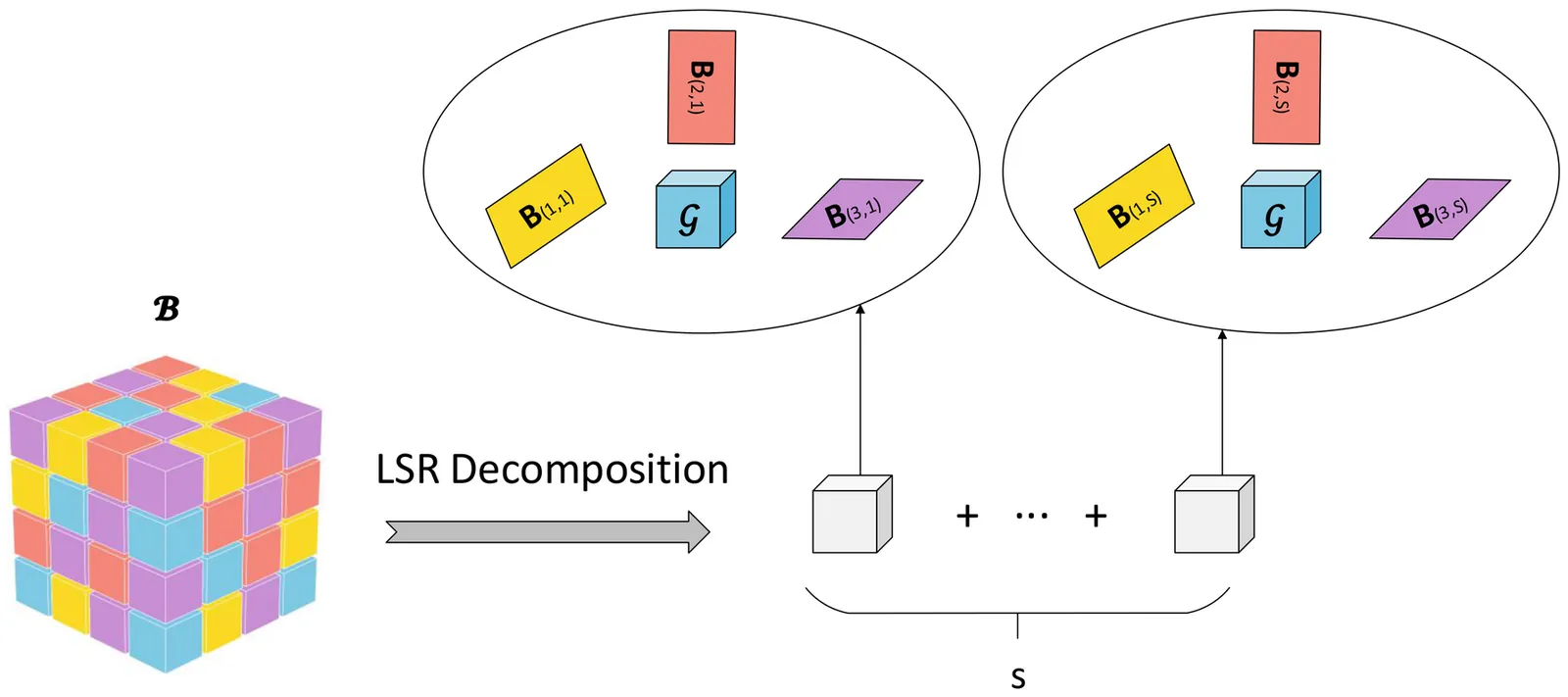
Trending in Statistical Learning
Harnessing Synthetic Data from Generative AI for Statistical Inference
The emergence of generative AI models has dramatically expanded the availability and use of synthetic data across scientific, industrial, and policy domains. While these developments open new possibilities for data analysis, they also raise fundamental statistical questions about when synthetic data can be used in a valid, reliable, and principled manner. This paper reviews the current landscape of synthetic data generation and use from a statistical perspective, with the goal of clarifying the assumptions under which synthetic data can meaningfully support downstream discovery, inference, and prediction. We survey major classes of modern generative models, their intended use cases, and the benefits they offer, while also highlighting their limitations and characteristic failure modes. We additionally examine common pitfalls that arise when synthetic data are treated as surrogates for real observations, including biases from model misspecification, attenuated uncertainty, and difficulties in generalization. Building on these insights, we discuss emerging frameworks for the principled use of synthetic data. We conclude with practical recommendations, open problems, and cautions intended to guide both method developers and applied researchers.
2603.05396
Mar 2026Statistical Learning
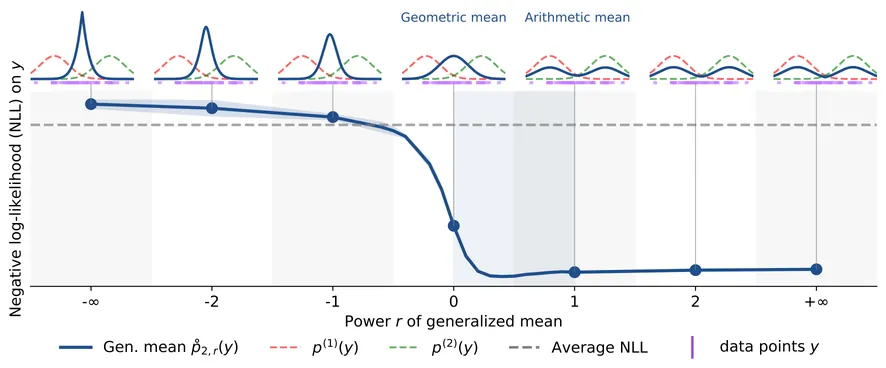
Beyond Mixtures and Products for Ensemble Aggregation: A Likelihood Perspective on Generalized Means
Density aggregation is a central problem in machine learning, for instance when combining predictions from a Deep Ensemble. The choice of aggregation remains an open question with two commonly proposed approaches being linear pooling (probability averaging) and geometric pooling (logit averaging). In this work, we address this question by studying the normalized generalized mean of order $r \in \mathbb{R} \cup \{-\infty,+\infty\}$ through the lens of log-likelihood, the standard evaluation criterion in machine learning. This provides a unifying aggregation formalism and shows different optimal configurations for different situations. We show that the regime $r \in [0,1]$ is the only range ensuring systematic improvements relative to individual distributions, thereby providing a principled justification for the reliability and widespread practical use of linear ($r=1$) and geometric ($r=0$) pooling. In contrast, we show that aggregation rules with $r \notin [0,1]$ may fail to provide consistent gains with explicit counterexamples. Finally, we corroborate our theoretical findings with empirical evaluations using Deep Ensembles on image and text classification benchmarks.
