254 papers

A Dataset of Nonlinear Equations for Subdivision
In this paper, we report on the largest labelled dataset constructed so far for solving zero-dimensional square nonlinear systems with subdivision-based methods. A brief, non-exhaustive survey with emphasis on the literature from the past two decades is also provided to accompany with the dataset. The value of the dataset has been demonstrated through benchmarking several solvers as well as being used for learning to classify the real roots of nonlinear parametric systems.
2603.27499Mar 2026
View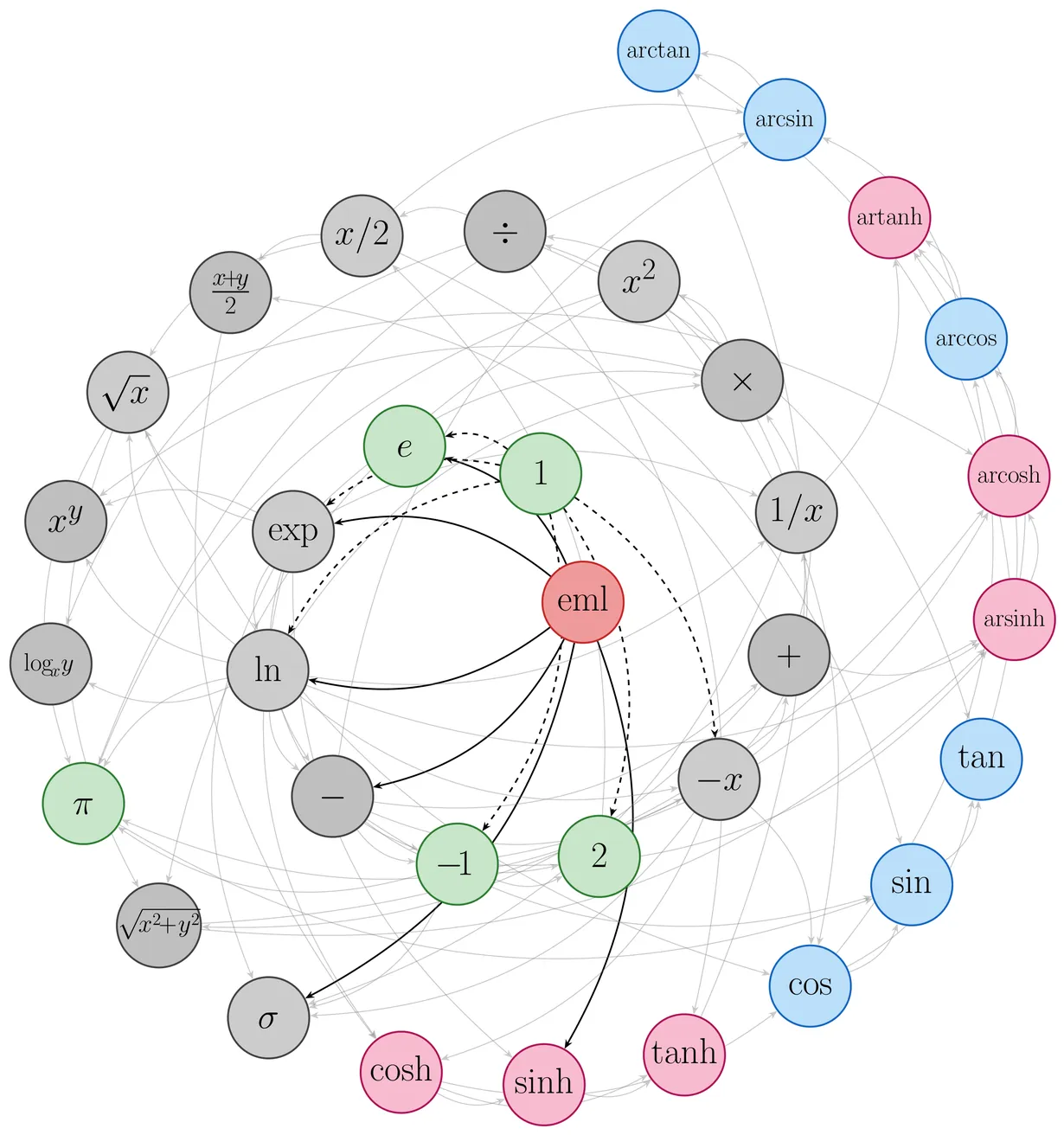
All elementary functions from a single binary operator
A single two-input gate suffices for all of Boolean logic in digital hardware. No comparable primitive has been known for continuous mathematics: computing elementary functions such as sin, cos, sqrt, and log has always required multiple distinct operations. Here I show that a single binary operator, eml(x,y)=exp(x)-ln(y), together with the constant 1, generates the standard repertoire of a scientific calculator. This includes constants such as $e$, $π$, and $i$; arithmetic operations including $+$, $-$, $\times$, $/$, and exponentiation as well as the usual transcendental and algebraic functions. For example, $e^x=\operatorname{eml}(x,1)$, $\ln x=\operatorname{eml}(1,\operatorname{eml}(\operatorname{eml}(1,x),1))$, and likewise for all other operations. That such an operator exists was not anticipated; I found it by systematic exhaustive search and established constructively that it suffices for the concrete scientific-calculator basis. In EML (Exp-Minus-Log) form, every such expression becomes a binary tree of identical nodes, yielding a grammar as simple as $S \to 1 \mid \operatorname{eml}(S,S)$. This uniform structure also enables gradient-based symbolic regression: using EML trees as trainable circuits with standard optimizers (Adam), I demonstrate the feasibility of exact recovery of closed-form elementary functions from numerical data at shallow tree depths up to 4. The same architecture can fit arbitrary data, but when the generating law is elementary, it may recover the exact formula.
