Trending in Robotics
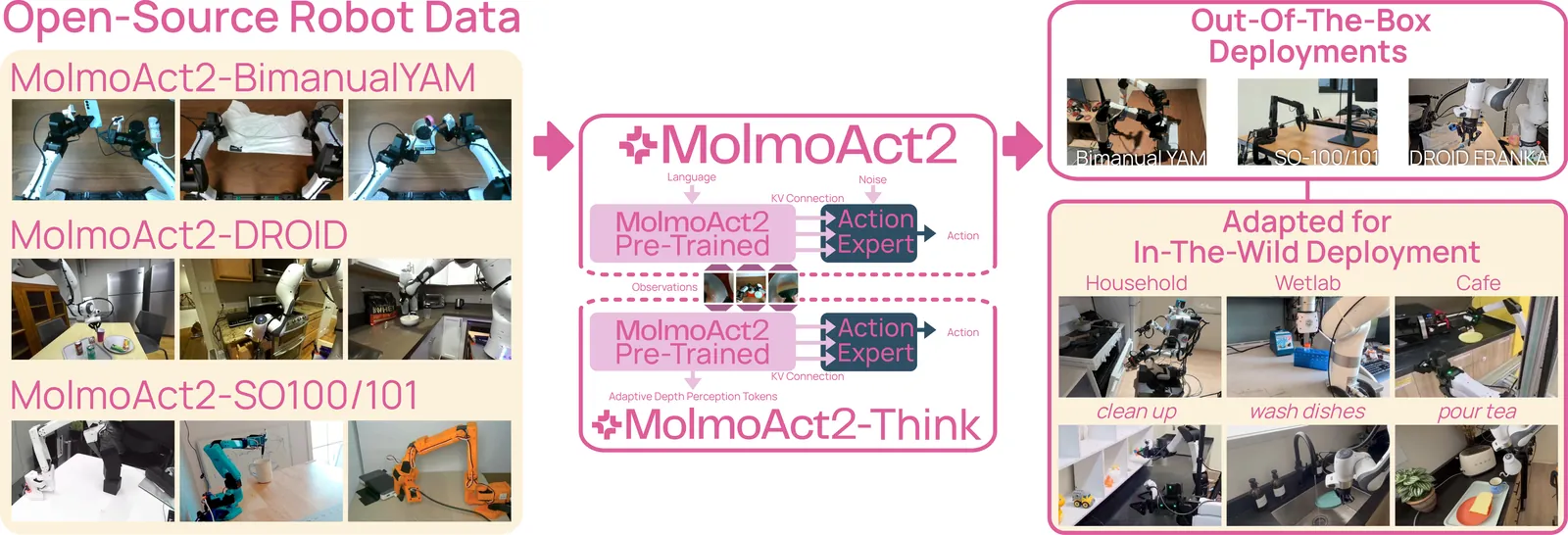
MolmoAct2: Action Reasoning Models for Real-world Deployment
Vision-Language-Action (VLA) models aim to provide a single generalist controller for robots, but today's systems fall short on the criteria that matter for real-world deployment. Frontier models are closed, open-weight alternatives are tied to expensive hardware, reasoning-augmented policies pay prohibitive latency for their grounding, and fine-tuned success rates remain below the threshold for dependable use. We present MolmoAct2, a fully open action reasoning model built for practical deployment, advancing its predecessor along five axes. We introduce MolmoER, a VLM backbone specialized for spatial and embodied reasoning, trained on a 3.3M-sample corpus with a specialize-then-rehearse recipe. We release three new datasets spanning low-to-medium cost platforms, including MolmoAct2-BimanualYAM, 720 hours of teleoperated bimanual trajectories that constitute the largest open bimanual dataset to date, together with quality-filtered Franka (DROID) and SO100/101 subsets. We provide OpenFAST, an open-weight, open-data action tokenizer trained on millions of trajectories across five embodiments. We redesign the architecture to graft a flow-matching continuous-action expert onto a discrete-token VLM via per-layer KV-cache conditioning. Finally, we propose MolmoThink, an adaptive-depth reasoning variant that re-predicts depth tokens only for scene regions that change between timesteps, retaining geometric grounding at a fraction of prior latency. In the most extensive empirical study of any open VLA to date, spanning 7 simulation and real-world benchmarks, MolmoAct2 outperforms strong baselines including Pi-05, while MolmoER surpasses GPT-5 and Gemini Robotics ER-1.5 across 13 embodied-reasoning benchmarks. We release model weights, training code, and complete training data. Project page: https://allenai.org/blog/molmoact2
2605.02881
May 2026Robotics
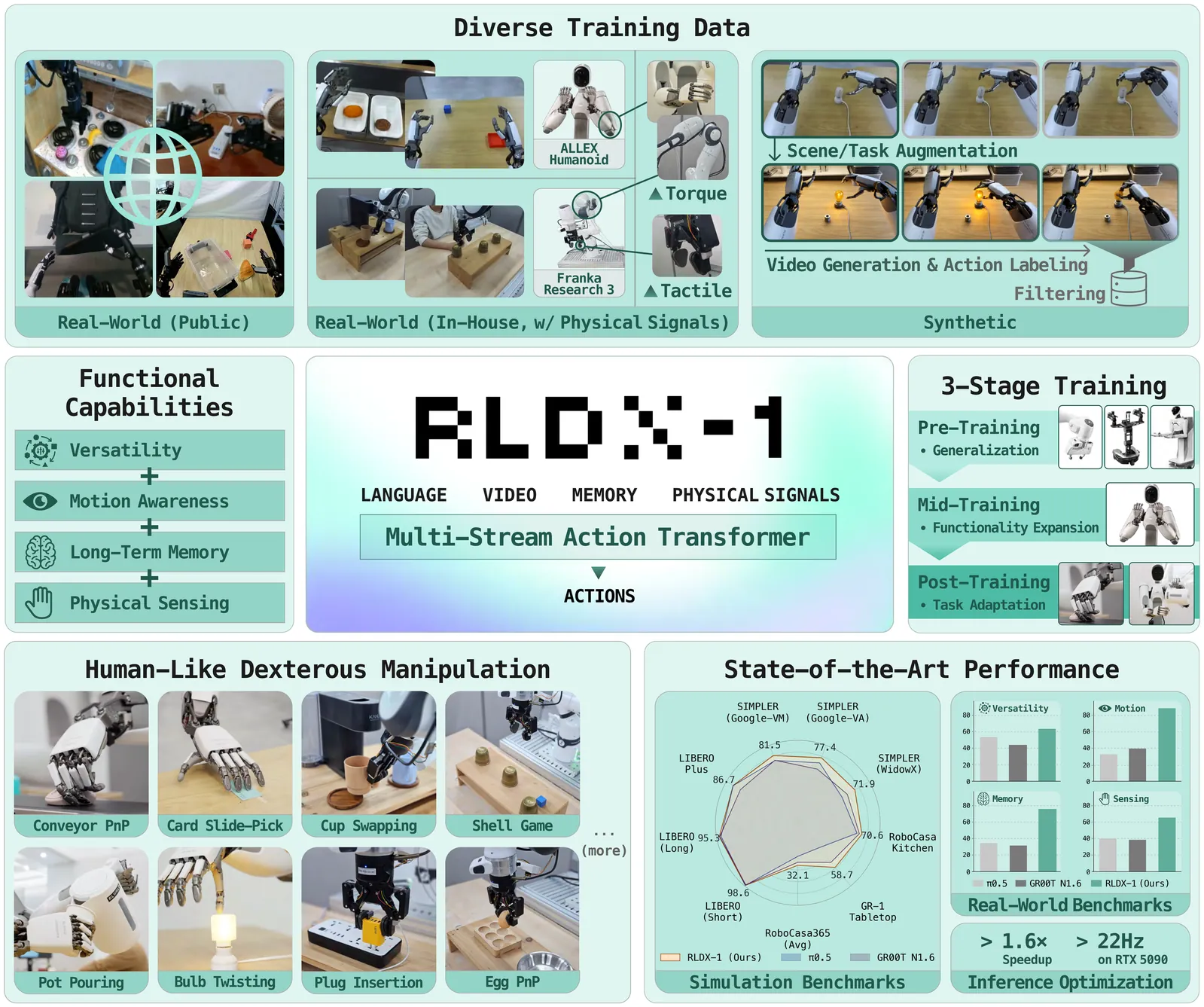
RLDX-1 Technical Report
While Vision-Language-Action models (VLAs) have shown remarkable progress toward human-like generalist robotic policies through the versatile intelligence (i.e. broad scene understanding and language-conditioned generalization) inherited from pre-trained Vision-Language Models, they still struggle with complex real-world tasks requiring broader functional capabilities (e.g. motion awareness, long-term memory, and physical sensing). To address this, we introduce RLDX-1, a general-purpose robotic policy for dexterous manipulation built on the Multi-Stream Action Transformer (MSAT), an architecture that unifies these capabilities by integrating heterogeneous modalities through modality-specific streams with cross-modal joint self-attention. RLDX-1 further combines this architecture with system-level design choices, including data synthesis for rare manipulation scenarios, learning procedures specialized for human-like manipulation, and inference optimizations for real-time deployment. Through empirical evaluation, we show that RLDX-1 consistently outperforms recent frontier VLAs (e.g. $π_{0.5}$ and GR00T N1.6) across both simulation benchmarks and real-world tasks that require broad functional capabilities beyond general versatility. In particular, RLDX-1 shows superiority in ALLEX humanoid tasks by achieving success rates of 86.8% while $π_{0.5}$ and GR00T N1.6 achieve around 40%, highlighting the ability of RLDX-1 to control a high-DoF humanoid robot under diverse functional demands. Together, these results position RLDX-1 as a promising step toward reliable VLAs for complex, contact-rich, and dynamic real-world dexterous manipulation.
