Trending in Applied Statistics
Statistical Reinforcement Learning in the Real World: A Survey of Challenges and Future Directions
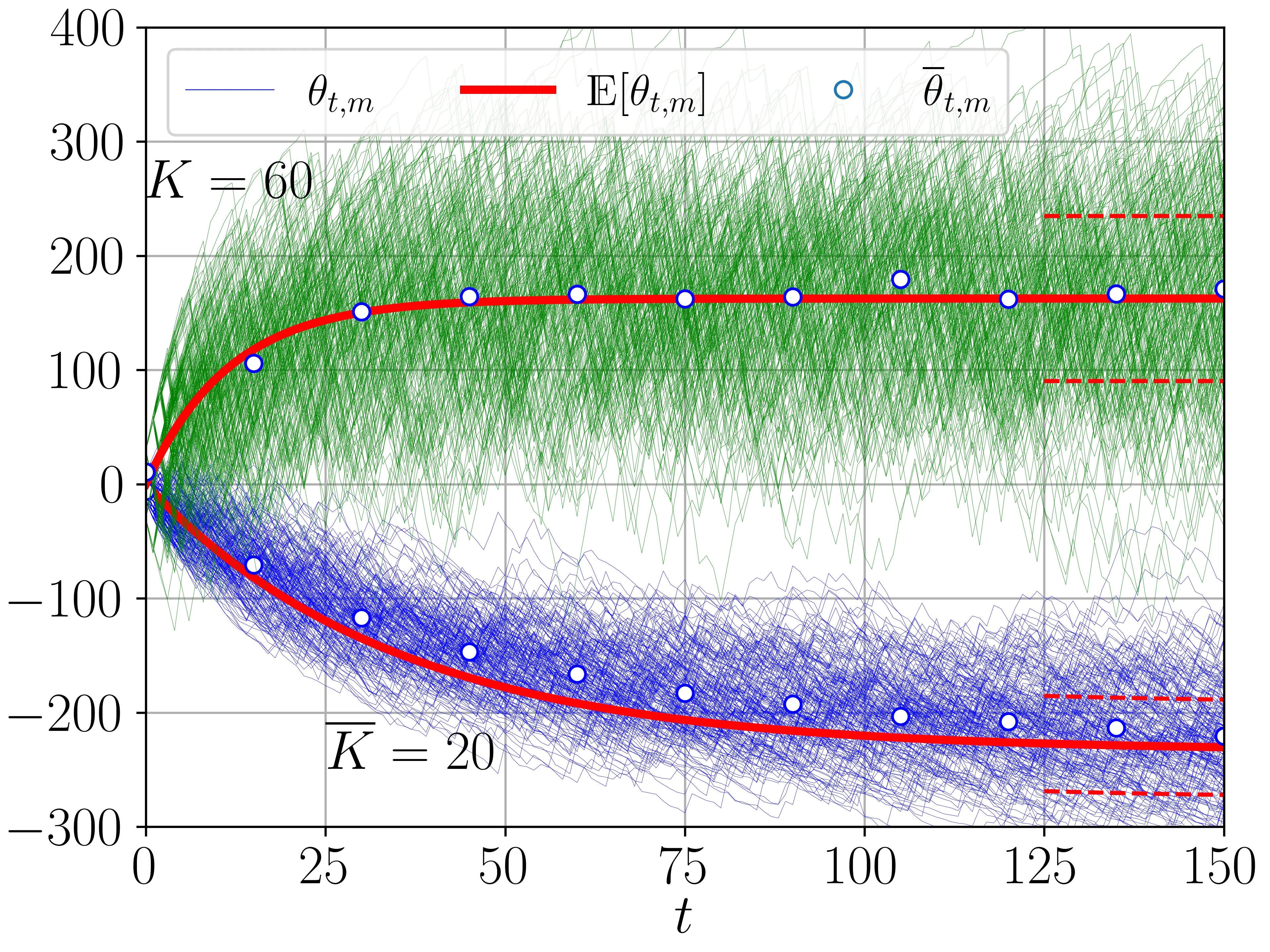
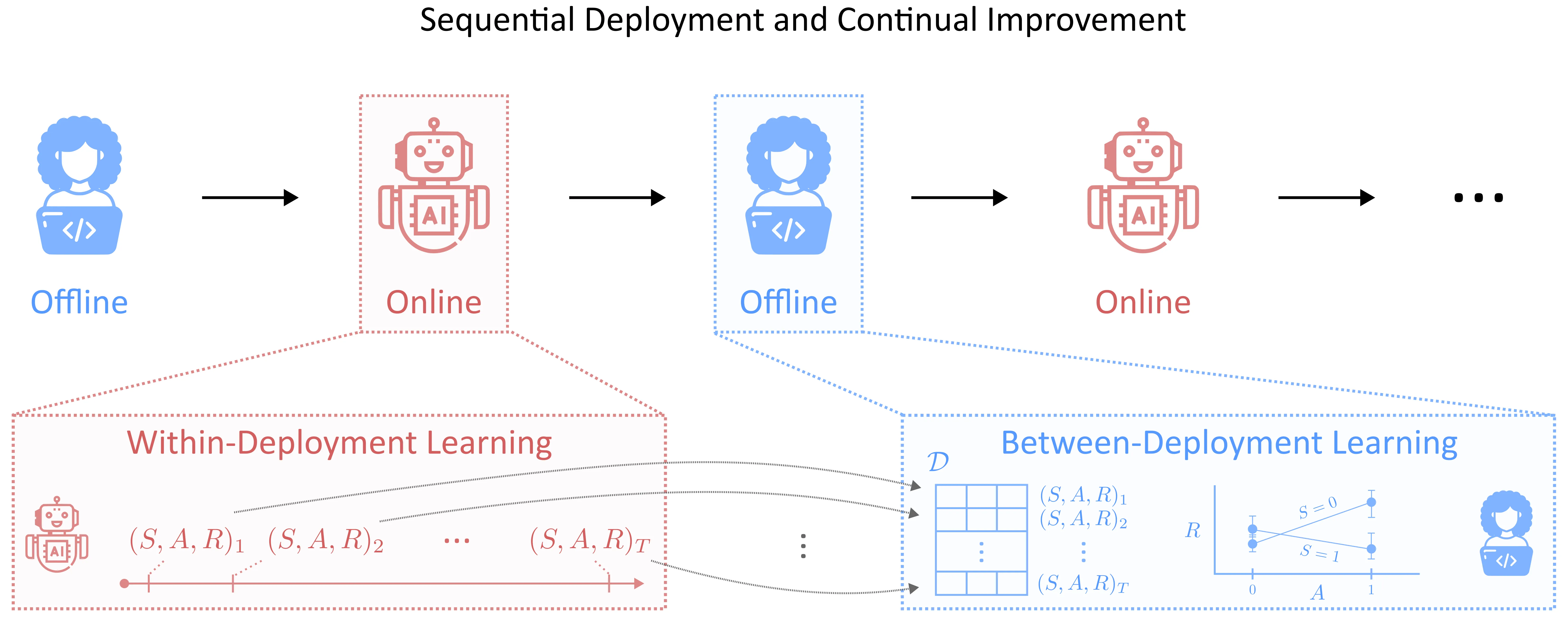
Reinforcement learning (RL) has achieved remarkable success in real-world decision-making across diverse domains, including gaming, robotics, online advertising, public health, and natural language processing. Despite these advances, a substantial gap remains between RL research and its deployment in many practical settings. Two recurring challenges often underlie this gap. First, many settings offer limited opportunity for the agent to interact extensively with the target environment due to practical constraints. Second, many target environments often undergo substantial changes, requiring redesign and redeployment of RL systems (e.g., advancements in science and technology that change the landscape of healthcare delivery). Addressing these challenges and bridging the gap between basic research and application requires theory and methodology that directly inform the design, implementation, and continual improvement of RL systems in real-world settings. In this paper, we frame the application of RL in practice as a three-component process: (i) online learning and optimization during deployment, (ii) post- or between-deployment offline analyses, and (iii) repeated cycles of deployment and redeployment to continually improve the RL system. We provide a narrative review of recent advances in statistical RL that address these components, including methods for maximizing data utility for between-deployment inference, enhancing sample efficiency for online learning within-deployment, and designing sequences of deployments for continual improvement. We also outline future research directions in statistical RL that are use-inspired -- aiming for impactful application of RL in practice.
