Computation
arXiv:stat.CO
Algorithms, simulation, graphics, visualization, software development.
Algorithms, simulation, graphics, visualization, software development.
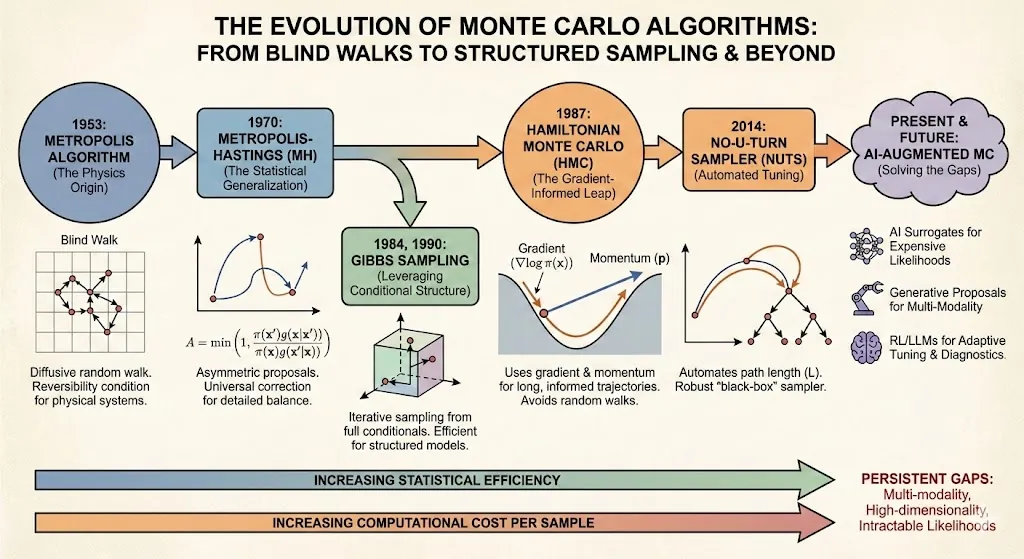
Monte Carlo algorithms are a foundational pillar of modern computational science, yet their effective application hinges on a deep understanding of their performance trade offs. This paper presents a critical analysis of the evolution of Monte Carlo algorithms, focusing on the persistent tension between statistical efficiency and computational cost. We describe the historical development from the foundational Metropolis Hastings algorithm to contemporary methods like Hamiltonian Monte Carlo. A central emphasis of this survey is the rigorous discussion of time and space complexity, including upper, lower, and asymptotic tight bounds for each major algorithm class. We examine the specific motivations for developing these methods and the key theoretical and practical observations such as the introduction of gradient information and adaptive tuning in HMC that led to successively better solutions. Furthermore, we provide a justification framework that discusses explicit situations in which using one algorithm is demonstrably superior to another for the same problem. The paper concludes by assessing the profound significance and impact of these algorithms and detailing major current research challenges.

We introduce shielded Langevin Monte Carlo (LMC), a constrained sampler inspired by navigation functions, capable of sampling from unnormalized target distributions defined over punctured supports. In other words, this approach samples from non-convex spaces defined as convex sets with convex holes. This defines a novel and challenging problem in constrained sampling. To do so, the sampler incorporates a combination of a spatially adaptive temperature and a repulsive drift to ensure that samples remain within the feasible region. Experiments on a 2D Gaussian mixture and multiple-input multiple-output (MIMO) symbol detection showcase the advantages of the proposed shielded LMC in contrast to unconstrained cases.
Learning probabilistic surrogates for PDEs remains challenging in data-scarce regimes: neural operators require large amounts of high-fidelity data, while generative approaches typically sacrifice resolution invariance. We formulate flow matching in an infinite-dimensional function space to learn a probabilistic transport that maps low-fidelity approximations to the manifold of high-fidelity PDE solutions via learned residual corrections. We develop a conditional neural operator architecture based on feature-wise linear modulation for flow-matching vector fields directly in function space, enabling inference at arbitrary spatial resolutions without retraining. To improve stability and representational control of the induced neural ODE, we parameterize the flow vector field as a sum of a linear operator and a nonlinear operator, combining lightweight linear components with a conditioned Fourier neural operator for expressive, input-dependent dynamics. We then formulate a residual-augmented learning strategy where the flow model learns probabilistic corrections from inexpensive low-fidelity surrogates to high-fidelity solutions, rather than learning the full solution mapping from scratch. Finally, we derive tractable training objectives that extend conditional flow matching to the operator setting with input-function-dependent couplings. To demonstrate the effectiveness of our approach, we present numerical experiments on a range of PDEs, including the 1D advection and Burgers' equation, and a 2D Darcy flow problem for flow through a porous medium. We show that the proposed method can accurately learn solution operators across different resolutions and fidelities and produces uncertainty estimates that appropriately reflect model confidence, even when trained on limited high-fidelity data.
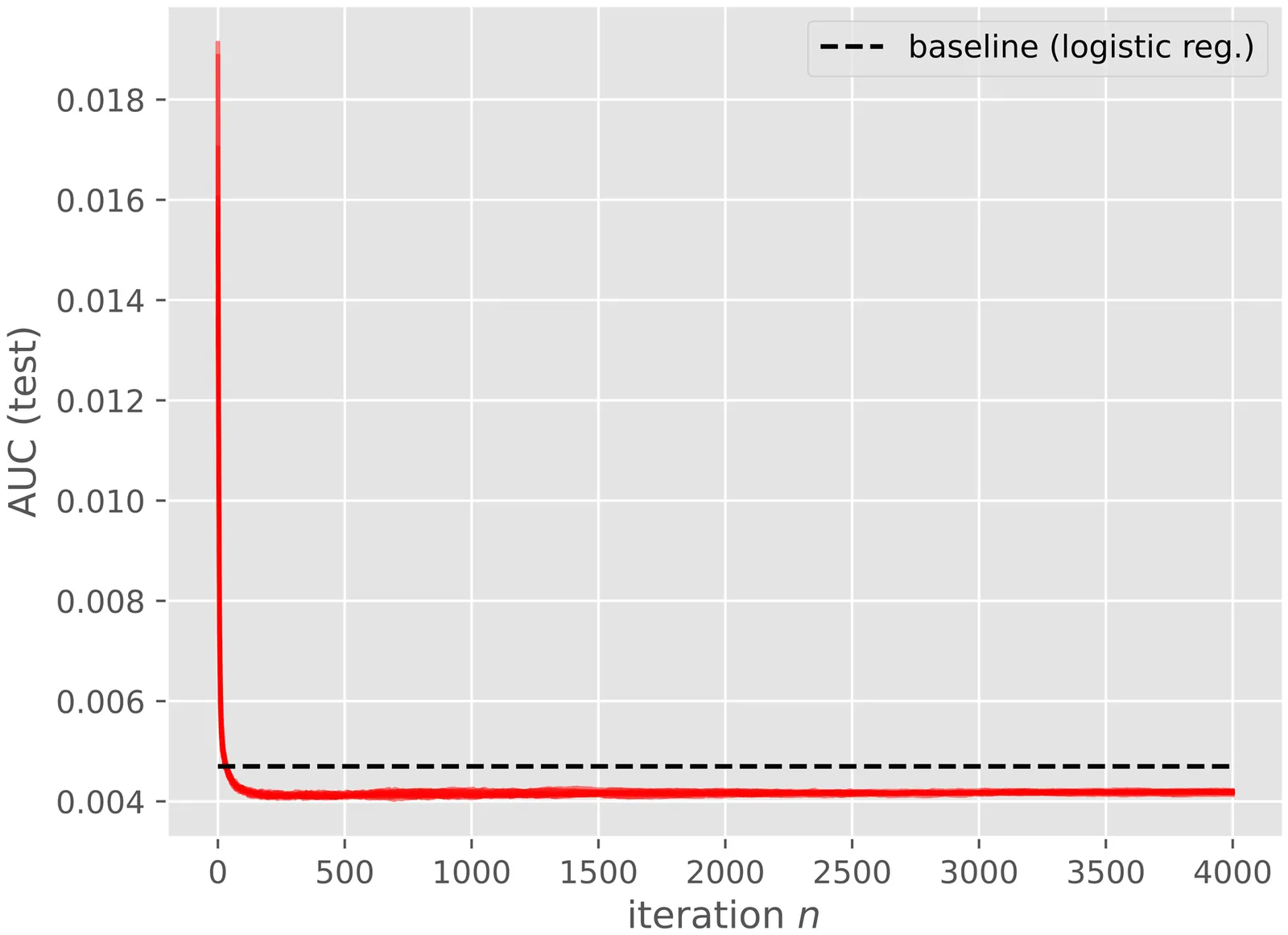
We investigate the convergence properties of a class of iterative algorithms designed to minimize a potentially non-smooth and noisy objective function, which may be algebraically intractable and whose values may be obtained as the output of a black box. The algorithms considered can be cast under the umbrella of a generalised gradient descent recursion, where the gradient is that of a smooth approximation of the objective function. The framework we develop includes as special cases model-based and mollification methods, two classical approaches to zero-th order optimisation. The convergence results are obtained under very weak assumptions on the regularity of the objective function and involve a trade-off between the degree of smoothing and size of the steps taken in the parameter updates. As expected, additional assumptions are required in the stochastic case. We illustrate the relevance of these algorithms and our convergence results through a challenging classification example from machine learning.
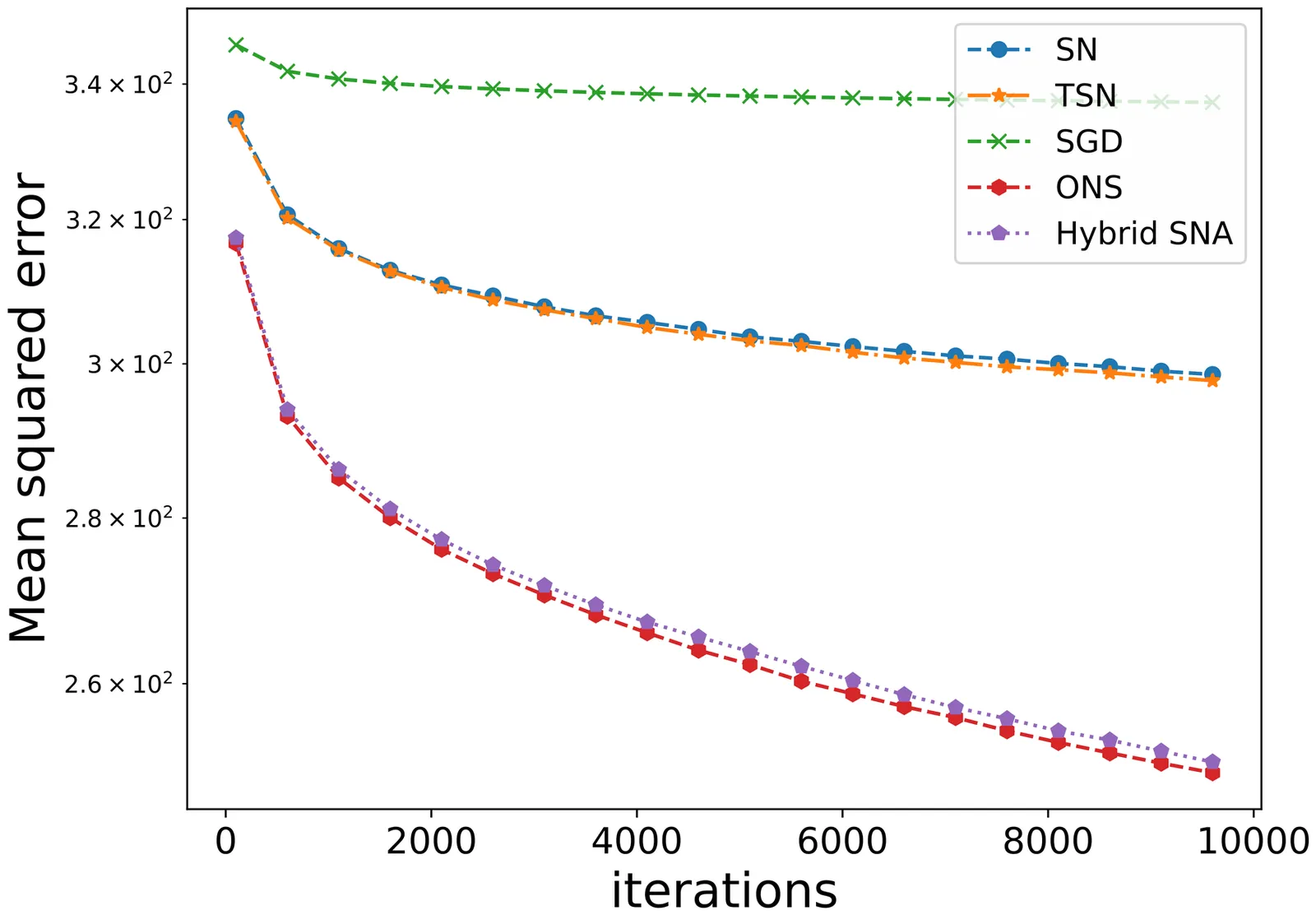
In this paper, we investigate a second-order stochastic algorithm for solving large-scale binary classification problems. We propose to make use of a new hybrid stochastic Newton algorithm that includes two weighted components in the Hessian matrix estimation: the first one coming from the natural Hessian estimate and the second associated with the stochastic gradient information. Our motivation comes from the fact that both parts evaluated at the true parameter of logistic regression, are equal to the Hessian matrix. This new formulation has several advantages and it enables us to prove the almost sure convergence of our stochastic algorithm to the true parameter. Moreover, we significantly improve the almost sure rate of convergence to the Hessian matrix. Furthermore, we establish the central limit theorem for our hybrid stochastic Newton algorithm. Finally, we show a surprising result on the almost sure convergence of the cumulative excess risk.
