Trending in Human-Computer Interaction
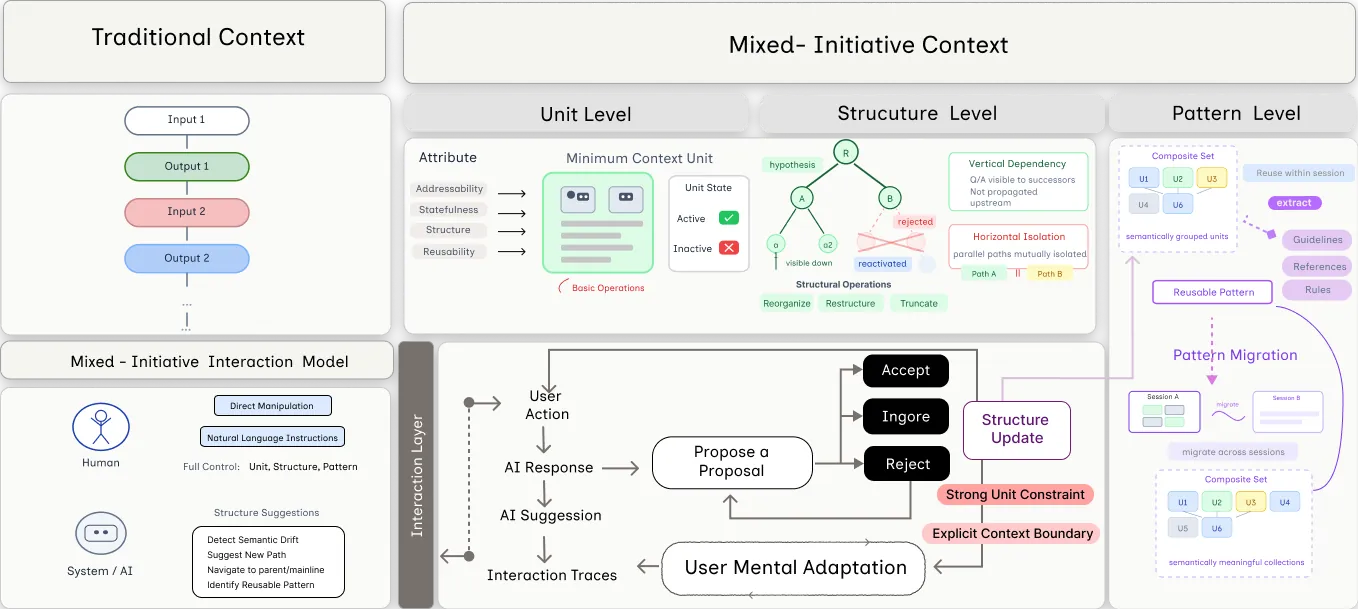
Mixed-Initiative Context: Structuring and Managing Context for Human-AI Collaboration
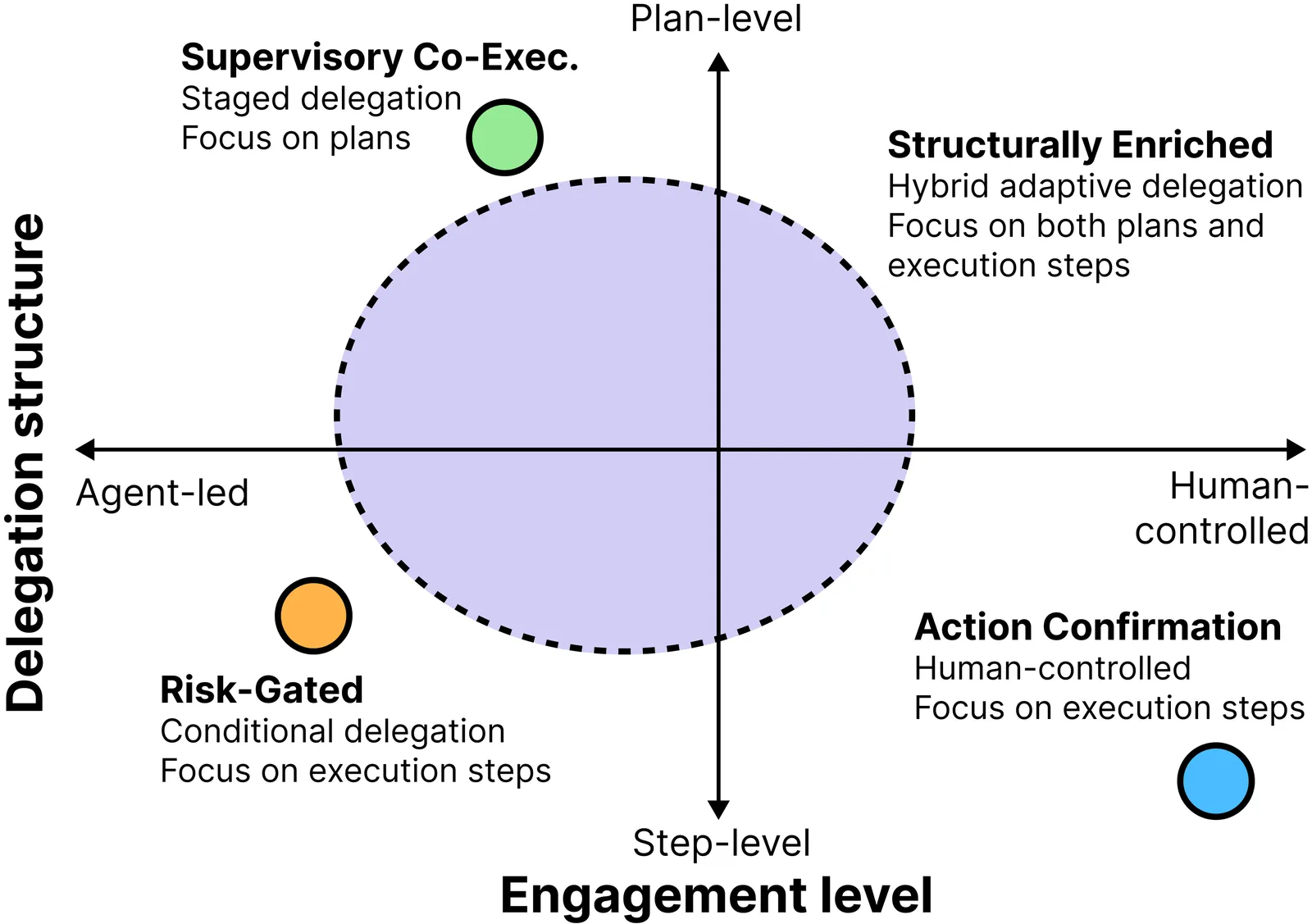
In the human-AI collaboration area, the context formed naturally through multi-turn interactions is typically flattened into a chronological sequence and treated as a fixed whole in subsequent reasoning, with no mechanism for dynamic organization and management along the collaboration workflow. Yet these contexts differ substantially in lifecycle, structural hierarchy, and relevance. For instance, temporary or abandoned exchanges and parallel topic threads persist in the limited context window, causing interference and even conflict. Meanwhile, users are largely limited to influencing context indirectly through input modifications (e.g., corrections, references, or ignoring), leaving their control neither explicit nor verifiable. To address this, we propose Mixed-Initiative Context, which reconceptualizes the context formed across multi-turn interactions as an explicit, structured, and manipulable interactive object. Under this concept, the structure, scope, and content of context can be dynamically organized and adjusted according to task needs, enabling both humans and AI to actively participate in context construction and regulation. To explore this concept, we implement Contextify as a probe system and conduct a user study examining users' context management behaviors, attitudes toward AI initiative, and overall collaboration experience. We conclude by discussing the implications of this concept for the HCI community.
