General Economics
arXiv:econ.GN
General methodological, applied, and empirical contributions to economics.
General methodological, applied, and empirical contributions to economics.
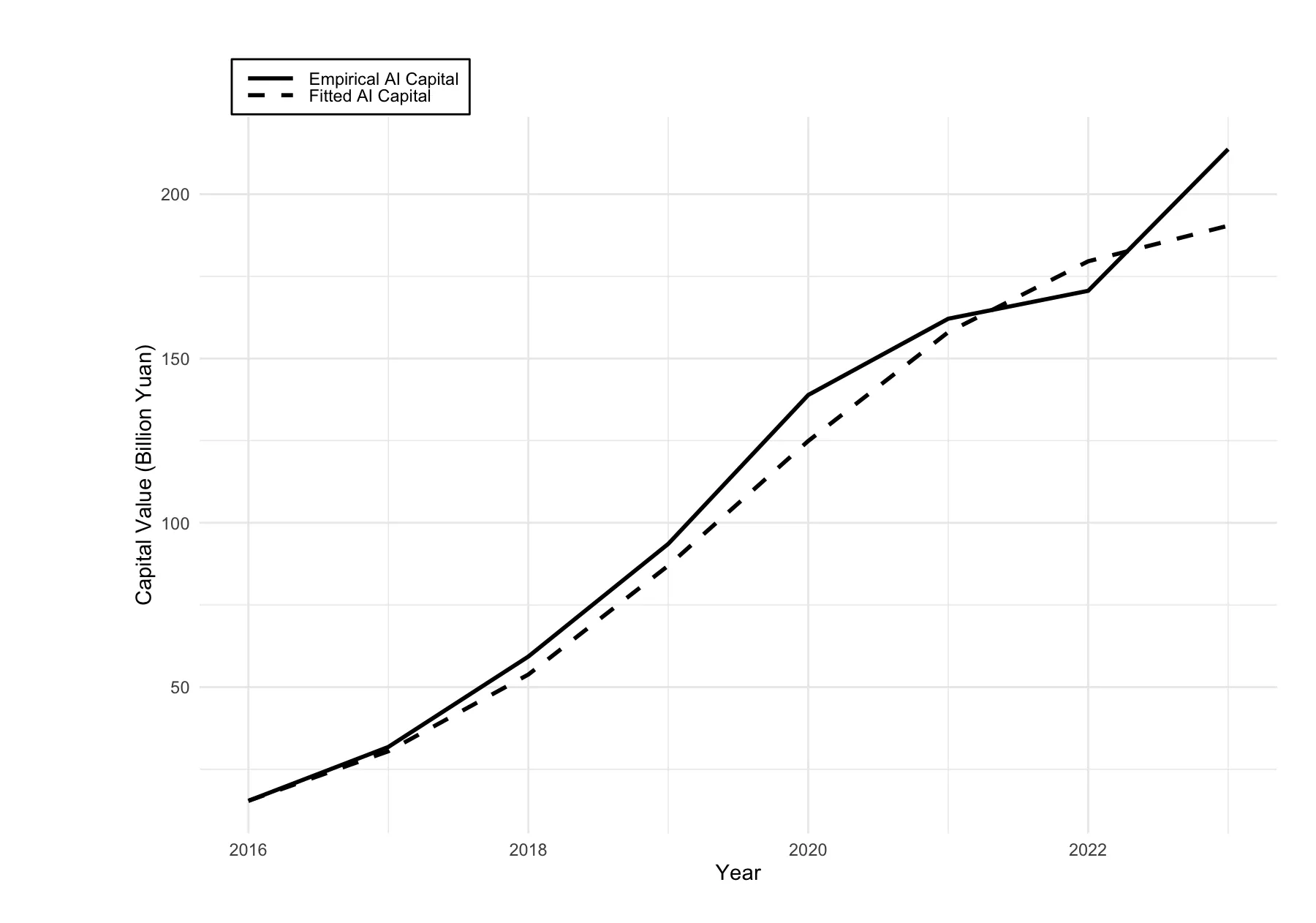
The rapid integration of Artificial Intelligence (AI) into China's economy presents a classic governance challenge: how to harness its growth potential while managing its disruptive effects on traditional capital and labor markets. This study addresses this policy dilemma by modeling the dynamic interactions between AI capital, physical capital, and labor within a Lotka-Volterra predator-prey framework. Using annual Chinese data (2016-2023), we quantify the interaction strengths, identify stable equilibria, and perform a global sensitivity analysis. Our results reveal a consistent pattern where AI capital acts as the 'prey', stimulating both physical capital accumulation and labor compensation (wage bill), while facing only weak constraining feedback. The equilibrium points are stable nodes, indicating a policy-mediated convergence path rather than volatile cycles. Critically, the sensitivity analysis shows that the labor market equilibrium is overwhelmingly driven by AI-related parameters, whereas the physical capital equilibrium is also influenced by its own saturation dynamics. These findings provide a systemic, quantitative basis for policymakers: (1) to calibrate AI promotion policies by recognizing the asymmetric leverage points in capital vs. labor markets; (2) to anticipate and mitigate structural rigidities that may arise from current regulatory settings; and (3) to prioritize interventions that foster complementary growth between AI and traditional economic structures while ensuring broad-base distribution of technological gains.
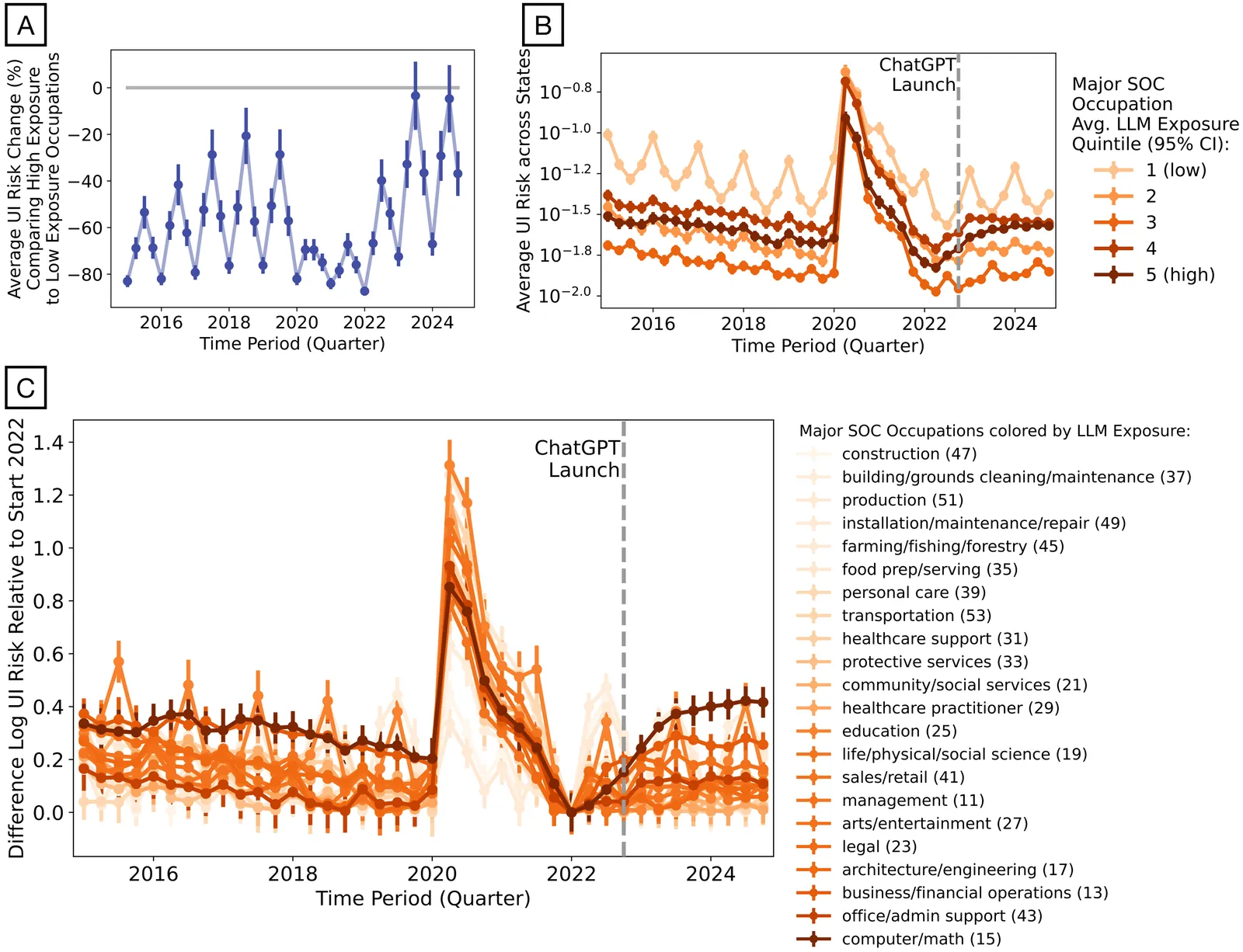
Public debate links worsening job prospects for AI-exposed occupations to the release of ChatGPT in late 2022. Using monthly U.S. unemployment insurance records, we measure occupation- and location-specific unemployment risk and find that risk rose in AI-exposed occupations beginning in early 2022, months before ChatGPT. Analyzing millions of LinkedIn profiles, we show that graduate cohorts from 2021 onward entered AI-exposed jobs at lower rates than earlier cohorts, with gaps opening before late 2022. Finally, from millions of university syllabi, we find that graduates taking more AI-exposed curricula had higher first-job pay and shorter job searches after ChatGPT. Together, these results point to forces pre-dating generative AI and to the ongoing value of LLM-relevant education.
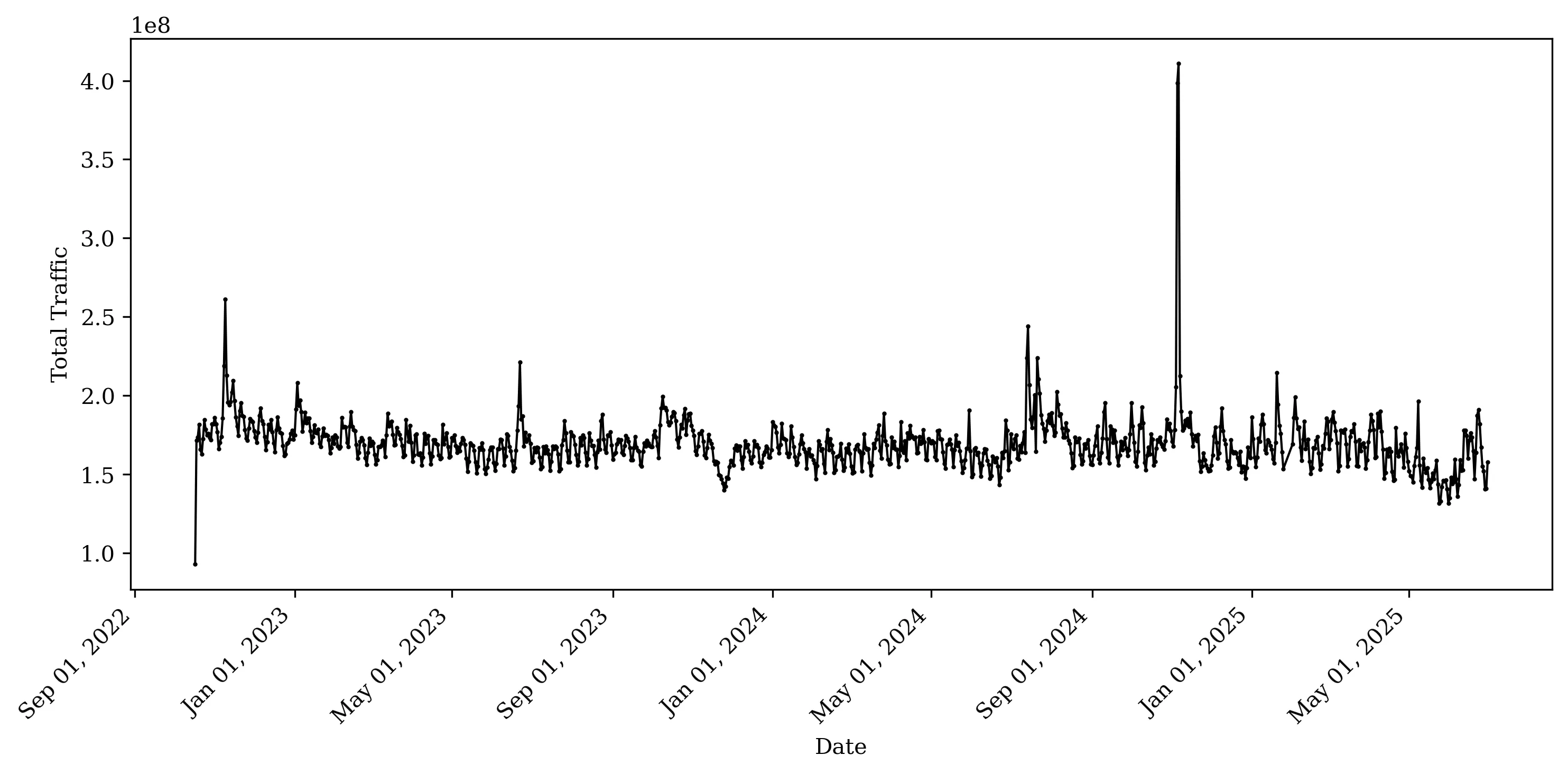
Large language models (LLMs) change how consumers acquire information online; their bots also crawl news publishers' websites for training data and to answer consumer queries; and they provide tools that can lower the cost of content creation. These changes lead to predictions of adverse impact on news publishers in the form of lowered consumer demand, reduced demand for newsroom employees, and an increase in news "slop." Consequently, some publishers strategically responded by blocking LLM access to their websites using the robots.txt file standard. Using high-frequency granular data, we document four effects related to the predicted shifts in news publishing following the introduction of generative AI (GenAI). First, we find a consistent and moderate decline in traffic to news publishers occurring after August 2024. Second, using a difference-in-differences approach, we find that blocking GenAI bots can have adverse effects on large publishers by reducing total website traffic by 23% and real consumer traffic by 14% compared to not blocking. Third, on the hiring side, we do not find evidence that LLMs are replacing editorial or content-production jobs yet. The share of new editorial and content-production job listings increases over time. Fourth, regarding content production, we find no evidence that large publishers increased text volume; instead, they significantly increased rich content and use more advertising and targeting technologies. Together, these findings provide early evidence of some unforeseen impacts of the introduction of LLMs on news production and consumption.