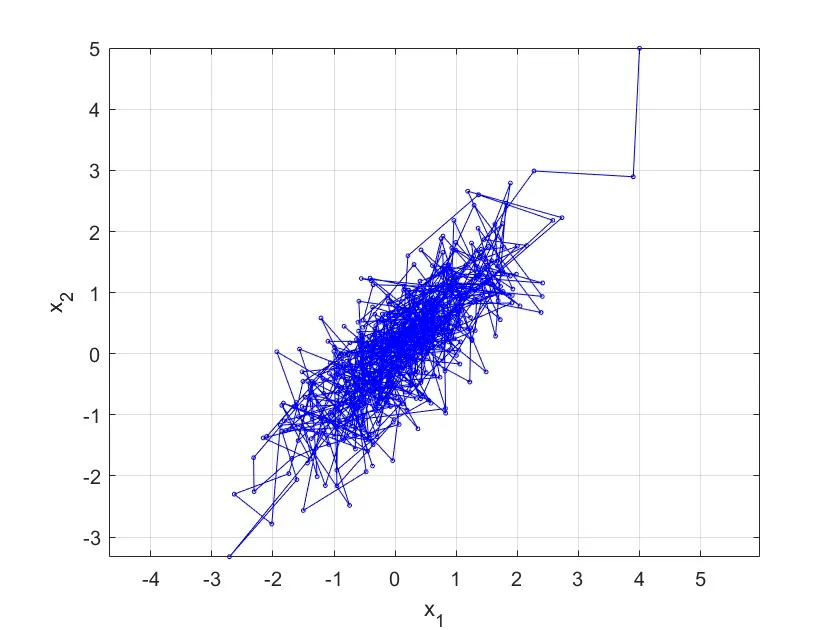
Iterated sampling importance resampling (i-SIR) is a Markov chain Monte Carlo (MCMC) algorithm which is based on $N$ independent proposals. As $N$ grows, its samples become nearly independent, but with an increased computational cost. We discuss a method which finds an approximately optimal number of proposals $N$ in terms of the asymptotic efficiency. The optimal $N$ depends on both the mixing properties of the i-SIR chain and the (parallel) computing costs. Our method for finding an appropriate $N$ is based on an approximate asymptotic variance of the i-SIR, which has similar properties as the i-SIR asymptotic variance, and a generalised i-SIR transition having fractional `number of proposals.' These lead to an adaptive i-SIR algorithm, which tunes the number of proposals automatically during sampling. Our experiments demonstrate that our approximate efficiency and the adaptive i-SIR algorithm have promising empirical behaviour. We also present new theoretical results regarding the i-SIR, such as the convexity of asymptotic variance in the number of proposals, which can be of independent interest.
In an earlier joint work, we studied a sequential Monte Carlo algorithm to sample from the Gibbs measure supported on torus with a non-convex energy function at a low temperature, where we proved that the time complexity of the algorithm is polynomial in the inverse temperature. However, the analysis in that torus setting relied crucially on compactness and does not directly extend to unbounded domains. This work introduces a new approach that resolves this issue and establishes a similar result for sampling from Gibbs measures supported on Rd. In particular, our main result shows that for double-well energy with equal well depths, the time complexity scales as seventh power of the inverse temperature, and quadratically in both the inverse allowed absolute error and probability error.
Markov Chain Monte Carlo (MCMC) is a flexible approach to approximate sampling from intractable probability distributions, with a rich theoretical foundation and comprising a wealth of exemplar algorithms. While the qualitative correctness of MCMC algorithms is often easy to ensure, their practical efficiency is contingent on the `target' distribution being reasonably well-behaved. In this work, we concern ourself with the scenario in which this good behaviour is called into question, reviewing an emerging line of work on `robust' MCMC algorithms which can perform acceptably even in the face of certain pathologies. We focus on two particular pathologies which, while simple, can already have dramatic effects on standard `local' algorithms. The first is roughness, whereby the target distribution varies so rapidly that the numerical stability of the algorithm is tenuous. The second is flatness, whereby the landscape of the target distribution is instead so barren and uninformative that one becomes lost in uninteresting parts of the state space. In each case, we formulate the pathology in concrete terms, review a range of proposed algorithmic remedies to the pathology, and outline promising directions for future research.

This paper proposes a novel Bayesian framework for solving Poisson inverse problems by devising a Monte Carlo sampling algorithm which accounts for the underlying non-Euclidean geometry. To address the challenges posed by the Poisson likelihood -- such as non-Lipschitz gradients and positivity constraints -- we derive a Bayesian model which leverages exact and asymptotically exact data augmentations. In particular, the augmented model incorporates two sets of splitting variables both derived through a Bregman divergence based on the Burg entropy. Interestingly the resulting augmented posterior distribution is characterized by conditional distributions which benefit from natural conjugacy properties and preserve the intrinsic geometry of the latent and splitting variables. This allows for efficient sampling via Gibbs steps, which can be performed explicitly for all conditionals, except the one incorporating the regularization potential. For this latter, we resort to a Hessian Riemannian Langevin Monte Carlo (HRLMC) algorithm which is well suited to handle priors with explicit or easily computable score functions. By operating on a mirror manifold, this Langevin step ensures that the sampling satisfies the positivity constraints and more accurately reflects the underlying problem structure. Performance results obtained on denoising, deblurring, and positron emission tomography (PET) experiments demonstrate that the method achieves competitive performance in terms of reconstruction quality compared to optimization- and sampling-based approaches.
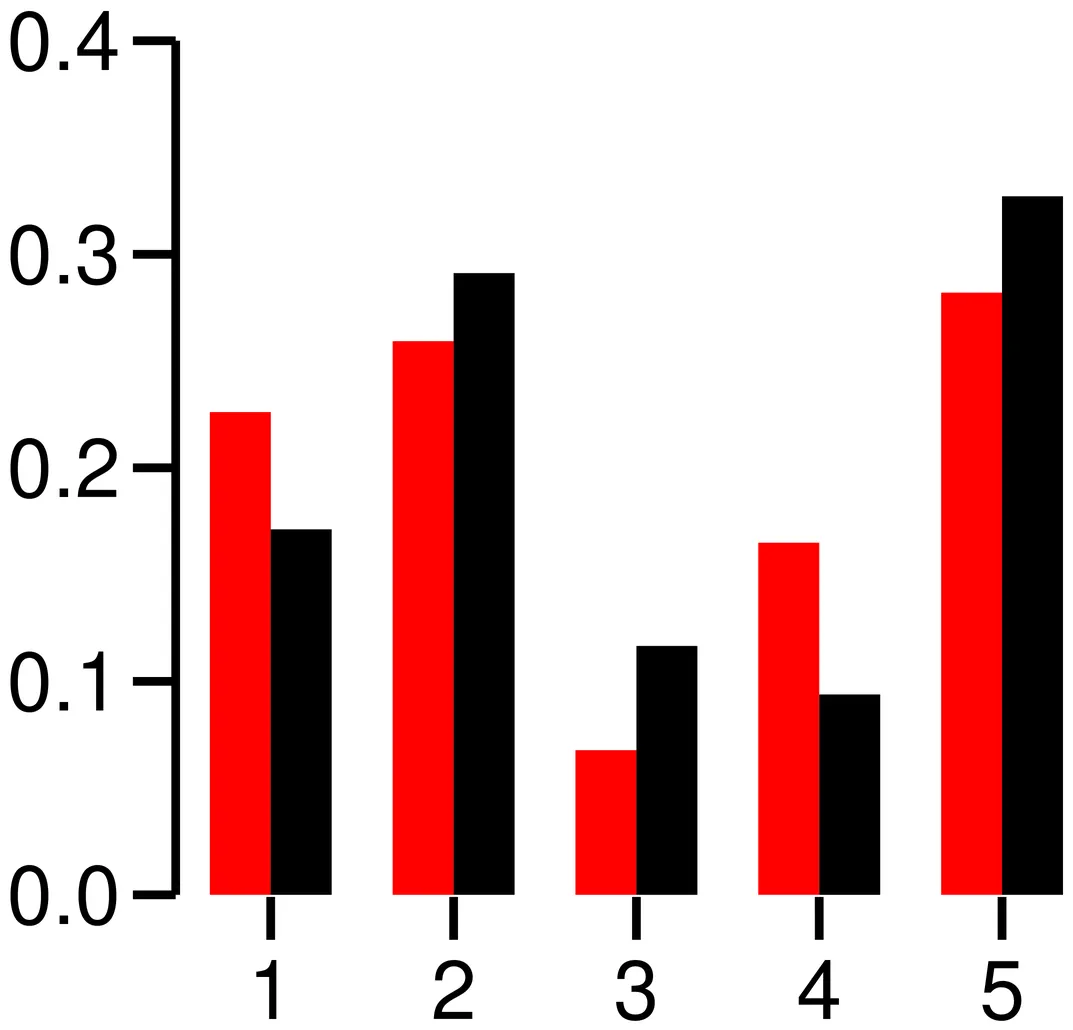
The Metropolis-Hastings algorithm has been extensively studied in the estimation and simulation literature, with most prior work focusing on convergence behavior and asymptotic theory. However, its covariance structure-an important statistical property for both theory and implementation-remains less understood. In this work, we provide new theoretical insights into the scalar case, focusing primarily on symmetric unimodal target distributions with symmetric random walk proposals, where we also establish an optimal proposal design. In addition, we derive some more general results beyond this setting. For the high-dimensional case, we relate the covariance matrix to the classical 0.23 average acceptance rate tuning criterion.
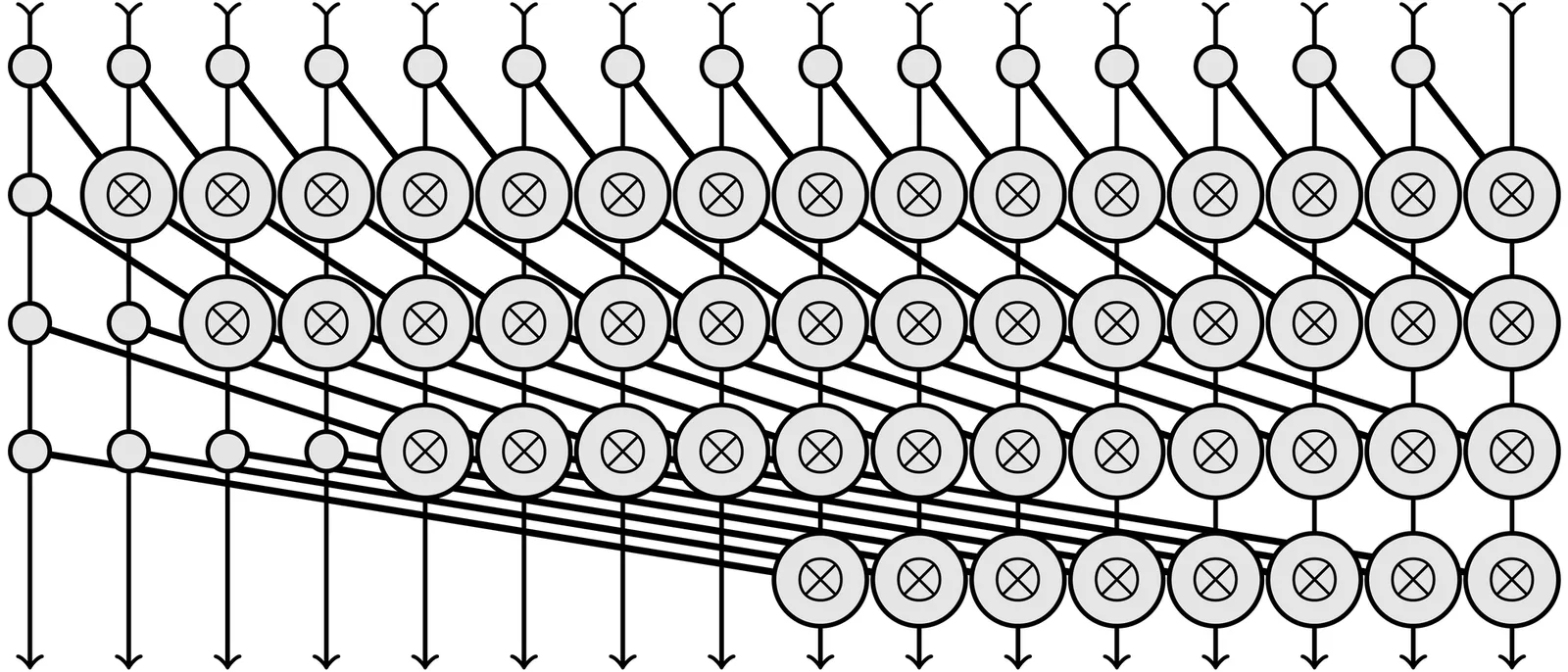
This paper presents an experimental evaluation of parallel-in-time Kalman filters and smoothers using graphics processing units (GPUs). In particular, the paper evaluates different all-prefix-sum algorithms, that is, parallel scan algorithms for temporal parallelization of Kalman filters and smoothers in two ways: by calculating the required number of operations via simulation, and by measuring the actual run time of the algorithms on real GPU hardware. In addition, a novel parallel-in-time two-filter smoother is proposed and experimentally evaluated. Julia code for Metal and CUDA implementations of all the algorithms is made publicly available.
