79 papers
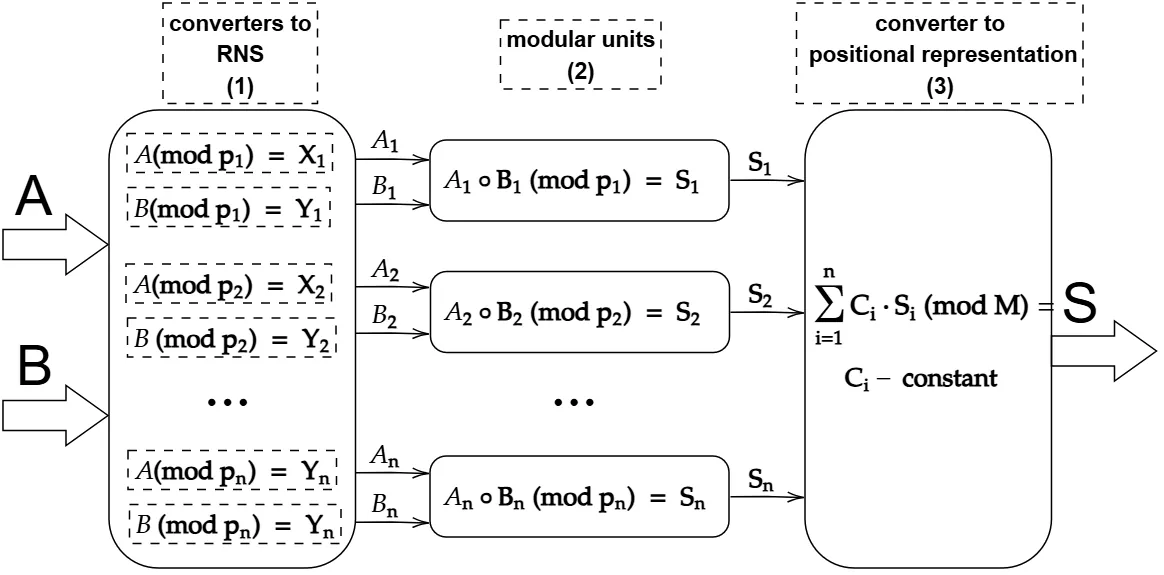
Optimal Small-Bitwidth Moduli Set for Residue Number Systems
This technical note presents a algorithmic approach for generating optimal sets of co-prime moduli within specified integer ranges. The proposed method addresses the challenge of balancing moduli bit-lengths while maximizing the dynamic range in Residue Number System (RNS) implementations. Experimental results demonstrate that the generated moduli sets achieve optimal dynamic range coverage while maintaining balanced bit-length distribution, making them particularly suitable for parallel hardware implementations based on RNS.
2603.24387Mar 2026
View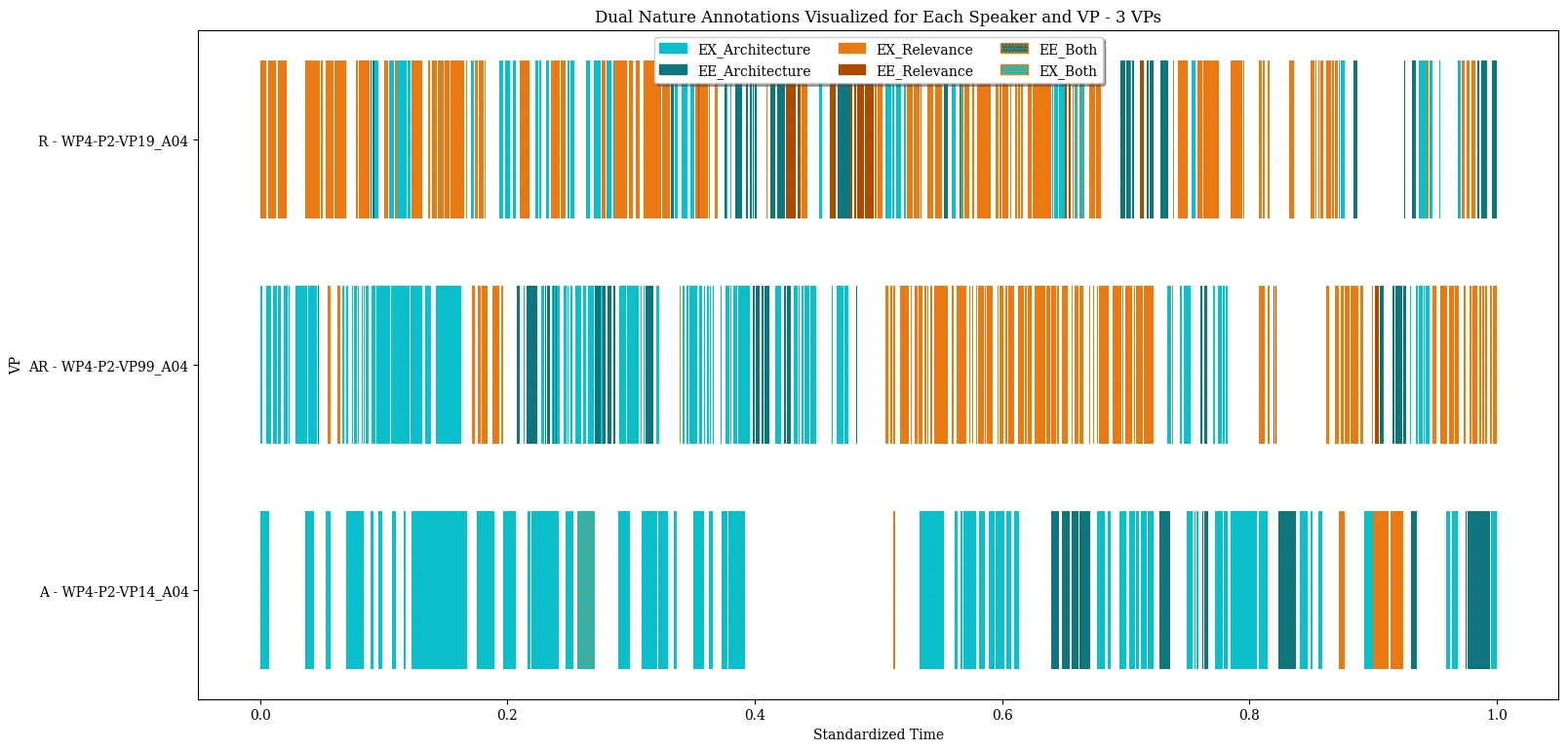
Bridging the Dual Nature: How Integrated Explanations Enhance Understanding of Technical Artifacts
Purpose: Understanding a technical artifact requires grasping both its internal structure (Architecture) and its purpose and significance (Relevance), as formalized by Dual Nature Theory. This controlled experimental study investigates whether how explainers address these perspectives affects explainees' understanding. Methods: In a between-subjects experiment, 104 participants received explanations of the board game Quarto! from trained confederates in one of three conditions: Architecture-focused (A), Relevance-focused (R), or Integrated (AR). Understanding was assessed on comprehension (knowing that) and enabledness (knowing how). Results: The A and R conditions produced equivalent understanding despite different explanation content. The AR condition yielded significantly higher enabledness than the focused conditions combined $\mathrm{F}(1, 102) = 4.83$, $p = .030$, $η^2_p = .045$}, while no differences emerged for comprehension. Conclusion: Integrating Architecture and Relevance specifically enhances explainees' ability to apply their understanding in practice, suggesting that fostering agency with technical artifacts requires bridging both perspectives. This has implications for technology education and explainable AI design.
