Trending in Electrical Engineering and Systems Science

Video Generation Models as World Models: Efficient Paradigms, Architectures and Algorithms
The rapid evolution of video generation has enabled models to simulate complex physical dynamics and long-horizon causalities, positioning them as potential world simulators. However, a critical gap still remains between the theoretical capacity for world simulation and the heavy computational costs of spatiotemporal modeling. To address this, we comprehensively and systematically review video generation frameworks and techniques that consider efficiency as a crucial requirement for practical world modeling. We introduce a novel taxonomy in three dimensions: efficient modeling paradigms, efficient network architectures, and efficient inference algorithms. We further show that bridging this efficiency gap directly empowers interactive applications such as autonomous driving, embodied AI, and game simulation. Finally, we identify emerging research frontiers in efficient video-based world modeling, arguing that efficiency is a fundamental prerequisite for evolving video generators into general-purpose, real-time, and robust world simulators.
2603.28489
Mar 2026Image and Video Processing
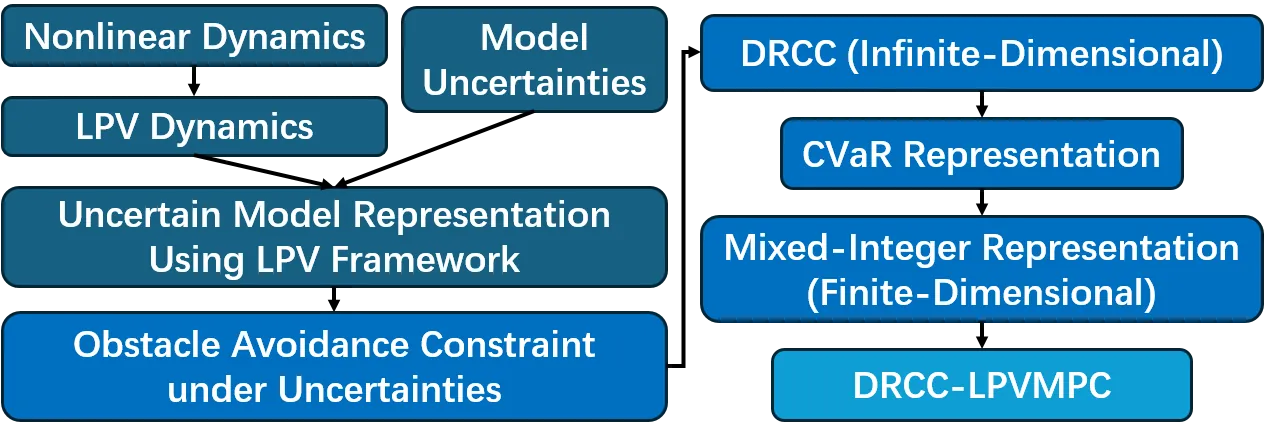
DRCC-LPVMPC: Robust Data-Driven Control for Autonomous Driving and Obstacle Avoidance
Safety in obstacle avoidance is critical for autonomous driving. While model predictive control (MPC) is widely used, simplified prediction models such as linearized or single-track vehicle models introduce discrepancies between predicted and actual behavior that can compromise safety. This paper proposes a distributionally robust chance-constrained linear parameter-varying MPC (DRCC-LPVMPC) framework that explicitly accounts for such discrepancies. The single-track vehicle dynamics are represented in a quasi-linear parameter-varying (quasi-LPV) form, with model mismatches treated as additive uncertainties of unknown distribution. By constructing chance constraints from finite sampled data and employing a Wasserstein ambiguity set, the proposed method avoids restrictive assumptions on boundedness or Gaussian distributions. The resulting DRCC problem is reformulated as tractable convex constraints and solved in real time using a quadratic programming solver. Recursive feasibility of the approach is formally established. Simulation and real-world experiments demonstrate that DRCC-LPVMPC maintains safer obstacle clearance and more reliable tracking than conventional nonlinear MPC and LPVMPC controllers under significant uncertainties.
2603.14408
Mar 2026Systems and Control
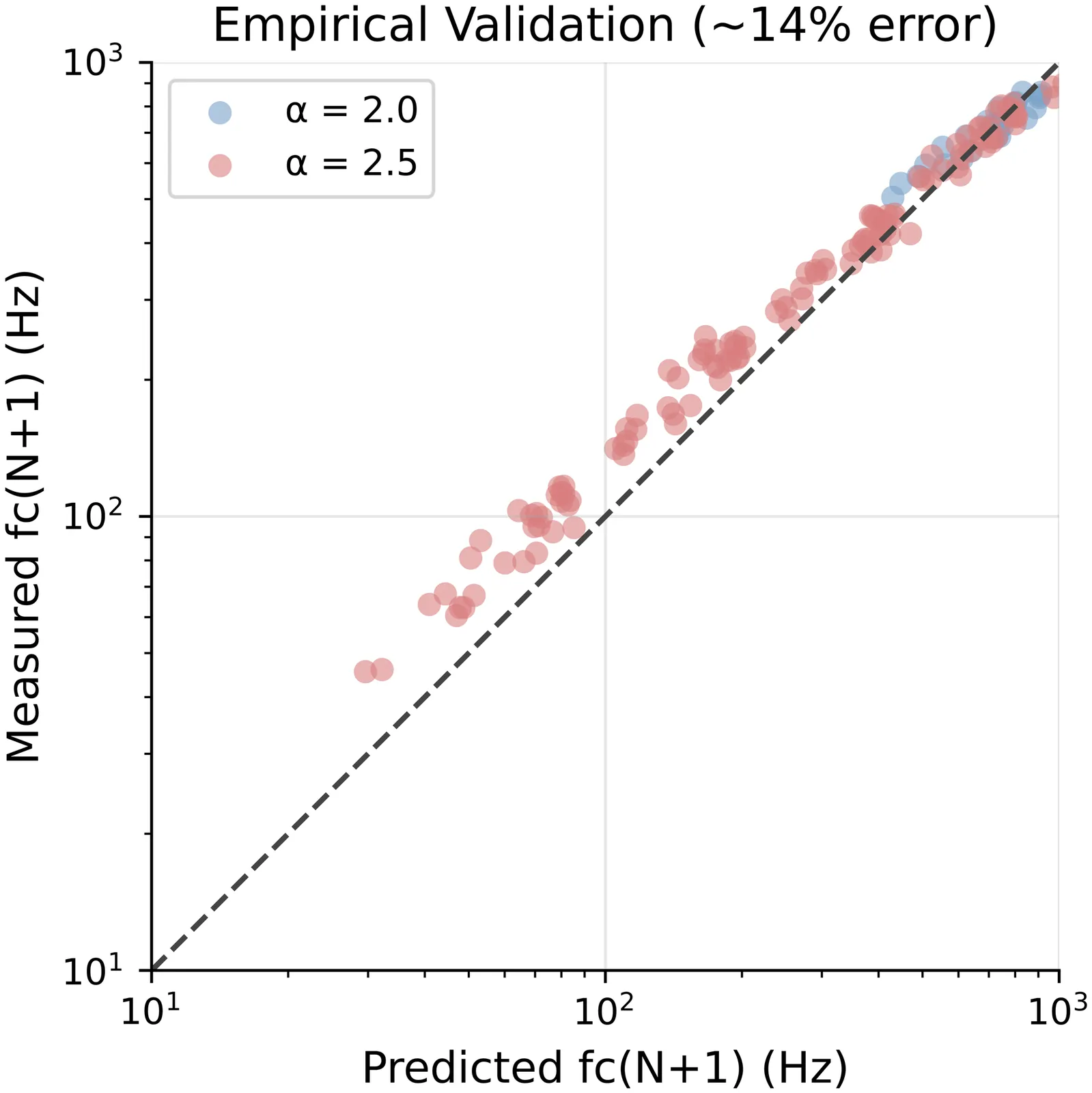
A Scaling Law for Bandwidth Under Quantization
We derive a scaling law relating ADC bit depth to effective bandwidth for signals with $1/f^α$ power spectra. Quantization introduces a flat noise floor whose intersection with the declining signal spectrum defines an effective cutoff frequency $f_c$. We show that each additional bit extends this cutoff by a factor of $2^{2/α}$, approximately doubling bandwidth per bit for $α= 2$. The law requires that quantization noise be approximately white, a condition whose minimum bit depth $N_{\min}$ we show to be $α$-dependent. Validation on synthetic $1/f^α$ signals for $α\in \{1.5, 2.0, 2.5\}$ yields prediction errors below 3\% using the theoretical noise floor $Δ^2/(6f_s)$, and approximately 14\% when the noise floor is estimated empirically from the quantized signal's spectrum. We illustrate practical implications on real EEG data.
