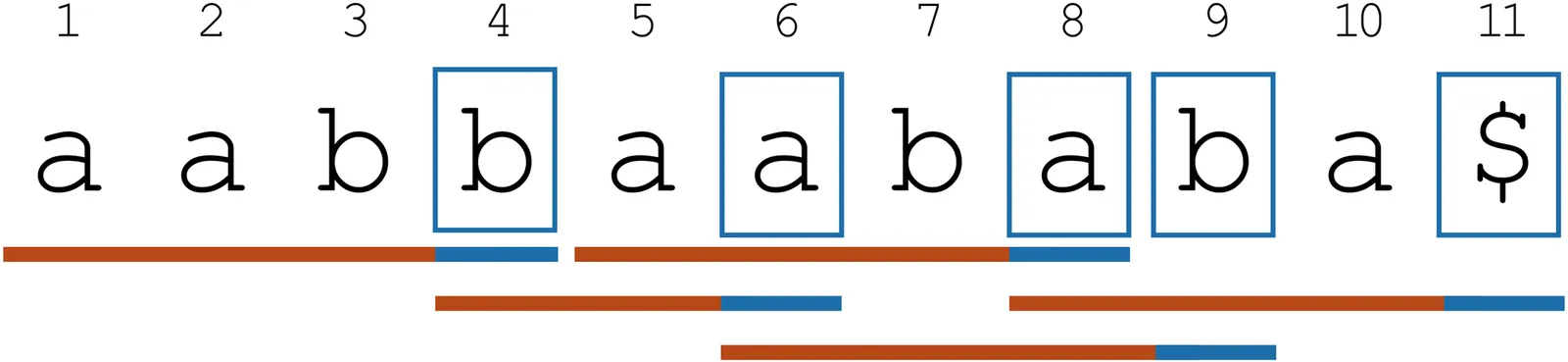Trending in Theory & Algorithms

Generalizing Fair Top-$k$ Selection: An Integrative Approach
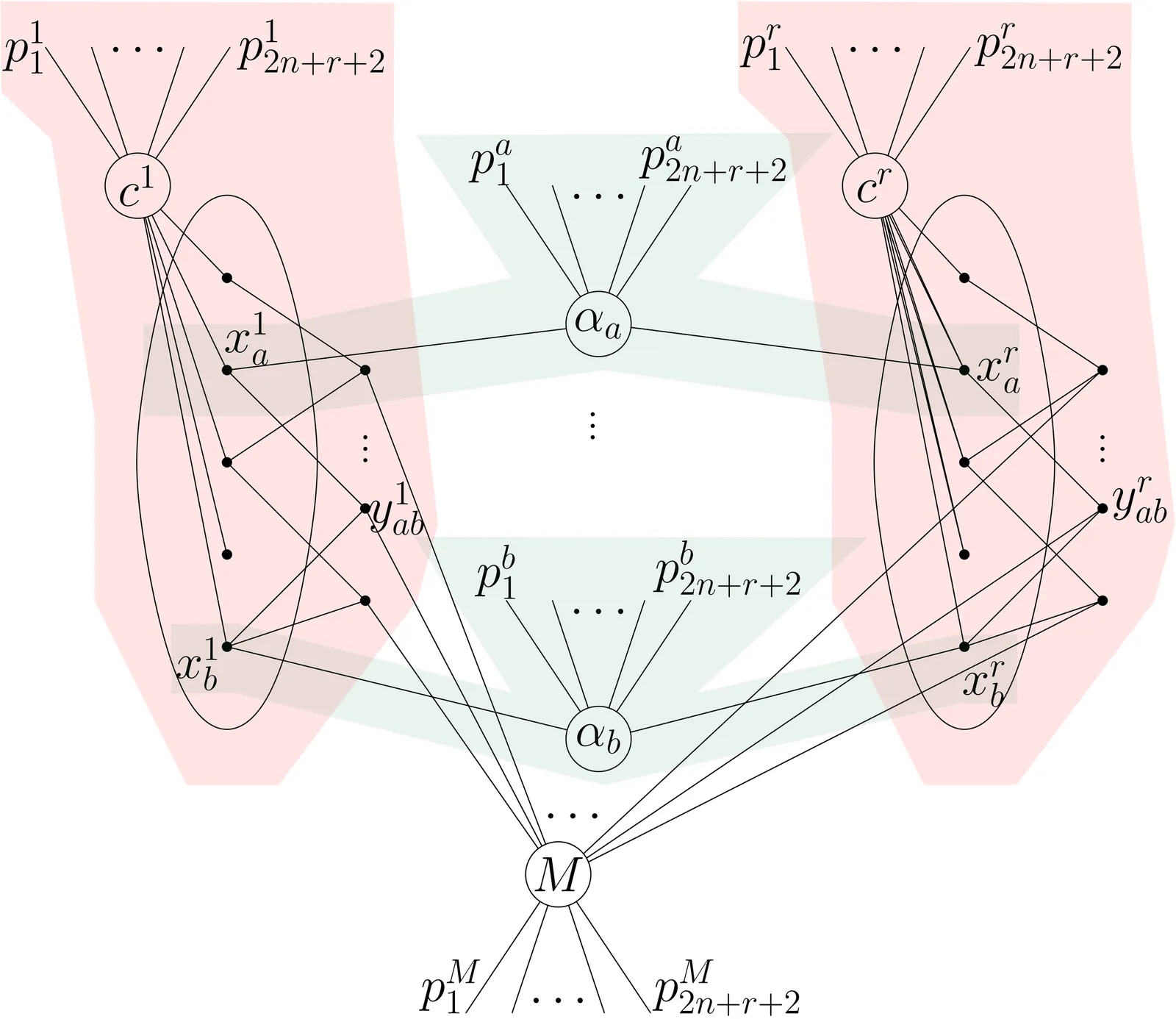
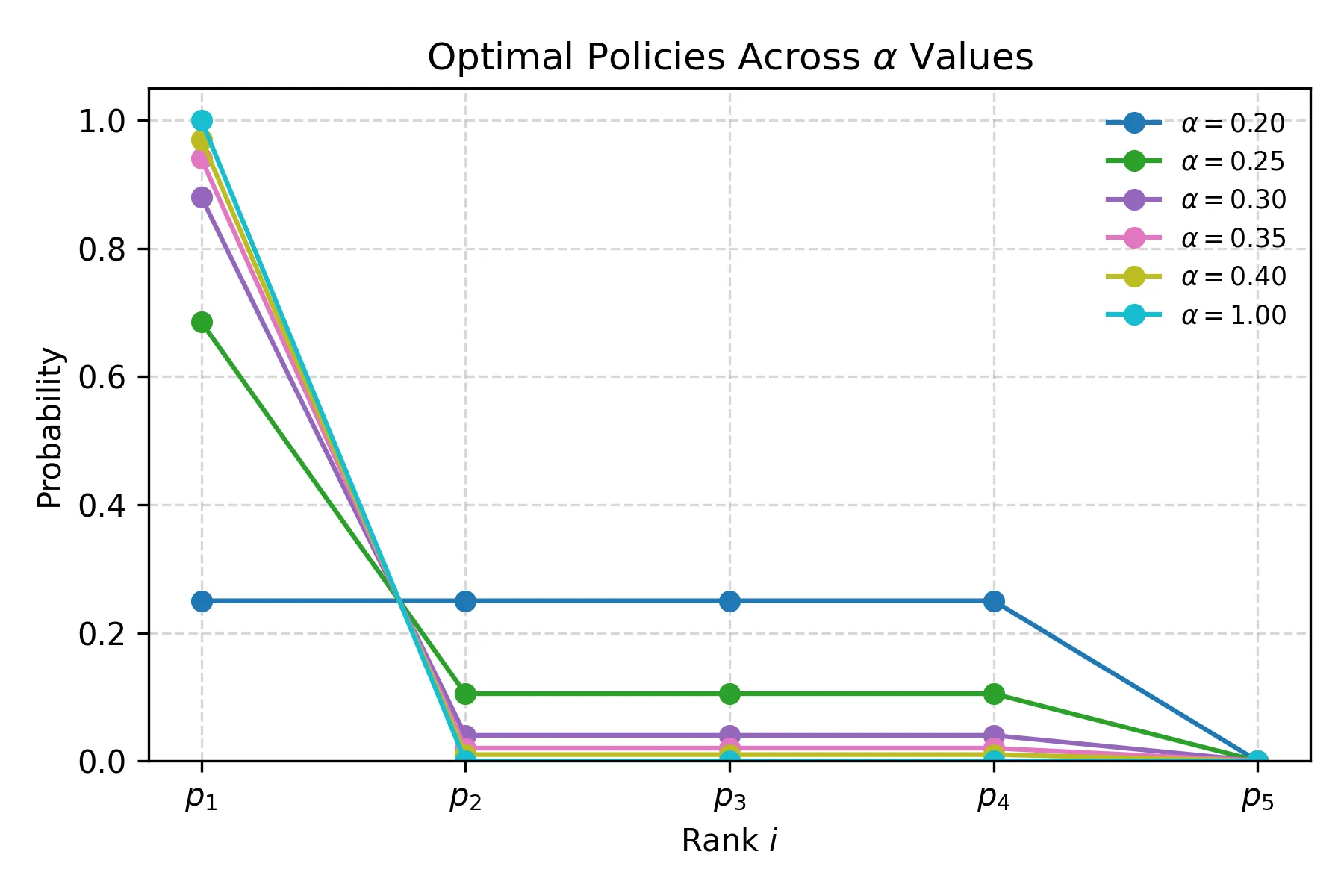
Fair top-$k$ selection, which ensures appropriate proportional representation of members from minority or historically disadvantaged groups among the top-$k$ selected candidates, has drawn significant attention. We study the problem of finding a fair (linear) scoring function with multiple protected groups while also minimizing the disparity from a reference scoring function. This generalizes the prior setup, which was restricted to the single-group setting without disparity minimization. Previous studies imply that the number of protected groups may have a limited impact on the runtime efficiency. However, driven by the need for experimental exploration, we find that this implication overlooks a critical issue that may affect the fairness of the outcome. Once this issue is