General Finance
arXiv:q-fin.GN
Development of general quantitative methodologies for financial markets.
Development of general quantitative methodologies for financial markets.
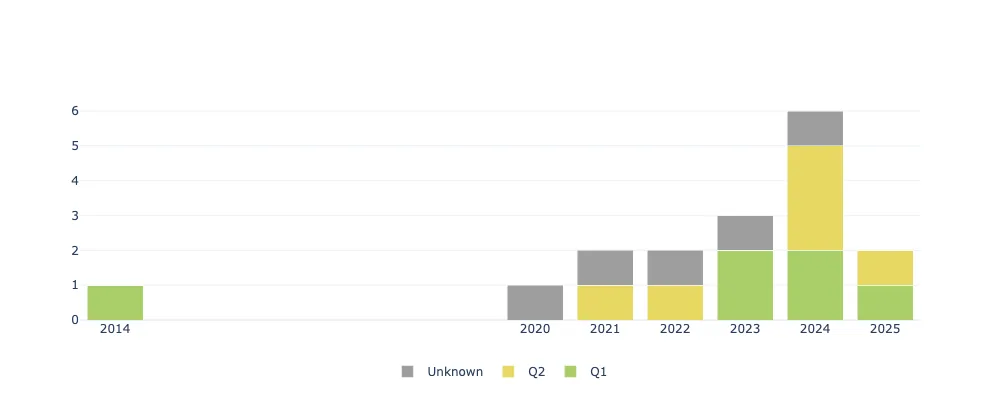
This paper introduces an algorithmic framework for conducting systematic literature reviews (SLRs), designed to improve efficiency, reproducibility, and selection quality assessment in the literature review process. The proposed method integrates Natural Language Processing (NLP) techniques, clustering algorithms, and interpretability tools to automate and structure the selection and analysis of academic publications. The framework is applied to a case study focused on financial narratives, an emerging area in financial economics that examines how structured accounts of economic events, formed by the convergence of individual interpretations, influence market dynamics and asset prices. Drawing from the Scopus database of peer-reviewed literature, the review highlights research efforts to model financial narratives using various NLP techniques. Results reveal that while advances have been made, the conceptualization of financial narratives remains fragmented, often reduced to sentiment analysis, topic modeling, or their combination, without a unified theoretical framework. The findings underscore the value of more rigorous and dynamic narrative modeling approaches and demonstrate the effectiveness of the proposed algorithmic SLR methodology.

We develop a statistical test to detect lookahead bias in economic forecasts generated by large language models (LLMs). Using state-of-the-art pre-training data detection techniques, we estimate the likelihood that a given prompt appeared in an LLM's training corpus, a statistic we term Lookahead Propensity (LAP). We formally show that a positive correlation between LAP and forecast accuracy indicates the presence and magnitude of lookahead bias, and apply the test to two forecasting tasks: news headlines predicting stock returns and earnings call transcripts predicting capital expenditures. Our test provides a cost-efficient, diagnostic tool for assessing the validity and reliability of LLM-generated forecasts.
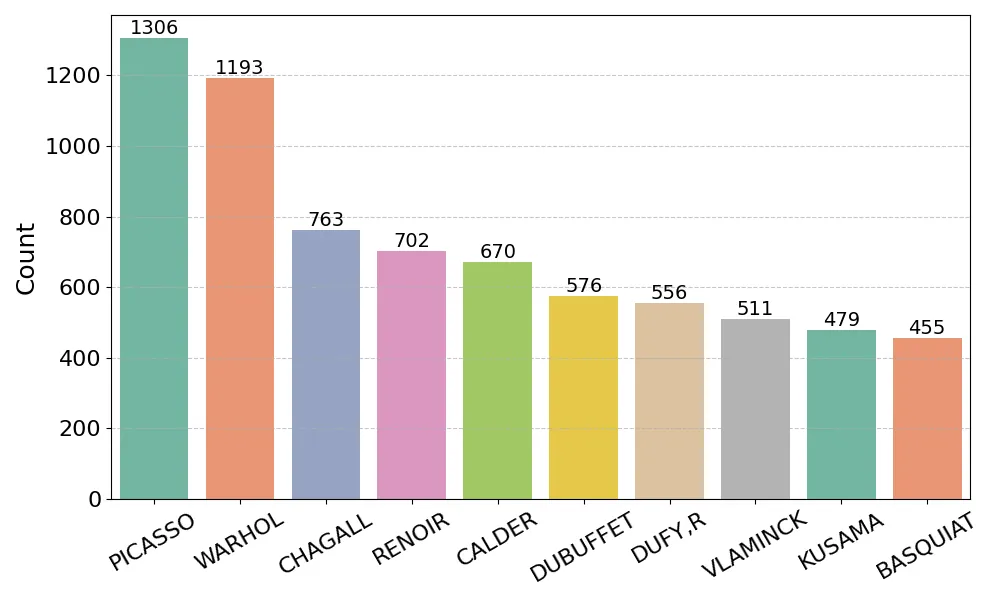
We study how deep learning can improve valuation in the art market by incorporating the visual content of artworks into predictive models. Using a large repeated-sales dataset from major auction houses, we benchmark classical hedonic regressions and tree-based methods against modern deep architectures, including multi-modal models that fuse tabular and image data. We find that while artist identity and prior transaction history dominate overall predictive power, visual embeddings provide a distinct and economically meaningful contribution for fresh-to-market works where historical anchors are absent. Interpretability analyses using Grad-CAM and embedding visualizations show that models attend to compositional and stylistic cues. Our findings demonstrate that multi-modal deep learning delivers significant value precisely when valuation is hardest, namely first-time sales, and thus offers new insights for both academic research and practice in art market valuation.

