Trending in Econometrics
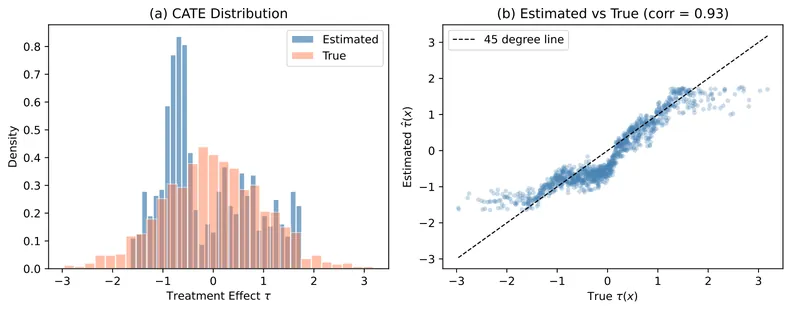
causalfe: Causal Forests with Fixed Effects in Python
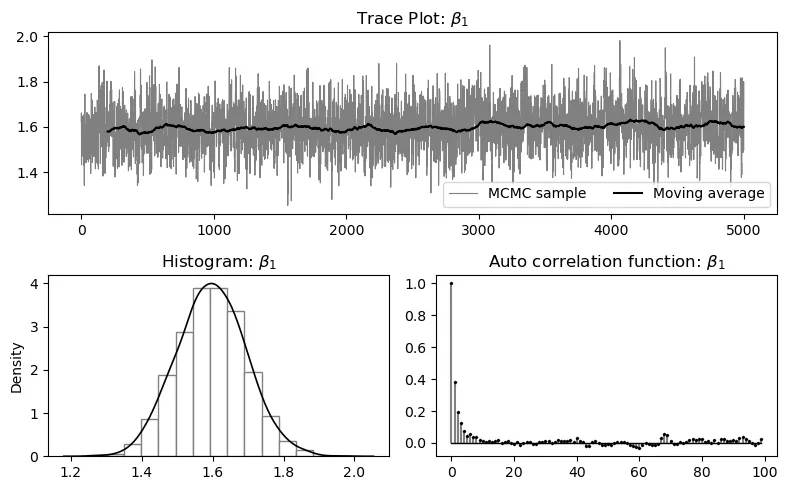
The causalfe package provides a Python implementation of Causal Forests with Fixed Effects (CFFE) for estimating heterogeneous treatment effects in panel data settings. Standard causal forest methods struggle with panel data because unit and time fixed effects induce spurious heterogeneity in treatment effect estimates. The CFFE approach addresses this by performing node-level residualization during tree construction, removing fixed effects within each candidate split rather than globally. This paper describes the methodology, documents the software interface, and demonstrates the package through simulation studies that validate the estimator's performance under various data generating processes.
2601.10555
Jan 2026Econometrics
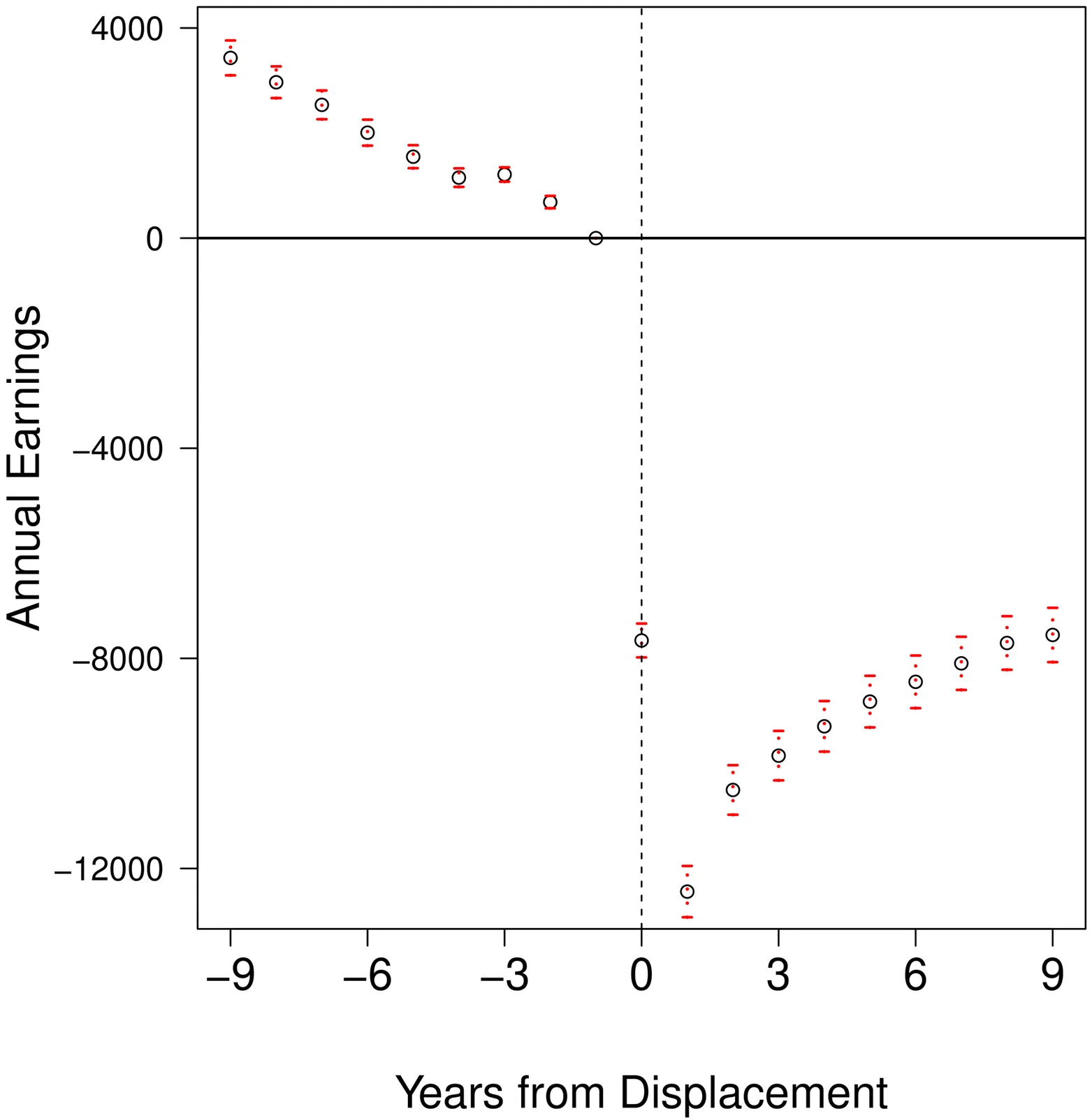
Estimating Treatment Effects in Panel Data Without Parallel Trends
