141 papers
Neural posterior estimation for scalable and accurate inverse parameter inference in Li-ion batteries
Diagnosing the internal state of Li-ion batteries is critical for battery research, operation of real-world systems, and prognostic evaluation of remaining lifetime. By using physics-based models to perform probabilistic parameter estimation via Bayesian calibration, diagnostics can account for the uncertainty due to model fitness, data noise, and the observability of any given parameter. However, Bayesian calibration in Li-ion batteries using electrochemical data is computationally intensive even when using a fast surrogate in place of physics-based models, requiring many thousands of model evaluations. A fully amortized alternative is neural posterior estimation (NPE). NPE shifts the computational burden from the parameter estimation step to data generation and model training, reducing the parameter estimation time from minutes to milliseconds, enabling real-time applications. The present work shows that NPE calibrates parameters equally or more accurately than Bayesian calibration, and we demonstrate that the higher computational costs for data generation are tractable even in high-dimensional cases (ranging from 6 to 27 estimated parameters), but the NPE method can lead to higher voltage prediction errors. The NPE method also offers several interpretability advantages over Bayesian calibration, such as local parameter sensitivity to specific regions of the voltage curve. The NPE method is demonstrated using an experimental fast charge dataset, with parameter estimates validated against measurements of loss of lithium inventory and loss of active material. The implementation is made available in a companion repository (https://github.com/NatLabRockies/BatFIT).
2604.02520Apr 2026
View
Growth-rate distributions at stationarity
We propose new analytical tools for describing growth-rate distributions generated by stationary time-series. Our analysis shows how deviations from normality are not pathological behaviour, as suggested by some traditional views, but instead can be accounted for by clean and general statistical considerations. In contrast, strict normality is the effect of specific modelling choices. Systems characterized by stationary Gamma or heavy-tailed abundance distributions produce log-growth-rate distributions well described by a generalized logistic distribution, which can describe tent-shaped or nearly normal datasets and serves as a useful null model for these observables. These results prove that, for large enough time lags, in practice, growth-rate distributions cease to be time-dependent and exhibit finite variance. Based on this analysis, we identify some key stylized macroecological patterns and specific stochastic differential equations capable of reproducing them. A pragmatic workflow for heuristic selection between these models is then introduced. This approach is particularly useful for systems with limited data-tracking quality, where applying sophisticated inference methods is challenging.
2603.29916Mar 2026
View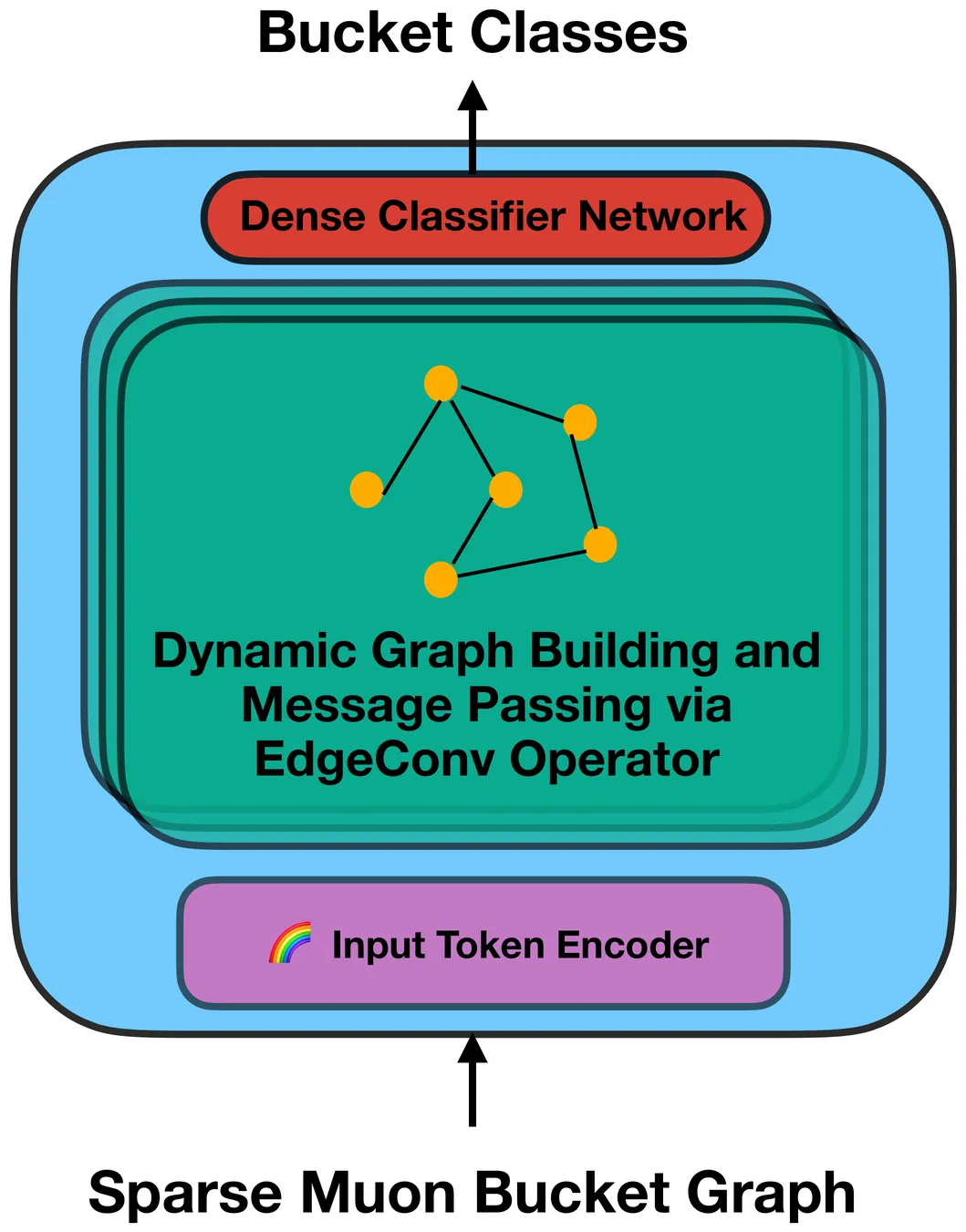
Vision Transformers and Graph Neural Networks for Charged Particle Tracking in the ATLAS Muon Spectrometer
The identification and reconstruction of charged particles, such as muons, is a main challenge for the physics program of the ATLAS experiment at the Large Hadron Collider. This task will become increasingly difficult with the start of the High-Luminosity LHC era after 2030, when the number of proton-proton collisions per bunch crossing will increase from 60 to up to 200. This elevated interaction density will also increase the occupancy within the ATLAS Muon Spectrometer, requiring more efficient and robust real-time data processing strategies within the experiment's trigger system, particularly the Event Filter. To address these algorithmic challenges, we present two machine-learning-based approaches. First, we target the problem of background-hit rejection in the Muon Spectrometer using Graph Neural Networks integrated into the non-ML baseline reconstruction chain, demonstrating a 15 % improvement in reconstruction speed (from 255 ms to 217 ms). Second, we present a proof-of-concept for end-to-end muon tracking using state-of-the-art Vision Transformer architectures, achieving ultra-fast approximate muon reconstruction in 2.3 ms on consumer-grade GPUs at 98 % tracking efficiency.