2603.04204
Mar 2026Statistical Learning
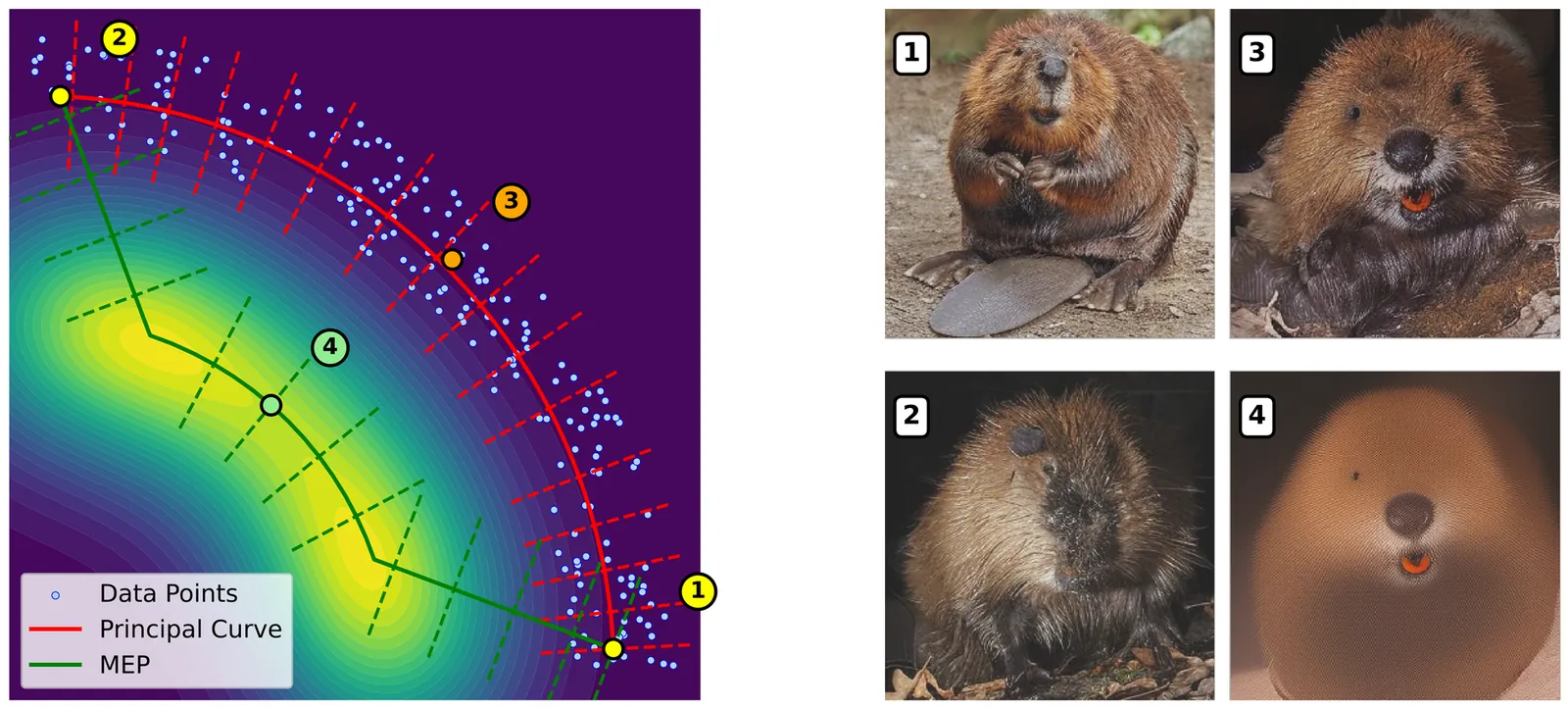
Probing the Geometry of Diffusion Models with the String Method
Understanding the geometry of learned distributions is fundamental to improving and interpreting diffusion models, yet systematic tools for exploring their landscape remain limited. Standard latent-space interpolations fail to respect the structure of the learned distribution, often traversing low-density regions. We introduce a framework based on the string method that computes continuous paths between samples by evolving curves under the learned score function. Operating on pretrained models without retraining, our approach interpolates between three regimes: pure generative transport, which yields continuous sample paths; gradient-dominated dynamics, which recover minimum energy paths (MEPs); and finite-temperature string dynamics, which compute principal curves -- self-consistent paths that balance energy and entropy. We demonstrate that the choice of regime matters in practice. For image diffusion models, MEPs contain high-likelihood but unrealistic ''cartoon'' images, confirming prior observations that likelihood maxima appear unrealistic; principal curves instead yield realistic morphing sequences despite lower likelihood. For protein structure prediction, our method computes transition pathways between metastable conformers directly from models trained on static structures, yielding paths with physically plausible intermediates. Together, these results establish the string method as a principled tool for probing the modal structure of diffusion models -- identifying modes, characterizing barriers, and mapping connectivity in complex learned distributions.