2605.03269
May 2026Robotics
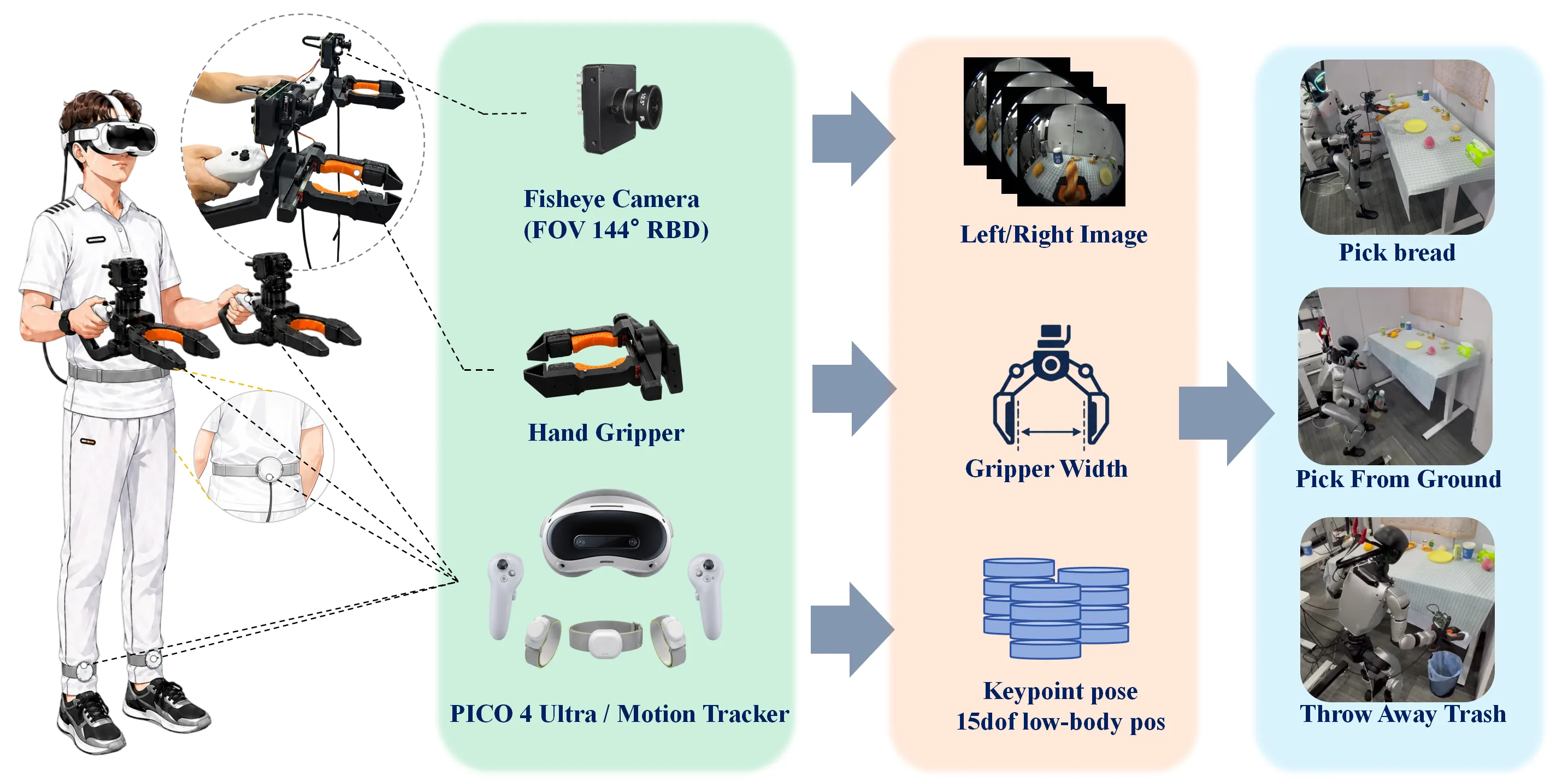
BifrostUMI: Bridging Robot-Free Demonstrations and Humanoid Whole-Body Manipulation
High-quality data collection is a fundamental cornerstone for training humanoid whole-body visuomotor policies. Current data acquisition paradigms predominantly rely on robot teleoperation, which is often hindered by limited hardware accessibility and low operational efficiency. Inspired by the Universal Manipulation Interface (UMI), we propose BifrostUMI, a portable, efficient, and robot-free data collection framework tailored for humanoid robots. BifrostUMI leverages lightweight VR devices to capture human demonstrations as sparse keypoint trajectories while simultaneously recording wrist-mounted visual data. These multimodal data are subsequently utilized to train a high-level policy network that predicts future keypoint trajectories conditioned on the captured visual features. Through a robust keypoint retargeting pipeline, keypoint trajectories are precisely mapped onto the robot's morphology and executed via a whole-body controller. This approach enables the seamless transfer of diverse and agile behaviors from natural human demonstrations to humanoid embodiments. We demonstrate the efficacy and versatility of the proposed framework across two distinct experimental scenarios.
2605.03452
May 2026Robotics
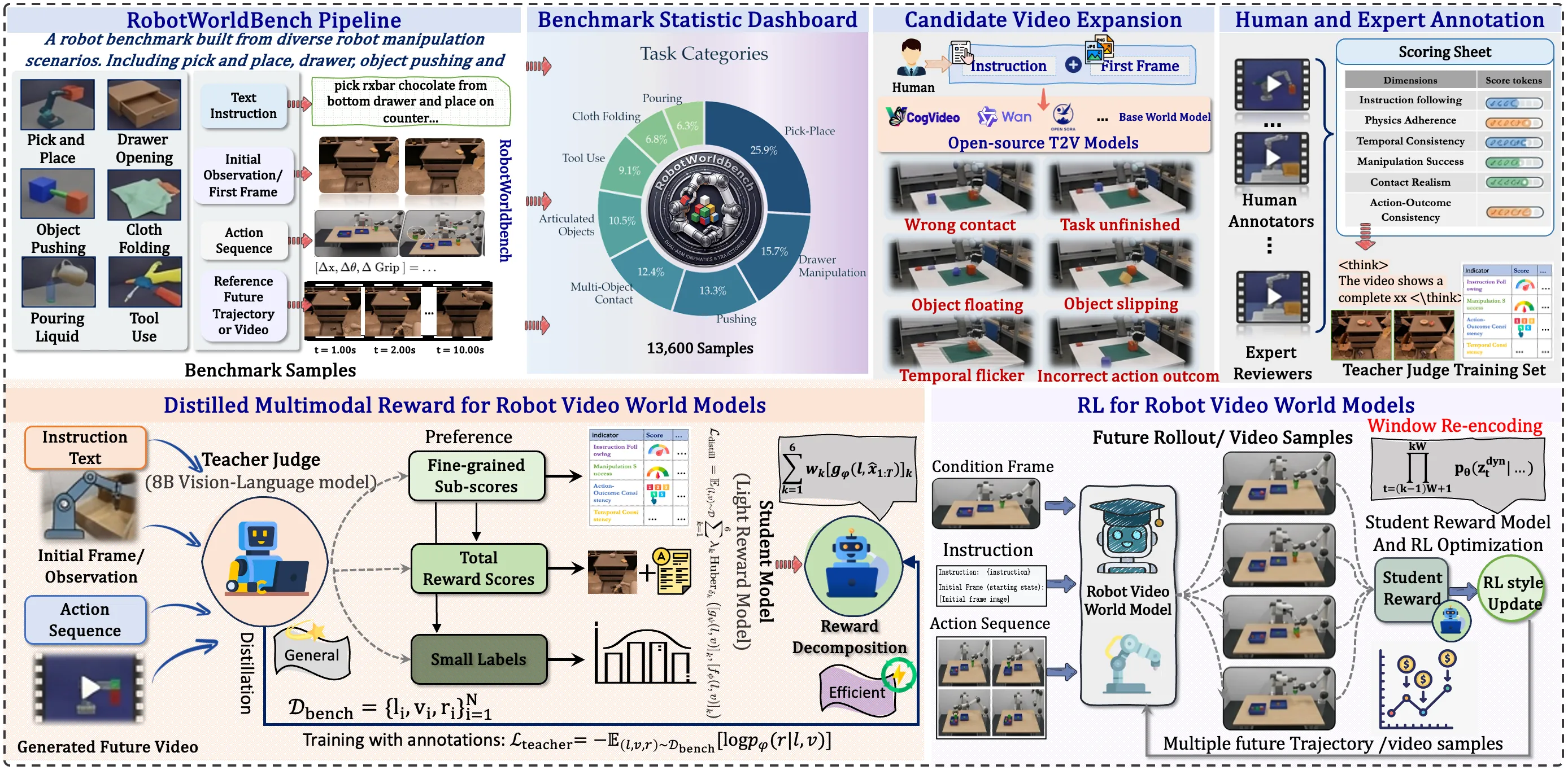
RoboAlign-R1: Distilled Multimodal Reward Alignment for Robot Video World Models
Existing robot video world models are typically trained with low-level objectives such as reconstruction and perceptual similarity, which are poorly aligned with the capabilities that matter most for robot decision making, including instruction following, manipulation success, and physical plausibility. They also suffer from error accumulation in long-horizon autoregressive prediction. We present RoboAlign-R1, a framework that combines reward-aligned post-training with stabilized long-horizon inference for robot video world models. We construct RobotWorldBench, a benchmark of 10,000 annotated video-instruction pairs collected from four robot data sources, and train a multimodal teacher judge, RoboAlign-Judge, to provide fine-grained six-dimensional evaluation of generated videos. We then distill the teacher into a lightweight student reward model for efficient reinforcement-learning-based post-training. To reduce long-horizon rollout drift, we further introduce Sliding Window Re-encoding (SWR), a training-free inference strategy that periodically refreshes the generation context. Under our in-domain evaluation protocol, RoboAlign-R1 improves the aggregate six-dimension score by 10.1% over the strongest baseline, including gains of 7.5% on Manipulation Accuracy and 4.6% on Instruction Following; these ranking improvements are further supported by an external VLM-based cross-check and a blinded human study. Meanwhile, SWR improves long-horizon prediction quality with only about 1% additional latency, yielding a 2.8% gain in SSIM and a 9.8% reduction in LPIPS. Together, these results show that reward-aligned post-training and stabilized long-horizon decoding improve task consistency, physical realism, and long-horizon prediction quality in robot video world models.