2603.25793Mar 2026
ViewBeyond the Central Limit: Universality of the Gamma Distribution from Padé-Enhanced Large Deviations
The central limit theorem provides the theoretical foundation for the universality of the normal distribution: under broad conditions, the asymptotic distribution of a sum of independent random variables approaches a Gaussian. Yet, physical systems described by positive random variable -- from earthquakes to microbial growth to epidemic spreading -- consistently exhibit gamma rather than Gaussian statistics -- what leads to field-specific mechanistic explanations that are non robust to small changes in the model details. We show that gamma distributions emerge naturally from large deviation theory when Padé approximants replace polynomial expansions of the derivative of the scaled cumulant generating function, respecting positivity constraints that the central limit theorem violates. Gamma universality thus emerges as the constrained analog of Gaussian universality, providing a mechanism-free explanation for its pervasive appearance across different disciplines.
2603.23567Mar 2026
ViewConstruction of the Global $χ^2$ Function for the Simultaneous Fitting of Correlated Energy-Dependent Cross Sections
In this paper, the global $χ^2$ function for the simultaneous fitting of correlated energy-dependent cross sections is constructed, where the correlations between the measured cross sections of different processes and/or at different center-of-mass energy points, as well as the contributions from the integrated luminosity measurement and the center-of-mass energy measurement, are taken into account.
2603.21126Mar 2026
View
VecAmpFit: vectorized amplitude-analysis fitting library
A new library VecAmpFit for multidimensional amplitude analyses in high-energy physics has been developed for an ongoing amplitude analysis at Belle II experiment. It includes a fitter performing likelihood calculation and explicitly-vectorized subprograms for amplitude implementation. The fitter supports explicit gradient calculation and simultaneous fitting of multiple data sets.
2603.20066Mar 2026
View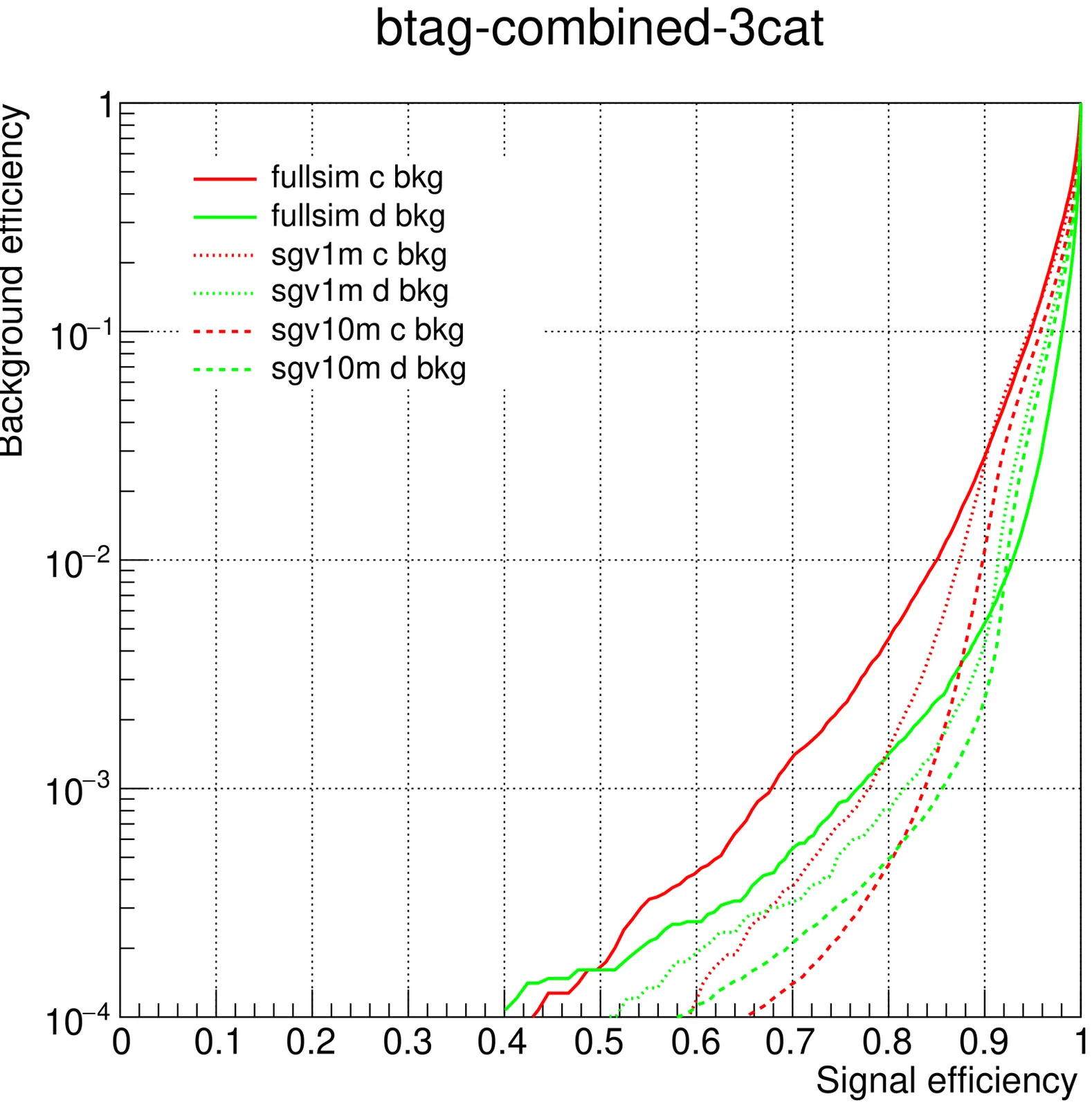
Jet flavor tagging with Particle Transformer for Higgs factories
We study the performance of the Particle Transformer (ParT) for jet flavor tagging using ILD full simulation events (1M jets) as well as fast simulation samples (10M and 1M jets). We perform 3-category ($b/c/d$), 6-category ($b/c/d/u/s/g$), and 11-category trainings (including quark--antiquark separation), incorporating multivariate hadron particle identification information from $dE/dx$ and time-of-flight. For $b$/$c$ tagging, we observe a factor of 5--10 improvement over previous BDT-based taggers, and we obtain reasonable performance for strange tagging and quark/antiquark separation. The 10M-jet fast simulation study indicates that further gains are possible with higher training statistics.
