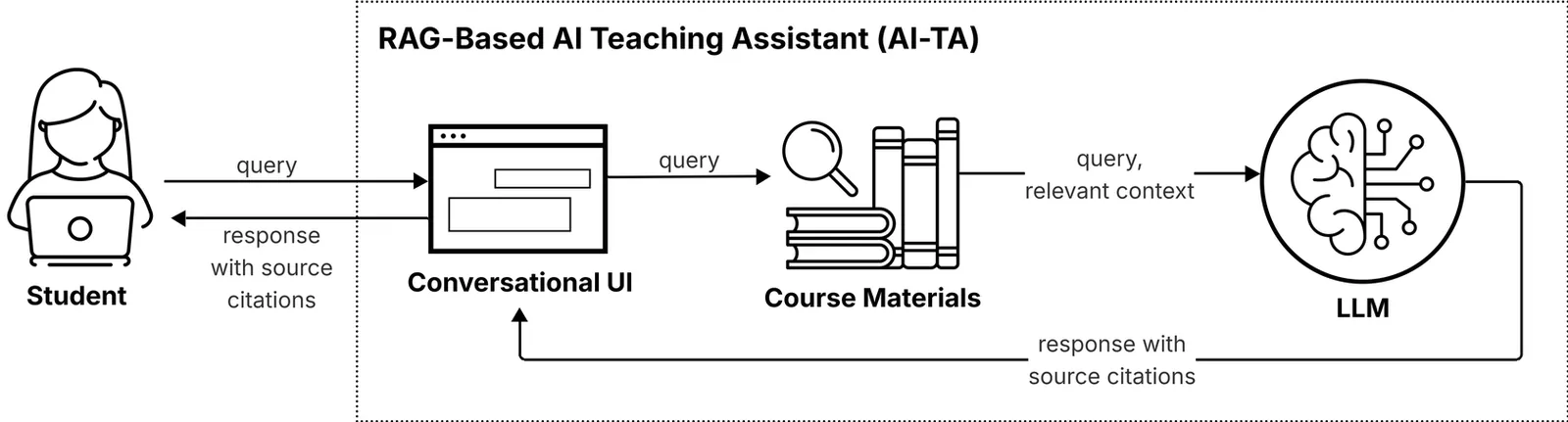
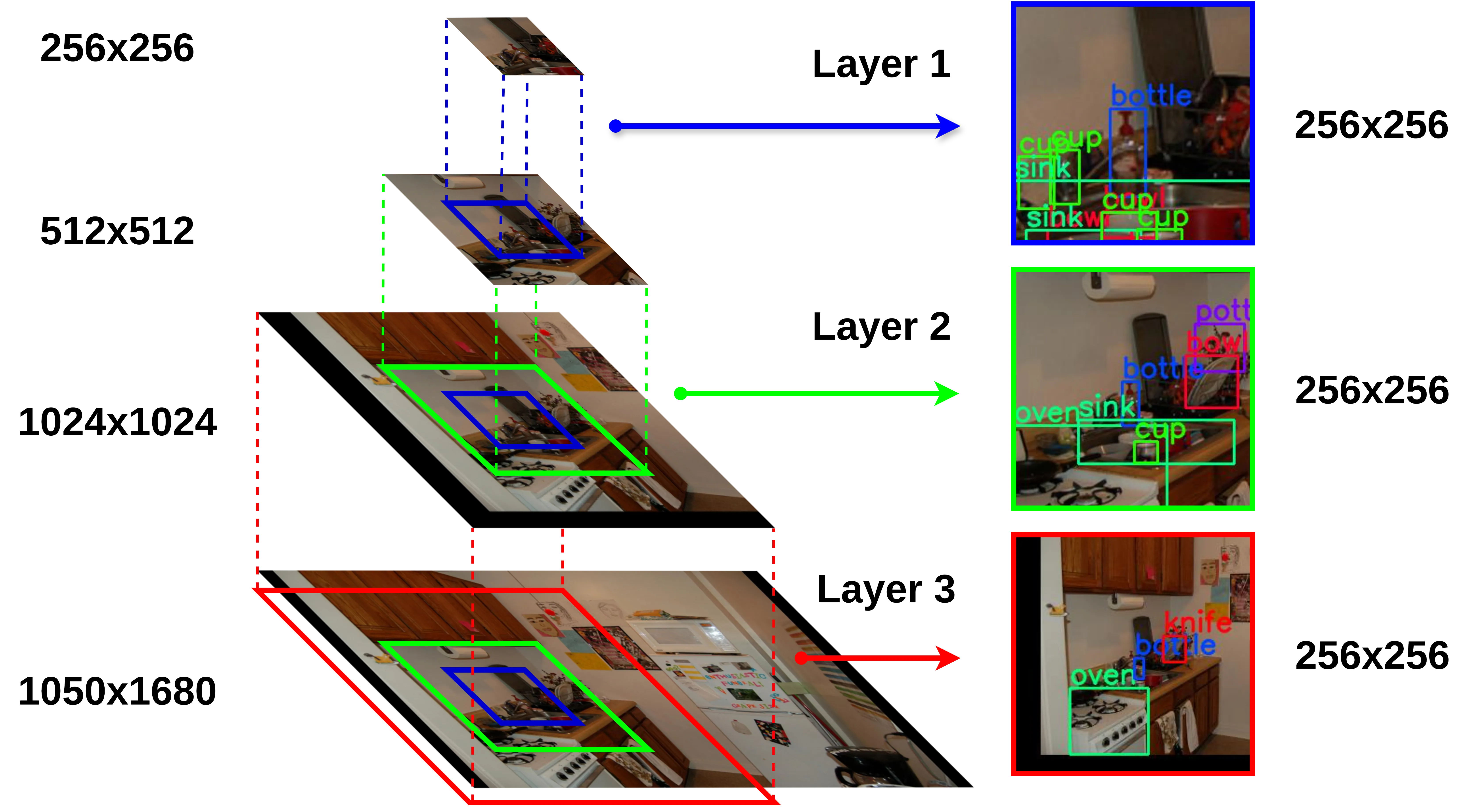
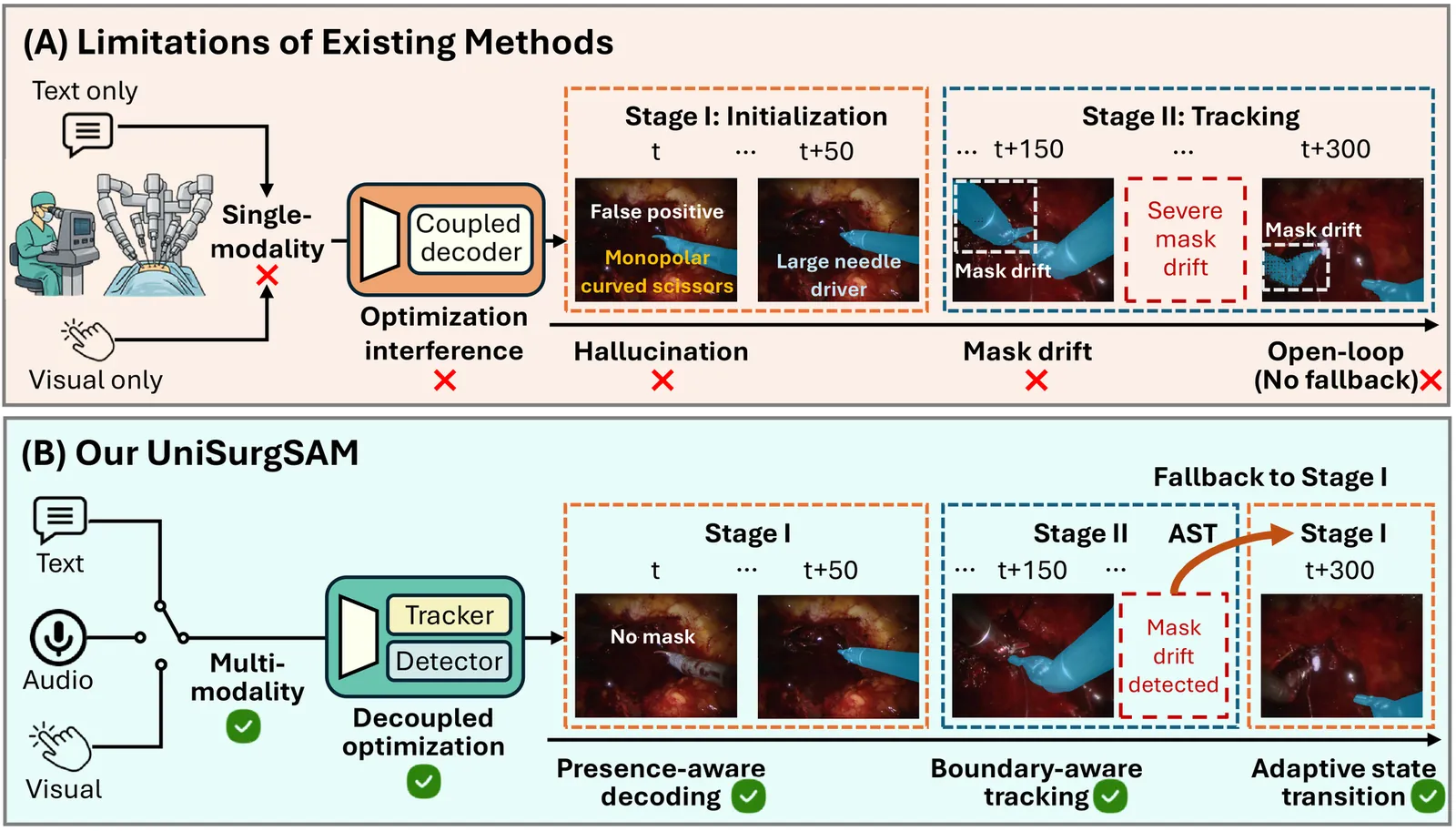
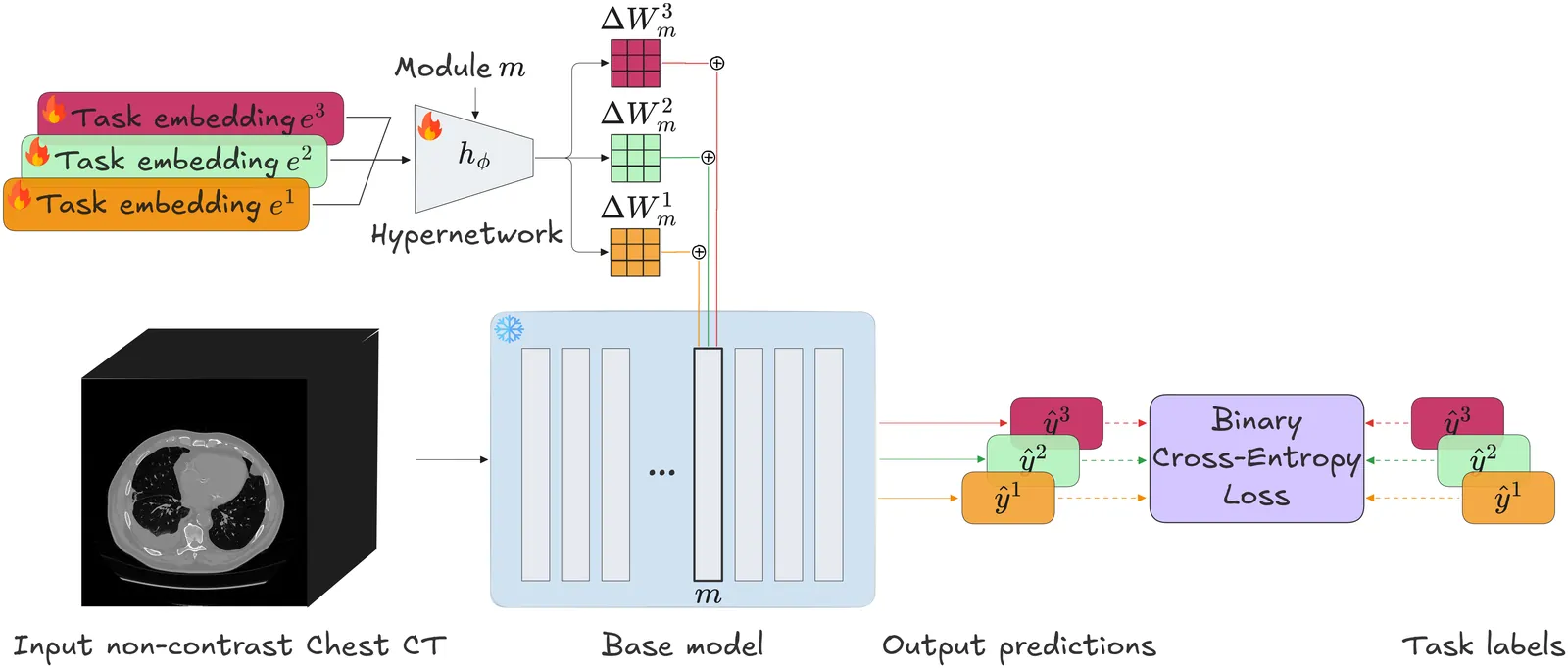
Trending in Image & Video Processing

Video Generation Models as World Models: Efficient Paradigms, Architectures and Algorithms
The rapid evolution of video generation has enabled models to simulate complex physical dynamics and long-horizon causalities, positioning them as potential world simulators. However, a critical gap still remains between the theoretical capacity for world simulation and the heavy computational costs of spatiotemporal modeling. To address this, we comprehensively and systematically review video generation frameworks