properly considered, our hardness analysis shows that the problem may become computationally intractable even for a two-dimensional dataset and small values of $k$. However, our analysis also reveals a gap in the hardness barrier, enabling us to recover the efficiency for the case of small $k$ when the number of protected groups is sufficiently small. Furthermore, beyond measuring disparity as the "distance" between the fair and the reference scoring functions, we introduce an alternative disparity measure$\unicode{x2014}$utility loss$\unicode{x2014}$that may yield a more stable scoring function under small weight perturbations. Through careful engineering trade-offs that balance implementation complexity, robustness, and performance, our augmented two-pronged solution demonstrates strong empirical performance on real-world datasets, with experimental observations also informing algorithm design and implementation decisions.
2603.04689
Mar 2026Data Structures and Algorithms

MerLean: An Agentic Framework for Autoformalization in Quantum Computation
We introduce MerLean, a fully automated agentic framework for autoformalization in quantum computation. MerLean extracts mathematical statements from \LaTeX{} source files, formalizes them into verified Lean~4 code built on Mathlib, and translates the result back into human-readable \LaTeX{} for semantic review. We evaluate MerLean on three theoretical quantum computing papers producing 2,050 Lean declarations from 114 statements in total. MerLean achieves end-to-end formalization on all three papers, reducing the verification burden to only the newly introduced definitions and axioms. Our results demonstrate that agentic autoformalization can scale to frontier research, offering both a practical tool for machine-verified peer review and a scalable engine for mining high-quality synthetic data to train future reasoning models. Our approach can also be generalized to any other rigorous research in mathematics and theoretical physics.
