7,848 papers
ProgramBench: Can Language Models Rebuild Programs From Scratch?
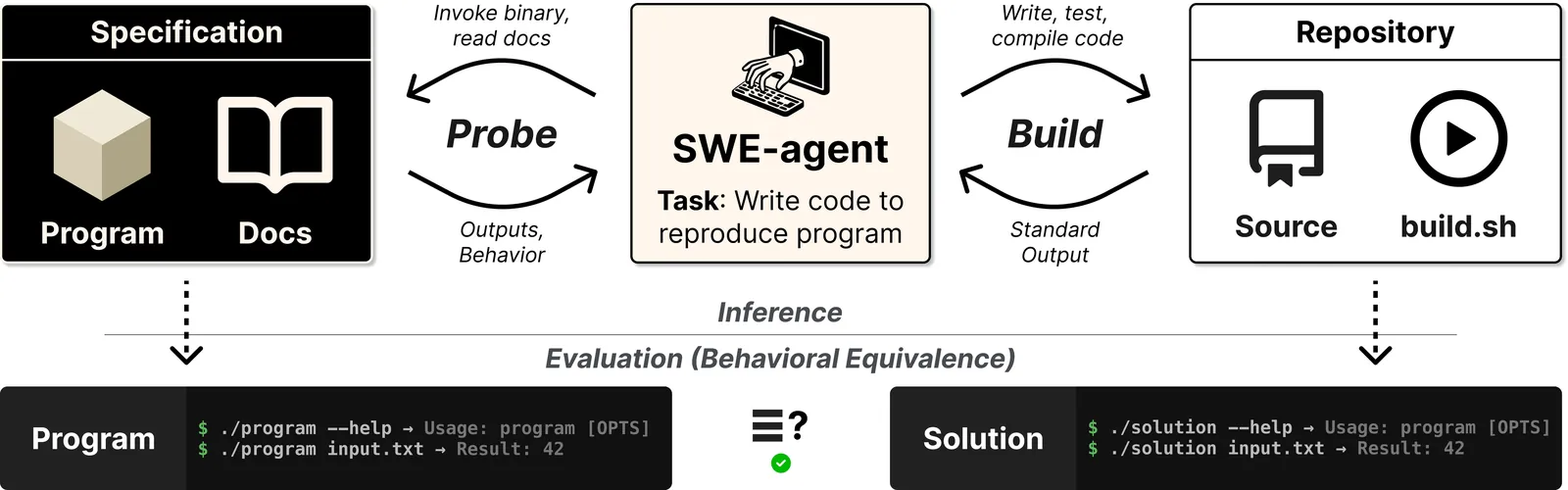
Turning ideas into full software projects from scratch has become a popular use case for language models. Agents are being deployed to seed, maintain, and grow codebases over extended periods with minimal human oversight. Such settings require models to make high-level software architecture decisions. However, existing benchmarks measure focused, limited tasks such as fixing a single bug or developing a single, specified feature. We therefore introduce ProgramBench to measure the ability of software engineering agents to develop software holisitically. In ProgramBench, given only a program and its documentation, agents must architect and implement a codebase that matches the reference executable's behavior. End-to-end behavioral tests are generated via agent-driven fuzzing, enabling evaluation without prescribing implementation structure. Our 200 tasks range from compact CLI tools to widely used software such as FFmpeg, SQLite, and the PHP interpreter. We evaluate 9 LMs and find that none fully resolve any task, with the best model passing 95\% of tests on only 3\% of tasks. Models favor monolithic, single-file implementations that diverge sharply from human-written code.
2605.03546May 2026
View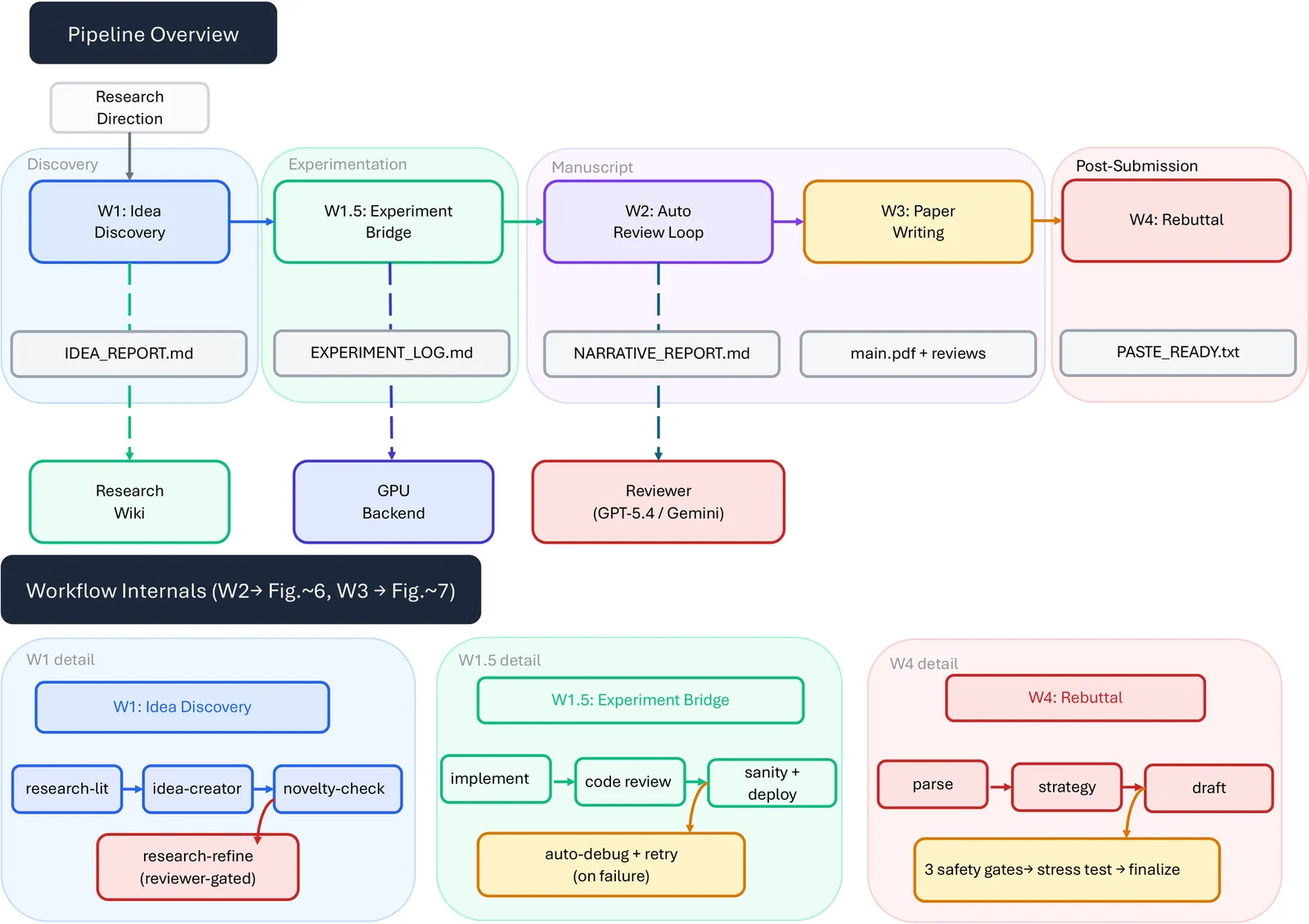
ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
This report describes ARIS (Auto-Research-in-sleep), an open-source research harness for autonomous research, including its architecture, assurance mechanisms, and early deployment experience. The performance of agent systems built on LLMs depends on both the model weights and the harness around them, which governs what information to store, retrieve, and present to the model. For long-horizon research workflows, the central failure mode is not a visible breakdown but a plausible unsupported success: a long-running agent can produce claims whose evidential support is incomplete, misreported, or silently inherited from the executor's framing. Therefore, we present ARIS as a research harness that coordinates machine-learning research workflows through cross-model adversarial collaboration as a default configuration: an executor model drives forward progress while a reviewer from a different model family is recommended to critique intermediate artifacts and request revisions. ARIS has three architectural layers. The execution layer provides more than 65 reusable Markdown-defined skills, model integrations via MCP, a persistent research wiki for iterative reuse of prior findings, and deterministic figure generation. The orchestration layer coordinates five end-to-end workflows with adjustable effort settings and configurable routing to reviewer models. The assurance layer includes a three-stage process for checking whether experimental claims are supported by evidence: integrity verification, result-to-claim mapping, and claim auditing that cross-checks manuscript statements against the claim ledger and raw evidence, as well as a five-pass scientific-editing pipeline, mathematical-proof checks, and visual inspection of the rendered PDF. A prototype self-improvement loop records research traces and proposes harness improvements that are adopted only after reviewer approval.