The Federal Open Market Committee (FOMC) sets the federal funds rate, shaping monetary policy and the broader economy. We introduce \emph{FedSight AI}, a multi-agent framework that uses large language models (LLMs) to simulate FOMC deliberations and predict policy outcomes. Member agents analyze structured indicators and unstructured inputs such as the Beige Book, debate options, and vote, replicating committee reasoning. A Chain-of-Draft (CoD) extension further improves efficiency and accuracy by enforcing concise multistage reasoning. Evaluated at 2023-2024 meetings, FedSight CoD achieved accuracy of 93.75\% and stability of 93.33\%, outperforming baselines including MiniFed and Ordinal Random Forest (RF), while offering transparent reasoning aligned with real FOMC communications.
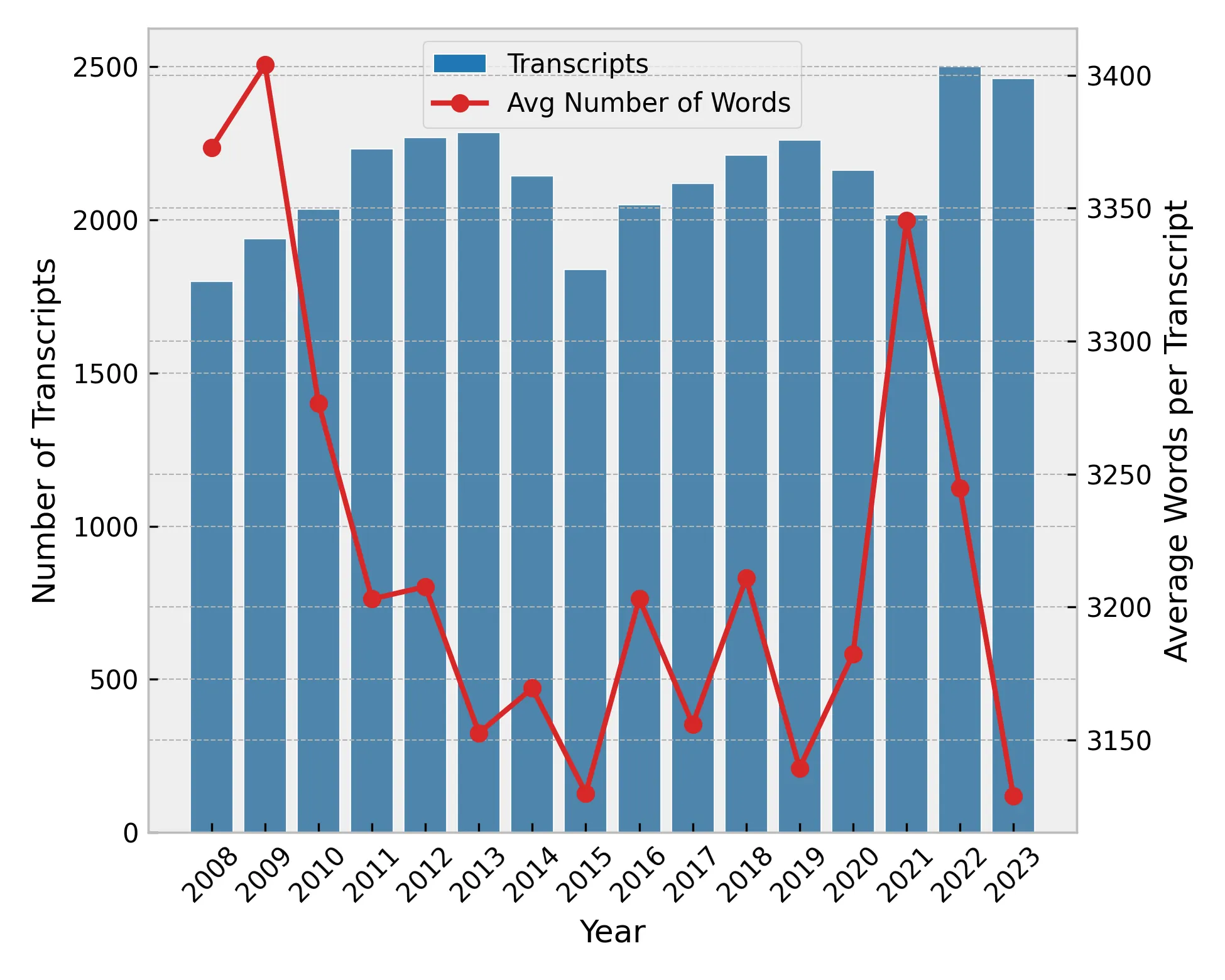
Economic behavior is shaped not only by quantitative information but also by the narratives through which such information is communicated and interpreted (Shiller, 2017). I show that narratives extracted from earnings calls significantly improve the prediction of both realized earnings and analyst expectations. To uncover the underlying mechanisms, I introduce a novel text-morphing methodology in which large language models generate