2603.18814Mar 2026
View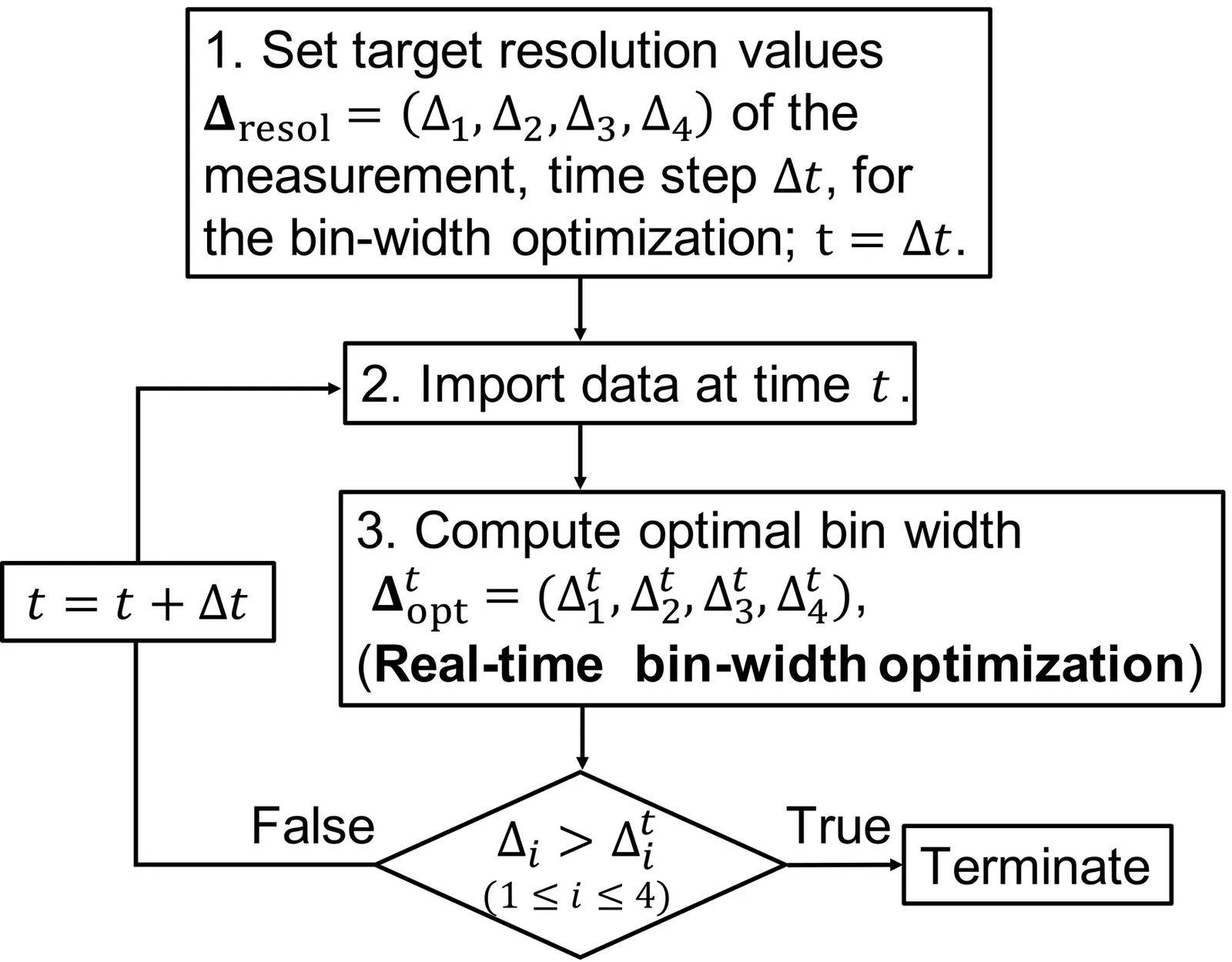
Automatic Termination Strategy of Inelastic Neutron-scattering Measurement Using Bayesian Optimization for Bin-width Selection
Currently, an excessive amount of event data is being obtained in four-dimensional inelastic neutron-scattering experiments. A method for automatic bin-width optimization of multidimensional histograms has been developed and recently validated on real inelastic neutron-scattering data. However, measuring beyond the equipment resolution leads to inefficient use of valuable beam time. To improve experimental efficiency, an automatic termination strategy is essential. We propose a Bayesian-optimization-based method to compute stopping criteria and determine whether to continue or terminate the experiment in real time. In the proposed method, the bin-width optimization is performed using Bayesian optimization to efficiently compute the optimal bin widths. The experiment is terminated when the optimal bin widths become smaller than the target resolutions. In numerical experiments using real inelastic neutron-scattering data, the optimal bin widths decrease as the number of events increases. Even the optimal bin widths for data downsampled to 1/5 are comparable with the resolutions limited by the sample size, choppers, and so on. This implies excessive measurement of the inelastic neutron experiments for the moment. Moreover, we found that Bayesian optimization can reduce the search cost to approximately 10% of an exhaustive search in our numerical experiments.
2603.16946Mar 2026
View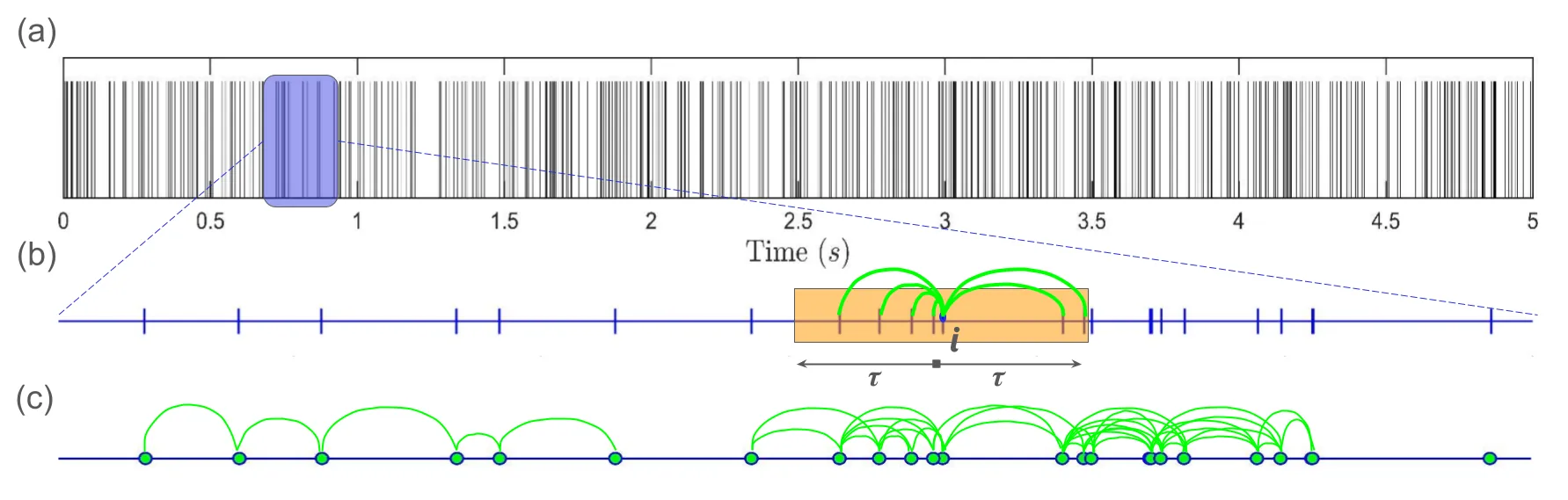
A complex network approach to characterize clustering of events in irregular time series
In complex systems, events occur at irregular intervals that inherently encode the underlying dynamics of the system. Analyzing the temporal clustering of these events reveals critical insights into the non-random patterns and the temporal evolution. Existing techniques can effectively quantify the overall clustering tendency of events using global statistical measures. However, these macroscopic approaches leave a critical gap, as they do not attempt to investigate the dynamics of individual clusters. Analyzing individual clusters is essential, as it helps comprehend the local interactions that actively drive the system dynamics, which may be obscured by global averaging, while simultaneously revealing the time scales involved. To address these limitations, we propose a complex network-based framework for analyzing clustering of events occurring at irregular intervals. The framework establishes connections using arrival times, transforming the time series into a network. Network properties are then used to quantify the clustering. Further, a community detection algorithm is used to identify individual clusters in time series. We illustrate the method by applying it to standard arrival processes, such as the Poisson process and the Markov-modulated Poisson process. To further demonstrate its scope, we apply the method to two diverse systems: the time series of droplet arrivals in turbulent flows and the R-R intervals in electrocardiogram (ECG) signals.
