615 papers
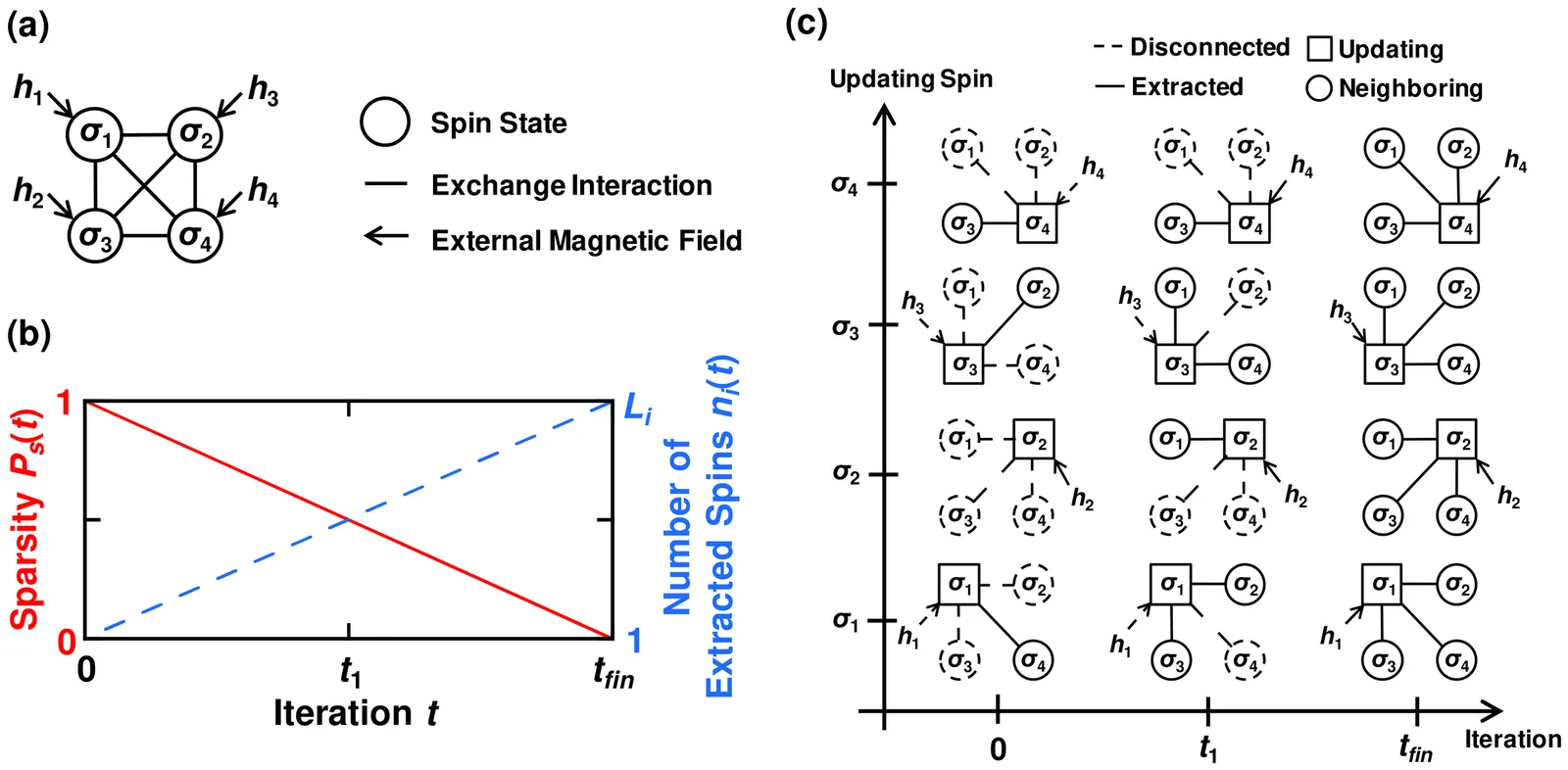
Quantum-inspired Ising machine using sparsified spin connectivity
Combinatorial optimization problems become computationally intractable as these NP-hard problems scale. We previously proposed extraction-type majority voting logic (E-MVL), a quantum-inspired algorithm using digital logic circuits. E-MVL mimics the thermal spin dynamics of simulated annealing (SA) through controlled sparsification of spin interactions for efficient ground-state search. This study investigates the performance potential of E-MVL through systematic optimization and comprehensive benchmarking against SA. The target problem is the Sherrington-Kirkpatrick (SK) model with bimodal and Gaussian coupling distributions. Through equilibrium state analysis, we demonstrate that the sparsity control mechanism provides a consistent search of the solution space regardless of the problem's coupling distribution (bimodal, Gaussian) or size. E-MVL not only achieves the best performance among all tested algorithms-solving exact solutions up to 1600 spins where the best SA baseline is limited to 400 spins-but also provides insights that significantly improve SA's own temperature scheduling. These results establish E-MVL's dual contribution as both an efficient optimizer and a practical methodology for enhancing SA performance. Moreover, FPGA implementation achieved an approximately 6-fold faster solution speed than SA.
2604.04606Apr 2026
View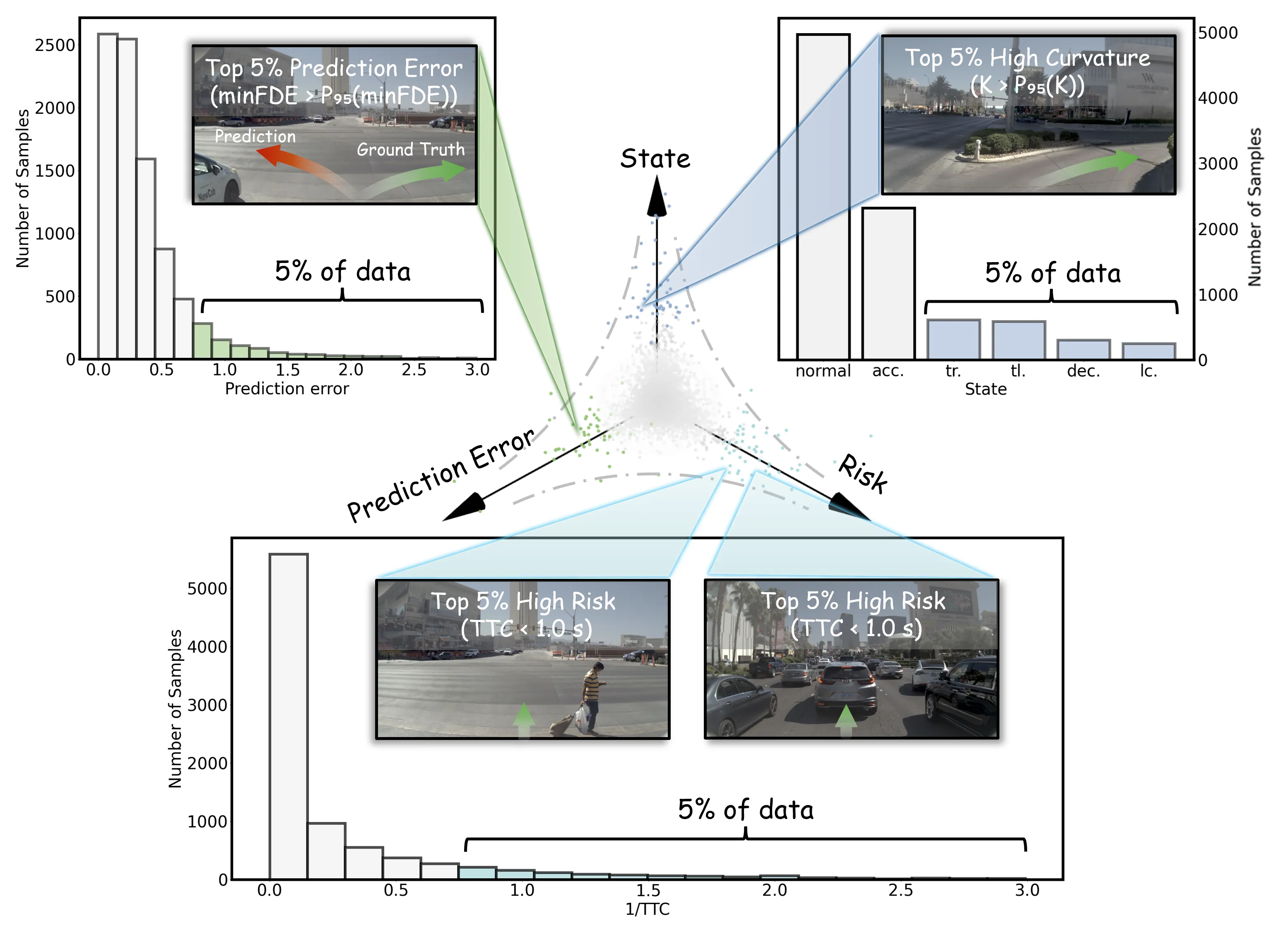
SAIL: Scene-aware Adaptive Iterative Learning for Long-Tail Trajectory Prediction in Autonomous Vehicles
Autonomous vehicles (AVs) rely on accurate trajectory prediction for safe navigation in diverse traffic environments, yet existing models struggle with long-tail scenarios-rare but safety-critical events characterized by abrupt maneuvers, high collision risks, and complex interactions. These challenges stem from data imbalance, inadequate definitions of long-tail trajectories, and suboptimal learning strategies that prioritize common behaviors over infrequent ones. To address this, we propose SAIL, a novel framework that systematically tackles the long-tail problem by first defining and modeling trajectories across three key attribute dimensions: prediction error, collision risk, and state complexity. Our approach then synergizes an attribute-guided augmentation and feature extraction process with a highly adaptive contrastive learning strategy. This strategy employs a continuous cosine momentum schedule, similarity-weighted hard-negative mining, and a dynamic pseudo-labeling mechanism based on evolving feature clustering. Furthermore, it incorporates a focusing mechanism to intensify learning on hard-positive samples within each identified class. This comprehensive design enables SAIL to excel at identifying and forecasting diverse and challenging long-tail events. Extensive evaluations on the nuScenes and ETH/UCY datasets demonstrate SAIL's superior performance, achieving up to 28.8% reduction in prediction error on the hardest 1% of long-tail samples compared to state-of-the-art baselines, while maintaining competitive accuracy across all scenarios. This framework advances reliable AV trajectory prediction in real-world, mixed-autonomy settings.