counterfactual transcripts that systematically vary topical emphasis (the prevailing narrative) while holding quantitative content fixed. This framework allows me to precisely measure how analysts under- and over-react to specific narrative dimensions. The results reveal systematic biases: analysts over-react to sentiment (optimism) and under-react to narratives of risk and uncertainty. Overall, the analysis offers a granular perspective on the mechanisms of expectation formation through the competing narratives embedded in corporate communication.
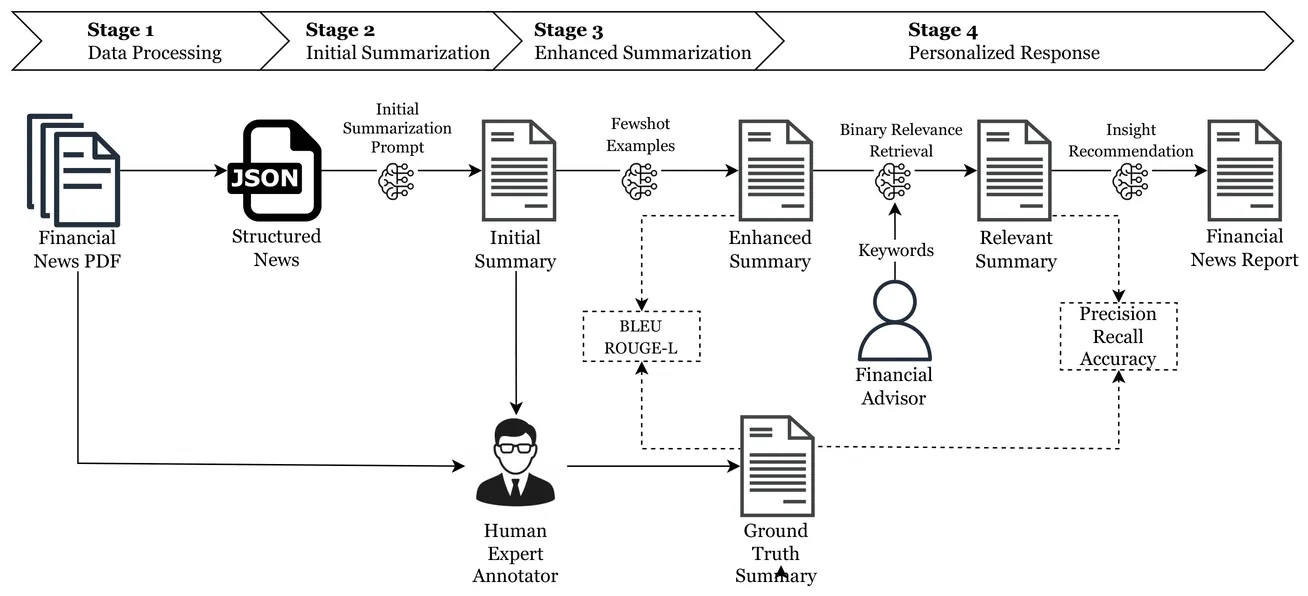
Financial advisors and investors struggle with information overload from financial news, where irrelevant content and noise obscure key market signals and hinder timely investment decisions. To address this, we propose a novel Chain-of-Thought (CoT) summarization framework that condenses financial news into concise, event-driven summaries. The framework integrates user-specified keywords to generate personalized outputs, ensuring that only the most relevant contexts are highlighted. These personalized summaries provide an intermediate layer that supports language models in producing investor-focused narratives, bridging the gap between raw news and actionable insights.