2602.23252
Feb 2026Signal Processing
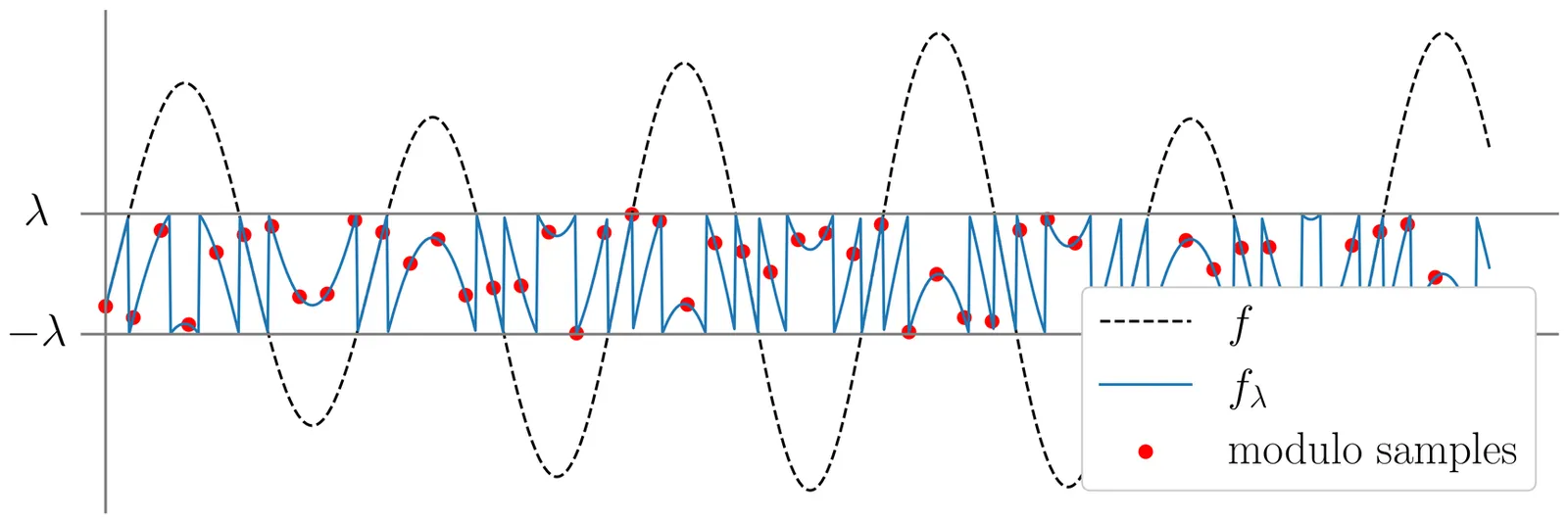
Reconstruction of Piecewise-Constant Sparse Signals for Modulo Sampling
Modulo sampling is a promising technology to preserve amplitude information that exceeds the observable range of analog-to-digital converters during the digitization of analog signals. Since conventional methods typically reconstruct the original signal by estimating the differences of the residual signal and computing their cumulative sum, each estimation error inevitably propagates through subsequent time samples. In this paper, to eliminate this error-propagation problem, we propose an algorithm that reconstructs the residual signal directly. The proposed method takes advantage of the high-frequency characteristics of the modulo samples and the sparsity of both the residual signal and its difference. Simulation results show that the proposed method reconstructs the original signal more accurately than a conventional method based on the differences of the residual signal.
2602.16418
Feb 2026Signal Processing
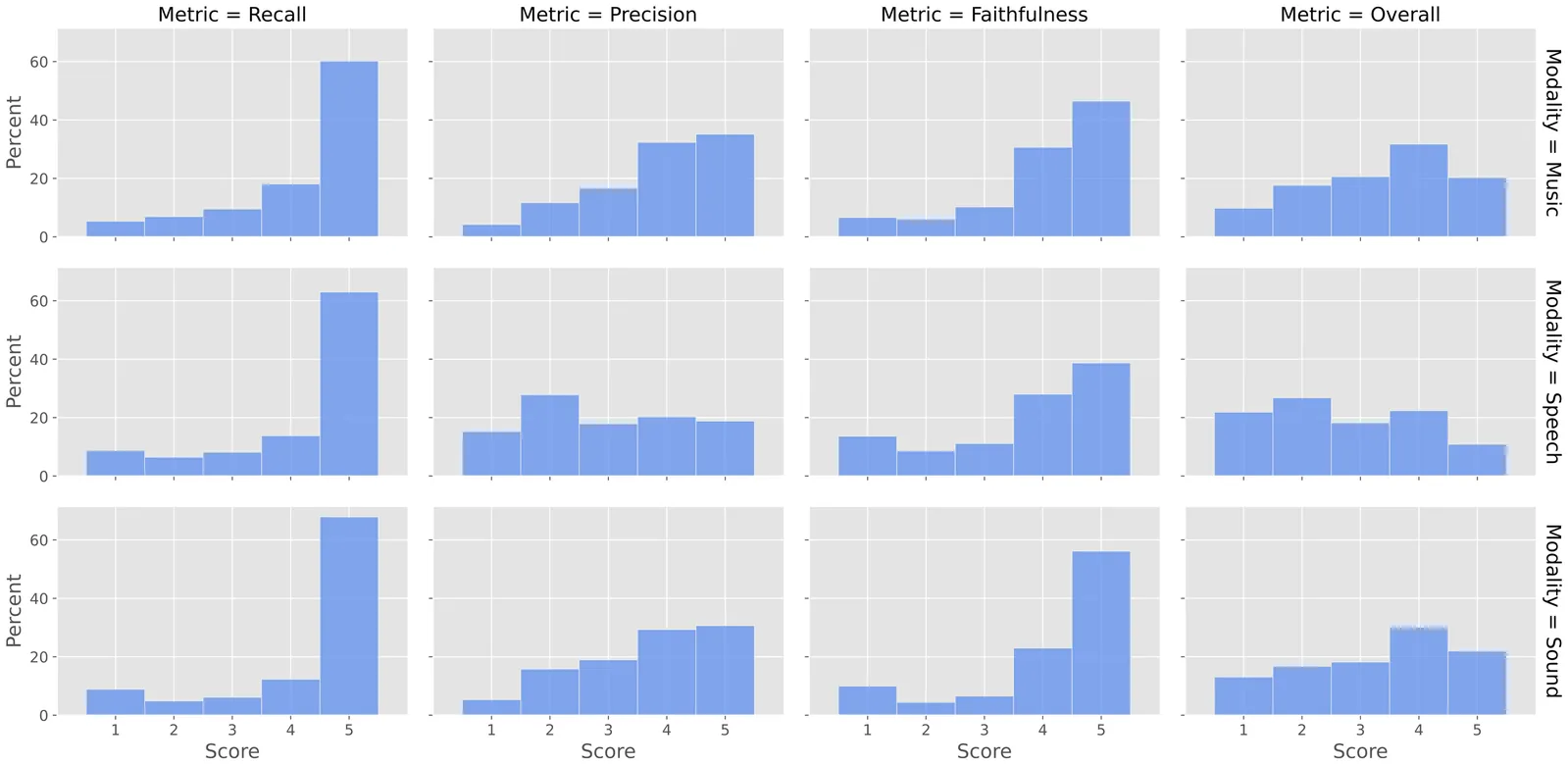
SAM Audio Judge: A Unified Multimodal Framework for Perceptual Evaluation of Audio Separation
The performance evaluation remains a complex challenge in audio separation, and existing evaluation metrics are often misaligned with human perception, course-grained, relying on ground truth signals. On the other hand, subjective listening tests remain the gold standard for real-world evaluation, but they are expensive, time-consuming, and difficult to scale. This paper addresses the growing need for automated systems capable of evaluating audio separation without human intervention. The proposed evaluation metric, SAM Audio Judge (SAJ), is a multimodal fine-grained reference-free objective metric, which shows highly alignment with human perceptions. SAJ supports three audio domains (speech, music and general sound events) and three prompt inputs (text, visual and span), covering four different dimensions of evaluation (recall, percision, faithfulness, and overall). SAM Audio Judge also shows potential applications in data filtering, pseudo-labeling large datasets and reranking in audio separation models. We release our code and pre-trained models at: https://github.com/facebookresearch/sam-audio.