2604.04573Apr 2026
View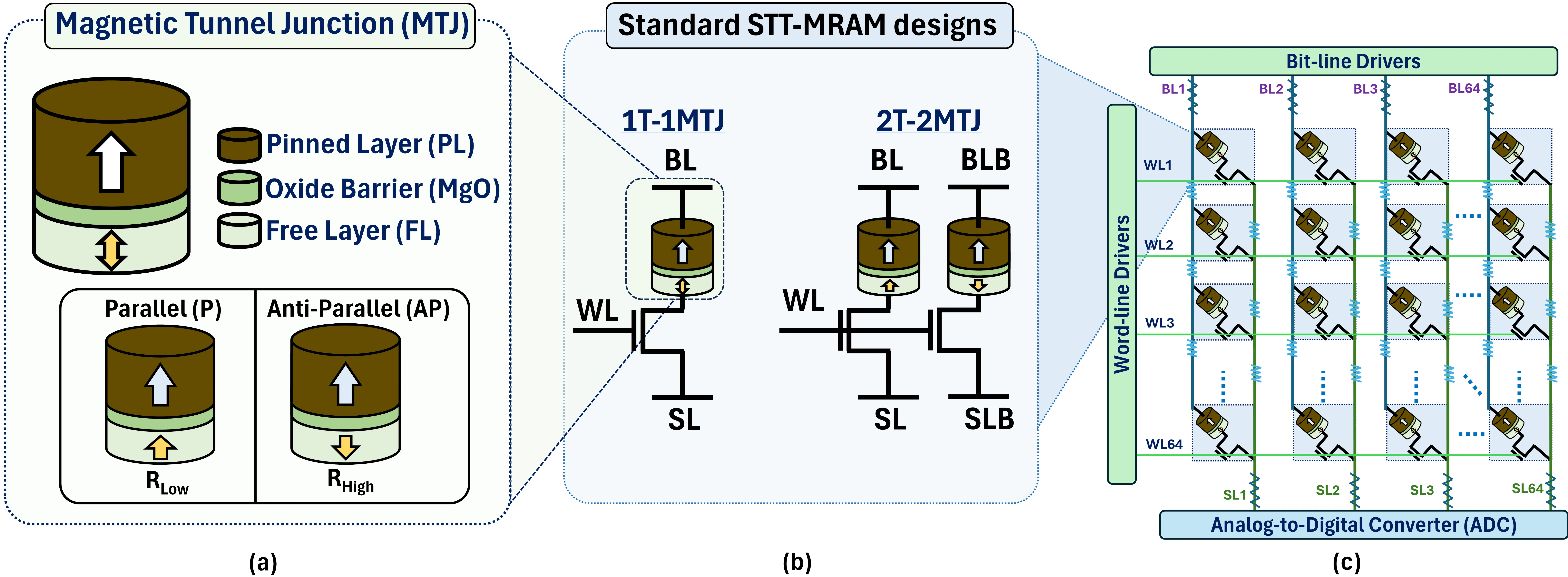
STRIDe: Cross-Coupled STT-MRAM Enabling Robust In-Memory-Computing for Deep Neural Network Accelerators
As deep neural network (DNN) models are growing exponentially in size, their deployment on resource-constrained edge platforms is becoming increasingly challenging. In-memory-computing (IMC) with non-volatile memories (NVMs) has emerged as a potential solution by virtue of its higher energy efficiency compared to standard DNN hardware platforms. Amongst various NVMs, STT-MRAM is highly promising owing to its high endurance and other benefits. However, their IMC implementation is challenging because of their inherently low distinguishability. This issue is exacerbated due to array non-idealities and process-variations, leading to poor IMC robustness and severe inference accuracy degradation. To address this problem, we propose STRIDe - STT-MRAM-based IMC leveraging cross-coupling action to boost the bitcell-level high-to-low current ratio to up to 8000. We propose two flavors of STRIDe designs, both offering robust IMC for inputs and weights in {-1, 1}(XNOR-IMC) and {0, 1}(AND-IMC) regime. Our evaluations for STRIDe arrays show up to 3.86x and 1.77x sense margin (SM) improvement for XNOR-IMC and AND-IMC, respectively, and up to 27.6% read disturb margin (RDM) improvement over standard MRAM-IMC designs. The enhanced robustness of STRIDe translates to near-software inference accuracies (considering crossbar non-idealities and process variations) for ResNet18 BNN and 4-bit DNN trained on CIFAR10 dataset. We observe accuracy improvements of up to 70% (for BNN) and up to 35%(for 4-bit DNN) over standard MRAM designs, albeit with some energy-area-latency penalty.
2604.04483Apr 2026
View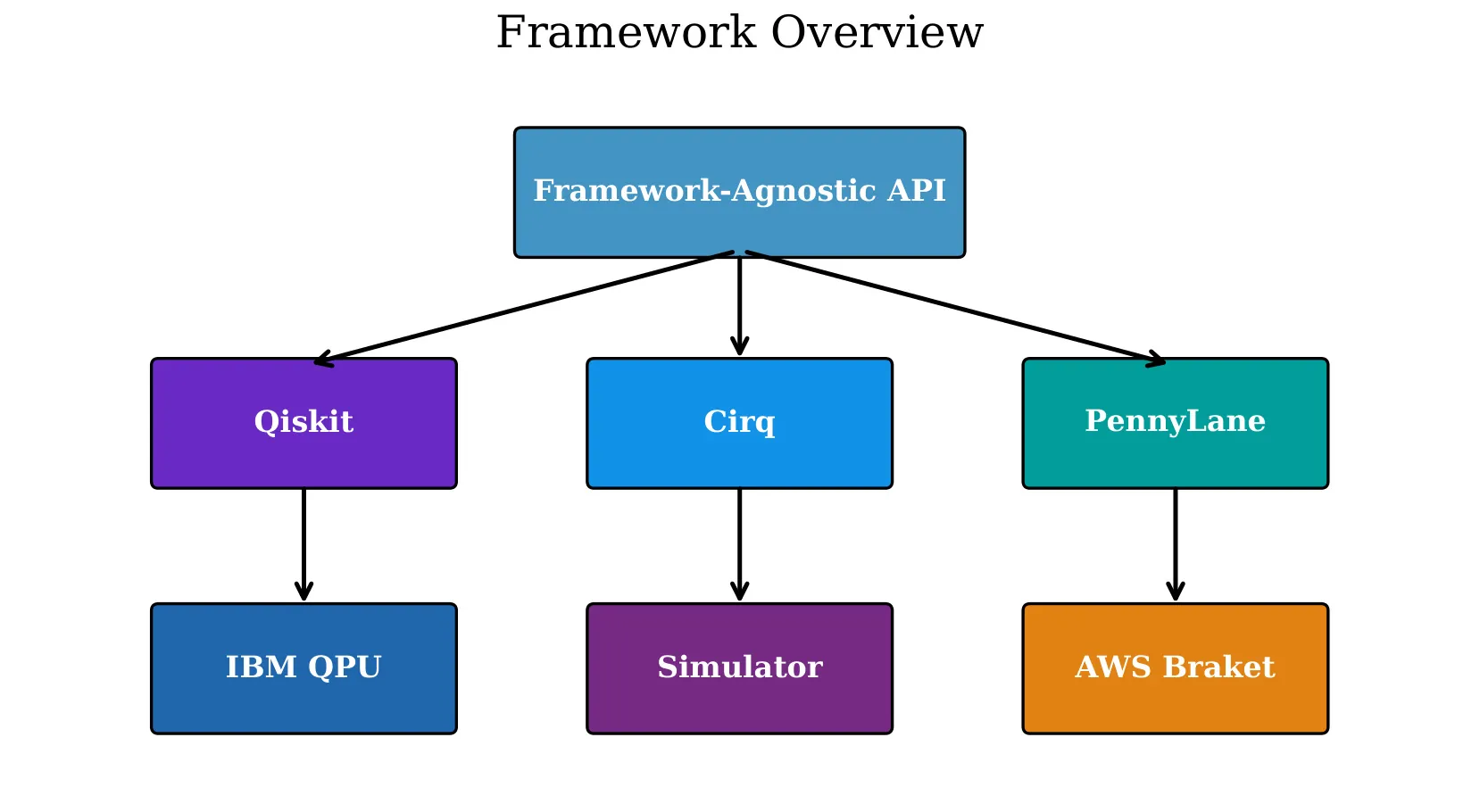
Eliminating Vendor Lock-In in Quantum Machine Learning via Framework-Agnostic Neural Networks
Quantum machine learning (QML) stands at the intersection of quantum computing and artificial intelligence, offering the potential to solve problems that remain intractable for classical methods. However, the current landscape of QML software frameworks suffers from severe fragmentation: models developed in TensorFlow Quantum cannot execute on PennyLane backends, circuits authored in Qiskit Machine Learning cannot be deployed to Amazon Braket hardware, and researchers who invest in one ecosystem face prohibitive switching costs when migrating to another. This vendor lock-in impedes reproducibility, limits hardware access, and slows the pace of scientific discovery. In this paper, we present a framework-agnostic quantum neural network (QNN) architecture that abstracts away vendor-specific interfaces through a unified computational graph, a hardware abstraction layer (HAL), and a multi-framework export pipeline. The core architecture supports simultaneous integration with TensorFlow, PyTorch, and JAX as classical co-processors, while the HAL provides transparent access to IBM Quantum, Amazon Braket, Azure Quantum, IonQ, and Rigetti backends through a single application programming interface (API). We introduce three pluggable data encoding strategies (amplitude, angle, and instantaneous quantum polynomial encoding) that are compatible with all supported backends. An export module leveraging Open Neural Network Exchange (ONNX) metadata enables lossless circuit translation across Qiskit, Cirq, PennyLane, and Braket representations. We benchmark our framework on the Iris, Wine, and MNIST-4 classification tasks, demonstrating training time parity (within 8\% overhead) compared to native framework implementations, while achieving identical classification accuracy.
2604.04414Apr 2026
View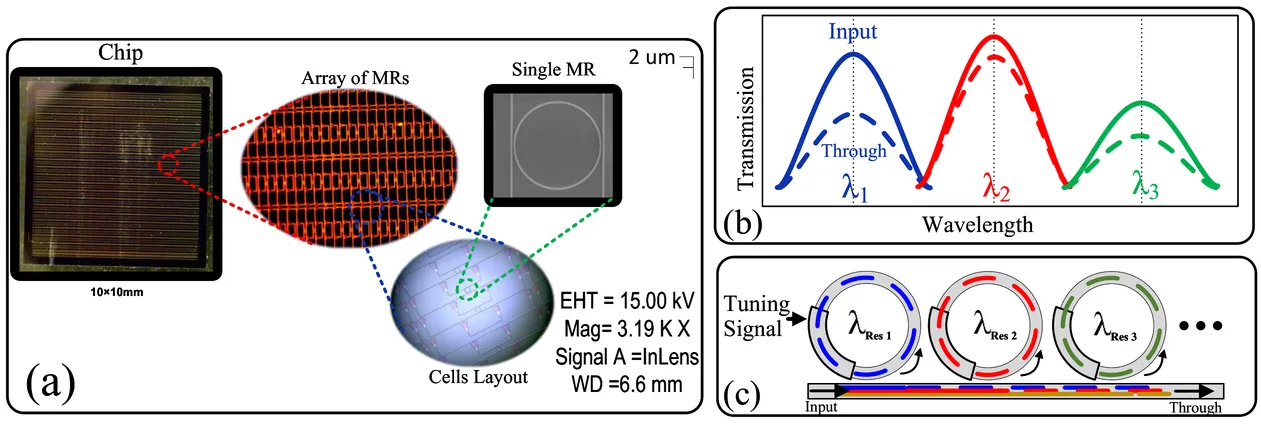
Light-Bound Transformers: Hardware-Anchored Robustness for Silicon-Photonic Computer Vision Systems
Deploying Vision Transformers (ViTs) on near-sensor analog accelerators demands training pipelines that are explicitly aligned with device-level noise and energy constraints. We introduce a compact framework for silicon-photonic execution of ViTs that integrates measured hardware noise, robust attention training, and an energy-aware processing flow. We first characterize bank-level noise in microring-resonator (MR) arrays, including fabrication variation, thermal drift, and amplitude noise, and convert these measurements into closed-form, activation-dependent variance proxies for attention logits and feed-forward activations. Using these proxies, we develop Chance-Constrained Training (CCT), which enforces variance-normalized logit margins to bound attention rank flips, and a noise-aware LayerNorm that stabilizes feature statistics without changing the optical schedule. These components yield a practical ``measure $\rightarrow$ model $\rightarrow$ train $\rightarrow$ run'' pipeline that optimizes accuracy under noise while respecting system energy limits. Hardware-in-the-loop experiments with MR photonic banks show that our approach restores near-clean accuracy under realistic noise budgets, with no in-situ learning or additional optical MACs.
