Trading and Market Microstructure
arXiv:q-fin.TR
Market microstructure, optimal execution, liquidity, automated trading.
Looking for a broader view? This category is part of:
Market microstructure, optimal execution, liquidity, automated trading.
Looking for a broader view? This category is part of:
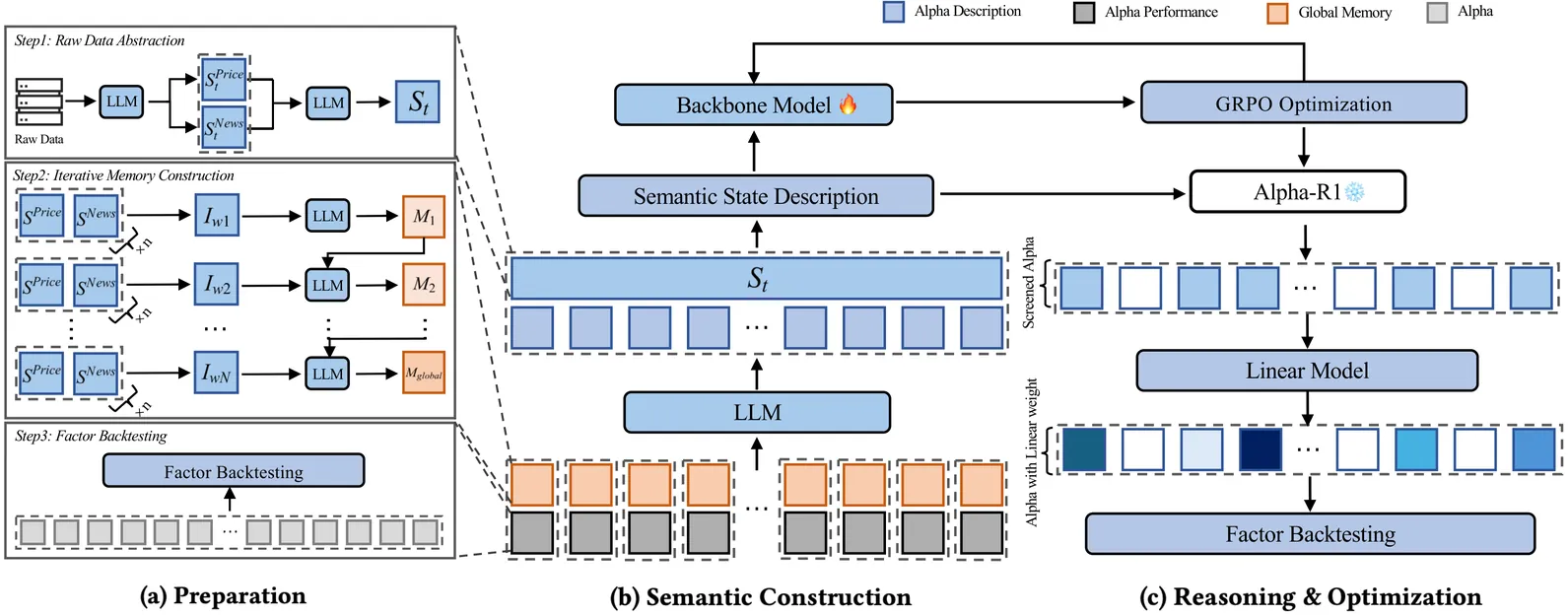
Signal decay and regime shifts pose recurring challenges for data-driven investment strategies in non-stationary markets. Conventional time-series and machine learning approaches, which rely primarily on historical correlations, often struggle to generalize when the economic environment changes. While large language models (LLMs) offer strong capabilities for processing unstructured information, their potential to support quantitative factor screening through explicit economic reasoning remains underexplored. Existing factor-based methods typically reduce alphas to numerical time series, overlooking the semantic rationale that determines when a factor is economically relevant. We propose Alpha-R1, an 8B-parameter reasoning model trained via reinforcement learning for context-aware alpha screening. Alpha-R1 reasons over factor logic and real-time news to evaluate alpha relevance under changing market conditions, selectively activating or deactivating factors based on contextual consistency. Empirical results across multiple asset pools show that Alpha-R1 consistently outperforms benchmark strategies and exhibits improved robustness to alpha decay. The full implementation and resources are available at https://github.com/FinStep-AI/Alpha-R1.
Signal decay and regime shifts pose recurring challenges for data-driven investment strategies in non-stationary markets. Conventional time-series and machine learning approaches, which rely primarily on historical correlations, often struggle to generalize when the economic environment changes. While large language models (LLMs) offer strong capabilities for processing unstructured information, their potential to support quantitative factor screening through explicit economic reasoning remains underexplored. Existing factor-based methods typically reduce alphas to numerical time series, overlooking the semantic rationale that determines when a factor is economically relevant. We propose Alpha-R1, an 8B-parameter reasoning model trained via reinforcement learning for context-aware alpha screening. Alpha-R1 reasons over factor logic and real-time news to evaluate alpha relevance under changing market conditions, selectively activating or deactivating factors based on contextual consistency. Empirical results across multiple asset pools show that Alpha-R1 consistently outperforms benchmark strategies and exhibits improved robustness to alpha decay. The full implementation and resources are available at https://github.com/FinStep-AI/Alpha-R1.

Accurate volatility forecasting is essential in banking, investment, and risk management, because expectations about future market movements directly influence current decisions. This study proposes a hybrid modelling framework that integrates a Stochastic Volatility model with a Long Short Term Memory neural network. The SV model improves statistical precision and captures latent volatility dynamics, especially in response to unforeseen events, while the LSTM network enhances the model's ability to detect complex nonlinear patterns in financial time series. The forecasting is conducted using daily data from the S and P 500 index, covering the period from January 1 1998 to December 31 2024. A rolling window approach is employed to train the model and generate one step ahead volatility forecasts. The performance of the hybrid SV-LSTM model is evaluated through both statistical testing and investment simulations. The results show that the hybrid approach outperforms both the standalone SV and LSTM models and contributes to the development of volatility modelling techniques, providing a foundation for improving risk assessment and strategic investment planning in the context of the S and P 500.