2603.21852Mar 2026
View
A complexity analysis of the F4 Gröbner basis algorithm with tracer data
We provide a new complexity bound for the computation of grevlex Gröbner bases in the generic zero-dimensional case, relying on Moreno-Socías' conjecture. We first formalize a property of regular sequences that implies a well-known folklore consequence, which we call the increasing degree property. We then derive a new understanding of the selection of pairs in the F4 algorithm based on Moreno-Socías' conjecture. Moreover, we obtain an exact formula for the number of elements in the grevlex Gröbner basis of a given degree, for half of the relevant degrees. Combining these results, we derive a precise complexity formula for the F4 Tracer algorithm, together with its asymptotic behavior when the number of variables tends to infinity. These results yield an improvement over the state-of-the-art complexity bounds by a factor which is exponential in the number of variables.
2603.16378Mar 2026
ViewComputing the connected components of real algebraic curves
Connected components of real algebraic sets are semi-algebraic, i.e. they are described by a boolean formula whose atoms are polynomial constraints with real coefficients. Computing such descriptions finds topical applications in optical system design and robotics. In this paper, we design a new algorithm for computing such semi-algebraic descriptions for real algebraic curves. Notably, its complexity is less than the best known one for computing a graph which is isotopic to the real space curve under study.
2603.16283Mar 2026
View
Introducing the vfunc R package
$f,g\colon\mathbb{R}\longrightarrow\mathbb{R}$, it is natural to define $f+g$ as the function that maps $x\in\mathbb{R}$ to $f(x) + g(x)$. However, in base R, objects of class function do not have arithmetic methods defined, so idiom such as "f + g" returns an error, even though it has a perfectly reasonable expectation. The vfunc package offers this functionality. Other similar features are provided, which lead to compact and readable idiom. A wide class of coding bugs is eliminated.
2603.15156Mar 2026
View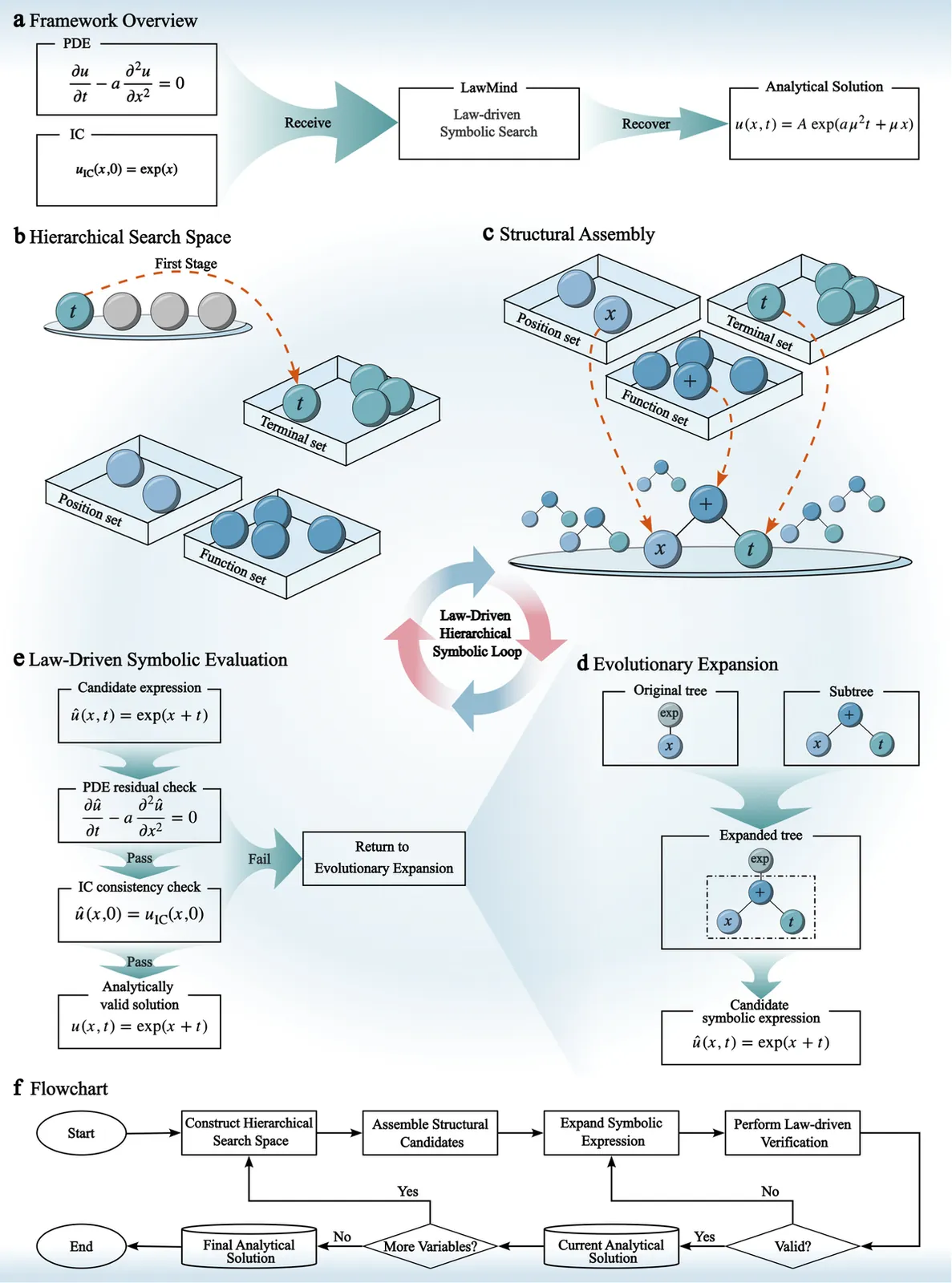
LawMind: A Law-Driven Paradigm for Discovering Analytical Solutions to Partial Differential Equations
Partial differential equations (PDEs) encode fundamental physical laws, yet closed-form analytical solutions for many important equations remain unknown and typically require substantial human insight to derive. Existing numerical, physics-informed, and data-driven approaches approximate solutions from data rather than systematically deriving symbolic expressions directly from governing equations. Here we introduce LawMind, a law-driven symbolic discovery framework that autonomously constructs closed-form solutions from PDEs and their associated conditions without relying on