2601.15353
Jan 2026Applications
Robust Bayesian Optimization via Tempered Posteriors
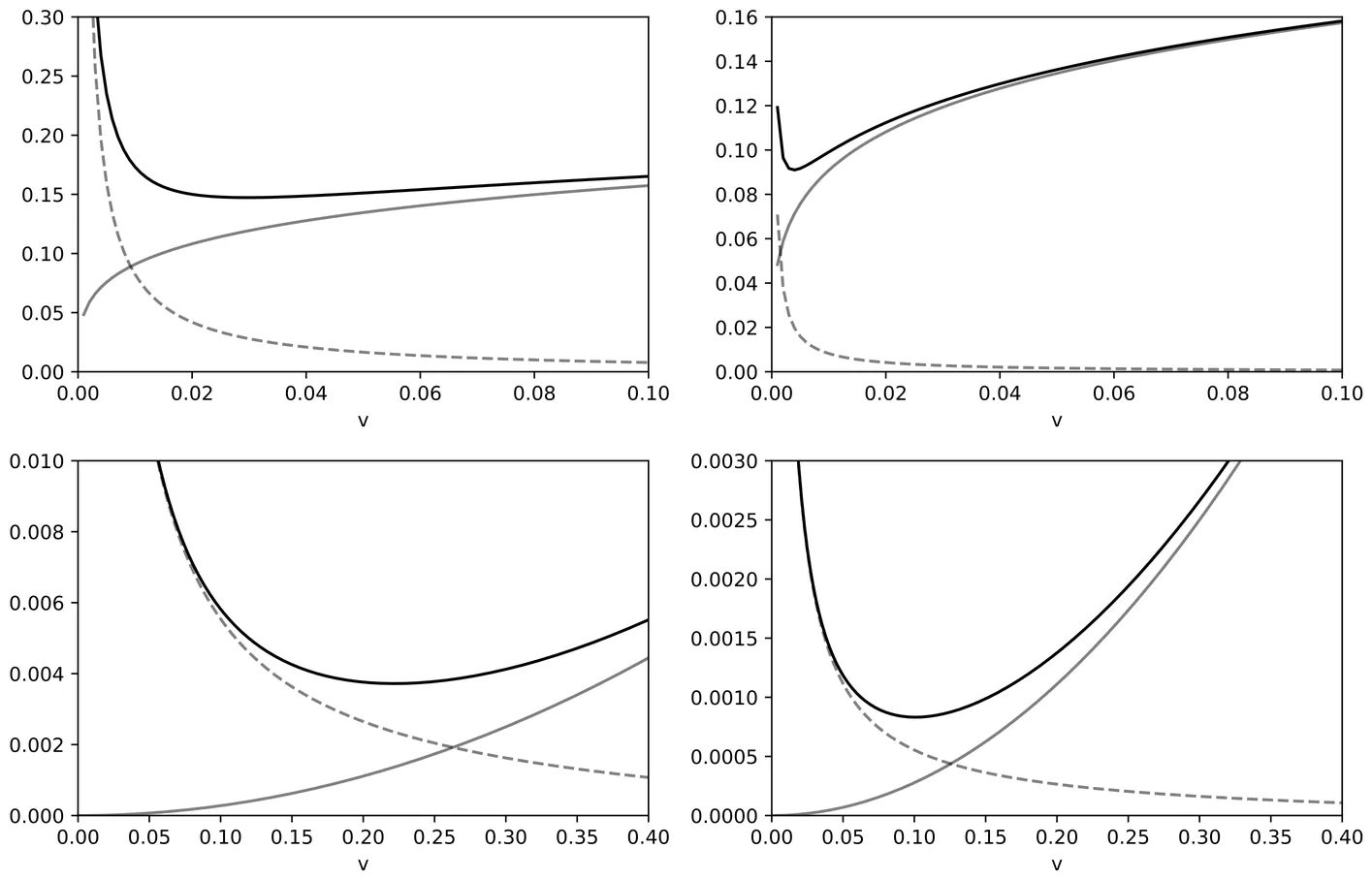
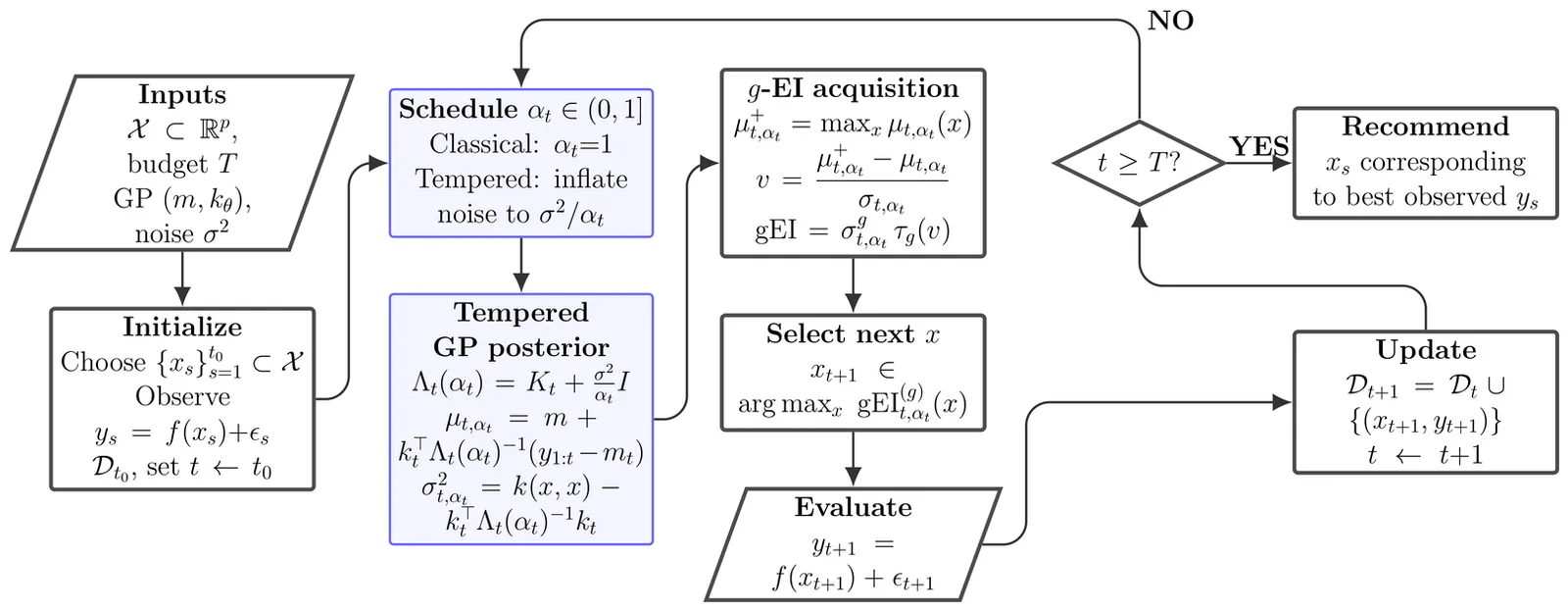
Bayesian optimization (BO) iteratively fits a Gaussian process (GP) surrogate to accumulated evaluations and selects new queries via an acquisition function such as expected improvement (EI). In practice, BO often concentrates evaluations near the current incumbent, causing the surrogate to become overconfident and to understate predictive uncertainty in the region guiding subsequent decisions. We develop a robust GP-based BO via tempered posterior updates, which downweight the likelihood by a power $α\in (0,1]$ to mitigate overconfidence under local misspecification. We establish cumulative regret bounds for tempered BO under a family of generalized improvement rules, including EI, and show that tempering yields strictly sharper worst-case regret guarantees than the standard posterior $(α=1)$, with the most favorable guarantees occurring near the classical EI choice. Motivated by our theoretic findings, we propose a prequential procedure for selecting $α$ online: it decreases $α$ when realized prediction errors exceed model-implied uncertainty and returns $α$ toward one as calibration improves. Empirical results demonstrate that tempering provides a practical yet theoretically grounded tool for stabilizing BO surrogates under localized sampling.