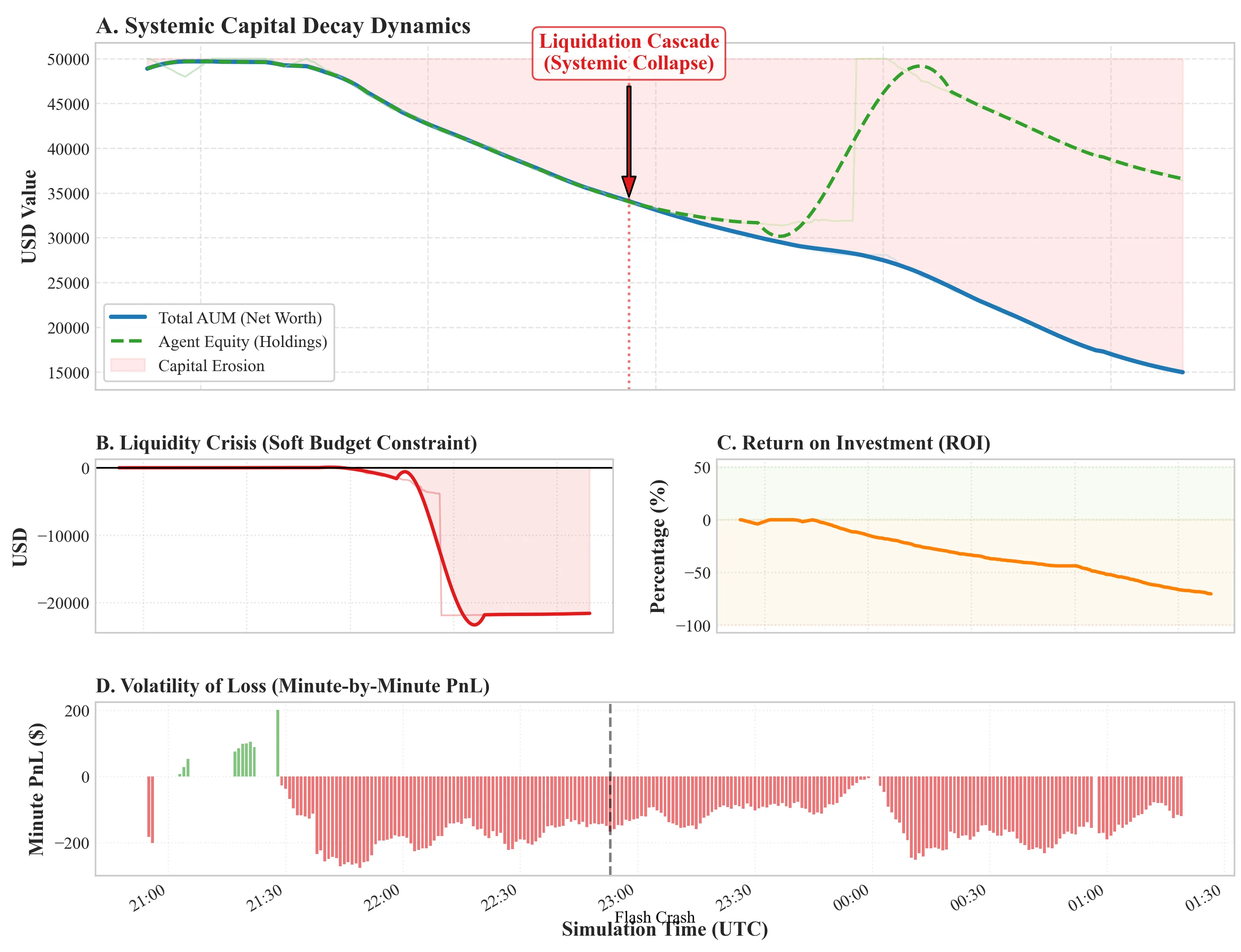
The integration of Deep Reinforcement Learning (DRL) and Evolutionary Computation (EC) is frequently hypothesized to be the "Holy Grail" of algorithmic trading, promising systems that adapt autonomously to non-stationary market regimes. This paper presents a rigorous post-mortem analysis of "Galaxy Empire," a hybrid framework coupling LSTM/Transformer-based perception with a genetic "Time-is-Life" survival mechanism. Deploying a population of 500 autonomous agents in a high-frequency cryptocurrency environment, we observed a catastrophic divergence between training metrics (Validation APY $>300\%$) and live performance (Capital Decay $>70\%$). We deconstruct this failure through a multi-disciplinary lens, identifying three critical failure modes: the overfitting of \textit{Aleatoric Uncertainty} in low-entropy time-series, the \textit{Survivor Bias} inherent in evolutionary selection under high variance, and the mathematical impossibility of overcoming microstructure friction without order-flow data. Our findings provide empirical evidence that increasing model complexity in the absence of information asymmetry exacerbates systemic fragility.
Conventional models of matching markets assume that monetary transfers can clear markets by compensating for utility differentials. However, empirical patterns show that such transfers often fail to close structural preference gaps. This paper introduces a market microstructure framework that models matching decisions as a limit order book system with rigid bid ask spreads. Individual preferences are represented by a latent preference state matrix, where the spread between an agent's internal ask price (the unconditional maximum) and the market's best bid (the reachable maximum) creates a structural liquidity constraint. We establish a Threshold Impossibility Theorem showing that linear compensation cannot close these spreads unless it induces a categorical identity shift. A dynamic discrete choice execution model further demonstrates that matches occur only when the market to book ratio crosses a time decaying liquidity threshold, analogous to order execution under inventory pressure. Numerical experiments validate persistent slippage, regional invariance of preference orderings, and high tier zero spread executions. The model provides a unified microstructure explanation for matching failures, compensation inefficiency, and post match regret in illiquid order driven environments.
We investigate the use of Reinforcement Learning for the optimal execution of meta-orders, where the objective is to execute incrementally large orders while minimizing implementation shortfall and market impact over an extended period of time. Departing from traditional parametric approaches to price dynamics and impact modeling, we adopt a model-free, data-driven framework. Since policy optimization requires counterfactual feedback that historical data cannot provide, we employ the Queue-Reactive Model to generate realistic and tractable limit order book simulations that encompass transient price impact, and nonlinear and dynamic order flow responses. Methodologically, we train a Double Deep Q-Network agent on a state space comprising time, inventory, price, and depth variables, and evaluate its performance against established benchmarks. Numerical simulation results show that the agent learns a policy that is both strategic and tactical, adapting effectively to order book conditions and outperforming standard approaches across multiple training configurations. These findings provide strong evidence that model-free Reinforcement Learning can yield adaptive and robust solutions to the optimal execution problem.
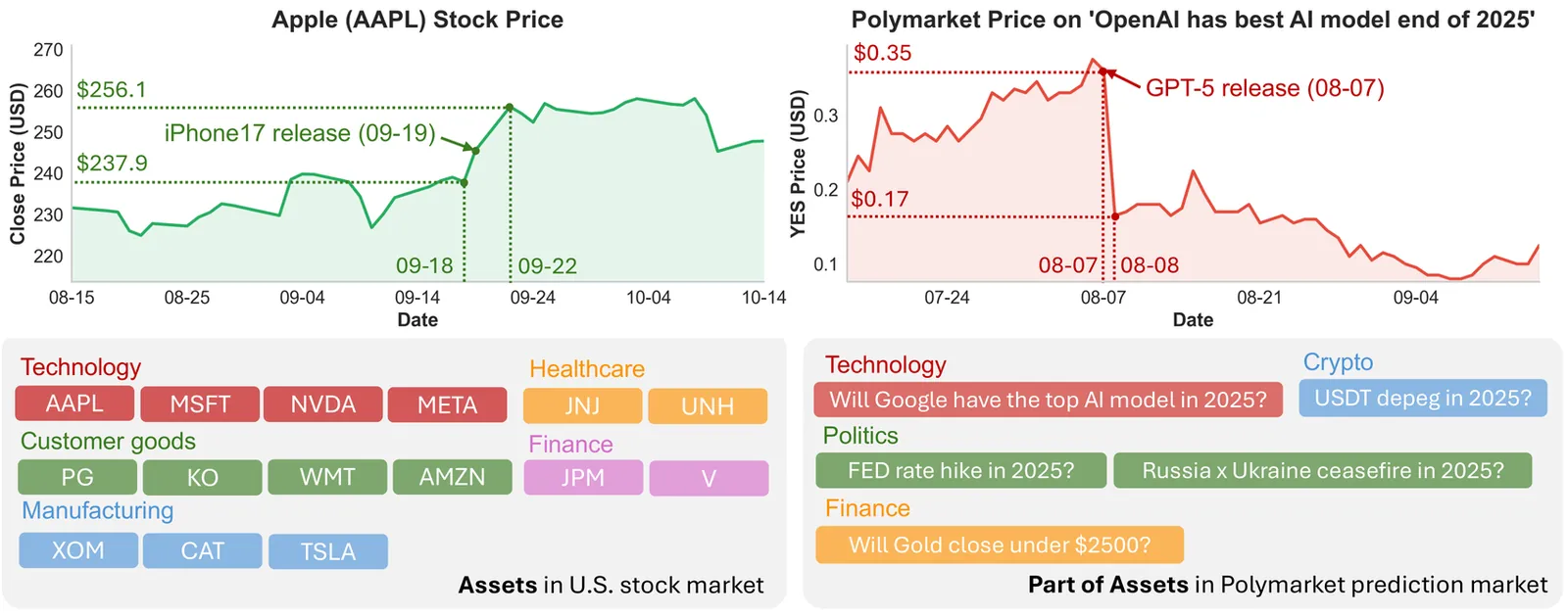
Large language models (LLMs) achieve strong performance across benchmarks--from knowledge quizzes and math reasoning to web-agent tasks--but these tests occur in static settings, lacking real dynamics and uncertainty. Consequently, they evaluate isolated reasoning or problem-solving rather than decision-making under uncertainty. To address this, we introduce LiveTradeBench, a live trading environment for evaluating LLM agents in realistic and evolving markets. LiveTradeBench follows three design principles: (i) Live data streaming of market prices and news, eliminating dependence on offline backtesting and preventing information leakage while capturing real-time uncertainty; (ii) a portfolio-management abstraction that extends control from single-asset actions to multi-asset allocation, integrating risk management and cross-asset reasoning; and (iii) multi-market evaluation across structurally distinct environments--U.S. stocks and Polymarket prediction markets--differing in volatility, liquidity, and information flow. At each step, an agent observes prices, news, and its portfolio, then outputs percentage allocations that balance risk and return. Using LiveTradeBench, we run 50-day live evaluations of 21 LLMs across families. Results show that (1) high LMArena scores do not imply superior trading outcomes; (2) models display distinct portfolio styles reflecting risk appetite and reasoning dynamics; and (3) some LLMs effectively leverage live signals to adapt decisions. These findings expose a gap between static evaluation and real-world competence, motivating benchmarks that test sequential decision making and consistency under live uncertainty.