2605.03042May 2026
ViewVulnerability Identification by Harnessing Inter-connected Multi-Source Information
The utilization of third-party open-source libraries is widespread in modern software development. Due to the dependency relationships, vulnerabilities within open-source libraries pose significant security threats to downstream software. However, the library vulnerabilities are usually implicitly reported and patched, without explicit notification to dependent software, leaving the downstream software vulnerable to potential attacks. Existing research efforts primarily focus on identifying vulnerability patches according to bug reports, commit messages, or code changes, overlooking the rich semantic connections among various sources of information. In this paper, our main insight is that various sources of information, including the vulnerability descriptions (e.g., bug reports) and its fixing strategies (e.g., commit messages and code changes), are highly interconnected. They express the high-level semantic information about the symptom, root cause and fixing strategies of the bugs. Hence, we propose an approach that involves training an AI model to integrate multiple sources, thus enhancing the effectiveness of vulnerability identification and vulnerability type classification. We introduce VPFinder, a tool that utilizes multi-head attention mechanisms to extract high-level semantic information from diverse sources. Evaluation results demonstrate that VPFinder achieves remarkable 0.941 F1-score in vulnerability identification task and 0.610 F1-score in vulnerability type classification task, outperforming state-of-the-art approaches by 5.4%.
2604.24028Apr 2026
View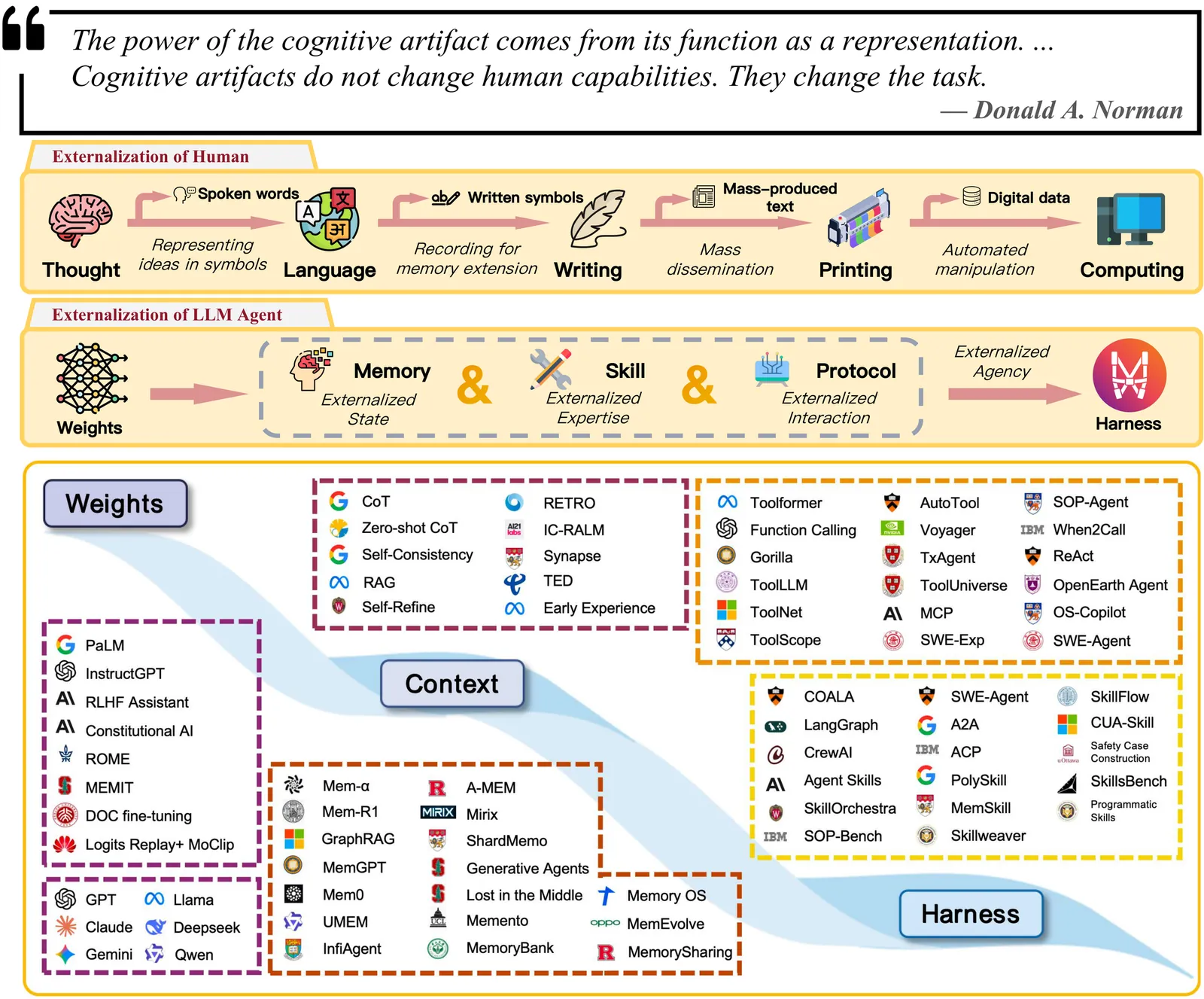
Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering
Large language model (LLM) agents are increasingly built less by changing model weights than by reorganizing the runtime around them. Capabilities that earlier systems expected the model to recover internally are now externalized into memory stores, reusable skills, interaction protocols, and the surrounding harness that makes these modules reliable in practice. This paper reviews that shift through the lens of externalization. Drawing on the idea of cognitive artifacts, we argue that agent infrastructure matters not merely because it adds auxiliary components, but because it transforms hard cognitive burdens into forms that the model can solve more reliably. Under this view, memory externalizes state across time, skills externalize procedural expertise, protocols externalize interaction structure, and harness engineering serves as the unification layer that coordinates them into governed execution. We trace a historical progression from weights to context to harness, analyze memory, skills, and protocols as three distinct but coupled forms of externalization, and examine how they interact inside a larger agent system. We further discuss the trade-off between parametric and externalized capability, identify emerging directions such as self-evolving harnesses and shared agent infrastructure, and discuss open challenges in evaluation, governance, and the long-term co-evolution of models and external infrastructure. The result is a systems-level framework for explaining why practical agent progress increasingly depends not only on stronger models, but on better external cognitive infrastructure.
2604.08224Apr 2026
View
StatsClaw: An AI-Collaborative Workflow for Statistical Software Development
Translating statistical methods into reliable software is a persistent bottleneck in quantitative research. Existing AI code-generation tools produce code quickly but cannot guarantee faithful implementation -- a critical requirement for statistical software. We introduce StatsClaw, a multi-agent architecture for Claude Code that enforces information barriers between code generation and validation. A planning agent produces independent specifications for implementation, simulation, and testing, dispatching them to separate agents that cannot see each other's instructions: the builder implements without knowing the ground-truth parameters, the simulator generates data without knowing the algorithm, and the tester validates using deterministic criteria. We describe the approach, demonstrate it end-to-end on a probit estimation package, and evaluate it across three applications to the authors' own R and Python packages. The results show that structured AI-assisted workflows can absorb the engineering overhead of the software lifecycle while preserving researcher control over every substantive methodological decision.
2604.04871Apr 2026
View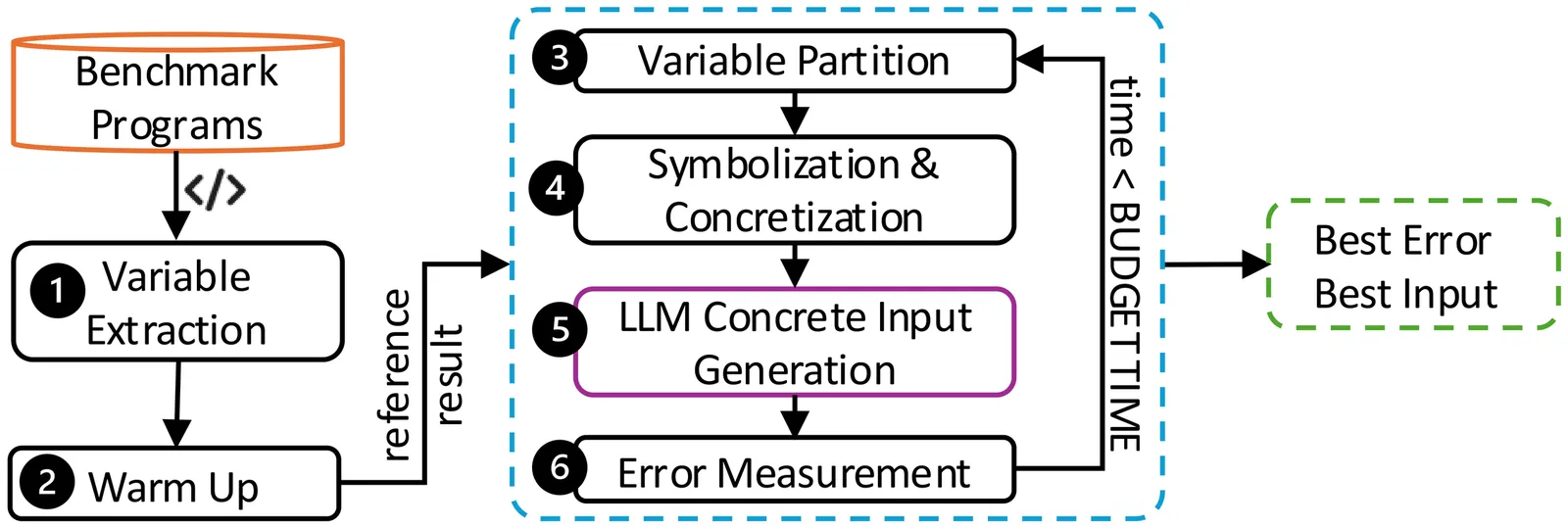
Assessing Large Language Models for Stabilizing Numerical Expressions in Scientific Software
Scientific software relies on high-precision computation, yet finite floating-point representations can introduce precision errors that propagate in safety-critical domains. Despite the growing use of large language models (LLMs) in scientific applications, their reliability in handling floating-point numerical stability has not been systematically evaluated. This paper evaluates LLMs' reasoning on high-precision numerical computation through two numerical stabilization tasks: (1) detecting instability in numerical expressions by generating error-inducing inputs (detection), and (2) rewriting expressions to improve numerical stability (stabilization). Using popular numerical benchmarks, we assess six LLMs on nearly 2,470 numerical structures, including nested conditionals, high-precision literals, and multi-variable arithmetic. Our results show that LLMs are equally effective as state-of-the-art traditional approaches in detecting and stabilizing numerically unstable computations. More notably, LLMs outperform baseline methods precisely where the latter fail: in 17.4% (431) of expressions where the baseline does not improve accuracy, LLMs successfully stabilize 422 (97.9%) of them, and achieve greater stability than the baseline across 65.4% (1,615) of all expressions. However, LLMs struggle with control flow and high-precision literals, consistently removing such structures rather than reasoning about their numerical implications, whereas they perform substantially better on purely symbolic expressions. Together, these findings suggest that LLMs are effective at stabilizing expressions that classical techniques cannot, yet struggle when exact numerical magnitudes and control flow semantics must be precisely reasoned about, as such concrete patterns are rarely encountered during training.