2605.03821
May 2026Robotics
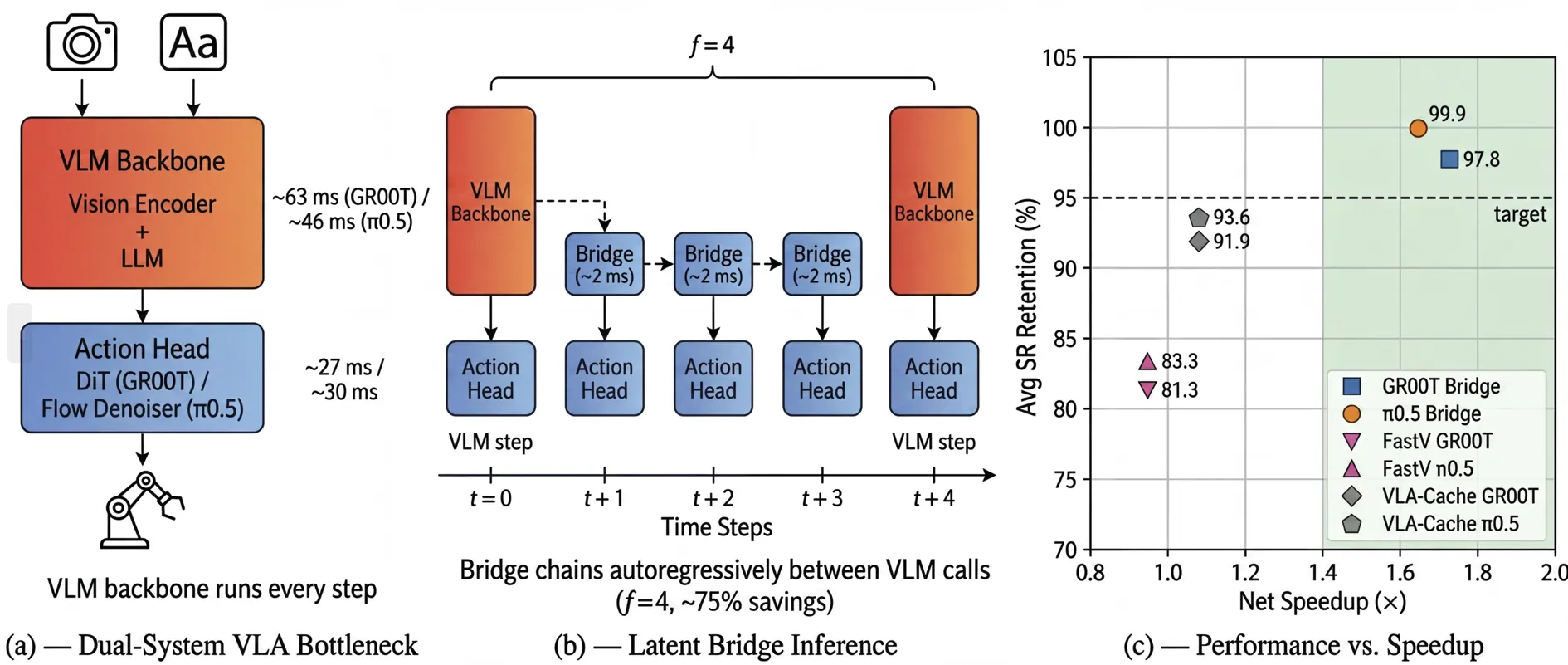
Latent Bridge: Feature Delta Prediction for Efficient Dual-System Vision-Language-Action Model Inference
Dual-system Vision-Language-Action (VLA) models achieve state-of-the-art robotic manipulation but are bottlenecked by the VLM backbone, which must execute at every control step while producing temporally redundant features. We propose Latent Bridge, a lightweight model that predicts VLM output deltas between timesteps, enabling the action head to operate on predicted outputs while the expensive VLM backbone is called only periodically. We instantiate Latent Bridge on two architecturally distinct VLAs: GR00T-N1.6 (feature-space bridge) and π0.5 (KV-cache bridge), demonstrating that the approach generalizes across VLA designs. Our task-agnostic DAgger training pipeline transfers across benchmarks without modification. Across four LIBERO suites, 24 RoboCasa kitchen tasks, and the ALOHA sim transfer-cube task, Latent Bridge achieves 95-100% performance retention while reducing VLM calls by 50-75%, yielding 1.65-1.73x net per-episode speedup.
2605.02739
May 2026Robotics

Learning Reactive Dexterous Grasping via Hierarchical Task-Space RL Planning and Joint-Space QP Control
In this work, we propose a hybrid hierarchical control framework for reactive dexterous grasping that explicitly decouples high-level spatial intent from low-level joint execution. We introduce a multi-agent reinforcement learning architecture, specialized into distinct arm and hand agents, that acts as a high-level planner by generating desired task-space velocity commands. These commands are then processed by a GPU-parallelized quadratic programming controller, which translates them into feasible joint velocities while strictly enforcing kinematic limits and collision avoidance. This structural isolation not only accelerates training convergence but also strictly enforces hardware safety. Furthermore, the architecture unlocks zero-shot steerability, allowing system operators to dynamically adjust safety margins and avoid dynamic obstacles without retraining the policy. We extensively validate the proposed framework through a rigorous simulation-to-reality pipeline. Real-world hardware experiments on a 7-DoF arm equipped with a 20-DoF anthropomorphic hand demonstrate highly robust zero-shot transferability for dexterous grasping to a diverse set of unseen objects, highlighting the system's ability to reactively recover from unexpected physical disturbances in unstructured environments.