Financial networks based on Pearson correlations have been intensively studied. However, previous studies may have led to misleading and catastrophic results because of several critical shortcomings of the Pearson correlation. The local Gaussian correlation coefficient, a new measurement of statistical dependence between variables, has unique advantages including capturing local nonlinear dependence and handling heavy-tailed distributions. This study constructs financial networks using the local Gaussian correlation coefficients between tail regions of stock returns in the Shanghai Stock Exchange. The work systematically analyzes fundamental network metrics including node centrality, average shortest path length, and entropy. Compared with the local Gaussian correlation network among positive tails and the conventional Pearson correlation network, the properties of the local Gaussian correlation network among negative tails are more sensitive to the stock market risks. This finding suggests researchers should prioritize the local Gaussian correlation network among negative tails. Future work should reevaluate existing findings using the local Gaussian correlation method.

When the traded energy and reserve products between zones are co-allocated to optimize the infrastructure usage, both deterministic and stochastic flows have to be accounted for on interconnector lines. We focus on allocation models, which guarantee deliverability in the context of the portfolio bidding European day-ahead market framework, assuming a flow-based description of network constraints. In such models, as each unit of allocated reserve supply implies additional cost, it is straightforward to assume that the amount of allocated reserve is equal to the accepted reserve demand quantity. However, as it is illustrated by the proposed work, overprocurement of reserves may imply counterintuitive benefits. Reserve supplies not used for balancing may be used for congestion management, thus allowing valuable additional flows in the network.

Small and Medium-sized Enterprises (SMEs) are known to play a vital role in economic growth, employment, and innovation. However, they tend to face significant challenges in accessing credit due to limited financial histories, collateral constraints, and exposure to macroeconomic shocks. These challenges make an accurate credit risk assessment by lenders crucial, particularly since SMEs frequently operate within interconnected firm networks through which default risk can propagate. This paper presents and tests a novel approach for modelling the risk of SME credit, using a unique large data set of SME loans provided by a prominent financial institution. Specifically, our approach employs Graph Neural Networks to predict SME default using multilayer network data derived from common ownership and financial transactions between firms. We show that combining this information with traditional structured data not only improves application scoring performance, but also explicitly models contagion risk between companies. Further analysis shows how the directionality and intensity of these connections influence financial risk contagion, offering a deeper understanding of the underlying processes. Our findings highlight the predictive power of network data, as well as the role of supply chain networks in exposing SMEs to correlated default risk.

This paper investigates the impact of the adoption of generative AI on financial stability. We conduct laboratory-style experiments using large language models to replicate classic studies on herd behavior in trading decisions. Our results show that AI agents make more rational decisions than humans, relying predominantly on private information over market trends. Increased reliance on AI-powered trading advice could therefore potentially lead to fewer asset price bubbles arising from animal spirits that trade by following the herd. However, exploring variations in the experimental settings reveals that AI agents can be induced to herd optimally when explicitly guided to make profit-maximizing decisions. While optimal herding improves market discipline, this behavior still carries potential implications for financial stability. In other experimental variations, we show that AI agents are not purely algorithmic, but have inherited some elements of human conditioning and bias.

The Sleeping Beauty problem was presented by Elga and highlights the role of probabilities in situations with imperfect recall. One approach to solving the Sleeping Beauty problem is to allow Sleeping Beauty to make decisions based on her beliefs, and then characterize what it takes for her decisions to be "rational". In particular, she can be allowed to make monetary bets based on her beliefs, with the assumption that she wants to gain wealth rather than lose it. However, this approach is often coupled with the assumption that Sleeping Beauty should maximize the expected value of her bets. Here, I argue instead that it is rational for Sleeping Beauty to maximize the growth rate of her wealth using the Kelly Criterion, which leads us to the "thirder" position. Furthermore, this position is shown to be "rational" by Dutch book arguments. If Sleeping Kelly only accepts bets that have a growth rate greater than 1 as a "thirder" then she is not vulnerable to Dutch books. By contrast, if Sleeping Beauty takes the "halfer" position, she is vulnerable to Dutch books. If the bets offered to Sleeping Beauty were to be structured differently and lead to non-multiplicative wealth dynamics, she may no longer be a "thirder".