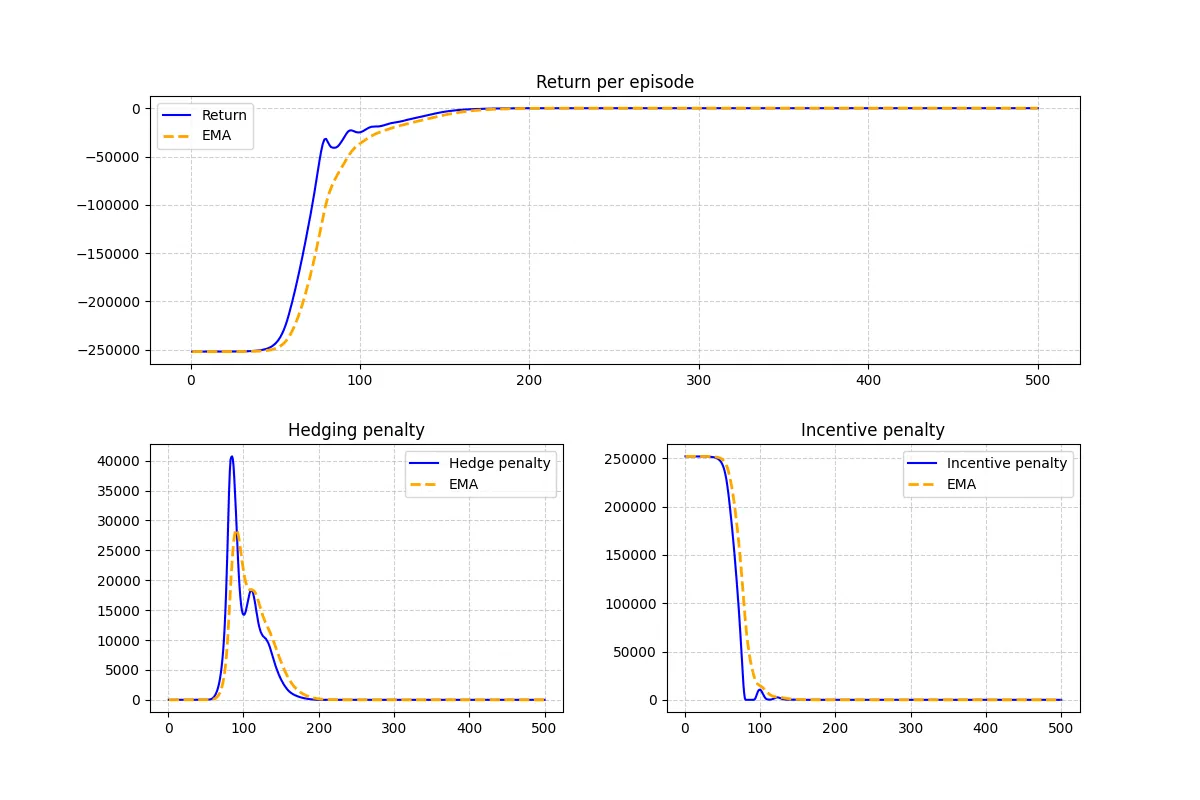
This paper develops a model for option market making in which the hedging activity of the market maker generates price impact on the underlying asset. The option order flow is modeled by Cox processes, with intensities depending on the state of the underlying and on the market maker's quoted prices. The resulting dynamics combine stochastic option demand with both permanent and transient impact on the underlying, leading to a coupled evolution of inventory and price. We first study market manipulation and arbitrage phenomena that may arise from the feedback between option trading and underlying impact. We then establish the well-posedness of the mixed control problem, which involves continuous quoting decisions and impulsive hedging actions. Finally, we implement a numerical method based on policy optimization to approximate optimal strategies and illustrate the interplay between option market liquidity, inventory risk, and underlying impact.
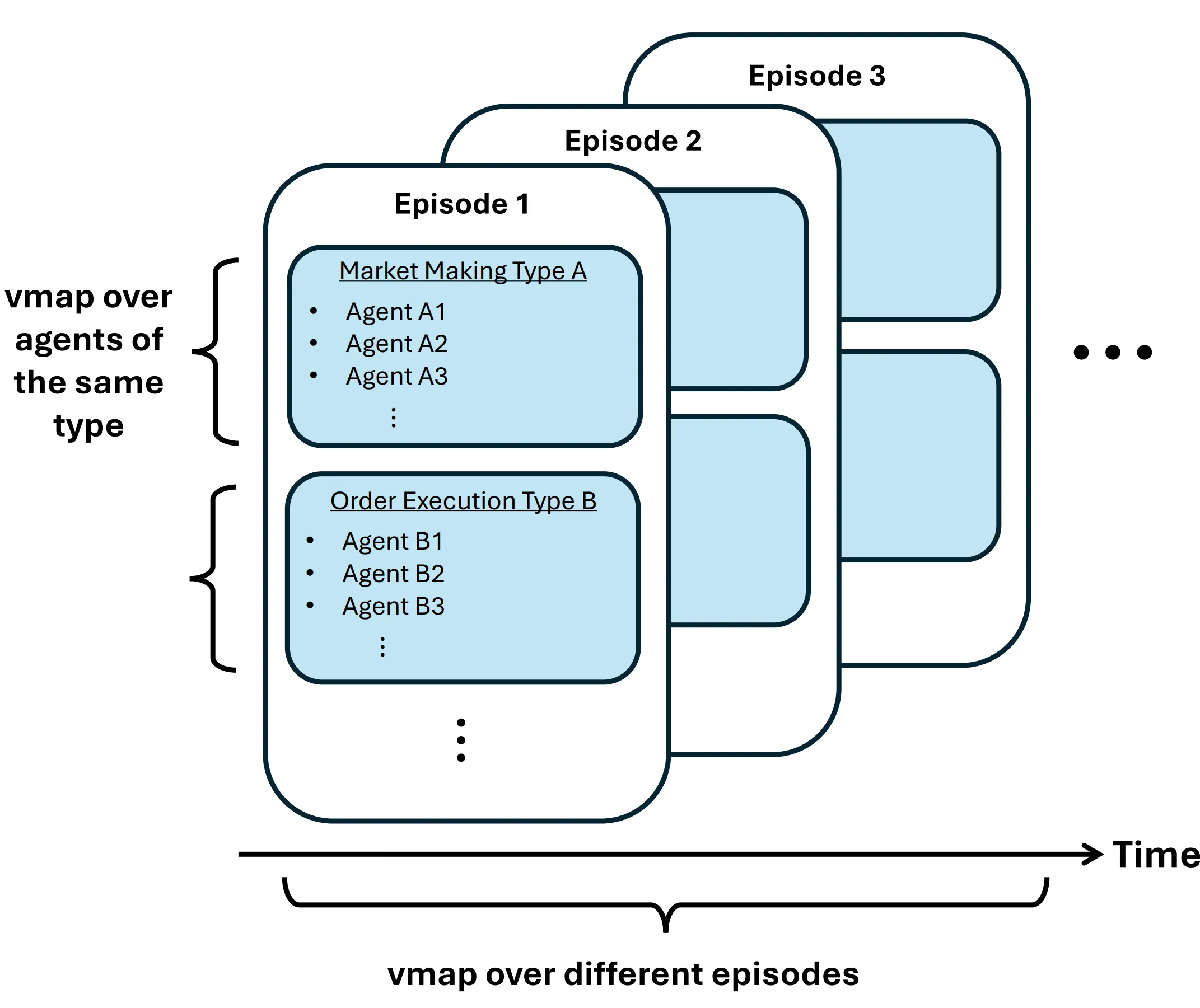
Agent-based modelling (ABM) approaches for high-frequency financial markets are difficult to calibrate and validate, partly due to the large parameter space created by defining fixed agent policies. Multi-agent reinforcement learning (MARL) enables more realistic agent behaviour and reduces the number of free parameters, but the heavy computational cost has so far limited research efforts. To address this, we introduce JaxMARL-HFT (JAX-based Multi-Agent Reinforcement Learning for High-Frequency Trading), the first GPU-accelerated open-source multi-agent reinforcement learning environment for high-frequency trading (HFT) on market-by-order (MBO) data. Extending the JaxMARL framework and building on the JAX-LOB implementation, JaxMARL-HFT is designed to handle a heterogeneous set of agents, enabling diverse observation/action spaces and reward functions. It is designed flexibly, so it can also be used for single-agent RL, or extended to act as an ABM with fixed-policy agents. Leveraging JAX enables up to a 240x reduction in end-to-end training time, compared with state-of-the-art reference implementations on the