2602.16554
Feb 2026Logic in Computer Science
Causal and Compositional Abstraction
Abstracting from a low level to a more explanatory high level of description, and ideally while preserving causal structure, is fundamental to scientific practice, to causal inference problems, and to robust, efficient and interpretable AI. We present a general account of abstractions between low and high level models as natural transformations, focusing on the case of causal models. This provides a new formalisation of causal abstraction, unifying several notions in the literature, including constructive causal abstraction, Q-$τ$ consistency, abstractions based on interchange interventions, and `distributed' causal abstractions. Our approach is formalised in terms of category theory, and uses the general notion of a compositional model with a given set of queries and semantics in a monoidal, cd- or Markov category; causal models and their queries such as interventions being special cases. We identify two basic notions of abstraction: downward abstractions mapping queries from high to low level; and upward abstractions, mapping concrete queries such as Do-interventions from low to high. Although usually presented as the latter, we show how common causal abstractions may, more fundamentally, be understood in terms of the former. Our approach also leads us to consider a new stronger notion of `component-level' abstraction, applying to the individual components of a model. In particular, this yields a novel, strengthened form of constructive causal abstraction at the mechanism-level, for which we prove characterisation results. Finally, we show that abstraction can be generalised to further compositional models, including those with a quantum semantics implemented by quantum circuits, and we take first steps in exploring abstractions between quantum compositional circuit models and high-level classical causal models as a means to explainable quantum AI.
2602.16612
Feb 2026Logic in Computer Science
130k Lines of Formal Topology in Two Weeks: Simple and Cheap Autoformalization for Everyone?
This is a brief description of a project that has already autoformalized a large portion of the general topology from the Munkres textbook (which has in total 241 pages in 7 chapters and 39 sections). The project has been running since November 21, 2025 and has as of January 4, 2026, produced 160k lines of formalized topology. Most of it (about 130k lines) have been done in two weeks,from December 22 to January 4, for an LLM subscription cost of about \$100. This includes a 3k-line proof of Urysohn's lemma, a 2k-line proof of Urysohn's Metrization theorem, over 10k-line proof of the Tietze extension theorem, and many more (in total over 1.5k lemmas/theorems). The approach is quite simple and cheap: build a long-running feedback loop between an LLM and a reasonably fast proof checker equipped with a core foundational library. The LLM is now instantiated as ChatGPT (mostly 5.2) or Claude Sonnet (4.5) run through the respective Codex or Claude Code command line interfaces. The proof checker is Chad Brown's higher-order set theory system Megalodon, and the core library is Brown's formalization of basic set theory and surreal numbers (including reals, etc). The rest is some prompt engineering and technical choices which we describe here. Based on the fast progress, low cost, virtually unknown ITP/library, and the simple setup available to everyone, we believe that (auto)formalization may become quite easy and ubiquitous in 2026, regardless of which proof assistant is used.
2601.03298
Jan 2026Logic in Computer Science

Quantifier Elimination Meets Treewidth
In this paper, we address the complexity barrier inherent in Fourier-Motzkin elimination (FME) and cylindrical algebraic decomposition (CAD) when eliminating a block of (existential) quantifiers. To mitigate this, we propose exploiting structural sparsity in the variable dependency graph of quantified formulas. Utilizing tools from parameterized algorithms, we investigate the role of treewidth, a parameter that measures the graph's tree-likeness, in the process of quantifier elimination. A novel dynamic programming framework, structured over a tree decomposition of the dependency graph, is developed for applying FME and CAD, and is also extensible to general quantifier elimination procedures. Crucially, we prove that when the treewidth is a constant, the framework achieves a significant exponential complexity improvement for both FME and CAD, reducing the worst-case complexity bound from doubly exponential to single exponential. Preliminary experiments on sparse linear real arithmetic (LRA) and nonlinear real arithmetic (NRA) benchmarks confirm that our algorithm outperforms the existing popular heuristic-based approaches on instances exhibiting low treewidth.