2603.18044Mar 2026
View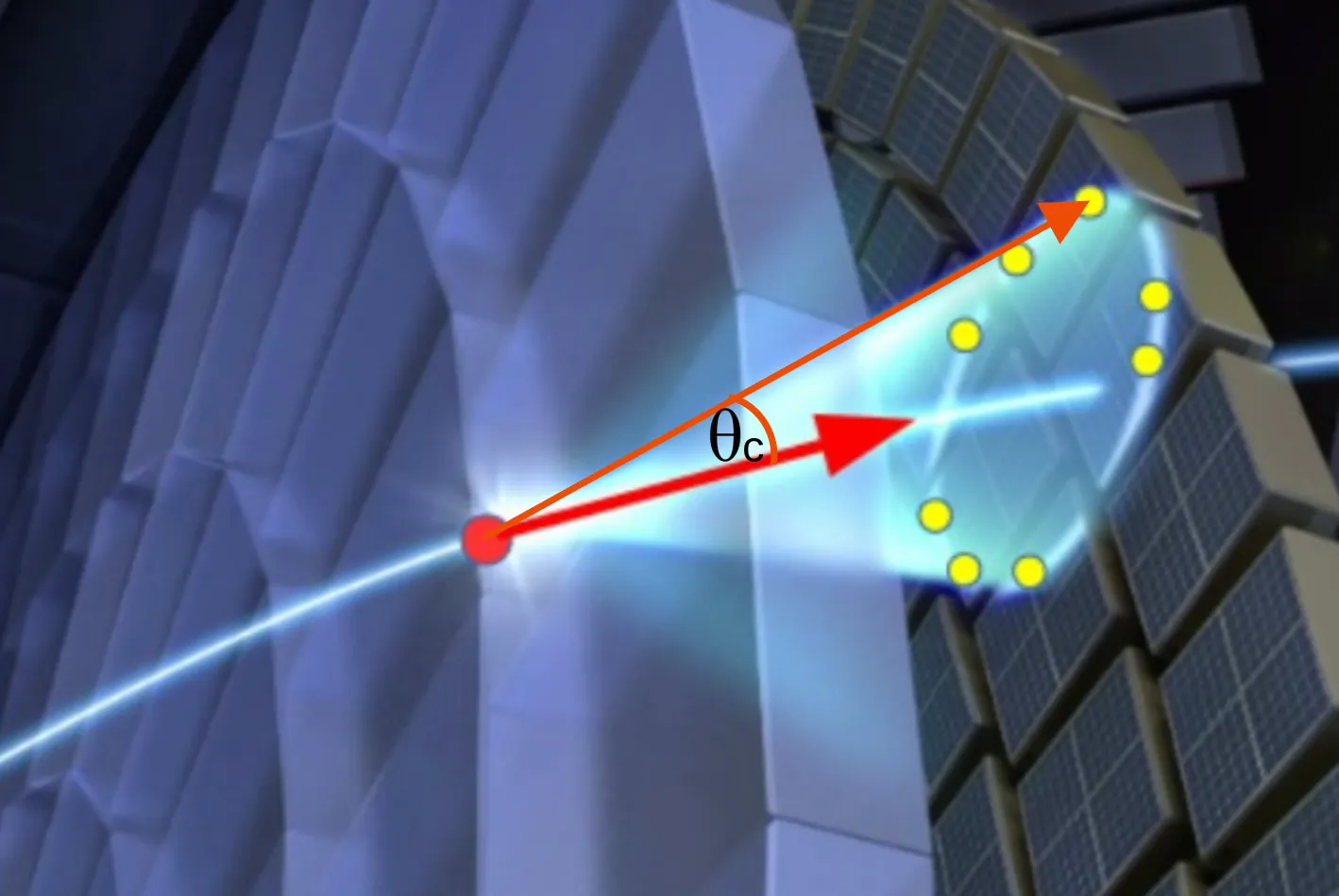
Recent advances and trends in pattern recognition and data analysis for RICH detectors
Ring Imaging Cherenkov (RICH) detectors are a key component of particle identification systems in many particle, nuclear and astroparticle physics experiments. Their ultimate performance depends not only on detector design and hardware implementation, but also crucially on the quality of pattern recognition and data analysis algorithms used to reconstruct Cherenkov ring images and to perform particle identification. In recent years, significant advances have been made both in traditional reconstruction approaches, such as likelihood-based methods and Hough-transform techniques, and in the application of modern machine learning tools. This contribution reviews the current state of RICH reconstruction algorithms, highlights representative use cases from operating experiments, and discusses emerging trends including global particle identification strategies and generative machine learning approaches for fast simulation and reconstruction.
