Trending in Probability & Statistics
$K-$means with leraned metrics
We study the Fréchet {\it k-}means of a metric measure space when both the measure and the distance are unknown and have to be estimated. We prove a general result that states that the {\it k-}means are continuous with respect to the measured Gromov-Hausdorff topology. In this situation, we also prove a stability result for the Voronoi clusters they determine. We do not assume uniqueness of the set of {\it k-}means, but when it is unique, the results are stronger. {This framework provides a unified approach to proving consistency for a wide range of metric learning procedures. As concrete applications, we obtain new consistency results for several important estimators that were previously unestablished, even when $k=1$. These include {\it k-}means based on: (i) Isomap and Fermat geodesic distances on manifolds, (ii) difussion distances, (iii) Wasserstein distances computed with respect to learned ground metrics. Finally, we consider applications beyond the statistical inference paradigm like (iv) first passage percolation and (v) discrete approximations of length spaces.}
2603.14601
Mar 2026Statistics Theory
Spin Glass Concepts in Computer Science, Statistics, and Learning
Spin glass theory studies the structure of sublevel sets and minima (or near-minima) of certain classes of random functions in high dimension. Near-minima of random functions also play an important role in high-dimensional statistics and statistical learning, where minimizing the empirical risk (which is a random function of the model parameters) is the method of choice for learning a statistical model from noisy data. Finally, near-minima of random functions are obviously central to average-case analysis of optimization algorithms. Computer science, statistics, and machine learning naturally lead to questions that are traditionally not addressed within physics and mathematical physics. I will try to explain how ideas from spin glass theory have seeded recent developments in these fields. (This article was written on the occasion of the 2024 Abel Prize to Michel Talagrand.)
2602.23326
Feb 2026Probability
HAL-MLE Log-Splines Density Estimation (Part I: Univariate)
We study nonparametric maximum likelihood estimation of probability densities under a total variation (TV) type penalty, sectional variation norm (also named as Hardy-Krause variation). TV regularization has a long history in regression and density estimation, including results on $L^2$ and KL divergence convergence rates. Here, we revisit this task using the Highly Adaptive Lasso (HAL) framework. We formulate a HAL-based maximum likelihood estimator (HAL-MLE) using the log-spline link function from \citet{kooperberg1992logspline}, and show that in the univariate setting the bounded sectional variation norm assumption underlying HAL coincides with the classical bounded TV assumption. This equivalence directly connects HAL-MLE to existing TV-penalized approaches such as local adaptive splines \citep{mammen1997locally}. We establish three new theoretical results: (i) the univariate HAL-MLE is asymptotically linear, (ii) it admits pointwise asymptotic normality, and (iii) it achieves uniform convergence at rate $n^{-(k+1)/(2k+3)}$ up to logarithmic factors for the smoothness order $k \geq 1$. These results extend existing results from \citet{van2017uniform}, which previously guaranteed only uniform consistency without rates when $k=0$. We will include the uniform convergence for general dimension $d$ in the follow-up work of this paper. The intention of this paper is to provide a unified framework for the TV-penalized density estimation methods, and to connect the HAL-MLE to the existing TV-penalized methods in the univariate case, despite that the general HAL-MLE is defined for multivariate cases.
2602.16259
Feb 2026Statistics Theory
Do More Predictions Improve Statistical Inference? Filtered Prediction-Powered Inference
Recent advances in artificial intelligence have enabled the generation of large-scale, low-cost predictions with increasingly high fidelity. As a result, the primary challenge in statistical inference has shifted from data scarcity to data reliability. Prediction-powered inference methods seek to exploit such predictions to improve efficiency when labeled data are limited. However, existing approaches implicitly adopt a use-all philosophy, under which incorporating more predictions is presumed to improve inference. When prediction quality is heterogeneous, this assumption can fail, and indiscriminate use of unlabeled data may dilute informative signals and degrade inferential accuracy. In this paper, we propose Filtered Prediction-Powered Inference (FPPI), a framework that selectively incorporates predictions by identifying a data-adaptive filtered region in which predictions are informative for inference. We show that this region can be consistently estimated under a margin condition, achieving fast rates of convergence. By restricting the prediction-powered correction to the estimated filtered region, FPPI adaptively mitigates the impact of biased or noisy predictions. We establish that FPPI attains strictly improved asymptotic efficiency compared with existing prediction-powered inference methods. Numerical studies and a real-data application to large language model evaluation demonstrate that FPPI substantially reduces reliance on expensive labels by selectively leveraging reliable predictions, yielding accurate inference even in the presence of heterogeneous prediction quality.
