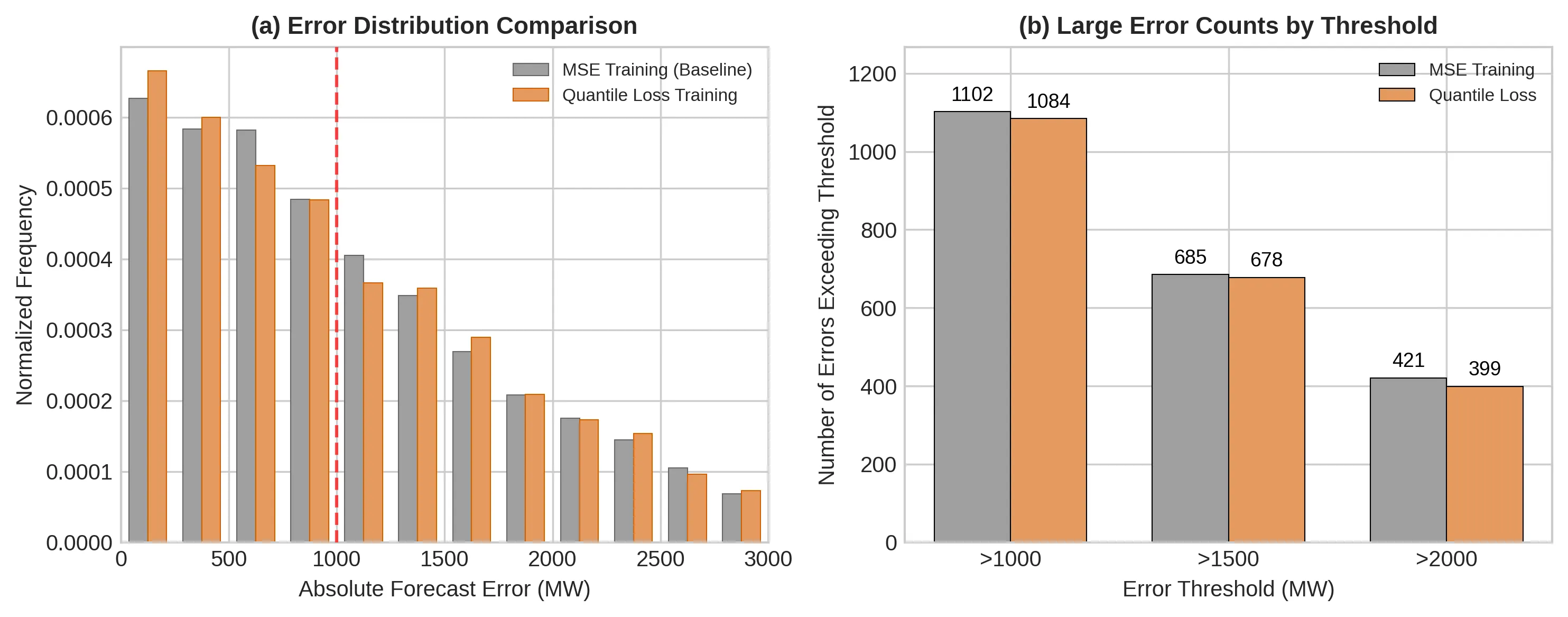
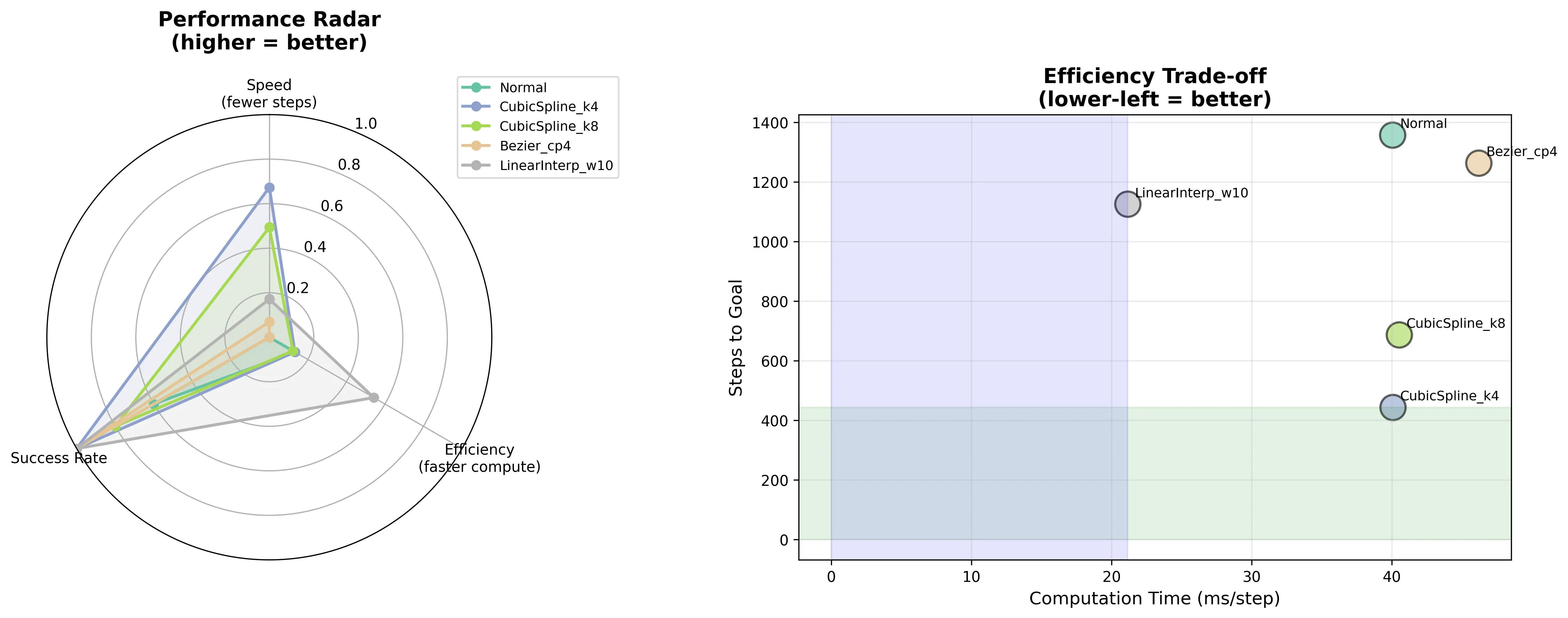
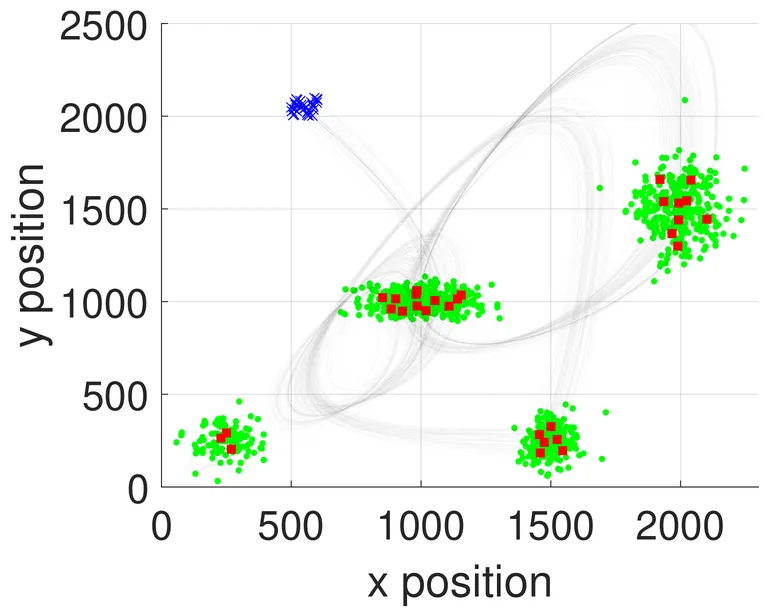
$α^3$-Bench: A Unified Benchmark of Safety, Robustness, and Efficiency for LLM-Based UAV Agents over 6G Networks
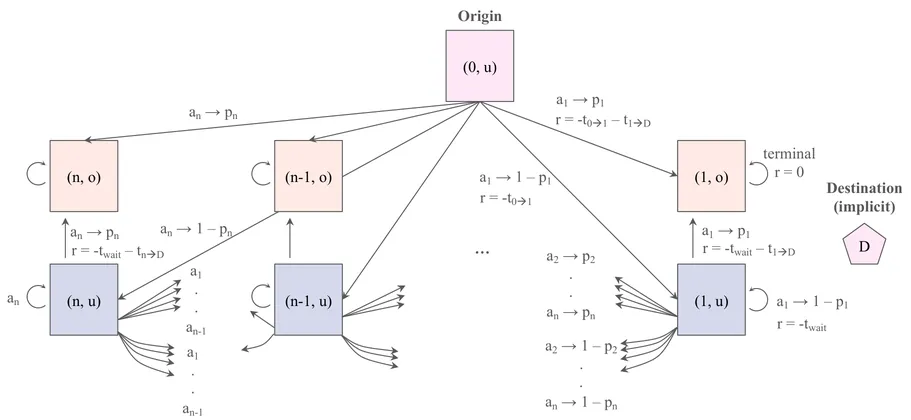
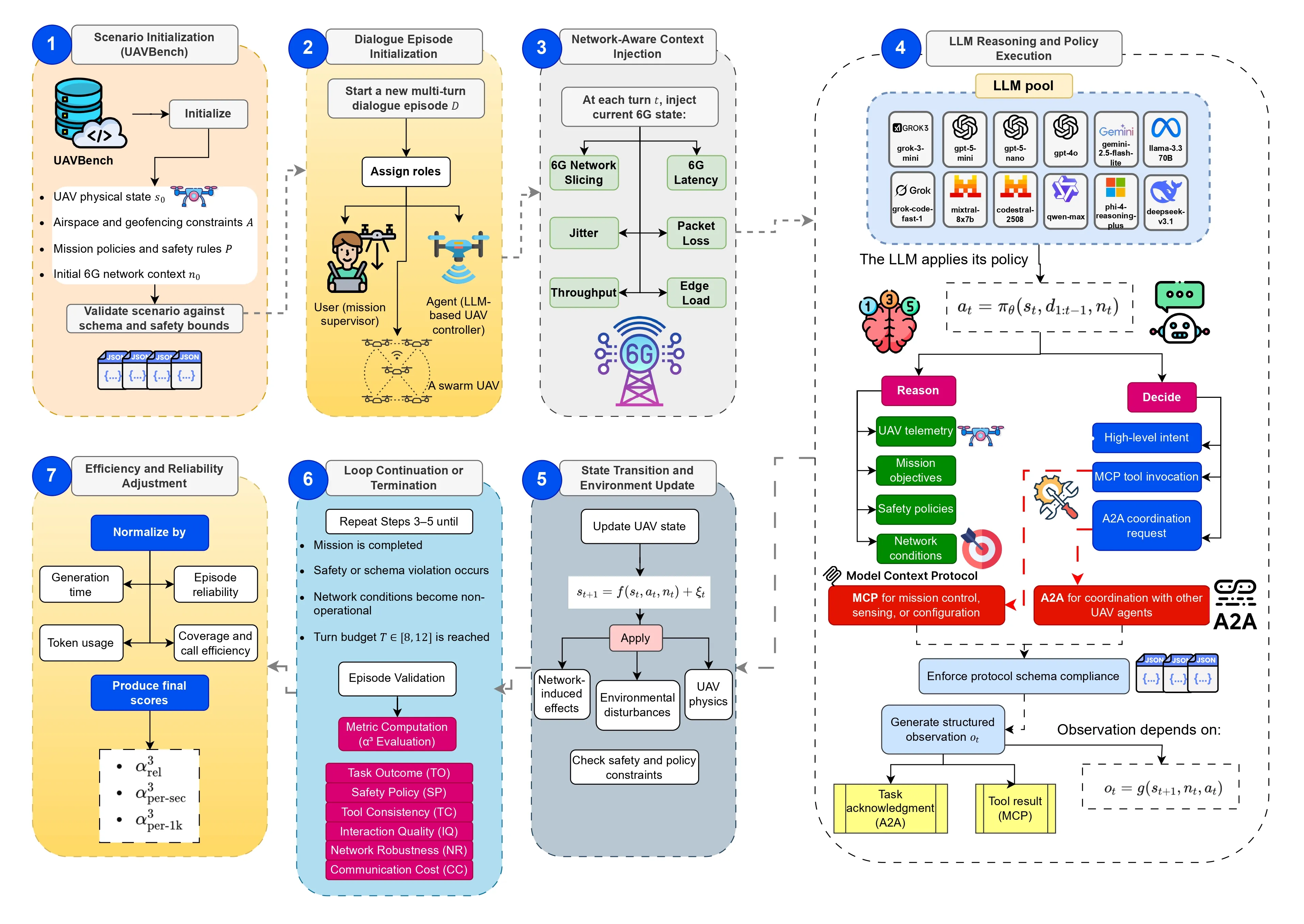
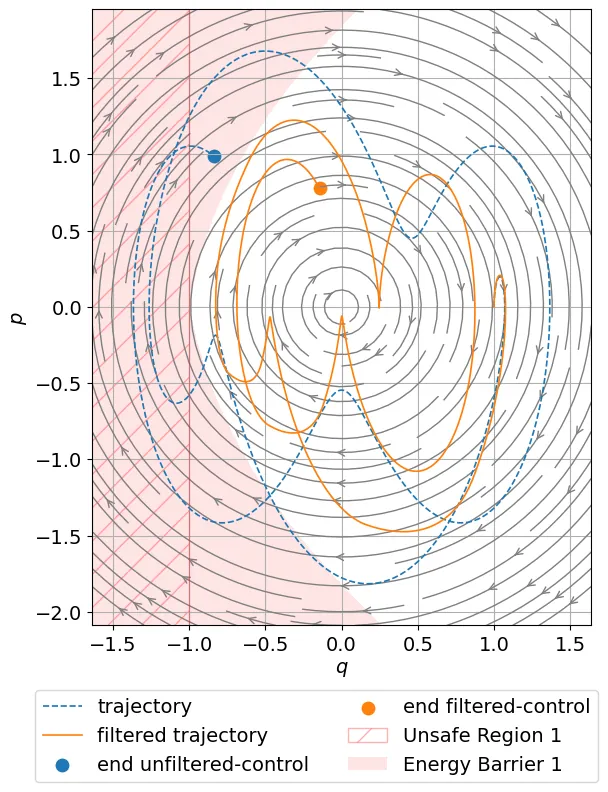
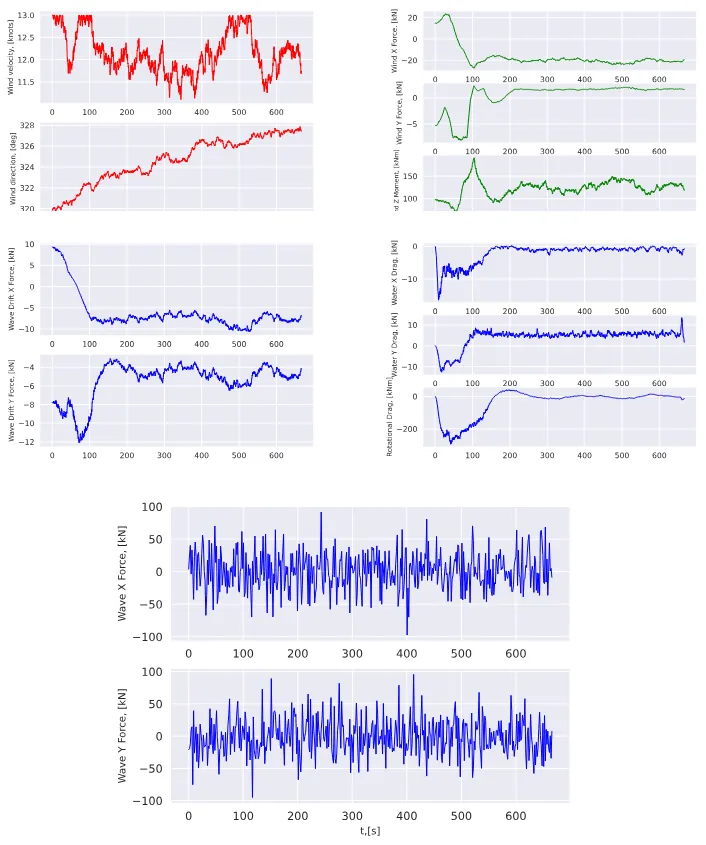
Large Language Models (LLMs) are increasingly used as high level controllers for autonomous Unmanned Aerial Vehicle (UAV) missions. However, existing evaluations