Optimization and Control
arXiv:math.OC
Operations research, linear programming, control theory, systems theory, optimal control, game theory.
Looking for a broader view? This category is part of:
Operations research, linear programming, control theory, systems theory, optimal control, game theory.
Looking for a broader view? This category is part of:

In this paper we study the value function of Bolza problems governed by stochastic difference equations, with particular emphasis on the convex non-anticipative case. Our goal is to provide some insights on the structure of the subdiferential of the value function. In particular, we establish a connection between the evolution of the subgradients of the value function and a stochastic difference equation of Hamiltonian type. This result can be seen as a transposition of the method of characteristics, introduced by Rockafellar and Wolenski in the 2000s, to the stochastic discrete-time setting. Similarly as done in the literature for the deterministic case, the analysis is based on a duality approach. For this reason we study first a dual representation for the value function in terms of the value function of a dual problem, which is a pseudo Bolza problem. The main difference with the deterministic case is that (due to the non-anticipativity) the symmetry between the Bolza problem and its dual is no longer valid. This in turn implies that ensuring the existence of minimizers for the Bolza problem (which is a key point for establishing the method of characteristics) is not as simple as in the deterministic case, and it should be addressed differently. To complete the exposition, we study the existence of minimizers for a particular class of Bolza problems governed by linear stochastic difference equations, the so-called linear-convex optimal control problems.
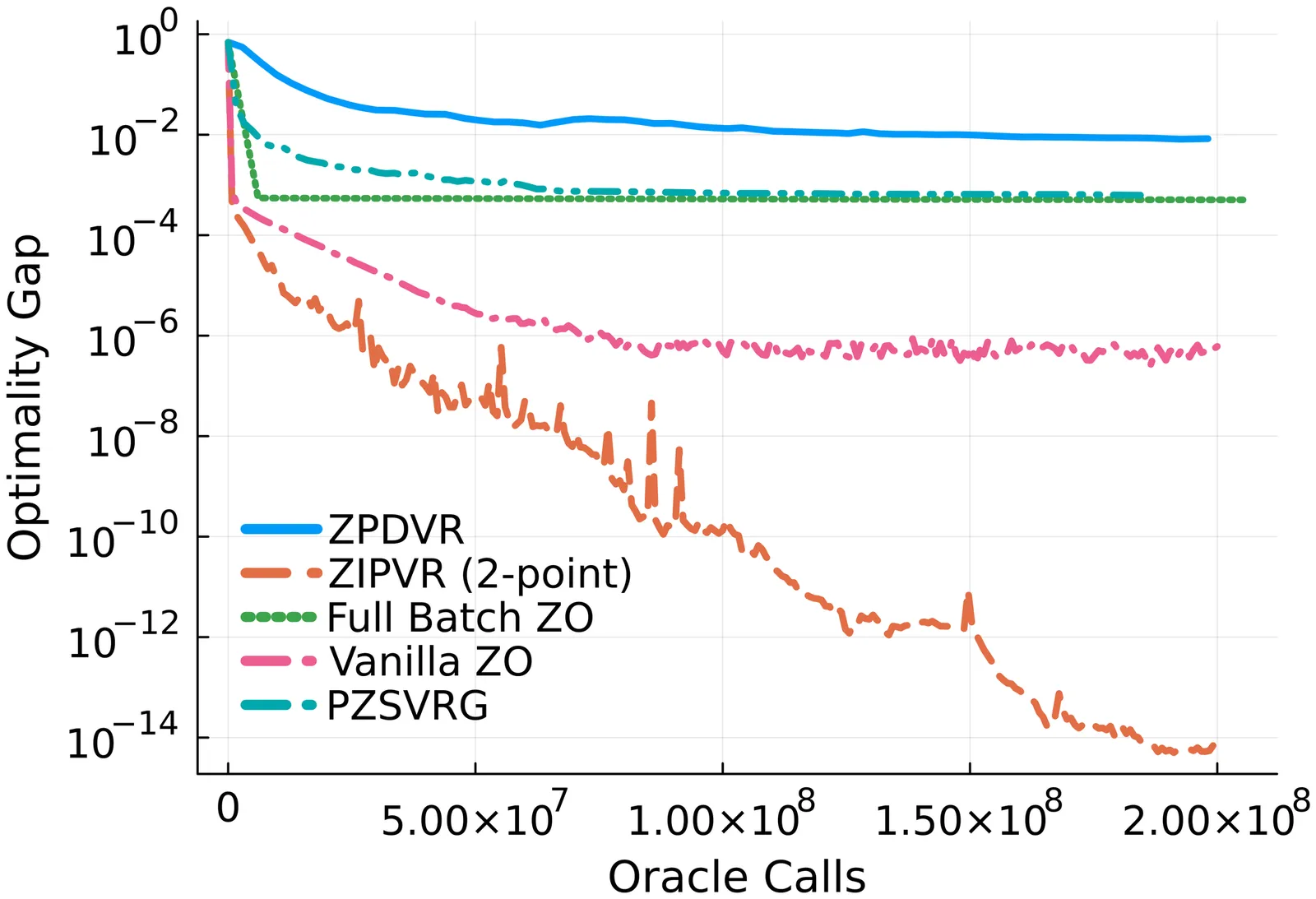
This paper investigates zeroth-order (ZO) finite-sum composite optimization. Recently, variance reduction techniques have been applied to ZO methods to mitigate the non-vanishing variance of 2-point estimators in constrained/composite optimization, yielding improved convergence rates. However, existing ZO variance reduction methods typically involve batch sampling of size at least $Θ(n)$ or $Θ(d)$, which can be computationally prohibitive for large-scale problems. In this work, we propose a general variance reduction framework, Zeroth-Order Incremental Variance Reduction (ZIVR), which supports flexible implementations$\unicode{x2014}$including a pure 2-point zeroth-order algorithm that eliminates the need for large batch sampling. Furthermore, we establish comprehensive convergence guarantees for ZIVR across strongly-convex, convex, and non-convex settings that match their first-order counterparts. Numerical experiments validate the effectiveness of our proposed algorithm.

Greedy Sampling Methods (GSMs) are widely used to construct approximate solutions of Configuration Optimization Problems (COPs), where a loss functional is minimized over finite configurations of points in a compact domain. While effective in practice, deterministic convergence analyses of greedy-type algorithms are often restrictive and difficult to verify. We propose a stochastic framework in which greedy-type methods are formulated as continuous-time Markov processes on the space of configurations. This viewpoint enables convergence analysis in expectation and in probability under mild structural assumptions on the error functional and the transition kernel. For global error functionals, we derive explicit convergence rates, including logarithmic, polynomial, and exponential decay, depending on an abstract improvement condition. As a pedagogical example, we study stochastic greedy sampling for one-dimensional piecewise linear interpolation and prove exponential convergence of the $L^1$-interpolation error for $C^2$-functions. Motivated by this analysis, we introduce the Randomized Polytope Division Method (R-PDM), a randomized variant of the classical Polytope Division Method, and demonstrate its effectiveness and variance reduction in numerical experiments
We study positive semi-definite (PSD) biquadratic forms and their sum-of-squares (SOS) representations. For the class of partially symmetric biquadratic forms, we establish necessary and sufficient conditions for positive semi-definiteness and prove that every PSD partially symmetric biquadratic form is a sum of squares of bilinear forms. This extends the known result for fully symmetric biquadratic forms. We describe an efficient computational procedure for constructing SOS decompositions, exploiting the Kronecker-product structure of the associated matrix representation. We present a $2 \times 2$ PSD biquadratic form, and show that it can be expressed as the sum of three squares, but cannot be expressed as the sum of two squares. Furthermore, we present a $3 \times 2$ PSD biquadratic form, and show that it can be expressed as the sum of four squares, but cannot be expressed as the sum of three squares. These show that previously proved results that a $2 \times 2$ PSD biquadratic form can be expressed as the sum of three squares, and a $3 \times 2$ PSD biquadratic form can be expressed as the sum of four squares, are tight.

This paper is concerned with a stochastic linear-quadratic optimal control problem of Markovian regime switching system with model uncertainty and partial information, where the information available to the control is based on a sub-$σ$-algebra of the filtration generated by the underlying Brownian motion and the Markov chain. Based on $H_\infty$ control theory, we turn to deal with a soft-constrained zero-sum linear-quadratic stochastic differential game with Markov chain and partial information. By virtue of the filtering technique, the Riccati equation approach, the method of orthogonal decomposition, and the completion-of-squares method, we obtain the closed-loop saddle point of the zero-sum game via the optimal feedback control-strategy pair. Subsequently, we prove that the corresponding outcome of the closed-loop saddle point satisfies the $H_\infty$ performance criterion. Finally, the obtained theoretical results are applied to a stock market investment problem to further illustrate the practical significance and effectiveness.