2601.00312
Jan 2026Logic in Computer Science
Policy-Conditioned Policies for Multi-Agent Task Solving
In multi-agent tasks, the central challenge lies in the dynamic adaptation of strategies. However, directly conditioning on opponents' strategies is intractable in the prevalent deep reinforcement learning paradigm due to a fundamental ``representational bottleneck'': neural policies are opaque, high-dimensional parameter vectors that are incomprehensible to other agents. In this work, we propose a paradigm shift that bridges this gap by representing policies as human-interpretable source code and utilizing Large Language Models (LLMs) as approximate interpreters. This programmatic representation allows us to operationalize the game-theoretic concept of \textit{Program Equilibrium}. We reformulate the learning problem by utilizing LLMs to perform optimization directly in the space of programmatic policies. The LLM functions as a point-wise best-response operator that iteratively synthesizes and refines the ego agent's policy code to respond to the opponent's strategy. We formalize this process as \textit{Programmatic Iterated Best Response (PIBR)}, an algorithm where the policy code is optimized by textual gradients, using structured feedback derived from game utility and runtime unit tests. We demonstrate that this approach effectively solves several standard coordination matrix games and a cooperative Level-Based Foraging environment.
2512.21024
Dec 2025Computer Science and Game Theory
Sub-$n^k$ Deterministic algorithm for minimum $k$-way cut in simple graphs
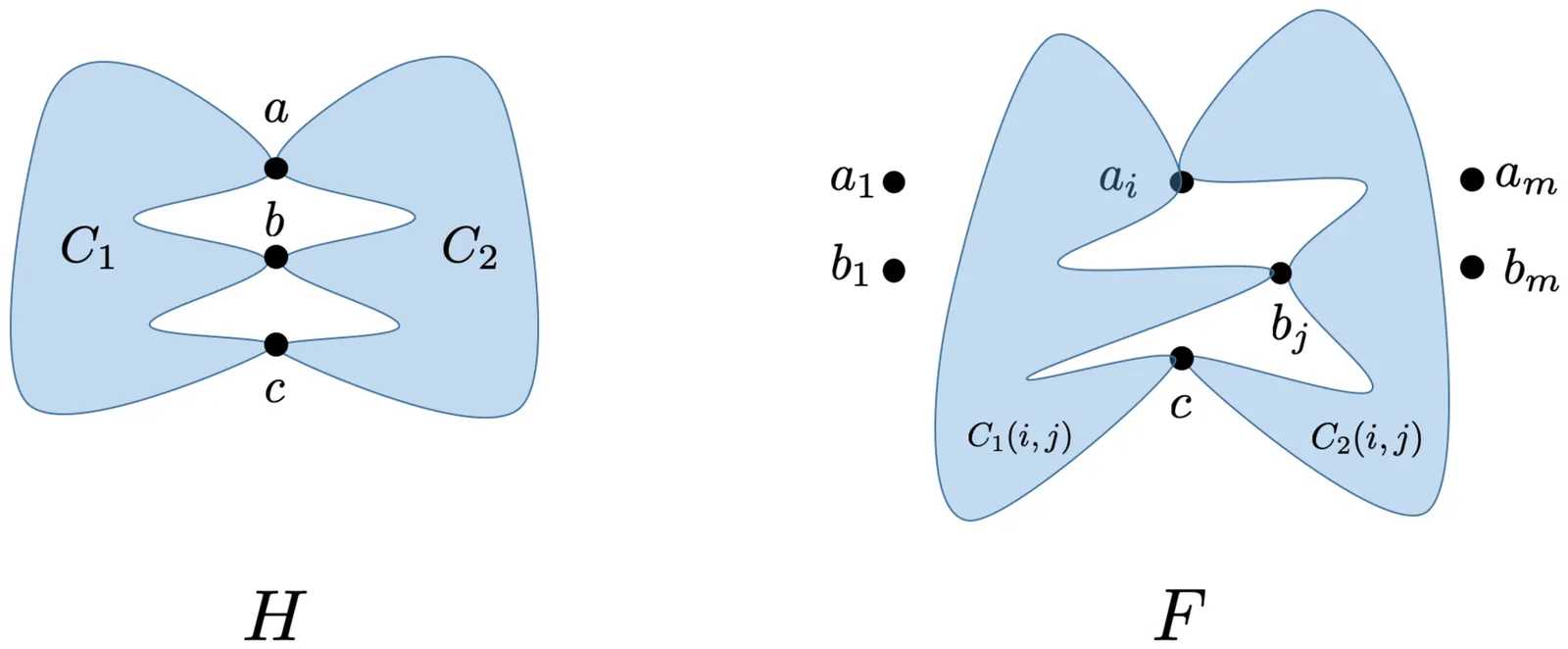
We present a \emph{deterministic exact algorithm} for the \emph{minimum $k$-cut problem} on simple graphs. Our approach combines the \emph{principal sequence of partitions (PSP)}, derived canonically from ideal loads, with a single level of \emph{Kawarabayashi--Thorup (KT)} contractions at the critical PSP threshold~$λ_j$. Let $j$ be the smallest index with $κ(P_j)\ge k$ and $R := k - κ(P_{j-1})$. We prove a structural decomposition theorem showing that an optimal $k$-cut can be expressed as the level-$(j\!