2602.10464
Feb 2026Statistics Theory
High-Probability Minimax Adaptive Estimation in Besov Spaces via Online-to-Batch
We study nonparametric regression over Besov spaces from noisy observations under sub-exponential noise, aiming to achieve minimax-optimal guarantees on the integrated squared error that hold with high probability and adapt to the unknown noise level. To this end, we propose a wavelet-based online learning algorithm that dynamically adjusts to the observed gradient noise by adaptively clipping it at an appropriate level, eliminating the need to tune parameters such as the noise variance or gradient bounds. As a by-product of our analysis, we derive high-probability adaptive regret bounds that scale with the $\ell_1$-norm of the competitor. Finally, in the batch statistical setting, we obtain adaptive and minimax-optimal estimation rates for Besov spaces via a refined online-to-batch conversion. This approach carefully exploits the structure of the squared loss in combination with self-normalized concentration inequalities.
2602.11747
Feb 2026Statistics Theory
Ergodic Theorems and Equivalence of Green's Kernel for Random Walks in Random Environments
We study the Ergodic Properties of Random Walks in stationary ergodic environments without uniform ellipticity under a minimal assumption. There are two main components in our work. The first step is to adopt the arguments of Lawler to first prove a uniqueness principle. We use a more general definition of environments using~\textit{Environment Functions}. As a corollary, we can deduce an invariance principle under these assumptions for balanced environments under some assumptions. We also use the uniqueness principle to show that any balanced, elliptic random walk must have the same transience behaviour as the simple symmetric random walk. The second is to transfer the results we deduce in balanced environments to general ergodic environments(under some assumptions) using a control technique to derive a measure under which the \textit{local process} is stationary and ergodic. As a consequence of our results, we deduce the Law of Large Numbers for the Random Walk and an Invariance Principle under our assumptions.
2601.04161
Jan 2026Probability

Counterfactual Spaces
We mathematically axiomatise the stochastics of counterfactuals, by introducing two related frameworks, called counterfactual probability spaces and counterfactual causal spaces, which we collectively term counterfactual spaces. They are, respectively, probability and causal spaces whose underlying measurable spaces are products of world-specific measurable spaces. In contrast to more familiar accounts of counterfactuals founded on causal models, we do not view interventions as a necessary component of a theory of counterfactuals. As an alternative to Pearl's celebrated ladder of causation, we view counterfactuals and interventions are orthogonal concepts, respectively mathematised in counterfactual probability spaces and causal spaces. The two concepts are then combined to form counterfactual causal spaces. At the heart of our theory is the notion of shared information between the worlds, encoded completely within the probability measure and causal kernels, and whose extremes are characterised by independence and synchronisation of worlds. Compared to existing frameworks, counterfactual spaces enable the mathematical treatment of a strictly broader spectrum of counterfactuals.
2601.00507
Jan 2026Statistics Theory
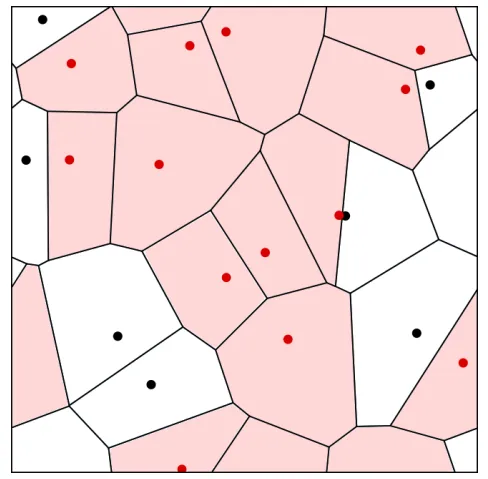
Voronoi Percolation: Topological Stability and Giant Cycles
We study the topological stability of Voronoi percolation in higher dimensions. We show that slightly increasing p allows a discretization that preserves increasing topological properties with high probability. This strengthens a theorem of Bollobás and Riordan and generalizes it to higher dimensions. As a consequence, we prove a sharp phase transition for the emergence of i-dimensional giant cycles in Voronoi percolation on the 2i-dimensional torus.