2604.04330Apr 2026
View
ADAPT: AI-Driven Decentralized Adaptive Publishing Testbed
Scholarly publishing faces increasingly strong stressors, including submission overload, reviewer fatigue, inconsistent evaluation, governance opacity, and vulnerability to manipulation in old and new forms. While recent studies applied artificial intelligence to improve specific steps (e.g., triage, reviewer recommendation, or automated critique), they typically work under centralized editorial control and offer limited mechanisms for system-level adaptivity and auditability. Here we present ADAPT (AI-Driven Decentralized Adaptive Publishing Testbed), an agent-based environment that models journal management as a closed-loop control system rather than a fixed editorial workflow. ADAPT integrates interacting agents in various pools (authors, reviewers -- human and AI -- and rotating editors) coupled through policy-level control and diverse feedback signals. Governance adapts to backlog pressure, reviewer disagreement, paper quality drifting, and other relevant factors, while keeping human decision authority, role non-permanence, and data confidentiality. We evaluate ADAPT in a discrete-time simulation setting across multiple operational regimes, including baseline operation, submission surges, quality drift, disagreement escalation, post-publication learning, and collusion suppression. Across regimes, we quantify backlog dynamics, reviewer load, coordination activity, and management performance. The results indicate that ADAPT works under nominal and perturbed conditions, exhibits bounded and interpretable responses under stress, and mitigates clusters with embedded interventions. This feasibility demonstration suggests a promising direction of academic publishing practice, and can be extended to real-world implementations in suitable scenarios.
2604.04077Apr 2026
View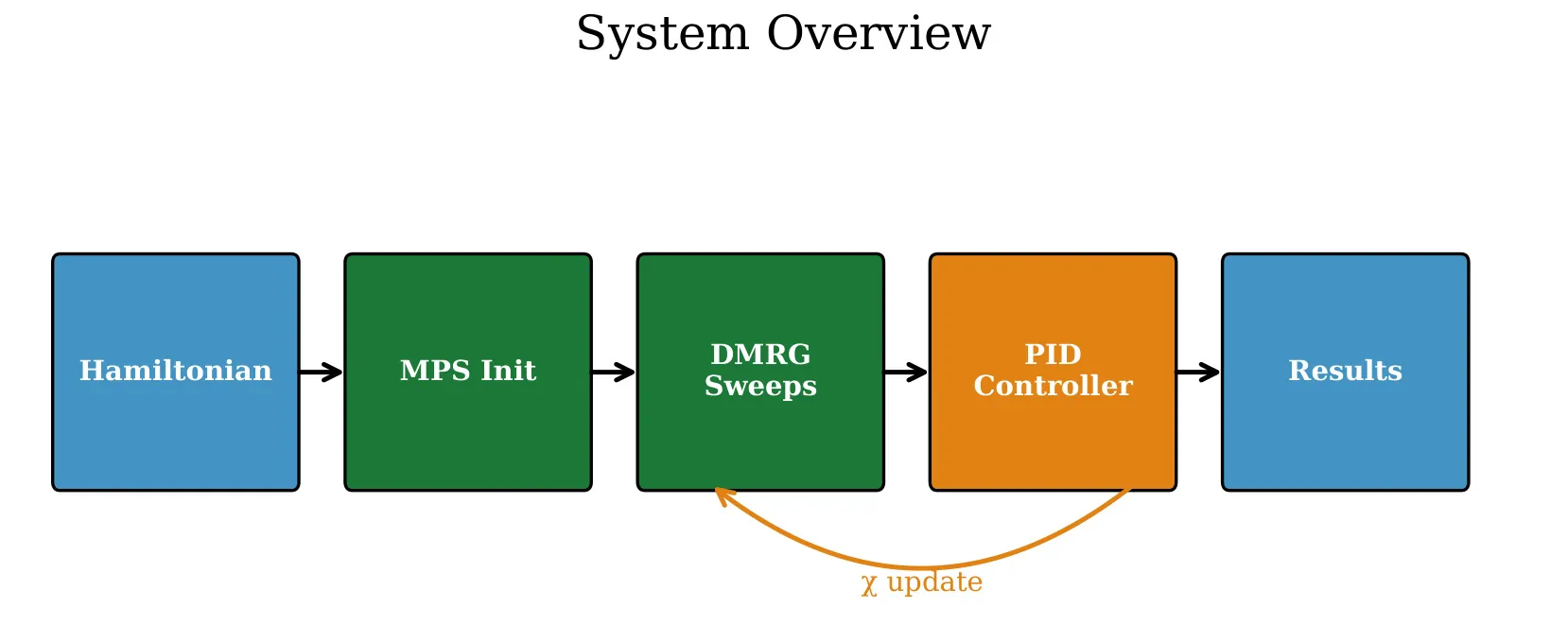
Adaptive Tensor Network Simulation via Entropy-Feedback PID Control and GPU-Accelerated SVD
Tensor network methods, particularly those based on Matrix Product States (MPS), provide a powerful framework for simulating quantum many-body systems. A persistent computational challenge in these methods is the selection of the bond dimension chi, which controls the trade-off between accuracy and computational cost. Fixed bond dimension strategies either waste resources in low-entanglement regions or lose fidelity in high-entanglement regions. This work introduces an adaptive bond dimension management framework that uses von Neumann entropy feedback coupled with a Proportional-Integral-Derivative (PID) controller to dynamically adjust chi at each bond during simulation. An Exponential Moving Average (EMA) filter stabilizes entropy measurements against transient fluctuations, and a predictive scheduling module anticipates future bond dimension requirements from entropy trends. The per-bond granularity of the allocation ensures that computational resources concentrate where entanglement is largest. The framework integrates GPU-accelerated Singular Value Decomposition (SVD) via CuPy and the cuSOLVER backend, achieving individual SVD speedups of 4.1x at chi=256 and 7.1x at chi=2048 relative to CPU-based NumPy for isolated matrix factorisations (measured on an NVIDIA A100-SXM4-40GB GPU with CuPy 13.4.1 and CUDA 12.8). At the system level, benchmarks on the spin-1/2 antiferromagnetic Heisenberg chain demonstrate a 2.7x reduction in total DMRG wall time compared to fixed-chi simulations, with energy accuracy within 0.1% of the Bethe ansatz solution. Integration with the Density Matrix Renormalization Group (DMRG) algorithm yields ground-state energies per site converging to E/N = -0.4432 for the isotropic Heisenberg model at chi = 128. Validation against Amazon Web Services (AWS) Braket SV1 statevector simulator confirms agreement within 2-5% for small systems.
2604.03960Apr 2026
View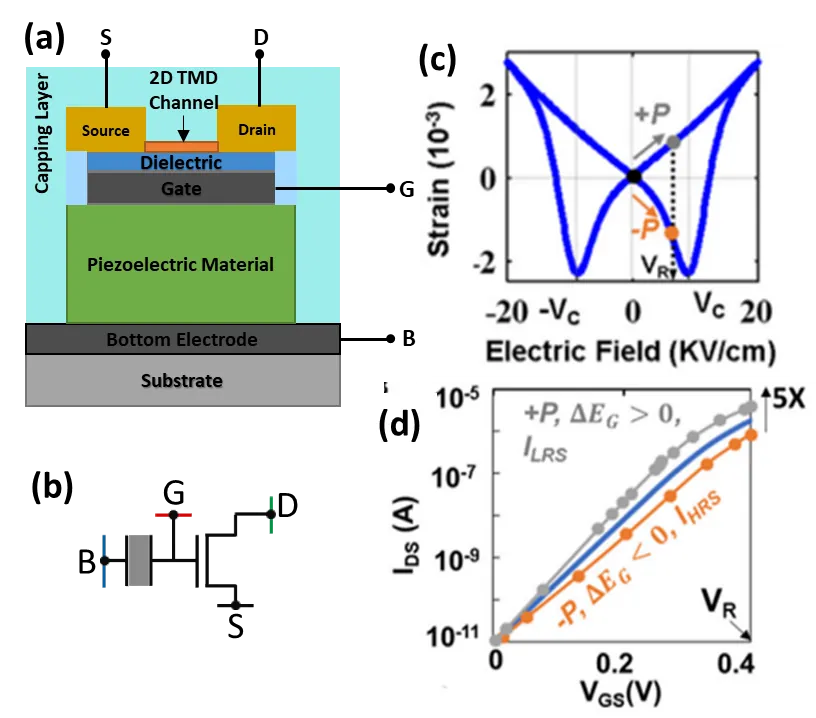
Negative-Voltage-Enabled Energy Efficient Nonvolatile Memories And In-Memory Computing Based On 2D Piezoelectric Transistors
Piezoelectric FET (PeFET) is a promising non-volatile-memory (NVM) device that integrates a piezoelectric (PE)/ferroelectric (FE) capacitor with a 2D transistor. It uses the polarization of the FE capacitor for bit-storage and strain-induced bandgap change of the 2D channel during read. Previous PeFET-based NVM designs have shown immense promise in achieving high density and energy-efficiency compared to SRAM. However, a key limitation of these designs is that they must trade-off integration density to enhance energy-efficiency or augment the memory functionality with in-memory computing (IMC). In this work, we show that the unique structure of the PeFET presents an appealing opportunity to counter these limitations, thereby simultaneously achieving high density, high energy-efficiency, and IMC-compatibility. First, we highlight the key reasons for the limited energy-efficiency of the previous PeFET designs. Based on these insights, we propose two flavors of PeFET memories that utilize negative voltage (NeVo) to reduce the major energy-consuming components significantly. Compared to 6T-SRAM (prior PeFET-based NVMs), the proposed designs achieve substantial reductions in energy, lowering read energy to 0.08x(0.03x) and write energy to 0.19x(0.53x), respectively. We then leverage these cells to implement IMC primitives, such as addition, subtraction, and multiply-and-accumulate (MAC), achieving 0.03x the energy consumption of prior PeFET-based designs.