2602.22122
Feb 2026Statistical Learning
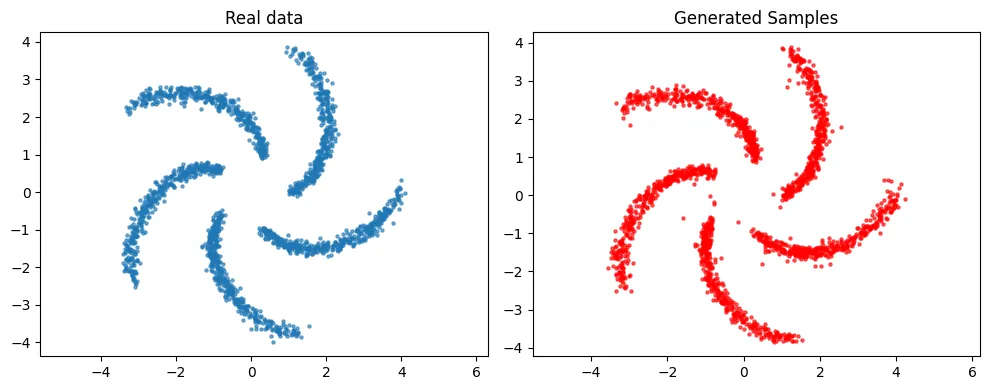
Flow Matching is Adaptive to Manifold Structures
Flow matching has emerged as a simulation-free alternative to diffusion-based generative modeling, producing samples by solving an ODE whose time-dependent velocity field is learned along an interpolation between a simple source distribution (e.g., a standard normal) and a target data distribution. Flow-based methods often exhibit greater training stability and have achieved strong empirical performance in high-dimensional settings where data concentrate near a low-dimensional manifold, such as text-to-image synthesis, video generation, and molecular structure generation. Despite this success, existing theoretical analyses of flow matching assume target distributions with smooth, full-dimensional densities, leaving its effectiveness in manifold-supported settings largely unexplained. To this end, we theoretically analyze flow matching with linear interpolation when the target distribution is supported on a smooth manifold. We establish a non-asymptotic convergence guarantee for the learned velocity field, and then propagate this estimation error through the ODE to obtain statistical consistency of the implicit density estimator induced by the flow-matching objective. The resulting convergence rate is near minimax-optimal, depends only on the intrinsic dimension, and reflects the smoothness of both the manifold and the target distribution. Together, these results provide a principled explanation for how flow matching adapts to intrinsic data geometry and circumvents the curse of dimensionality.
2602.22486
Feb 2026Statistical Learning
A Researcher's Guide to Empirical Risk Minimization
This guide develops high-probability regret bounds for empirical risk minimization (ERM). The presentation is modular: we state broadly applicable guarantees under high-level conditions and give tools for verifying them for specific losses and function classes. We emphasize that many ERM rate derivations can be organized around a three-step recipe -- a basic inequality, a uniform local concentration bound, and a fixed-point argument -- which yields regret bounds in terms of a critical radius, defined via localized Rademacher complexity, under a mild Bernstein-type variance--risk condition. To make these bounds concrete, we upper bound the critical radius using local maximal inequalities and metric-entropy integrals, recovering familiar rates for VC-subgraph, Sobolev/Hölder, and bounded-variation classes. We also review ERM with nuisance components -- including weighted ERM and Neyman-orthogonal losses -- as they arise in causal inference, missing data, and domain adaptation. Following the orthogonal learning framework, we highlight that these problems often admit regret-transfer bounds linking regret under an estimated loss to population regret under the target loss. These bounds typically decompose regret into (i) statistical error under the estimated (optimized) loss and (ii) approximation error due to nuisance estimation. Under sample splitting or cross-fitting, the first term can be controlled using standard fixed-loss ERM regret bounds, while the second term depends only on nuisance-estimation accuracy. We also treat the in-sample regime, where nuisances and the ERM are fit on the same data, deriving regret bounds and giving sufficient conditions for fast rates.
2602.21501
Feb 2026Statistical Learning
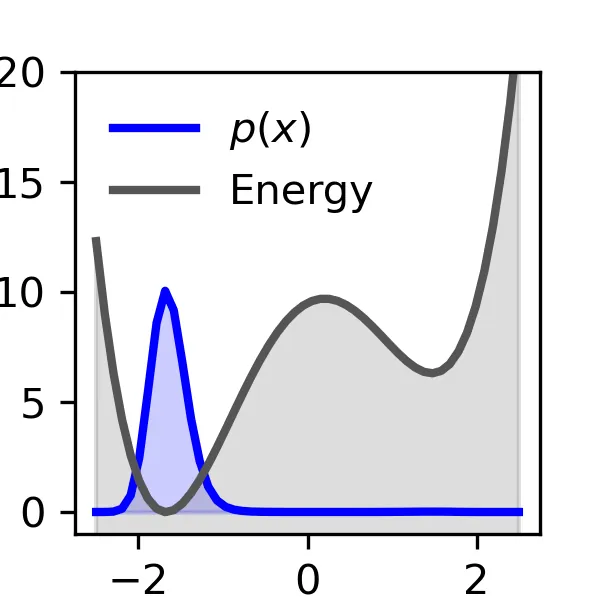
Enhanced Diffusion Sampling: Efficient Rare Event Sampling and Free Energy Calculation with Diffusion Models
The rare-event sampling problem has long been the central limiting factor in molecular dynamics (MD), especially in biomolecular simulation. Recently, diffusion models such as BioEmu have emerged as powerful equilibrium samplers that generate independent samples from complex molecular distributions, eliminating the cost of sampling rare transition events. However, a sampling problem remains when computing observables that rely on states which are rare in equilibrium, for example folding free energies. Here, we introduce enhanced diffusion sampling, enabling efficient exploration of rare-event regions while preserving unbiased thermodynamic estimators. The key idea is to perform quantitatively accurate steering protocols to generate biased ensembles and subsequently recover equilibrium statistics via exact reweighting. We instantiate our framework in three algorithms: UmbrellaDiff (umbrella sampling with diffusion models), $Δ$G-Diff (free-energy differences via tilted ensembles), and MetaDiff (a batchwise analogue for metadynamics). Across toy systems, protein folding landscapes and folding free energies, our methods achieve fast, accurate, and scalable estimation of equilibrium properties within GPU-minutes to hours per system -- closing the rare-event sampling gap that remained after the advent of diffusion-model equilibrium samplers.