2604.07121
Apr 2026Human-Computer Interaction
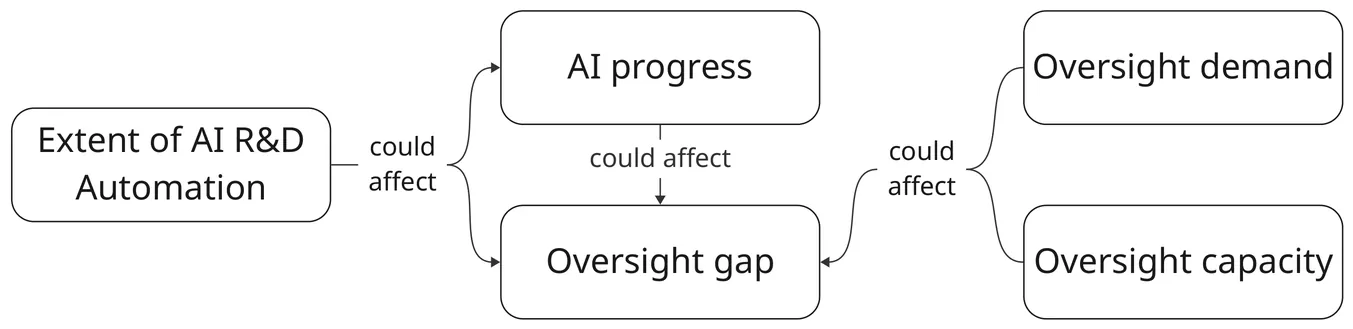
Measuring AI R&D Automation
The automation of AI R&D (AIRDA) could have significant implications, but its extent and ultimate effects remain uncertain. We need empirical data to resolve these uncertainties, but existing data (primarily capability benchmarks) may not reflect real-world automation or capture its broader consequences, such as whether AIRDA accelerates capabilities more than safety progress or whether our ability to oversee AI R&D can keep pace with its acceleration. To address these gaps, this work proposes metrics to track the extent of AIRDA and its effects on AI progress and oversight. The metrics span dimensions such as capital share of AI R&D spending, researcher time allocation, and AI subversion incidents, and could help decision makers understand the potential consequences of AIRDA, implement appropriate safety measures, and maintain awareness of the pace of AI development. We recommend that companies and third parties (e.g. non-profit research organisations) start to track these metrics, and that governments support these efforts.
2603.03992
Mar 2026Computers and Society
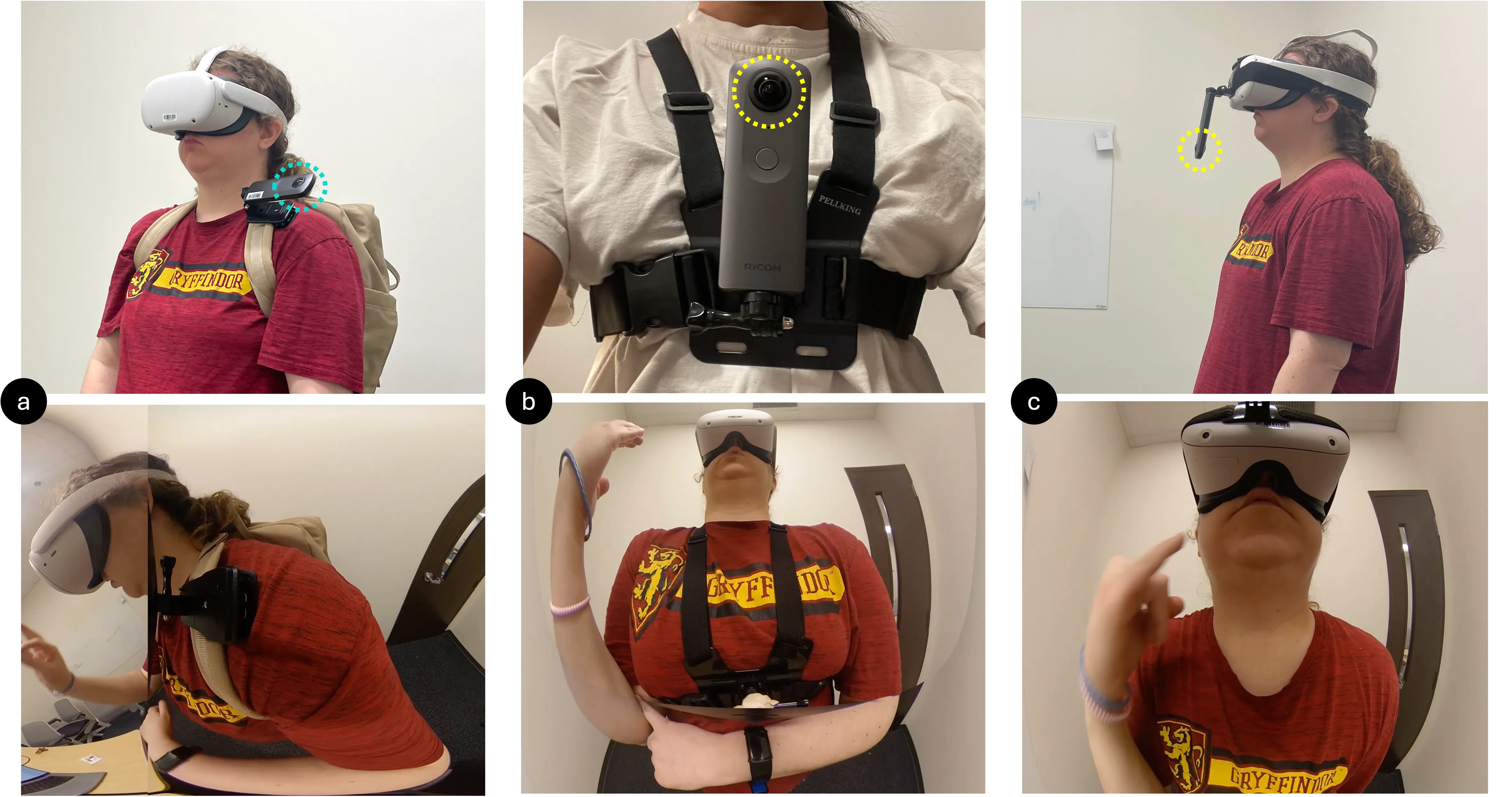
VRSL:Exploring the Comprehensibility of 360-Degree Camera Feeds for Sign Language Communication in Virtual Reality
This study explores integrating sign language into virtual reality (VR) by examining the comprehensibility and user experience of viewing American Sign Language (ASL) videos captured with body-mounted 360-degree cameras. Ten participants identified ASL signs from videos recorded at three body-mounted positions: head, shoulder, and chest. Results showed the shoulder-mounted camera achieved the highest accuracy (85%), though differences between positions were not statistically significant. Participants noted that peripheral distortion in 360-degree videos impacted clarity, highlighting areas for