2604.03959Apr 2026
View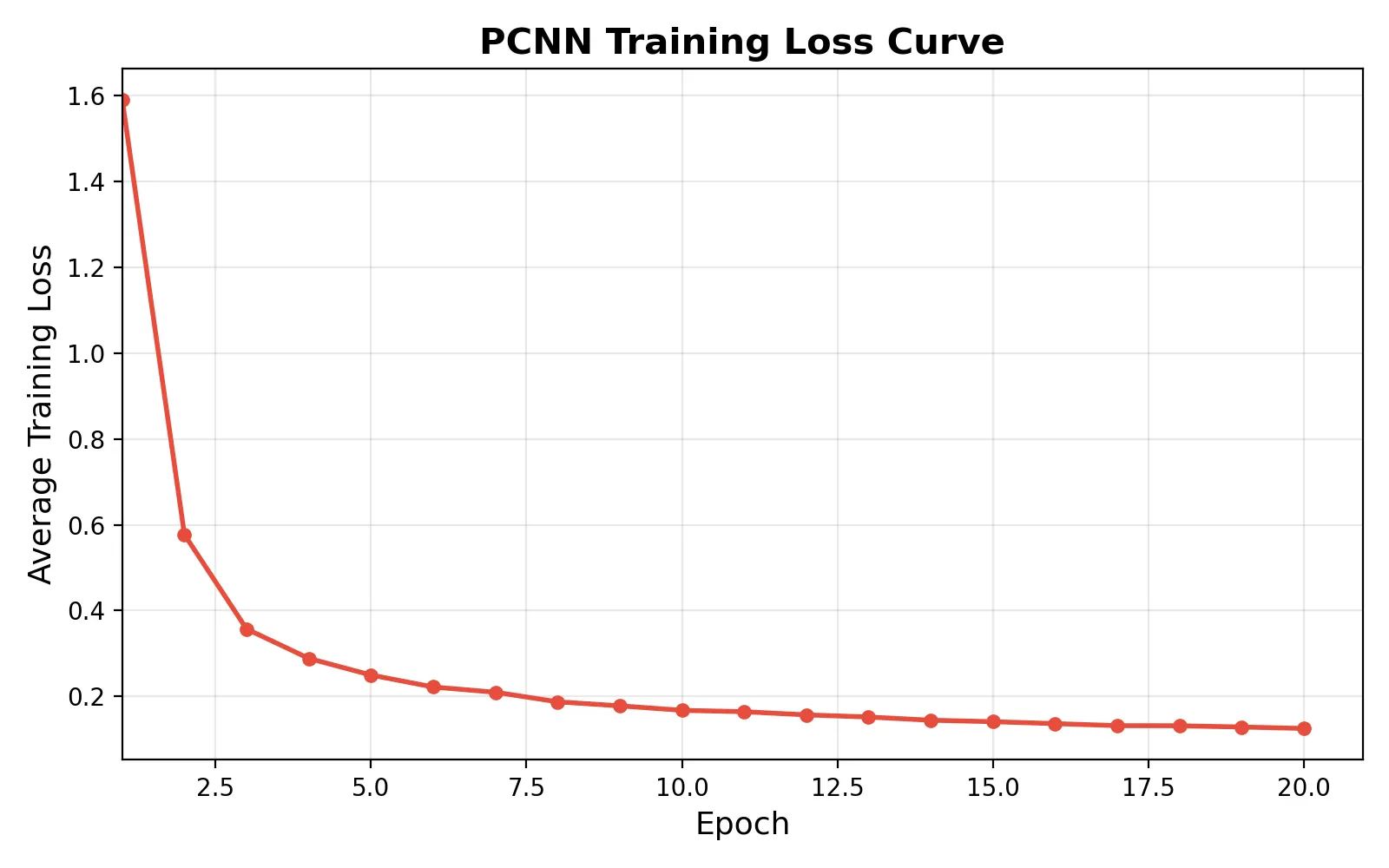
Photonic convolutional neural network with pre-trained in-situ training
Photonic computing is a computing paradigm which have great potential to overcome the energy bottlenecks of electronic von Neumann architecture. Throughput and power consumption are fundamental limitations of Complementary-metal-oxide-semiconductor (CMOS) chips, therefore convolutional neural network (CNN) is revolutionising machine learning, computer vision and other image based applications. In this work, we propose and validate a fully photonic convolutional neural network (PCNN) that performs MNIST image classification entirely in the optical domain, achieving 94 percent test accuracy. Unlike existing architectures that rely on frequent in-between conversions from optical to electrical and back to optical (O/E/O), our system maintains coherent processing utilizing Mach-Zehnder interferometer (MZI) meshes, wavelength-division multiplexed (WDM) pooling, and microring resonator-based nonlinearities. The max pooling unit is fully implemented on silicon photonics, which does not require opto-electrical or electrical conversions. To overcome the challenges of training physical phase shifter parameters, we introduce a hybrid training methodology deploying a mathematically exact differentiable digital twin for ex-situ backpropagation, followed by in-situ fine-tuning via Simultaneous Perturbation Stochastic Approximation (SPSA) algorithm. Our evaluation demonstrates significant robustness to thermal crosstalk (only 0.43 percent accuracy degradation at severe coupling) and achieves 100 to 242 times better energy efficiency than state-of-the-art electronic GPUs for single-image inference.
2604.02429Apr 2026
View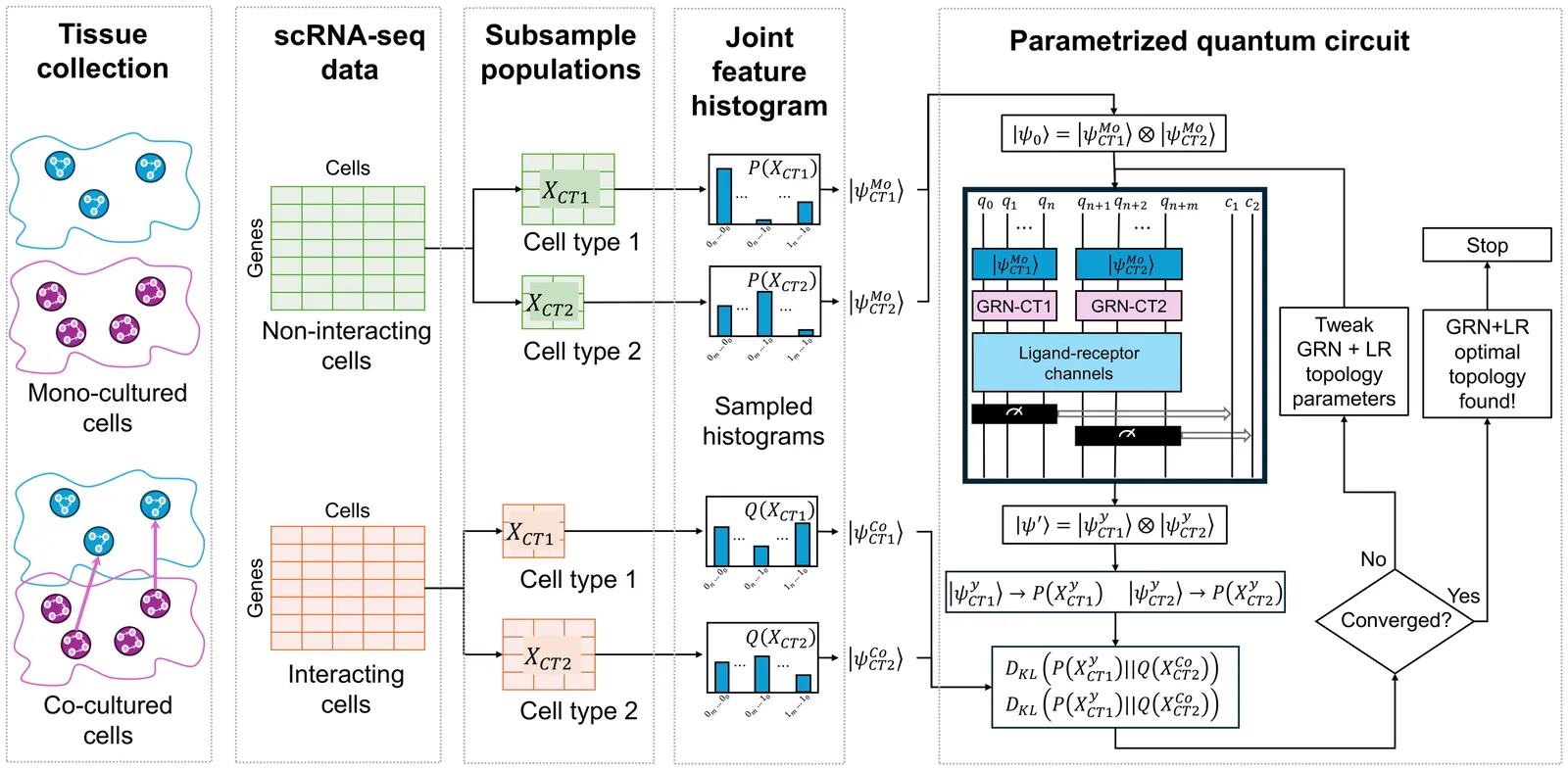
QuantumXCT: Learning Interaction-Induced State Transformation in Cell-Cell Communication via Quantum Entanglement and Generative Modeling
Inferring cell-cell communication (CCC) from single-cell transcriptomics remains fundamentally limited by reliance on curated ligand-receptor databases, which primarily capture co-expression rather than the system-level effects of signaling on cellular states. Here, we introduce QuantumXCT, a hybrid quantum-classical generative framework that reframes CCC as the problem of learning interaction-induced state transformations between cellular state distributions. By encoding transcriptomic profiles into a high-dimensional Hilbert space, QuantumXCT trains parameterized quantum circuits to learn a unitary transformation that maps a baseline non-interacting cellular state to an interacting state. This approach enables the discovery of communication-driven changes in cellular state distributions without requiring prior biological assumptions. We validate QuantumXCT using both synthetic data with known ground-truth interactions and single-cell RNA-seq data from ovarian cancer-fibroblast co-culture systems. The model accurately recovers complex regulatory dependencies, including feedback structures, and identifies dominant communication hubs such as the PDGFB-PDGFRB-STAT3 axis. Importantly, the learned quantum circuit is interpretable: its entangling topology can be translated into biologically meaningful interaction networks, while post hoc contribution analysis quantifies the relative influence of individual interactions on the observed state transitions. By shifting CCC inference from static interaction lookup to learning data-driven state transformations, QuantumXCT provides a generative framework for modeling intercellular communication. This work establishes a new paradigm for de novo discovery of communication programs in complex biological systems and highlights the potential of quantum machine learning in single-cell biology.