same hardware. This significant speed-up makes it feasible to exploit the large, granular datasets available in high-frequency trading, and to perform the extensive hyperparameter sweeps required for robust and efficient MARL research in trading. We demonstrate the use of JaxMARL-HFT with independent Proximal Policy Optimization (IPPO) for a two-player environment, with an order execution and a market making agent, using one year of LOB data (400 million orders), and show that these agents learn to outperform standard benchmarks. The code for the JaxMARL-HFT framework is available on GitHub.
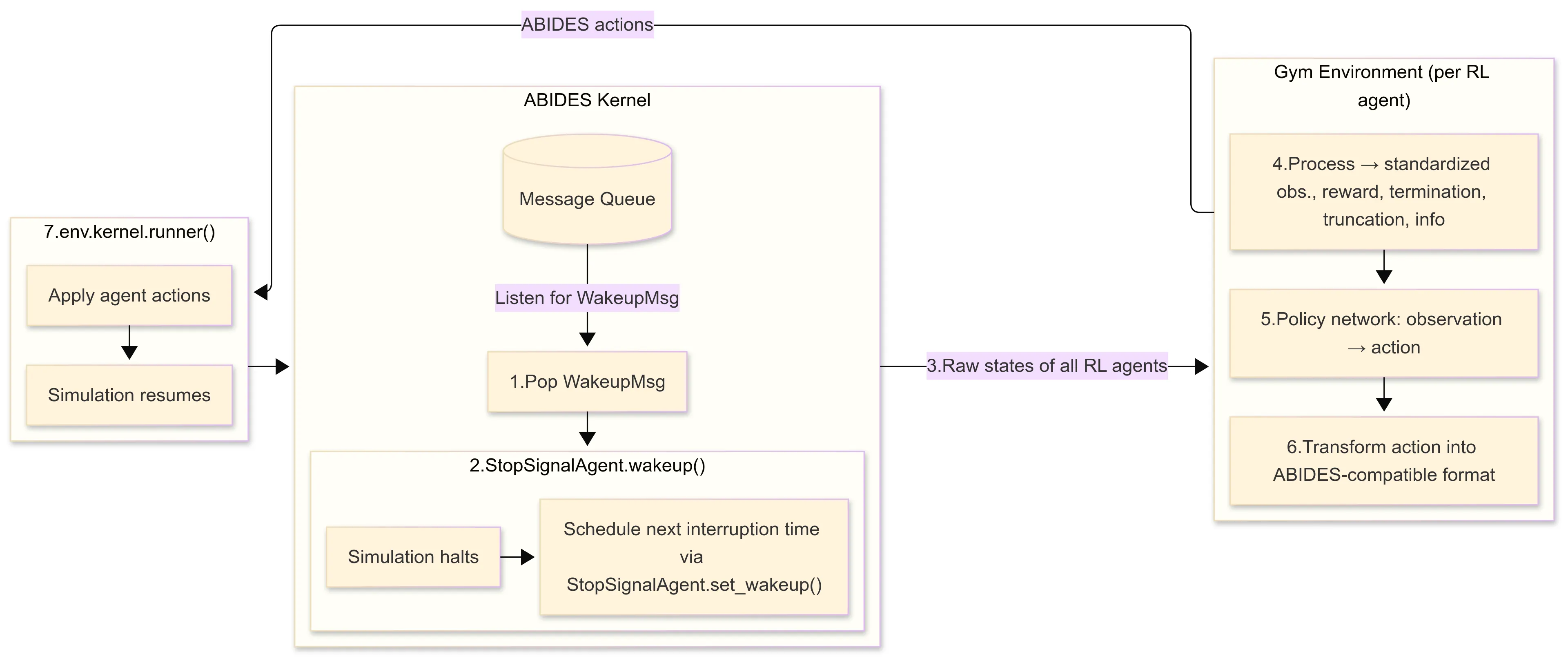
We present ABIDES-MARL, a framework that combines a new multi-agent reinforcement learning (MARL) methodology with a new realistic limit-order-book (LOB) simulation system to study equilibrium behavior in complex financial market games. The system extends ABIDES-Gym by decoupling state collection from kernel interruption, enabling synchronized learning and decision-making for multiple adaptive agents while maintaining compatibility with standard RL libraries. It preserves key market features such as price-time priority and discrete tick sizes. Methodologically, we use MARL to approximate equilibrium-like behavior in multi-period trading games with a finite number of heterogeneous agents-an informed trader, a liquidity trader, noise traders, and competing market makers-all with individual price impacts. This setting bridges optimal execution and market microstructure by embedding the liquidity trader's optimization problem within a strategic trading environment. We validate the approach by solving an extended Kyle model within the simulation system, recovering the gradual price discovery phenomenon. We then extend the analysis to a liquidity trader's problem where market liquidity arises endogenously and show that, at equilibrium, execution strategies shape market-maker behavior and price dynamics. ABIDES-MARL provides a reproducible foundation for analyzing equilibrium and strategic adaptation in realistic markets and contributes toward building economically interpretable agentic AI systems for finance.