improvement. Despite challenges, the overall comprehension success rate of 83.3% demonstrates the potential of video-based ASL communication in VR. Feedback emphasized the need to refine camera angles, reduce distortion, and explore alternative mounting positions. Participants expressed a preference for signing over text-based communication in VR, highlighting the importance of developing this approach to enhance accessibility and collaboration for Deaf and Hard of Hearing (DHH) users in virtual environments.
2602.23265
Feb 2026Human-Computer Interaction

Understanding Usage and Engagement in AI-Powered Scientific Research Tools: The Asta Interaction Dataset
AI-powered scientific research tools are rapidly being integrated into research workflows, yet the field lacks a clear lens into how researchers use these systems in real-world settings. We present and analyze the Asta Interaction Dataset, a large-scale resource comprising over 200,000 user queries and interaction logs from two deployed tools (a literature discovery interface and a scientific question-answering interface) within an LLM-powered retrieval-augmented generation platform. Using this dataset, we characterize query patterns, engagement behaviors, and how usage evolves with experience. We find that users submit longer and more complex queries than in traditional search, and treat the system as a collaborative research partner, delegating tasks such as drafting content and identifying research gaps. Users treat generated responses as persistent artifacts, revisiting and navigating among outputs and cited evidence in non-linear ways. With experience, users issue more targeted queries and engage more deeply with supporting citations, although keyword-style queries persist even among experienced users. We release the anonymized dataset and analysis with a new query intent taxonomy to inform future designs of real-world AI research assistants and to support realistic evaluation.