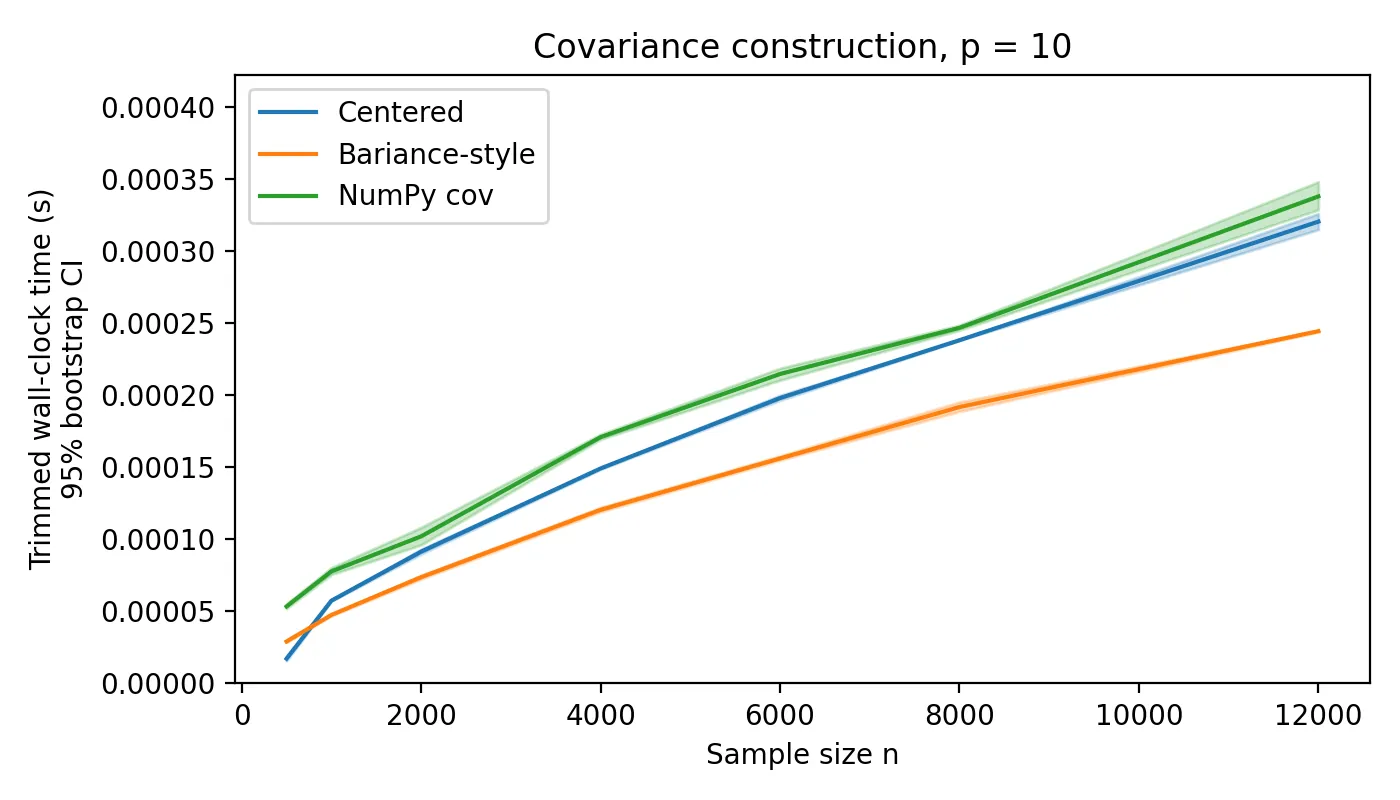
Reichel (2025) defined the bariance as a pairwise-difference measure that can be rewritten in linear time using only scalar sums. We extend this idea to the covariance matrix by showing that the standard matrix expression involving the uncentered Gram matrix and a correction term is algebraically identical to the pairwise-difference definition while avoiding explicit centering. The computation then reduces to one outer product of dimension p-by-p and a single subtraction. Benchmarks in Python show clear runtime gains, especially when BLAS optimizations are absent. Optionally faster Gram-matrix routines such as RXTX (Rybin et al., 2025) further reduce overall cost.
We present a suite of packages in R, Python, Julia, and C++ that efficiently solve the Sorted L-One Penalized Estimation (SLOPE) problem. The packages feature a highly efficient hybrid coordinate descent algorithm that fits generalized linear models (GLMs) and supports a variety of loss functions, including Gaussian, binomial, Poisson, and multinomial logistic regression. Our implementation is designed to be fast, memory-efficient, and flexible. The packages support a variety of data structures (dense, sparse, and out-of-memory matrices) and are designed to efficiently fit the full SLOPE path as well as handle cross-validation of SLOPE models, including the relaxed SLOPE. We present examples of how to use the packages and benchmarks that demonstrate the performance of the packages on both real and simulated data and show that our packages outperform existing implementations of SLOPE in terms of speed.
We study the theoretical complexity of simulated tempering for sampling from mixtures of log-concave components differing only by location shifts. The main result establishes the first polynomial-time guarantee for simulated tempering combined with the Metropolis-adjusted Langevin algorithm (MALA) with respect to the problem dimension $d$, maximum mode displacement $D$, and logarithmic accuracy $\log ε^{-1}$. The proof builds on a general state decomposition theorem for $s$-conductance, applied to an auxiliary Markov chain constructed on an augmented space. We also obtain an improved complexity estimate for simulated tempering combined with random-walk Metropolis. Our bounds assume an inverse-temperature ladder with smallest value $β_1 = O(D^{-2})$ and spacing $β_{i+1}/β_i = 1 + O( d^{-1/2} )$, both of which are shown to be asymptotically optimal up to logarithmic factors.
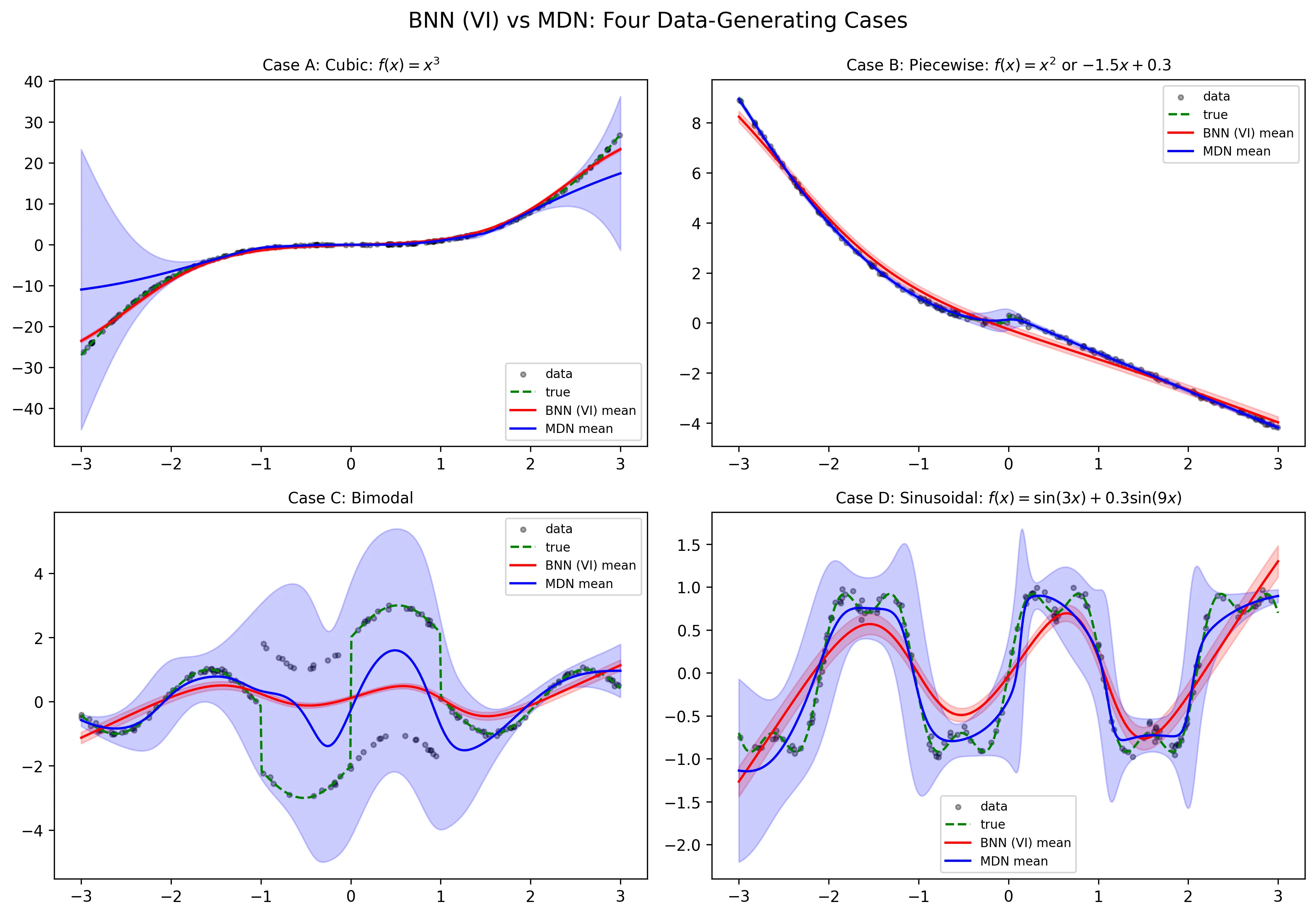
This paper investigates two prominent probabilistic neural modeling paradigms: Bayesian Neural Networks (BNNs) and Mixture Density Networks (MDNs) for uncertainty-aware nonlinear regression. While BNNs incorporate epistemic uncertainty by placing prior distributions over network parameters, MDNs directly model the conditional output distribution, thereby capturing multimodal and heteroscedastic data-generating mechanisms. We present a unified theoretical and empirical framework comparing these approaches. On the theoretical side, we derive convergence rates and error bounds under Hölder smoothness conditions, showing that MDNs achieve faster Kullback-Leibler (KL) divergence convergence due to their likelihood-based nature, whereas BNNs exhibit additional approximation bias induced by variational inference. Empirically, we evaluate both architectures on synthetic nonlinear datasets and a radiographic benchmark (RSNA Pediatric Bone Age Challenge). Quantitative and qualitative results demonstrate that MDNs more effectively capture multimodal responses and adaptive uncertainty, whereas BNNs provide more interpretable epistemic uncertainty under limited data. Our findings clarify the complementary strengths of posterior-based and likelihood-based probabilistic learning, offering guidance for uncertainty-aware modeling in nonlinear systems.