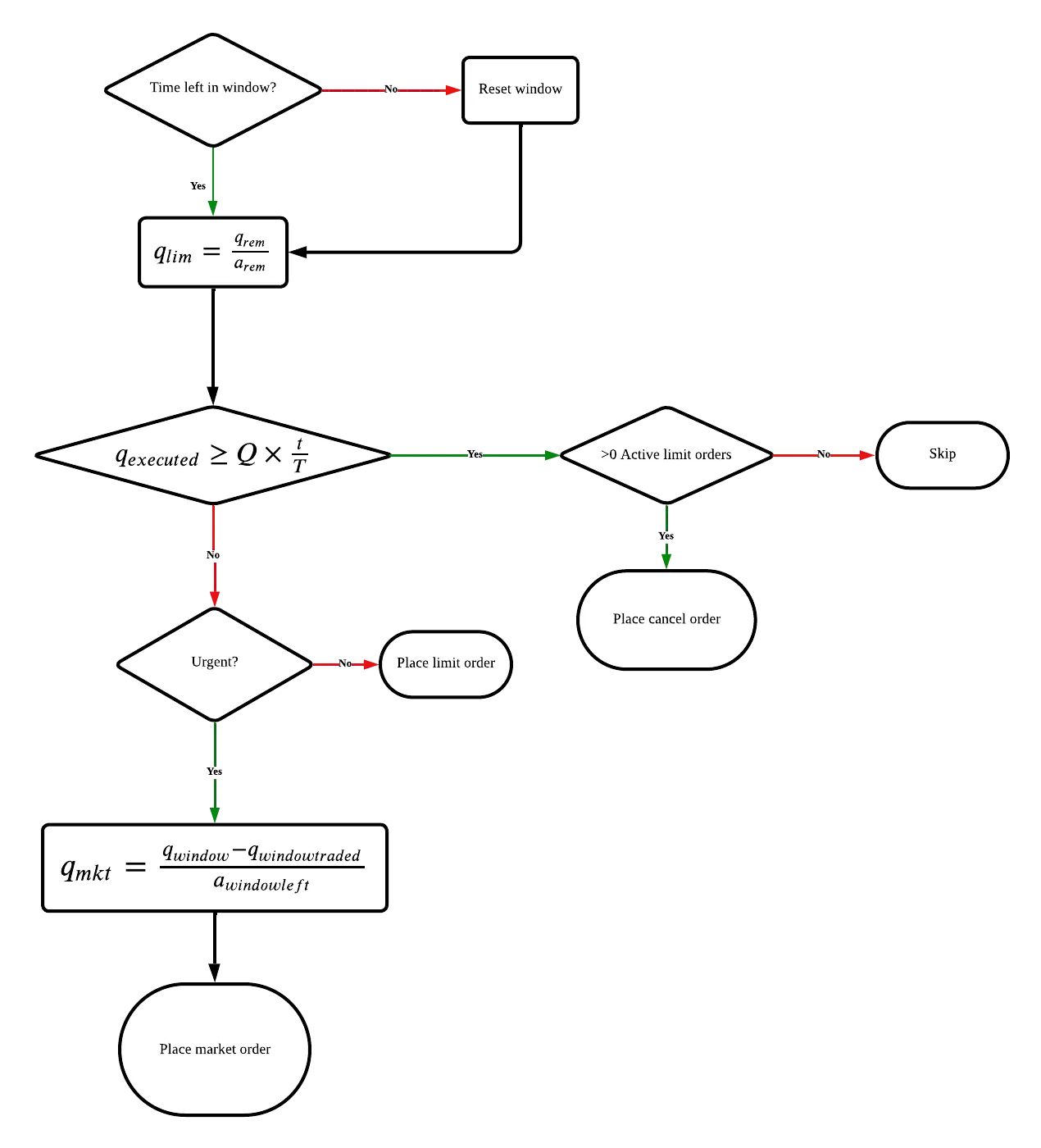
We investigate the mechanisms by which medium-frequency trading agents are adversely selected by opportunistic high-frequency traders. We use reinforcement learning (RL) within a Hawkes Limit Order Book (LOB) model in order to replicate the behaviours of high-frequency market makers. In contrast to the classical models with exogenous price impact assumptions, the Hawkes model accounts for endogenous price impact and other key properties of the market (Jain et al. 2024a). Given the real-world impracticalities of the market maker updating strategies for every event in the LOB, we formulate the high-frequency market making agent via an impulse control reinforcement learning framework (Jain et al. 2025). The RL used in the simulation utilises Proximal Policy Optimisation (PPO) and self-imitation learning. To replicate the adverse selection phenomenon, we test the RL agent trading against a medium frequency trader (MFT) executing a meta-order and demonstrate that, with training against the MFT meta-order execution agent, the RL market making agent learns to capitalise on the price drift induced by the meta-order. Recent empirical studies have shown that medium-frequency traders are increasingly subject to adverse selection by high-frequency trading agents. As high-frequency trading continues to proliferate across financial markets, the slippage costs incurred by medium-frequency traders are likely to increase over time. However, we do not observe that increased profits for the market making RL agent necessarily cause significantly increased slippages for the MFT agent.

We formalize the paradox of an omniscient yet lazy investor - a perfectly informed agent who trades infrequently due to execution or computational frictions. Starting from a deterministic geometric construction, we derive a closed-form expected profit function linking trading frequency, execution cost, and path roughness. We prove existence and uniqueness of the optimal trading frequency and show that this optimum can be interpreted through the fractal dimension of the price path. A stochastic extension under fractional Brownian motion provides analytical expressions for the optimal interval and comparative statics with respect to the Hurst exponent. Empirical illustrations on equity data confirm the theoretical scaling behavior.
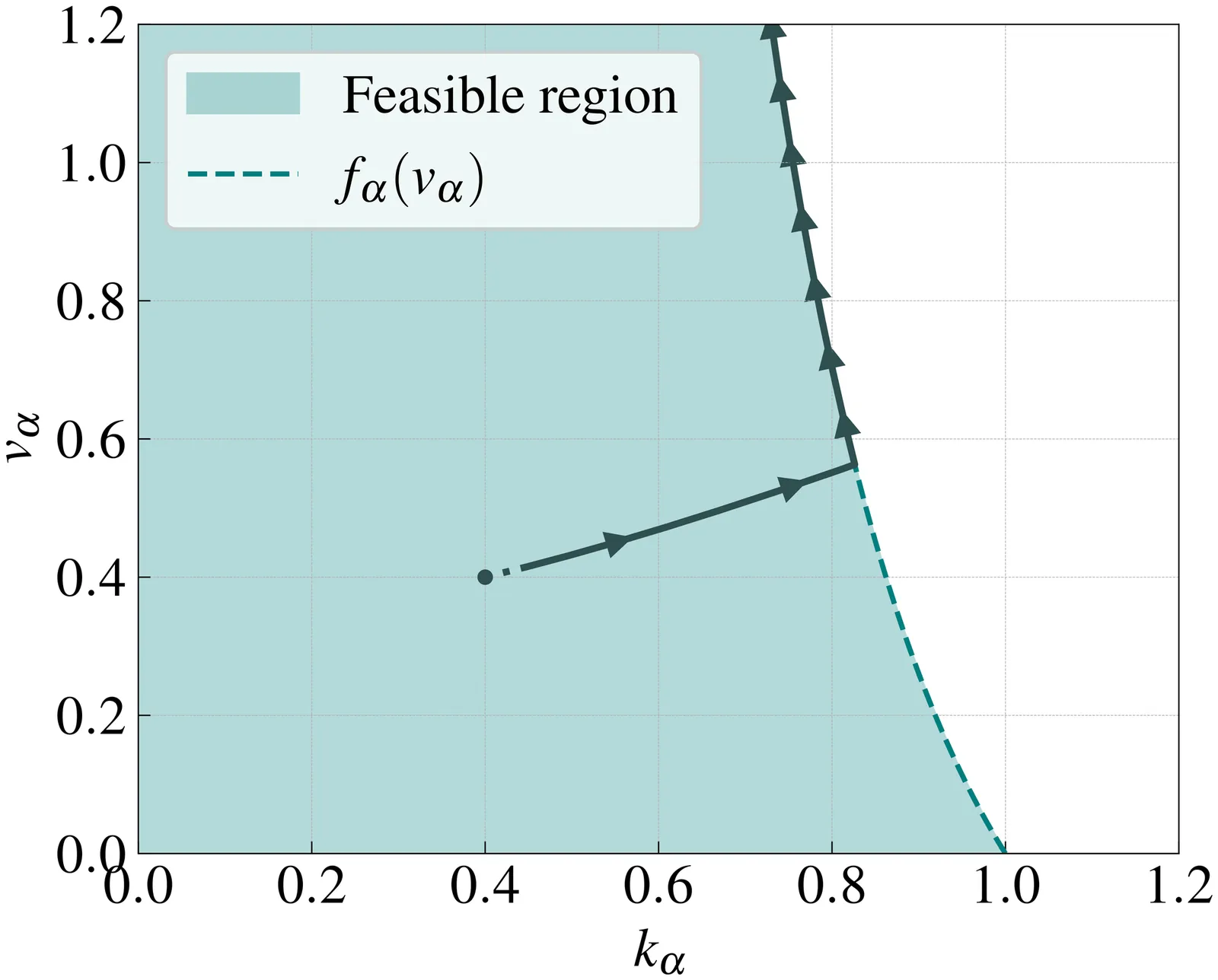
We study the emergence of tacit collusion between adaptive trading agents in a stochastic market with endogenous price formation. Using a two-player repeated game between a market maker and a market taker, we characterize feasible and collusive strategy profiles that raise prices beyond competitive levels. We show that, when agents follow simple learning algorithms (e.g., gradient ascent) to maximize their own wealth, the resulting dynamics converge to collusive strategy profiles, even in highly liquid markets with small trade sizes. By highlighting how simple learning strategies naturally lead to tacit collusion, our results offer new insights into the dynamics of AI-driven markets.