2603.24325Mar 2026
View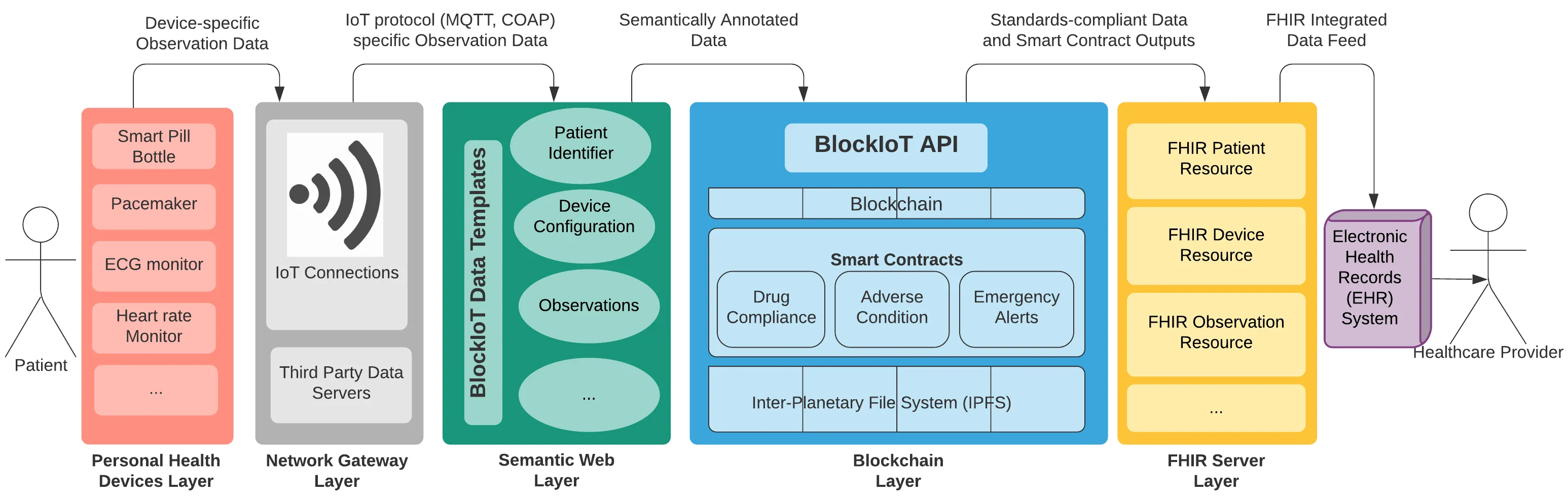
Personal Health Data Integration and Intelligence through Semantic Web and Blockchain Technologies
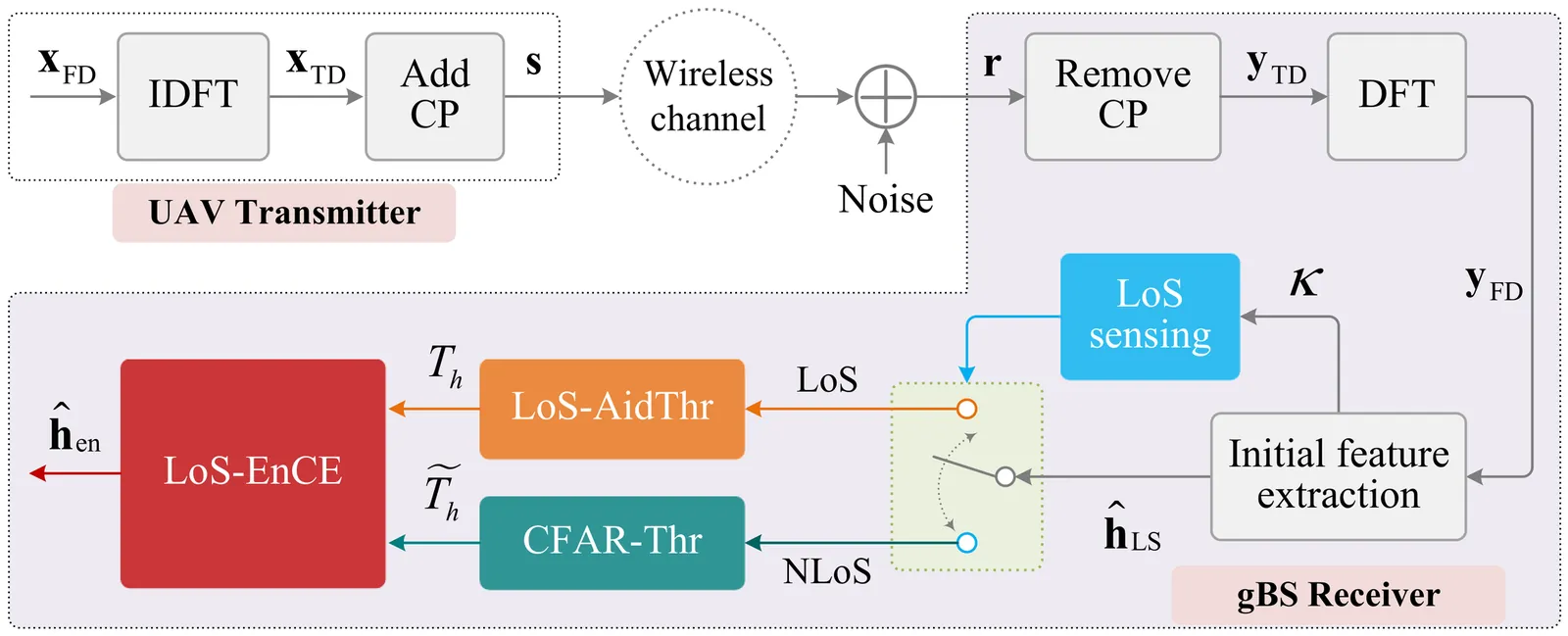
Data integration among various stakeholders in the healthcare space remains a challenge, despite the impressive advances in Health AI in the past decade. There is a lot of ``messy'' non-standard but structured data that are continually being collected from personal health devices. While efforts such as the Fast Healthcare Interoperability of Resources (FHIR) are underway in standardizing the data representation formats, there is currently a gap in the standard in addressing the health data ecosystem's decentralized nature. As we see explosive growth in chronic diseases such as diabetes, healthcare providers need Observations of Daily Living (ODL) of their patients to treat them effectively. The best way to obtain ODL is through personal health devices. However, such devices are manufactured by various device makers, and they may not follow standards or integrate with existing Electronic Health Record (EHR) systems. It is also imperative that any data sharing that happens will occur in a secure and trustworthy environment, without being too restrictive, i.e., tied to a particular EHR vendor. This paper presents a scalable solution to bridge this gap using a system that implements semantic web and blockchain technologies. Our solution uses FHIR compliant semantic web based data templates in conjunction with smart contracts on the blockchain to provide healthcare providers with insights on their patients' daily activity that cannot be readily determined solely through patient encounters at the clinic.
2603.02192Mar 2026
View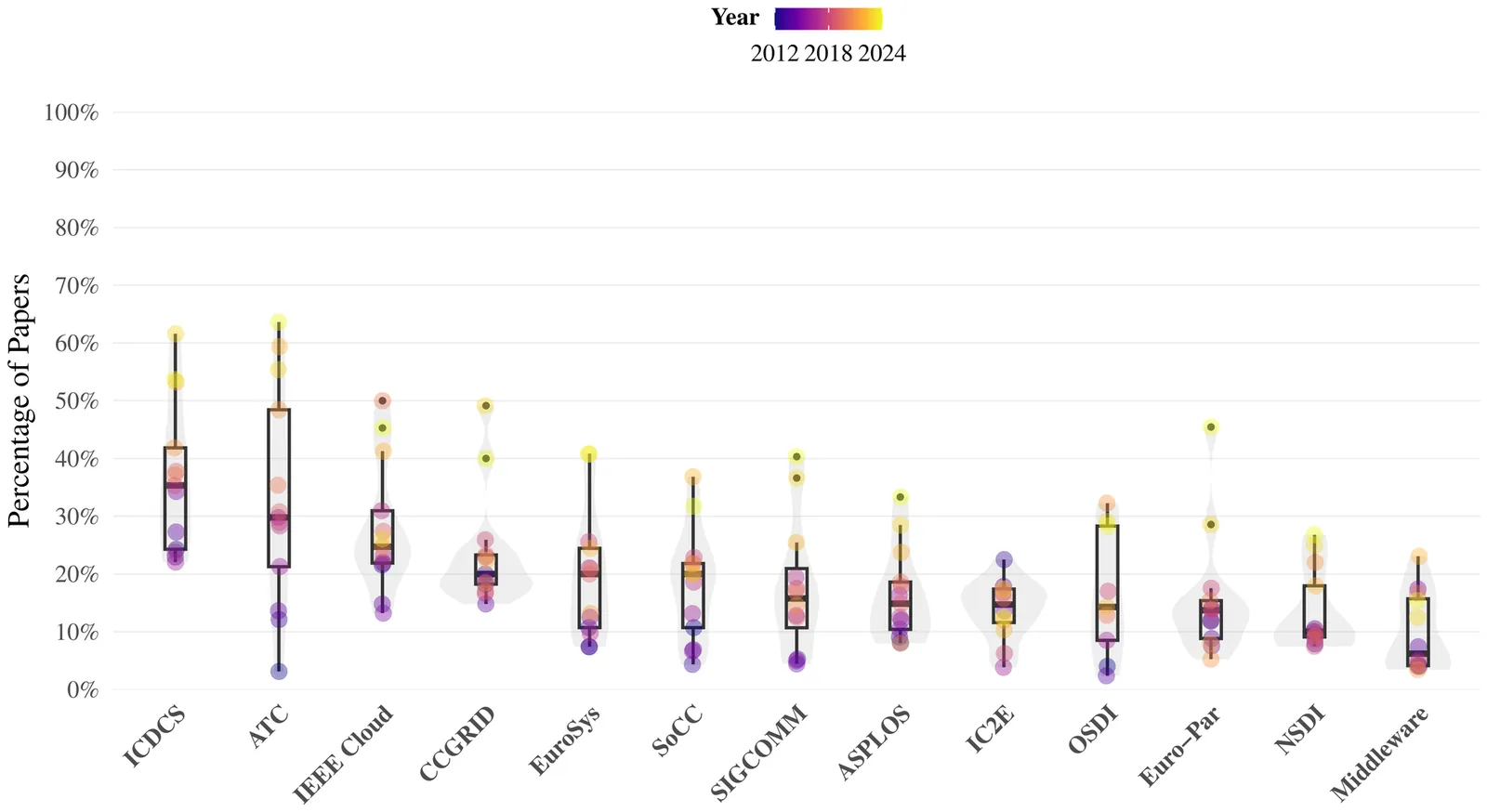
How international are international computing conferences? -- An exploration with systems research conferences
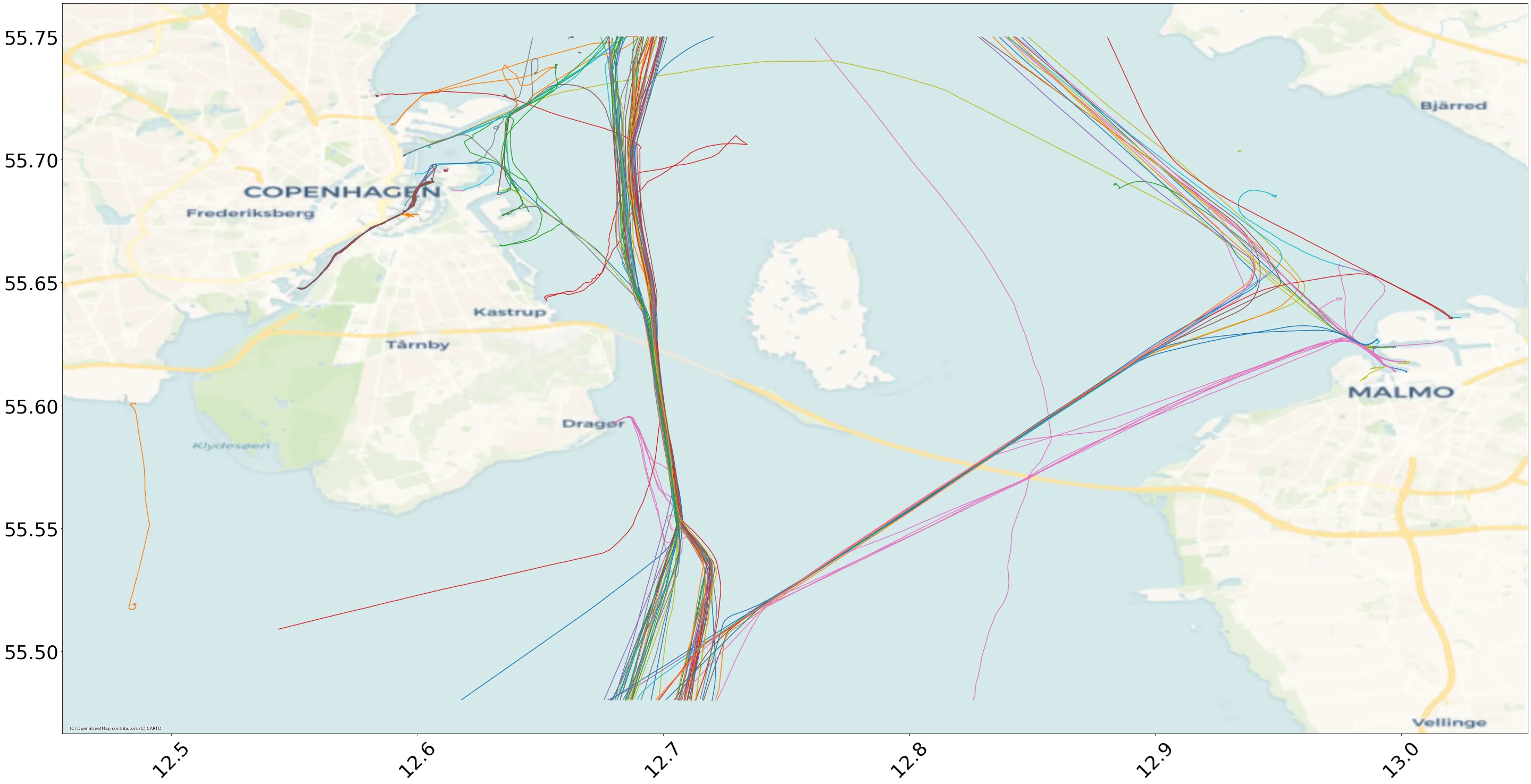
In recent years, Asia's rapid growth in research output has been reshaping the computing research landscape. What was once a two-block system (America and Europe) is evolving into a multipolar world with three major hubs: America, Europe, and Asia. To study these pivotal changes and evaluate international diversity, we have analyzed the past 13 years of 13 international systems research conferences: ASPLOS, NSDI, OSDI, SIGCOMM, ATC, EuroSys, ICDCS, Middleware, SoCC, CCGRID, IC2E, IEEE Cloud and EuroPar. Our analysis focuses on accepted papers and participation in the Program Committee, grouping the results by region (America, Europe, and Asia). Surprisingly, we find a pronounced historical imbalance in international diversity among top-tier systems conferences (ASPLOS, OSDI, NSDI, SIGCOMM). While most other conferences have progressively reflected Asia's growing research presence over the past decades, this group has shown a noticeable adjustment only in the recent four years. We also identify persistent rigidities in how program committee (PC) diversity adapts to shifts in accepted paper origins, with a consistent under-representation of researchers from Asian organizations in many PCs.
2603.19245Feb 2026
View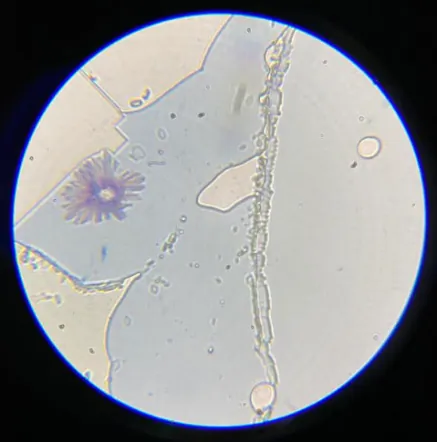
