8 papers
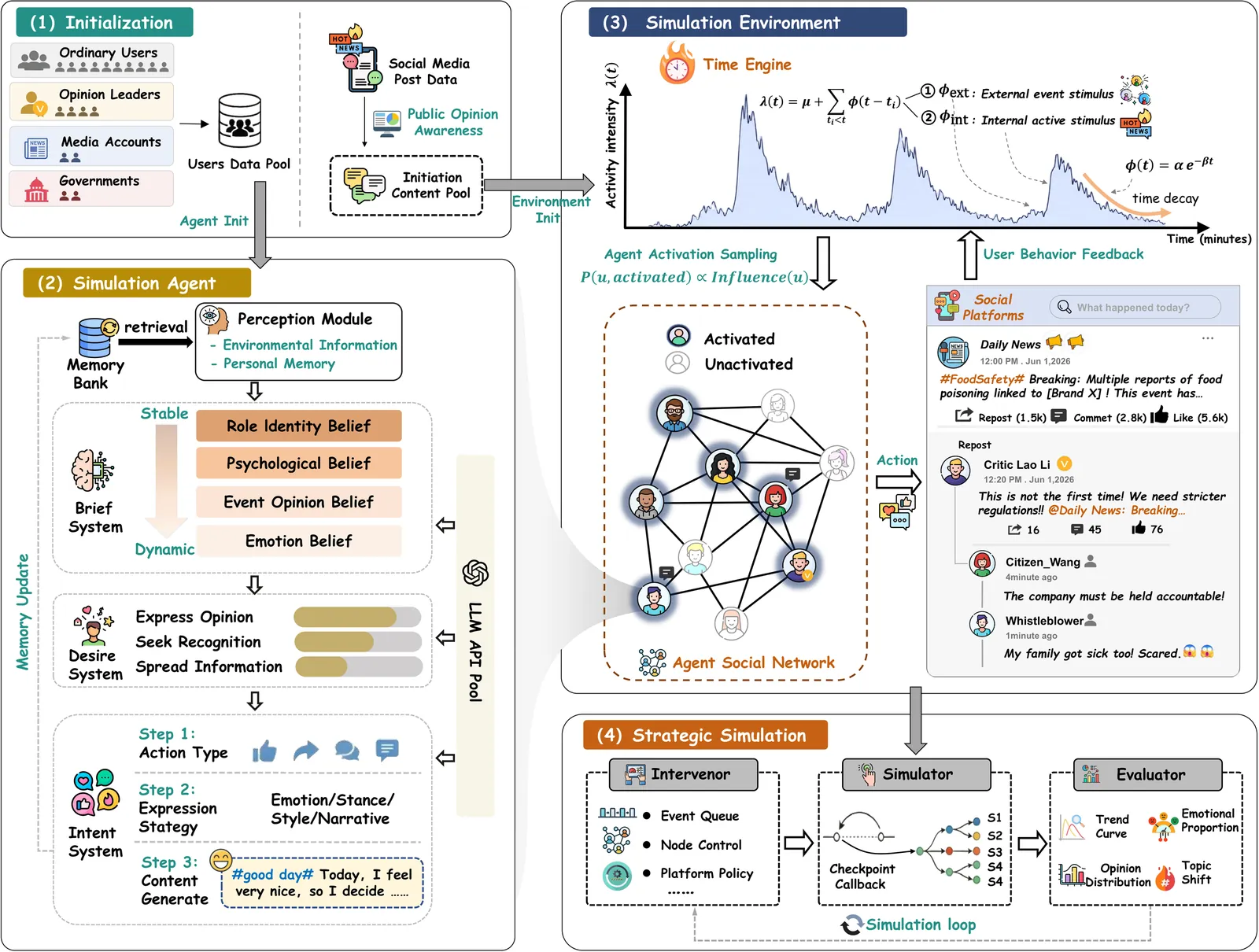
POSIM: A Multi-Agent Simulation Framework for Social Media Public Opinion Evolution and Governance
Modeling social media public opinion evolution is essential for governance decision-making. Traditional epidemic models and rule-based agent-based models (ABMs) fail to capture the cognitive processes and adaptive behaviors of real users. Recent large language model (LLM)-based social simulations can reproduce group-level phenomena like polarization and conformity, yet remain unable to recreate the irrational interactions and multi-phase dynamics of real public opinion events. We present POSIM (Public Opinion Simulator), a multi-agent simulation framework for social media public opinion evolution and governance. POSIM integrates LLM-driven agents with a Belief--Desire--Intention (BDI) cognitive architecture that accounts for irrational factors, places them in a virtual social media environment with social networks and recommendation mechanisms, and drives temporal dynamics through a Hawkes point process engine that captures the co-evolution of agents and the environment across event phases. To validate the framework, we collect real-world public opinion datasets from the Weibo platform covering the full interaction chain of users. Experiments show that POSIM successfully reproduces key characteristics of public opinion evolution from individual mechanisms to collective phenomena, and its effectiveness is further supported by multiple statistical metrics. Building on POSIM, governance-oriented guidance and intervention experiments uncover a counterintuitive empathy paradox: empathetic guidance deepens negative sentiment instead of easing it under certain conditions, offering new insights for governance strategy design. These results demonstrate that the proposed framework can fully serve as a computational experimentation platform for proactive strategy evaluation and evidence-based governance. All source code is available at https://github.com/DeepCogLab/posim/.