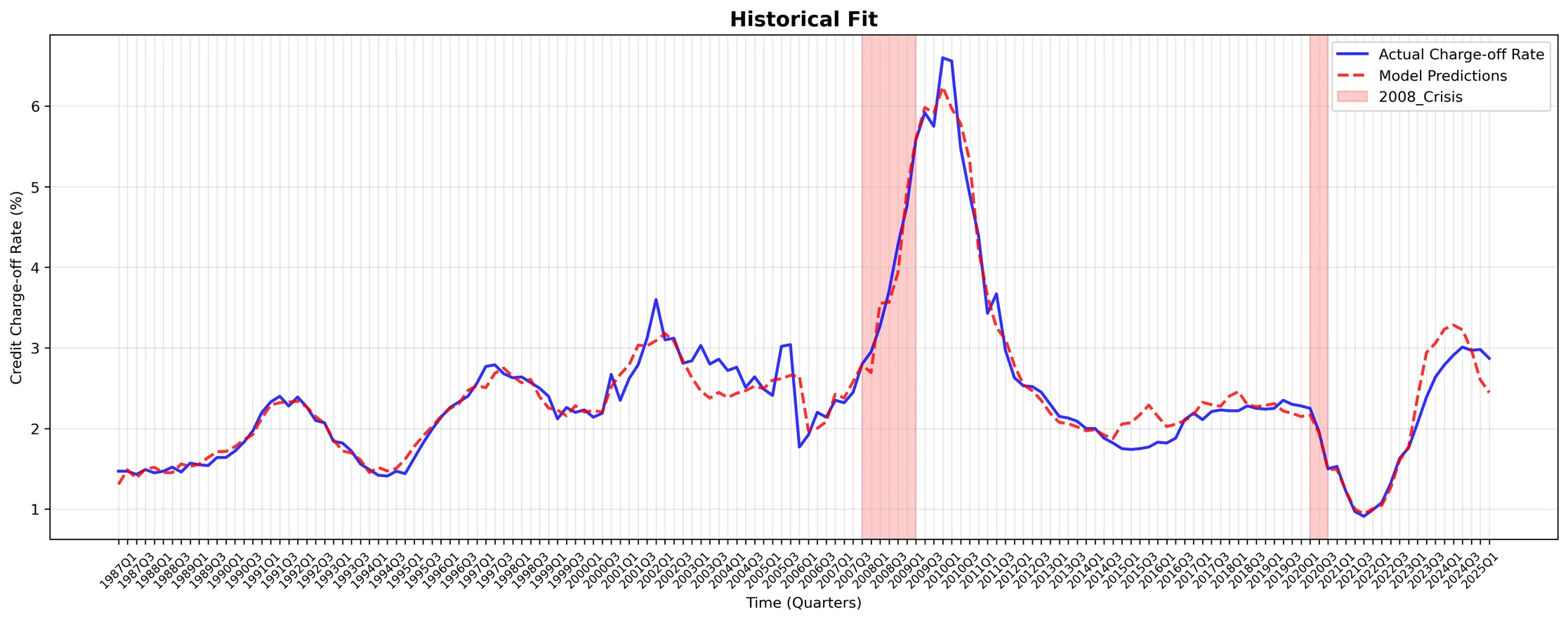
This study introduces geometric algebra to decompose credit system relationships into their projective (correlation-like) and rotational (feedback-spiral) components. We represent economic states as multi-vectors in Clifford algebra, where bivector elements capture the rotational coupling between unemployment, consumption, savings, and credit utilization. This mathematical framework reveals interaction patterns invisible to conventional analysis: when unemployment and credit contraction enter simultaneous feedback loops, their geometric relationship shifts from simple correlation to dangerous rotational dynamics that characterize systemic crises.

Across the globe there are growing calls to streamline and improve ever more complex income tax codes. Executing reform has proven difficult. Even when the desired outcomes are clear, the tools to design fitting reforms are lacking. To remedy this, we developed \texttt{TaxSolver}: a methodology to help policymakers realize optimal tax reform. \texttt{TaxSolver} allows policymakers to focus solely on what they aim to achieve with a reform -- like redistributing wealth, incentivizing labor market participation or reducing complexity -- and the guarantees within which reform is acceptable -- like limited fluctuations in taxpayer incomes or shocks to overall tax revenue. Given these goals and fiscal guarantees, \texttt{TaxSolver} finds the optimal set of tax rules that satisfies all the criteria or shows that the set of demands are not mathematically feasible. We illustrate \texttt{TaxSolver} by reforming various simulated examples of tax codes, including some that reflect the complexity and size of a real-world tax system.