A Novel Approach for Testing Water Safety Using Deep Learning Inference of Microscopic Images of Unincubated Water Samples
Fecal-contaminated water causes diseases and even death. Current microbial water safety tests require pathogen incubation, taking 24-72 hours and costing \$20-\$50 per test. This paper presents a solution (DeepScope) exceeding UNICEF's ideal Target Product Profile requirements for presence/absence testing, with an estimated per-test cost of \$0.44. By eliminating the need for pathogen incubation, DeepScope reduces testing time by over 98\%. In DeepScope, a dataset of microscope images of bacteria and water samples was assembled. An innovative augmentation technique, generating up to 21 trillion images from a single microscope image, was developed. Four convolutional neural network models were developed using transfer learning and regularization techniques, then evaluated on a field-test dataset comprising 100,000 microscope images of unseen, real-world water samples collected from fourteen different water sources across Sammamish, WA. Precision-recall analysis showed the DeepScope model achieves 93\% accuracy, with precision of 90\% and recall exceeding 94\%. The DeepScope model was deployed on a web server, and mobile applications for Android and iOS were developed, enabling Internet-based or smartphone-based water safety testing, with results obtained in seconds.
2603.06611Feb 2026
View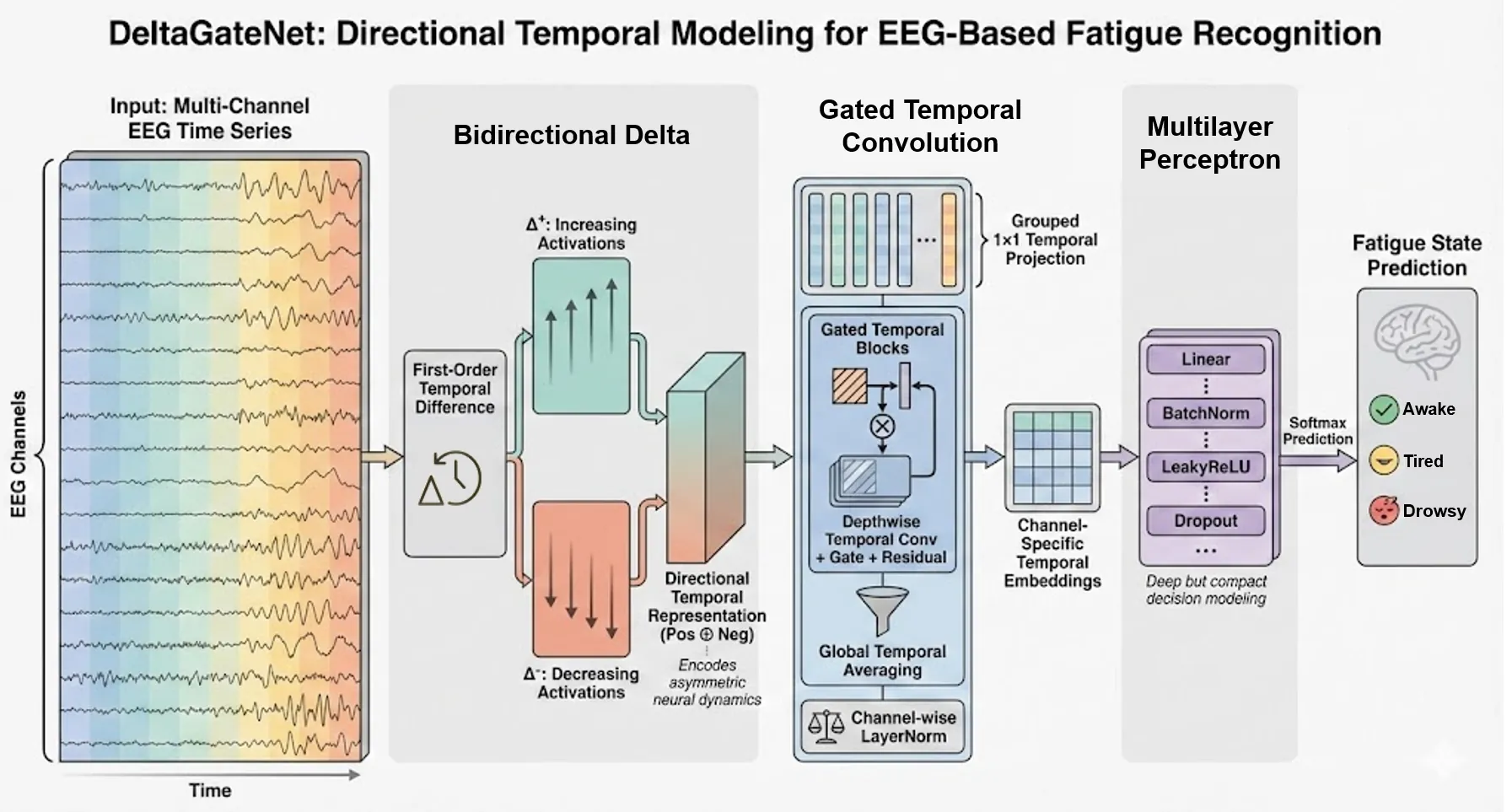
Bidirectional Temporal Dynamics Modeling for EEG-based Driving Fatigue Recognition
Driving fatigue is a major contributor to traffic accidents and poses a serious threat to road safety. Electroencephalography (EEG) provides a direct measurement of neural activity, yet EEG-based fatigue recognition is hindered by strong non-stationarity and asymmetric neural dynamics. To address these challenges, we propose DeltaGateNet, a novel framework that explicitly captures Bidirectional temporal dynamics for EEG-based driving fatigue recognition. Our key idea is to introduce a Bidirectional Delta module that decomposes first-order temporal differences into positive and negative components, enabling explicit modeling of asymmetric neural activation and suppression patterns. Furthermore, we design a Gated Temporal Convolution module to capture long-term temporal dependencies for each EEG channel using depthwise temporal convolutions and residual learning, preserving channel-wise specificity while enhancing temporal representation robustness. Extensive experiments conducted under both intra-subject and inter-subject evaluation settings on the public SEED-VIG and SADT driving fatigue datasets demonstrate that DeltaGateNet consistently outperforms existing methods. On SEED-VIG, DeltaGateNet achieves an intra-subject accuracy of 81.89% and an inter-subject accuracy of 55.55%. On the balanced SADT 2022 dataset, it attains intra-subject and inter-subject accuracies of 96.81% and 83.21%, respectively, while on the unbalanced SADT 2952 dataset, it achieves 96.84% intra-subject and 84.49% inter-subject accuracy. These results indicate that explicitly modeling Bidirectional temporal dynamics yields robust and generalizable performance under varying subject and class-distribution conditions.