2605.03363
May 2026Robotics

SIM1: Physics-Aligned Simulator as Zero-Shot Data Scaler in Deformable Worlds
Robotic manipulation with deformable objects represents a data-intensive regime in embodied learning, where shape, contact, and topology co-evolve in ways that far exceed the variability of rigids. Although simulation promises relief from the cost of real-world data acquisition, prevailing sim-to-real pipelines remain rooted in rigid-body abstractions, producing mismatched geometry, fragile soft dynamics, and motion primitives poorly suited for cloth interaction. We posit that simulation fails not for being synthetic, but for being ungrounded. To address this, we introduce SIM1, a physics-aligned real-to-sim-to-real data engine that grounds simulation in the physical world. Given limited demonstrations, the system digitizes scenes into metric-consistent twins, calibrates deformable dynamics through elastic modeling, and expands behaviors via diffusion-based trajectory generation with quality filtering. This pipeline transforms sparse observations into scaled synthetic supervision with near-demonstration fidelity. Experiments show that policies trained on purely synthetic data achieve parity with real-data baselines at a 1:15 equivalence ratio, while delivering 90% zero-shot success and 50% generalization gains in real-world deployment. These results validate physics-aligned simulation as scalable supervision for deformable manipulation and a practical pathway for data-efficient policy learning.
2604.08544
Apr 2026Robotics
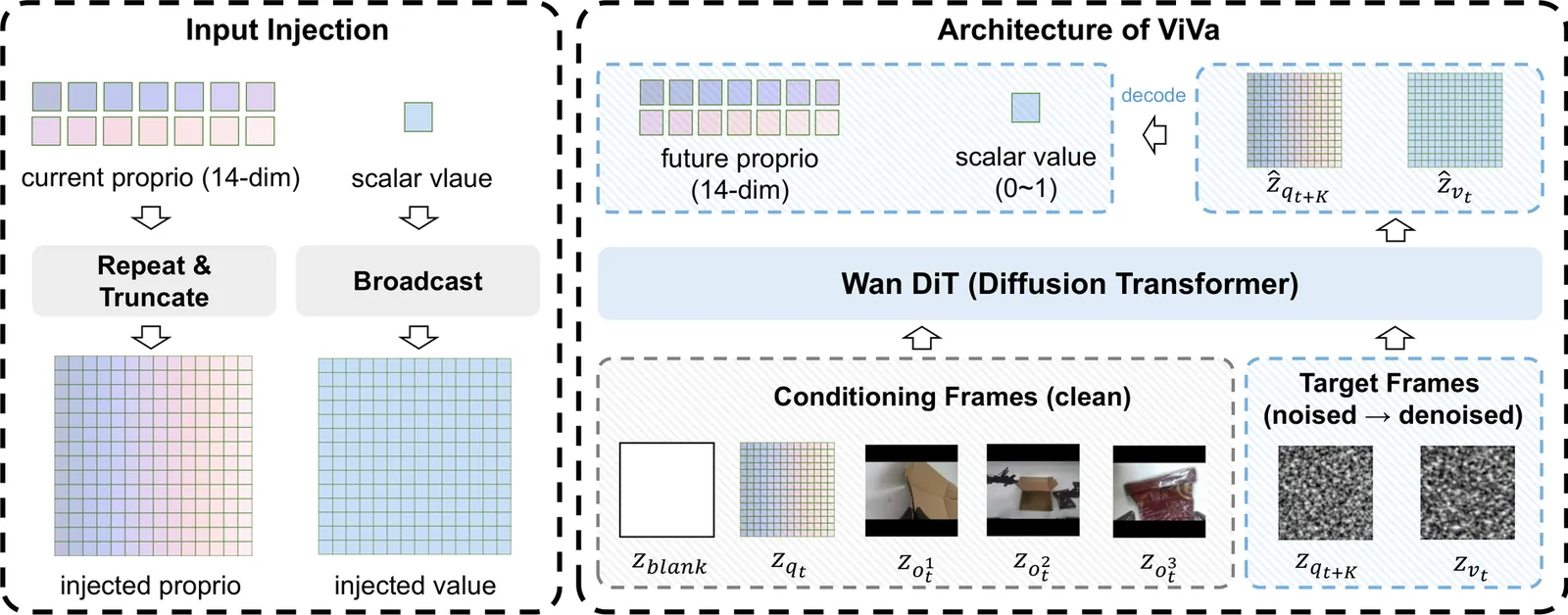
ViVa: A Video-Generative Value Model for Robot Reinforcement Learning
Vision-language-action (VLA) models have advanced robot manipulation through large-scale pretraining, but real-world deployment remains challenging due to partial observability and delayed feedback. Reinforcement learning addresses this via value functions, which assess task progress and guide policy improvement. However, existing value models built on vision-language models (VLMs) struggle to capture temporal dynamics, undermining reliable value estimation in long-horizon tasks. In this paper, we propose ViVa, a video-generative value model that repurposes a pretrained video generator for value estimation. Taking the current observation and robot proprioception as input, ViVa jointly predicts future proprioception and a scalar value for the current state. By leveraging the spatiotemporal priors of a pretrained video generator, our approach grounds value estimation in anticipated embodiment dynamics, moving beyond static snapshots to intrinsically couple value with foresight. Integrated into RECAP, ViVa delivers substantial improvements on real-world box assembly. Qualitative analysis across all three tasks confirms that ViVa produces more reliable value signals, accurately reflecting task progress. By leveraging spatiotemporal priors from video corpora, ViVa also generalizes to novel objects, highlighting the promise of video-generative models for value estimation.
2604.08168
Apr 2026Robotics

EgoVerse: An Egocentric Human Dataset for Robot Learning from Around the World
Robot learning increasingly depends on large and diverse data, yet robot data collection remains expensive and difficult to scale. Egocentric human data offer a promising alternative by capturing rich manipulation behavior across everyday environments. However, existing human datasets are often limited in scope, difficult to extend, and fragmented across institutions. We introduce EgoVerse, a collaborative platform for human data-driven robot learning that unifies data collection, processing, and access under a shared framework, enabling contributions from individual researchers, academic labs, and industry partners. The current release includes 1,362 hours (80k episodes) of human demonstrations spanning 1,965 tasks, 240 scenes, and 2,087 unique demonstrators, with standardized formats, manipulation-relevant annotations, and tooling for downstream learning. Beyond the dataset, we conduct a large-scale study of human-to-robot transfer with experiments replicated across multiple labs, tasks, and robot embodiments under shared protocols. We find that policy performance generally improves with increased human data, but that effective scaling depends on alignment between human data and robot learning objectives. Together, the dataset, platform, and study establish a foundation for reproducible progress in human data-driven robot learning. Videos and additional information can be found at https://egoverse.ai/
2604.07607
Apr 2026Robotics
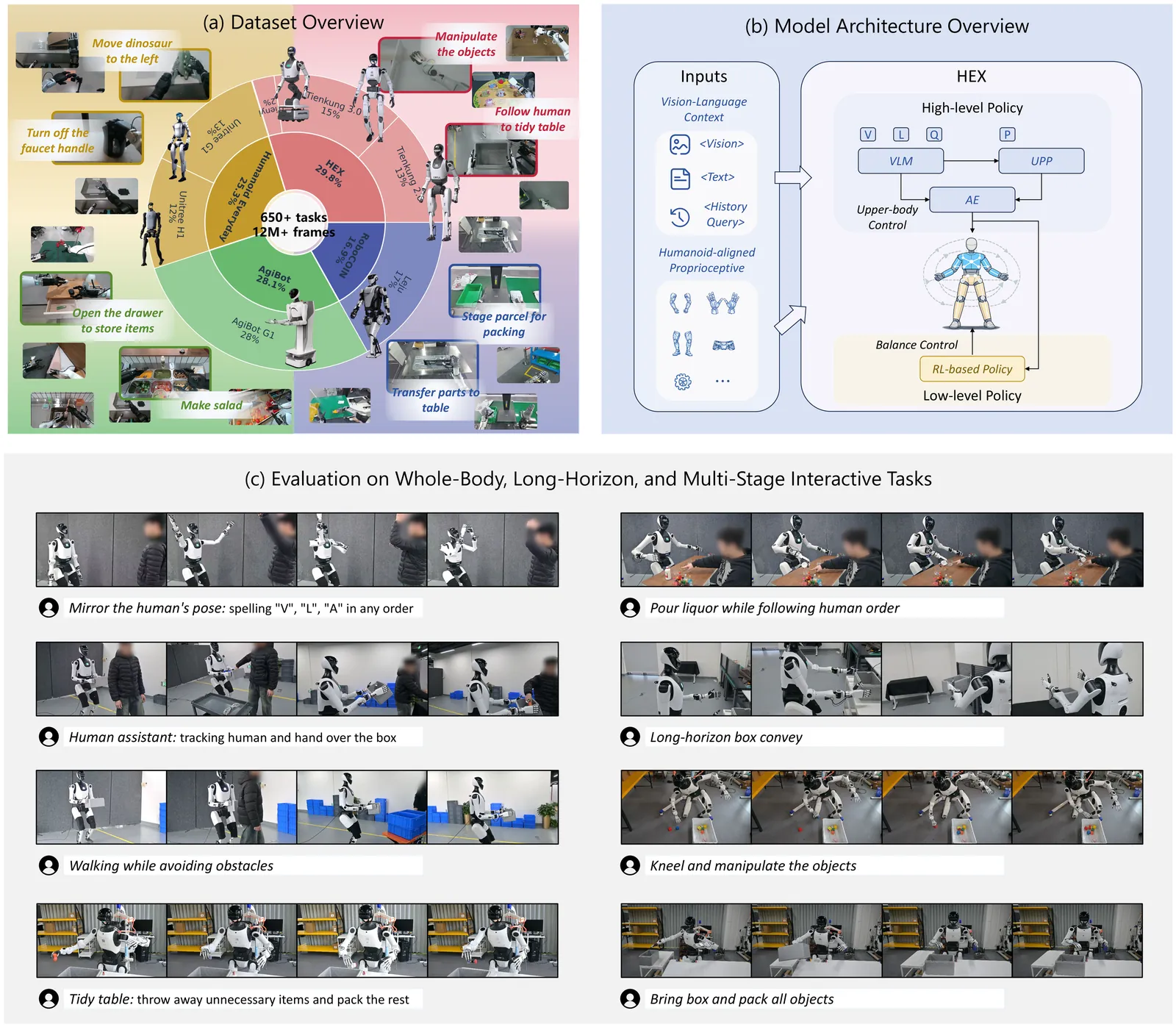
HEX: Humanoid-Aligned Experts for Cross-Embodiment Whole-Body Manipulation
Humans achieve complex manipulation through coordinated whole-body control, whereas most Vision-Language-Action (VLA) models treat robot body parts largely independently, making high-DoF humanoid control challenging and often unstable. We present HEX, a state-centric framework for coordinated manipulation on full-sized bipedal humanoid robots. HEX introduces a humanoid-aligned universal state representation for scalable learning across heterogeneous embodiments, and incorporates a Mixture-of-Experts Unified Proprioceptive Predictor to model whole-body coordination and temporal motion dynamics from large-scale multi-embodiment trajectory data. To efficiently capture temporal visual context, HEX uses lightweight history tokens to summarize past observations, avoiding repeated encoding of historical images during inference. It further employs a residual-gated fusion mechanism with a flow-matching action head to adaptively integrate visual-language cues with proprioceptive dynamics for action generation. Experiments on real-world humanoid manipulation tasks show that HEX achieves state-of-the-art performance in task success rate and generalization, particularly in fast-reaction and long-horizon scenarios.
