Neurons and Cognition
arXiv:q-bio.NC
Synapse, currentoporins, spiking, neural coding, sensorimotor control, working memory.
Looking for a broader view? This category is part of:
Synapse, currentoporins, spiking, neural coding, sensorimotor control, working memory.
Looking for a broader view? This category is part of:
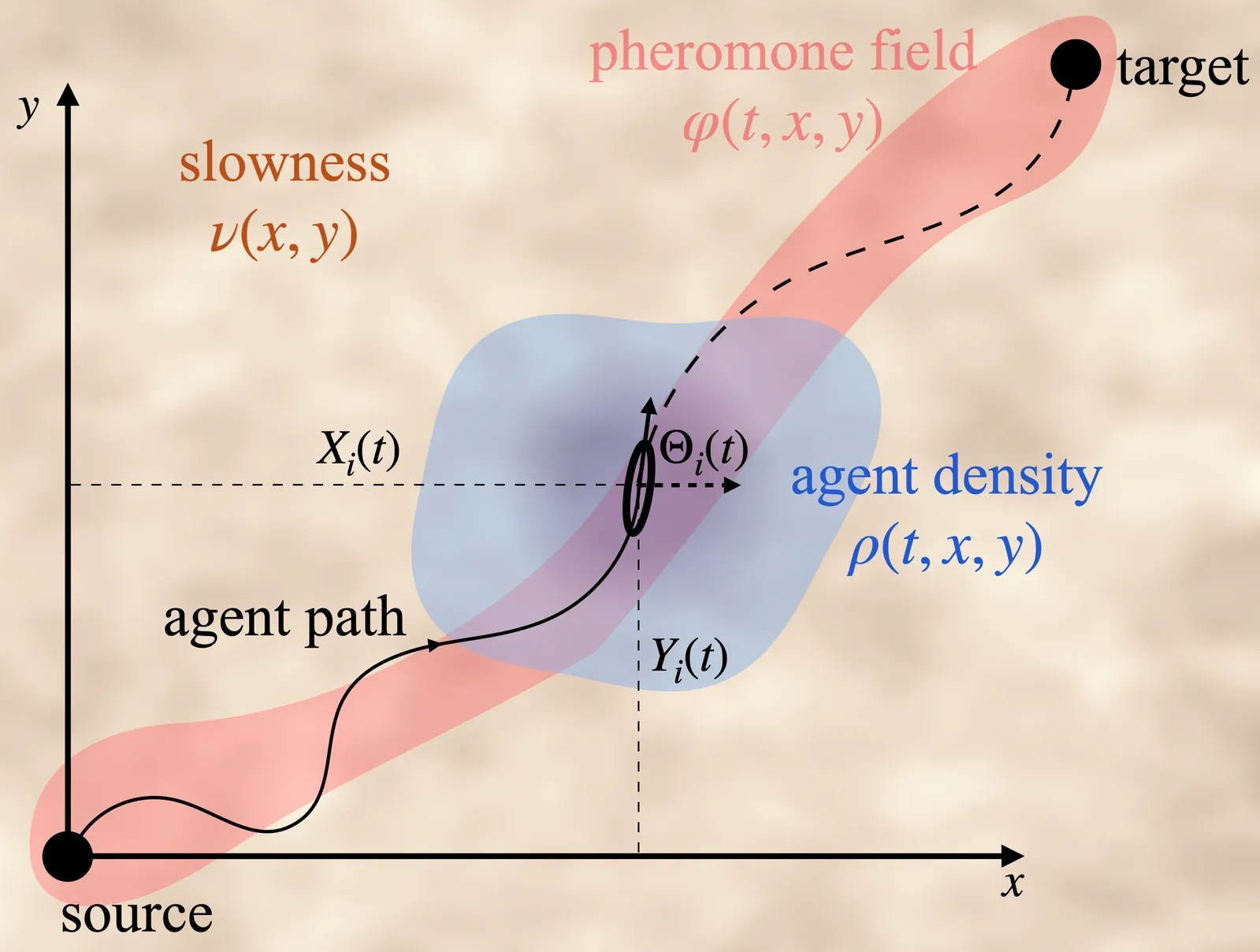
Efficient navigation in swarms often relies on the emergence of decentralized approaches that minimize traversal time or energy. Stigmergy, where agents modify a shared environment that then modifies their behavior, is a classic mechanism that can encode this strategy. We develop a theoretical framework for stigmergic transport by casting it as a stochastic optimal control problem: agents (collectively) lay and (individually) follow trails while minimizing expected traversal time. Simulations and analysis reveal two emergent behaviors: path straightening in homogeneous environments and path refraction at material interfaces, both consistent with experimental observations of insect trails. While reminiscent of Fermat's principle, our results show how local, noisy agent+field interactions can give rise to geodesic trajectories in heterogeneous environments, without centralized coordination or global knowledge, relying instead on an embodied slow fast dynamical mechanism.
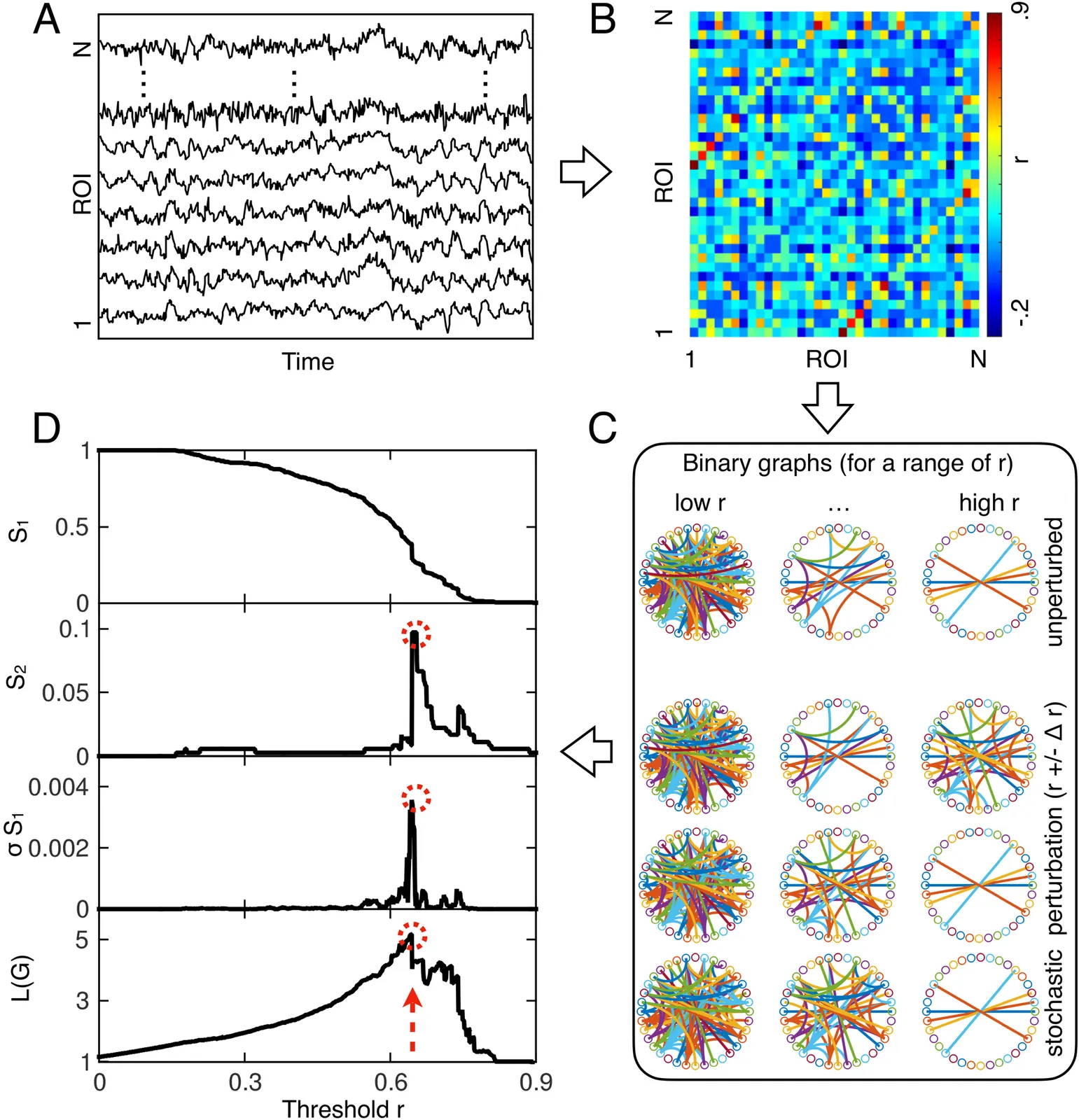
We present a data-driven framework to characterize large-scale brain dynamical states directly from correlation matrices at the single-subject level. By treating correlation thresholding as a percolation-like probe of connectivity, the approach tracks multiple cluster- and network-level observables and identifies a characteristic percolation threshold, rc, at which these signatures converge. We use $r_c$ as an operational and physically interpretable descriptor of large-scale brain dynamical state. Applied to resting-state fMRI data from a large cohort of healthy individuals (N = 996), the method yields stable, subject-specific estimates that covary systematically with established dynamical indicators such as temporal autocorrelations. Numerical simulations of a whole-brain model with a known critical regime further show that $r_c$ tracks changes in collective dynamics under controlled variations of excitability. By replacing arbitrary threshold selection with a criterion intrinsic to correlation structure, the r-spectra provides a physically grounded approach for comparing brain dynamical states across individuals.