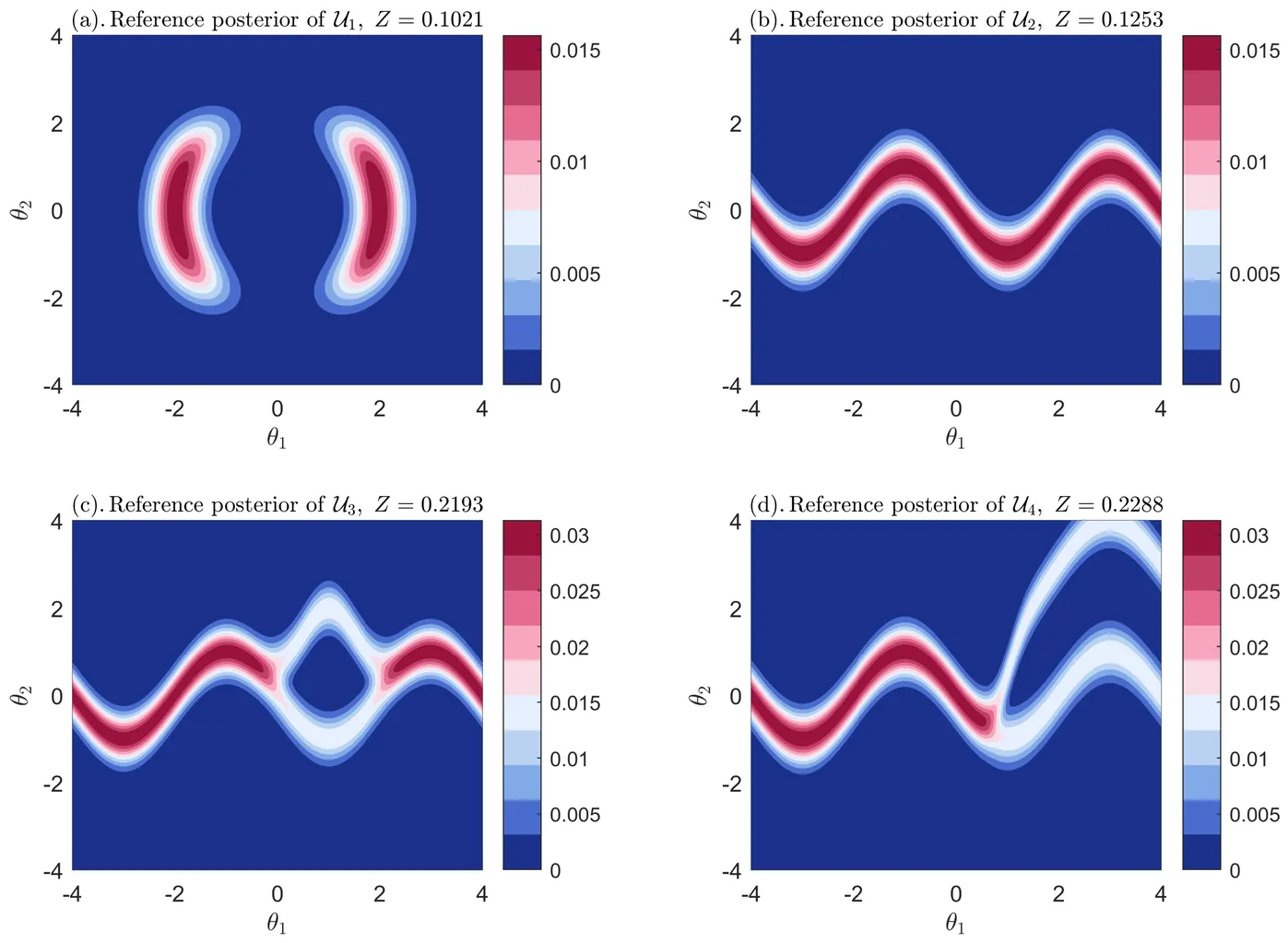
Estimating posteriors and the associated model evidences is a core issue of Bayesian model inference, and can be of great challenge given complex features of the posteriors such as multi-modalities of unequal importance, nonlinear dependencies and high sharpness. Bayesian Quadrature (BQ) has emerged as a competitive framework for tackling this challenge, as it provides flexible balance between computational cost and accuracy. The performance of a BQ scheme is fundamentally dictated by the acquisition function as it exclusively governs the generation of integration points. After reexamining one of the most advanced acquisition function from a prospective inference perspective and reformulating the quadrature rules for prediction, four new acquisition functions, inspired by distinct intuitions on expected rewards, are primarily developed, all of which are accompanied by elegant interpretations and highly efficient numerical estimators. Mathematically, these four acquisition functions measure, respectively, the prediction uncertainty of posterior, the contribution to prediction uncertainty of evidence, as well as the expected reduction of prediction uncertainties concerning posterior and evidence, and thus provide flexibility for highly effective design of integration points. These acquisition functions are further extended to the transitional BQ scheme, along with several specific refinements, to tackle the above-mentioned challenges with high efficiency and robustness. Effectiveness of the developments is ultimately demonstrated with extensive benchmark studies and application to an engineering example.

A long-standing gap exists between the theoretical analysis of Markov chain Monte Carlo convergence, which is often based on statistical divergences, and the diagnostics used in practice. We introduce the first general convergence diagnostics for Markov chain Monte Carlo based on any f-divergence, allowing users to directly monitor, among others, the Kullback--Leibler and the $χ^2$ divergences as well as the Hellinger and the total variation distances. Our first key contribution is a coupling-based `weight harmonization' scheme that produces a direct, computable, and consistent weighting of interacting Markov chains with respect to their target distribution. The second key contribution is to show how such consistent weightings of empirical measures can be used to provide upper bounds to f-divergences in general. We prove that these bounds are guaranteed to tighten over time and converge to zero as the chains approach stationarity, providing a concrete diagnostic. Numerical experiments demonstrate that our method is a practical and competitive diagnostic tool.
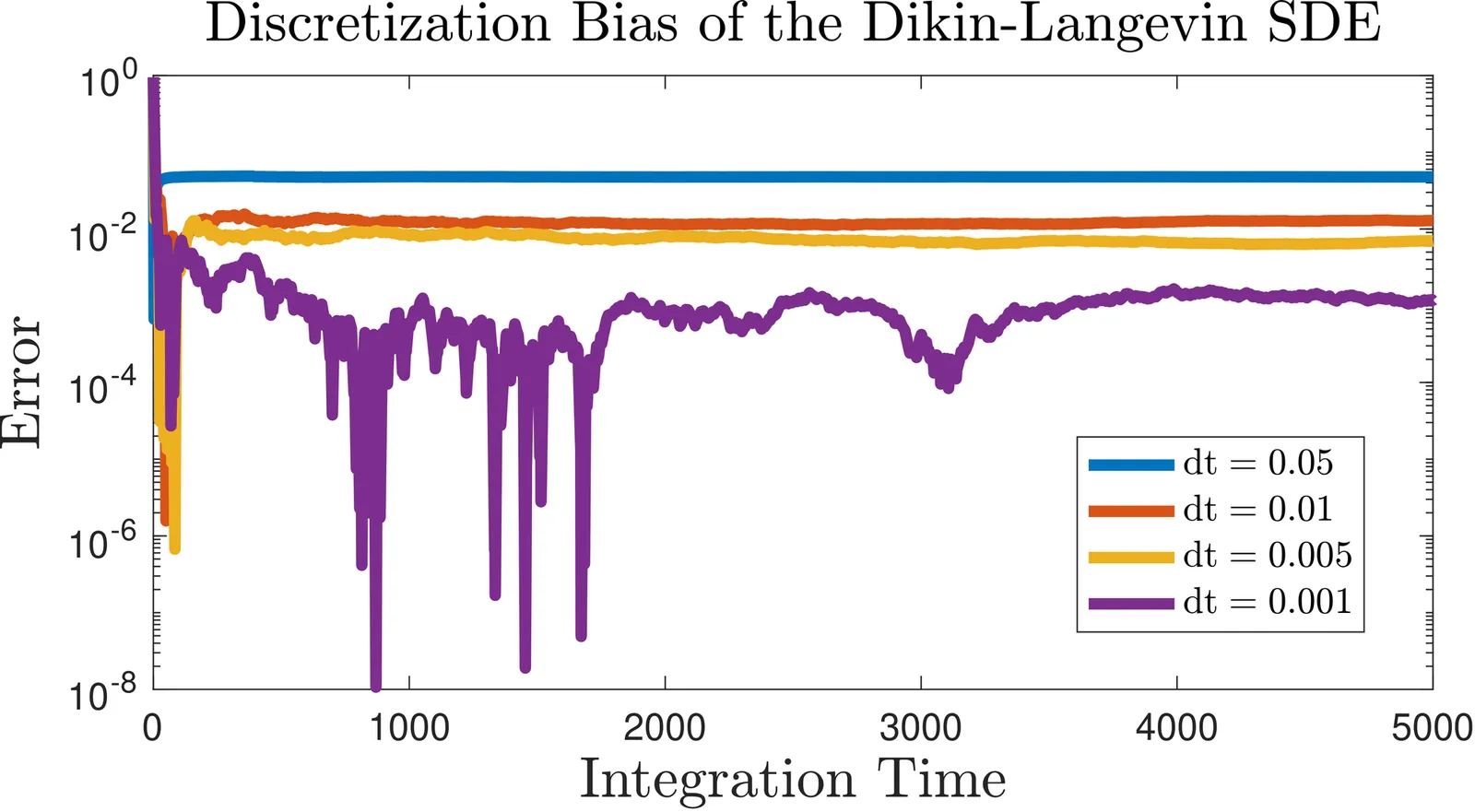
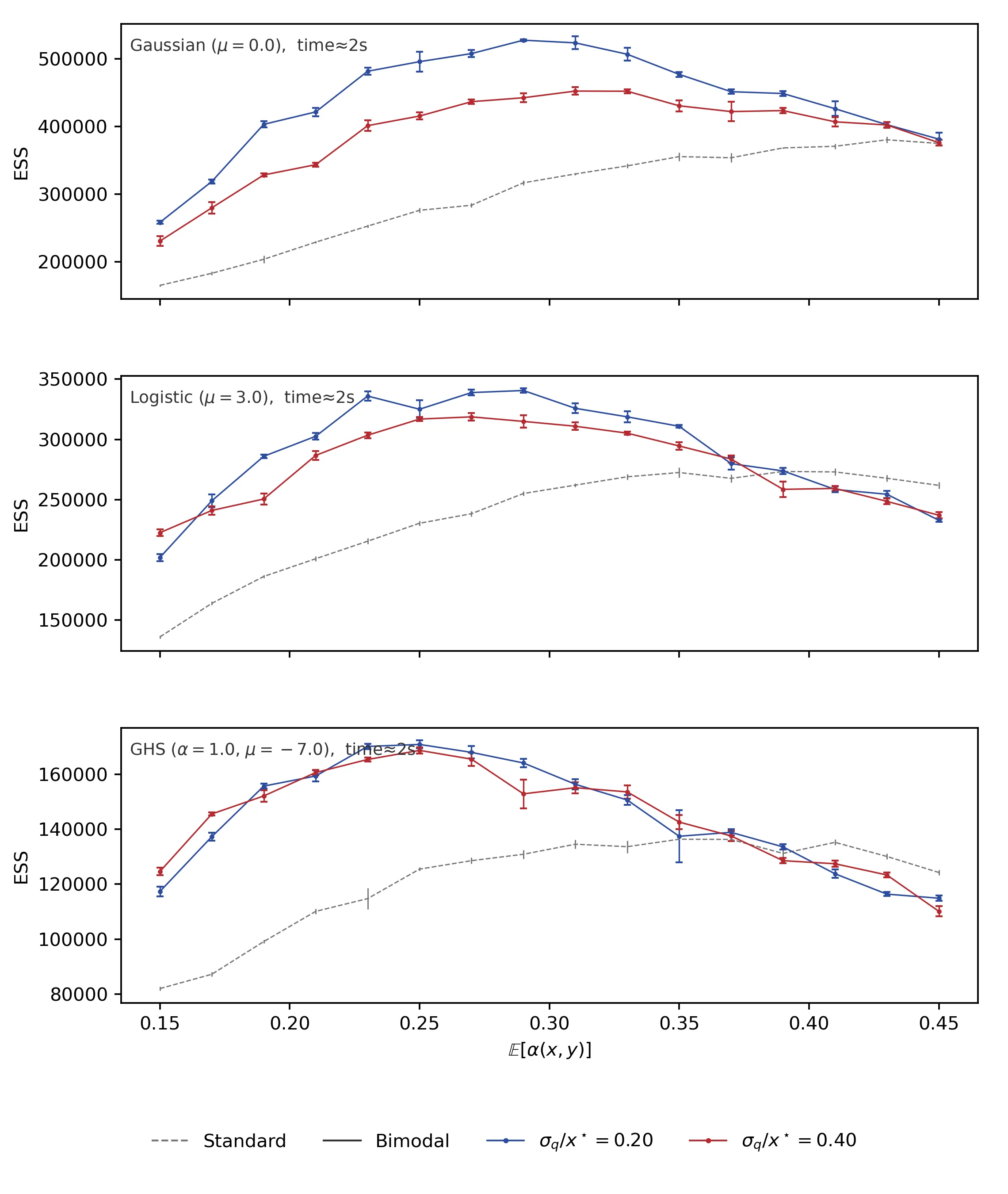
Interior-point geometry offers a straightforward approach to constrained sampling and optimization on polyhedra, eliminating reflections and ad hoc projections. We exploit the Dikin log-barrier to define a Dikin--Langevin diffusion whose drift and noise are modulated by the inverse barrier Hessian. In continuous time, we establish a boundary no-flux property; trajectories started in the interior remain in $U$ almost surely, so feasibility is maintained by construction. For computation, we adopt a discretize-then-correct design: an Euler--Maruyama proposal with state-dependent covariance, followed by a Metropolis--Hastings correction that targets the exact constrained law and reduces to a Dikin random walk when $f$ is constant. Numerically, the unadjusted diffusion exhibits the expected first-order step size bias, while the MH-adjusted variant delivers strong convergence diagnostics on anisotropic, box-constrained Gaussians (rank-normalized split-$\hat{R}$ concentrated near $1$) and higher inter-well transition counts on a bimodal target, indicating superior cross-well mobility. Taken together, these results demonstrate that coupling calibrated stochasticity with interior-point preconditioning provides a practical, reflection-free approach to sampling and optimization over polyhedral domains, offering clear advantages near faces, corners, and in nonconvex landscapes.