2604.07993
Apr 2026Robotics
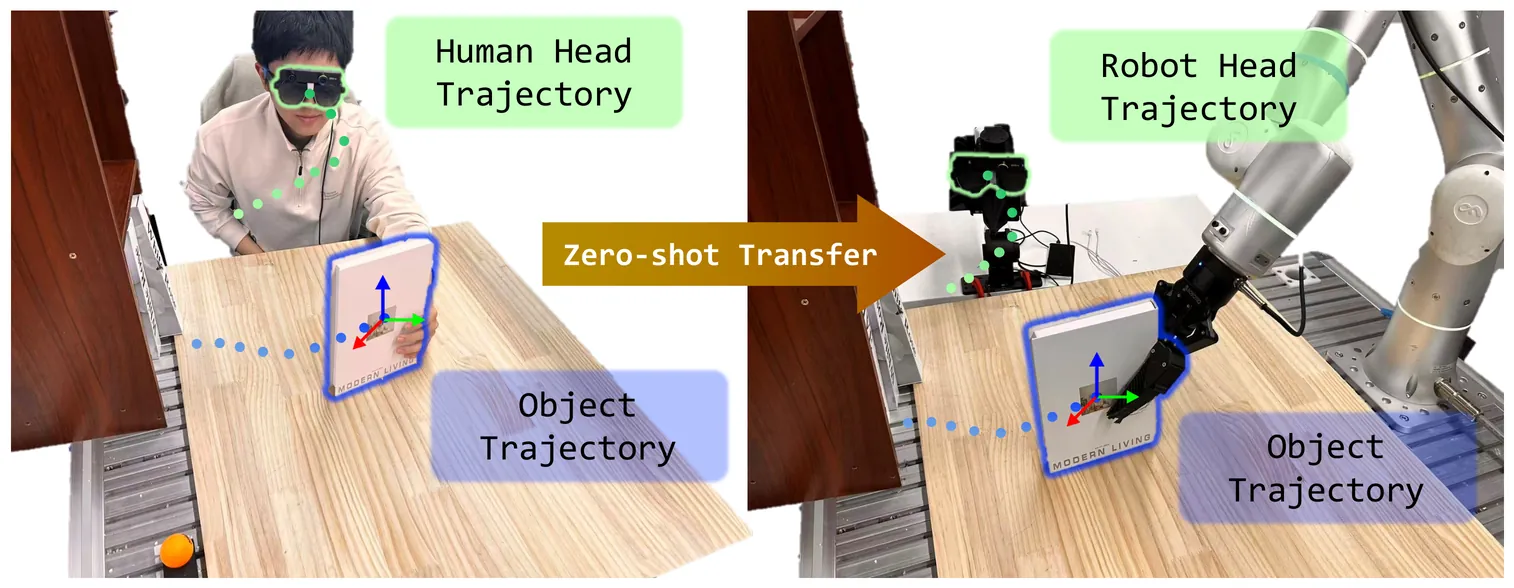
ActiveGlasses: Learning Manipulation with Active Vision from Ego-centric Human Demonstration
Large-scale real-world robot data collection is a prerequisite for bringing robots into everyday deployment. However, existing pipelines often rely on specialized handheld devices to bridge the embodiment gap, which not only increases operator burden and limits scalability, but also makes it difficult to capture the naturally coordinated perception-manipulation behaviors of human daily interaction. This challenge calls for a more natural system that can faithfully capture human manipulation and perception behaviors while enabling zero-shot transfer to robotic platforms. We introduce ActiveGlasses, a system for learning robot manipulation from ego-centric human demonstrations with active vision. A stereo camera mounted on smart glasses serves as the sole perception device for both data collection and policy inference: the operator wears it during bare-hand demonstrations, and the same camera is mounted on a 6-DoF perception arm during deployment to reproduce human active vision. To enable zero-transfer, we extract object trajectories from demonstrations and use an object-centric point-cloud policy to jointly predict manipulation and head movement. Across several challenging tasks involving occlusion and precise interaction, ActiveGlasses achieves zero-shot transfer with active vision, consistently outperforms strong baselines under the same hardware setup, and generalizes across two robot platforms.
2604.08534
Apr 2026Robotics

Heracles: Bridging Precise Tracking and Generative Synthesis for General Humanoid Control
Achieving general-purpose humanoid control requires a delicate balance between the precise execution of commanded motions and the flexible, anthropomorphic adaptability needed to recover from unpredictable environmental perturbations. Current general controllers predominantly formulate motion control as a rigid reference-tracking problem. While effective in nominal conditions, these trackers often exhibit brittle, non-anthropomorphic failure modes under severe disturbances, lacking the generative adaptability inherent to human motor control. To overcome this limitation, we propose Heracles, a novel state-conditioned diffusion middleware that bridges precise motion tracking and generative synthesis. Rather than relying on rigid tracking paradigms or complex explicit mode-switching, Heracles operates as an intermediary layer between high-level reference motions and low-level physics trackers. By conditioning on the robot's real-time state, the diffusion model implicitly adapts its behavior: it approximates an identity map when the state closely aligns with the reference, preserving zero-shot tracking fidelity. Conversely, when encountering significant state deviations, it seamlessly transitions into a generative synthesizer to produce natural, anthropomorphic recovery trajectories. Our framework demonstrates that integrating generative priors into the control loop not only significantly enhances robustness against extreme perturbations but also elevates humanoid control from a rigid tracking paradigm to an open-ended, generative general-purpose architecture.