2601.00793
Jan 2026Probability
Score-based sampling without diffusions: Guidance from a simple and modular scheme
Sampling based on score diffusions has led to striking empirical results, and has attracted considerable attention from various research communities. It depends on availability of (approximate) Stein score functions for various levels of additive noise. We describe and analyze a modular scheme that reduces score-based sampling to solving a short sequence of ``nice'' sampling problems, for which high-accuracy samplers are known. We show how to design forward trajectories such that both (a) the terminal distribution, and (b) each of the backward conditional distribution is defined by a strongly log concave (SLC) distribution. This modular reduction allows us to exploit \emph{any} SLC sampling algorithm in order to traverse the backwards path, and we establish novel guarantees with short proofs for both uni-modal and multi-modal densities. The use of high-accuracy routines yields $\varepsilon$-accurate answers, in either KL or Wasserstein distances, with polynomial dependence on $\log(1/\varepsilon)$ and $\sqrt{d}$ dependence on the dimension.
2512.24152
Dec 2025Statistics Theory
A general framework for deep learning
This paper develops a general approach for deep learning for a setting that includes nonparametric regression and classification. We perform a framework from data that fulfills a generalized Bernstein-type inequality, including independent, $φ$-mixing, strongly mixing and $\mathcal{C}$-mixing observations. Two estimators are proposed: a non-penalized deep neural network estimator (NPDNN) and a sparse-penalized deep neural network estimator (SPDNN). For each of these estimators, bounds of the expected excess risk on the class of Hölder smooth functions and composition Hölder functions are established. Applications to independent data, as well as to $φ$-mixing, strongly mixing, $\mathcal{C}$-mixing processes are considered. For each of these examples, the upper bounds of the expected excess risk of the proposed NPDNN and SPDNN predictors are derived. It is shown that both the NPDNN and SPDNN estimators are minimax optimal (up to a logarithmic factor) in many classical settings.
2512.23425
Dec 2025Statistics Theory
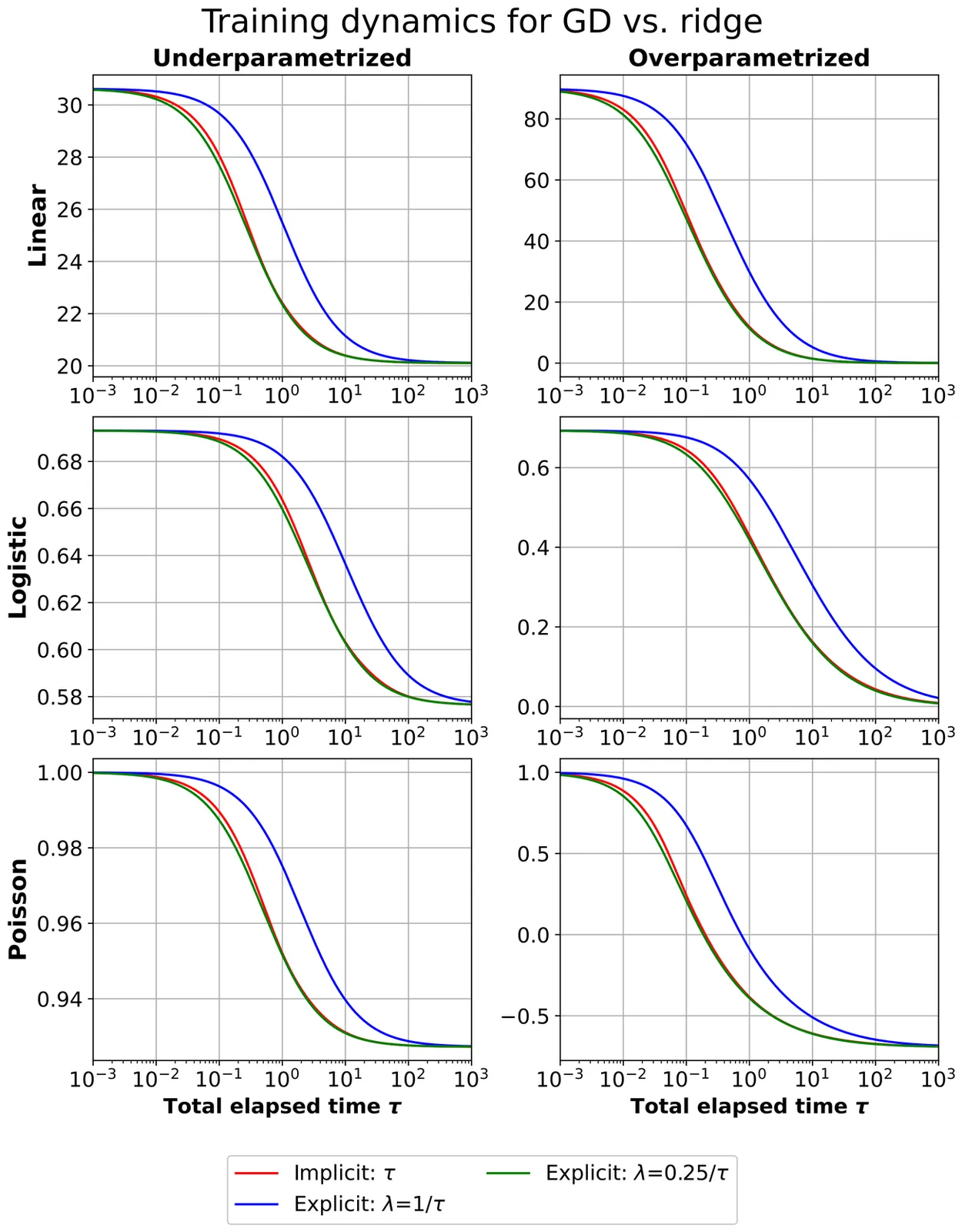
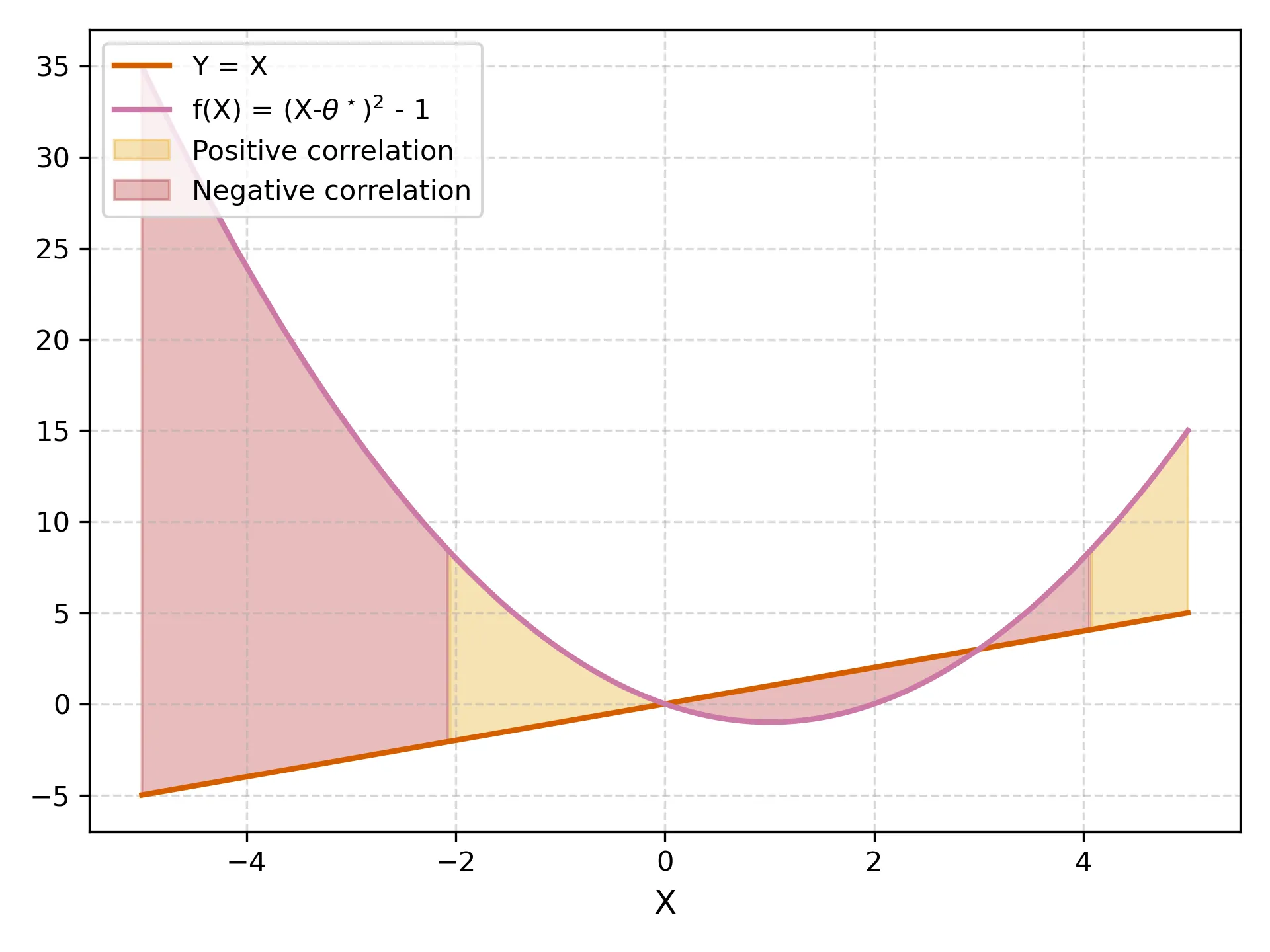
Basic Inequalities for First-Order Optimization with Applications to Statistical Risk Analysis
We introduce \textit{basic inequalities} for first-order iterative optimization algorithms, forming a simple and versatile framework that connects implicit and explicit regularization. While related inequalities appear in the literature, we isolate and highlight a specific form and develop it as a well-rounded tool for statistical analysis. Let $f$ denote the objective function to be optimized. Given a first-order iterative algorithm initialized at $θ_0$ with current iterate $θ_T$, the basic inequality upper bounds $f(θ_T)-f(z)$ for any reference point $z$ in terms of the accumulated step sizes and the distances between $θ_0$, $θ_T$, and $z$. The bound translates the number of iterations into an effective regularization coefficient in the loss function. We demonstrate this framework through analyses of training dynamics and prediction risk bounds. In addition to revisiting and refining known results on gradient descent, we provide new results for mirror descent with Bregman divergence projection, for generalized linear models trained by gradient descent and exponentiated gradient descent, and for randomized predictors. We illustrate and supplement these theoretical findings with experiments on generalized linear models.