rarely assess whether such agents remain safe, protocol compliant, and effective under realistic next generation networking constraints. This paper introduces $α^3$-Bench, a benchmark for evaluating LLM driven UAV autonomy as a multi turn conversational reasoning and control problem operating under dynamic 6G conditions. Each mission is formulated as a language mediated control loop between an LLM based UAV agent and a human operator, where decisions must satisfy strict schema validity, mission policies, speaker alternation, and safety constraints while adapting to fluctuating network slices, latency, jitter, packet loss, throughput, and edge load variations.
To reflect modern agentic workflows, $α^3$-Bench integrates a dual action layer supporting both tool calls and agent to agent coordination, enabling evaluation of tool use consistency and multi agent interactions. We construct a large scale corpus of 113k conversational UAV episodes grounded in UAVBench scenarios and evaluate 17 state of the art LLMs using a fixed subset of 50 episodes per scenario under deterministic decoding. We propose a composite $α^3$ metric that unifies six pillars: Task Outcome, Safety Policy, Tool Consistency, Interaction Quality, Network Robustness, and Communication Cost, with efficiency normalized scores per second and per thousand tokens. Results show that while several models achieve high mission success and safety compliance, robustness and efficiency vary significantly under degraded 6G conditions, highlighting the need for network aware and resource efficient LLM based UAV agents. The dataset is publicly available on GitHub : https://github.com/maferrag/AlphaBench