2601.19702
Jan 2026Audio and Speech Processing
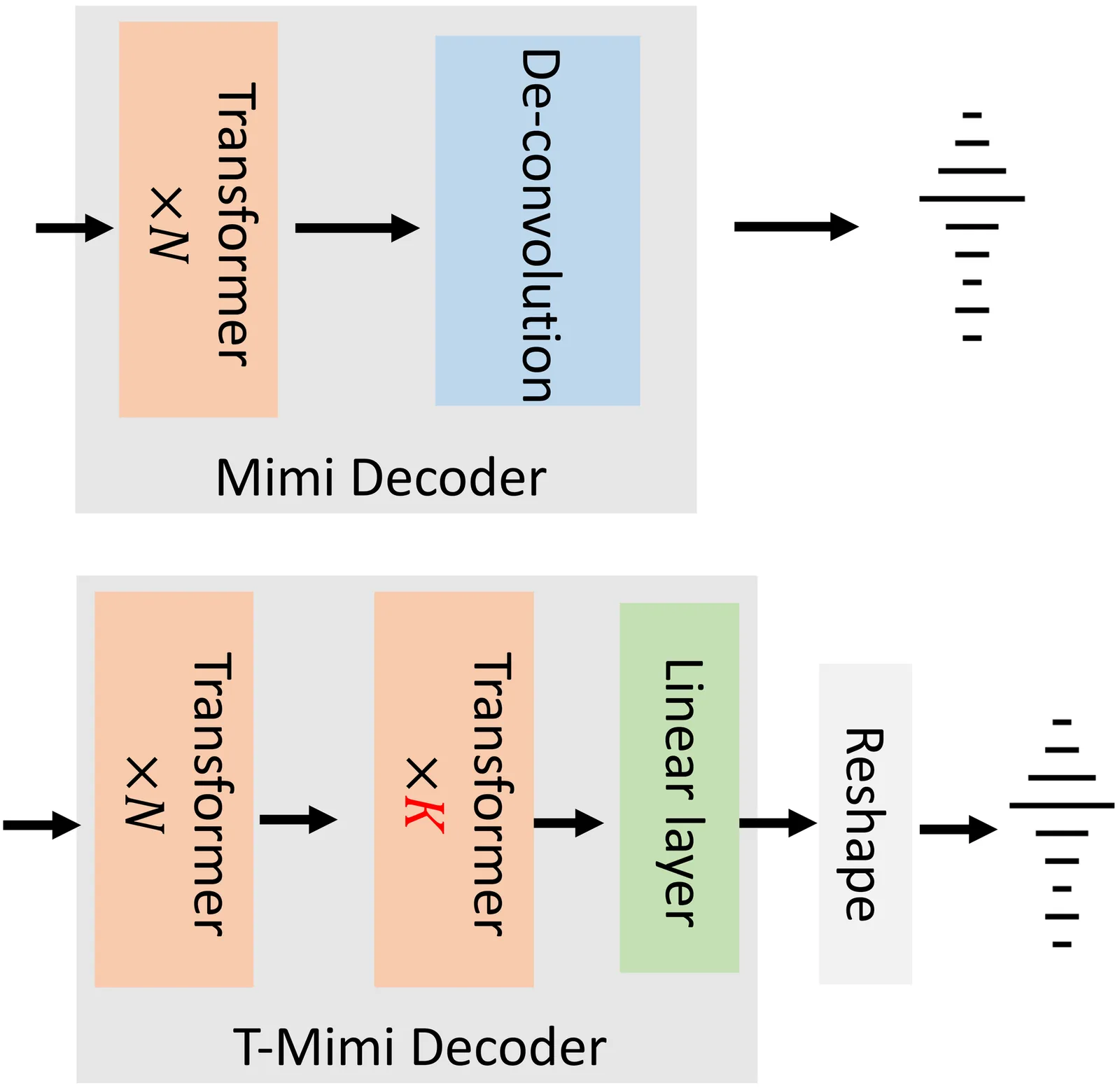
T-Mimi: A Transformer-based Mimi Decoder for Real-Time On-Phone TTS
Neural audio codecs provide promising acoustic features for speech synthesis, with representative streaming codecs like Mimi providing high-quality acoustic features for real-time Text-to-Speech (TTS) applications. However, Mimi's decoder, which employs a hybrid transformer and convolution architecture, introduces significant latency bottlenecks on edge devices due to the the compute intensive nature of deconvolution layers which are not friendly for mobile-CPUs, such as the most representative framework XNNPACK. This paper introduces T-Mimi, a novel modification of the Mimi codec decoder that replaces its convolutional components with a purely transformer-based decoder, inspired by the TS3-Codec architecture. This change dramatically reduces on-device TTS latency from 42.1ms to just 4.4ms. Furthermore, we conduct quantization aware training and derive a crucial finding: the final two transformer layers and the concluding linear layers of the decoder, which are close to the waveform, are highly sensitive to quantization and must be preserved at full precision to maintain audio quality.
2601.20094
Jan 2026Audio and Speech Processing
OpenVision 3: A Family of Unified Visual Encoder for Both Understanding and Generation
This paper presents a family of advanced vision encoder, named OpenVision 3, that learns a single, unified visual representation that can serve both image understanding and image generation. Our core architecture is simple: we feed VAE-compressed image latents to a ViT encoder and train its output to support two complementary roles. First, the encoder output is passed to the ViT-VAE decoder to reconstruct the original image, encouraging the representation to capture generative structure. Second, the same representation is optimized with contrastive learning and image-captioning objectives, strengthening semantic features. By jointly optimizing reconstruction- and semantics-driven signals in a shared latent space, the encoder learns representations that synergize and generalize well across both regimes. We validate this unified design through extensive downstream evaluations with the encoder frozen. For multimodal understanding, we plug the encoder into the LLaVA-1.5 framework: it performs comparably with a standard CLIP vision encoder (e.g., 62.4 vs 62.2 on SeedBench, and 83.7 vs 82.9 on POPE). For generation, we test it under the RAE framework: ours substantially surpasses the standard CLIP-based encoder (e.g., gFID: 1.89 vs 2.54 on ImageNet). We hope this work can spur future research on unified modeling.
2601.15369
Jan 2026Image and Video Processing

VoiceSculptor: Your Voice, Designed By You
Despite rapid progress in text-to-speech (TTS), open-source systems still lack truly instruction-following, fine-grained control over core speech attributes (e.g., pitch, speaking rate, age, emotion, and style). We present VoiceSculptor, an open-source unified system that bridges this gap by integrating instruction-based voice design and high-fidelity voice cloning in a single framework. It generates controllable speaker timbre directly from natural-language descriptions, supports iterative refinement via Retrieval-Augmented Generation (RAG), and provides attribute-level edits across multiple dimensions. The designed voice is then rendered into a prompt waveform and fed into a cloning model to enable high-fidelity timbre transfer for downstream speech synthesis. VoiceSculptor achieves open-source state-of-the-art (SOTA) on InstructTTSEval-Zh, and is fully open-sourced, including code and pretrained models, to advance reproducible instruction-controlled TTS research.
2601.10629
Jan 2026Audio and Speech Processing
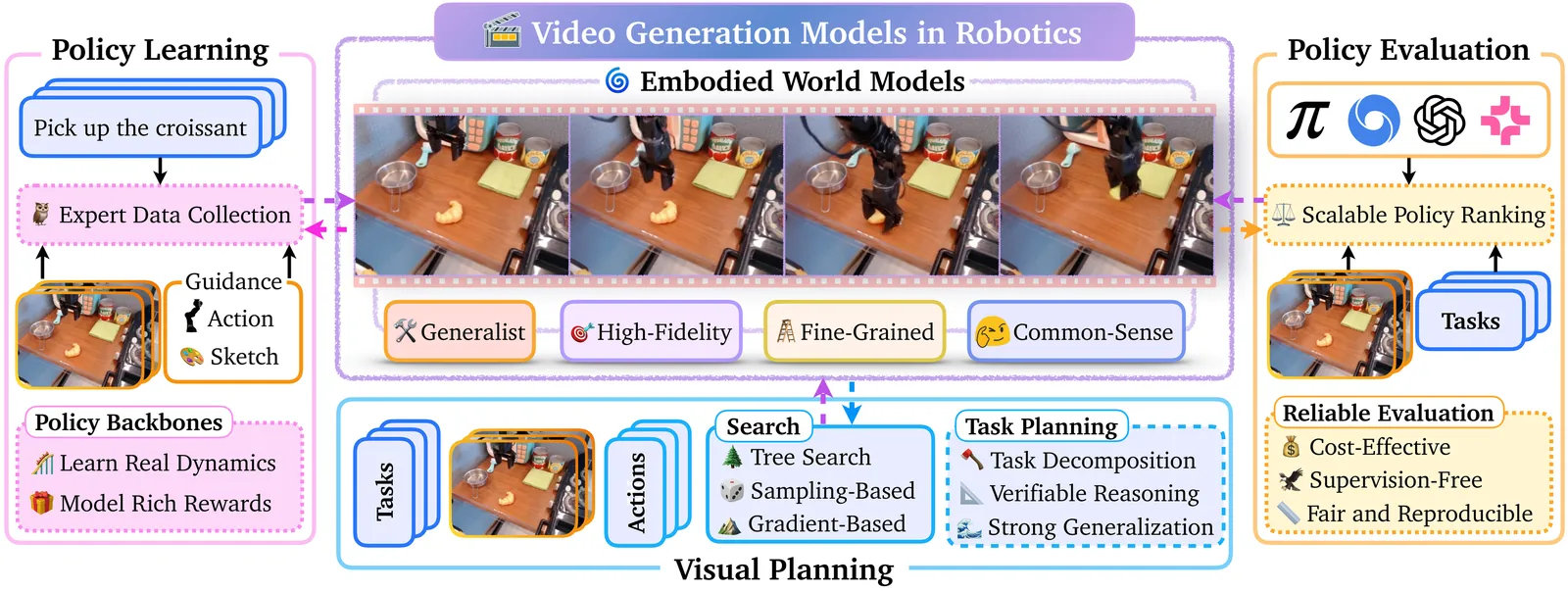
Video Generation Models in Robotics -- Applications, Research Challenges, Future Directions
Video generation models have emerged as high-fidelity models of the physical world, capable of synthesizing high-quality videos capturing fine-grained interactions between agents and their environments conditioned on multi-modal user inputs. Their impressive capabilities address many of the long-standing challenges faced by physics-based simulators, driving broad adoption in many problem domains, e.g., robotics. For example, video models enable photorealistic, physically consistent deformable-body simulation without making prohibitive simplifying assumptions, which is a major bottleneck in physics-based simulation. Moreover, video models can serve as foundation world models that capture the dynamics of the world in a fine-grained and expressive way. They thus overcome the limited expressiveness of language-only abstractions in describing intricate physical interactions. In this survey, we provide a review of video models and their applications as embodied world models in robotics, encompassing cost-effective data generation and action prediction in imitation learning, dynamics and rewards modeling in reinforcement learning, visual planning, and policy evaluation. Further, we highlight important challenges hindering the trustworthy integration of video models in robotics, which include poor instruction following, hallucinations such as violations of physics, and unsafe content generation, in addition to fundamental limitations such as significant data curation, training, and inference costs. We present potential future directions to address these open research challenges to motivate research and ultimately facilitate broader applications, especially in safety-critical settings.