2604.04854Apr 2026
View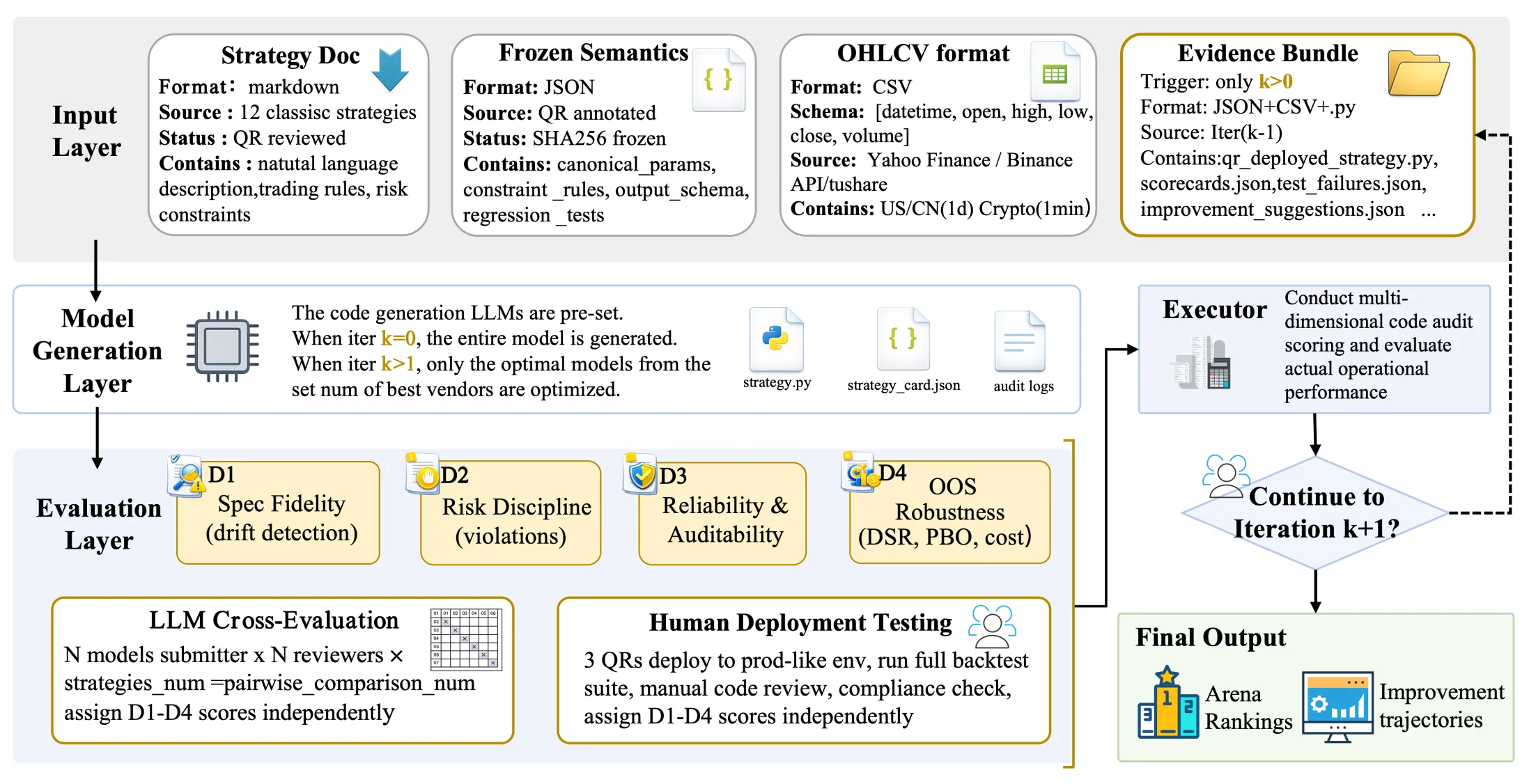
SysTradeBench: An Iterative Build-Test-Patch Benchmark for Strategy-to-Code Trading Systems with Drift-Aware Diagnostics
Large language models (LLMs) are increasingly used as quantitative research copilots to translate natural-language strategy specifications into executable trading code. Yet most existing evaluations either focus on static financial knowledge or summarize performance with a single profitability metric, leaving a gap for benchmarking strategy-to-code trading systems as governed, auditable software. We introduce SysTradeBench (SysTB), an iterative build-test-patch benchmark that evaluates LLM-generated trading systems under drift-aware diagnostics. Given a standardized Base Strategy Doc and frozen semantics, each model must produce (i) a strategy card, (ii) executable code, and (iii) mandatory audit logs. A sandboxed harness runs determinism and anti-leakage checks, detects rule drift across iterations, and returns evidence bundles to support constrained patches. SysTradeBench reports multi-dimensional scorecards for spec fidelity, risk discipline, reliability, and out-of-sample robustness indicators, together with cost-effectiveness signals. We evaluate 17 models across 12 strategies. Top models achieve validity above 91.7 percent with strong aggregate scores, but evidence-driven iteration also induces code convergence by Iter2. These findings suggest that LLM iteration complements rather than replaces human quantitative researcher governance: LLMs excel at rapid prototyping and shallow bug fixes, while human oversight remains essential for critical strategies requiring solution diversity and ensemble robustness.
2604.04812Apr 2026
View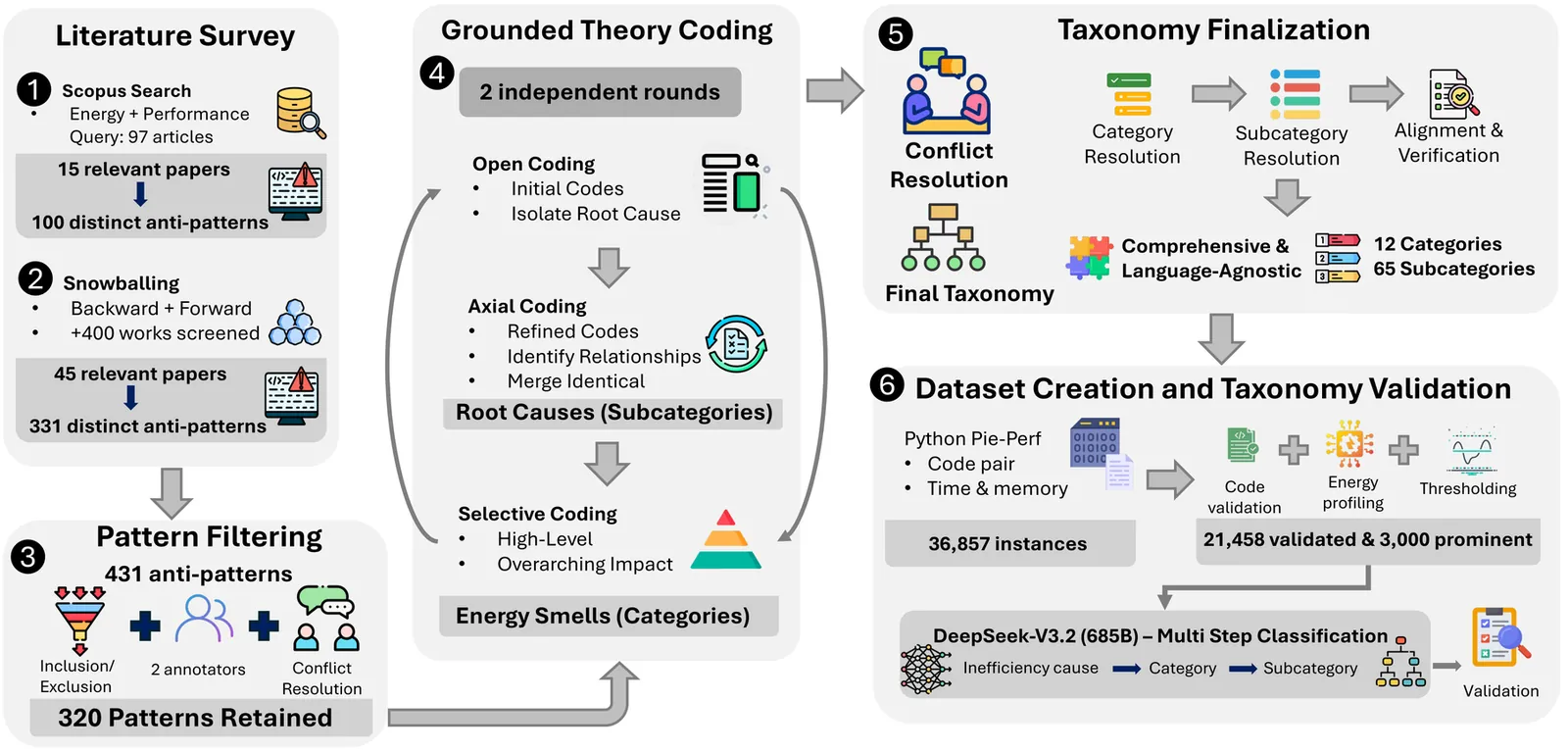
A Validated Taxonomy on Software Energy Smells
As software proliferates across domains, its aggregate energy footprint has become a major concern. To reduce software's growing environmental footprint, developers need to identify and refactor energy smells: source code implementations, design choices, or programming practices that lead to inefficient use of computing resources. Existing catalogs of such smells are either domain-specific, limited to performance anti-patterns, lack fine-grained root cause classification, or remain unvalidated against measured energy data. In this paper, we present a comprehensive, language-agnostic, taxonomy of software energy smells. Through a systematic literature review of 60 papers and exhaustive snowballing, we coded 320 inefficiency patterns into 12 primary energy smells and 65 root causes mapped to the primary smells. To empirically validate this taxonomy, we profile over 21,000 functionally equivalent Python code pairs for energy, time, and memory, and classified the top 3000 pairs by energy difference using a multi-step LLM pipeline, mapping 55 of the 65 root causes to real code. The analysis reveals that 71% of samples exhibit multiple co-occurring smells, memory-related smells yield the highest per-fix energy savings, while power draw variation across patterns confirms that energy optimization cannot be reduced to performance optimization alone. Along with the taxonomy, we release the labeled dataset, including energy profiles and reasoning traces, to the community. Together, they provide a shared vocabulary, actionable refactoring guidelines, and an empirical foundation for energy smell detection, energy-efficient code generation, and green software engineering at large.
