Trending in Trading & Market Microstructure
Deep Learning for Financial Time Series: A Large-Scale Benchmark of Risk-Adjusted Performance
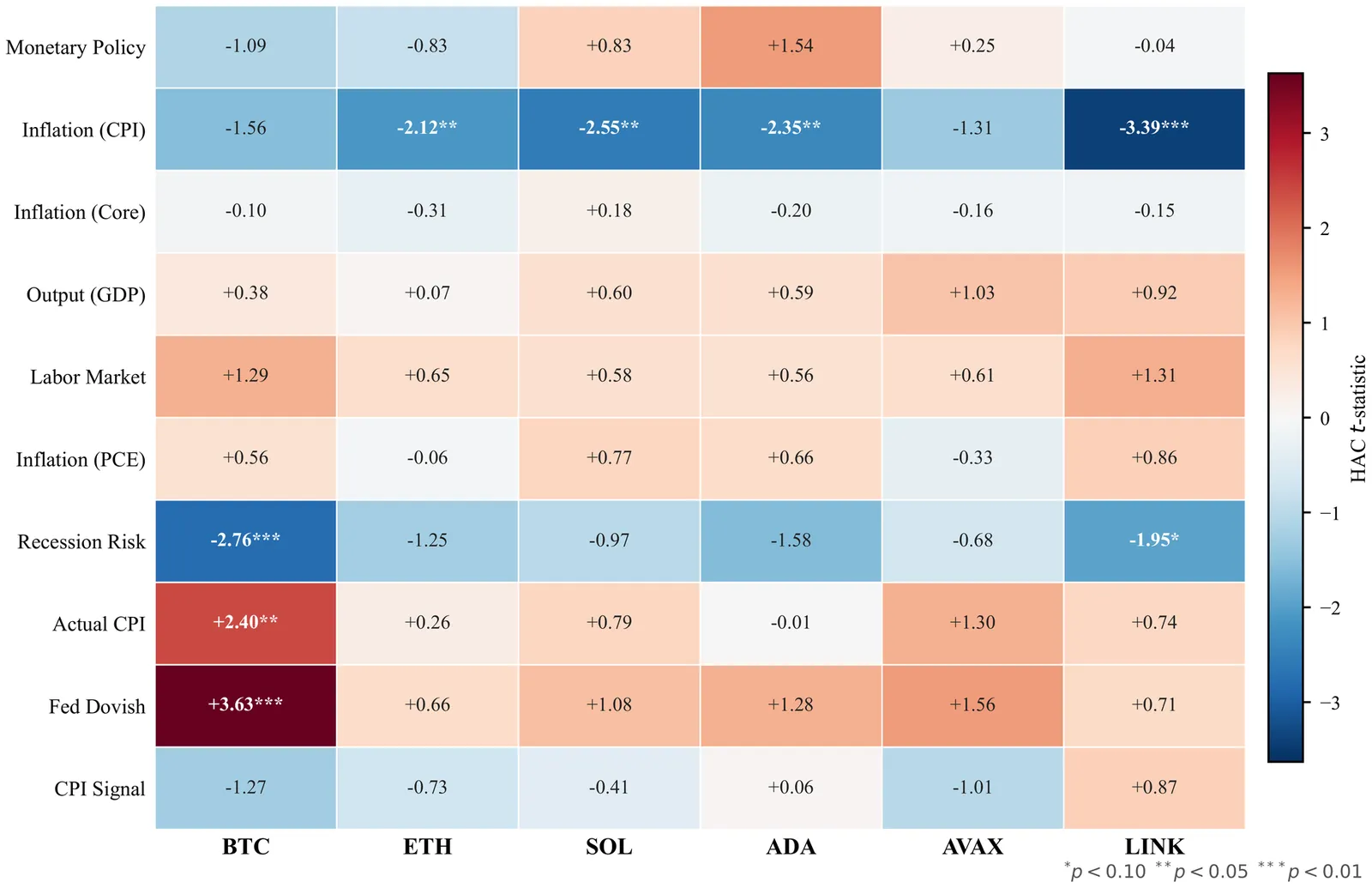
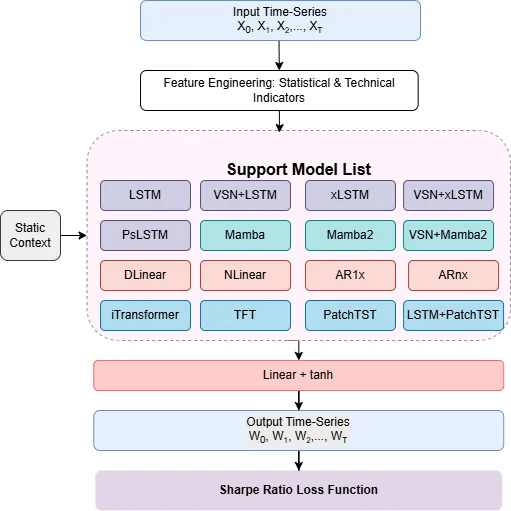
We present a large scale benchmark of modern deep learning architectures for a financial time series prediction and position sizing task, with a primary focus on Sharpe ratio optimization. Evaluating linear models, recurrent networks, transformer based architectures, state space models, and recent sequence representation approaches, we assess out of sample performance on a daily futures dataset spanning commodities, equity indices, bonds, and FX spanning 2010 to 2025. Our evaluation goes beyond average returns and includes statistical significance, downside and tail risk measures, breakeven transaction cost analysis, robustness to random seed selection, and computational efficiency. We find that models explicitly designed to learn rich