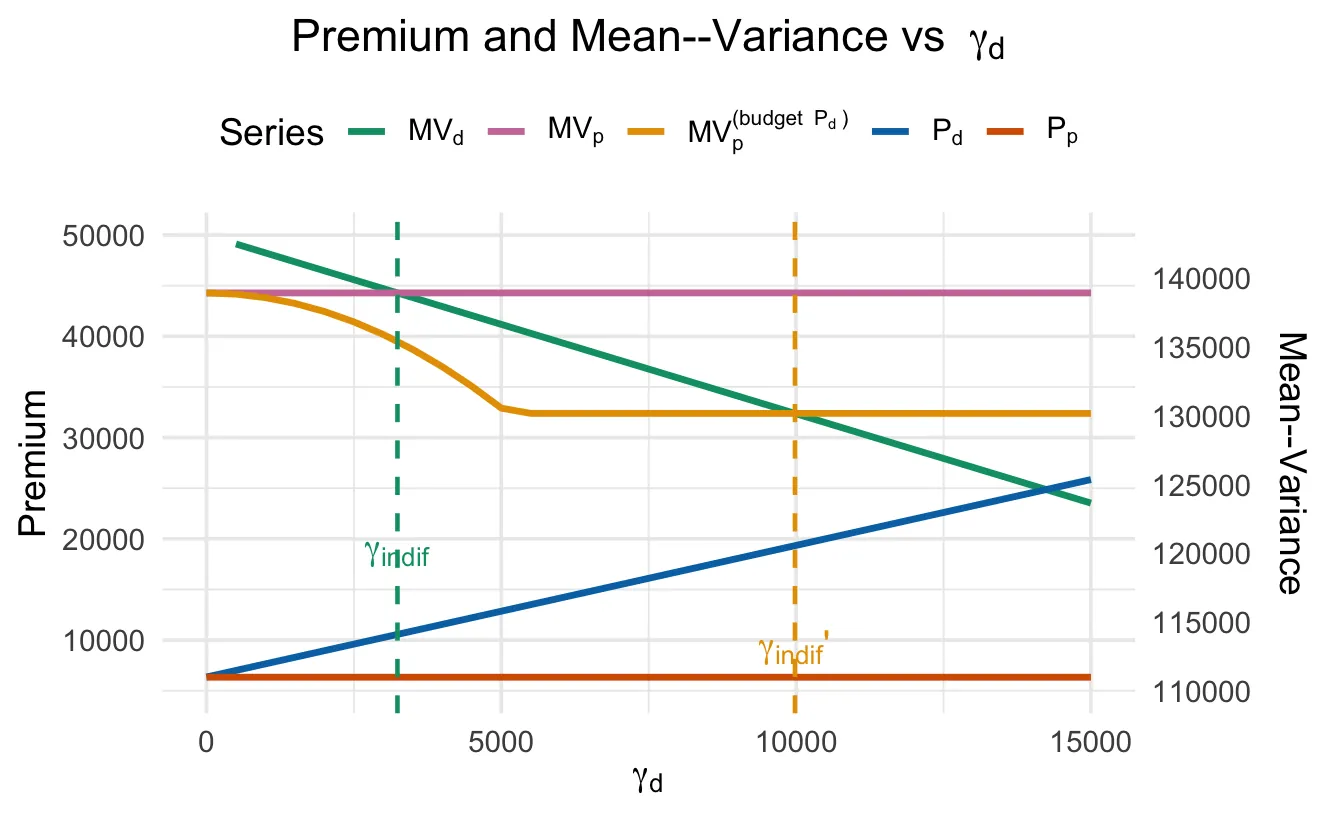
In high-risk environments, traditional indemnity insurance is often unaffordable or ineffective, despite its well-known optimality under expected utility. We compare excess-of-loss indemnity insurance with parametric insurance within a common mean-variance framework, allowing for fixed costs, heterogeneous premium loadings, and binding budget constraints. We show that, once these realistic frictions are introduced, parametric insurance can yield higher welfare for risk-averse individuals, even under the same utility objective. The welfare advantage arises precisely when indemnity insurance becomes impractical, and disappears once both contracts are unconstrained. Our results help reconcile classical insurance theory with the growing use of parametric risk transfer in high-risk settings.

This paper derives `Scaling Laws for Economic Impacts' -- empirical relationships between the training compute of Large Language Models (LLMs) and professional productivity. In a preregistered experiment, over 500 consultants, data analysts, and managers completed professional tasks using one of 13 LLMs. We find that each year of AI model progress reduced task time by 8%, with 56% of gains driven by increased compute and 44% by algorithmic progress. However, productivity gains were significantly larger for non-agentic analytical tasks compared to agentic workflows requiring tool use. These findings suggest continued model scaling could boost U.S. productivity by approximately 20% over the next decade.

We leverage multimodal large language models (LLMs) to construct a dataset of 306,070 German patents (1877-1918) from 9,562 archival image scans using our LLM-based pipeline powered by Gemini-2.5-Pro and Gemini-2.5-Flash-Lite. Our benchmarking exercise provides tentative evidence that multimodal LLMs can create higher quality datasets than our research assistants, while also being more than 795 times faster and 205 times cheaper in constructing the patent dataset from our image corpus. About 20 to 50 patent entries are embedded on each page, arranged in a double-column format and printed in Gothic and Roman fonts. The font and layout complexity of our primary source material suggests to us that multimodal LLMs are a paradigm shift in how datasets are constructed in economic history. We open-source our benchmarking and patent datasets as well as our LLM-based data pipeline, which can be easily adapted to other image corpora using LLM-assisted coding tools, lowering the barriers for less technical researchers. Finally, we explain the economics of deploying LLMs for historical dataset construction and conclude by speculating on the potential implications for the field of economic history.
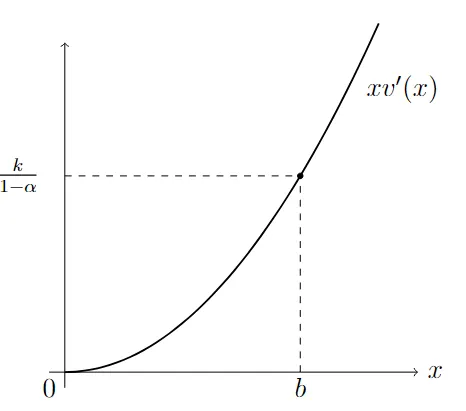
We analyze the problem of optimal reduction of the debt-to-GDP ratio in a stochastic control setting. The debt-to-GDP dynamics are modeled through a stochastic differential equation in which fiscal policy simultaneously affects both debt accumulation and GDP growth. A key feature of the framework is the introduction of a cost functional that captures the disutility of fiscal surpluses and the perceived benefit of fiscal deficits, thus incorporating the macroeconomic trade-off between tighten and expansionary policies. By applying the Hamilton-Jacobi-Bellman approach, we provide explicit solutions in the case of linear GDP response to the fiscal policies. We rigorously analyze threshold-type fiscal strategies in the case of linear impact of the fiscal policy and provide closed-form solutions for the associated value function in relevant regimes. A sensitivity analysis is conducted by varying key model parameters, confirming the robustness of our theoretical findings. The application to debt reduction highlights how fiscal costs and benefits influence optimal interventions, offering valuable insights into sustainable public debt management under uncertainty.
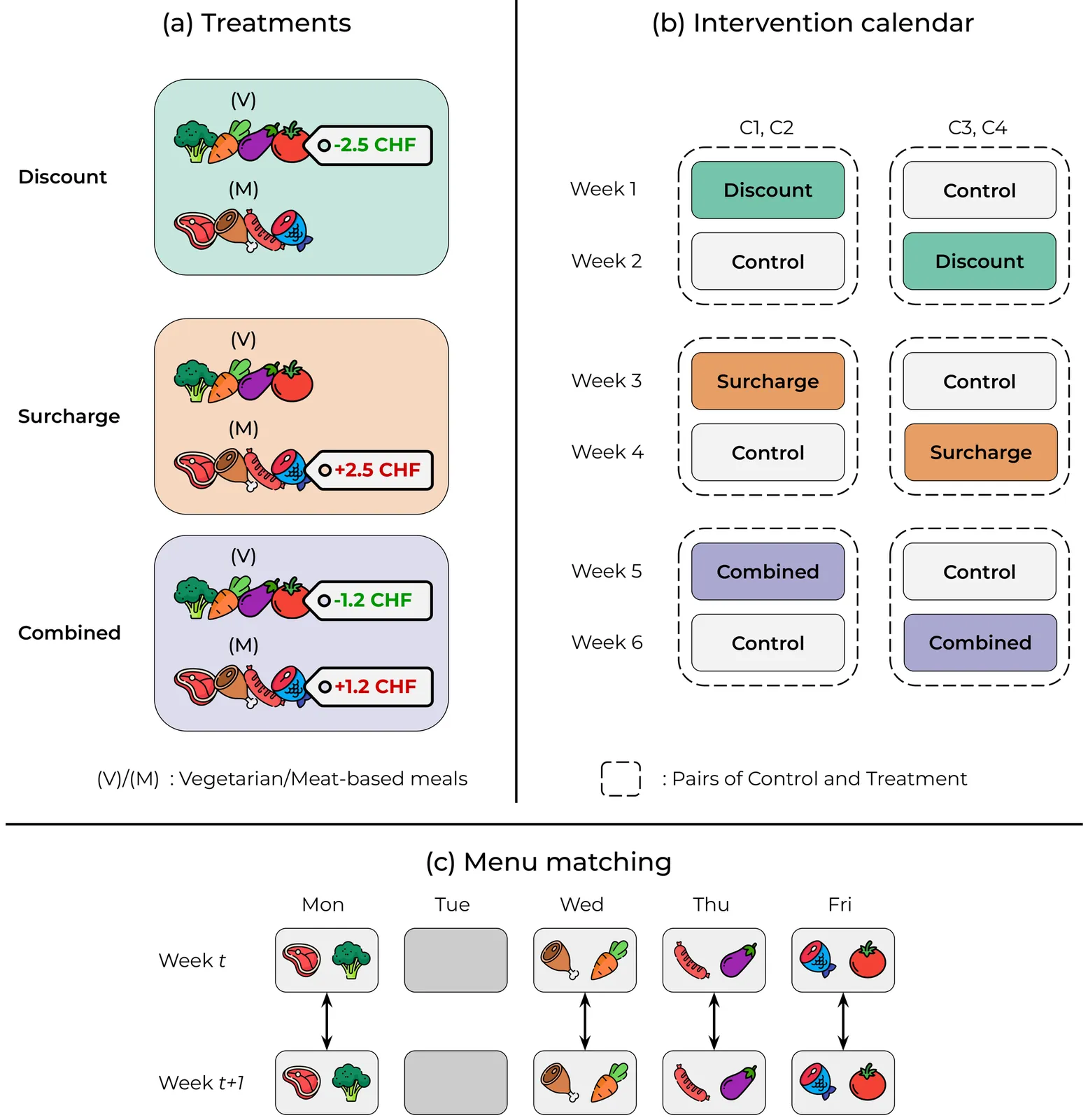
Meat consumption is a major driver of global greenhouse gas emissions. While pricing interventions have shown potential to reduce meat intake, previous studies have focused on highly constrained environments with limited consumer choice. Here, we present the first large-scale field experiment to evaluate multiple pricing interventions in a real-world, competitive setting. Using a sequential crossover design with matched menus in a Swiss university campus, we systematically compared vegetarian-meal discounts (-2.5 CHF), meat surcharges (+2.5 CHF), and a combined scheme (-1.2 CHF=+1.2 CHF) across four campus cafeterias. Only the surcharge and combined interventions led to significant increases in vegetarian meal uptake--by 26.4% and 16.6%, respectively--and reduced CO2 emissions per meal by 7.4% and 11.3%, respectively. The surcharge, while effective, triggered a 12.3% drop in sales at intervention sites and a corresponding 14.9% increase in non-treated locations, hence causing a spillover effect that completely offset environmental gains. In contrast, the combined approach achieved meaningful emission reductions without significant effects on overall sales or revenue, making it both effective and economically viable. Notably, pricing interventions were equally effective for both vegetarian-leaning customers and habitual meat-eaters, stimulating change even within entrenched dietary habits. Our results show that balanced pricing strategies can reduce the carbon footprint of realistic food environments, but require coordinated implementation to maximize climate benefits and avoid unintended spillover effects.