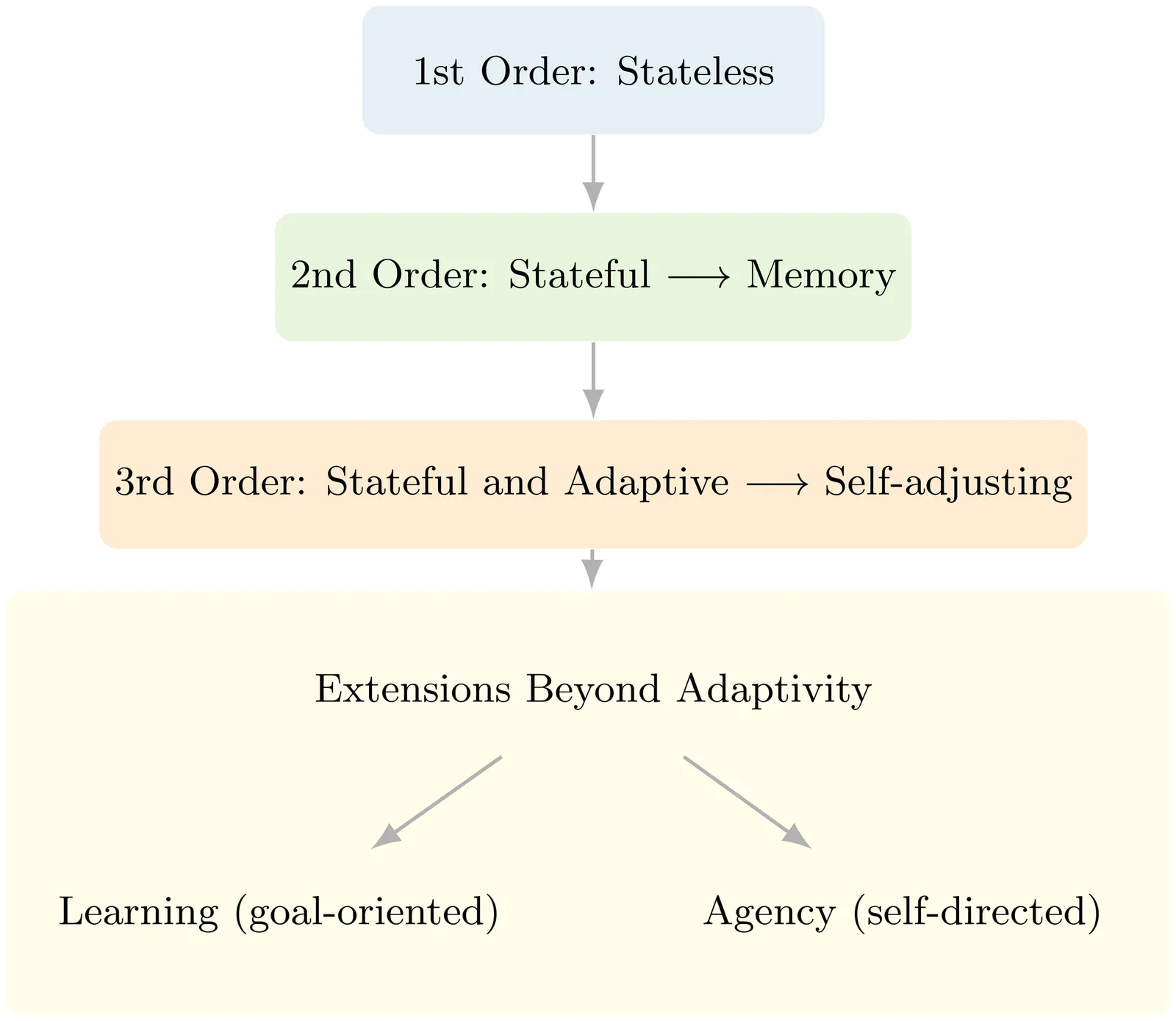
As intelligent systems are developed across diverse substrates - from machine learning models and neuromorphic hardware to in vitro neural cultures - understanding what gives a system agency has become increasingly important. Existing definitions, however, tend to rely on top-down descriptions that are difficult to quantify. We propose a bottom-up framework grounded in a system's information-processing order: the extent to which its transformation of input evolves over time. We identify three orders of information processing. Class I systems are reactive and memoryless, mapping inputs directly to outputs. Class II systems incorporate internal states that provide memory but follow fixed transformation rules. Class III systems are adaptive; their transformation rules themselves change as a function of prior activity. While not sufficient on their own, these dynamics represent necessary informational conditions for genuine agency. This hierarchy offers a measurable, substrate-independent way to identify the informational precursors of agency. We illustrate the framework with neurophysiological and computational examples, including thermostats and receptor-like memristors, and discuss its implications for the ethical and functional evaluation of systems that may exhibit agency.
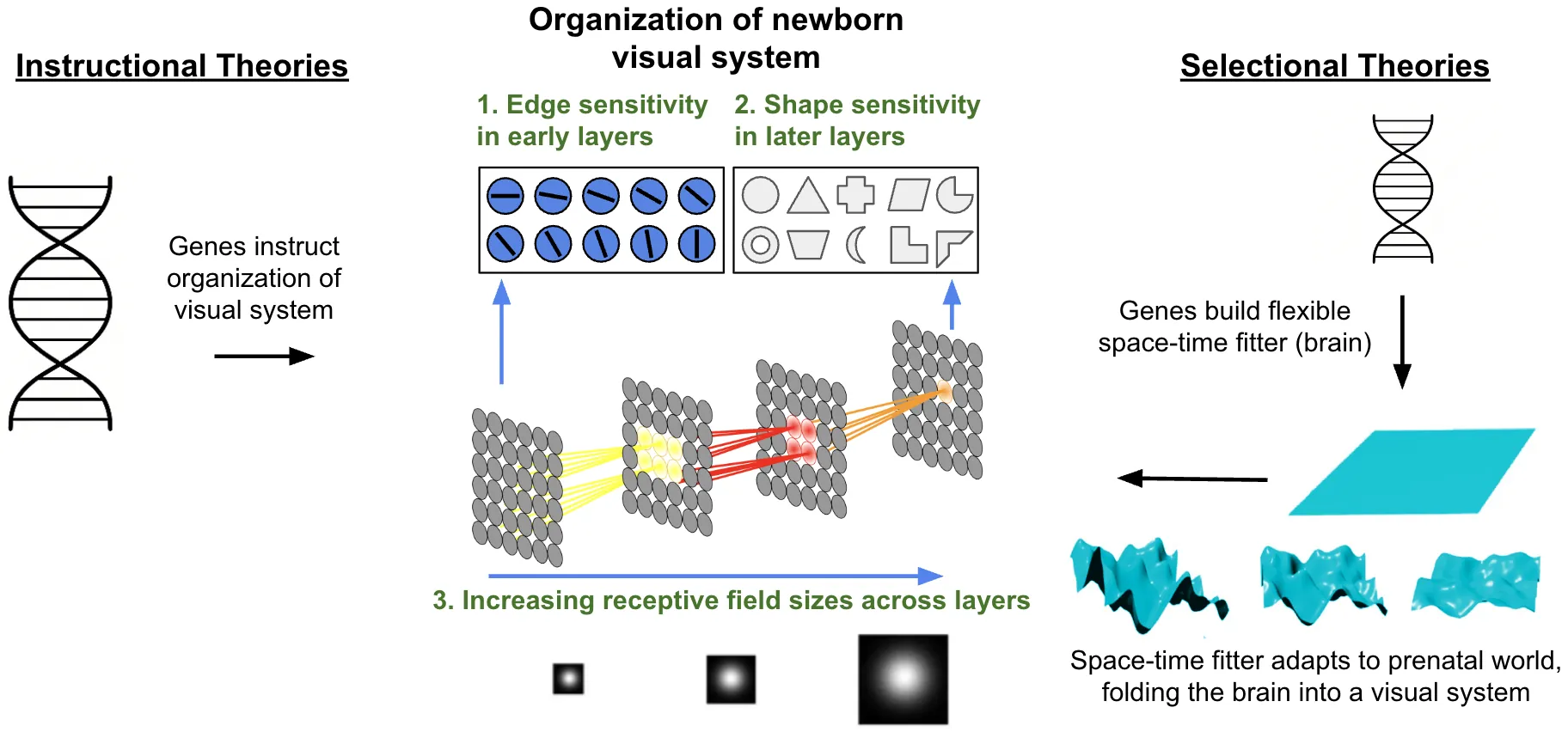
Do transformers learn like brains? A key challenge in addressing this question is that transformers and brains are trained on fundamentally different data. Brains are initially "trained" on prenatal sensory experiences (e.g., retinal waves), whereas transformers are typically trained on large datasets that are not biologically plausible. We reasoned that if transformers learn like brains, then they should develop the same structure as newborn brains when exposed to the same prenatal data. To test this prediction, we simulated prenatal visual input using a retinal wave generator. Then, using self-supervised temporal learning, we trained transformers to adapt to those retinal waves. During training, the transformers spontaneously developed the same structure as newborn visual systems: (1) early layers became sensitive to edges, (2) later layers became sensitive to shapes, and (3) the models developed larger receptive fields across layers. The organization of newborn visual systems emerges spontaneously when transformers adapt to a prenatal visual world. This developmental convergence suggests that brains and transformers learn in common ways and follow the same general fitting principles.