temporal representations consistently outperform linear benchmarks and generic deep learning models, which often lead the ranking in standard time series benchmarks. Hybrid models such as VSN with LSTM, a combination of Variable Selection Networks (VSN) and LSTMs, achieves the highest overall Sharpe ratio, while VSN with xLSTM and LSTM with PatchTST exhibit superior downside adjusted characteristics. xLSTM demonstrates the largest breakeven transaction cost buffer, indicating improved robustness to trading frictions.
2603.01820
Mar 2026Trading and Market Microstructure
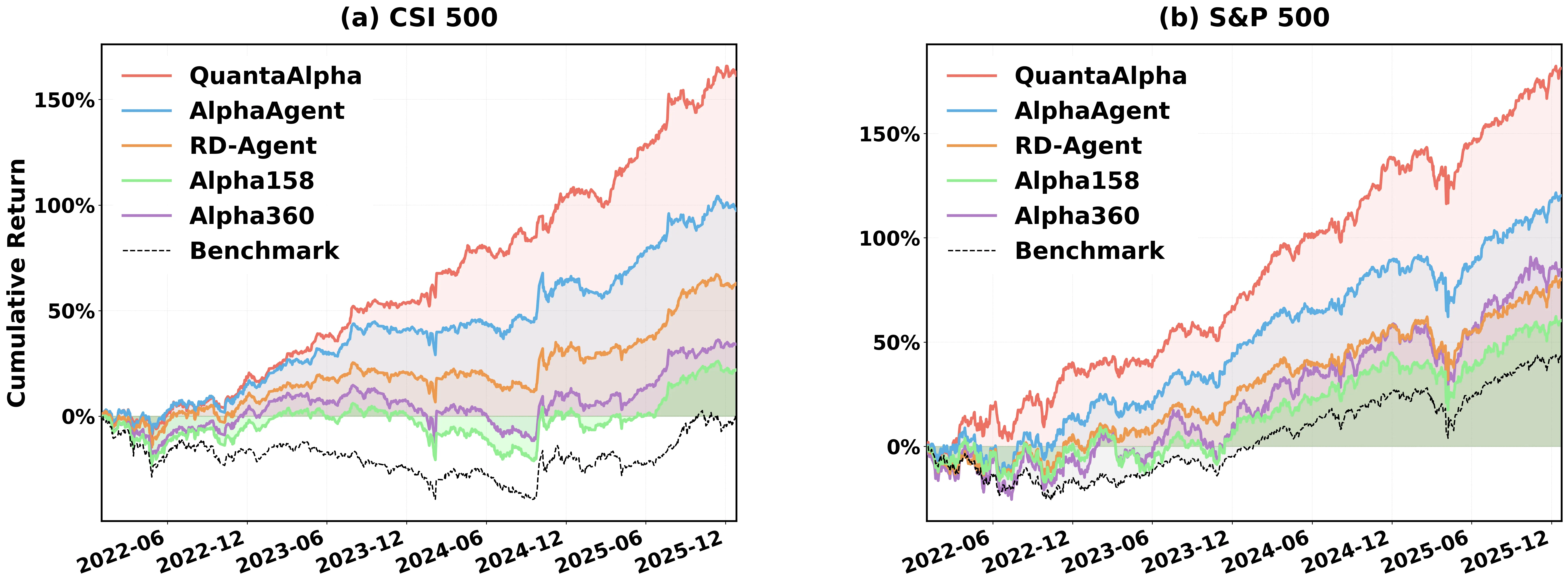
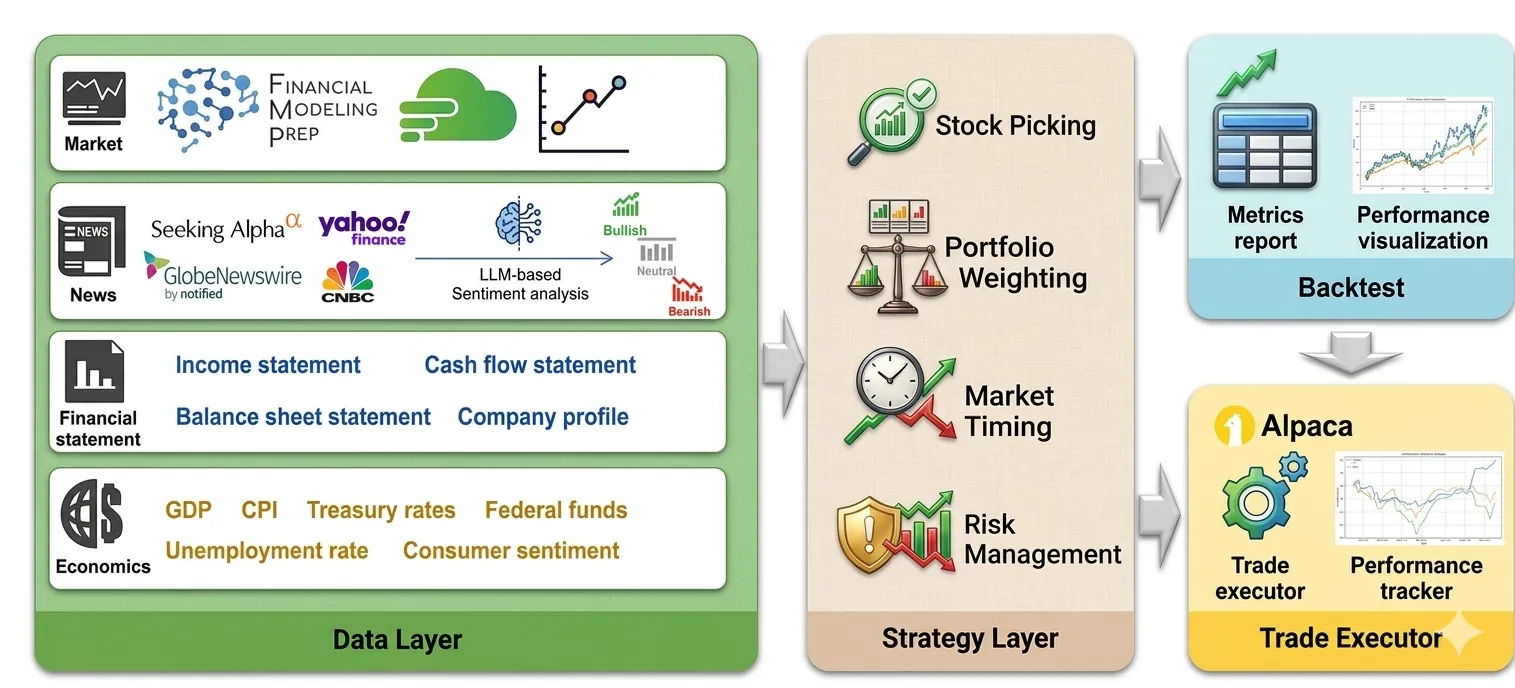
QuantaAlpha: An Evolutionary Framework for LLM-Driven Alpha Mining
Financial markets are noisy and non-stationary, making alpha mining highly sensitive to noise in backtesting results and sudden market regime shifts. While recent agentic frameworks improve alpha mining automation, they often lack controllable