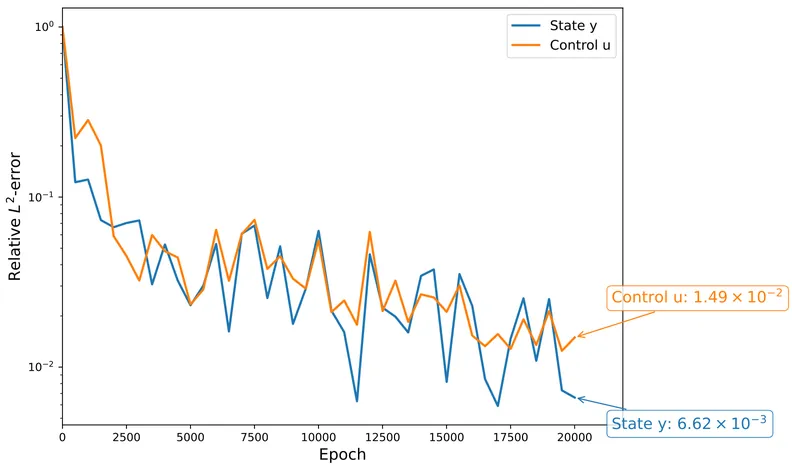
Optimal control of obstacle problems arises in a wide range of applications and is computationally challenging due to its nonsmoothness, nonlinearity, and bilevel structure. Classical numerical approaches rely on mesh-based discretization and typically require solving a sequence of costly subproblems. In this work, we propose a single-loop bilevel deep learning method, which is mesh-free, scalable to high-dimensional and complex domains, and avoids repeated solution of discretized subproblems. The method employs constraint-embedding neural networks to approximate the state and control and preserves the bilevel structure. To train the neural networks efficiently, we propose a Single-Loop Stochastic First-Order Bilevel Algorithm (S2-FOBA), which eliminates nested optimization and does not rely on restrictive lower-level uniqueness assumptions. We analyze the convergence behavior of S2-FOBA under mild assumptions. Numerical experiments on benchmark examples, including distributed and obstacle control problems with regular and irregular obstacles on complex domains, demonstrate that the proposed method achieves satisfactory accuracy while reducing computational cost compared to classical numerical methods.

We aim to solve a topology optimization problem where the distribution of material in the design domain is represented by a density function. To obtain candidates for local minima, we want to solve the first order optimality system via Newton's method. This requires the initial guess to be sufficiently close to the a priori unknown solution. Introducing a stepsize rule often allows for less restrictions on the initial guess while still preserving convergence. In topology optimization one typically encounters nonconvex problems where this approach might fail. We therefore opt for a homotopy (continuation) approach which is based on solving a sequence of parametrized problems to approach the solution of the original problem. In the density based framework the values of the design variable are constrained by 0 from below and 1 from above. Coupling the homotopy method with a barrier strategy enforces these constraints to be satisified. The numerical results for a PDE-constrained compliance minimization problem demonstrate that this combined approach maintains feasibility of the density function and converges to a (candidate for a) locally optimal design without a priori knowledge of the solution.
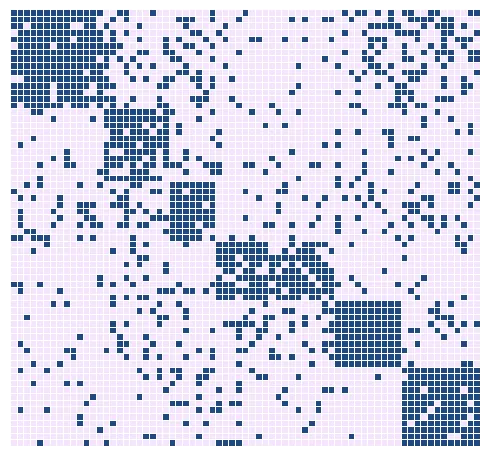
We consider the densest submatrix problem, which seeks the submatrix of fixed size of a given binary matrix that contains the most nonzero entries. This problem is a natural generalization of fundamental problems in combinatorial optimization, e.g., the densest subgraph, maximum clique, and maximum edge biclique problems, and has wide application the study of complex networks. Much recent research has focused on the development of sufficient conditions for exact solution of the densest submatrix problem via convex relaxation. The vast majority of these sufficient conditions establish identification of the densest submatrix within a graph containing exactly one large dense submatrix hidden by noise. The assumptions of these underlying models are not observed in real-world networks, where the data may correspond to a matrix containing many dense submatrices of varying sizes. We extend and generalize these results to the more realistic setting where the input matrix may contain \emph{many} large dense subgraphs. Specifically, we establish sufficient conditions under which we can expect to solve the densest submatrix problem in polynomial time for random input matrices sampled from a generalization of the stochastic block model. Moreover, we also provide sufficient conditions for perfect recovery under a deterministic adversarial. Numerical experiments involving randomly generated problem instances and real-world collaboration and communication networks are used empirically to verify the theoretical phase-transitions to perfect recovery given by these sufficient conditions.
We consider the well-known max-(relative) entropy problem $Θ$(y) = infQ$\ll$P DKL(Q P ) with Kullback-Leibler divergence on a domain $Ω$ $\subset$ R d , and with ''moment'' constraints h dQ = y, y $\in$ R m . We show that when m $\le$ d, $Θ$ is the Cram{é}r transform of a function v that solves a simply related computational geometry problem. Also, and remarkably, to the canonical LP: min x$\ge$0 {c T x\,: A x = y}, with A $\in$ R mxd , one may associate a max-entropy problem with a suitably chosen reference measure P on R d + and linear mapping h(x) = Ax, such that its associated perspective function $ε$ $Θ$(y/$ε$) is the optimal value of the log-barrier formulation (with parameter $ε$) of the dual LP (and so it converges to the LP optimal value as $ε$ $\rightarrow$ 0). An analogous result also holds for the canonical SDP: min X 0 { C, X\,: A(X) = y }.
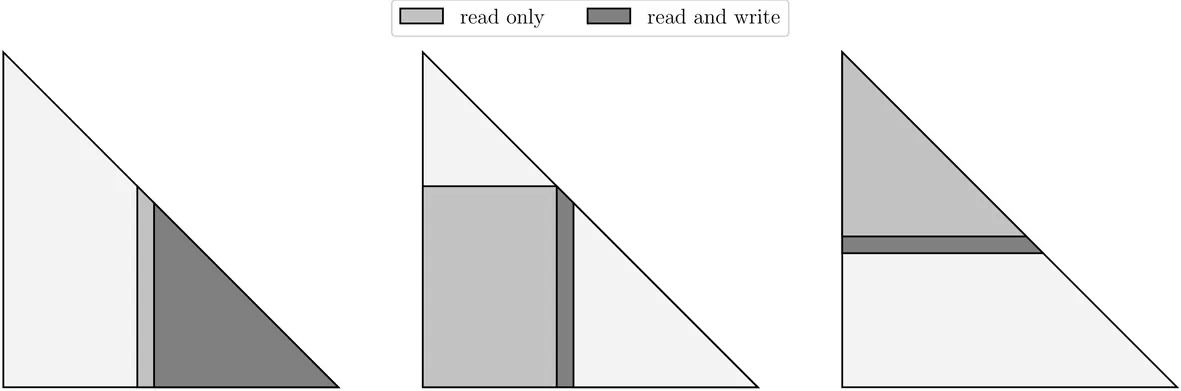
This paper presents a GPU-accelerated framework for solving block tridiagonal linear systems that arise naturally in numerous real-time applications across engineering and scientific computing. Through a multi-stage permutation strategy based on nested dissection, we reduce the computational complexity from $\mathcal{O}(Nn^3)$ for sequential Cholesky factorization to $\mathcal{O}(\log_2(N)n^3)$ when sufficient parallel resources are available, where $n$ is the block size and $N$ is the number of blocks. The algorithm is implemented using NVIDIA's Warp library and CUDA to exploit parallelism at multiple levels within the factorization algorithm. Our implementation achieves speedups exceeding 100x compared to the sparse solver QDLDL, 25x compared to a highly optimized CPU implementation using BLASFEO, and more than 2x compared to NVIDIA's CUDSS library. The logarithmic scaling with horizon length makes this approach particularly attractive for long-horizon problems in real-time applications. Comprehensive numerical experiments on NVIDIA GPUs demonstrate the practical effectiveness across different problem sizes and precisions. The framework provides a foundation for GPU-accelerated optimization solvers in robotics, autonomous systems, and other domains requiring repeated solution of structured linear systems. The implementation is open-source and available at https://github.com/PREDICT-EPFL/socu.
We analyze a class of multidimensional linear-quadratic stochastic control problems with random coefficients, motivated by multi-asset optimal trade execution. The problems feature non-diffusive controlled state dynamics and a terminal constraint that restricts the terminal state to a prescribed random linear subspace. We derive the associated Riccati backward stochastic differential equation (BSDE) and identify a suitable formalization of its singular terminal condition. Via a penalization approach, we establish existence of a minimal supersolution of the Riccati BSDE and use it to characterize both the value function and the optimal control. We analyze the asymptotic behavior of the supersolution near terminal time and discuss special cases where closed-form solutions can be obtained.