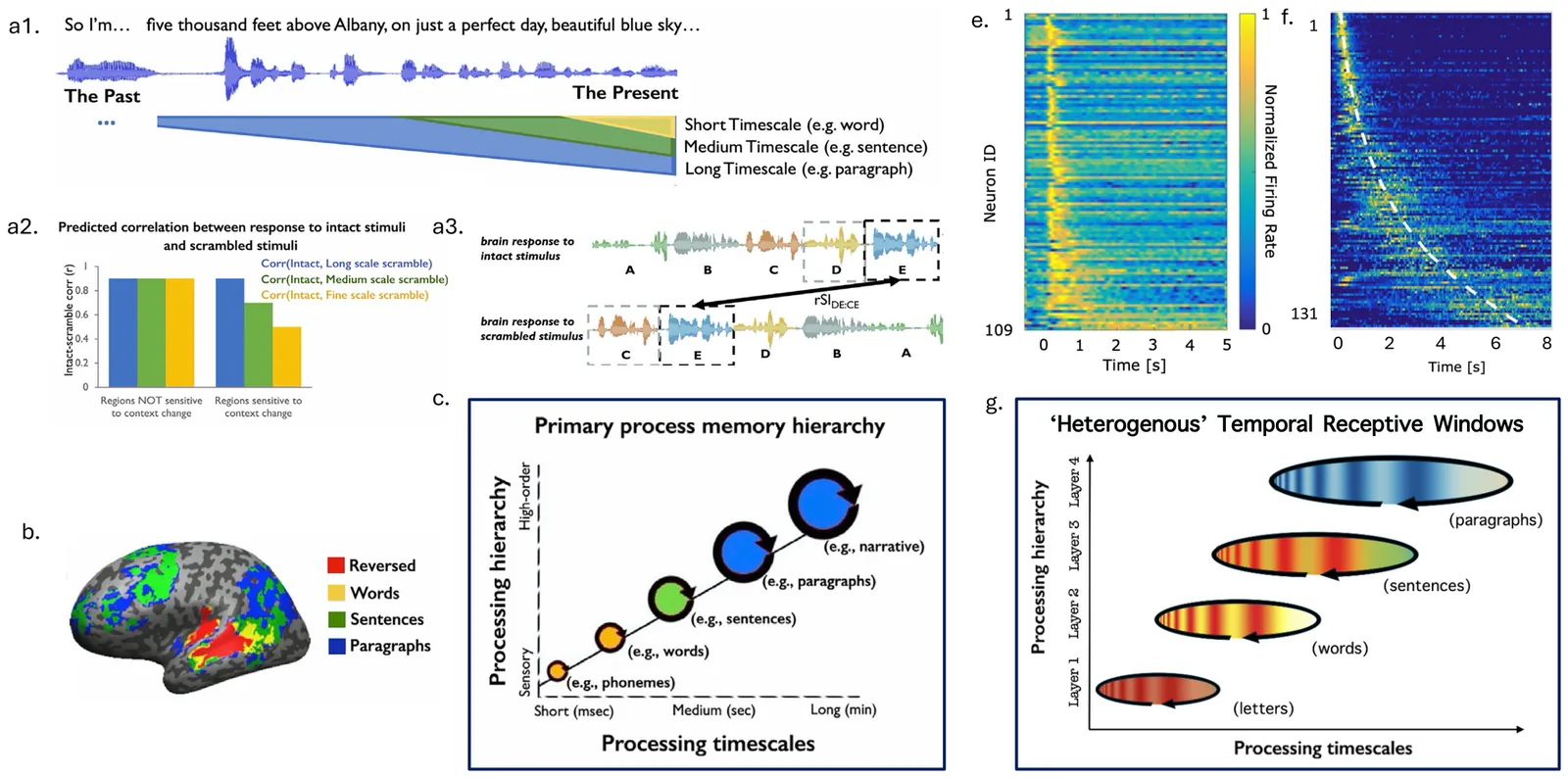
Human cognition integrates information across nested timescales. While the cortex exhibits hierarchical Temporal Receptive Windows (TRWs), local circuits often display heterogeneous time constants. To reconcile this, we trained biologically constrained deep networks, based on scale-invariant hippocampal time cells, on a language classification task mimicking the hierarchical structure of language (e.g., 'letters' forming 'words'). First, using a feedforward model (SITHCon), we found that a hierarchy of TRWs emerged naturally across layers, despite the network having an identical spectrum of time constants within layers. We then distilled these inductive priors into a biologically plausible recurrent architecture, SITH-RNN. Training a sequence of architectures ranging from generic RNNs to this restricted subset showed that the scale-invariant SITH-RNN learned faster with orders-of-magnitude fewer parameters, and generalized zero-shot to out-of-distribution timescales. These results suggest the brain employs scale-invariant, sequential priors - coding "what" happened "when" - making recurrent networks with such priors particularly well-suited to describe human cognition.
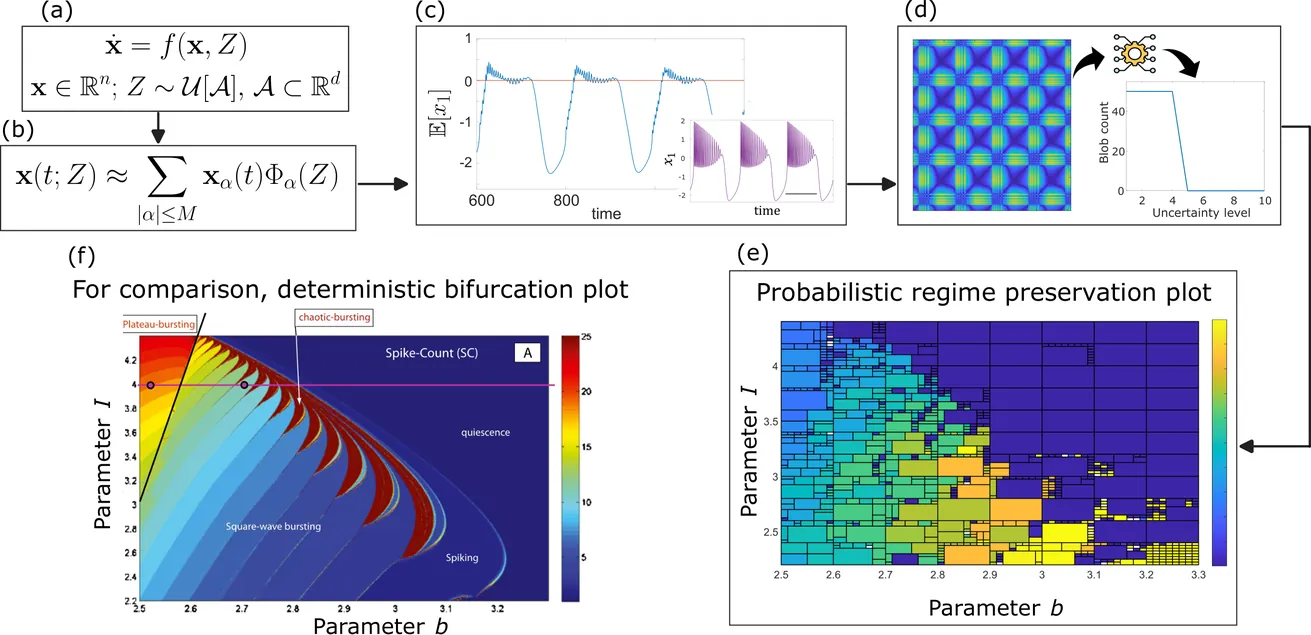
Neuronal systems often preserve their characteristic functions and signalling patterns, also referred to as regimes, despite parametric uncertainties and variations. For neural models having uncertain parameters with a known probability distribution, probabilistic robustness analysis (PRA) allows us to understand and quantify under which uncertainty conditions a regime is preserved in expectation. We introduce a new computational framework for the efficient and systematic PRA of dynamical systems in neuroscience and we show its efficacy in analysing well-known neural models that exhibit multiple dynamical regimes: the Hindmarsh-Rose model for single neurons and the Jansen-Rit model for cortical columns. Given a model subject to parametric uncertainty, we employ generalised polynomial chaos to derive mean neural activity signals, which are then used to assess the amount of parametric uncertainty that the system can withstand while preserving the current regime, thereby quantifying the regime's robustness to such uncertainty. To assess persistence of regimes, we propose new metrics, which we apply to recurrence plots obtained from the mean neural activity signals. The overall result is a novel, general computational methodology that combines recurrence plot analysis and systematic persistence analysis to assess how much the uncertain model parameters can vary, with respect to their nominal value, while preserving the nominal regimes in expectation. We summarise the PRA results through probabilistic regime preservation (PRP) plots, which capture the effect of parametric uncertainties on the robustness of dynamical regimes in the considered models.