2602.23335
Feb 2026Human-Computer Interaction
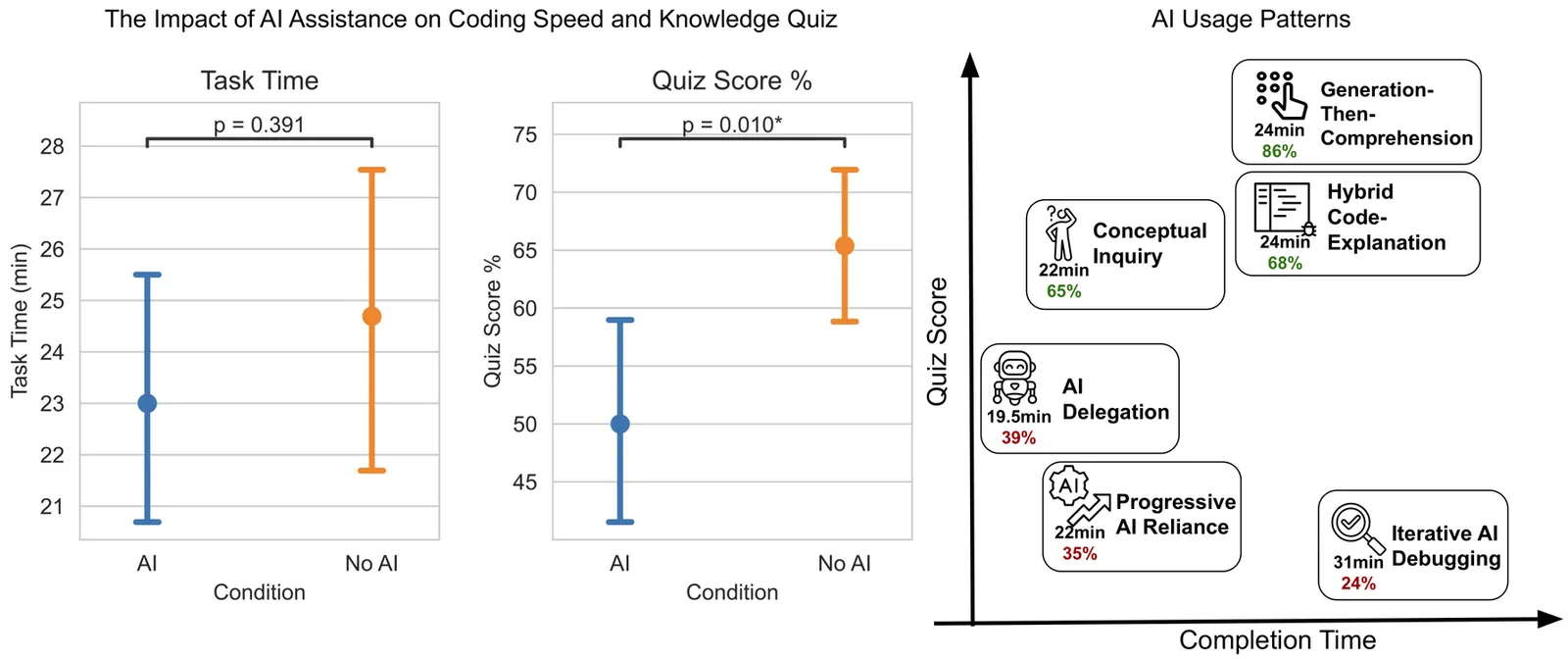
How AI Impacts Skill Formation
AI assistance produces significant productivity gains across professional domains, particularly for novice workers. Yet how this assistance affects the development of skills required to effectively supervise AI remains unclear. Novice workers who rely heavily on AI to complete unfamiliar tasks may compromise their own skill acquisition in the process. We conduct randomized experiments to study how developers gained mastery of a new asynchronous programming library with and without the assistance of AI. We find that AI use impairs conceptual understanding, code reading, and debugging abilities, without delivering significant efficiency gains on average. Participants who fully delegated coding tasks showed some productivity improvements, but at the cost of learning the library. We identify six distinct AI interaction patterns, three of which involve cognitive engagement and preserve learning outcomes even when participants receive AI assistance. Our findings suggest that AI-enhanced productivity is not a shortcut to competence and AI assistance should be carefully adopted into workflows to preserve skill formation -- particularly in safety-critical domains.