2602.16634
Feb 2026Statistical Learning
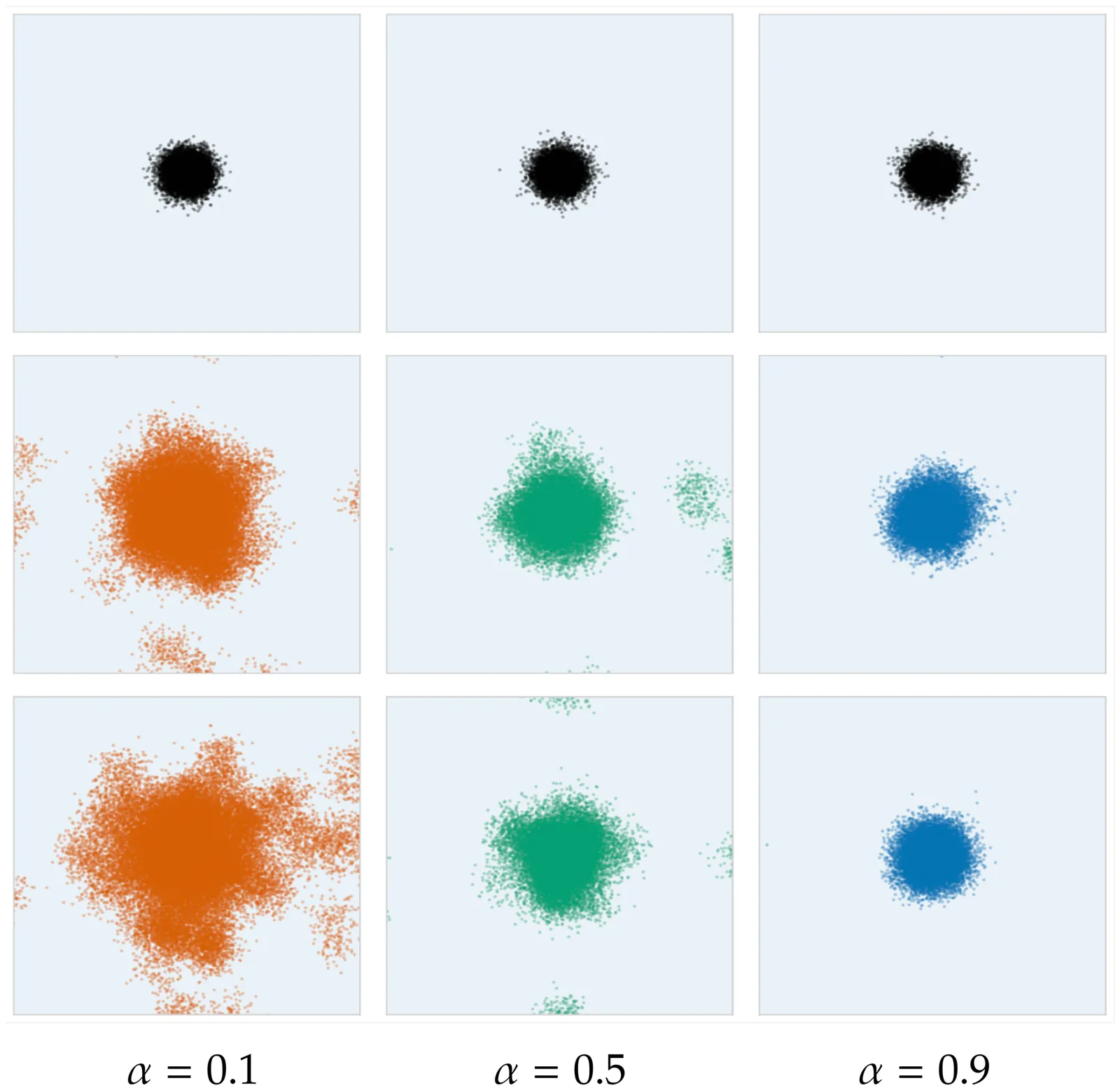
Error Propagation and Model Collapse in Diffusion Models: A Theoretical Study
Machine learning models are increasingly trained or fine-tuned on synthetic data. Recursively training on such data has been observed to significantly degrade performance in a wide range of tasks, often characterized by a progressive drift away from the target distribution. In this work, we theoretically analyze this phenomenon in the setting of score-based diffusion models. For a realistic pipeline where each training round uses a combination of synthetic data and fresh samples from the target distribution, we obtain upper and lower bounds on the accumulated divergence between the generated and target distributions. This allows us to characterize different regimes of drift, depending on the score estimation error and the proportion of fresh data used in each generation. We also provide empirical results on synthetic data and images to illustrate the theory.
2602.16601
Feb 2026Statistical Learning

Functional Central Limit Theorem for Stochastic Gradient Descent
We study the asymptotic shape of the trajectory of the stochastic gradient descent algorithm applied to a convex objective function. Under mild regularity assumptions, we prove a functional central limit theorem for the properly rescaled trajectory. Our result characterizes the long-term fluctuations of the algorithm around the minimizer by providing a diffusion limit for the trajectory. In contrast with classical central limit theorems for the last iterate or Polyak-Ruppert averages, this functional result captures the temporal structure of the fluctuations and applies to non-smooth settings such as robust location estimation, including the geometric median.
2602.15538
Feb 2026Statistical Learning
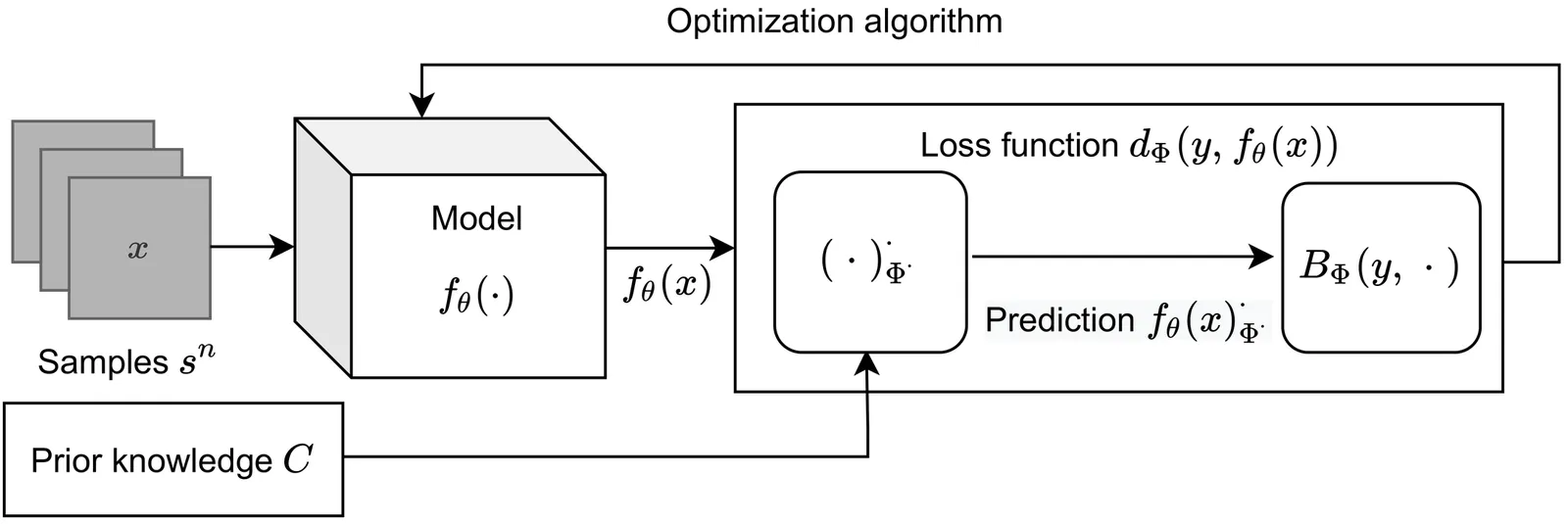
Conjugate Learning Theory: Uncovering the Mechanisms of Trainability and Generalization in Deep Neural Networks
In this work, we propose a notion of practical learnability grounded in finite sample settings, and develop a conjugate learning theoretical framework based on convex conjugate duality to characterize this learnability property. Building on this foundation, we demonstrate that training deep neural networks (DNNs) with mini-batch stochastic gradient descent (SGD) achieves global optima of empirical risk by jointly controlling the extreme eigenvalues of a structure matrix and the gradient energy, and we establish a corresponding convergence theorem. We further elucidate the impact of batch size and model architecture (including depth, parameter count, sparsity, skip connections, and other characteristics) on non-convex optimization. Additionally, we derive a model-agnostic lower bound for the achievable empirical risk, theoretically demonstrating that data determines the fundamental limit of trainability. On the generalization front, we derive deterministic and probabilistic bounds on generalization error based on generalized conditional entropy measures. The former explicitly delineates the range of generalization error, while the latter characterizes the distribution of generalization error relative to the deterministic bounds under independent and identically distributed (i.i.d.) sampling conditions. Furthermore, these bounds explicitly quantify the influence of three key factors: (i) information loss induced by irreversibility in the model, (ii) the maximum attainable loss value, and (iii) the generalized conditional entropy of features with respect to labels. Moreover, they offer a unified theoretical lens for understanding the roles of regularization, irreversible transformations, and network depth in shaping the generalization behavior of deep neural networks. Extensive experiments validate all theoretical predictions, confirming the framework's correctness and consistency.