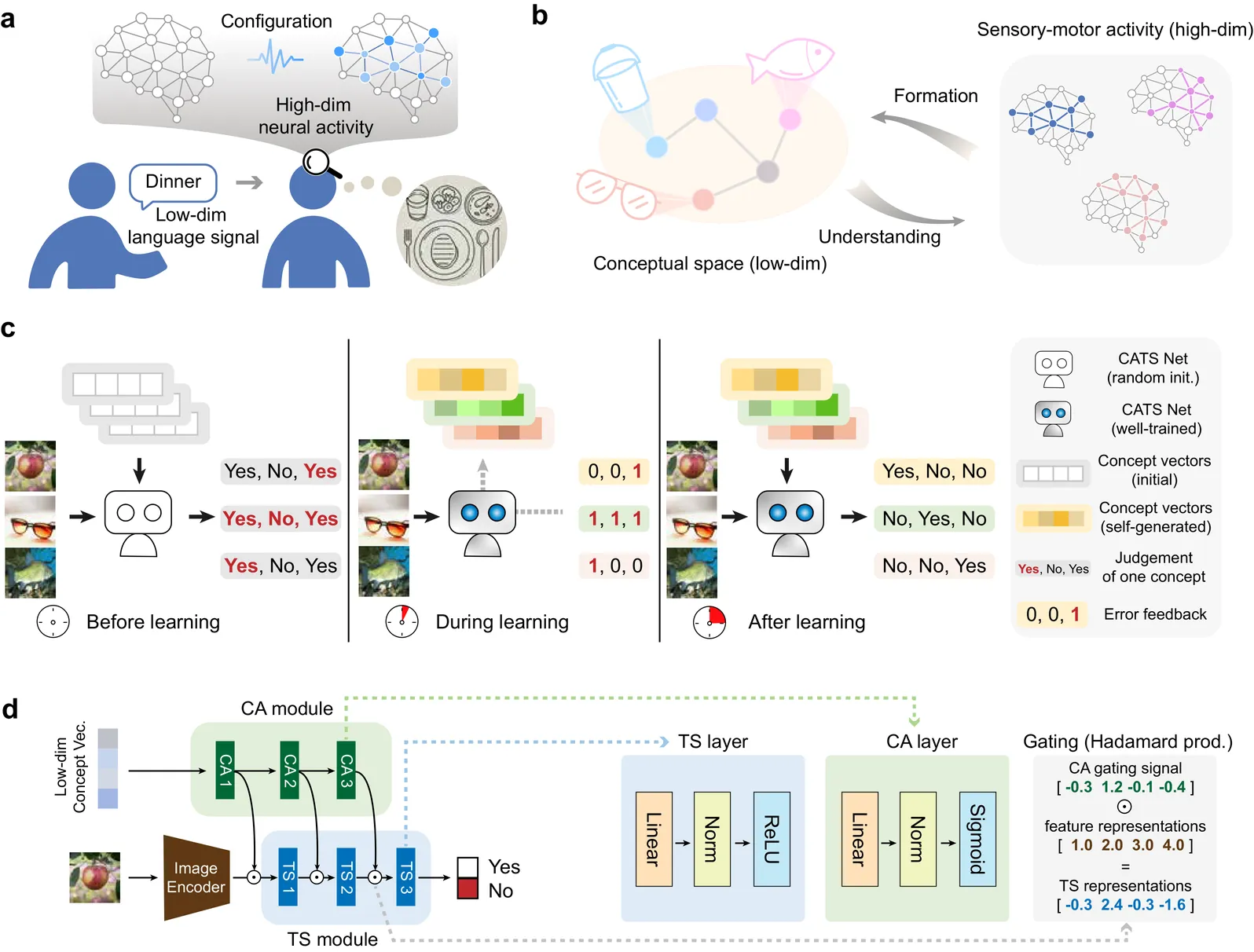
A remarkable capability of the human brain is to form more abstract conceptual representations from sensorimotor experiences and flexibly apply them independent of direct sensory inputs. However, the computational mechanism underlying this ability remains poorly understood. Here, we present a dual-module neural network framework, the CATS Net, to bridge this gap. Our model consists of a concept-abstraction module that extracts low-dimensional conceptual representations, and a task-solving module that performs visual judgement tasks under the hierarchical gating control of the formed concepts. The system develops transferable semantic structure based on concept representations that enable cross-network knowledge transfer through conceptual communication. Model-brain fitting analyses reveal that these emergent concept spaces align with both neurocognitive semantic model and brain response structures in the human ventral occipitotemporal cortex, while the gating mechanisms mirror that in the semantic control brain network. This work establishes a unified computational framework that can offer mechanistic insights for understanding human conceptual cognition and engineering artificial systems with human-like conceptual intelligence.
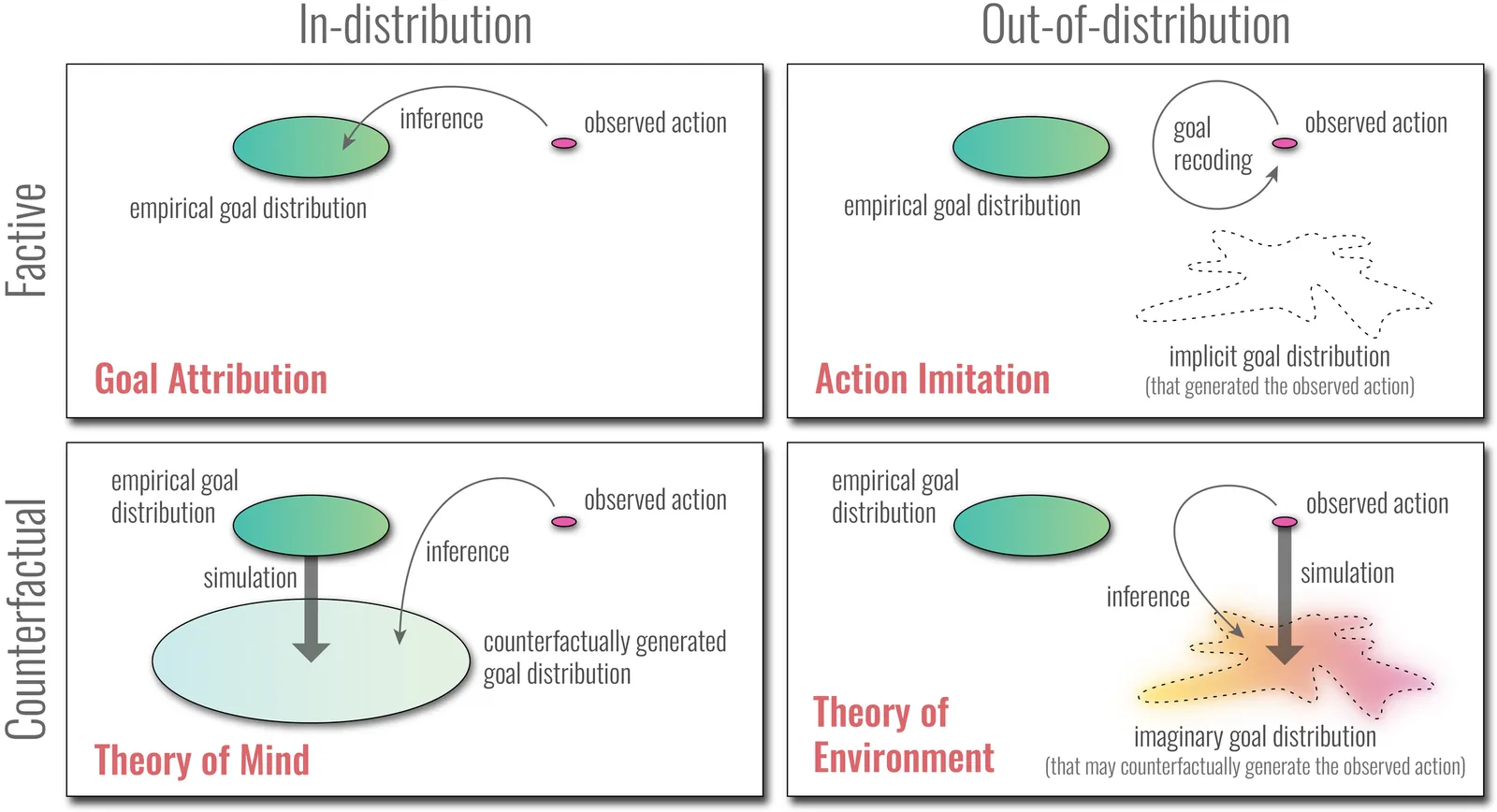
The vertebrate motor system employs dimensionality-reducing strategies to limit the complexity of movement coordination, for efficient motor control. But when environments are dense with hidden action-outcome contingencies, movement complexity can promote behavioral innovation. Humans, perhaps uniquely, may infer the presence of hidden environmental dynamics from social cues, by drawing upon computational mechanisms shared with Theory of Mind. This proposed "Theory of Environment" supports behavioral innovation by expanding the dimensionality of motor exploration.
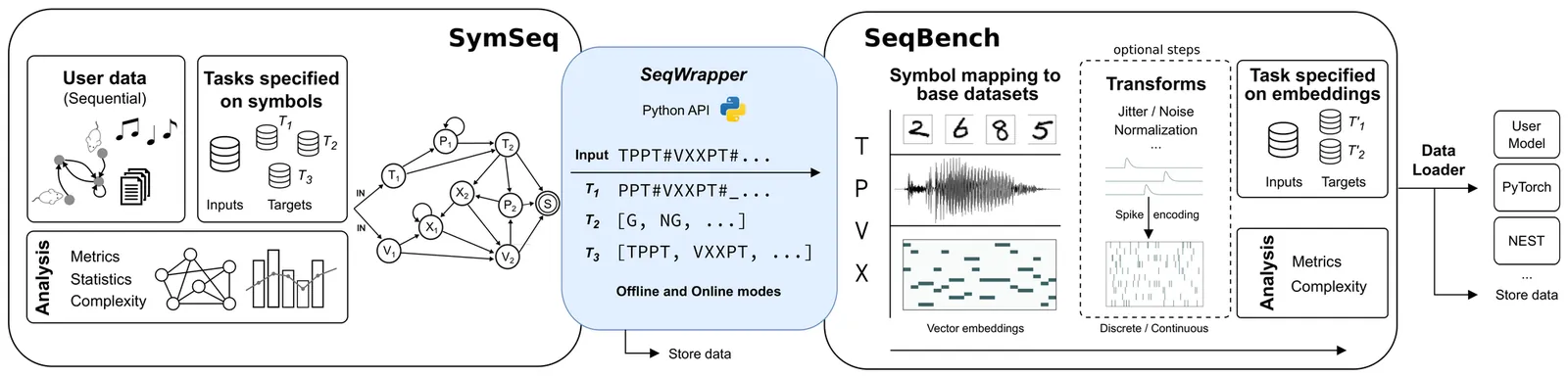
Sequential structure is a key feature of multiple domains of natural cognition and behavior, such as language, movement and decision-making. Likewise, it is also a central property of tasks to which we would like to apply artificial intelligence. It is therefore of great importance to develop frameworks that allow us to evaluate sequence learning and processing in a domain agnostic fashion, whilst simultaneously providing a link to formal theories of computation and computability. To address this need, we introduce two complementary software tools: SymSeq, designed to rigorously generate and analyze structured symbolic sequences, and SeqBench, a comprehensive benchmark suite of rule-based sequence processing tasks to evaluate the performance of artificial learning systems in cognitively relevant domains. In combination, SymSeqBench offers versatility in investigating sequential structure across diverse knowledge domains, including experimental psycholinguistics, cognitive psychology, behavioral analysis, neuromorphic computing and artificial intelligence. Due to its basis in Formal Language Theory (FLT), SymSeqBench provides researchers in multiple domains with a convenient and practical way to apply the concepts of FLT to conceptualize and standardize their experiments, thus advancing our understanding of cognition and behavior through shared computational frameworks and formalisms. The tool is modular, openly available and accessible to the research community.