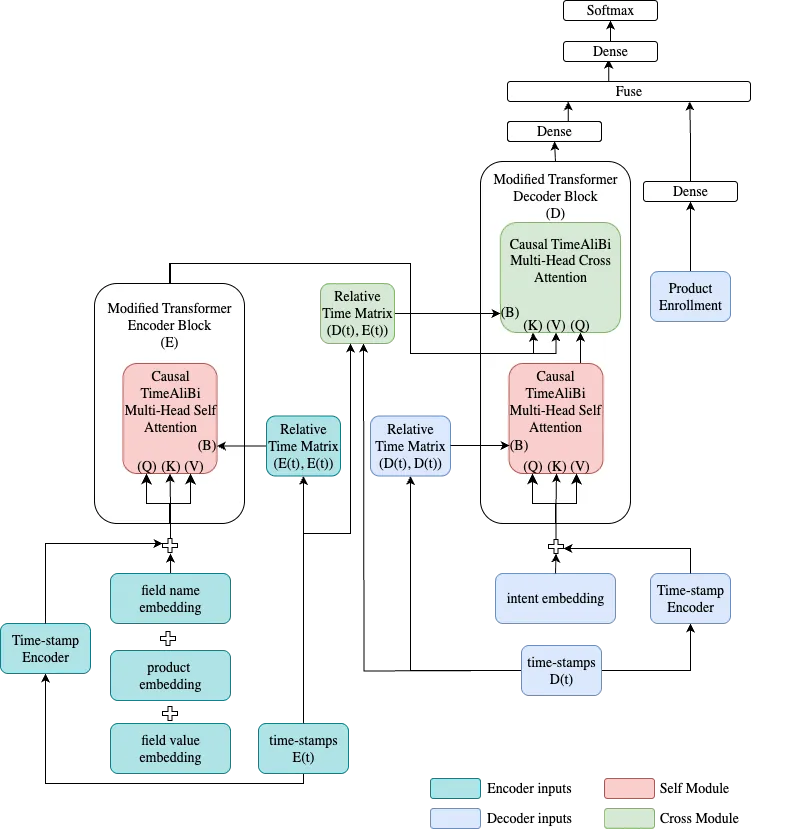
Users engage with financial services companies through multiple channels, often interacting with mobile applications, web platforms, call centers, and physical locations to service their accounts. The resulting interactions are recorded at heterogeneous temporal resolutions across these domains. This multi-channel data can be combined and encoded to create a comprehensive representation of the customer's journey for accurate intent prediction. This demands sequential learning solutions. NMT transformers achieve state-of-the-art sequential representation learning by encoding context and decoding for the next best action to represent long-range dependencies. However, three major challenges exist while combining multi-domain sequences within an encoder-decoder transformers architecture for intent prediction applications: a) aligning sequences with different sampling rates b) learning temporal dynamics across multi-variate, multi-domain sequences c) combining dynamic and static sequences. We propose an encoder-decoder transformer model to address these challenges for contextual and sequential intent prediction in financial servicing applications. Our experiments show significant improvement over the existing tabular method.
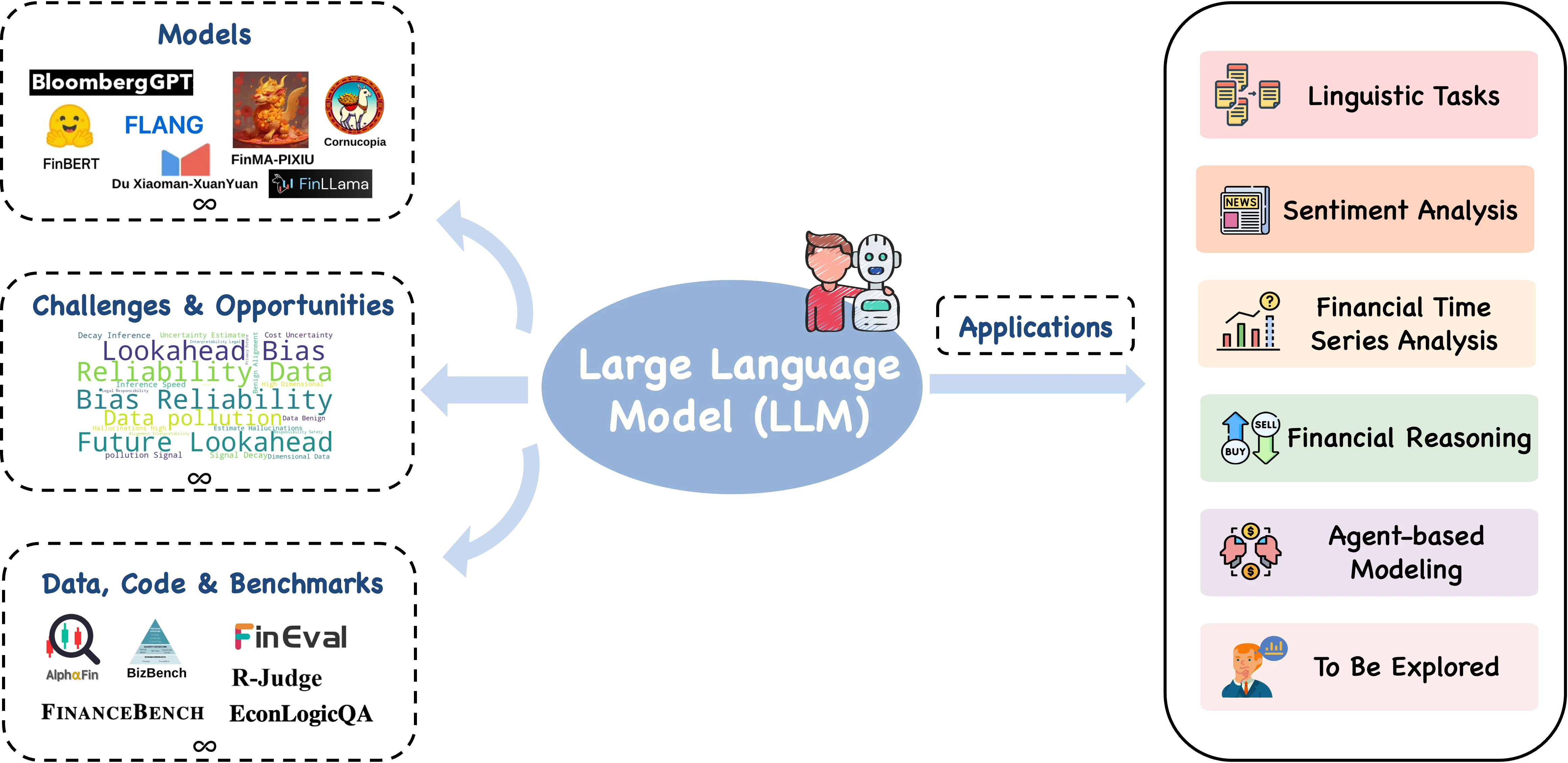
Recent advances in large language models (LLMs) have unlocked novel opportunities for machine learning applications in the financial domain. These models have demonstrated remarkable capabilities in understanding context, processing vast amounts of data, and generating human-preferred contents. In this survey, we explore the application of LLMs on various financial tasks, focusing on their potential to transform traditional practices and drive innovation. We provide a discussion of the progress and advantages of LLMs in financial contexts, analyzing their advanced technologies as well as prospective capabilities in contextual understanding, transfer learning flexibility, complex emotion detection, etc. We then highlight this survey for categorizing the existing literature into key application areas, including linguistic tasks, sentiment analysis, financial time series, financial