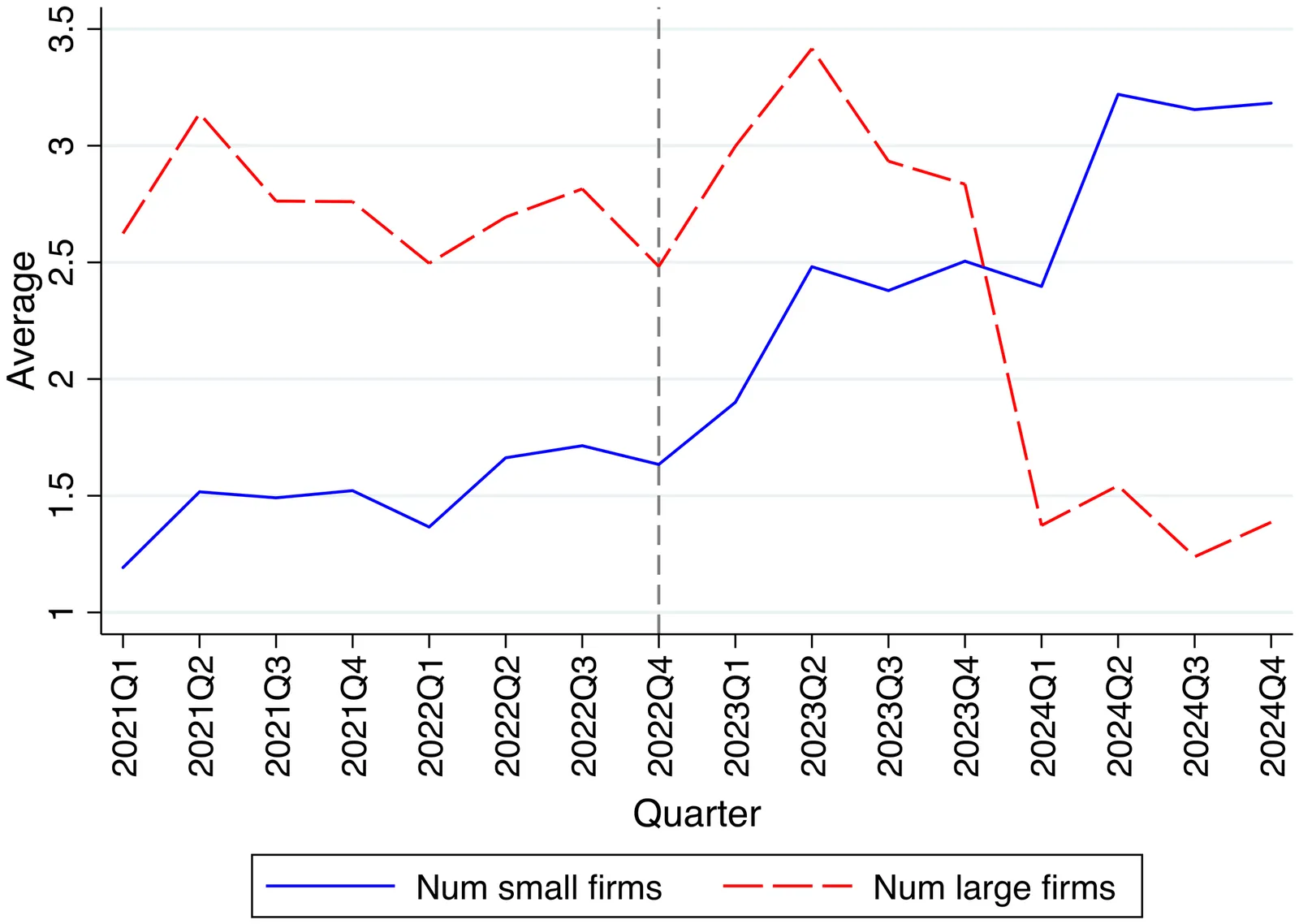
This paper studies whether, how, and for whom generative artificial intelligence (GenAI) facilitates firm creation. Our identification strategy exploits the November 2022 release of ChatGPT as a global shock that lowered start-up costs and leverages variations across geo-coded grids with differential pre-existing AI-specific human capital. Using high-resolution and universal data on Chinese firm registrations by the end of 2024, we find that grids with stronger AI-specific human capital experienced a sharp surge in new firm formation$\unicode{x2013}$driven entirely by small firms, contributing to 6.0% of overall national firm entry. Large-firm entry declines, consistent with a shift toward leaner ventures. New firms are smaller in capital, shareholder number, and founding team size, especially among small firms. The effects are strongest among firms with potential AI applications, weaker financing needs, and among first-time entrepreneurs. Overall, our results highlight that GenAI serves as a pro-competitive force by disproportionately boosting small-firm entry.
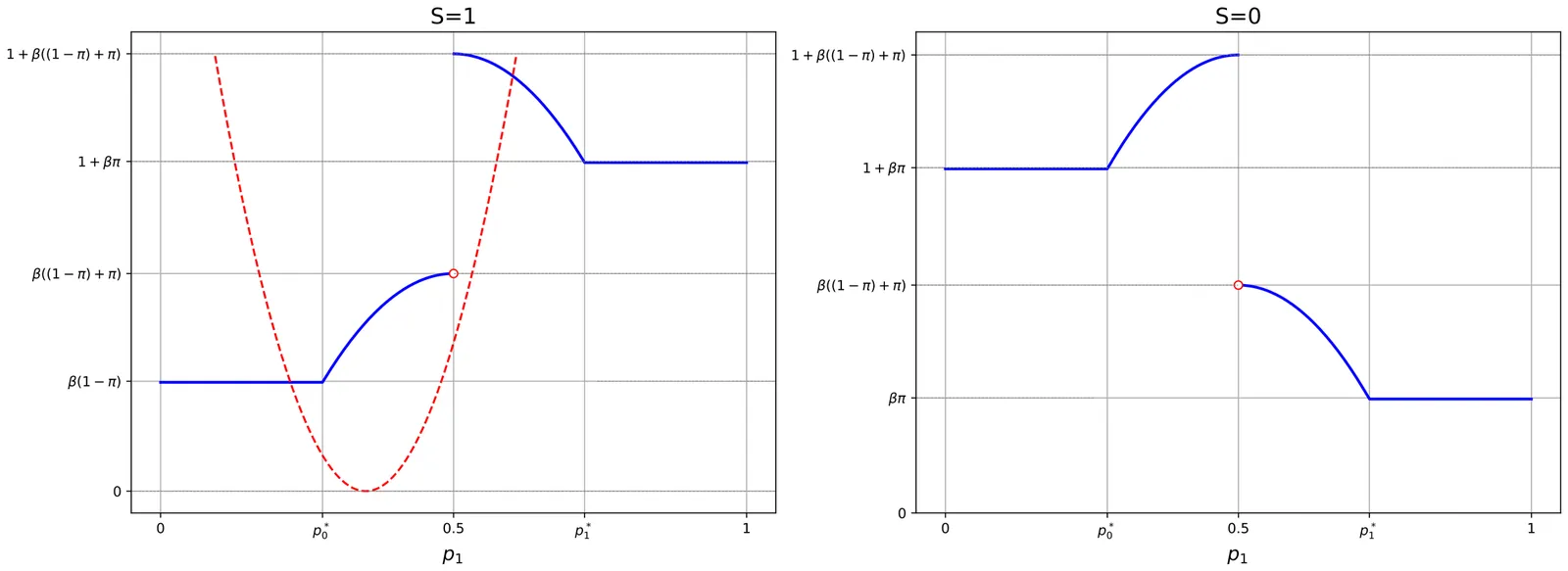
In democracies, major policy decisions typically require some form of majority or consensus, so elites must secure mass support to govern. Historically, elites could shape support only through limited instruments like schooling and mass media; advances in AI-driven persuasion sharply reduce the cost and increase the precision of shaping public opinion, making the distribution of preferences itself an object of deliberate design. We develop a dynamic model in which elites choose how much to reshape the distribution of policy preferences, subject to persuasion costs and a majority rule constraint. With a single elite, any optimal intervention tends to push society toward more polarized opinion profiles - a ``polarization pull'' - and improvements in persuasion technology accelerate this drift. When two opposed elites alternate in power, the same technology also creates incentives to park society in ``semi-lock'' regions where opinions are more cohesive and harder for a rival to overturn, so advances in persuasion can either heighten or dampen polarization depending on the environment. Taken together, cheaper persuasion technologies recast polarization as a strategic instrument of governance rather than a purely emergent social byproduct, with important implications for democratic stability as AI capabilities advance.
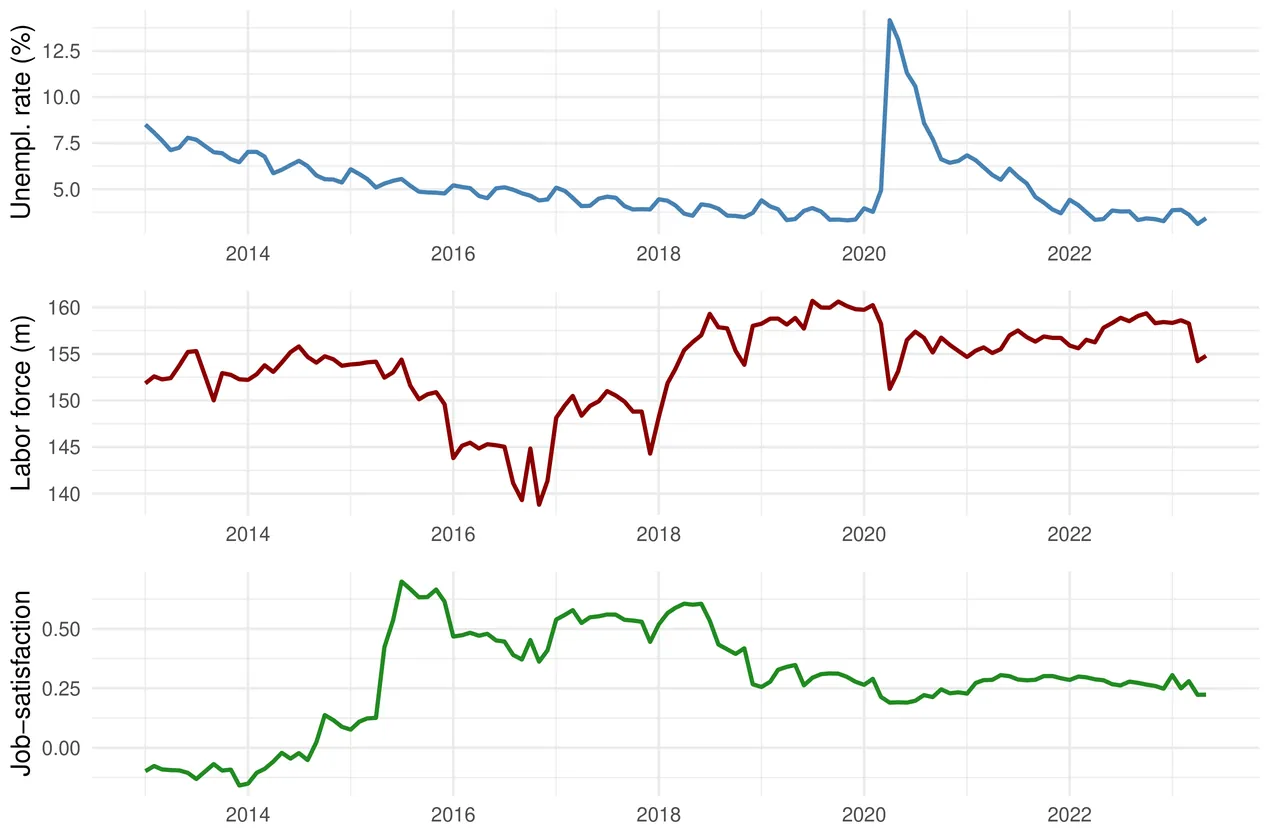
We analyze a novel large-scale social-media-based measure of U.S. job satisfaction, constructed by applying a fine-tuned large language model to 2.6 billion georeferenced tweets, and link it to county-level labor market conditions (2013-2023). Logistic regressions show that rural counties consistently report lower job satisfaction sentiment than urban ones, but this gap decreases under tight labor markets. In contrast to widening rural-urban income disparities, perceived job quality converges when unemployment is low, suggesting that labor market slack, not income alone, drives spatial inequality in subjective work-related well-being.
This paper develops an algorithm to reconstruct large weighted firm-to-firm networks using information about the size of the firms and sectoral input-output flows. Our algorithm is based on a four-step procedure. We first generate a matrix of probabilities of connections between all firms in the economy using an augmented gravity model embedded in a logistic function that takes firm size as mass. The model is parameterized to allow for the probability of a link between two firms to depend not only on their sizes but also on flows across the sectors to which they belong. We then use a Bernoulli draw to construct a directed but unweighted random graph from the probability distribution generated by the logistic-gravity function. We make the graph aperiodic by adding self-loops and irreducible by adding links between Strongly Connected Components while limiting distortions to sectoral flows. We convert the unweighted network to a weighted network by solving a convex quadratic programming problem that minimizes the Euclidean norm of the weights. The solution preserves the observed firm sizes and sectoral flows within reasonable bounds, while limiting the strength of the self-loops. Computationally, the algorithm is O(N2) in the worst case, but it can be evaluated in O(N) via sector-wise binning of firm sizes, albeit with an approximation error. We implement the algorithm to reconstruct the full US production network with more than 5 million firms and 100 million buyer-seller connections. The reconstructed network exhibits topological properties consistent with small samples of the real US buyer-seller networks, including fat-tails in degree distribution, mild clustering, and near-zero reciprocity. We provide open-source code of the algorithm to enable researchers to reconstruct large-scale granular production networks from publicly available data.