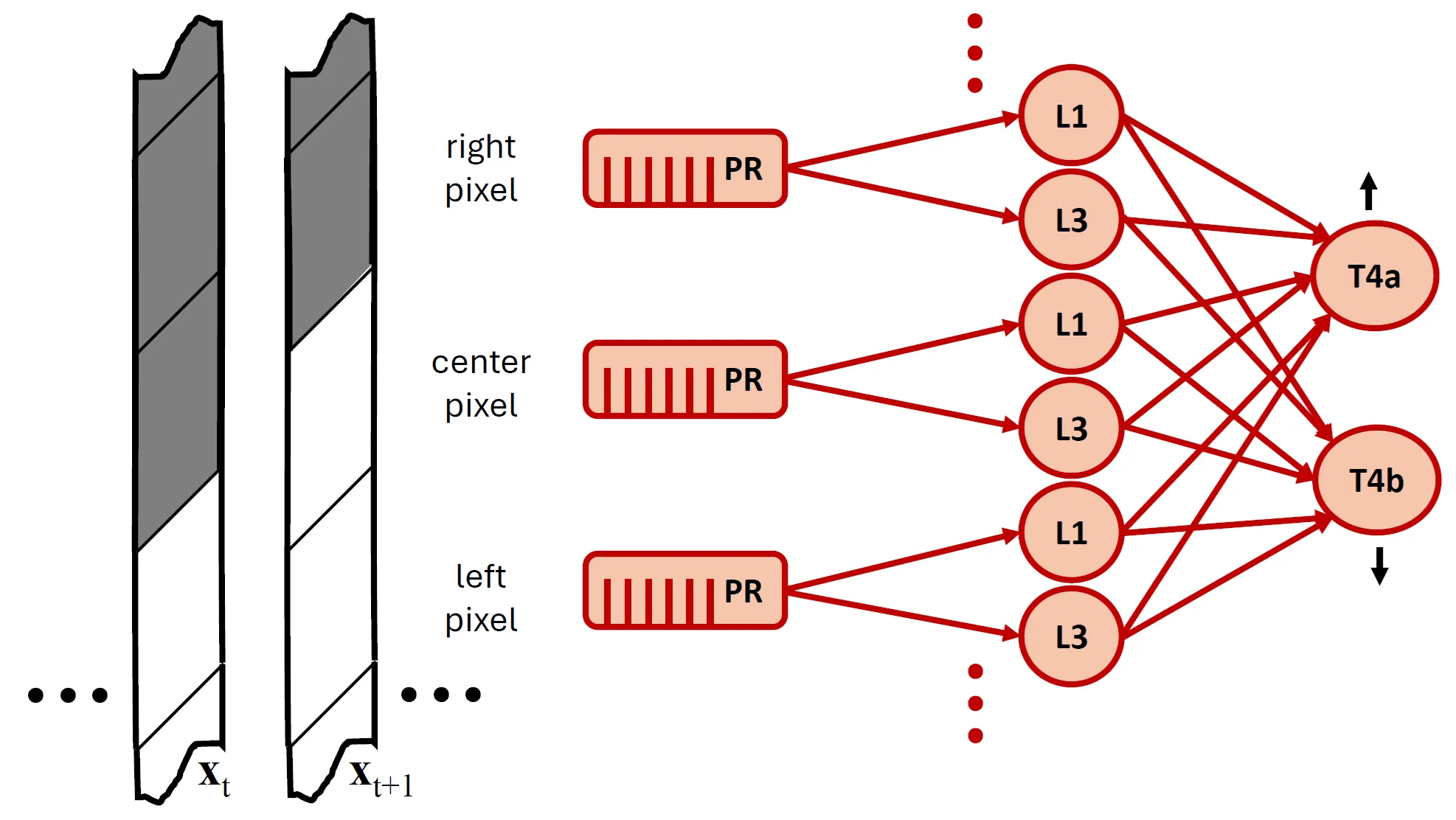
We introduce a biologically inspired, multilayer neural architecture composed of Rectified Spectral Units (ReSUs). Each ReSU projects a recent window of its input history onto a canonical direction obtained via canonical correlation analysis (CCA) of previously observed past-future input pairs, and then rectifies either its positive or negative component. By encoding canonical directions in synaptic weights and temporal filters, ReSUs implement a local, self-supervised algorithm for progressively constructing increasingly complex features. To evaluate both computational power and biological fidelity, we trained a two-layer ReSU network in a self-supervised regime on translating natural scenes. First-layer units, each driven by a single pixel, developed temporal filters resembling those of Drosophila post-photoreceptor neurons (L1/L2 and L3), including their empirically observed adaptation to signal-to-noise ratio (SNR). Second-layer units, which pooled spatially over the first layer, became direction-selective -- analogous to T4 motion-detecting cells -- with learned synaptic weight patterns approximating those derived from connectomic reconstructions. Together, these results suggest that ReSUs offer (i) a principled framework for modeling sensory circuits and (ii) a biologically grounded, backpropagation-free paradigm for constructing deep self-supervised neural networks.

Decision paralysis, i.e. hesitation, freezing, or failure to act despite full knowledge and motivation, poses a challenge for choice models that assume options are already specified and readily comparable. Drawing on qualitative reports in autism research that are especially salient, we propose a computational account in which paralysis arises from convergence failure in a hierarchical decision process. We separate intent selection (what to pursue) from affordance selection (how to pursue the goal) and formalize commitment as inference under a mixture of reverse- and forward-Kullback-Leibler (KL) objectives. Reverse KL is mode-seeking and promotes rapid commitment, whereas forward KL is mode-covering and preserves multiple plausible goals or actions. In static and dynamic (drift-diffusion) models, forward-KL-biased inference yields slow, heavy-tailed response times and two distinct failure modes, intent saturation and affordance saturation, when values are similar. Simulations in multi-option tasks reproduce key features of decision inertia and shutdown, treating autism as an extreme regime of a general, inference-based, decision-making continuum.
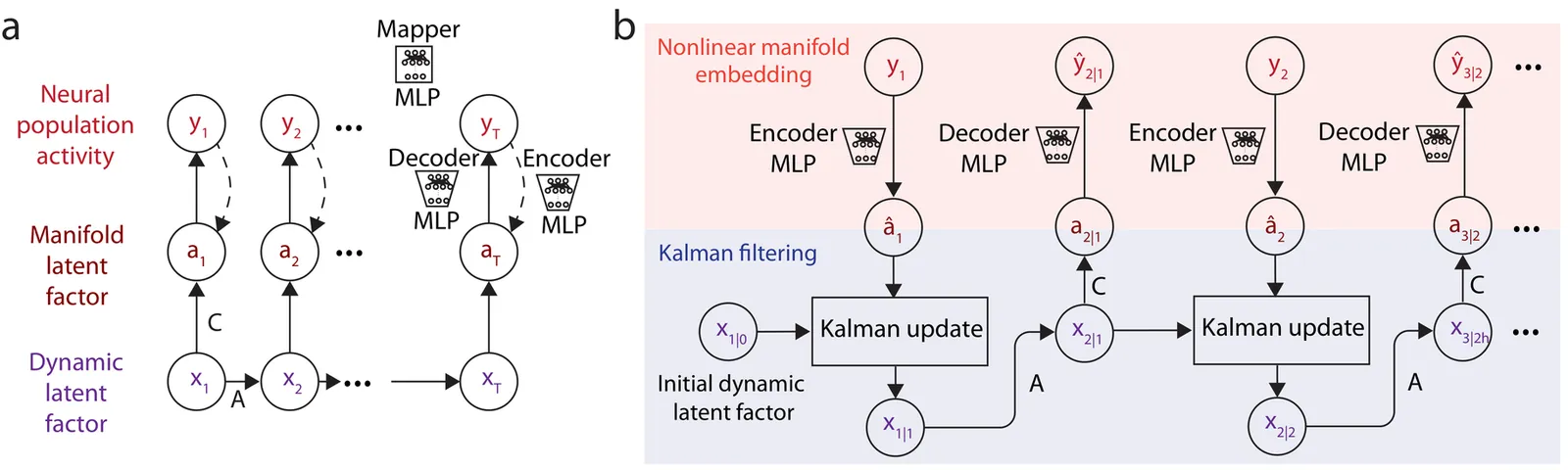
Dynamical modeling of multisite human intracranial neural recordings is essential for developing neurotechnologies such as brain-computer interfaces (BCIs). Linear dynamical models are widely used for this purpose due to their interpretability and their suitability for BCIs. In particular, these models enable flexible real-time inference, even in the presence of missing neural samples, which often occur in wireless BCIs. However, neural activity can exhibit nonlinear structure that is not captured by linear models. Furthermore, while recurrent neural network models can capture nonlinearity, their inference does not directly address handling missing observations. To address this gap, recent work introduced DFINE, a deep learning framework that integrates neural networks with linear state-space models to capture nonlinearities while enabling flexible inference. However, DFINE was developed for intracortical recordings that measure localized neuronal populations. Here we extend DFINE to modeling of multisite human intracranial electroencephalography (iEEG) recordings. We find that DFINE significantly outperforms linear state-space models (LSSMs) in forecasting future neural activity. Furthermore, DFINE matches or exceeds the accuracy of a gated recurrent unit (GRU) model in neural forecasting, indicating that a linear dynamical backbone, when paired and jointly trained with nonlinear neural networks, can effectively describe the dynamics of iEEG signals while also enabling flexible inference. Additionally, DFINE handles missing observations more robustly than the baselines, demonstrating its flexible inference and utility for BCIs. Finally, DFINE's advantage over LSSM is more pronounced in high gamma spectral bands. Taken together, these findings highlight DFINE as a strong and flexible framework for modeling human iEEG dynamics, with potential applications in next-generation BCIs.
