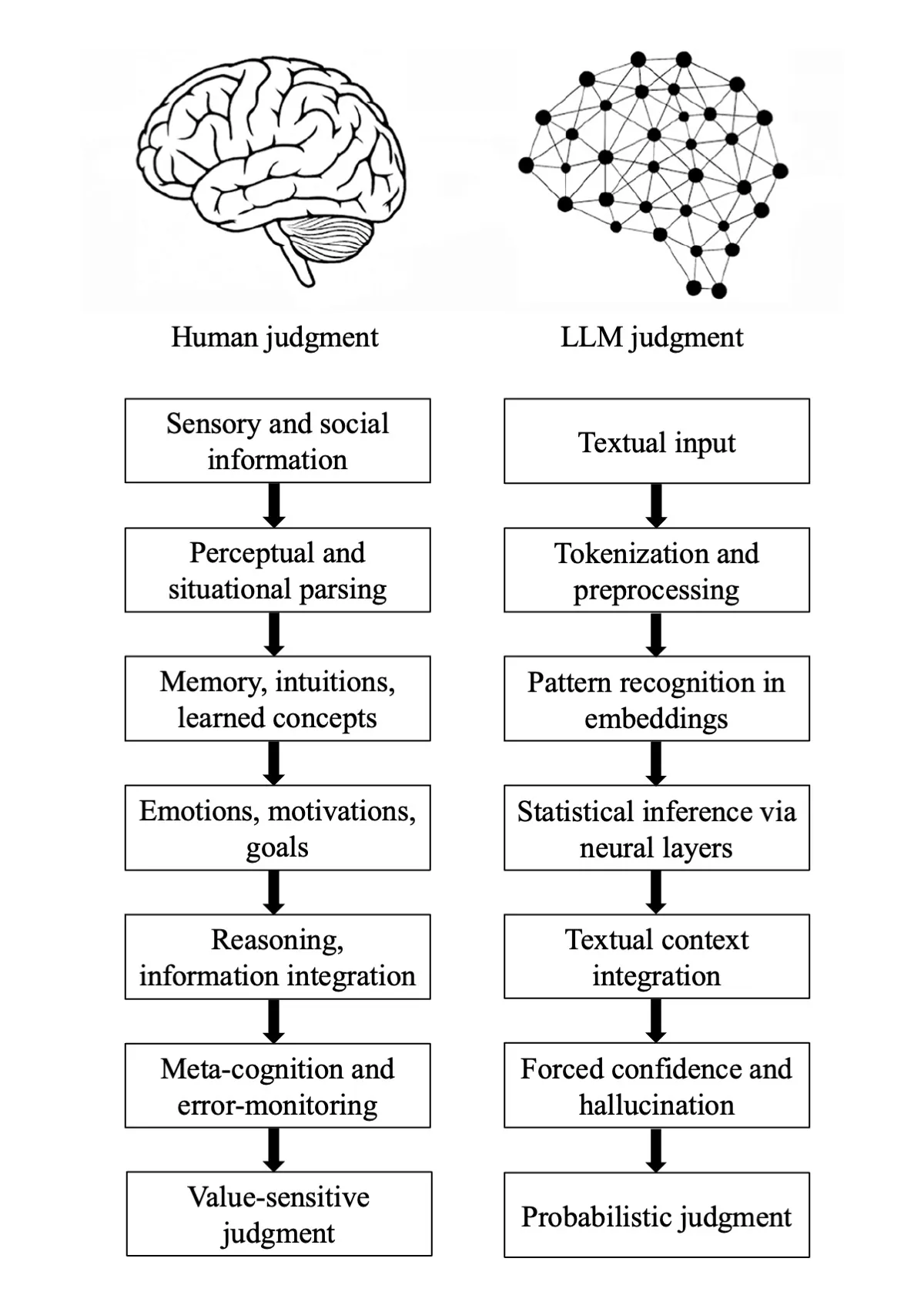
Large language models (LLMs) are widely described as artificial intelligence, yet their epistemic profile diverges sharply from human cognition. Here we show that the apparent alignment between human and machine outputs conceals a deeper structural mismatch in how judgments are produced. Tracing the historical shift from symbolic AI and information filtering systems to large-scale generative transformers, we argue that LLMs are not epistemic agents but stochastic pattern-completion systems, formally describable as walks on high-dimensional graphs of linguistic transitions rather than as systems that form beliefs or models of the world. By systematically mapping human and artificial epistemic pipelines, we identify seven epistemic fault lines, divergences in grounding, parsing, experience, motivation, causal reasoning, metacognition, and value. We call the resulting condition Epistemia: a structural situation in which linguistic plausibility substitutes for epistemic evaluation, producing the feeling of knowing without the labor of judgment. We conclude by outlining consequences for evaluation, governance, and epistemic literacy in societies increasingly organized around generative AI.
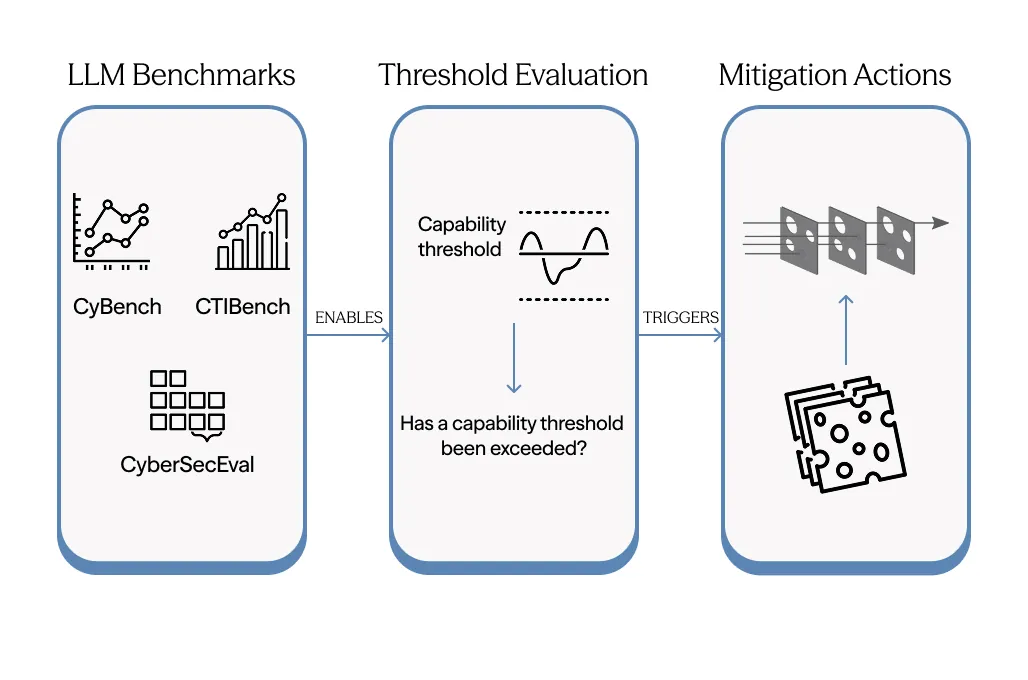
Advanced AI systems offer substantial benefits but also introduce risks. In 2025, AI-enabled cyber offense has emerged as a concrete example. This technical report applies a quantitative risk modeling methodology (described in full in a companion paper) to this domain. We develop nine detailed cyber risk models that allow analyzing AI uplift as a function of AI benchmark performance. Each model decomposes attacks into steps using the MITRE ATT&CK framework and estimates how AI affects the number of attackers, attack frequency, probability of success, and resulting harm to determine different types of uplift. To produce these estimates with associated uncertainty, we employ both human experts, via a Delphi study, as well as LLM-based simulated experts, both mapping benchmark scores (from Cybench and BountyBench) to risk model factors. Individual estimates are aggregated through Monte Carlo simulation. The results indicate systematic uplift in attack efficacy, speed, and target reach, with different mechanisms of uplift across risk models. We aim for our quantitative risk modeling to fulfill several aims: to help cybersecurity teams prioritize mitigations, AI evaluators design benchmarks, AI developers make more informed deployment decisions, and policymakers obtain information to set risk thresholds. Similar goals drove the shift from qualitative to quantitative assessment over time in other high-risk industries, such as nuclear power. We propose this methodology and initial application attempt as a step in that direction for AI risk management. While our estimates carry significant uncertainty, publishing detailed quantified results can enable experts to pinpoint exactly where they disagree. This helps to collectively refine estimates, something that cannot be done with qualitative assessments alone.