2602.16177
Feb 2026Statistical Learning
From Average Sensitivity to Small-Loss Regret Bounds under Random-Order Model
We study online learning in the random-order model, where the multiset of loss functions is chosen adversarially but revealed in a uniformly random order. Building on the batch-to-online conversion by Dong and Yoshida (2023), we show that if an offline algorithm admits a $(1+\varepsilon)$-approximation guarantee and the effect of $\varepsilon$ on its average sensitivity is characterized by a function $\varphi(\varepsilon)$, then an adaptive choice of $\varepsilon$ yields a small-loss regret bound of $\tilde O(\varphi^{\star}(\mathrm{OPT}_T))$, where $\varphi^{\star}$ is the concave conjugate of $\varphi$, $\mathrm{OPT}_T$ is the offline optimum over $T$ rounds, and $\tilde O$ hides polylogarithmic factors in $T$. Our method requires no regularity assumptions on loss functions, such as smoothness, and can be viewed as a generalization of the AdaGrad-style tuning applied to the approximation parameter $\varepsilon$. Our result recovers and strengthens the $(1+\varepsilon)$-approximate regret bounds of Dong and Yoshida (2023) and yields small-loss regret bounds for online $k$-means clustering, low-rank approximation, and regression. We further apply our framework to online submodular function minimization using $(1\pm\varepsilon)$-cut sparsifiers of submodular hypergraphs, obtaining a small-loss regret bound of $\tilde O(n^{3/4}(1 + \mathrm{OPT}_T^{3/4}))$, where $n$ is the ground-set size. Our approach sheds light on the power of sparsification and related techniques in establishing small-loss regret bounds in the random-order model.
2602.09457
Feb 2026Statistical Learning
Meta Flow Maps enable scalable reward alignment
Controlling generative models is computationally expensive. This is because optimal alignment with a reward function--whether via inference-time steering or fine-tuning--requires estimating the value function. This task demands access to the conditional posterior $p_{1|t}(x_1|x_t)$, the distribution of clean data $x_1$ consistent with an intermediate state $x_t$, a requirement that typically compels methods to resort to costly trajectory simulations. To address this bottleneck, we introduce Meta Flow Maps (MFMs), a framework extending consistency models and flow maps into the stochastic regime. MFMs are trained to perform stochastic one-step posterior sampling, generating arbitrarily many i.i.d. draws of clean data $x_1$ from any intermediate state. Crucially, these samples provide a differentiable reparametrization that unlocks efficient value function estimation. We leverage this capability to solve bottlenecks in both paradigms: enabling inference-time steering without inner rollouts, and facilitating unbiased, off-policy fine-tuning to general rewards. Empirically, our single-particle steered-MFM sampler outperforms a Best-of-1000 baseline on ImageNet across multiple rewards at a fraction of the compute.