data or supervision. By integrating structured symbolic exploration with physics-constrained evaluation, LawMind progressively assembles valid solution components guided solely by governing laws. Evaluated on 100 benchmark PDEs drawn from two authoritative handbooks, LawMind successfully recovers closed-form analytical solutions for all cases. Beyond known solutions, LawMind further discovers previously unreported closed-form solutions to both linear and nonlinear PDEs. These findings establish a computational paradigm in which governing equations alone drive autonomous symbolic discovery, enabling the systematic derivation of analytical PDE solutions.
2603.14353Mar 2026
View
Interpreting Contrastive Embeddings in Specific Domains with Fuzzy Rules
Free-style text is still one of the common ways in which data is registered in real environments, like legal procedures and medical records. Because of that, there have been significant efforts in the area of natural language processing to convert these texts into a structured format, which standard machine learning methods can then exploit. One of the most popular methods to embed text into a vectorial representation is the Contrastive Language-Image Pre-training model (CLIP), which was trained using both image and text. Although the representations computed by CLIP have been very successful in zero-show and few-shot learning problems, they still have problems when applied to a particular domain. In this work, we use a fuzzy rule-based classification system along with some standard text procedure techniques to map some of our features of interest to the space created by a CLIP model. Then, we discuss the rules and associations obtained and the importance of each feature considered. We apply this approach in two different data domains, clinical reports and film reviews, and compare the results obtained individually and when considering both. Finally, we discuss the limitations of this approach and how it could be further improved.
2603.12227Mar 2026
View
Avoiding Big Integers: Parallel Multimodular Algebraic Verification of Arithmetic Circuits
Word-level verification of arithmetic circuits with large operands typically relies on arbitrary-precision arithmetic, which can lead to significant computational overhead as word sizes grow. In this paper, we present a hybrid algebraic verification technique based on polynomial reasoning that combines linear and nonlinear rewriting. Our approach relies on multimodular reasoning using homomorphic images, where computations are performed in parallel modulo different primes, thereby avoiding any large-integer arithmetic. We implement the proposed method in the verification tool TalisMan2.0 and evaluate it on a suite of multiplier benchmarks. Our results show that hybrid multimodular reasoning significantly improves upon existing approaches.