2604.04809Apr 2026
View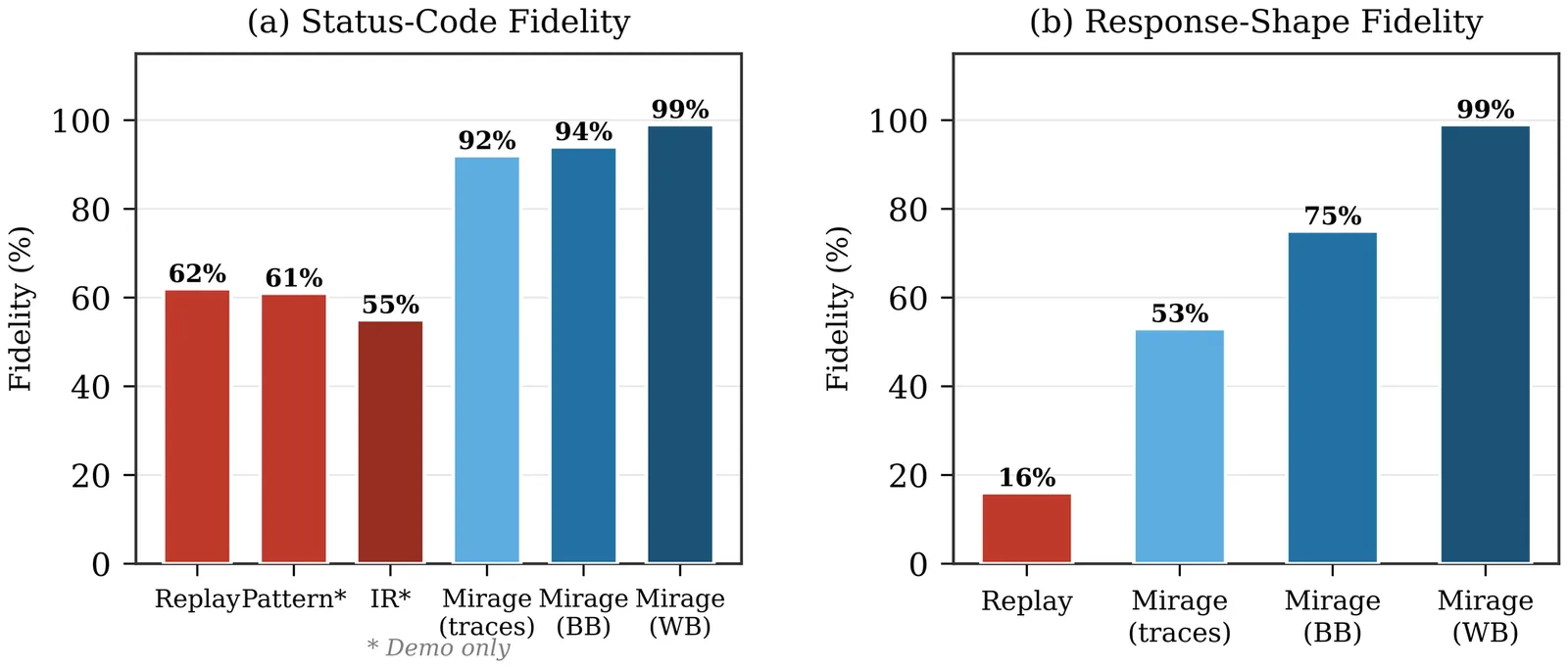
MIRAGE: Online LLM Simulation for Microservice Dependency Testing
Existing approaches to microservice dependency simulation--record-replay, pattern-mining, and specification-driven stubs--generate static artifacts before test execution. We propose online LLM simulation, a runtime approach where the LLM directly answers each dependency request as it arrives, maintaining cross-request state throughout a test scenario. No mock specification is pre-generated; the model reads the dependency's source code, caller code, and production traces, then simulates dependency behavior on demand. We instantiate this approach in MIRAGE and evaluate it on 110 test scenarios spanning 14 caller-dependency pairs across three microservice systems (Google's Online Boutique, Weaveworks' Sock Shop, and a custom system). In white-box mode (dependency source available), MIRAGE achieves 99% status-code fidelity (109/110) and 99% response-shape fidelity, compared to 62% / 16% for record-replay. End-to-end, caller integration tests produce the same pass/fail outcomes with MIRAGE as with real dependencies (8/8 scenarios). A signal ablation shows dependency source code is often sufficient for high-fidelity runtime simulation (100% alone); without it, the model still infers correct error codes (94%) but loses response-structure accuracy (75%). Constraining LLM output through typed intermediate representations reduces fidelity on complex stateful services (55%) while performing adequately on simple APIs (86%), suggesting that the runtime approach's implicit state tracking matters for behavioral complexity. Results are stable across three LLM families (within 3%) at $0.16 to $0.82 per dependency.