We present spd-metrics-id, a Python package for computing distances and divergences between symmetric positive-definite (SPD) matrices. Unlike traditional toolkits that focus on specific applications, spd-metrics-id provides a unified, extensible, and reproducible framework for SPD distance computation. The package supports a wide variety of geometry-aware metrics, including Alpha-z Bures-Wasserstein, Alpha-Procrustes, affine-invariant Riemannian, log-Euclidean, and others, and is accessible both via a command-line interface and a Python API. Reproducibility is ensured through Docker images and Zenodo archiving. We illustrate usage through a connectome fingerprinting example, but the package is broadly applicable to covariance analysis, diffusion tensor imaging, and other domains requiring SPD matrix comparison. The package is openly available at https://pypi.org/project/spd-metrics-id/.

Simulating the kinetic Langevin dynamics is a popular approach for sampling from distributions, where only their unnormalized densities are available. Various discretizations of the kinetic Langevin dynamics have been considered, where the resulting algorithm is collectively referred to as the kinetic Langevin Monte Carlo (KLMC) or underdamped Langevin Monte Carlo. Specifically, the stochastic exponential Euler discretization, or exponential integrator for short, has previously been studied under strongly log-concave and log-Lipschitz smooth potentials via the synchronous Wasserstein coupling strategy. Existing analyses, however, impose restrictions on the parameters that do not explain the behavior of KLMC under various choices of parameters. In particular, all known results fail to hold in the overdamped regime, suggesting that the exponential integrator degenerates in the overdamped limit. In this work, we revisit the synchronous Wasserstein coupling analysis of KLMC with the exponential integrator. Our refined analysis results in Wasserstein contractions and bounds on the asymptotic bias that hold under weaker restrictions on the parameters, which assert that the exponential integrator is capable of stably simulating the kinetic Langevin dynamics in the overdamped regime, as long as proper time acceleration is applied.
This paper presents an experimental evaluation of parallel-in-time Kalman filters and smoothers using graphics processing units (GPUs). In particular, the paper evaluates different all-prefix-sum algorithms, that is, parallel scan algorithms for temporal parallelization of Kalman filters and smoothers in two ways: by calculating the required number of operations via simulation, and by measuring the actual run time of the algorithms on real GPU hardware. In addition, a novel parallel-in-time two-filter smoother is proposed and experimentally evaluated. Julia code for Metal and CUDA implementations of all the algorithms is made publicly available.
We study the theoretical complexity of simulated tempering for sampling from mixtures of log-concave components differing only by location shifts. The main result establishes the first polynomial-time guarantee for simulated tempering combined with the Metropolis-adjusted Langevin algorithm (MALA) with respect to the problem dimension $d$, maximum mode displacement $D$, and logarithmic accuracy $\log ε^{-1}$. The proof builds on a general state decomposition theorem for $s$-conductance, applied to an auxiliary Markov chain constructed on an augmented space. We also obtain an improved complexity estimate for simulated tempering combined with random-walk Metropolis. Our bounds assume an inverse-temperature ladder with smallest value $β_1 = O(D^{-2})$ and spacing $β_{i+1}/β_i = 1 + O( d^{-1/2} )$, both of which are shown to be asymptotically optimal up to logarithmic factors.
We present spd-metrics-id, a Python package for computing distances and divergences between symmetric positive-definite (SPD) matrices. Unlike traditional toolkits that focus on specific applications, spd-metrics-id provides a unified, extensible, and reproducible framework for SPD distance computation. The package supports a wide variety of geometry-aware metrics, including Alpha-z Bures-Wasserstein, Alpha-Procrustes, affine-invariant Riemannian, log-Euclidean, and others, and is accessible both via a command-line interface and a Python API. Reproducibility is ensured through Docker images and Zenodo archiving. We illustrate usage through a connectome fingerprinting example, but the package is broadly applicable to covariance analysis, diffusion tensor imaging, and other domains requiring SPD matrix comparison. The package is openly available at https://pypi.org/project/spd-metrics-id/.
We present a MATLAB package, which is the first of its kind, for Higher Order Markov Chains (HOMC). It can be used to easily compute all important quantities in our recent works relevant to higher order Markov chains, such as the $k$-step transition tensor, limiting probability distribution, ever-reaching probability tensor, and mean first passage time tensor. It can also be used to check whether a higher order chain is ergodic or regular, to construct the transition matrix of the associated reduced first order chain, and to determine whether a state is recurrent or transient. A key function in the package is an implementation of the tensor ``box'' product which has a probabilistic interpretation and is different from other tensor products in the literature. This HOMC package is useful to researchers and practitioners alike for tasks such as numerical experimentation and algorithm prototyping involving higher order Markov chains.
Recent advances in quasi-Monte Carlo integration demonstrate that the median of linearly scrambled digital net estimators achieves near-optimal convergence rates for high-dimensional integrals without requiring a priori knowledge of the integrand's smoothness. Building on this framework, we prove that the median estimator attains dimension-independent convergence, a property known as strong tractability in complexity theory, under tractability conditions characterized by low effective dimensionality. Using a probabilistic, integrand-specific error criterion, our analysis establishes both faster and dimension-independent convergence under weaker assumptions than previously possible in the worst-case setting.

This paper proposes a multilevel sampling algorithm for fiber sampling problems in algebraic statistics, inspired by Henry Wynn's suggestion to adapt multilevel Monte Carlo (MLMC) ideas to discrete models. Focusing on log-linear models, we sample from high-dimensional lattice fibers defined by algebraic constraints. Building on Markov basis methods and results from Diaconis and Sturmfels, our algorithm uses variable step sizes to accelerate exploration and reduce the need for long burn-in. We introduce a novel Fiber Coverage Score (FCS) based on Voronoi partitioning to assess sample quality, and highlight the utility of the Maximum Mean Discrepancy (MMD) quality metric. Simulations on benchmark fibers show that multilevel sampling outperforms naive MCMC approaches. Our results demonstrate that multilevel methods, when properly applied, provide practical benefits for discrete sampling in algebraic statistics.
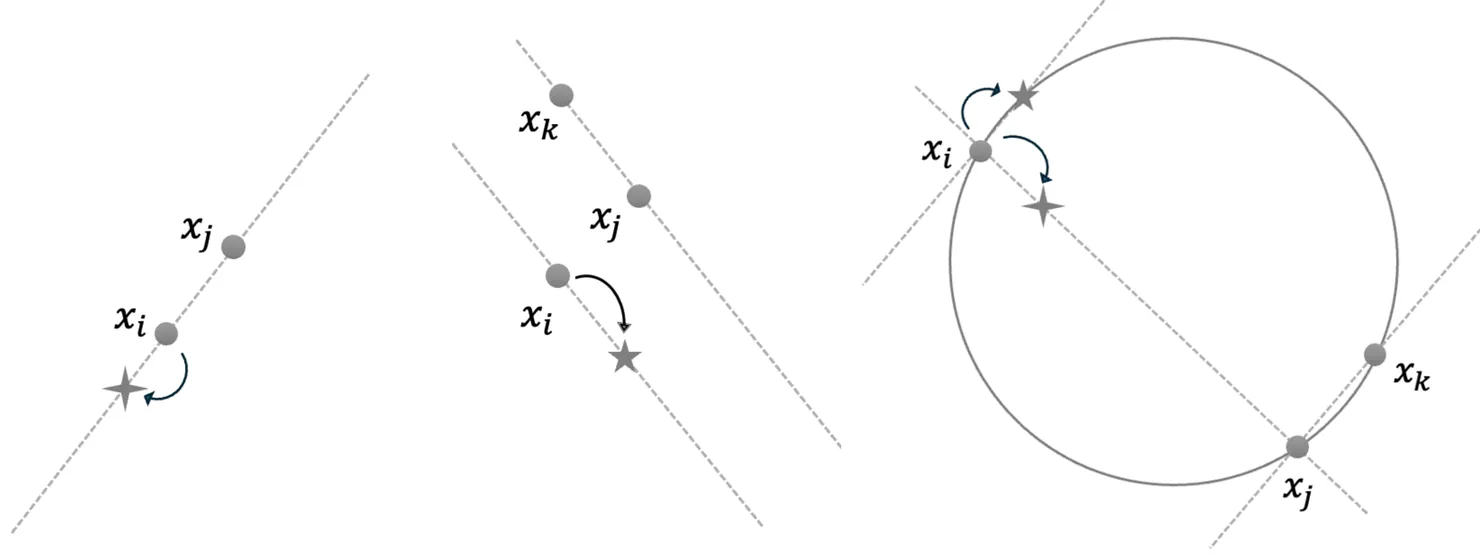
We introduce new affine invariant ensemble Markov chain Monte Carlo (MCMC) samplers that are easy to construct and improve upon existing methods, especially for high-dimensional problems. We first propose a simple derivative-free side move sampler that improves upon popular samplers in the \texttt{emcee} package by generating more effective proposal directions. We then develop a class of derivative-based affine invariant ensemble Hamiltonian Monte Carlo (HMC) samplers based on antisymmetric preconditioning using complementary ensembles, which outperform standard, non-affine-invariant HMC when sampling highly anisotropic distributions. We provide asymptotic scaling analysis for high-dimensional Gaussian targets to further elucidate the properties of these affine invariant ensemble samplers. In particular, with derivative information, the affine invariant ensemble HMC can scale much better with dimension compared to derivative-free ensemble samplers.
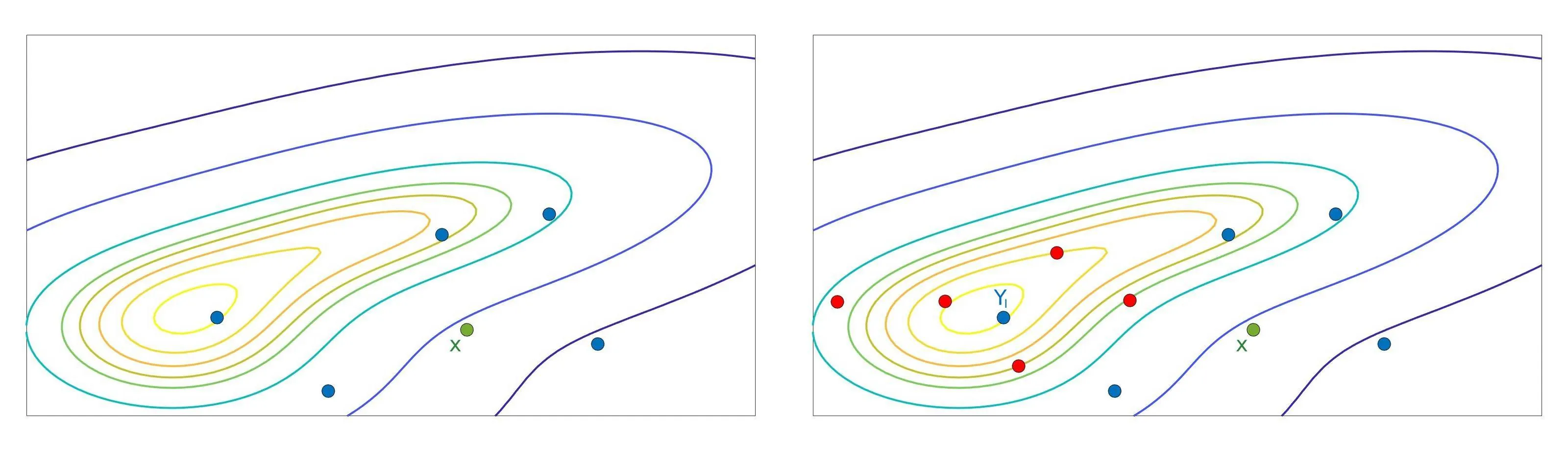
We study the Multiple-try Metropolis algorithm using the framework of Poincaré inequalities. We describe the Multiple-try Metropolis as an auxiliary variable implementation of a resampling approximation to an ideal Metropolis--Hastings algorithm. Under suitable moment conditions on the importance weights, we derive explicit Poincaré comparison results between the Multiple-try algorithm and the ideal algorithm. We characterize the spectral gap of the latter, and finally in the Gaussian case prove explicit non-asymptotic convergence bounds for Multiple-try Metropolis by comparison.