2602.14071Feb 2026
View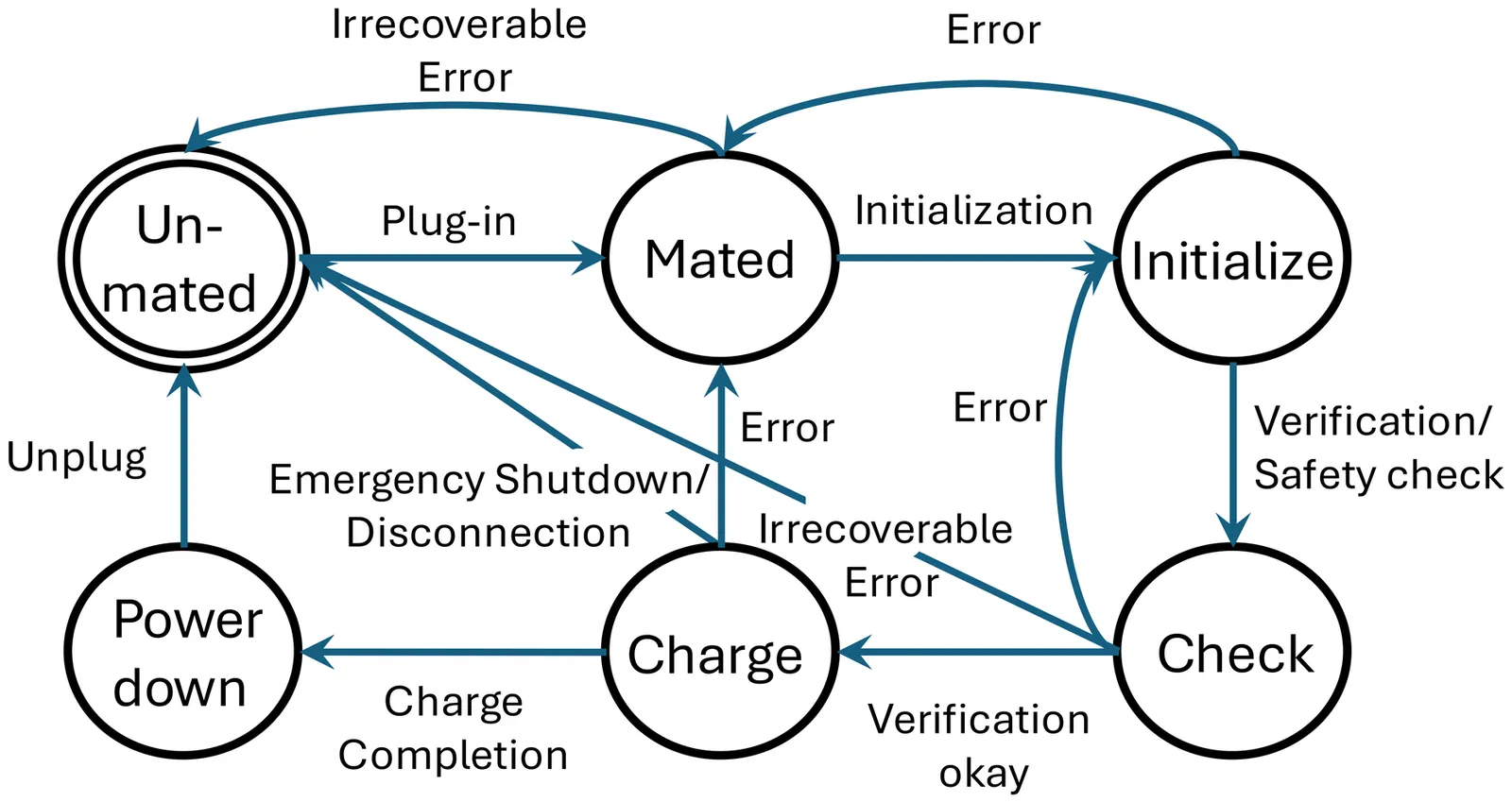
EVECTOR: An orchestrator for analysing attacks in electric vehicles charging system
Electric Vehicle (EV) charging infrastructure is critical for the widespread adoption of EVs, ensuring efficient and secure charging processes. Evaluating the security and performance of EV charging systems in real-world infrastructure poses significant challenges due to the diversity of information exchange between vehicles and charging stations/Electric Vehicle Supply Equipment (EVSE), including complex network protocols, scale of deployment and a variety of potential threats. Existing simulation frameworks are unable to handle complex security scenarios across these differing data exchange protocols. In this paper, we propose a novel EV orchestration framework: EVECTOR, which addresses the limitations of existing simulation systems by enabling both quantitative and qualitative analyses of EV charging scenarios. EVECTOR also provides a flexible attack orchestrator to simulate realistic attack behaviours on EV charging infrastructure. We validate the EVECTOR framework through two case studies: (a) cyber-physical attacks such as broken wire; and (b) cyber-specific attacks such as frame fuzzification. The case studies highlight the effectiveness of EVECTOR in providing deeper insights into the security and performance of EV charging systems.
2602.13926Feb 2026
View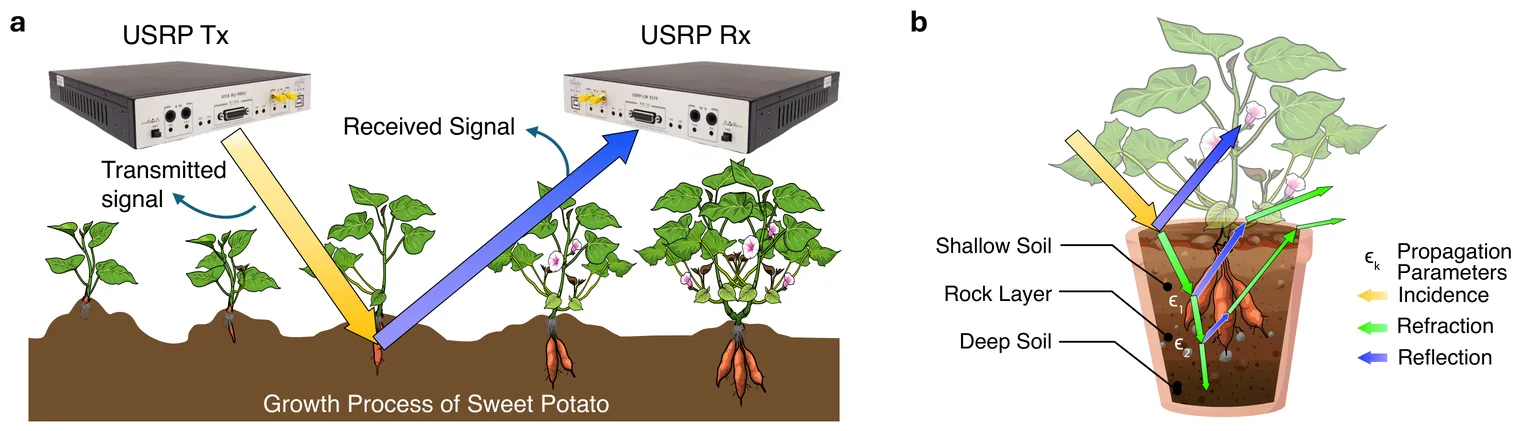
Commodity RF Sensing of Belowground Tuber Growth
Belowground yield-forming organs of root and tuber crops are difficult to measure during growth, and management therefore relies on aboveground proxies and destructive sampling. Aboveground wireless links could provide a low-cost, non-invasive alternative, but strong attenuation and soil-dependent variability make repeatable subsurface sensing challenging. In a controlled greenhouse pot study of sweet potato, we deploy aboveground antennas in a line-of-sight-suppressed geometry and collect daily swept-frequency channel spectra together with standardized cellular link indicators, revealing consistent frequency-dependent attenuation and rippling as tubers develop. Here, we show that swept-frequency measurements in the 2.0-3.5 gigahertz band yield four interpretable spectral features that classify day-indexed growth stages with up to 87.5% accuracy across two soil recipes and two moisture regimes, and that fusing cellular link-quality indicators enables 5-centimeter-grid tuber localization with up to 95.0% accuracy, providing a proof-of-concept for subsurface crop monitoring without buried sensors, and motivating validation across cultivars and larger soil volumes.