2601.14430
Jan 2026Statistical Learning
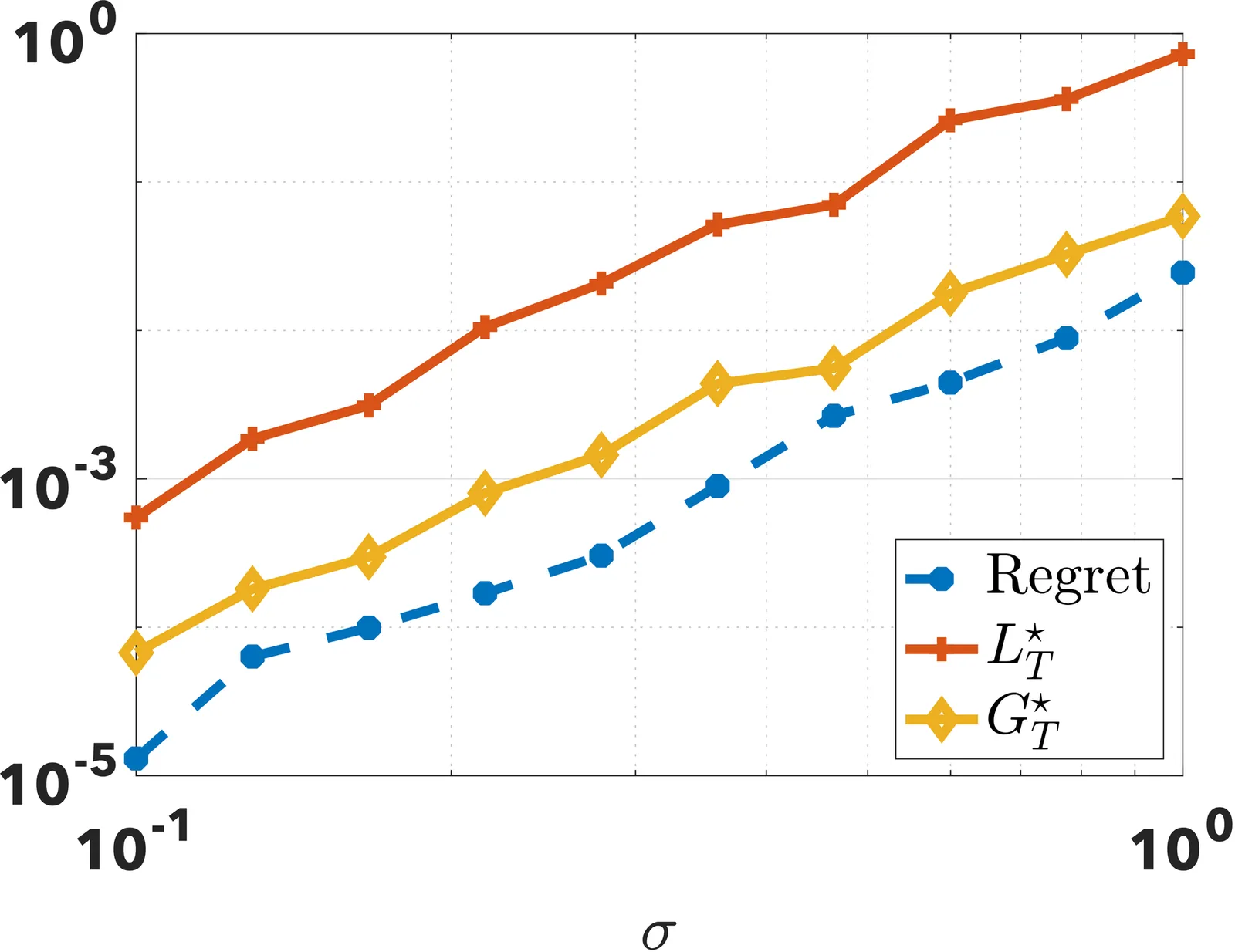
Small Gradient Norm Regret for Online Convex Optimization
This paper introduces a new problem-dependent regret measure for online convex optimization with smooth losses. The notion, which we call the $G^\star$ regret, depends on the cumulative squared gradient norm evaluated at the decision in hindsight $\sum_{t=1}^T \|\nabla \ell(x^\star)\|^2$. We show that the $G^\star$ regret strictly refines the existing $L^\star$ (small loss) regret, and that it can be arbitrarily sharper when the losses have vanishing curvature around the hindsight decision. We establish upper and lower bounds on the $G^\star$ regret and extend our results to dynamic regret and bandit settings. As a byproduct, we refine the existing convergence analysis of stochastic optimization algorithms in the interpolation regime. Some experiments validate our theoretical findings.
2601.13519
Jan 2026Statistical Learning
Low-Dimensional Adaptation of Rectified Flow: A New Perspective through the Lens of Diffusion and Stochastic Localization
In recent years, Rectified flow (RF) has gained considerable popularity largely due to its generation efficiency and state-of-the-art performance. In this paper, we investigate the degree to which RF automatically adapts to the intrinsic low dimensionality of the support of the target distribution to accelerate sampling. We show that, using a carefully designed choice of the time-discretization scheme and with sufficiently accurate drift estimates, the RF sampler enjoys an iteration complexity of order $O(k/\varepsilon)$ (up to log factors), where $\varepsilon$ is the precision in total variation distance and $k$ is the intrinsic dimension of the target distribution. In addition, we show that the denoising diffusion probabilistic model (DDPM) procedure is equivalent to a stochastic version of RF by establishing a novel connection between these processes and stochastic localization. Building on this connection, we further design a stochastic RF sampler that also adapts to the low-dimensionality of the target distribution under milder requirements on the accuracy of the drift estimates, and also with a specific time schedule. We illustrate with simulations on the synthetic data and text-to-image data experiments the improved performance of the proposed samplers implementing the newly designed time-discretization schedules.
2601.15500
Jan 2026Statistical Learning

Efficient and Minimax-optimal In-context Nonparametric Regression with Transformers
We study in-context learning for nonparametric regression with $α$-Hölder smooth regression functions, for some $α>0$. We prove that, with $n$ in-context examples and $d$-dimensional regression covariates, a pretrained transformer with $Θ(\log n)$ parameters and $Ω\bigl(n^{2α/(2α+d)}\log^3 n\bigr)$ pretraining sequences can achieve the minimax-optimal rate of convergence $O\bigl(n^{-2α/(2α+d)}\bigr)$ in mean squared error. Our result requires substantially fewer transformer parameters and pretraining sequences than previous results in the literature. This is achieved by showing that transformers are able to approximate local polynomial estimators efficiently by implementing a kernel-weighted polynomial basis and then running gradient descent.
