Trending in Audio & Speech Processing
SAM Audio Judge: A Unified Multimodal Framework for Perceptual Evaluation of Audio Separation
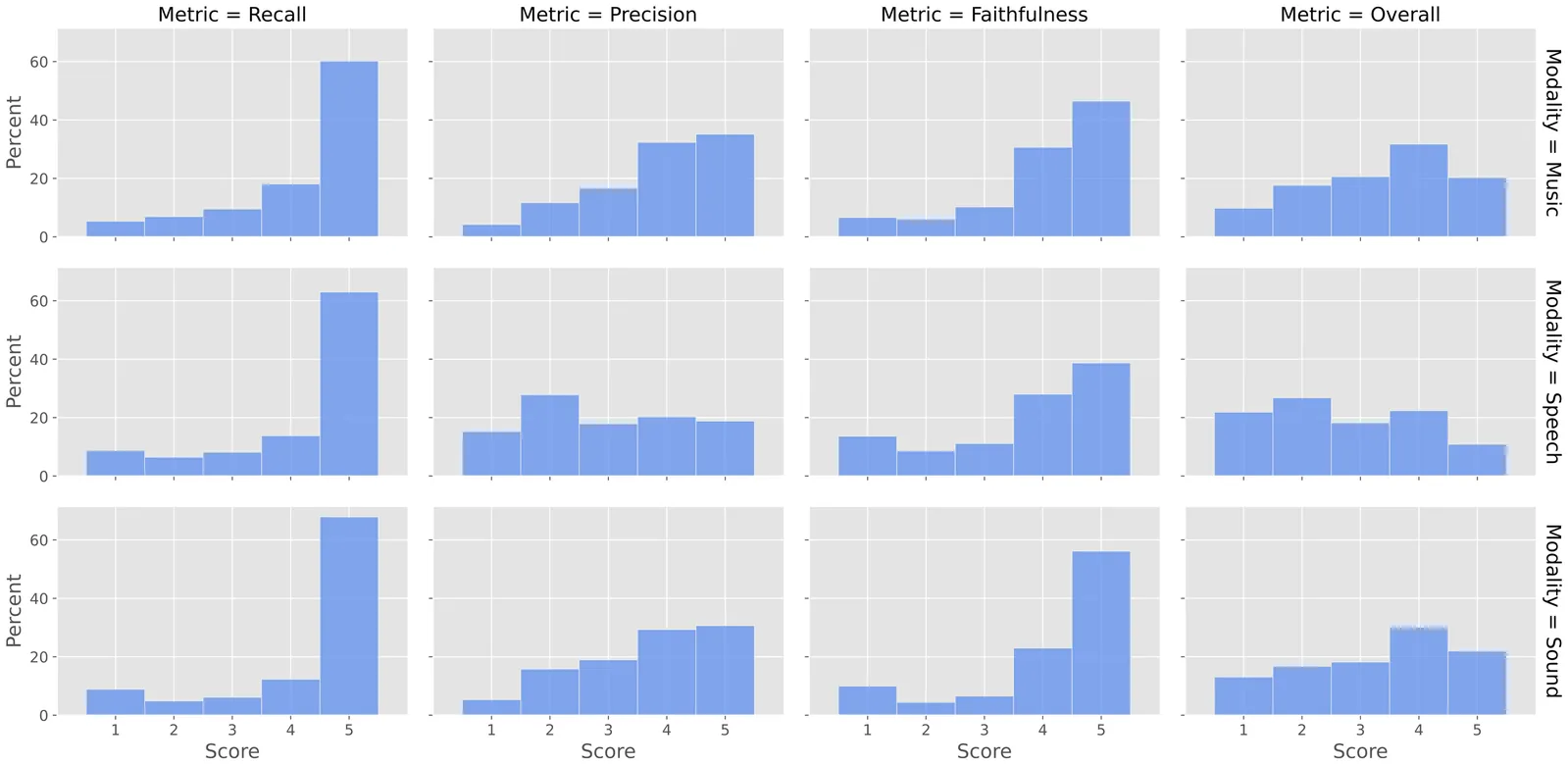
The performance evaluation remains a complex challenge in audio separation, and existing evaluation metrics are often misaligned with human perception, course-grained, relying on ground truth signals. On the other hand, subjective listening tests remain the gold standard for real-world evaluation, but they are expensive, time-consuming, and difficult to scale. This paper addresses the growing need for automated systems capable of evaluating audio separation without human intervention. The proposed evaluation metric, SAM Audio Judge (SAJ), is a multimodal fine-grained reference-free objective metric, which shows highly alignment with human perceptions. SAJ supports three audio domains (speech, music and general sound events) and three prompt inputs (text, visual and span), covering four different dimensions of evaluation (recall, percision, faithfulness, and overall). SAM Audio Judge also shows potential applications in data filtering, pseudo-labeling large datasets and reranking in audio separation models. We release our code and pre-trained models at: https://github.com/facebookresearch/sam-audio.