2602.00418Jan 2026
View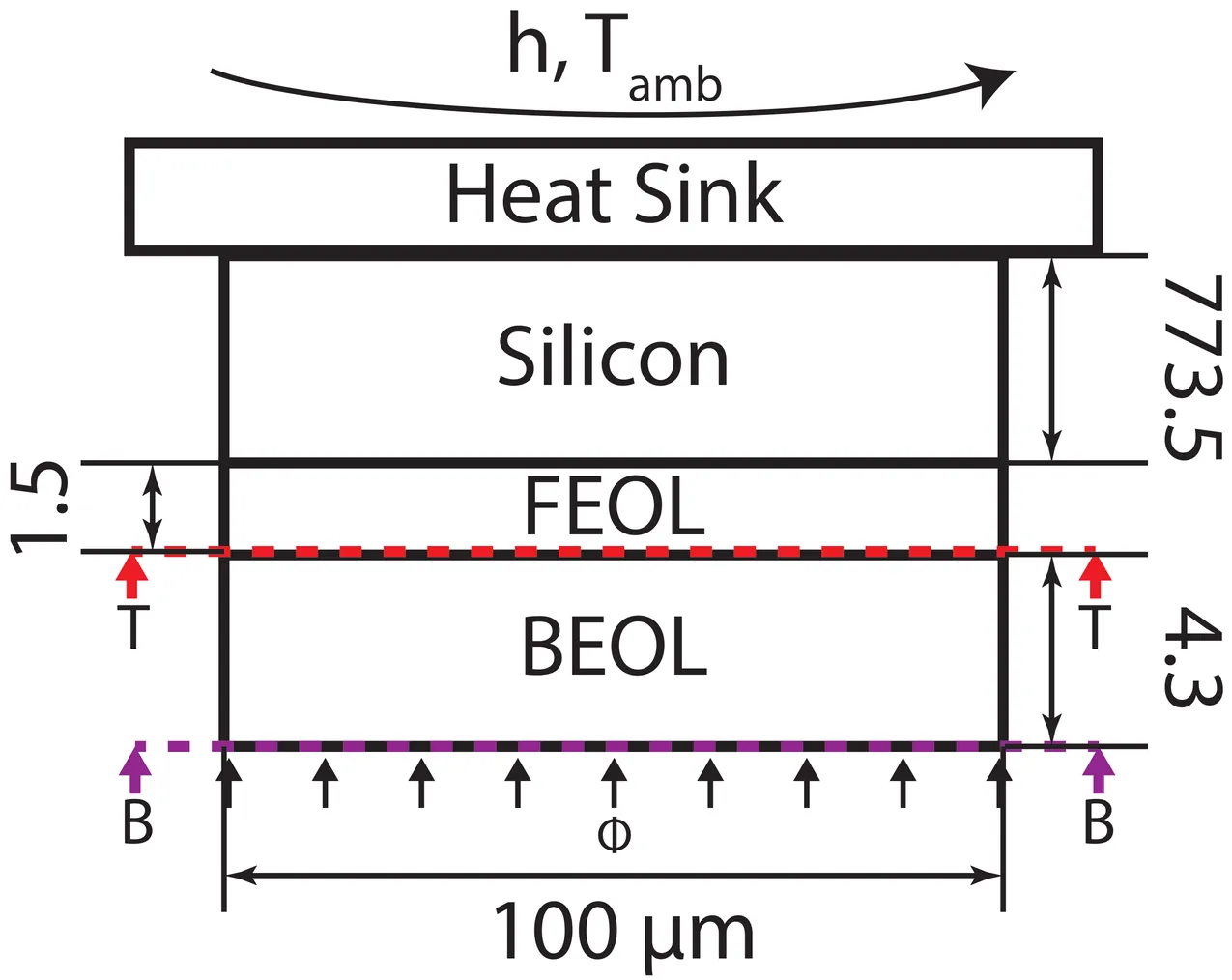
A Multiscale Workflow for Thermal Analysis of 3DI Chip Stacks
Thermally aware design of 2.5D and 3D advanced packaging systems will require fast, accurate, and powerful thermal analysis of chiplets, stacks, and packages. These systems contain multiple materials with non-linear heat transfer properties and geometric feature sizes that span many orders of magnitude. The smallest heterostructures in the front and back ends of the line present significant thermal modeling and analysis challenges in isolation. Replicated millions or billions of times in a chiplet stack, these structures present a near insurmountable hurdle to meeting the speed and accuracy needed of analysis in the design process. Additionally, establishing precise parameter values for the materials in these systems, when size and temperature dependencies create significant deviations from bulk properties, further complicates the problem. To address these issues, we have developed a multiscale methodology that advances the current state of the field by enabling die-scale simulations that capture phenomena arising from the structural details of the BEOL metallization stack. Taking advantage of the large length-scale separation between the BEOL features and the die-level structures, we employ a hierarchical, multiscale, finite-element approach. This hierarchical method uses a standard finite element method (FEM) formulation on a die or package scale, using computational homogenization to obtain effective thermal conductivities in the BEOL. Referring to industry-standard layout and design files, we construct and solve a locally appropriate subscale FEM problem in a representative volume element (RVE) at every quadrature point in the macroscale FEM problem. To accomplish this, RVE models are automatically constructed, meshed, and used to compute homogenized, anisotropic, thermal conductivities from the relevant GDSII or OASIS.
2602.06999Jan 2026
View
Fixing ill-formed UTF-16 strings with SIMD instructions
UTF-16 is a widely used Unicode encoding representing characters with one or two 16-bit code units. The format relies on surrogate pairs to encode characters beyond the Basic Multilingual Plane, requiring a high surrogate followed by a low surrogate. Ill-formed UTF-16 strings -- where surrogates are mismatched -- can arise from data corruption or improper encoding, posing security and reliability risks. Consequently, programming languages such as JavaScript include functions to fix ill-formed UTF-16 strings by replacing mismatched surrogates with the Unicode replacement character (U+FFFD). We propose using Single Instruction, Multiple Data (SIMD) instructions to handle multiple code units in parallel, enabling faster and more efficient execution. Our software is part of the Google JavaScript engine (V8) and thus part of several major Web browsers.
2601.06349Jan 2026
View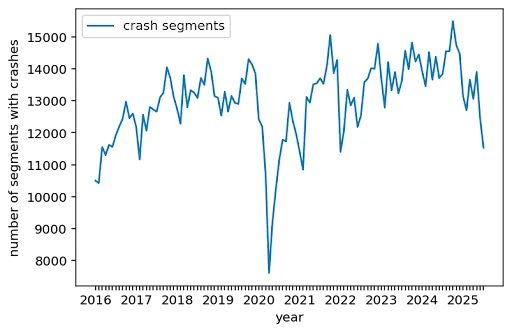
From Lagging to Leading: Validating Hard Braking Events as High-Density Indicators of Segment Crash Risk
Identifying high crash risk road segments and accurately predicting crash incidence is fundamental to implementing effective safety countermeasures. While collision data inherently reflects risk, the infrequency and inconsistent reporting of crashes present a major challenge to robust risk prediction models. The proliferation of connected vehicle technology offers a promising avenue to leverage high-density safety metrics for enhanced crash forecasting. A Hard-Braking Event (HBE), interpreted as an evasive maneuver, functions as a potent proxy for elevated driving risk due to its demonstrable correlation with underlying crash causal factors. Crucially, HBE data is significantly more readily available across the entire road network than conventional collision records. This study systematically evaluated the correlation at individual road segment level between police-reported collisions and aggregated and anonymized HBEs identified via the Google Android Auto platform, utilizing datasets from California and Virginia. Empirical evidence revealed that HBEs occur at a rate magnitudes higher than traffic crashes. Employing the state-of-the-practice Negative-Binomial regression models, the analysis established a statistically significant positive correlation between the HBE rate and the crash rate: road segments exhibiting a higher frequency of HBEs were consistently associated with a greater incidence of crashes. This sophisticated model incorporated and controlled for various confounding factors, including road type, speed profile, proximity to ramps, and road segment slope. The HBEs derived from connected vehicle technology thus provide a scalable, high-density safety surrogate metric for network-wide traffic safety assessment, with the potential to optimize safer routing recommendations and inform the strategic deployment of active safety countermeasures.