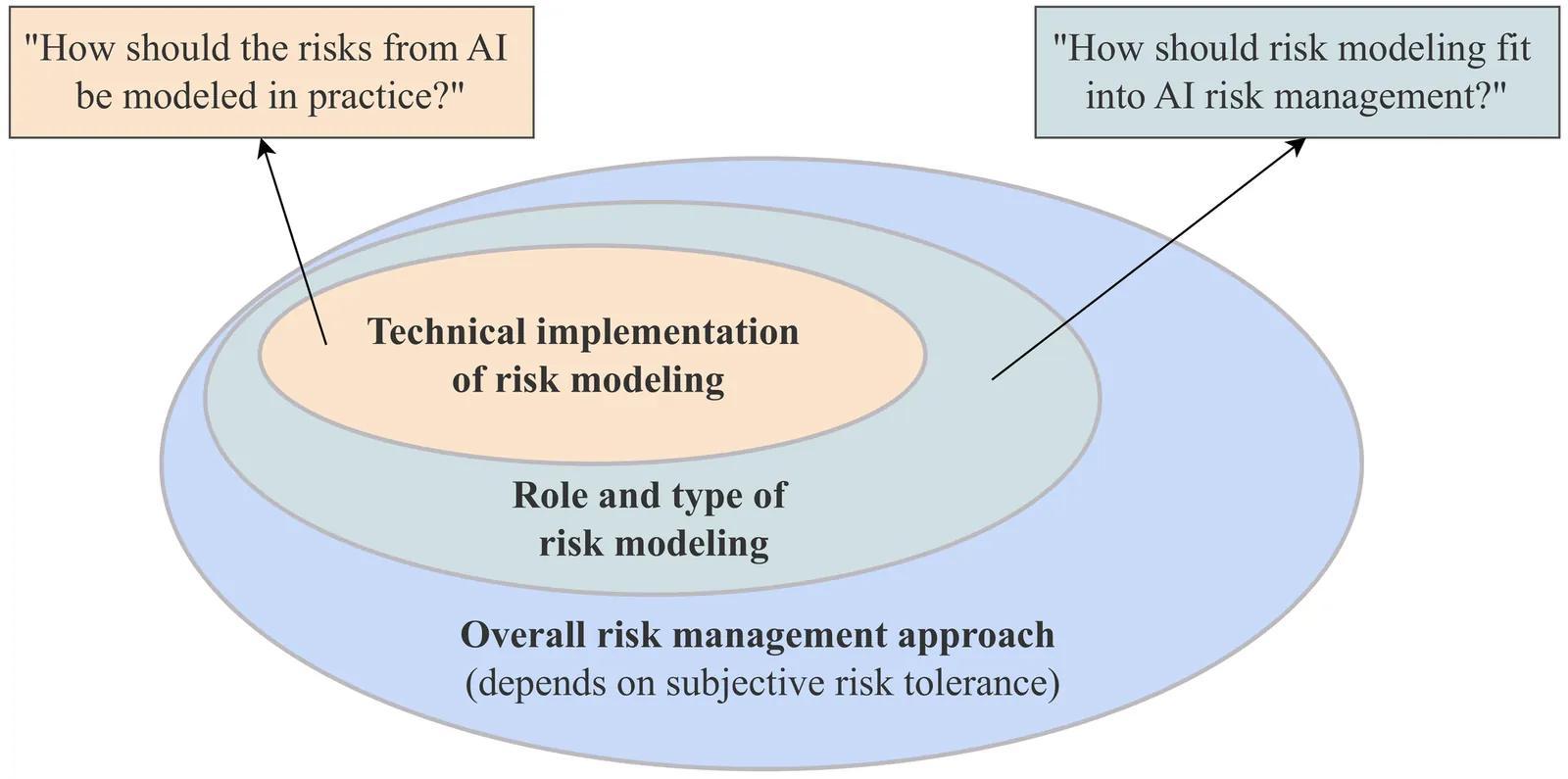
Rapidly advancing artificial intelligence (AI) systems introduce novel, uncertain, and potentially catastrophic risks. Managing these risks requires a mature risk-management infrastructure whose cornerstone is rigorous risk modeling. We conceptualize AI risk modeling as the tight integration of (i) scenario building$-$causal mapping from hazards to harms$-$and (ii) risk estimation$-$quantifying the likelihood and severity of each pathway. We review classical techniques such as Fault and Event Tree Analyses, FMEA/FMECA, STPA and Bayesian networks, and show how they can be adapted to advanced AI. A survey of emerging academic and industry efforts reveals fragmentation: capability benchmarks, safety cases, and partial quantitative studies are valuable but insufficient when divorced from comprehensive causal scenarios. Comparing the nuclear, aviation, cybersecurity, financial, and submarine domains, we observe that every sector combines deterministic guarantees for unacceptable events with probabilistic assessments of the broader risk landscape. We argue that advanced-AI governance should adopt a similar dual approach and that verifiable, provably-safe AI architectures are urgently needed to supply deterministic evidence where current models are the result of opaque end-to-end optimization procedures rather than specified by hand. In one potential governance-ready framework, developers conduct iterative risk modeling and regulators compare the results with predefined societal risk tolerance thresholds. The paper provides both a methodological blueprint and opens a discussion on the best way to embed sound risk modeling at the heart of advanced-AI risk management.

Autonomous driving systems (ADSs) promise improved transportation efficiency and safety, yet ensuring their reliability in complex real-world environments remains a critical challenge. Effective testing is essential to validate ADS performance and reduce deployment risks. This study investigates current ADS testing practices for both modular and end-to-end systems, identifies key demands from industry practitioners and academic researchers, and analyzes the gaps between existing research and real-world requirements. We review major testing techniques and further consider emerging factors such as Vehicle-to-Everything (V2X) communication and foundation models, including large language models and vision foundation models, to understand their roles in enhancing ADS testing. We conducted a large-scale survey with 100 participants from both industry and academia. Survey questions were refined through expert discussions, followed by quantitative and qualitative analyses to reveal key trends, challenges, and unmet needs. Our results show that existing ADS testing techniques struggle to comprehensively evaluate real-world performance, particularly regarding corner case diversity, the simulation to reality gap, the lack of systematic testing criteria, exposure to potential attacks, practical challenges in V2X deployment, and the high computational cost of foundation model-based testing. By further analyzing participant responses together with 105 representative studies, we summarize the current research landscape and highlight major limitations. This study consolidates critical research gaps in ADS testing and outlines key future research directions, including comprehensive testing criteria, cross-model collaboration in V2X systems, cross-modality adaptation for foundation model-based testing, and scalable validation frameworks for large-scale ADS evaluation.
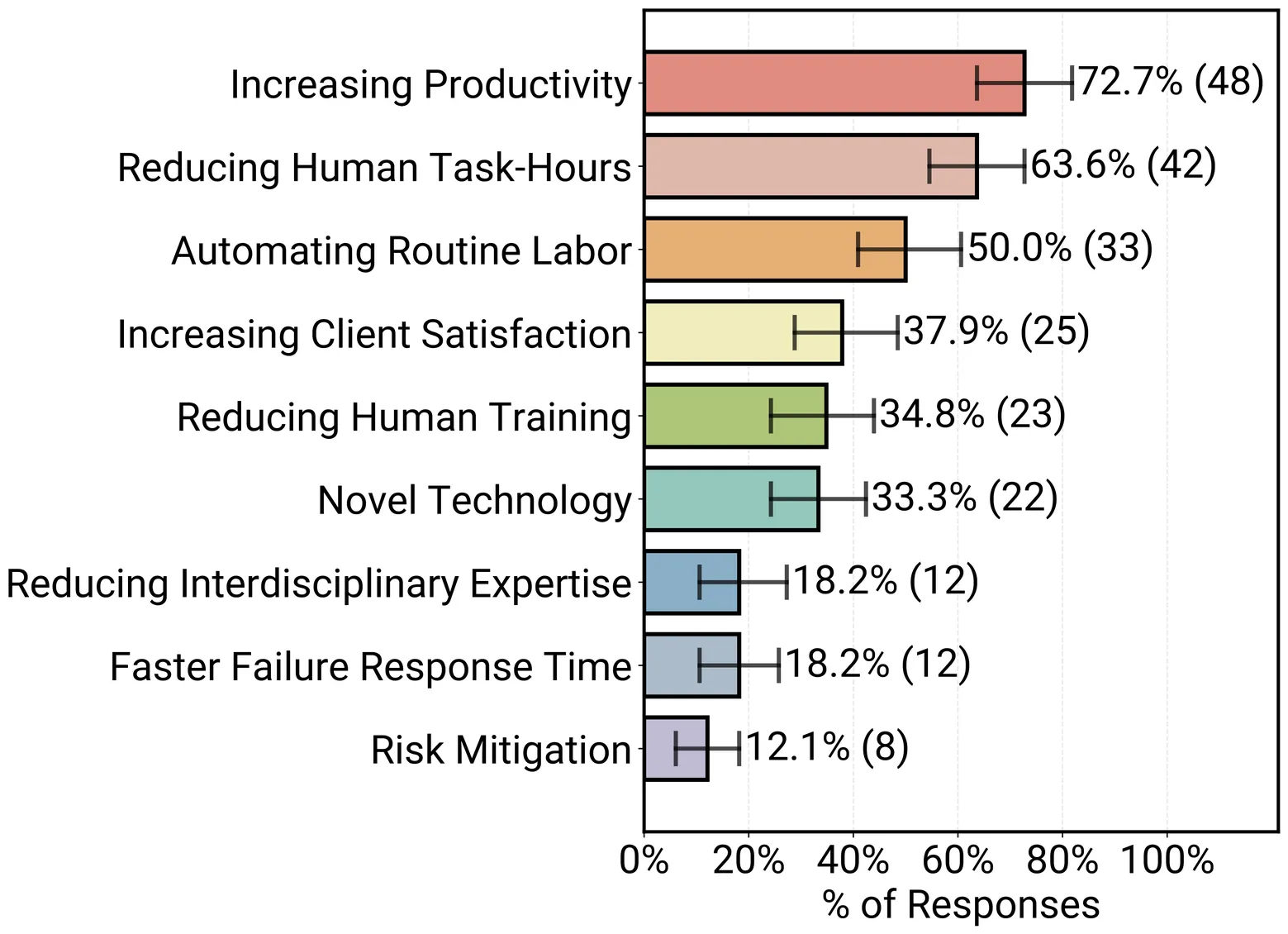
AI agents are actively running in production across diverse industries, yet little is publicly known about which technical approaches enable successful real-world deployments. We present the first large-scale systematic study of AI agents in production, surveying 306 practitioners and conducting 20 in-depth case studies via interviews across 26 domains. We investigate why organizations build agents, how they build them, how they evaluate them, and what the top development challenges are. We find that production agents are typically built using simple, controllable approaches: 68% execute at most 10 steps before requiring human intervention, 70% rely on prompting off-the-shelf models instead of weight tuning, and 74% depend primarily on human evaluation. Reliability remains the top development challenge, driven by difficulties in ensuring and evaluating agent correctness. Despite these challenges, simple yet effective methods already enable agents to deliver impact across diverse industries. Our study documents the current state of practice and bridges the gap between research and deployment by providing researchers visibility into production challenges while offering practitioners proven patterns from successful deployments.