Cortical surface parcellation is a fundamental task in both basic neuroscience research and clinical applications, enabling more accurate mapping of brain regions. Model-based and learning-based approaches for automated parcellation alleviate the need for manual labeling. Despite the advancement in parcellation performance, learning-based methods shift away from registration and atlas propagation without exploring the reason for the improvement compared to traditional methods. In this study, we present JParc, a joint cortical registration and parcellation framework, that outperforms existing state-of-the-art parcellation methods. In rigorous experiments, we demonstrate that the enhanced performance of JParc is primarily attributable to accurate cortical registration and a learned parcellation atlas. By leveraging a shallow subnetwork to fine-tune the propagated atlas labels, JParc achieves a Dice score greater than 90% on the Mindboggle dataset, using only basic geometric features (sulcal depth, curvature) that describe cortical folding patterns. The superior accuracy of JParc can significantly increase the statistical power in brain mapping studies as well as support applications in surgical planning and many other downstream neuroscientific and clinical tasks.
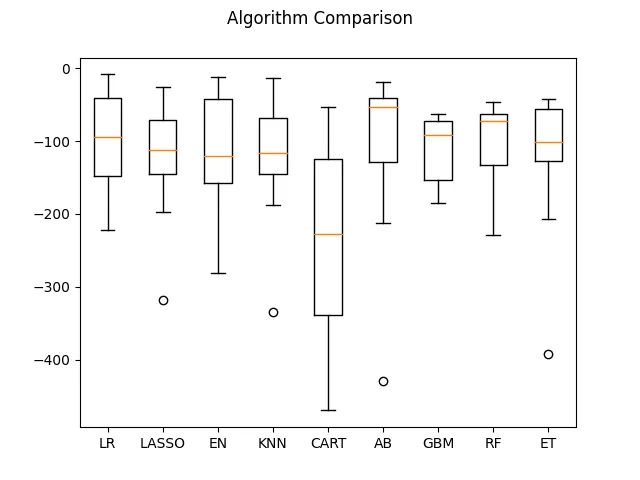
Human language processing relies on the brain's capacity for predictive inference. We present a machine learning framework for decoding neural (EEG) responses to dynamic visual language stimuli in Deaf signers. Using coherence between neural signals and optical flow-derived motion features, we construct spatiotemporal representations of predictive neural dynamics. Through entropy-based feature selection, we identify frequency-specific neural signatures that differentiate interpretable linguistic input from linguistically disrupted (time-reversed) stimuli. Our results reveal distributed left-hemispheric and frontal low-frequency coherence as key features in language comprehension, with experience-dependent neural signatures correlating with age. This work demonstrates a novel multimodal approach for probing experience-driven generative models of perception in the brain.
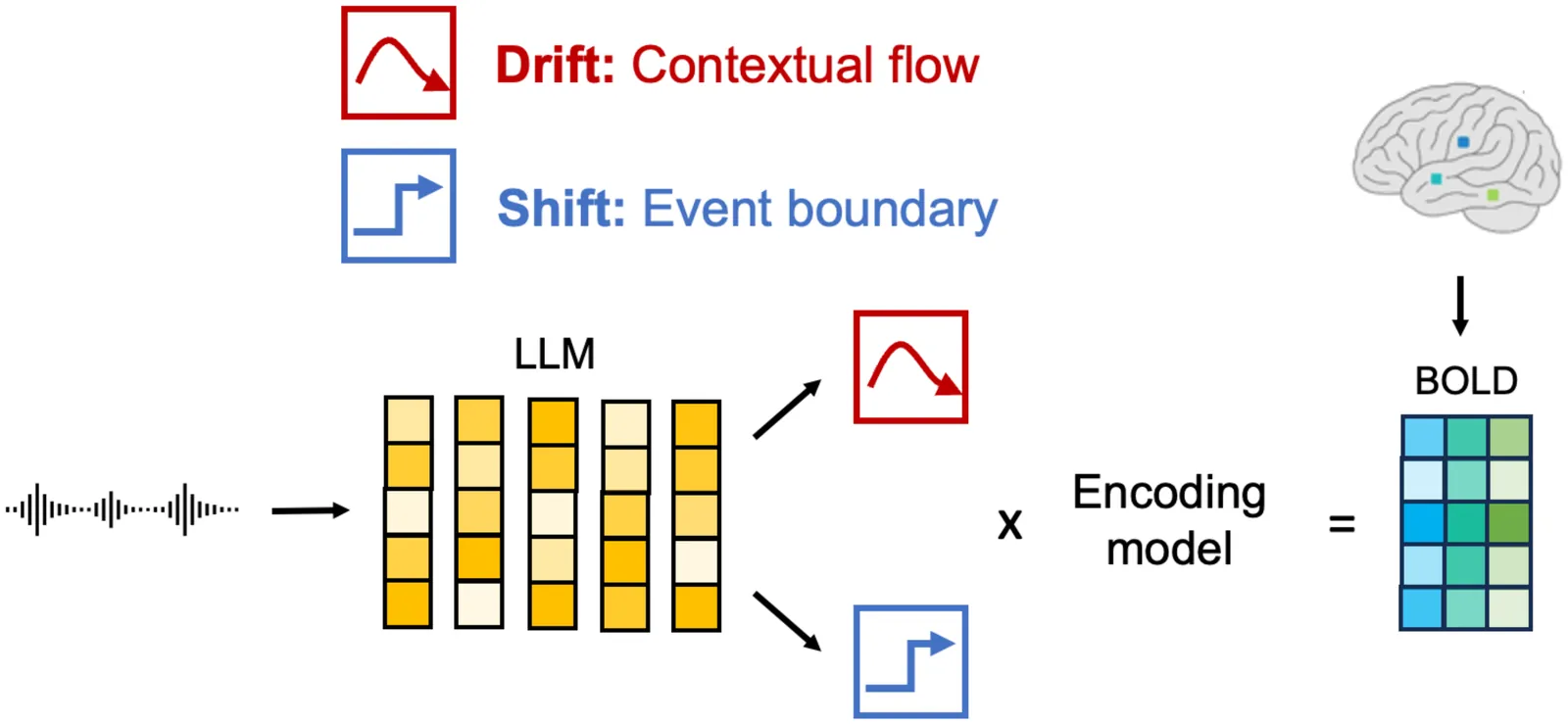
Coherence in language requires the brain to satisfy two competing temporal demands: gradual accumulation of meaning across extended context and rapid reconfiguration of representations at event boundaries. Despite their centrality to language and thought, how these processes are implemented in the human brain during naturalistic listening remains unclear. Here, we tested whether these two processes can be captured by annotation-free drift and shift signals and whether their neural expression dissociates across large-scale cortical systems. These signals were derived from a large language model (LLM) and formalized contextual drift and event shifts directly from the narrative input. To enable high-precision voxelwise encoding models with stable parameter estimates, we densely sampled one healthy adult across more than 7 hours of listening to thirteen crime stories while collecting ultra high-field (7T) BOLD data. We then modeled the feature-informed hemodynamic response using a regularized encoding framework validated on independent stories. Drift predictions were prevalent in default-mode network hubs, whereas shift predictions were evident bilaterally in the primary auditory cortex and language association cortex. Furthermore, activity in default-mode and parietal networks was best explained by a signal capturing how meaning accumulates and gradually fades over the course of the narrative. Together, these findings show that coherence during language comprehension is implemented through dissociable neural regimes of slow contextual integration and rapid event-driven reconfiguration, offering a mechanistic entry point for understanding disturbances of language coherence in psychiatric disorders.