2601.19702
Jan 2026Audio and Speech Processing
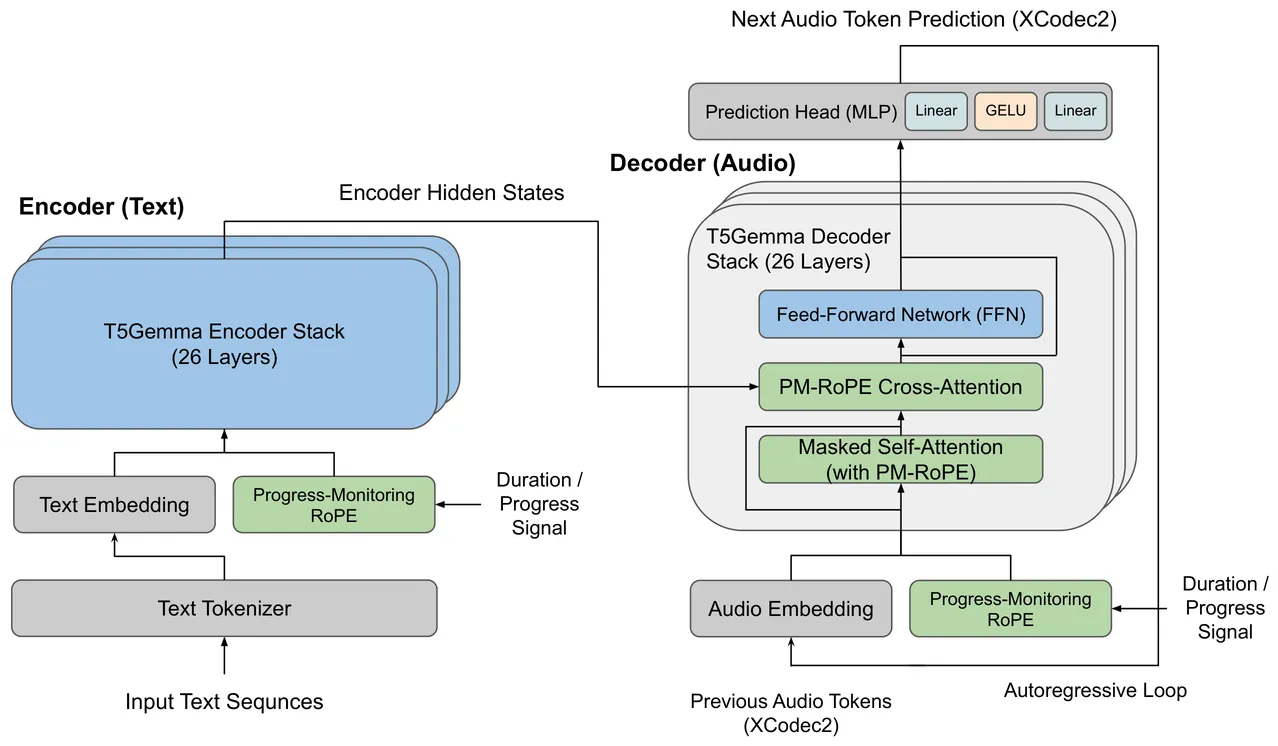
T-Mimi: A Transformer-based Mimi Decoder for Real-Time On-Phone TTS
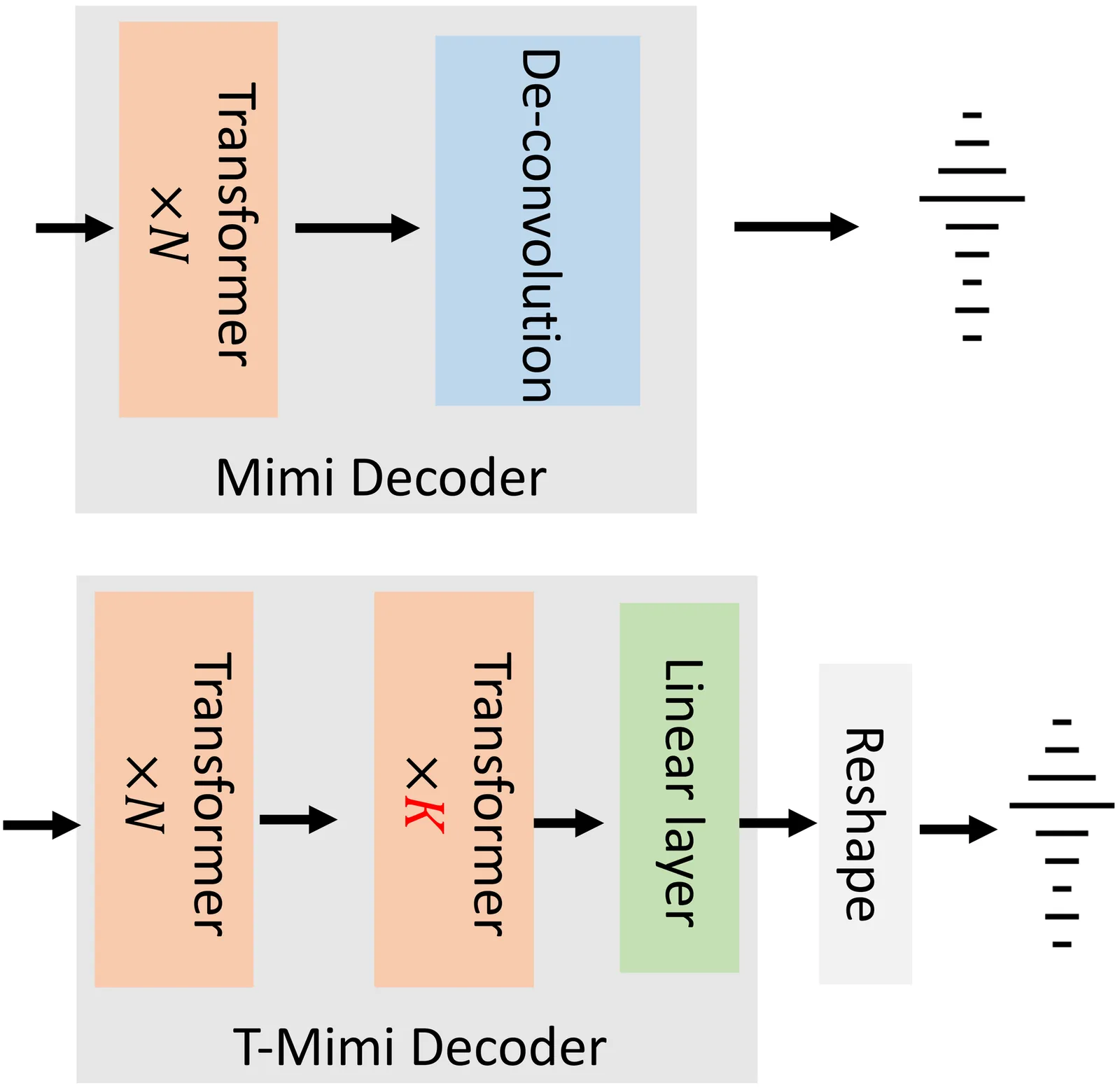
Neural audio codecs provide promising acoustic features for speech synthesis, with representative streaming codecs like Mimi providing high-quality acoustic features for real-time Text-to-Speech (TTS) applications. However, Mimi's decoder, which employs a hybrid transformer and convolution architecture, introduces significant latency bottlenecks on edge devices due to the the compute intensive nature of deconvolution layers which are not friendly for mobile-CPUs, such as the most representative framework XNNPACK. This paper introduces T-Mimi, a novel modification of the Mimi codec decoder that replaces its convolutional components with a purely transformer-based decoder, inspired by the TS3-Codec architecture. This change dramatically reduces on-device TTS latency from 42.1ms to just 4.4ms. Furthermore, we conduct quantization aware training and derive a crucial finding: the final two transformer layers and the concluding linear layers of the decoder, which are close to the waveform, are highly sensitive to quantization and must be preserved at full precision to maintain audio quality.