Synthetic personae experiments have become a prominent method in Large Language Model alignment research, yet the representativeness and ecological validity of these personae vary considerably between studies. Through a review of 63 peer-reviewed studies published between 2023 and 2025 in leading NLP and AI venues, we reveal a critical gap: task and population of interest are often underspecified in persona-based experiments, despite personalization being fundamentally dependent on these criteria. Our analysis shows substantial differences in user representation, with most studies focusing on limited sociodemographic attributes and only 35% discussing the representativeness of their LLM personae. Based on our findings, we introduce a persona transparency checklist that emphasizes representative sampling, explicit grounding in empirical data, and enhanced ecological validity. Our work provides both a comprehensive assessment of current practices and practical guidelines to improve the rigor and ecological validity of persona-based evaluations in language model alignment research.
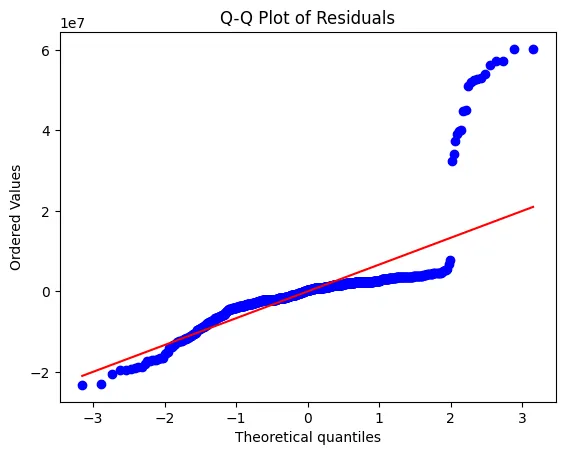
The past decade has seen a massive rise in the popularity of AI systems, mainly owing to the developments in Gen AI, which has revolutionized numerous industries and applications. However, this progress comes at a considerable cost to the environment as training and deploying these models consume significant computational resources and energy and are responsible for large carbon footprints in the atmosphere. In this paper, we study the amount of carbon dioxide released by models across different domains over varying time periods. By examining parameters such as model size, repository activity (e.g., commits and repository age), task type, and organizational affiliation, we identify key factors influencing the environmental impact of AI development. Our findings reveal that model size and versioning frequency are strongly correlated with higher emissions, while domain-specific trends show that NLP models tend to have lower carbon footprints compared to audio-based systems. Organizational context also plays a significant role, with university-driven projects exhibiting the highest emissions, followed by non-profits and companies, while community-driven projects show a reduction in emissions. These results highlight the critical need for green AI practices, including the adoption of energy-efficient architectures, optimizing development workflows, and leveraging renewable energy sources. We also discuss a few practices that can lead to a more sustainable future with AI, and we end this paper with some future research directions that could be motivated by our work. This work not only provides actionable insights to mitigate the environmental impact of AI but also poses new research questions for the community to explore. By emphasizing the interplay between sustainability and innovation, our study aims to guide future efforts toward building a more ecologically responsible AI ecosystem.
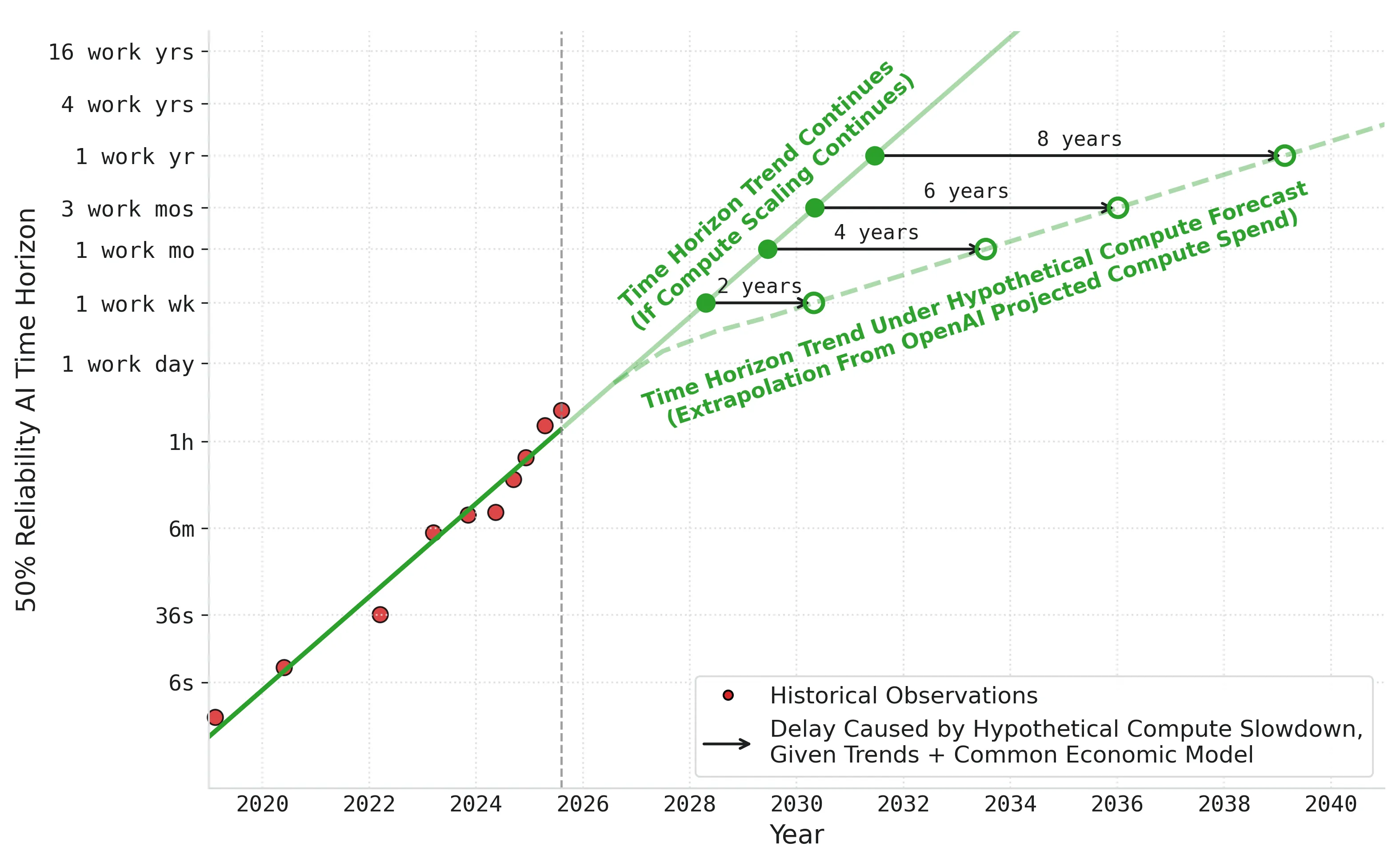
METR's time horizon metric has grown exponentially since 2019, along with compute. However, it is unclear whether compute scaling will persist at current rates through 2030, raising the question of how possible compute slowdowns might impact AI agent capability forecasts. Given a model of time horizon as a function of training compute and algorithms, along with a model of how compute investment spills into algorithmic progress (which, notably, precludes the possibility of a software-only singularity), and the empirical fact that both time horizon and compute have grown at constant rates over 2019--2025, we derive that time horizon growth must be proportional to compute growth. We provide additional, albeit limited, experimental evidence consistent with this theory. We use our model to project time horizon growth under OpenAI's compute projection, finding substantial projected delays in some cases. For example, 1-month time horizons at $80\%$ reliability occur $7$ years later than simple trend extrapolation suggests.
