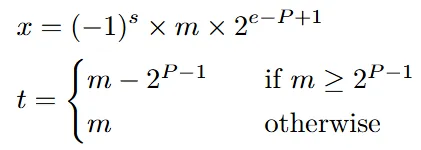Trending in Mathematical Software
Scorio.jl: A Julia package for ranking stochastic responses
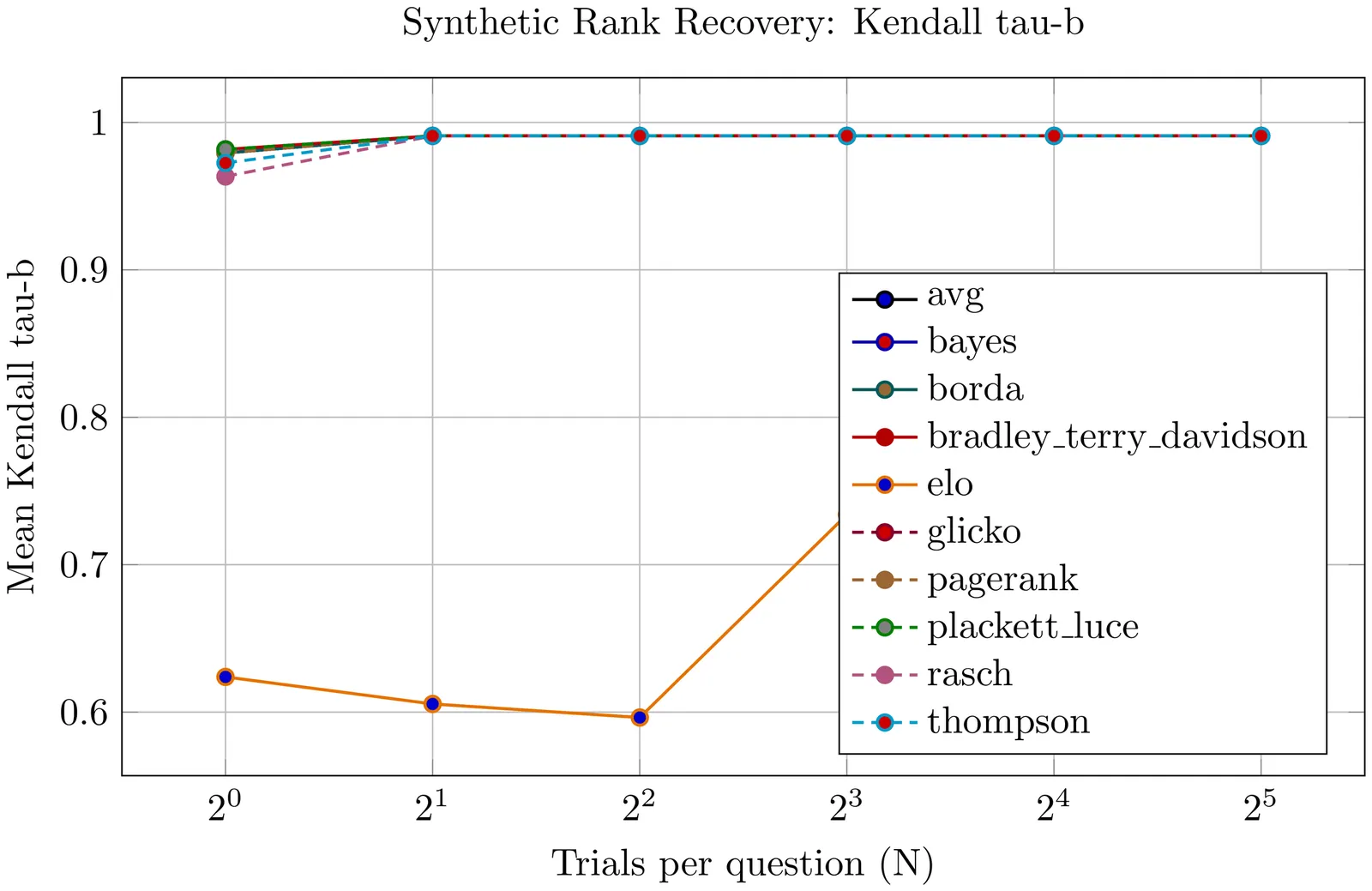
Scorio.jl is a Julia package for evaluating and ranking systems from repeated responses to shared tasks. It provides a common tensor-based interface for direct score-based, pairwise, psychometric, voting, graph, and listwise methods, so the same benchmark can be analyzed under multiple ranking assumptions. We describe the package design, position it relative to existing Julia tools, and report pilot experiments on synthetic rank recovery, stability under limited trials, and runtime scaling.