2604.04806Apr 2026
View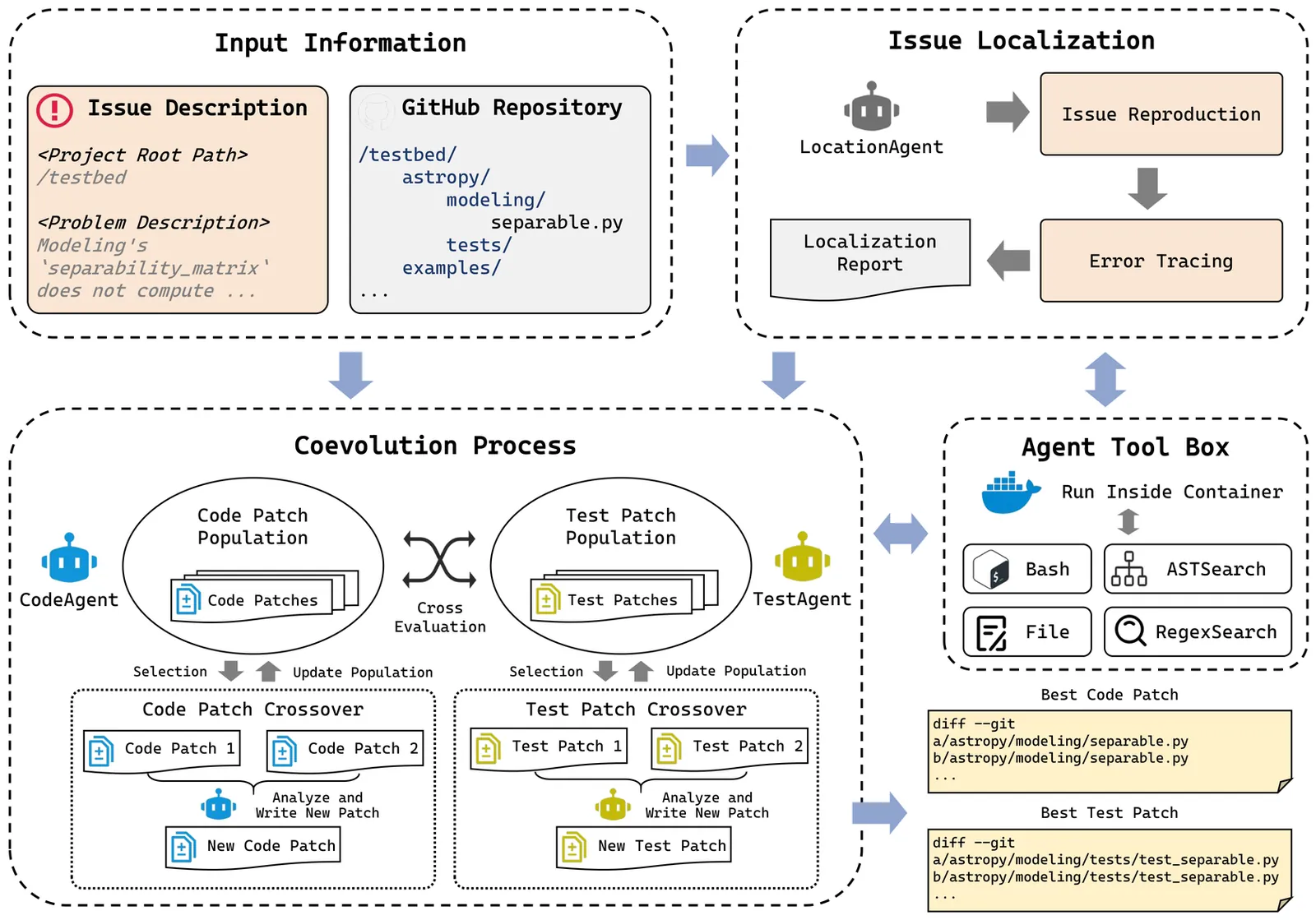
Beyond Fixed Tests: Repository-Level Issue Resolution as Coevolution of Code and Behavioral Constraints
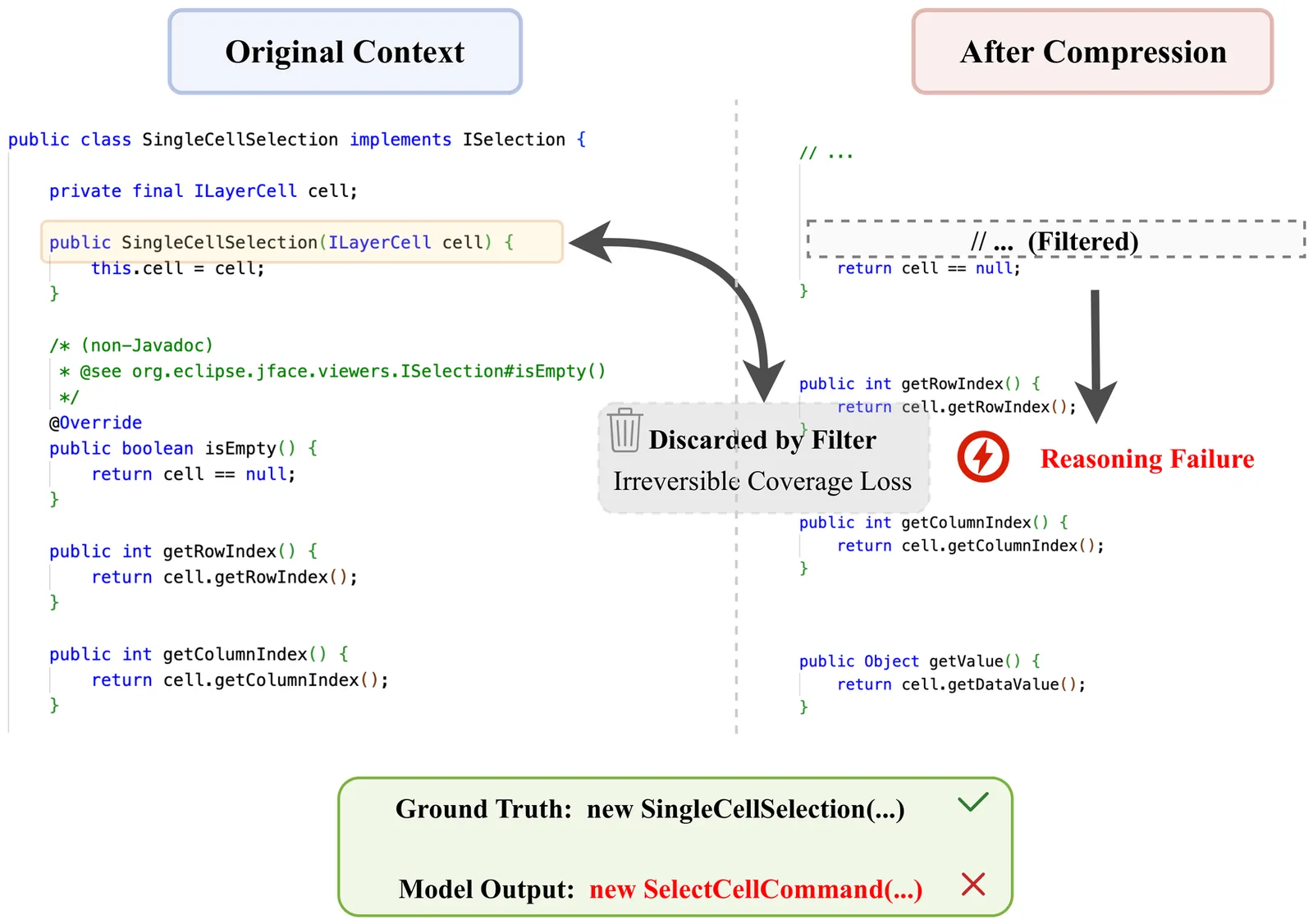
Software engineers resolving repository-level issues do not treat existing tests as immutable correctness oracles. Instead, they iteratively refine both code and the tests used to characterize intended behavior, as new modifications expose missing assumptions or misinterpreted failure conditions. In contrast, most existing large language model (LLM)-based repair systems adopt a linear pipeline in which tests or other validation signals act mostly as post-hoc filters, treating behavioral constraints as fixed during repair. This formulation reduces repair to optimizing code under static and potentially misaligned constraints, leading to under-constrained search and brittle or overfitted fixes. We argue that repository-level issue resolution is fundamentally not optimization under fixed tests, but search over evolving behavioral constraints. To operationalize this view, we propose Agent-CoEvo, a coevolutionary multi-agent framework in which candidate code patches and test patches are jointly explored and iteratively refined. Rather than treating tests as immutable oracles, our framework models them as dynamic constraints that both guide and are revised by the repair process. Through mutual evaluation and semantic recombination, code and test candidates progressively narrow the space of behavior consistent with the issue description. Evaluated on SWE-bench Lite and SWT-bench Lite, Agent-CoEvo consistently outperforms state-of-the-art agent-based and agentless baselines in both repair success and test reproduction quality. Our findings suggest that enabling repair agents to revise behavioral constraints during search is critical for reliable issue resolution, pointing toward a shift from code-only optimization to coevolution of implementation and specification.