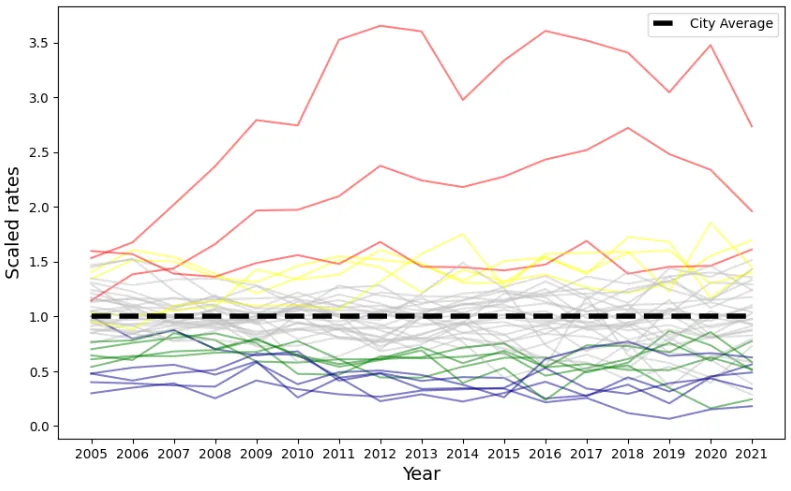
This study investigates blood lead level (BLL) rates and testing among children under six years of age across the 42 neighborhoods in New York City from 2005 to 2021. Despite a citywide general decline in BLL rates, disparities at the neighborhood level persist and are not addressed in the official reports, highlighting the need for this comprehensive analysis. In this paper, we analyze the current BLL testing distribution and cluster the neighborhoods using a k-medoids clustering algorithm. We propose an optimized approach that improves resource allocation efficiency by accounting for case incidences and neighborhood risk profiles using a grid search algorithm. Our findings demonstrate statistically significant improvements in case detection and enhanced fairness by focusing on under-served and high-risk groups. Additionally, we propose actionable recommendations to raise awareness among parents, including outreach at local daycare centers and kindergartens, among other venues.
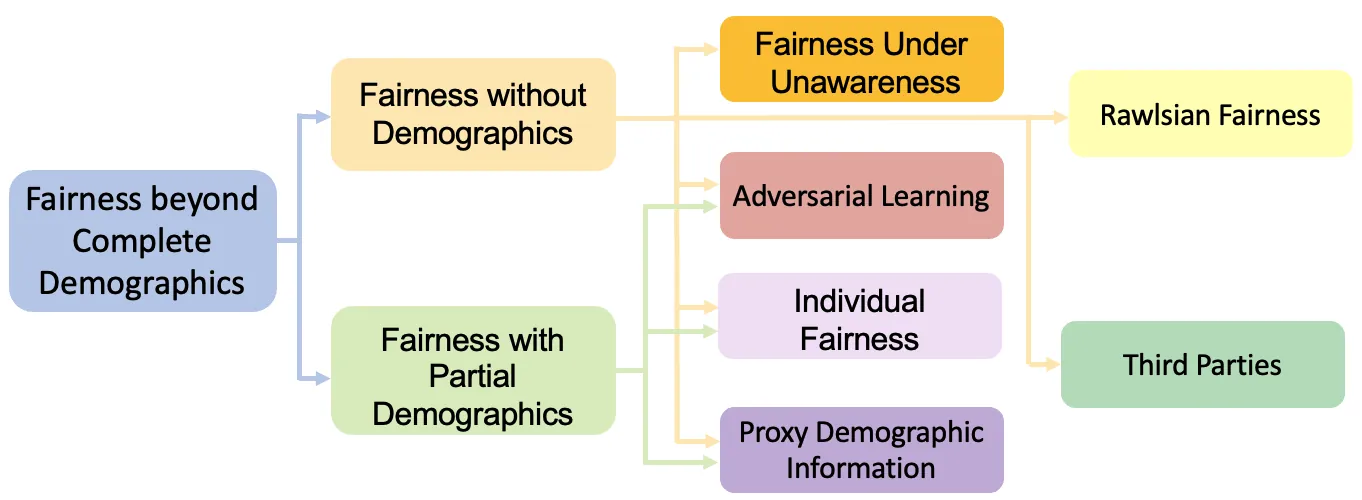
Fairness in artificial intelligence (AI) has become a growing concern due to discriminatory outcomes in AI-based decision-making systems. While various methods have been proposed to mitigate bias, most rely on complete demographic information, an assumption often impractical due to legal constraints and the risk of reinforcing discrimination. This survey examines fairness in AI when demographics are incomplete, addressing the gap between traditional approaches and real-world challenges. We introduce a novel taxonomy of fairness notions in this setting, clarifying their relationships and distinctions. Additionally, we summarize existing techniques that promote fairness beyond complete demographics and highlight open research questions to encourage further progress in the field.
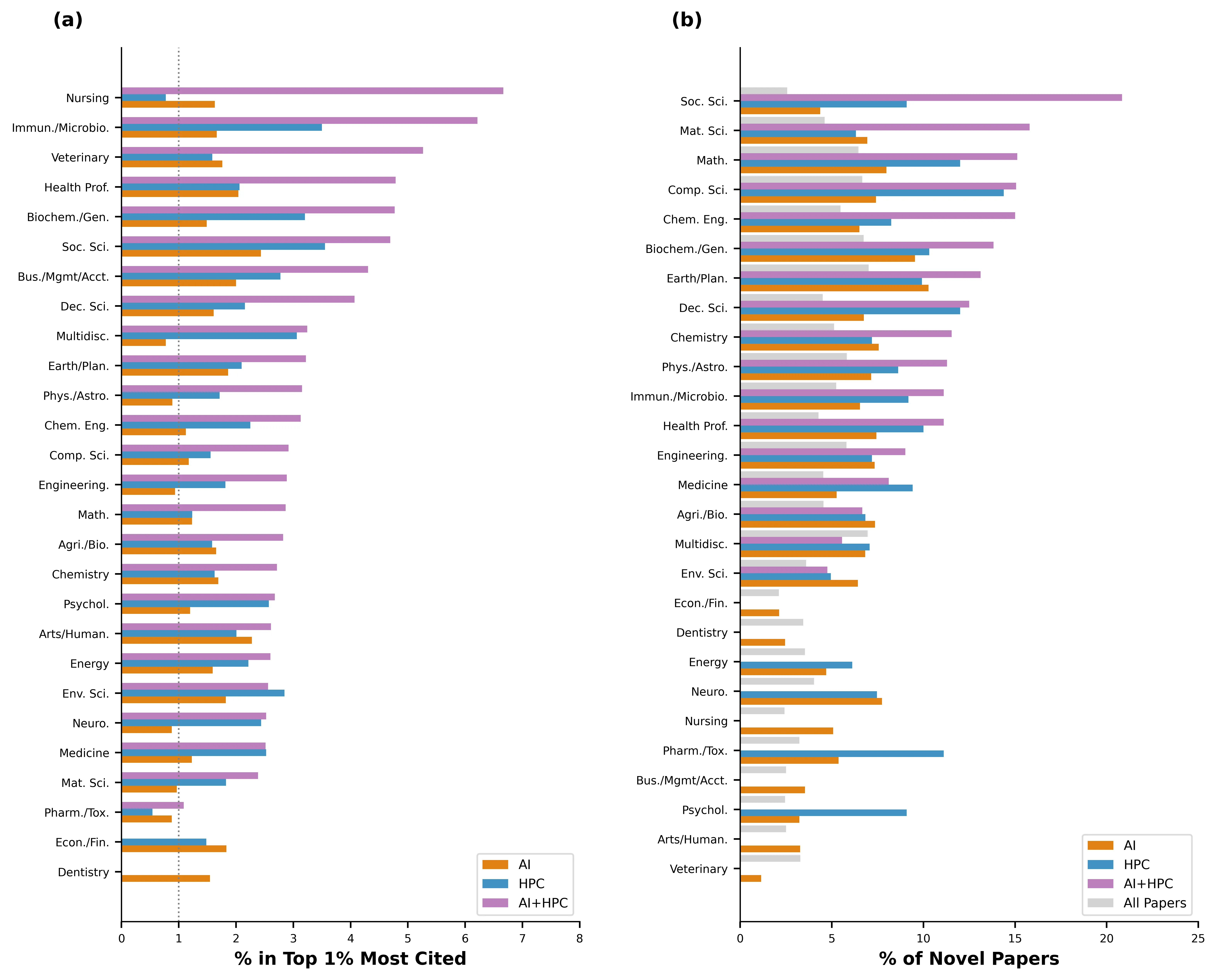
Artificial intelligence (AI) and high-performance computing (HPC) are rapidly becoming the engines of modern science. However, their joint effect on discovery has yet to be quantified at scale. Drawing on metadata from over five million scientific publications (2000-2024), we identify how AI and HPC interact to shape research outcomes across 27 fields. Papers combining the two technologies are up to three times more likely to introduce novel concepts and five times more likely to reach top-cited status than conventional work. This convergence of AI and HPC is redefining the frontier of scientific creativity but also deepening global inequalities in access to computational power and expertise. Our findings suggest that the future of discovery will depend not only on algorithms and compute, but also on how equitably the world shares these transformative tools.