2601.20245
Jan 2026Computers and Society
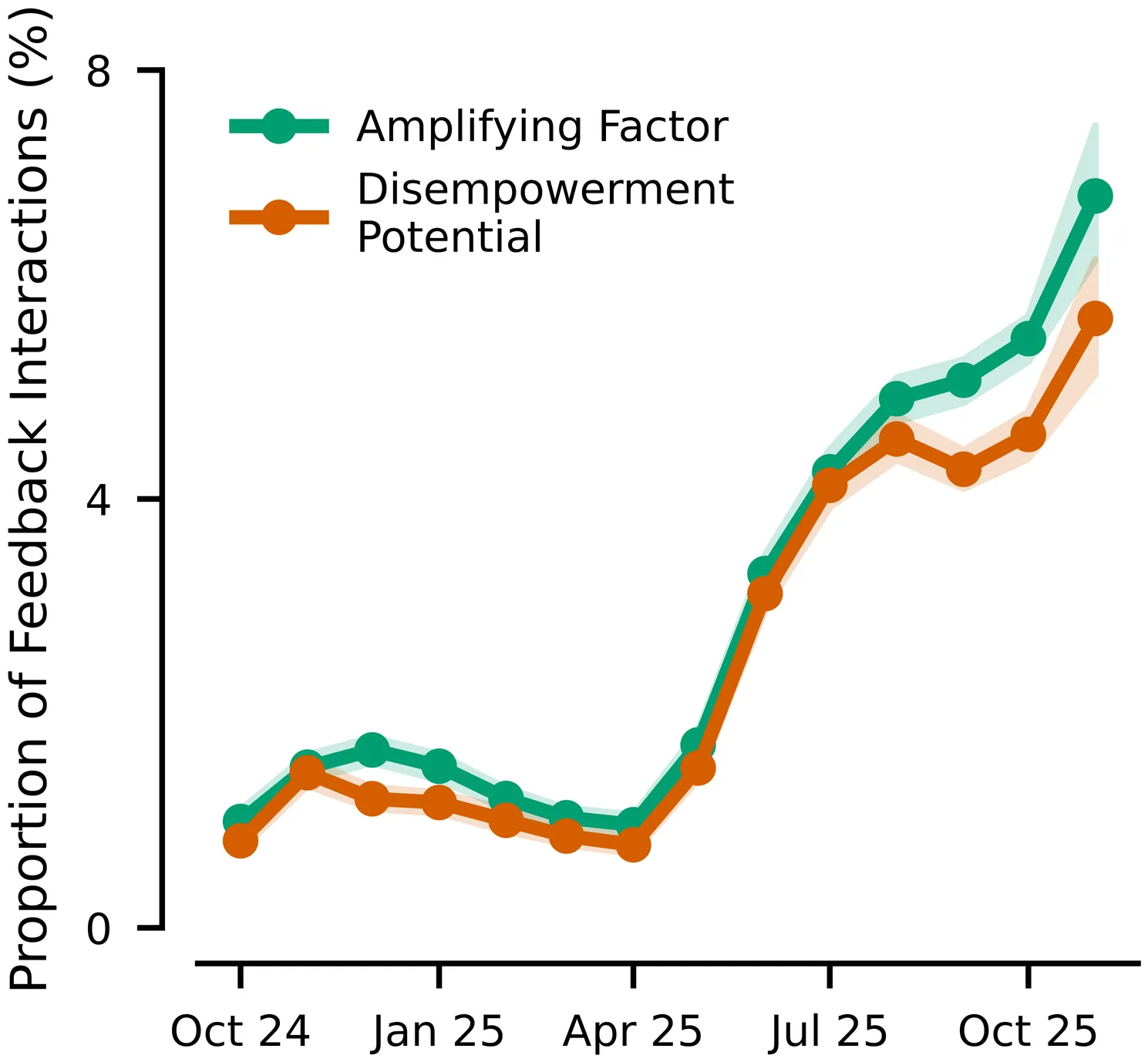
Who's in Charge? Disempowerment Patterns in Real-World LLM Usage
Although AI assistants are now deeply embedded in society, there has been limited empirical study of how their usage affects human empowerment. We present the first large-scale empirical analysis of disempowerment patterns in real-world AI assistant interactions, analyzing 1.5 million consumer Claude$.$ai conversations using a privacy-preserving approach. We focus on situational disempowerment potential, which occurs when AI assistant interactions risk leading users to form distorted perceptions of reality, make inauthentic value judgments, or act in ways misaligned with their values. Quantitatively, we find that severe forms of disempowerment potential occur in fewer than one in a thousand conversations, though rates are substantially higher in personal domains like relationships and lifestyle. Qualitatively, we uncover several concerning patterns, such as validation of persecution narratives and grandiose identities with emphatic sycophantic language, definitive moral judgments about third parties, and complete scripting of value-laden personal communications that users appear to implement verbatim. Analysis of historical trends reveals an increase in the prevalence of disempowerment potential over time. We also find that interactions with greater disempowerment potential receive higher user approval ratings, possibly suggesting a tension between short-term user preferences and long-term human empowerment. Our findings highlight the need for AI systems designed to robustly support human autonomy and flourishing.