2601.07823
Jan 2026Systems and Control
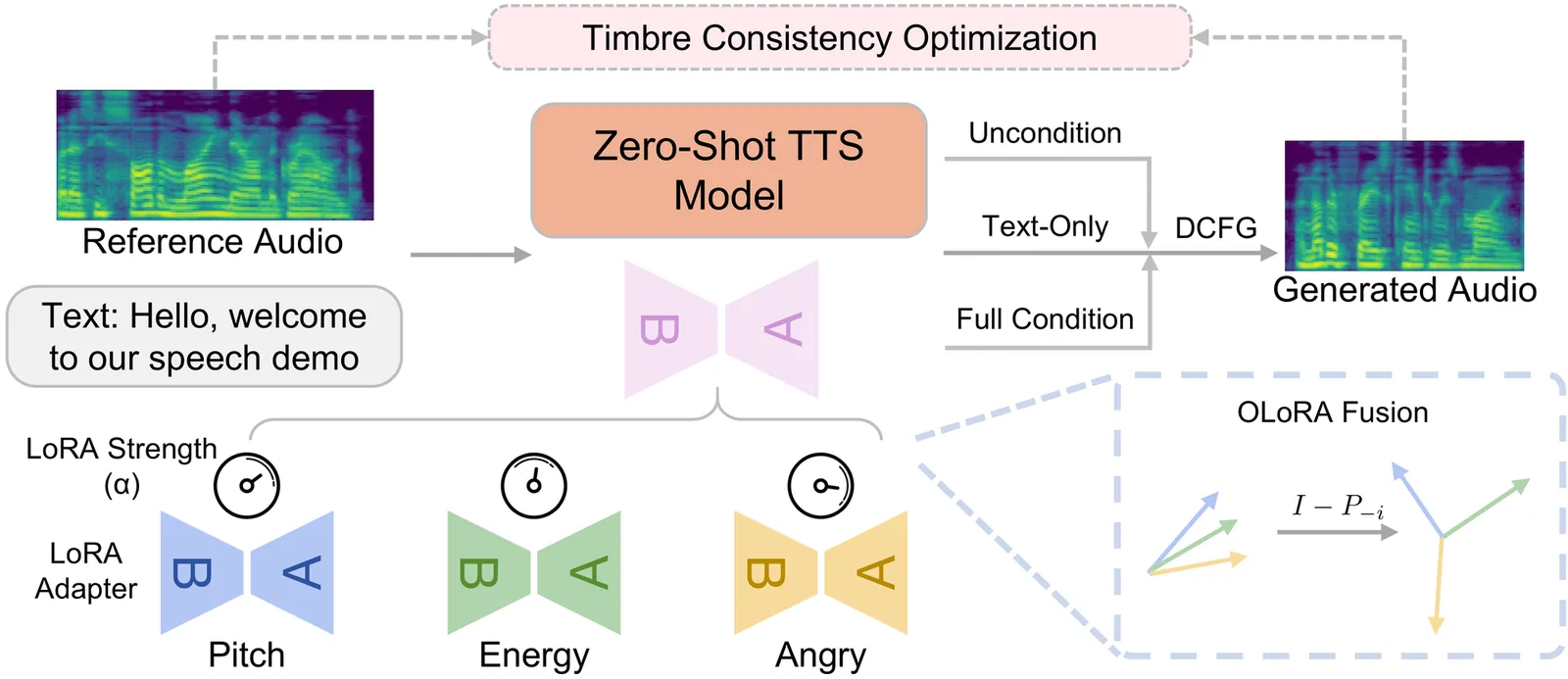
ReStyle-TTS: Relative and Continuous Style Control for Zero-Shot Speech Synthesis
Zero-shot text-to-speech models can clone a speaker's timbre from a short reference audio, but they also strongly inherit the speaking style present in the reference. As a result, synthesizing speech with a desired style often requires carefully selecting reference audio, which is impractical when only limited or mismatched references are available. While recent controllable TTS methods attempt to address this issue, they typically rely on absolute style targets and discrete textual prompts, and therefore do not support continuous and reference-relative style control. We propose ReStyle-TTS, a framework that enables continuous and reference-relative style control in zero-shot TTS. Our key insight is that effective style control requires first reducing the model's implicit dependence on reference style before introducing explicit control mechanisms. To this end, we introduce Decoupled Classifier-Free Guidance (DCFG), which independently controls text and reference guidance, reducing reliance on reference style while preserving text fidelity. On top of this, we apply style-specific LoRAs together with Orthogonal LoRA Fusion to enable continuous and disentangled multi-attribute control, and introduce a Timbre Consistency Optimization module to mitigate timbre drift caused by weakened reference guidance. Experiments show that ReStyle-TTS enables user-friendly, continuous, and relative control over pitch, energy, and multiple emotions while maintaining intelligibility and speaker timbre, and performs robustly in challenging mismatched reference-target style scenarios.
2601.03632
Jan 2026Audio and Speech Processing

Towards Fine-Grained and Multi-Granular Contrastive Language-Speech Pre-training
Modeling fine-grained speaking styles remains challenging for language-speech representation pre-training, as existing speech-text models are typically trained with coarse captions or task-specific supervision, and scalable fine-grained style annotations are unavailable. We present FCaps, a large-scale dataset with fine-grained free-text style descriptions, encompassing 47k hours of speech and 19M fine-grained captions annotated via a novel end-to-end pipeline that directly grounds detailed captions in audio, thereby avoiding the error propagation caused by LLM-based rewriting in existing cascaded pipelines. Evaluations using LLM-as-a-judge demonstrate that our annotations surpass existing cascaded annotations in terms of correctness, coverage, and naturalness. Building on FCaps, we propose CLSP, a contrastive language-speech pre-trained model that integrates global and fine-grained supervision, enabling unified representations across multiple granularities. Extensive experiments demonstrate that CLSP learns fine-grained and multi-granular speech-text representations that perform reliably across global and fine-grained speech-text retrieval, zero-shot paralinguistic classification, and speech style similarity scoring, with strong alignment to human judgments. All resources will be made publicly available.