Decentralized optimization has become a fundamental tool for large-scale learning systems; however, most existing methods rely on the classical Lipschitz smoothness assumption, which is often violated in problems with rapidly varying gradients. Motivated by this limitation, we study decentralized optimization under the generalized $(L_0, L_1)$-smoothness framework, in which the Hessian norm is allowed to grow linearly with the gradient norm, thereby accommodating rapidly varying gradients beyond classical Lipschitz smoothness. We integrate gradient-tracking techniques with gradient clipping and carefully design the clipping threshold to ensure accurate convergence over directed communication graphs under generalized smoothness. In contrast to existing distributed optimization results under generalized smoothness that require a bounded gradient dissimilarity assumption, our results remain valid even when the gradient dissimilarity is unbounded, making the proposed framework more applicable to realistic heterogeneous data environments. We validate our approach via numerical experiments on standard benchmark datasets, including LIBSVM and CIFAR-10, using regularized logistic regression and convolutional neural networks, demonstrating superior stability and faster convergence over existing methods.
This paper develops a systematic and geometric theory of optimal quantization on the unit sphere $\mathbb S^2$, focusing on finite uniform probability distributions supported on the spherical surface - rather than on lower-dimensional geodesic subsets such as circles or arcs. We first establish the existence of optimal sets of $n$-means and characterize them through centroidal spherical Voronoi tessellations. Three fundamental structural results are obtained. First, a cluster - purity theorem shows that when the support consists of well-separated components, each optimal Voronoi region remains confined to a single component. Second, a ring - allocation (discrete water - filling) theorem provides an explicit rule describing how optimal representatives are distributed across multiple latitudinal rings, together with closed-form distortion formulas. Third, a Lipschitz - type stability theorem quantifies the robustness of optimal configurations under small geodesic perturbations of the support. In addition, a spherical analogue of Lloyd's algorithm is presented, in which intrinsic (Karcher) means replace Euclidean centroids for iterative refinement. These results collectively provide a unified and transparent framework for understanding the geometric and algorithmic structure of optimal quantization on $\mathbb S^2$.
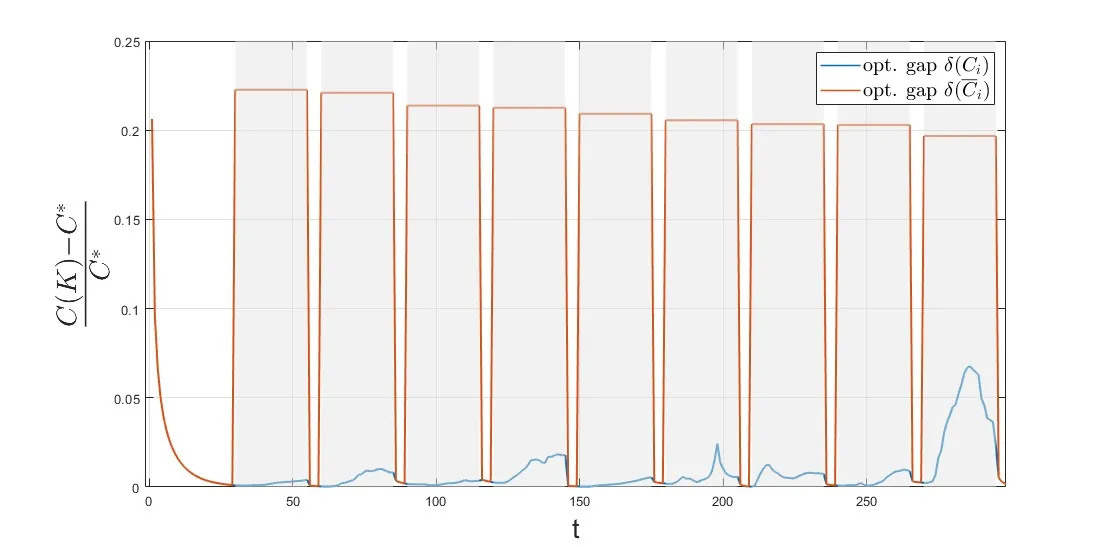
We consider the policy gradient adaptive control (PGAC) framework, which adaptively updates a control policy in real time, by performing data-based gradient descent steps on the linear quadratic regulator cost. This method has empirically shown to react to changing circumstances, such as model parameters, efficiently. To formalize this observation, we design a PGAC method which stabilizes linear switched systems, where both model parameters and switching time are unknown. We use sliding window data for the policy gradient estimate and show that under a dwell time condition and small dynamics variation, the policy can track the switching dynamics and ensure closed-loop stability. We perform simulations to validate our theoretical results.

Recent studies have shown that fractional calculus is an effective alternative mathematical tool in various scientific fields. However, some investigations indicate that results established in differential and integral calculus do not necessarily hold true in fractional calculus. In this work we will compare various methods presented in the literature to improve the Gradient Descent Method, in terms of convergence of the method, convergence to the extreme point, and convergence rate. In general, these methods that generalize the gradient descent algorithm by replacing the gradient with a fractional-order operator are inefficient in achieving convergence to the extremum point of the objective function. To avoid these difficulties, we proposed to choose the Fractional Continuous Time algorithm to generalize the gradient method. In this approach, the convergence of the method to the extreme point of the function is guaranteed by introducing the fractional order in the time derivative, rather than in of the gradient. In this case, the issue of finding the extreme point is resolved, while the issue of stability at the equilibrium point remains. Fractional Continuous Time method converges to extreme point of cost function when fractional-order is between 0 and 1. The simulations shown in this work suggests that a similar result can be found when $1 \leq α\leq 2$. { This paper highlights the main advantages and disadvantages of generalizations of the gradient method using fractional derivatives, aiming to optimize convergence in complex problems. Some chemical problems, with n=11 and 24 optimization parameters, are employed as means of evaluating the efficacy of the propose algorithms. In general, previous studies are restricted to mathematical questions and simple illustrative examples.
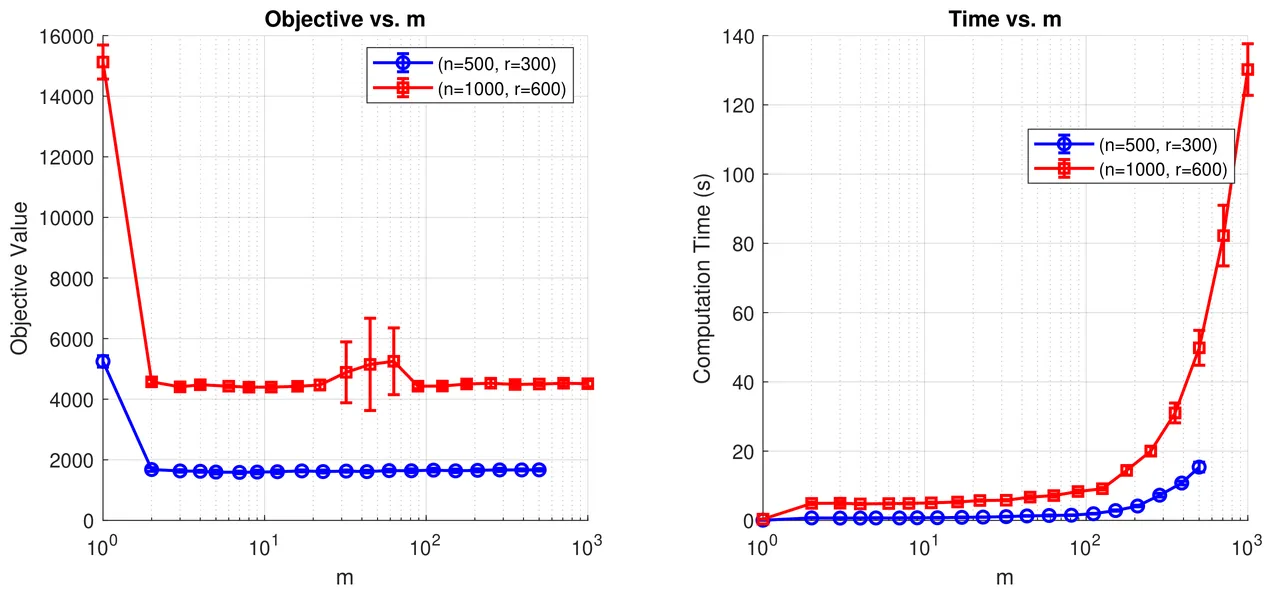
We study binary optimization problems of the form \( \min_{x\in\{-1,1\}^n} f(Ax-b) \) with possibly nonsmooth loss \(f\). Following the lifted rank-one semidefinite programming (SDP) approach\cite{qian2023matrix}, we develop a majorization-minimization algorithm by using the difference-of-convexity (DC) reformuation for the rank-one constraint and the Moreau envelop for the nonsmooth loss. We provide global complexity guarantees for the proposed \textbf{D}ifference of \textbf{C}onvex \textbf{R}elaxation \textbf{A}lgorithm (DCRA) and show that it produces an approximately feasible binary solution with an explicit bound on the optimality gap. Numerical experiments on synthetic and real datasets confirm that our method achieves superior accuracy and scalability compared with existing approaches.