2601.07094
Jan 2026Methodology
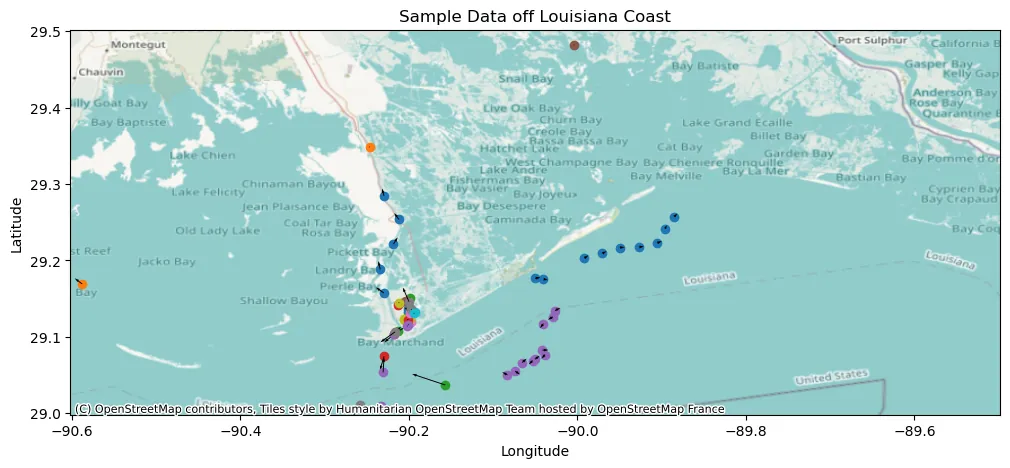
Maritime Vessel Tracking
The Automatic Identification System (AIS) provides time stamped vessel positions and kinematic reports that enable maritime authorities to monitor traffic. We consider the problem of relabeling AIS trajectories when vessel identifiers are missing, focusing on a challenging nationwide setting in which tracks are heavily downsampled and span diverse operating environments across continental U.S. waters. We propose a hybrid pipeline that first applies a physics-based screening step to project active track endpoints forward in time and select a small set of plausible ancestors for each new observation. A supervised neural classifier then chooses among these candidates, or initiates a new track, using engineered space time and kinematic consistency features. On held out data, this approach improves posit accuracy relative to unsupervised baselines, demonstrating that combining simple motion models with learned disambiguation can scale vessel relabeling to heterogeneous, high volume AIS streams.
2512.11707
Dec 2025Applications
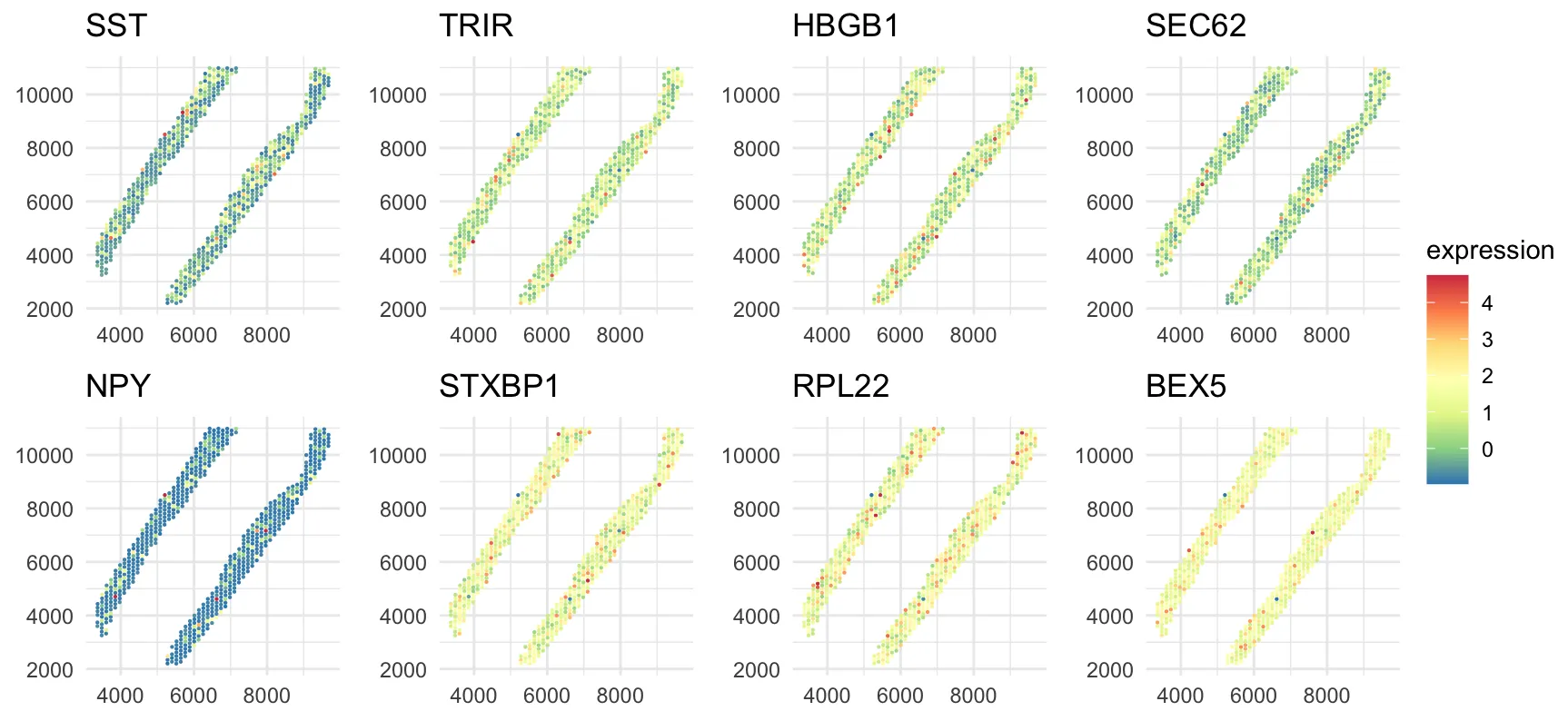
Spatially Varying Gene Regulatory Networks via Bayesian Nonparametric Covariate-Dependent Directed Cyclic Graphical Models