2601.15014
Jan 2026Statistical Learning
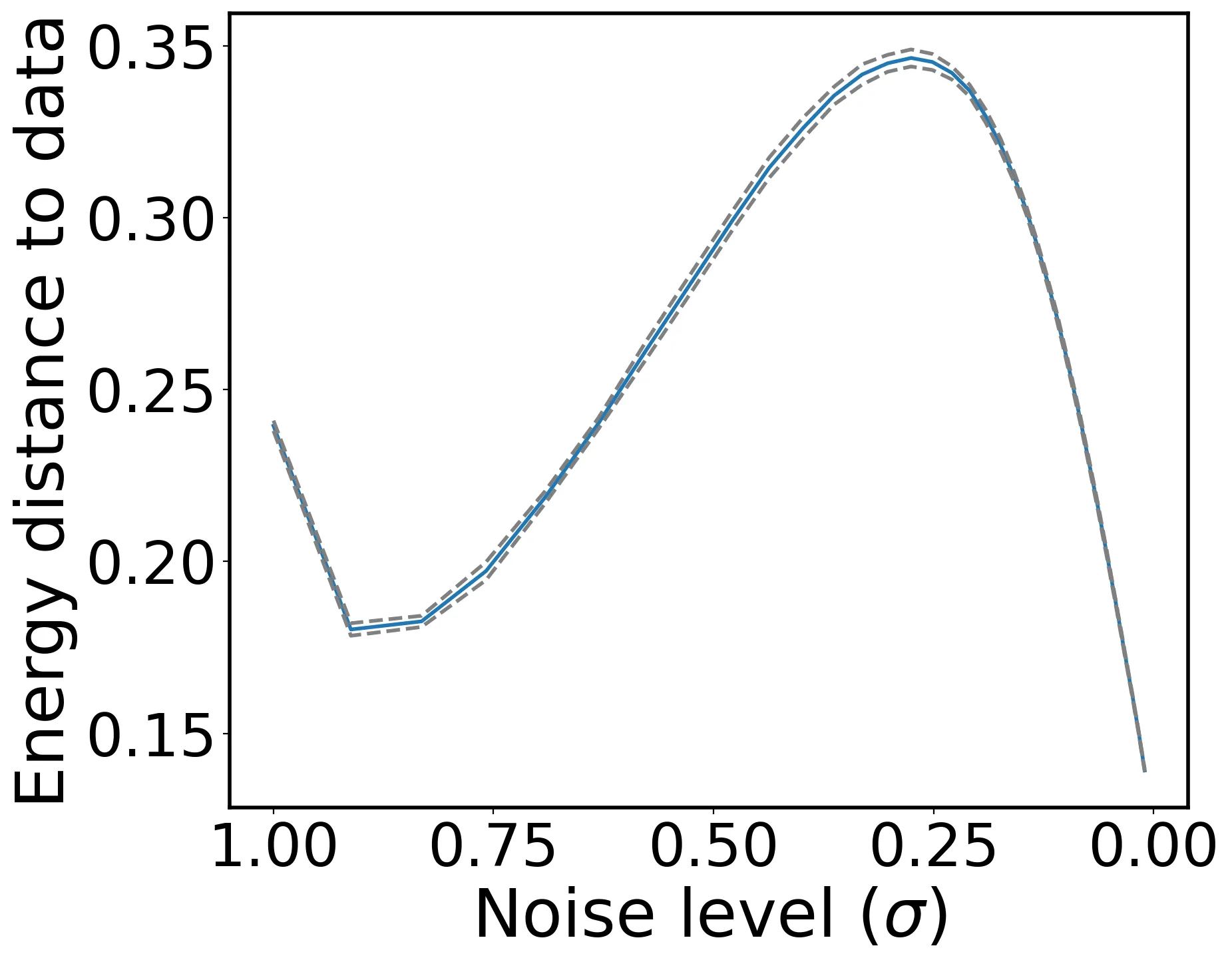
Energy-Tweedie: Score meets Score, Energy meets Energy
Denoising and score estimation have long been known to be linked via the classical Tweedie's formula. In this work, we first extend the latter to a wider range of distributions often called "energy models" and denoted elliptical distributions in this work. Next, we examine an alternative view: we consider the denoising posterior $P(X|Y)$ as the optimizer of the energy score (a scoring rule) and derive a fundamental identity that connects the (path-) derivative of a (possibly) non-Euclidean energy score to the score of the noisy marginal. This identity can be seen as an analog of Tweedie's identity for the energy score, and allows for several interesting applications; for example, score estimation, noise distribution parameter estimation, as well as using energy score models in the context of "traditional" diffusion model samplers with a wider array of noising distributions.
2512.23818
Dec 2025Statistical Learning
Probabilistic Modelling is Sufficient for Causal Inference
Causal inference is a key research area in machine learning, yet confusion reigns over the tools needed to tackle it. There are prevalent claims in the machine learning literature that you need a bespoke causal framework or notation to answer causal questions. In this paper, we want to make it clear that you \emph{can} answer any causal inference question within the realm of probabilistic modelling and inference, without causal-specific tools or notation. Through concrete examples, we demonstrate how causal questions can be tackled by writing down the probability of everything. Lastly, we reinterpret causal tools as emerging from standard probabilistic modelling and inference, elucidating their necessity and utility.
2512.23408
Dec 2025Statistical Learning

Gradient Dynamics of Attention: How Cross-Entropy Sculpts Bayesian Manifolds
Transformers empirically perform precise probabilistic reasoning in carefully constructed ``Bayesian wind tunnels'' and in large-scale language models, yet the mechanisms by which gradient-based learning creates the required internal geometry remain opaque. We provide a complete first-order analysis of how cross-entropy training reshapes attention scores and value vectors in a transformer attention head. Our core result is an \emph{advantage-based routing law} for attention scores, \[ \frac{\partial L}{\partial s_{ij}} = α_{ij}\bigl(b_{ij}-\mathbb{E}_{α_i}[b]\bigr), \qquad b_{ij} := u_i^\top v_j, \] coupled with a \emph{responsibility-weighted update} for values, \[ Δv_j = -η\sum_i α_{ij} u_i, \] where $u_i$ is the upstream gradient at position $i$ and $α_{ij}$ are attention weights. These equations induce a positive feedback loop in which routing and content specialize together: queries route more strongly to values that are above-average for their error signal, and those values are pulled toward the queries that use them. We show that this coupled specialization behaves like a two-timescale EM procedure: attention weights implement an E-step (soft responsibilities), while values implement an M-step (responsibility-weighted prototype updates), with queries and keys adjusting the hypothesis frame. Through controlled simulations, including a sticky Markov-chain task where we compare a closed-form EM-style update to standard SGD, we demonstrate that the same gradient dynamics that minimize cross-entropy also sculpt the low-dimensional manifolds identified in our companion work as implementing Bayesian inference. This yields a unified picture in which optimization (gradient flow) gives rise to geometry (Bayesian manifolds), which in turn supports function (in-context probabilistic reasoning).