2603.14103
Mar 2026Mathematical Software

CuTe Layout Representation and Algebra
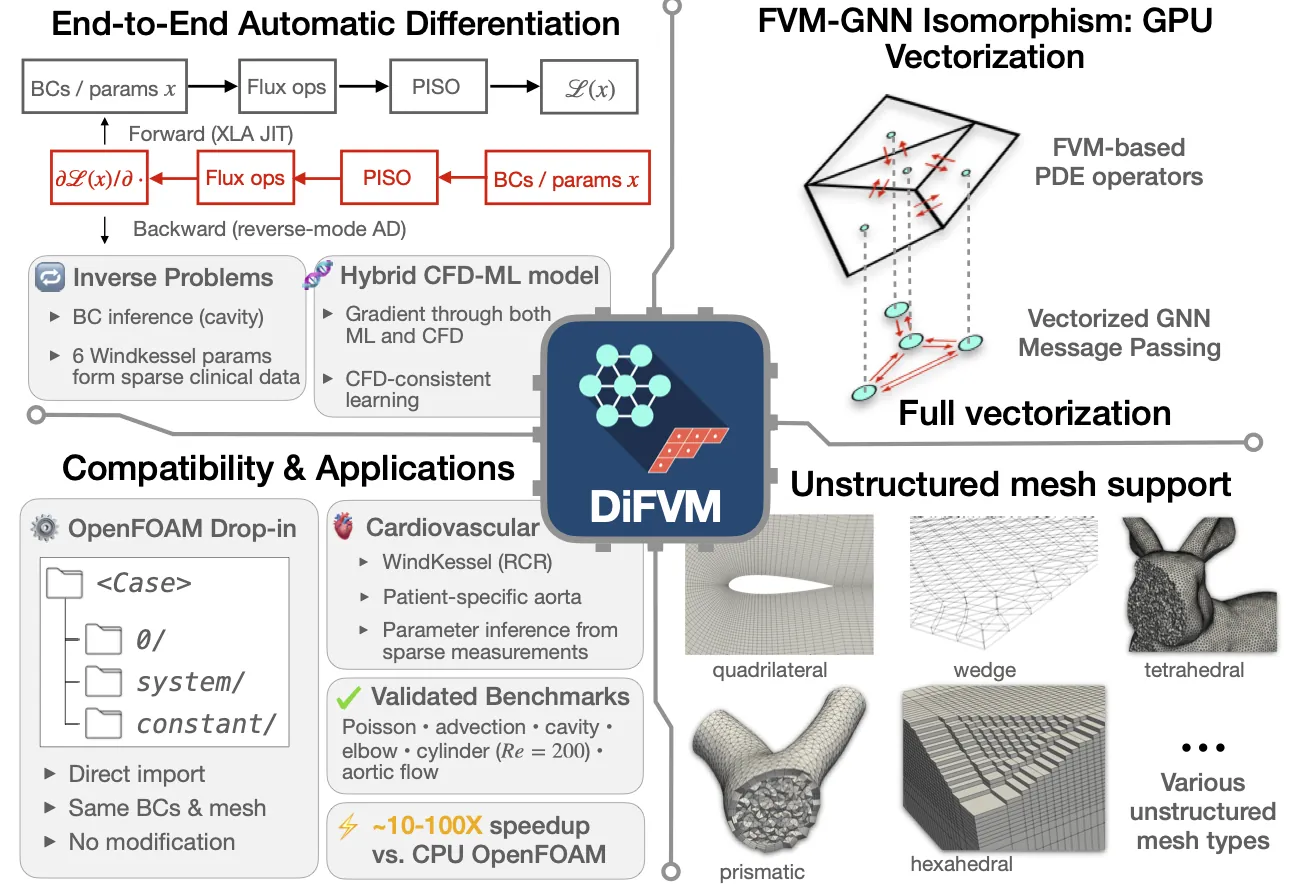
Modern architectures for high-performance computing and deep learning increasingly incorporate specialized tensor instructions, including tensor cores for matrix multiplication and hardware-optimized copy operations for multi-dimensional data. These instructions prescribe fixed, often complex data layouts that must be correctly propagated through the entire execution pipeline to ensure both correctness and optimal performance. We present CuTe, a novel mathematical specification for representing and manipulating tensors. CuTe introduces two key innovations: (1) a hierarchical layout representation that directly extends traditional flat-shape and flat-stride tensor representations, enabling the representation of complex mappings required by modern hardware instructions, and (2) a rich algebra of layout operations -- including concatenation, coalescence, composition, complementation, division, tiling, and inversion -- that enables sophisticated layout manipulation, derivation, verification, and static analysis. CuTe layouts provide a framework for managing both data layouts and thread arrangements in GPU kernels, while the layout algebra enables powerful compile-time reasoning about layout properties and the expression of generic tensor transformations. In this work, we demonstrate that CuTe's abstractions significantly aid software development compared to traditional approaches, promote compile-time verification of architecturally prescribed layouts, facilitate the implementation of algorithmic primitives that generalize to a wide range of applications, and enable the concise expression of tiling and partitioning patterns required by modern specialized tensor instructions. CuTe has been successfully deployed in production systems, forming the foundation of NVIDIA's CUTLASS library and a number of related efforts including CuTe DSL.
2603.02298
Mar 2026Mathematical Software

TorchLean: Formalizing Neural Networks in Lean
Neural networks are increasingly deployed in safety- and mission-critical pipelines, yet many verification and analysis results are produced outside the programming environment that defines and runs the model. This separation creates a semantic gap between the executed network and the analyzed artifact, so guarantees can hinge on implicit conventions such as operator semantics, tensor layouts, preprocessing, and floating-point corner cases. We introduce TorchLean, a framework in the Lean 4 theorem prover that treats learned models as first-class mathematical objects with a single, precise semantics shared by execution and verification. TorchLean unifies (1) a PyTorch-style verified API with eager and compiled modes that lower to a shared op-tagged SSA/DAG computation-graph IR, (2) explicit Float32 semantics via an executable IEEE-754 binary32 kernel and proof-relevant rounding models, and (3) verification via IBP and CROWN/LiRPA-style bound propagation with certificate checking. We validate TorchLean end-to-end on certified robustness, physics-informed residual bounds for PINNs, and Lyapunov-style neural controller verification, alongside mechanized theoretical results including a universal approximation theorem. These results demonstrate a semantics-first infrastructure for fully formal, end-to-end verification of learning-enabled systems.
2602.22631
Feb 2026Mathematical Software