Spatial transcriptomics technologies enable the measurement of gene expression with spatial context, providing opportunities to understand how gene regulatory networks vary across tissue regions. However, existing graphical models focus primarily on undirected graphs or directed acyclic graphs, limiting their ability to capture feedback loops that are prevalent in gene regulation. Moreover, ensuring the so-called stability condition of cyclic graphs, while allowing graph structures to vary continuously with spatial covariates, presents significant statistical and computational challenges. We propose BNP-DCGx, a Bayesian nonparametric approach for learning spatially varying gene regulatory networks via covariate-dependent directed cyclic graphical models. Our method introduces a covariate-dependent random partition as an intermediary layer in a hierarchical model, which discretizes the covariate space into clusters with cluster-specific stable directed cyclic graphs. Through partition averaging, we obtain smoothly varying graph structures over space while maintaining theoretical guarantees of stability. We develop an efficient parallel tempered Markov chain Monte Carlo algorithm for posterior inference and demonstrate through simulations that our method accurately recovers both piecewise constant and continuously varying graph structures. Application to spatial transcriptomics data from human dorsolateral prefrontal cortex reveals spatially varying regulatory networks with feedback loops, identifies potential cell subtypes within established cell types based on distinct regulatory mechanisms, and provides new insights into spatial organization of gene regulation in brain tissue.