reasoning, agent-based modeling, and other applications. For each application area, we delve into specific methodologies, such as textual analysis, knowledge-based analysis, forecasting, data augmentation, planning, decision support, and simulations. Furthermore, a comprehensive collection of datasets, model assets, and useful codes associated with mainstream applications are presented as resources for the researchers and practitioners. Finally, we outline the challenges and opportunities for future research, particularly emphasizing a number of distinctive aspects in this field. We hope our work can help facilitate the adoption and further development of LLMs in the financial sector.
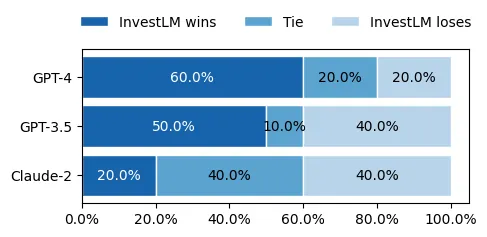
We present a new financial domain large language model, InvestLM, tuned on LLaMA-65B (Touvron et al., 2023), using a carefully curated instruction dataset related to financial investment. Inspired by less-is-more-for-alignment (Zhou et al., 2023), we manually curate a small yet diverse instruction dataset, covering a wide range of financial related topics, from Chartered Financial Analyst (CFA) exam questions to SEC filings to Stackexchange quantitative finance discussions. InvestLM shows strong capabilities in understanding financial text and provides helpful responses to investment related questions. Financial experts, including hedge fund managers and research analysts, rate InvestLM's response as comparable to those of state-of-the-art commercial models (GPT-3.5, GPT-4 and Claude-2). Zero-shot evaluation on a set of financial NLP benchmarks demonstrates strong generalizability. From a research perspective, this work suggests that a high-quality domain specific LLM can be tuned using a small set of carefully curated instructions on a well-trained foundation model, which is consistent with the Superficial Alignment Hypothesis (Zhou et al., 2023). From a practical perspective, this work develops a state-of-the-art financial domain LLM with superior capability in understanding financial texts and providing helpful investment advice, potentially enhancing the work efficiency of financial professionals. We release the model parameters to the research community.