2604.04580Apr 2026
View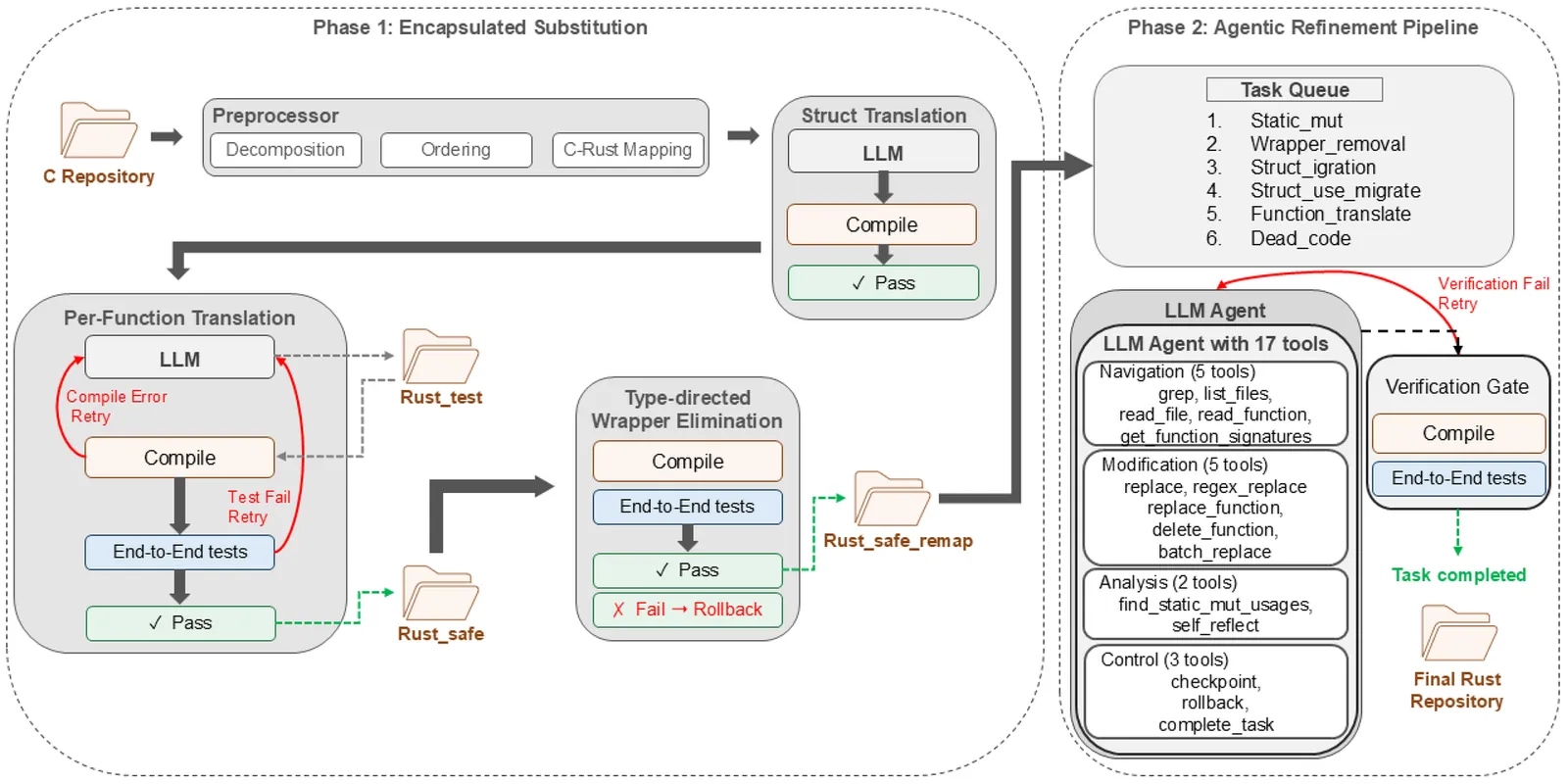
ENCRUST: Encapsulated Substitution and Agentic Refinement on a Live Scaffold for Safe C-to-Rust Translation
We present Encapsulated Substitution and Agentic Refinement on a Live Scaffold for Safe C-to-Rust Translation, a two-phase pipeline for translating real-world C projects to safe Rust. Existing approaches either produce unsafe output without memory-safety guarantees or translate functions in isolation, failing to detect cross-unit type mismatches or handle unsafe constructs requiring whole-program reasoning. Furthermore, function-level LLM pipelines require coordinated caller updates when type signatures change, while project-scale systems often fail to produce compilable output under real-world dependency complexity. Encrust addresses these limitations by decoupling boundary adaptation from function logic via an Application Binary Interface (ABI)-preserving wrapper pattern and validating each intermediate state against the integrated codebase. Phase 1 (Encapsulated Substitution) translates each function using an ABI-preserving wrapper that splits it into two components: a caller-transparent shim retaining the original raw-pointer signature, and a safe inner function targeted by the LLM with a clean, scope-limited prompt. This enables independent per-function type changes with automatic rollback on failure, without coordinated caller updates. A deterministic, type-directed wrapper elimination pass then removes wrappers after successful translation. Phase 2 (Agentic Refinement) resolves unsafe constructs beyond per-function scope, including static mut globals, skipped wrapper pairs, and failed translations, using an LLM agent operating on the whole codebase under a baseline-aware verification gate. We evaluate Encrust on 7 GNU Coreutils programs and 8 libraries from the Laertes benchmark, showing substantial unsafe-construct reduction across all 15 programs while maintaining full test-vector correctness.
2604.04527Apr 2026
ViewTrace-Guided Synthesis of Effectful Test Generators
Several recently proposed program logics have incorporated notions of underapproximation into their design, enabling them to reason about reachability rather than safety. In this paper, we explore how similar ideas can be integrated into an expressive type and effect system. We use the resulting underapproximate type specifications to guide the synthesis of test generators that probe the behavior of effectful black-box systems. A key novelty of our type language is its ability to capture underapproximate behaviors of effectful operations using symbolic traces that expose latent data and control dependencies, constraints that must be preserved by the test sequences the generator outputs. We implement this approach in a tool called Clouseau, and evaluate it on a diverse range of applications by integrating Clouseau's synthesized generators into property-based testing frameworks like QCheck and model-checking tools like P. In both settings, the generators synthesized by Clouseau are significantly more effective than the default testing strategy, and are competitive with state-of-the-art, handwritten solutions.
2604.04345Apr 2026
View
Agentic Code Optimization via Compiler-LLM Cooperation
Generating performant executables from high level languages is critical to software performance across a wide range of domains. Modern compilers perform this task by passing code through a series of well-studied optimizations at progressively lower levels of abstraction, but may miss optimization opportunities that require high-level reasoning about a program's purpose. Recent work has proposed using LLMs to fill this gap. While LLMs can achieve large speedups on some programs, they frequently generate code that is incorrect. In this work, we propose a method to balance the correctness of conventional compiler optimizations with the ``creativity'' of LLM-based code generation: compiler-LLM cooperation. Our approach integrates existing compiler optimization passes with LLM-based code generation at multiple levels of abstraction, retaining the best features of both types of code optimization. We realize our approach with a multi-agent system that includes (1) LLM-based optimization agents for each level of abstraction, (2) individual compiler constituents as tools, (3) an LLM-based test generation agent that probes the correctness and performance of generated code, and (4) a guiding LLM that orchestrates the other components. The strategy enables LLM-based optimization of input programs at multiple levels of abstraction and introduces a method for distributing computational budget between levels. Our extensive evaluation shows that compiler-LLM cooperation outperforms both existing compiler optimizations and level-specific LLM-based baselines, producing speedups up to 1.25x.
2604.04238Apr 2026
View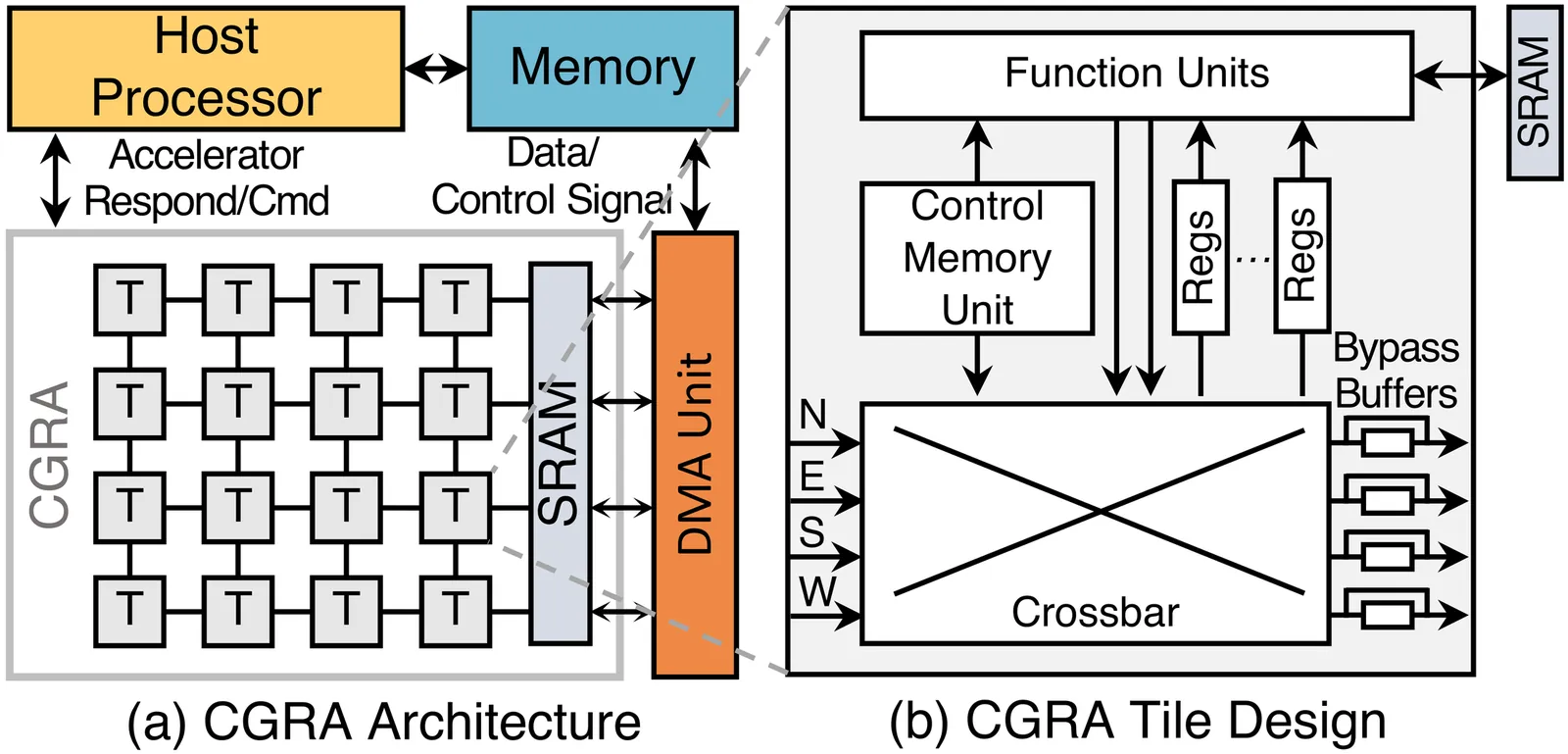
NEURA: A Unified and Retargetable Compilation Framework for Coarse-Grained Reconfigurable Architectures
Coarse-Grained Reconfigurable Architectures (CGRAs) are a promising and versatile accelerator platform, offering a balance between the performance and efficiency of specialized accelerators and the software programmability. However, their full potential is severely hindered by control flow in accelerated kernels, as the control flow (e.g., loops, branches) is fundamentally incompatible with the parallel, data-driven CGRA fabric. Prior strategies to resolve this mismatch in CGRA kernel acceleration are either inefficient, sacrificing performance for generality, or lack generality due to the difficulty of adapting them across different execution models. Thus, a general and unified solution for efficient CGRA kernel acceleration remains elusive. This paper introduces NEURA, a unified and retargetable compilation framework that systematically resolves the control-dataflow mismatch in CGRAs. NEURA's core innovation is a novel, pure dataflow intermediate representation (IR) built on a predicated type system. In this IR, control contexts are embedded as a predicate within each data, making control an intrinsic property of data. This mechanism enables NEURA to systematically flatten complex control flow into a single unified dataflow graph. This unified representation decouples kernel representation from hardware, empowering NEURA to retarget diverse CGRAs with different execution models and microarchitectural features. When targeted to a high-performance spatio-temporal CGRA, NEURA delivers a 2.20x speedup on kernel benchmarks and up to 2.71x geometric mean speedup on real-world applications over state-of-the-art (SOTA) high-performance baselines. It also provides a competitive solution against the SOTA low-power CGRA when retargeted to a spatial-only CGRA. NEURA is open-source and available at https://github.com/coredac/neura.