Uncertainty Quantification (UQ) is essential for the reliable application of computational models in engineering and science. Among surrogate modeling techniques, Gaussian Process Regression (GPR) is particularly valuable for its non-parametric flexibility and inherent probabilistic output. This paper presents an introductory review of GPR-based methodologies within the context of UQ. We begin with an introduction to UQ and outline its key tasks, including uncertainty propagation, risk estimation, optimization under uncertainty, parameter estimation, and sensitivity analysis. We then introduce Gaussian Processes as a surrogate modeling technique, detailing their formulation, choice of covariance kernels, hyperparameter estimation, and active learning strategies for efficient data acquisition. The tutorial further explores how GPR can be applied to different UQ tasks, including Bayesian quadrature for uncertainty propagation, active learning-based risk estimation, Bayesian optimization for optimization under uncertainty, and surrogate-based sensitivity analysis. Throughout, we emphasize how to leverage the unique formulation of GP for these UQ tasks, rather than simply using it as a standard surrogate model. This work offers a comprehensive guide and unified framework for researchers seeking to rigorously apply probabilistic modeling to complex computational systems.
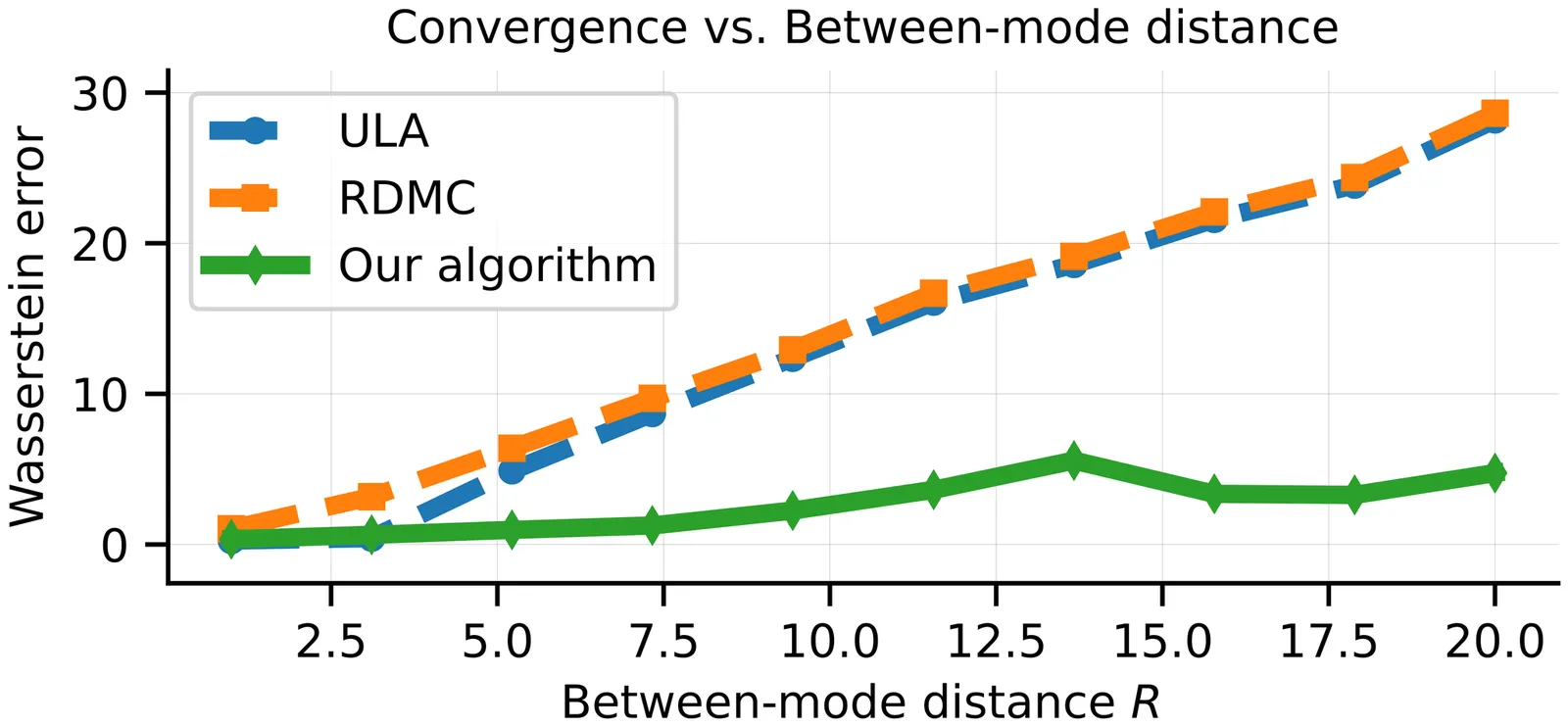
Even in low dimensions, sampling from multi-modal distributions is challenging. We provide the first sampling algorithm for a broad class of distributions -- including all Gaussian mixtures -- with a query complexity that is polynomial in the parameters governing multi-modality, assuming fixed dimension. Our sampling algorithm simulates a time-reversed diffusion process, using a self-normalized Monte Carlo estimator of the intermediate score functions. Unlike previous works, it avoids metastability, requires no prior knowledge of the mode locations, and relaxes the well-known log-smoothness assumption which excluded general Gaussian mixtures so far.
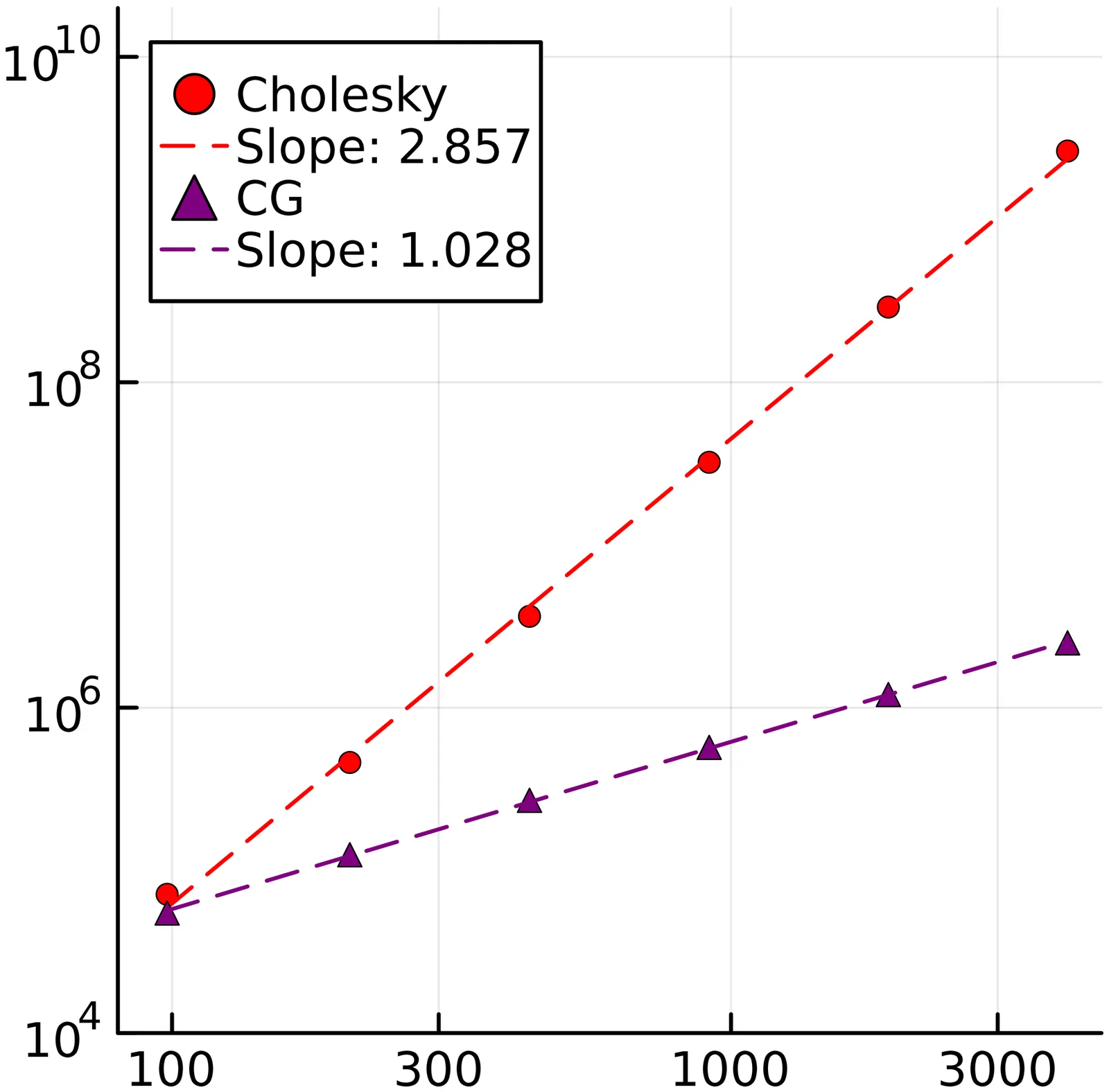
Generalized linear mixed models (GLMMs) are a widely used tool in statistical analysis. The main bottleneck of many computational approaches lies in the inversion of the high dimensional precision matrices associated with the random effects. Such matrices are typically sparse; however, the sparsity pattern resembles a multi partite random graph, which does not lend itself well to default sparse linear algebra techniques. Notably, we show that, for typical GLMMs, the Cholesky factor is dense even when the original precision is sparse. We thus turn to approximate iterative techniques, in particular to the conjugate gradient (CG) method. We combine a detailed analysis of the spectrum of said precision matrices with results from random graph theory to show that CG-based methods applied to high-dimensional GLMMs typically achieve a fixed approximation error with a total cost that scales linearly with the number of parameters and observations. Numerical illustrations with both real and simulated data confirm the theoretical findings, while at the same time illustrating situations, such as nested structures, where CG-based methods struggle.
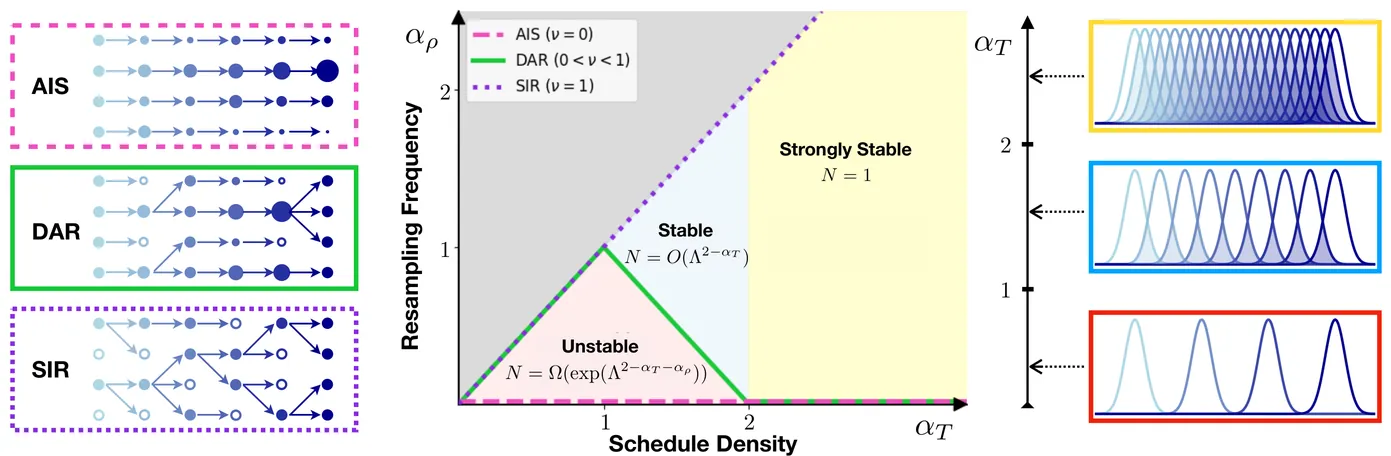
Annealed Sequential Monte Carlo (ASMC) samplers are special cases of SMC samplers where the sequence of distributions can be embedded in a smooth path of distributions. Using this underlying path and a performance model based on the variance of the normalising constant estimator, we systematically study dense-schedule limits. From our theory emerges a notion of global barrier, capturing the inherent complexity of normalising constant approximation under our performance model. We then turn the resulting approximations into surrogate objective functions of algorithm performance, using them to guide method development. This leads to novel adaptive methods, Optimised Annealed SMC (OASMC), which address practical difficulties inherent in previous adaptive SMC methods. First, our OASMC algorithms are predictable: they produce a sequence of increasingly precise estimates at deterministic, known times. Second, Optimised Annealed Importance Sampling (OAIS), a special case of OASMC, enables schedule adaptation at a memory cost constant in the number of particles, requiring significantly less communication. Finally, these characteristics make OAIS highly efficient on GPUs. We provide an open-source, high-performance GPU implementation of our method and demonstrate up to a hundred-fold speed improvement compared to state-of-the-art adaptive AIS methods.