2603.13000Mar 2026
View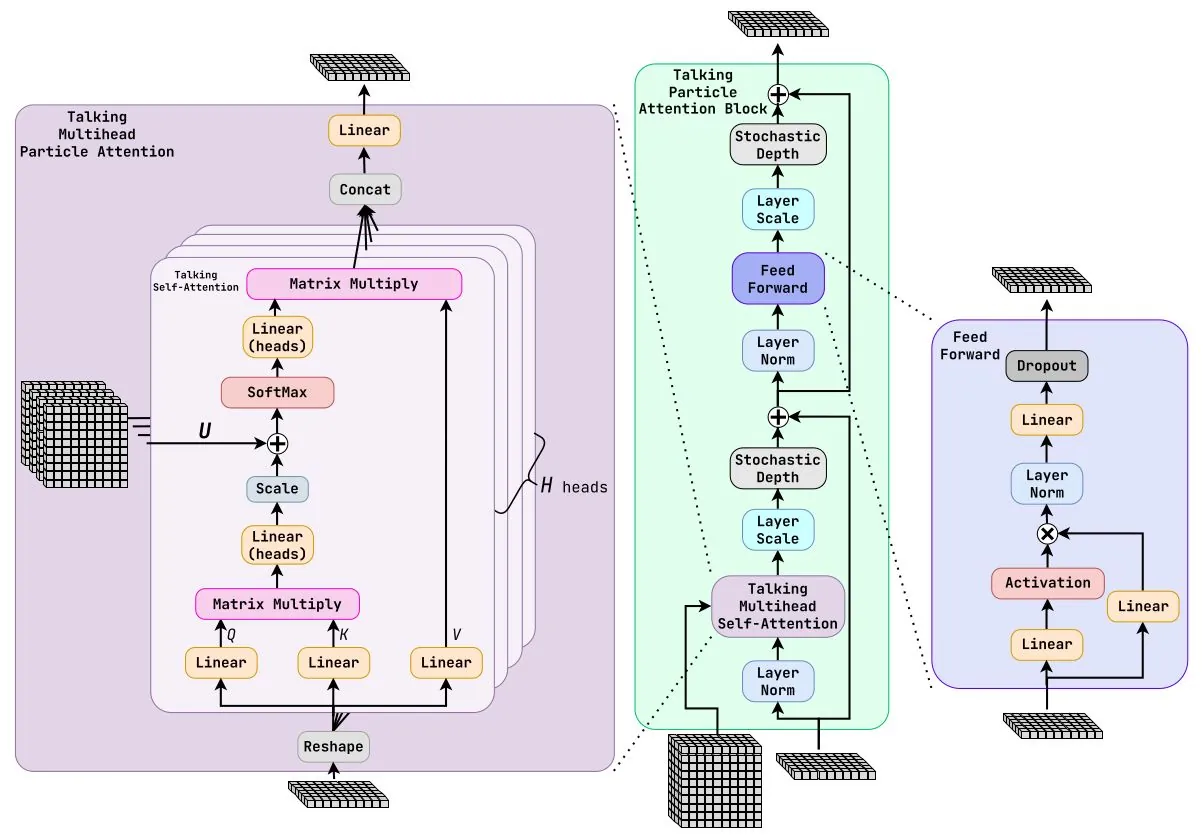
Classifying hadronic objects in ATLAS with ML/AI algorithms
The identification of hadronic final states plays a crucial role in the physics programme of the ATLAS Experiment at the CERN LHC. Sophisticated artificial intelligence (AI) algorithms are employed to classify jets according to their origin, distinguishing between quark- and gluon-initiated jets, and identifying hadronically decaying heavy objects such as W bosons and top quarks. This contribution summarises recent developments in constituent-based tagging architectures, including graph neural networks (GNNs) and transformer-based approaches, their performance in simulated and real data, and future perspectives towards data-driven optimisation and model-independent tagging strategies.
2603.12306Mar 2026
View
Learning the Standard Model Manifold: Bayesian Latent Diffusion for Collider Anomaly Detection
We propose a physics-informed anomaly detection framework for collider data based on a Bayesian latent diffusion model. Our method combines a probabilistic encoder with diffusion dynamics in the latent space, allowing for stable and flexible density estimation while explicitly enforcing physics constraints, such as mass decorrelation and regularization of latent correlations. We train and test the model on simulated LHC jet data and evaluate its performance using seed-averaged ROC curves together with discovery-oriented metrics. Through a series of ablation studies, we show that the diffusion process, Bayesian regularization, and physics-motivated loss terms each contribute in a complementary way: they help stabilize training and improve generalization, even when the gains in peak performance are moderate. Overall, our results emphasize the importance of incorporating both uncertainty estimates and physics consistency when building reliable anomaly detection methods for new Physics searches in high-energy physics.
2603.06754Mar 2026
ViewData Unfolding: From Problem Formulation to Result Assessment
Experimental data in particle and nuclear physics, particle astrophysics, and radiation protection dosimetry are collected using experimental facilities that consist of a complex system of sensors, electronics, and software. Measured spectra or cross sections are considered as Probability Density Functions (PDFs) that deviate from true PDFs due to resolution, bias, and efficiency effects. Unfolding is viewed as a procedure for estimating an unknown true PDF. Reliable estimates of the true PDF are necessary for testing theoretical models, comparing results from different experiments, and combining results from various research endeavors. Both external and internal quality assessment methods can be applied for this purpose. In some cases, external criteria exist to evaluate deconvolution quality. A typical example is the deconvolution of a blurred image, where the sharpness of the restored image serves as an indicator of quality. However, defining such external criteria can be challenging, particularly when a measurement has not been performed previously. This paper discusses various internal criteria for assessing the quality of the results independently of external information, as well as factors that influence the quality of the unfolded distribution.
2603.03168Mar 2026
View
GNN For Muon Particle Momentum estimation
Due to a high rate of overall data generation relative to data generation of interest, the CMS experiment at the Large Hadron Collider uses a combination of hardware- and software-based triggers to select data for capture. Accurate momentum calculation is crucial for improving the efficiency of the CMS trigger systems, enabling better classification of low- and high- momentum particles and reducing false triggers. This paper explores the use of Graph Neural Networks (GNNs) for the momentum estimation task. We present two graph construction methods and apply a GNN model to leverage the inherent graph structure of the data. In this paper firstly, we show that the GNN outperforms traditional models like TabNet in terms of Mean Absolute Error (MAE), demonstrating its effectiveness in capturing complex dependencies within the data. Secondly we show that the dimension of the node feature is crucial for the efficiency of GNN.