2604.02203Apr 2026
View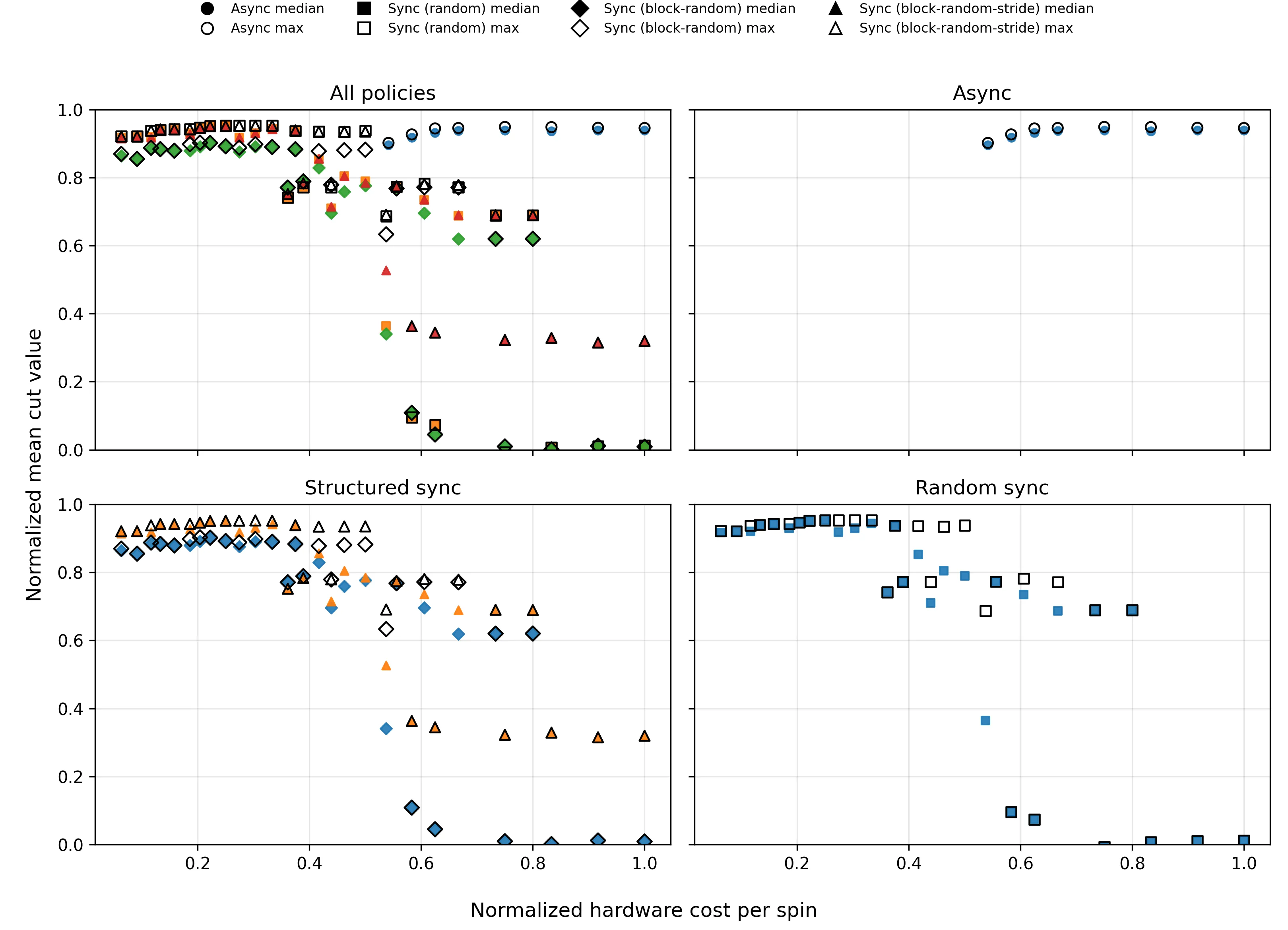
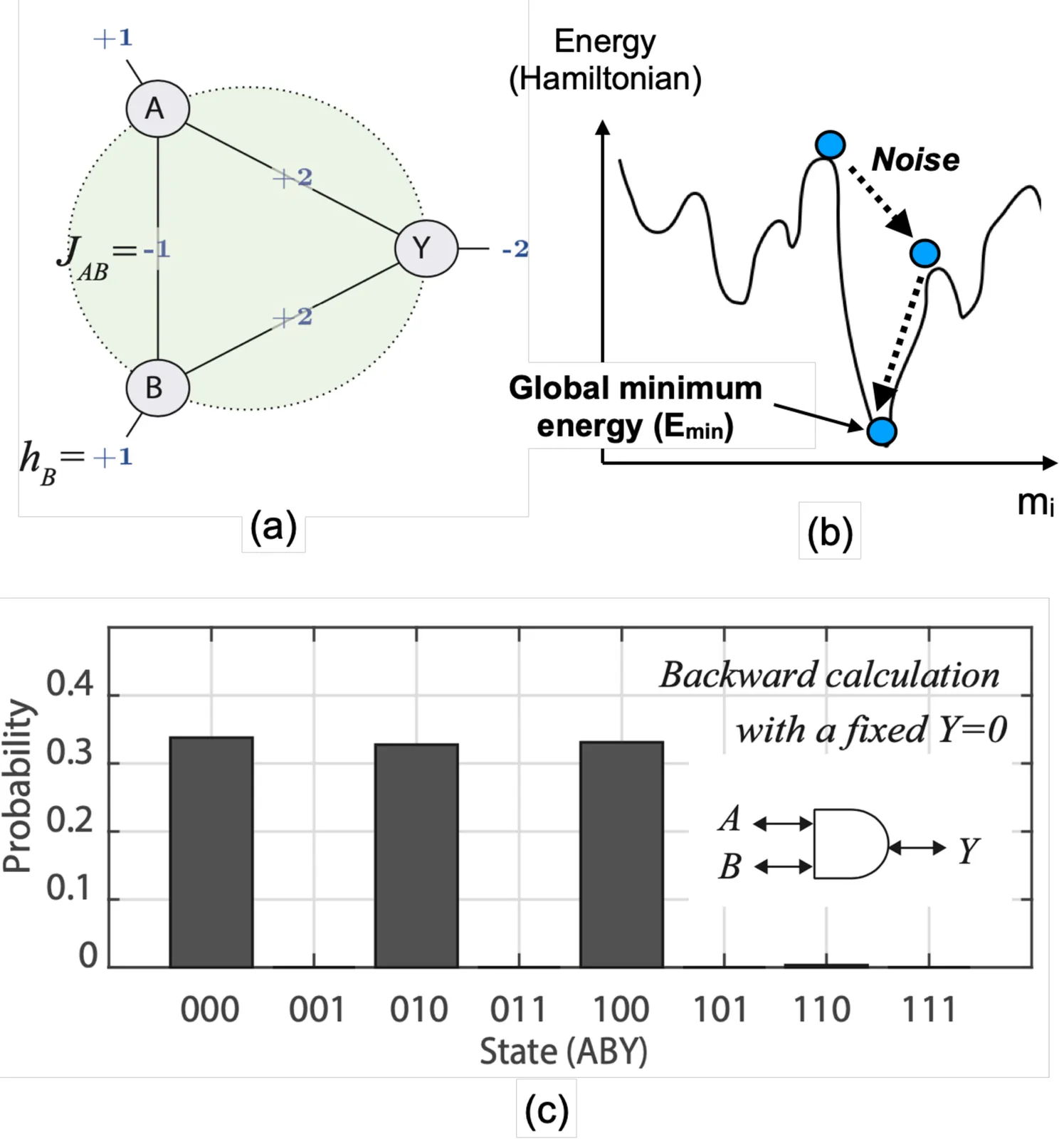
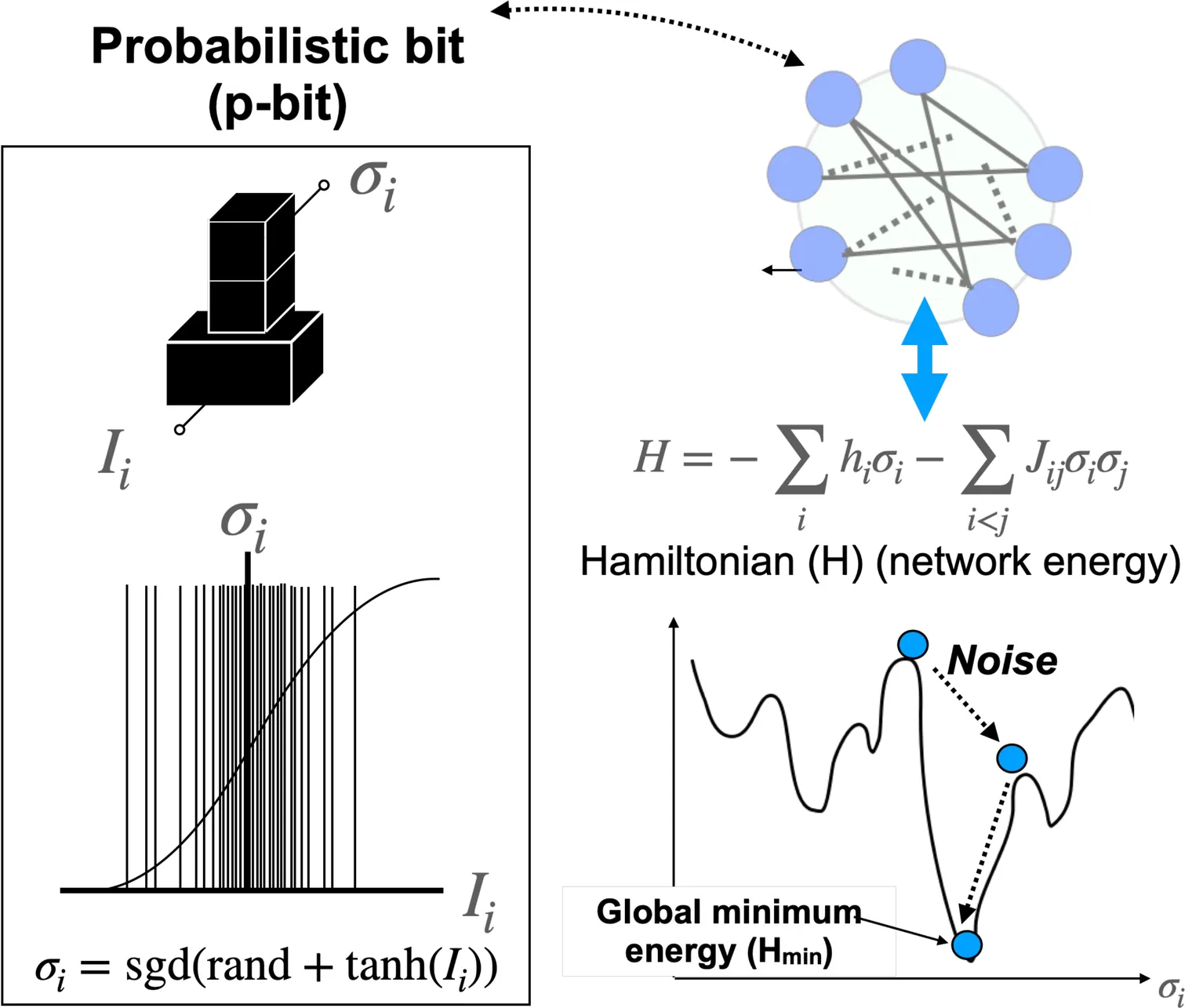
A Unified Performance-Cost Landscape of Parallel p-bit Ising Machines Based on Update Dynamics
Parallel p-bit Ising machines are a promising platform for fast and energy-efficient combinatorial optimization, but their scalability depends on update synchronization, hardware delay, and architectural cost. In this work, we establish a unified performance-cost framework by analyzing synchronous and asynchronous update schemes under realistic constraints, including finite delay, time-multiplexed p-bit reuse, and limited DAC precision. We show that synchronous updates are not inherently unstable but can exhibit oscillations under excessive simultaneity, while asynchronous updates require slower operation due to hardware delay. To address this trade-off, we introduce time-multiplexed p-bit reuse with structured synchronous control, preserving correct annealing dynamics while reducing hardware requirements. This approach decouples statistical correctness from physical resources, enabling the number of p-bits and DACs to scale inversely with the reuse factor. As a result, synchronous architectures achieve comparable or better solution quality at less than half the hardware cost of optimized asynchronous designs on G-set MaxCut benchmarks (800-2000 nodes). We also show that low-resolution DACs (3-4 bits) are sufficient to reach near-optimal solutions when annealing time is properly adjusted. These findings provide practical design guidelines for scalable probabilistic computing hardware under realistic constraints.