2601.20094
Jan 2026Audio and Speech Processing

VoiceSculptor: Your Voice, Designed By You
Despite rapid progress in text-to-speech (TTS), open-source systems still lack truly instruction-following, fine-grained control over core speech attributes (e.g., pitch, speaking rate, age, emotion, and style). We present VoiceSculptor, an open-source unified system that bridges this gap by integrating instruction-based voice design and high-fidelity voice cloning in a single framework. It generates controllable speaker timbre directly from natural-language descriptions, supports iterative refinement via Retrieval-Augmented Generation (RAG), and provides attribute-level edits across multiple dimensions. The designed voice is then rendered into a prompt waveform and fed into a cloning model to enable high-fidelity timbre transfer for downstream speech synthesis. VoiceSculptor achieves open-source state-of-the-art (SOTA) on InstructTTSEval-Zh, and is fully open-sourced, including code and pretrained models, to advance reproducible instruction-controlled TTS research.
2601.10629
Jan 2026Audio and Speech Processing
ReStyle-TTS: Relative and Continuous Style Control for Zero-Shot Speech Synthesis
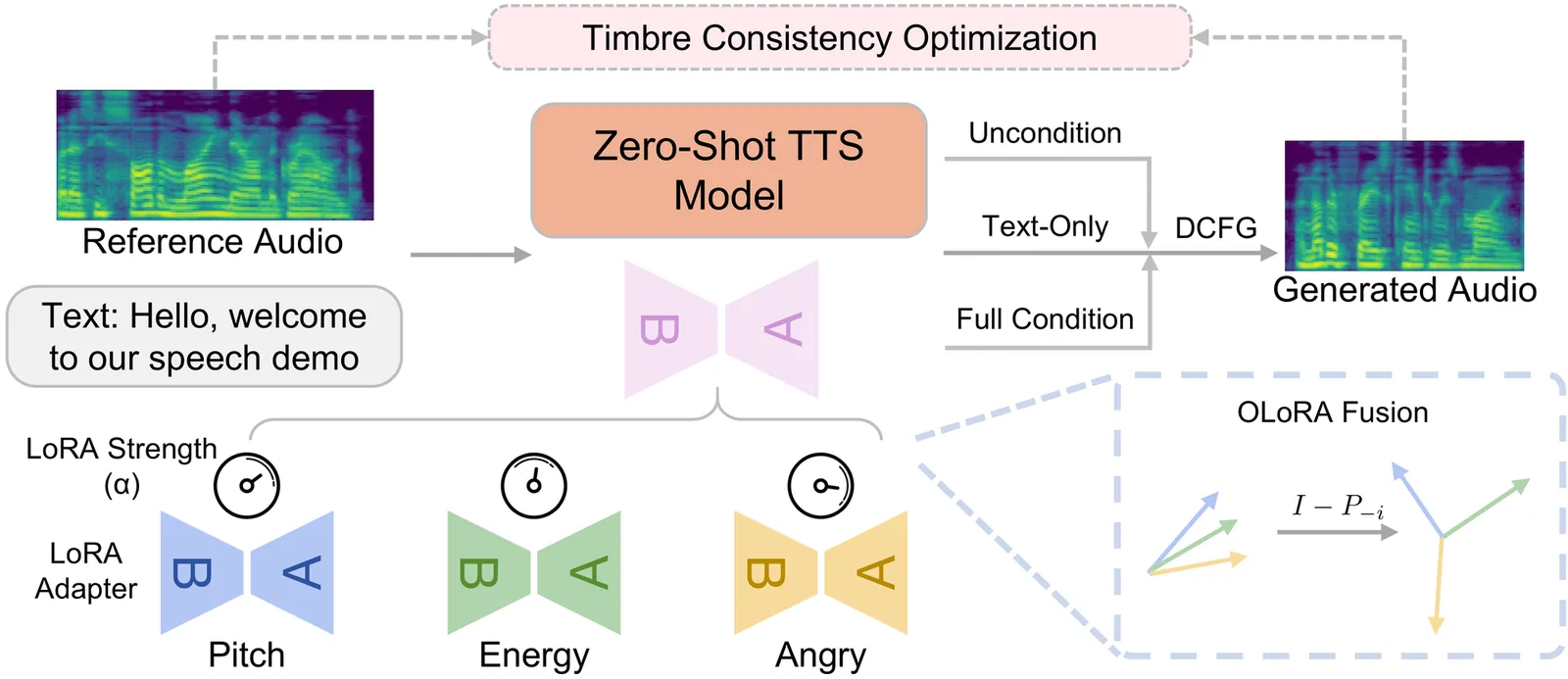
Zero-shot text-to-speech models can clone a speaker's timbre from a short reference audio, but they also strongly inherit the speaking style present in the reference. As a result, synthesizing speech with a desired style often requires carefully selecting reference audio, which is impractical when only limited or mismatched references are available. While recent controllable TTS methods attempt to address this issue, they typically rely on absolute style targets and discrete textual prompts, and therefore do not support continuous and reference-relative style control. We propose ReStyle-TTS, a framework that enables continuous and reference-relative style control in zero-shot TTS. Our key insight is that effective style control requires first reducing the model's implicit dependence on reference style before introducing explicit control mechanisms. To this end, we introduce Decoupled Classifier-Free Guidance (DCFG), which independently controls text and reference guidance, reducing reliance on reference style while preserving text fidelity. On top of this, we apply style-specific LoRAs together with Orthogonal LoRA Fusion to enable continuous and disentangled multi-attribute control, and introduce a Timbre Consistency Optimization module to mitigate timbre drift caused by weakened reference guidance. Experiments show that ReStyle-TTS enables user-friendly, continuous, and relative control over pitch, energy, and multiple emotions while maintaining intelligibility and speaker timbre, and performs robustly in challenging mismatched reference-target style scenarios.