2601.06327Jan 2026
View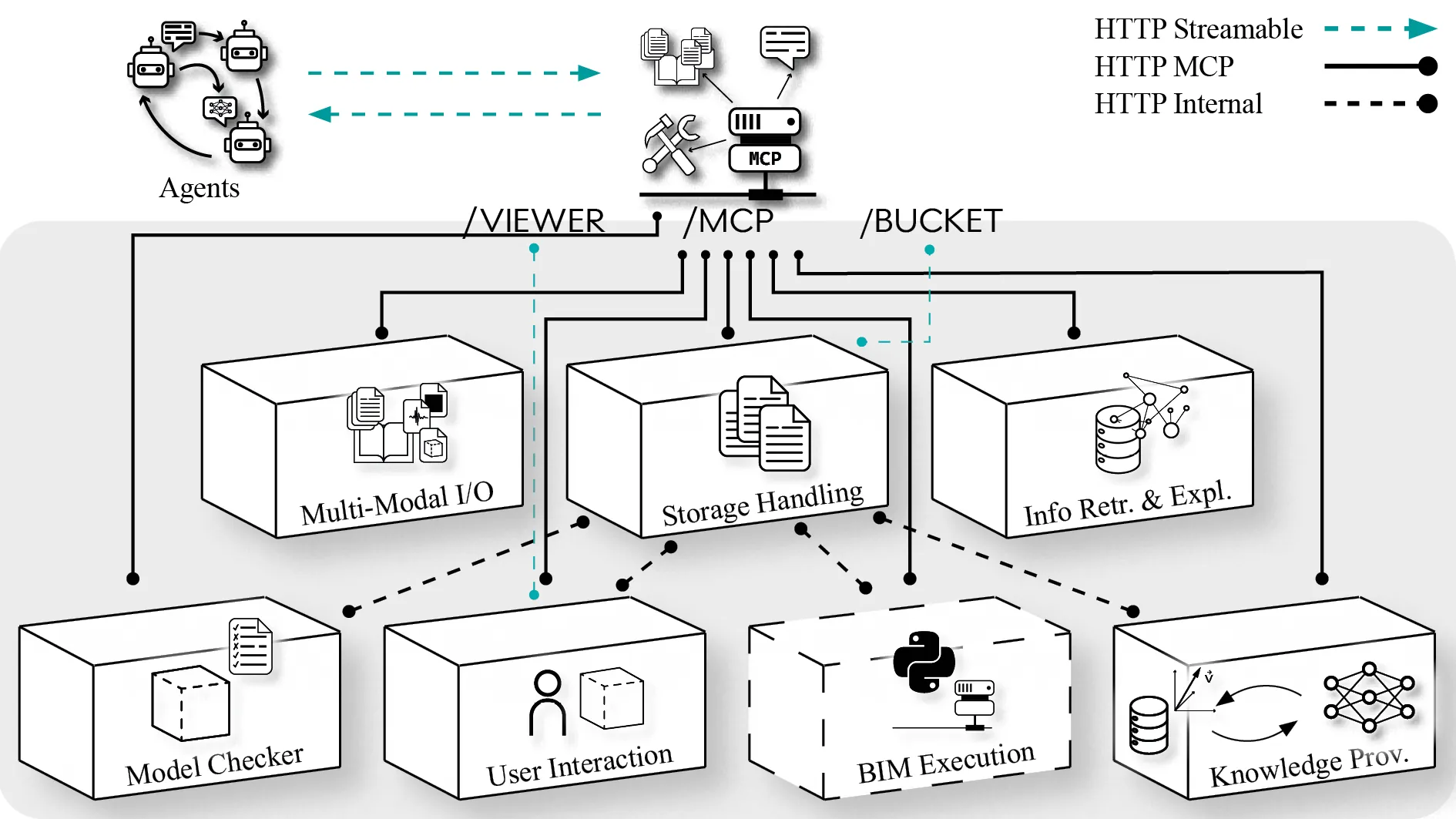
A Modular Reference Architecture for MCP-Servers Enabling Agentic BIM Interaction
Agentic workflows driven by large language models (LLMs) are increasingly applied to Building Information Modelling (BIM), enabling natural-language retrieval, modification and generation of IFC models. Recent work has begun adopting the emerging Model Context Protocol (MCP) as a uniform tool-calling interface for LLMs, simplifying the agent side of BIM interaction. While MCP standardises how LLMs invoke tools, current BIM-side implementations are still authoring tool-specific and ad hoc, limiting reuse, evaluation, and workflow portability across environments. This paper addresses this gap by introducing a modular reference architecture for MCP servers that enables API-agnostic, isolated and reproducible agentic BIM interactions. From a systematic analysis of recurring capabilities in recent literature, we derive a core set of requirements. These inform a microservice architecture centred on an explicit adapter contract that decouples the MCP interface from specific BIM-APIs. A prototype implementation using IfcOpenShell demonstrates feasibility across common modification and generation tasks. Evaluation across representative scenarios shows that the architecture enables reliable workflows, reduces coupling, and provides a reusable foundation for systematic research.
2601.00809Dec 2025
View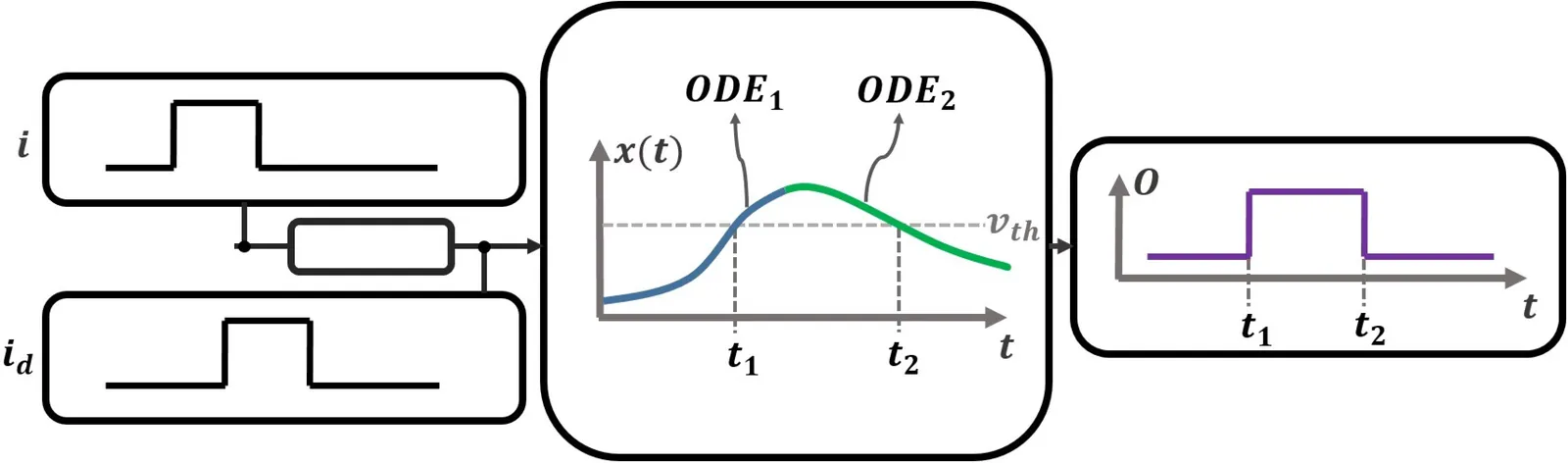
Drafting and Multi-Input Switching in Digital Dynamic Timing Simulation for Multi-Input Gates
We present a prototype multi-input gate extension of the publicly available Involution Tool for accurate digital timing simulation and power analysis of integrated circuits introduced by Oehlinger et al. (Integration, 2021). Relying on discrete event simulation, the Involution Tool allows fast timing simulation of circuits made up of an arbitrary composition of supported gates, provides automatic random input stimulus generation, and supports parameter sweeping. It also enables a detailed comparison of the delay predictions obtained by different models, including pure and inertial delays as well as digitized SPICE-generated reference traces. Our extension added support for 2-input gates like NOR and NAND, by implementing novel analytic delay formulas obtained via a refined analysis of a recently proposed thresholded first-order hybrid model of such gates. The resulting formulas faithfully cover not only multi-input switching effects (also known as Charlie effects), but also the decay of short pulses (aka Drafting effects). Besides the fact that our analytic models not only allow the derivation of closed-form delay formulas for arbitrary compositions of such gates, they are also key for a strikingly simple procedure for model parametrization, i.e., for gate characterization, which only needs three characteristic delay values. Using the extended Involution Tool, we compare the delay and power predictions for some benchmarking circuits stimulated by randomly generated input traces. Overall, our results reveal considerably improved prediction accuracy compared to the original Involution Tool, without a noticeable performance penalty.
2512.01309Dec 2025
View
Fast Resource Management Algorithm for Passive Surveillance Systems
Passive surveillance systems (PSS) detect and track objects that emit electromagnetic signals from hundreds of kilometers away. These systems have a limited number of receivers and can only observe a fraction of the frequencies of interest simultaneously. To improve its behavior, we propose the ResourceTune algorithm, which iteratively constructs optimized schedules to determine which frequencies each receiver should observe at a given time step. The algorithm's main component is the optimization of receiver configurations using a left-right heuristic combined with linear programming. Our approach is unique because, unlike others, we focus on optimizing available resources and observed frequencies, which was never done before. We experimentally compared the proposed algorithm with a greedy and the state-of-the-art method for construction of PSS schedules. In most of the considered scenarios, ResourceTune outperformed both algorithms, and in the most extreme case, its objective value was more than 2.7 times better than the values reached by other methods.