-\!1)$ boundary $A_{\le j-1}$ together with exactly $(R-r)$ \emph{non-trivial} internal cuts of value at most~$λ_j$ and $r$ \emph{singleton isolations} (``islands'') inside the parts of~$P_{j-1}$. At this level, KT contractions yield kernels of total size $\widetilde{O}(n / λ_j)$, and from them we build a \emph{canonical border family}~$\mathcal{B}$ of the same order that deterministically covers all optimal refinement choices. Branching only over~$\mathcal{B}$ (and also including an explicit ``island'' branch) gives total running time $$ T(n,m,k) = \widetilde{O}\left(\mathrm{poly}(m)+\Bigl(\tfrac{n}{λ_j}+n^{ω/3}\Bigr)^{R}\right), $$ where $ω< 2.373$ is the matrix multiplication exponent. In particular, if $λ_j \ge n^{\varepsilon}$ for some constant $\varepsilon > 0$, we obtain a \emph{deterministic sub-$n^k$-time algorithm}, running in $n^{(1-\varepsilon)(k-1)+o(k)}$ time. Finally, combining our PSP$\times$KT framework with a small-$λ$ exact subroutine via a simple meta-reduction yields a deterministic $n^{c k+O(1)}$ algorithm for $c = \max\{ t/(t+1), ω/3 \} < 1$, aligning with the exponent in the randomized bound of He--Li (STOC~2022) under the assumed subroutine.
2512.12900
Dec 2025Data Structures and Algorithms
Space Efficient Algorithms for Parameterised Problems
We study "space efficient" FPT algorithms for graph problems with limited memory. Let n be the size of the input graph and k be the parameter. We present algorithms that run in time f(k)*poly(n) and use g(k)*polylog(n) working space, where f and g are functions of k alone, for k-Path, MaxLeaf SubTree and Multicut in Trees. These algorithms are motivated by big-data settings where very large problem instances must be solved, and using poly(n) memory is prohibitively expensive. They are also theoretically interesting, since most of the standard methods tools, such as deleting a large set of vertices or edges, are unavailable, and we must a develop different way to tackle them.