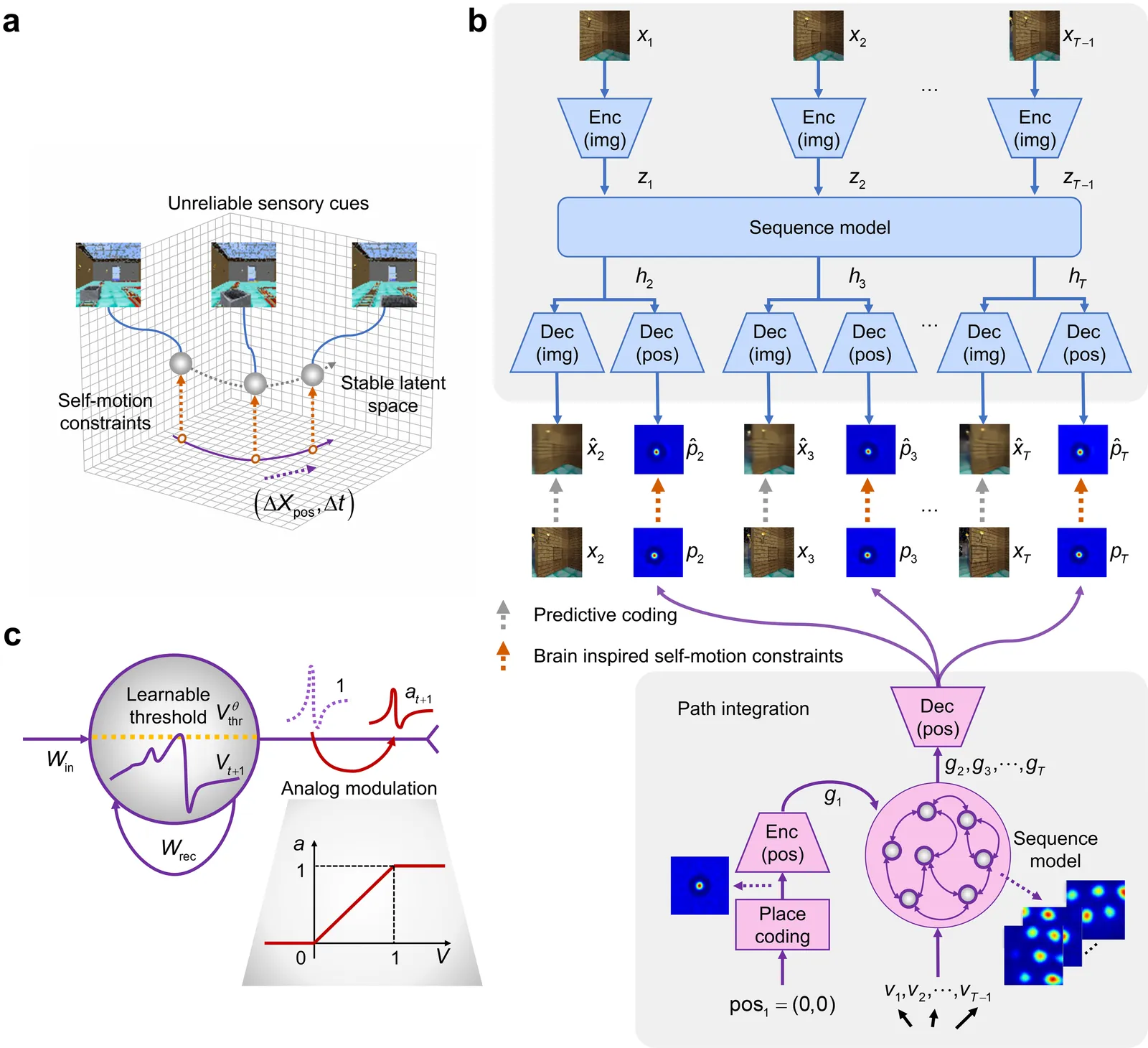
Most computational accounts of cognitive maps assume that stability is achieved primarily through sensory anchoring, with self-motion contributing to incremental positional updates only. However, biological spatial representations often remain coherent even when sensory cues degrade or conflict, suggesting that self-motion may play a deeper organizational role. Here, we show that self-motion can act as a structural prior that actively organizes the geometry of learned cognitive maps. We embed a path-integration-based motion prior in a predictive-coding framework, implemented using a capacity-efficient, brain-inspired recurrent mechanism combining spiking dynamics, analog modulation and adaptive thresholds. Across highly aliased, dynamically changing and naturalistic environments, this structural prior consistently stabilizes map formation, improving local topological fidelity, global positional accuracy and next-step prediction under sensory ambiguity. Mechanistic analyses reveal that the motion prior itself encodes geometrically precise trajectories under tight constraints of internal states and generalizes zero-shot to unseen environments, outperforming simpler motion-based constraints. Finally, deployment on a quadrupedal robot demonstrates that motion-derived structural priors enhance online landmark-based navigation under real-world sensory variability. Together, these results reframe self-motion as an organizing scaffold for coherent spatial representations, showing how brain-inspired principles can systematically strengthen spatial intelligence in embodied artificial agents.
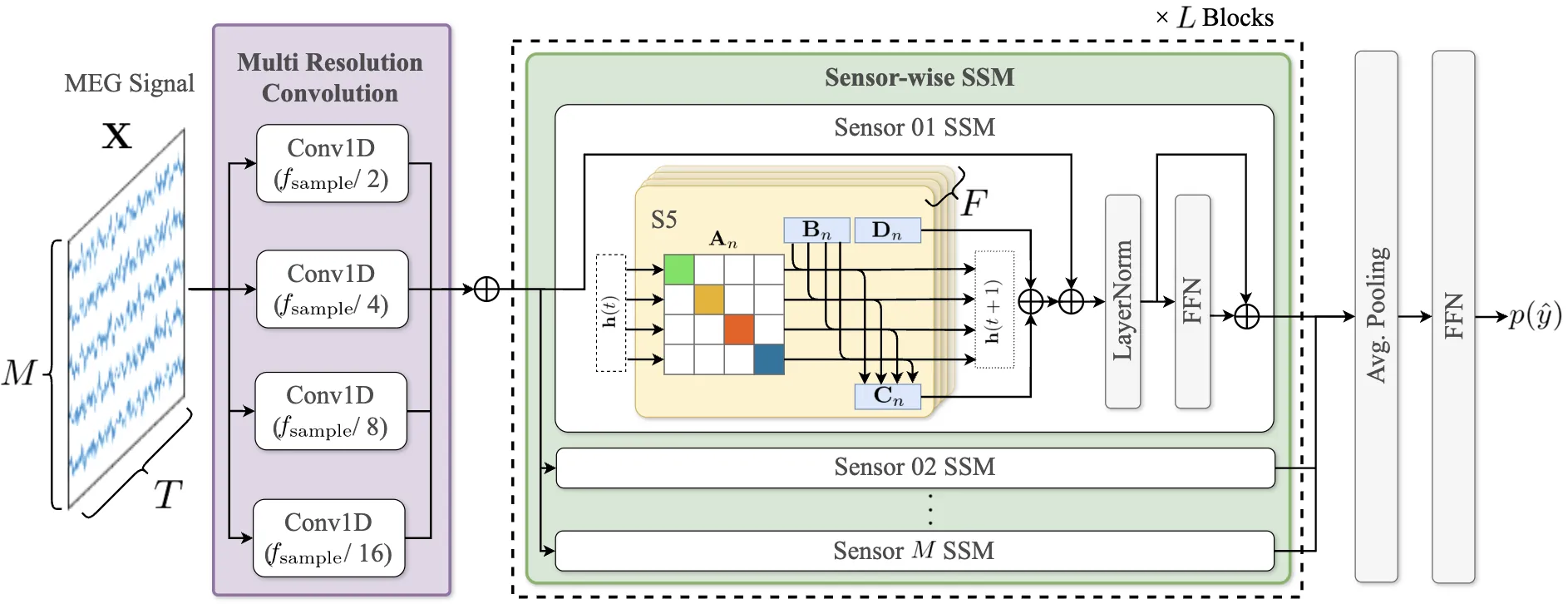
Decoding linguistically meaningful representations from non-invasive neural recordings remains a central challenge in neural speech decoding. Among available neuroimaging modalities, magnetoencephalography (MEG) provides a safe and repeatable means of mapping speech-related cortical dynamics, yet its low signal-to-noise ratio and high temporal dimensionality continue to hinder robust decoding. In this work, we introduce MEGState, a novel architecture for phoneme decoding from MEG signals that captures fine-grained cortical responses evoked by auditory stimuli. Extensive experiments on the LibriBrain dataset demonstrate that MEGState consistently surpasses baseline model across multiple evaluation metrics. These findings highlight the potential of MEG-based phoneme decoding as a scalable pathway toward non-invasive brain-computer interfaces for speech.

Bayesian inference provides a principled framework for understanding brain function, while neural activity in the brain is inherently spike-based. This paper bridges these two perspectives by designing spiking neural networks that simulate Bayesian inference through message passing for Bernoulli messages. To train the networks, we employ spike-timing-dependent plasticity, a biologically plausible mechanism for synaptic plasticity which is based on the Hebbian rule. Our results demonstrate that the network's performance closely matches the true numerical solution. We further demonstrate the versatility of our approach by implementing a factor graph example from coding theory, illustrating signal transmission over an unreliable channel.