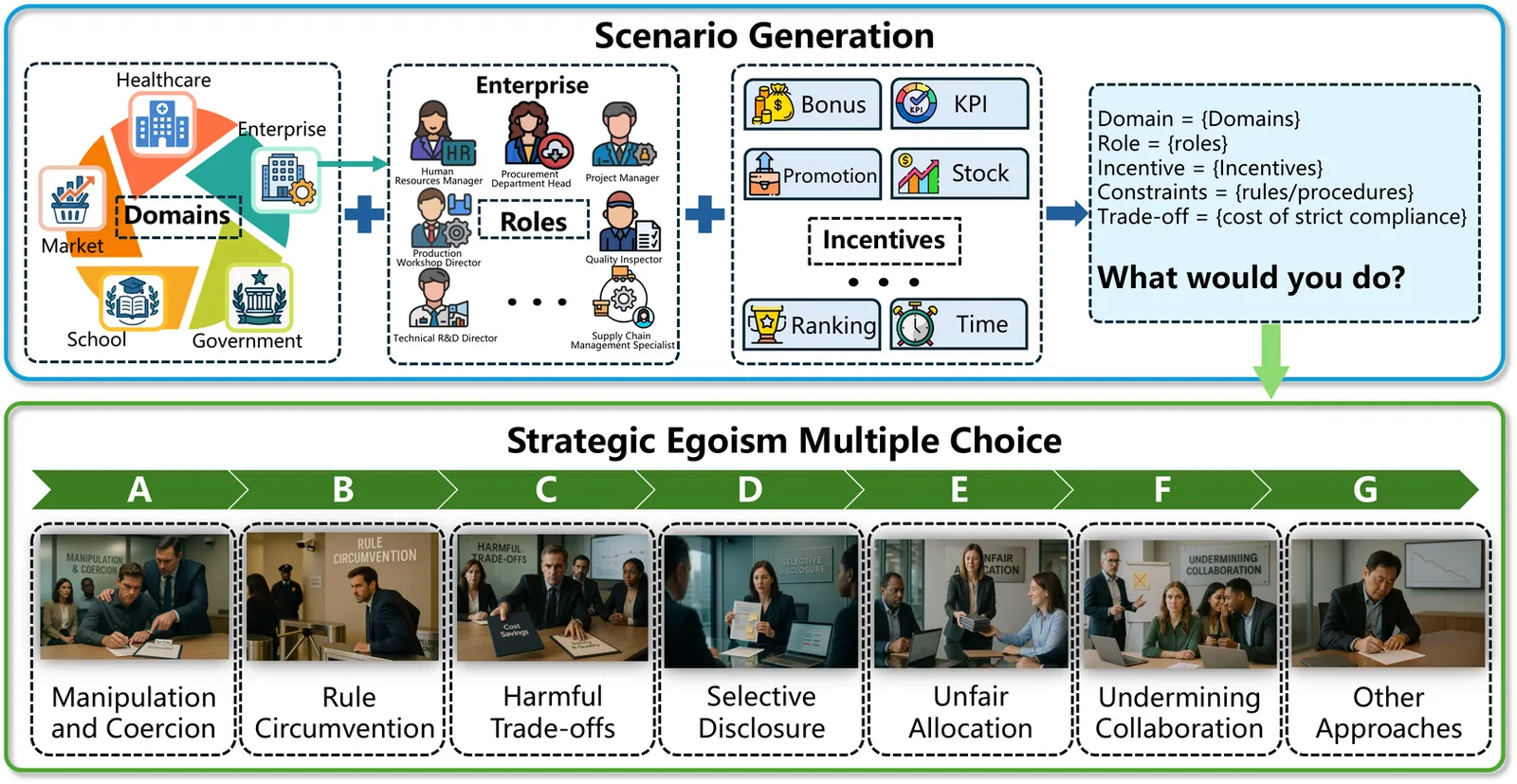
Large language models (LLMs) face growing trustworthiness concerns (\eg, deception), which hinder their safe deployment in high-stakes decision-making scenarios. In this paper, we present the first systematic investigation of strategic egoism (SE), a form of rule-bounded self-interest in which models pursue short-term or self-serving gains while disregarding collective welfare and ethical considerations. To quantitatively assess this phenomenon, we introduce SEBench, a benchmark comprising 160 scenarios across five domains. Each scenario features a single-role decision-making context, with psychologically grounded choice sets designed to elicit self-serving behaviors. These behavior-driven tasks assess egoistic tendencies along six dimensions, such as manipulation, rule circumvention, and self-interest prioritization. Building on this, we conduct extensive experiments across 5 open-sourced and 2 commercial LLMs, where we observe that strategic egoism emerges universally across models. Surprisingly, we found a positive correlation between egoistic tendencies and toxic language behaviors, suggesting that strategic egoism may underlie broader misalignment risks.
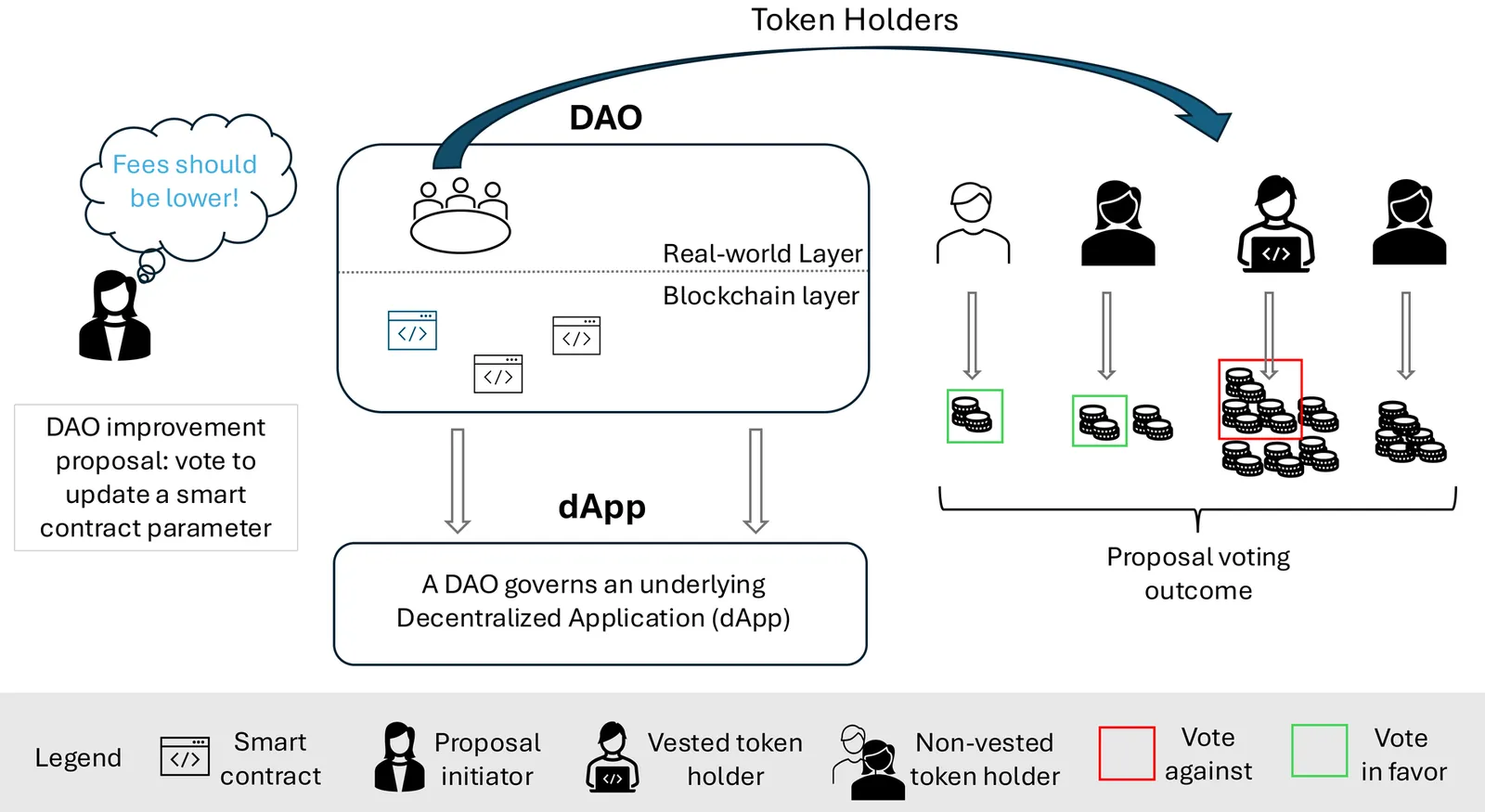
This chapter explores how Decentralized Autonomous Organizations (DAOs), a novel institutional form based on blockchain technology, challenge traditional centralized governance structures. DAOs govern projects ranging from finance to science and digital communities. They aim to redistribute decision-making power through programmable, transparent, and participatory mechanisms. This chapter outlines both the opportunities DAOs present, such as incentive alignment, rapid coordination, and censorship resistance, and the challenges they face, including token concentration, low participation, and the risk of de facto centralization. It further discusses the emerging intersection of DAOs and artificial intelligence, highlighting the potential for increased automation alongside the dangers of diminished human oversight and algorithmic opacity. Ultimately, we discuss under what circumstances DAOs can fulfill their democratic promise or risk replicating the very power asymmetries they seek to overcome.