The structure of continuous Hopfield networks is revisited from a system-theoretic point of view. After adopting a novel electrical network interpretation involving nonlinear capacitors, it is shown that Hopfield networks admit a port-Hamiltonian formulation provided an extra passivity condition is satisfied. Subsequently it is shown that any Hopfield network can be represented as a gradient system, with Riemannian metric given by the inverse of the Hessian matrix of the total energy stored in the nonlinear capacitors. On the other hand, the well-known 'energy' function employed by Hopfield turns out to be the dissipation potential of the gradient system, and this potential is shown to satisfy a dissipation inequality that can be used for analysis and interconnection.
Variance reduction (VR) is a crucial tool for solving finite-sum optimization problems, including the composite general convex setting, which is the focus of this work. On the one hand, denoting the number of component functions as $n$ and the target accuracy as $ε$, some VR methods achieve the near-optimal complexity $\widetilde{\mathcal{O}}\left(n+\sqrt{n}/\sqrtε\right)$, but they all have nested structure and fail to provide convergence guarantee for the iterate sequence itself. On the other hand, single-loop VR methods, being free from the aforementioned disadvantages, have complexity no better than $\mathcal{O}\left(n+n/\sqrtε\right)$ which is the complexity of the deterministic method FISTA, thus leaving a critical gap unaddressed. In this work, we propose the \textit{Harmonia} technique which relates checkpoint update probabilities to momentum parameters in single-loop VR methods. Based on this technique, we further propose to vary the growth rate of the momentum parameter, creating a novel continuous trade-off between acceleration and variance reduction, controlled by the key parameter $α\in[0,1]$. The proposed techniques lead to following favourable consequences. First, several known complexity of quite different algorithms are re-discovered under the proposed unifying algorithmic framework Katyusha-H. Second, under an extra mild condition, Katyusha-H achieves the near-optimal complexity for $α$ belonging to a certain interval, highlighting the effectiveness of the acceleration-variance reduction trade-off. Last, without extra conditions, Katyusha-H achieves the complexity $\widetilde{\mathcal{O}}(n+\sqrt{n}/\sqrtε)$ with $α=1$ and proper mini-batch sizes. The proposed idea and techniques may be of general interest beyond the considered problem in this work.
We study an optimization problem in which the objective is given as a sum of logarithmic-polynomial functions. This formulation is motivated by statistical estimation principles such as maximum likelihood estimation, and by loss functions including cross-entropy and Kullback-Leibler divergence. We propose a hierarchy of moment relaxations based on the truncated $K$-moment problems to solve log-polynomial optimization. We provide sufficient conditions for the hierarchy to be tight and introduce a numerical method to extract the global optimizers when the tightness is achieved. In addition, we modify relaxations with optimality conditions to better fit log-polynomial optimization with convenient Lagrange multipliers expressions. Various applications and numerical experiments are presented to show the efficiency of our method.

In combinatorial optimization, ordinal costs can be used to model the quality of elements whenever numerical values are not available. When considering, for example, routing problems for cyclists, the safety of a street can be ranked in ordered categories like safe (separate bike lane), medium safe (street with a bike lane) and unsafe (street without a bike lane). However, ordinal optimization may suggest unrealistic solutions with huge detours to avoid unsafe street segments. In this paper, we investigate how partial preference information regarding the relative quality of the ordinal categories can be used to improve the relevance of the computed solutions. By introducing preference weights which describe how much better a category is at least or at most, compared to the subsequent category, we enlarge the ordinal dominance cone. This leads to a smaller set of alternatives, i. e., of ordinally efficient solutions. We show that the corresponding weighted ordinal ordering cone is a polyhedral cone and provide descriptions via its extreme rays and via its facets. The latter implies a linear transformation to an associated multi-objective optimization problem. This paves the way for the application of standard multi-objective solution approaches. We demonstrate the usefulness of the weighted ordinal ordering cone by investigating a safest path problem with different preference weights. Moreover, we investigate the interrelation between the weighted ordering cone to standard dominance concepts of multi-objective optimization, like, e.g., Pareto dominance, lexicographic dominance and weighted sum dominance.
In this paper we study a nonconvex-strongly-concave constrained minimax problem. Specifically, we propose a first-order augmented Lagrangian method for solving it, whose subproblems are nonconvex-strongly-concave unconstrained minimax problems and suitably solved by a first-order method developed in this paper that leverages the strong concavity structure. Under suitable assumptions, the proposed method achieves an \emph{operation complexity} of $O(\varepsilon^{-3.5}\log\varepsilon^{-1})$, measured in terms of its fundamental operations, for finding an $\varepsilon$-KKT solution of the constrained minimax problem, which improves the previous best-known operation complexity by a factor of $\varepsilon^{-0.5}$.
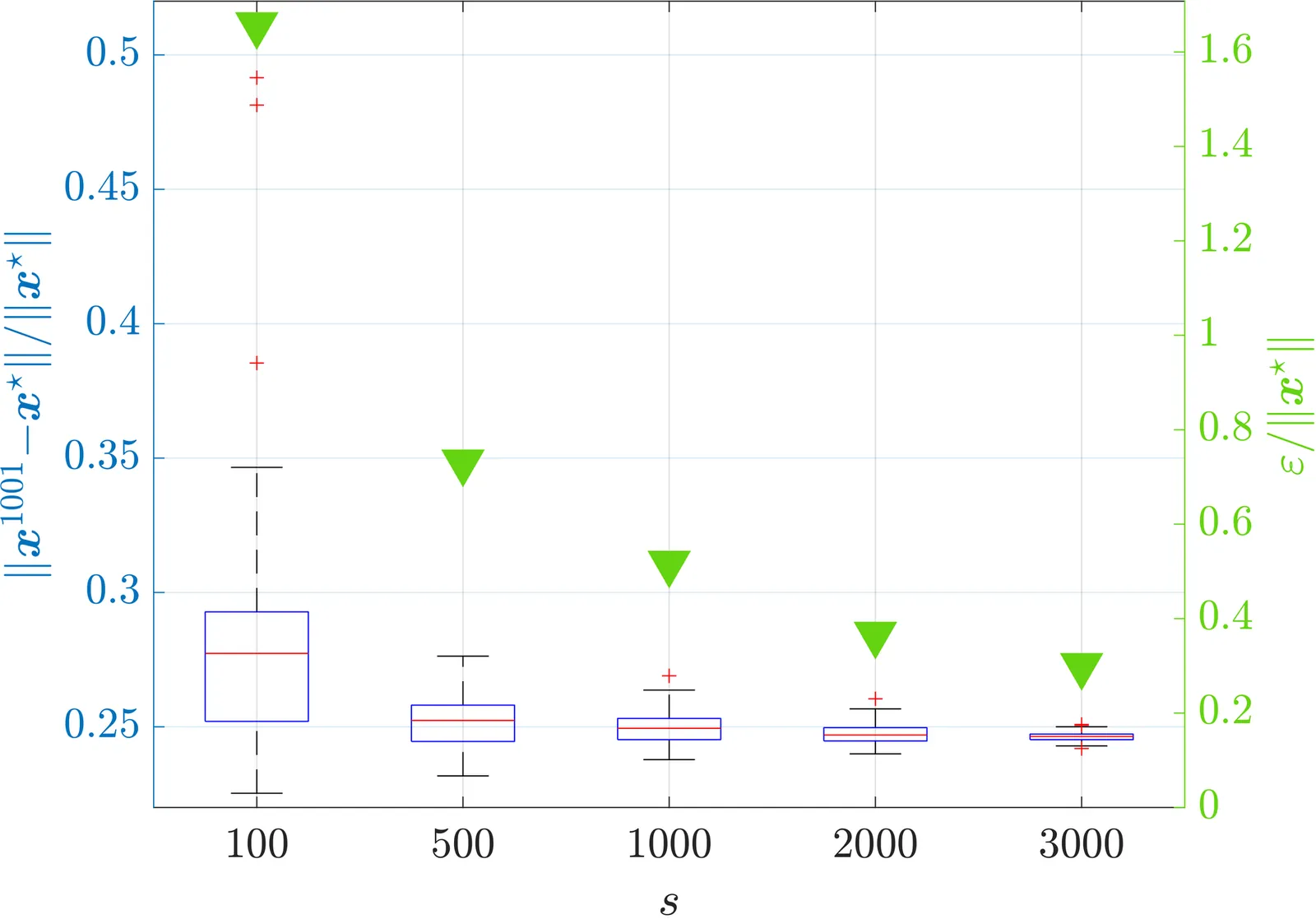
We establish finite sample certificates on the quality of solutions produced by data-based forward-backward (FB) operator splitting schemes. As frequently happens in stochastic regimes, we consider the problem of finding a zero of the sum of two operators, where one is either unavailable in closed form or computationally expensive to evaluate, and shall therefore be approximated using a finite number of noisy oracle samples. Under the lens of algorithmic stability, we then derive probabilistic bounds on the distance between a true zero and the FB output without making specific assumptions about the underlying data distribution. We show that under weaker conditions ensuring the convergence of FB schemes, stability bounds grow proportionally to the number of iterations. Conversely, stronger assumptions yield stability guarantees that are independent of the iteration count. We then specialize our results to a popular FB stochastic Nash equilibrium seeking algorithm and validate our theoretical bounds on a control problem for smart grids, where the energy price uncertainty is approximated by means of historical data.