2511.19174Nov 2025
View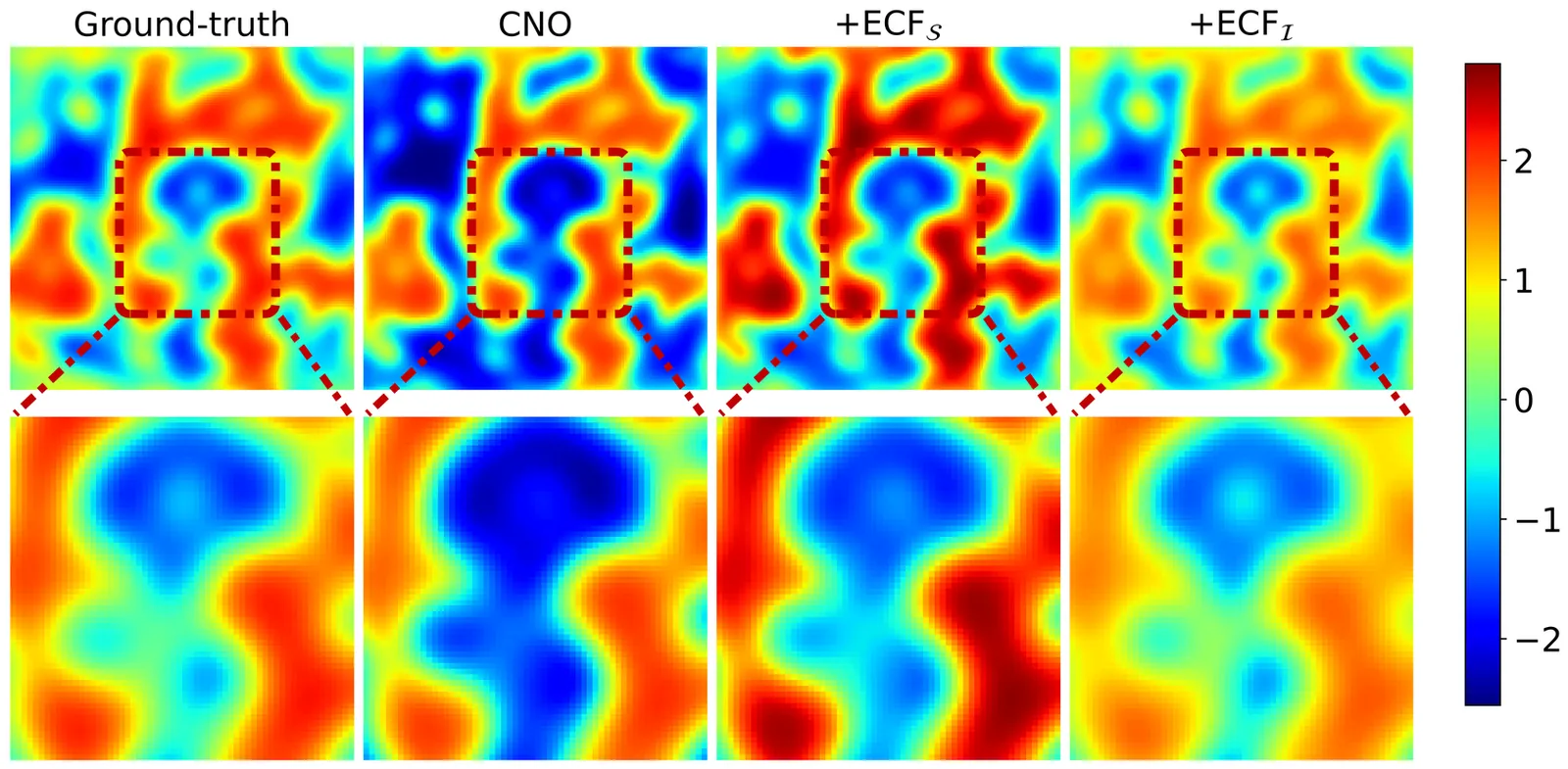
An Exterior-Embedding Neural Operator Framework for Preserving Conservation Laws
Neural operators have demonstrated considerable effectiveness in accelerating the solution of time-dependent partial differential equations (PDEs) by directly learning governing physical laws from data. However, for PDEs governed by conservation laws(e.g., conservation of mass, energy, or matter), existing neural operators fail to satisfy conservation properties, which leads to degraded model performance and limited generalizability. Moreover, we observe that distinct PDE problems generally require different optimal neural network architectures. This finding underscores the inherent limitations of specialized models in generalizing across diverse problem domains. To address these limitations, we propose Exterior-Embedded Conservation Framework (ECF), a universal conserving framework that can be integrated with various data-driven neural operators to enforce conservation laws strictly in predictions. The framework consists of two key components: a conservation quantity encoder that extracts conserved quantities from input data, and a conservation quantity decoder that adjusts the neural operator's predictions using these quantities to ensure strict conservation compliance in the final output. Since our architecture enforces conservation laws, we theoretically prove that it enhances model performance. To validate the performance of our method, we conduct experiments on multiple conservation-law-constrained PDE scenarios, including adiabatic systems, shallow water equations, and the Allen-Cahn problem. These baselines demonstrate that our method effectively improves model accuracy while strictly enforcing conservation laws in the predictions.
2511.16573Nov 2025
View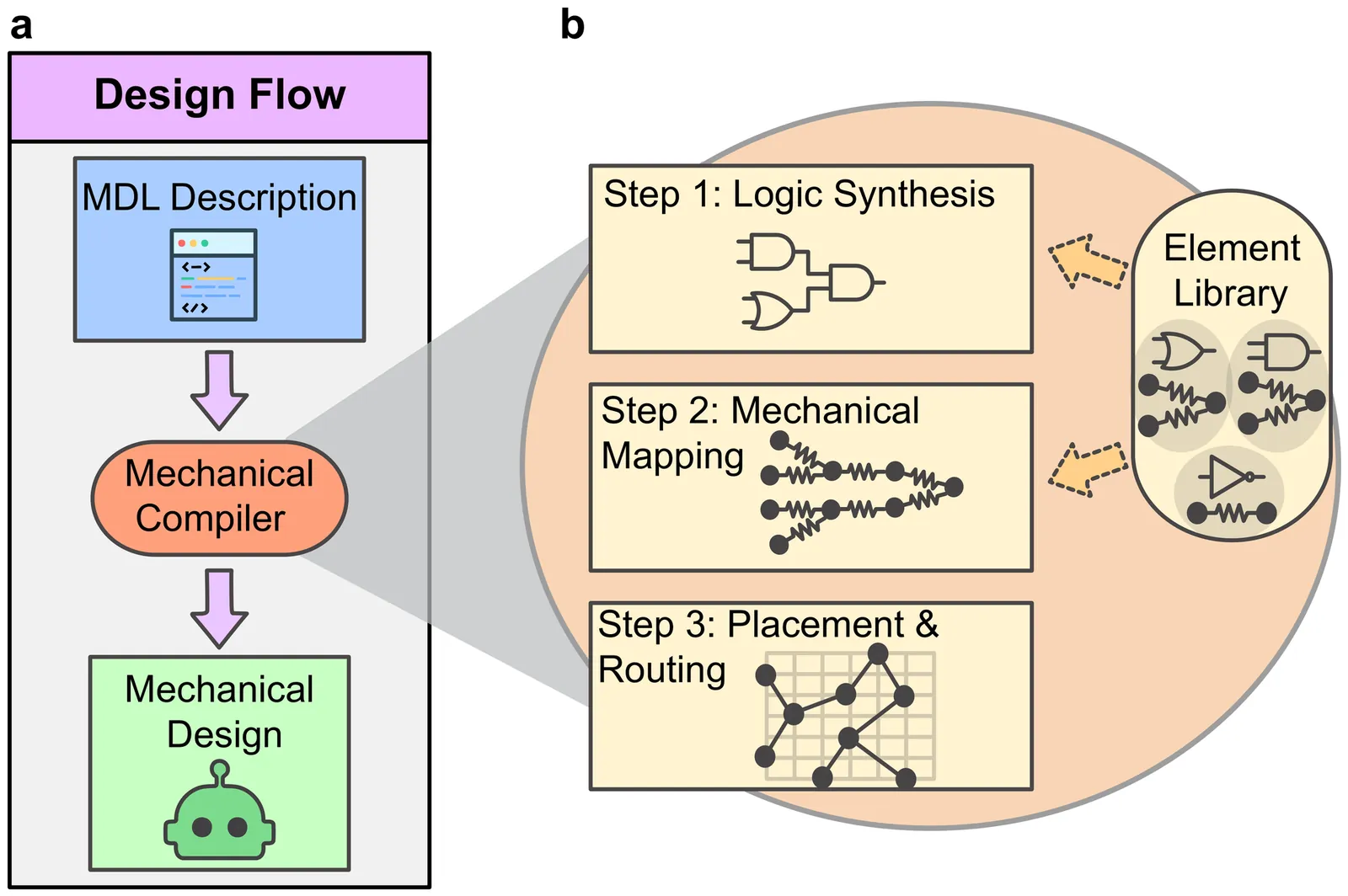
Synthesis of mass-spring networks from high-level code descriptions
Structural nonlinearity can be harnessed to program complex functionalities in robotic devices. However, it remains a challenge to design nonlinear systems that will accomplish a specific, desired task. The responses that we typically describe as intelligent -- such a robot navigating a maze -- require a large number of degrees of freedom and cannot be captured by traditional optimization objective functions. In this work, we explore a code-based synthesis approach to design mass-spring systems with embodied intelligence. The approach starts from a source code, written in a \emph{mechanical description language}, that details the system boundary, sensor and actuator locations, and desired behavior. A synthesizer software then automatically generates a mass-spring network that performs the described function from the source code description. We exemplify this methodology by designing mass-spring systems realizing a maze-navigating robot and a programmable lock. Remarkably, mechanical description languages can be combined with large-language models, to translate a natural-language description of a task into a functional device.