2601.03632
Jan 2026Audio and Speech Processing

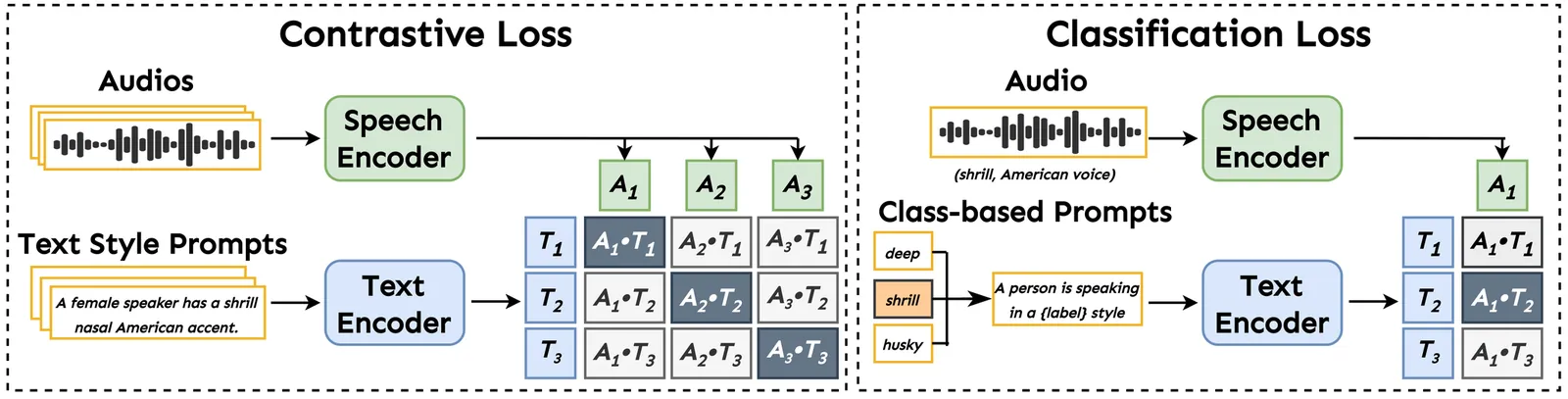
Towards Fine-Grained and Multi-Granular Contrastive Language-Speech Pre-training
Modeling fine-grained speaking styles remains challenging for language-speech representation pre-training, as existing speech-text models are typically trained with coarse captions or task-specific supervision, and scalable fine-grained style annotations are unavailable. We present FCaps, a large-scale dataset with fine-grained free-text style descriptions, encompassing 47k hours of speech and 19M fine-grained captions annotated via a novel end-to-end pipeline that directly grounds detailed captions in audio, thereby avoiding the error propagation caused by LLM-based rewriting in existing cascaded pipelines. Evaluations using LLM-as-a-judge demonstrate that our annotations surpass existing cascaded annotations in terms of correctness, coverage, and naturalness. Building on FCaps, we propose CLSP, a contrastive language-speech pre-trained model that integrates global and fine-grained supervision, enabling unified representations across multiple granularities. Extensive experiments demonstrate that CLSP learns fine-grained and multi-granular speech-text representations that perform reliably across global and fine-grained speech-text retrieval, zero-shot paralinguistic classification, and speech style similarity scoring, with strong alignment to human judgments. All resources will be made publicly available.