2601.03065
Jan 2026Audio and Speech Processing
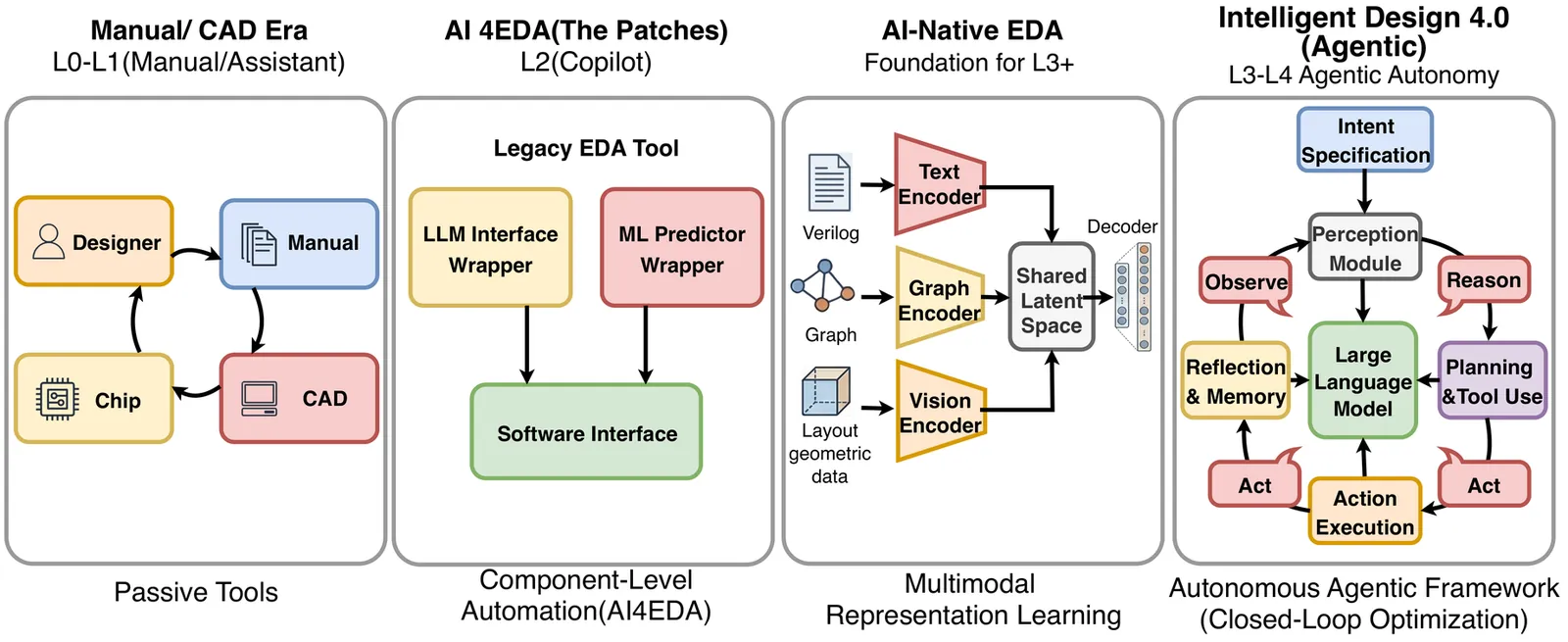
The Dawn of Agentic EDA: A Survey of Autonomous Digital Chip Design
This survey provides a comprehensive overview of the integration of Generative AI and Agentic AI within the field of Digital Electronic Design Automation (EDA). The paper first reviews the paradigmatic evolution from traditional Computer-Aided Design (CAD) to AI-assisted EDA (AI4EDA), and finally to the emerging AI-Native and Agentic design paradigms. We detail the application of these paradigms across the digital chip design flow, including the construction of agentic cognitive architectures based on multimodal foundation models, frontend RTL code generation and intelligent verification, and backend physical design featuring algorithmic innovations and tool orchestration. We validate these methodologies through integrated case studies, demonstrating practical viability from microarchitecture definition to GDSII. Special emphasis is placed on the potential for cross-stage feedback loops where agents utilize backend PPA metrics to autonomously refine frontend logic. Furthermore, this survey delves into the dual-faceted impact on security, covering novel adversarial risks, automated vulnerability repair, and privacy-preserving infrastructure. Finally, the paper critically summarizes current challenges related to hallucinations, data scarcity, and black-box tools, and outlines future trends towards L4 autonomous chip design. Ultimately, this work aims to define the emerging field of Agentic EDA and provide a strategic roadmap for the transition from AI-assisted tools to fully autonomous design engineers.
2512.23189
Dec 2025Systems and Control
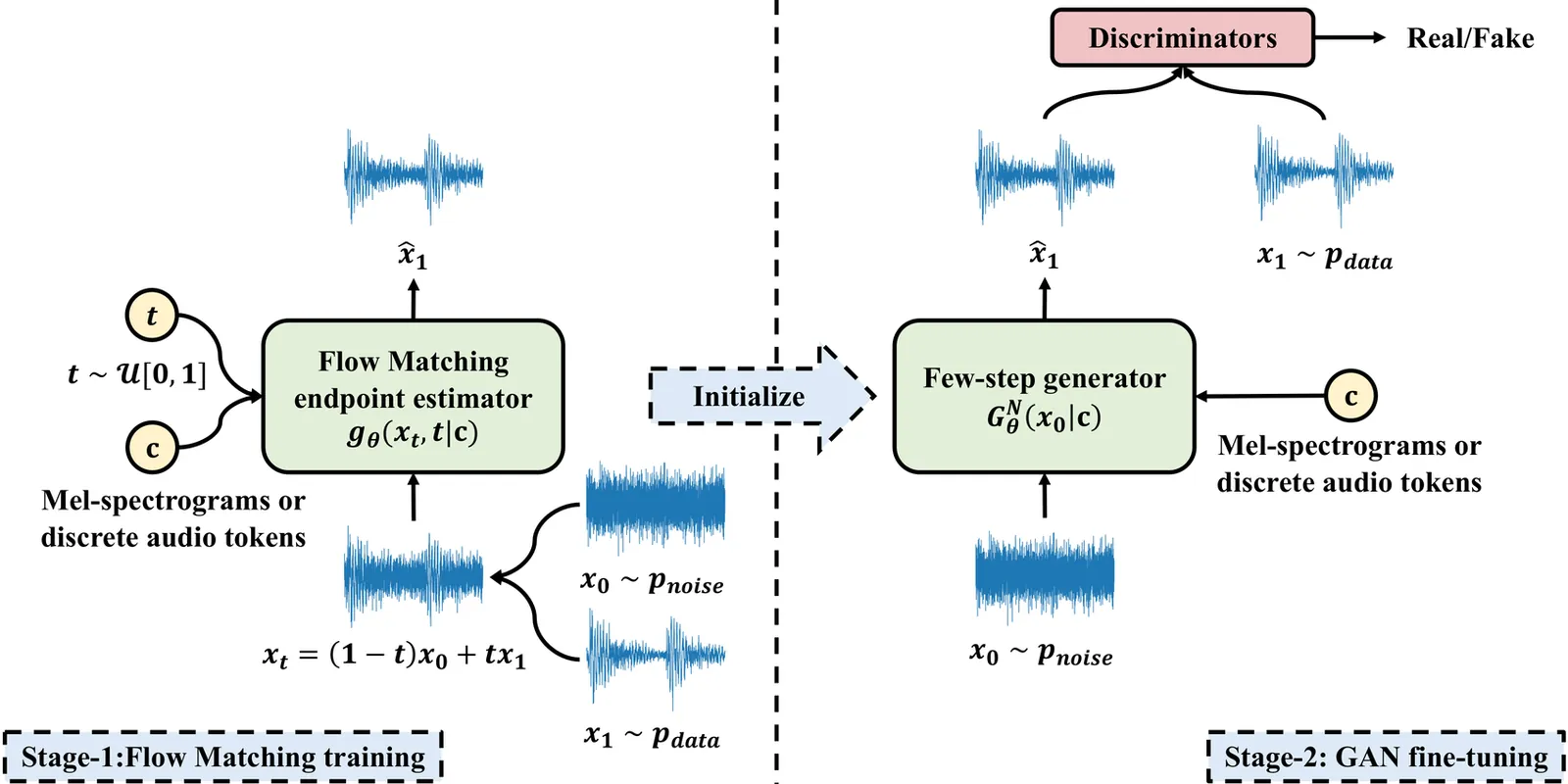
Flow2GAN: Hybrid Flow Matching and GAN with Multi-Resolution Network for Few-step High-Fidelity Audio Generation
Existing dominant methods for audio generation include Generative Adversarial Networks (GANs) and diffusion-based methods like Flow Matching. GANs suffer from slow convergence and potential mode collapse during training, while diffusion methods require multi-step inference that introduces considerable computational overhead. In this work, we introduce Flow2GAN, a two-stage framework that combines Flow Matching training for learning generative capabilities with GAN fine-tuning for efficient few-step inference. Specifically, given audio's unique properties, we first improve Flow Matching for audio modeling through: 1) reformulating the objective as endpoint estimation, avoiding velocity estimation difficulties when involving empty regions; 2) applying spectral energy-based loss scaling to emphasize perceptually salient quieter regions. Building on these Flow Matching adaptations, we demonstrate that a further stage of lightweight GAN fine-tuning enables us to obtain one-step generator that produces high-quality audio. In addition, we develop a multi-branch network architecture that processes Fourier coefficients at different time-frequency resolutions, which improves the modeling capabilities compared to prior single-resolution designs. Experimental results indicate that our Flow2GAN delivers high-fidelity audio generation from Mel-spectrograms or discrete audio tokens, achieving better quality-efficiency trade-offs than existing state-of-the-art GAN-based and Flow Matching-based methods. Online demo samples are available at https://flow2gan.github.io, and the source code is released at https://github.com/k2-fsa/Flow2GAN.