2512.224733
Dec 2025Statistical Learning

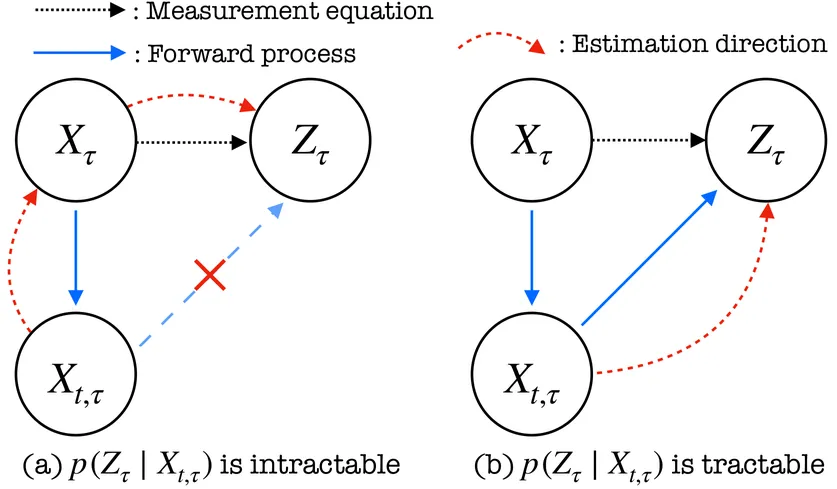
Diffusion Models in Simulation-Based Inference: A Tutorial Review
Diffusion models have recently emerged as powerful learners for simulation-based inference (SBI), enabling fast and accurate estimation of latent parameters from simulated and real data. Their score-based formulation offers a flexible way to learn conditional or joint distributions over parameters and observations, thereby providing a versatile solution to various modeling problems. In this tutorial review, we synthesize recent developments on diffusion models for SBI, covering design choices for training, inference, and evaluation. We highlight opportunities created by various concepts such as guidance, score composition, flow matching, consistency models, and joint modeling. Furthermore, we discuss how efficiency and statistical accuracy are affected by noise schedules, parameterizations, and samplers. Finally, we illustrate these concepts with case studies across parameter dimensionalities, simulation budgets, and model types, and outline open questions for future research.
2512.206851
Dec 2025Statistical Learning
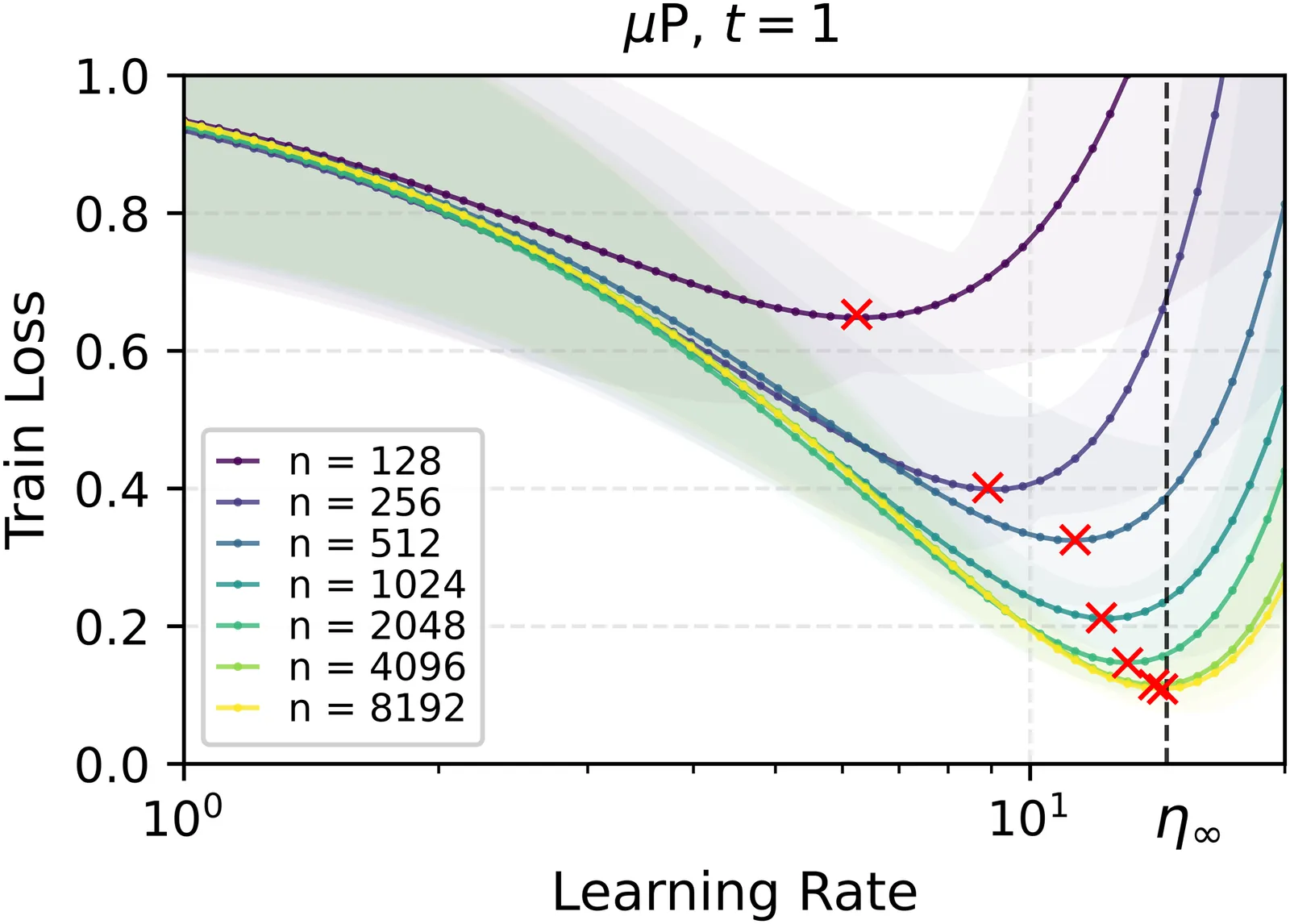
A Proof of Learning Rate Transfer under $μ$P
We provide the first proof of learning rate transfer with width in a linear multi-layer perceptron (MLP) parametrized with $\mu$P, a neural network parameterization designed to ``maximize'' feature learning in the infinite-width limit. We show that under $\mu P$, the optimal learning rate converges to a \emph{non-zero constant} as width goes to infinity, providing a theoretical explanation to learning rate transfer. In contrast, we show that this property fails to hold under alternative parametrizations such as Standard Parametrization (SP) and Neural Tangent Parametrization (NTP). We provide intuitive proofs and support the theoretical findings with extensive empirical results.
2511.017341
Nov 2025Statistical Learning