2603.09501Mar 2026
ViewMatrices with displacement structure: a deterministic approach for linear systems and nullspace bases
The fastest known algorithms for dealing with structured matrices, in the sense of the displacement rank measure, are randomized. For handling classical displacement structures, they achieve the complexity bounds $\tilde{O}(α^{ω-1} n)$ for solving linear systems and $\tilde{O}(α^2 n)$ for computing the nullspace. Here $n \times n$ is the size of the square matrix, $α$ is its displacement rank, $ω> 2$ is a feasible exponent for matrix multiplication, and the notation $\tilde{O}(\cdot)$ counts arithmetic operations in the base field while hiding logarithmic factors. These algorithms rely on an adaptation of Strassen's divide and conquer Gaussian elimination to the context of structured matrices. This approach requires the input matrix to have generic rank profile; this constraint is lifted via pre- and post-multiplications by special matrices generated from random coefficients chosen in a sufficiently large subset of the base field. This work introduces a fast and deterministic approach, which solves both problems within $\tilde{O}(α^{ω-1} (m+n))$ operations in the base field for an arbitrary rectangular $m \times n$ input matrix. We provide explicit algorithms that instantiate this approach for Toeplitz-like, Vandermonde-like, and Cauchy-like structures. The starting point of the approach is to reformulate a structured linear system as a modular equation on univariate polynomials. Then, a description of all solutions to this equation is found in three steps, all using fast and deterministic operations on polynomial matrices. Specifically, one first computes a basis of solutions to a vector M-Padé approximation problem; then one performs linear system solving over the polynomials to isolate away unwanted unknowns and restrict to those that are actually sought; and finally the latter are found by simultaneous M-Padé approximation.
2603.02425Mar 2026
View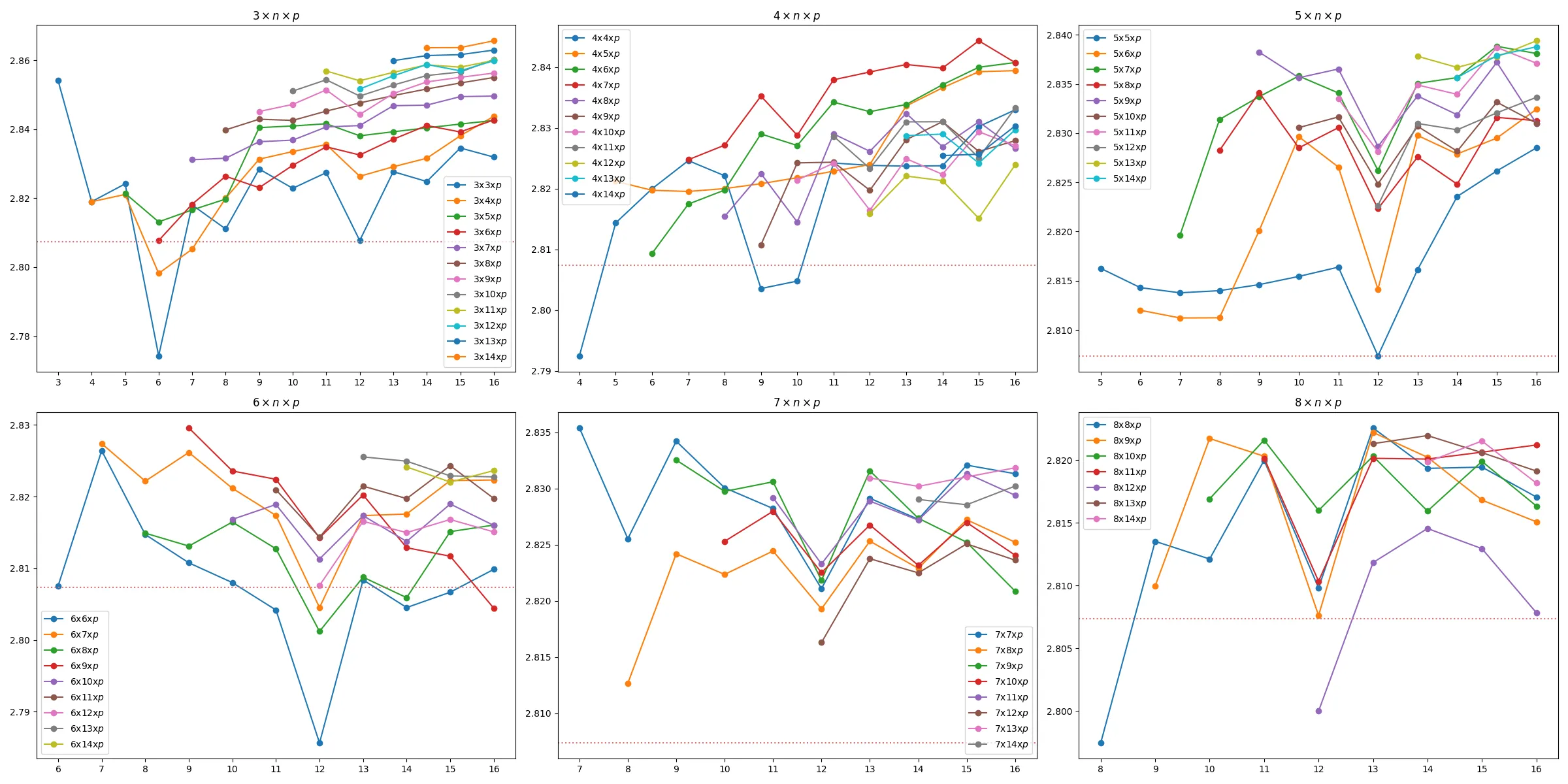
Fast Matrix Multiplication in Small Formats: Discovering New Schemes with an Open-Source Flip Graph Framework
An open-source C++ framework for discovering fast matrix multiplication schemes using the flip graph approach is presented. The framework supports multiple coefficient rings -- binary ($\mathbb{Z}_2$), modular ternary ($\mathbb{Z}_3$) and integer ternary ($\mathbb{Z}_T = \{-1,0,1\}$) -- and implements both fixed-dimension and meta-dimensional search operators. Using efficient bit-level encoding of coefficient vectors and OpenMP parallelism, the tools enable large-scale exploration on commodity hardware. The study covers 680 schemes ranging from $(2 \times 2 \times 2)$ to $(16 \times 16 \times 16)$, with 276 schemes now in $\mathbb{Z}_T$ coefficients and 117 in integer coefficients. With this framework, the multiplicative complexity (rank) is improved for 79 matrix multiplication schemes. Notably, a new $4 \times 4 \times 10$ scheme requiring only 115 multiplications is discovered, achieving $ω\approx 2.80478$ and beating Strassen's exponent for this specific size. Additionally, 93 schemes are rediscovered in ternary coefficients that were previously known only over rationals or integers, and 68 schemes in integer coefficients that previously required fractions. All tools and discovered schemes are made publicly available to enable reproducible research.