2604.04236Apr 2026
ViewC2|Q>: A Robust Framework for Bridging Classical and Quantum Software Development -- RCR Report
This is the Replicated Computational Results (RCR) Report for the paper C2|Q>: A Robust Framework for Bridging Classical and Quantum Software Development. The paper introduces a modular, hardware-agnostic framework that translates classical problem specifications - Python code or structured JSON - into executable quantum programs across ten problem families and multiple hardware backends. We release the framework source code on GitHub at https://github.com/C2-Q/C2Q, a pretrained parser model on Zenodo at https://zenodo.org/records/19061125, evaluation data in a separate Zenodo record at https://zenodo.org/records/17071667, and a PyPI package at https://pypi.org/project/c2q-framework/ for lightweight CLI and API use. Experiment 1 is supported through a released pretrained model and training notebook, while Experiments 2 and 3 are directly executable via documented make targets. This report describes the artifact structure, setup instructions, and the mapping from each execution route to the corresponding experiment.
2604.04112Apr 2026
View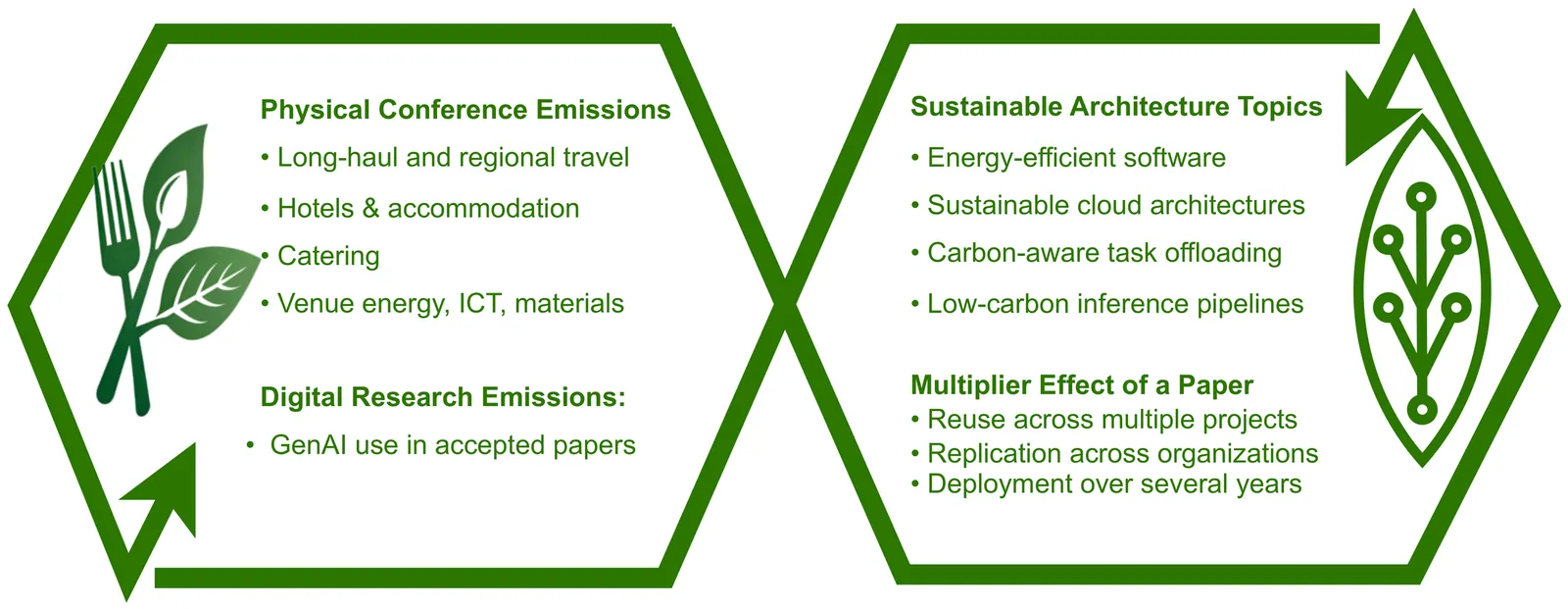
Toward a Sustainable Software Architecture Community: Evaluating ICSA's Environmental Impact
Generative AI (GenAI) tools are increasingly integrated into software architecture research, yet the environmental impact of their computational usage remains largely undocumented. This study presents the first systematic audit of the carbon footprint of both the digital footprint from GenAI usage in research papers, and the traditional footprint from conference activities within the context of the IEEE International Conference on Software Architecture (ICSA). We report two separate carbon inventories relevant to the software architecture research community: i) an exploratory estimate of the footprint of GenAI inference usage associated with accepted papers within a research-artifact boundary, and ii) the conference attendance and operations footprint of ICSA 2025 (travel, accommodation, catering, venue energy, and materials) within the conference time boundary. These two inventories, with different system boundaries and completeness, support transparency and community reflection. We discuss implications for sustainable software architecture, including recommendations for transparency, greener conference planning, and improved energy efficiency in GenAI operations. Our work supports a more climate-conscious research culture within the ICSA community and beyond
2604.04096Apr 2026
View
Humans Integrate, Agents Fix: How Agent-Authored Pull Requests Are Referenced in Practice
Although coding agents have introduced new coordination dynamics in collaborative software development, detailed interactions in practice remain underexplored, especially for the code review process. In this study, we mine agent-authored PR references from the AIDev dataset and introduce a taxonomy to characterize the intent of these references across Human-to-Agent and Agent-to-Agent interactions in the form of Pull Requests (i.e. PRs). Our analysis shows that while humans initiate most references to agent-authored PRs, a substantial portion of these interactions are AI-assisted, indicating the emergence of meta-collaborative workflows, where humans mostly use references to build new features, whereas agents make them to fix errors. We further find that referencing/referenced PRs are associated with substantially longer lifespans and review times compared to isolated PRs, suggesting higher coordination or integration effort. We then list three key takeaways as potential future research directions into how to utilize these dynamics for optimizing AI coding agents in the code review process.
2604.04059Apr 2026
View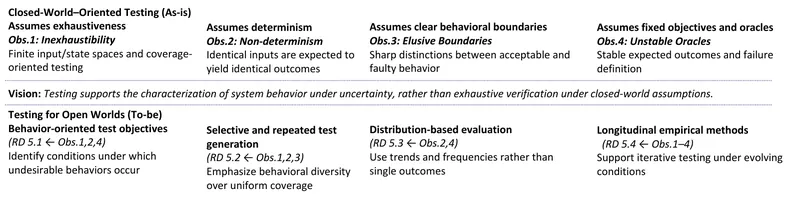
Software Testing Beyond Closed Worlds: Open-World Games as an Extreme Case
Software testing research has traditionally relied on closed-world assumptions, such as finite state spaces, reproducible executions, and stable test oracles. However, many modern software systems operate under uncertainty, non-determinism, and evolving conditions, challenging these assumptions. This paper uses open-world games as an extreme case to examine the limitations of closed-world testing. Through a set of observations grounded in prior work, we identify recurring characteristics that complicate testing in such systems, including inexhaustible behavior spaces, non-deterministic execution outcomes, elusive behavioral boundaries, and unstable test oracles. Based on these observations, we articulate a vision of software testing beyond closed-world assumptions, in which testing supports the characterization and interpretation of system behavior under uncertainty. We further discuss research directions for automated test generation, evaluation metrics, and empirical study design. Although open-world games serve as the motivating domain, the challenges and directions discussed in this paper extend to a broader class of software systems operating in dynamic and uncertain environments.