2603.06675Mar 2026
View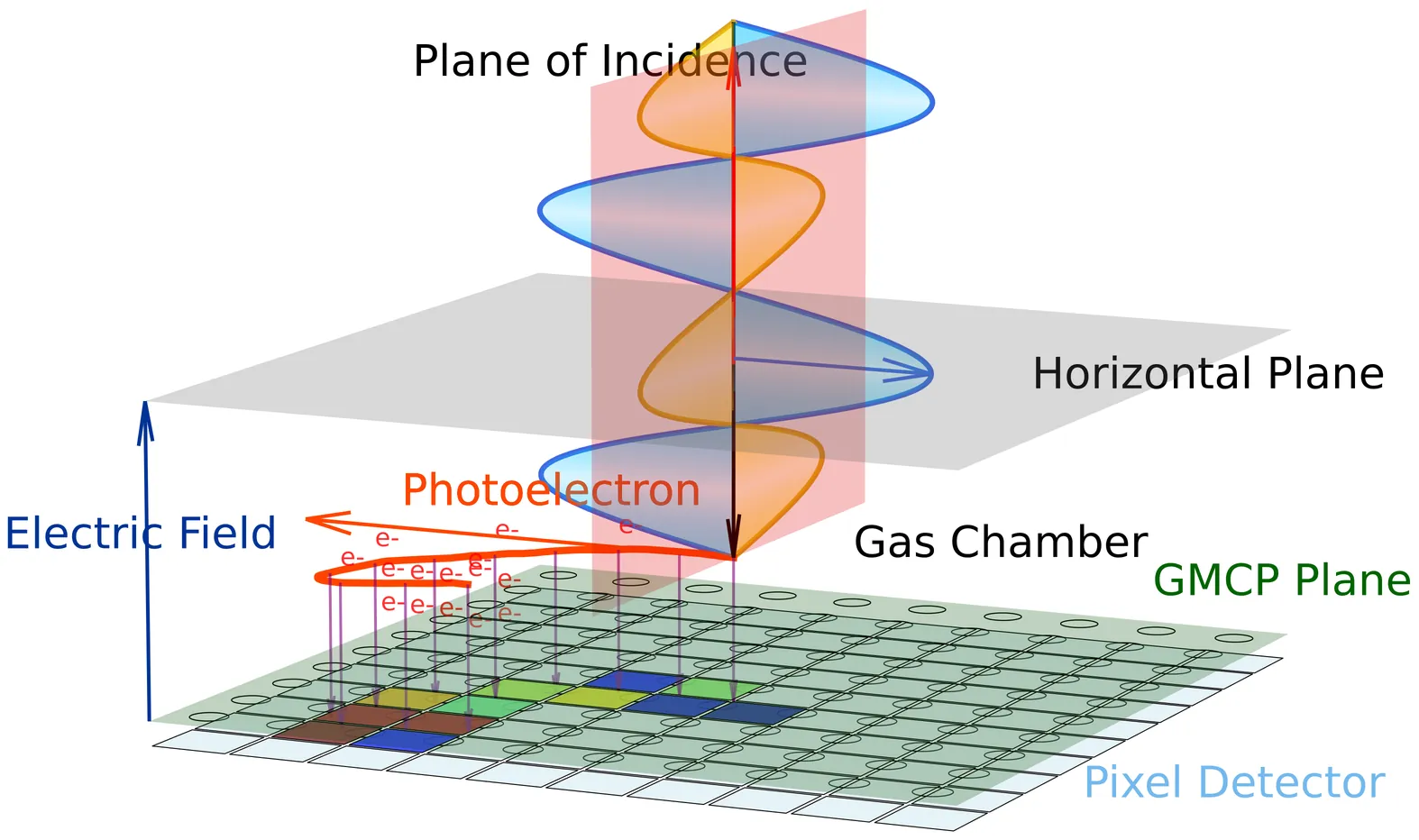
Structured generalized sliced Wasserstein distance for keV X-ray polarization analysis with Gas Pixel Detector
Because of the special angular distribution of excited electrons by the photoelectric effect, the Gas Pixel Detector (GPD) is effective in measuring keV X-ray polarization of astrophysical events (e.g. gamma-ray bursts), by capturing ionization tracks of excited electrons as polarized images. Traditionally, the emission angles of photoelectrons are extracted from polarized images first, and statistics are then performed on these angles to infer the polarization direction and intensity. However, observation with the wide field of view requires the incident angle of X-rays not directly attainable through the traditional analysis process. In this paper, we propose using the generalized sliced Wasserstein (GSW) distance, projected by neural networks with random weights, as a completely data-driven approach to analyze X-ray polarization based on two-dimensional polarized images. We find the structures of the randomized neural networks matter when focusing on different aspects of the polarized images, and take advantage of the discrimination abilities by different neural network structures. The proposed method, named the structured GSW distance, successfully distinguishes polarized images with different configurations of incident angles and polarization directions. Furthermore, we build a simplified statistical model based on the von Mises distribution and the circular Wasserstein distance and compare the model against the proposed method, showing their high consistency. The computational method reported in this paper may benefit GPD-based polarimetry in astroparticle experiments and also pattern analysis on raw data from pixel detectors.
2603.03384Mar 2026
View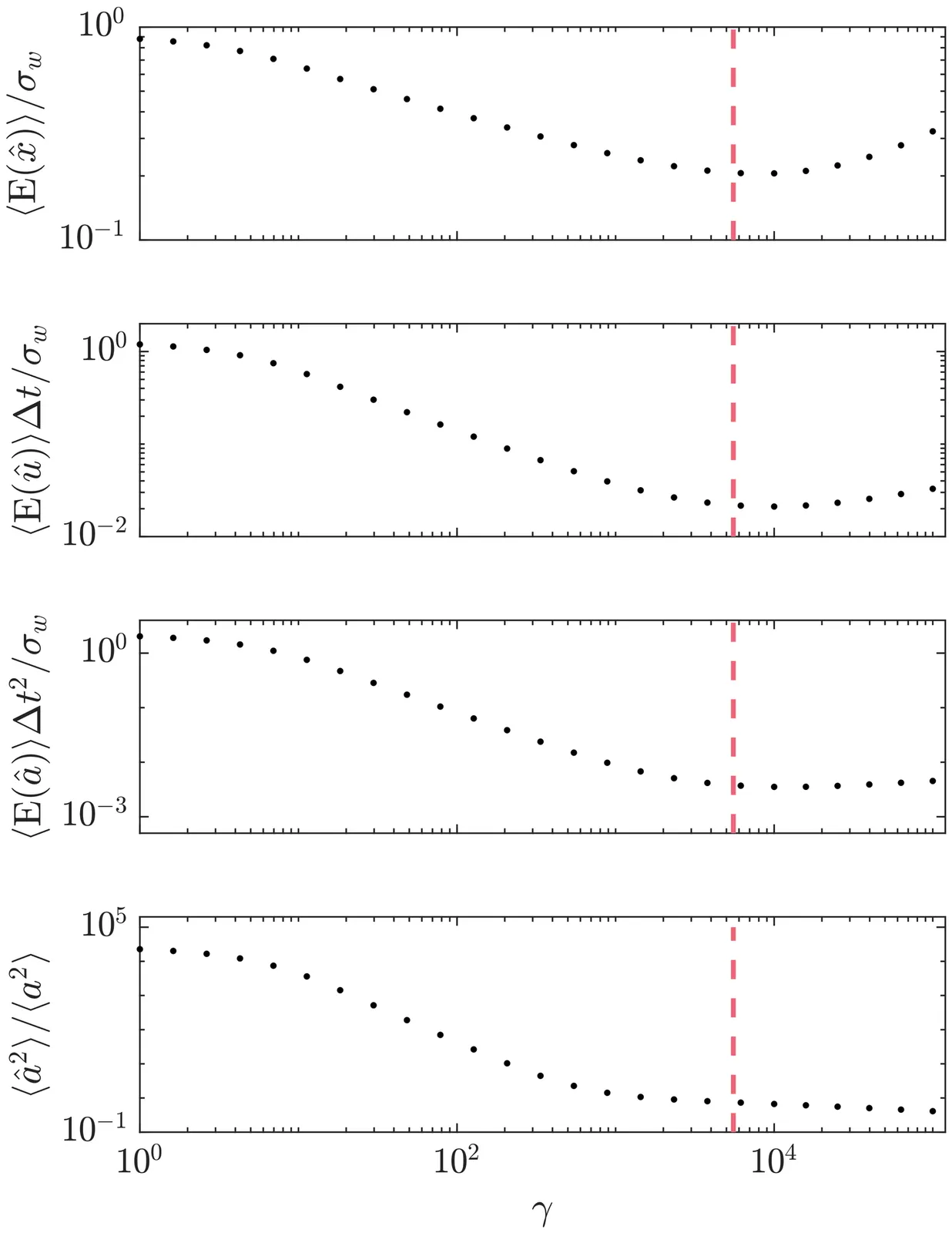
Maximum Likelihood Particle Tracking in Turbulent Flows via Sparse Optimization
Lagrangian particle tracking is essential for characterizing turbulent flows, but inferring particle acceleration from inherently noisy position data remains a significant challenge. Fluid particles in turbulence experience extreme, intermittent accelerations, resulting in heavy-tailed probability density functions (PDFs) that deviate strongly from Gaussian predictions. Existing filtering techniques, such as Gaussian kernels and penalized B-splines, implicitly assume Gaussian-distributed jerk, thereby penalizing sparse, high-magnitude acceleration changes and artificially suppressing the intermittent tails. In this work, we develop a novel maximum likelihood estimation (MLE) framework that explicitly accounts for this non-Gaussian intermittency. By formulating a modified Gaussian process to model the random incremental forcing, we introduce a sparse optimization scheme utilizing a convex 1-norm relaxation. To overcome the numerical stiffness associated with high-order difference operators, the problem is efficiently solved using an iteratively reweighted least squares (IRLS) algorithm. The proposed filter is evaluated against direct numerical simulation (DNS) data of homogeneous, isotropic turbulence (Re approx. 310). Results demonstrate that the IRLS approach consistently outperforms state-of-the-art discrete MLE, continuous MLE, and B-spline methods, yielding systematic reductions in root-mean-squared error (RMSE) across position, velocity, and acceleration. Most importantly, the proposed framework succeeds in better recovering the heavy-tailed statistical structure of both acceleration and acceleration differences (jerk) across temporal scales, preserving the physical intermittency characteristic of high-Reynoldsnumber turbulent flows that baseline methods severely attenuate.