2601.19062
Jan 2026Computers and Society
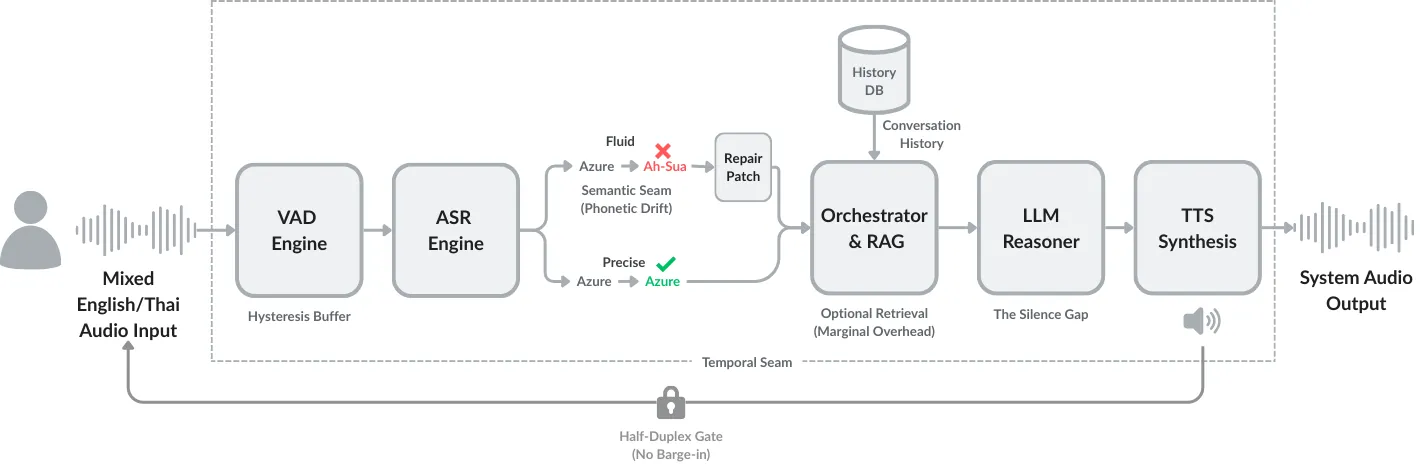
From Signal to Turn: Interactional Friction in Modular Speech-to-Speech Pipelines
While voice-based AI systems have achieved remarkable generative capabilities, their interactions often feel conversationally broken. This paper examines the interactional friction that emerges in modular Speech-to-Speech Retrieval-Augmented Generation (S2S-RAG) pipelines. By analyzing a representative production system, we move beyond simple latency metrics to identify three recurring patterns of conversational breakdown: (1) Temporal Misalignment, where system delays violate user expectations of conversational rhythm; (2) Expressive Flattening, where the loss of paralinguistic cues leads to literal, inappropriate responses; and (3) Repair Rigidity, where architectural gating prevents users from correcting errors in real-time. Through system-level analysis, we demonstrate that these friction points should not be understood as defects or failures, but as structural consequences of a modular design that prioritizes control over fluidity. We conclude that building natural spoken AI is an infrastructure design challenge, requiring a shift from optimizing isolated components to carefully choreographing the seams between them.