2604.04047Apr 2026
View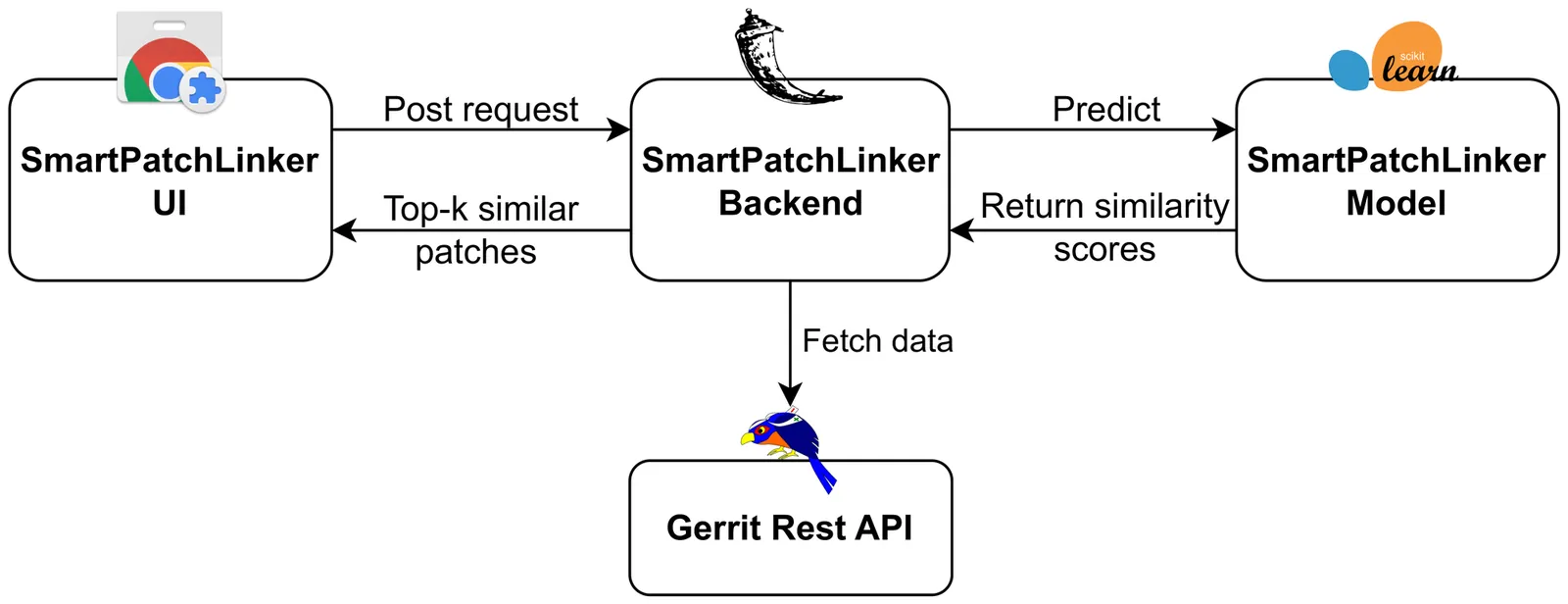
SmartPatchLinker: An Open-Source Tool to Linked Changes Detection for Code Review
In large software ecosystems, semantically related code changes, such as alternative solutions or overlapping modifications are often discovered only days after submission, leading to duplicated effort and delayed reviews. We present SmartPatchLinker, a browser based tool that supports the discovery of related patches directly within the code review interface. SmartPatchLinker is implemented as a lightweight Chrome extension with a local inference backend and integrates with Gerrit to retrieve and rank semantically linked changes when a reviewer opens a patch. The tool allows reviewers to configure the search scope, view ranked candidates with confidence indicators, and examine related work without leaving their workflow or relying on server-side installations. We perform both usefulness and usability evaluations to study how SmartPatchLinker can support reviewers during code review. SmartPatchLinker is open source, and its source code, Docker containers, and the replication package used in our evaluation are publicly available on GitHub at https://github.com/islem-kms/gerrit-chrome-extension . A video demonstrating the tool is also available online at https://drive.google.com/drive/folders/1MCcTj5OSlT7lHVBFMq5m9iatas2joaGb
2604.04045Apr 2026
View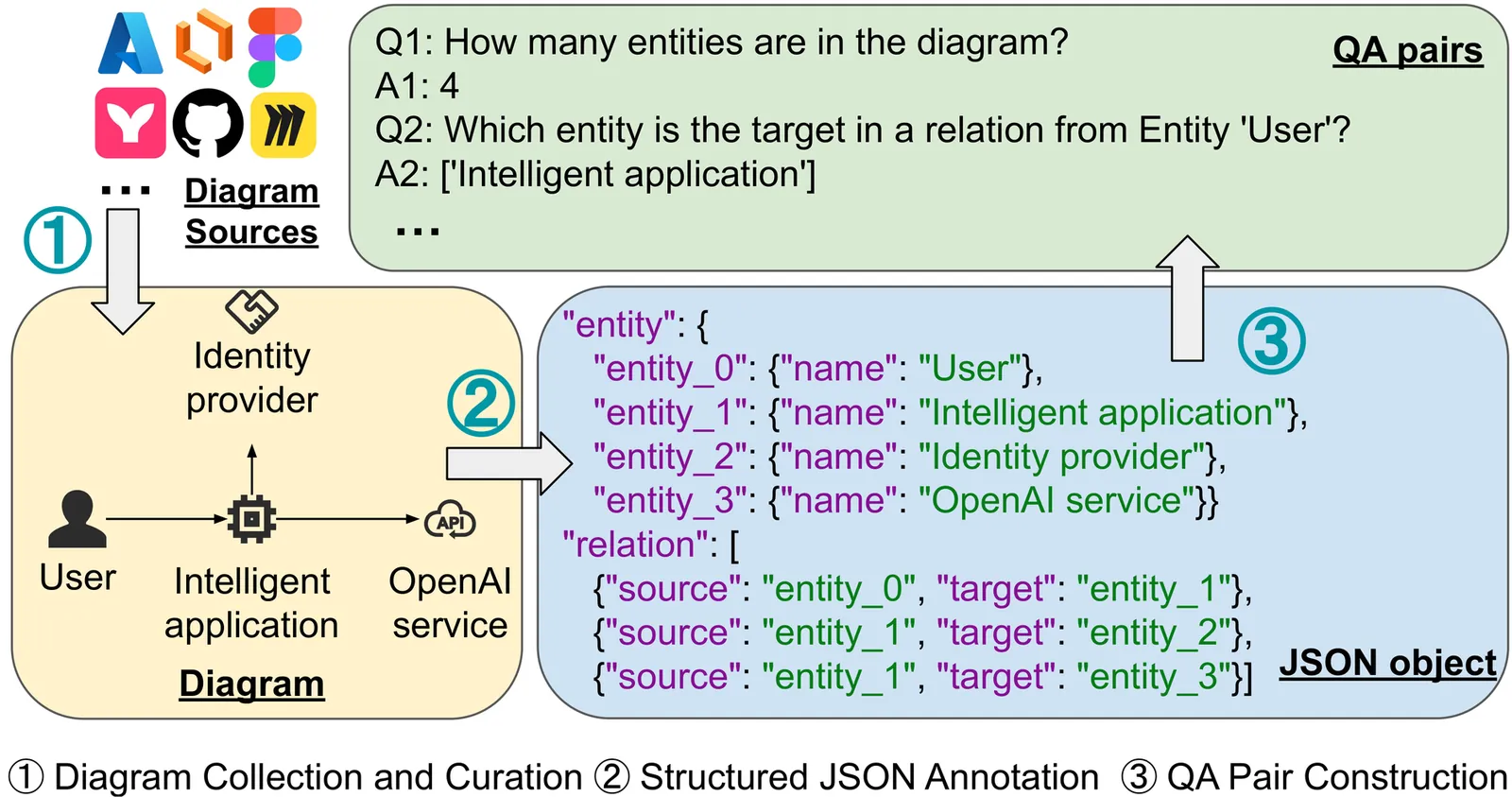
Benchmarking and Evaluating VLMs for Software Architecture Diagram Understanding
Software architecture diagrams are important design artifacts for communicating system structure, behavior, and data organization throughout the software development lifecycle. Although recent progress in large language models has substantially advanced code-centric software engineering tasks such as code generation, testing, and maintenance, the ability of modern vision-language models (VLMs) to understand software architecture diagrams remains underexplored. To address this gap, we present SADU, a benchmark for Software Architecture Diagram Understanding that evaluates VLMs on architecture diagrams as structured software engineering artifacts rather than generic images. SADU contains 154 carefully curated diagrams spanning behavioral, structural, and ER diagrams, paired with structured annotations and 2,431 question-answer tasks covering counting and retrieval reasoning. We evaluate 11 state-of-the-art VLMs from the Gemini, Claude, GPT, and Qwen families. Our results show that software architecture diagram understanding remains challenging for current models: the best-performing model gemini-3-flash-preview achieves only 70.18\% accuracy, while gpt-4o-mini only achieves 17.77\% accuracy. The results further reveal the weaknesses in diagram reasoning and visual relation grounding, highlighting a gap between current VLMs and the needs of design-stage software engineering. SADU provides a foundation for future research on diagram-aware AI systems and more faithful AI-assisted software engineering workflows.
2604.04009Apr 2026
ViewPage 1 of 393