2602.22257Feb 2026
View
Symmetry-Constrained Forecasting of Periodically Correlated Energy Processes
Time series in energy systems, such as solar irradiance, wind speed, or electrical load, are characterized by strong diurnal and seasonal periodicities. Accurate forecasting requires accounting for time varying statistical properties that stationary or classical persistence models cannot capture. \cyr{A family of analytical forecasting operators for cyclostationary processes is introduced, extending persistence through a closed form coefficient $\tildeλ(t,τ)=\tfrac{1}{2}\bigl(1+ρ(t,τ)\bigr)$, where $ρ(t,τ)$ denotes the local correlation between the current observation and its phase aligned counterpart}. This formulation preserves periodic variance and covariance, achieving a symmetry induced reduction of effective degrees of freedom. The resulting operator defines a training free analytical limit of persistence under periodic non stationarity. Validation on synthetic cyclostationary signals and empirical renewable energy datasets demonstrates consistent accuracy gains over classical persistence, particularly at multi hour horizons. By embedding temporal symmetry into the prediction process, the framework provides a physically interpretable, reproducible, and computationally minimal baseline for forecasting periodic processes across energy and complex systems.
2602.18949Feb 2026
View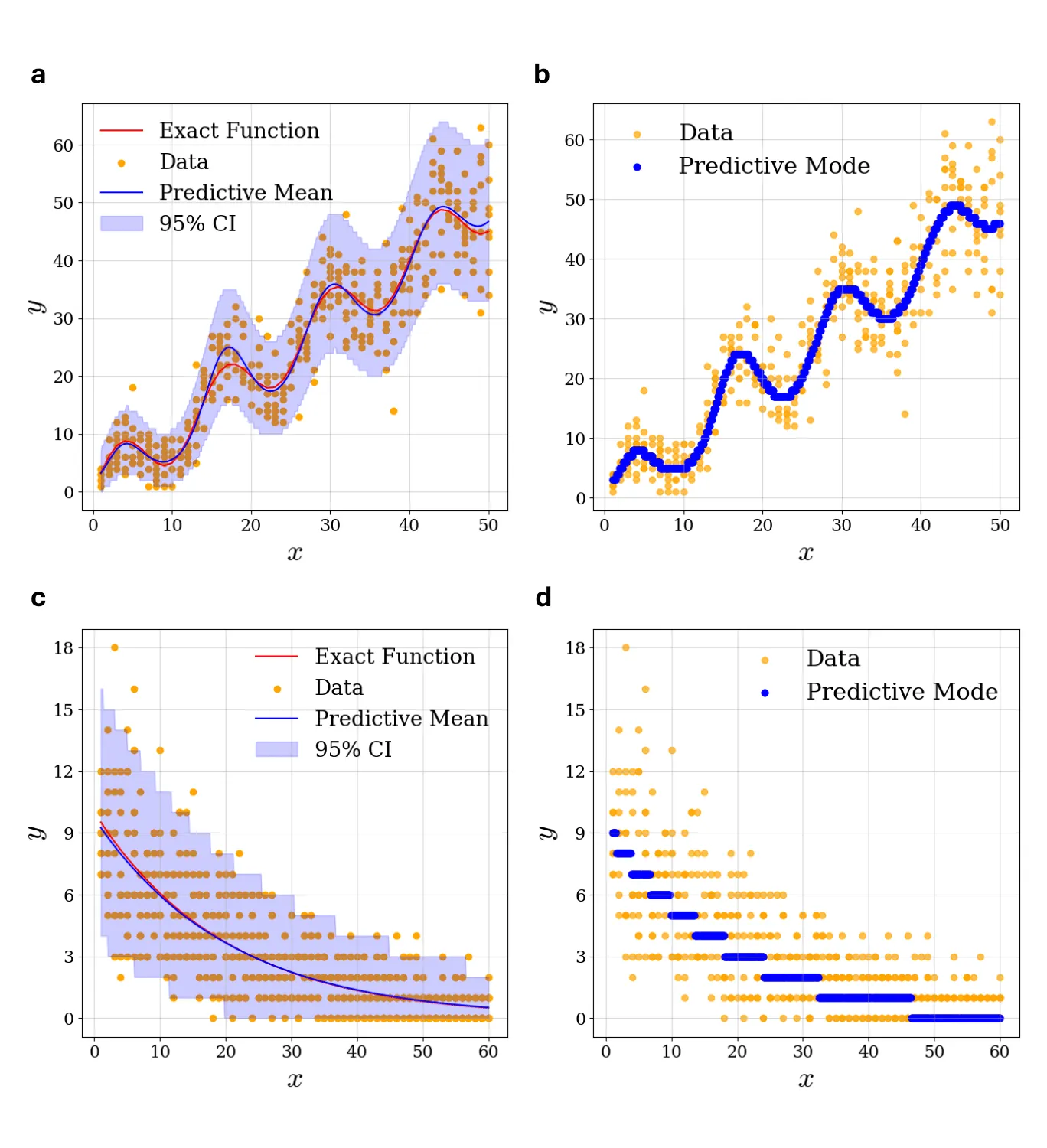
Poisson Log-Normal Process for Count Data Prediction
Modeling count data is important in physics and other scientific disciplines, where measurements often involve discrete, non-negative quantities such as photon or neutrino detection events. Traditional parametric approaches can be trained to generate integer-count predictions but may struggle with capturing complex, non-linear dependencies often observed in the data. Gaussian process (GP) regression provides a robust non-parametric alternative to modeling continuous data; however, it cannot generate integer outputs. We propose the Poisson Log-Normal (PoLoN) process, a framework that employs GP to model Poisson log-rates. As in GP regression, our approach relies on the correlations between data points captured via GP kernel structure rather than explicit functional parameterizations. We demonstrate that the PoLoN predictive distribution is Poisson-LogNormal and provide an algorithm for optimizing kernel hyperparameters. Furthermore, we adapt the PoLoN approach to the problem of detecting weak localized signals superimposed on a smoothly varying background - a task of considerable interest in many areas of science and engineering. Our framework allows us to predict the strength, location and width of the detected signals. We evaluate PoLoN's performance using both synthetic and real-world datasets, including the open dataset from CERN which was used to detect the Higgs boson at the Large Hadron Collider. Our results indicate that the PoLoN process can be used as a non-parametric alternative for analyzing, predicting, and extracting signals from integer-valued data.