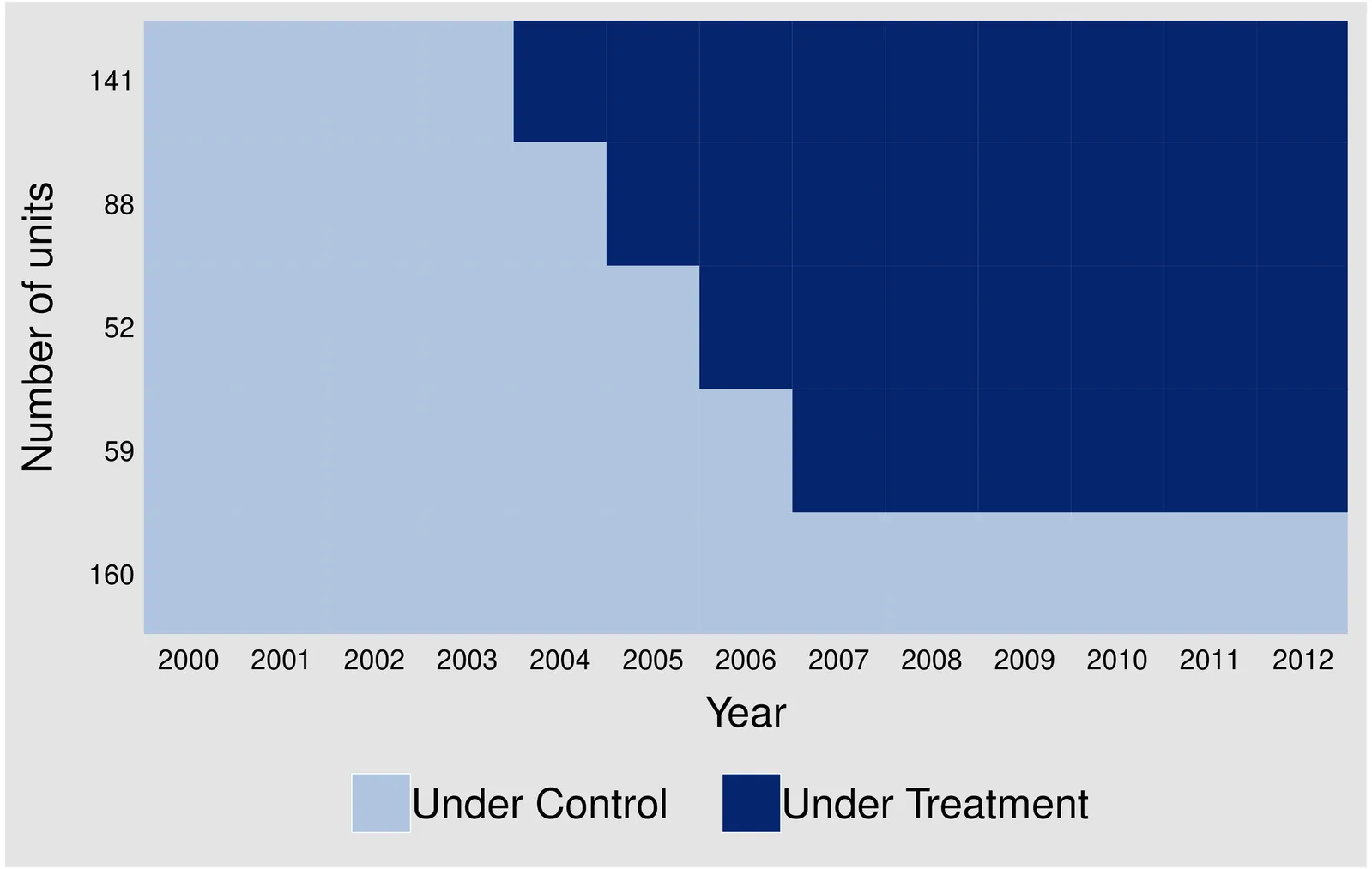
This paper proposes a novel approach for estimating treatment effects in panel data settings, addressing key limitations of the standard difference-in-differences (DID) approach. The standard approach relies on the parallel trends assumption, implicitly requiring that unobservable factors correlated with treatment assignment be unidimensional, time-invariant, and affect untreated potential outcomes in an additively separable manner. This paper introduces a more flexible framework that allows for multidimensional unobservables and non-additive separability, and provides sufficient conditions for identifying the average treatment effect on the treated. An empirical application to job displacement reveals substantially smaller long-run earnings losses compared to the standard DID approach, demonstrating the framework's ability to account for unobserved heterogeneity that manifests as differential outcome trajectories between treated and control groups.
2601.08281
Jan 2026Econometrics