Linear time-invariant control systems can be considered as finitely generated modules over the commutative principal ideal ring $\mathbb{R}[\frac{d}{dt}]$ of linear differential operators with respect to the time derivative. The Kalman controllability in this algebraic language is translated as the freeness of the system module. Linear quadratic regulators rely on quadratic Lagrangians, or cost functions. Any flat output, i.e., any basis of the corresponding free module leads to an open-loop control strategy via an Euler-Lagrange equation, which becomes here a linear ordinary differential equation with constant coefficients. In this approach, the two-point boundary value problem, including the control variables, becomes tractable. It yields notions of optimal time horizon, optimal parameter design and optimal rest-to-rest trajectories. The loop is closed via an intelligent controller derived from model-free control, which is known to exhibit excellent performance concerning model mismatches and disturbances.
Several problems in machine learning are naturally expressed as the design and analysis of time-evolving probability distributions. This includes sampling via diffusion methods, optimizing the weights of neural networks, and analyzing the evolution of token distributions across layers of large language models. While the targeted applications differ (samples, weights, tokens), their mathematical descriptions share a common structure. A key idea is to switch from the Eulerian representation of densities to their Lagrangian counterpart through vector fields that advect particles. This dual view introduces challenges, notably the non-uniqueness of Lagrangian vector fields, but also opportunities to craft density evolutions and flows with favorable properties in terms of regularity, stability, and computational tractability. This survey presents an overview of these methods, with emphasis on two complementary approaches: diffusion methods, which rely on stochastic interpolation processes and underpin modern generative AI, and optimal transport, which defines interpolation by minimizing displacement cost. We illustrate how both approaches appear in applications ranging from sampling, neural network optimization, to modeling the dynamics of transformers for large language models.
Energy and pollution are urging problems of the 21th century. By gradually changing the actual power grid system, smart grid may evolve into different systems by means of size, elements and strategies, but its fundamental requirements and objectives will not change such as optimizing production, transmission, and consumption. Studying the smart grid through modeling and simulation provides us with valuable results which cannot be obtained in real world due to time and cost related constraints. Moreover, due to the complexity of the smart grid, achieving global optimization is not an easy task. In this paper, we propose a complex system based approach to the smart grid modeling, accentuating on the optimization by combining game theoretical and classical methods in different levels. Thanks to this combination, the optimization can be achieved with flexibility and scalability, while keeping its generality.
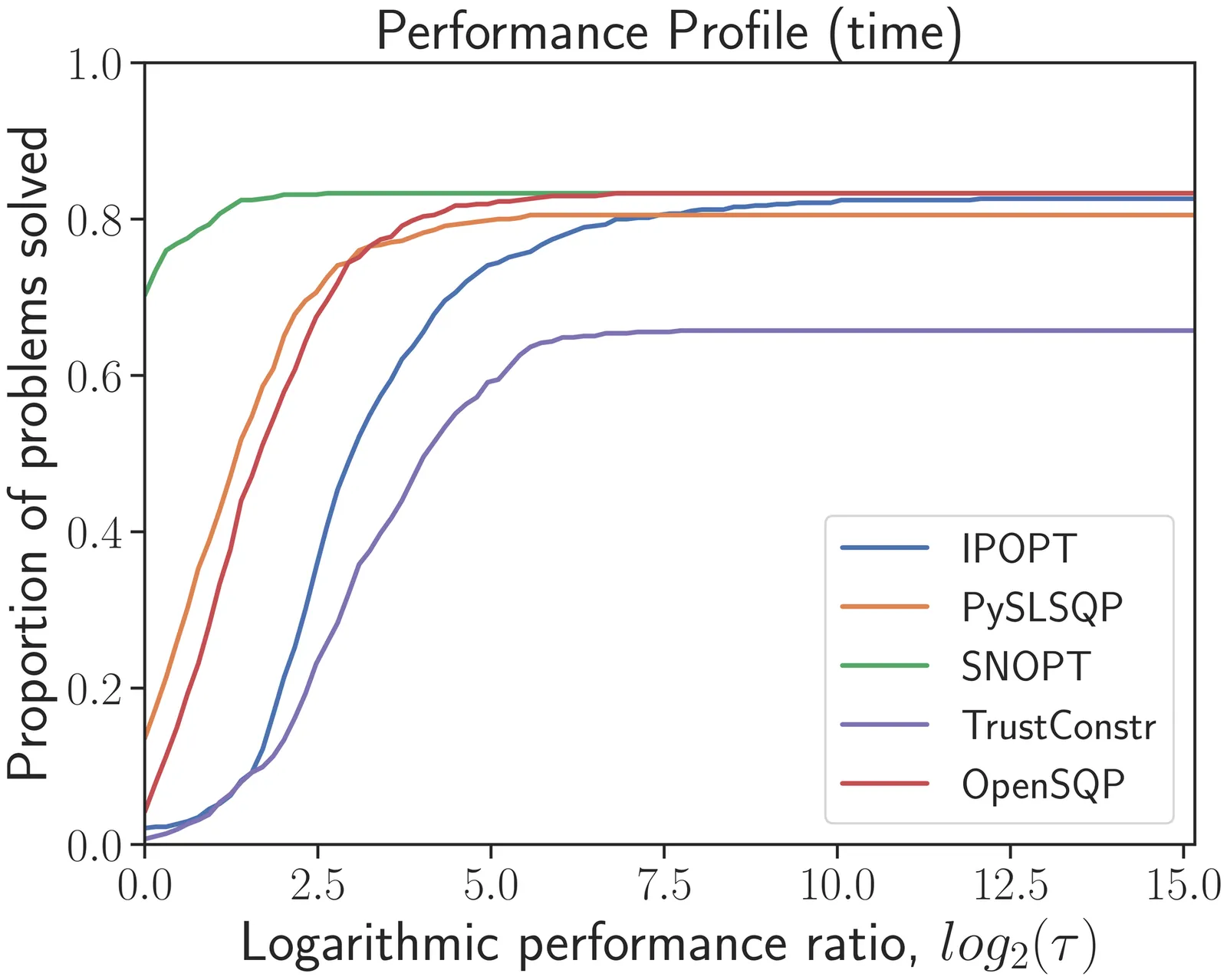
Sequential quadratic programming (SQP) methods have been remarkably successful in solving a broad range of nonlinear optimization problems. These methods iteratively construct and solve quadratic programming (QP) subproblems to compute directions that converge to a local minimum. While numerous open-source and commercial SQP algorithms are available, their implementations lack the transparency and modularity necessary to adapt and fine-tune them for specific applications or to swap out different modules to create a new optimizer. To address this gap, we present OpenSQP, a modular and reconfigurable SQP algorithm implemented in Python that achieves robust performance comparable to leading algorithms. We implement OpenSQP in a manner that allows users to easily modify or replace components such as merit functions, line search procedures, Hessian approximations, and QP solvers. This flexibility enables the creation of tailored variants of the algorithm for specific needs. To demonstrate reliability, we present numerical results using the standard configuration of OpenSQP that employs a smooth augmented Lagrangian merit function for the line search and a quasi-Newton BFGS method for approximating the Hessians. We benchmark this configuration on a comprehensive set of problems from the CUTEst test suite. The results demonstrate performance that is competitive with proven nonlinear optimization algorithms such as SLSQP, SNOPT, and IPOPT.