2512.13342
Dec 2025Data Structures and Algorithms

Bounded treewidth, multiple context-free grammars, and downward closures
The reachability problem in multi-pushdown automata (MPDA) has many applications in static analysis of recursive programs. An example is safety verification of multi-threaded recursive programs with shared memory. Since these problems are undecidable, the literature contains many decidable (and efficient) underapproximations of MPDA. A uniform framework that captures many of these underapproximations is that of bounded treewidth (tw): To each execution of the MPDA, we associate a graph; then we consider the subset of all graphs that have a wt at most $k$, for some constant $k$. In fact, bounding tw is a generic approach to obtain classes of systems with decidable reachability, even beyond MPDA underapproximations. The resulting systems are also called MSO-definable bounded-tw systems. While bounded tw is a powerful tool for reachability and similar types of analysis, the word languages (i.e. action sequences corresponding to executions) of these systems remain far from understood. For the slight restriction of bounded special tw, or "bounded-stw" (which is equivalent to bounded tw on MPDA, and even includes all bounded-tw systems studied in the literature), this work reveals a connection with multiple context-free languages (MCFL), a concept from computational linguistics. We show that the word languages of MSO-definable bounded-stw systems are exactly the MCFL. We exploit this connection to provide an optimal algorithm for computing downward closures (dcl) for MSO-definable bounded-stw systems. Computing dcl is a notoriously difficult task that has many applications in the verification of complex systems: As an example application, we show that in programs with dynamic spawning of MSO-definable bounded-stw processes, safety verification has the same complexity as in the case of processes with sequential recursive processes.
2512.019731
Dec 2025Formal Languages and Automata Theory
Halfspaces are hard to test with relative error
Several recent works [DHLNSY25, CPPS25a, CPPS25b] have studied a model of property testing of Boolean functions under a \emph{relative-error} criterion. In this model, the distance from a target function $f: \{0,1\}^n \to \{0,1\}$ that is being tested to a function $g$ is defined relative to the number of inputs $x$ for which $f(x)=1$; moreover, testing algorithms in this model have access both to a black-box oracle for $f$ and to independent uniform satisfying assignments of $f$. The motivation for this model is that it provides a natural framework for testing \emph{sparse} Boolean functions that have few satisfying assignments, analogous to well-studied models for property testing of sparse graphs. The main result of this paper is a lower bound for testing \emph{halfspaces} (i.e., linear threshold functions) in the relative error model: we show that $\tildeΩ(\log n)$ oracle calls are required for any relative-error halfspace testing algorithm over the Boolean hypercube $\{0,1\}^n$. This stands in sharp contrast both with the constant-query testability (independent of $n$) of halfspaces in the standard model [MORS10], and with the positive results for relative-error testing of many other classes given in [DHLNSY25, CPPS25a, CPPS25b]. Our lower bound for halfspaces gives the first example of a well-studied class of functions for which relative-error testing is provably more difficult than standard-model testing.
2511.06171
Nov 2025Computational Complexity
GenAI vs. Human Creators: Procurement Mechanism Design in Two-/Three-Layer Markets
With the rapid advancement of generative AI (GenAI), mechanism design adapted to its unique characteristics poses new theoretical and practical challenges. Unlike traditional goods, content from one domain can enhance the training and performance of GenAI models in other domains. For example, OpenAI's video generation model Sora (Liu et al., 2024b) relies heavily on image data to improve video generation quality. In this work, we study nonlinear procurement mechanism design under data transferability, where online platforms employ both human creators and GenAI to satisfy cross-domain content demand. We propose optimal mechanisms that maximize either platform revenue or social welfare and identify the specific properties of GenAI that make such high-dimensional design problems tractable. Our analysis further reveals which domains face stronger competitive pressure and which tend to experience overproduction. Moreover, the growing role of data intermediaries, including labeling companies such as Scale AI and creator organizations such as The Wall Street Journal, introduces a third layer into the traditional platform-creator structure. We show that this three-layer market can result in a lose-lose outcome, reducing both platform revenue and social welfare, as large pre-signed contracts distort creators' incentives and lead to inefficiencies in the data market. These findings suggest a need for government regulation of the GenAI data ecosystem, and our theoretical insights are further supported by numerical simulations.
2511.06559
Nov 2025Computer Science and Game Theory