2601.03065
Jan 2026Audio and Speech Processing
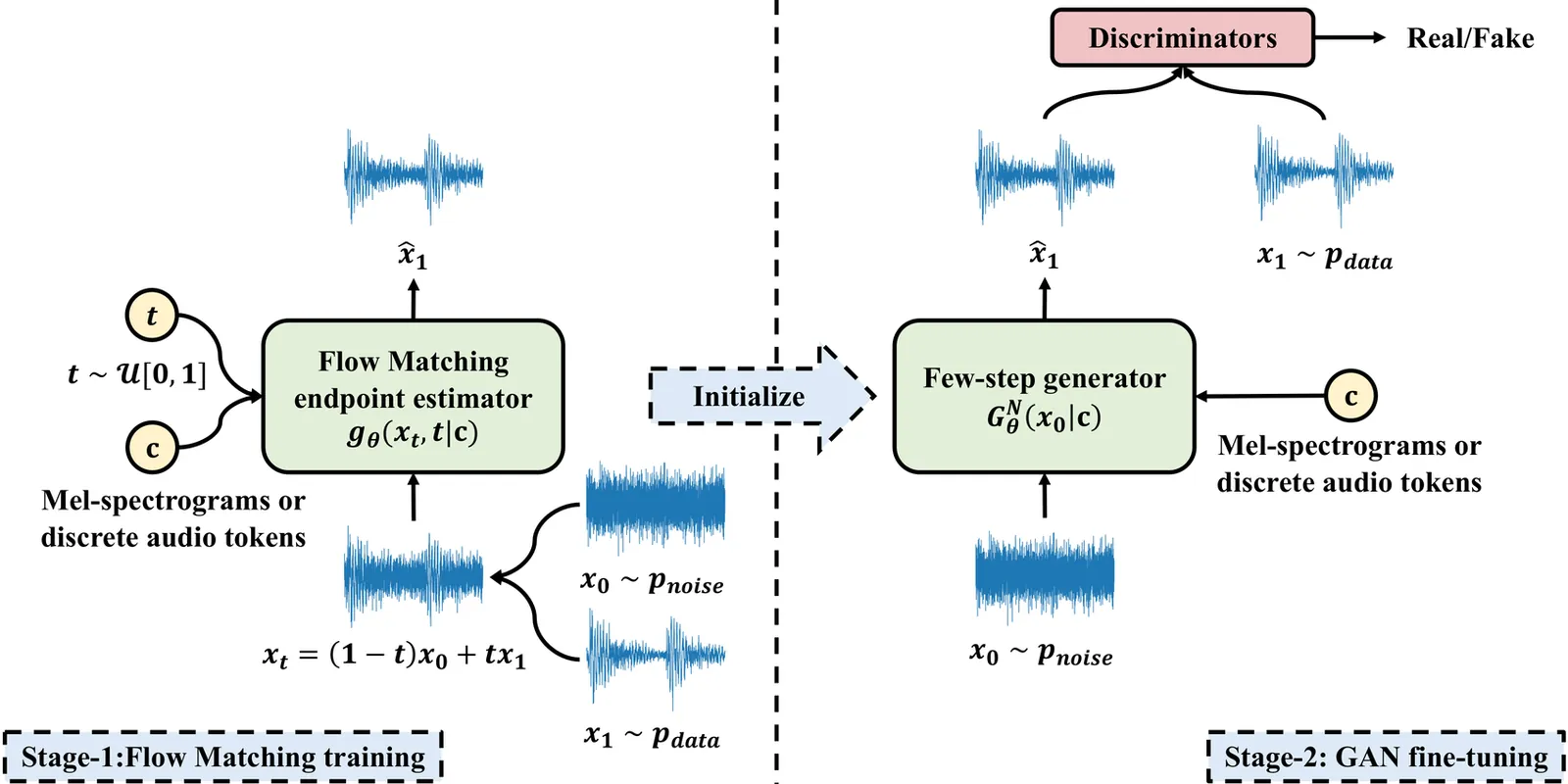
Flow2GAN: Hybrid Flow Matching and GAN with Multi-Resolution Network for Few-step High-Fidelity Audio Generation
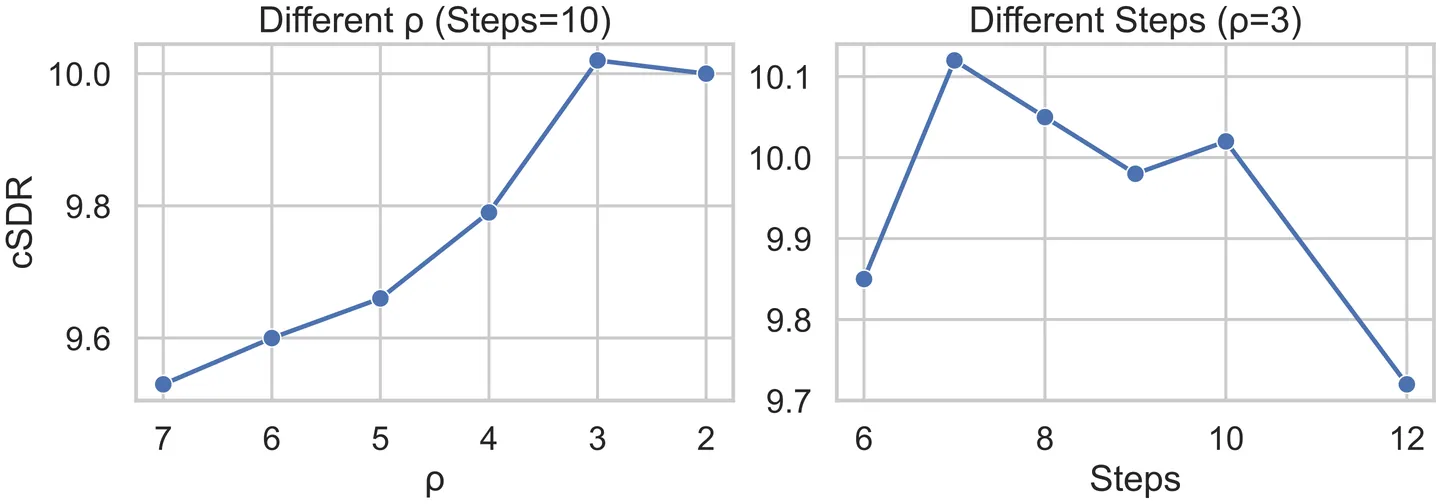
Existing dominant methods for audio generation include Generative Adversarial Networks (GANs) and diffusion-based methods like Flow Matching. GANs suffer from slow convergence and potential mode collapse during training, while diffusion methods require multi-step inference that introduces considerable computational overhead. In this work, we introduce Flow2GAN, a two-stage framework that combines Flow Matching training for learning generative capabilities with GAN fine-tuning for efficient few-step inference. Specifically, given audio's unique properties, we first improve Flow Matching for audio modeling through: 1) reformulating the objective as endpoint estimation, avoiding velocity estimation difficulties when involving empty regions; 2) applying spectral energy-based loss scaling to emphasize perceptually salient quieter regions. Building on these Flow Matching adaptations, we demonstrate that a further stage of lightweight GAN fine-tuning enables us to obtain one-step generator that produces high-quality audio. In addition, we develop a multi-branch network architecture that processes Fourier coefficients at different time-frequency resolutions, which improves the modeling capabilities compared to prior single-resolution designs. Experimental results indicate that our Flow2GAN delivers high-fidelity audio generation from Mel-spectrograms or discrete audio tokens, achieving better quality-efficiency trade-offs than existing state-of-the-art GAN-based and Flow Matching-based methods. Online demo samples are available at https://flow2gan.github.io, and the source code is released at https://github.com/k2-fsa/Flow2GAN.