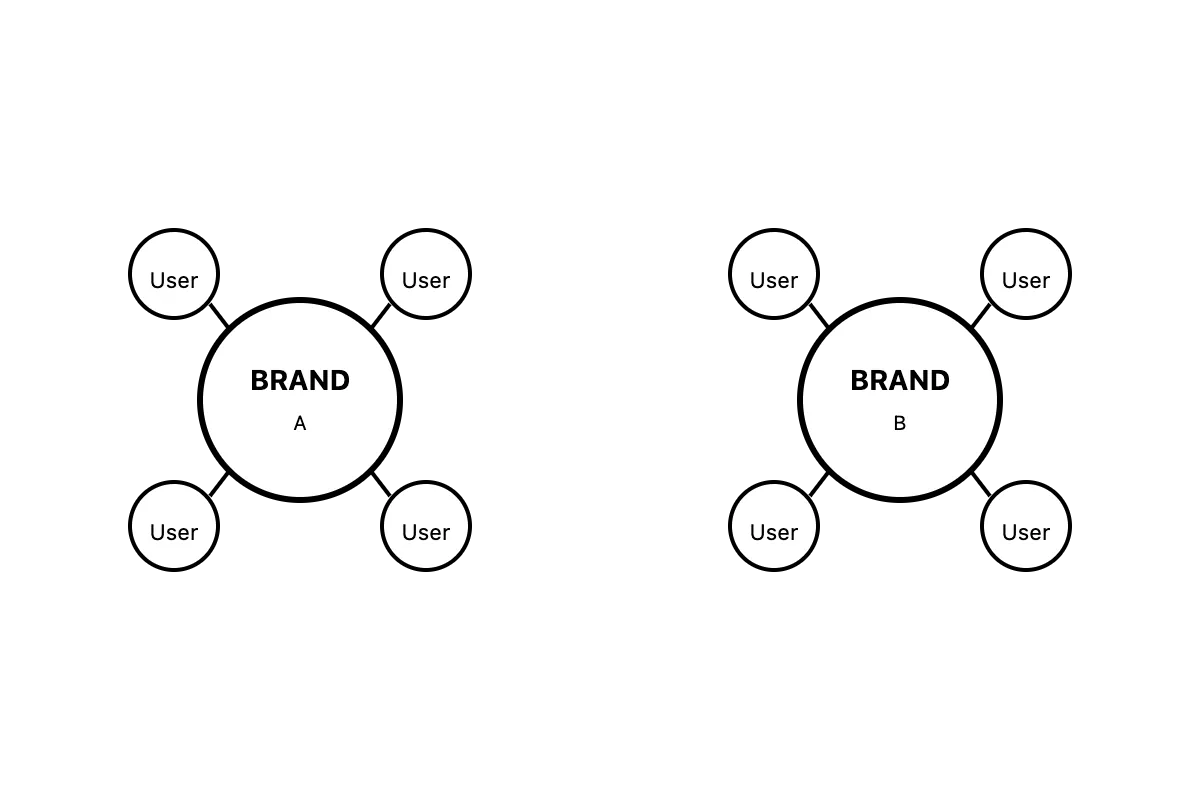
Despite their evolution from early copper-token schemes to sophisticated digital solutions, loyalty programs remain predominantly closed ecosystems, with brands retaining full control over all components. Coalition loyalty programs emerged to enable cross-brand interoperability, but approximately 60\% fail within 10 years in spite of theoretical advantages rooted in network economics. This paper demonstrates that coalition failures stem from fundamental architectural limitations in centralized operator models rather than operational deficiencies, and argues further that neither closed nor coalition systems can scale in intelligence-driven paradigms where AI agents mediate commerce and demand trustless, protocol-based coordination that existing architectures cannot provide. We propose a hybrid framework where brands maintain sovereign control over their programs while enabling cross-brand interoperability through trustless exchange mechanisms. Our framework preserves closed system advantages while enabling open system benefits without the structural problems that doom traditional coalitions. We derive a mathematical pricing model accounting for empirically-validated market factors while enabling fair value exchange across interoperable reward systems.
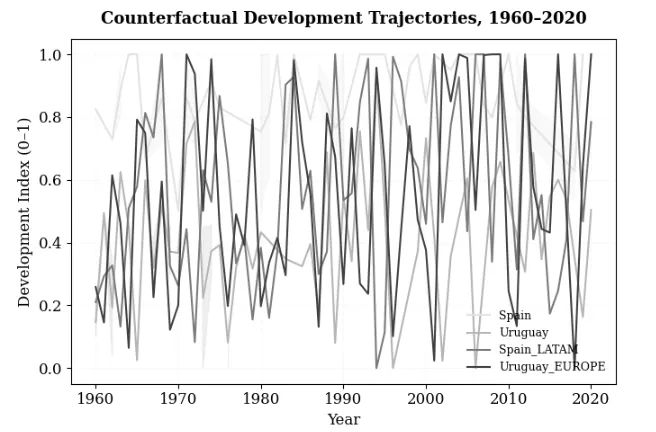
This paper examines how institutional belonging shapes long-term development by comparing Spain and Uruguay, two small democracies with similar historical endowments whose trajectories diverged sharply after the 1960s. While Spain integrated into dense European institutional architectures, Uruguay remained embedded within the Latin American governance regime, characterized by weaker coordination and lower institutional coherence. To assess how alternative institutional embeddings could have altered these paths, the study develops a generative counterfactual framework grounded in economic complexity, institutional path dependence, and a Wasserstein GAN trained on data from 1960-2020. The resulting Expected Developmental Shift (EDS) quantifies structural gains or losses from hypothetical re-embedding in different institutional ecosystems. Counterfactual simulations indicate that Spain would have experienced significant developmental decline under a Latin American configuration, while Uruguay would have achieved higher complexity and resilience within a European regime. These findings suggest that development is not solely determined by domestic reforms but emerges from a country's structural position within transnational institutional networks.
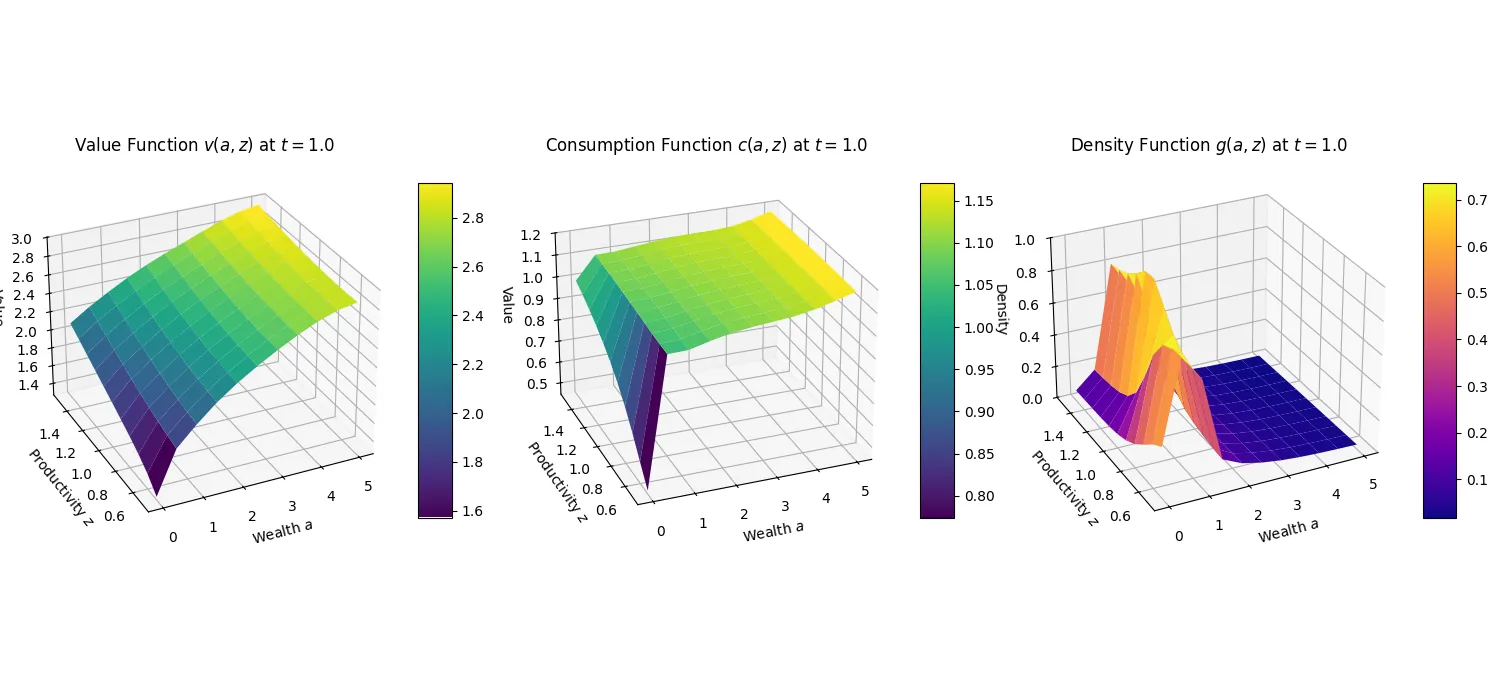
Understanding household behaviour is essential for modelling macroeconomic dynamics and designing effective policy. While heterogeneous agent models offer a more realistic alternative to representative agent frameworks, their implementation poses significant computational challenges, particularly in continuous time. The Aiyagari-Bewley-Huggett (ABH) framework, recast as a system of partial differential equations, typically relies on grid-based solvers that suffer from the curse of dimensionality, high computational cost, and numerical inaccuracies. This paper introduces the ABH-PINN solver, an approach based on Physics-Informed Neural Networks (PINNs), which embeds the Hamilton-Jacobi-Bellman and Kolmogorov Forward equations directly into the neural network training objective. By replacing grid-based approximation with mesh-free, differentiable function learning, the ABH-PINN solver benefits from the advantages of PINNs of improved scalability, smoother solutions, and computational efficiency. Preliminary results show that the PINN-based approach is able to obtain economically valid results matching the established finite-difference solvers.
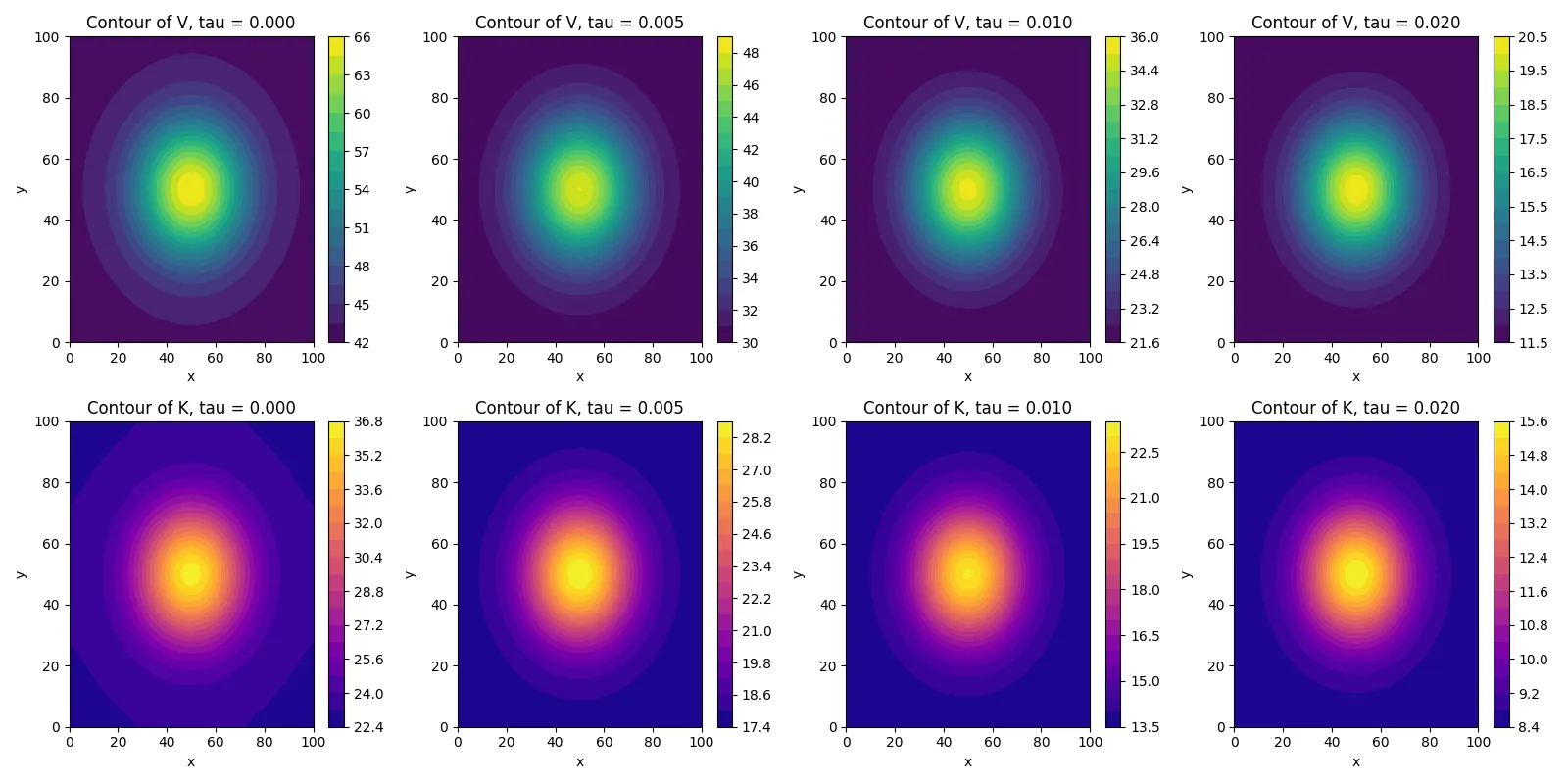
This paper develops a spatial-dynamic framework to analyze the theoretical and quantitative effects of a Land Value Tax (LVT) on urban land markets, capital accumulation, and spatial redistribution. Building upon the Georgist distinction between produced value and unearned rent, the model departs from the static equilibrium tradition by introducing an explicit diffusion process for land values and a local investment dynamic governed by profitability thresholds. Land value $V (x, y, t)$ and built capital $K(x, y, t)$evolve over a two-dimensional urban domain according to coupled nonlinear partial differential equations, incorporating local productivity $A(x, y)$, centrality effects $μ(x, y)$, depreciation $δ$, and fiscal pressure $τ$ . Analytical characterization of the steady states reveals a transcritical bifurcation in the parameter $τ$ , separating inactive (low-investment) and active (self-sustaining) spatial regimes. The equilibrium pair $(V ^*, K^*)$ is shown to exist only when the effective decay rate $α= r + τ- μ(x, y)$ exceeds a profitability threshold $θ= κ+ δ/ I_0$, and becomes locally unstable beyond this boundary. The introduction of diffusion, $D_V ΔV$, stabilizes spatial dynamics and generates continuous gradients of land value and capital intensity, mitigating speculative clustering while preserving productive incentives. Numerical simulations confirm these analytical properties and display the emergence of spatially heterogeneous steady states driven by urban centrality and local productivity. The model also quantifies key aggregate outcomes, including dynamic tax revenues, adjusted capital-to-land ratios, and net present values under spatial heterogeneity and temporal discounting. Sensitivity analyses demonstrate that the main qualitative mechanisms-critical activation, spatial recomposition, and bifurcation structure-remain robust under alternative spatial profiles $(A, μ)$, discretization schemes, and moderate differentiation of the tax rate $τ(x, y)$. From an economic perspective, the results clarify the dual nature of the LVT: while it erodes unproductive rents and speculative land holding, its dynamic incidence on built capital depends on local profitability and financing constraints. The taxation parameter $τ$ thus acts as a control variable in a nonlinear spatial system, shaping transitions between rent-driven and production-driven equilibria. Within a critical range around $τ_c$, the LVT functions as an efficient spatial reallocation operator-reducing inequality in land values and investment density without impairing aggregate productivity. Beyond this range, excessive taxation induces systemic contraction and investment stagnation. Overall, this research bridges static urban tax theory with dynamic spatial economics by formalizing how a land-based fiscal instrument can reshape the geography of value creation through endogenous diffusion and nonlinear feedback. The framework provides a foundation for future extensions involving stochastic shocks, adaptive policy feedbacks, or endogenous public investment, offering a unified quantitative perspective on the dynamic efficiency and spatial equity of land value taxation.