An approximation method for construction of optimal strategies in the bid \& ask limit order book in the high-frequency trading (HFT) is studied. The basis is the article by M. Avellaneda \& S. Stoikov 2008, in which certain seemingly serious gaps have been found; in the present paper they are carefully corrected. However, a bit surprisingly, our corrections do not change the main answer in the cited paper, so that, in fact, the gaps turn out to be unimportant. An explanation of this effect is offered.
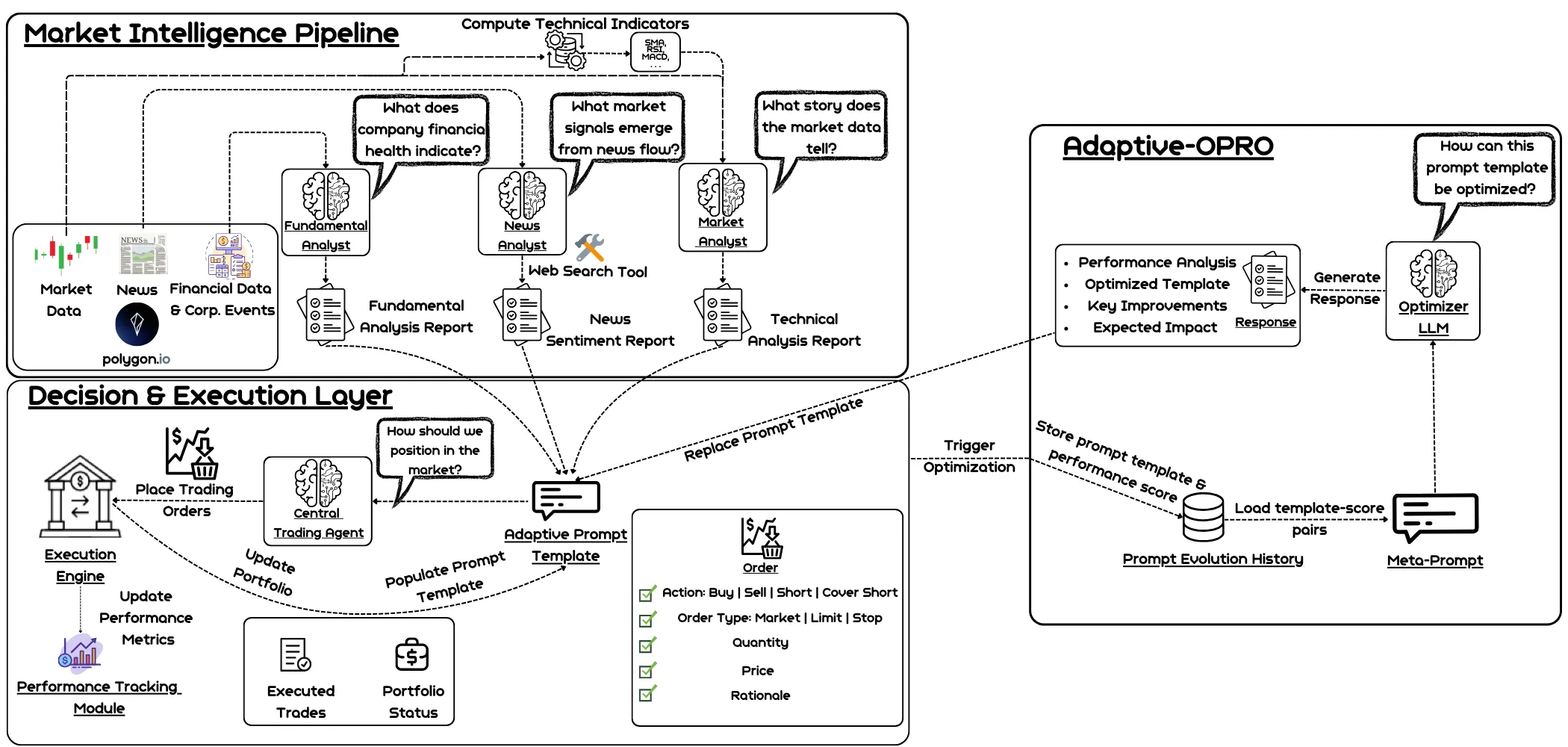
Large language models show promise for financial decision-making, yet deploying them as autonomous trading agents raises fundamental challenges: how to adapt instructions when rewards arrive late and obscured by market noise, how to synthesize heterogeneous information streams into coherent decisions, and how to bridge the gap between model outputs and executable market actions. We present ATLAS (Adaptive Trading with LLM AgentS), a unified multi-agent framework that integrates structured information from markets, news, and corporate fundamentals to support robust trading decisions. Within ATLAS, the central trading agent operates in an order-aware action space, ensuring that outputs correspond to executable market orders rather than abstract signals. The agent can incorporate feedback while trading using Adaptive-OPRO, a novel prompt-optimization technique that dynamically adapts the prompt by incorporating real-time, stochastic feedback, leading to increasing performance over time. Across regime-specific equity studies and multiple LLM families, Adaptive-OPRO consistently outperforms fixed prompts, while reflection-based feedback fails to provide systematic gains.