2512.23278
Dec 2025Audio and Speech Processing

QuarkAudio Technical Report
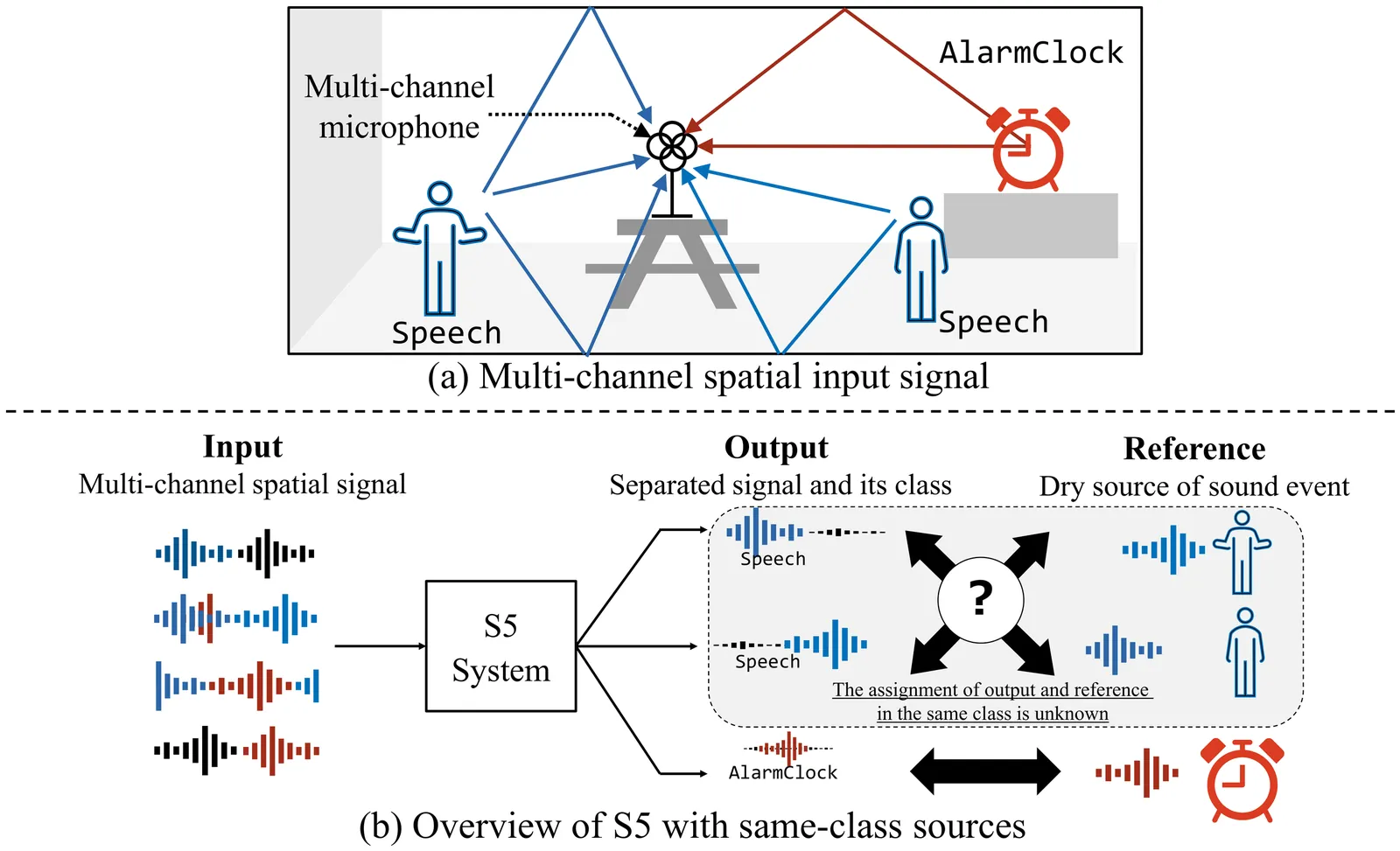
Many existing audio processing and generation models rely on task-specific architectures, resulting in fragmented development efforts and limited extensibility. It is therefore promising to design a unified framework capable of handling multiple tasks, while providing robust instruction and audio understanding and high-quality audio generation. This requires a compatible paradigm design, a powerful backbone, and a high-fidelity audio reconstruction module. To meet these requirements, this technical report introduces QuarkAudio, a decoder-only autoregressive (AR) LM-based generative framework that unifies multiple tasks. The framework includes a unified discrete audio tokenizer, H-Codec, which incorporates self-supervised learning (SSL) representations into the tokenization and reconstruction process. We further propose several improvements to H-Codec, such as a dynamic frame-rate mechanism and extending the audio sampling rate to 48 kHz. QuarkAudio unifies tasks by using task-specific conditional information as the conditioning sequence of the decoder-only LM, and predicting discrete target audio tokens in an AR manner. The framework supports a wide range of audio processing and generation tasks, including speech restoration (SR), target speaker extraction (TSE), speech separation (SS), voice conversion (VC), and language-queried audio source separation (LASS). In addition, we extend downstream tasks to universal free-form audio editing guided by natural language instructions (including speech semantic editing and audio event editing). Experimental results show that H-Codec achieves high-quality audio reconstruction with a low frame rate, improving both the efficiency and performance of downstream audio generation, and that QuarkAudio delivers competitive or comparable performance to state-of-the-art task-specific or multi-task systems across multiple tasks.