2604.01564Apr 2026
View
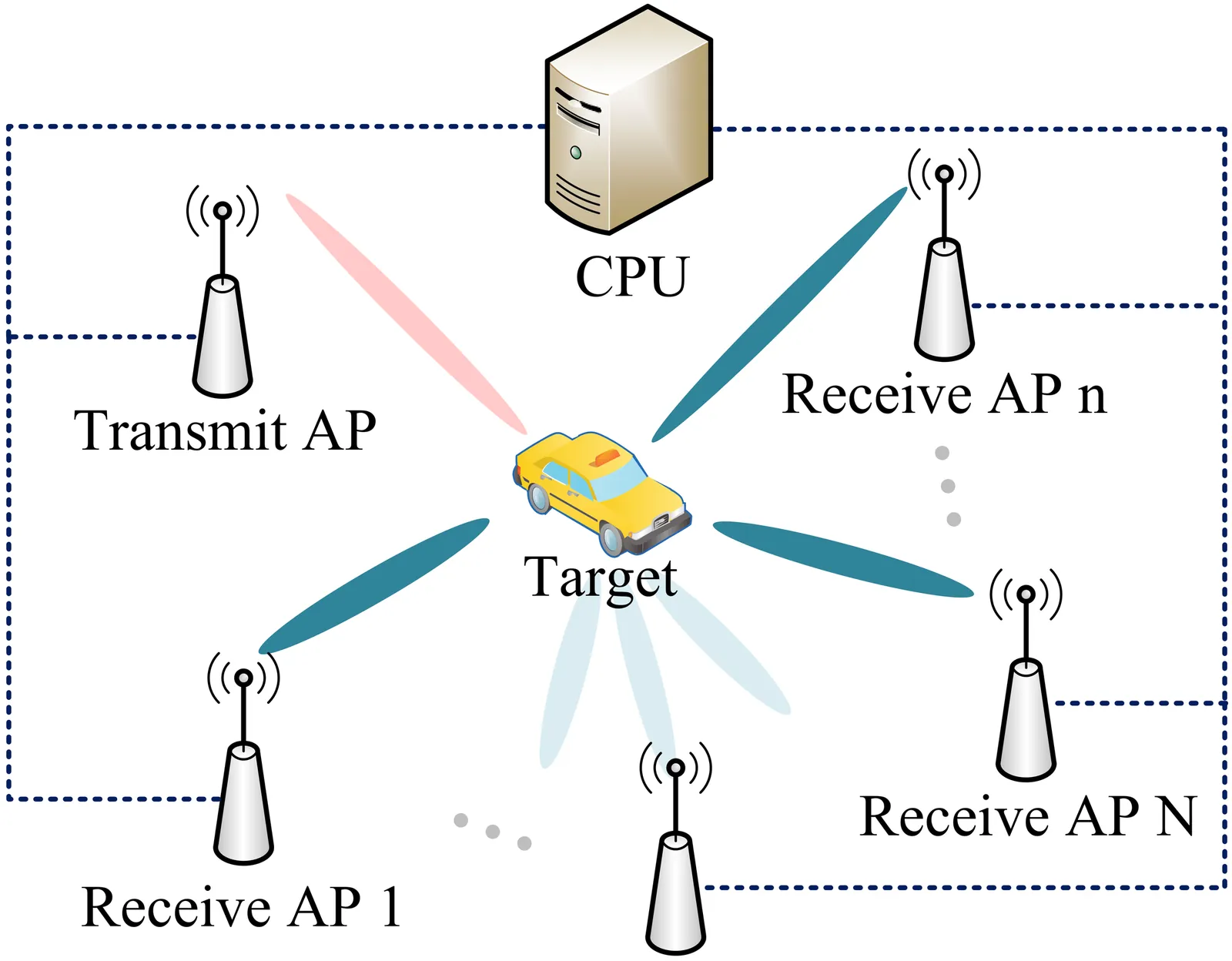
Semantically Annotated Multimodal Dataset for RF Interpretation and Prediction
Current limitations in wireless modeling and radio frequency (RF)-based AI are primarily driven by a lack of high-quality, measurement-based datasets that connect RF signals to their physical environments. RF heatmaps, the typical form of such data, are high-dimensional and complex but lack the geometric and semantic context needed for interpretation, constraining the development of supervised machine learning models. To address this bottleneck, we propose a new class of multimodal datasets that combines RF measurements with auxiliary modalities like high-resolution cameras and lidar to bridge the gap between RF signals and their physical causes. The proposed data collection will span diverse indoor and outdoor environments, featuring both static and dynamic scenarios, including human activities ranging from walking to subtle gestures. By achieving precise spatial and temporal co-registration and creating digital replicas for voxel-level annotation, this dataset will enable transformative AI research. Key tasks include the forward problem of predicting RF heatmaps from visual data to revolutionize wireless system design, and the inverse problem of inferring scene semantics from RF signals, creating a new form of RF-based perception.
2604.01433Apr 2026
View
Internal APIs Are All You Need: Shadow APIs, Shared Discovery, and the Case Against Browser-First Agent Architectures
Autonomous agents increasingly interact with the web, yet most websites remain designed for human browsers -- a fundamental mismatch that the emerging ``Agentic Web'' must resolve. Agents must repeatedly browse pages, inspect DOMs, and reverse-engineer callable routes -- a process that is slow, brittle, and redundantly repeated across agents. We observe that every modern website already exposes internal APIs (sometimes called \emph{shadow APIs}) behind its user interface -- first-party endpoints that power the site's own functionality. We present Unbrowse, a shared route graph that transforms browser-based route discovery into a collectively maintained index of these callable first-party interfaces. The system passively learns routes from real browsing traffic and serves cached routes via direct API calls. In a single-host live-web benchmark of equivalent information-retrieval tasks across 94 domains, fully warmed cached execution averaged 950\,ms versus 3{,}404\,ms for Playwright browser automation (3.6$\times$ mean speedup, 5.4$\times$ median), with well-cached routes completing in under 100\,ms. A three-path execution model -- local cache, shared graph, or browser fallback -- ensures the system is voluntary and self-correcting. A three-tier micropayment model via the x402 protocol charges per-query search fees for graph lookups (Tier~3), a one-time install fee for discovery documentation (Tier~1), and optional per-execution fees for site owners who opt in (Tier~2). All tiers are grounded in a necessary condition for rational adoption: an agent uses the shared graph only when the total fee is lower than the expected cost of browser rediscovery.
2604.00694Apr 2026
View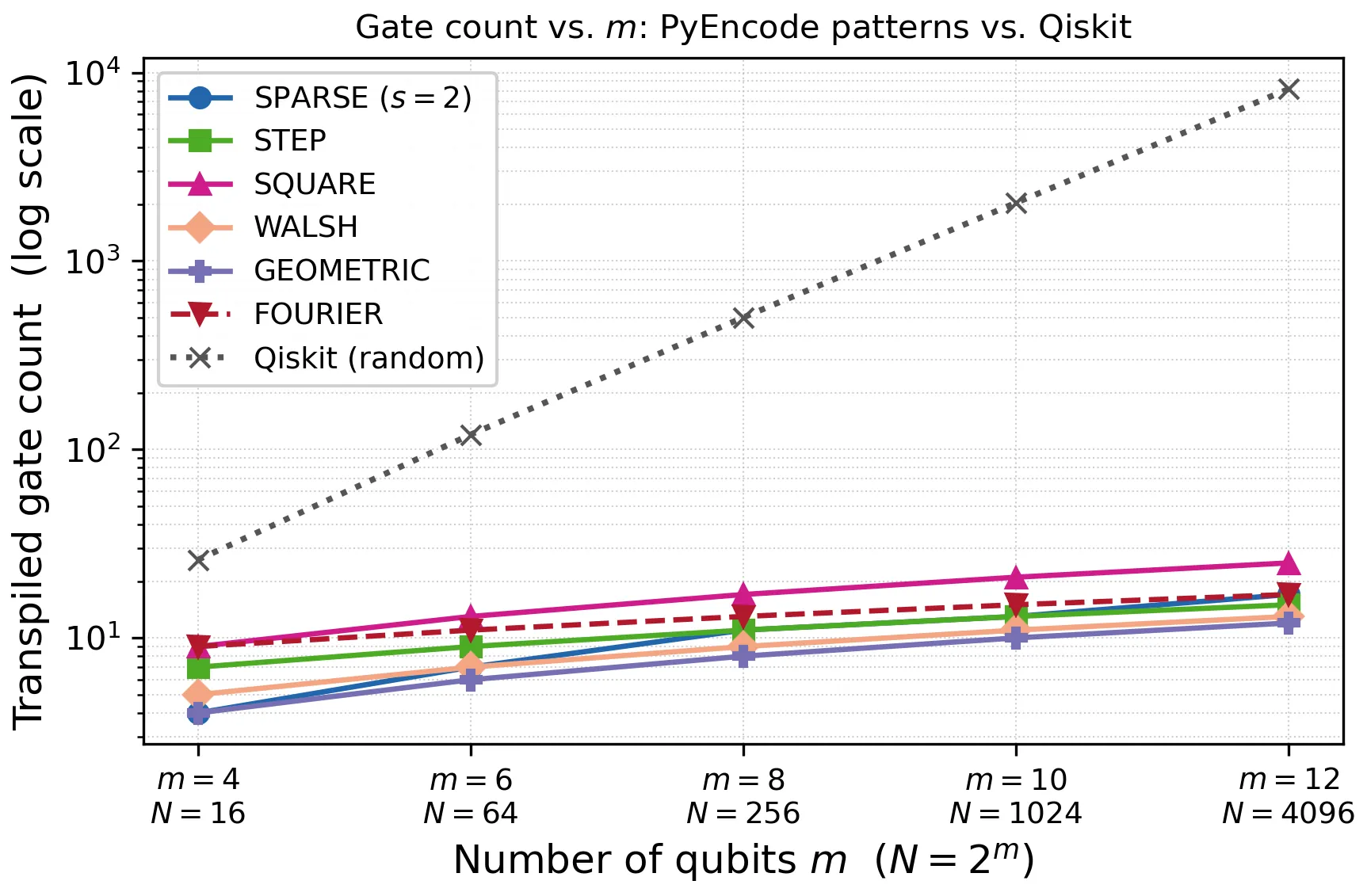
PyEncode: An Open-Source Library for Structured Quantum State Preparation
Quantum algorithms require encoding classical vectors as quantum states, a step known as amplitude encoding. General-purpose state preparation routines accept any input vector of length $N = 2^m$ and produce circuits with $\bigO{2^m}$ gates. However, vectors arising in scientific and engineering applications often exhibit mathematical structure that admits far more efficient encoding. Recent theoretical work has established closed-form circuits for several structured vector classes, but without open-source implementations. We present PyEncode, an open-source Python library that implements this body of theory in a unified, immediately deployable framework. The library covers sparse, step, square (general interval), Walsh, geometric, and Fourier patterns, and supports weighted superpositions of pattern states via the linear combination of unitaries (LCU) protocol, enabling exact preparation of piecewise-structured vectors such as multi-interval Hamiltonians. PyEncode exposes a single function encode(VectorObj, N) that maps a typed parameter declaration directly to a verified Qiskit circuit, with no vector materialization and no approximation. Sparse, step, and Walsh vectors require only $\bigO{m}$ gates; geometric (exponential-decay) vectors require $\bigO{m}$ gates with zero two-qubit gates; square (general interval) vectors require $\bigO{m^2}$ gates via a QFT-based constant adder, with $\bigO{m}$ special cases; Fourier (sinusoidal) vectors require $\bigO{m^2}$ gates via the inverse Quantum Fourier Transform -- all exponentially fewer than the $\bigO{2^m}$ cost of general state preparation. LCU combines $r$ component circuits whose total gate cost is the sum of individual component costs, with success probability $p \in (0,1]$ determined analytically. The library is available at https://github.com/UW-ERSL/PyEncode.
2603.28259Mar 2026
View
A new approach to rating scale definition with quantum-inspired optimization
In finance, assessing the creditworthiness of loan applicants requires lenders to cluster borrowers using rating scales. Financial institutions must define the scales in compliance with strict institutional constraints, resulting in solving a complex combinatorial constrained optimization problem. This contribution studies how to solve this problem using a Quadratic Unconstrained Binary Optimization (QUBO) model, a formulation suitable for quantum hardware. We validate this approach by testing the proposed formulation with classical heuristics. We then benchmark the results against a brute-force method to demonstrate consistent solution quality and highlight the framework's suitability for more complex scenarios.