2512.23278
Dec 2025Audio and Speech Processing

QuarkAudio Technical Report
Many existing audio processing and generation models rely on task-specific architectures, resulting in fragmented development efforts and limited extensibility. It is therefore promising to design a unified framework capable of handling multiple tasks, while providing robust instruction and audio understanding and high-quality audio generation. This requires a compatible paradigm design, a powerful backbone, and a high-fidelity audio reconstruction module. To meet these requirements, this technical report introduces QuarkAudio, a decoder-only autoregressive (AR) LM-based generative framework that unifies multiple tasks. The framework includes a unified discrete audio tokenizer, H-Codec, which incorporates self-supervised learning (SSL) representations into the tokenization and reconstruction process. We further propose several improvements to H-Codec, such as a dynamic frame-rate mechanism and extending the audio sampling rate to 48 kHz. QuarkAudio unifies tasks by using task-specific conditional information as the conditioning sequence of the decoder-only LM, and predicting discrete target audio tokens in an AR manner. The framework supports a wide range of audio processing and generation tasks, including speech restoration (SR), target speaker extraction (TSE), speech separation (SS), voice conversion (VC), and language-queried audio source separation (LASS). In addition, we extend downstream tasks to universal free-form audio editing guided by natural language instructions (including speech semantic editing and audio event editing). Experimental results show that H-Codec achieves high-quality audio reconstruction with a low frame rate, improving both the efficiency and performance of downstream audio generation, and that QuarkAudio delivers competitive or comparable performance to state-of-the-art task-specific or multi-task systems across multiple tasks.
2512.20151
Dec 2025Audio and Speech Processing
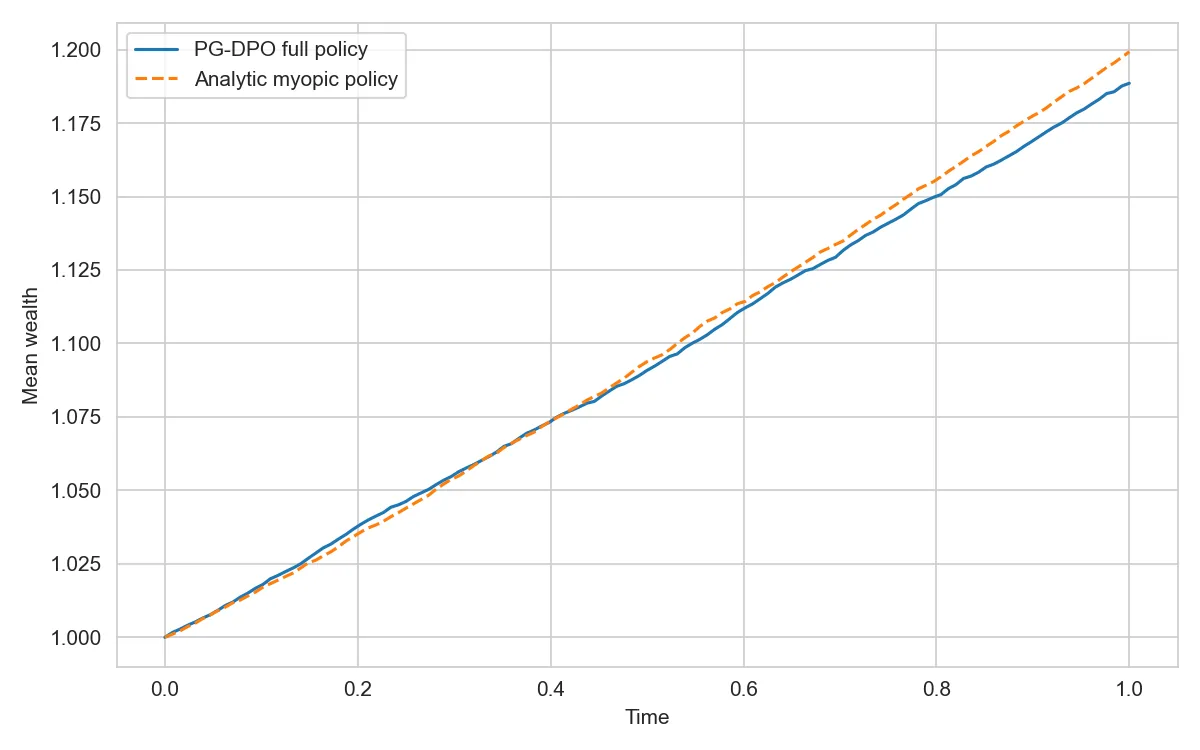
Intertemporal Hedging Demand under Epstein-Zin Preferences in a Multi-Asset Long-Run Risk Model: Evidence from Projected Pontryagin-Guided Deep Policy Optimization
I study intertemporal hedging demand in a continuous-time multi-asset long-run risk (LRR) model under Epstein--Zin (EZ) recursive preferences. The investor trades a risk-free asset and several risky assets whose drifts and volatilities depend on an Ornstein--Uhlenbeck type LRR factor. Preferences are described by EZ utility with risk aversion $R$, elasticity of intertemporal substitution $ψ$, and discount rate $δ$, so that the standard time-additive CRRA case appears as a limiting benchmark. To handle the high-dimensional consumption--investment problem, I use a projected Pontryagin-guided deep policy optimization (P-PGDPO) scheme adapted to EZ preferences. The method starts from the continuous-time Hamiltonian implied by the Pontryagin maximum principle, represents the value and costate processes with neural networks, and updates the policy along the Hamiltonian gradient. Portfolio constraints and a lower bound on wealth are enforced by explicit projection operators rather than by adding ad hoc penalties. Three main findings emerge from numerical experiments in a five-asset LRR economy: \textbf{(1)} the P-PGDPO algorithm achieves stable convergence across multiple random seeds, validating its reliability for solving high-dimensional EZ problems; \textbf{(2)} wealth floors materially reduce hedging demand by limiting the investor's ability to exploit intertemporal risk-return tradeoffs; and \textbf{(3)} the learned hedging portfolios concentrate exposure in assets with high correlation to the LRR factor, confirming that EZ agents actively hedge long-run uncertainty rather than merely following myopic rules. Because EZ preferences nest time-additive CRRA in the limit $ψ\to 1/R$, I use CRRA as an explicit diagnostic benchmark and, when needed, a warm start to stabilize training in high dimensions.