2512.11724
Dec 2025Human-Computer Interaction
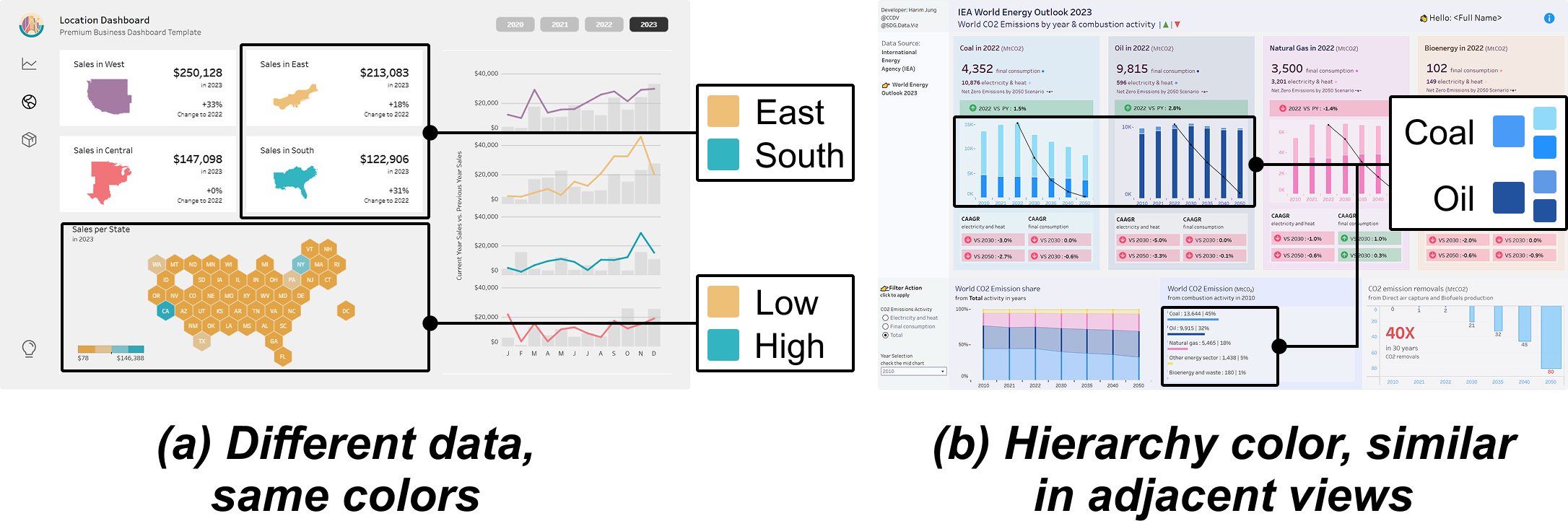
C2Views: Knowledge-based Colormap Design for Multiple-View Consistency
Multiple-view (MV) visualization provides a comprehensive and integrated perspective on complex data, establishing itself as an effective method for visual communication and exploratory data analysis. While existing studies have predominantly focused on designing explicit visual linkages and coordinated interactions to facilitate the exploration of MV visualizations, these approaches often demand extra graphical and interactive effort, overlooking the potential of color as an effective channel for encoding data and relationships. Addressing this oversight, we introduce C2Views, a new framework for colormap design that implicitly shows the relation across views. We begin by structuring the components and their relationships within MVs into a knowledge-based graph specification, wherein colormaps, data, and views are denoted as entities, and the interactions among them are illustrated as relations. Building on this representation, we formulate the design criteria as an optimization problem and employ a genetic algorithm enhanced by Pareto optimality, generating colormaps that balance single-view effectiveness and multiple-view consistency. Our approach is further complemented with an interactive interface for user-intended refinement. We demonstrate the feasibility of C2Views through various colormap design examples for MVs, underscoring its adaptability to diverse data relationships and view layouts. Comparative user studies indicate that our method outperforms the existing approach in facilitating color distinction and enhancing multiple-view consistency, thereby simplifying data exploration processes.
2511.11112
Nov 2025Human-Computer Interaction