2511.17588Nov 2025
View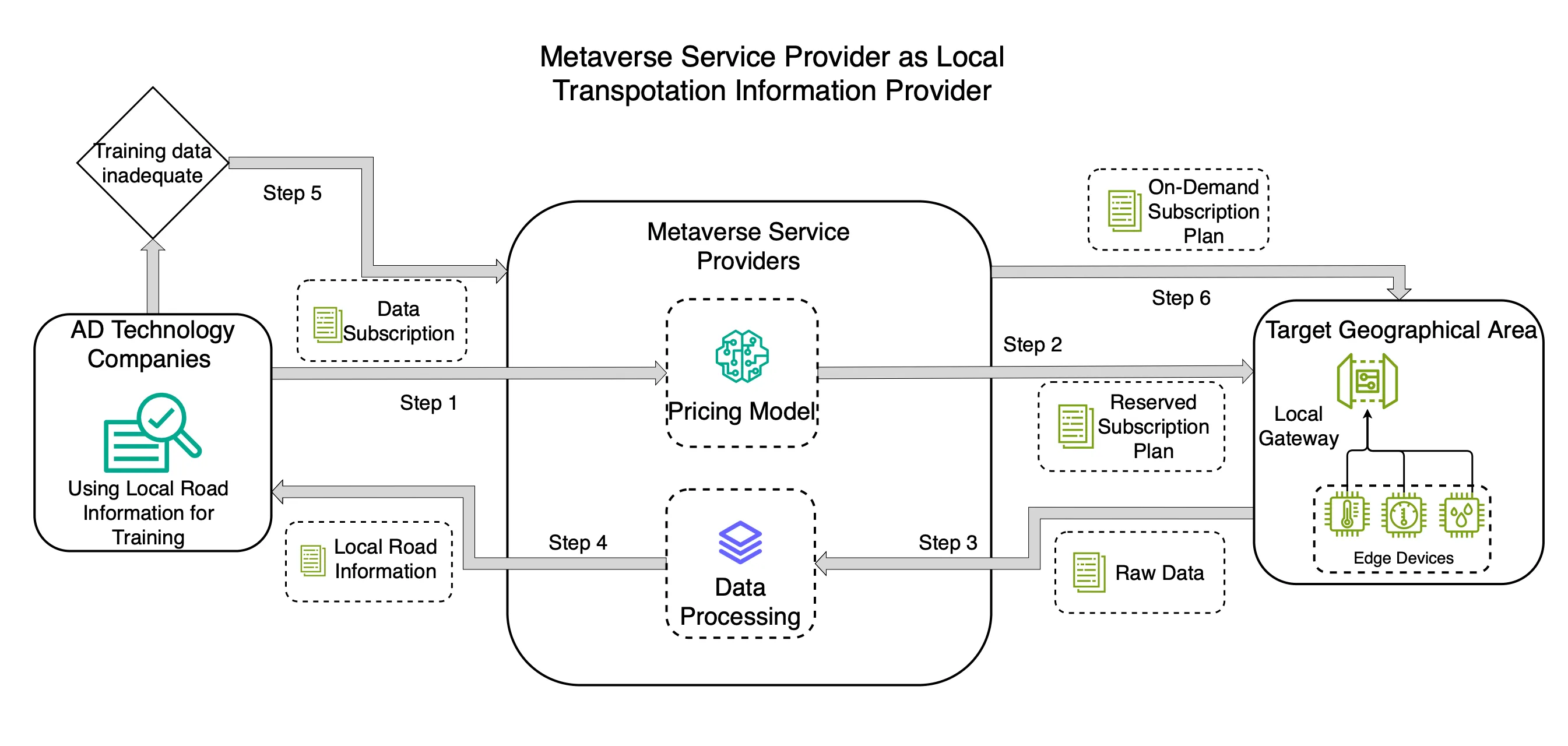
Coherent Optical Quantum Computing-Aided Resource Optimization for Transportation Digital Twin Construction
Constructing realistic digital twins for applications such as training autonomous driving models requires the efficient allocation of real-world data, yet data sovereignty regulations present a major challenge. To address this, we tackle the optimization problem faced by metaverse service providers (MSPs) responsible for allocating geographically constrained data resources. We propose a two-stage stochastic integer programming (SIP) model that incorporates reservation and on-demand planning, enabling MSPs to efficiently subscribe and allocate data from specific regions to clients for training their models on local road conditions. The SIP model is transformed into a quadratic unconstrained binary optimization (QUBO) formulation and implemented for the first time at a practical scale on a 550-qubit coherent Ising machine (CIM), representing an exploratory step toward future quantum computing paradigms. Our approach introduces an MSP-centric framework for compliant data collection under sovereignty constraints, a hybrid cost model combining deterministic fees with probabilistic penalties, and a practical implementation on quantum hardware. Experimental results demonstrate that CIM-based optimization finds high-quality solutions with millisecond-scale ($10^3$ second) computation times, significantly outperforming quantum-inspired solvers like PyQUBO. Although classical solvers such as Gurobi can achieve marginally better solution quality, CIM is orders of magnitude faster, establishing a practical paradigm for quantum-enhanced resource management.
2511.09760Nov 2025
View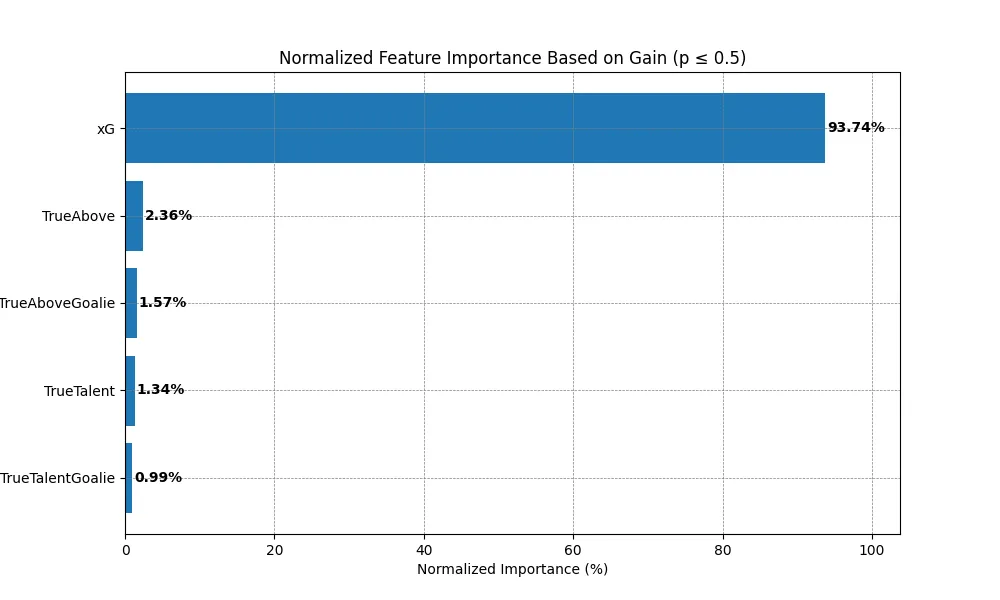
Expected by Whom? A Skill-Adjusted Expected Goals Model for NHL Shooters and Goaltenders
This study outlines a light gradient boosted model aimed at predicting shot outcomes in the NHL. The model uses the NHL's spatiotemporal data to account for both the skill of shooters and goaltenders. This approach involves isolating and engineering features for different aspects of shooter and goaltender skill. These aspects include the overall skill, the locational skill, which is engineered using a shot binning technique previously outlined by Shuckers and Curro, and the situational skill, which is engineered using Gower distance. Three separate datasets were created based on the skill of the shooter and goaltender. For each, a baseline model was created in order to compare and contrast its performance with the skill-adjusted model. The results seen in this study show performance increases for the skill-adjusted model over the baseline model in log loss, brier scores, and area under the ROC curve. These performance increases have a high of 5\% and outperform previous works, which have attempted to account only for player skill. This highlights the importance of accounting for both player and goaltender skill, while also accounting for different aspects of their skill. In future works, a skill-adjusted expected goals model could benefit models interested in predicting other aspects of the game, such as scoring leaders or individual game outcomes.
2511.07703Nov 2025
View
Reconfigurable Analog Computers
The Achilles heel of classic analog computers was the complex, error prone, and time consuming process of programming. This typically involved manually patching hundreds or even thousands of connections between individual computing elements as well as setting many precision 10-turn potentiometers manually, often taking hours, or even days. Albeit being simplified by means of removable patch panels, switching from one program to another still was time consuming and thus expensive. With digital computers about to hit physical boundaries with respect to energy consumption, clock frequency, and integration density, analog computers have gained a lot of interest as co-processors for certain application areas in recent years. This requires some means for automatic reconfiguration of these systems under control of an attached digital computer. The following sections give an overview of classic and modern approaches towards such autopatch systems.
2510.25942Oct 2025
View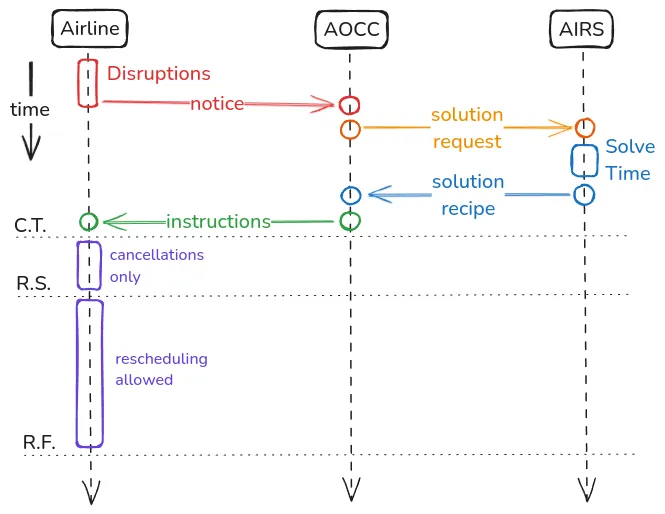
Disruption Management in Airline Operations: A Solver-based Approach using Time-Space Network Optimization
This paper presents AIRS, a day-of-operations disruption-recovery system. AIRS.ACR models integrated aircraft-crew recovery on a Time-Space Network (TSN) and solves a mixed-integer linear program (MILP) that enforces rotation continuity, crew legality, maintenance windows, slot capacities, and multi-leg integrity via flow-balance constraints; disruption-aware search-space construction and warm starts control combinatorial growth. A companion module, AIRS.PaxR, performs rapid passenger re-accommodation using greedy assignment and lightweight evolutionary search while preserving aircraft-crew feasibility. Across realistic evaluations, AIRS meets operational decision windows and reduces recovery costs relative to manual or sequential methods, providing a scalable, extensible decision-support capability for operations control centers.
2510.26831Oct 2025
ViewPage 1 of 4