2512.24999
Dec 2025Statistics Theory
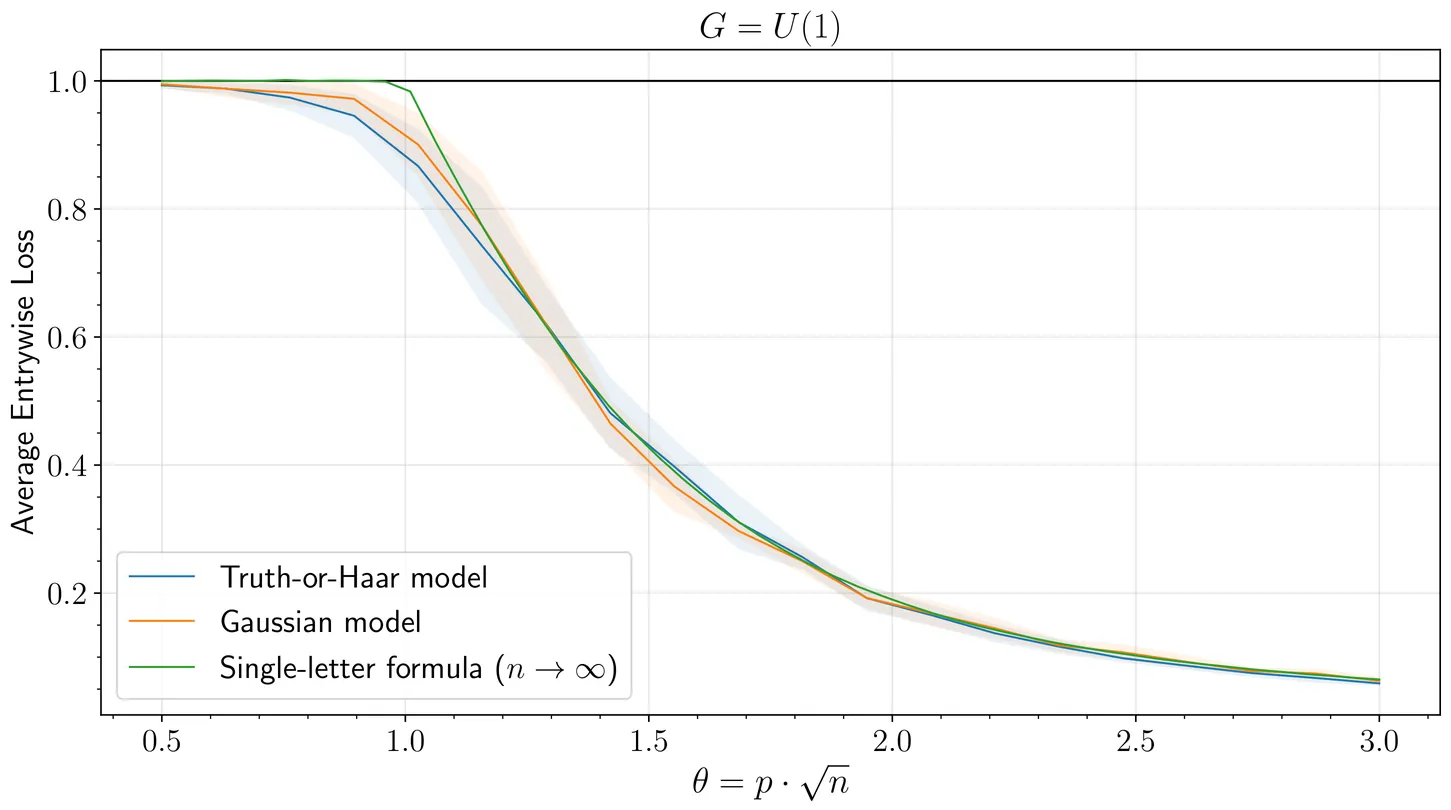
Universal entrywise eigenvector fluctuations in delocalized spiked matrix models and asymptotics of rounded spectral algorithms
We consider the distribution of the top eigenvector $\widehat{v}$ of a spiked matrix model of the form $H = θvv^* + W$, in the supercritical regime where $H$ has an outlier eigenvalue of comparable magnitude to $\|W\|$. We show that, if $v$ is sufficiently delocalized, then the distribution of the individual entries of $\widehat{v}$ (not, we emphasize, merely the inner product $\langle \widehat{v}, v\rangle$) is universal over a large class of generalized Wigner matrices $W$ having independent entries, depending only on the first two moments of the distributions of the entries of $W$. This complements the observation of Capitaine and Donati-Martin (2018) that these distributions are not universal when $v$ is instead sufficiently localized. Further, for $W$ having entrywise variances close to constant and thus resembling a Wigner matrix, we show by comparing to the case of $W$ drawn from the Gaussian orthogonal or unitary ensembles that averages of entrywise functions of $\widehat{v}$ behave as they would if $\widehat{v}$ had Gaussian fluctuations around a suitable multiple of $v$. We apply these results to study spectral algorithms followed by rounding procedures in dense stochastic block models and synchronization problems over the cyclic and circle groups, obtaining the first precise asymptotic characterizations of the error rates of such algorithms.