2603.26583Mar 2026
View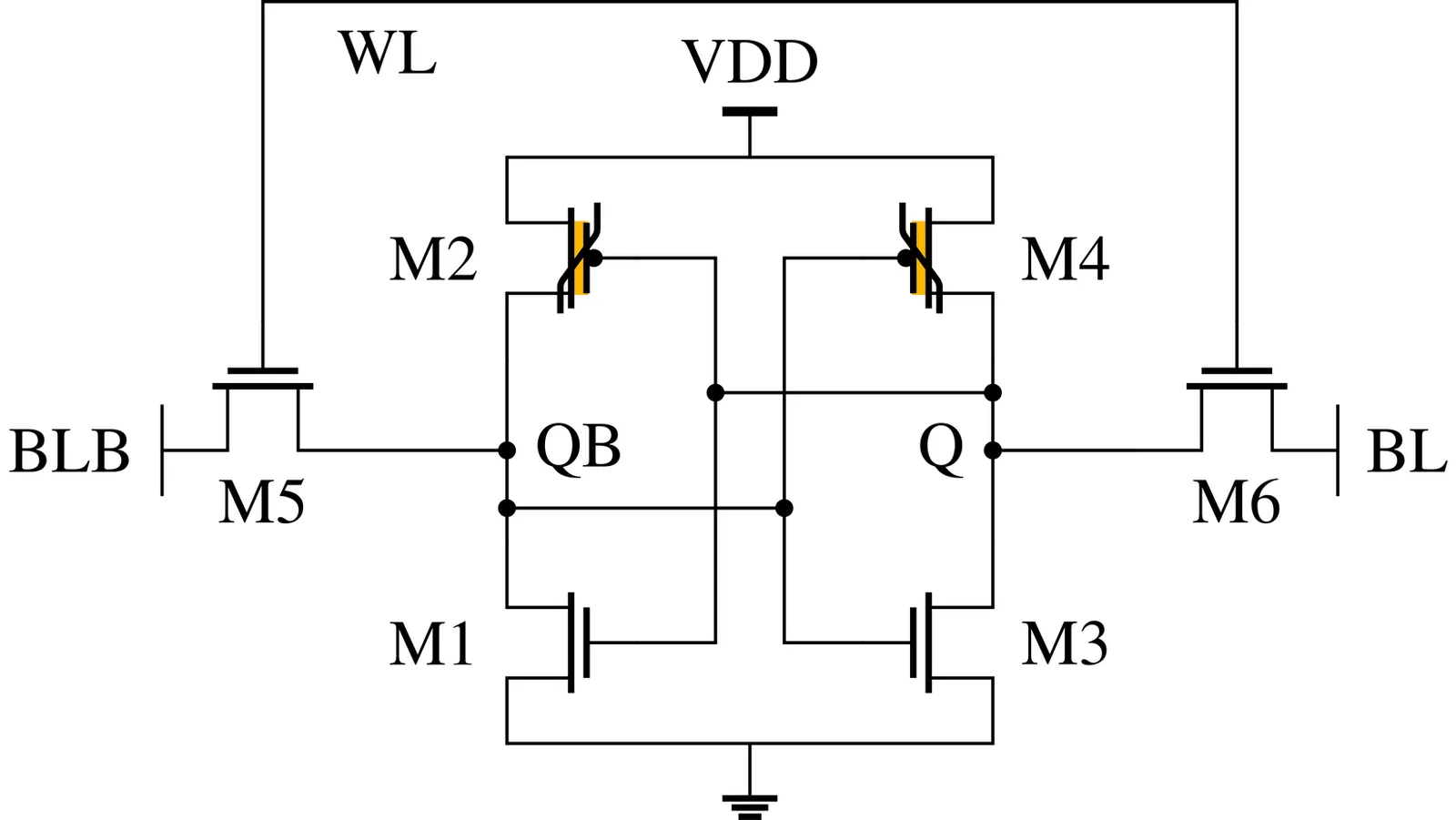
First Demonstration of 28 nm Fabricated FeFET-Based Nonvolatile 6T SRAM
With the staggering increase of edge compute applications like Internet-of-Things (IoT) and artificial intelligence (AI), the demand for fast, energy-efficient on-chip memory is growing. While the fast and mature static random-access memory (SRAM) technology is the standard choice, its volatility requires a constant supply voltage to operate and store data. Especially in edge AI and IoT devices that often idle, the leakage power consumes a significant portion of the constrained power budget. For this, emerging non-volatile memory (NVM) technologies such as Resistive RAM and ferroelectric FET (FeFET) offer zero-standby power consumption but suffer from integration and performance tradeoffs. To harness the benefits of the different technologies, hybrid architectures have been proposed, combining SRAM with NVM devices. This work proposes a hybrid non-volatile SRAM (nvSRAM) architecture based on recently demonstrated PMOS FeFETs (p-FeFETs). By replacing the two PMOS pull-up transistors with p-FeFETs, we achieve non-volatility without additional transistors. The design supports seamless power-down and restore operation, thus eliminating standby leakage. SPICE simulations in a commercial 28 nm technology show read latency comparable to conventional SRAM, and on-silicon measurements show robust restore behavior. With this, we are the first to demonstrate a fabricated 6T nvSRAM cell design. The resulting cell achieves an area footprint of 99 $μm^2$. The read path remains identical to baseline SRAM, enabling high-speed operation while being non-volatile, making it ideal for IoT and edge systems.
2603.26439Mar 2026
View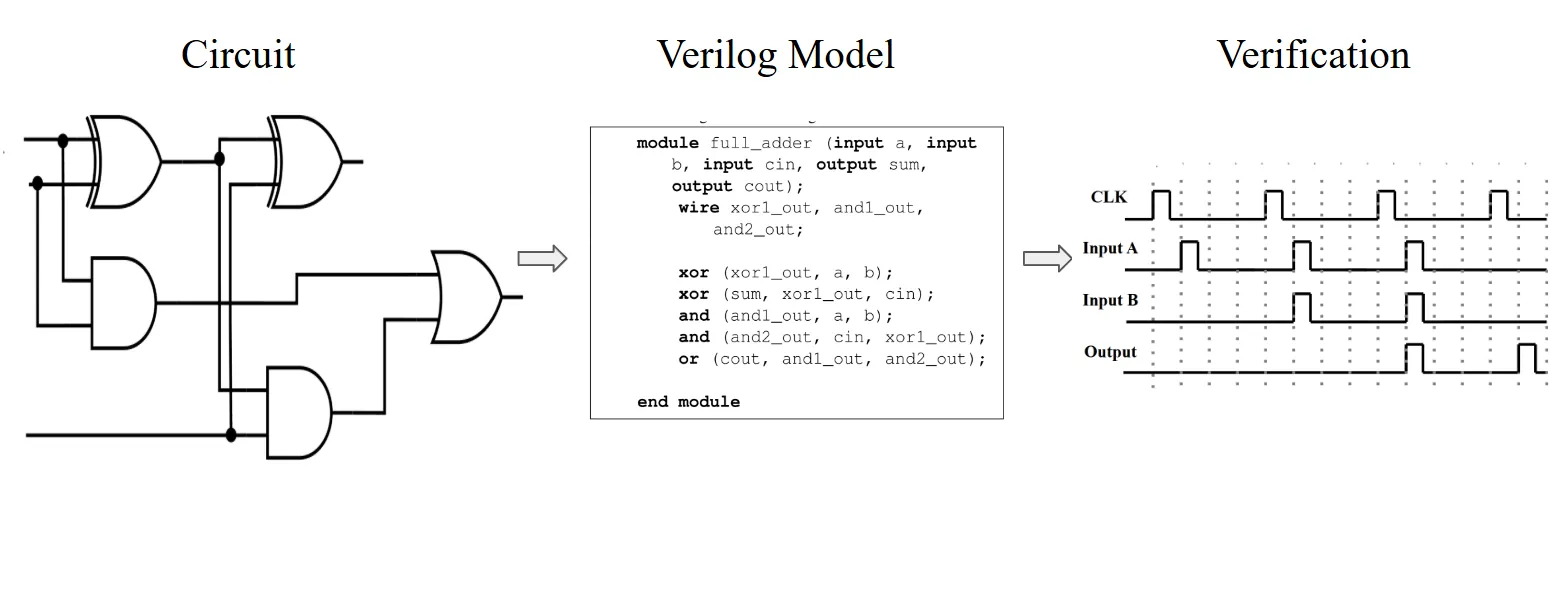
Generalizable Verilog Modeling Framework for Synchronous and Asynchronous Superconducting Pulse-Based Logic Gates
Superconducting Single Flux Quantum (SFQ) logic offers a promising platform for ultra-low-power, high-frequency computing. However, their pulse-based nature poses challenges for scalable modeling, design, and verification using conventional hardware description languages (HDLs), which are designed for level-based digital logic. Prior efforts have required complex Verilog support modules to enable Standard Delay Format (SDF) compatibility and have provided limited coverage of SFQ cell types. This work presents a Verilog-based modeling framework for SFQ gates that enables functional and timing verification while maintaining compatibility with Standard Delay Format (SDF) back annotation and is the first framework to support both synchronous and asynchronous SFQ gates. The proposed models are validated through device-level simulations, demonstrating correct functionality and timing constraint coverage. RTL simulation of mixed synchronous-asynchronous circuits further demonstrate the utility of the proposed framework.
2603.25885Mar 2026
View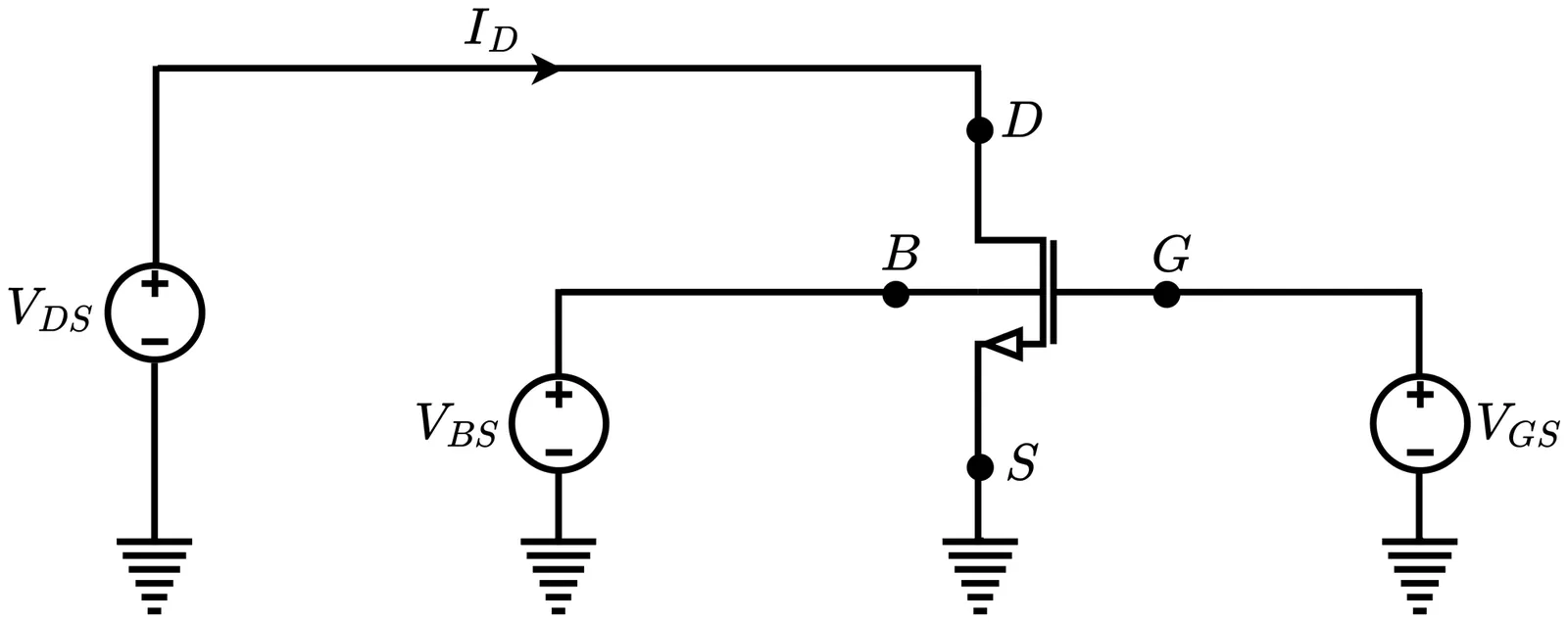
Closed-Form Formulas for Designing Ultra-Low Phase-Noise Cross-Coupled Dynamically Body-Biased Only-NMOS LCVCOs
This paper presents a system-level analytical framework for modeling and minimizing phase noise in body-biased cross-coupled LC-tank voltage-controlled oscillators (LC-VCOs). Building upon Impulse Sensitivity Function (ISF) theory, the impulse sensitivity and noise modulation mechanisms associated with both flicker and thermal noise sources are systematically characterized. By modeling the oscillator as a nonlinear dynamical system and incorporating transistor operation across multiple regions, analytical expressions for device-level noise power spectral densities (PSDs) are derived as functions of transconductance parameters under symmetric body excitation. Using these results, effective ISF representations corresponding to dominant noise sources are formulated, enabling a unified description of noise-to-phase conversion dynamics. The phase noise minimization problem is then cast as an optimization over system parameters, where both DC and RMS components of the effective ISF are analytically evaluated and minimized. This leads to the derivation of three closed-form expressions that explicitly capture the interaction between circuit parameters and the applied body-bias signals. The proposed framework provides insight into parameter sensitivity and design trade-offs in nonlinear oscillator systems and offers generalizable analytical tools for guiding the design of ultra-low phase noise LC-VCOs, as well as for exploring new oscillator architectures.