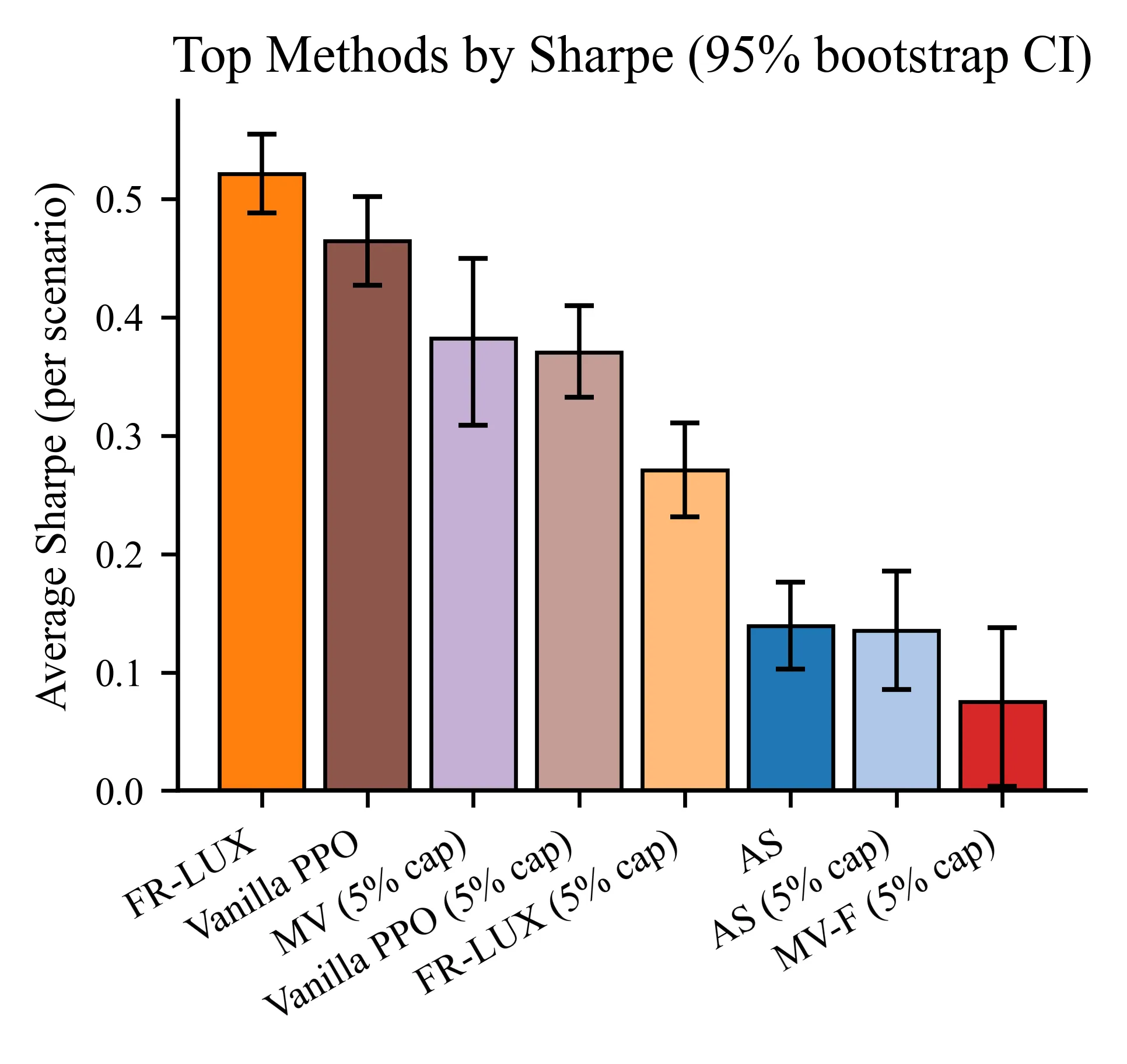
Transaction costs and regime shifts are major reasons why paper portfolios fail in live trading. We introduce FR-LUX (Friction-aware, Regime-conditioned Learning under eXecution costs), a reinforcement learning framework that learns after-cost trading policies and remains robust across volatility-liquidity regimes. FR-LUX integrates three ingredients: (i) a microstructure-consistent execution model combining proportional and impact costs, directly embedded in the reward; (ii) a trade-space trust region that constrains changes in inventory flow rather than logits, yielding stable low-turnover updates; and (iii) explicit regime conditioning so the policy specializes to LL/LH/HL/HH states without fragmenting the data. On a 4 x 5 grid of regimes and cost levels with multiple random seeds, FR-LUX achieves the top average Sharpe ratio with narrow bootstrap confidence intervals, maintains a flatter cost-performance slope than strong baselines, and attains superior risk-return efficiency for a given turnover budget. Pairwise scenario-level improvements are strictly positive and remain statistically significant after multiple-testing corrections. We provide formal guarantees on optimality under convex frictions, monotonic improvement under a KL trust region, long-run turnover bounds and induced inaction bands due to proportional costs, positive value advantage for regime-conditioned policies, and robustness to cost misspecification. The methodology is implementable: costs are calibrated from standard liquidity proxies, scenario-level inference avoids pseudo-replication, and all figures and tables are reproducible from released artifacts.

The Santa Fe model is an established econophysics model for describing stochastic dynamics of the limit order book from the viewpoint of the zero-intelligence approach. While its foundation was studied by combining a dimensional analysis and a mean-field theory by E. Smith et al. in Quantitative Finance 2003, their arguments are rather heuristic and lack solid mathematical foundation; indeed, their mean-field equations were derived with heuristic arguments and their solutions were not explicitly obtained. In this work, we revisit the mean-field theory of the Santa Fe model from the viewpoint of kinetic theory -- a traditional mathematical program in statistical physics. We study the exact master equation for the Santa Fe model and systematically derive the Bogoliubov-Born-Green-Kirkwood-Yvon (BBGKY) hierarchical equation. By applying the mean-field approximation, we derive the mean-field equation for the order-book density profile, parallel to the Boltzmann equation in conventional statistical physics. Furthermore, we obtain explicit and closed expression of the mean-field solutions. Our solutions have several implications: (1)Our scaling formulas are available for both $μ\to 0$ and $μ\to \infty$ asymptotics, where $μ$ is the market-order submission intensity. Particularly, the mean-field theory works very well for small $μ$, while its validity is partially limited for large $μ$. (2)The ``method of image'' solution, heuristically derived by Bouchaud-Mézard-Potters in Quantitative Finance 2002, is obtained for large $μ$, serving as a mathematical foundation for their heuristic arguments. (3)Finally, we point out an error in E. Smith et al. 2003 in the scaling law for the diffusion constant due to a misspecification in their dimensional analysis.
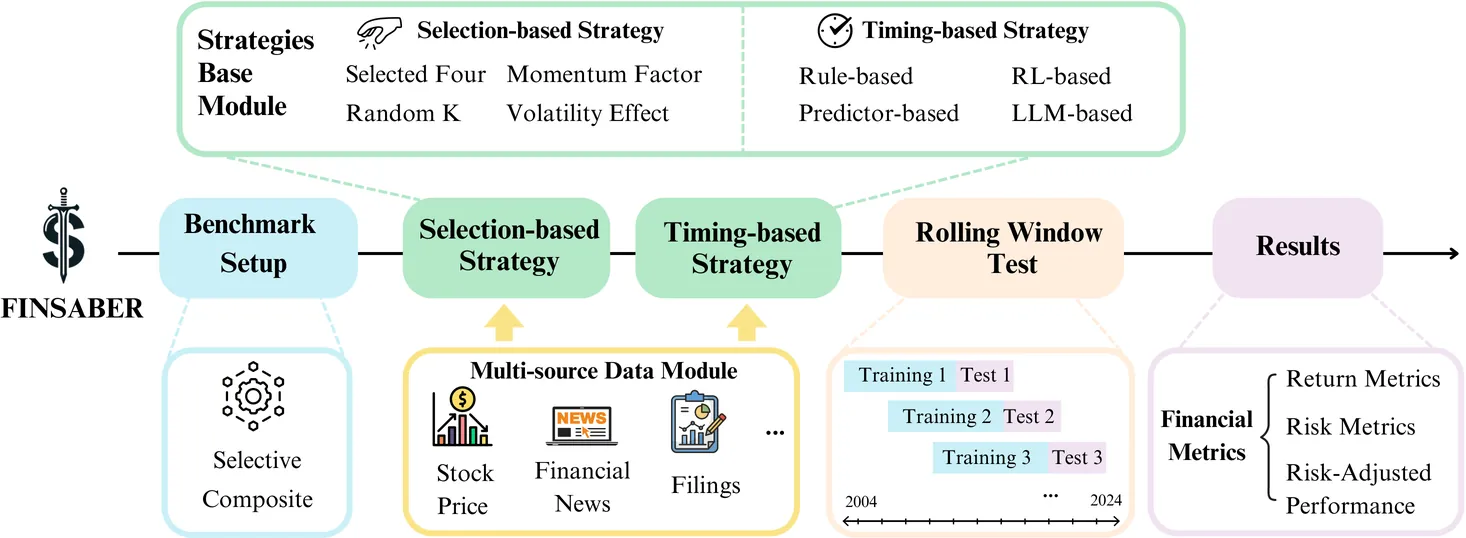
Large Language Models (LLMs) have recently been leveraged for asset pricing tasks and stock trading applications, enabling AI agents to generate investment decisions from unstructured financial data. However, most evaluations of LLM timing-based investing strategies are conducted on narrow timeframes and limited stock universes, overstating effectiveness due to survivorship and data-snooping biases. We critically assess their generalizability and robustness by proposing FINSABER, a backtesting framework evaluating timing-based strategies across longer periods and a larger universe of symbols. Systematic backtests over two decades and 100+ symbols reveal that previously reported LLM advantages deteriorate significantly under broader cross-section and over a longer-term evaluation. Our market regime analysis further demonstrates that LLM strategies are overly conservative in bull markets, underperforming passive benchmarks, and overly aggressive in bear markets, incurring heavy losses. These findings highlight the need to develop LLM strategies that are able to prioritise trend detection and regime-aware risk controls over mere scaling of framework complexity.