2512.20151
Dec 2025Audio and Speech Processing
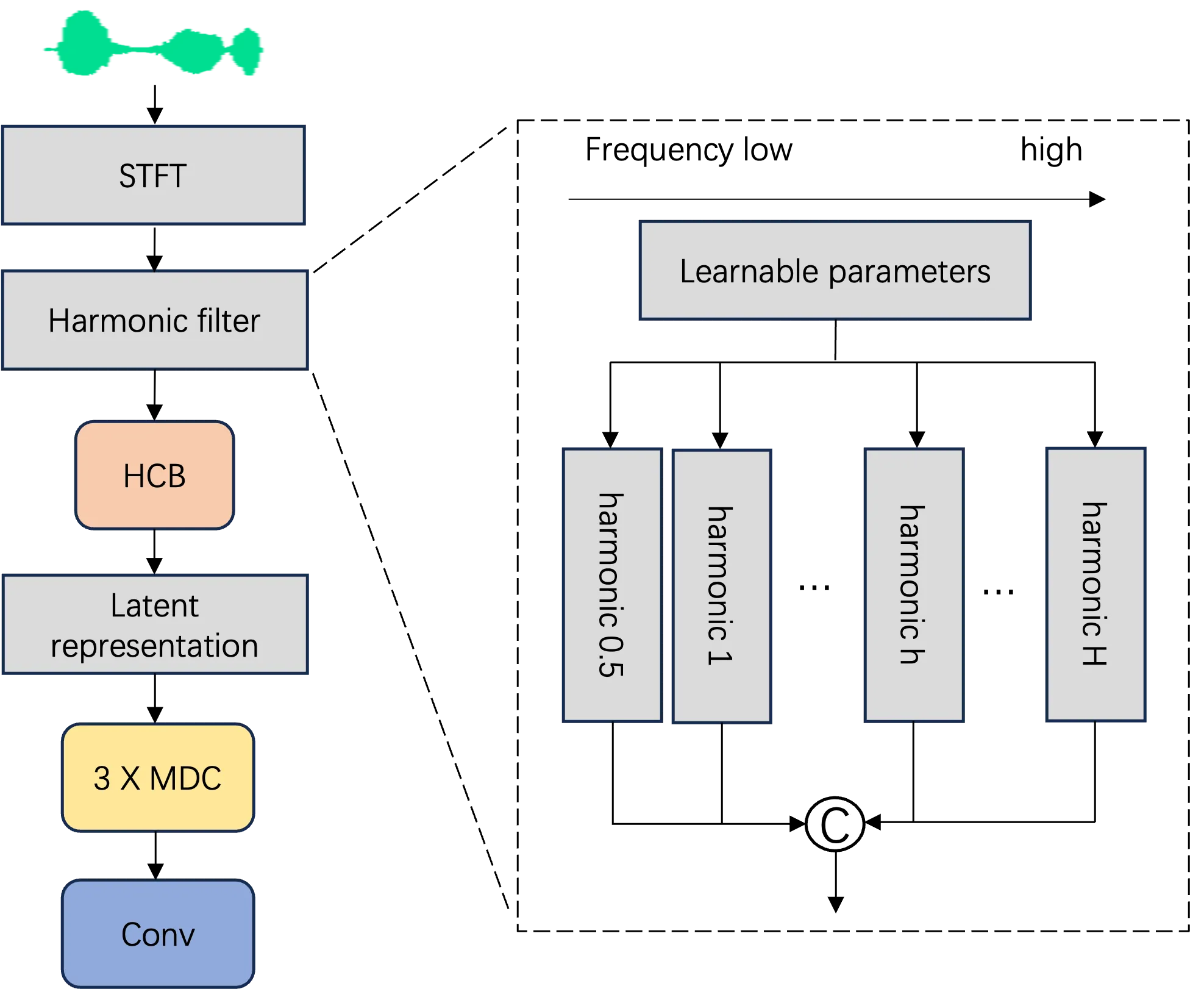
A Universal Harmonic Discriminator for High-quality GAN-based Vocoder
With the emergence of GAN-based vocoders, the discriminator, as a crucial component, has been developed recently. In our work, we focus on improving the time-frequency based discriminator. Particularly, Short-Time Fourier Transform (STFT) representation is usually used as input of time-frequency based discriminator. However, the STFT spectrogram has the same frequency resolution at different frequency bins, which results in an inferior performance, especially for singing voices. Motivated by this, we propose a universal harmonic discriminator for dynamic frequency resolution modeling and harmonic tracking. Specifically, we design a harmonic filter with learnable triangular band-pass filter banks, where each frequency bin has a flexible bandwidth. Additionally, we add a half-harmonic to capture fine-grained harmonic relationships at low-frequency band. Experiments on speech and singing datasets validate the effectiveness of the proposed discriminator on both subjective and objective metrics.