2603.27756
Mar 2026Robotics
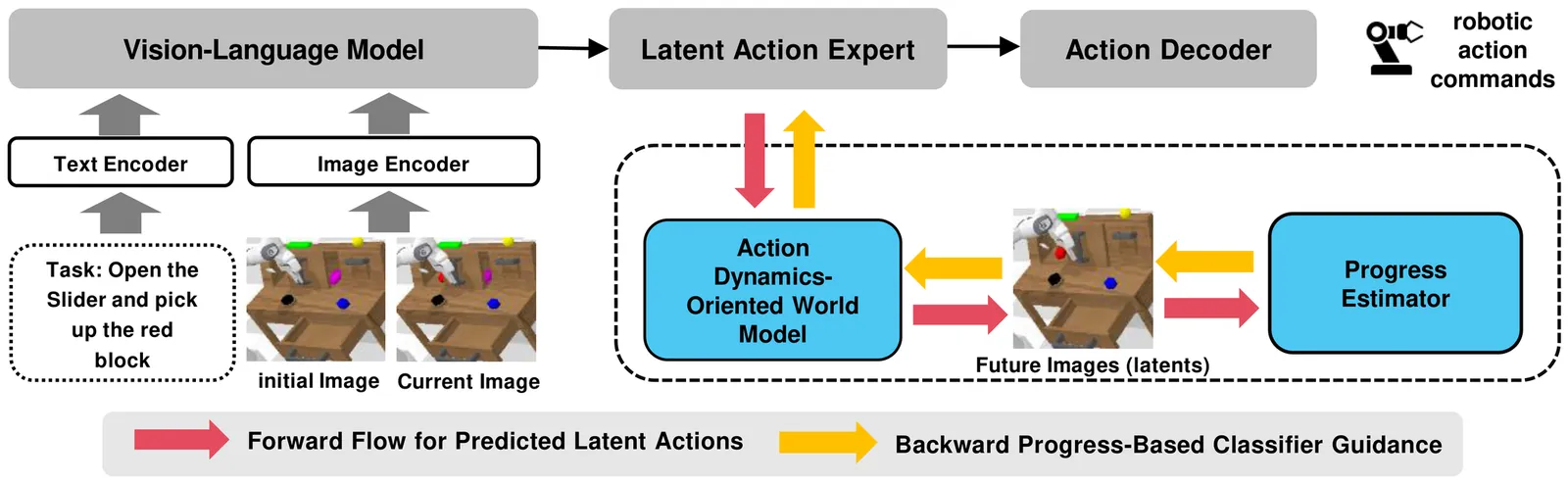
ProgressVLA: Progress-Guided Diffusion Policy for Vision-Language Robotic Manipulation
Most existing vision-language-action (VLA) models for robotic manipulation lack progress awareness, typically relying on hand-crafted heuristics for task termination. This limitation is particularly severe in long-horizon tasks involving cascaded sub-goals. In this work, we investigate the estimation and integration of task progress, proposing a novel model named {\textbf \vla}. Our technical contributions are twofold: (1) \emph{robust progress estimation}: We pre-train a progress estimator on large-scale, unsupervised video-text robotic datasets. This estimator achieves a low prediction residual (0.07 on a scale of $[0, 1]$) in simulation and demonstrates zero-shot generalization to unseen real-world samples, and (2) \emph{differentiable progress guidance}: We introduce an inverse dynamics world model that maps predicted action tokens into future latent visual states. These latents are then processed by the progress estimator; by applying a maximal progress regularization, we establish a differentiable pipeline that provides progress-piloted guidance to refine action tokens. Extensive experiments on the CALVIN and LIBERO benchmarks, alongside real-world robot deployment, consistently demonstrate substantial improvements in success rates and generalization over strong baselines.
2603.27670
Mar 2026Robotics

ManipArena: Comprehensive Real-world Evaluation of Reasoning-Oriented Generalist Robot Manipulation
Vision-Language-Action (VLA) models and world models have recently emerged as promising paradigms for general-purpose robotic intelligence, yet their progress is hindered by the lack of reliable evaluation protocols that reflect real-world deployment. Existing benchmarks are largely simulator-centric, which provide controllability but fail to capture the reality gap caused by perception noise, complex contact dynamics, hardware constraints, and system latency. Moreover, fragmented real-world evaluations across different robot platforms prevent fair and reproducible comparison. To address these challenges, we introduce ManipArena, a standardized evaluation framework designed to bridge simulation and real-world execution. ManipArena comprises 20 diverse tasks across 10,812 expert trajectories emphasizing reasoning-oriented manipulation tasks requiring semantic and spatial reasoning, supports multi-level generalization through controlled out-of-distribution settings, and incorporates long-horizon mobile manipulation beyond tabletop scenarios. The framework further provides rich sensory diagnostics, including low-level motor signals, and synchronized real-to-sim environments constructed via high-quality 3D scanning. Together, these features enable fair, realistic, and reproducible evaluation for both VLA and world model approaches, providing a scalable foundation for diagnosing and advancing embodied intelligence systems.
2603.28545
Mar 2026Robotics
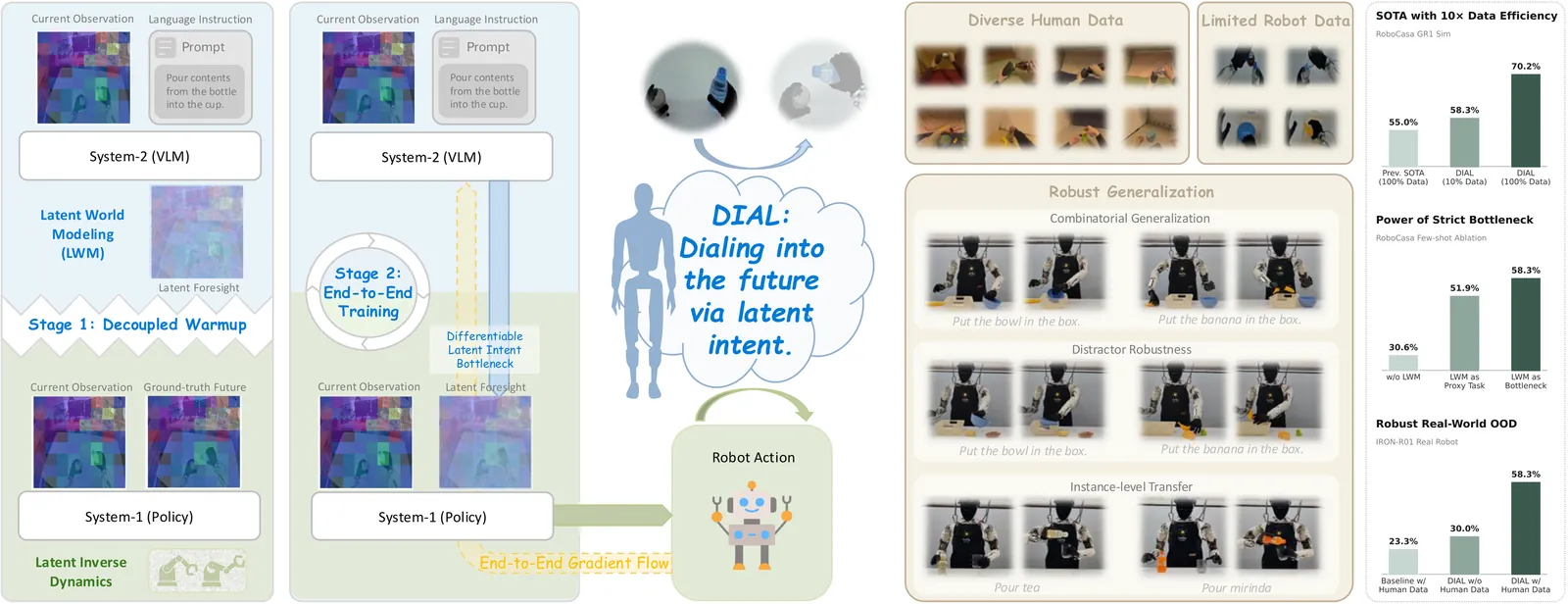
DIAL: Decoupling Intent and Action via Latent World Modeling for End-to-End VLA
The development of Vision-Language-Action (VLA) models has been significantly accelerated by pre-trained Vision-Language Models (VLMs). However, most existing end-to-end VLAs treat the VLM primarily as a multimodal encoder, directly mapping vision-language features to low-level actions. This paradigm underutilizes the VLM's potential in high-level decision making and introduces training instability, frequently degrading its rich semantic representations. To address these limitations, we introduce DIAL, a framework bridging high-level decision making and low-level motor execution through a differentiable latent intent bottleneck. Specifically, a VLM-based System-2 performs latent world modeling by synthesizing latent visual foresight within the VLM's native feature space; this foresight explicitly encodes intent and serves as the structural bottleneck. A lightweight System-1 policy then decodes this predicted intent together with the current observation into precise robot actions via latent inverse dynamics. To ensure optimization stability, we employ a two-stage training paradigm: a decoupled warmup phase where System-2 learns to predict latent futures while System-1 learns motor control under ground-truth future guidance within a unified feature space, followed by seamless end-to-end joint optimization. This enables action-aware gradients to refine the VLM backbone in a controlled manner, preserving pre-trained knowledge. Extensive experiments on the RoboCasa GR1 Tabletop benchmark show that DIAL establishes a new state-of-the-art, achieving superior performance with 10x fewer demonstrations than prior methods. Furthermore, by leveraging heterogeneous human demonstrations, DIAL learns physically grounded manipulation priors and exhibits robust zero-shot generalization to unseen objects and novel configurations during real-world deployment on a humanoid robot.