Quantum models based on the mathematics of quantum mechanics (QM) have been developed in cognitive sciences, game theory and econophysics. In this work a generalization of credit loans is introduced by using the vector space formalism of QM. Operators for the debt, amortization, interest and periodic installments are defined and its mean values in an arbitrary orthonormal basis of the vectorial space give the corresponding values at each period of the loan. Endowing the vector space of dimension M, where M is the loan duration, with a SO(M) symmetry, it is possible to rotate the eigenbasis to obtain better schedule periodic payments for the borrower, by using the rotation angles of the SO(M) transformation. Given that a rotation preserves the length of the vectors, the total amortization, debt and periodic installments are not changed. For a general description of the formalism introduced, the loan operator relations are given in terms of a generalized Heisenberg algebra, where finite dimensional representations are considered and commutative operators are defined for the specific loan types. The results obtained are an improvement of the usual financial instrument of credit because introduce several degrees of freedom through the rotation angles, which allows to select superposition states of the corresponding commutative operators that enables the borrower to tune the periodic installments in order to obtain better benefits without changing what the lender earns.
Recent advances in large language models (LLMs) have unlocked novel opportunities for machine learning applications in the financial domain. These models have demonstrated remarkable capabilities in understanding context, processing vast amounts of data, and generating human-preferred contents. In this survey, we explore the application of LLMs on various financial tasks, focusing on their potential to transform traditional practices and drive innovation. We provide a discussion of the progress and advantages of LLMs in financial contexts, analyzing their advanced technologies as well as prospective capabilities in contextual understanding, transfer learning flexibility, complex emotion detection, etc. We then highlight this survey for categorizing the existing literature into key application areas, including linguistic tasks, sentiment analysis, financial time series, financial reasoning, agent-based modeling, and other applications. For each application area, we delve into specific methodologies, such as textual analysis, knowledge-based analysis, forecasting, data augmentation, planning, decision support, and simulations. Furthermore, a comprehensive collection of datasets, model assets, and useful codes associated with mainstream applications are presented as resources for the researchers and practitioners. Finally, we outline the challenges and opportunities for future research, particularly emphasizing a number of distinctive aspects in this field. We hope our work can help facilitate the adoption and further development of LLMs in the financial sector.
We present a new financial domain large language model, InvestLM, tuned on LLaMA-65B (Touvron et al., 2023), using a carefully curated instruction dataset related to financial investment. Inspired by less-is-more-for-alignment (Zhou et al., 2023), we manually curate a small yet diverse instruction dataset, covering a wide range of financial related topics, from Chartered Financial Analyst (CFA) exam questions to SEC filings to Stackexchange quantitative finance discussions. InvestLM shows strong capabilities in understanding financial text and provides helpful responses to investment related questions. Financial experts, including hedge fund managers and research analysts, rate InvestLM's response as comparable to those of state-of-the-art commercial models (GPT-3.5, GPT-4 and Claude-2). Zero-shot evaluation on a set of financial NLP benchmarks demonstrates strong generalizability. From a research perspective, this work suggests that a high-quality domain specific LLM can be tuned using a small set of carefully curated instructions on a well-trained foundation model, which is consistent with the Superficial Alignment Hypothesis (Zhou et al., 2023). From a practical perspective, this work develops a state-of-the-art financial domain LLM with superior capability in understanding financial texts and providing helpful investment advice, potentially enhancing the work efficiency of financial professionals. We release the model parameters to the research community.
Quantum models based on the mathematics of quantum mechanics (QM) have been developed in cognitive sciences, game theory and econophysics. In this work a generalization of credit loans is introduced by using the vector space formalism of QM. Operators for the debt, amortization, interest and periodic installments are defined and its mean values in an arbitrary orthonormal basis of the vectorial space give the corresponding values at each period of the loan. Endowing the vector space of dimension M, where M is the loan duration, with a SO(M) symmetry, it is possible to rotate the eigenbasis to obtain better schedule periodic payments for the borrower, by using the rotation angles of the SO(M) transformation. Given that a rotation preserves the length of the vectors, the total amortization, debt and periodic installments are not changed. For a general description of the formalism introduced, the loan operator relations are given in terms of a generalized Heisenberg algebra, where finite dimensional representations are considered and commutative operators are defined for the specific loan types. The results obtained are an improvement of the usual financial instrument of credit because introduce several degrees of freedom through the rotation angles, which allows to select superposition states of the corresponding commutative operators that enables the borrower to tune the periodic installments in order to obtain better benefits without changing what the lender earns.