2603.25853Mar 2026
View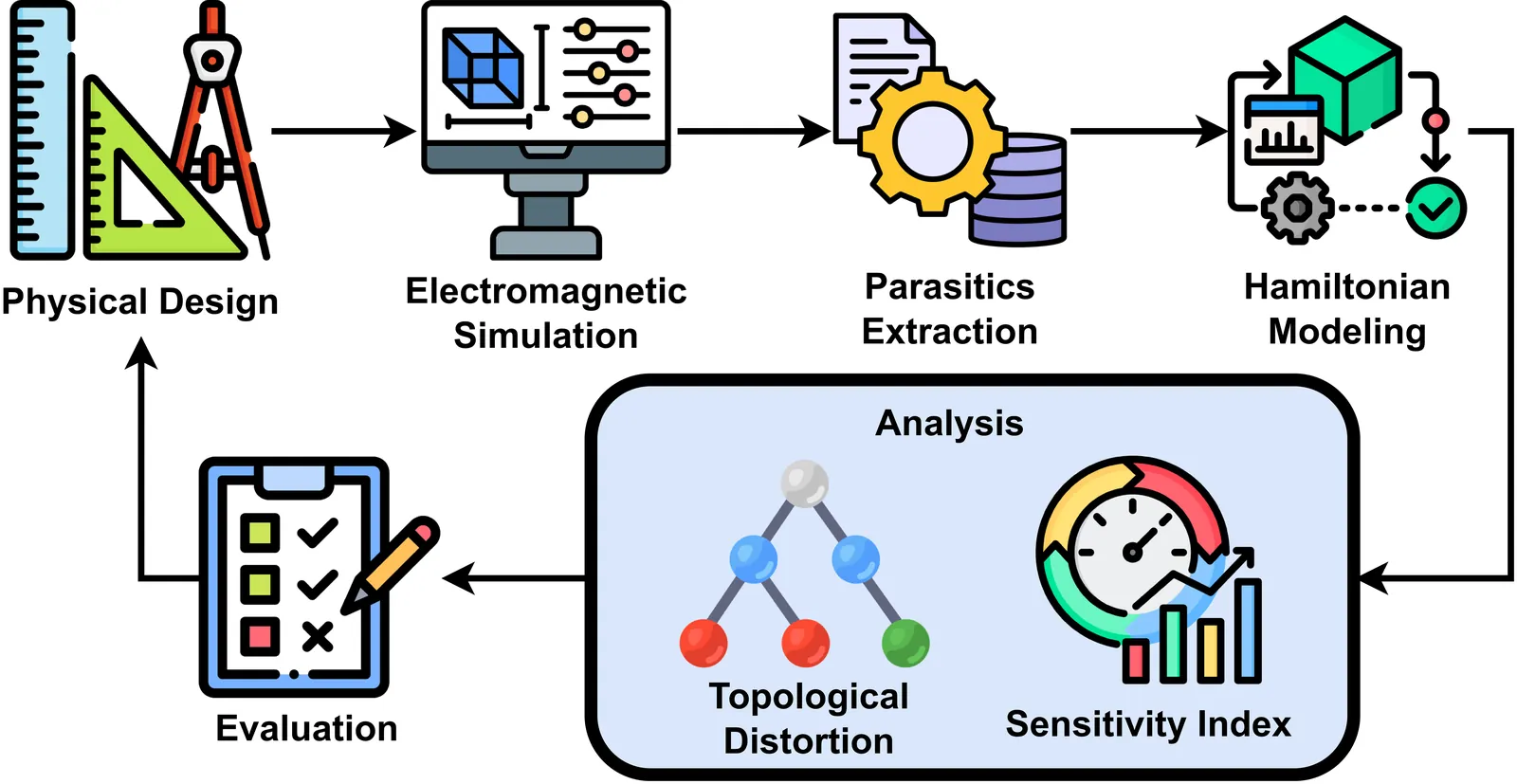
EPAR: Electromagnetic Pathways to Architectural Reliability in Quantum Processors
As superconducting processors scale, understanding how physical layout shapes qubit interactions is essential for architectural reliability. Existing methods offer limited insight into how electromagnetic design choices translate into execution-level behavior. We present EPAR, an electromagnetic-to-architecture framework that predicts robustness early directly from physical design by reconstructing how design distortion modifies the effective Hamiltonian, reroutes mediated connectivity, and influences control-pulse response. Across all tested layouts, EPAR's structural scores show 100% agreement with two-qubit error trends yet reveal over 10X robustness differences among edges with identical calibrated error rates, going beyond conventional metrics to provide improved and actionable compiler guidance.
2603.25671Mar 2026
View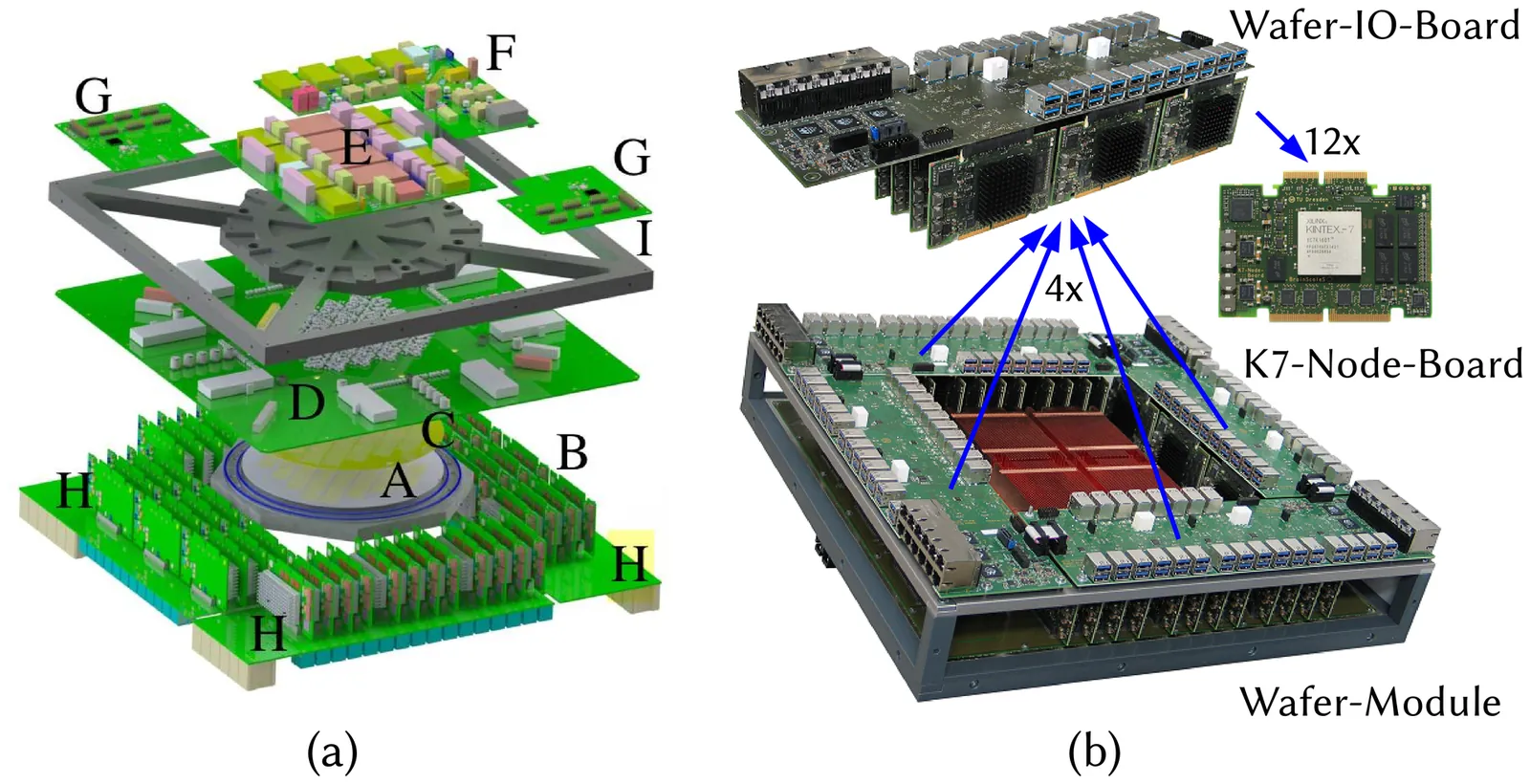
Characterization of Off-wafer Pulse Communication in BrainScaleS Neuromorphic System
Neuromorphic VLSI systems take inspiration from biology to enable efficient emulation of large-scale spiking neural networks and to explore new computational paradigms. To establish large neuromorphic systems, a sophisticated routing infrastructure is needed to communicate spikes between chips and to/from the host computer. For the BrainScaleS wafer-scale neuromorphic system considered in this work, especially the stimulation with input spikes and the recording of spikes is demanding, requiring high bandwidth and temporal resolution due to the accelerated emulation of neural dynamics 10.000 faster than biological real time. Here, we present a systematic characterization of the BrainScaleS off-wafer communication infrastructure implemented around Kintex7 FPGAs. The communication flow is characterized in terms of throughput, transmission delay, jitter and pulse loss. Further, we analyze the effect of the communication distortions (like pulse loss and jitter) on a neural benchmark model with highly varying spike activity. The presented methods and techniques for communication evaluation are general applicable and provide useful insights for the mapping of network models to the hardware such as the distribution of input spikes across communication channels.
2603.24854Mar 2026
ViewPage 1 of 31