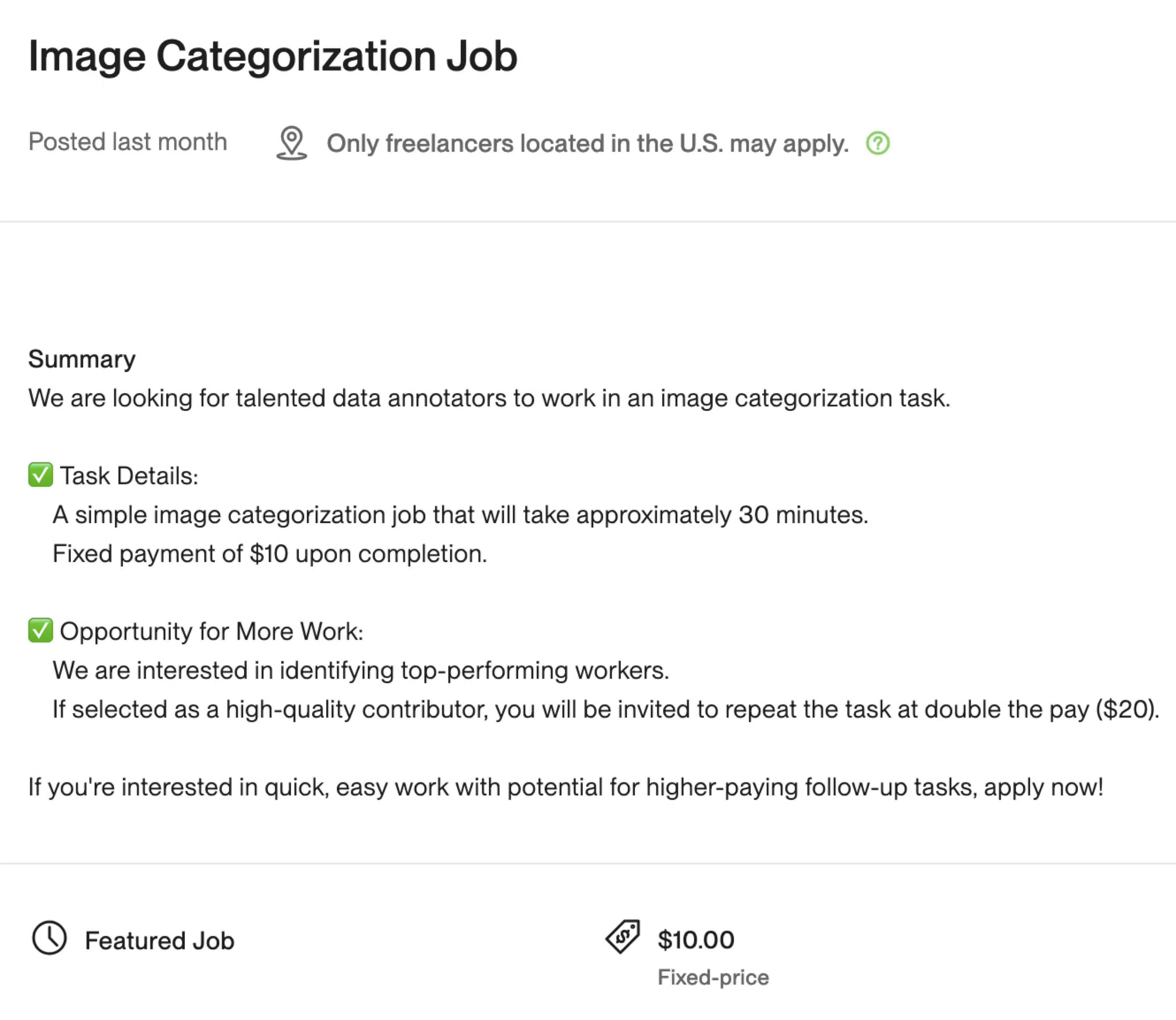
Concerns about how workers are perceived can deter effective collaboration with artificial intelligence (AI). In a field experiment on a large online labor market, I hired 450 U.S.-based remote workers to complete an image-categorization job assisted by AI recommendations. Workers were incentivized by the prospect of a contract extension based on an HR evaluator's feedback. I find that workers adopt AI recommendations at lower rates when their reliance on AI is visible to the evaluator, resulting in a measurable decline in task performance. The effects are present despite a conservative design in which workers know that the evaluator is explicitly instructed to assess expected accuracy on the same AI-assisted task. This reduction in AI reliance persists even when the evaluator is reassured about workers' strong performance history on the platform, underscoring how difficult these concerns are to alleviate. Leveraging the platform's public feedback feature, I introduce a novel incentive-compatible elicitation method showing that workers fear heavy reliance on AI signals a lack of confidence in their own judgment, a trait they view as essential when collaborating with AI.
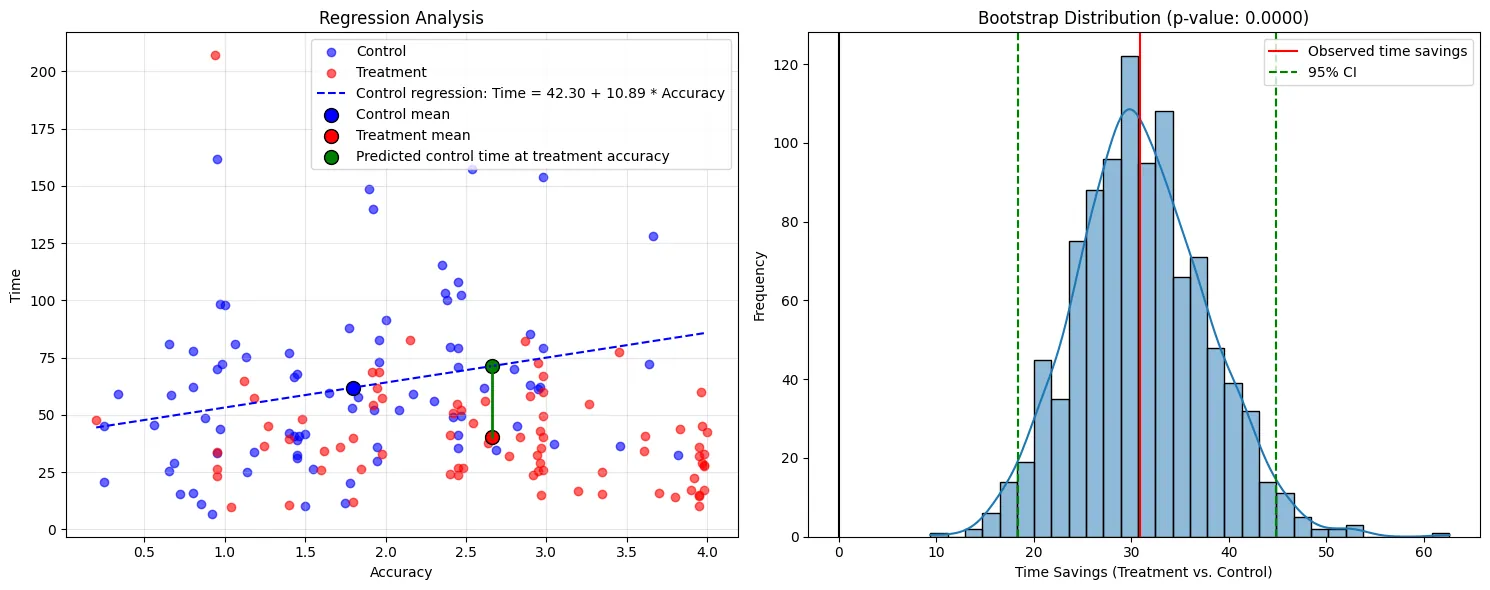
AI agents are increasingly deployed to automate complex enterprise workflows, yet evidence of their effectiveness in identity governance is limited. We report results from the first randomized controlled trial (RCT) evaluating an AI agent for Conditional Access (CA) policy management in Microsoft Entra. The agent assists with four high-value tasks: policy merging, Zero-Trust baseline gap detection, phased rollout planning, and user-policy alignment. In a production-grade environment, 162 identity administrators were randomly assigned to a control group (no agent) or treatment group (agent-assisted) and asked to perform these tasks. Agent access produced substantial gains: accuracy improved by 48% and task completion time decreased by 43% while holding accuracy constant. The largest benefits emerged on cognitively demanding tasks such as baseline gap detection. These findings demonstrate that purpose-built AI agents can significantly enhance both speed and accuracy in identity administration.
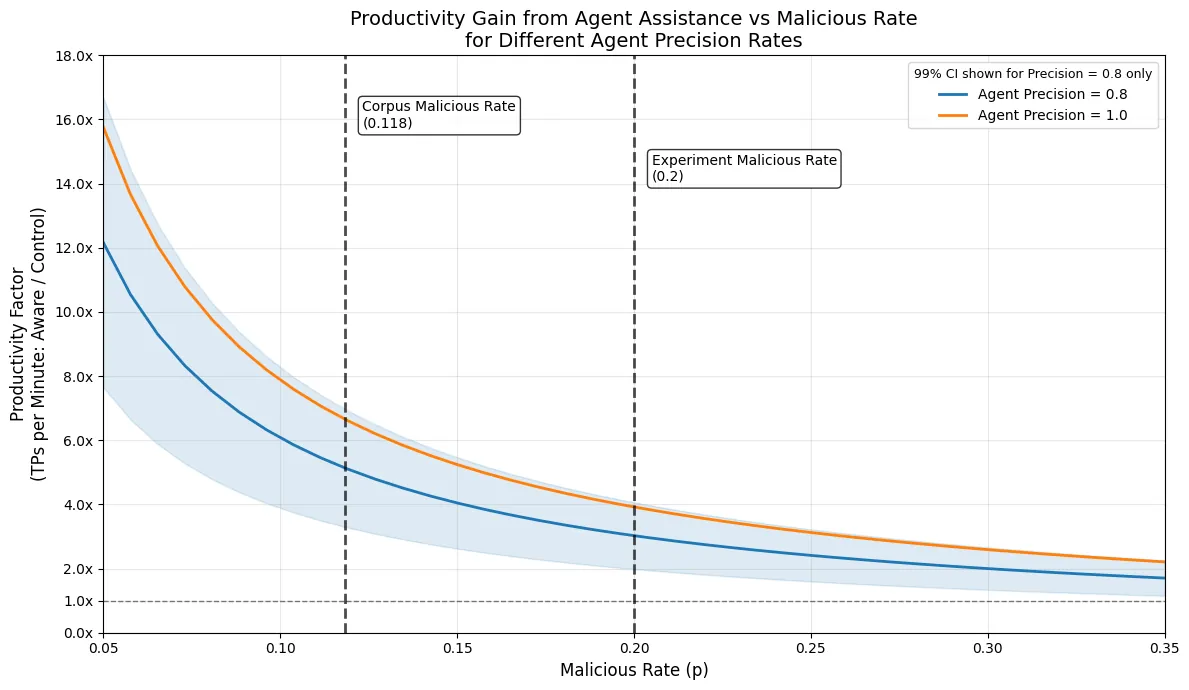
Security operations centers (SOCs) face a persistent challenge: efficiently triaging a high volume of user-reported phishing emails while maintaining robust protection against threats. This paper presents the first randomized controlled trial (RCT) evaluating the impact of a domain-specific AI agent - the Microsoft Security Copilot Phishing Triage Agent - on analyst productivity and accuracy. Our results demonstrate that agent-augmented analysts achieved up to 6.5 times as many true positives per analyst minute and a 77% improvement in verdict accuracy compared to a control group. The agent's queue prioritization and verdict explanations were both significant drivers of efficiency. Behavioral analysis revealed that agent-augmented analysts reallocated their attention, spending 53% more time on malicious emails, and were not prone to rubber-stamping the agent's malicious verdicts. These findings offer actionable insights for SOC leaders considering AI adoption, including the potential for agents to fundamentally change the optimal allocation of SOC resources.
Large language models (LLMs) increasingly mediate economic and organisational processes, from automated customer support and recruitment to investment advice and policy analysis. These systems are often assumed to embody rational decision making free from human error; yet they are trained on human language corpora that may embed cognitive and social biases. This study investigates whether advanced LLMs behave as rational agents or whether they reproduce human behavioural tendencies when faced with classic decision problems. Using two canonical experiments in behavioural economics, the ultimatum game and a gambling game, we elicit decisions from two state of the art models, Google Gemma7B and Qwen, under neutral and gender conditioned prompts. We estimate parameters of inequity aversion and loss-aversion and compare them with human benchmarks. The models display attenuated but persistent deviations from rationality, including moderate fairness concerns, mild loss aversion, and subtle gender conditioned differences.
We present an extended version of the AI Productivity Index (APEX-v1-extended), a benchmark for assessing whether frontier models are capable of performing economically valuable tasks in four jobs: investment banking associate, management consultant, big law associate, and primary care physician (MD). This technical report details the extensions to APEX-v1, including an increase in the held-out evaluation set from n = 50 to n = 100 cases per job (n = 400 total) and updates to the grading methodology. We present a new leaderboard, where GPT5 (Thinking = High) remains the top performing model with a score of 67.0%. APEX-v1-extended shows that frontier models still have substantial limitations when performing typical professional tasks. To support further research, we are open sourcing n = 25 non-benchmark example cases per role (n = 100 total) along with our evaluation harness.