2603.02398Mar 2026
View
Quadratization of Autonomous Partial Differential Equations: Theory and Algorithms
Quadratization for partial differential equations (PDEs) is a process that transforms a nonquadratic PDE into a quadratic form by introducing auxiliary variables. This symbolic transformation has been used in diverse fields to simplify the analysis, simulation, and control of nonlinear and nonquadratic PDE models. This paper presents a rigorous definition of PDE quadratization, theoretical results for the PDE quadratization problem of spatially one-dimensional PDEs-including results on existence and complexity-and introduces QuPDE, an algorithm based on symbolic computation and discrete optimization that outputs a quadratization for any spatially one-dimensional polynomial or rational PDE. This algorithm is the first computational tool to find quadratizations for PDEs to date. We demonstrate QuPDE's performance by applying it to fourteen nonquadratic PDEs in diverse areas such as fluid mechanics, space physics, chemical engineering, and biological processes. QuPDE delivers a low-order quadratization in each case, uncovering quadratic transformations with fewer auxiliary variables than those previously discovered in the literature for some examples, and finding quadratizations for systems that had not been transformed to quadratic form before.
2602.22371Feb 2026
ViewOrder Bounds for Hypergeometric and q-Hypergeometric Creative Telescoping
Leveraging a general framework adapted from symbolic integration, a unified reduction-based algorithm for computing telescopers of minimal order for hypergeometric and q-hypergeometric terms has been recently developed. In this paper, we conduct a deeper exploration and put forth a new argument for the termination of the algorithm. This not only provides an independent proof of existence of telescopers, but also allows us to derive unified upper and lower bounds on the order of telescopers for hypergeometric terms and their q-analogues. Compared with known bounds in the literature, our bounds, in the hypergeometric case, are exactly the same as the tight ones obtained in 2016; while in the q-hypergeometric case, no lower bounds were known before, and our upper bound is sometimes better and never worse than the known one.
2602.19886Feb 2026
View
A Separation Method of the Positivity of A Quartic Polynomial
Although the positivity of a quartic polynomial is a well-researched topic, existing conditions are often highly complex. Some necessary and sufficient conditions for the positivity of a quartic polynomial are presented through a separation method based on Ferrari's technique of solving a quartic equation. We apply the result to the problem of the projection of the coefficient space.