and techniques that consider efficiency as a crucial requirement for practical world modeling. We introduce a novel taxonomy in three dimensions: efficient modeling paradigms, efficient network architectures, and efficient inference algorithms. We further show that bridging this efficiency gap directly empowers interactive applications such as autonomous driving, embodied AI, and game simulation. Finally, we identify emerging research frontiers in efficient video-based world modeling, arguing that efficiency is a fundamental prerequisite for evolving video generators into general-purpose, real-time, and robust world simulators.
2603.28489
Mar 2026Image and Video Processing
OpenVision 3: A Family of Unified Visual Encoder for Both Understanding and Generation
This paper presents a family of advanced vision encoder, named OpenVision 3, that learns a single, unified visual representation that can serve both image understanding and image generation. Our core architecture is simple: we feed VAE-compressed image latents to a ViT encoder and train its output to support two complementary roles. First, the encoder output is passed to the ViT-VAE decoder to reconstruct the original image, encouraging the representation to capture generative structure. Second, the same representation is optimized with contrastive learning and image-captioning objectives, strengthening semantic features. By jointly optimizing reconstruction- and semantics-driven signals in a shared latent space, the encoder learns representations that synergize and generalize well across both regimes. We validate this unified design through extensive downstream evaluations with the encoder frozen. For multimodal understanding, we plug the encoder into the LLaVA-1.5 framework: it performs comparably with a standard CLIP vision encoder (e.g., 62.4 vs 62.2 on SeedBench, and 83.7 vs 82.9 on POPE). For generation, we test it under the RAE framework: ours substantially surpasses the standard CLIP-based encoder (e.g., gFID: 1.89 vs 2.54 on ImageNet). We hope this work can spur future research on unified modeling.
2601.15369
Jan 2026Image and Video Processing