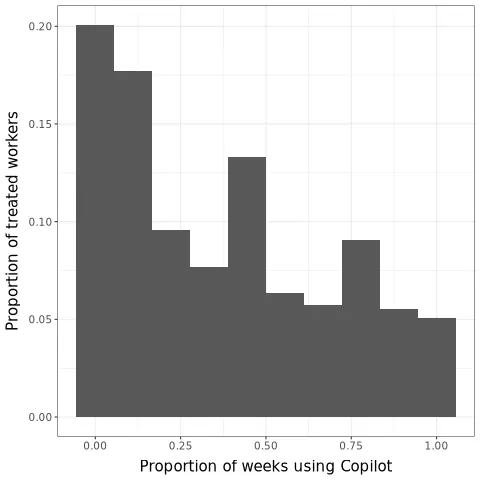
We present evidence from a field experiment across 66 firms and 7,137 knowledge workers. Workers were randomly selected to access a generative AI tool integrated into applications they already used at work for email, meetings, and writing. In the second half of the 6-month experiment, the 80% of treated workers who used this tool spent two fewer hours on email each week and reduced their time working outside of regular hours. Apart from these individual time savings, we do not detect shifts in the quantity or composition of workers' tasks resulting from individual-level AI provision.
We propose a demand estimation method that leverages unstructured text and image data to infer substitution patterns. Using pre-trained deep learning models, we extract embeddings from product images and textual descriptions and incorporate them into a random coefficients logit model. This approach enables researchers to estimate demand even when they lack data on product attributes or when consumers value hard-to-quantify attributes, such as visual design or functional benefits. Using data from a choice experiment, we show that our approach outperforms standard attribute-based models in counterfactual predictions of consumers' second choices. We also apply it across 40 product categories on Amazon and consistently find that text and image data help identify close substitutes within each category.
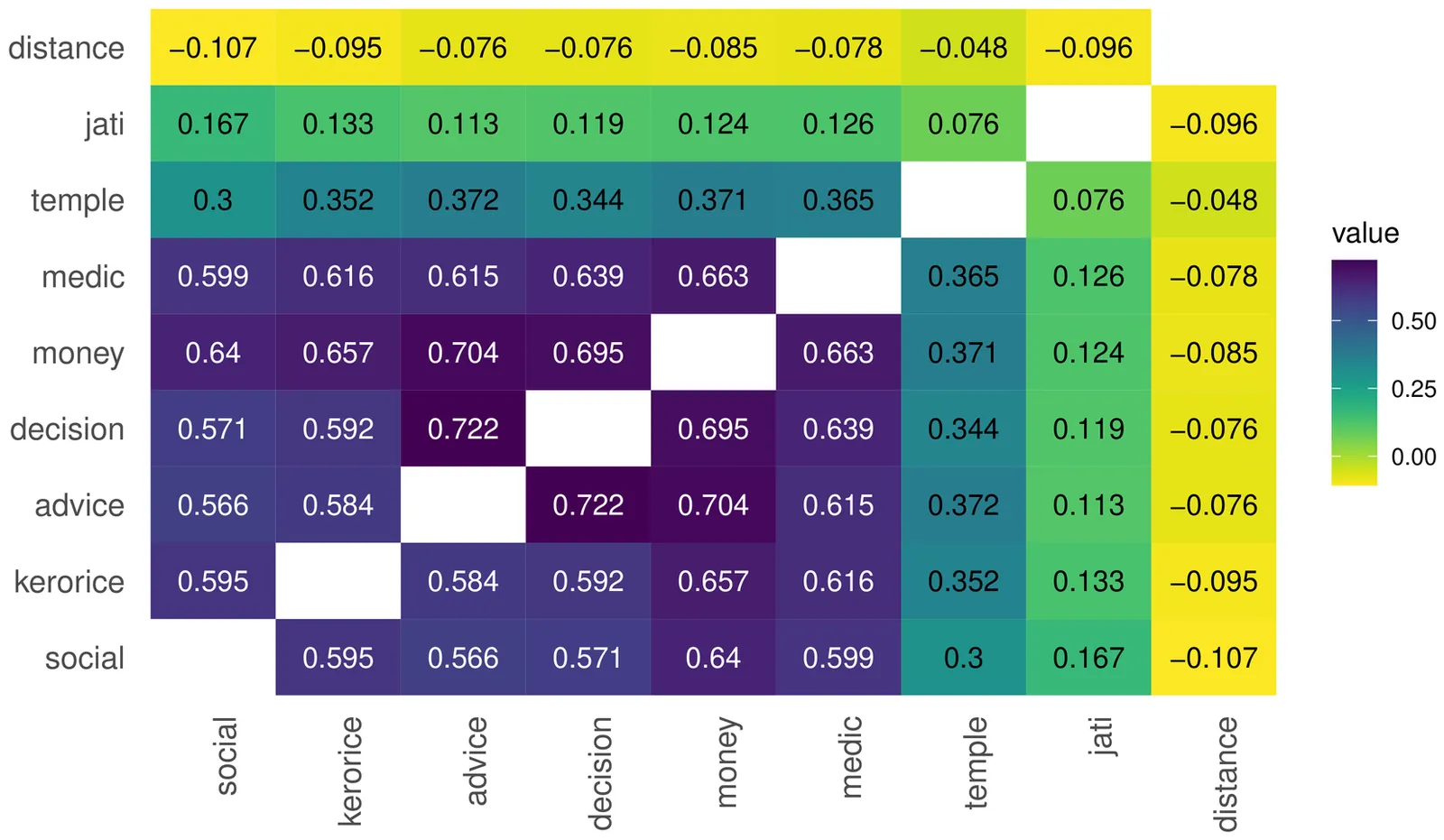
Social and economic networks are often multiplexed, meaning that people are connected by different types of relationships -- such as borrowing goods and giving advice. We make two contributions to the study of multiplexing and the understanding of simple versus complex contagion. On the theoretical side, we introduce a model and theoretical results about diffusion in multiplex networks. We show that multiplexing impedes the spread of simple contagions, such as diseases or basic information that only require one interaction to transmit an infection. We show, however that multiplexing enhances the spread of a complex contagion when infection rates are low, but then impedes complex contagion if infection rates become high. On the empirical side, we document empirical multiplexing patterns in Indian village data. We show that relationships such as socializing, advising, helping, and lending are correlated but distinct, while commonly used proxies for networks based on ethnicity and geography are nearly uncorrelated with actual relationships. We also show that these layers and their overlap affect information diffusion in a field experiment. The advice network is the best predictor of diffusion, but combining layers improves predictions further. Villages with greater overlap between layers -- more multiplexing -- experience less overall diffusion. Finally, we identify differences in multiplexing by gender and connectedness. These have implications for inequality in diffusion-mediated outcomes such as access to information and adherence to norms.
This paper establishes an empirical baseline of public sentiment toward Fourth Industrial Revolution (4IR) technologies across six European countries during the period 2006--2019, prior to the widespread adoption of generative AI systems. Employing transformer-based natural language processing models on a corpus of approximately 90,000 tweets and news articles, I document a European public sphere increasingly divided in its assessment of technological change: neutral sentiment declined markedly over the study period as citizens sorted into camps of enthusiasm and concern, a pattern that manifests distinctively across national contexts and technology domains. Approximately 6\% of users inhabit echo chambers characterized by sentiment-aligned networks, with privacy discourse exhibiting the highest susceptibility to such dynamics. These findings provide a methodologically rigorous reference point for evaluating how the introduction of ChatGPT and subsequent generative AI systems has transformed public discourse on automation, employment, and technological change. The results carry implications for policymakers seeking to align technological governance with societal values in an era of rapid AI advancement.
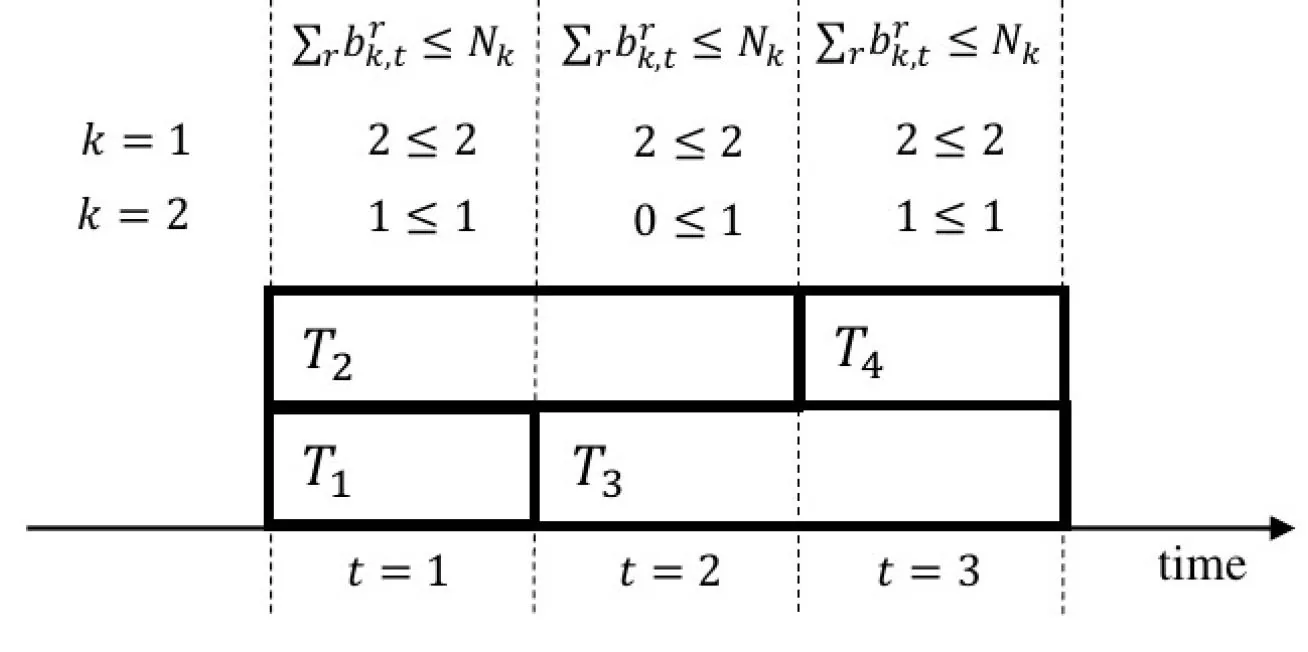
In airport operations, optimally using dedicated personnel for baggage handling tasks plays a crucial role in the design of resource-efficient processes. Teams of workers with different qualifications must be formed, and loading or unloading tasks must be assigned to them. Each task has a time window within which it can be started and should be finished. Violating these temporal restrictions incurs severe financial penalties for the operator. In practice, various components of this process are subject to uncertainties. We consider the aforementioned problem under the assumption of stochastic travel times across the apron. We present two binary program formulations to model the problem at hand and propose a novel solution approach that we call Branch-Price-Cut-and-Switch, in which we dynamically switch between two master problem formulations. Furthermore, we use an exact separation method to identify violated rank-1 Chvátal-Gomory cuts and utilize an efficient branching rule relying on task finish times. We test the algorithm on instances generated based on real-world data from a major European hub airport with a planning horizon of up to two hours, 30 flights per hour, and three available task execution modes to choose from. Our results indicate that our algorithm is able to significantly outperform existing solution approaches. Moreover, an explicit consideration of stochastic travel times allows for solutions that utilize the available workforce more efficiently, while simultaneously guaranteeing a stable service level for the baggage handling operator.