multi-round search and reliable reuse of validated experience. To address these challenges, we propose QuantaAlpha, an evolutionary alpha mining framework that treats each end-to-end mining run as a trajectory and improves factors through trajectory-level mutation and crossover operations. QuantaAlpha localizes suboptimal steps in each trajectory for targeted revision and recombines complementary high-reward segments to reuse effective patterns, enabling structured exploration and refinement across mining iterations. During factor generation, QuantaAlpha enforces semantic consistency across the hypothesis, factor expression, and executable code, while constraining the complexity and redundancy of the generated factor to mitigate crowding. Extensive experiments on the China Securities Index 300 (CSI 300) demonstrate consistent gains over strong baseline models and prior agentic systems. When utilizing GPT-5.2, QuantaAlpha achieves an Information Coefficient (IC) of 0.1501, with an Annualized Rate of Return (ARR) of 27.75% and a Maximum Drawdown (MDD) of 7.98%. Moreover, factors mined on CSI 300 transfer effectively to the China Securities Index 500 (CSI 500) and the Standard & Poor's 500 Index (S&P 500), delivering 160% and 137% cumulative excess return over four years, respectively, which indicates strong robustness of QuantaAlpha under market distribution shifts.
2602.07085
Feb 2026Statistical Finance
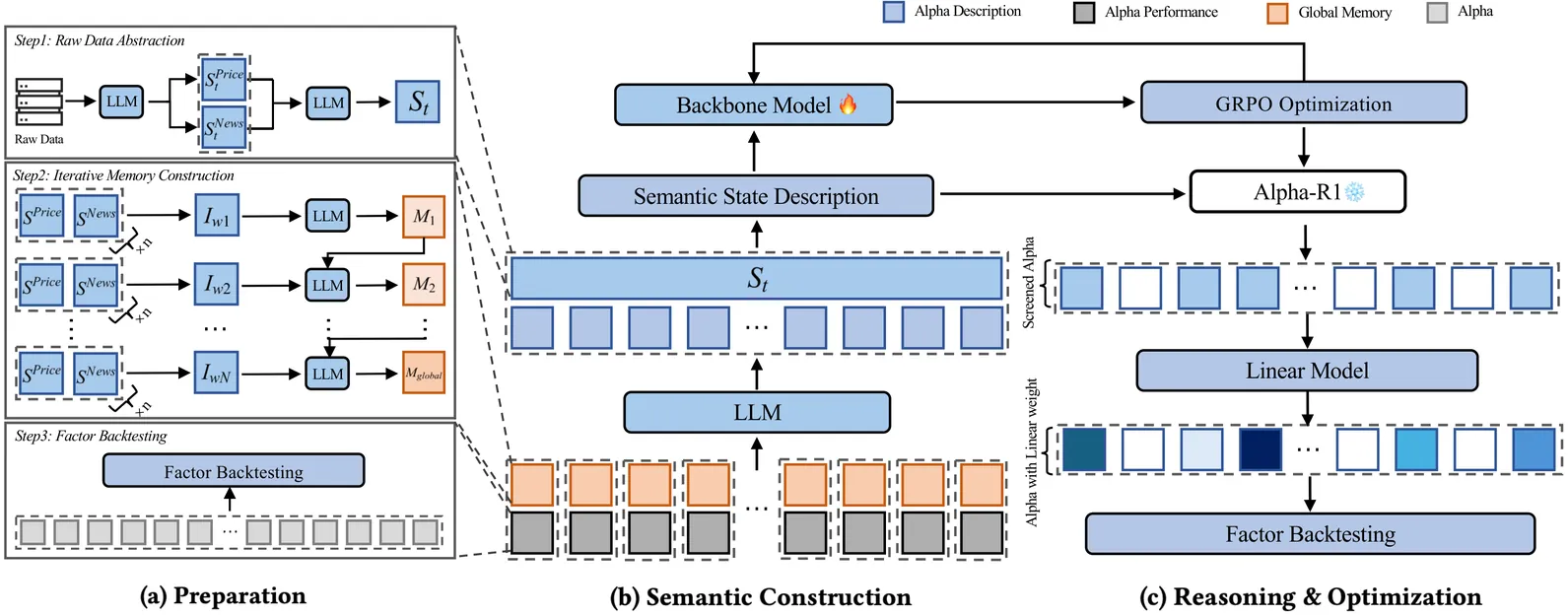
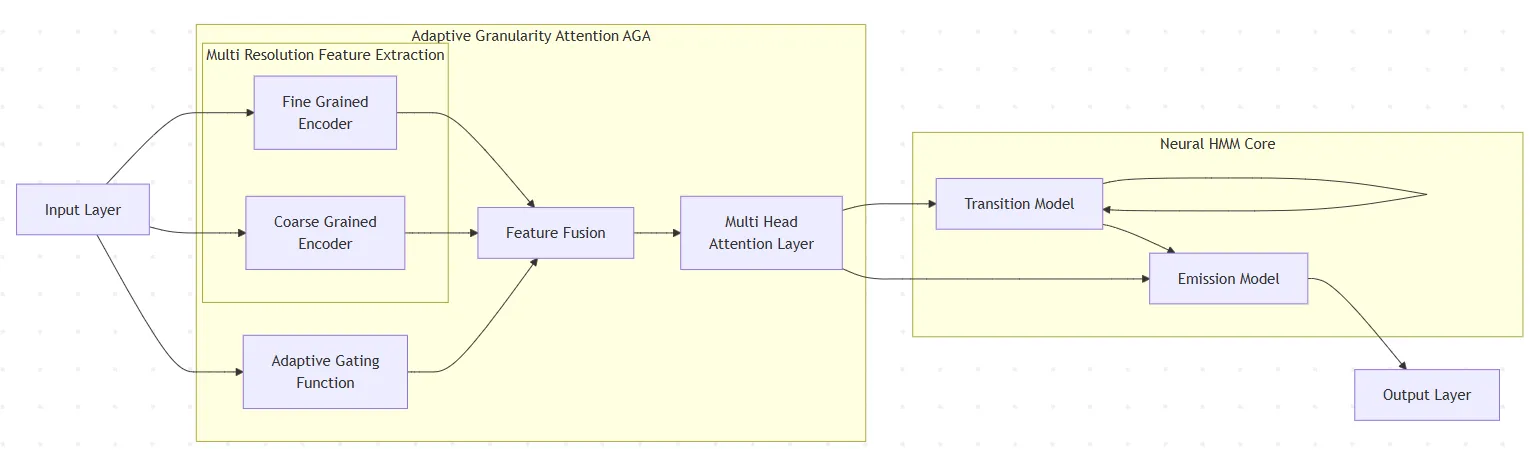
Alpha-R1: Alpha Screening with LLM Reasoning via Reinforcement Learning
Signal decay and regime shifts pose recurring challenges for data-driven investment strategies in non-stationary markets. Conventional time-series and machine learning approaches, which rely primarily on historical correlations, often struggle to generalize when the economic environment changes. While large language models (LLMs) offer strong capabilities for processing unstructured information, their potential to support quantitative factor screening through explicit economic reasoning remains underexplored. Existing factor-based methods typically reduce alphas to numerical time series, overlooking the semantic rationale that determines when a factor is economically relevant. We propose Alpha-R1, an 8B-parameter reasoning model trained via reinforcement learning for context-aware alpha screening. Alpha-R1 reasons over factor logic and real-time news to evaluate alpha relevance under changing market conditions, selectively activating or deactivating factors based on contextual consistency. Empirical results across multiple asset pools show that Alpha-R1 consistently outperforms benchmark strategies and exhibits improved robustness to alpha decay. The full implementation and resources are available at https://github.com/FinStep-AI/Alpha-R1.
2512.23515
Dec 2025Trading and Market Microstructure