2603.00073Feb 2026
View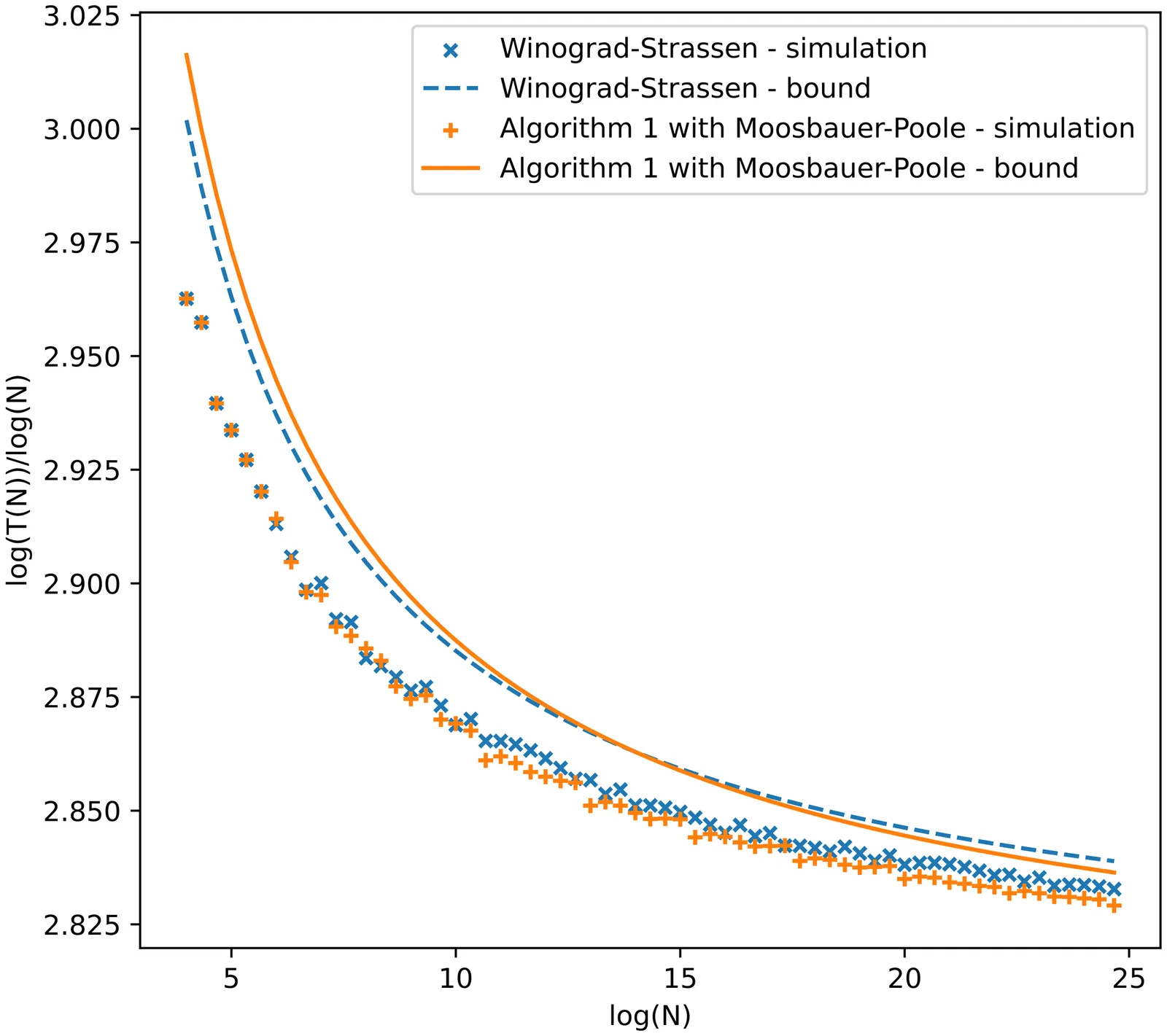
Exploiting the Structure in Tensor Decompositions for Matrix Multiplication
We present a new algorithm for fast matrix multiplication using tensor decompositions which have special features. Thanks to these features we obtain exponents lower than what the rank of the tensor decomposition suggests. In particular for $6\times 6$ matrix multiplication we reduce the exponent of the recent algorithm by Moosbauer and Poole from $2.8075$ to $2.8016$, while retaining a reasonable leading coefficient.