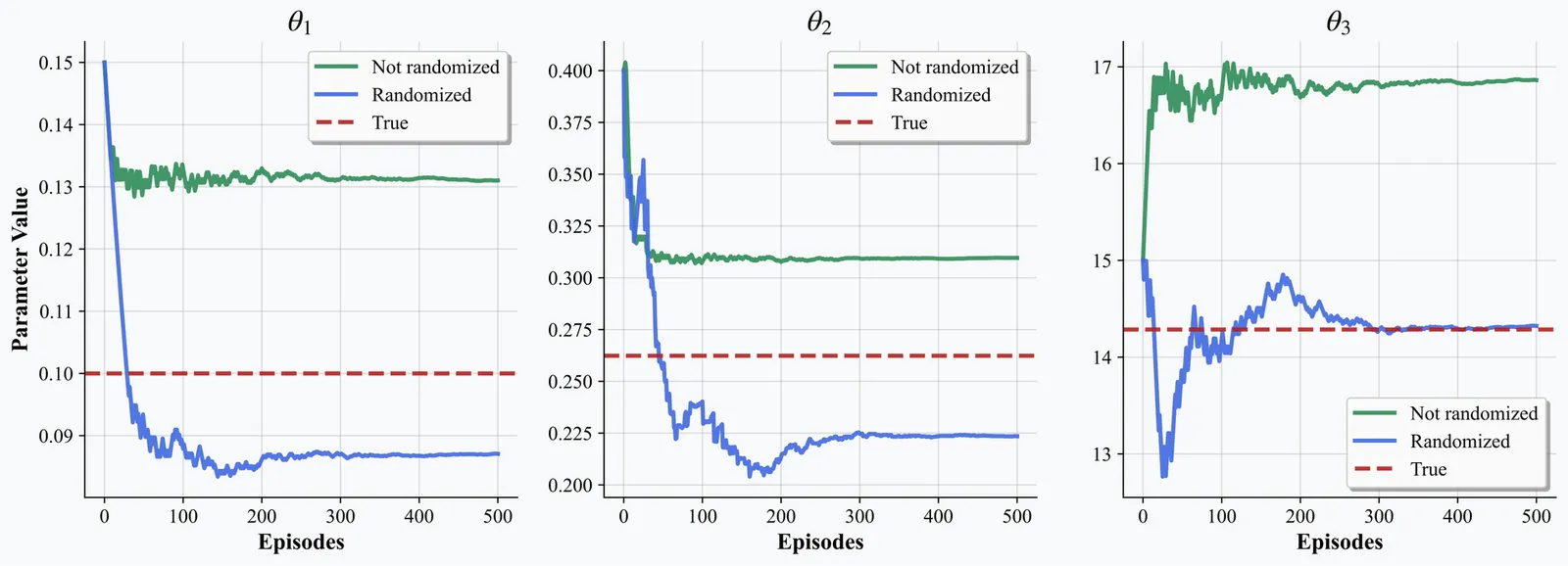
This paper studies the continuous-time reinforcement learning for stochastic singular control with the application to an infinite-horizon irreversible reinsurance problems. The singular control is equivalently characterized as a pair of regions of time and the augmented states, called the singular control law. To encourage the exploration in the learning procedure, we propose a randomization method for the singular control laws, new to the literature, by considering an auxiliary singular control and entropy regularization. The exploratory singular control problem is formulated as a two-stage optimal control problem, where the time-inconsistency issue arises in the outer problem. In the specific model setup with known model coefficients, we provide the full characterization of the time-consistent equilibrium singular controls for the two-stage problem. Taking advantage of the solution structure, we can consider the proper parameterization of the randomized equilibrium policy and the value function when the model is unknown and further devise the actor-critic reinforcement learning algorithms. In the numerical experiment, we present the superior convergence of parameter iterations towards the true values based on the randomized equilibrium policy and illustrate how the exploration may advance the learning performance in the context of singular controls.
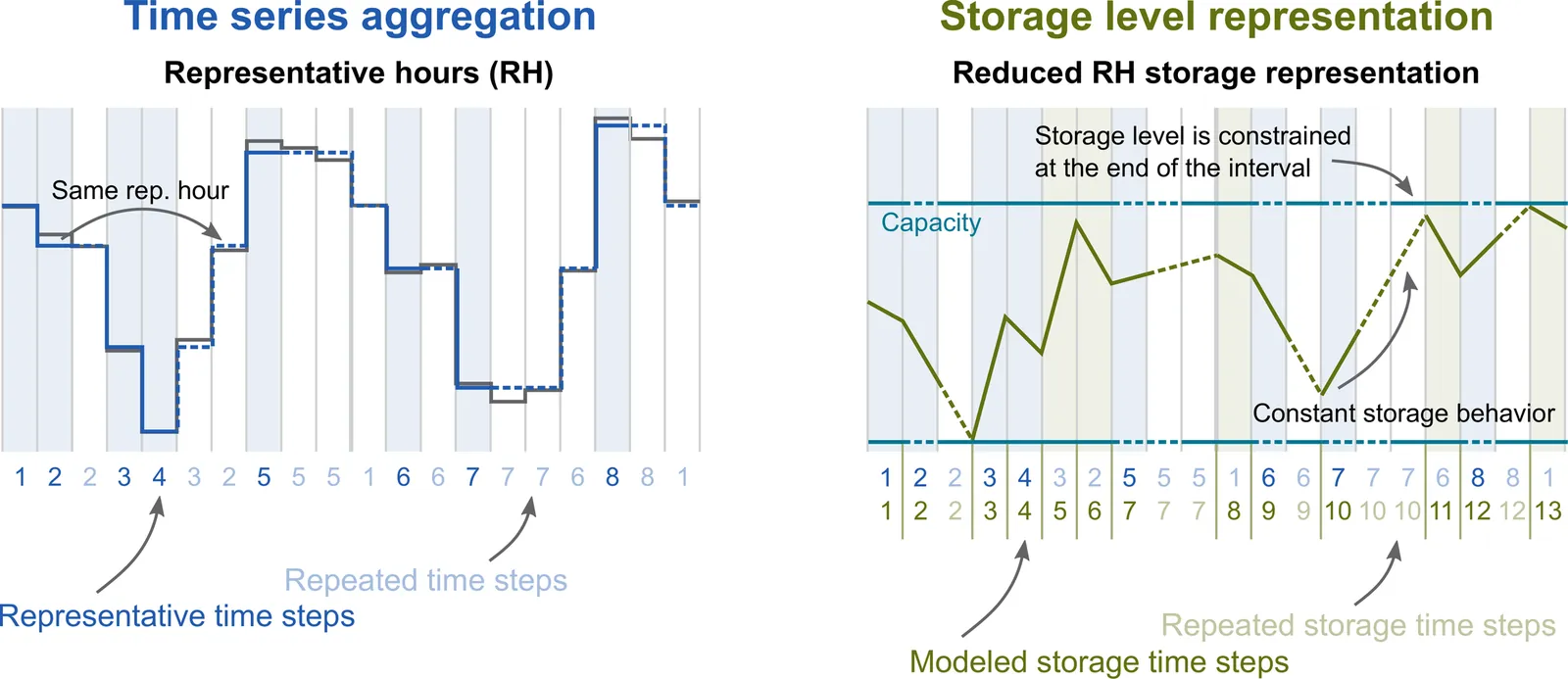
Energy system optimization often relies on time series aggregation to ensure computational tractability. Aggregation generally loses the chronology of time steps, which renders the storage level representation challenging. Typically, this challenge is addressed by using representative days (RD) to utilize intra-day chronology, even though representative hours (RH) can describe the input time series more accurately at fewer representative time steps than RD. However, until now, the use of RH storage representation methods has been limited by either high computational complexity, poor accuracy in clustering and storage representation, or restricted applicability. Here, we present a novel storage representation method based on RH that combines the high accuracy of RH time series aggregation with the high computational efficiency of methods based on RD. Through benchmarking the four most established storage representation methods on a model of a net-zero European energy system, we find that the proposed method can reduce the solving time by over 95% for the same objective value compared to the most established RD and RH methods. The proposed method exhibits particular strengths at strong aggregations of around 100 to 500 representative hours per year, making the method especially applicable to large-scale and sector-coupled transition pathway models. The developed method for accurately modeling both short-term and long-term storage, along with the presented findings, is of practical relevance to energy system modelers who seek computational tractability in large-scale applications while avoiding the misallocation of storage and conversion capacities.

A multi-variable adaptive controller is derived as the explicit solution to a minimax dynamic game. The minimizing player selects the control action as a function of past state measurements and inputs. The maximizing player selects disturbances and model parameters for the underlying linear time-invariant dynamics. This leads to a Bellman equation that can be solved explicitly for the case with unitary B-matrix known up to a sign and no input penalty. The minimizing policy is a dual controller that optimizes the tradeoff between exploration and exploitation.