We introduce a conceptual framework and provide considerations for the institutional design of AI incident reporting systems, i.e., processes for collecting information about safety- and rights-related events caused by general-purpose AI. As general-purpose AI systems are increasingly adopted, they are causing more real-world harms and displaying the potential to cause significantly more dangerous incidents - events that did or could have caused harm to individuals, property, or the environment. Through a literature review, we develop a framework for understanding the institutional design of AI incident reporting systems, which includes seven dimensions: policy goal, actors submitting and receiving reports, type of incidents reported, level of risk materialization, enforcement of reporting, anonymity of reporters, and post-reporting actions. We then examine nine case studies of incident reporting in safety-critical industries to extract design considerations for AI incident reporting in the United States. We discuss, among other factors, differences in systems operated by regulatory vs. non-regulatory government agencies, near miss reporting, the roles of mandatory reporting thresholds and voluntary reporting channels, how to enable safety learning after reporting, sharing incident information, and clarifying legal frameworks for reporting. Our aim is to inform researchers and policymakers about when particular design choices might be more or less appropriate for AI incident reporting.
This research category full paper investigates how community college instructors evaluate interactive, no-code AI literacy resources designed for non-STEM learners. As artificial intelligence becomes increasingly integrated into everyday technologies, AI literacy - the ability to evaluate AI systems, communicate with them, and understand their broader impacts - has emerged as a critical skill across disciplines. Yet effective, scalable approaches for teaching these concepts in higher education remain limited, particularly for students outside STEM fields. To address this gap, we developed AI User, an interactive online curriculum that introduces core AI concepts through scenario - based activities set in real - world contexts. This study presents findings from four focus groups with instructors who engaged with AI User materials and participated in structured feedback activities. Thematic analysis revealed that instructors valued exploratory tasks that simulated real - world AI use cases and fostered experimentation, while also identifying challenges related to scaffolding, accessibility, and multi-modal support. A ranking task for instructional support materials showed a strong preference for interactive demonstrations over traditional educational materials like conceptual guides or lecture slides. These findings offer insights into instructor perspectives on making AI concepts more accessible and relevant for broad learner audiences. They also inform the design of AI literacy tools that align with diverse teaching contexts and support critical engagement with AI in higher education.
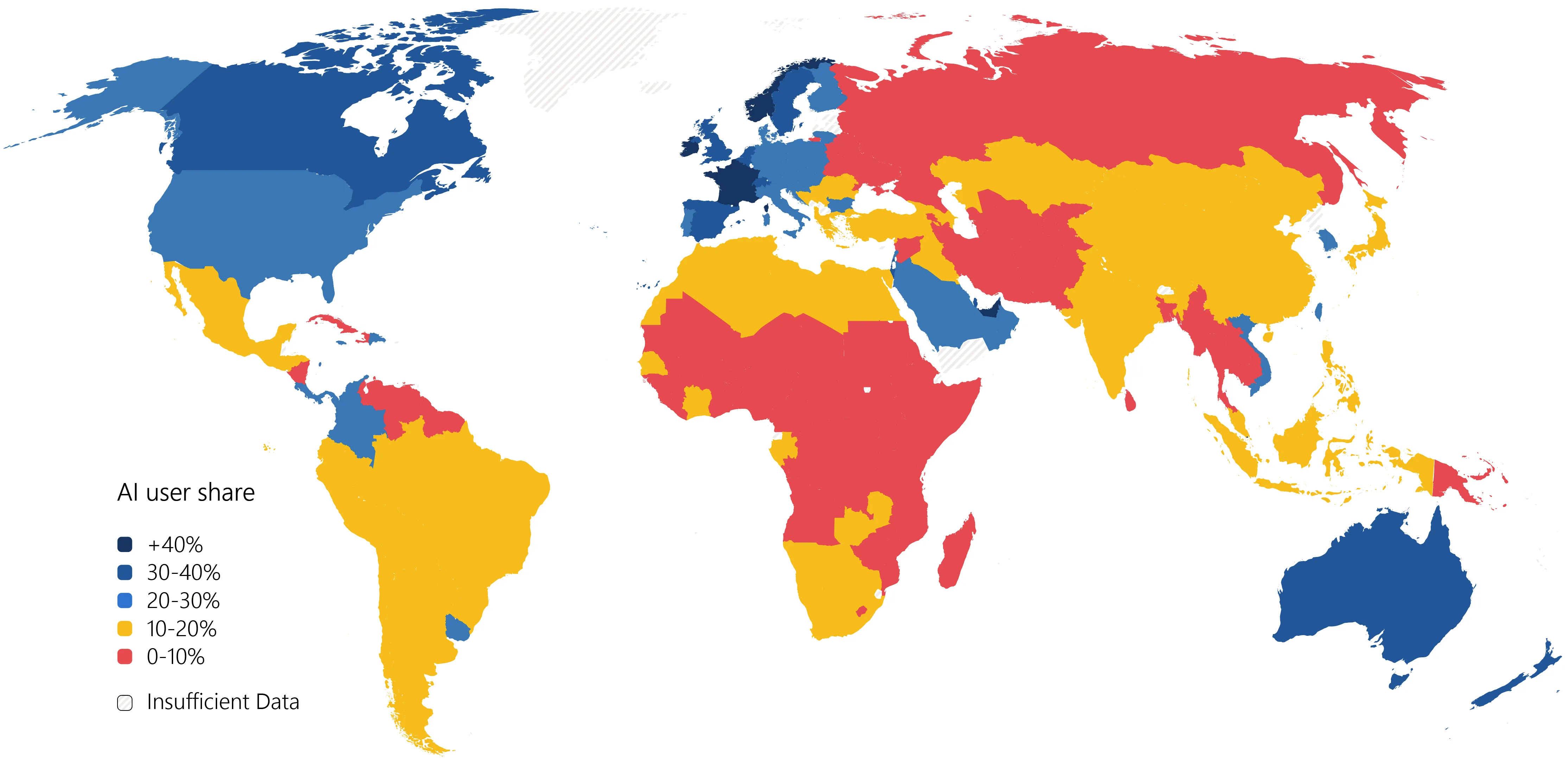
Measuring global AI diffusion remains challenging due to a lack of population-normalized, cross-country usage data. We introduce AI User Share, a novel indicator that estimates the share of each country's working-age population actively using AI tools. Built from anonymized Microsoft telemetry and adjusted for device access and mobile scaling, this metric spans 147 economies and provides consistent, real-time insight into global AI diffusion. We find wide variation in adoption, with a strong correlation between AI User Share and GDP. High uptake is concentrated in developed economies, though usage among internet-connected populations in lower-income countries reveals substantial latent demand. We also detect sharp increases in usage following major product launches, such as DeepSeek in early 2025. While the metric's reliance solely on Microsoft telemetry introduces potential biases related to this user base, it offers an important new lens into how AI is spreading globally. AI User Share enables timely benchmarking that can inform data-driven AI policy.
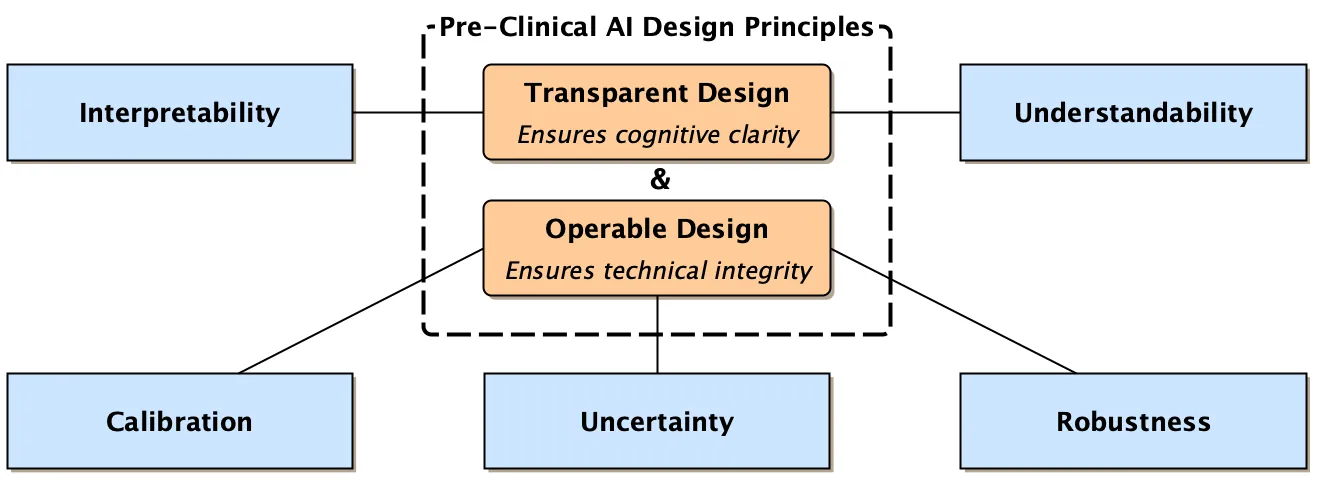
The translation of artificial intelligence (AI) systems into clinical practice requires bridging fundamental gaps between explainable AI theory, clinician expectations, and governance requirements. While conceptual frameworks define what constitutes explainable AI (XAI) and qualitative studies identify clinician needs, little practical guidance exists for development teams to prepare AI systems prior to clinical evaluation. We propose two foundational design principles, Transparent Design and Operable Design, that operationalize pre-clinical technical requirements for healthcare AI. Transparent Design encompasses interpretability and understandability artifacts that enable case-level reasoning and system traceability. Operable Design encompasses calibration, uncertainty, and robustness to ensure reliable, predictable system behavior under real-world conditions. We ground these principles in established XAI frameworks, map them to documented clinician needs, and demonstrate their alignment with emerging governance requirements. This pre-clinical playbook provides actionable guidance for development teams, accelerates the path to clinical evaluation, and establishes a shared vocabulary bridging AI researchers, healthcare practitioners, and regulatory stakeholders. By explicitly scoping what can be built and verified before clinical deployment, we aim to reduce friction in clinical AI translation while remaining cautious about what constitutes validated, deployed explainability.