2602.11041Feb 2026
ViewSimple generators of rational function fields
Consider a subfield of the field of rational functions in several indeterminates. We present an algorithm that, given a set of generators of such a subfield, finds a simple generating set. We provide an implementation of the algorithm and show that it improves upon the state of the art both in efficiency and the quality of the results. Furthermore, we demonstrate the utility of simplified generators through several case studies from different application domains, such as structural parameter identifiability. The main algorithmic novelties include performing only partial Gröbner basis computation via sparse interpolation and efficient search for polynomials of a fixed degree in a subfield of the rational function field.
2602.10878Feb 2026
ViewThe Neurosymbolic Frontier of Nonuniform Ellipticity: Formalizing Sharp Schauder Theory via Topos-Theoretic Reasoning Models
This white paper presents a critical synthesis of the recent breakthrough in nonuniformly elliptic regularity theory and the burgeoning field of neurosymbolic large reasoning models (LRMs). We explore the resolution of the long-standing sharp growth rate conjecture in Schauder theory, achieved by Cristiana De Filippis and Giuseppe Mingione, which identifies the exact threshold $q/p < 1 + α/n$ for gradient Hölder continuity. Central to this mathematical achievement is the ``ghost equation'' methodology, a sophisticated auxiliary derivation that bypasses the non-differentiability of classical Euler-Lagrange systems. We propose that the next era of mathematical discovery lies in the integration of these pure analytical constructs with LRMs grounded in topos theory and formal verification frameworks such as Safe and Typed Chain-of-Thought (PC-CoT). By modeling the reasoning process as a categorical colimit in a slice topos, we demonstrate how LRMs can autonomously navigate the ``Dark Side'' of the calculus of variations, providing machine-checkable proofs for regularity bounds in complex, multi-phase physical systems.
2602.10632Feb 2026
ViewComputational Explorations on Semifields
A finite semifield is a division algebra over a finite field where multiplication is not necessarily associative. We consider here the complexity of the multiplication in small semifields and finite field extensions. For this operation, the number of required base field multiplications is the tensor rank, or the multiplicative complexity. The other base field operations are additions and scalings by constants, which together we refer to as the additive complexity. When used recursively, the tensor rank determines the exponent while the other operations determine the constant of the associated asymptotic complexity bounds. For small extensions, both measures are of similar importance. In this paper, we establish the tensor rank of some semifields and finite fields of characteristics 2 and 3. We also propose new upper and lower bounds on their additive complexity, and give new associated algorithms improving on the state-of-the-art in terms of overall complexity. We achieve this by considering short straight line programs for encoding linear codes with given parameters.
2602.09577Feb 2026
View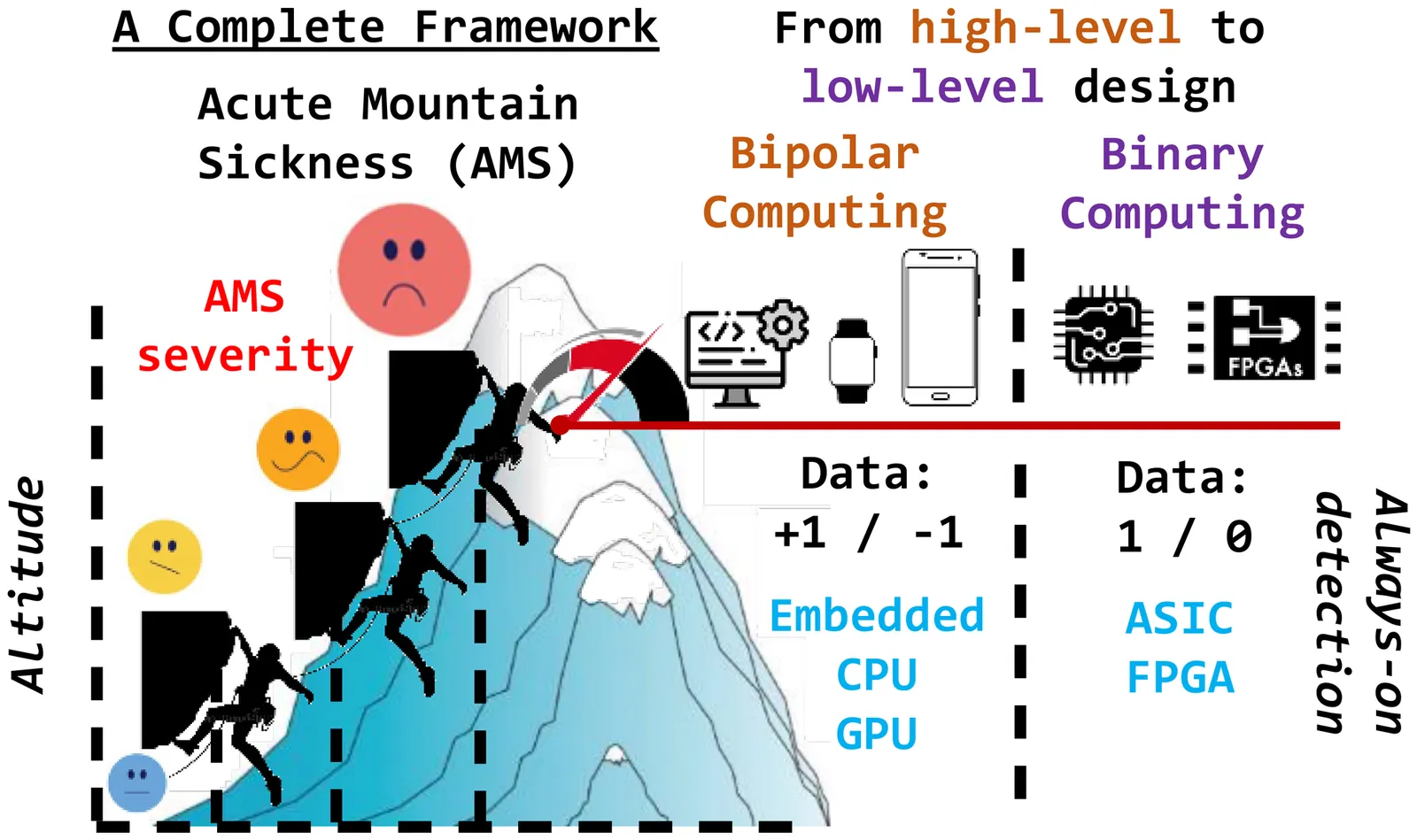
AMS-HD: Hyperdimensional Computing for Real-Time and Energy-Efficient Acute Mountain Sickness Detection