2512.15175
Dec 2025Systems and Control
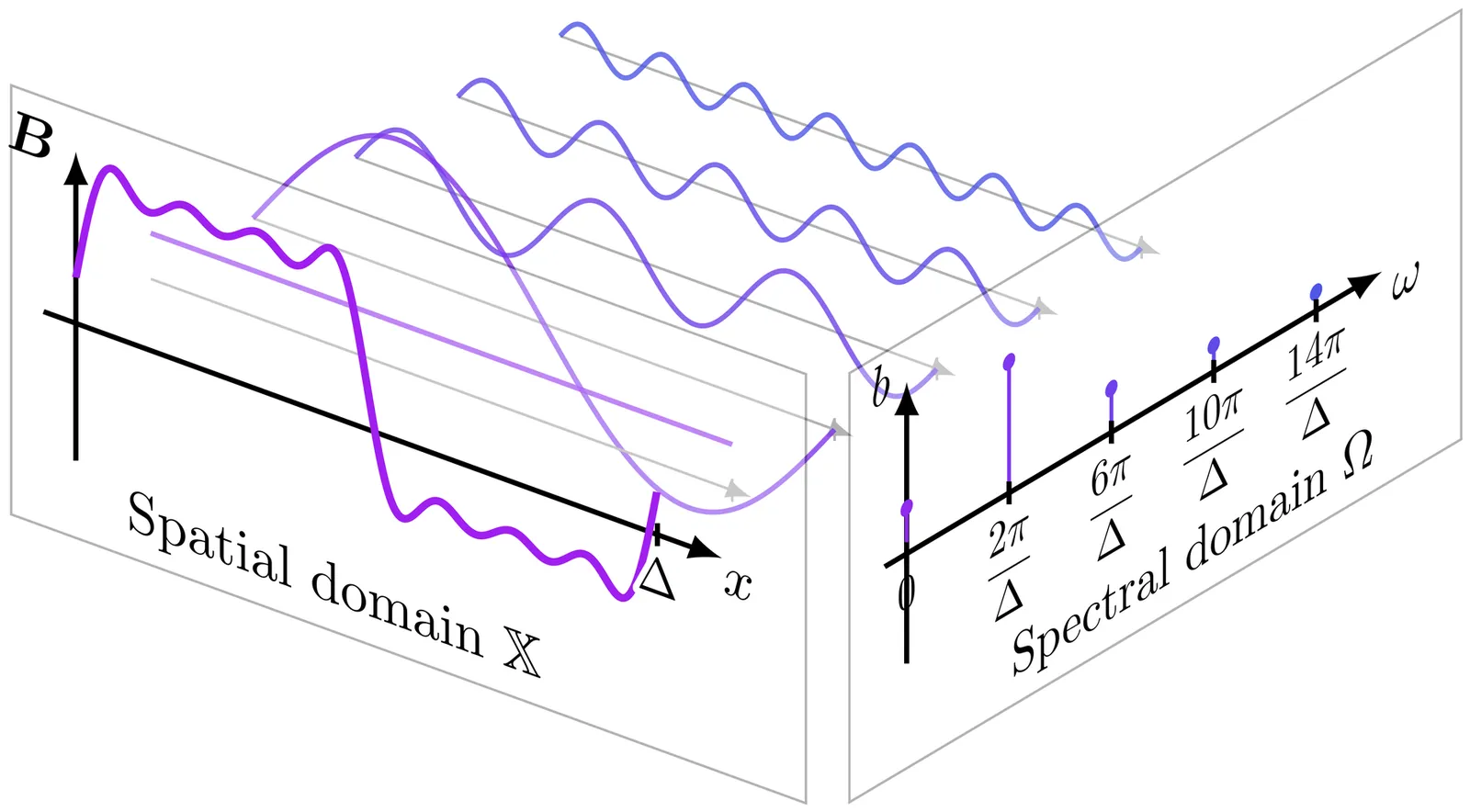
LUCID: Learning-Enabled Uncertainty-Aware Certification of Stochastic Dynamical Systems
Ensuring the safety of AI-enabled systems, particularly in high-stakes domains such as autonomous driving and healthcare, has become increasingly critical. Traditional formal verification tools fall short when faced with systems that embed both opaque, black-box AI components and complex stochastic dynamics. To address these challenges, we introduce LUCID (Learning-enabled Uncertainty-aware Certification of stochastIc Dynamical systems), a verification engine for certifying safety of black-box stochastic dynamical systems from a finite dataset of random state transitions. As such, LUCID is the first known tool capable of establishing quantified safety guarantees for such systems. Thanks to its modular architecture and extensive documentation, LUCID is designed for easy extensibility. LUCID employs a data-driven methodology rooted in control barrier certificates, which are learned directly from system transition data, to ensure formal safety guarantees. We use conditional mean embeddings to embed data into a reproducing kernel Hilbert space (RKHS), where an RKHS ambiguity set is constructed that can be inflated to robustify the result to out-of-distribution behavior. A key innovation within LUCID is its use of a finite Fourier kernel expansion to reformulate a semi-infinite non-convex optimization problem into a tractable linear program. The resulting spectral barrier allows us to leverage the fast Fourier transform to generate the relaxed problem efficiently, offering a scalable yet distributionally robust framework for verifying safety. LUCID thus offers a robust and efficient verification framework, able to handle the complexities of modern black-box systems while providing formal guarantees of safety. These unique capabilities are demonstrated on challenging benchmarks.
2512.11750
Dec 2025Systems and Control
Model Error Resonance: The Geometric Nature of Error Dynamics
This paper introduces a geometric theory of model error, treating true and model dynamics as geodesic flows generated by distinct affine connections on a smooth manifold. When these connections differ, the resulting trajectory discrepancy--termed the Latent Error Dynamic Response (LEDR)--acquires an intrinsic dynamical structure governed by curvature. We show that the LEDR satisfies a Jacobi-type equation, where curvature mismatch acts as an explicit forcing term. In the important case of a flat model connection, the LEDR reduces to a classical Jacobi field on the true manifold, causing Model Error Resonance (MER) to emerge under positive sectional curvature. The theory is extended to a discrete-time analogue, establishing that this geometric structure and its resonant behavior persist in sampled systems. A closed-form analysis of a sphere--plane example demonstrates that curvature can be inferred directly from the LEDR evolution. This framework provides a unified geometric interpretation of structured error dynamics and offers foundational tools for curvature-informed model validation.
2512.11734
Dec 2025Systems and Control
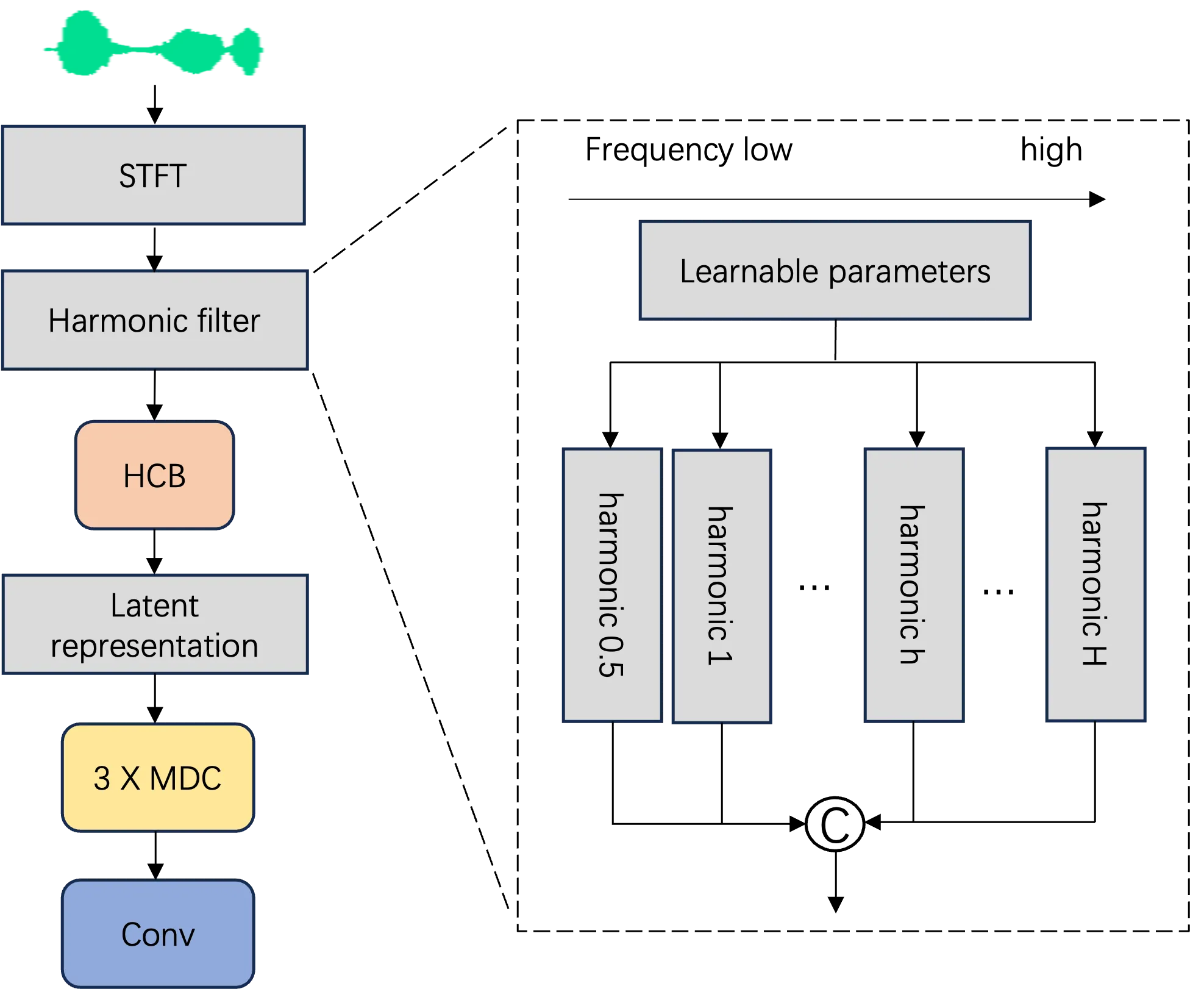
A Universal Harmonic Discriminator for High-quality GAN-based Vocoder
With the emergence of GAN-based vocoders, the discriminator, as a crucial component, has been developed recently. In our work, we focus on improving the time-frequency based discriminator. Particularly, Short-Time Fourier Transform (STFT) representation is usually used as input of time-frequency based discriminator. However, the STFT spectrogram has the same frequency resolution at different frequency bins, which results in an inferior performance, especially for singing voices. Motivated by this, we propose a universal harmonic discriminator for dynamic frequency resolution modeling and harmonic tracking. Specifically, we design a harmonic filter with learnable triangular band-pass filter banks, where each frequency bin has a flexible bandwidth. Additionally, we add a half-harmonic to capture fine-grained harmonic relationships at low-frequency band. Experiments on speech and singing datasets validate the effectiveness of the proposed discriminator on both subjective and objective metrics.