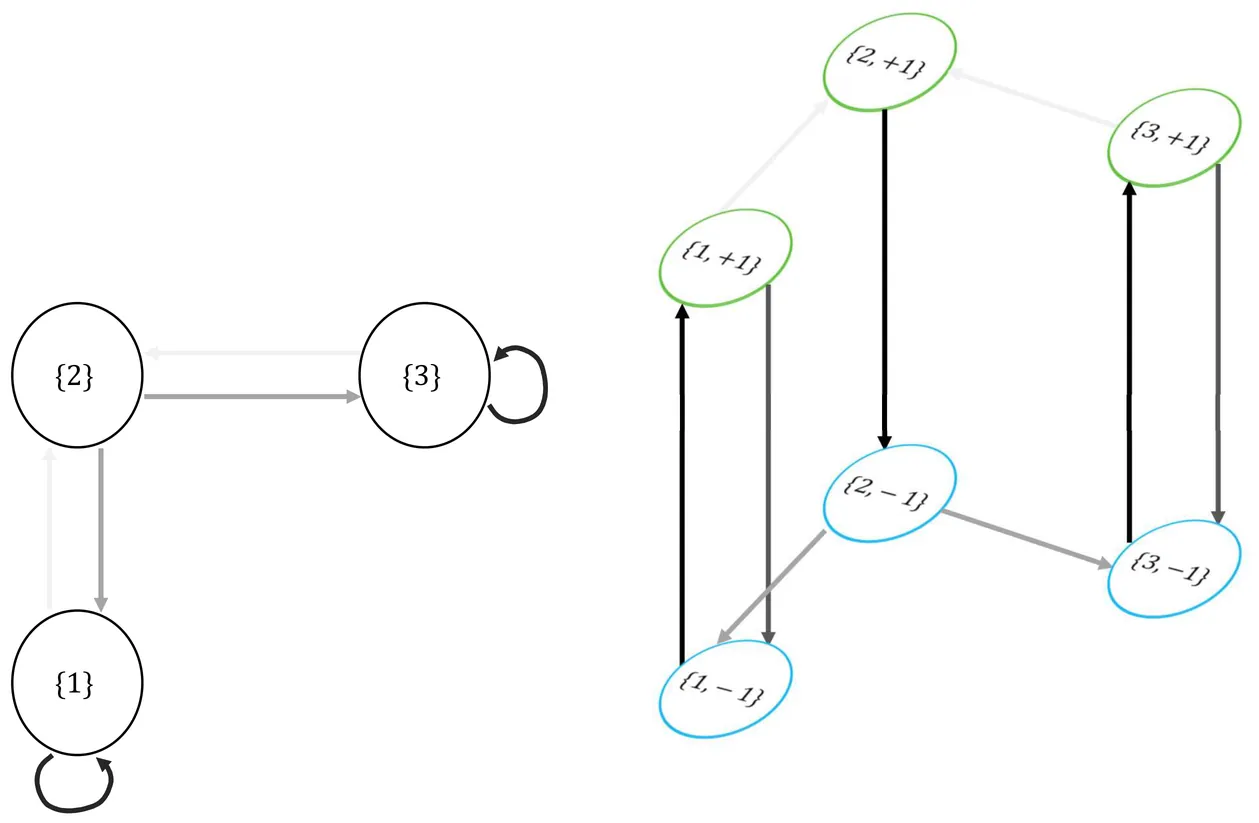
Lifted samplers form a class of Markov chain Monte Carlo methods which has drawn a lot attention in recent years due to superior performance in challenging Bayesian applications. A canonical example of such sampler is the one that is derived from a random walk Metropolis algorithm for a totally-ordered state space such as the integers or the real numbers. The lifted sampler is derived by splitting into two the proposal distribution: one part in the increasing direction, and the other part in the decreasing direction. It keeps following a direction, until a rejection occurs, upon which it flips the direction. In terms of asymptotic variances, it outperforms the random walk Metropolis algorithm, regardless of the target distribution, at no additional computational cost. Other studies show, however, that beyond this simple case, lifted samplers do not always outperform their Metropolis counterparts. In this paper, we leverage the celebrated work of Tierney (1998) to provide an analysis in a general framework encompassing a broad class of lifted samplers. Our finding is that, essentially, the asymptotic variances cannot increase by a factor of more than 2, regardless of the target distribution, the way the directions are induced, and the type of algorithm from which the lifted sampler is derived (be it a Metropolis--Hastings algorithm, a reversible jump algorithm, etc.). This result indicates that, while there is potentially a lot to gain from lifting a sampler, there is not much to lose.
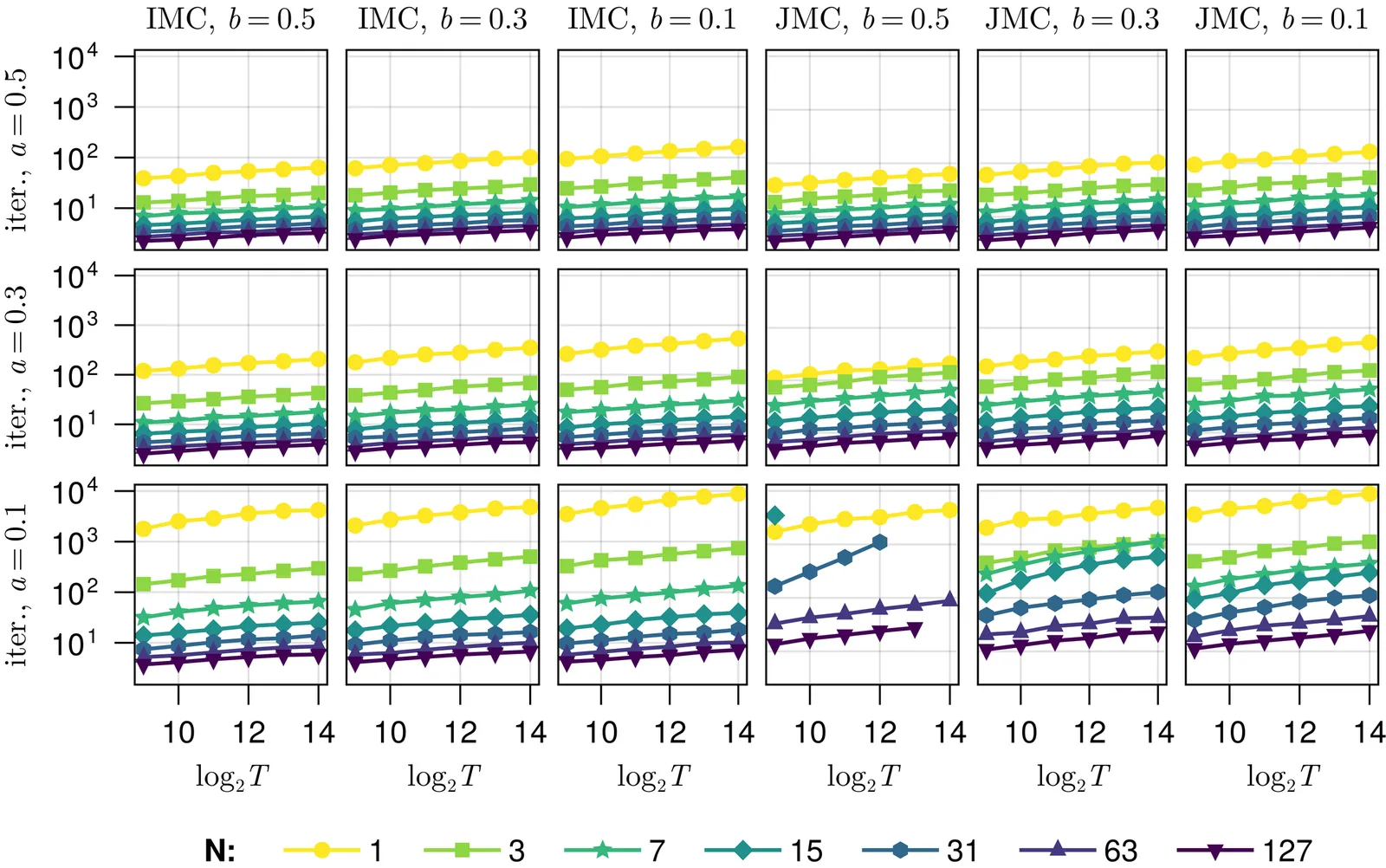
The conditional backward sampling particle filter (CBPF) is a powerful Markov chain Monte Carlo sampler for general state space hidden Markov model (HMM) smoothing. It was proposed as an improvement over the conditional particle filter (CPF), which has an $O(T^2)$ complexity under a general `strong' mixing assumption, where $T$ is the time horizon. Empirical evidence of the superiority of the CBPF over the CPF has never been theoretically quantified. We show that the CBPF has $O(T \log T)$ time complexity under strong mixing: its mixing time is upper bounded by $O(\log T)$, for any sufficiently large number of particles $N$ independent of $T$. This $O(\log T)$ mixing time is optimal. To prove our main result, we introduce a novel coupling of two CBPFs, which employs a maximal coupling of two particle systems at each time instant. The coupling is implementable and we use it to construct unbiased, finite variance, estimates of functionals which have arbitrary dependence on the latent state's path, with a total expected cost of $O(T \log T)$. We use this to construct unbiased estimates of the HMM's score function, and also investigate other couplings which can exhibit improved behaviour. We demonstrate our methods on financial and calcium imaging applications.

We present an unbiased method for Bayesian posterior means based on kinetic Langevin dynamics that combines advanced splitting methods with enhanced gradient approximations. Our approach avoids Metropolis correction by coupling Markov chains at different discretization levels in a multilevel Monte Carlo approach. Theoretical analysis demonstrates that our proposed estimator is unbiased, attains finite variance, and satisfies a central limit theorem. It can achieve accuracy $ε>0$ for estimating expectations of Lipschitz functions in $d$ dimensions with $\mathcal{O}(d^{1/4}ε^{-2})$ expected gradient evaluations, without assuming warm start. We exhibit similar bounds using both approximate and stochastic gradients, and our method's computational cost is shown to scale independently of the size of the dataset. The proposed method is tested using a multinomial regression problem on the MNIST dataset and a Poisson regression model for soccer scores. Experiments indicate that the number of gradient evaluations per effective sample is independent of dimension, even when using inexact gradients. For product distributions, we give dimension-independent variance bounds. Our results demonstrate that in large-scale applications, the unbiased algorithm we present can be 2-3 orders of magnitude more efficient than the ``gold-standard" randomized Hamiltonian Monte Carlo.