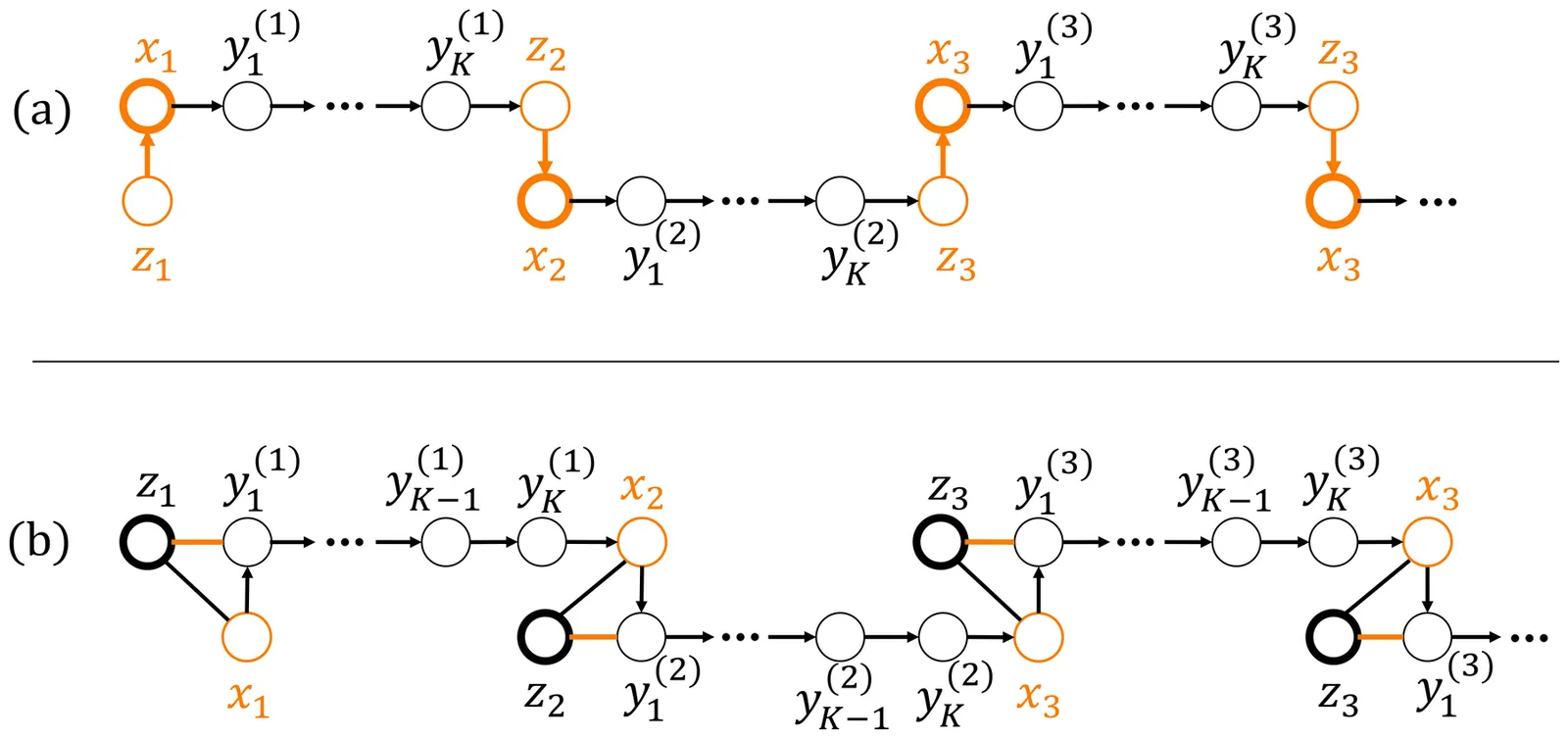
Bilevel optimization minimizes an objective function, defined by an upper-level problem whose feasible region is the solution of a lower-level problem. We study the oracle complexity of finding an $ε$-stationary point with first-order methods when the upper-level problem is nonconvex and the lower-level problem is strongly convex. Recent works (Ji et al., ICML 2021; Arbel and Mairal, ICLR 2022; Chen el al., JMLR 2025) achieve a $\tilde{\mathcal{O}}(κ^4 ε^{-2})$ upper bound that is near-optimal in $ε$. However, the optimal dependency on the condition number $κ$ is unknown. In this work, we establish a new $Ω(κ^2 ε^{-2})$ lower bound and $\tilde{\mathcal{O}}(κ^{7/2} ε^{-2})$ upper bound for this problem, establishing the first provable gap between bilevel problems and minimax problems in this setup. Our lower bounds can be extended to various settings, including high-order smooth functions, stochastic oracles, and convex hyper-objectives: (1) For second-order and arbitrarily smooth problems, we show $Ω(κ_y^{13/4} ε^{-12/7})$ and $Ω(κ^{17/10} ε^{-8/5})$ lower bounds, respectively. (2) For convex-strongly-convex problems, we improve the previously best lower bound (Ji and Liang, JMLR 2022) from $Ω(κ/\sqrtε)$ to $Ω(κ^{5/4} / \sqrtε)$. (3) For smooth stochastic problems, we show an $Ω(κ^4 ε^{-4})$ lower bound.

The home space for optimal control is a Sobolev space. The home space for pseudospectral theory is also a Sobolev space. It thus seems natural to combine pseudospectral theory with optimal control theory and construct ``pseudospectral optimal control theory,'' a term coined by Ross. In this paper, we review key theoretical results in pseudospectral optimal control that have proven to be critical for a successful flight. Implementation details of flight demonstrations onboard NASA spacecraft are discussed along with emerging trends and techniques in both theory and practice. The 2011 launch of pseudospectral optimal control in embedded platforms is changing the way in which we see solutions to challenging control problems in aerospace and autonomous systems.
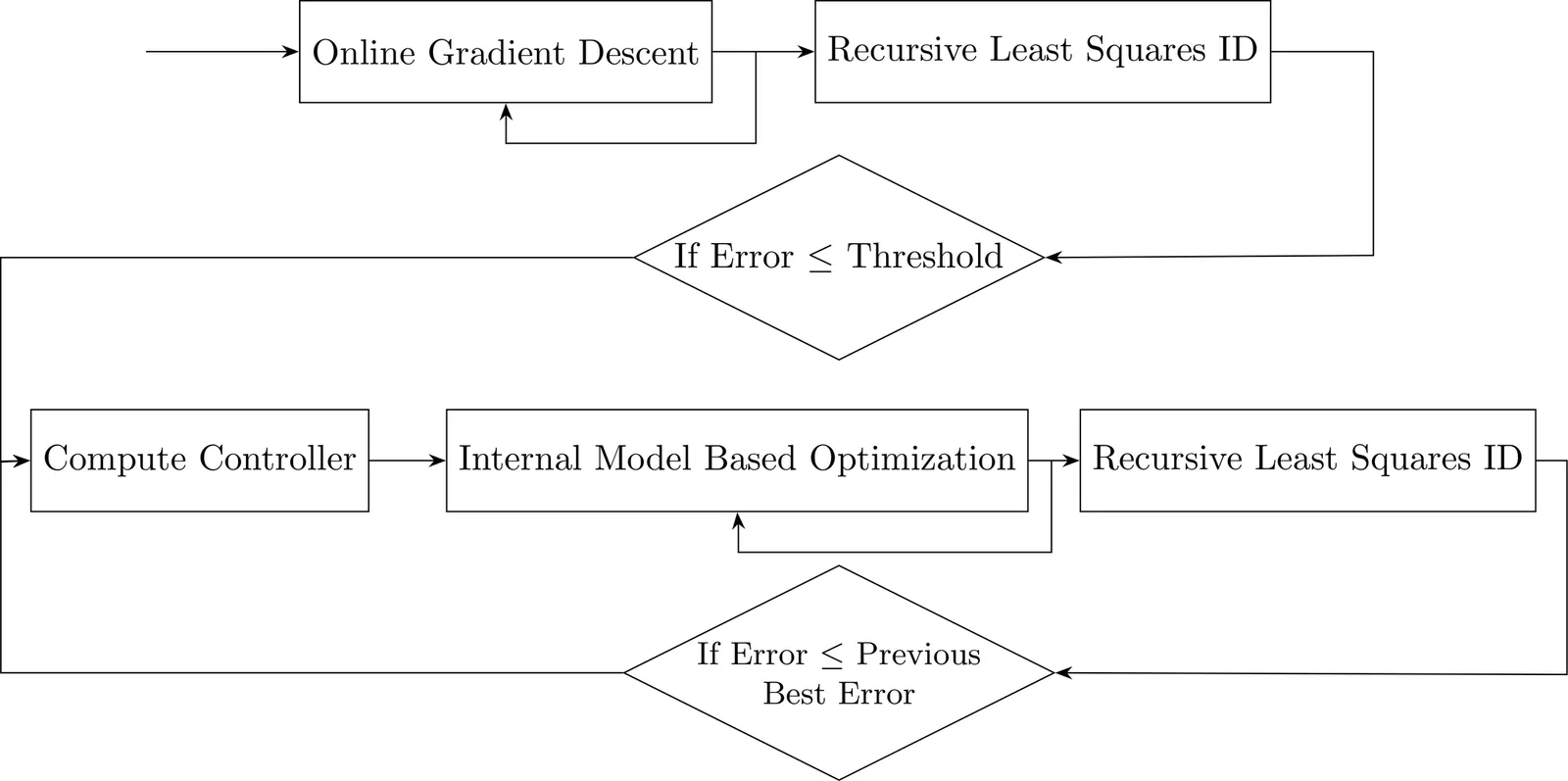
In this paper, we propose a novel online optimization algorithm built by combining ideas from control theory and system identification. The foundation of our algorithm is a control-based design that makes use of the internal model of the online problem. Since such prior knowledge of this internal model might not be available in practice, we incorporate an identification routine that learns this model on the fly. The algorithm is designed starting from quadratic online problems but can be applied to general problems. For quadratic cases, we characterize the asymptotic convergence to the optimal solution trajectory. We compare the proposed algorithm with existing approaches, and demonstrate how the identification routine ensures its adaptability to changes in the underlying internal model. Numerical results also indicate strong performance beyond the quadratic setting.