2512.03486
Dec 2025Audio and Speech Processing
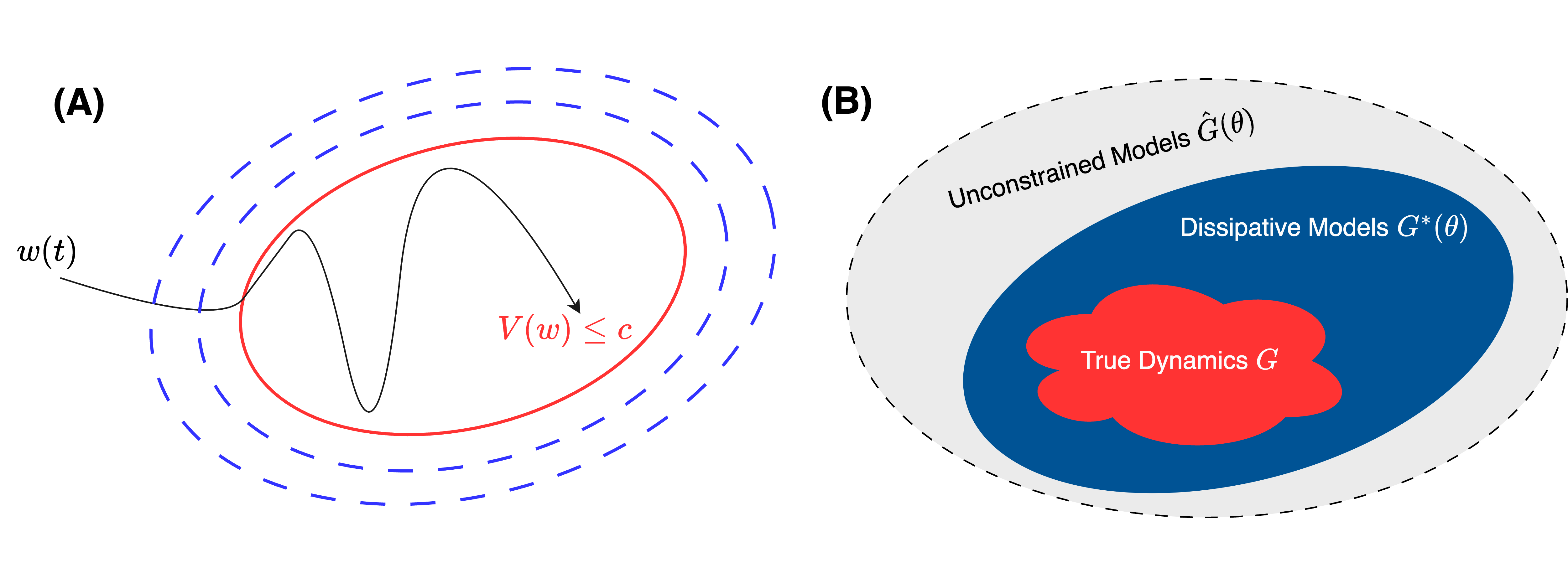
ECO: Energy-Constrained Operator Learning for Chaotic Dynamics with Boundedness Guarantees
Chaos is a fundamental feature of many complex dynamical systems, including weather systems and fluid turbulence. These systems are inherently difficult to predict due to their extreme sensitivity to initial conditions. Many chaotic systems are dissipative and ergodic, motivating data-driven models that aim to learn invariant statistical properties over long time horizons. While recent models have shown empirical success in preserving invariant statistics, they are prone to generating unbounded predictions, which prevent meaningful statistics evaluation. To overcome this, we introduce the Energy-Constrained Operator (ECO) that simultaneously learns the system dynamics while enforcing boundedness in predictions. We leverage concepts from control theory to develop algebraic conditions based on a learnable energy function, ensuring the learned dynamics is dissipative. ECO enforces these algebraic conditions through an efficient closed-form quadratic projection layer, which provides provable trajectory boundedness. To our knowledge, this is the first work establishing such formal guarantees for data-driven chaotic dynamics models. Additionally, the learned invariant level set provides an outer estimate for the strange attractor, a complex structure that is computationally intractable to characterize. We demonstrate empirical success in ECO's ability to generate stable long-horizon forecasts, capturing invariant statistics on systems governed by chaotic PDEs, including the Kuramoto--Sivashinsky and the Navier--Stokes equations.
2512.01984
Dec 2025Systems and Control
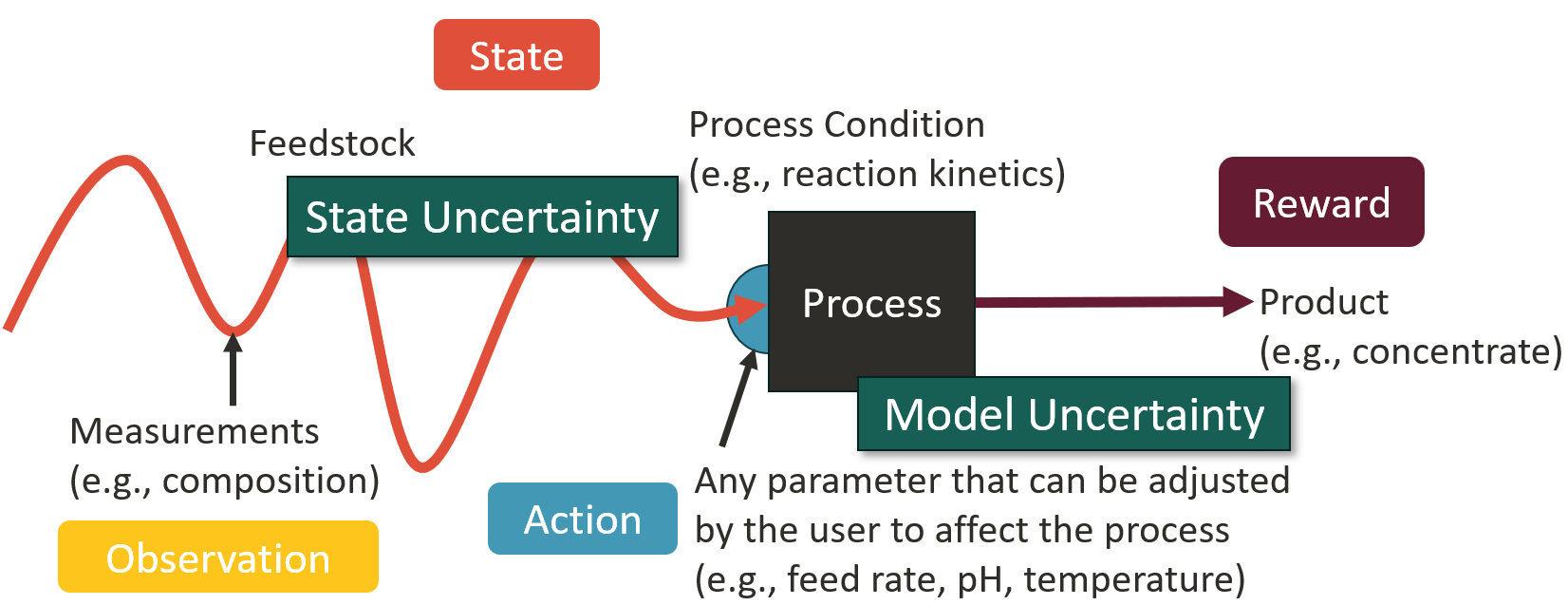
AI-Driven Optimization under Uncertainty for Mineral Processing Operations
The global capacity for mineral processing must expand rapidly to meet the demand for critical minerals, which are essential for building the clean energy technologies necessary to mitigate climate change. However, the efficiency of mineral processing is severely limited by uncertainty, which arises from both the variability of feedstock and the complexity of process dynamics. To optimize mineral processing circuits under uncertainty, we introduce an AI-driven approach that formulates mineral processing as a Partially Observable Markov Decision Process (POMDP). We demonstrate the capabilities of this approach in handling both feedstock uncertainty and process model uncertainty to optimize the operation of a simulated, simplified flotation cell as an example. We show that by integrating the process of information gathering (i.e., uncertainty reduction) and process optimization, this approach has the potential to consistently perform better than traditional approaches at maximizing an overall objective, such as net present value (NPV). Our methodological demonstration of this optimization-under-uncertainty approach for a synthetic case provides a mathematical and computational framework for later real-world application, with the potential to improve both the laboratory-scale design of experiments and industrial-scale operation of mineral processing circuits without any additional hardware.
2512.01977
Dec 2025Systems and Control