2603.23884Mar 2026
ViewOn the First Computer Science Research Paper in an Indian Language and the Future of Science in Indian Languages
I describe my experience writing the first original, modern Computer Science research paper expressed entirely in an Indian language. The paper is in Telugu, a language with approximately 100 million speakers. The paper is in the field of distributed computing and it introduces a technique for proving epistemic logic based lower bounds for multiprocessor algorithms. A key hurdle to writing the paper was developing technical terminology for advanced computer science concepts, including those in algorithms, distributed computing, and discrete mathematics. I overcame this challenge by deriving and coining native language scientific terminology through the powerful, productive, Pāninian grammar of Samskrtam. The typesetting of the paper was an additional challenge, since mathematical typesetting in Telugu is underdeveloped. I overcame this problem by developing a Telugu XeLaTeX template, which I call TeluguTeX. Leveraging this experience of writing an original computer science research paper in an Indian language, I lay out a vision for how to ameliorate the state of scientific writing at all levels in Indic languages -- languages whose native speakers exceed one billion people -- through the further development of the Sanskrit technical lexicon and through technological internationalization.
2604.03265Mar 2026
View
Education Paradigm Shift To Maintain Human Competitive Advantage Over AI
Discussion about the replacement of intellectual human labour by ``thinking machines'' has been present in the public and expert discourse since the creation of Artificial Intelligence (AI) as an idea and terminology since the middle of the twentieth century. Until recently, it was more of a hypothetical concern. However, in recent years, with the rise of Generative AI, especially Large Language Models (LLM), and particularly with the widespread popularity of the ChatGPT model, that concern became practical. Many domains of human intellectual labour have to adapt to the new AI tools that give humans new functionality and opportunity, but also question the viability and necessity of some human work that used to be considered intellectual yet has now become an easily automatable commodity. Education, unexpectedly, has now become burdened by an especially crucial role of charting long-range strategies for discovering viable human skills that would guarantee their place in the world of the ubiquitous use of AI in the intellectual sphere. We highlight weaknesses of the current AI and, especially, of its LLM-based core, show that root causes of LLMs' weaknesses are unfixable by the current technologies, and propose directions in the constructivist paradigm for the changes in Education that ensure long-term advantages of humans over AI tools.
2510.234361Oct 2025
View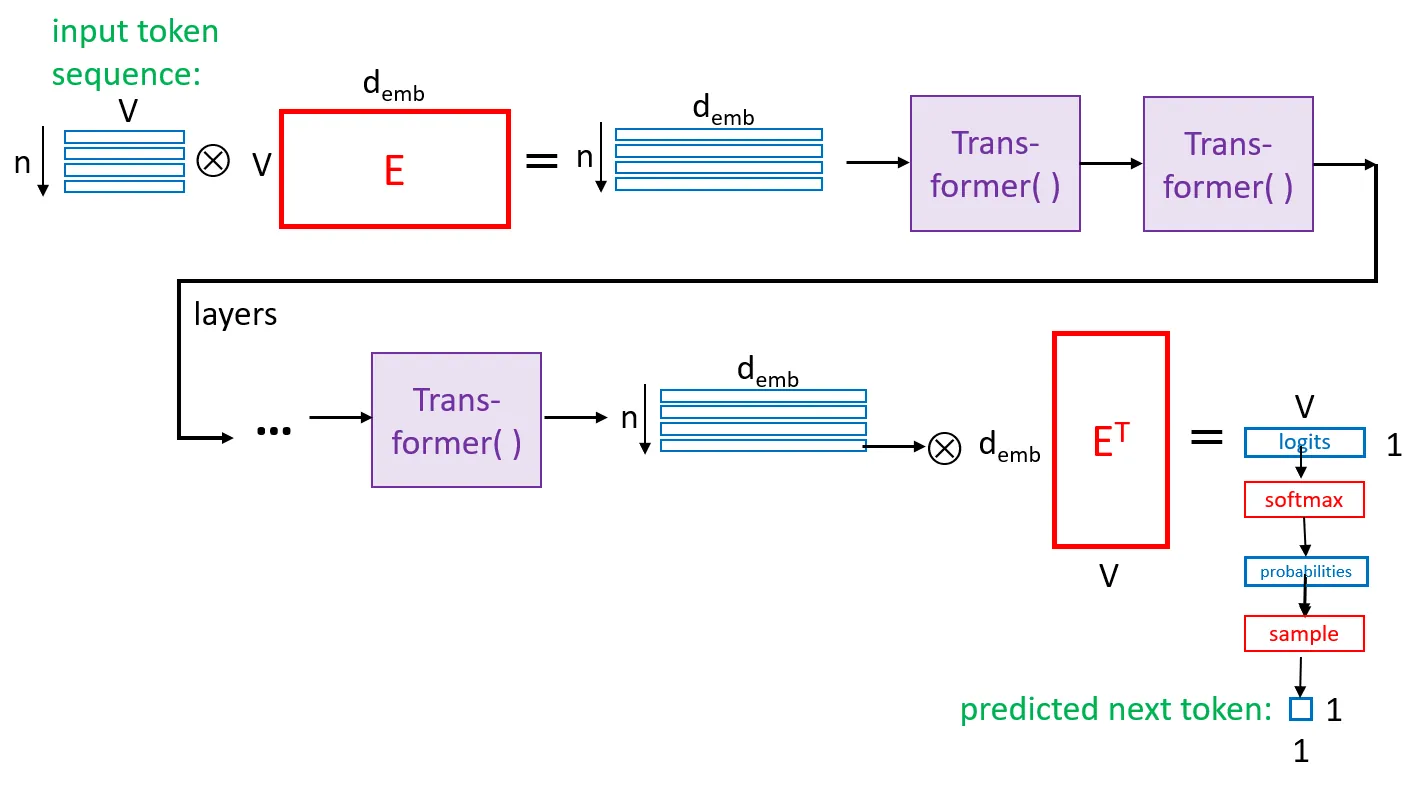
LLM Architecture, Scaling Laws, and Economics: A Quick Summary
The current standard architecture of Large Language Models (LLMs) with QKV self-attention is briefly summarized, including the architecture of a typical Transformer. Scaling laws for compute (flops) and memory (parameters plus data) are given, along with their present (2025) rough cost estimates for the parameters of present LLMs of various scales, including discussion of whether DeepSeek should be viewed as a special case. Nothing here is new, but this material seems not otherwise readily available in summary form.
2511.11572Sep 2025
ViewMesterséges Intelligencia Kutatások Magyarországon