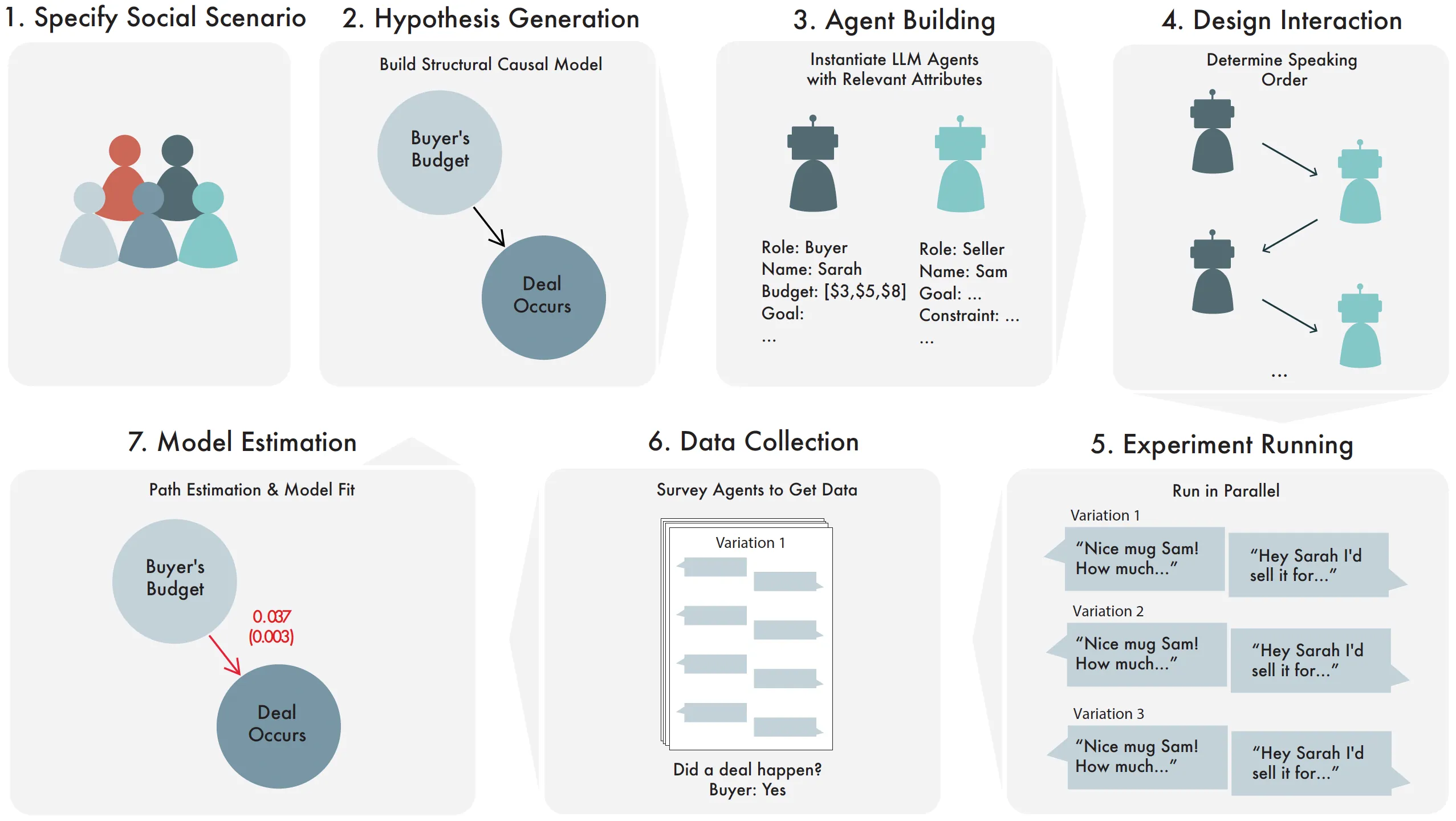
We present an approach for automatically generating and testing, in silico, social scientific hypotheses. This automation is made possible by recent advances in large language models (LLM), but the key feature of the approach is the use of structural causal models. Structural causal models provide a language to state hypotheses, a blueprint for constructing LLM-based agents, an experimental design, and a plan for data analysis. The fitted structural causal model becomes an object available for prediction or the planning of follow-on experiments. We demonstrate the approach with several scenarios: a negotiation, a bail hearing, a job interview, and an auction. In each case, causal relationships are both proposed and tested by the system, finding evidence for some and not others. We provide evidence that the insights from these simulations of social interactions are not available to the LLM purely through direct elicitation. When given its proposed structural causal model for each scenario, the LLM is good at predicting the signs of estimated effects, but it cannot reliably predict the magnitudes of those estimates. In the auction experiment, the in silico simulation results closely match the predictions of auction theory, but elicited predictions of the clearing prices from the LLM are inaccurate. However, the LLM's predictions are dramatically improved if the model can condition on the fitted structural causal model. In short, the LLM knows more than it can (immediately) tell.
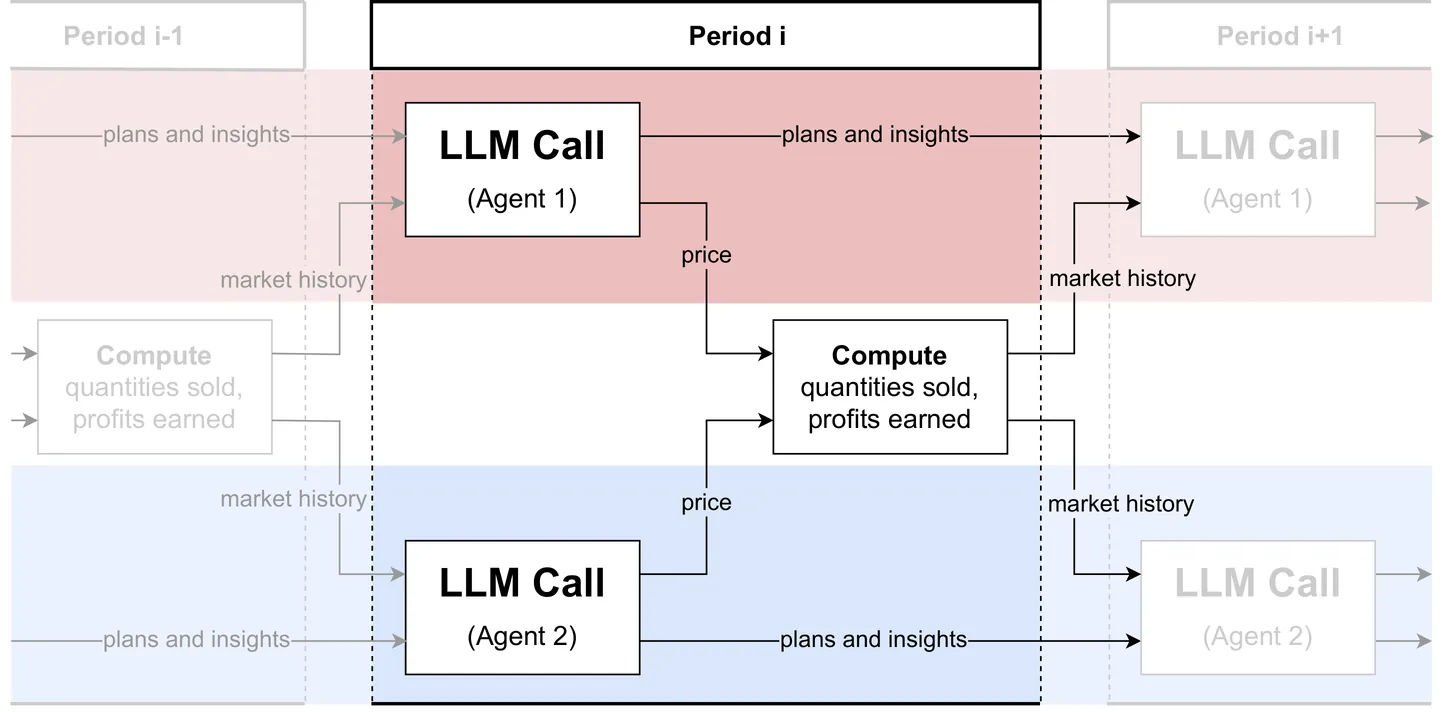
The rise of algorithmic pricing raises concerns of algorithmic collusion. We conduct experiments with algorithmic pricing agents based on Large Language Models (LLMs). We find that LLM-based pricing agents quickly and autonomously reach supracompetitive prices and profits in oligopoly settings and that variation in seemingly innocuous phrases in LLM instructions ("prompts") may substantially influence the degree of supracompetitive pricing. Off-path analysis using novel techniques uncovers price-war concerns as contributing to these phenomena. Our results extend to auction settings. Our findings uncover unique challenges to any future regulation of LLM-based pricing agents, and AI-based pricing agents more broadly.
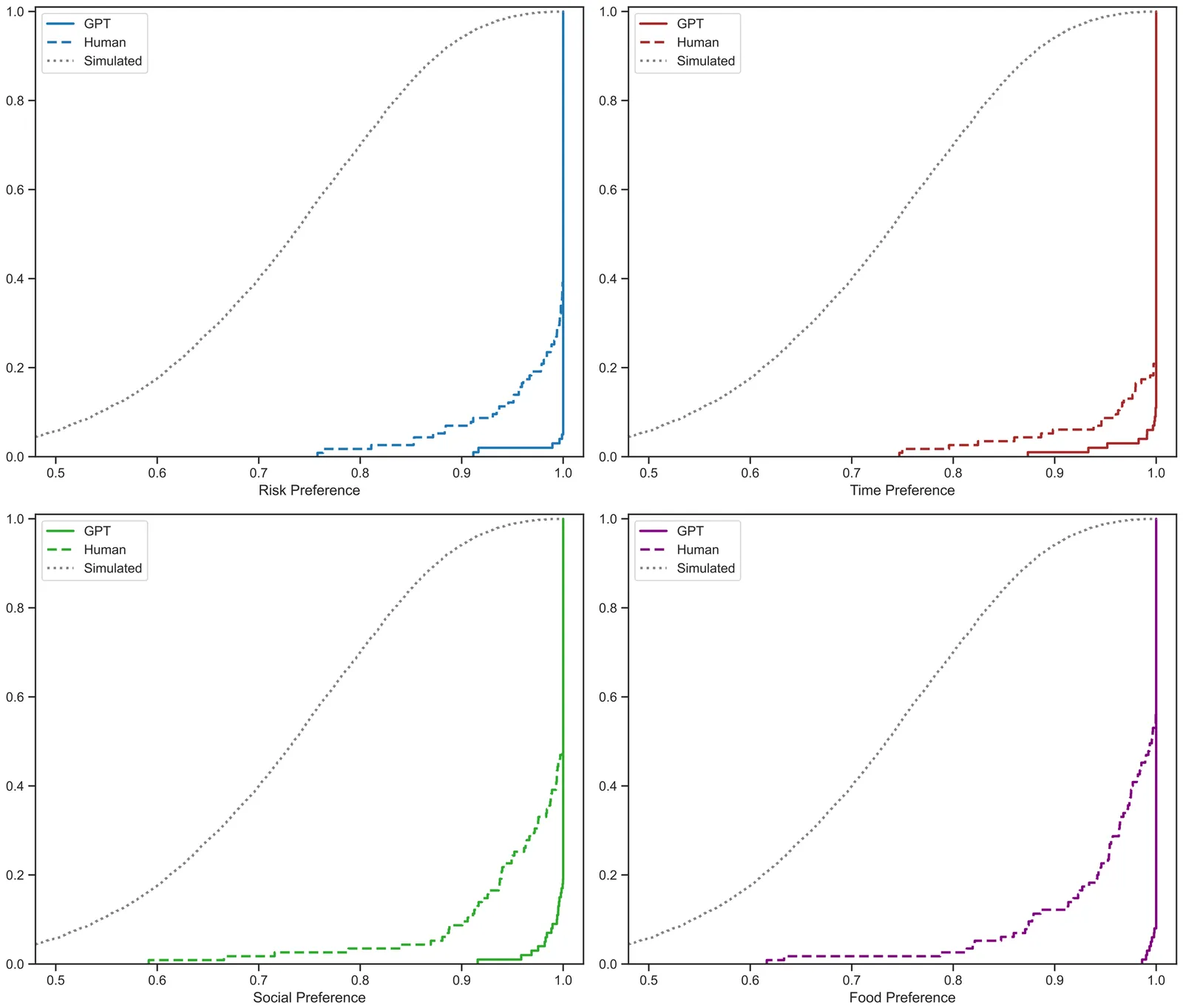
As large language models (LLMs) like GPT become increasingly prevalent, it is essential that we assess their capabilities beyond language processing. This paper examines the economic rationality of GPT by instructing it to make budgetary decisions in four domains: risk, time, social, and food preferences. We measure economic rationality by assessing the consistency of GPT's decisions with utility maximization in classic revealed preference theory. We find that GPT's decisions are largely rational in each domain and demonstrate higher rationality score than those of human subjects in a parallel experiment and in the literature. Moreover, the estimated preference parameters of GPT are slightly different from human subjects and exhibit a lower degree of heterogeneity. We also find that the rationality scores are robust to the degree of randomness and demographic settings such as age and gender, but are sensitive to contexts based on the language frames of the choice situations. These results suggest the potential of LLMs to make good decisions and the need to further understand their capabilities, limitations, and underlying mechanisms.
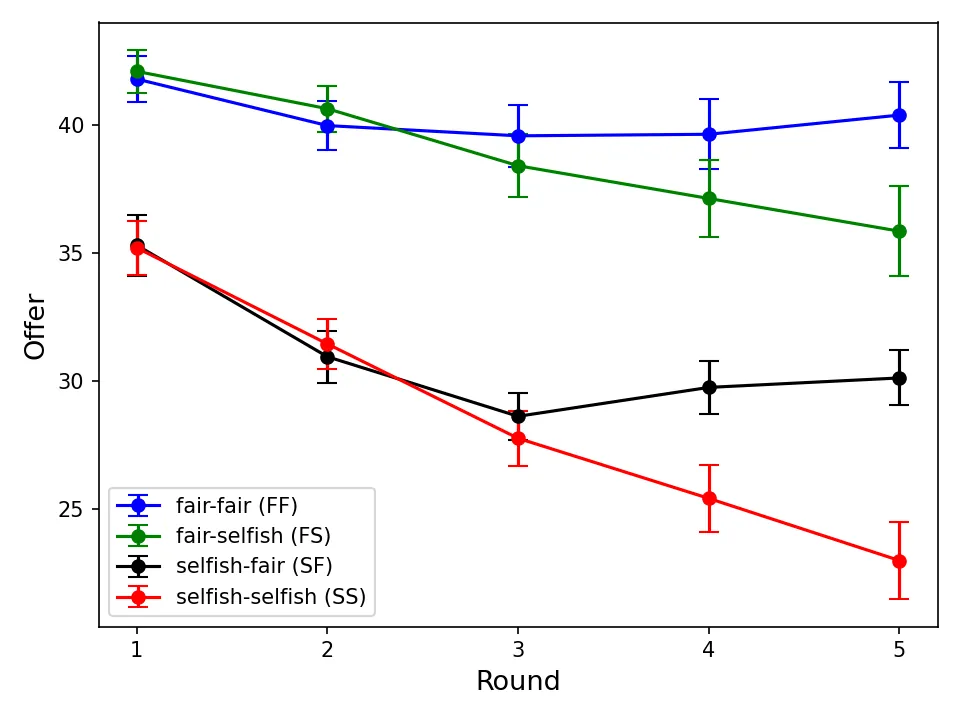
This paper explores the use of Generative Pre-trained Transformers (GPT) in strategic game experiments, specifically the ultimatum game and the prisoner's dilemma. I designed prompts and architectures to enable GPT to understand the game rules and to generate both its choices and the reasoning behind decisions. The key findings show that GPT exhibits behaviours similar to human responses, such as making positive offers and rejecting unfair ones in the ultimatum game, along with conditional cooperation in the prisoner's dilemma. The study explores how prompting GPT with traits of fairness concern or selfishness influences its decisions. Notably, the "fair" GPT in the ultimatum game tends to make higher offers and reject offers more frequently compared to the "selfish" GPT. In the prisoner's dilemma, high cooperation rates are maintained only when both GPT players are "fair". The reasoning statements GPT produces during gameplay reveal the underlying logic of certain intriguing patterns observed in the games. Overall, this research shows the potential of GPT as a valuable tool in social science research, especially in experimental studies and social simulations.