2603.29844
Mar 2026Robotics

SOLE-R1: Video-Language Reasoning as the Sole Reward for On-Robot Reinforcement Learning
Vision-language models (VLMs) have shown impressive capabilities across diverse tasks, motivating efforts to leverage these models to supervise robot learning. However, when used as evaluators in reinforcement learning (RL), today's strongest models often fail under partial observability and distribution shift, enabling policies to exploit perceptual errors rather than solve the task. To address this limitation, we introduce SOLE-R1 (Self-Observing LEarner), a video-language reasoning model explicitly designed to serve as the sole reward signal for online RL. Given only raw video observations and a natural-language goal, SOLE-R1 performs per-timestep spatiotemporal chain-of-thought (CoT) reasoning and produces dense estimates of task progress that can be used directly as rewards. To train SOLE-R1, we develop a large-scale video trajectory and reasoning synthesis pipeline that generates temporally grounded CoT traces aligned with continuous progress supervision. This data is combined with foundational spatial and multi-frame temporal reasoning, and used to train the model with a hybrid framework that couples supervised fine-tuning with RL from verifiable rewards. Across four different simulation environments and a real-robot setting, SOLE-R1 enables zero-shot online RL from random initialization: robots learn previously unseen manipulation tasks without ground-truth rewards, success indicators, demonstrations, or task-specific tuning. SOLE-R1 succeeds on 24 unseen tasks and substantially outperforms strong vision-language rewarders, including GPT-5 and Gemini-3-Pro, while exhibiting markedly greater robustness to reward hacking.
2603.28730
Mar 2026Robotics
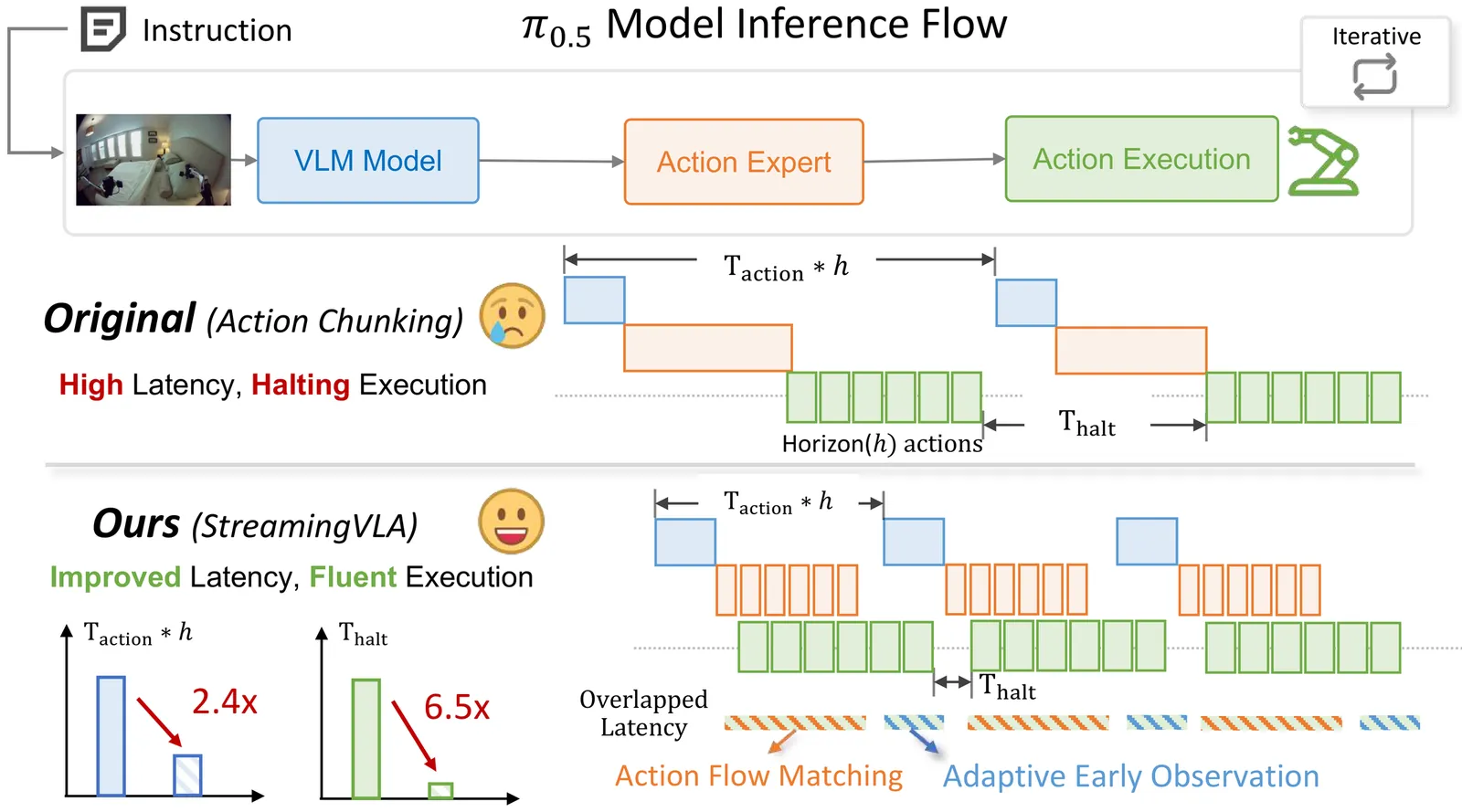
StreamingVLA: Streaming Vision-Language-Action Model with Action Flow Matching and Adaptive Early Observation
Vision-language-action (VLA) models have demonstrated exceptional performance in natural language-driven perception and control. However, the high computational cost of VLA models poses significant efficiency challenges, particularly for resource-constrained edge platforms in real-world deployments. However, since different stages of VLA (observation, action generation and execution) must proceed sequentially, and wait for the completion of the preceding stage, the system suffers from frequent halting and high latency. To address this, We conduct a systematic analysis to identify the challenges for fast and fluent generation, and propose enabling VLAs with the ability to asynchronously parallelize across VLA stages in a "streaming" manner. First, we eliminate the reliance on action chunking and adopt action flow matching, which learns the trajectory of action flows rather than denoising chunk-wise actions. It overlaps the latency of action generation and execution. Second, we design an action saliency-aware adaptive observation mechanism, thereby overlapping the latency of execution and observation. Without sacrificing performance, StreamingVLA achieves substantial speedup and improves the fluency of execution. It achieves a 2.4 $\times$ latency speedup and reduces execution halting by 6.5 $\times$.
2603.28565
Mar 2026Robotics
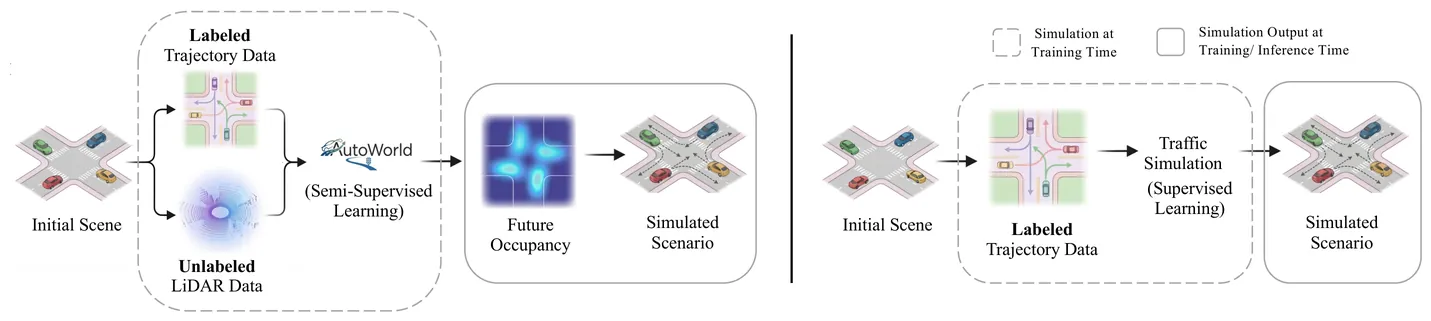
AutoWorld: Scaling Multi-Agent Traffic Simulation with Self-Supervised World Models
Multi-agent traffic simulation is central to developing and testing autonomous driving systems. Recent data-driven simulators have achieved promising results, but rely heavily on supervised learning from labeled trajectories or semantic annotations, making it costly to scale their performance. Meanwhile, large amounts of unlabeled sensor data can be collected at scale but remain largely unused by existing traffic simulation frameworks. This raises a key question: How can a method harness unlabeled data to improve traffic simulation performance? In this work, we propose AutoWorld, a traffic simulation framework that employs a world model learned from unlabeled occupancy representations of LiDAR data. Given world model samples, AutoWorld constructs a coarse-to-fine predictive scene context as input to a multi-agent motion generation model. To promote sample diversity, AutoWorld uses a cascaded Determinantal Point Process framework to guide the sampling processes of both the world model and the motion model. Furthermore, we designed a motion-aware latent supervision objective that enhances AutoWorld's representation of scene dynamics. Experiments on the WOSAC benchmark show that AutoWorld ranks first on the leaderboard according to the primary Realism Meta Metric (RMM). We further show that simulation performance consistently improves with the inclusion of unlabeled LiDAR data, and study the efficacy of each component with ablations. Our method paves the way for scaling traffic simulation realism without additional labeling. Our project page contains additional visualizations and released code.