Altitude sickness is a potentially life-threatening condition that impacts many individuals traveling to elevated altitudes. Timely detection is critical as symptoms can escalate rapidly. Early recognition enables simple interventions such as descent, oxygen, or medication, and prompt treatment can save lives by significantly lowering the risk of severe complications. Although conventional machine learning (ML) techniques have been applied to identify altitude sickness using physiological signals, such as heart rate, oxygen saturation, respiration rate, blood pressure, and body temperature, they often struggle to balance predictive performance with low hardware demands. In contrast, hyperdimensional computing (HDC) remains under-explored for this task with limited biomedical features, where it may offer a compelling alternative to existing classification models. Its vector symbolic framework is inherently suited to hardware-efficient design, making it a strong candidate for low-power systems like wearables. Leveraging lightweight computation and efficient streamlined memory usage, HDC enables real-time detection of altitude sickness from physiological parameters collected by wearable devices, achieving accuracy comparable to that of traditional ML models. We present AMS-HD, a novel system that integrates tailored feature extraction and Hadamard HV encoding to enhance both the precision and efficiency of HDC-based detection. This framework is well-positioned for deployment in wearable health monitoring platforms, enabling continuous, on-the-go tracking of acute altitude sickness.
2602.08916Feb 2026
View
Automatic Generation of Polynomial Symmetry Breaking Constraints
Symmetry in integer programming causes redundant search and is often handled with symmetry breaking constraints that remove as many equivalent solutions as possible. We propose an algebraic method which allows to generate a random family of polynomial inequalities which can be used as symmetry breakers. The method requires as input an arbitrary base polynomial and a group of permutations which is specific to the integer program. The computations can be easily carried out in any major symbolic computation software. In order to test our approach, we describe a case study on near half-capacity 0-1 bin packing instances which exhibit substantial symmetries. We statically generate random quadratic breakers and add them to a baseline integer programming problem which we then solve with Gurobi. It turns out that simple symmetry breakers, especially combining few variables and permutations, most consistently reduce work time.
2602.08297Feb 2026
View
Computing submatrices of the Hermite normal form of a structured polynomial matrix
Following several decades of successive algorithmic improvements, works from the 2010s have showed how to compute the Hermite normal form (HNF) of a univariate polynomial matrix within a complexity bound which is essentially that of polynomial matrix multiplication. Recently, several results on bivariate polynomials and Gröbner bases have highlighted the interest of computing determinants or HNFs of polynomial matrices that happen to be structured, with a small displacement rank. In such contexts, a small leading principal submatrix of the HNF often contains all the sought information. In this article, we show how the displacement structure can be exploited in order to accelerate the computation of such submatrices. To achieve this, we rely on structured linear algebra over the field thanks to evaluation-interpolation. This allows us to recover some rows of the inverse of the input matrix, from which we deduce the sought HNF submatrix via bases of relations.
2602.08027Feb 2026
ViewPage 1 of 13