2512.11732
Dec 2025Methodology
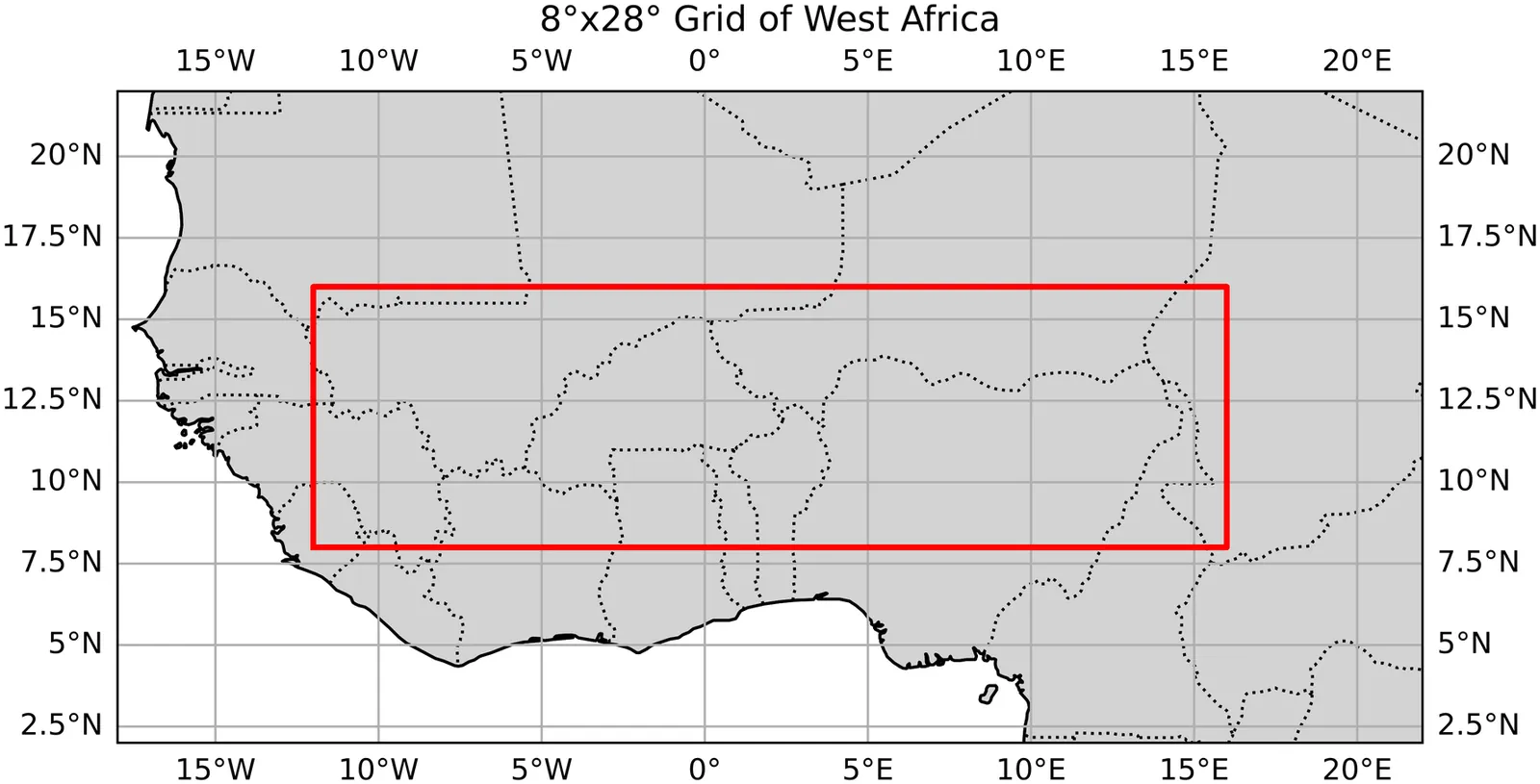
Predicting Onsets and Dry Spells of the West African Monsoon Season Using Machine Learning Methods
The beginning of the rainy season and the occurrence of dry spells in West Africa is notoriously difficult to predict, however these are the key indicators farmers use to decide when to plant crops, having a major influence on their overall yield. While many studies have shown correlations between global sea surface temperatures and characteristics of the West African monsoon season, there are few that effectively implementing this information into machine learning (ML) prediction models. In this study we investigated the best ways to define our target variables, onset and dry spell, and produced methods to predict them for upcoming seasons using sea surface temperature teleconnections. Defining our target variables required the use of a combination of two well known definitions of onset. We then applied custom statistical techniques -- like total variation regularization and predictor selection -- to the two models we constructed, the first being a linear model and the other an adaptive-threshold logistic regression model. We found mixed results for onset prediction, with spatial verification showing signs of significant skill, while temporal verification showed little to none. For dry spell though, we found significant accuracy through the analysis of multiple binary classification metrics. These models overcome some limitations that current approaches have, such as being computationally intensive and needing bias correction. We also introduce this study as a framework to use ML methods for targeted prediction of certain weather phenomenon using climatologically relevant variables. As we apply ML techniques to more problems, we see clear benefits for fields like meteorology and lay out a few new directions for further research.
2512.01965
Dec 2025Applications