2603.28963
Mar 2026Robotics
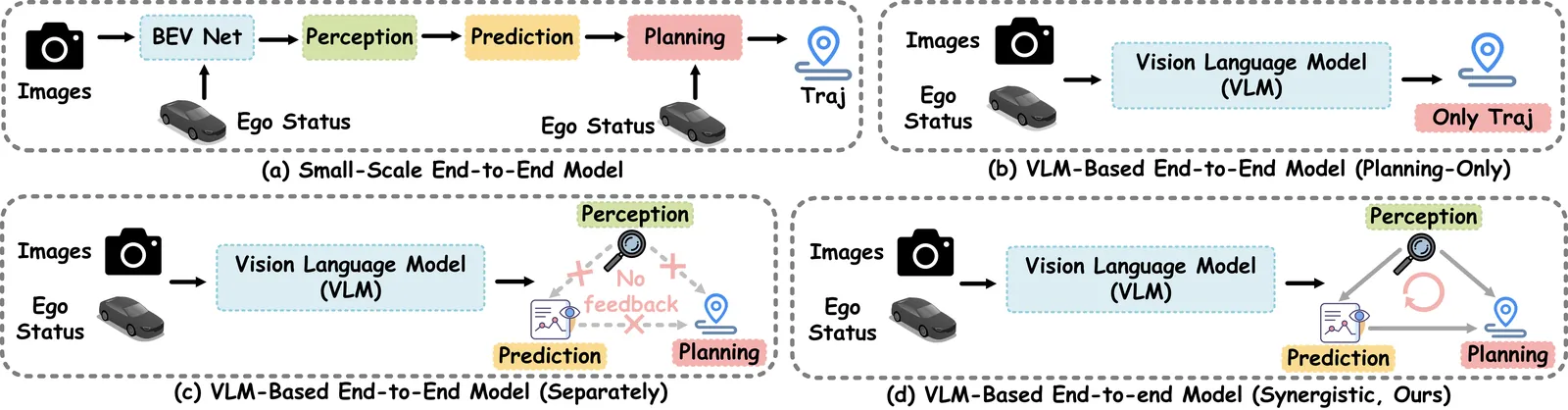
$AutoDrive\text{-}P^3$: Unified Chain of Perception-Prediction-Planning Thought via Reinforcement Fine-Tuning
Vision-language models (VLMs) are increasingly being adopted for end-to-end autonomous driving systems due to their exceptional performance in handling long-tail scenarios. However, current VLM-based approaches suffer from two major limitations: 1) Some VLMs directly output planning results without chain-of-thought (CoT) reasoning, bypassing crucial perception and prediction stages which creates a significant domain gap and compromises decision-making capability; 2) Other VLMs can generate outputs for perception, prediction, and planning tasks but employ a fragmented decision-making approach where these modules operate separately, leading to a significant lack of synergy that undermines true planning performance. To address these limitations, we propose ${AutoDrive\text{-}P^3}$, a novel framework that seamlessly integrates $\textbf{P}$erception, $\textbf{P}$rediction, and $\textbf{P}$lanning through structured reasoning. We introduce the ${P^3\text{-}CoT}$ dataset to facilitate coherent reasoning and propose ${P^3\text{-}GRPO}$, a hierarchical reinforcement learning algorithm that provides progressive supervision across all three tasks. Specifically, ${AutoDrive\text{-}P^3}$ progressively generates CoT reasoning and answers for perception, prediction, and planning, where perception provides essential information for subsequent prediction and planning, while both perception and prediction collectively contribute to the final planning decisions, enabling safer and more interpretable autonomous driving. Additionally, to balance inference efficiency with performance, we introduce dual thinking modes: detailed thinking and fast thinking. Extensive experiments on both open-loop (nuScenes) and closed-loop (NAVSIMv1/v2) benchmarks demonstrate that our approach achieves state-of-the-art performance in planning tasks. Code is available at https://github.com/haha-yuki-haha/AutoDrive-P3.
2603.28116
Mar 2026Robotics
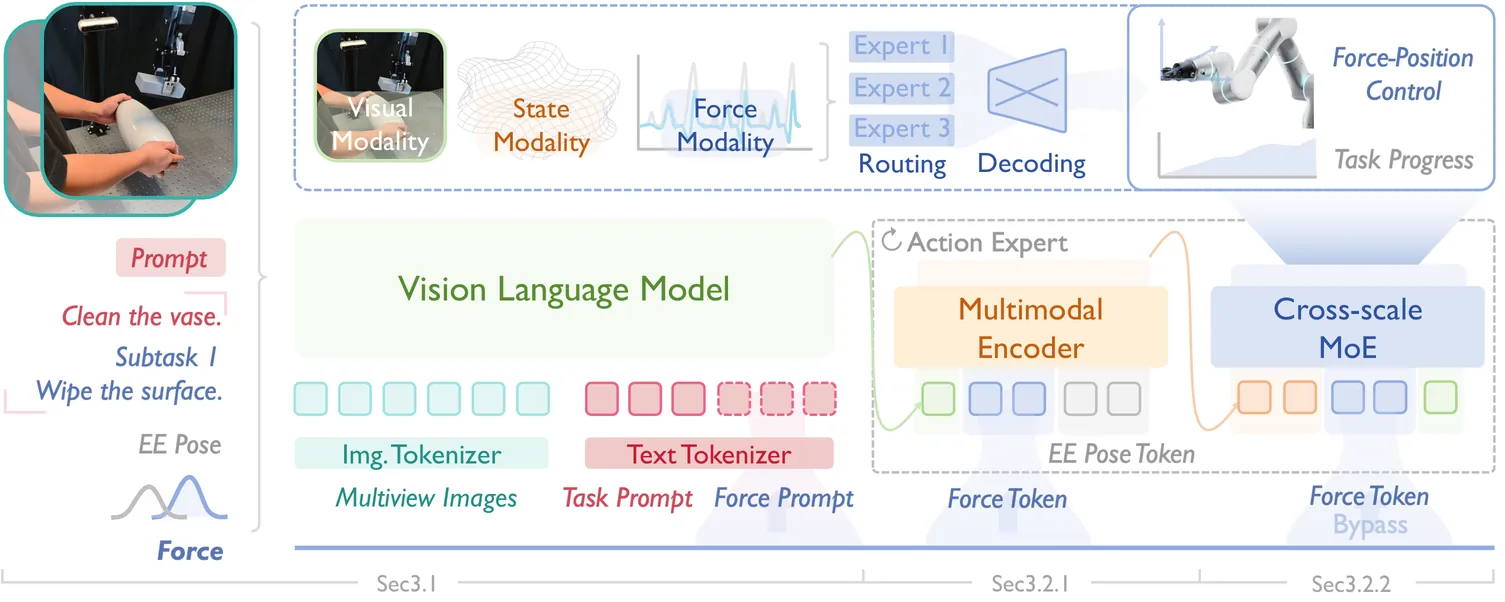
ForceVLA2: Unleashing Hybrid Force-Position Control with Force Awareness for Contact-Rich Manipulation
Embodied intelligence for contact-rich manipulation has predominantly relied on position control, while explicit awareness and regulation of interaction forces remain under-explored, limiting stability, precision, and robustness in real-world tasks. We propose ForceVLA2, an end-to-end vision-language-action framework that equips robots with hybrid force-position control and explicit force awareness. ForceVLA2 introduces force-based prompts into the VLM expert to construct force-aware task concepts across stages, and employs a Cross-Scale Mixture-of-Experts (MoE) in the action expert to adaptively fuse these concepts with real-time interaction forces for closed-loop hybrid force-position regulation. To support learning and evaluation, we construct ForceVLA2-Dataset, containing 1,000 trajectories over 5 contact-rich tasks, including wiping, pressing, and assembling, with multi-view images, task prompts, proprioceptive state, and force signals. Extensive experiments show that ForceVLA2 substantially improves success rates and reliability in contact-rich manipulation, outperforming pi0 and pi0.5 by 48.0% and 35.0%, respectively, across the 5 tasks, and mitigating common failure modes such as arm overload and unstable contact, thereby actively advancing force-aware interactive physical intelligence in VLAs. The project page is available at https://sites.google.com/view/force-vla2/home.
2603.15169
Mar 2026Robotics