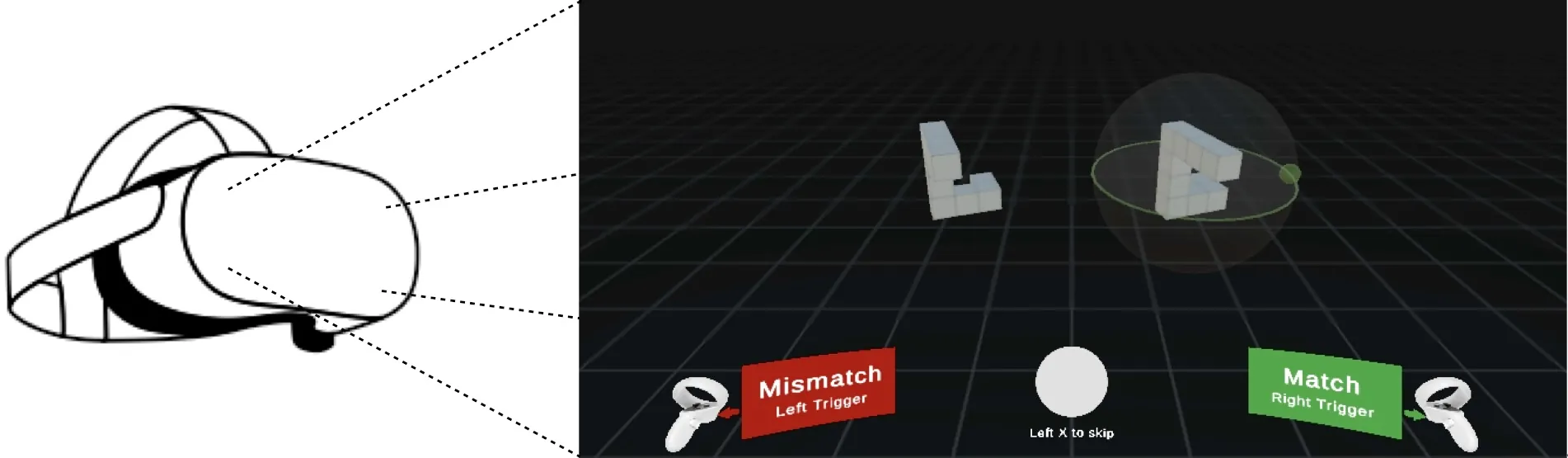
Mental rotation -- the ability to compare objects seen from different viewpoints -- is a fundamental example of mental simulation and spatial world modelling in humans. Here we propose a mechanistic model of human mental rotation, leveraging advances in deep, equivariant, and neuro-symbolic learning. Our model consists of three stacked components: (1) an equivariant neural encoder, taking images as input and producing 3D spatial representations of objects, (2) a neuro-symbolic object encoder, deriving symbolic descriptions of objects from these spatial representations, and (3) a neural decision agent, comparing these symbolic descriptions to prescribe rotation simulations in 3D latent space via a recurrent pathway. Our model design is guided by the abundant experimental literature on mental rotation, which we complemented with experiments in VR where participants could at times manipulate the objects to compare, providing us with additional insights into the cognitive process of mental rotation. Our model captures well the performance, response times and behavior of participants in our and others' experiments. The necessity of each model component is shown through systematic ablations. Our work adds to a recent collection of deep neural models of human spatial reasoning, further demonstrating the potency of integrating deep, equivariant, and symbolic representations to model the human mind.

The requirements for a falsifiable and non-trivial theory of consciousness significantly constrain such theories. Specifically, recent research on the Unfolding Argument and the Substitution Argument has given us formal tools to analyze requirements for a theory of consciousness. I show via a new Proximity Argument that these requirements especially constrain the potential consciousness of contemporary Large Language Models (LLMs) because of their proximity to systems that are equivalent to LLMs in terms of input/output function; yet, for these functionally equivalent systems, there cannot be any non-trivial theory of consciousness that judges them conscious. This forms the basis of a disproof of contemporary LLM consciousness. I then show a positive result, which is that theories of consciousness based on (or requiring) continual learning do satisfy the stringent formal constraints for a theory of consciousness in humans. Intriguingly, this work supports a hypothesis: If continual learning is linked to consciousness in humans, the current limitations of LLMs (which do not continually learn) are intimately tied to their lack of consciousness.
We introduce a biologically inspired, multilayer neural architecture composed of Rectified Spectral Units (ReSUs). Each ReSU projects a recent window of its input history onto a canonical direction obtained via canonical correlation analysis (CCA) of previously observed past-future input pairs, and then rectifies either its positive or negative component. By encoding canonical directions in synaptic weights and temporal filters, ReSUs implement a local, self-supervised algorithm for progressively constructing increasingly complex features. To evaluate both computational power and biological fidelity, we trained a two-layer ReSU network in a self-supervised regime on translating natural scenes. First-layer units, each driven by a single pixel, developed temporal filters resembling those of Drosophila post-photoreceptor neurons (L1/L2 and L3), including their empirically observed adaptation to signal-to-noise ratio (SNR). Second-layer units, which pooled spatially over the first layer, became direction-selective -- analogous to T4 motion-detecting cells -- with learned synaptic weight patterns approximating those derived from connectomic reconstructions. Together, these results suggest that ReSUs offer (i) a principled framework for modeling sensory circuits and (ii) a biologically grounded, backpropagation-free paradigm for constructing deep self-supervised neural networks.
Mental rotation -- the ability to compare objects seen from different viewpoints -- is a fundamental example of mental simulation and spatial world modelling in humans. Here we propose a mechanistic model of human mental rotation, leveraging advances in deep, equivariant, and neuro-symbolic learning. Our model consists of three stacked components: (1) an equivariant neural encoder, taking images as input and producing 3D spatial representations of objects, (2) a neuro-symbolic object encoder, deriving symbolic descriptions of objects from these spatial representations, and (3) a neural decision agent, comparing these symbolic descriptions to prescribe rotation simulations in 3D latent space via a recurrent pathway. Our model design is guided by the abundant experimental literature on mental rotation, which we complemented with experiments in VR where participants could at times manipulate the objects to compare, providing us with additional insights into the cognitive process of mental rotation. Our model captures well the performance, response times and behavior of participants in our and others' experiments. The necessity of each model component is shown through systematic ablations. Our work adds to a recent collection of deep neural models of human spatial reasoning, further demonstrating the potency of integrating deep, equivariant, and symbolic representations to model the human mind.
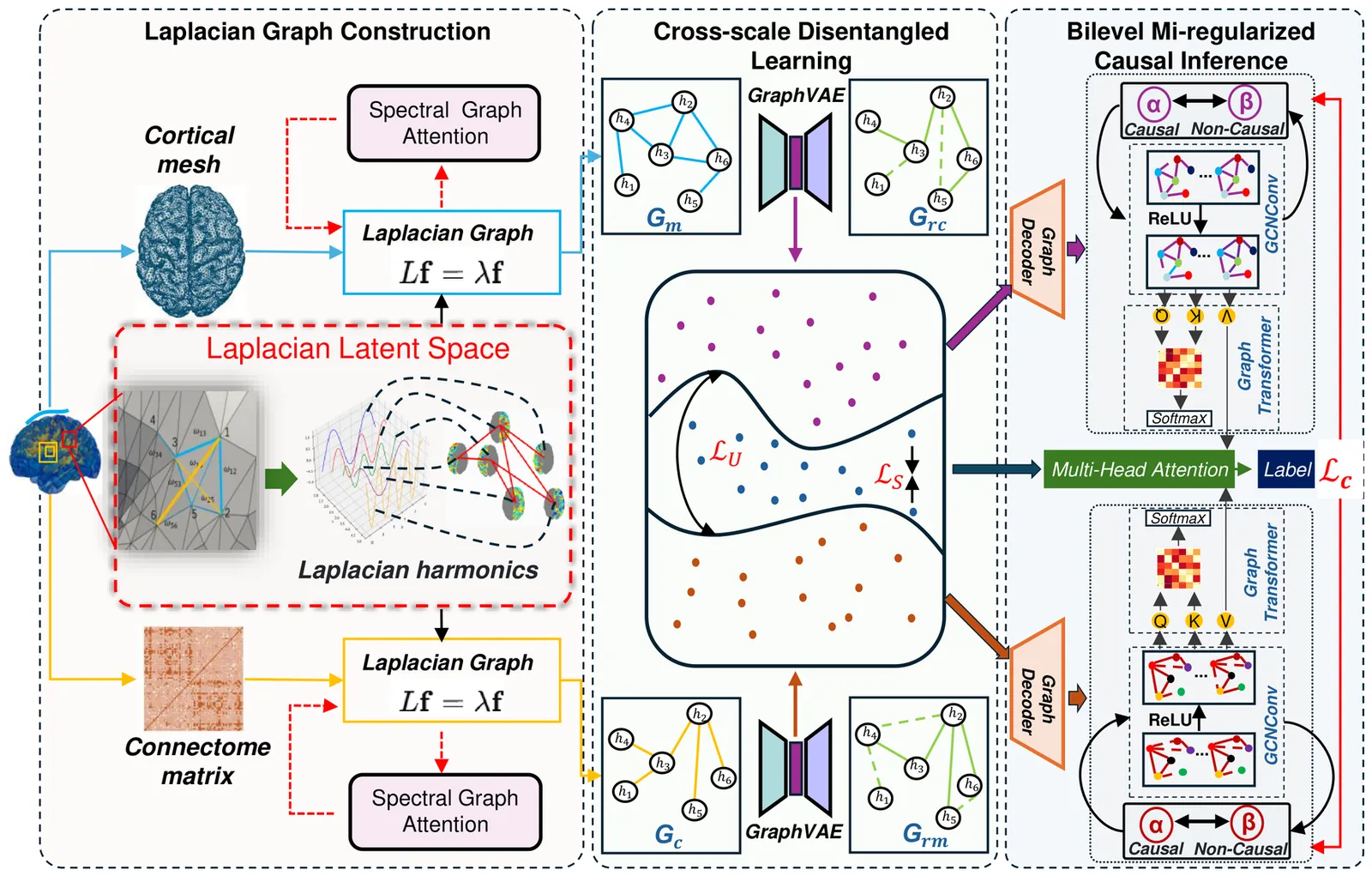
Multimodal MRI offers complementary multi-scale information to characterize the brain structure. However, it remains challenging to effectively integrate multimodal MRI while achieving neuroscience interpretability. Here we propose to use Laplacian harmonics and spectral graph theory for multimodal alignment and multiscale integration. Based on the cortical mesh and connectome matrix that offer multi-scale representations, we devise Laplacian operators and spectral graph attentions to construct a shared latent space for model alignment. Next, we employ a disentangled learning combined with Graph Variational Autoencoder architectures to separate scale-specific and shared features. Lastly, we design a mutual information-informed bilevel regularizer to separate causal and non-causal factors based on the disentangled features, achieving robust model performance with enhanced interpretability. Our model outperforms baselines and other state-of-the-art models. The ablation studies confirmed the effectiveness of the proposed modules. Our model promises to offer a robust and interpretable framework for multi-scale brain structure analysis.