Financial markets are complex systems characterized by high statistical noise, nonlinearity, volatility, and constant evolution. Thus, modeling them is extremely hard. Here, we address the task of generating realistic and responsive Limit Order Book (LOB) market simulations, which are fundamental for calibrating and testing trading strategies, performing market impact experiments, and generating synthetic market data. We propose a novel TRAnsformer-based Denoising Diffusion Probabilistic Engine for LOB Simulations (TRADES). TRADES generates realistic order flows as time series conditioned on the state of the market, leveraging a transformer-based architecture that captures the temporal and spatial characteristics of high-frequency market data. There is a notable absence of quantitative metrics for evaluating generative market simulation models in the literature. To tackle this problem, we adapt the predictive score, a metric measured as an MAE, to market data by training a stock price predictive model on synthetic data and testing it on real data. We compare TRADES with previous works on two stocks, reporting a 3.27 and 3.48 improvement over SoTA according to the predictive score, demonstrating that we generate useful synthetic market data for financial downstream tasks. Furthermore, we assess TRADES's market simulation realism and responsiveness, showing that it effectively learns the conditional data distribution and successfully reacts to an experimental agent, giving sprout to possible calibrations and evaluations of trading strategies and market impact experiments. To perform the experiments, we developed DeepMarket, the first open-source Python framework for LOB market simulation with deep learning. In our repository, we include a synthetic LOB dataset composed of TRADES's generated simulations.
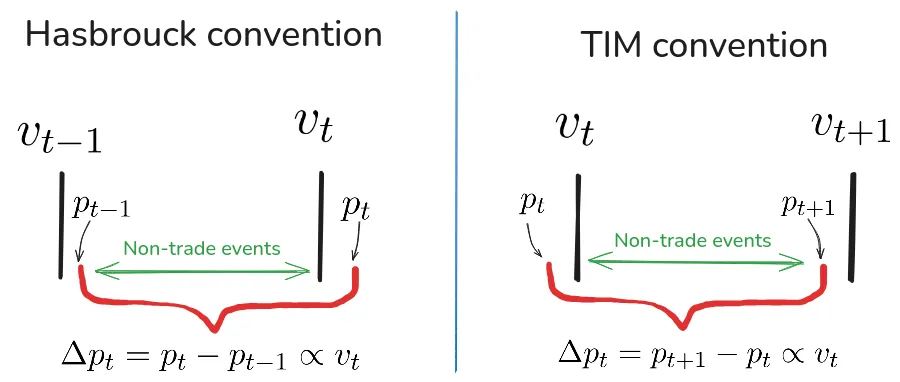
Estimating market impact and transaction costs of large trades (metaorders) is a very important topic in finance. However, using models of price and trade based on public market data provide average price trajectories which are qualitatively different from what is observed during real metaorder executions: the price increases linearly, rather than in a concave way, during the execution and the amount of reversion after its end is very limited. We claim that this is a generic phenomenon due to the fact that even sophisticated statistical models are unable to correctly describe the origin of the autocorrelation of the order flow. We propose a modified Transient Impact Model which provides more realistic trajectories by assuming that only a fraction of the metaorder trading triggers market order flow. Interestingly, in our model there is a critical condition on the kernels of the price and order flow equations in which market impact becomes permanent.
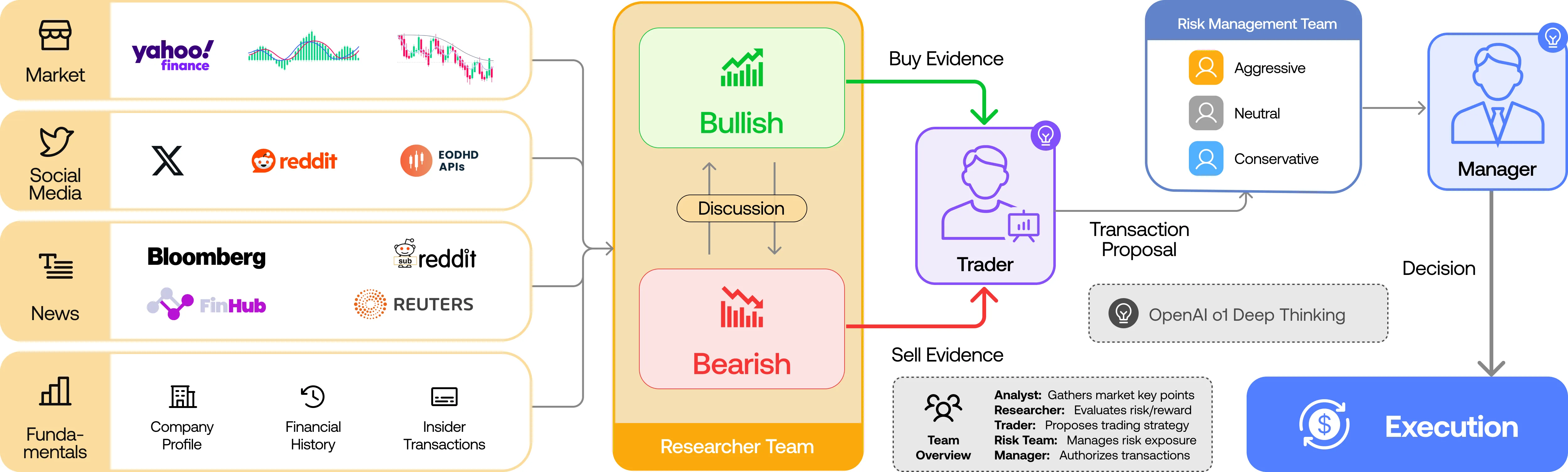
Significant progress has been made in automated problem-solving using societies of agents powered by large language models (LLMs). In finance, efforts have largely focused on single-agent systems handling specific tasks or multi-agent frameworks independently gathering data. However, the multi-agent systems' potential to replicate real-world trading firms' collaborative dynamics remains underexplored. TradingAgents proposes a novel stock trading framework inspired by trading firms, featuring LLM-powered agents in specialized roles such as fundamental analysts, sentiment analysts, technical analysts, and traders with varied risk profiles. The framework includes Bull and Bear researcher agents assessing market conditions, a risk management team monitoring exposure, and traders synthesizing insights from debates and historical data to make informed decisions. By simulating a dynamic, collaborative trading environment, this framework aims to improve trading performance. Detailed architecture and extensive experiments reveal its superiority over baseline models, with notable improvements in cumulative returns, Sharpe ratio, and maximum drawdown, highlighting the potential of multi-agent LLM frameworks in financial trading. TradingAgents is available at https://github.com/TauricResearch/TradingAgents.