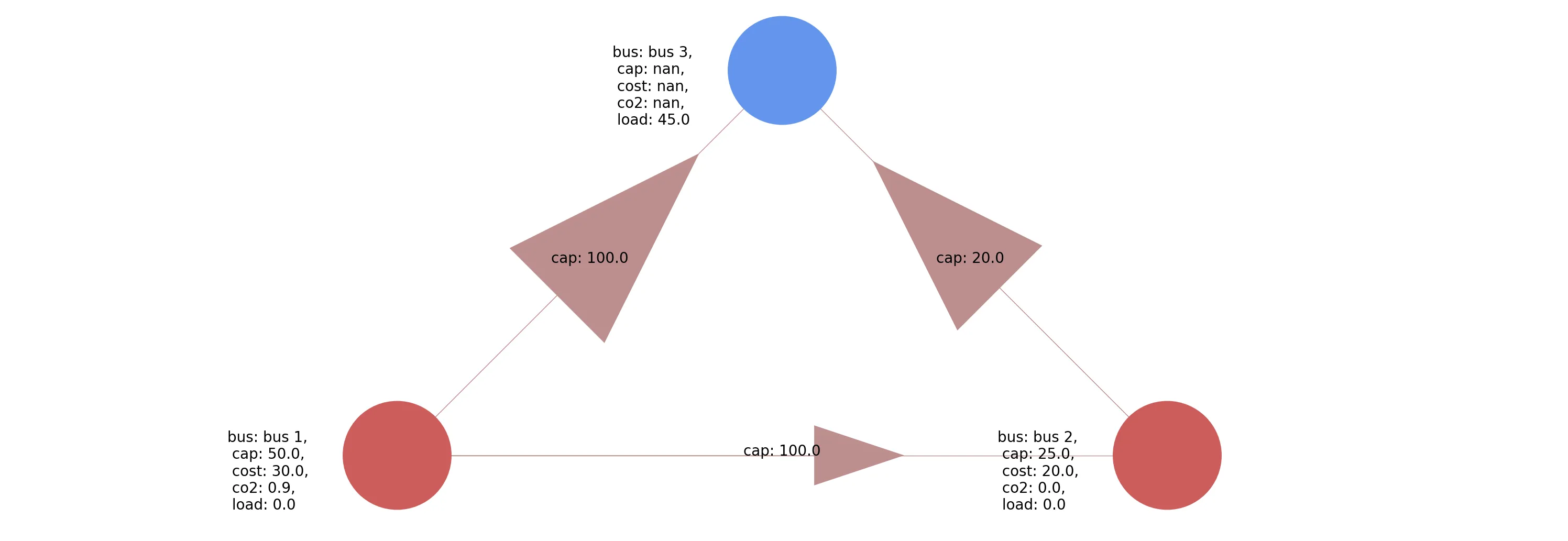
Carbon matching aims to improve corporate carbon accounting by tracking emissions rather than energy consumption and production. We present a mathematical derivation of carbon matching using marginal emission rates, where the unit of matching is tons of carbon emitted. We present analysis and open source notebooks showing how marginal emissions can be calculated on simulated electric bus networks. Importantly, we prove mathematically that distinct emissions rates can be assigned to all aspects of the electric grid - including transmission, storage, generation, and consumption - completely allocating electric grid emissions. We show that carbon matching is an accurate carbon accounting framework that can inspire ambitious and impactful action. This research fills a gap by blending carbon accounting expertise and power systems modeling to consider the effectiveness of alternative methodologies for allocating electric system emissions.
The SCIP Optimization Suite provides a collection of software packages for mathematical optimization, centered around the constraint integer programming (CIP) framework SCIP. This report discusses the enhancements and extensions included in SCIP Optimization Suite 10.0. The updates in SCIP 10.0 include a new solving mode for exactly solving rational mixed-integer linear programs, a new presolver for detecting implied integral variables, a novel cut-based conflict analysis and separator for flower inequalities, two new heuristics, a novel tool for explaining infeasibility, a new interface for nonlinear solvers as well as improvements in symmetry handling, branching strategies, and SCIP's Benders' decomposition framework. SCIP Optimization Suite 10.0 also includes new and improved features in the the presolving library PaPILO, the parallel framework UG, and the decomposition framework GCG. Moreover, the SCIP Optimization Suite 10.0 contains MIP-DD, the first open-source delta debugger for mixed-integer programming solvers. These additions and enhancements have resulted in an overall performance improvement of SCIP in terms of solving time, number of nodes in the branch-and-bound tree, as well as the reliability of the solver.
This paper develops a data-driven framework for stabilization of discrete-time infinite-dimensional systems. We investigate informativity for stabilization, defined as the existence of a feedback gain that stabilizes all systems compatible with the available input-state data. Assuming that infinite-length data are Bessel sequences, we first establish a sufficient condition for data informativity in the noise-free case. We next show that this sufficient condition is also necessary under a mild data assumption when the input space is one-dimensional. Furthermore, if the state sequence forms a frame, then the sufficient condition can be extended to the case of noisy data. Finally, when the unstable part of the true system is known to be finite-dimensional, we derive a necessary and sufficient condition for data informativity of finite-length data.
The paper presents new sufficient conditions for the property of strong bi-metric regularity of the optimality map associated with an optimal control problem which is affine with respect to the control variable ({\em affine problem}). The optimality map represents the system of first order optimality conditions (Pontryagin maximum principle), and its regularity is of key importance for the qualitative and numerical analysis of optimal control problems. The case of affine problems is especially challenging due to the typical discontinuity of the optimal control functions. A remarkable feature of the obtained sufficient conditions is that they do not require convexity of the objective functional. As an application, the result is used for proving uniform convergence of the Euler discretization method for a family of affine optimal control problems.
This paper revisits the issue of Hölder Strong Metric sub-Regularity (HSMs-R) of the optimality system associated with ODE optimal control problems that are affine with respect to the control. The main contributions are as follows. First, the metric in the control space, introduced in this paper, differs from the ones used so far in the literature in that it allows to take into consideration the bang-bang structure of the optimal control functions. This is especially important in the analysis of Model Predictive Control algorithms. Second, the obtained sufficient conditions for HSMs-R extend the known ones in a way which makes them applicable to some problems which are non-linear in the state variable and the Hölder exponent is smaller than one (that is, the regularity is not Lipschitz).

This paper derives various Hessians associated with Birkhoff-theoretic methods for trajectory optimization. According to a theorem proved in this paper, approximately 80% of the eigenvalues are contained in the narrow interval [-2, 4] for all Birkhoff-discretized optimal control problems. A preliminary analysis of computational complexity is also presented with further discussions on the grand challenge of solving a million point trajectory optimization problem.
This paper considers nonsmooth convex optimization with either a subgradient or proximal operator oracle. In both settings, we identify algorithms that achieve the recently introduced game-theoretic optimality notion for algorithms known as subgame perfection. Subgame perfect algorithms meet a more stringent requirement than just minimax optimality. Not only must they provide optimal uniform guarantees on the entire problem class, but also on any subclass determined by information revealed during the execution of the algorithm. In the setting of nonsmooth convex optimization with a subgradient oracle, we show that the Kelley cutting plane-Like Method due to Drori and Teboulle [1] is subgame perfect. For nonsmooth convex optimization with a proximal operator oracle, we develop a new algorithm, the Subgame Perfect Proximal Point Algorithm, and establish that it is subgame perfect. Both of these methods solve a history-aware second-order cone program within each iteration, independent of the ambient problem dimension, to plan their next steps. This yields performance guarantees that are never worse than the minimax optimal guarantees and often substantially better.
Recently, several instances of non-Euclidean SGD, including SignSGD, Lion, and Muon, have attracted significant interest from the optimization community due to their practical success in training deep neural networks. Consequently, a number of works have attempted to explain this success by developing theoretical convergence analyses. Unfortunately, these results cannot properly justify the superior performance of these methods, as they could not beat the convergence rate of vanilla Euclidean SGD. We resolve this important open problem by developing a new unified convergence analysis under the structured smoothness and gradient noise assumption. In particular, our results indicate that non-Euclidean SGD (i) can exploit the sparsity or low-rank structure of the upper bounds on the Hessian and gradient noise, (ii) can provably benefit from popular algorithmic tools such as extrapolation or momentum variance reduction, and (iii) can match the state-of-the-art convergence rates of adaptive and more complex optimization algorithms such as AdaGrad and Shampoo.