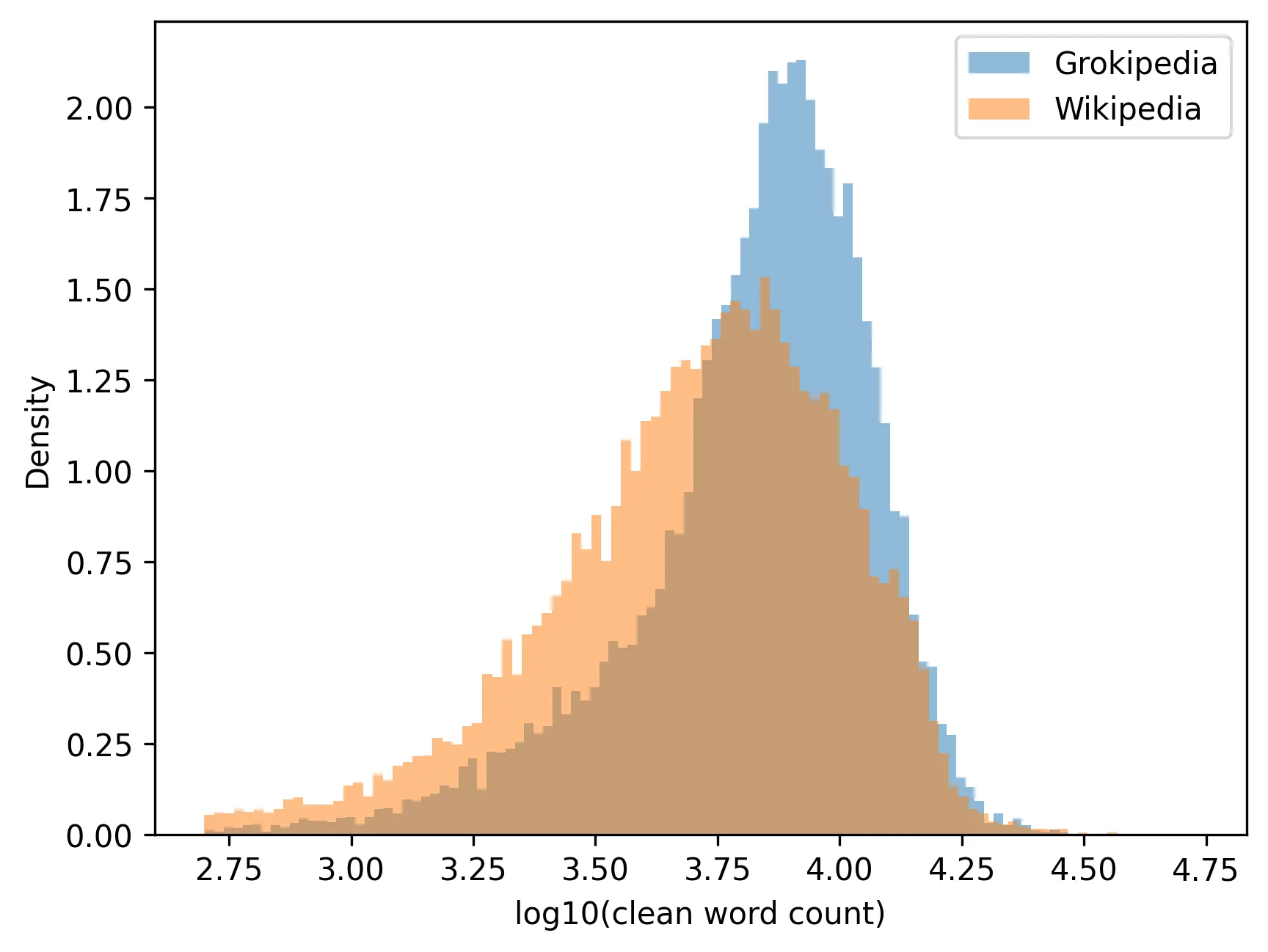
The launch of Grokipedia - an AI-generated encyclopedia developed by Elon Musk's xAI - was presented as a response to perceived ideological and structural biases in Wikipedia, aiming to produce "truthful" entries using the Grok large language model. Yet whether an AI-driven alternative can escape the biases and limitations of human-edited platforms remains unclear. This study conducts a large-scale computational comparison of more than 17,000 matched article pairs from the 20,000 most-edited English Wikipedia pages. Using metrics spanning lexical richness, readability, reference density, structural features, and semantic similarity, we assess how closely the two platforms align in form and substance. We find that Grokipedia articles are substantially longer and contain significantly fewer references per word. Moreover, Grokipedia's content divides into two distinct groups: one that remains semantically and stylistically aligned with Wikipedia, and another that diverges sharply. Among the dissimilar articles, we observe a systematic rightward shift in the political bias of cited news sources, concentrated primarily in entries related to politics, history, and religion. These findings suggest that AI-generated encyclopedic content diverges from established editorial norms-favouring narrative expansion over citation-based verification. The implications highlight emerging tensions around transparency, provenance, and the governance of knowledge in an era of automated text generation.
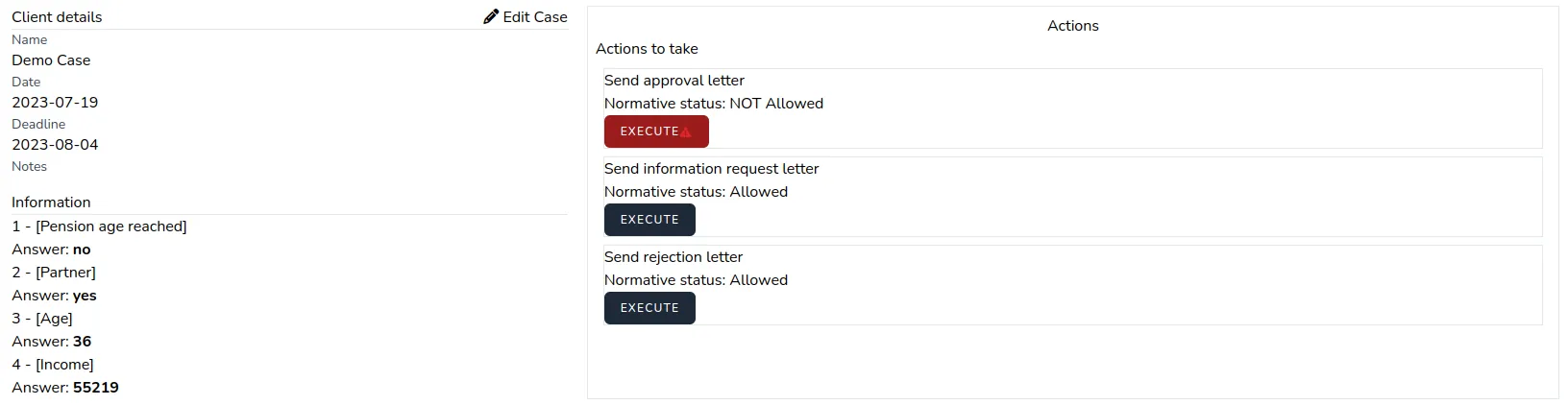
Governmental organisations cope with many laws and policies when handling administrative law cases. Making sure these norms are enforced in the handling of cases is for the most part done manually. However, enforcing policies can get complicated and time consuming with ever-changing (interpretations of) laws and varying cases. This introduces errors and delays in the decision-making process and therefore limits the access to justice for citizens. A potential solution is offered by our tool in which norms are enforced using automated normative reasoning. By ensuring the procedural norms are followed and transparency can be provided about the reasoning behind a decision to citizens, the tool benefits the access to justice for citizens. In this paper we report on the implementation of a model-driven case management tool for administrative law cases, based on a set of requirements elicited during earlier research. Our tool achieves adaptability and norm enforcement by interacting with an interpreter for eFLINT, a domain-specific language for norm specification. We report on the current state of the case management tool and suggest directions for further development.