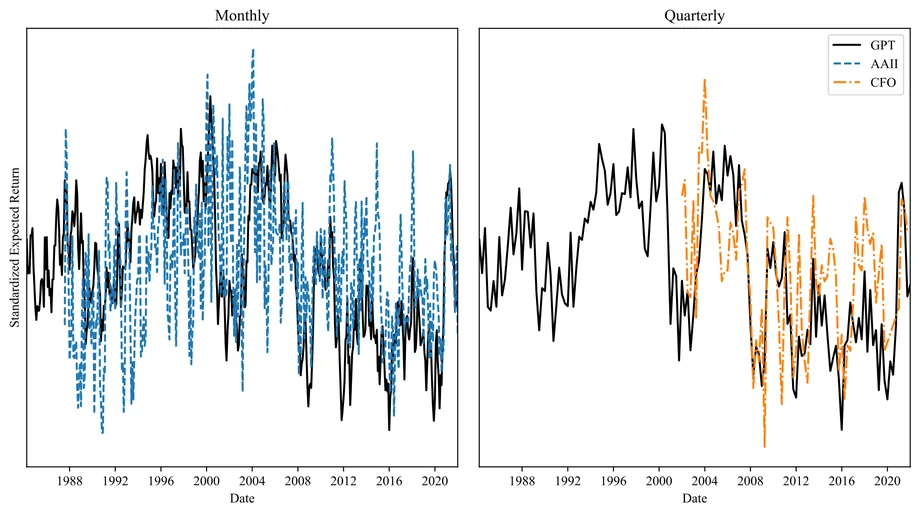
I introduce a survey of economic expectations formed by querying a large language model (LLM)'s expectations of various financial and macroeconomic variables based on a sample of news articles from the Wall Street Journal between 1984 and 2021. I find the resulting expectations closely match existing surveys including the Survey of Professional Forecasters (SPF), the American Association of Individual Investors, and the Duke CFO Survey. Importantly, I document that LLM based expectations match many of the deviations from full-information rational expectations exhibited in these existing survey series. The LLM's macroeconomic expectations exhibit under-reaction commonly found in consensus SPF forecasts. Additionally, its return expectations are extrapolative, disconnected from objective measures of expected returns, and negatively correlated with future realized returns. Finally, using a sample of articles outside of the LLM's training period I find that the correlation with existing survey measures persists -- indicating these results do not reflect memorization but generalization on the part of the LLM. My results provide evidence for the potential of LLMs to help us better understand human beliefs and navigate possible models of nonrational expectations.
We develop empirical models that efficiently process large amounts of unstructured product data (text, images, prices, quantities) to produce accurate hedonic price estimates and derived indices. To achieve this, we generate abstract product attributes (or ``features'') from descriptions and images using deep neural networks. These attributes are then used to estimate the hedonic price function. To demonstrate the effectiveness of this approach, we apply the models to Amazon's data for first-party apparel sales, and estimate hedonic prices. The resulting models have a very high out-of-sample predictive accuracy, with $R^2$ ranging from $80\%$ to $90\%$. Finally, we construct the AI-based hedonic Fisher price index, chained at the year-over-year frequency, and contrast it with the CPI and other electronic indices.
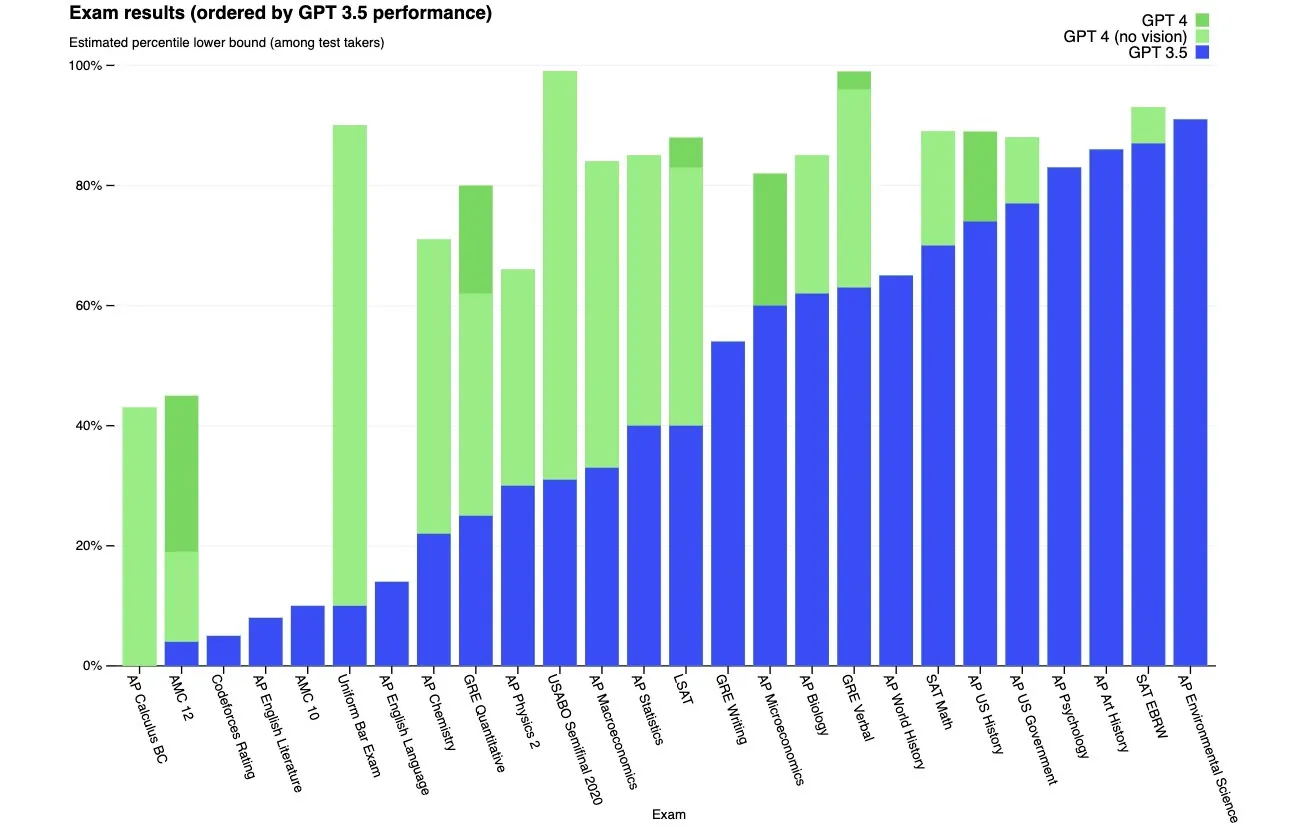
We investigate the potential implications of large language models (LLMs), such as Generative Pre-trained Transformers (GPTs), on the U.S. labor market, focusing on the increased capabilities arising from LLM-powered software compared to LLMs on their own. Using a new rubric, we assess occupations based on their alignment with LLM capabilities, integrating both human expertise and GPT-4 classifications. Our findings reveal that around 80% of the U.S. workforce could have at least 10% of their work tasks affected by the introduction of LLMs, while approximately 19% of workers may see at least 50% of their tasks impacted. We do not make predictions about the development or adoption timeline of such LLMs. The projected effects span all wage levels, with higher-income jobs potentially facing greater exposure to LLM capabilities and LLM-powered software. Significantly, these impacts are not restricted to industries with higher recent productivity growth. Our analysis suggests that, with access to an LLM, about 15% of all worker tasks in the US could be completed significantly faster at the same level of quality. When incorporating software and tooling built on top of LLMs, this share increases to between 47 and 56% of all tasks. This finding implies that LLM-powered software will have a substantial effect on scaling the economic impacts of the underlying models. We conclude that LLMs such as GPTs exhibit traits of general-purpose technologies, indicating that they could have considerable economic, social, and policy implications.

Newly-developed large language models (LLM) -- because of how they are trained and designed -- are implicit computational models of humans -- a homo silicus. These models can be used the same way economists use homo economicus: they can be given endowments, information, preferences, and so on and then their behavior can be explored in scenarios via simulation. I demonstrate this approach using OpenAI's GPT3 with experiments derived from Charness and Rabin (2002), Kahneman, Knetsch and Thaler (1986) and Samuelson and Zeckhauser (1988). The findings are qualitatively similar to the original results, but it is also trivially easy to try variations that offer fresh insights. Departing from the traditional laboratory paradigm, I also create a hiring scenario where an employer faces applicants that differ in experience and wage ask and then analyze how a minimum wage affects realized wages and the extent of labor-labor substitution.

In an infinitely repeated general-sum pricing game, independent reinforcement learners may exhibit collusive behavior without any communication, raising concerns about algorithmic collusion. To better understand the learning dynamics, we incorporate agents' relative performance (RP) among competitors using experience replay (ER) techniques. Experimental results indicate that RP considerations play a critical role in long-run outcomes. Agents that are averse to underperformance converge to the Bertrand-Nash equilibrium, while those more tolerant of underperformance tend to charge supra-competitive prices. This finding also helps mitigate the overfitting issue in independent Q-learning. Additionally, the impact of relative ER varies with the number of agents and the choice of algorithms.
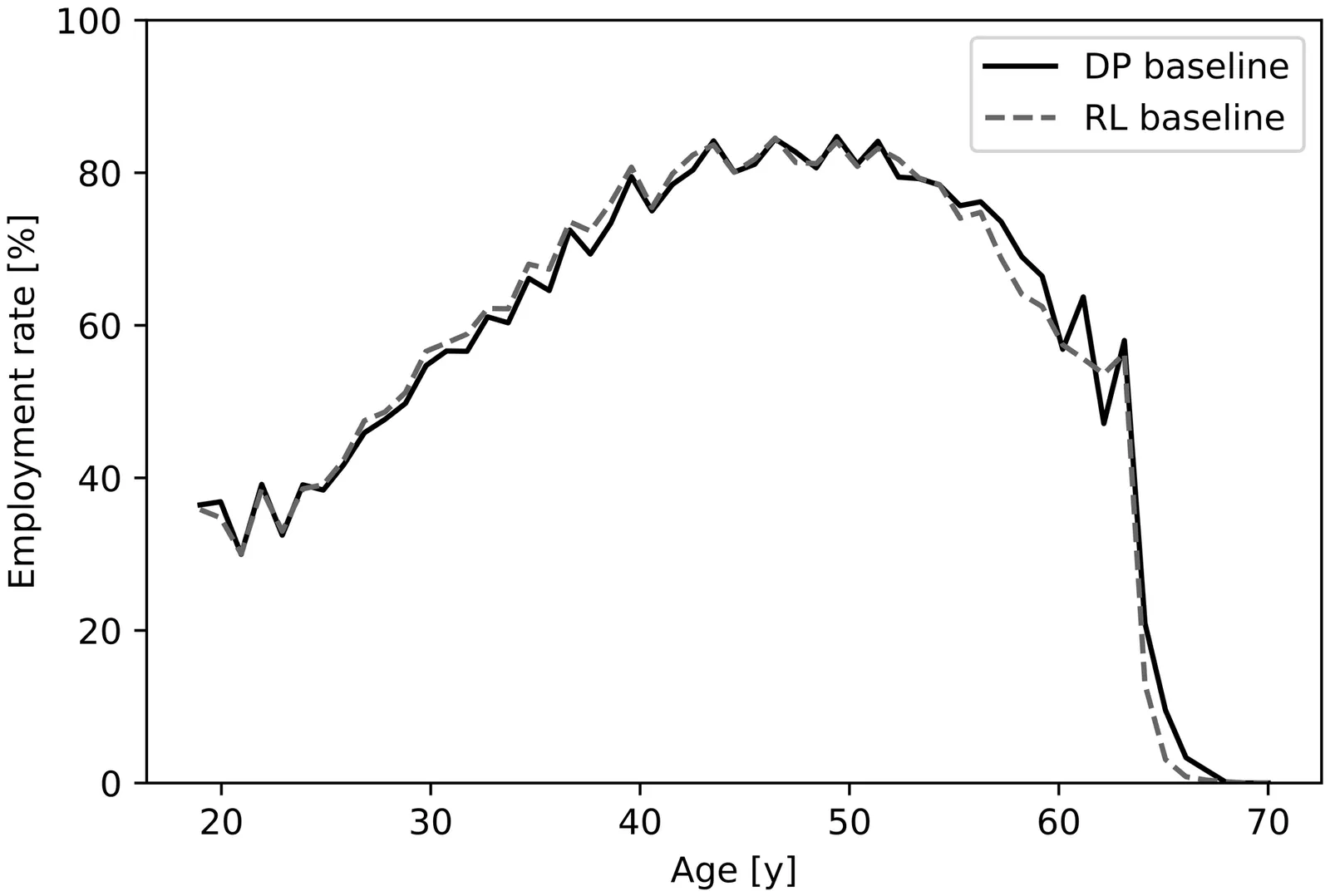
Discrete-choice life cycle models of labor supply can be used to estimate how social security reforms influence employment rate. In a life cycle model, optimal employment choices during the life course of an individual must be solved. Mostly, life cycle models have been solved with dynamic programming, which is not feasible when the state space is large, as often is the case in a realistic life cycle model. Solving a complex life cycle model requires the use of approximate methods, such as reinforced learning algorithms. We compare how well a deep reinforced learning algorithm ACKTR and dynamic programming solve a relatively simple life cycle model. To analyze results, we use a selection of statistics and also compare the resulting optimal employment choices at various states. The statistics demonstrate that ACKTR yields almost as good results as dynamic programming. Qualitatively, dynamic programming yields more spiked aggregate employment profiles than ACKTR. The results obtained with ACKTR provide a good, yet not perfect, approximation to the results of dynamic programming. In addition to the baseline case, we analyze two social security reforms: (1) an increase of retirement age, and (2) universal basic income. Our results suggest that reinforced learning algorithms can be of significant value in developing social security reforms.