2512.03486
Dec 2025Audio and Speech Processing
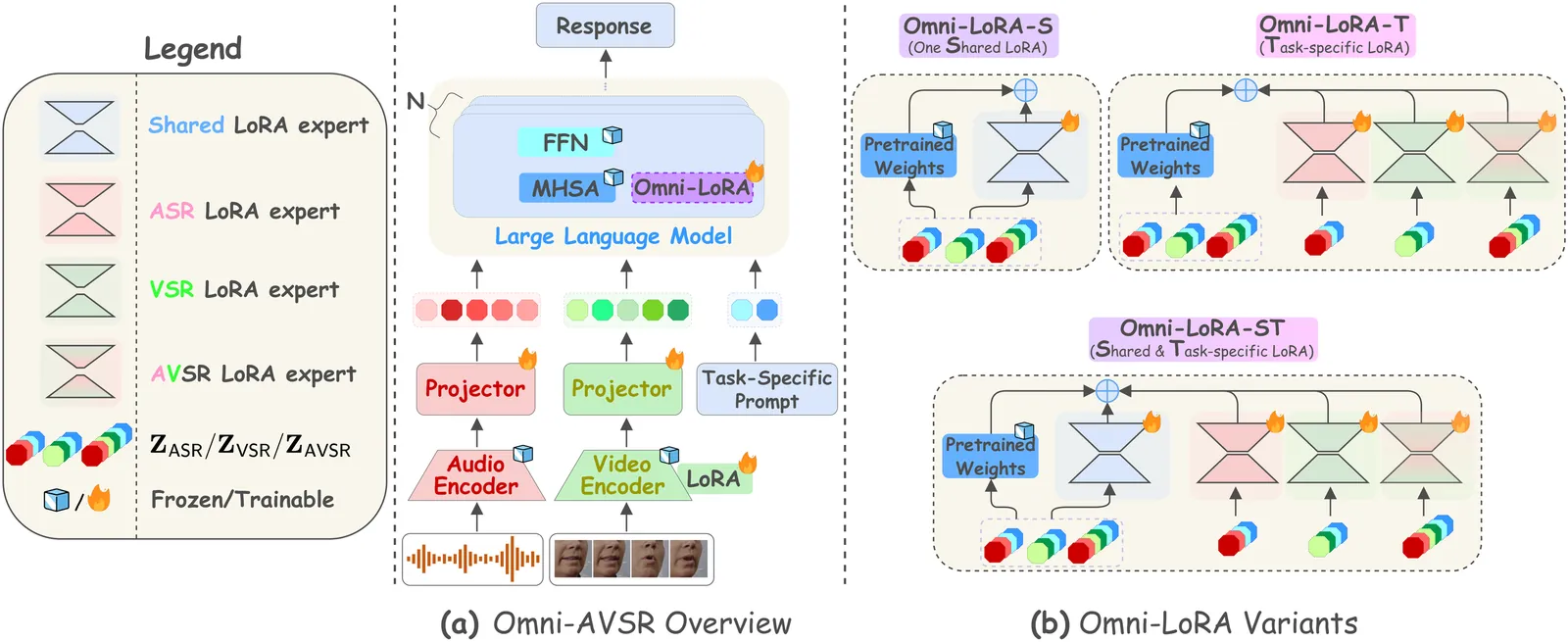
Omni-AVSR: Towards Unified Multimodal Speech Recognition with Large Language Models
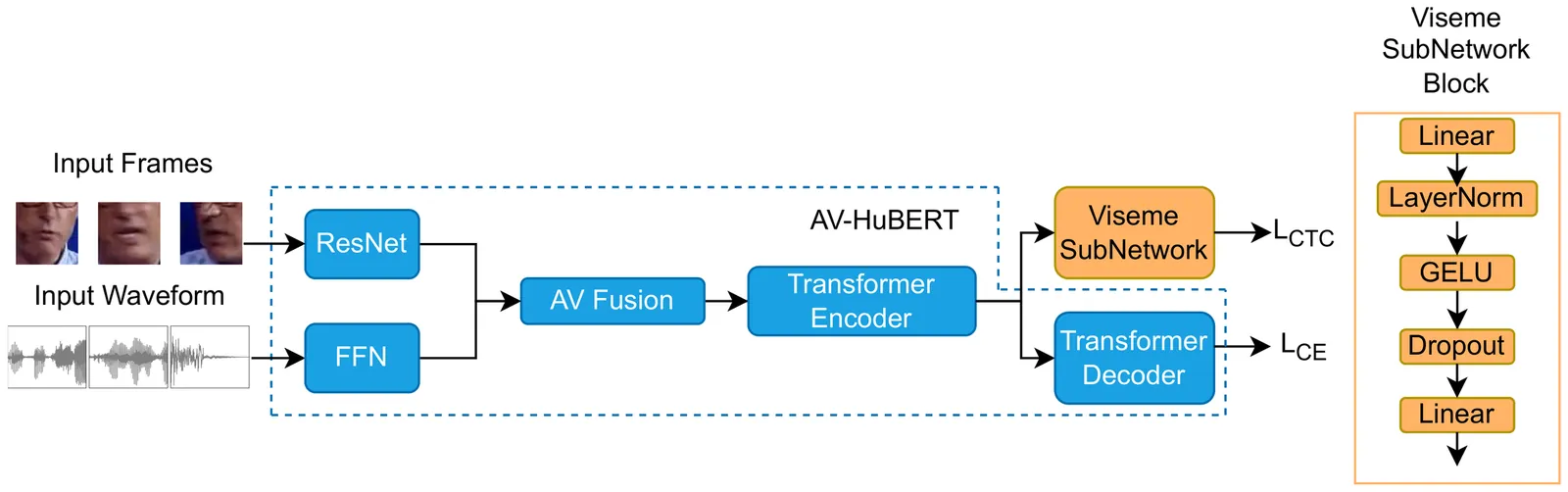
Large language models (LLMs) have recently achieved impressive results in speech recognition across multiple modalities, including Auditory Speech Recognition (ASR), Visual Speech Recognition (VSR), and Audio-Visual Speech Recognition (AVSR). Despite this progress, current LLM-based approaches typically address each task independently, training separate models that raise computational and deployment resource use while missing potential cross-task synergies. They also rely on fixed-rate token compression, which restricts flexibility in balancing accuracy with efficiency. These limitations highlight the need for a unified framework that can support ASR, VSR, and AVSR while enabling elastic inference. To this end, we present Omni-AVSR, a unified audio-visual LLM that combines efficient multi-granularity training with parameter-efficient adaptation. Specifically, we adapt the matryoshka representation learning paradigm to efficiently train across multiple audio and visual granularities, reducing its inherent training resource use. Furthermore, we explore three LoRA-based strategies for adapting the backbone LLM, balancing shared and task-specific specialization. Experiments on LRS2 and LRS3 show that Omni-AVSR achieves comparable or superior accuracy to state-of-the-art baselines while training a single model at substantially lower training and deployment resource use. The model also remains robust under acoustic noise, and we analyze its scaling behavior as LLM size increases, providing insights into the trade-off between performance and efficiency.
2511.07253
Nov 2025Audio and Speech Processing