2512.11785
Dec 2025Probability
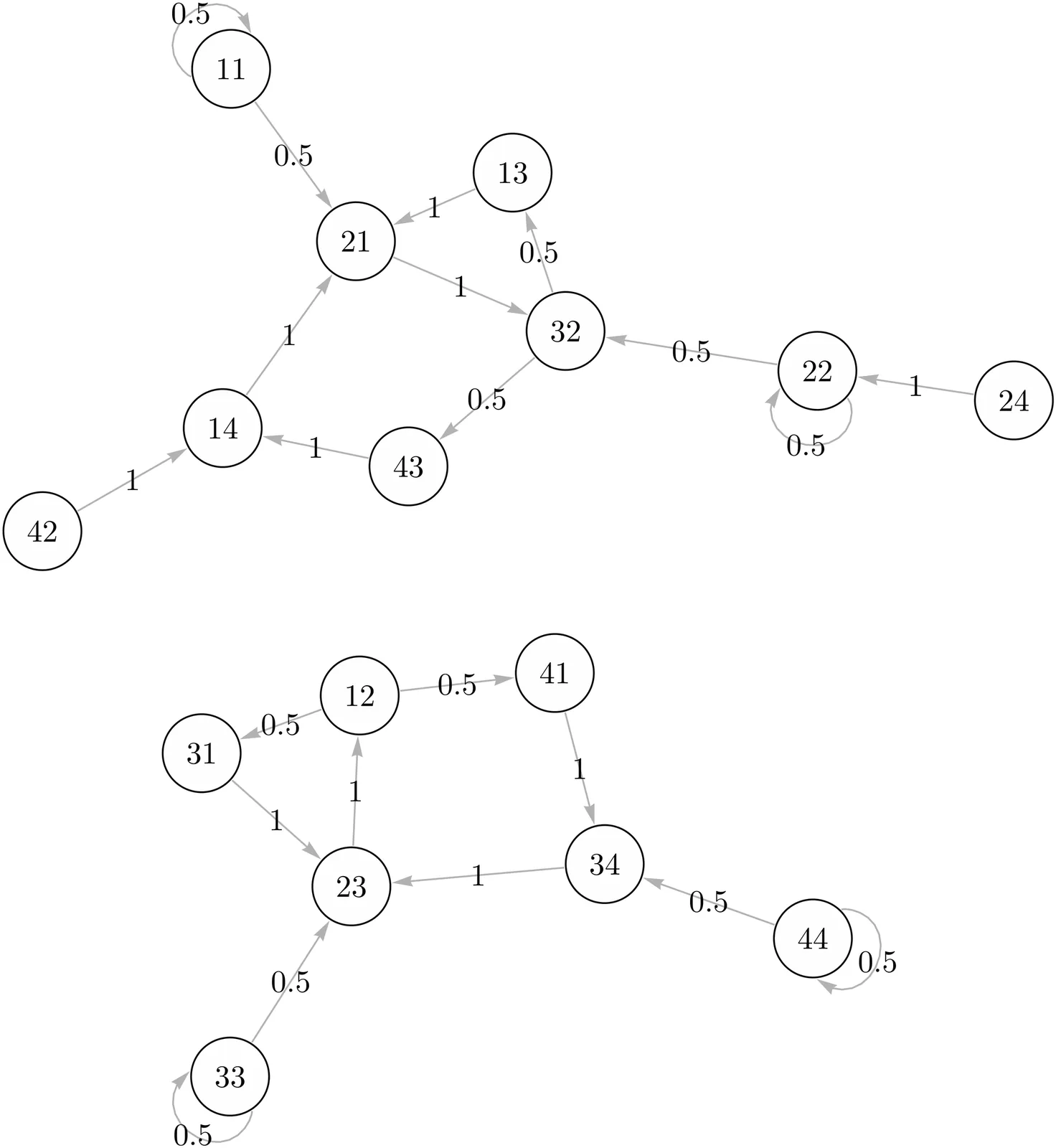
Can a Higher Order Markov Chain Be Treated as a First Order Markov Chain?
It is well known that any higher order Markov chain can be associated with a first order Markov chain. In this primarily expository article, we present the first fairly comprehensive analysis of the relationship between higher order and first order Markov chains, together with illustrative examples. Our main objective is to address the central question as posed in the title.
2512.01969
Dec 2025Probability