Artificial intelligence (AI) has undergone remarkable development since the mid-2000s, particularly in the fields of machine learning and deep learning, driven by the explosive growth of large databases and computational capacity. Hungarian researchers recognized the significance of AI early on, actively participating in international research and achieving significant results in both theoretical and practical domains. This article presents some key achievements in Hungarian AI research. It highlights the results from the period before the rise of deep learning (the early 2010s), then discusses major theoretical advancements in Hungary after 2010. Finally, it provides a brief overview of AI-related applied scientific achievements from 2010 onward.
2503.05767Feb 2025
ViewSymbolic Mathematical Computation 1965--1975: The View from a Half-Century Perspective
The 2025 ISSAC conference in Guanajuato, Mexico, marks the 50th event in this significant series, making it an ideal moment to reflect on the field's history. This paper reviews the formative years of symbolic computation up to 1975, fifty years ago. By revisiting a period unfamiliar to most current participants, this survey aims to shed light on once-pressing issues that are now largely resolved and to highlight how some of today's challenges were recognized earlier than expected.
2501.164571Jan 2025
ViewEternal Sunshine of the Mechanical Mind: The Irreconcilability of Machine Learning and the Right to be Forgotten
As we keep rapidly advancing toward an era where artificial intelligence is a constant and normative experience for most of us, we must also be aware of what this vision and this progress entail. By first approximating neural connections and activities in computer circuits and then creating more and more sophisticated versions of this crude approximation, we are now facing an age to come where modern deep learning-based artificial intelligence systems can rightly be called thinking machines, and they are sometimes even lauded for their emergent behavior and black-box approaches. But as we create more powerful electronic brains, with billions of neural connections and parameters, can we guarantee that these mammoths built of artificial neurons will be able to forget the data that we store in them? If they are at some level like a brain, can the right to be forgotten still be protected while dealing with these AIs? The essential gap between machine learning and the RTBF is explored in this article, with a premonition of far-reaching conclusions if the gap is not bridged or reconciled any time soon. The core argument is that deep learning models, due to their structure and size, cannot be expected to forget or delete a data as it would be expected from a tabular database, and they should be treated more like a mechanical brain, albeit still in development.
2403.055922Mar 2024
View
The History of Quantum Games
In this paper, we explore the historical development of playable quantum physics related games (\textit{\textbf{quantum games}}). For the purpose of this examination, we have collected over 260 quantum games ranging from commercial games, applied and serious games, and games that have been developed at quantum themed game jams and educational courses. We provide an overview of the journey of quantum games across three dimensions: \textit{the perceivable dimension of quantum physics, the dimension of scientific purposes, and the dimension of quantum technologies}. We then further reflect on the definition of quantum games and its implications. While motivations behind developing quantum games have typically been educational or academic, themes related to quantum physics have begun to be more broadly utilised across a range of commercial games. In addition, as the availability of quantum computer hardware has grown, entirely new variants of quantum games have emerged to take advantage of these machines' inherent capabilities, \textit{quantum computer games}
2309.015258Sep 2023
View