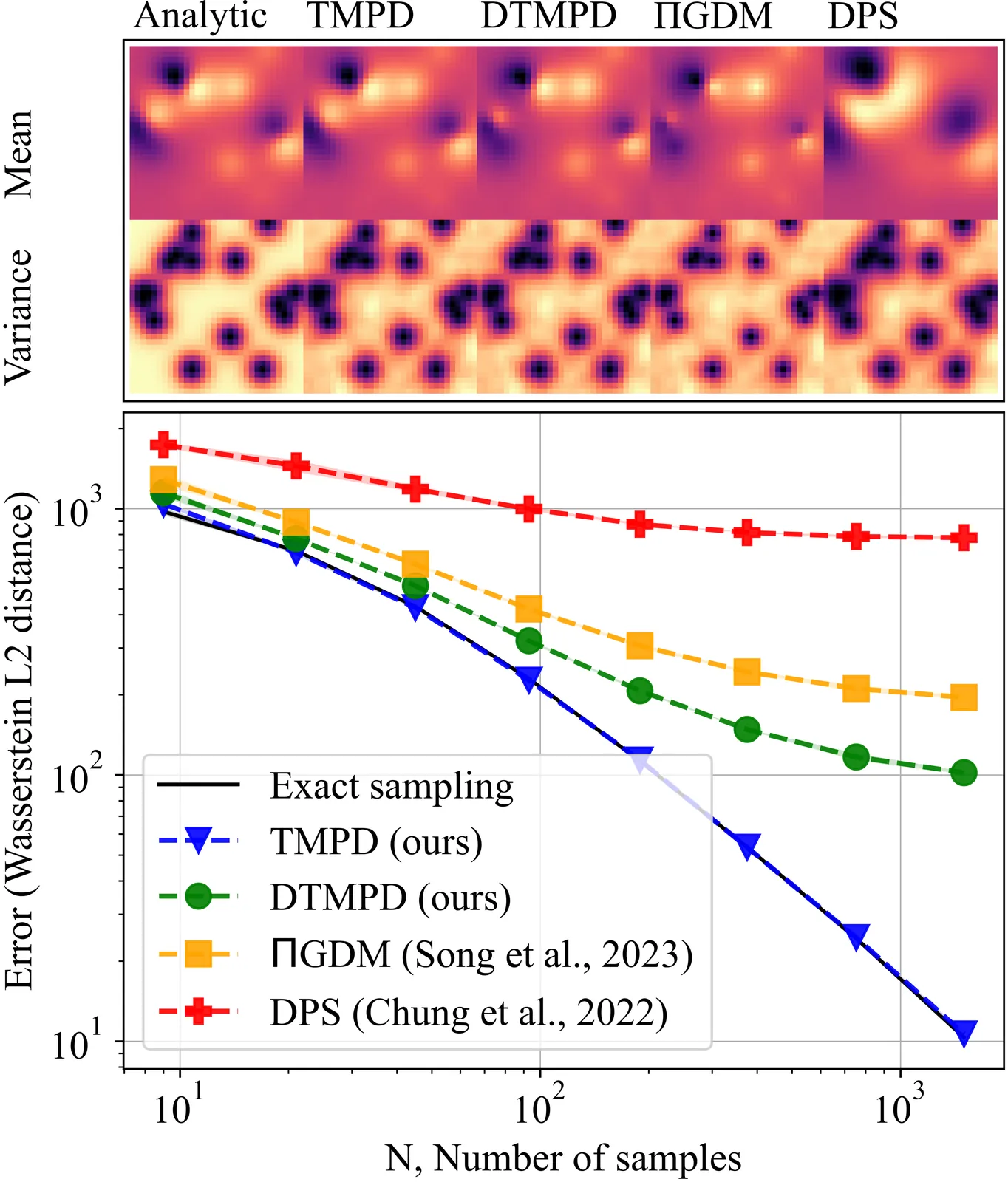
Diffusion generative models unlock new possibilities for inverse problems as they allow for the incorporation of strong empirical priors in scientific inference. Recently, diffusion models are repurposed for solving inverse problems using Gaussian approximations to conditional densities of the reverse process via Tweedie's formula to parameterise the mean, complemented with various heuristics. To address various challenges arising from these approximations, we leverage higher order information using Tweedie's formula and obtain a statistically principled approximation. We further provide a theoretical guarantee specifically for posterior sampling which can lead to a better theoretical understanding of diffusion-based conditional sampling. Finally, we illustrate the empirical effectiveness of our approach for general linear inverse problems on toy synthetic examples as well as image restoration. We show that our method (i) removes any time-dependent step-size hyperparameters required by earlier methods, (ii) brings stability and better sample quality across multiple noise levels, (iii) is the only method that works in a stable way with variance exploding (VE) forward processes as opposed to earlier works.
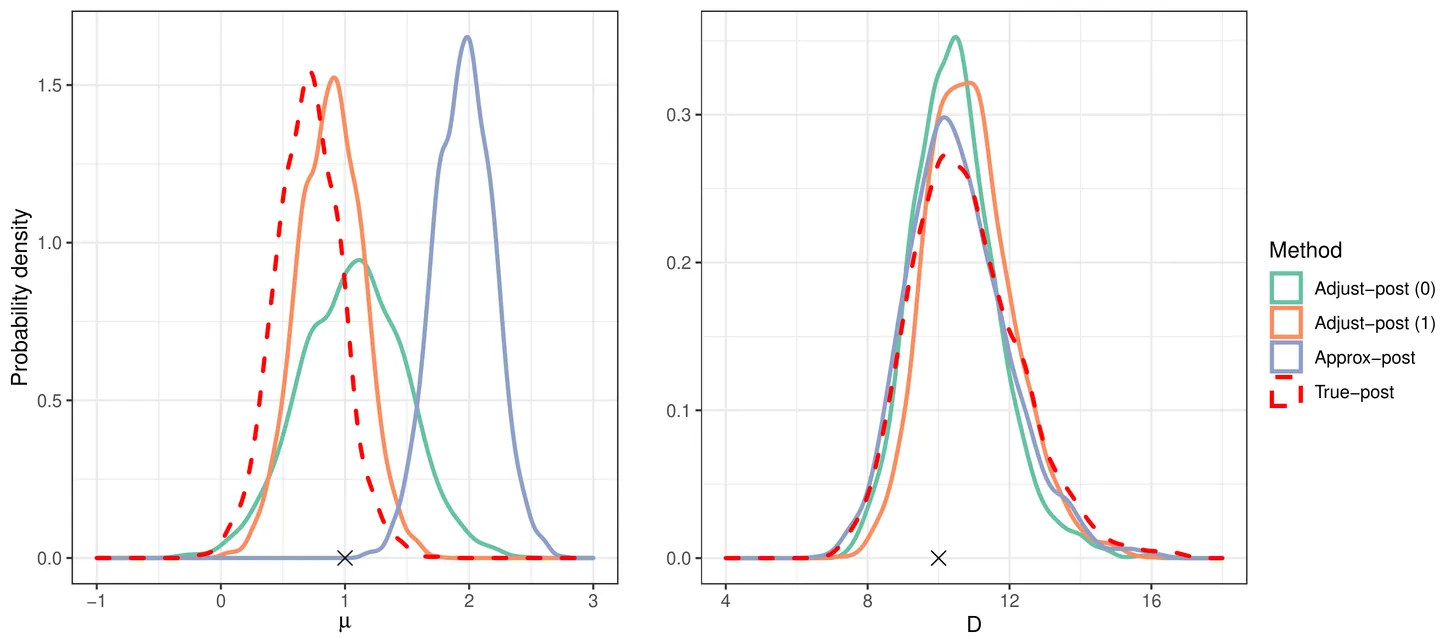
Scientists continue to develop increasingly complex mechanistic models to reflect their knowledge more realistically. Statistical inference using these models can be challenging since the corresponding likelihood function is often intractable and model simulation may be computationally burdensome. Fortunately, in many of these situations it is possible to adopt a surrogate model or approximate likelihood function. It may be convenient to conduct Bayesian inference directly with a surrogate, but this can result in a posterior with poor uncertainty quantification. In this paper, we propose a new method for adjusting approximate posterior samples to reduce bias and improve posterior coverage properties. We do this by optimizing a transformation of the approximate posterior, the result of which maximizes a scoring rule. Our approach requires only a (fixed) small number of complex model simulations and is numerically stable. We develop supporting theory for our method and demonstrate beneficial corrections to approximate posteriors across several examples of increasing complexity.

When implementing Markov Chain Monte Carlo (MCMC) algorithms, perturbation caused by numerical errors is sometimes inevitable. This paper studies how perturbation of MCMC affects the convergence speed and Monte Carlo estimation accuracy. Our results show that when the original Markov chain converges to stationarity fast enough and the perturbed transition kernel is a good approximation to the original transition kernel, the corresponding perturbed sampler has similar convergence speed and high approximation accuracy as well. We discuss two different analysis frameworks: ergodicity and spectral gap, both are widely used in the literature. Our results can be easily extended to obtain non-asymptotic error bounds for MCMC estimators. We also demonstrate how to apply our convergence and approximation results to the analysis of specific sampling algorithms, including Random walk Metropolis and Metropolis adjusted Langevin algorithm with perturbed target densities, and parallel tempering Monte Carlo with perturbed densities. Finally we present some simple numerical examples to verify our theoretical claims.

We consider the problem of simulating diffusion bridges, which are diffusion processes that are conditioned to initialize and terminate at two given states. The simulation of diffusion bridges has applications in diverse scientific fields and plays a crucial role in the statistical inference of discretely-observed diffusions. This is known to be a challenging problem that has received much attention in the last two decades. This article contributes to this rich body of literature by presenting a new avenue to obtain diffusion bridge approximations. Our approach is based on a backward time representation of a diffusion bridge, which may be simulated if one can time-reverse the unconditioned diffusion. We introduce a variational formulation to learn this time-reversal with function approximation and rely on a score matching method to circumvent intractability. Another iteration of our proposed methodology approximates the Doob's $h$-transform defining the forward time representation of a diffusion bridge. We discuss algorithmic considerations and extensions, and present numerical results on an Ornstein--Uhlenbeck process, a model from financial econometrics for interest rates, and a model from genetics for cell differentiation and development to illustrate the effectiveness of our approach.
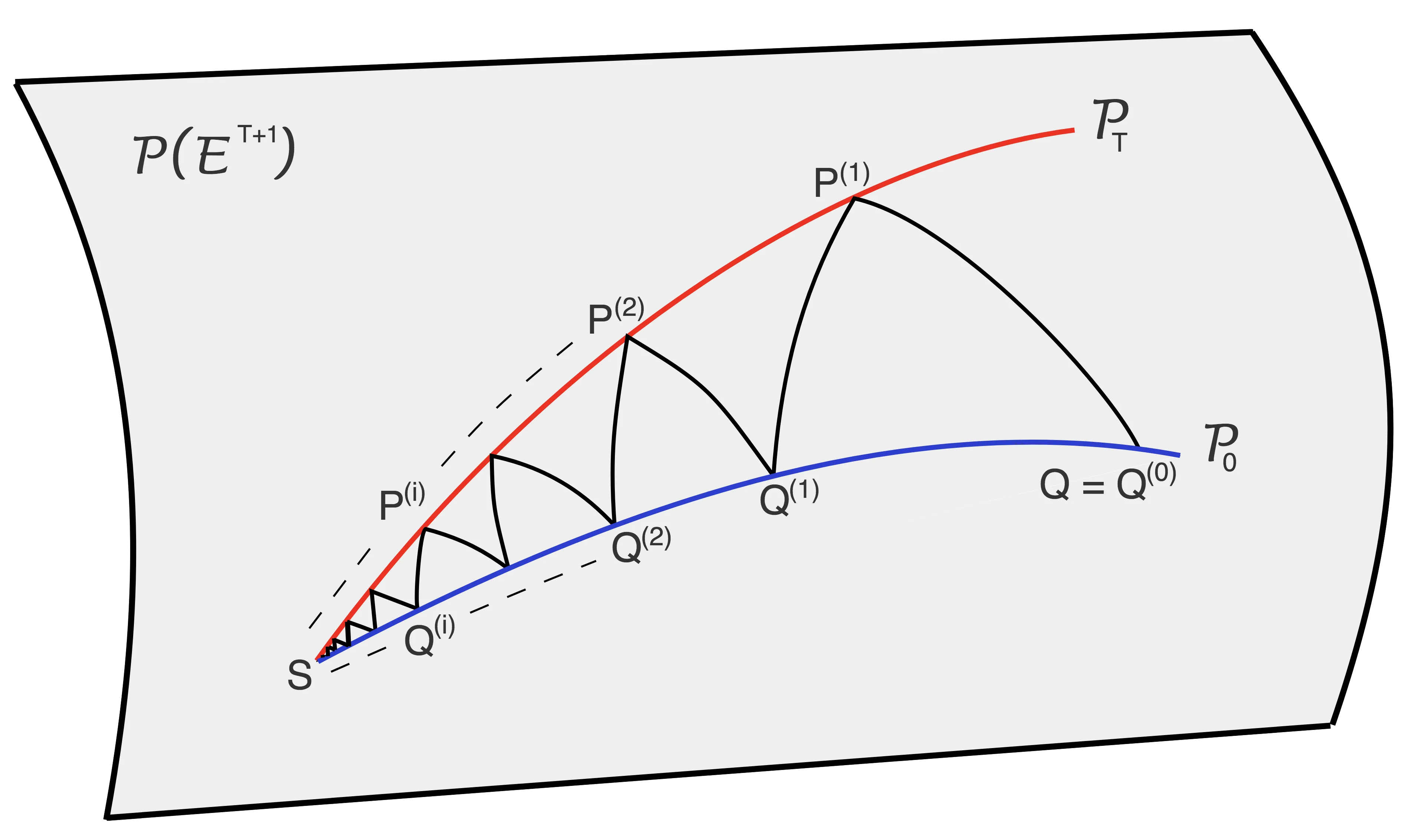
Consider a reference Markov process with initial distribution $π_{0}$ and transition kernels $\{M_{t}\}_{t\in[1:T]}$, for some $T\in\mathbb{N}$. Assume that you are given distribution $π_{T}$, which is not equal to the marginal distribution of the reference process at time $T$. In this scenario, Schrödinger addressed the problem of identifying the Markov process with initial distribution $π_{0}$ and terminal distribution equal to $π_{T}$ which is the closest to the reference process in terms of Kullback--Leibler divergence. This special case of the so-called Schrödinger bridge problem can be solved using iterative proportional fitting, also known as the Sinkhorn algorithm. We leverage these ideas to develop novel Monte Carlo schemes, termed Schrödinger bridge samplers, to approximate a target distribution $π$ on $\mathbb{R}^{d}$ and to estimate its normalizing constant. This is achieved by iteratively modifying the transition kernels of the reference Markov chain to obtain a process whose marginal distribution at time $T$ becomes closer to $π_T = π$, via regression-based approximations of the corresponding iterative proportional fitting recursion. We report preliminary experiments and make connections with other problems arising in the optimal transport, optimal control and physics literatures.