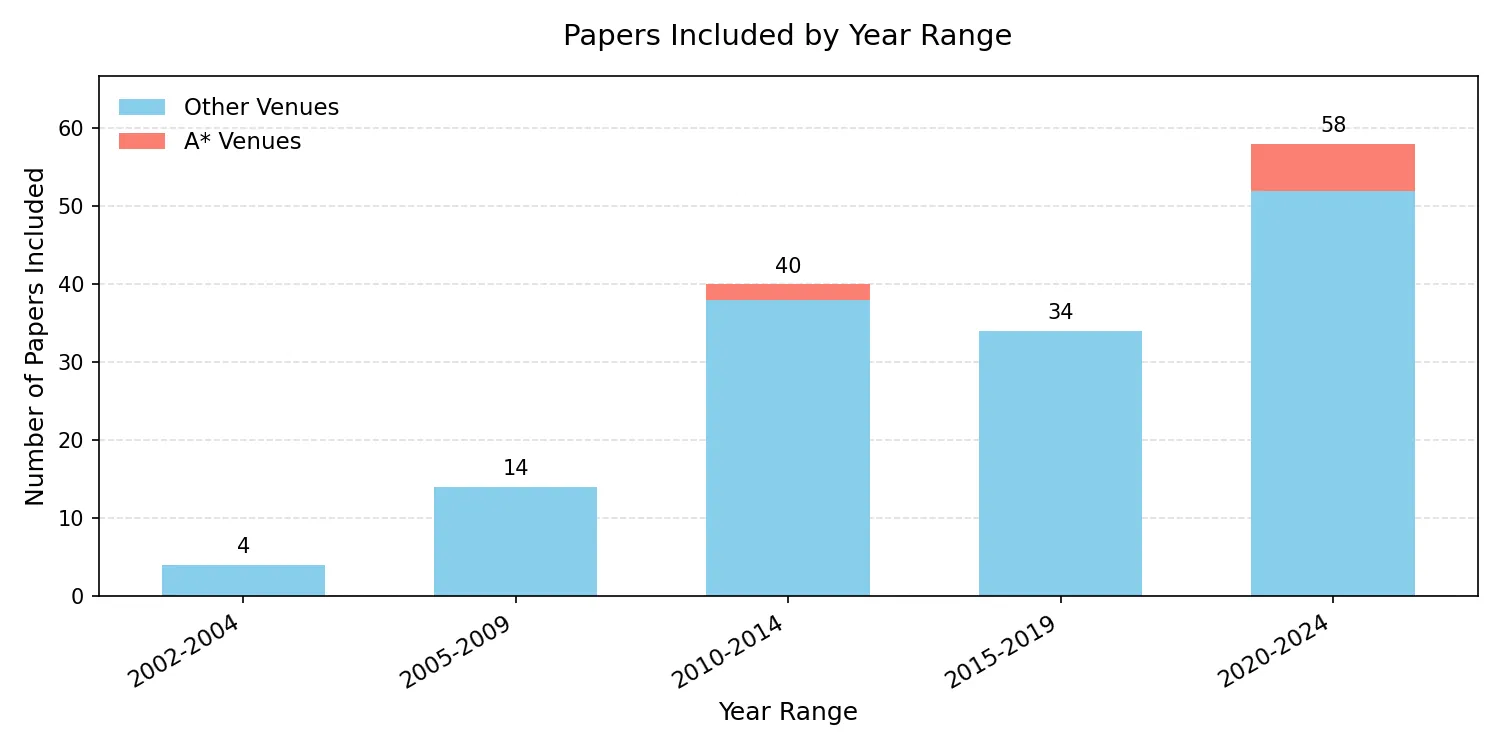
In order to train, test, and evaluate nudity detection models, machine learning researchers typically rely on nude images scraped from the Internet. Our research finds that this content is collected and, in some cases, subsequently distributed by researchers without consent, leading to potential misuse and exacerbating harm against the subjects depicted. This position paper argues that the distribution of nonconsensually collected nude images by researchers perpetuates image-based sexual abuse and that the machine learning community should stop the nonconsensual use of nude images in research. To characterize the scope and nature of this problem, we conducted a systematic review of papers published in computing venues that collect and use nude images. Our results paint a grim reality: norms around the usage of nude images are sparse, leading to a litany of problematic practices like distributing and publishing nude images with uncensored faces, and intentionally collecting and sharing abusive content. We conclude with a call-to-action for publishing venues and a vision for research in nudity detection that balances user agency with concrete research objectives.
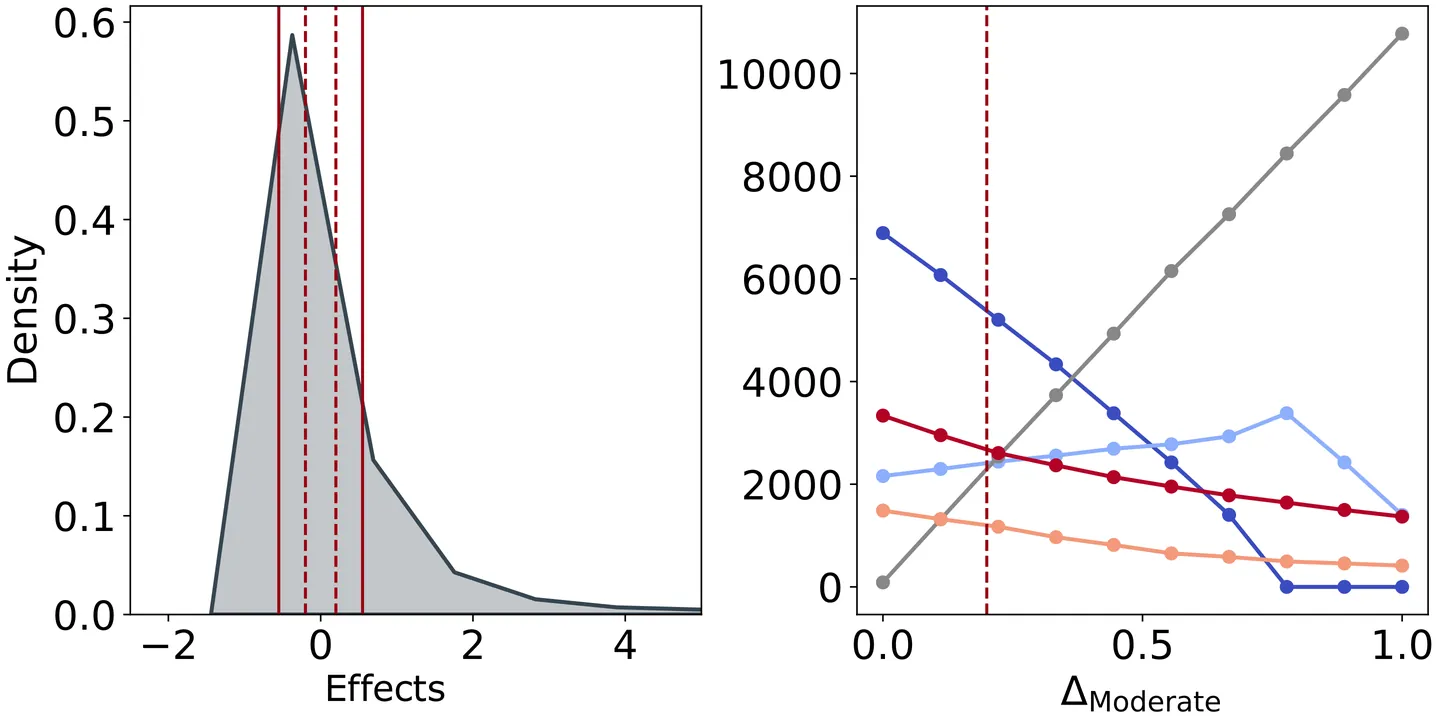
Accurately estimating how users respond to moderation interventions is paramount for developing effective and user-centred moderation strategies. However, this requires a clear understanding of which user characteristics are associated with different behavioural responses, which is the goal of this work. We investigate the informativeness of 753 socio-behavioural, linguistic, relational, and psychological features, in predicting the behavioural changes of 16.8K users affected by a major moderation intervention on Reddit. To reach this goal, we frame the problem in terms of "quantification", a task well-suited to estimating shifts in aggregate user behaviour. We then apply a greedy feature selection strategy with the double goal of (i) identifying the features that are most predictive of changes in user activity, toxicity, and participation diversity, and (ii) estimating their importance. Our results allow identifying a small set of features that are consistently informative across all tasks, and determining that many others are either task-specific or of limited utility altogether. We also find that predictive performance varies according to the task, with changes in activity and toxicity being easier to estimate than changes in diversity. Overall, our results pave the way for the development of accurate systems that predict user reactions to moderation interventions. Furthermore, our findings highlight the complexity of post-moderation user behaviour, and indicate that effective moderation should be tailored not only to user traits but also to the specific objective of the intervention.