2602.05926Feb 2026
View
Comparison of Image Processing Models in Quark Gluon Jet Classification
We present a comprehensive comparison of convolutional and transformer-based models for distinguishing quark and gluon jets using simulated jet images from Pythia 8. By encoding jet substructure into a three-channel representation of particle kinematics, we evaluate the performance of convolutional neural networks (CNNs), Vision Transformers (ViTs), and Swin Transformers (Swin-Tiny) under both supervised and self-supervised learning setups. Our results show that fine-tuning only the final two transformer blocks of the Swin-Tiny model achieves the best trade-off between efficiency and accuracy, reaching 81.4% accuracy and an AUC (area under the ROC curve) of 88.9%. Self-supervised pretraining with Momentum Contrast (MoCo) further enhances feature robustness and reduces the number of trainable parameters. These findings highlight the potential of hierarchical attention-based models for jet substructure studies and for domain transfer to real collision data.
2602.00141Jan 2026
View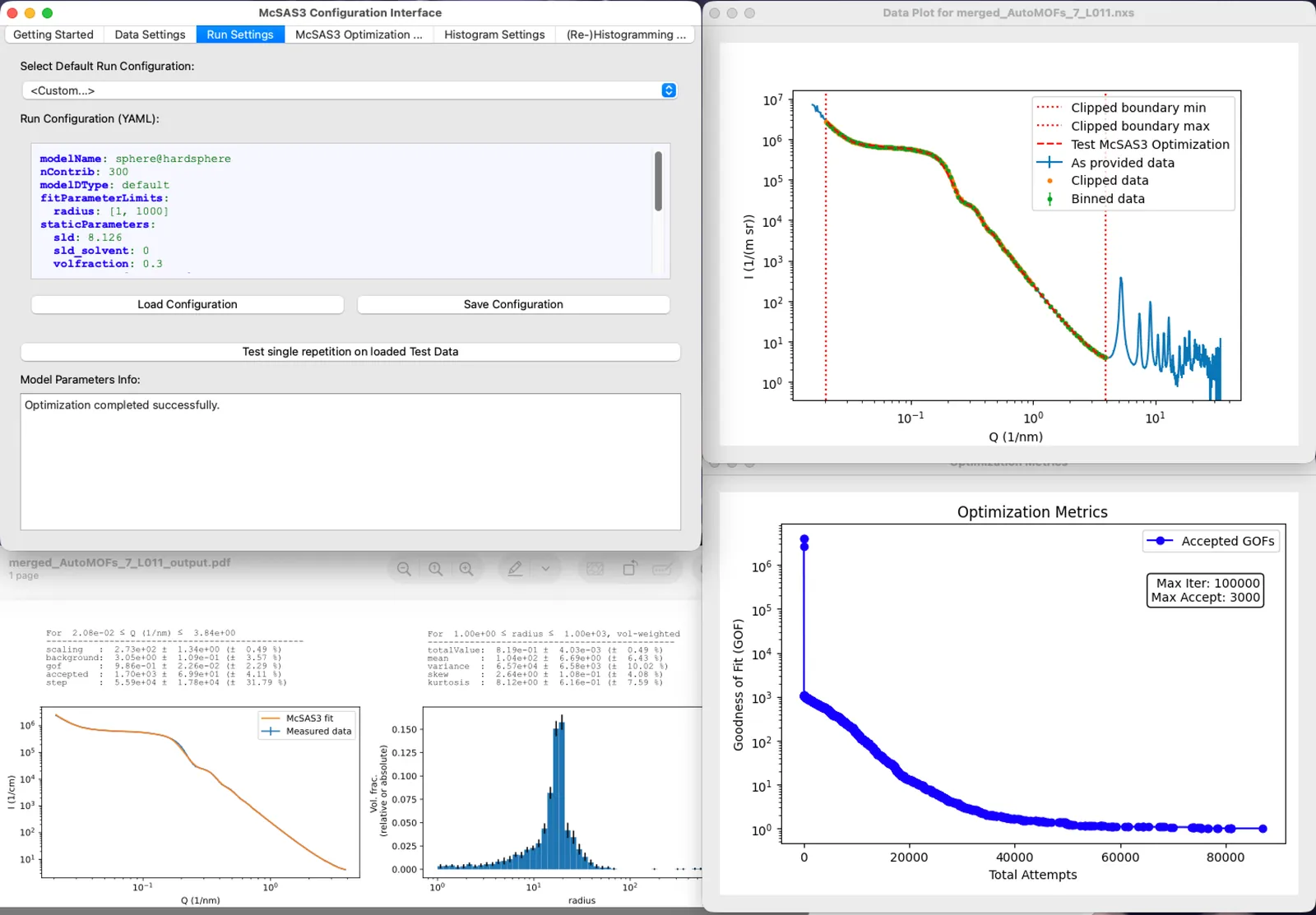
McSAS3: improved Monte Carlo small-angle scattering analysis software for dilute and dense scatterers
McSAS3 is the refactored successor to the original McSAS Monte Carlo small-angle scattering analysis software. It is intended to be integrated in automated data processing pipelines, but can also be used to process individual (batches of) scattering data. McSAS3 comes with a graphical user interface (McSAS3GUI), complete with guides, examples and videos. McSAS3GUI will help to generate and test the three configuration files that McSAS3 needs for data read-in, Monte Carlo optimization and histogramming. The user interface can also be used to process individual files or batches, and can be augmented with machine-specific use templates. The Monte Carlo (MC) approach is able to fit most practical scattering patterns extremely well, resulting in form-free model parameter distributions. Theoretically, these can be distributions on any model parameter, but in practice the MC-optimized parameter is usually a (volume-weighted) size distribution, in absolute volume fraction for absolute-scaled data.
2601.18659Jan 2026
ViewPage 1 of 8